




Presentación de modificaciones de IA sutiles pero impactantes en el contenido de video auténtico
En 2019, un video engañoso de Nancy Pelosi, entonces presidenta de la Cámara de Representantes de EE. UU., circuló ampliamente. El video, que fue editado para hacerla parecer intoxicada, fue un recordatorio claro de cuán fácilmente los medios manipulados pueden engañar al público. A pesar de su simplicidad, este incidente destacó el daño potencial de incluso ediciones audiovisuales básicas.
En ese momento, el panorama de los deepfakes estaba dominado en gran medida por tecnologías de reemplazo de rostros basadas en autoencoders, que existían desde finales de 2017. Estos sistemas iniciales tenían dificultades para realizar los cambios matizados vistos en el video de Pelosi, enfocándose en cambio en intercambios de rostros más evidentes.
 El marco 'Neural Emotion Director' de 2022 cambia el estado de ánimo de un rostro famoso. Fuente: https://www.youtube.com/watch?v=Li6W8pRDMJQ
El marco 'Neural Emotion Director' de 2022 cambia el estado de ánimo de un rostro famoso. Fuente: https://www.youtube.com/watch?v=Li6W8pRDMJQ
Avanzando hasta hoy, la industria del cine y la televisión está explorando cada vez más ediciones de posproducción impulsadas por IA. Esta tendencia ha generado tanto interés como críticas, ya que la IA permite un nivel de perfeccionismo que antes era inalcanzable. En respuesta, la comunidad de investigación ha desarrollado varios proyectos enfocados en 'ediciones locales' de capturas faciales, como Diffusion Video Autoencoders, Stitch it in Time, ChatFace, MagicFace y DISCO.
 Edición de expresiones con el proyecto MagicFace de enero de 2025. Fuente: https://arxiv.org/pdf/2501.02260
Edición de expresiones con el proyecto MagicFace de enero de 2025. Fuente: https://arxiv.org/pdf/2501.02260
Nuevos Rostros, Nuevas Arrugas
Sin embargo, la tecnología para crear estas ediciones sutiles está avanzando mucho más rápido que nuestra capacidad para detectarlas. La mayoría de los métodos de detección de deepfakes están obsoletos, enfocándose en técnicas y conjuntos de datos más antiguos. Esto fue así hasta un reciente avance de investigadores en India.
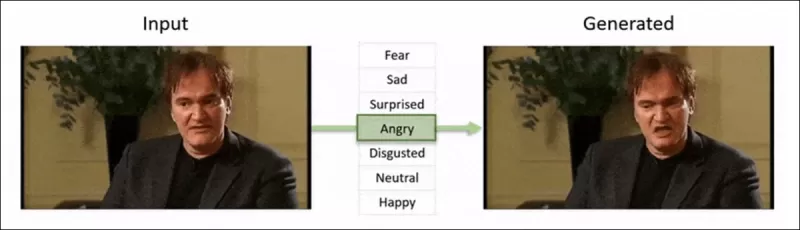
 Detección de Ediciones Locales Sutiles en Deepfakes: Un video real es alterado para producir falsificaciones con cambios matizados como cejas levantadas, rasgos de género modificados y cambios en la expresión hacia el disgusto (ilustrado aquí con un solo fotograma). Fuente: https://arxiv.org/pdf/2503.22121
Detección de Ediciones Locales Sutiles en Deepfakes: Un video real es alterado para producir falsificaciones con cambios matizados como cejas levantadas, rasgos de género modificados y cambios en la expresión hacia el disgusto (ilustrado aquí con un solo fotograma). Fuente: https://arxiv.org/pdf/2503.22121
Esta nueva investigación se centra en la detección de manipulaciones faciales sutiles y localizadas, un tipo de falsificación que a menudo se pasa por alto. En lugar de buscar inconsistencias amplias o discrepancias de identidad, el método se enfoca en detalles finos como cambios leves en la expresión o ediciones menores en características faciales específicas. Utiliza el Sistema de Codificación de Acción Facial (FACS), que descompone las expresiones faciales en 64 áreas mutables.
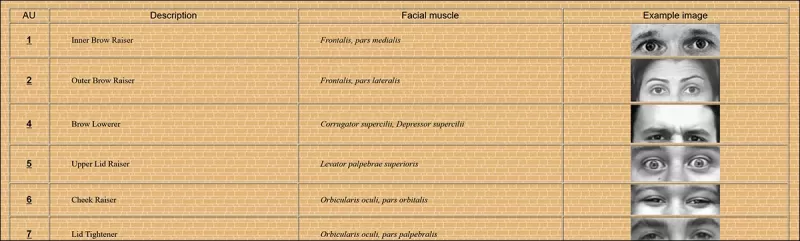 Algunas de las 64 partes de expresión constituyentes en FACS. Fuente: https://www.cs.cmu.edu/~face/facs.htm
Algunas de las 64 partes de expresión constituyentes en FACS. Fuente: https://www.cs.cmu.edu/~face/facs.htm
Los investigadores probaron su enfoque contra varios métodos de edición recientes y encontraron que superaba consistentemente las soluciones existentes, incluso con conjuntos de datos más antiguos y nuevos vectores de ataque.
