




Открытие тонких, но эффективных модификаций ИИ в аутентичном видеоконтенте
В 2019 году широко распространилось обманное видео с Нэнси Пелоси, тогда спикером Палаты представителей США. Видео, отредактированное так, чтобы она выглядела пьяной, стало ярким напоминанием о том, как легко манипулируемые медиа могут ввести в заблуждение общественность. Несмотря на свою простоту, этот инцидент подчеркнул потенциальный ущерб даже от базовых аудиовизуальных правок.
В то время ландшафт дипфейков в основном определялся технологиями замены лиц на основе автоэнкодеров, появившихся в конце 2017 года. Эти ранние системы с трудом справлялись с тонкими изменениями, как в видео с Пелоси, сосредотачиваясь вместо этого на более явных заменах лиц.
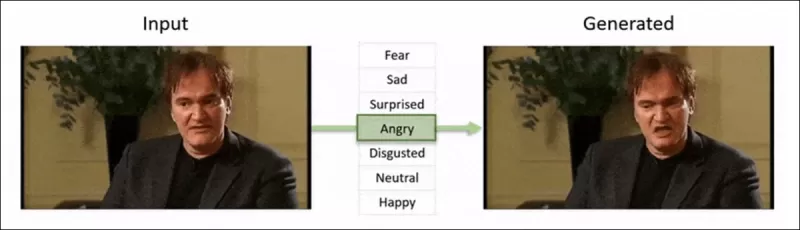 Структура 2022 года ‘Neural Emotion Director' изменяет настроение известного лица. Источник: https://www.youtube.com/watch?v=Li6W8pRDMJQ
Структура 2022 года ‘Neural Emotion Director' изменяет настроение известного лица. Источник: https://www.youtube.com/watch?v=Li6W8pRDMJQ
Сегодня кино- и телеиндустрия всё больше исследует правки постпроизводства с использованием ИИ. Эта тенденция вызвала как интерес, так и критику, поскольку ИИ позволяет достичь уровня перфекционизма, ранее недоступного. В ответ научное сообщество разработало различные проекты, сосредоточенные на «локальных правках» захвата лиц, такие как Diffusion Video Autoencoders, Stitch it in Time, ChatFace, MagicFace и DISCO.
 Редактирование выражений с проектом MagicFace января 2025 года. Источник: https://arxiv.org/pdf/2501.02260
Редактирование выражений с проектом MagicFace января 2025 года. Источник: https://arxiv.org/pdf/2501.02260
Новые лица, новые морщины
Однако технологии для создания таких тонких правок развиваются гораздо быстрее, чем наша способность их обнаруживать. Большинство методов обнаружения дипфейков устарели, сосредотачиваясь на старых техниках и наборах данных. Это продолжалось до недавнего прорыва от исследователей из Индии.
 Обнаружение тонких локальных правок в дипфейках: реальное видео изменяется для создания подделок с нюансными изменениями, такими как поднятые брови, изменённые гендерные черты и сдвиги в выражении в сторону отвращения (показано здесь на одном кадре). Источник: https://arxiv.org/pdf/2503.22121
Обнаружение тонких локальных правок в дипфейках: реальное видео изменяется для создания подделок с нюансными изменениями, такими как поднятые брови, изменённые гендерные черты и сдвиги в выражении в сторону отвращения (показано здесь на одном кадре). Источник: https://arxiv.org/pdf/2503.22121
Это новое исследование направлено на обнаружение тонких, локализованных манипуляций с лицами, тип подделки, который часто игнорируется. Вместо поиска широких несоответствий или несовпадений идентичности метод сосредотачивается на мелких деталях, таких как лёгкие сдвиги в выражении или незначительные правки отдельных черт лица. Он использует систему кодирования лицевых движений (FACS), которая разбивает выражения лица на 64 изменяемые области.
