




प्रामाणिक वीडियो सामग्री में सूक्ष्म अभी तक प्रभावशाली एआई संशोधनों का अनावरण
2019 में, नैन्सी पेलोसी, जो उस समय अमेरिकी प्रतिनिधि सभा की स्पीकर थीं, का एक भ्रामक वीडियो व्यापक रूप से प्रसारित हुआ। यह वीडियो, जिसे संपादित करके उन्हें नशे में दिखाया गया था, एक स्पष्ट अनुस्मारक था कि हेरफेर किए गए मीडिया जनता को कितनी आसानी से गुमराह कर सकते हैं। इसकी सादगी के बावजूद, इस घटना ने ऑडियो-विजुअल संपादनों के संभावित नुकसान को उजागर किया।
उस समय, डीपफेक परिदृश्य में मुख्य रूप से ऑटोएन्कोडर-आधारित चेहरा-प्रतिस्थापन तकनीकों का वर्चस्व था, जो 2017 के अंत से मौजूद थीं। ये शुरुआती सिस्टम पेलोसी वीडियो में दिखाए गए सूक्ष्म परिवर्तनों को करने में संघर्ष करते थे, और इसके बजाय अधिक स्पष्ट चेहरा-स्वैप पर ध्यान केंद्रित करते थे।
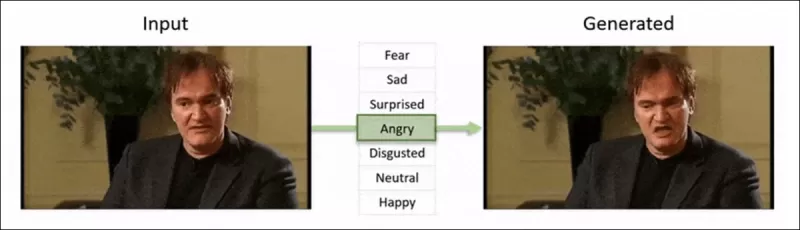 2022 का ‘Neural Emotion Director' ढांचा एक प्रसिद्ध चेहरे के मूड को बदलता है। स्रोत: https://www.youtube.com/watch?v=Li6W8pRDMJQ
2022 का ‘Neural Emotion Director' ढांचा एक प्रसिद्ध चेहरे के मूड को बदलता है। स्रोत: https://www.youtube.com/watch?v=Li6W8pRDMJQ
आज की तारीख में, फिल्म और टीवी उद्योग तेजी से AI-चालित पोस्ट-प्रोडक्शन संपादनों की खोज कर रहा है। इस प्रवृत्ति ने रुचि और आलोचना दोनों को जन्म दिया है, क्योंकि AI ऐसी पूर्णता का स्तर सक्षम बनाता है जो पहले असंभव था। जवाब में, शोध समुदाय ने चेहरे के कैप्चर के ‘स्थानीय संपादनों’ पर केंद्रित विभिन्न परियोजनाएं विकसित की हैं, जैसे कि Diffusion Video Autoencoders, Stitch it in Time, ChatFace, MagicFace, और DISCO।
 जनवरी 2025 की परियोजना MagicFace के साथ अभिव्यक्ति-संपादन। स्रोत: https://arxiv.org/pdf/2501.02260
जनवरी 2025 की परियोजना MagicFace के साथ अभिव्यक्ति-संपादन। स्रोत: https://arxiv.org/pdf/2501.02260
नए चेहरे, नई झुर्रियां
हालांकि, इन सूक्ष्म संपादनों को बनाने की तकनीक हमारी उन्हें पहचानने की क्षमता से कहीं तेजी से प्रगति कर रही है। अधिकांश डीपफेक पहचान विधियां पुरानी हो चुकी हैं, जो पुरानी तकनीकों और डेटासेट पर केंद्रित हैं। यह तब तक था, जब तक भारत के शोधकर्ताओं ने हाल ही में एक सफलता हासिल नहीं की।
 डीपफेक में सूक्ष्म स्थानीय संपादनों का पता लगाना: एक वास्तविक वीडियो को सूक्ष्म परिवर्तनों जैसे उठी हुई भौहें, संशोधित लिंग विशेषताएं, और घृणा की ओर अभिव्यक्ति में बदलाव (यहां एकल फ्रेम के साथ चित्रित) के साथ नकली वीडियो बनाने के लिए बदल दिया जाता है। स्रोत: https://arxiv.org/pdf/2503.22121
डीपफेक में सूक्ष्म स्थानीय संपादनों का पता लगाना: एक वास्तविक वीडियो को सूक्ष्म परिवर्तनों जैसे उठी हुई भौहें, संशोधित लिंग विशेषताएं, और घृणा की ओर अभिव्यक्ति में बदलाव (यहां एकल फ्रेम के साथ चित्रित) के साथ नकली वीडियो बनाने के लिए बदल दिया जाता है। स्रोत: https://arxiv.org/pdf/2503.22121
यह नया शोध सूक्ष्म, स्थानीय चेहरे के हेरफेर का पता लगाने पर लक्षित है, जो एक प्रकार की जालसाजी है जिसे अक्सर नजरअंदाज किया जाता है। व्यापक असंगतियों या पहचान के बेमेल की तलाश करने के बजाय, यह विधि सूक्ष्म अभिव्यक्ति परिवर्तनों या विशिष्ट चेहरे की विशेषताओं में छोटे संपादनों जैसे बारीक विवरणों पर केंद्रित है। यह Facial Action Coding System (FACS) का उपयोग करता है, जो चेहरे की अभिव्यक्तियों को 64 परिवर्तनीय क्षेत्रों में तोड़ता है।
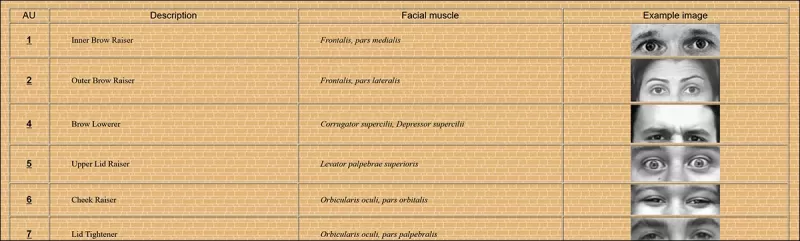 FACS में 64 अभिव्यक्ति भागों में से कुछ। स्रोत: https://www.cs.cmu.edu/~face/facs.htm
FACS में 64 अभिव्यक्ति भागों में से कुछ। स्रोत: https://www.cs.cmu.edu/~face/facs.htm
शोधकर्ताओं ने अपनी विधि को विभिन्न हालिया संपादन विधियों के खिलाफ परखा और पाया कि यह मौजूदा समाधानों को लगातार बेहतर प्रदर्शन देता है, यहां तक कि पुराने डेटासेट और नए हमले के वैक्टरों के साथ भी।
‘मास्क्ड ऑटोएन्कोडर्स (MAE) के माध्यम से सीखे गए वीडियो प्रतिनिधित्वों को मार्गदर्शन करने के लिए AU-आधारित विशेषताओं का उपयोग करके, हमारी विधि डीपफेक में सूक्ष्म चेहरे के संपादनों का पता लगाने के लिए महत्वपूर्ण स्थानीय परिवर्तनों को प्रभावी ढंग से कैप्चर करती है।
‘यह दृष्टिकोण हमें एक एकीकृत अव्यक्त प्रतिनिधित्व बनाने में सक्षम बनाता है जो चेहरा-केंद्रित वीडियो में स्थानीय संपादनों और व्यापक परिवर्तनों दोनों को एन्कोड करता है, डीपफेक पहचान के लिए एक व्यापक और अनुकूलनीय समाधान प्रदान करता है।'