‘Al usar características basadas en AU para guiar representaciones de video aprendidas a través de Autoencoders Enmascarados (MAE), nuestro método captura eficazmente cambios localizados cruciales para detectar ediciones faciales sutiles.
‘Este enfoque nos permite construir una representación latente unificada que codifica tanto ediciones localizadas como alteraciones más amplias en videos centrados en rostros, proporcionando una solución integral y adaptable para la detección de deepfakes.'
El artículo, titulado Detección de Manipulaciones Deepfake Localizadas Usando Representaciones de Video Guiadas por Unidades de Acción, fue escrito por investigadores del Instituto Indio de Tecnología en Madras.
Método
El método comienza detectando rostros en un video y muestreando fotogramas espaciados uniformemente centrados en estos rostros. Estos fotogramas luego se dividen en pequeños parches 3D, capturando detalles espaciales y temporales locales.
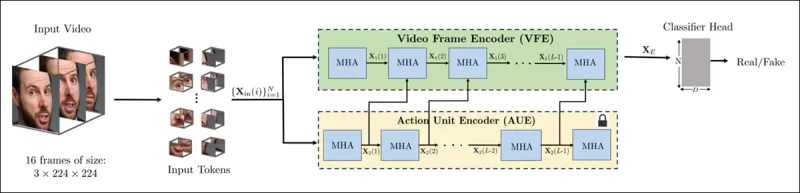 Esquema para el nuevo método. El video de entrada se procesa con detección de rostros para extraer fotogramas espaciados uniformemente y centrados en rostros, que luego se dividen en parches ‘tubulares’ y se pasan a través de un codificador que fusiona representaciones latentes de dos tareas de pretexto preentrenadas. El vector resultante es luego usado por un clasificador para determinar si el video es real o falso.
Esquema para el nuevo método. El video de entrada se procesa con detección de rostros para extraer fotogramas espaciados uniformemente y centrados en rostros, que luego se dividen en parches ‘tubulares’ y se pasan a través de un codificador que fusiona representaciones latentes de dos tareas de pretexto preentrenadas. El vector resultante es luego usado por un clasificador para determinar si el video es real o falso.
Cada parche contiene una pequeña ventana de píxeles de unos pocos fotogramas sucesivos, permitiendo al modelo aprender movimientos y cambios de expresión a corto plazo. Estos parches se incrustan y codifican posicionalmente antes de ser alimentados a un codificador diseñado para distinguir videos reales de falsos.
El desafío de detectar manipulaciones sutiles se aborda utilizando un codificador que combina dos tipos de representaciones aprendidas a través de un mecanismo de atención cruzada, con el objetivo de crear un espacio de características más sensible y generalizable.
Tareas de Pretexto
La primera representación proviene de un codificador entrenado con una tarea de autoencodificación enmascarada. Al ocultar la mayoría de los parches 3D del video, el codificador aprende a reconstruir las partes faltantes, capturando patrones espacio-temporales importantes como el movimiento facial.
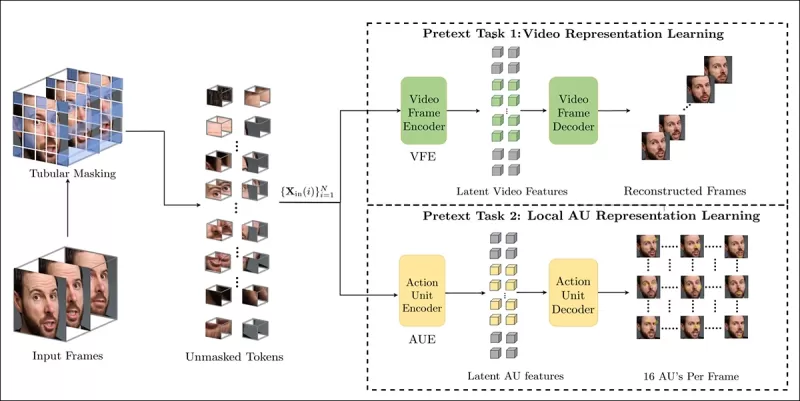 El entrenamiento de tareas de pretexto implica enmascarar partes de la entrada de video y usar una configuración de codificador-decodificador para reconstruir ya sea los fotogramas originales o mapas de unidades de acción por fotograma, dependiendo de la tarea.