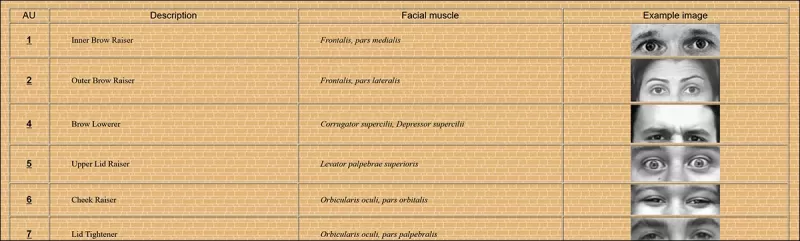 Некоторые из 64 составных частей выражений в FACS. Источник: https://www.cs.cmu.edu/~face/facs.htm
Некоторые из 64 составных частей выражений в FACS. Источник: https://www.cs.cmu.edu/~face/facs.htm
Исследователи протестировали свой подход против различных недавних методов редактирования и обнаружили, что он стабильно превосходит существующие решения, даже с более старыми наборами данных и новыми векторами атак.
«Используя функции на основе AU для управления видеоизображениями, изученными через маскированные автоэнкодеры (MAE), наш метод эффективно фиксирует локализованные изменения, критически важные для обнаружения тонких правок лица.»
«Этот подход позволяет нам создать единое скрытое представление, которое кодирует как локализованные правки, так и более широкие изменения в видео, сосредоточенных на лице, предоставляя всестороннее и адаптируемое решение для обнаружения дипфейков.»
Статья, озаглавленная Обнаружение локализованных манипуляций дипфейков с использованием видеоизображений, управляемых единицами действия, была написана исследователями из Индийского института технологий в Мадрасе.
Метод
Метод начинается с обнаружения лиц в видео и выборки равномерно распределённых кадров, центрированных на этих лицах. Эти кадры затем разбиваются на небольшие 3D-патчи, фиксирующие локальные пространственные и временные детали.
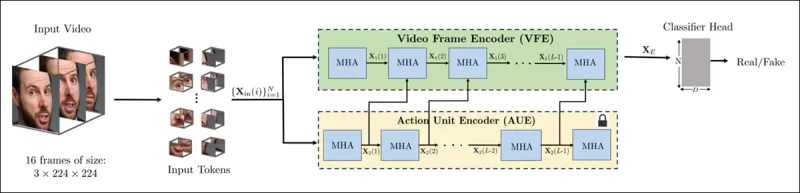 Схема нового метода. Входное видео обрабатывается с обнаружением лиц для извлечения равномерно распределённых, центрированных на лице кадров, которые затем делятся на «трубчатые» патчи и проходят через энкодер, который объединяет скрытые представления из двух предварительно обученных задач. Получившийся вектор затем используется классификатором для определения, является ли видео реальным или поддельным.
Схема нового метода. Входное видео обрабатывается с обнаружением лиц для извлечения равномерно распределённых, центрированных на лице кадров, которые затем делятся на «трубчатые» патчи и проходят через энкодер, который объединяет скрытые представления из двух предварительно обученных задач. Получившийся вектор затем используется классификатором для определения, является ли видео реальным или поддельным.
Каждый патч содержит небольшое окно пикселей из нескольких последовательных кадров, позволяя модели изучать краткосрочные движения и изменения выражений. Эти патчи встраиваются и позиционно кодируются перед подачей в энкодер, предназначенный для различения реальных и поддельных видео.
Задача обнаружения тонких манипуляций решается с использованием энкодера, который объединяет два типа изученных представлений через механизм перекрестного внимания, стремясь создать более чувствительное и обобщающее пространство признаков.
Предварительные задачи
Первое представление исходит от энкодера, обученного задаче маскированного автоэнкодирования. Скрывая большую часть 3D-патчей видео, энкодер учится восстанавливать недостающие части, фиксируя важные пространственно-временные шаблоны, такие как движения лица.