यह पेपर, जिसका शीर्षक Detecting Localized Deepfake Manipulations Using Action Unit-Guided Video Representations है, भारतीय प्रौद्योगिकी संस्थान, मद्रास के शोधकर्ताओं द्वारा लिखा गया था।
विधि
यह विधि वीडियो में चेहरों का पता लगाने और इन चेहरों पर केंद्रित समान रूप से दूरी वाले फ्रेम्स को सैंपल करने से शुरू होती है। इन फ्रेम्स को फिर छोटे 3D पैच में तोड़ा जाता है, जो स्थानीय स्थानिक और अस्थायी विवरणों को कैप्चर करते हैं।
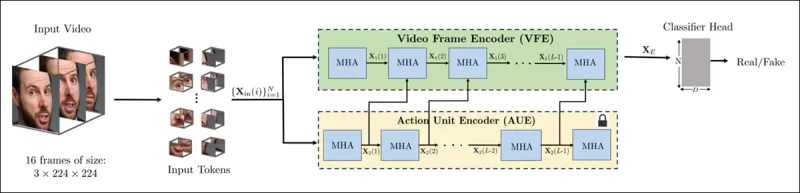 नई विधि का स्कीमा। इनपुट वीडियो को चेहरा पहचान के साथ संसाधित किया जाता है ताकि समान रूप से दूरी वाले, चेहरा-केंद्रित फ्रेम्स निकाले जा सकें, जिन्हें फिर ‘ट्यूबलर’ पैच में विभाजित किया जाता है और एक एन्कोडर के माध्यम से पारित किया जाता है जो दो प्रीट्रेंड प्रीटेक्स्ट कार्यों से अव्यक्त प्रतिनिधित्वों को फ्यूज करता है। परिणामी वेक्टर को फिर एक क्लासिफायर द्वारा उपयोग किया जाता है ताकि यह निर्धारित किया जा सके कि वीडियो वास्तविक है या नकली।
नई विधि का स्कीमा। इनपुट वीडियो को चेहरा पहचान के साथ संसाधित किया जाता है ताकि समान रूप से दूरी वाले, चेहरा-केंद्रित फ्रेम्स निकाले जा सकें, जिन्हें फिर ‘ट्यूबलर’ पैच में विभाजित किया जाता है और एक एन्कोडर के माध्यम से पारित किया जाता है जो दो प्रीट्रेंड प्रीटेक्स्ट कार्यों से अव्यक्त प्रतिनिधित्वों को फ्यूज करता है। परिणामी वेक्टर को फिर एक क्लासिफायर द्वारा उपयोग किया जाता है ताकि यह निर्धारित किया जा सके कि वीडियो वास्तविक है या नकली।
प्रत्येक पैच में कुछ क्रमिक फ्रेम्स से पिक्सल का एक छोटा सा खिड़की शामिल होती है, जो मॉडल को अल्पकालिक गति और अभिव्यक्ति परिवर्तनों को सीखने की अनुमति देता है। इन पैच को एम्बेड किया जाता है और स्थिति-एन्कोड किया जाता है, फिर एक एन्कोडर में डाला जाता है जो वास्तविक और नकली वीडियो को अलग करने के लिए डिज़ाइन किया गया है।
सूक्ष्म हेरफेर का पता लगाने की चुनौती को एक एन्कोडर का उपयोग करके संबोधित किया जाता है जो क्रॉस-अटेंशन तंत्र के माध्यम से दो प्रकार के सीखे गए प्रतिनिधित्वों को जोड़ता है, जिसका उद्देश्य अधिक संवेदनशील और सामान्यीकृत विशेषता स्थान बनाना है।
प्रीटेक्स्ट कार्य
पहला प्रतिनिधित्व एक एन्कोडर से आता है जो मास्क्ड ऑटोएन्कोडिंग कार्य के साथ प्रशिक्षित किया गया है। वीडियो के अधिकांश 3D पैच को छिपाकर, एन्कोडर लापता हिस्सों का पुनर्निर्माण करना सीखता है, चेहरे की गति जैसे महत्वपूर्ण स्थान-कालिक पैटर्न को कैप्चर करता है।
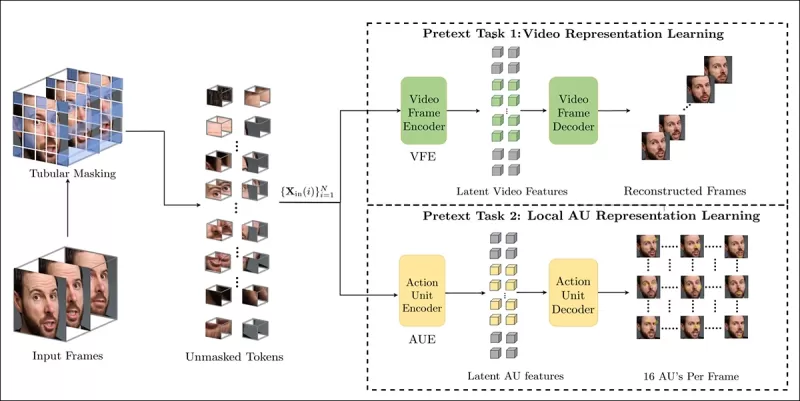 प्रीटेक्स्ट कार्य प्रशिक्षण में वीडियो इनपुट के हिस्सों को मास्क करना और मूल फ्रेम्स या प्रति-फ्रेम एक्शन यूनिट मैप्स को पुनर्निर्माण करने के लिए एक एन्कोडर-डिकोडर सेटअप का उपयोग करना शामिल है, जो कार्य पर निर्भर करता है।
प्रीटेक्स्ट कार्य प्रशिक्षण में वीडियो इनपुट के हिस्सों को मास्क करना और मूल फ्रेम्स या प्रति-फ्रेम एक्शन यूनिट मैप्स को पुनर्निर्माण करने के लिए एक एन्कोडर-डिकोडर सेटअप का उपयोग करना शामिल है, जो कार्य पर निर्भर करता है।
हालांकि, यह अकेले सूक्ष्म संपादनों का पता लगाने के लिए पर्याप्त नहीं है। शोधकर्ताओं ने एक दूसरा एन्कोडर पेश किया जो चेहरे की एक्शन यूनिट्स (AUs) का पता लगाने के लिए प्रशिक्षित है, इसे उन स्थानीय मांसपेशी गतिविधियों पर ध्यान केंद्रित करने के लिए प्रोत्साहित करता है जहां सूक्ष्म डीपफेक संपादन अक्सर होते हैं।
 चेहरे की एक्शन यूनिट्स (FAUs, या AUs) के और उदाहरण। स्रोत: https://www.eiagroup.com/the-facial-action-coding-system/
चेहरे की एक्शन यूनिट्स (FAUs, या AUs) के और उदाहरण। स्रोत: https://www.eiagroup.com/the-facial-action-coding-system/
प्रीट्रेनिंग के बाद, दोनों एन्कोडरों के आउटपुट को क्रॉस-अटेंशन का उपयोग करके जोड़ा जाता है, जिसमें AU-आधारित विशेषताएं स्थान-कालिक विशेषताओं पर ध्यान को मार्गदर्शन करती हैं। इससे एक फ्यूज्ड अव्यक्त प्रतिनिधित्व प्राप्त होता है जो व्यापक गति संदर्भ और स्थानीय अभिव्यक्ति विवरण दोनों को कैप्चर करता है, जिसे अंतिम वर्गीकरण कार्य के लिए उपयोग किया जाता है।
डेटा और परीक्षण
कारyan्वयन
