
















 집
집정통 비디오 컨텐츠에서 미묘하면서도 영향을 미치는 AI 수정 공개
2019년, 당시 미국 하원의장이었던 낸시 펠로시의 기만적인 영상이 널리 유포되었다. 그녀가 취한 것처럼 보이도록 편집된 이 영상은 조작된 미디어가 대중을 얼마나 쉽게 오도할 수 있는지를 강하게 상기시켰다. 단순했음에도 불구하고, 이 사건은 기본적인 오디오-비주얼 편집이 초래할 수 있는 잠재적 피해를 부각시켰다.
당시 딥페이크 환경은 2017년 말부터 존재했던 오토인코더 기반 얼굴 교체 기술이 주로 지배했다. 이러한 초기 시스템은 펠로시 영상에서 보인 미묘한 변화를 구현하는 데 어려움을 겪었으며, 대신 더 명백한 얼굴 교체에 초점을 맞췄다.
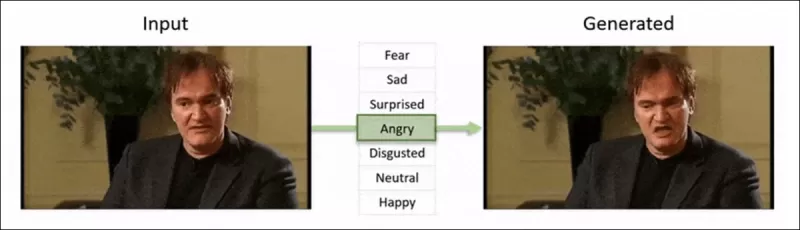 2022년 ‘Neural Emotion Director' 프레임워크는 유명한 얼굴의 분위기를 변화시킨다. 출처: https://www.youtube.com/watch?v=Li6W8pRDMJQ
2022년 ‘Neural Emotion Director' 프레임워크는 유명한 얼굴의 분위기를 변화시킨다. 출처: https://www.youtube.com/watch?v=Li6W8pRDMJQ
현재로 빠르게 넘어오면, 영화와 TV 산업은 점점 더 AI 기반 포스트프로덕션 편집을 탐구하고 있다. 이 트렌드는 이전에는 달성할 수 없었던 완벽주의를 가능하게 하며, 관심과 비판을 동시에 불러일으켰다. 이에 대응하여 연구 커뮤니티는 Diffusion Video Autoencoders, Stitch it in Time, ChatFace, MagicFace, DISCO와 같은 얼굴 캡처의 '로컬 편집'에 초점을 맞춘 다양한 프로젝트를 개발했다.
 2025년 1월 MagicFace 프로젝트를 통한 표정 편집. 출처: https://arxiv.org/pdf/2501.02260
2025년 1월 MagicFace 프로젝트를 통한 표정 편집. 출처: https://arxiv.org/pdf/2501.02260
새로운 얼굴, 새로운 주름
그러나 이러한 미묘한 편집을 만드는 기술은 그것을 탐지하는 우리의 능력보다 훨씬 빠르게 발전하고 있다. 대부분의 딥페이크 탐지 방법은 구식이며, 오래된 기술과 데이터셋에 초점을 맞춘다. 이는 인도 연구자들의 최근 돌파구가 나오기 전까지의 상황이었다.
 딥페이크의 미묘한 로컬 편집 탐지: 실제 영상이 눈썹을 올리거나, 성별 특성을 수정하거나, 혐오감으로 표정이 변화하는 등의 미묘한 변화로 위조된 가짜를 생성한다(여기서는 단일 프레임으로 예시). 출처: https://arxiv.org/pdf/2503.22121
딥페이크의 미묘한 로컬 편집 탐지: 실제 영상이 눈썹을 올리거나, 성별 특성을 수정하거나, 혐오감으로 표정이 변화하는 등의 미묘한 변화로 위조된 가짜를 생성한다(여기서는 단일 프레임으로 예시). 출처: https://arxiv.org/pdf/2503.22121
이 새로운 연구는 종종 간과되는 미묘한 얼굴 조작 탐지에 초점을 맞춘다. 광범위한 불일치나 신원 불일치를 찾는 대신, 이 방법은 약간의 표정 변화나 특정 얼굴 특징의 사소한 편집과 같은 세밀한 디테일에 집중한다. 이는 얼굴 표정을 64개의 가변 영역으로 분해하는 Facial Action Coding System(FACS)을 활용한다.
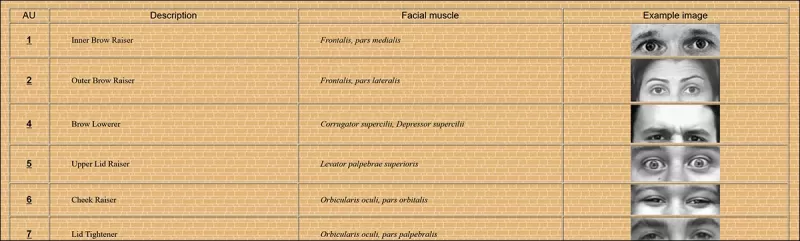 FACS의 64개 표정 구성 요소 중 일부. 출처: https://www.cs.cmu.edu/~face/facs.htm
FACS의 64개 표정 구성 요소 중 일부. 출처: https://www.cs.cmu.edu/~face/facs.htm
연구자들은 다양한 최신 편집 방법에 대해 이 접근법을 테스트했으며, 오래된 데이터셋과 새로운 공격 벡터에서도 기존 솔루션을 지속적으로 능가했다.
‘마스크드 오토인코더(MAE)를 통해 학습된 비디오 표현을 AU 기반 특징을 사용하여 안내함으로써, 우리의 방법은 미묘한 얼굴 편집 탐지에 중요한 로컬라이즈된 변화를 효과적으로 포착한다.
‘이 접근법은 얼굴 중심 비디오에서 로컬라이즈된 편집과 더 광범위한 변화를 모두 인코딩하는 통합된 잠재 표현을 구성할 수 있게 하며, 딥페이크 탐지를 위한 포괄적이고 적응 가능한 솔루션을 제공한다.'
