




Revelando modificações sutis, porém impactantes, no conteúdo de vídeo autêntico
Em 2019, um vídeo enganoso de Nancy Pelosi, então Presidente da Câmara dos Representantes dos EUA, circulou amplamente. O vídeo, editado para fazer parecer que ela estava intoxicada, foi um lembrete claro de como a mídia manipulada pode facilmente enganar o público. Apesar de sua simplicidade, esse incidente destacou o potencial dano de edições audiovisuais até mesmo básicas.
Na época, o cenário dos deepfakes era amplamente dominado por tecnologias de substituição facial baseadas em autoencoders, que existiam desde o final de 2017. Esses sistemas iniciais tinham dificuldade em realizar as mudanças sutis vistas no vídeo de Pelosi, focando, em vez disso, em trocas faciais mais evidentes.
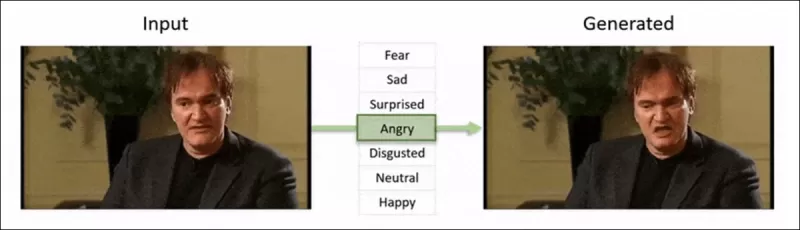 O framework 'Neural Emotion Director' de 2022 altera o humor de um rosto famoso. Fonte: https://www.youtube.com/watch?v=Li6W8pRDMJQ
O framework 'Neural Emotion Director' de 2022 altera o humor de um rosto famoso. Fonte: https://www.youtube.com/watch?v=Li6W8pRDMJQ
Avançando para hoje, a indústria de cinema e TV está explorando cada vez mais edições de pós-produção impulsionadas por IA. Essa tendência despertou tanto interesse quanto críticas, pois a IA permite um nível de perfeccionismo anteriormente inatingível. Em resposta, a comunidade de pesquisa desenvolveu vários projetos focados em 'edições locais' de capturas faciais, como Diffusion Video Autoencoders, Stitch it in Time, ChatFace, MagicFace e DISCO.
 Edição de expressões com o projeto MagicFace de janeiro de 2025. Fonte: https://arxiv.org/pdf/2501.02260
Edição de expressões com o projeto MagicFace de janeiro de 2025. Fonte: https://arxiv.org/pdf/2501.02260
Novos Rostos, Novas Rugas
No entanto, a tecnologia para criar essas edições sutis está avançando muito mais rápido do que nossa capacidade de detectá-las. A maioria dos métodos de detecção de deepfakes está desatualizada, focando em técnicas e conjuntos de dados mais antigos. Isso é, até um recente avanço de pesquisadores na Índia.
 Detecção de Edições Locais Sutis em Deepfakes: Um vídeo real é alterado para produzir falsificações com mudanças sutis, como sobrancelhas levantadas, traços de gênero modificados e mudanças na expressão para desgosto (ilustrado aqui com um único quadro). Fonte: https://arxiv.org/pdf/2503.22121
Detecção de Edições Locais Sutis em Deepfakes: Um vídeo real é alterado para produzir falsificações com mudanças sutis, como sobrancelhas levantadas, traços de gênero modificados e mudanças na expressão para desgosto (ilustrado aqui com um único quadro). Fonte: https://arxiv.org/pdf/2503.22121
Esta nova pesquisa visa a detecção de manipulações faciais sutis e localizadas, um tipo de falsificação frequentemente ignorado. Em vez de procurar inconsistências amplas ou incompatibilidades de identidade, o método se concentra em detalhes finos, como mudanças sutis de expressão ou pequenas edições em características faciais específicas. Ele utiliza o Sistema de Codificação de Ação Facial (FACS), que decompõe as expressões faciais em 64 áreas mutáveis.
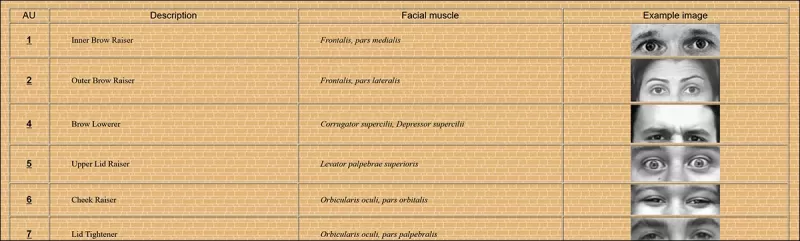 Algumas das 64 partes constituintes das expressões no FACS. Fonte: https://www.cs.cmu.edu/~face/facs.htm
Algumas das 64 partes constituintes das expressões no FACS. Fonte: https://www.cs.cmu.edu/~face/facs.htm
Os pesquisadores testaram sua abordagem contra vários métodos de edição recentes e descobriram que ela superou consistentemente as soluções existentes, mesmo com conjuntos de dados mais antigos e novos vetores de ataque.
