
















 Heim
Heim
Enthüllen Sie subtile, aber wirkungsvolle KI -Modifikationen in authentischen Videoinhalten
Im Jahr 2019 verbreitete sich ein täuschendes Video von Nancy Pelosi, damals Sprecherin des US-Repräsentantenhauses, weithin. Das Video, das so bearbeitet wurde, dass sie betrunken erschien, war eine eindringliche Erinnerung daran, wie leicht manipulierte Medien die Öffentlichkeit täuschen können. Trotz seiner Einfachheit verdeutlichte dieser Vorfall das potenzielle Schadensausmaß selbst grundlegender audiovisueller Bearbeitungen.
Zu dieser Zeit war die Deepfake-Landschaft weitgehend von autoencoderbasierten Gesichtsaustauschtechnologien dominiert, die seit Ende 2017 existierten. Diese frühen Systeme hatten Schwierigkeiten, die nuancierten Veränderungen wie im Pelosi-Video vorzunehmen, und konzentrierten sich stattdessen auf offensichtlichere Gesichtstausche.
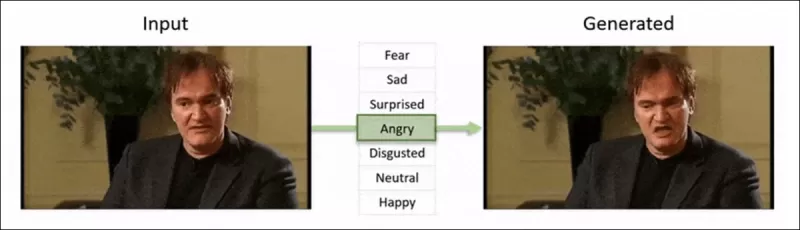 Das 2022 ‘Neural Emotion Director'-Framework verändert die Stimmung eines bekannten Gesichts. Quelle: https://www.youtube.com/watch?v=Li6W8pRDMJQ
Das 2022 ‘Neural Emotion Director'-Framework verändert die Stimmung eines bekannten Gesichts. Quelle: https://www.youtube.com/watch?v=Li6W8pRDMJQ
Schnell vorwärts bis heute, und die Film- und Fernsehindustrie erforscht zunehmend KI-gesteuerte Nachbearbeitungen. Dieser Trend hat sowohl Interesse als auch Kritik ausgelöst, da KI ein Maß an Perfektionismus ermöglicht, das zuvor unerreichbar war. Als Reaktion darauf hat die Forschungsgemeinschaft verschiedene Projekte entwickelt, die sich auf „lokale Bearbeitungen“ von Gesichtsaufnahmen konzentrieren, wie Diffusion Video Autoencoders, Stitch it in Time, ChatFace, MagicFace und DISCO.
 Ausdrucks-Bearbeitung mit dem Januar 2025 Projekt MagicFace. Quelle: https://arxiv.org/pdf/2501.02260
Ausdrucks-Bearbeitung mit dem Januar 2025 Projekt MagicFace. Quelle: https://arxiv.org/pdf/2501.02260
Neue Gesichter, neue Falten
Die Technologie zur Erstellung dieser subtilen Bearbeitungen entwickelt sich jedoch viel schneller als unsere Fähigkeit, sie zu erkennen. Die meisten Deepfake-Erkennungsmethoden sind veraltet und konzentrieren sich auf ältere Techniken und Datensätze. Das war so, bis zu einem kürzlichen Durchbruch von Forschern in Indien.
 Erkennung subtiler lokaler Bearbeitungen in Deepfakes: Ein echtes Video wird verändert, um Fälschungen mit nuancierten Änderungen wie hochgezogenen Augenbrauen, modifizierten Geschlechtsmerkmalen und Verschiebungen des Ausdrucks hin zu Ekel zu erzeugen (hier mit einem einzelnen Frame illustriert). Quelle: https://arxiv.org/pdf/2503.22121
Erkennung subtiler lokaler Bearbeitungen in Deepfakes: Ein echtes Video wird verändert, um Fälschungen mit nuancierten Änderungen wie hochgezogenen Augenbrauen, modifizierten Geschlechtsmerkmalen und Verschiebungen des Ausdrucks hin zu Ekel zu erzeugen (hier mit einem einzelnen Frame illustriert). Quelle: https://arxiv.org/pdf/2503.22121
Diese neue Forschung zielt auf die Erkennung subtiler, lokalisierter Gesichtsmanipulationen ab, eine Art von Fälschung, die oft übersehen wird. Anstelle von breiten Inkonsistenzen oder Identitätsunterschieden konzentriert sich die Methode auf feine Details wie leichte Ausdrucksverschiebungen oder geringfügige Bearbeitungen bestimmter Gesichtszüge. Sie nutzt das Facial Action Coding System (FACS), das Gesichtsausdrücke in 64 veränderbare Bereiche unterteilt.
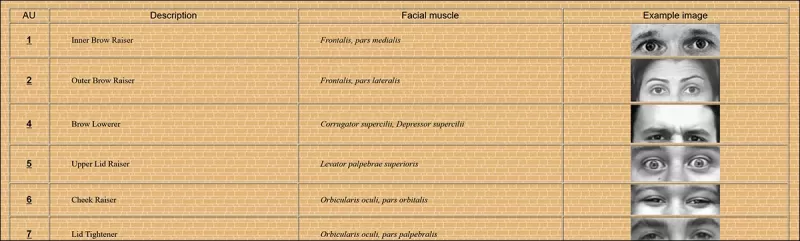 Einige der 64 Bestandteile des Ausdrucks in FACS. Quelle: https://www.cs.cmu.edu/~face/facs.htm
Einige der 64 Bestandteile des Ausdrucks in FACS. Quelle: https://www.cs.cmu.edu/~face/facs.htm
Die Forscher testeten ihren Ansatz gegen verschiedene aktuelle Bearbeitungsmethoden und stellten fest, dass er bestehende Lösungen durchweg übertraf, selbst bei älteren Datensätzen und neueren Angriffsvektoren.