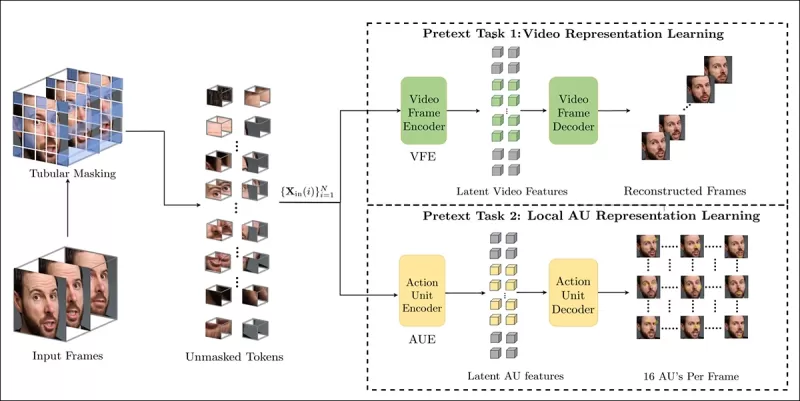 Обучение предварительной задаче включает маскирование частей входного видео и использование конфигурации энкодер-декодер для восстановления либо исходных кадров, либо карт единиц действия по кадрам, в зависимости от задачи.
Обучение предварительной задаче включает маскирование частей входного видео и использование конфигурации энкодер-декодер для восстановления либо исходных кадров, либо карт единиц действия по кадрам, в зависимости от задачи.
Однако этого недостаточно для обнаружения мелкозернистых правок. Исследователи ввели второй энкодер, обученный обнаружению единиц лицевых действий (AUs), побуждая его сосредотачиваться на локализованной мышечной активности, где часто происходят тонкие правки дипфейков.
 Дополнительные примеры единиц лицевых действий (FAUs, или AUs). Источник: https://www.eiagroup.com/the-facial-action-coding-system/
Дополнительные примеры единиц лицевых действий (FAUs, или AUs). Источник: https://www.eiagroup.com/the-facial-action-coding-system/
После предварительного обучения выходы обоих энкодеров объединяются с использованием перекрестного внимания, при этом функции на основе AU направляют внимание на пространственно-временные признаки. Это приводит к объединённому скрытому представлению, которое фиксирует как более широкий контекст движения, так и локализованные детали выражений, используемые для финальной задачи классификации.
Данные и тесты
Реализация
Система была реализована с использованием фреймворка обнаружения лиц FaceXZoo на базе PyTorch, извлекая 16 центрированных на лице кадров из каждого видеоклипа. Предварительные задачи обучались на наборе данных CelebV-HQ, который включает 35 000 высококачественных видеороликов с лицами.
 Из исходной статьи, примеры из набора данных CelebV-HQ, использованного в новом проекте. Источник: https://arxiv.org/pdf/2207.12393
Из исходной статьи, примеры из набора данных CelebV-HQ, использованного в новом проекте. Источник: https://arxiv.org/pdf/2207.12393
Половина данных была замаскирована для предотвращения переобучения. Для задачи восстановления маскированных кадров модель обучалась предсказывать недостающие области с использованием функции потерь L1. Для второй задачи она обучалась генерировать карты для 16 единиц лицевых действий, контролируемых функцией потерь L1.
После предварительного обучения энкодеры были объединены и тонко настроены для обнаружения дипфейков с использованием набора данных FaceForensics++, который включает как реальные, так и манипулированные видео.
 Набор данных FaceForensics++ является основой для обнаружения дипфейков с 2017 года, хотя он теперь значительно устарел в отношении новейших техник синтеза лиц. Источник: https://www.youtube.com/watch?v=x2g48Q2I2ZQ
Набор данных FaceForensics++ является основой для обнаружения дипфейков с 2017 года, хотя он теперь значительно устарел в отношении новейших техник синтеза лиц. Источник: https://www.youtube.com/watch?v=x2g48Q2I2ZQ
Для решения проблемы дисбаланса классов авторы использовали функцию потерь Focal Loss, акцентируя внимание на более сложных примерах во время обучения. Всё обучение проводилось на одном GPU RTX 4090 с 24 ГБ видеопамяти, используя предварительно обученные контрольные точки от VideoMAE.