सिस्टम को FaceXZoo PyTorch-आधारित चेहरा पहचान ढांचे का उपयोग करके लागू किया गया था, जिसमें प्रत्येक वीडियो क्लिप से 16 चेहरा-केंद्रित फ्रेम्स निकाले गए थे। प्रीटेक्स्ट कार्यों को CelebV-HQ डेटासेट पर प्रशिक्षित किया गया था, जिसमें 35,000 उच्च-गुणवत्ता वाले चेहरे के वीडियो शामिल हैं।
 स्रोत पेपर से, नई परियोजना में उपयोग किए गए CelebV-HQ डेटासेट के उदाहरण। स्रोत: https://arxiv.org/pdf/2207.12393
स्रोत पेपर से, नई परियोजना में उपयोग किए गए CelebV-HQ डेटासेट के उदाहरण। स्रोत: https://arxiv.org/pdf/2207.12393
आधे डेटा को ओवरफिटिंग से बचाने के लिए मास्क किया गया था। मास्क्ड फ्रेम पुनर्निर्माण कार्य के लिए, मॉडल को L1 हानि का उपयोग करके लापता क्षेत्रों की भविष्यवाणी करने के लिए प्रशिक्षित किया गया था। दूसरे कार्य के लिए, इसे 16 चेहरे की एक्शन यूनिट्स के लिए मैप्स उत्पन्न करने के लिए प्रशिक्षित किया गया था, जिसे L1 हानि द्वारा पर्यवेक्षित किया गया था।
प्रीट्रेनिंग के बाद, एन्कोडरों को फ्यूज किया गया और FaceForensics++ डेटासेट का उपयोग करके डीपफेक पहचान के लिए फाइन-ट्यून किया गया, जिसमें वास्तविक और हेरफेर किए गए वीडियो दोनों शामिल हैं।
 FaceForensics++ डेटासेट 2017 से डीपफेक पहचान का आधार रहा है, हालांकि यह अब नवीनतम चेहरे संश्लेषण तकनीकों के संबंध में काफी पुराना हो चुका है। स्रोत: https://www.youtube.com/watch?v=x2g48Q2I2ZQ
FaceForensics++ डेटासेट 2017 से डीपफेक पहचान का आधार रहा है, हालांकि यह अब नवीनतम चेहरे संश्लेषण तकनीकों के संबंध में काफी पुराना हो चुका है। स्रोत: https://www.youtube.com/watch?v=x2g48Q2I2ZQ
क्लास असंतुलन को संबोधित करने के लिए, लेखकों ने Focal Loss का उपयोग किया, जो प्रशिक्षण के दौरान अधिक चुनौतीपूर्ण उदाहरणों पर जोर देता है। सभी प्रशिक्षण एक एकल RTX 4090 GPU पर 24Gb VRAM के साथ किया गया था, जिसमें VideoMAE से प्री-ट्रेंड चेकपॉइंट्स का उपयोग किया गया था।
परीक्षण
इस विधि का मूल्यांकन विभिन्न डीपफेक पहचान तकनीकों के खिलाफ किया गया, जो स्थानीय रूप से संपादित डीपफेक्स पर केंद्रित था। परीक्षणों में विभिन्न संपादन विधियों और पुराने डीपफेक डेटासेट शामिल थे, जिनमें Area Under Curve (AUC), Average Precision, और Mean F1 Score जैसे मेट्रिक्स का उपयोग किया गया।
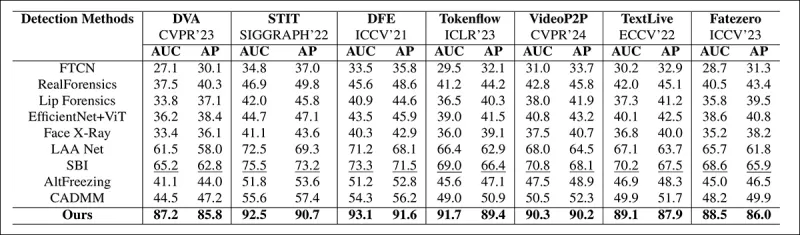 पेपर से: हाल के स्थानीय डीपफेक्स पर तुलना से पता चलता है कि प्रस्तावित विधि ने सभी अन्य को बेहतर प्रदर्शन दिया, जिसमें अगले सबसे अच्छे दृष्टिकोण की तुलना में AUC और औसत परिशुद्धता में 15 से 20 प्रतिशत की वृद्धि हुई।
पेपर से: हाल के स्थानीय डीपफेक्स पर तुलना से पता चलता है कि प्रस्तावित विधि ने सभी अन्य को बेहतर प्रदर्शन दिया, जिसमें अगले सबसे अच्छे दृष्टिकोण की तुलना में AUC और औसत परिशुद्धता में 15 से 20 प्रतिशत की वृद्धि हुई।
लेखकों ने स्थानीय रूप से हेरफेर किए गए वीडियो की दृश्य तुलना प्रदान की, जिसमें उनकी विधि की सूक्ष्म संपादनों के प्रति बेहतर संवेदनशीलता दिखाई दी।
 एक वास्तविक वीडियो को तीन अलग-अलग स्थानीय हेरफेरों का उपयोग करके बदला गया था ताकि नकली वीडियो बनाए जा सकें जो मूल के समान दृश्य रूप से दिखें। यहां प्रतिनिधि फ्रेम्स दिखाए गए हैं, साथ ही प्रत्येक विधि के लिए औसत नकली पहचान स्कोर भी। जबकि मौजूदा डिटेक्टर इन सूक्ष्म संपादनों के साथ संघर्ष करते थे, प्रस्तावित मॉडल ने लगातार उच्च नकली संभावनाएं प्रदान कीं, जो स्थानीय परिवर्तनों के प्रति अधिक संवेदनशीलता को दर्शाता है।
एक वास्तविक वीडियो को तीन अलग-अलग स्थानीय हेरफेरों का उपयोग करके बदला गया था ताकि नकली वीडियो बनाए जा सकें जो मूल के समान दृश्य रूप से दिखें। यहां प्रतिनिधि फ्रेम्स दिखाए गए हैं, साथ ही प्रत्येक विधि के लिए औसत नकली पहचान स्कोर भी। जबकि मौजूदा डिटेक्टर इन सूक्ष्म संपादनों के साथ संघर्ष करते थे, प्रस्तावित मॉडल ने लगातार उच्च नकली संभावनाएं प्रदान कीं, जो स्थानीय परिवर्तनों के प्रति अधिक संवेदनशीलता को दर्शाता है।
शोधकर्ताओं ने नोट किया कि मौजूदा अत्याधुनिक पहचान विधियां नवीनतम डीपफेक जनन तकनीकों के साथ संघर्ष करती थीं, जबकि उनकी विधि ने मजबूत सामान्यीकरण दिखाया, उच्च AUC और औसत परिशुद्धता स्कोर प्राप्त किए।
 पारंपरिक डीपफेक डेटासेट पर प्रदर्शन से पता चलता है कि प्रस्तावित विधि अग्रणी दृष्टिकोणों के साथ प्रतिस्पर्धी रही, जो हेरफेर प्रकारों की एक श्रृंखला में मजबूत सामान्यीकरण को दर्शाता है।