El entrenamiento de tareas de pretexto implica enmascarar partes de la entrada de video y usar una configuración de codificador-decodificador para reconstruir ya sea los fotogramas originales o mapas de unidades de acción por fotograma, dependiendo de la tarea.
Sin embargo, esto por sí solo no es suficiente para detectar ediciones de grano fino. Los investigadores introdujeron un segundo codificador entrenado para detectar unidades de acción facial (AUs), animándolo a enfocarse en la actividad muscular localizada donde a menudo ocurren ediciones deepfake sutiles.
 Ejemplos adicionales de Unidades de Acción Facial (FAUs, o AUs). Fuente: https://www.eiagroup.com/the-facial-action-coding-system/
Ejemplos adicionales de Unidades de Acción Facial (FAUs, o AUs). Fuente: https://www.eiagroup.com/the-facial-action-coding-system/
Tras el preentrenamiento, las salidas de ambos codificadores se combinan usando atención cruzada, con las características basadas en AU guiando la atención sobre las características espacio-temporales. Esto resulta en una representación latente fusionada que captura tanto el contexto de movimiento más amplio como los detalles de expresión localizados, utilizada para la tarea de clasificación final.
Datos y Pruebas
Implementación
El sistema fue implementado usando el marco de detección de rostros basado en PyTorch FaceXZoo, extrayendo 16 fotogramas centrados en rostros de cada clip de video. Las tareas de pretexto fueron entrenadas en el conjunto de datos CelebV-HQ, que incluye 35,000 videos faciales de alta calidad.
 Del artículo fuente, ejemplos del conjunto de datos CelebV-HQ usado en el nuevo proyecto. Fuente: https://arxiv.org/pdf/2207.12393
Del artículo fuente, ejemplos del conjunto de datos CelebV-HQ usado en el nuevo proyecto. Fuente: https://arxiv.org/pdf/2207.12393
La mitad de los datos fue enmascarada para prevenir el sobreajuste. Para la tarea de reconstrucción de fotogramas enmascarados, el modelo fue entrenado para predecir regiones faltantes usando la pérdida L1. Para la segunda tarea, se entrenó para generar mapas para 16 unidades de acción facial, supervisado por la pérdida L1.
Tras el preentrenamiento, los codificadores fueron fusionados y ajustados para la detección de deepfakes usando el conjunto de datos FaceForensics++, que incluye videos reales y manipulados.
 El conjunto de datos FaceForensics++ ha sido la piedra angular de la detección de deepfakes desde 2017, aunque ahora está considerablemente desactualizado con respecto a las últimas técnicas de síntesis facial. Fuente: https://www.youtube.com/watch?v=x2g48Q2I2ZQ
El conjunto de datos FaceForensics++ ha sido la piedra angular de la detección de deepfakes desde 2017, aunque ahora está considerablemente desactualizado con respecto a las últimas técnicas de síntesis facial. Fuente: https://www.youtube.com/watch?v=x2g48Q2I2ZQ
Para abordar el desequilibrio de clases, los autores usaron la Pérdida Focal, enfatizando ejemplos más desafiantes durante el entrenamiento. Todo el entrenamiento se realizó en una sola GPU RTX 4090 con 24Gb de VRAM, usando puntos de control preentrenados de VideoMAE.
Pruebas
El método fue evaluado contra varias técnicas de detección de deepfakes, enfocándose en deepfakes editados localmente. Las pruebas incluyeron una gama de métodos de edición y conjuntos de datos de deepfakes más antiguos, usando métricas como Área Bajo la Curva (AUC), Precisión Promedio y Puntaje F1 Medio.
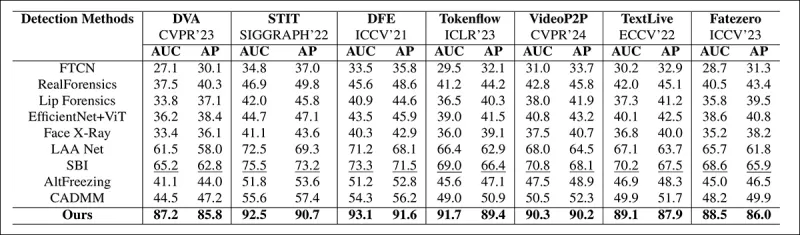 Del artículo: la comparación en deepfakes localizados recientes muestra que el método propuesto superó a todos los demás, con una ganancia de 15 a 20 por ciento en AUC y precisión promedio sobre el siguiente mejor enfoque.
Del artículo: la comparación en deepfakes localizados recientes muestra que el método propuesto superó a todos los demás, con una ganancia de 15 a 20 por ciento en AUC y precisión promedio sobre el siguiente mejor enfoque.