Тесты
Метод был протестирован против различных техник обнаружения дипфейков, сосредоточившись на локально отредактированных дипфейках. Тесты включали ряд методов редактирования и более старые наборы данных дипфейков, используя метрики, такие как площадь под кривой (AUC), средняя точность и средний F1-показатель.
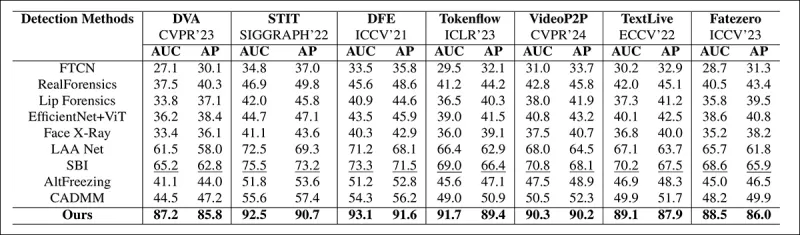 Из статьи: сравнение на недавних локализованных дипфейках показывает, что предложенный метод превзошёл все остальные, с приростом на 15–20 процентов как в AUC, так и в средней точности по сравнению с ближайшим подходом.
Из статьи: сравнение на недавних локализованных дипфейках показывает, что предложенный метод превзошёл все остальные, с приростом на 15–20 процентов как в AUC, так и в средней точности по сравнению с ближайшим подходом.
Авторы предоставили визуальные сравнения локально манипулированных видео, демонстрируя превосходную чувствительность их метода к тонким правкам.
 Реальное видео было изменено с использованием трёх различных локализованных манипуляций для создания подделок, которые оставались визуально похожими на оригинал. Показаны здесь представительские кадры вместе со средними оценками обнаружения подделок для каждого метода. В то время как существующие детекторы испытывали трудности с этими тонкими правками, предложенная модель стабильно присваивала высокие вероятности подделки, указывая на большую чувствительность к локализованным изменениям.
Реальное видео было изменено с использованием трёх различных локализованных манипуляций для создания подделок, которые оставались визуально похожими на оригинал. Показаны здесь представительские кадры вместе со средними оценками обнаружения подделок для каждого метода. В то время как существующие детекторы испытывали трудности с этими тонкими правками, предложенная модель стабильно присваивала высокие вероятности подделки, указывая на большую чувствительность к локализованным изменениям.
Исследователи отметили, что существующие современные методы обнаружения испытывали трудности с новейшими техниками генерации дипфейков, в то время как их метод показал устойчивую обобщающую способность, достигая высоких показателей AUC и средней точности.
 Производительность на традиционных наборах данных дипфейков показывает, что предложенный метод оставался конкурентоспособным с ведущими подходами, указывая на сильную обобщающую способность для различных типов манипуляций.
Производительность на традиционных наборах данных дипфейков показывает, что предложенный метод оставался конкурентоспособным с ведущими подходами, указывая на сильную обобщающую способность для различных типов манипуляций.
Авторы также протестировали надёжность модели в реальных условиях, обнаружив, что она устойчива к обычным искажениям видео, таким как корректировка насыщенности, гауссово размытие и пикселизация.
