




Dévoiler des modifications subtiles mais percutantes d'IA dans le contenu vidéo authentique
En 2019, une vidéo trompeuse de Nancy Pelosi, alors présidente de la Chambre des représentants des États-Unis, a largement circulé. La vidéo, modifiée pour la faire apparaître intoxiquée, a été un rappel frappant de la facilité avec laquelle les médias manipulés peuvent induire le public en erreur. Malgré sa simplicité, cet incident a mis en évidence le potentiel de dommage des montages audiovisuels même basiques.
À l'époque, le paysage des deepfakes était largement dominé par des technologies de remplacement de visage basées sur des autoencodeurs, présentes depuis fin 2017. Ces systèmes précoces peinaient à effectuer les modifications nuancées observées dans la vidéo de Pelosi, se concentrant plutôt sur des échanges de visages plus évidents.
 Le cadre ‘Neural Emotion Director' de 2022 modifie l'humeur d'un visage célèbre. Source : https://www.youtube.com/watch?v=Li6W8pRDMJQ
Le cadre ‘Neural Emotion Director' de 2022 modifie l'humeur d'un visage célèbre. Source : https://www.youtube.com/watch?v=Li6W8pRDMJQ
Aujourd'hui, l'industrie du cinéma et de la télévision explore de plus en plus les montages de post-production pilotés par l'IA. Cette tendance suscite à la fois intérêt et critiques, car l'IA permet un niveau de perfectionnisme auparavant inatteignable. En réponse, la communauté scientifique a développé divers projets axés sur les 'modifications locales' des captures faciales, tels que Diffusion Video Autoencoders, Stitch it in Time, ChatFace, MagicFace et DISCO.
 Modification d'expression avec le projet MagicFace de janvier 2025. Source : https://arxiv.org/pdf/2501.02260
Modification d'expression avec le projet MagicFace de janvier 2025. Source : https://arxiv.org/pdf/2501.02260
Nouveaux visages, nouvelles rides
Cependant, la technologie pour créer ces modifications subtiles progresse beaucoup plus rapidement que notre capacité à les détecter. La plupart des méthodes de détection de deepfakes sont obsolètes, se concentrant sur des techniques et des ensembles de données plus anciens. Cela, jusqu'à une récente percée de chercheurs en Inde.
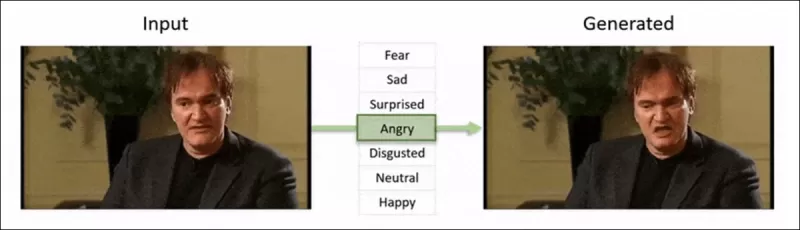
 Détection de modifications locales subtiles dans les deepfakes : une vidéo réelle est altérée pour produire des faux avec des changements nuancés tels que des sourcils relevés, des traits de genre modifiés et des changements d'expression vers le dégoût (illustré ici par une seule image). Source : https://arxiv.org/pdf/2503.22121
Détection de modifications locales subtiles dans les deepfakes : une vidéo réelle est altérée pour produire des faux avec des changements nuancés tels que des sourcils relevés, des traits de genre modifiés et des changements d'expression vers le dégoût (illustré ici par une seule image). Source : https://arxiv.org/pdf/2503.22121
Cette nouvelle recherche cible la détection de manipulations faciales subtiles et localisées, un type de falsification souvent négligé. Au lieu de chercher des incohérences générales ou des discordances d'identité, la méthode se concentre sur des détails fins comme de légers changements d'expression ou des modifications mineures de caractéristiques faciales spécifiques. Elle s'appuie sur le Facial Action Coding System (FACS), qui décompose les expressions faciales en 64 zones modifiables.
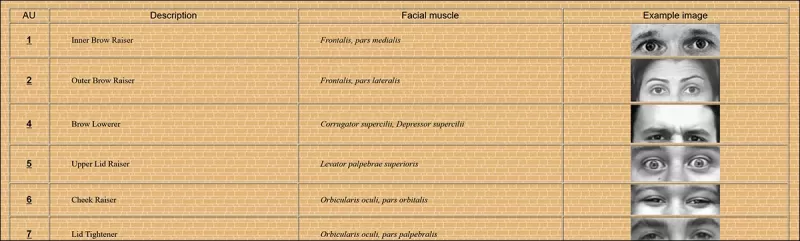 Certaines des 64 parties constitutives des expressions dans le FACS. Source : https://www.cs.cmu.edu/~face/facs.htm
Certaines des 64 parties constitutives des expressions dans le FACS. Source : https://www.cs.cmu.edu/~face/facs.htm
Les chercheurs ont testé leur approche contre diverses méthodes d'édition récentes et ont constaté qu'elle surpassait systématiquement les solutions existantes, même avec des ensembles de données plus anciens et de nouveaux vecteurs d'attaque.