Los autores proporcionaron comparaciones visuales de videos manipulados localmente, mostrando la sensibilidad superior de su método a ediciones sutiles.
 Un video real fue alterado usando tres manipulaciones localizadas diferentes para producir falsificaciones que permanecían visualmente similares al original. Se muestran aquí fotogramas representativos junto con los puntajes promedio de detección de falsificaciones para cada método. Mientras que los detectores existentes tuvieron dificultades con estas ediciones sutiles, el modelo propuesto asignó consistentemente altas probabilidades de falsificación, indicando mayor sensibilidad a cambios localizados.
Un video real fue alterado usando tres manipulaciones localizadas diferentes para producir falsificaciones que permanecían visualmente similares al original. Se muestran aquí fotogramas representativos junto con los puntajes promedio de detección de falsificaciones para cada método. Mientras que los detectores existentes tuvieron dificultades con estas ediciones sutiles, el modelo propuesto asignó consistentemente altas probabilidades de falsificación, indicando mayor sensibilidad a cambios localizados.
Los investigadores notaron que los métodos de detección de vanguardia existentes tuvieron dificultades con las últimas técnicas de generación de deepfakes, mientras que su método mostró una generalización robusta, logrando altos puntajes de AUC y precisión promedio.
 El rendimiento en conjuntos de datos de deepfakes tradicionales muestra que el método propuesto permaneció competitivo con los enfoques líderes, indicando una fuerte generalización en una gama de tipos de manipulación.
El rendimiento en conjuntos de datos de deepfakes tradicionales muestra que el método propuesto permaneció competitivo con los enfoques líderes, indicando una fuerte generalización en una gama de tipos de manipulación.
Los autores también probaron la confiabilidad del modelo bajo condiciones del mundo real, encontrando que era resistente a distorsiones de video comunes como ajustes de saturación, desenfoque gaussiano y pixelación.
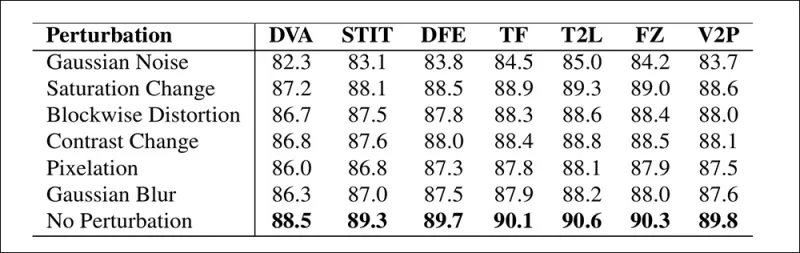 Una ilustración de cómo cambia la precisión de detección bajo diferentes distorsiones de video. El nuevo método permaneció resistente en la mayoría de los casos, con solo una pequeña disminución en AUC. La caída más significativa ocurrió cuando se introdujo ruido gaussiano.
Una ilustración de cómo cambia la precisión de detección bajo diferentes distorsiones de video. El nuevo método permaneció resistente en la mayoría de los casos, con solo una pequeña disminución en AUC. La caída más significativa ocurrió cuando se introdujo ruido gaussiano.
Conclusión
Mientras que el público a menudo piensa en los deepfakes como intercambios de identidad, la realidad de la manipulación de IA es más matizada y potencialmente más insidiosa. El tipo de edición local discutido en esta nueva investigación podría no captar la atención pública hasta que ocurra otro incidente de alto perfil. Sin embargo, como ha señalado el actor Nic Cage, el potencial de las ediciones de posproducción para alterar actuaciones es una preocupación de la que todos deberíamos estar conscientes. Somos naturalmente sensibles incluso a los cambios más leves en las expresiones faciales, y el contexto puede alterar drásticamente su impacto.