„Durch die Verwendung von AU-basierten Merkmalen zur Steuerung von Videodarstellungen, die durch Masked Autoencoders (MAE) gelernt wurden, erfasst unsere Methode effektiv lokalisierte Änderungen, die für die Erkennung subtiler Gesichtsbearbeitungen entscheidend sind.“
„Dieser Ansatz ermöglicht es uns, eine einheitliche latente Darstellung zu konstruieren, die sowohl lokalisierte Bearbeitungen als auch breitere Veränderungen in gesichtszentrierten Videos kodiert und eine umfassende und anpassungsfähige Lösung für die Deepfake-Erkennung bietet.“
Das Papier mit dem Titel Erkennung lokalisierter Deepfake-Manipulationen mittels Action Unit-gesteuerter Videodarstellungen wurde von Forschern am Indian Institute of Technology in Madras verfasst.
Methode
Die Methode beginnt mit der Erkennung von Gesichtern in einem Video und der gleichmäßigen Abtastung von Frames, die auf diesen Gesichtern zentriert sind. Diese Frames werden dann in kleine 3D-Patches unterteilt, die lokale räumliche und zeitliche Details erfassen.
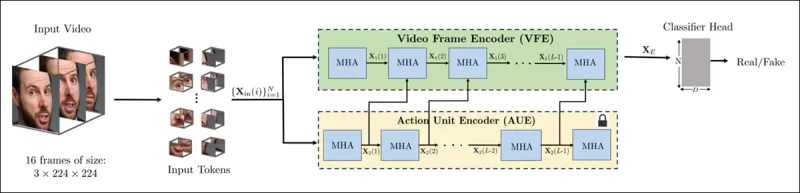 Schema für die neue Methode. Das Eingabevideo wird mit Gesichtserkennung verarbeitet, um gleichmäßig verteilte, gesichtszentrierte Frames zu extrahieren, die dann in „röhrenförmige“ Patches unterteilt und durch einen Encoder geleitet werden, der latente Darstellungen aus zwei vortrainierten Pretext-Aufgaben fusioniert. Der resultierende Vektor wird dann von einem Klassifikator verwendet, um zu bestimmen, ob das Video echt oder gefälscht ist.
Schema für die neue Methode. Das Eingabevideo wird mit Gesichtserkennung verarbeitet, um gleichmäßig verteilte, gesichtszentrierte Frames zu extrahieren, die dann in „röhrenförmige“ Patches unterteilt und durch einen Encoder geleitet werden, der latente Darstellungen aus zwei vortrainierten Pretext-Aufgaben fusioniert. Der resultierende Vektor wird dann von einem Klassifikator verwendet, um zu bestimmen, ob das Video echt oder gefälscht ist.
Jeder Patch enthält ein kleines Fenster von Pixeln aus einigen aufeinanderfolgenden Frames, wodurch das Modell kurzfristige Bewegungs- und Ausdrucksänderungen lernen kann. Diese Patches werden eingebettet und positionskodiert, bevor sie in einen Encoder eingespeist werden, der darauf ausgelegt ist, echte von gefälschten Videos zu unterscheiden.
Die Herausforderung, subtile Manipulationen zu erkennen, wird durch die Verwendung eines Encoders angegangen, der zwei Arten von gelernten Darstellungen durch einen Cross-Attention-Mechanismus kombiniert, um einen sensibleren und verallgemeinerungsfähigeren Merkmalsraum zu schaffen.
Pretext-Aufgaben
Die erste Darstellung stammt von einem Encoder, der mit einer Masked Autoencoding-Aufgabe trainiert wurde. Durch das Ausblenden der meisten 3D-Patches des Videos lernt der Encoder, die fehlenden Teile zu rekonstruieren und erfasst wichtige raumzeitliche Muster wie Gesichtsbewegungen.
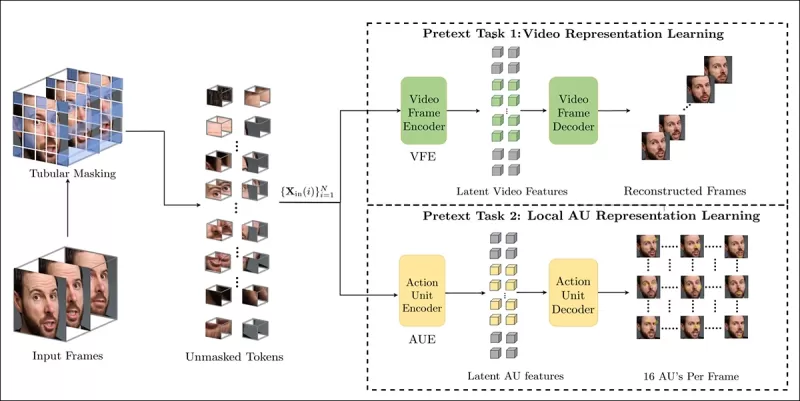 Das Training der Pretext-Aufgabe beinhaltet das Maskieren von Teilen des Videoeingangs und die Verwendung einer Encoder-Decoder-Konfiguration, um entweder die ursprünglichen Frames oder pro-Frame-Action-Unit-Karten zu rekonstruieren, je nach Aufgabe.
Das Training der Pretext-Aufgabe beinhaltet das Maskieren von Teilen des Videoeingangs und die Verwendung einer Encoder-Decoder-Konfiguration, um entweder die ursprünglichen Frames oder pro-Frame-Action-Unit-Karten zu rekonstruieren, je nach Aufgabe.
Dies allein reicht jedoch nicht aus, um feinkörnige Bearbeitungen zu erkennen. Die Forscher führten einen zweiten Encoder ein, der darauf trainiert wurde, Gesichts-Action-Units (AUs) zu erkennen, und förderten so den Fokus auf lokalisierte Muskelaktivitäten, wo subtile Deepfake-Bearbeitungen häufig vorkommen.
 Weitere Beispiele für Gesichts-Action-Units (FAUs oder AUs). Quelle: https://www.eiagroup.com/the-facial-action-coding-system/
Weitere Beispiele für Gesichts-Action-Units (FAUs oder AUs). Quelle: https://www.eiagroup.com/the-facial-action-coding-system/
Nach dem Pretraining werden die Ausgaben beider Encoder mithilfe von Cross-Attention kombiniert, wobei die AU-basierten Merkmale die Aufmerksamkeit auf die raumzeitlichen Merkmale lenken. Dies führt zu einer fusionierten latenten Darstellung, die sowohl den breiteren Bewegungskontext als auch lokalisierte Ausdrucksdetails erfasst, die für die endgültige Klassifizierungsaufgabe verwendet werden.