पारंपरिक डीपफेक डेटासेट पर प्रदर्शन से पता चलता है कि प्रस्तावित विधि अग्रणी दृष्टिकोणों के साथ प्रतिस्पर्धी रही, जो हेरफेर प्रकारों की एक श्रृंखला में मजबूत सामान्यीकरण को दर्शाता है।
लेखकों ने वास्तविक दुनिया की परिस्थितियों में मॉडल की विश्वसनीयता का भी परीक्षण किया, जिसमें पाया गया कि यह संतृप्ति समायोजन, Gaussian blur, और पिक्सलेशन जैसे सामान्य वीडियो विकृतियों के प्रति लचीला रहा।
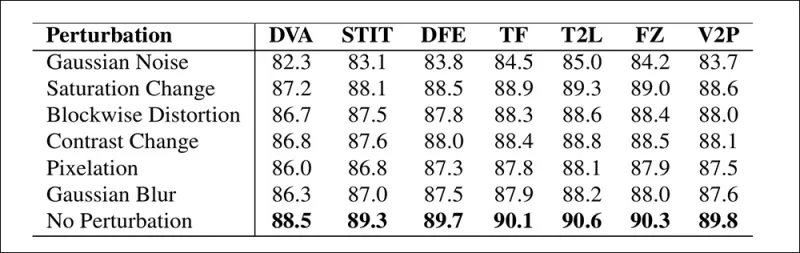 विभिन्न वीडियो विकृतियों के तहत पहचान सटीकता में परिवर्तन का एक चित्रण। नई विधि अधिकांश मामलों में लचीली रही, जिसमें AUC में केवल थोड़ी कमी आई। सबसे महत्वपूर्ण कमी तब हुई जब Gaussian noise पेश किया गया।
विभिन्न वीडियो विकृतियों के तहत पहचान सटीकता में परिवर्तन का एक चित्रण। नई विधि अधिकांश मामलों में लचीली रही, जिसमें AUC में केवल थोड़ी कमी आई। सबसे महत्वपूर्ण कमी तब हुई जब Gaussian noise पेश किया गया।
निष्कर्ष
जबकि जनता अक्सर डीपफेक्स को पहचान स्वैप के रूप में सोचती है, AI हेरफेर की वास्तविकता अधिक सूक्ष्म और संभावित रूप से अधिक कपटी है। इस नए शोध में चर्चा किए गए स्थानीय संपादन का प्रकार तब तक सार्वजनिक ध्यान आकर्षित नहीं कर सकता जब तक कि कोई और हाई-प्रोफाइल घटना न हो। फिर भी, जैसा कि अभिनेता Nic Cage ने बताया है, पोस्ट-प्रोडक्शन संपादनों की प्रदर्शन को बदलने की संभावना एक ऐसी चिंता है जिसके बारे में हम सभी को जागरूक होना चाहिए। हम स्वाभाविक रूप से चेहरे की अभिव्यक्तियों में मामूली परिवर्तनों के प्रति संवेदनशील हैं, और संदर्भ उनके प्रभाव को नाटकीय रूप से बदल सकता है।
पहली बार बुधवार, 2 अप्रैल, 2025 को प्रकाशित
संबंधित लेख
 सिविटई मास्टरकार्ड और वीजा के दबाव के बीच डीपफेक नियमों को मजबूत करता है
Civitai, इंटरनेट पर सबसे प्रमुख AI मॉडल रिपॉजिटरी में से एक, ने हाल ही में NSFW सामग्री पर अपनी नीतियों में महत्वपूर्ण बदलाव किए हैं, विशेष रूप से सेलिब्रिटी लोरस के विषय में। इन परिवर्तनों को भुगतान फैसिलिटेटर्स मास्टरकार्ड और वीजा के दबाव से प्रेरित किया गया था। सेलिब्रिटी लोरस, जो यू हैं
Google संदिग्ध धोखाधड़ी के लिए 39 मिलियन से अधिक विज्ञापन खातों को निलंबित करने के लिए AI का उपयोग करता है
Google ने बुधवार को घोषणा की कि उसने 2024 में अपने प्लेटफ़ॉर्म पर 39.2 मिलियन विज्ञापनदाता खातों को निलंबित करके विज्ञापन धोखाधड़ी से लड़ने में एक बड़ा कदम उठाया था। यह संख्या पिछले वर्ष की रिपोर्ट की गई थी।
एआई वीडियो पीढ़ी पूर्ण नियंत्रण की ओर बढ़ती है
हुनयुआन और वान 2.1 जैसे वीडियो फाउंडेशन मॉडल ने महत्वपूर्ण प्रगति की है, लेकिन वे अक्सर कम हो जाते हैं जब यह फिल्म और टीवी उत्पादन में आवश्यक विस्तृत नियंत्रण की बात आती है, विशेष रूप से दृश्य प्रभावों (वीएफएक्स) के दायरे में। पेशेवर VFX स्टूडियो में, ये मॉडल, पहले की छवि-बास के साथ-साथ
सूचना (41)
0/200
सिविटई मास्टरकार्ड और वीजा के दबाव के बीच डीपफेक नियमों को मजबूत करता है
Civitai, इंटरनेट पर सबसे प्रमुख AI मॉडल रिपॉजिटरी में से एक, ने हाल ही में NSFW सामग्री पर अपनी नीतियों में महत्वपूर्ण बदलाव किए हैं, विशेष रूप से सेलिब्रिटी लोरस के विषय में। इन परिवर्तनों को भुगतान फैसिलिटेटर्स मास्टरकार्ड और वीजा के दबाव से प्रेरित किया गया था। सेलिब्रिटी लोरस, जो यू हैं
Google संदिग्ध धोखाधड़ी के लिए 39 मिलियन से अधिक विज्ञापन खातों को निलंबित करने के लिए AI का उपयोग करता है
Google ने बुधवार को घोषणा की कि उसने 2024 में अपने प्लेटफ़ॉर्म पर 39.2 मिलियन विज्ञापनदाता खातों को निलंबित करके विज्ञापन धोखाधड़ी से लड़ने में एक बड़ा कदम उठाया था। यह संख्या पिछले वर्ष की रिपोर्ट की गई थी।
एआई वीडियो पीढ़ी पूर्ण नियंत्रण की ओर बढ़ती है
हुनयुआन और वान 2.1 जैसे वीडियो फाउंडेशन मॉडल ने महत्वपूर्ण प्रगति की है, लेकिन वे अक्सर कम हो जाते हैं जब यह फिल्म और टीवी उत्पादन में आवश्यक विस्तृत नियंत्रण की बात आती है, विशेष रूप से दृश्य प्रभावों (वीएफएक्स) के दायरे में। पेशेवर VFX स्टूडियो में, ये मॉडल, पहले की छवि-बास के साथ-साथ
सूचना (41)
0/200
![RyanPerez]() RyanPerez
RyanPerez
 29 जुलाई 2025 5:55:16 अपराह्न IST
29 जुलाई 2025 5:55:16 अपराह्न IST
That Pelosi video from 2019 is wild! It’s scary how a few tweaks can make someone look totally out of it. AI’s power to mess with reality is no joke—makes you wonder what’s real anymore. 🫣


