
















 Home
HomeUnveiling Subtle Yet Impactful AI Modifications in Authentic Video Content
In 2019, a deceptive video of Nancy Pelosi, then Speaker of the US House of Representatives, circulated widely. The video, which was edited to make her appear intoxicated, was a stark reminder of how easily manipulated media can mislead the public. Despite its simplicity, this incident highlighted the potential damage of even basic audio-visual edits.
At the time, the deepfake landscape was largely dominated by autoencoder-based face-replacement technologies, which had been around since late 2017. These early systems struggled to make the nuanced changes seen in the Pelosi video, focusing instead on more overt face swaps.
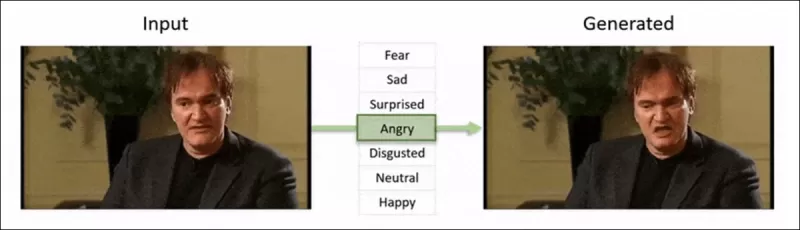 The 2022 ‘Neural Emotion Director' framework changes the mood of a famous face. Source: https://www.youtube.com/watch?v=Li6W8pRDMJQ
The 2022 ‘Neural Emotion Director' framework changes the mood of a famous face. Source: https://www.youtube.com/watch?v=Li6W8pRDMJQ
Fast forward to today, and the film and TV industry is increasingly exploring AI-driven post-production edits. This trend has sparked both interest and criticism, as AI enables a level of perfectionism that was previously unattainable. In response, the research community has developed various projects focused on 'local edits' of facial captures, such as Diffusion Video Autoencoders, Stitch it in Time, ChatFace, MagicFace, and DISCO.
 Expression-editing with the January 2025 project MagicFace. Source: https://arxiv.org/pdf/2501.02260
Expression-editing with the January 2025 project MagicFace. Source: https://arxiv.org/pdf/2501.02260
New Faces, New Wrinkles
However, the technology for creating these subtle edits is advancing much faster than our ability to detect them. Most deepfake detection methods are outdated, focusing on older techniques and datasets. That is, until a recent breakthrough from researchers in India.
 Detection of Subtle Local Edits in Deepfakes: A real video is altered to produce fakes with nuanced changes such as raised eyebrows, modified gender traits, and shifts in expression toward disgust (illustrated here with a single frame). Source: https://arxiv.org/pdf/2503.22121
Detection of Subtle Local Edits in Deepfakes: A real video is altered to produce fakes with nuanced changes such as raised eyebrows, modified gender traits, and shifts in expression toward disgust (illustrated here with a single frame). Source: https://arxiv.org/pdf/2503.22121
This new research targets the detection of subtle, localized facial manipulations, a type of forgery often overlooked. Instead of looking for broad inconsistencies or identity mismatches, the method zeroes in on fine details like slight expression shifts or minor edits to specific facial features. It leverages the Facial Action Coding System (FACS), which breaks down facial expressions into 64 mutable areas.
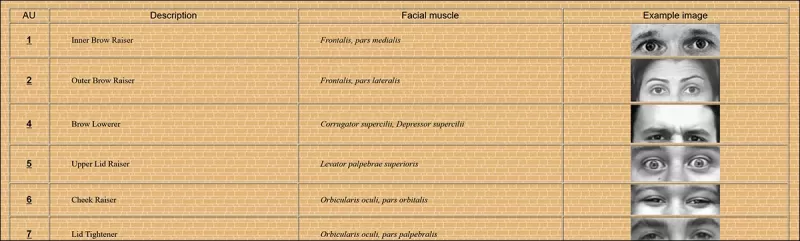 Some of the constituent 64 expression parts in FACS. Source: https://www.cs.cmu.edu/~face/facs.htm
Some of the constituent 64 expression parts in FACS. Source: https://www.cs.cmu.edu/~face/facs.htm
The researchers tested their approach against various recent editing methods and found it consistently outperformed existing solutions, even with older datasets and newer attack vectors.