« En utilisant des caractéristiques basées sur les AU pour guider les représentations vidéo apprises à travers des autoencodeurs masqués (MAE), notre méthode capture efficacement les changements localisés cruciaux pour détecter les modifications faciales subtiles.
« Cette approche nous permet de construire une représentation latente unifiée qui encode à la fois les modifications localisées et les altérations plus larges dans les vidéos centrées sur les visages, offrant une solution complète et adaptable pour la détection de deepfakes. »
L'article, intitulé Détection des manipulations de deepfakes localisées à l'aide de représentations vidéo guidées par les unités d'action, a été rédigé par des chercheurs de l'Indian Institute of Technology à Madras.
Méthode
La méthode commence par détecter les visages dans une vidéo et échantillonner des images espacées uniformément centrées sur ces visages. Ces images sont ensuite divisées en petits patches 3D, capturant des détails spatiaux et temporels locaux.
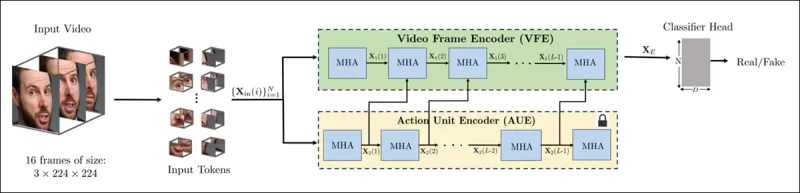 Schéma de la nouvelle méthode. La vidéo d'entrée est traitée avec une détection de visage pour extraire des images centrées sur le visage, espacées uniformément, qui sont ensuite divisées en patches tubulaires et passées à travers un encodeur qui fusionne les représentations latentes de deux tâches de prétexte pré-entraînées. Le vecteur résultant est ensuite utilisé par un classificateur pour déterminer si la vidéo est réelle ou fausse.
Schéma de la nouvelle méthode. La vidéo d'entrée est traitée avec une détection de visage pour extraire des images centrées sur le visage, espacées uniformément, qui sont ensuite divisées en patches tubulaires et passées à travers un encodeur qui fusionne les représentations latentes de deux tâches de prétexte pré-entraînées. Le vecteur résultant est ensuite utilisé par un classificateur pour déterminer si la vidéo est réelle ou fausse.
Chaque patch contient une petite fenêtre de pixels provenant de quelques images successives, permettant au modèle d'apprendre les mouvements et les changements d'expression à court terme. Ces patches sont intégrés et encodés positionnellement avant d'être introduits dans un encodeur conçu pour distinguer les vidéos réelles des fausses.
Le défi de détecter des manipulations subtiles est abordé en utilisant un encodeur qui combine deux types de représentations apprises à travers un mécanisme d'attention croisée, visant à créer un espace de caractéristiques plus sensible et généralisable.
Tâches de prétexte
La première représentation provient d'un encodeur entraîné avec une tâche d'autoencodage masqué. En masquant la plupart des patches 3D de la vidéo, l'encodeur apprend à reconstruire les parties manquantes, capturant des motifs spatiotemporels importants comme les mouvements faciaux.
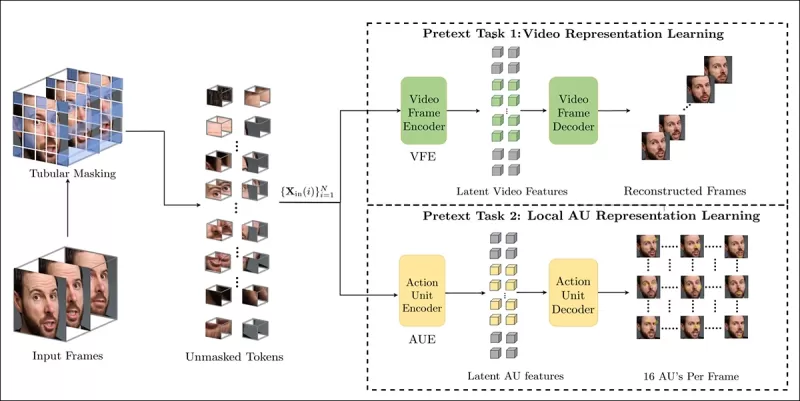 L'entraînement des tâches de prétexte implique de masquer des parties de l'entrée vidéo et d'utiliser une configuration encodeur-décodeur pour reconstruire soit les images originales, soit les cartes d'unités d'action par image, selon la tâche.