Daten und Tests
Implementierung
Das System wurde mit dem FaceXZoo PyTorch-basierten Gesichtserkennungs-Framework implementiert, das 16 gesichtszentrierte Frames aus jedem Videoclip extrahiert. Die Pretext-Aufgaben wurden auf dem CelebV-HQ-Datensatz trainiert, der 35.000 hochwertige Gesichtsvideos umfasst.
 Aus dem Quellpapier, Beispiele aus dem CelebV-HQ-Datensatz, der im neuen Projekt verwendet wurde. Quelle: https://arxiv.org/pdf/2207.12393
Aus dem Quellpapier, Beispiele aus dem CelebV-HQ-Datensatz, der im neuen Projekt verwendet wurde. Quelle: https://arxiv.org/pdf/2207.12393
Die Hälfte der Daten wurde maskiert, um Overfitting zu verhindern. Für die Masked-Frame-Rekonstruktionsaufgabe wurde das Modell trainiert, um fehlende Regionen mit L1-Verlust vorherzusagen. Für die zweite Aufgabe wurde es trainiert, Karten für 16 Gesichts-Action-Units zu generieren, überwacht durch L1-Verlust.
Nach dem Pretraining wurden die Encoder fusioniert und für die Deepfake-Erkennung mit dem FaceForensics++-Datensatz, der sowohl echte als auch manipulierte Videos umfasst, optimiert.
 Der FaceForensics++-Datensatz ist seit 2017 der zentrale Maßstab für die Deepfake-Erkennung, obwohl er in Bezug auf die neuesten Gesichtssynthesetechniken inzwischen deutlich veraltet ist. Quelle: https://www.youtube.com/watch?v=x2g48Q2I2ZQ
Der FaceForensics++-Datensatz ist seit 2017 der zentrale Maßstab für die Deepfake-Erkennung, obwohl er in Bezug auf die neuesten Gesichtssynthesetechniken inzwischen deutlich veraltet ist. Quelle: https://www.youtube.com/watch?v=x2g48Q2I2ZQ
Um das Klassenungleichgewicht zu adressieren, verwendeten die Autoren Focal Loss, wobei schwierigere Beispiele während des Trainings stärker gewichtet wurden. Das gesamte Training wurde auf einer einzigen RTX 4090 GPU mit 24 GB VRAM durchgeführt, unter Verwendung vortrainierter Checkpoints von VideoMAE.
Tests
Die Methode wurde gegen verschiedene Deepfake-Erkennungstechniken getestet, mit Fokus auf lokal bearbeitete Deepfakes. Die Tests umfassten eine Reihe von Bearbeitungsmethoden und älteren Deepfake-Datensätzen, unter Verwendung von Metriken wie Area Under Curve (AUC), Average Precision und Mean F1 Score.
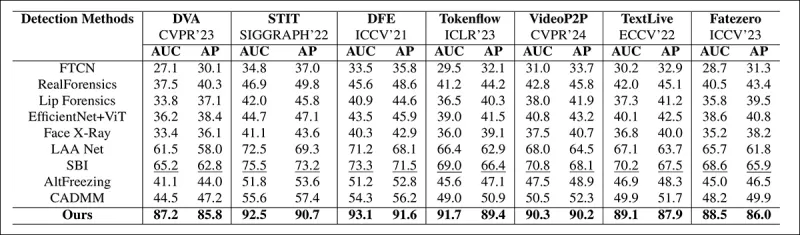 Aus dem Papier: Vergleich bei aktuellen lokalisierten Deepfakes zeigt, dass die vorgeschlagene Methode alle anderen übertraf, mit einem Zuwachs von 15 bis 20 Prozent sowohl bei AUC als auch bei der durchschnittlichen Präzision gegenüber dem nächstbesten Ansatz.
Aus dem Papier: Vergleich bei aktuellen lokalisierten Deepfakes zeigt, dass die vorgeschlagene Methode alle anderen übertraf, mit einem Zuwachs von 15 bis 20 Prozent sowohl bei AUC als auch bei der durchschnittlichen Präzision gegenüber dem nächstbesten Ansatz.
Die Autoren lieferten visuelle Vergleiche von lokal manipulierten Videos, die die überlegene Sensitivität ihrer Methode für subtile Bearbeitungen zeigen.
 Ein echtes Video wurde mit drei verschiedenen lokalisierten Manipulationen verändert, um Fälschungen zu erzeugen, die dem Original visuell ähnlich bleiben. Hier werden repräsentative Frames zusammen mit den durchschnittlichen Fälschungserkennungswerten für jede Methode gezeigt. Während bestehende Detektoren mit diesen subtilen Bearbeitungen Schwierigkeiten hatten, wies das vorgeschlagene Modell durchweg hohe Fälschungswahrscheinlichkeiten zu, was eine größere Sensitivität für lokalisierte Änderungen anzeigt.
Ein echtes Video wurde mit drei verschiedenen lokalisierten Manipulationen verändert, um Fälschungen zu erzeugen, die dem Original visuell ähnlich bleiben. Hier werden repräsentative Frames zusammen mit den durchschnittlichen Fälschungserkennungswerten für jede Methode gezeigt. Während bestehende Detektoren mit diesen subtilen Bearbeitungen Schwierigkeiten hatten, wies das vorgeschlagene Modell durchweg hohe Fälschungswahrscheinlichkeiten zu, was eine größere Sensitivität für lokalisierte Änderungen anzeigt.
Die Forscher stellten fest, dass bestehende hochmoderne Erkennungsmethoden mit den neuesten Deepfake-Generierungstechniken Schwierigkeiten hatten, während ihre Methode eine robuste Verallgemeinerung zeigte und hohe AUC- und durchschnittliche Präzisionswerte erzielte.
 Leistung bei traditionellen Deepfake-Datensätzen zeigt, dass die vorgeschlagene Methode mit führenden Ansätzen wettbewerbsfähig blieb, was eine starke Verallgemeinerung über eine Reihe von Manipulationstypen hinweg anzeigt.