‘By using AU-based features to guide video representations learned through Masked Autoencoders (MAE), our method effectively captures localized changes crucial for detecting subtle facial edits.
‘This approach enables us to construct a unified latent representation that encodes both localized edits and broader alterations in face-centered videos, providing a comprehensive and adaptable solution for deepfake detection.'
The paper, titled Detecting Localized Deepfake Manipulations Using Action Unit-Guided Video Representations, was authored by researchers at the Indian Institute of Technology at Madras.
Method
The method starts by detecting faces in a video and sampling evenly spaced frames centered on these faces. These frames are then broken down into small 3D patches, capturing local spatial and temporal details.
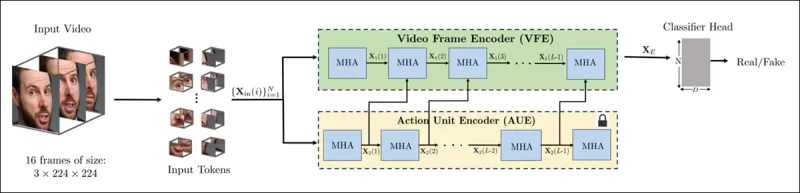 Schema for the new method. The input video is processed with face detection to extract evenly spaced, face-centered frames, which are then divided into ‘tubular' patches and passed through an encoder that fuses latent representations from two pretrained pretext tasks. The resulting vector is then used by a classifier to determine whether the video is real or fake.
Schema for the new method. The input video is processed with face detection to extract evenly spaced, face-centered frames, which are then divided into ‘tubular' patches and passed through an encoder that fuses latent representations from two pretrained pretext tasks. The resulting vector is then used by a classifier to determine whether the video is real or fake.
Each patch contains a small window of pixels from a few successive frames, allowing the model to learn short-term motion and expression changes. These patches are embedded and positionally encoded before being fed into an encoder designed to distinguish real from fake videos.
The challenge of detecting subtle manipulations is addressed by using an encoder that combines two types of learned representations through a cross-attention mechanism, aiming to create a more sensitive and generalizable feature space.
Pretext Tasks
The first representation comes from an encoder trained with a masked autoencoding task. By hiding most of the video's 3D patches, the encoder learns to reconstruct the missing parts, capturing important spatiotemporal patterns like facial motion.
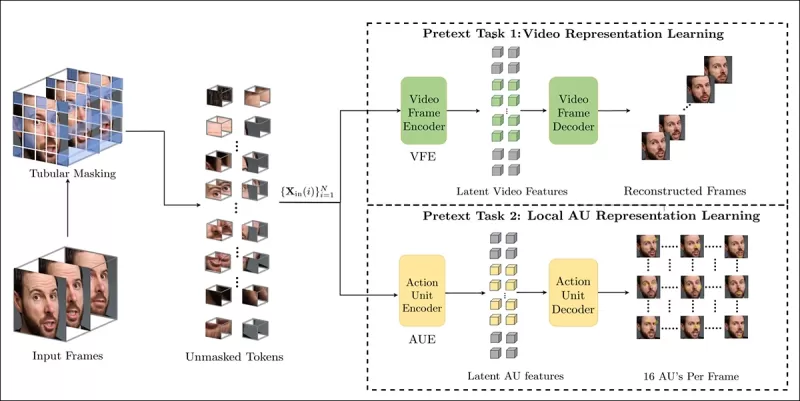 Pretext task training involves masking parts of the video input and using an encoder-decoder setup to reconstruct either the original frames or per-frame action unit maps, depending on the task.
Pretext task training involves masking parts of the video input and using an encoder-decoder setup to reconstruct either the original frames or per-frame action unit maps, depending on the task.
However, this alone isn't enough to detect fine-grained edits. The researchers introduced a second encoder trained to detect facial action units (AUs), encouraging it to focus on localized muscle activity where subtle deepfake edits often occur.