 0
0
![MarkRoberts]() MarkRoberts
24 अप्रैल 2025 7:54:54 पूर्वाह्न IST
MarkRoberts
24 अप्रैल 2025 7:54:54 पूर्वाह्न IST
Este herramienta de IA me mostró lo fácil que es manipular videos. El incidente de Nancy Pelosi fue un recordatorio impactante. Es aterrador pensar en cuántas noticias falsas pueden existir. Ahora estoy más atento a lo que creo en línea. ¡Cuidado, amigos! 👀
0
![RobertMartin]() RobertMartin
21 अप्रैल 2025 2:12:51 पूर्वाह्न IST
RobertMartin
21 अप्रैल 2025 2:12:51 पूर्वाह्न IST
このAIツールは、ビデオを操作するのがどれほど簡単かを教えてくれました。ナンシー・ペロシの事件は衝撃的でした。偽ニュースがどれだけあるかと思うと恐ろしいです。オンラインで何を信じるかについて、今はもっと注意しています。みなさんも気をつけてくださいね!👀
0
![PaulMartínez]() PaulMartínez
19 अप्रैल 2025 3:55:50 अपराह्न IST
PaulMartínez
19 अप्रैल 2025 3:55:50 अपराह्न IST
Dieses KI-Tool hat mir gezeigt, wie einfach es ist, Videos zu manipulieren! Der Vorfall mit Nancy Pelosi war ein Weckruf. Es ist beängstigend, wie viele gefälschte Nachrichten es geben könnte. Ich bin jetzt vorsichtiger mit dem, was ich online glaube. Seid wachsam, Leute! 👀
0
![HarryWilliams]() HarryWilliams
19 अप्रैल 2025 3:47:36 अपराह्न IST
HarryWilliams
19 अप्रैल 2025 3:47:36 अपराह्न IST
This AI tool really opened my eyes to how easy it is to manipulate videos! The Nancy Pelosi incident was a wake-up call. It's scary to think how much fake news could be out there. Definitely makes me more cautious about what I believe online. Keep an eye out, folks! 👀
0
![EricRoberts]() EricRoberts
15 अप्रैल 2025 3:35:37 अपराह्न IST
EricRoberts
15 अप्रैल 2025 3:35:37 अपराह्न IST
이 앱은 눈을 뜨게 합니다! AI의 미묘한 변화가 비디오의 진위성을 어떻게 망칠 수 있는지를 보여줍니다. 낸시 펠로시의 예는 경고였어요. 하지만 설명이 때때로 나에게는 너무 기술적이어서요. 더 간단하게 설명해주면 좋겠어요! 그래도 AI의 영향을 이해하는 데는 좋은 도구입니다. 👀
0
2019 में, नैन्सी पेलोसी, जो उस समय अमेरिकी प्रतिनिधि सभा की स्पीकर थीं, का एक भ्रामक वीडियो व्यापक रूप से प्रसारित हुआ। यह वीडियो, जिसे संपादित करके उन्हें नशे में दिखाया गया था, एक स्पष्ट अनुस्मारक था कि हेरफेर किए गए मीडिया जनता को कितनी आसानी से गुमराह कर सकते हैं। इसकी सादगी के बावजूद, इस घटना ने ऑडियो-विजुअल संपादनों के संभावित नुकसान को उजागर किया।
उस समय, डीपफेक परिदृश्य में मुख्य रूप से ऑटोएन्कोडर-आधारित चेहरा-प्रतिस्थापन तकनीकों का वर्चस्व था, जो 2017 के अंत से मौजूद थीं। ये शुरुआती सिस्टम पेलोसी वीडियो में दिखाए गए सूक्ष्म परिवर्तनों को करने में संघर्ष करते थे, और इसके बजाय अधिक स्पष्ट चेहरा-स्वैप पर ध्यान केंद्रित करते थे।
2022 का ‘Neural Emotion Director' ढांचा एक प्रसिद्ध चेहरे के मूड को बदलता है। स्रोत: https://www.youtube.com/watch?v=Li6W8pRDMJQ
आज की तारीख में, फिल्म और टीवी उद्योग तेजी से AI-चालित पोस्ट-प्रोडक्शन संपादनों की खोज कर रहा है। इस प्रवृत्ति ने रुचि और आलोचना दोनों को जन्म दिया है, क्योंकि AI ऐसी पूर्णता का स्तर सक्षम बनाता है जो पहले असंभव था। जवाब में, शोध समुदाय ने चेहरे के कैप्चर के ‘स्थानीय संपादनों’ पर केंद्रित विभिन्न परियोजनाएं विकसित की हैं, जैसे कि Diffusion Video Autoencoders, Stitch it in Time, ChatFace, MagicFace, और DISCO।
जनवरी 2025 की परियोजना MagicFace के साथ अभिव्यक्ति-संपादन। स्रोत: https://arxiv.org/pdf/2501.02260
नए चेहरे, नई झुर्रियां
हालांकि, इन सूक्ष्म संपादनों को बनाने की तकनीक हमारी उन्हें पहचानने की क्षमता से कहीं तेजी से प्रगति कर रही है। अधिकांश डीपफेक पहचान विधियां पुरानी हो चुकी हैं, जो पुरानी तकनीकों और डेटासेट पर केंद्रित हैं। यह तब तक था, जब तक भारत के शोधकर्ताओं ने हाल ही में एक सफलता हासिल नहीं की।
डीपफेक में सूक्ष्म स्थानीय संपादनों का पता लगाना: एक वास्तविक वीडियो को सूक्ष्म परिवर्तनों जैसे उठी हुई भौहें, संशोधित लिंग विशेषताएं, और घृणा की ओर अभिव्यक्ति में बदलाव (यहां एकल फ्रेम के साथ चित्रित) के साथ नकली वीडियो बनाने के लिए बदल दिया जाता है। स्रोत: https://arxiv.org/pdf/2503.22121