L'entraînement des tâches de prétexte implique de masquer des parties de l'entrée vidéo et d'utiliser une configuration encodeur-décodeur pour reconstruire soit les images originales, soit les cartes d'unités d'action par image, selon la tâche.
Cependant, cela seul ne suffit pas pour détecter les modifications à grain fin. Les chercheurs ont introduit un second encodeur entraîné à détecter les unités d'action faciales (AU), l'encourageant à se concentrer sur l'activité musculaire localisée où les modifications subtiles des deepfakes se produisent souvent.
 Autres exemples d'unités d'action faciales (FAUs, ou AUs). Source : https://www.eiagroup.com/the-facial-action-coding-system/
Autres exemples d'unités d'action faciales (FAUs, ou AUs). Source : https://www.eiagroup.com/the-facial-action-coding-system/
Après le pré-entraînement, les sorties des deux encodeurs sont combinées à l'aide d'une attention croisée, les caractéristiques basées sur les AU guidant l'attention sur les caractéristiques spatio-temporelles. Cela donne une représentation latente fusionnée qui capture à la fois le contexte de mouvement plus large et les détails d'expression localisés, utilisée pour la tâche de classification finale.
Données et tests
Mise en œuvre
Le système a été implémenté en utilisant le cadre de détection de visage FaceXZoo basé sur PyTorch, extrayant 16 images centrées sur le visage de chaque clip vidéo. Les tâches de prétexte ont été entraînées sur l'ensemble de données CelebV-HQ, qui comprend 35 000 vidéos faciales de haute qualité.
 Extrait de l'article source, exemples de l'ensemble de données CelebV-HQ utilisé dans le nouveau projet. Source : https://arxiv.org/pdf/2207.12393
Extrait de l'article source, exemples de l'ensemble de données CelebV-HQ utilisé dans le nouveau projet. Source : https://arxiv.org/pdf/2207.12393
La moitié des données a été masquée pour éviter le surajustement. Pour la tâche de reconstruction d'images masquées, le modèle a été entraîné à prédire les régions manquantes en utilisant la perte L1. Pour la seconde tâche, il a été entraîné à générer des cartes pour 16 unités d'action faciales, supervisé par la perte L1.
Après le pré-entraînement, les encodeurs ont été fusionnés et affinés pour la détection de deepfakes en utilisant l'ensemble de données FaceForensics++, qui comprend à la fois des vidéos réelles et manipulées.
 L'ensemble de données FaceForensics++ est le point de référence central pour la détection de deepfakes depuis 2017, bien qu'il soit maintenant considérablement dépassé en ce qui concerne les dernières techniques de synthèse faciale. Source : https://www.youtube.com/watch?v=x2g48Q2I2ZQ
L'ensemble de données FaceForensics++ est le point de référence central pour la détection de deepfakes depuis 2017, bien qu'il soit maintenant considérablement dépassé en ce qui concerne les dernières techniques de synthèse faciale. Source : https://www.youtube.com/watch?v=x2g48Q2I2ZQ
Pour résoudre le problème de déséquilibre des classes, les auteurs ont utilisé la perte focale, mettant l'accent sur les exemples plus difficiles pendant l'entraînement. Tout l'entraînement a été effectué sur un seul GPU RTX 4090 avec 24 Go de VRAM, en utilisant des points de contrôle pré-entraînés de VideoMAE.
Tests
La méthode a été évaluée par rapport à diverses techniques de détection de deepfakes, en se concentrant sur les deepfakes modifiés localement. Les tests incluaient une gamme de méthodes d'édition et d'ensembles de données deepfake plus anciens, en utilisant des métriques telles que l'aire sous la courbe (AUC), la précision moyenne et le score F1 moyen.
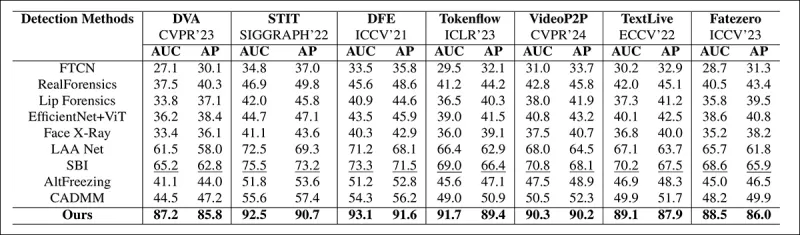 Extrait de l'article : la comparaison sur les deepfakes localisés récents montre que la méthode proposée a surpassé toutes les autres, avec un gain de 15 à 20 pour cent en AUC et en précision moyenne par rapport à l'approche suivante la meilleure.
Extrait de l'article : la comparaison sur les deepfakes localisés récents montre que la méthode proposée a surpassé toutes les autres, avec un gain de 15 à 20 pour cent en AUC et en précision moyenne par rapport à l'approche suivante la meilleure.