 Further examples of Facial Action Units (FAUs, or AUs). Source: https://www.eiagroup.com/the-facial-action-coding-system/
Further examples of Facial Action Units (FAUs, or AUs). Source: https://www.eiagroup.com/the-facial-action-coding-system/
After pretraining, the outputs of both encoders are combined using cross-attention, with the AU-based features guiding the attention over the spatial-temporal features. This results in a fused latent representation that captures both broader motion context and localized expression details, used for the final classification task.
Data and Tests
Implementation
The system was implemented using the FaceXZoo PyTorch-based face detection framework, extracting 16 face-centered frames from each video clip. The pretext tasks were trained on the CelebV-HQ dataset, which includes 35,000 high-quality facial videos.
 From the source paper, examples from the CelebV-HQ dataset used in the new project. Source: https://arxiv.org/pdf/2207.12393
From the source paper, examples from the CelebV-HQ dataset used in the new project. Source: https://arxiv.org/pdf/2207.12393
Half of the data was masked to prevent overfitting. For the masked frame reconstruction task, the model was trained to predict missing regions using L1 loss. For the second task, it was trained to generate maps for 16 facial action units, supervised by L1 loss.
After pretraining, the encoders were fused and fine-tuned for deepfake detection using the FaceForensics++ dataset, which includes both real and manipulated videos.
 The FaceForensics++ dataset has been the cornerstone of deepfake detection since 2017, though it is now considerably out of date, in regards to the latest facial synthesis techniques. Source: https://www.youtube.com/watch?v=x2g48Q2I2ZQ
The FaceForensics++ dataset has been the cornerstone of deepfake detection since 2017, though it is now considerably out of date, in regards to the latest facial synthesis techniques. Source: https://www.youtube.com/watch?v=x2g48Q2I2ZQ
To address class imbalance, the authors used Focal Loss, emphasizing more challenging examples during training. All training was conducted on a single RTX 4090 GPU with 24Gb of VRAM, using pre-trained checkpoints from VideoMAE.
Tests
The method was evaluated against various deepfake detection techniques, focusing on locally-edited deepfakes. The tests included a range of editing methods and older deepfake datasets, using metrics like Area Under Curve (AUC), Average Precision, and Mean F1 Score.
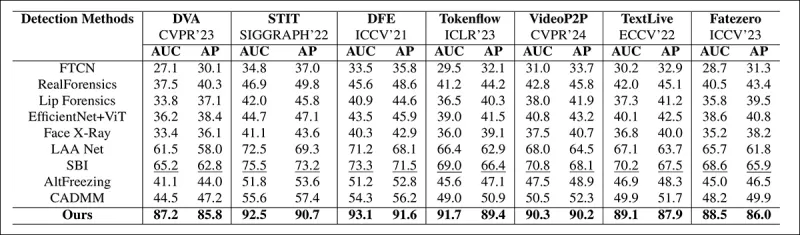 From the paper: comparison on recent localized deepfakes shows that the proposed method outperformed all others, with a 15 to 20 percent gain in both AUC and average precision over the next-best approach.
From the paper: comparison on recent localized deepfakes shows that the proposed method outperformed all others, with a 15 to 20 percent gain in both AUC and average precision over the next-best approach.
The authors provided visual comparisons of locally manipulated videos, showing their method's superior sensitivity to subtle edits.
 A real video was altered using three different localized manipulations to produce fakes that remained visually similar to the original. Shown here are representative frames along with the average fake detection scores for each method. While existing detectors struggled with these subtle edits, the proposed model consistently assigned high fake probabilities, indicating greater sensitivity to localized changes.
A real video was altered using three different localized manipulations to produce fakes that remained visually similar to the original. Shown here are representative frames along with the average fake detection scores for each method. While existing detectors struggled with these subtle edits, the proposed model consistently assigned high fake probabilities, indicating greater sensitivity to localized changes.
The researchers noted that existing state-of-the-art detection methods struggled with the latest deepfake generation techniques, while their method showed robust generalization, achieving high AUC and average precision scores.
 Performance on traditional deepfake datasets shows that the proposed method remained competitive with leading approaches, indicating strong generalization across a range of manipulation types.