यह नया शोध सूक्ष्म, स्थानीय चेहरे के हेरफेर का पता लगाने पर लक्षित है, जो एक प्रकार की जालसाजी है जिसे अक्सर नजरअंदाज किया जाता है। व्यापक असंगतियों या पहचान के बेमेल की तलाश करने के बजाय, यह विधि सूक्ष्म अभिव्यक्ति परिवर्तनों या विशिष्ट चेहरे की विशेषताओं में छोटे संपादनों जैसे बारीक विवरणों पर केंद्रित है। यह Facial Action Coding System (FACS) का उपयोग करता है, जो चेहरे की अभिव्यक्तियों को 64 परिवर्तनीय क्षेत्रों में तोड़ता है।
FACS में 64 अभिव्यक्ति भागों में से कुछ। स्रोत: https://www.cs.cmu.edu/~face/facs.htm
शोधकर्ताओं ने अपनी विधि को विभिन्न हालिया संपादन विधियों के खिलाफ परखा और पाया कि यह मौजूदा समाधानों को लगातार बेहतर प्रदर्शन देता है, यहां तक कि पुराने डेटासेट और नए हमले के वैक्टरों के साथ भी।
‘मास्क्ड ऑटोएन्कोडर्स (MAE) के माध्यम से सीखे गए वीडियो प्रतिनिधित्वों को मार्गदर्शन करने के लिए AU-आधारित विशेषताओं का उपयोग करके, हमारी विधि डीपफेक में सूक्ष्म चेहरे के संपादनों का पता लगाने के लिए महत्वपूर्ण स्थानीय परिवर्तनों को प्रभावी ढंग से कैप्चर करती है।
‘यह दृष्टिकोण हमें एक एकीकृत अव्यक्त प्रतिनिधित्व बनाने में सक्षम बनाता है जो चेहरा-केंद्रित वीडियो में स्थानीय संपादनों और व्यापक परिवर्तनों दोनों को एन्कोड करता है, डीपफेक पहचान के लिए एक व्यापक और अनुकूलनीय समाधान प्रदान करता है।'
यह पेपर, जिसका शीर्षक Detecting Localized Deepfake Manipulations Using Action Unit-Guided Video Representations है, भारतीय प्रौद्योगिकी संस्थान, मद्रास के शोधकर्ताओं द्वारा लिखा गया था।
विधि
यह विधि वीडियो में चेहरों का पता लगाने और इन चेहरों पर केंद्रित समान रूप से दूरी वाले फ्रेम्स को सैंपल करने से शुरू होती है। इन फ्रेम्स को फिर छोटे 3D पैच में तोड़ा जाता है, जो स्थानीय स्थानिक और अस्थायी विवरणों को कैप्चर करते हैं।
नई विधि का स्कीमा। इनपुट वीडियो को चेहरा पहचान के साथ संसाधित किया जाता है ताकि समान रूप से दूरी वाले, चेहरा-केंद्रित फ्रेम्स निकाले जा सकें, जिन्हें फिर ‘ट्यूबलर’ पैच में विभाजित किया जाता है और एक एन्कोडर के माध्यम से पारित किया जाता है जो दो प्रीट्रेंड प्रीटेक्स्ट कार्यों से अव्यक्त प्रतिनिधित्वों को फ्यूज करता है। परिणामी वेक्टर को फिर एक क्लासिफायर द्वारा उपयोग किया जाता है ताकि यह निर्धारित किया जा सके कि वीडियो वास्तविक है या नकली।
प्रत्येक पैच में कुछ क्रमिक फ्रेम्स से पिक्सल का एक छोटा सा खिड़की शामिल होती है, जो मॉडल को अल्पकालिक गति और अभिव्यक्ति परिवर्तनों को सीखने की अनुमति देता है। इन पैच को एम्बेड किया जाता है और स्थिति-एन्कोड किया जाता है, फिर एक एन्कोडर में डाला जाता है जो वास्तविक और नकली वीडियो को अलग करने के लिए डिज़ाइन किया गया है।
सूक्ष्म हेरफेर का पता लगाने की चुनौती को एक एन्कोडर का उपयोग करके संबोधित किया जाता है जो क्रॉस-अटेंशन तंत्र के माध्यम से दो प्रकार के सीखे गए प्रतिनिधित्वों को जोड़ता है, जिसका उद्देश्य अधिक संवेदनशील और सामान्यीकृत विशेषता स्थान बनाना है।
प्रीटेक्स्ट कार्य
पहला प्रतिनिधित्व एक एन्कोडर से आता है जो मास्क्ड ऑटोएन्कोडिंग कार्य के साथ प्रशिक्षित किया गया है। वीडियो के अधिकांश 3D पैच को छिपाकर, एन्कोडर लापता हिस्सों का पुनर्निर्माण करना सीखता है, चेहरे की गति जैसे महत्वपूर्ण स्थान-कालिक पैटर्न को कैप्चर करता है।
प्रीटेक्स्ट कार्य प्रशिक्षण में वीडियो इनपुट के हिस्सों को मास्क करना और मूल फ्रेम्स या प्रति-फ्रेम एक्शन यूनिट मैप्स को पुनर्निर्माण करने के लिए एक एन्कोडर-डिकोडर सेटअप का उपयोग करना शामिल है, जो कार्य पर निर्भर करता है।
हालांकि, यह अकेले सूक्ष्म संपादनों का पता लगाने के लिए पर्याप्त नहीं है। शोधकर्ताओं ने एक दूसरा एन्कोडर पेश किया जो चेहरे की एक्शन यूनिट्स (AUs) का पता लगाने के लिए प्रशिक्षित है, इसे उन स्थानीय मांसपेशी गतिविधियों पर ध्यान केंद्रित करने के लिए प्रोत्साहित करता है जहां सूक्ष्म डीपफेक संपादन अक्सर होते हैं।
चेहरे की एक्शन यूनिट्स (FAUs, या AUs) के और उदाहरण। स्रोत: https://www.eiagroup.com/the-facial-action-coding-system/
प्रीट्रेनिंग के बाद, दोनों एन्कोडरों के आउटपुट को क्रॉस-अटेंशन का उपयोग करके जोड़ा जाता है, जिसमें AU-आधारित विशेषताएं स्थान-कालिक विशेषताओं पर ध्यान को मार्गदर्शन करती हैं। इससे एक फ्यूज्ड अव्यक्त प्रतिनिधित्व प्राप्त होता है जो व्यापक गति संदर्भ और स्थानीय अभिव्यक्ति विवरण दोनों को कैप्चर करता है, जिसे अंतिम वर्गीकरण कार्य के लिए उपयोग किया जाता है।