Les auteurs ont fourni des comparaisons visuelles de vidéos manipulées localement, montrant la sensibilité supérieure de leur méthode aux modifications subtiles.
 Une vidéo réelle a été altérée à l'aide de trois manipulations localisées différentes pour produire des faux qui restaient visuellement similaires à l'original. Sont présentées ici des images représentatives ainsi que les scores moyens de détection de faux pour chaque méthode. Alors que les détecteurs existants avaient du mal avec ces modifications subtiles, le modèle proposé a constamment attribué des probabilités élevées de faux, indiquant une plus grande sensibilité aux changements localisés.
Une vidéo réelle a été altérée à l'aide de trois manipulations localisées différentes pour produire des faux qui restaient visuellement similaires à l'original. Sont présentées ici des images représentatives ainsi que les scores moyens de détection de faux pour chaque méthode. Alors que les détecteurs existants avaient du mal avec ces modifications subtiles, le modèle proposé a constamment attribué des probabilités élevées de faux, indiquant une plus grande sensibilité aux changements localisés.
Les chercheurs ont noté que les méthodes de détection de pointe existantes avaient du mal avec les dernières techniques de génération de deepfakes, tandis que leur méthode montrait une généralisation robuste, obtenant des scores élevés en AUC et en précision moyenne.
 Les performances sur les ensembles de données deepfake traditionnels montrent que la méthode proposée restait compétitive avec les approches de pointe, indiquant une forte généralisation sur une gamme de types de manipulation.
Les performances sur les ensembles de données deepfake traditionnels montrent que la méthode proposée restait compétitive avec les approches de pointe, indiquant une forte généralisation sur une gamme de types de manipulation.
Les auteurs ont également testé la fiabilité du modèle dans des conditions réelles, le trouvant résilient aux distorsions vidéo courantes telles que les ajustements de saturation, le flou gaussien et la pixellisation.
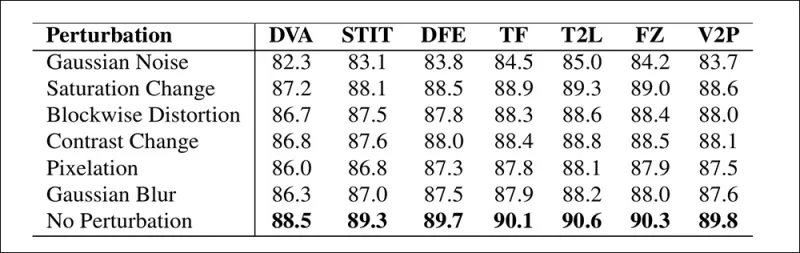 Une illustration de la manière dont la précision de la détection change sous différentes distorsions vidéo. La nouvelle méthode est restée résiliente dans la plupart des cas, avec seulement une légère baisse en AUC. La baisse la plus significative s'est produite lorsque du bruit gaussien a été introduit.
Une illustration de la manière dont la précision de la détection change sous différentes distorsions vidéo. La nouvelle méthode est restée résiliente dans la plupart des cas, avec seulement une légère baisse en AUC. La baisse la plus significative s'est produite lorsque du bruit gaussien a été introduit.
Conclusion
Bien que le public pense souvent aux deepfakes comme à des échanges d'identité, la réalité de la manipulation par IA est plus nuancée et potentiellement plus insidieuse. Le type de modification locale discuté dans cette nouvelle recherche pourrait ne pas attirer l'attention du public jusqu'à ce qu'un autre incident de grande envergure se produise. Pourtant, comme l'a souligné l'acteur Nic Cage, le potentiel des modifications de post-production pour altérer les performances est une préoccupation dont nous devrions tous être conscients. Nous sommes naturellement sensibles aux moindres changements dans les expressions faciales, et le contexte peut considérablement en modifier l'impact.