Performance on traditional deepfake datasets shows that the proposed method remained competitive with leading approaches, indicating strong generalization across a range of manipulation types.
The authors also tested the model's reliability under real-world conditions, finding it resilient to common video distortions like saturation adjustments, Gaussian blur, and pixelation.
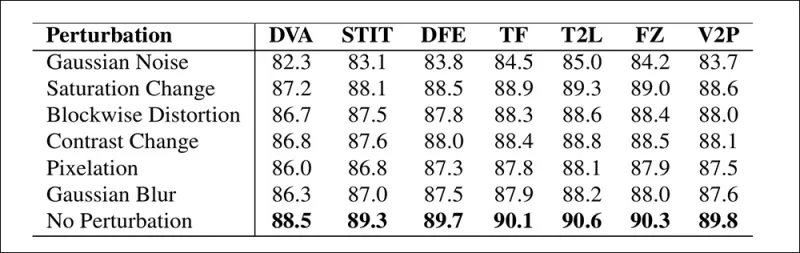 An illustration of how detection accuracy changes under different video distortions. The new method remained resilient in most cases, with only a small decline in AUC. The most significant drop occurred when Gaussian noise was introduced.
An illustration of how detection accuracy changes under different video distortions. The new method remained resilient in most cases, with only a small decline in AUC. The most significant drop occurred when Gaussian noise was introduced.
Conclusion
While the public often thinks of deepfakes as identity swaps, the reality of AI manipulation is more nuanced and potentially more insidious. The kind of local editing discussed in this new research might not capture public attention until another high-profile incident occurs. Yet, as actor Nic Cage has pointed out, the potential for post-production edits to alter performances is a concern we should all be aware of. We're naturally sensitive to even the slightest changes in facial expressions, and context can dramatically alter their impact.
First published Wednesday, April 2, 2025
Related article
 YouTube expands AI deepfake detection to politicians, government officials, and journalists
On Tuesday, YouTube announced it is expanding its deepfake detection technology to a select group of government officials, political candidates, and journalists. The tool identifies AI-generated likenesses and lets pilot participants request the remo
YouTube bolsters AI deepfake protections for politicians, officials, and journalists
YouTube is extending access to its likeness detection technology, designed to identify AI-generated deepfakes, to a pilot program for government officials, political candidates, and journalists, the company announced on Tuesday. Participants in this
Exclusive: Luma AI Debuts Creative Agents Fueled by 'Unified Intelligence' Models
On Thursday, AI video generation startup Luma introduced Luma Agents, a system built to manage complete creative workflows spanning text, images, video, and audio. These agents are driven by Luma’s Unified Intelligence model family, featuring an arch
Related Special Topic Recommendations
Business
YouTube expands AI deepfake detection to politicians, government officials, and journalists
On Tuesday, YouTube announced it is expanding its deepfake detection technology to a select group of government officials, political candidates, and journalists. The tool identifies AI-generated likenesses and lets pilot participants request the remo
YouTube bolsters AI deepfake protections for politicians, officials, and journalists
YouTube is extending access to its likeness detection technology, designed to identify AI-generated deepfakes, to a pilot program for government officials, political candidates, and journalists, the company announced on Tuesday. Participants in this
Exclusive: Luma AI Debuts Creative Agents Fueled by 'Unified Intelligence' Models
On Thursday, AI video generation startup Luma introduced Luma Agents, a system built to manage complete creative workflows spanning text, images, video, and audio. These agents are driven by Luma’s Unified Intelligence model family, featuring an arch
Related Special Topic Recommendations
Business
 Best AI Expense Trackers: Scan Receipts & Categorize Corporate Spend Automatically
Best AI Expense Trackers: Scan Receipts & Categorize Corporate Spend Automatically
2026 Latest Best AI Expense Trackers: Top-rated tools to scan receipts & categorize corporate spend automatically. Discover powerful, game-changing solutions for effortless expense management, accurate financial tracking, and streamlined compliance. Our curated, weekly-updated comparison of free vs paid options helps you find the perfect fit. Unlock your AI edge with XIX.AI's expert picks.