‘Ao usar recursos baseados em AU para guiar representações de vídeo aprendidas por meio de Autoencoders Mascarados (MAE), nosso método captura efetivamente mudanças localizadas cruciais para detectar edições faciais sutis.
‘Essa abordagem nos permite construir uma representação latente unificada que codifica tanto edições localizadas quanto alterações mais amplas em vídeos centrados em rostos, fornecendo uma solução abrangente e adaptável para detecção de deepfakes.’
O artigo, intitulado Detectando Manipulações Deepfake Localizadas Usando Representações de Vídeo Guiadas por Unidades de Ação, foi escrito por pesquisadores do Instituto Indiano de Tecnologia em Madras.
Método
O método começa detectando rostos em um vídeo e amostrando quadros espaçados uniformemente centrados nesses rostos. Esses quadros são então divididos em pequenos patches 3D, capturando detalhes espaciais e temporais locais.
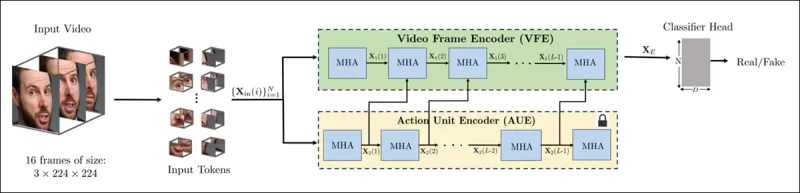 Esquema do novo método. O vídeo de entrada é processado com detecção de rosto para extrair quadros espaçados uniformemente, centrados no rosto, que são então divididos em patches ‘tubulares’ e passados por um codificador que funde representações latentes de duas tarefas de pretexto pré-treinadas. O vetor resultante é então usado por um classificador para determinar se o vídeo é real ou falso.
Esquema do novo método. O vídeo de entrada é processado com detecção de rosto para extrair quadros espaçados uniformemente, centrados no rosto, que são então divididos em patches ‘tubulares’ e passados por um codificador que funde representações latentes de duas tarefas de pretexto pré-treinadas. O vetor resultante é então usado por um classificador para determinar se o vídeo é real ou falso.
Cada patch contém uma pequena janela de pixels de alguns quadros sucessivos, permitindo que o modelo aprenda movimentos de curto prazo e mudanças de expressão. Esses patches são incorporados e codificados posicionalmente antes de serem alimentados em um codificador projetado para distinguir vídeos reais de falsos.
O desafio de detectar manipulações sutis é abordado usando um codificador que combina dois tipos de representações aprendidas por meio de um mecanismo de atenção cruzada, visando criar um espaço de características mais sensível e generalizável.
Tarefas de Pretexto
A primeira representação vem de um codificador treinado com uma tarefa de autoencodificação mascarada. Ao ocultar a maior parte dos patches 3D do vídeo, o codificador aprende a reconstruir as partes ausentes, capturando padrões espaço-temporais importantes, como movimentos faciais.
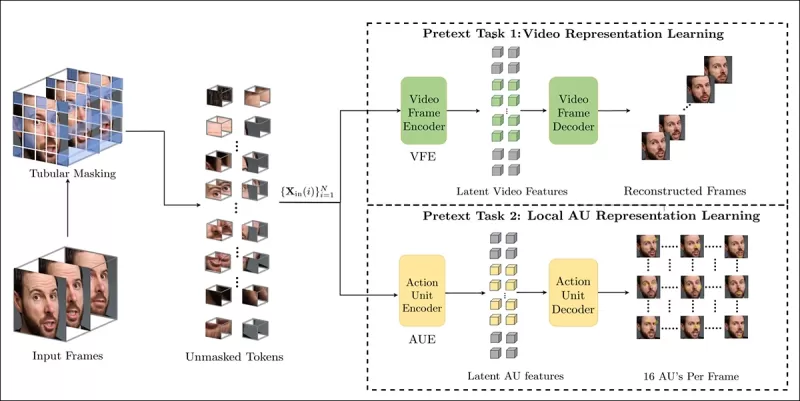 O treinamento de tarefas de pretexto envolve mascarar partes da entrada de vídeo e usar uma configuração de codificador-decodificador para reconstruir os quadros originais ou mapas de unidades de ação por quadro, dependendo da tarefa.