Première publication mercredi 2 avril 2025
Article connexe
 Tencent dévoile HunyuanCustom pour la personnalisation vidéo à partir d'une seule image
Cet article explore le lancement de HunyuanCustom, un modèle de génération vidéo multimodal par Tencent. L'ampleur considérable du document de recherche accompagnant et les défis posés par les vidéos
Civitai renforce les réglementations DeepFake au milieu de la pression de MasterCard et Visa
Civitai, l'un des référentiels de modèles d'IA les plus importants sur Internet, a récemment apporté des modifications importantes à ses politiques sur le contenu NSFW, en particulier concernant les loras de célébrités. Ces modifications ont été stimulées par la pression des facilitateurs de paiement MasterCard et Visa. Celebrity Loras, qui êtes-vous
Google utilise l'IA pour suspendre plus de 39 millions de comptes d'annonces pour une fraude présumée
Google a annoncé mercredi qu'il avait pris une étape majeure dans la lutte contre la fraude publicitaire en suspendant un comptes stupéfaits de 39,2 millions d'annonces sur sa plate-forme en 2024. Ce nombre est plus que triple ce qui a été signalé l'année précédente, présentant les efforts intensifiés de Google pour nettoyer son écosie publicitaire publicitaire
commentaires (43)
0/200
Tencent dévoile HunyuanCustom pour la personnalisation vidéo à partir d'une seule image
Cet article explore le lancement de HunyuanCustom, un modèle de génération vidéo multimodal par Tencent. L'ampleur considérable du document de recherche accompagnant et les défis posés par les vidéos
Civitai renforce les réglementations DeepFake au milieu de la pression de MasterCard et Visa
Civitai, l'un des référentiels de modèles d'IA les plus importants sur Internet, a récemment apporté des modifications importantes à ses politiques sur le contenu NSFW, en particulier concernant les loras de célébrités. Ces modifications ont été stimulées par la pression des facilitateurs de paiement MasterCard et Visa. Celebrity Loras, qui êtes-vous
Google utilise l'IA pour suspendre plus de 39 millions de comptes d'annonces pour une fraude présumée
Google a annoncé mercredi qu'il avait pris une étape majeure dans la lutte contre la fraude publicitaire en suspendant un comptes stupéfaits de 39,2 millions d'annonces sur sa plate-forme en 2024. Ce nombre est plus que triple ce qui a été signalé l'année précédente, présentant les efforts intensifiés de Google pour nettoyer son écosie publicitaire publicitaire
commentaires (43)
0/200
![WilliamCarter]() WilliamCarter
WilliamCarter
 19 août 2025 23:01:13 UTC+02:00
19 août 2025 23:01:13 UTC+02:00
That Pelosi video from 2019 is wild! It’s scary how a few tweaks can make someone look totally drunk. AI’s power to mess with videos is both cool and creepy—makes you wonder what’s real anymore. 😬


 0
0
![JuanMartínez]() JuanMartínez
19 août 2025 19:01:10 UTC+02:00
JuanMartínez
19 août 2025 19:01:10 UTC+02:00
This Pelosi video incident is wild! 🤯 It’s scary how a few tweaks can make someone look totally out of it. Makes me wonder how much of what we see online is real anymore. AI’s cool, but this kind of stuff could mess with trust big time.
0
![RyanPerez]() RyanPerez
29 juillet 2025 14:25:16 UTC+02:00
RyanPerez
29 juillet 2025 14:25:16 UTC+02:00
That Pelosi video from 2019 is wild! It’s scary how a few tweaks can make someone look totally out of it. AI’s power to mess with reality is no joke—makes you wonder what’s real anymore. 🫣
0
![MarkRoberts]() MarkRoberts
24 avril 2025 04:24:54 UTC+02:00
MarkRoberts
24 avril 2025 04:24:54 UTC+02:00
Este herramienta de IA me mostró lo fácil que es manipular videos. El incidente de Nancy Pelosi fue un recordatorio impactante. Es aterrador pensar en cuántas noticias falsas pueden existir. Ahora estoy más atento a lo que creo en línea. ¡Cuidado, amigos! 👀
0
![RobertMartin]() RobertMartin
20 avril 2025 22:42:51 UTC+02:00
RobertMartin
20 avril 2025 22:42:51 UTC+02:00
このAIツールは、ビデオを操作するのがどれほど簡単かを教えてくれました。ナンシー・ペロシの事件は衝撃的でした。偽ニュースがどれだけあるかと思うと恐ろしいです。オンラインで何を信じるかについて、今はもっと注意しています。みなさんも気をつけてくださいね!👀
0
![PaulMartínez]() PaulMartínez
19 avril 2025 12:25:50 UTC+02:00
PaulMartínez
19 avril 2025 12:25:50 UTC+02:00
Dieses KI-Tool hat mir gezeigt, wie einfach es ist, Videos zu manipulieren! Der Vorfall mit Nancy Pelosi war ein Weckruf. Es ist beängstigend, wie viele gefälschte Nachrichten es geben könnte. Ich bin jetzt vorsichtiger mit dem, was ich online glaube. Seid wachsam, Leute! 👀
0
En 2019, une vidéo trompeuse de Nancy Pelosi, alors présidente de la Chambre des représentants des États-Unis, a largement circulé. La vidéo, modifiée pour la faire apparaître intoxiquée, a été un rappel frappant de la facilité avec laquelle les médias manipulés peuvent induire le public en erreur. Malgré sa simplicité, cet incident a mis en évidence le potentiel de dommage des montages audiovisuels même basiques.
À l'époque, le paysage des deepfakes était largement dominé par des technologies de remplacement de visage basées sur des autoencodeurs, présentes depuis fin 2017. Ces systèmes précoces peinaient à effectuer les modifications nuancées observées dans la vidéo de Pelosi, se concentrant plutôt sur des échanges de visages plus évidents.