 10 tools
10 tools
 xix.ai
Business
Best AI Recruiting Tools: Screen Resumes & Automate Candidate Interview Scheduling
xix.ai
Business
Best AI Recruiting Tools: Screen Resumes & Automate Candidate Interview Scheduling
Discover the 2026 latest top-rated AI recruiting tools on XIX.AI. Our curated list features powerful, game-changing solutions for screening resumes and automating candidate interview scheduling. Compare free vs paid options with real-world tests and weekly updated rankings. Find your perfect hiring assistant and streamline your recruitment today!
10 tools
xix.ai
Productivity
AI Personal Wellness & Focus Coaches: Manage Burnout & Boost Mental Energy Levels
Discover the 2026 best AI personal wellness and focus coaches on XIX.AI. Our curated rankings feature top-rated, game-changing tools to manage burnout and boost mental energy. Compare free vs paid options with real-world insights. Unlock your path to peak productivity and well-being today.
10 tools
xix.ai
chatbot
Top-Rated AI Romantic Chatbots: Build Long-Term Relationships with Consistent Personalities
Discover the 2026 latest top-rated AI romantic chatbots for building genuine, long-term connections. Our curated list features powerful, consistent personalities, free vs paid comparisons, and real-world tests. Find your perfect companion and start building today at XIX.AI.
10 tools
xix.ai
Education and Learning
Best AI Data Science Mentors: Master SQL, Pandas & Machine Learning Workflows
Discover the 2026 best AI data science mentors to master SQL, Pandas & ML workflows. Explore our top-rated, curated selection at XIX.AI for powerful, game-changing guidance. Compare free vs paid options with real-world insights. Unlock your data science mastery today.
10 tools
xix.ai
chatbot
Best AI Flirting & Conversation Trainers: Improve Social Charisma and Confidence in Real-Time
Discover the 2026 best AI flirting and conversation trainers on XIX.AI. Our curated, top-rated selection helps you build social charisma and confidence in real-time. Explore must-try, game-changing tools with free vs paid comparisons and weekly updated rankings. Unlock your social edge today.
10 tools
xix.ai

 Comments (46)
0/500
Comments (46)
0/500
![RalphMitchell]()
この記事を読んで、AIによる映像改ざんがこんなに簡単にできるなんて怖いですね。ペロシ議長の例は氷山の一角で、もっと巧妙な偽動画がSNSで拡散される可能性があります。一般ユーザーとして、どうやって本物と偽物を見分ければいいのか悩みます。技術の進歩は素晴らしいけど、悪用されないための規制も必要じゃないかな🤔
![JustinHarris]()
Honestly, this Pelosi video case is a perfect example of how 'low-tech' AI manipulation can be the most dangerous. It doesn't need deepfakes; just slowing down footage creates a narrative. Makes you wonder what subtle edits we're already consuming daily without a second thought. The real battle for truth is in these tiny, almost invisible tweaks. 😳
![DavidRodriguez]()
Dieser Artikel erinnert mich daran, wie wichtig Medienkompetenz heute ist. Die Pelosi-Video-Manipulation war ja noch relativ plump, aber mit aktueller KI wird das bestimmt viel subtiler. Macht mir schon etwas Sorgen, vor Wahlen oder so. Wie soll man da noch zwischen echt und fake unterscheiden? 😕
![WilliamCarter]()
That Pelosi video from 2019 is wild! It’s scary how a few tweaks can make someone look totally drunk. AI’s power to mess with videos is both cool and creepy—makes you wonder what’s real anymore. 😬
![JuanMartínez]()
This Pelosi video incident is wild! 🤯 It’s scary how a few tweaks can make someone look totally out of it. Makes me wonder how much of what we see online is real anymore. AI’s cool, but this kind of stuff could mess with trust big time.
![RyanPerez]()
That Pelosi video from 2019 is wild! It’s scary how a few tweaks can make someone look totally out of it. AI’s power to mess with reality is no joke—makes you wonder what’s real anymore. 🫣
In 2019, a deceptive video of Nancy Pelosi, then Speaker of the US House of Representatives, circulated widely. The video, which was edited to make her appear intoxicated, was a stark reminder of how easily manipulated media can mislead the public. Despite its simplicity, this incident highlighted the potential damage of even basic audio-visual edits.