이 논문은 Action Unit-Guided Video Representations를 사용한 로컬라이즈된 딥페이크 조작 탐지라는 제목으로, 인도공과대학 마드라스(IIT Madras)의 연구자들이 저술했다.
방법
이 방법은 비디오에서 얼굴을 탐지하고, 얼굴을 중심으로 균등하게 간격을 둔 프레임을 샘플링하는 것으로 시작한다. 이 프레임들은 로컬 공간 및 시간적 디테일을 포착하는 작은 3D 패치로 분해�된다.
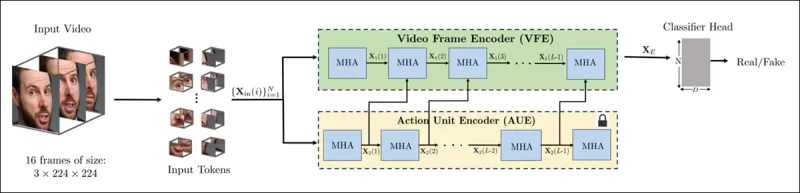 새로운 방법의 스키마. 입력 비디오는 얼굴 탐지를 통해 처리되어 균등하게 간격을 둔 얼굴 중심 프레임을 추출하고, 이를 ‘튜브형’ 패치로 나눈 뒤 두 개의 사전 학습된 프리텍스트 작업에서 잠재 표현을 융합하는 인코더를 거친다. 결과 벡터는 비디오가 진짜인지 가짜인지 판단하는 분류기에 사용된다.
새로운 방법의 스키마. 입력 비디오는 얼굴 탐지를 통해 처리되어 균등하게 간격을 둔 얼굴 중심 프레임을 추출하고, 이를 ‘튜브형’ 패치로 나눈 뒤 두 개의 사전 학습된 프리텍스트 작업에서 잠재 표현을 융합하는 인코더를 거친다. 결과 벡터는 비디오가 진짜인지 가짜인지 판단하는 분류기에 사용된다.
각 패치는 몇 개의 연속된 프레임에서 작은 픽셀 창을 포함하여, 모델이 단기적인 움직임과 표정 변화를 학습할 수 있게 한다. 이 패치들은 임베딩되고 위치적으로 인코딩된 후, 진짜와 가짜 비디오를 구분하도록 설계된 인코더에 입력된다.
미묘한 조작 탐지의 도전은 크로스-어텐션 메커니즘을 통해 두 가지 학습된 표현을 결합하는 인코더를 사용하여 해결되며, 이는 더 민감하고 일반화 가능한 특징 공간을 생성하는 것을 목표로 한다.
프리텍스트 작업
첫 번째 표현은 마스크드 오토인코딩 작업으로 훈련된 인코더에서 나온다. 비디오의 3D 패치 대부분을 숨김으로써, 인코더는 누락된 부분을 재구성하며 얼굴 움직임과 같은 중요한 시공간적 패턴을 포착한다.
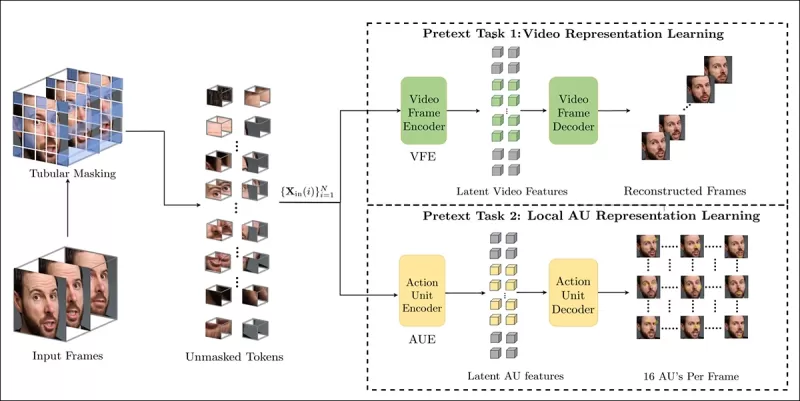 프리텍스트 작업 훈련은 비디오 입력의 일부를 마스킹하고, 인코더-디코더 설정을 사용하여 작업에 따라 원본 프레임 또는 프레임별 액션 유닛 맵을 재구성한다.
프리텍스트 작업 훈련은 비디오 입력의 일부를 마스킹하고, 인코더-디코더 설정을 사용하여 작업에 따라 원본 프레임 또는 프레임별 액션 유닛 맵을 재구성한다.
그러나 이것만으로는 세밀한 편집을 탐지하기에 충분하지 않다. 연구자들은 미묘한 딥페이크 편집이 자주 발생하는 로컬라이즈된 근육 활동에 초점을 맞추도록 두 번째 인코더를 훈련시켜 얼굴 액션 유닛(AU)을 탐지하도록 했다.
 Facial Action Units(FAUs, 또는 AUs)의 추가 예시. 출처: https://www.eiagroup.com/the-facial-action-coding-system/
Facial Action Units(FAUs, 또는 AUs)의 추가 예시. 출처: https://www.eiagroup.com/the-facial-action-coding-system/
사전 훈련 후, 두 인코더의 출력은 크로스-어텐션을 사용하여 결합되며, AU 기반 특징이 시공간적 특징에 대한 어텐션을 안내한다. 이는 더 넓은 움직임 맥락과 로컬라이즈된 표정 디테일을 모두 포착하는 융합된 잠재 표현을 생성하여 최종 분류 작업에 사용된다.
데이터 및 테스트
구현
이 시스템은 FaceXZoo PyTorch 기반 얼굴 탐지 프레임워크를 사용하여 구현되었으며, 각 비디오 클립에서 16개의 얼굴 중심 프레임을 추출했다. 프리텍스트 작업은 35,000개의 고품질 얼굴 비디오를 포함하는 CelebV-HQ 데이터셋에서 훈련되었다.
 소스 논문에서, 새 프로젝트에 사용된 CelebV-HQ 데이터셋의 예시. 출처: https://arxiv.org/pdf/2207.12393
소스 논문에서, 새 프로젝트에 사용된 CelebV-HQ 데이터셋의 예시. 출처: https://arxiv.org/pdf/2207.12393
데이터의 절반은 오버피팅을 방지하기 위해 마스킹되었다. 마스크드 프레임 재구성 작업의 경우, 모델은 L1 손실을 사용하여 누락된 영역을 예측하도록 훈련되었다. 두 번째 작업에서는 16개의 얼굴 액션 유닛에 대한 맵을 생성하도록 훈련되었으며, L1 손실로 감독되었다.