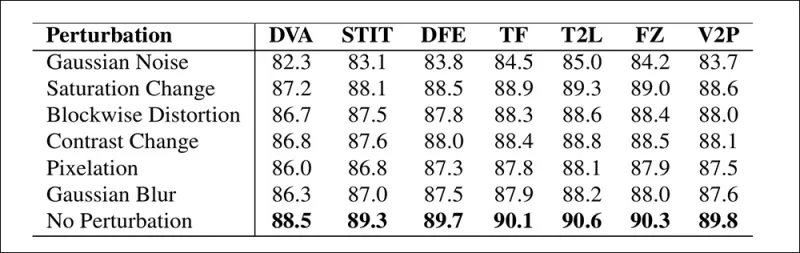 Иллюстрация того, как точность обнаружения изменяется при различных искажениях видео. Новый метод оставался устойчивым в большинстве случаев, с лишь небольшим снижением AUC. Наиболее значительное падение произошло при введении гауссова шума.
Иллюстрация того, как точность обнаружения изменяется при различных искажениях видео. Новый метод оставался устойчивым в большинстве случаев, с лишь небольшим снижением AUC. Наиболее значительное падение произошло при введении гауссова шума.
Заключение
Хотя общественность часто ассоциирует дипфейки с заменой идентичности, реальность манипуляций ИИ более тонкая и потенциально более коварная. Тип локального редактирования, обсуждаемый в этом новом исследовании, может не привлечь внимания общественности до очередного громкого инцидента. Однако, как отметил актёр Ник Кейдж, потенциал правок постпроизводства для изменения актёрских выступлений — это проблема, о которой мы все должны знать. Мы естественно чувствительны даже к малейшим изменениям в выражениях лица, и контекст может кардинально изменить их воздействие.
Впервые опубликовано в среду, 2 апреля 2025 года
Связанная статья
 Tencent представляет HunyuanCustom для видеонастройки на основе одного изображения
Эта статья посвящена запуску HunyuanCustom, мультимодальной модели генерации видео от Tencent. Обширный объем сопроводительной исследовательской статьи и проблемы с предоставленными примерами видео на
Civitai укрепляет правила глубоких положений на фоне давления со стороны MasterCard и Visa
Civitai, один из самых выдающихся репозиториев моделей искусственного интеллекта в Интернете, недавно внесла значительные изменения в свои политики в отношении содержания NSFW, особенно в отношении знаменитостей Лораса. Эти изменения были подкреплены давлением со стороны платежных фасилитаторов MasterCard и Visa. Знаменитости Лорас, которые ты
Google использует ИИ для приостановки более 39 миллионов счетов объявлений о подозрении на мошенничество
Google объявил в среду, что он сделал серьезный шаг в борьбе с мошенничеством с рекламой, приостановив ошеломляющие 39,2 миллиона рекламодателей на своей платформе в 2024 году. Этот номер более чем в три раза, о чем сообщалось в предыдущем году, демонстрируя усиленные усилия Google по очистке своей рекламной экосии
Комментарии (43)
Tencent представляет HunyuanCustom для видеонастройки на основе одного изображения
Эта статья посвящена запуску HunyuanCustom, мультимодальной модели генерации видео от Tencent. Обширный объем сопроводительной исследовательской статьи и проблемы с предоставленными примерами видео на
Civitai укрепляет правила глубоких положений на фоне давления со стороны MasterCard и Visa
Civitai, один из самых выдающихся репозиториев моделей искусственного интеллекта в Интернете, недавно внесла значительные изменения в свои политики в отношении содержания NSFW, особенно в отношении знаменитостей Лораса. Эти изменения были подкреплены давлением со стороны платежных фасилитаторов MasterCard и Visa. Знаменитости Лорас, которые ты
Google использует ИИ для приостановки более 39 миллионов счетов объявлений о подозрении на мошенничество
Google объявил в среду, что он сделал серьезный шаг в борьбе с мошенничеством с рекламой, приостановив ошеломляющие 39,2 миллиона рекламодателей на своей платформе в 2024 году. Этот номер более чем в три раза, о чем сообщалось в предыдущем году, демонстрируя усиленные усилия Google по очистке своей рекламной экосии
Комментарии (43)
![WilliamCarter]() WilliamCarter
WilliamCarter
 20 августа 2025 г., 0:01:13 GMT+03:00
20 августа 2025 г., 0:01:13 GMT+03:00
That Pelosi video from 2019 is wild! It’s scary how a few tweaks can make someone look totally drunk. AI’s power to mess with videos is both cool and creepy—makes you wonder what’s real anymore. 😬


 0
0
![JuanMartínez]() JuanMartínez
19 августа 2025 г., 20:01:10 GMT+03:00
JuanMartínez
19 августа 2025 г., 20:01:10 GMT+03:00
This Pelosi video incident is wild! 🤯 It’s scary how a few tweaks can make someone look totally out of it. Makes me wonder how much of what we see online is real anymore. AI’s cool, but this kind of stuff could mess with trust big time.