At the time, the deepfake landscape was largely dominated by autoencoder-based face-replacement technologies, which had been around since late 2017. These early systems struggled to make the nuanced changes seen in the Pelosi video, focusing instead on more overt face swaps.
The 2022 ‘Neural Emotion Director' framework changes the mood of a famous face. Source: https://www.youtube.com/watch?v=Li6W8pRDMJQ
Fast forward to today, and the film and TV industry is increasingly exploring AI-driven post-production edits. This trend has sparked both interest and criticism, as AI enables a level of perfectionism that was previously unattainable. In response, the research community has developed various projects focused on 'local edits' of facial captures, such as Diffusion Video Autoencoders, Stitch it in Time, ChatFace, MagicFace, and DISCO.
Expression-editing with the January 2025 project MagicFace. Source: https://arxiv.org/pdf/2501.02260
New Faces, New Wrinkles
However, the technology for creating these subtle edits is advancing much faster than our ability to detect them. Most deepfake detection methods are outdated, focusing on older techniques and datasets. That is, until a recent breakthrough from researchers in India.
Detection of Subtle Local Edits in Deepfakes: A real video is altered to produce fakes with nuanced changes such as raised eyebrows, modified gender traits, and shifts in expression toward disgust (illustrated here with a single frame). Source: https://arxiv.org/pdf/2503.22121
This new research targets the detection of subtle, localized facial manipulations, a type of forgery often overlooked. Instead of looking for broad inconsistencies or identity mismatches, the method zeroes in on fine details like slight expression shifts or minor edits to specific facial features. It leverages the Facial Action Coding System (FACS), which breaks down facial expressions into 64 mutable areas.
Some of the constituent 64 expression parts in FACS. Source: https://www.cs.cmu.edu/~face/facs.htm
The researchers tested their approach against various recent editing methods and found it consistently outperformed existing solutions, even with older datasets and newer attack vectors.
‘By using AU-based features to guide video representations learned through Masked Autoencoders (MAE), our method effectively captures localized changes crucial for detecting subtle facial edits.
‘This approach enables us to construct a unified latent representation that encodes both localized edits and broader alterations in face-centered videos, providing a comprehensive and adaptable solution for deepfake detection.'
The paper, titled Detecting Localized Deepfake Manipulations Using Action Unit-Guided Video Representations, was authored by researchers at the Indian Institute of Technology at Madras.
Method
The method starts by detecting faces in a video and sampling evenly spaced frames centered on these faces. These frames are then broken down into small 3D patches, capturing local spatial and temporal details.
Schema for the new method. The input video is processed with face detection to extract evenly spaced, face-centered frames, which are then divided into ‘tubular' patches and passed through an encoder that fuses latent representations from two pretrained pretext tasks. The resulting vector is then used by a classifier to determine whether the video is real or fake.
Each patch contains a small window of pixels from a few successive frames, allowing the model to learn short-term motion and expression changes. These patches are embedded and positionally encoded before being fed into an encoder designed to distinguish real from fake videos.
The challenge of detecting subtle manipulations is addressed by using an encoder that combines two types of learned representations through a cross-attention mechanism, aiming to create a more sensitive and generalizable feature space.
Pretext Tasks
The first representation comes from an encoder trained with a masked autoencoding task. By hiding most of the video's 3D patches, the encoder learns to reconstruct the missing parts, capturing important spatiotemporal patterns like facial motion.
Pretext task training involves masking parts of the video input and using an encoder-decoder setup to reconstruct either the original frames or per-frame action unit maps, depending on the task.
However, this alone isn't enough to detect fine-grained edits. The researchers introduced a second encoder trained to detect facial action units (AUs), encouraging it to focus on localized muscle activity where subtle deepfake edits often occur.
Further examples of Facial Action Units (FAUs, or AUs). Source: https://www.eiagroup.com/the-facial-action-coding-system/
After pretraining, the outputs of both encoders are combined using cross-attention, with the AU-based features guiding the attention over the spatial-temporal features. This results in a fused latent representation that captures both broader motion context and localized expression details, used for the final classification task.