사전 훈련 후, 인코더는 융합되어 FaceForensics++ 데이터셋을 사용하여 딥페이크 탐지를 위해 미세 조정되었다. 이 데이터셋은 진짜와 조작된 비디오를 모두 포함한다.
 FaceForensics++ 데이터셋은 2017년 이후 딥페이크 탐지의 핵심 기준이 되어 왔지만, 최신 얼굴 합성 기술과 관련하여 현재는 상당히 구식이다. 출처: https://www.youtube.com/watch?v=x2g48Q2I2ZQ
FaceForensics++ 데이터셋은 2017년 이후 딥페이크 탐지의 핵심 기준이 되어 왔지만, 최신 얼굴 합성 기술과 관련하여 현재는 상당히 구식이다. 출처: https://www.youtube.com/watch?v=x2g48Q2I2ZQ
클래스 불균형 문제를 해결하기 위해 저자들은 Focal Loss를 사용하여 훈련 중 더 어려운 예시에 중점을 두었다. 모든 훈련은 VideoMAE의 사전 훈련된 체크포인트를 사용하여 24Gb VRAM이 있는 단일 RTX 4090 GPU에서 수행되었다.
테스트
이 방법은 로컬 편집된 딥페이크에 초점을 맞춘 다양한 딥페이크 탐지 기술과 비교 평가되었다. 테스트는 다양한 편집 방법과 오래된 딥페이크 데이터셋을 포함했으며, Area Under Curve(AUC), 평균 정밀도, 평균 F1 점수와 같은 메트릭을 사용했다.
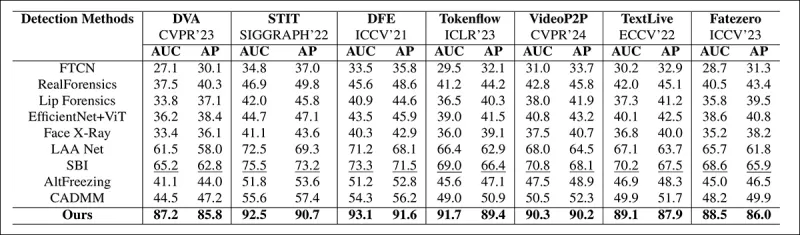 논문에서: 최근 로컬라이즈된 딥페이크에 대한 비교에서 제안된 방법은 모든 다른 방법을 능가했으며, 다음으로 우수한 접근법 대비 AUC와 평균 정밀도에서 15~20%의 성능 향상을 보였다.
논문에서: 최근 로컬라이즈된 딥페이크에 대한 비교에서 제안된 방법은 모든 다른 방법을 능가했으며, 다음으로 우수한 접근법 대비 AUC와 평균 정밀도에서 15~20%의 성능 향상을 보였다.
저자들은 로컬 조작된 비디오의 시각적 비교를 제공하여, 그들의 방법이 미묘한 편집에 대해 우수한 민감도를 보임을 보여주었다.
 실제 비디오가 세 가지 서로 다른 로컬라이즈된 조작을 사용하여 원본과 시각적으로 유사한 가짜를 생성하도록 변경되었다. 여기에는 각 방법에 대한 대표 프레임과 평균 가짜 탐지 점수가 표시된다. 기존 탐지기는 이러한 미묘한 편집에 어려움을 겪었지만, 제안된 모델은 지속적으로 높은 가짜 확률을 부여하여 로컬라이즈된 변화에 대한 더 큰 민감도를 나타냈다.
실제 비디오가 세 가지 서로 다른 로컬라이즈된 조작을 사용하여 원본과 시각적으로 유사한 가짜를 생성하도록 변경되었다. 여기에는 각 방법에 대한 대표 프레임과 평균 가짜 탐지 점수가 표시된다. 기존 탐지기는 이러한 미묘한 편집에 어려움을 겪었지만, 제안된 모델은 지속적으로 높은 가짜 확률을 부여하여 로컬라이즈된 변화에 대한 더 큰 민감도를 나타냈다.
연구자들은 기존의 최첨단 탐지 방법이 최신 딥페이크 생성 기술에 어려움을 겪는 반면, 그들의 방법은 높은 AUC와 평균 정밀도 점수를 달성하며 강력한 일반화를 보여주었다.
 전통적인 딥페이크 데이터셋에서의 성능은 제안된 방법이 선도적인 접근법과 경쟁력 있는 결과를 유지하며, 다양한 조작 유형에 걸쳐 강력한 일반화를 나타냄을 보여준다.
전통적인 딥페이크 데이터셋에서의 성능은 제안된 방법이 선도적인 접근법과 경쟁력 있는 결과를 유지하며, 다양한 조작 유형에 걸쳐 강력한 일반화를 나타냄을 보여준다.
저자들은 또한 실세계 조건에서 모델의 신뢰성을 테스트했으며, 채도 조정, 가우시안 블러, 픽셀화와 같은 일반적인 비디오 왜곡에 대해 견고함을 발견했다.
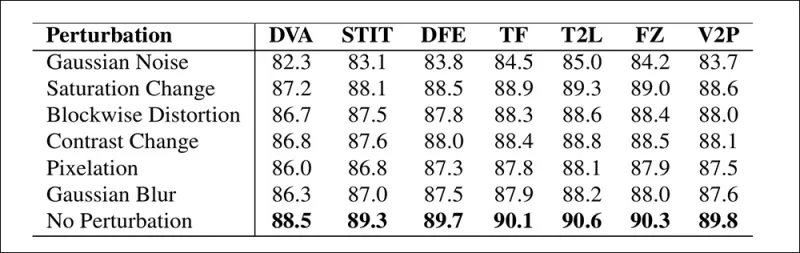 다양한 비디오 왜곡 하에서 탐지 정확도가 어떻게 변하는지를 보여주는 예시. 새로운 방법은 대부분의 경우 견고했으며, AUC에서 약간의 하락만 보였다. 가장 큰 하락은 가우시안 노이즈가 도입되었을 때 발생했다.