Leistung bei traditionellen Deepfake-Datensätzen zeigt, dass die vorgeschlagene Methode mit führenden Ansätzen wettbewerbsfähig blieb, was eine starke Verallgemeinerung über eine Reihe von Manipulationstypen hinweg anzeigt.
Die Autoren testeten auch die Zuverlässigkeit des Modells unter realen Bedingungen und fanden es widerstandsfähig gegen gängige Videoverzerrungen wie Sättigungsanpassungen, Gaußsche Unschärfe und Pixelrauschen.
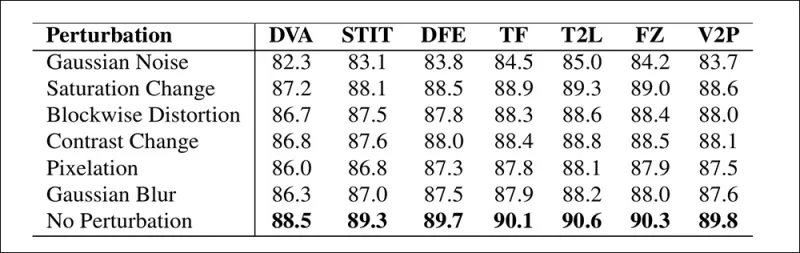 Eine Illustration, wie sich die Erkennungsgenauigkeit unter verschiedenen Videoverzerrungen ändert. Die neue Methode blieb in den meisten Fällen widerstandsfähig, mit nur einem geringen Rückgang bei AUC. Der bedeutendste Rückgang trat auf, wenn Gaußsches Rauschen eingeführt wurde.
Eine Illustration, wie sich die Erkennungsgenauigkeit unter verschiedenen Videoverzerrungen ändert. Die neue Methode blieb in den meisten Fällen widerstandsfähig, mit nur einem geringen Rückgang bei AUC. Der bedeutendste Rückgang trat auf, wenn Gaußsches Rauschen eingeführt wurde.
Fazit
Während die Öffentlichkeit Deepfakes oft als Identitätswechsel wahrnimmt, ist die Realität der KI-Manipulation nuancierter und potenziell heimtückischer. Die Art der lokalen Bearbeitung, die in dieser neuen Forschung diskutiert wird, erregt möglicherweise nicht die Aufmerksamkeit der Öffentlichkeit, bis ein weiterer prominenter Vorfall auftritt. Doch wie der Schauspieler Nic Cage betont hat, ist das Potenzial von Nachbearbeitungen, Auftritte zu verändern, ein Anliegen, das uns alle bewusst sein sollte. Wir sind von Natur aus empfindlich gegenüber selbst den kleinsten Veränderungen in Gesichtsausdrücken, und der Kontext kann ihre Wirkung dramatisch verändern.
Erstmals veröffentlicht am Mittwoch, 2. April 2025
Verwandter Artikel
 YouTube weitet die KI-basierte Deepfake-Erkennung auf Politiker, Regierungsvertreter und Journalisten aus
Am Dienstag gab YouTube bekannt, dass es seine Deepfake-Erkennungstechnologie auf eine ausgewählte Gruppe von Regierungsbeamten, politischen Kandidaten und Journalisten ausweiten wird. Das Tool identi
YouTube verstärkt den Schutz vor KI-Deepfakes für Politiker, Amtsträger und Journalisten
YouTube weitet den Zugang zu seiner Technologie zur Erkennung von Personenabbildern, die dazu dient, KI-generierte Deepfakes zu identifizieren, auf ein Pilotprogramm für Regierungsbeamte, politische K
Exklusiv: Luma AI stellt kreative Agenten vor, die auf „Unified Intelligence”-Modellen basieren
Am Donnerstag stellte das Start-up-Unternehmen Luma, das sich mit der Erstellung von KI-Videos befasst, Luma Agents vor, ein System zur Verwaltung kompletter kreativer Workflows, die Text, Bilder, Vid
Empfehlungen zu verwandten Spezialthemen
Geschäft
YouTube weitet die KI-basierte Deepfake-Erkennung auf Politiker, Regierungsvertreter und Journalisten aus
Am Dienstag gab YouTube bekannt, dass es seine Deepfake-Erkennungstechnologie auf eine ausgewählte Gruppe von Regierungsbeamten, politischen Kandidaten und Journalisten ausweiten wird. Das Tool identi
YouTube verstärkt den Schutz vor KI-Deepfakes für Politiker, Amtsträger und Journalisten
YouTube weitet den Zugang zu seiner Technologie zur Erkennung von Personenabbildern, die dazu dient, KI-generierte Deepfakes zu identifizieren, auf ein Pilotprogramm für Regierungsbeamte, politische K
Exklusiv: Luma AI stellt kreative Agenten vor, die auf „Unified Intelligence”-Modellen basieren
Am Donnerstag stellte das Start-up-Unternehmen Luma, das sich mit der Erstellung von KI-Videos befasst, Luma Agents vor, ein System zur Verwaltung kompletter kreativer Workflows, die Text, Bilder, Vid
Empfehlungen zu verwandten Spezialthemen
Geschäft
 Die besten KI-Tools für die Personalbeschaffung: Lebensläufe prüfen und die Terminplanung für Vorstellungsgespräche automatisieren
Die besten KI-Tools für die Personalbeschaffung: Lebensläufe prüfen und die Terminplanung für Vorstellungsgespräche automatisieren
Entdecken Sie auf XIX.AI die besten KI-Tools für die Personalbeschaffung des Jahres 2026. Unsere sorgfältig zusammengestellte Liste umfasst leistungsstarke, bahnbrechende Lösungen für die Sichtung von Lebensläufen und die automatisierte Terminplanung für Vorstellungsgespräche. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Finden Sie Ihren perfekten Assistenten für die Personalbeschaffung und optimieren Sie noch heute Ihren Rekrutierungsprozess!
 10 Tools
10 Tools
 xix.ai
Produktivität
KI-Coaches für persönliches Wohlbefinden und Konzentration: Burnout bewältigen und die geistige Energie steigern
xix.ai
Produktivität
KI-Coaches für persönliches Wohlbefinden und Konzentration: Burnout bewältigen und die geistige Energie steigern
Entdecken Sie auf XIX.AI die besten KI-basierten Coaches für persönliches Wohlbefinden und Konzentration des Jahres 2026. Unsere sorgfältig zusammengestellte Rangliste umfasst erstklassige, bahnbrechende Tools zur Bewältigung von Burnout und zur Steigerung der mentalen Energie. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Erfahrungsberichten aus der Praxis. Schlagen Sie noch heute den Weg zu höchster Produktivität und Wohlbefinden ein.