Data and Tests
Implementation
The system was implemented using the FaceXZoo PyTorch-based face detection framework, extracting 16 face-centered frames from each video clip. The pretext tasks were trained on the CelebV-HQ dataset, which includes 35,000 high-quality facial videos.
From the source paper, examples from the CelebV-HQ dataset used in the new project. Source: https://arxiv.org/pdf/2207.12393
Half of the data was masked to prevent overfitting. For the masked frame reconstruction task, the model was trained to predict missing regions using L1 loss. For the second task, it was trained to generate maps for 16 facial action units, supervised by L1 loss.
After pretraining, the encoders were fused and fine-tuned for deepfake detection using the FaceForensics++ dataset, which includes both real and manipulated videos.
The FaceForensics++ dataset has been the cornerstone of deepfake detection since 2017, though it is now considerably out of date, in regards to the latest facial synthesis techniques. Source: https://www.youtube.com/watch?v=x2g48Q2I2ZQ
To address class imbalance, the authors used Focal Loss, emphasizing more challenging examples during training. All training was conducted on a single RTX 4090 GPU with 24Gb of VRAM, using pre-trained checkpoints from VideoMAE.
Tests
The method was evaluated against various deepfake detection techniques, focusing on locally-edited deepfakes. The tests included a range of editing methods and older deepfake datasets, using metrics like Area Under Curve (AUC), Average Precision, and Mean F1 Score.
From the paper: comparison on recent localized deepfakes shows that the proposed method outperformed all others, with a 15 to 20 percent gain in both AUC and average precision over the next-best approach.
The authors provided visual comparisons of locally manipulated videos, showing their method's superior sensitivity to subtle edits.
A real video was altered using three different localized manipulations to produce fakes that remained visually similar to the original. Shown here are representative frames along with the average fake detection scores for each method. While existing detectors struggled with these subtle edits, the proposed model consistently assigned high fake probabilities, indicating greater sensitivity to localized changes.
The researchers noted that existing state-of-the-art detection methods struggled with the latest deepfake generation techniques, while their method showed robust generalization, achieving high AUC and average precision scores.
Performance on traditional deepfake datasets shows that the proposed method remained competitive with leading approaches, indicating strong generalization across a range of manipulation types.
The authors also tested the model's reliability under real-world conditions, finding it resilient to common video distortions like saturation adjustments, Gaussian blur, and pixelation.
An illustration of how detection accuracy changes under different video distortions. The new method remained resilient in most cases, with only a small decline in AUC. The most significant drop occurred when Gaussian noise was introduced.
Conclusion
While the public often thinks of deepfakes as identity swaps, the reality of AI manipulation is more nuanced and potentially more insidious. The kind of local editing discussed in this new research might not capture public attention until another high-profile incident occurs. Yet, as actor Nic Cage has pointed out, the potential for post-production edits to alter performances is a concern we should all be aware of. We're naturally sensitive to even the slightest changes in facial expressions, and context can dramatically alter their impact.
First published Wednesday, April 2, 2025










 YouTube expands AI deepfake detection to politicians, government officials, and journalists
On Tuesday, YouTube announced it is expanding its deepfake detection technology to a select group of government officials, political candidates, and journalists. The tool identifies AI-generated likenesses and lets pilot participants request the remo
YouTube expands AI deepfake detection to politicians, government officials, and journalists
On Tuesday, YouTube announced it is expanding its deepfake detection technology to a select group of government officials, political candidates, and journalists. The tool identifies AI-generated likenesses and lets pilot participants request the remo
 YouTube bolsters AI deepfake protections for politicians, officials, and journalists
YouTube is extending access to its likeness detection technology, designed to identify AI-generated deepfakes, to a pilot program for government officials, political candidates, and journalists, the company announced on Tuesday. Participants in this
YouTube bolsters AI deepfake protections for politicians, officials, and journalists
YouTube is extending access to its likeness detection technology, designed to identify AI-generated deepfakes, to a pilot program for government officials, political candidates, and journalists, the company announced on Tuesday. Participants in this
 Exclusive: Luma AI Debuts Creative Agents Fueled by 'Unified Intelligence' Models
On Thursday, AI video generation startup Luma introduced Luma Agents, a system built to manage complete creative workflows spanning text, images, video, and audio. These agents are driven by Luma’s Unified Intelligence model family, featuring an arch
Exclusive: Luma AI Debuts Creative Agents Fueled by 'Unified Intelligence' Models
On Thursday, AI video generation startup Luma introduced Luma Agents, a system built to manage complete creative workflows spanning text, images, video, and audio. These agents are driven by Luma’s Unified Intelligence model family, featuring an arch

2026 Latest Best AI Expense Trackers: Top-rated tools to scan receipts & categorize corporate spend automatically. Discover powerful, game-changing solutions for effortless expense management, accurate financial tracking, and streamlined compliance. Our curated, weekly-updated comparison of free vs paid options helps you find the perfect fit. Unlock your AI edge with XIX.AI's expert picks.