डेटा और परीक्षण
कारyan्वयन
सिस्टम को FaceXZoo PyTorch-आधारित चेहरा पहचान ढांचे का उपयोग करके लागू किया गया था, जिसमें प्रत्येक वीडियो क्लिप से 16 चेहरा-केंद्रित फ्रेम्स निकाले गए थे। प्रीटेक्स्ट कार्यों को CelebV-HQ डेटासेट पर प्रशिक्षित किया गया था, जिसमें 35,000 उच्च-गुणवत्ता वाले चेहरे के वीडियो शामिल हैं।
स्रोत पेपर से, नई परियोजना में उपयोग किए गए CelebV-HQ डेटासेट के उदाहरण। स्रोत: https://arxiv.org/pdf/2207.12393
आधे डेटा को ओवरफिटिंग से बचाने के लिए मास्क किया गया था। मास्क्ड फ्रेम पुनर्निर्माण कार्य के लिए, मॉडल को L1 हानि का उपयोग करके लापता क्षेत्रों की भविष्यवाणी करने के लिए प्रशिक्षित किया गया था। दूसरे कार्य के लिए, इसे 16 चेहरे की एक्शन यूनिट्स के लिए मैप्स उत्पन्न करने के लिए प्रशिक्षित किया गया था, जिसे L1 हानि द्वारा पर्यवेक्षित किया गया था।
प्रीट्रेनिंग के बाद, एन्कोडरों को फ्यूज किया गया और FaceForensics++ डेटासेट का उपयोग करके डीपफेक पहचान के लिए फाइन-ट्यून किया गया, जिसमें वास्तविक और हेरफेर किए गए वीडियो दोनों शामिल हैं।
FaceForensics++ डेटासेट 2017 से डीपफेक पहचान का आधार रहा है, हालांकि यह अब नवीनतम चेहरे संश्लेषण तकनीकों के संबंध में काफी पुराना हो चुका है। स्रोत: https://www.youtube.com/watch?v=x2g48Q2I2ZQ
क्लास असंतुलन को संबोधित करने के लिए, लेखकों ने Focal Loss का उपयोग किया, जो प्रशिक्षण के दौरान अधिक चुनौतीपूर्ण उदाहरणों पर जोर देता है। सभी प्रशिक्षण एक एकल RTX 4090 GPU पर 24Gb VRAM के साथ किया गया था, जिसमें VideoMAE से प्री-ट्रेंड चेकपॉइंट्स का उपयोग किया गया था।
परीक्षण
इस विधि का मूल्यांकन विभिन्न डीपफेक पहचान तकनीकों के खिलाफ किया गया, जो स्थानीय रूप से संपादित डीपफेक्स पर केंद्रित था। परीक्षणों में विभिन्न संपादन विधियों और पुराने डीपफेक डेटासेट शामिल थे, जिनमें Area Under Curve (AUC), Average Precision, और Mean F1 Score जैसे मेट्रिक्स का उपयोग किया गया।
पेपर से: हाल के स्थानीय डीपफेक्स पर तुलना से पता चलता है कि प्रस्तावित विधि ने सभी अन्य को बेहतर प्रदर्शन दिया, जिसमें अगले सबसे अच्छे दृष्टिकोण की तुलना में AUC और औसत परिशुद्धता में 15 से 20 प्रतिशत की वृद्धि हुई।
लेखकों ने स्थानीय रूप से हेरफेर किए गए वीडियो की दृश्य तुलना प्रदान की, जिसमें उनकी विधि की सूक्ष्म संपादनों के प्रति बेहतर संवेदनशीलता दिखाई दी।
एक वास्तविक वीडियो को तीन अलग-अलग स्थानीय हेरफेरों का उपयोग करके बदला गया था ताकि नकली वीडियो बनाए जा सकें जो मूल के समान दृश्य रूप से दिखें। यहां प्रतिनिधि फ्रेम्स दिखाए गए हैं, साथ ही प्रत्येक विधि के लिए औसत नकली पहचान स्कोर भी। जबकि मौजूदा डिटेक्टर इन सूक्ष्म संपादनों के साथ संघर्ष करते थे, प्रस्तावित मॉडल ने लगातार उच्च नकली संभावनाएं प्रदान कीं, जो स्थानीय परिवर्तनों के प्रति अधिक संवेदनशीलता को दर्शाता है।
शोधकर्ताओं ने नोट किया कि मौजूदा अत्याधुनिक पहचान विधियां नवीनतम डीपफेक जनन तकनीकों के साथ संघर्ष करती थीं, जबकि उनकी विधि ने मजबूत सामान्यीकरण दिखाया, उच्च AUC और औसत परिशुद्धता स्कोर प्राप्त किए।
पारंपरिक डीपफेक डेटासेट पर प्रदर्शन से पता चलता है कि प्रस्तावित विधि अग्रणी दृष्टिकोणों के साथ प्रतिस्पर्धी रही, जो हेरफेर प्रकारों की एक श्रृंखला में मजबूत सामान्यीकरण को दर्शाता है।
लेखकों ने वास्तविक दुनिया की परिस्थितियों में मॉडल की विश्वसनीयता का भी परीक्षण किया, जिसमें पाया गया कि यह संतृप्ति समायोजन, Gaussian blur, और पिक्सलेशन जैसे सामान्य वीडियो विकृतियों के प्रति लचीला रहा।
विभिन्न वीडियो विकृतियों के तहत पहचान सटीकता में परिवर्तन का एक चित्रण। नई विधि अधिकांश मामलों में लचीली रही, जिसमें AUC में केवल थोड़ी कमी आई। सबसे महत्वपूर्ण कमी तब हुई जब Gaussian noise पेश किया गया।
निष्कर्ष
जबकि जनता अक्सर डीपफेक्स को पहचान स्वैप के रूप में सोचती है, AI हेरफेर की वास्तविकता अधिक सूक्ष्म और संभावित रूप से अधिक कपटी है। इस नए शोध में चर्चा किए गए स्थानीय संपादन का प्रकार तब तक सार्वजनिक ध्यान आकर्षित नहीं कर सकता जब तक कि कोई और हाई-प्रोफाइल घटना न हो। फिर भी, जैसा कि अभिनेता Nic Cage ने बताया है, पोस्ट-प्रोडक्शन संपादनों की प्रदर्शन को बदलने की संभावना एक ऐसी चिंता है जिसके बारे में हम सभी को जागरूक होना चाहिए। हम स्वाभाविक रूप से चेहरे की अभिव्यक्तियों में मामूली परिवर्तनों के प्रति संवेदनशील हैं, और संदर्भ उनके प्रभाव को नाटकीय रूप से बदल सकता है।