Le cadre ‘Neural Emotion Director' de 2022 modifie l'humeur d'un visage célèbre. Source : https://www.youtube.com/watch?v=Li6W8pRDMJQ
Aujourd'hui, l'industrie du cinéma et de la télévision explore de plus en plus les montages de post-production pilotés par l'IA. Cette tendance suscite à la fois intérêt et critiques, car l'IA permet un niveau de perfectionnisme auparavant inatteignable. En réponse, la communauté scientifique a développé divers projets axés sur les 'modifications locales' des captures faciales, tels que Diffusion Video Autoencoders, Stitch it in Time, ChatFace, MagicFace et DISCO.
Modification d'expression avec le projet MagicFace de janvier 2025. Source : https://arxiv.org/pdf/2501.02260
Nouveaux visages, nouvelles rides
Cependant, la technologie pour créer ces modifications subtiles progresse beaucoup plus rapidement que notre capacité à les détecter. La plupart des méthodes de détection de deepfakes sont obsolètes, se concentrant sur des techniques et des ensembles de données plus anciens. Cela, jusqu'à une récente percée de chercheurs en Inde.
Détection de modifications locales subtiles dans les deepfakes : une vidéo réelle est altérée pour produire des faux avec des changements nuancés tels que des sourcils relevés, des traits de genre modifiés et des changements d'expression vers le dégoût (illustré ici par une seule image). Source : https://arxiv.org/pdf/2503.22121
Cette nouvelle recherche cible la détection de manipulations faciales subtiles et localisées, un type de falsification souvent négligé. Au lieu de chercher des incohérences générales ou des discordances d'identité, la méthode se concentre sur des détails fins comme de légers changements d'expression ou des modifications mineures de caractéristiques faciales spécifiques. Elle s'appuie sur le Facial Action Coding System (FACS), qui décompose les expressions faciales en 64 zones modifiables.
Certaines des 64 parties constitutives des expressions dans le FACS. Source : https://www.cs.cmu.edu/~face/facs.htm
Les chercheurs ont testé leur approche contre diverses méthodes d'édition récentes et ont constaté qu'elle surpassait systématiquement les solutions existantes, même avec des ensembles de données plus anciens et de nouveaux vecteurs d'attaque.
« En utilisant des caractéristiques basées sur les AU pour guider les représentations vidéo apprises à travers des autoencodeurs masqués (MAE), notre méthode capture efficacement les changements localisés cruciaux pour détecter les modifications faciales subtiles.
« Cette approche nous permet de construire une représentation latente unifiée qui encode à la fois les modifications localisées et les altérations plus larges dans les vidéos centrées sur les visages, offrant une solution complète et adaptable pour la détection de deepfakes. »
L'article, intitulé Détection des manipulations de deepfakes localisées à l'aide de représentations vidéo guidées par les unités d'action, a été rédigé par des chercheurs de l'Indian Institute of Technology à Madras.
Méthode
La méthode commence par détecter les visages dans une vidéo et échantillonner des images espacées uniformément centrées sur ces visages. Ces images sont ensuite divisées en petits patches 3D, capturant des détails spatiaux et temporels locaux.
Schéma de la nouvelle méthode. La vidéo d'entrée est traitée avec une détection de visage pour extraire des images centrées sur le visage, espacées uniformément, qui sont ensuite divisées en patches tubulaires et passées à travers un encodeur qui fusionne les représentations latentes de deux tâches de prétexte pré-entraînées. Le vecteur résultant est ensuite utilisé par un classificateur pour déterminer si la vidéo est réelle ou fausse.
Chaque patch contient une petite fenêtre de pixels provenant de quelques images successives, permettant au modèle d'apprendre les mouvements et les changements d'expression à court terme. Ces patches sont intégrés et encodés positionnellement avant d'être introduits dans un encodeur conçu pour distinguer les vidéos réelles des fausses.
Le défi de détecter des manipulations subtiles est abordé en utilisant un encodeur qui combine deux types de représentations apprises à travers un mécanisme d'attention croisée, visant à créer un espace de caractéristiques plus sensible et généralisable.
Tâches de prétexte
La première représentation provient d'un encodeur entraîné avec une tâche d'autoencodage masqué. En masquant la plupart des patches 3D de la vidéo, l'encodeur apprend à reconstruire les parties manquantes, capturant des motifs spatiotemporels importants comme les mouvements faciaux.
L'entraînement des tâches de prétexte implique de masquer des parties de l'entrée vidéo et d'utiliser une configuration encodeur-décodeur pour reconstruire soit les images originales, soit les cartes d'unités d'action par image, selon la tâche.