10 Tools
xix.ai
Chatbot
Die besten KI-basierten Romantik-Chatbots: Bauen Sie langfristige Beziehungen mit beständiger Persönlichkeit auf
Entdecken Sie die besten KI-Romantik-Chatbots des Jahres 2026, mit denen Sie echte, langfristige Beziehungen aufbauen können. Unsere sorgfältig zusammengestellte Liste bietet Ihnen überzeugende, konsistente Persönlichkeiten, Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten sowie Tests aus der Praxis. Finden Sie Ihren perfekten Begleiter und legen Sie noch heute bei XIX.AI los.
10 Tools
xix.ai
Bildung und Lernen
Die besten AI-Datenwissenschafts-Mentoren: Beherrschen Sie SQL, Pandas und Arbeitsabläufe für maschinelles Lernen.
Entdecken Sie die besten AI-Data-Science-Mentoren von 2026, um SQL, Pandas und ML-Arbeitsabläufe zu meistern. Erfahren Sie mehr über unsere hochbewerteten, sorgfältig ausgewählten Angebote bei XIX.AI – für effektive und bahnbrechende Anleitung. Vergleichen Sie kostenlose und bezahlte Optionen mit praktischen Einblicken aus der Praxis. Entfalten Sie Ihr Potenzial in der Data Science noch heute.
10 Tools
xix.ai
Chatbot
Die besten KI-Flirt- und Konversationstrainer: Steigere dein soziales Charisma und dein Selbstvertrauen in Echtzeit
Entdecken Sie auf XIX.AI die besten KI-Flirt- und Konversationstrainer des Jahres 2026. Unsere sorgfältig zusammengestellte, erstklassige Auswahl hilft Ihnen dabei, Ihr soziales Charisma und Ihr Selbstvertrauen in Echtzeit zu stärken. Entdecken Sie unverzichtbare, bahnbrechende Tools mit Vergleichen zwischen kostenlosen und kostenpflichtigen Angeboten sowie wöchentlich aktualisierten Rankings. Schaffen Sie sich noch heute einen sozialen Vorsprung.
10 Tools
xix.ai
Code
Die besten KI-Tools für automatisierte Einheitstests: Generieren Sie mit nur einem Klick Jest-, PyTest- und JUnit-Testfälle.
Entdecken Sie die neuesten, hochbewerteten KI-Tools von 2026 für den automatisierten Unit-Testing-Prozess. Unsere sorgfältig ausgewählten Lösungen bieten leistungsstarke und bahnbrechende Funktionen, um sofort Jest-, PyTest- und JUnit-Testfälle zu generieren. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von tatsächlichen Tests sowie wöchentlich aktualisierten Rankings auf XIX.AI. Entfalten Sie Ihr KI-Potenzial und steigern Sie noch heute die Produktivität Ihrer Entwicklungstätigkeit.
10 Tools
xix.ai

 Kommentare (46)
Kommentare (46)
![RalphMitchell]()
この記事を読んで、AIによる映像改ざんがこんなに簡単にできるなんて怖いですね。ペロシ議長の例は氷山の一角で、もっと巧妙な偽動画がSNSで拡散される可能性があります。一般ユーザーとして、どうやって本物と偽物を見分ければいいのか悩みます。技術の進歩は素晴らしいけど、悪用されないための規制も必要じゃないかな🤔
![JustinHarris]()
Honestly, this Pelosi video case is a perfect example of how 'low-tech' AI manipulation can be the most dangerous. It doesn't need deepfakes; just slowing down footage creates a narrative. Makes you wonder what subtle edits we're already consuming daily without a second thought. The real battle for truth is in these tiny, almost invisible tweaks. 😳
![DavidRodriguez]()
Dieser Artikel erinnert mich daran, wie wichtig Medienkompetenz heute ist. Die Pelosi-Video-Manipulation war ja noch relativ plump, aber mit aktueller KI wird das bestimmt viel subtiler. Macht mir schon etwas Sorgen, vor Wahlen oder so. Wie soll man da noch zwischen echt und fake unterscheiden? 😕
![WilliamCarter]()
That Pelosi video from 2019 is wild! It’s scary how a few tweaks can make someone look totally drunk. AI’s power to mess with videos is both cool and creepy—makes you wonder what’s real anymore. 😬
![JuanMartínez]()
This Pelosi video incident is wild! 🤯 It’s scary how a few tweaks can make someone look totally out of it. Makes me wonder how much of what we see online is real anymore. AI’s cool, but this kind of stuff could mess with trust big time.
![RyanPerez]()
That Pelosi video from 2019 is wild! It’s scary how a few tweaks can make someone look totally out of it. AI’s power to mess with reality is no joke—makes you wonder what’s real anymore. 🫣
Im Jahr 2019 verbreitete sich ein täuschendes Video von Nancy Pelosi, damals Sprecherin des US-Repräsentantenhauses, weithin. Das Video, das so bearbeitet wurde, dass sie betrunken erschien, war eine eindringliche Erinnerung daran, wie leicht manipulierte Medien die Öffentlichkeit täuschen können. Trotz seiner Einfachheit verdeutlichte dieser Vorfall das potenzielle Schadensausmaß selbst grundlegender audiovisueller Bearbeitungen.
Zu dieser Zeit war die Deepfake-Landschaft weitgehend von autoencoderbasierten Gesichtsaustauschtechnologien dominiert, die seit Ende 2017 existierten. Diese frühen Systeme hatten Schwierigkeiten, die nuancierten Veränderungen wie im Pelosi-Video vorzunehmen, und konzentrierten sich stattdessen auf offensichtlichere Gesichtstausche.