10 tools
xix.ai

Discover the 2026 latest top-rated AI recruiting tools on XIX.AI. Our curated list features powerful, game-changing solutions for screening resumes and automating candidate interview scheduling. Compare free vs paid options with real-world tests and weekly updated rankings. Find your perfect hiring assistant and streamline your recruitment today!
10 tools
xix.ai

Discover the 2026 best AI personal wellness and focus coaches on XIX.AI. Our curated rankings feature top-rated, game-changing tools to manage burnout and boost mental energy. Compare free vs paid options with real-world insights. Unlock your path to peak productivity and well-being today.
10 tools
xix.ai

Discover the 2026 latest top-rated AI romantic chatbots for building genuine, long-term connections. Our curated list features powerful, consistent personalities, free vs paid comparisons, and real-world tests. Find your perfect companion and start building today at XIX.AI.
10 tools
xix.ai

Discover the 2026 best AI data science mentors to master SQL, Pandas & ML workflows. Explore our top-rated, curated selection at XIX.AI for powerful, game-changing guidance. Compare free vs paid options with real-world insights. Unlock your data science mastery today.
10 tools
xix.ai

Discover the 2026 best AI flirting and conversation trainers on XIX.AI. Our curated, top-rated selection helps you build social charisma and confidence in real-time. Explore must-try, game-changing tools with free vs paid comparisons and weekly updated rankings. Unlock your social edge today.
10 tools
xix.ai

この記事を読んで、AIによる映像改ざんがこんなに簡単にできるなんて怖いですね。ペロシ議長の例は氷山の一角で、もっと巧妙な偽動画がSNSで拡散される可能性があります。一般ユーザーとして、どうやって本物と偽物を見分ければいいのか悩みます。技術の進歩は素晴らしいけど、悪用されないための規制も必要じゃないかな🤔
Honestly, this Pelosi video case is a perfect example of how 'low-tech' AI manipulation can be the most dangerous. It doesn't need deepfakes; just slowing down footage creates a narrative. Makes you wonder what subtle edits we're already consuming daily without a second thought. The real battle for truth is in these tiny, almost invisible tweaks. 😳
Dieser Artikel erinnert mich daran, wie wichtig Medienkompetenz heute ist. Die Pelosi-Video-Manipulation war ja noch relativ plump, aber mit aktueller KI wird das bestimmt viel subtiler. Macht mir schon etwas Sorgen, vor Wahlen oder so. Wie soll man da noch zwischen echt und fake unterscheiden? 😕
That Pelosi video from 2019 is wild! It’s scary how a few tweaks can make someone look totally drunk. AI’s power to mess with videos is both cool and creepy—makes you wonder what’s real anymore. 😬
This Pelosi video incident is wild! 🤯 It’s scary how a few tweaks can make someone look totally out of it. Makes me wonder how much of what we see online is real anymore. AI’s cool, but this kind of stuff could mess with trust big time.
That Pelosi video from 2019 is wild! It’s scary how a few tweaks can make someone look totally out of it. AI’s power to mess with reality is no joke—makes you wonder what’s real anymore. 🫣