O treinamento de tarefas de pretexto envolve mascarar partes da entrada de vídeo e usar uma configuração de codificador-decodificador para reconstruir os quadros originais ou mapas de unidades de ação por quadro, dependendo da tarefa.
No entanto, isso sozinho não é suficiente para detectar edições detalhadas. Os pesquisadores introduziram um segundo codificador treinado para detectar unidades de ação facial (AUs), incentivando-o a focar na atividade muscular localizada, onde edições sutis de deepfake frequentemente ocorrem.
 Outros exemplos de Unidades de Ação Facial (FAUs, ou AUs). Fonte: https://www.eiagroup.com/the-facial-action-coding-system/
Outros exemplos de Unidades de Ação Facial (FAUs, ou AUs). Fonte: https://www.eiagroup.com/the-facial-action-coding-system/
Após o pré-treinamento, as saídas de ambos os codificadores são combinadas usando atenção cruzada, com os recursos baseados em AU guiando a atenção sobre os recursos espaço-temporais. Isso resulta em uma representação latente fundida que captura tanto o contexto de movimento mais amplo quanto os detalhes de expressão localizados, usada para a tarefa de classificação final.
Dados e Testes
Implementação
O sistema foi implementado usando o framework de detecção de rosto FaceXZoo baseado em PyTorch, extraindo 16 quadros centrados no rosto de cada clipe de vídeo. As tarefas de pretexto foram treinadas no conjunto de dados CelebV-HQ, que inclui 35.000 vídeos faciais de alta qualidade.
 Do artigo original, exemplos do conjunto de dados CelebV-HQ usado no novo projeto. Fonte: https://arxiv.org/pdf/2207.12393
Do artigo original, exemplos do conjunto de dados CelebV-HQ usado no novo projeto. Fonte: https://arxiv.org/pdf/2207.12393
Metade dos dados foi mascarada para evitar overfitting. Para a tarefa de reconstrução de quadros mascarados, o modelo foi treinado para prever regiões ausentes usando perda L1. Para a segunda tarefa, ele foi treinado para gerar mapas para 16 unidades de ação facial, supervisionado por perda L1.
Após o pré-treinamento, os codificadores foram fundidos e ajustados para detecção de deepfakes usando o conjunto de dados FaceForensics++, que inclui vídeos reais e manipulados.
 O conjunto de dados FaceForensics++ tem sido a pedra angular da detecção de deepfakes desde 2017, embora agora esteja consideravelmente desatualizado em relação às mais recentes técnicas de síntese facial. Fonte: https://www.youtube.com/watch?v=x2g48Q2I2ZQ
O conjunto de dados FaceForensics++ tem sido a pedra angular da detecção de deepfakes desde 2017, embora agora esteja consideravelmente desatualizado em relação às mais recentes técnicas de síntese facial. Fonte: https://www.youtube.com/watch?v=x2g48Q2I2ZQ
Para abordar o desequilíbrio de classes, os autores usaram a Perda Focal, enfatizando exemplos mais desafiadores durante o treinamento. Todo o treinamento foi conduzido em uma única GPU RTX 4090 com 24Gb de VRAM, usando pontos de verificação pré-treinados do VideoMAE.
Testes
O método foi avaliado contra várias técnicas de detecção de deepfakes, focando em deepfakes editados localmente. Os testes incluíram uma gama de métodos de edição e conjuntos de dados de deepfakes mais antigos, usando métricas como Área Sob a Curva (AUC), Precisão Média e Pontuação F1 Média.
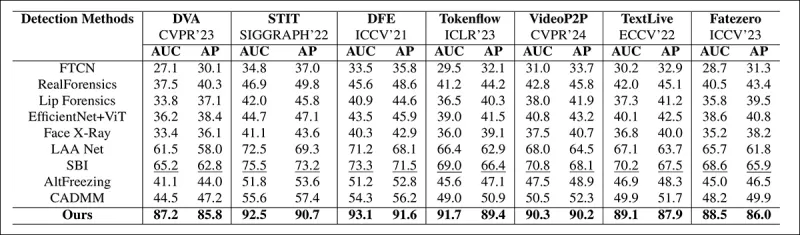 Do artigo: a comparação em deepfakes localizados recentes mostra que o método proposto superou todos os outros, com um ganho de 15 a 20 por cento em AUC e precisão média em relação à próxima melhor abordagem.
Do artigo: a comparação em deepfakes localizados recentes mostra que o método proposto superou todos os outros, com um ganho de 15 a 20 por cento em AUC e precisão média em relação à próxima melhor abordagem.
Os autores forneceram comparações visuais de vídeos manipulados localmente, mostrando a sensibilidade superior do método a edições sutis.