다양한 비디오 왜곡 하에서 탐지 정확도가 어떻게 변하는지를 보여주는 예시. 새로운 방법은 대부분의 경우 견고했으며, AUC에서 약간의 하락만 보였다. 가장 큰 하락은 가우시안 노이즈가 도입되었을 때 발생했다.
결론
대중은 종종 딥페이크를 신원 교체로 생각하지만, AI 조작의 현실은 더 미묘하고 잠재적으로 더 위험하다. 이 새로운 연구에서 논의된 로컬 편집은 또 다른 주목할 만한 사건이 발생할 때까지 대중의 관심을 끌지 않을 수 있다. 그러나 배우 Nic Cage가 지적했듯이, 포스트프로덕션 편집이 공연을 변경할 가능성은 우리 모두가 알아야 할 우려 사항이다. 우리는 얼굴 표정의 미세한 변화에도 자연스럽게 민감하며, 맥락은 그 영향을 극적으로 바꿀 수 있다.
최초 게시일: 2025년 4월 2일 수요일
관련 기사
 유튜브, 정치인·공직자·언론인을 대상으로 AI 딥페이크 탐지 기능 확대
화요일, 유튜브는 딥페이크 탐지 기술을 일부 정부 관계자, 정치 후보자 및 언론인 대상으로 확대한다고 발표했다. 이 도구는 AI로 생성된 유사 영상을 식별하며, 시범 운영 참여자들은 유튜브 정책을 위반한다고 판단되는 무단 콘텐츠의 삭제를 요청할 수 있다.이 탐지 시스템은 초기 테스트 단계를 거친 후, 작년 유튜브 파트너 프로그램에 가입된 약 400만 명의
유튜브, 정치인·공직자·언론인을 위한 AI 딥페이크 방지 조치 강화
유튜브는 화요일, AI로 생성된 딥페이크를 식별하기 위해 개발된 ‘외모 유사도 탐지 기술’의 적용 범위를 정부 관계자, 정치 후보자, 언론인을 대상으로 한 시범 프로그램으로 확대한다고 발표했다. 이 시범 프로그램 참가자들은 자신의 외모가 무단으로 사용된 AI 생성 콘텐츠를 찾아내고, 해당 콘텐츠가 유튜브 정책을 위반할 경우 삭제 요청을 제출할 수 있는 도구
독점: 루마 AI, '통합 지능' 모델로 구동되는 크리에이티브 에이전트 선보여
목요일, AI 영상 생성 스타트업 루마(Luma)는 텍스트, 이미지, 영상, 오디오에 걸친 완전한 크리에이티브 워크플로우를 관리하기 위해 구축된 시스템인 '루마 에이전트(Luma Agents)'를 공개했다. 이 에이전트들은 단일 다중 모달 추론 엔진으로 훈련된 아키텍처를 특징으로 하는 루마의 통합 인텔리전스 모델 패밀리(Unified In
관련 특별 주제 추천
사업
유튜브, 정치인·공직자·언론인을 대상으로 AI 딥페이크 탐지 기능 확대
화요일, 유튜브는 딥페이크 탐지 기술을 일부 정부 관계자, 정치 후보자 및 언론인 대상으로 확대한다고 발표했다. 이 도구는 AI로 생성된 유사 영상을 식별하며, 시범 운영 참여자들은 유튜브 정책을 위반한다고 판단되는 무단 콘텐츠의 삭제를 요청할 수 있다.이 탐지 시스템은 초기 테스트 단계를 거친 후, 작년 유튜브 파트너 프로그램에 가입된 약 400만 명의
유튜브, 정치인·공직자·언론인을 위한 AI 딥페이크 방지 조치 강화
유튜브는 화요일, AI로 생성된 딥페이크를 식별하기 위해 개발된 ‘외모 유사도 탐지 기술’의 적용 범위를 정부 관계자, 정치 후보자, 언론인을 대상으로 한 시범 프로그램으로 확대한다고 발표했다. 이 시범 프로그램 참가자들은 자신의 외모가 무단으로 사용된 AI 생성 콘텐츠를 찾아내고, 해당 콘텐츠가 유튜브 정책을 위반할 경우 삭제 요청을 제출할 수 있는 도구
독점: 루마 AI, '통합 지능' 모델로 구동되는 크리에이티브 에이전트 선보여
목요일, AI 영상 생성 스타트업 루마(Luma)는 텍스트, 이미지, 영상, 오디오에 걸친 완전한 크리에이티브 워크플로우를 관리하기 위해 구축된 시스템인 '루마 에이전트(Luma Agents)'를 공개했다. 이 에이전트들은 단일 다중 모달 추론 엔진으로 훈련된 아키텍처를 특징으로 하는 루마의 통합 인텔리전스 모델 패밀리(Unified In
관련 특별 주제 추천
사업
 최고의 AI 경비 관리 앱: 영수증을 스캔하고 기업 경비를 자동으로 분류하세요
최고의 AI 경비 관리 앱: 영수증을 스캔하고 기업 경비를 자동으로 분류하세요
2026년 최신 최고의 AI 경비 관리 도구: 영수증을 스캔하고 기업 경비를 자동으로 분류해 주는 최고 평점의 도구들. 손쉬운 경비 관리, 정확한 재무 추적, 효율적인 규정 준수를 위한 강력하고 혁신적인 솔루션을 만나보세요. 무료 및 유료 옵션을 엄선하여 매주 업데이트되는 비교 자료를 통해 귀사에 딱 맞는 도구를 찾으실 수 있습니다. XIX.AI의 전문가 추천 목록으로 AI의 장점을 최대한 활용하세요.
 10 도구
10 도구
 xix.ai
사업
최고의 AI 채용 도구: 이력서 심사 및 후보자 면접 일정 자동화
xix.ai
사업
최고의 AI 채용 도구: 이력서 심사 및 후보자 면접 일정 자동화
XIX.AI에서 2026년 최신 최고 평점을 받은 AI 채용 도구를 확인해 보세요. 저희가 엄선한 이 목록에는 이력서 심사 및 후보자 면접 일정 자동화를 위한 강력하고 혁신적인 솔루션이 포함되어 있습니다. 실제 테스트 결과와 매주 업데이트되는 순위를 바탕으로 무료 및 유료 옵션을 비교해 보세요. 지금 바로 귀사에 딱 맞는 채용 도우미를 찾아 채용 프로세스를 효율화하세요!