पहली बार बुधवार, 2 अप्रैल, 2025 को प्रकाशित









 सिविटई मास्टरकार्ड और वीजा के दबाव के बीच डीपफेक नियमों को मजबूत करता है
Civitai, इंटरनेट पर सबसे प्रमुख AI मॉडल रिपॉजिटरी में से एक, ने हाल ही में NSFW सामग्री पर अपनी नीतियों में महत्वपूर्ण बदलाव किए हैं, विशेष रूप से सेलिब्रिटी लोरस के विषय में। इन परिवर्तनों को भुगतान फैसिलिटेटर्स मास्टरकार्ड और वीजा के दबाव से प्रेरित किया गया था। सेलिब्रिटी लोरस, जो यू हैं
सिविटई मास्टरकार्ड और वीजा के दबाव के बीच डीपफेक नियमों को मजबूत करता है
Civitai, इंटरनेट पर सबसे प्रमुख AI मॉडल रिपॉजिटरी में से एक, ने हाल ही में NSFW सामग्री पर अपनी नीतियों में महत्वपूर्ण बदलाव किए हैं, विशेष रूप से सेलिब्रिटी लोरस के विषय में। इन परिवर्तनों को भुगतान फैसिलिटेटर्स मास्टरकार्ड और वीजा के दबाव से प्रेरित किया गया था। सेलिब्रिटी लोरस, जो यू हैं
 Google संदिग्ध धोखाधड़ी के लिए 39 मिलियन से अधिक विज्ञापन खातों को निलंबित करने के लिए AI का उपयोग करता है
Google ने बुधवार को घोषणा की कि उसने 2024 में अपने प्लेटफ़ॉर्म पर 39.2 मिलियन विज्ञापनदाता खातों को निलंबित करके विज्ञापन धोखाधड़ी से लड़ने में एक बड़ा कदम उठाया था। यह संख्या पिछले वर्ष की रिपोर्ट की गई थी।
Google संदिग्ध धोखाधड़ी के लिए 39 मिलियन से अधिक विज्ञापन खातों को निलंबित करने के लिए AI का उपयोग करता है
Google ने बुधवार को घोषणा की कि उसने 2024 में अपने प्लेटफ़ॉर्म पर 39.2 मिलियन विज्ञापनदाता खातों को निलंबित करके विज्ञापन धोखाधड़ी से लड़ने में एक बड़ा कदम उठाया था। यह संख्या पिछले वर्ष की रिपोर्ट की गई थी।
 एआई वीडियो पीढ़ी पूर्ण नियंत्रण की ओर बढ़ती है
हुनयुआन और वान 2.1 जैसे वीडियो फाउंडेशन मॉडल ने महत्वपूर्ण प्रगति की है, लेकिन वे अक्सर कम हो जाते हैं जब यह फिल्म और टीवी उत्पादन में आवश्यक विस्तृत नियंत्रण की बात आती है, विशेष रूप से दृश्य प्रभावों (वीएफएक्स) के दायरे में। पेशेवर VFX स्टूडियो में, ये मॉडल, पहले की छवि-बास के साथ-साथ
29 जुलाई 2025 5:55:16 अपराह्न IST
एआई वीडियो पीढ़ी पूर्ण नियंत्रण की ओर बढ़ती है
हुनयुआन और वान 2.1 जैसे वीडियो फाउंडेशन मॉडल ने महत्वपूर्ण प्रगति की है, लेकिन वे अक्सर कम हो जाते हैं जब यह फिल्म और टीवी उत्पादन में आवश्यक विस्तृत नियंत्रण की बात आती है, विशेष रूप से दृश्य प्रभावों (वीएफएक्स) के दायरे में। पेशेवर VFX स्टूडियो में, ये मॉडल, पहले की छवि-बास के साथ-साथ
29 जुलाई 2025 5:55:16 अपराह्न IST
That Pelosi video from 2019 is wild! It’s scary how a few tweaks can make someone look totally out of it. AI’s power to mess with reality is no joke—makes you wonder what’s real anymore. 🫣
0
24 अप्रैल 2025 7:54:54 पूर्वाह्न IST
Este herramienta de IA me mostró lo fácil que es manipular videos. El incidente de Nancy Pelosi fue un recordatorio impactante. Es aterrador pensar en cuántas noticias falsas pueden existir. Ahora estoy más atento a lo que creo en línea. ¡Cuidado, amigos! 👀
0
21 अप्रैल 2025 2:12:51 पूर्वाह्न IST
このAIツールは、ビデオを操作するのがどれほど簡単かを教えてくれました。ナンシー・ペロシの事件は衝撃的でした。偽ニュースがどれだけあるかと思うと恐ろしいです。オンラインで何を信じるかについて、今はもっと注意しています。みなさんも気をつけてくださいね!👀
0
19 अप्रैल 2025 3:55:50 अपराह्न IST
Dieses KI-Tool hat mir gezeigt, wie einfach es ist, Videos zu manipulieren! Der Vorfall mit Nancy Pelosi war ein Weckruf. Es ist beängstigend, wie viele gefälschte Nachrichten es geben könnte. Ich bin jetzt vorsichtiger mit dem, was ich online glaube. Seid wachsam, Leute! 👀
0
19 अप्रैल 2025 3:47:36 अपराह्न IST
This AI tool really opened my eyes to how easy it is to manipulate videos! The Nancy Pelosi incident was a wake-up call. It's scary to think how much fake news could be out there. Definitely makes me more cautious about what I believe online. Keep an eye out, folks! 👀
0
15 अप्रैल 2025 3:35:37 अपराह्न IST
이 앱은 눈을 뜨게 합니다! AI의 미묘한 변화가 비디오의 진위성을 어떻게 망칠 수 있는지를 보여줍니다. 낸시 펠로시의 예는 경고였어요. 하지만 설명이 때때로 나에게는 너무 기술적이어서요. 더 간단하게 설명해주면 좋겠어요! 그래도 AI의 영향을 이해하는 데는 좋은 도구입니다. 👀
0