 Um vídeo real foi alterado usando três manipulações locais diferentes para produzir falsificações que permaneceram visualmente semelhantes ao original. Mostrados aqui estão quadros representativos junto com as pontuações médias de detecção de falsificações para cada método. Enquanto os detectores existentes tiveram dificuldade com essas edições sutis, o modelo proposto consistentemente atribuiu altas probabilidades de falsificação, indicando maior sensibilidade a mudanças localizadas.
Um vídeo real foi alterado usando três manipulações locais diferentes para produzir falsificações que permaneceram visualmente semelhantes ao original. Mostrados aqui estão quadros representativos junto com as pontuações médias de detecção de falsificações para cada método. Enquanto os detectores existentes tiveram dificuldade com essas edições sutis, o modelo proposto consistentemente atribuiu altas probabilidades de falsificação, indicando maior sensibilidade a mudanças localizadas.
Os pesquisadores observaram que os métodos de detecção de ponta existentes tiveram dificuldade com as mais recentes técnicas de geração de deepfakes, enquanto seu método demonstrou generalização robusta, alcançando altas pontuações de AUC e precisão média.
 O desempenho em conjuntos de dados de deepfakes tradicionais mostra que o método proposto permaneceu competitivo com as principais abordagens, indicando forte generalização em uma gama de tipos de manipulação.
O desempenho em conjuntos de dados de deepfakes tradicionais mostra que o método proposto permaneceu competitivo com as principais abordagens, indicando forte generalização em uma gama de tipos de manipulação.
Os autores também testaram a confiabilidade do modelo sob condições do mundo real, descobrindo que ele é resiliente a distorções de vídeo comuns, como ajustes de saturação, desfoque gaussiano e pixelização.
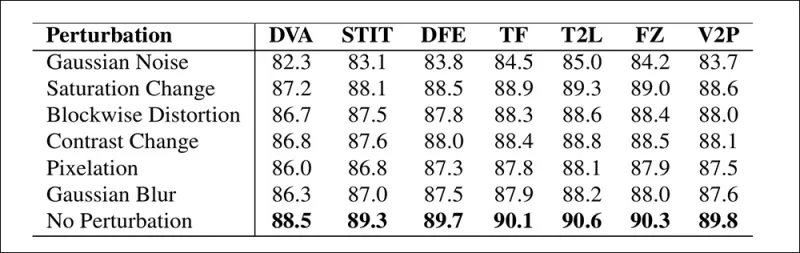 Uma ilustração de como a precisão de detecção muda sob diferentes distorções de vídeo. O novo método permaneceu resiliente na maioria dos casos, com apenas um pequeno declínio em AUC. A queda mais significativa ocorreu quando o ruído gaussiano foi introduzido.
Uma ilustração de como a precisão de detecção muda sob diferentes distorções de vídeo. O novo método permaneceu resiliente na maioria dos casos, com apenas um pequeno declínio em AUC. A queda mais significativa ocorreu quando o ruído gaussiano foi introduzido.
Conclusão
Embora o público frequentemente pense em deepfakes como trocas de identidade, a realidade da manipulação por IA é mais matizada e potencialmente mais insidiosa. O tipo de edição local discutido nesta nova pesquisa pode não capturar a atenção do público até que outro incidente de alto perfil ocorra. No entanto, como o ator Nic Cage apontou, o potencial para edições de pós-produção alterarem desempenhos é uma preocupação que todos devemos estar cientes. Somos naturalmente sensíveis até mesmo às menores mudanças nas expressões faciais, e o contexto pode alterar dramaticamente seu impacto.
Publicado pela primeira vez na quarta-feira, 2 de abril de 2025
Artigo relacionado
 Tencent Revela HunyuanCustom para Personalização de Vídeo com Imagem Única
Este artigo explora o lançamento do HunyuanCustom, um modelo de geração de vídeo multimodal da Tencent. O amplo escopo do artigo de pesquisa acompanhante e os desafios com os vídeos de exemplo forneci
Civitai fortalece os regulamentos deepfake em meio à pressão da MasterCard e Visa
A Civitai, um dos repositórios de modelos de IA mais proeminentes da Internet, fez recentemente mudanças significativas em suas políticas no conteúdo da NSFW, particularmente em relação a Celebrity Loras. Essas mudanças foram estimuladas pela pressão dos facilitadores de pagamento MasterCard e Visa. Celebridade loras, que são você
O Google utiliza a IA para suspender mais de 39 milhões de contas de anúncios por suspeita de fraude
O Google anunciou na quarta -feira que foi necessário um grande passo para combater a fraude de anúncios, suspendendo uma conta impressionante de 39,2 milhões de contas de anunciantes em sua plataforma em 2024. Esse número é mais do que o triplo do que foi relatado no ano anterior, mostrando os esforços intensificados do Google para limpar seu anúncio.