10 도구
xix.ai
생산력
AI 개인 웰니스 및 집중력 코치: 번아웃 관리 및 정신적 에너지 수준 향상
XIX.AI에서 2026년 최고의 AI 기반 개인 웰니스 및 집중력 코치들을 만나보세요. 저희가 엄선한 순위 목록에는 번아웃을 관리하고 정신적 에너지를 높여주는 최고 평점을 받은 혁신적인 도구들이 소개되어 있습니다. 실제 사용 후기를 바탕으로 무료 버전과 유료 버전을 비교해 보세요. 지금 바로 최고의 생산성과 웰빙을 향한 길을 열어보세요.
10 도구
xix.ai
챗봇
최고 평점을 받은 AI 로맨틱 챗봇: 일관된 성격으로 장기적인 관계를 구축하세요
진정성 있는 장기적인 관계를 형성할 수 있는 2026년 최신 최고 평점 AI 로맨틱 챗봇을 만나보세요. 저희가 엄선한 이 목록에는 강력하고 일관된 캐릭터, 무료 및 유료 버전 비교, 실제 사용 후기가 담겨 있습니다. XIX.AI에서 나에게 딱 맞는 파트너를 찾아 오늘 바로 관계를 시작해 보세요.
10 도구
xix.ai
교육 및 학습
최고의 AI 데이터 과학 멘토들: SQL, Pandas 및 머신 러닝 워크플로우 마스터하기
2026년 최고의 AI 데이터 과학 멘토들을 만나 SQL, Pandas 및 머신러닝 워크플로우를 마스터하세요. XIX.AI에서 선별한 최고의 멘토들을 통해 강력하고 혁신적인 지도를 받아보세요. 무료 옵션과 유료 옵션을 실제 사례를 바탕으로 비교해 보세요. 오늘 바로 데이터 과학의 전문성을 확보하세요.
10 도구
xix.ai
챗봇
최고의 AI 유혹 및 대화 트레이너: 실시간으로 사회적 매력과 자신감을 높여보세요
XIX.AI에서 2026년 최고의 AI 플러팅 및 대화 트레이너를 만나보세요. 엄선된 최고 평점의 제품들을 통해 실시간으로 사회적 매력과 자신감을 키울 수 있습니다. 무료와 유료 버전을 비교하고 매주 업데이트되는 순위를 확인하며, 꼭 사용해봐야 할 획기적인 도구들을 탐색해 보세요. 지금 바로 여러분의 사회적 경쟁력을 한 단계 높여보세요.
10 도구
xix.ai

 의견 (46)
0/500
의견 (46)
0/500
![RalphMitchell]()
この記事を読んで、AIによる映像改ざんがこんなに簡単にできるなんて怖いですね。ペロシ議長の例は氷山の一角で、もっと巧妙な偽動画がSNSで拡散される可能性があります。一般ユーザーとして、どうやって本物と偽物を見分ければいいのか悩みます。技術の進歩は素晴らしいけど、悪用されないための規制も必要じゃないかな🤔
![JustinHarris]()
Honestly, this Pelosi video case is a perfect example of how 'low-tech' AI manipulation can be the most dangerous. It doesn't need deepfakes; just slowing down footage creates a narrative. Makes you wonder what subtle edits we're already consuming daily without a second thought. The real battle for truth is in these tiny, almost invisible tweaks. 😳
![DavidRodriguez]()
Dieser Artikel erinnert mich daran, wie wichtig Medienkompetenz heute ist. Die Pelosi-Video-Manipulation war ja noch relativ plump, aber mit aktueller KI wird das bestimmt viel subtiler. Macht mir schon etwas Sorgen, vor Wahlen oder so. Wie soll man da noch zwischen echt und fake unterscheiden? 😕
![WilliamCarter]()
That Pelosi video from 2019 is wild! It’s scary how a few tweaks can make someone look totally drunk. AI’s power to mess with videos is both cool and creepy—makes you wonder what’s real anymore. 😬
![JuanMartínez]()
This Pelosi video incident is wild! 🤯 It’s scary how a few tweaks can make someone look totally out of it. Makes me wonder how much of what we see online is real anymore. AI’s cool, but this kind of stuff could mess with trust big time.
![RyanPerez]()
That Pelosi video from 2019 is wild! It’s scary how a few tweaks can make someone look totally out of it. AI’s power to mess with reality is no joke—makes you wonder what’s real anymore. 🫣
2019년, 당시 미국 하원의장이었던 낸시 펠로시의 기만적인 영상이 널리 유포되었다. 그녀가 취한 것처럼 보이도록 편집된 이 영상은 조작된 미디어가 대중을 얼마나 쉽게 오도할 수 있는지를 강하게 상기시켰다. 단순했음에도 불구하고, 이 사건은 기본적인 오디오-비주얼 편집이 초래할 수 있는 잠재적 피해를 부각시켰다.
당시 딥페이크 환경은 2017년 말부터 존재했던 오토인코더 기반 얼굴 교체 기술이 주로 지배했다. 이러한 초기 시스템은 펠로시 영상에서 보인 미묘한 변화를 구현하는 데 어려움을 겪었으며, 대신 더 명백한 얼굴 교체에 초점을 맞췄다.
2022년 ‘Neural Emotion Director' 프레임워크는 유명한 얼굴의 분위기를 변화시킨다. 출처: https://www.youtube.com/watch?v=Li6W8pRDMJQ
현재로 빠르게 넘어오면, 영화와 TV 산업은 점점 더 AI 기반 포스트프로덕션 편집을 탐구하고 있다. 이 트렌드는 이전에는 달성할 수 없었던 완벽주의를 가능하게 하며, 관심과 비판을 동시에 불러일으켰다. 이에 대응하여 연구 커뮤니티는 Diffusion Video Autoencoders, Stitch it in Time, ChatFace, MagicFace, DISCO와 같은 얼굴 캡처의 '로컬 편집'에 초점을 맞춘 다양한 프로젝트를 개발했다.