Publicado por primera vez el miércoles, 2 de abril de 2025
Artículo relacionado
 Tencent presenta HunyuanCustom para personalización de videos con una sola imagen
Este artículo explora el lanzamiento de HunyuanCustom, un modelo de generación de videos multimodal de Tencent. El amplio alcance del artículo de investigación adjunto y los desafíos con los videos de
Civitai fortalece las regulaciones de los defectos en medio de la presión de MasterCard y Visa
Civitai, uno de los repositorios de modelos de IA más destacados en Internet, recientemente ha realizado cambios significativos en sus políticas sobre el contenido de NSFW, particularmente en relación con las Loras de celebridades. Estos cambios fueron estimulados por la presión de los facilitadores de pago Mastercard y Visa. Celebrity Loras, que eres tú
Google utiliza IA para suspender más de 39 millones de cuentas publicitarias por sospecha de fraude
Google anunció el miércoles que había dado un paso importante para combatir el fraude publicitario al suspender las asombrosas cuentas de 39.2 millones de anunciantes en su plataforma en 2024. Este número es más que triple lo que se informó el año anterior, mostrando los esfuerzos intensificados de Google para limpiar su anuncio Ecosy
comentario (43)
0/200
Tencent presenta HunyuanCustom para personalización de videos con una sola imagen
Este artículo explora el lanzamiento de HunyuanCustom, un modelo de generación de videos multimodal de Tencent. El amplio alcance del artículo de investigación adjunto y los desafíos con los videos de
Civitai fortalece las regulaciones de los defectos en medio de la presión de MasterCard y Visa
Civitai, uno de los repositorios de modelos de IA más destacados en Internet, recientemente ha realizado cambios significativos en sus políticas sobre el contenido de NSFW, particularmente en relación con las Loras de celebridades. Estos cambios fueron estimulados por la presión de los facilitadores de pago Mastercard y Visa. Celebrity Loras, que eres tú
Google utiliza IA para suspender más de 39 millones de cuentas publicitarias por sospecha de fraude
Google anunció el miércoles que había dado un paso importante para combatir el fraude publicitario al suspender las asombrosas cuentas de 39.2 millones de anunciantes en su plataforma en 2024. Este número es más que triple lo que se informó el año anterior, mostrando los esfuerzos intensificados de Google para limpiar su anuncio Ecosy
comentario (43)
0/200
![WilliamCarter]() WilliamCarter
WilliamCarter
 19 de agosto de 2025 23:01:13 GMT+02:00
19 de agosto de 2025 23:01:13 GMT+02:00
That Pelosi video from 2019 is wild! It’s scary how a few tweaks can make someone look totally drunk. AI’s power to mess with videos is both cool and creepy—makes you wonder what’s real anymore. 😬


 0
0
![JuanMartínez]() JuanMartínez
19 de agosto de 2025 19:01:10 GMT+02:00
JuanMartínez
19 de agosto de 2025 19:01:10 GMT+02:00
This Pelosi video incident is wild! 🤯 It’s scary how a few tweaks can make someone look totally out of it. Makes me wonder how much of what we see online is real anymore. AI’s cool, but this kind of stuff could mess with trust big time.
0
![RyanPerez]() RyanPerez
29 de julio de 2025 14:25:16 GMT+02:00
RyanPerez
29 de julio de 2025 14:25:16 GMT+02:00
That Pelosi video from 2019 is wild! It’s scary how a few tweaks can make someone look totally out of it. AI’s power to mess with reality is no joke—makes you wonder what’s real anymore. 🫣
0
![MarkRoberts]() MarkRoberts
24 de abril de 2025 04:24:54 GMT+02:00
MarkRoberts
24 de abril de 2025 04:24:54 GMT+02:00
Este herramienta de IA me mostró lo fácil que es manipular videos. El incidente de Nancy Pelosi fue un recordatorio impactante. Es aterrador pensar en cuántas noticias falsas pueden existir. Ahora estoy más atento a lo que creo en línea. ¡Cuidado, amigos! 👀
0
![RobertMartin]() RobertMartin
20 de abril de 2025 22:42:51 GMT+02:00
RobertMartin
20 de abril de 2025 22:42:51 GMT+02:00
このAIツールは、ビデオを操作するのがどれほど簡単かを教えてくれました。ナンシー・ペロシの事件は衝撃的でした。偽ニュースがどれだけあるかと思うと恐ろしいです。オンラインで何を信じるかについて、今はもっと注意しています。みなさんも気をつけてくださいね!👀
0
![PaulMartínez]() PaulMartínez
19 de abril de 2025 12:25:50 GMT+02:00
PaulMartínez
19 de abril de 2025 12:25:50 GMT+02:00
Dieses KI-Tool hat mir gezeigt, wie einfach es ist, Videos zu manipulieren! Der Vorfall mit Nancy Pelosi war ein Weckruf. Es ist beängstigend, wie viele gefälschte Nachrichten es geben könnte. Ich bin jetzt vorsichtiger mit dem, was ich online glaube. Seid wachsam, Leute! 👀
0
En 2019, un video engañoso de Nancy Pelosi, entonces presidenta de la Cámara de Representantes de EE. UU., circuló ampliamente. El video, que fue editado para hacerla parecer intoxicada, fue un recordatorio claro de cuán fácilmente los medios manipulados pueden engañar al público. A pesar de su simplicidad, este incidente destacó el daño potencial de incluso ediciones audiovisuales básicas.
En ese momento, el panorama de los deepfakes estaba dominado en gran medida por tecnologías de reemplazo de rostros basadas en autoencoders, que existían desde finales de 2017. Estos sistemas iniciales tenían dificultades para realizar los cambios matizados vistos en el video de Pelosi, enfocándose en cambio en intercambios de rostros más evidentes.