Comentários (43)
0/200
Tencent Revela HunyuanCustom para Personalização de Vídeo com Imagem Única
Este artigo explora o lançamento do HunyuanCustom, um modelo de geração de vídeo multimodal da Tencent. O amplo escopo do artigo de pesquisa acompanhante e os desafios com os vídeos de exemplo forneci
Civitai fortalece os regulamentos deepfake em meio à pressão da MasterCard e Visa
A Civitai, um dos repositórios de modelos de IA mais proeminentes da Internet, fez recentemente mudanças significativas em suas políticas no conteúdo da NSFW, particularmente em relação a Celebrity Loras. Essas mudanças foram estimuladas pela pressão dos facilitadores de pagamento MasterCard e Visa. Celebridade loras, que são você
O Google utiliza a IA para suspender mais de 39 milhões de contas de anúncios por suspeita de fraude
O Google anunciou na quarta -feira que foi necessário um grande passo para combater a fraude de anúncios, suspendendo uma conta impressionante de 39,2 milhões de contas de anunciantes em sua plataforma em 2024. Esse número é mais do que o triplo do que foi relatado no ano anterior, mostrando os esforços intensificados do Google para limpar seu anúncio.
Comentários (43)
0/200
![WilliamCarter]() WilliamCarter
WilliamCarter
 19 de Agosto de 2025 à13 22:01:13 WEST
19 de Agosto de 2025 à13 22:01:13 WEST
That Pelosi video from 2019 is wild! It’s scary how a few tweaks can make someone look totally drunk. AI’s power to mess with videos is both cool and creepy—makes you wonder what’s real anymore. 😬


 0
0
![JuanMartínez]() JuanMartínez
19 de Agosto de 2025 à10 18:01:10 WEST
JuanMartínez
19 de Agosto de 2025 à10 18:01:10 WEST
This Pelosi video incident is wild! 🤯 It’s scary how a few tweaks can make someone look totally out of it. Makes me wonder how much of what we see online is real anymore. AI’s cool, but this kind of stuff could mess with trust big time.
0
![RyanPerez]() RyanPerez
29 de Julho de 2025 à16 13:25:16 WEST
RyanPerez
29 de Julho de 2025 à16 13:25:16 WEST
That Pelosi video from 2019 is wild! It’s scary how a few tweaks can make someone look totally out of it. AI’s power to mess with reality is no joke—makes you wonder what’s real anymore. 🫣
0
![MarkRoberts]() MarkRoberts
24 de Abril de 2025 à54 03:24:54 WEST
MarkRoberts
24 de Abril de 2025 à54 03:24:54 WEST
Este herramienta de IA me mostró lo fácil que es manipular videos. El incidente de Nancy Pelosi fue un recordatorio impactante. Es aterrador pensar en cuántas noticias falsas pueden existir. Ahora estoy más atento a lo que creo en línea. ¡Cuidado, amigos! 👀
0
![RobertMartin]() RobertMartin
20 de Abril de 2025 à51 21:42:51 WEST
RobertMartin
20 de Abril de 2025 à51 21:42:51 WEST
このAIツールは、ビデオを操作するのがどれほど簡単かを教えてくれました。ナンシー・ペロシの事件は衝撃的でした。偽ニュースがどれだけあるかと思うと恐ろしいです。オンラインで何を信じるかについて、今はもっと注意しています。みなさんも気をつけてくださいね!👀
0
![PaulMartínez]() PaulMartínez
19 de Abril de 2025 à50 11:25:50 WEST
PaulMartínez
19 de Abril de 2025 à50 11:25:50 WEST
Dieses KI-Tool hat mir gezeigt, wie einfach es ist, Videos zu manipulieren! Der Vorfall mit Nancy Pelosi war ein Weckruf. Es ist beängstigend, wie viele gefälschte Nachrichten es geben könnte. Ich bin jetzt vorsichtiger mit dem, was ich online glaube. Seid wachsam, Leute! 👀
0
Em 2019, um vídeo enganoso de Nancy Pelosi, então Presidente da Câmara dos Representantes dos EUA, circulou amplamente. O vídeo, editado para fazer parecer que ela estava intoxicada, foi um lembrete claro de como a mídia manipulada pode facilmente enganar o público. Apesar de sua simplicidade, esse incidente destacou o potencial dano de edições audiovisuais até mesmo básicas.
Na época, o cenário dos deepfakes era amplamente dominado por tecnologias de substituição facial baseadas em autoencoders, que existiam desde o final de 2017. Esses sistemas iniciais tinham dificuldade em realizar as mudanças sutis vistas no vídeo de Pelosi, focando, em vez disso, em trocas faciais mais evidentes.