2025년 1월 MagicFace 프로젝트를 통한 표정 편집. 출처: https://arxiv.org/pdf/2501.02260
새로운 얼굴, 새로운 주름
그러나 이러한 미묘한 편집을 만드는 기술은 그것을 탐지하는 우리의 능력보다 훨씬 빠르게 발전하고 있다. 대부분의 딥페이크 탐지 방법은 구식이며, 오래된 기술과 데이터셋에 초점을 맞춘다. 이는 인도 연구자들의 최근 돌파구가 나오기 전까지의 상황이었다.
딥페이크의 미묘한 로컬 편집 탐지: 실제 영상이 눈썹을 올리거나, 성별 특성을 수정하거나, 혐오감으로 표정이 변화하는 등의 미묘한 변화로 위조된 가짜를 생성한다(여기서는 단일 프레임으로 예시). 출처: https://arxiv.org/pdf/2503.22121
이 새로운 연구는 종종 간과되는 미묘한 얼굴 조작 탐지에 초점을 맞춘다. 광범위한 불일치나 신원 불일치를 찾는 대신, 이 방법은 약간의 표정 변화나 특정 얼굴 특징의 사소한 편집과 같은 세밀한 디테일에 집중한다. 이는 얼굴 표정을 64개의 가변 영역으로 분해하는 Facial Action Coding System(FACS)을 활용한다.
FACS의 64개 표정 구성 요소 중 일부. 출처: https://www.cs.cmu.edu/~face/facs.htm
연구자들은 다양한 최신 편집 방법에 대해 이 접근법을 테스트했으며, 오래된 데이터셋과 새로운 공격 벡터에서도 기존 솔루션을 지속적으로 능가했다.
‘마스크드 오토인코더(MAE)를 통해 학습된 비디오 표현을 AU 기반 특징을 사용하여 안내함으로써, 우리의 방법은 미묘한 얼굴 편집 탐지에 중요한 로컬라이즈된 변화를 효과적으로 포착한다.
‘이 접근법은 얼굴 중심 비디오에서 로컬라이즈된 편집과 더 광범위한 변화를 모두 인코딩하는 통합된 잠재 표현을 구성할 수 있게 하며, 딥페이크 탐지를 위한 포괄적이고 적응 가능한 솔루션을 제공한다.'
이 논문은 Action Unit-Guided Video Representations를 사용한 로컬라이즈된 딥페이크 조작 탐지라는 제목으로, 인도공과대학 마드라스(IIT Madras)의 연구자들이 저술했다.
방법
이 방법은 비디오에서 얼굴을 탐지하고, 얼굴을 중심으로 균등하게 간격을 둔 프레임을 샘플링하는 것으로 시작한다. 이 프레임들은 로컬 공간 및 시간적 디테일을 포착하는 작은 3D 패치로 분해�된다.
새로운 방법의 스키마. 입력 비디오는 얼굴 탐지를 통해 처리되어 균등하게 간격을 둔 얼굴 중심 프레임을 추출하고, 이를 ‘튜브형’ 패치로 나눈 뒤 두 개의 사전 학습된 프리텍스트 작업에서 잠재 표현을 융합하는 인코더를 거친다. 결과 벡터는 비디오가 진짜인지 가짜인지 판단하는 분류기에 사용된다.
각 패치는 몇 개의 연속된 프레임에서 작은 픽셀 창을 포함하여, 모델이 단기적인 움직임과 표정 변화를 학습할 수 있게 한다. 이 패치들은 임베딩되고 위치적으로 인코딩된 후, 진짜와 가짜 비디오를 구분하도록 설계된 인코더에 입력된다.
미묘한 조작 탐지의 도전은 크로스-어텐션 메커니즘을 통해 두 가지 학습된 표현을 결합하는 인코더를 사용하여 해결되며, 이는 더 민감하고 일반화 가능한 특징 공간을 생성하는 것을 목표로 한다.
프리텍스트 작업
첫 번째 표현은 마스크드 오토인코딩 작업으로 훈련된 인코더에서 나온다. 비디오의 3D 패치 대부분을 숨김으로써, 인코더는 누락된 부분을 재구성하며 얼굴 움직임과 같은 중요한 시공간적 패턴을 포착한다.
프리텍스트 작업 훈련은 비디오 입력의 일부를 마스킹하고, 인코더-디코더 설정을 사용하여 작업에 따라 원본 프레임 또는 프레임별 액션 유닛 맵을 재구성한다.
그러나 이것만으로는 세밀한 편집을 탐지하기에 충분하지 않다. 연구자들은 미묘한 딥페이크 편집이 자주 발생하는 로컬라이즈된 근육 활동에 초점을 맞추도록 두 번째 인코더를 훈련시켜 얼굴 액션 유닛(AU)을 탐지하도록 했다.
Facial Action Units(FAUs, 또는 AUs)의 추가 예시. 출처: https://www.eiagroup.com/the-facial-action-coding-system/
사전 훈련 후, 두 인코더의 출력은 크로스-어텐션을 사용하여 결합되며, AU 기반 특징이 시공간적 특징에 대한 어텐션을 안내한다. 이는 더 넓은 움직임 맥락과 로컬라이즈된 표정 디테일을 모두 포착하는 융합된 잠재 표현을 생성하여 최종 분류 작업에 사용된다.
데이터 및 테스트
구현
이 시스템은 FaceXZoo PyTorch 기반 얼굴 탐지 프레임워크를 사용하여 구현되었으며, 각 비디오 클립에서 16개의 얼굴 중심 프레임을 추출했다. 프리텍스트 작업은 35,000개의 고품질 얼굴 비디오를 포함하는 CelebV-HQ 데이터셋에서 훈련되었다.
소스 논문에서, 새 프로젝트에 사용된 CelebV-HQ 데이터셋의 예시. 출처: https://arxiv.org/pdf/2207.12393
데이터의 절반은 오버피팅을 방지하기 위해 마스킹되었다. 마스크드 프레임 재구성 작업의 경우, 모델은 L1 손실을 사용하여 누락된 영역을 예측하도록 훈련되었다. 두 번째 작업에서는 16개의 얼굴 액션 유닛에 대한 맵을 생성하도록 훈련되었으며, L1 손실로 감독되었다.