Cependant, cela seul ne suffit pas pour détecter les modifications à grain fin. Les chercheurs ont introduit un second encodeur entraîné à détecter les unités d'action faciales (AU), l'encourageant à se concentrer sur l'activité musculaire localisée où les modifications subtiles des deepfakes se produisent souvent.
Autres exemples d'unités d'action faciales (FAUs, ou AUs). Source : https://www.eiagroup.com/the-facial-action-coding-system/
Après le pré-entraînement, les sorties des deux encodeurs sont combinées à l'aide d'une attention croisée, les caractéristiques basées sur les AU guidant l'attention sur les caractéristiques spatio-temporelles. Cela donne une représentation latente fusionnée qui capture à la fois le contexte de mouvement plus large et les détails d'expression localisés, utilisée pour la tâche de classification finale.
Données et tests
Mise en œuvre
Le système a été implémenté en utilisant le cadre de détection de visage FaceXZoo basé sur PyTorch, extrayant 16 images centrées sur le visage de chaque clip vidéo. Les tâches de prétexte ont été entraînées sur l'ensemble de données CelebV-HQ, qui comprend 35 000 vidéos faciales de haute qualité.
Extrait de l'article source, exemples de l'ensemble de données CelebV-HQ utilisé dans le nouveau projet. Source : https://arxiv.org/pdf/2207.12393
La moitié des données a été masquée pour éviter le surajustement. Pour la tâche de reconstruction d'images masquées, le modèle a été entraîné à prédire les régions manquantes en utilisant la perte L1. Pour la seconde tâche, il a été entraîné à générer des cartes pour 16 unités d'action faciales, supervisé par la perte L1.
Après le pré-entraînement, les encodeurs ont été fusionnés et affinés pour la détection de deepfakes en utilisant l'ensemble de données FaceForensics++, qui comprend à la fois des vidéos réelles et manipulées.
L'ensemble de données FaceForensics++ est le point de référence central pour la détection de deepfakes depuis 2017, bien qu'il soit maintenant considérablement dépassé en ce qui concerne les dernières techniques de synthèse faciale. Source : https://www.youtube.com/watch?v=x2g48Q2I2ZQ
Pour résoudre le problème de déséquilibre des classes, les auteurs ont utilisé la perte focale, mettant l'accent sur les exemples plus difficiles pendant l'entraînement. Tout l'entraînement a été effectué sur un seul GPU RTX 4090 avec 24 Go de VRAM, en utilisant des points de contrôle pré-entraînés de VideoMAE.
Tests
La méthode a été évaluée par rapport à diverses techniques de détection de deepfakes, en se concentrant sur les deepfakes modifiés localement. Les tests incluaient une gamme de méthodes d'édition et d'ensembles de données deepfake plus anciens, en utilisant des métriques telles que l'aire sous la courbe (AUC), la précision moyenne et le score F1 moyen.
Extrait de l'article : la comparaison sur les deepfakes localisés récents montre que la méthode proposée a surpassé toutes les autres, avec un gain de 15 à 20 pour cent en AUC et en précision moyenne par rapport à l'approche suivante la meilleure.
Les auteurs ont fourni des comparaisons visuelles de vidéos manipulées localement, montrant la sensibilité supérieure de leur méthode aux modifications subtiles.
Une vidéo réelle a été altérée à l'aide de trois manipulations localisées différentes pour produire des faux qui restaient visuellement similaires à l'original. Sont présentées ici des images représentatives ainsi que les scores moyens de détection de faux pour chaque méthode. Alors que les détecteurs existants avaient du mal avec ces modifications subtiles, le modèle proposé a constamment attribué des probabilités élevées de faux, indiquant une plus grande sensibilité aux changements localisés.
Les chercheurs ont noté que les méthodes de détection de pointe existantes avaient du mal avec les dernières techniques de génération de deepfakes, tandis que leur méthode montrait une généralisation robuste, obtenant des scores élevés en AUC et en précision moyenne.
Les performances sur les ensembles de données deepfake traditionnels montrent que la méthode proposée restait compétitive avec les approches de pointe, indiquant une forte généralisation sur une gamme de types de manipulation.
Les auteurs ont également testé la fiabilité du modèle dans des conditions réelles, le trouvant résilient aux distorsions vidéo courantes telles que les ajustements de saturation, le flou gaussien et la pixellisation.
Une illustration de la manière dont la précision de la détection change sous différentes distorsions vidéo. La nouvelle méthode est restée résiliente dans la plupart des cas, avec seulement une légère baisse en AUC. La baisse la plus significative s'est produite lorsque du bruit gaussien a été introduit.