El marco 'Neural Emotion Director' de 2022 cambia el estado de ánimo de un rostro famoso. Fuente: https://www.youtube.com/watch?v=Li6W8pRDMJQ
Avanzando hasta hoy, la industria del cine y la televisión está explorando cada vez más ediciones de posproducción impulsadas por IA. Esta tendencia ha generado tanto interés como críticas, ya que la IA permite un nivel de perfeccionismo que antes era inalcanzable. En respuesta, la comunidad de investigación ha desarrollado varios proyectos enfocados en 'ediciones locales' de capturas faciales, como Diffusion Video Autoencoders, Stitch it in Time, ChatFace, MagicFace y DISCO.
Edición de expresiones con el proyecto MagicFace de enero de 2025. Fuente: https://arxiv.org/pdf/2501.02260
Nuevos Rostros, Nuevas Arrugas
Sin embargo, la tecnología para crear estas ediciones sutiles está avanzando mucho más rápido que nuestra capacidad para detectarlas. La mayoría de los métodos de detección de deepfakes están obsoletos, enfocándose en técnicas y conjuntos de datos más antiguos. Esto fue así hasta un reciente avance de investigadores en India.
Detección de Ediciones Locales Sutiles en Deepfakes: Un video real es alterado para producir falsificaciones con cambios matizados como cejas levantadas, rasgos de género modificados y cambios en la expresión hacia el disgusto (ilustrado aquí con un solo fotograma). Fuente: https://arxiv.org/pdf/2503.22121
Esta nueva investigación se centra en la detección de manipulaciones faciales sutiles y localizadas, un tipo de falsificación que a menudo se pasa por alto. En lugar de buscar inconsistencias amplias o discrepancias de identidad, el método se enfoca en detalles finos como cambios leves en la expresión o ediciones menores en características faciales específicas. Utiliza el Sistema de Codificación de Acción Facial (FACS), que descompone las expresiones faciales en 64 áreas mutables.
Algunas de las 64 partes de expresión constituyentes en FACS. Fuente: https://www.cs.cmu.edu/~face/facs.htm
Los investigadores probaron su enfoque contra varios métodos de edición recientes y encontraron que superaba consistentemente las soluciones existentes, incluso con conjuntos de datos más antiguos y nuevos vectores de ataque.
‘Al usar características basadas en AU para guiar representaciones de video aprendidas a través de Autoencoders Enmascarados (MAE), nuestro método captura eficazmente cambios localizados cruciales para detectar ediciones faciales sutiles.
‘Este enfoque nos permite construir una representación latente unificada que codifica tanto ediciones localizadas como alteraciones más amplias en videos centrados en rostros, proporcionando una solución integral y adaptable para la detección de deepfakes.'
El artículo, titulado Detección de Manipulaciones Deepfake Localizadas Usando Representaciones de Video Guiadas por Unidades de Acción, fue escrito por investigadores del Instituto Indio de Tecnología en Madras.
Método
El método comienza detectando rostros en un video y muestreando fotogramas espaciados uniformemente centrados en estos rostros. Estos fotogramas luego se dividen en pequeños parches 3D, capturando detalles espaciales y temporales locales.
Esquema para el nuevo método. El video de entrada se procesa con detección de rostros para extraer fotogramas espaciados uniformemente y centrados en rostros, que luego se dividen en parches ‘tubulares’ y se pasan a través de un codificador que fusiona representaciones latentes de dos tareas de pretexto preentrenadas. El vector resultante es luego usado por un clasificador para determinar si el video es real o falso.
Cada parche contiene una pequeña ventana de píxeles de unos pocos fotogramas sucesivos, permitiendo al modelo aprender movimientos y cambios de expresión a corto plazo. Estos parches se incrustan y codifican posicionalmente antes de ser alimentados a un codificador diseñado para distinguir videos reales de falsos.
El desafío de detectar manipulaciones sutiles se aborda utilizando un codificador que combina dos tipos de representaciones aprendidas a través de un mecanismo de atención cruzada, con el objetivo de crear un espacio de características más sensible y generalizable.
Tareas de Pretexto
La primera representación proviene de un codificador entrenado con una tarea de autoencodificación enmascarada. Al ocultar la mayoría de los parches 3D del video, el codificador aprende a reconstruir las partes faltantes, capturando patrones espacio-temporales importantes como el movimiento facial.
El entrenamiento de tareas de pretexto implica enmascarar partes de la entrada de video y usar una configuración de codificador-decodificador para reconstruir ya sea los fotogramas originales o mapas de unidades de acción por fotograma, dependiendo de la tarea.