사전 훈련 후, 인코더는 융합되어 FaceForensics++ 데이터셋을 사용하여 딥페이크 탐지를 위해 미세 조정되었다. 이 데이터셋은 진짜와 조작된 비디오를 모두 포함한다.
FaceForensics++ 데이터셋은 2017년 이후 딥페이크 탐지의 핵심 기준이 되어 왔지만, 최신 얼굴 합성 기술과 관련하여 현재는 상당히 구식이다. 출처: https://www.youtube.com/watch?v=x2g48Q2I2ZQ
클래스 불균형 문제를 해결하기 위해 저자들은 Focal Loss를 사용하여 훈련 중 더 어려운 예시에 중점을 두었다. 모든 훈련은 VideoMAE의 사전 훈련된 체크포인트를 사용하여 24Gb VRAM이 있는 단일 RTX 4090 GPU에서 수행되었다.
테스트
이 방법은 로컬 편집된 딥페이크에 초점을 맞춘 다양한 딥페이크 탐지 기술과 비교 평가되었다. 테스트는 다양한 편집 방법과 오래된 딥페이크 데이터셋을 포함했으며, Area Under Curve(AUC), 평균 정밀도, 평균 F1 점수와 같은 메트릭을 사용했다.
논문에서: 최근 로컬라이즈된 딥페이크에 대한 비교에서 제안된 방법은 모든 다른 방법을 능가했으며, 다음으로 우수한 접근법 대비 AUC와 평균 정밀도에서 15~20%의 성능 향상을 보였다.
저자들은 로컬 조작된 비디오의 시각적 비교를 제공하여, 그들의 방법이 미묘한 편집에 대해 우수한 민감도를 보임을 보여주었다.
실제 비디오가 세 가지 서로 다른 로컬라이즈된 조작을 사용하여 원본과 시각적으로 유사한 가짜를 생성하도록 변경되었다. 여기에는 각 방법에 대한 대표 프레임과 평균 가짜 탐지 점수가 표시된다. 기존 탐지기는 이러한 미묘한 편집에 어려움을 겪었지만, 제안된 모델은 지속적으로 높은 가짜 확률을 부여하여 로컬라이즈된 변화에 대한 더 큰 민감도를 나타냈다.
연구자들은 기존의 최첨단 탐지 방법이 최신 딥페이크 생성 기술에 어려움을 겪는 반면, 그들의 방법은 높은 AUC와 평균 정밀도 점수를 달성하며 강력한 일반화를 보여주었다.
전통적인 딥페이크 데이터셋에서의 성능은 제안된 방법이 선도적인 접근법과 경쟁력 있는 결과를 유지하며, 다양한 조작 유형에 걸쳐 강력한 일반화를 나타냄을 보여준다.
저자들은 또한 실세계 조건에서 모델의 신뢰성을 테스트했으며, 채도 조정, 가우시안 블러, 픽셀화와 같은 일반적인 비디오 왜곡에 대해 견고함을 발견했다.
다양한 비디오 왜곡 하에서 탐지 정확도가 어떻게 변하는지를 보여주는 예시. 새로운 방법은 대부분의 경우 견고했으며, AUC에서 약간의 하락만 보였다. 가장 큰 하락은 가우시안 노이즈가 도입되었을 때 발생했다.
결론
대중은 종종 딥페이크를 신원 교체로 생각하지만, AI 조작의 현실은 더 미묘하고 잠재적으로 더 위험하다. 이 새로운 연구에서 논의된 로컬 편집은 또 다른 주목할 만한 사건이 발생할 때까지 대중의 관심을 끌지 않을 수 있다. 그러나 배우 Nic Cage가 지적했듯이, 포스트프로덕션 편집이 공연을 변경할 가능성은 우리 모두가 알아야 할 우려 사항이다. 우리는 얼굴 표정의 미세한 변화에도 자연스럽게 민감하며, 맥락은 그 영향을 극적으로 바꿀 수 있다.
최초 게시일: 2025년 4월 2일 수요일










 유튜브, 정치인·공직자·언론인을 대상으로 AI 딥페이크 탐지 기능 확대
화요일, 유튜브는 딥페이크 탐지 기술을 일부 정부 관계자, 정치 후보자 및 언론인 대상으로 확대한다고 발표했다. 이 도구는 AI로 생성된 유사 영상을 식별하며, 시범 운영 참여자들은 유튜브 정책을 위반한다고 판단되는 무단 콘텐츠의 삭제를 요청할 수 있다.이 탐지 시스템은 초기 테스트 단계를 거친 후, 작년 유튜브 파트너 프로그램에 가입된 약 400만 명의
유튜브, 정치인·공직자·언론인을 대상으로 AI 딥페이크 탐지 기능 확대
화요일, 유튜브는 딥페이크 탐지 기술을 일부 정부 관계자, 정치 후보자 및 언론인 대상으로 확대한다고 발표했다. 이 도구는 AI로 생성된 유사 영상을 식별하며, 시범 운영 참여자들은 유튜브 정책을 위반한다고 판단되는 무단 콘텐츠의 삭제를 요청할 수 있다.이 탐지 시스템은 초기 테스트 단계를 거친 후, 작년 유튜브 파트너 프로그램에 가입된 약 400만 명의
 유튜브, 정치인·공직자·언론인을 위한 AI 딥페이크 방지 조치 강화
유튜브는 화요일, AI로 생성된 딥페이크를 식별하기 위해 개발된 ‘외모 유사도 탐지 기술’의 적용 범위를 정부 관계자, 정치 후보자, 언론인을 대상으로 한 시범 프로그램으로 확대한다고 발표했다. 이 시범 프로그램 참가자들은 자신의 외모가 무단으로 사용된 AI 생성 콘텐츠를 찾아내고, 해당 콘텐츠가 유튜브 정책을 위반할 경우 삭제 요청을 제출할 수 있는 도구
유튜브, 정치인·공직자·언론인을 위한 AI 딥페이크 방지 조치 강화
유튜브는 화요일, AI로 생성된 딥페이크를 식별하기 위해 개발된 ‘외모 유사도 탐지 기술’의 적용 범위를 정부 관계자, 정치 후보자, 언론인을 대상으로 한 시범 프로그램으로 확대한다고 발표했다. 이 시범 프로그램 참가자들은 자신의 외모가 무단으로 사용된 AI 생성 콘텐츠를 찾아내고, 해당 콘텐츠가 유튜브 정책을 위반할 경우 삭제 요청을 제출할 수 있는 도구
 독점: 루마 AI, '통합 지능' 모델로 구동되는 크리에이티브 에이전트 선보여
목요일, AI 영상 생성 스타트업 루마(Luma)는 텍스트, 이미지, 영상, 오디오에 걸친 완전한 크리에이티브 워크플로우를 관리하기 위해 구축된 시스템인 '루마 에이전트(Luma Agents)'를 공개했다. 이 에이전트들은 단일 다중 모달 추론 엔진으로 훈련된 아키텍처를 특징으로 하는 루마의 통합 인텔리전스 모델 패밀리(Unified In
독점: 루마 AI, '통합 지능' 모델로 구동되는 크리에이티브 에이전트 선보여