Das 2022 ‘Neural Emotion Director'-Framework verändert die Stimmung eines bekannten Gesichts. Quelle: https://www.youtube.com/watch?v=Li6W8pRDMJQ
Schnell vorwärts bis heute, und die Film- und Fernsehindustrie erforscht zunehmend KI-gesteuerte Nachbearbeitungen. Dieser Trend hat sowohl Interesse als auch Kritik ausgelöst, da KI ein Maß an Perfektionismus ermöglicht, das zuvor unerreichbar war. Als Reaktion darauf hat die Forschungsgemeinschaft verschiedene Projekte entwickelt, die sich auf „lokale Bearbeitungen“ von Gesichtsaufnahmen konzentrieren, wie Diffusion Video Autoencoders, Stitch it in Time, ChatFace, MagicFace und DISCO.
Ausdrucks-Bearbeitung mit dem Januar 2025 Projekt MagicFace. Quelle: https://arxiv.org/pdf/2501.02260
Neue Gesichter, neue Falten
Die Technologie zur Erstellung dieser subtilen Bearbeitungen entwickelt sich jedoch viel schneller als unsere Fähigkeit, sie zu erkennen. Die meisten Deepfake-Erkennungsmethoden sind veraltet und konzentrieren sich auf ältere Techniken und Datensätze. Das war so, bis zu einem kürzlichen Durchbruch von Forschern in Indien.
Erkennung subtiler lokaler Bearbeitungen in Deepfakes: Ein echtes Video wird verändert, um Fälschungen mit nuancierten Änderungen wie hochgezogenen Augenbrauen, modifizierten Geschlechtsmerkmalen und Verschiebungen des Ausdrucks hin zu Ekel zu erzeugen (hier mit einem einzelnen Frame illustriert). Quelle: https://arxiv.org/pdf/2503.22121
Diese neue Forschung zielt auf die Erkennung subtiler, lokalisierter Gesichtsmanipulationen ab, eine Art von Fälschung, die oft übersehen wird. Anstelle von breiten Inkonsistenzen oder Identitätsunterschieden konzentriert sich die Methode auf feine Details wie leichte Ausdrucksverschiebungen oder geringfügige Bearbeitungen bestimmter Gesichtszüge. Sie nutzt das Facial Action Coding System (FACS), das Gesichtsausdrücke in 64 veränderbare Bereiche unterteilt.
Einige der 64 Bestandteile des Ausdrucks in FACS. Quelle: https://www.cs.cmu.edu/~face/facs.htm
Die Forscher testeten ihren Ansatz gegen verschiedene aktuelle Bearbeitungsmethoden und stellten fest, dass er bestehende Lösungen durchweg übertraf, selbst bei älteren Datensätzen und neueren Angriffsvektoren.
„Durch die Verwendung von AU-basierten Merkmalen zur Steuerung von Videodarstellungen, die durch Masked Autoencoders (MAE) gelernt wurden, erfasst unsere Methode effektiv lokalisierte Änderungen, die für die Erkennung subtiler Gesichtsbearbeitungen entscheidend sind.“
„Dieser Ansatz ermöglicht es uns, eine einheitliche latente Darstellung zu konstruieren, die sowohl lokalisierte Bearbeitungen als auch breitere Veränderungen in gesichtszentrierten Videos kodiert und eine umfassende und anpassungsfähige Lösung für die Deepfake-Erkennung bietet.“
Das Papier mit dem Titel Erkennung lokalisierter Deepfake-Manipulationen mittels Action Unit-gesteuerter Videodarstellungen wurde von Forschern am Indian Institute of Technology in Madras verfasst.
Methode
Die Methode beginnt mit der Erkennung von Gesichtern in einem Video und der gleichmäßigen Abtastung von Frames, die auf diesen Gesichtern zentriert sind. Diese Frames werden dann in kleine 3D-Patches unterteilt, die lokale räumliche und zeitliche Details erfassen.
Schema für die neue Methode. Das Eingabevideo wird mit Gesichtserkennung verarbeitet, um gleichmäßig verteilte, gesichtszentrierte Frames zu extrahieren, die dann in „röhrenförmige“ Patches unterteilt und durch einen Encoder geleitet werden, der latente Darstellungen aus zwei vortrainierten Pretext-Aufgaben fusioniert. Der resultierende Vektor wird dann von einem Klassifikator verwendet, um zu bestimmen, ob das Video echt oder gefälscht ist.
Jeder Patch enthält ein kleines Fenster von Pixeln aus einigen aufeinanderfolgenden Frames, wodurch das Modell kurzfristige Bewegungs- und Ausdrucksänderungen lernen kann. Diese Patches werden eingebettet und positionskodiert, bevor sie in einen Encoder eingespeist werden, der darauf ausgelegt ist, echte von gefälschten Videos zu unterscheiden.
Die Herausforderung, subtile Manipulationen zu erkennen, wird durch die Verwendung eines Encoders angegangen, der zwei Arten von gelernten Darstellungen durch einen Cross-Attention-Mechanismus kombiniert, um einen sensibleren und verallgemeinerungsfähigeren Merkmalsraum zu schaffen.
Pretext-Aufgaben
Die erste Darstellung stammt von einem Encoder, der mit einer Masked Autoencoding-Aufgabe trainiert wurde. Durch das Ausblenden der meisten 3D-Patches des Videos lernt der Encoder, die fehlenden Teile zu rekonstruieren und erfasst wichtige raumzeitliche Muster wie Gesichtsbewegungen.
Das Training der Pretext-Aufgabe beinhaltet das Maskieren von Teilen des Videoeingangs und die Verwendung einer Encoder-Decoder-Konfiguration, um entweder die ursprünglichen Frames oder pro-Frame-Action-Unit-Karten zu rekonstruieren, je nach Aufgabe.
Dies allein reicht jedoch nicht aus, um feinkörnige Bearbeitungen zu erkennen. Die Forscher führten einen zweiten Encoder ein, der darauf trainiert wurde, Gesichts-Action-Units (AUs) zu erkennen, und förderten so den Fokus auf lokalisierte Muskelaktivitäten, wo subtile Deepfake-Bearbeitungen häufig vorkommen.
Weitere Beispiele für Gesichts-Action-Units (FAUs oder AUs). Quelle: https://www.eiagroup.com/the-facial-action-coding-system/
Nach dem Pretraining werden die Ausgaben beider Encoder mithilfe von Cross-Attention kombiniert, wobei die AU-basierten Merkmale die Aufmerksamkeit auf die raumzeitlichen Merkmale lenken. Dies führt zu einer fusionierten latenten Darstellung, die sowohl den breiteren Bewegungskontext als auch lokalisierte Ausdrucksdetails erfasst, die für die endgültige Klassifizierungsaufgabe verwendet werden.