Sin embargo, esto por sí solo no es suficiente para detectar ediciones de grano fino. Los investigadores introdujeron un segundo codificador entrenado para detectar unidades de acción facial (AUs), animándolo a enfocarse en la actividad muscular localizada donde a menudo ocurren ediciones deepfake sutiles.
Ejemplos adicionales de Unidades de Acción Facial (FAUs, o AUs). Fuente: https://www.eiagroup.com/the-facial-action-coding-system/
Tras el preentrenamiento, las salidas de ambos codificadores se combinan usando atención cruzada, con las características basadas en AU guiando la atención sobre las características espacio-temporales. Esto resulta en una representación latente fusionada que captura tanto el contexto de movimiento más amplio como los detalles de expresión localizados, utilizada para la tarea de clasificación final.
Datos y Pruebas
Implementación
El sistema fue implementado usando el marco de detección de rostros basado en PyTorch FaceXZoo, extrayendo 16 fotogramas centrados en rostros de cada clip de video. Las tareas de pretexto fueron entrenadas en el conjunto de datos CelebV-HQ, que incluye 35,000 videos faciales de alta calidad.
Del artículo fuente, ejemplos del conjunto de datos CelebV-HQ usado en el nuevo proyecto. Fuente: https://arxiv.org/pdf/2207.12393
La mitad de los datos fue enmascarada para prevenir el sobreajuste. Para la tarea de reconstrucción de fotogramas enmascarados, el modelo fue entrenado para predecir regiones faltantes usando la pérdida L1. Para la segunda tarea, se entrenó para generar mapas para 16 unidades de acción facial, supervisado por la pérdida L1.
Tras el preentrenamiento, los codificadores fueron fusionados y ajustados para la detección de deepfakes usando el conjunto de datos FaceForensics++, que incluye videos reales y manipulados.
El conjunto de datos FaceForensics++ ha sido la piedra angular de la detección de deepfakes desde 2017, aunque ahora está considerablemente desactualizado con respecto a las últimas técnicas de síntesis facial. Fuente: https://www.youtube.com/watch?v=x2g48Q2I2ZQ
Para abordar el desequilibrio de clases, los autores usaron la Pérdida Focal, enfatizando ejemplos más desafiantes durante el entrenamiento. Todo el entrenamiento se realizó en una sola GPU RTX 4090 con 24Gb de VRAM, usando puntos de control preentrenados de VideoMAE.
Pruebas
El método fue evaluado contra varias técnicas de detección de deepfakes, enfocándose en deepfakes editados localmente. Las pruebas incluyeron una gama de métodos de edición y conjuntos de datos de deepfakes más antiguos, usando métricas como Área Bajo la Curva (AUC), Precisión Promedio y Puntaje F1 Medio.
Del artículo: la comparación en deepfakes localizados recientes muestra que el método propuesto superó a todos los demás, con una ganancia de 15 a 20 por ciento en AUC y precisión promedio sobre el siguiente mejor enfoque.
Los autores proporcionaron comparaciones visuales de videos manipulados localmente, mostrando la sensibilidad superior de su método a ediciones sutiles.
Un video real fue alterado usando tres manipulaciones localizadas diferentes para producir falsificaciones que permanecían visualmente similares al original. Se muestran aquí fotogramas representativos junto con los puntajes promedio de detección de falsificaciones para cada método. Mientras que los detectores existentes tuvieron dificultades con estas ediciones sutiles, el modelo propuesto asignó consistentemente altas probabilidades de falsificación, indicando mayor sensibilidad a cambios localizados.
Los investigadores notaron que los métodos de detección de vanguardia existentes tuvieron dificultades con las últimas técnicas de generación de deepfakes, mientras que su método mostró una generalización robusta, logrando altos puntajes de AUC y precisión promedio.
El rendimiento en conjuntos de datos de deepfakes tradicionales muestra que el método propuesto permaneció competitivo con los enfoques líderes, indicando una fuerte generalización en una gama de tipos de manipulación.
Los autores también probaron la confiabilidad del modelo bajo condiciones del mundo real, encontrando que era resistente a distorsiones de video comunes como ajustes de saturación, desenfoque gaussiano y pixelación.
Una ilustración de cómo cambia la precisión de detección bajo diferentes distorsiones de video. El nuevo método permaneció resistente en la mayoría de los casos, con solo una pequeña disminución en AUC. La caída más significativa ocurrió cuando se introdujo ruido gaussiano.