Conclusion
Bien que le public pense souvent aux deepfakes comme à des échanges d'identité, la réalité de la manipulation par IA est plus nuancée et potentiellement plus insidieuse. Le type de modification locale discuté dans cette nouvelle recherche pourrait ne pas attirer l'attention du public jusqu'à ce qu'un autre incident de grande envergure se produise. Pourtant, comme l'a souligné l'acteur Nic Cage, le potentiel des modifications de post-production pour altérer les performances est une préoccupation dont nous devrions tous être conscients. Nous sommes naturellement sensibles aux moindres changements dans les expressions faciales, et le contexte peut considérablement en modifier l'impact.
Première publication mercredi 2 avril 2025










 Tencent dévoile HunyuanCustom pour la personnalisation vidéo à partir d'une seule image
Cet article explore le lancement de HunyuanCustom, un modèle de génération vidéo multimodal par Tencent. L'ampleur considérable du document de recherche accompagnant et les défis posés par les vidéos
Civitai renforce les réglementations DeepFake au milieu de la pression de MasterCard et Visa
Civitai, l'un des référentiels de modèles d'IA les plus importants sur Internet, a récemment apporté des modifications importantes à ses politiques sur le contenu NSFW, en particulier concernant les loras de célébrités. Ces modifications ont été stimulées par la pression des facilitateurs de paiement MasterCard et Visa. Celebrity Loras, qui êtes-vous
Tencent dévoile HunyuanCustom pour la personnalisation vidéo à partir d'une seule image
Cet article explore le lancement de HunyuanCustom, un modèle de génération vidéo multimodal par Tencent. L'ampleur considérable du document de recherche accompagnant et les défis posés par les vidéos
Civitai renforce les réglementations DeepFake au milieu de la pression de MasterCard et Visa
Civitai, l'un des référentiels de modèles d'IA les plus importants sur Internet, a récemment apporté des modifications importantes à ses politiques sur le contenu NSFW, en particulier concernant les loras de célébrités. Ces modifications ont été stimulées par la pression des facilitateurs de paiement MasterCard et Visa. Celebrity Loras, qui êtes-vous
 Google utilise l'IA pour suspendre plus de 39 millions de comptes d'annonces pour une fraude présumée
Google a annoncé mercredi qu'il avait pris une étape majeure dans la lutte contre la fraude publicitaire en suspendant un comptes stupéfaits de 39,2 millions d'annonces sur sa plate-forme en 2024. Ce nombre est plus que triple ce qui a été signalé l'année précédente, présentant les efforts intensifiés de Google pour nettoyer son écosie publicitaire publicitaire
19 août 2025 23:01:13 UTC+02:00
Google utilise l'IA pour suspendre plus de 39 millions de comptes d'annonces pour une fraude présumée
Google a annoncé mercredi qu'il avait pris une étape majeure dans la lutte contre la fraude publicitaire en suspendant un comptes stupéfaits de 39,2 millions d'annonces sur sa plate-forme en 2024. Ce nombre est plus que triple ce qui a été signalé l'année précédente, présentant les efforts intensifiés de Google pour nettoyer son écosie publicitaire publicitaire
19 août 2025 23:01:13 UTC+02:00
That Pelosi video from 2019 is wild! It’s scary how a few tweaks can make someone look totally drunk. AI’s power to mess with videos is both cool and creepy—makes you wonder what’s real anymore. 😬
0
19 août 2025 19:01:10 UTC+02:00
This Pelosi video incident is wild! 🤯 It’s scary how a few tweaks can make someone look totally out of it. Makes me wonder how much of what we see online is real anymore. AI’s cool, but this kind of stuff could mess with trust big time.
0
29 juillet 2025 14:25:16 UTC+02:00
That Pelosi video from 2019 is wild! It’s scary how a few tweaks can make someone look totally out of it. AI’s power to mess with reality is no joke—makes you wonder what’s real anymore. 🫣
0
24 avril 2025 04:24:54 UTC+02:00
Este herramienta de IA me mostró lo fácil que es manipular videos. El incidente de Nancy Pelosi fue un recordatorio impactante. Es aterrador pensar en cuántas noticias falsas pueden existir. Ahora estoy más atento a lo que creo en línea. ¡Cuidado, amigos! 👀
0
20 avril 2025 22:42:51 UTC+02:00
このAIツールは、ビデオを操作するのがどれほど簡単かを教えてくれました。ナンシー・ペロシの事件は衝撃的でした。偽ニュースがどれだけあるかと思うと恐ろしいです。オンラインで何を信じるかについて、今はもっと注意しています。みなさんも気をつけてくださいね!👀
0
19 avril 2025 12:25:50 UTC+02:00
Dieses KI-Tool hat mir gezeigt, wie einfach es ist, Videos zu manipulieren! Der Vorfall mit Nancy Pelosi war ein Weckruf. Es ist beängstigend, wie viele gefälschte Nachrichten es geben könnte. Ich bin jetzt vorsichtiger mit dem, was ich online glaube. Seid wachsam, Leute! 👀
0