Daten und Tests
Implementierung
Das System wurde mit dem FaceXZoo PyTorch-basierten Gesichtserkennungs-Framework implementiert, das 16 gesichtszentrierte Frames aus jedem Videoclip extrahiert. Die Pretext-Aufgaben wurden auf dem CelebV-HQ-Datensatz trainiert, der 35.000 hochwertige Gesichtsvideos umfasst.
Aus dem Quellpapier, Beispiele aus dem CelebV-HQ-Datensatz, der im neuen Projekt verwendet wurde. Quelle: https://arxiv.org/pdf/2207.12393
Die Hälfte der Daten wurde maskiert, um Overfitting zu verhindern. Für die Masked-Frame-Rekonstruktionsaufgabe wurde das Modell trainiert, um fehlende Regionen mit L1-Verlust vorherzusagen. Für die zweite Aufgabe wurde es trainiert, Karten für 16 Gesichts-Action-Units zu generieren, überwacht durch L1-Verlust.
Nach dem Pretraining wurden die Encoder fusioniert und für die Deepfake-Erkennung mit dem FaceForensics++-Datensatz, der sowohl echte als auch manipulierte Videos umfasst, optimiert.
Der FaceForensics++-Datensatz ist seit 2017 der zentrale Maßstab für die Deepfake-Erkennung, obwohl er in Bezug auf die neuesten Gesichtssynthesetechniken inzwischen deutlich veraltet ist. Quelle: https://www.youtube.com/watch?v=x2g48Q2I2ZQ
Um das Klassenungleichgewicht zu adressieren, verwendeten die Autoren Focal Loss, wobei schwierigere Beispiele während des Trainings stärker gewichtet wurden. Das gesamte Training wurde auf einer einzigen RTX 4090 GPU mit 24 GB VRAM durchgeführt, unter Verwendung vortrainierter Checkpoints von VideoMAE.
Tests
Die Methode wurde gegen verschiedene Deepfake-Erkennungstechniken getestet, mit Fokus auf lokal bearbeitete Deepfakes. Die Tests umfassten eine Reihe von Bearbeitungsmethoden und älteren Deepfake-Datensätzen, unter Verwendung von Metriken wie Area Under Curve (AUC), Average Precision und Mean F1 Score.
Aus dem Papier: Vergleich bei aktuellen lokalisierten Deepfakes zeigt, dass die vorgeschlagene Methode alle anderen übertraf, mit einem Zuwachs von 15 bis 20 Prozent sowohl bei AUC als auch bei der durchschnittlichen Präzision gegenüber dem nächstbesten Ansatz.
Die Autoren lieferten visuelle Vergleiche von lokal manipulierten Videos, die die überlegene Sensitivität ihrer Methode für subtile Bearbeitungen zeigen.
Ein echtes Video wurde mit drei verschiedenen lokalisierten Manipulationen verändert, um Fälschungen zu erzeugen, die dem Original visuell ähnlich bleiben. Hier werden repräsentative Frames zusammen mit den durchschnittlichen Fälschungserkennungswerten für jede Methode gezeigt. Während bestehende Detektoren mit diesen subtilen Bearbeitungen Schwierigkeiten hatten, wies das vorgeschlagene Modell durchweg hohe Fälschungswahrscheinlichkeiten zu, was eine größere Sensitivität für lokalisierte Änderungen anzeigt.
Die Forscher stellten fest, dass bestehende hochmoderne Erkennungsmethoden mit den neuesten Deepfake-Generierungstechniken Schwierigkeiten hatten, während ihre Methode eine robuste Verallgemeinerung zeigte und hohe AUC- und durchschnittliche Präzisionswerte erzielte.
Leistung bei traditionellen Deepfake-Datensätzen zeigt, dass die vorgeschlagene Methode mit führenden Ansätzen wettbewerbsfähig blieb, was eine starke Verallgemeinerung über eine Reihe von Manipulationstypen hinweg anzeigt.
Die Autoren testeten auch die Zuverlässigkeit des Modells unter realen Bedingungen und fanden es widerstandsfähig gegen gängige Videoverzerrungen wie Sättigungsanpassungen, Gaußsche Unschärfe und Pixelrauschen.
Eine Illustration, wie sich die Erkennungsgenauigkeit unter verschiedenen Videoverzerrungen ändert. Die neue Methode blieb in den meisten Fällen widerstandsfähig, mit nur einem geringen Rückgang bei AUC. Der bedeutendste Rückgang trat auf, wenn Gaußsches Rauschen eingeführt wurde.
Fazit
Während die Öffentlichkeit Deepfakes oft als Identitätswechsel wahrnimmt, ist die Realität der KI-Manipulation nuancierter und potenziell heimtückischer. Die Art der lokalen Bearbeitung, die in dieser neuen Forschung diskutiert wird, erregt möglicherweise nicht die Aufmerksamkeit der Öffentlichkeit, bis ein weiterer prominenter Vorfall auftritt. Doch wie der Schauspieler Nic Cage betont hat, ist das Potenzial von Nachbearbeitungen, Auftritte zu verändern, ein Anliegen, das uns alle bewusst sein sollte. Wir sind von Natur aus empfindlich gegenüber selbst den kleinsten Veränderungen in Gesichtsausdrücken, und der Kontext kann ihre Wirkung dramatisch verändern.