O framework 'Neural Emotion Director' de 2022 altera o humor de um rosto famoso. Fonte: https://www.youtube.com/watch?v=Li6W8pRDMJQ
Avançando para hoje, a indústria de cinema e TV está explorando cada vez mais edições de pós-produção impulsionadas por IA. Essa tendência despertou tanto interesse quanto críticas, pois a IA permite um nível de perfeccionismo anteriormente inatingível. Em resposta, a comunidade de pesquisa desenvolveu vários projetos focados em 'edições locais' de capturas faciais, como Diffusion Video Autoencoders, Stitch it in Time, ChatFace, MagicFace e DISCO.
Edição de expressões com o projeto MagicFace de janeiro de 2025. Fonte: https://arxiv.org/pdf/2501.02260
Novos Rostos, Novas Rugas
No entanto, a tecnologia para criar essas edições sutis está avançando muito mais rápido do que nossa capacidade de detectá-las. A maioria dos métodos de detecção de deepfakes está desatualizada, focando em técnicas e conjuntos de dados mais antigos. Isso é, até um recente avanço de pesquisadores na Índia.
Detecção de Edições Locais Sutis em Deepfakes: Um vídeo real é alterado para produzir falsificações com mudanças sutis, como sobrancelhas levantadas, traços de gênero modificados e mudanças na expressão para desgosto (ilustrado aqui com um único quadro). Fonte: https://arxiv.org/pdf/2503.22121
Esta nova pesquisa visa a detecção de manipulações faciais sutis e localizadas, um tipo de falsificação frequentemente ignorado. Em vez de procurar inconsistências amplas ou incompatibilidades de identidade, o método se concentra em detalhes finos, como mudanças sutis de expressão ou pequenas edições em características faciais específicas. Ele utiliza o Sistema de Codificação de Ação Facial (FACS), que decompõe as expressões faciais em 64 áreas mutáveis.
Algumas das 64 partes constituintes das expressões no FACS. Fonte: https://www.cs.cmu.edu/~face/facs.htm
Os pesquisadores testaram sua abordagem contra vários métodos de edição recentes e descobriram que ela superou consistentemente as soluções existentes, mesmo com conjuntos de dados mais antigos e novos vetores de ataque.
‘Ao usar recursos baseados em AU para guiar representações de vídeo aprendidas por meio de Autoencoders Mascarados (MAE), nosso método captura efetivamente mudanças localizadas cruciais para detectar edições faciais sutis.
‘Essa abordagem nos permite construir uma representação latente unificada que codifica tanto edições localizadas quanto alterações mais amplas em vídeos centrados em rostos, fornecendo uma solução abrangente e adaptável para detecção de deepfakes.’
O artigo, intitulado Detectando Manipulações Deepfake Localizadas Usando Representações de Vídeo Guiadas por Unidades de Ação, foi escrito por pesquisadores do Instituto Indiano de Tecnologia em Madras.
Método
O método começa detectando rostos em um vídeo e amostrando quadros espaçados uniformemente centrados nesses rostos. Esses quadros são então divididos em pequenos patches 3D, capturando detalhes espaciais e temporais locais.
Esquema do novo método. O vídeo de entrada é processado com detecção de rosto para extrair quadros espaçados uniformemente, centrados no rosto, que são então divididos em patches ‘tubulares’ e passados por um codificador que funde representações latentes de duas tarefas de pretexto pré-treinadas. O vetor resultante é então usado por um classificador para determinar se o vídeo é real ou falso.
Cada patch contém uma pequena janela de pixels de alguns quadros sucessivos, permitindo que o modelo aprenda movimentos de curto prazo e mudanças de expressão. Esses patches são incorporados e codificados posicionalmente antes de serem alimentados em um codificador projetado para distinguir vídeos reais de falsos.
O desafio de detectar manipulações sutis é abordado usando um codificador que combina dois tipos de representações aprendidas por meio de um mecanismo de atenção cruzada, visando criar um espaço de características mais sensível e generalizável.
Tarefas de Pretexto
A primeira representação vem de um codificador treinado com uma tarefa de autoencodificação mascarada. Ao ocultar a maior parte dos patches 3D do vídeo, o codificador aprende a reconstruir as partes ausentes, capturando padrões espaço-temporais importantes, como movimentos faciais.
O treinamento de tarefas de pretexto envolve mascarar partes da entrada de vídeo e usar uma configuração de codificador-decodificador para reconstruir os quadros originais ou mapas de unidades de ação por quadro, dependendo da tarefa.