목요일, AI 영상 생성 스타트업 루마(Luma)는 텍스트, 이미지, 영상, 오디오에 걸친 완전한 크리에이티브 워크플로우를 관리하기 위해 구축된 시스템인 '루마 에이전트(Luma Agents)'를 공개했다. 이 에이전트들은 단일 다중 모달 추론 엔진으로 훈련된 아키텍처를 특징으로 하는 루마의 통합 인텔리전스 모델 패밀리(Unified In

2026년 최신 최고의 AI 경비 관리 도구: 영수증을 스캔하고 기업 경비를 자동으로 분류해 주는 최고 평점의 도구들. 손쉬운 경비 관리, 정확한 재무 추적, 효율적인 규정 준수를 위한 강력하고 혁신적인 솔루션을 만나보세요. 무료 및 유료 옵션을 엄선하여 매주 업데이트되는 비교 자료를 통해 귀사에 딱 맞는 도구를 찾으실 수 있습니다. XIX.AI의 전문가 추천 목록으로 AI의 장점을 최대한 활용하세요.
10 도구
xix.ai

XIX.AI에서 2026년 최신 최고 평점을 받은 AI 채용 도구를 확인해 보세요. 저희가 엄선한 이 목록에는 이력서 심사 및 후보자 면접 일정 자동화를 위한 강력하고 혁신적인 솔루션이 포함되어 있습니다. 실제 테스트 결과와 매주 업데이트되는 순위를 바탕으로 무료 및 유료 옵션을 비교해 보세요. 지금 바로 귀사에 딱 맞는 채용 도우미를 찾아 채용 프로세스를 효율화하세요!
10 도구
xix.ai

XIX.AI에서 2026년 최고의 AI 기반 개인 웰니스 및 집중력 코치들을 만나보세요. 저희가 엄선한 순위 목록에는 번아웃을 관리하고 정신적 에너지를 높여주는 최고 평점을 받은 혁신적인 도구들이 소개되어 있습니다. 실제 사용 후기를 바탕으로 무료 버전과 유료 버전을 비교해 보세요. 지금 바로 최고의 생산성과 웰빙을 향한 길을 열어보세요.
10 도구
xix.ai

진정성 있는 장기적인 관계를 형성할 수 있는 2026년 최신 최고 평점 AI 로맨틱 챗봇을 만나보세요. 저희가 엄선한 이 목록에는 강력하고 일관된 캐릭터, 무료 및 유료 버전 비교, 실제 사용 후기가 담겨 있습니다. XIX.AI에서 나에게 딱 맞는 파트너를 찾아 오늘 바로 관계를 시작해 보세요.
10 도구
xix.ai

2026년 최고의 AI 데이터 과학 멘토들을 만나 SQL, Pandas 및 머신러닝 워크플로우를 마스터하세요. XIX.AI에서 선별한 최고의 멘토들을 통해 강력하고 혁신적인 지도를 받아보세요. 무료 옵션과 유료 옵션을 실제 사례를 바탕으로 비교해 보세요. 오늘 바로 데이터 과학의 전문성을 확보하세요.
10 도구
xix.ai

XIX.AI에서 2026년 최고의 AI 플러팅 및 대화 트레이너를 만나보세요. 엄선된 최고 평점의 제품들을 통해 실시간으로 사회적 매력과 자신감을 키울 수 있습니다. 무료와 유료 버전을 비교하고 매주 업데이트되는 순위를 확인하며, 꼭 사용해봐야 할 획기적인 도구들을 탐색해 보세요. 지금 바로 여러분의 사회적 경쟁력을 한 단계 높여보세요.
10 도구
xix.ai

この記事を読んで、AIによる映像改ざんがこんなに簡単にできるなんて怖いですね。ペロシ議長の例は氷山の一角で、もっと巧妙な偽動画がSNSで拡散される可能性があります。一般ユーザーとして、どうやって本物と偽物を見分ければいいのか悩みます。技術の進歩は素晴らしいけど、悪用されないための規制も必要じゃないかな🤔
Honestly, this Pelosi video case is a perfect example of how 'low-tech' AI manipulation can be the most dangerous. It doesn't need deepfakes; just slowing down footage creates a narrative. Makes you wonder what subtle edits we're already consuming daily without a second thought. The real battle for truth is in these tiny, almost invisible tweaks. 😳
Dieser Artikel erinnert mich daran, wie wichtig Medienkompetenz heute ist. Die Pelosi-Video-Manipulation war ja noch relativ plump, aber mit aktueller KI wird das bestimmt viel subtiler. Macht mir schon etwas Sorgen, vor Wahlen oder so. Wie soll man da noch zwischen echt und fake unterscheiden? 😕
That Pelosi video from 2019 is wild! It’s scary how a few tweaks can make someone look totally drunk. AI’s power to mess with videos is both cool and creepy—makes you wonder what’s real anymore. 😬
This Pelosi video incident is wild! 🤯 It’s scary how a few tweaks can make someone look totally out of it. Makes me wonder how much of what we see online is real anymore. AI’s cool, but this kind of stuff could mess with trust big time.
That Pelosi video from 2019 is wild! It’s scary how a few tweaks can make someone look totally out of it. AI’s power to mess with reality is no joke—makes you wonder what’s real anymore. 🫣