Conclusión
Mientras que el público a menudo piensa en los deepfakes como intercambios de identidad, la realidad de la manipulación de IA es más matizada y potencialmente más insidiosa. El tipo de edición local discutido en esta nueva investigación podría no captar la atención pública hasta que ocurra otro incidente de alto perfil. Sin embargo, como ha señalado el actor Nic Cage, el potencial de las ediciones de posproducción para alterar actuaciones es una preocupación de la que todos deberíamos estar conscientes. Somos naturalmente sensibles incluso a los cambios más leves en las expresiones faciales, y el contexto puede alterar drásticamente su impacto.
Publicado por primera vez el miércoles, 2 de abril de 2025










 Tencent presenta HunyuanCustom para personalización de videos con una sola imagen
Este artículo explora el lanzamiento de HunyuanCustom, un modelo de generación de videos multimodal de Tencent. El amplio alcance del artículo de investigación adjunto y los desafíos con los videos de
Civitai fortalece las regulaciones de los defectos en medio de la presión de MasterCard y Visa
Civitai, uno de los repositorios de modelos de IA más destacados en Internet, recientemente ha realizado cambios significativos en sus políticas sobre el contenido de NSFW, particularmente en relación con las Loras de celebridades. Estos cambios fueron estimulados por la presión de los facilitadores de pago Mastercard y Visa. Celebrity Loras, que eres tú
Tencent presenta HunyuanCustom para personalización de videos con una sola imagen
Este artículo explora el lanzamiento de HunyuanCustom, un modelo de generación de videos multimodal de Tencent. El amplio alcance del artículo de investigación adjunto y los desafíos con los videos de
Civitai fortalece las regulaciones de los defectos en medio de la presión de MasterCard y Visa
Civitai, uno de los repositorios de modelos de IA más destacados en Internet, recientemente ha realizado cambios significativos en sus políticas sobre el contenido de NSFW, particularmente en relación con las Loras de celebridades. Estos cambios fueron estimulados por la presión de los facilitadores de pago Mastercard y Visa. Celebrity Loras, que eres tú
 Google utiliza IA para suspender más de 39 millones de cuentas publicitarias por sospecha de fraude
Google anunció el miércoles que había dado un paso importante para combatir el fraude publicitario al suspender las asombrosas cuentas de 39.2 millones de anunciantes en su plataforma en 2024. Este número es más que triple lo que se informó el año anterior, mostrando los esfuerzos intensificados de Google para limpiar su anuncio Ecosy
19 de agosto de 2025 23:01:13 GMT+02:00
Google utiliza IA para suspender más de 39 millones de cuentas publicitarias por sospecha de fraude
Google anunció el miércoles que había dado un paso importante para combatir el fraude publicitario al suspender las asombrosas cuentas de 39.2 millones de anunciantes en su plataforma en 2024. Este número es más que triple lo que se informó el año anterior, mostrando los esfuerzos intensificados de Google para limpiar su anuncio Ecosy
19 de agosto de 2025 23:01:13 GMT+02:00
That Pelosi video from 2019 is wild! It’s scary how a few tweaks can make someone look totally drunk. AI’s power to mess with videos is both cool and creepy—makes you wonder what’s real anymore. 😬
0
19 de agosto de 2025 19:01:10 GMT+02:00
This Pelosi video incident is wild! 🤯 It’s scary how a few tweaks can make someone look totally out of it. Makes me wonder how much of what we see online is real anymore. AI’s cool, but this kind of stuff could mess with trust big time.
0
29 de julio de 2025 14:25:16 GMT+02:00
That Pelosi video from 2019 is wild! It’s scary how a few tweaks can make someone look totally out of it. AI’s power to mess with reality is no joke—makes you wonder what’s real anymore. 🫣
0
24 de abril de 2025 04:24:54 GMT+02:00
Este herramienta de IA me mostró lo fácil que es manipular videos. El incidente de Nancy Pelosi fue un recordatorio impactante. Es aterrador pensar en cuántas noticias falsas pueden existir. Ahora estoy más atento a lo que creo en línea. ¡Cuidado, amigos! 👀
0
20 de abril de 2025 22:42:51 GMT+02:00
このAIツールは、ビデオを操作するのがどれほど簡単かを教えてくれました。ナンシー・ペロシの事件は衝撃的でした。偽ニュースがどれだけあるかと思うと恐ろしいです。オンラインで何を信じるかについて、今はもっと注意しています。みなさんも気をつけてくださいね!👀
0
19 de abril de 2025 12:25:50 GMT+02:00
Dieses KI-Tool hat mir gezeigt, wie einfach es ist, Videos zu manipulieren! Der Vorfall mit Nancy Pelosi war ein Weckruf. Es ist beängstigend, wie viele gefälschte Nachrichten es geben könnte. Ich bin jetzt vorsichtiger mit dem, was ich online glaube. Seid wachsam, Leute! 👀
0