No entanto, isso sozinho não é suficiente para detectar edições detalhadas. Os pesquisadores introduziram um segundo codificador treinado para detectar unidades de ação facial (AUs), incentivando-o a focar na atividade muscular localizada, onde edições sutis de deepfake frequentemente ocorrem.
Outros exemplos de Unidades de Ação Facial (FAUs, ou AUs). Fonte: https://www.eiagroup.com/the-facial-action-coding-system/
Após o pré-treinamento, as saídas de ambos os codificadores são combinadas usando atenção cruzada, com os recursos baseados em AU guiando a atenção sobre os recursos espaço-temporais. Isso resulta em uma representação latente fundida que captura tanto o contexto de movimento mais amplo quanto os detalhes de expressão localizados, usada para a tarefa de classificação final.
Dados e Testes
Implementação
O sistema foi implementado usando o framework de detecção de rosto FaceXZoo baseado em PyTorch, extraindo 16 quadros centrados no rosto de cada clipe de vídeo. As tarefas de pretexto foram treinadas no conjunto de dados CelebV-HQ, que inclui 35.000 vídeos faciais de alta qualidade.
Do artigo original, exemplos do conjunto de dados CelebV-HQ usado no novo projeto. Fonte: https://arxiv.org/pdf/2207.12393
Metade dos dados foi mascarada para evitar overfitting. Para a tarefa de reconstrução de quadros mascarados, o modelo foi treinado para prever regiões ausentes usando perda L1. Para a segunda tarefa, ele foi treinado para gerar mapas para 16 unidades de ação facial, supervisionado por perda L1.
Após o pré-treinamento, os codificadores foram fundidos e ajustados para detecção de deepfakes usando o conjunto de dados FaceForensics++, que inclui vídeos reais e manipulados.
O conjunto de dados FaceForensics++ tem sido a pedra angular da detecção de deepfakes desde 2017, embora agora esteja consideravelmente desatualizado em relação às mais recentes técnicas de síntese facial. Fonte: https://www.youtube.com/watch?v=x2g48Q2I2ZQ
Para abordar o desequilíbrio de classes, os autores usaram a Perda Focal, enfatizando exemplos mais desafiadores durante o treinamento. Todo o treinamento foi conduzido em uma única GPU RTX 4090 com 24Gb de VRAM, usando pontos de verificação pré-treinados do VideoMAE.
Testes
O método foi avaliado contra várias técnicas de detecção de deepfakes, focando em deepfakes editados localmente. Os testes incluíram uma gama de métodos de edição e conjuntos de dados de deepfakes mais antigos, usando métricas como Área Sob a Curva (AUC), Precisão Média e Pontuação F1 Média.
Do artigo: a comparação em deepfakes localizados recentes mostra que o método proposto superou todos os outros, com um ganho de 15 a 20 por cento em AUC e precisão média em relação à próxima melhor abordagem.
Os autores forneceram comparações visuais de vídeos manipulados localmente, mostrando a sensibilidade superior do método a edições sutis.
Um vídeo real foi alterado usando três manipulações locais diferentes para produzir falsificações que permaneceram visualmente semelhantes ao original. Mostrados aqui estão quadros representativos junto com as pontuações médias de detecção de falsificações para cada método. Enquanto os detectores existentes tiveram dificuldade com essas edições sutis, o modelo proposto consistentemente atribuiu altas probabilidades de falsificação, indicando maior sensibilidade a mudanças localizadas.
Os pesquisadores observaram que os métodos de detecção de ponta existentes tiveram dificuldade com as mais recentes técnicas de geração de deepfakes, enquanto seu método demonstrou generalização robusta, alcançando altas pontuações de AUC e precisão média.
O desempenho em conjuntos de dados de deepfakes tradicionais mostra que o método proposto permaneceu competitivo com as principais abordagens, indicando forte generalização em uma gama de tipos de manipulação.
Os autores também testaram a confiabilidade do modelo sob condições do mundo real, descobrindo que ele é resiliente a distorções de vídeo comuns, como ajustes de saturação, desfoque gaussiano e pixelização.
Uma ilustração de como a precisão de detecção muda sob diferentes distorções de vídeo. O novo método permaneceu resiliente na maioria dos casos, com apenas um pequeno declínio em AUC. A queda mais significativa ocorreu quando o ruído gaussiano foi introduzido.
Conclusão
Embora o público frequentemente pense em deepfakes como trocas de identidade, a realidade da manipulação por IA é mais matizada e potencialmente mais insidiosa. O tipo de edição local discutido nesta nova pesquisa pode não capturar a atenção do público até que outro incidente de alto perfil ocorra. No entanto, como o ator Nic Cage apontou, o potencial para edições de pós-produção alterarem desempenhos é uma preocupação que todos devemos estar cientes. Somos naturalmente sensíveis até mesmo às menores mudanças nas expressões faciais, e o contexto pode alterar dramaticamente seu impacto.