Erstmals veröffentlicht am Mittwoch, 2. April 2025










 YouTube weitet die KI-basierte Deepfake-Erkennung auf Politiker, Regierungsvertreter und Journalisten aus
Am Dienstag gab YouTube bekannt, dass es seine Deepfake-Erkennungstechnologie auf eine ausgewählte Gruppe von Regierungsbeamten, politischen Kandidaten und Journalisten ausweiten wird. Das Tool identi
YouTube weitet die KI-basierte Deepfake-Erkennung auf Politiker, Regierungsvertreter und Journalisten aus
Am Dienstag gab YouTube bekannt, dass es seine Deepfake-Erkennungstechnologie auf eine ausgewählte Gruppe von Regierungsbeamten, politischen Kandidaten und Journalisten ausweiten wird. Das Tool identi
 YouTube verstärkt den Schutz vor KI-Deepfakes für Politiker, Amtsträger und Journalisten
YouTube weitet den Zugang zu seiner Technologie zur Erkennung von Personenabbildern, die dazu dient, KI-generierte Deepfakes zu identifizieren, auf ein Pilotprogramm für Regierungsbeamte, politische K
YouTube verstärkt den Schutz vor KI-Deepfakes für Politiker, Amtsträger und Journalisten
YouTube weitet den Zugang zu seiner Technologie zur Erkennung von Personenabbildern, die dazu dient, KI-generierte Deepfakes zu identifizieren, auf ein Pilotprogramm für Regierungsbeamte, politische K
 Exklusiv: Luma AI stellt kreative Agenten vor, die auf „Unified Intelligence”-Modellen basieren
Am Donnerstag stellte das Start-up-Unternehmen Luma, das sich mit der Erstellung von KI-Videos befasst, Luma Agents vor, ein System zur Verwaltung kompletter kreativer Workflows, die Text, Bilder, Vid
Exklusiv: Luma AI stellt kreative Agenten vor, die auf „Unified Intelligence”-Modellen basieren
Am Donnerstag stellte das Start-up-Unternehmen Luma, das sich mit der Erstellung von KI-Videos befasst, Luma Agents vor, ein System zur Verwaltung kompletter kreativer Workflows, die Text, Bilder, Vid

Entdecken Sie auf XIX.AI die besten KI-Tools für die Personalbeschaffung des Jahres 2026. Unsere sorgfältig zusammengestellte Liste umfasst leistungsstarke, bahnbrechende Lösungen für die Sichtung von Lebensläufen und die automatisierte Terminplanung für Vorstellungsgespräche. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Finden Sie Ihren perfekten Assistenten für die Personalbeschaffung und optimieren Sie noch heute Ihren Rekrutierungsprozess!
10 Tools
xix.ai

Entdecken Sie auf XIX.AI die besten KI-basierten Coaches für persönliches Wohlbefinden und Konzentration des Jahres 2026. Unsere sorgfältig zusammengestellte Rangliste umfasst erstklassige, bahnbrechende Tools zur Bewältigung von Burnout und zur Steigerung der mentalen Energie. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Erfahrungsberichten aus der Praxis. Schlagen Sie noch heute den Weg zu höchster Produktivität und Wohlbefinden ein.
10 Tools
xix.ai

Entdecken Sie die besten KI-Romantik-Chatbots des Jahres 2026, mit denen Sie echte, langfristige Beziehungen aufbauen können. Unsere sorgfältig zusammengestellte Liste bietet Ihnen überzeugende, konsistente Persönlichkeiten, Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten sowie Tests aus der Praxis. Finden Sie Ihren perfekten Begleiter und legen Sie noch heute bei XIX.AI los.
10 Tools
xix.ai

Entdecken Sie die besten AI-Data-Science-Mentoren von 2026, um SQL, Pandas und ML-Arbeitsabläufe zu meistern. Erfahren Sie mehr über unsere hochbewerteten, sorgfältig ausgewählten Angebote bei XIX.AI – für effektive und bahnbrechende Anleitung. Vergleichen Sie kostenlose und bezahlte Optionen mit praktischen Einblicken aus der Praxis. Entfalten Sie Ihr Potenzial in der Data Science noch heute.
10 Tools
xix.ai

Entdecken Sie auf XIX.AI die besten KI-Flirt- und Konversationstrainer des Jahres 2026. Unsere sorgfältig zusammengestellte, erstklassige Auswahl hilft Ihnen dabei, Ihr soziales Charisma und Ihr Selbstvertrauen in Echtzeit zu stärken. Entdecken Sie unverzichtbare, bahnbrechende Tools mit Vergleichen zwischen kostenlosen und kostenpflichtigen Angeboten sowie wöchentlich aktualisierten Rankings. Schaffen Sie sich noch heute einen sozialen Vorsprung.
10 Tools
xix.ai

Entdecken Sie die neuesten, hochbewerteten KI-Tools von 2026 für den automatisierten Unit-Testing-Prozess. Unsere sorgfältig ausgewählten Lösungen bieten leistungsstarke und bahnbrechende Funktionen, um sofort Jest-, PyTest- und JUnit-Testfälle zu generieren. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von tatsächlichen Tests sowie wöchentlich aktualisierten Rankings auf XIX.AI. Entfalten Sie Ihr KI-Potenzial und steigern Sie noch heute die Produktivität Ihrer Entwicklungstätigkeit.
10 Tools
xix.ai

この記事を読んで、AIによる映像改ざんがこんなに簡単にできるなんて怖いですね。ペロシ議長の例は氷山の一角で、もっと巧妙な偽動画がSNSで拡散される可能性があります。一般ユーザーとして、どうやって本物と偽物を見分ければいいのか悩みます。技術の進歩は素晴らしいけど、悪用されないための規制も必要じゃないかな🤔
Honestly, this Pelosi video case is a perfect example of how 'low-tech' AI manipulation can be the most dangerous. It doesn't need deepfakes; just slowing down footage creates a narrative. Makes you wonder what subtle edits we're already consuming daily without a second thought. The real battle for truth is in these tiny, almost invisible tweaks. 😳
Dieser Artikel erinnert mich daran, wie wichtig Medienkompetenz heute ist. Die Pelosi-Video-Manipulation war ja noch relativ plump, aber mit aktueller KI wird das bestimmt viel subtiler. Macht mir schon etwas Sorgen, vor Wahlen oder so. Wie soll man da noch zwischen echt und fake unterscheiden? 😕
That Pelosi video from 2019 is wild! It’s scary how a few tweaks can make someone look totally drunk. AI’s power to mess with videos is both cool and creepy—makes you wonder what’s real anymore. 😬
This Pelosi video incident is wild! 🤯 It’s scary how a few tweaks can make someone look totally out of it. Makes me wonder how much of what we see online is real anymore. AI’s cool, but this kind of stuff could mess with trust big time.
That Pelosi video from 2019 is wild! It’s scary how a few tweaks can make someone look totally out of it. AI’s power to mess with reality is no joke—makes you wonder what’s real anymore. 🫣