Publicado pela primeira vez na quarta-feira, 2 de abril de 2025










 Tencent Revela HunyuanCustom para Personalização de Vídeo com Imagem Única
Este artigo explora o lançamento do HunyuanCustom, um modelo de geração de vídeo multimodal da Tencent. O amplo escopo do artigo de pesquisa acompanhante e os desafios com os vídeos de exemplo forneci
Civitai fortalece os regulamentos deepfake em meio à pressão da MasterCard e Visa
A Civitai, um dos repositórios de modelos de IA mais proeminentes da Internet, fez recentemente mudanças significativas em suas políticas no conteúdo da NSFW, particularmente em relação a Celebrity Loras. Essas mudanças foram estimuladas pela pressão dos facilitadores de pagamento MasterCard e Visa. Celebridade loras, que são você
Tencent Revela HunyuanCustom para Personalização de Vídeo com Imagem Única
Este artigo explora o lançamento do HunyuanCustom, um modelo de geração de vídeo multimodal da Tencent. O amplo escopo do artigo de pesquisa acompanhante e os desafios com os vídeos de exemplo forneci
Civitai fortalece os regulamentos deepfake em meio à pressão da MasterCard e Visa
A Civitai, um dos repositórios de modelos de IA mais proeminentes da Internet, fez recentemente mudanças significativas em suas políticas no conteúdo da NSFW, particularmente em relação a Celebrity Loras. Essas mudanças foram estimuladas pela pressão dos facilitadores de pagamento MasterCard e Visa. Celebridade loras, que são você
 O Google utiliza a IA para suspender mais de 39 milhões de contas de anúncios por suspeita de fraude
O Google anunciou na quarta -feira que foi necessário um grande passo para combater a fraude de anúncios, suspendendo uma conta impressionante de 39,2 milhões de contas de anunciantes em sua plataforma em 2024. Esse número é mais do que o triplo do que foi relatado no ano anterior, mostrando os esforços intensificados do Google para limpar seu anúncio.
19 de Agosto de 2025 à13 22:01:13 WEST
O Google utiliza a IA para suspender mais de 39 milhões de contas de anúncios por suspeita de fraude
O Google anunciou na quarta -feira que foi necessário um grande passo para combater a fraude de anúncios, suspendendo uma conta impressionante de 39,2 milhões de contas de anunciantes em sua plataforma em 2024. Esse número é mais do que o triplo do que foi relatado no ano anterior, mostrando os esforços intensificados do Google para limpar seu anúncio.
19 de Agosto de 2025 à13 22:01:13 WEST
That Pelosi video from 2019 is wild! It’s scary how a few tweaks can make someone look totally drunk. AI’s power to mess with videos is both cool and creepy—makes you wonder what’s real anymore. 😬
0
19 de Agosto de 2025 à10 18:01:10 WEST
This Pelosi video incident is wild! 🤯 It’s scary how a few tweaks can make someone look totally out of it. Makes me wonder how much of what we see online is real anymore. AI’s cool, but this kind of stuff could mess with trust big time.
0
29 de Julho de 2025 à16 13:25:16 WEST
That Pelosi video from 2019 is wild! It’s scary how a few tweaks can make someone look totally out of it. AI’s power to mess with reality is no joke—makes you wonder what’s real anymore. 🫣
0
24 de Abril de 2025 à54 03:24:54 WEST
Este herramienta de IA me mostró lo fácil que es manipular videos. El incidente de Nancy Pelosi fue un recordatorio impactante. Es aterrador pensar en cuántas noticias falsas pueden existir. Ahora estoy más atento a lo que creo en línea. ¡Cuidado, amigos! 👀
0
20 de Abril de 2025 à51 21:42:51 WEST
このAIツールは、ビデオを操作するのがどれほど簡単かを教えてくれました。ナンシー・ペロシの事件は衝撃的でした。偽ニュースがどれだけあるかと思うと恐ろしいです。オンラインで何を信じるかについて、今はもっと注意しています。みなさんも気をつけてくださいね!👀
0
19 de Abril de 2025 à50 11:25:50 WEST
Dieses KI-Tool hat mir gezeigt, wie einfach es ist, Videos zu manipulieren! Der Vorfall mit Nancy Pelosi war ein Weckruf. Es ist beängstigend, wie viele gefälschte Nachrichten es geben könnte. Ich bin jetzt vorsichtiger mit dem, was ich online glaube. Seid wachsam, Leute! 👀
0