0
![RyanPerez]() RyanPerez
29 июля 2025 г., 15:25:16 GMT+03:00
RyanPerez
29 июля 2025 г., 15:25:16 GMT+03:00
That Pelosi video from 2019 is wild! It’s scary how a few tweaks can make someone look totally out of it. AI’s power to mess with reality is no joke—makes you wonder what’s real anymore. 🫣
0
![MarkRoberts]() MarkRoberts
24 апреля 2025 г., 5:24:54 GMT+03:00
MarkRoberts
24 апреля 2025 г., 5:24:54 GMT+03:00
Este herramienta de IA me mostró lo fácil que es manipular videos. El incidente de Nancy Pelosi fue un recordatorio impactante. Es aterrador pensar en cuántas noticias falsas pueden existir. Ahora estoy más atento a lo que creo en línea. ¡Cuidado, amigos! 👀
0
![RobertMartin]() RobertMartin
20 апреля 2025 г., 23:42:51 GMT+03:00
RobertMartin
20 апреля 2025 г., 23:42:51 GMT+03:00
このAIツールは、ビデオを操作するのがどれほど簡単かを教えてくれました。ナンシー・ペロシの事件は衝撃的でした。偽ニュースがどれだけあるかと思うと恐ろしいです。オンラインで何を信じるかについて、今はもっと注意しています。みなさんも気をつけてくださいね!👀
0
![PaulMartínez]() PaulMartínez
19 апреля 2025 г., 13:25:50 GMT+03:00
PaulMartínez
19 апреля 2025 г., 13:25:50 GMT+03:00
Dieses KI-Tool hat mir gezeigt, wie einfach es ist, Videos zu manipulieren! Der Vorfall mit Nancy Pelosi war ein Weckruf. Es ist beängstigend, wie viele gefälschte Nachrichten es geben könnte. Ich bin jetzt vorsichtiger mit dem, was ich online glaube. Seid wachsam, Leute! 👀
0
В 2019 году широко распространилось обманное видео с Нэнси Пелоси, тогда спикером Палаты представителей США. Видео, отредактированное так, чтобы она выглядела пьяной, стало ярким напоминанием о том, как легко манипулируемые медиа могут ввести в заблуждение общественность. Несмотря на свою простоту, этот инцидент подчеркнул потенциальный ущерб даже от базовых аудиовизуальных правок.
В то время ландшафт дипфейков в основном определялся технологиями замены лиц на основе автоэнкодеров, появившихся в конце 2017 года. Эти ранние системы с трудом справлялись с тонкими изменениями, как в видео с Пелоси, сосредотачиваясь вместо этого на более явных заменах лиц.
Структура 2022 года ‘Neural Emotion Director' изменяет настроение известного лица. Источник: https://www.youtube.com/watch?v=Li6W8pRDMJQ
Сегодня кино- и телеиндустрия всё больше исследует правки постпроизводства с использованием ИИ. Эта тенденция вызвала как интерес, так и критику, поскольку ИИ позволяет достичь уровня перфекционизма, ранее недоступного. В ответ научное сообщество разработало различные проекты, сосредоточенные на «локальных правках» захвата лиц, такие как Diffusion Video Autoencoders, Stitch it in Time, ChatFace, MagicFace и DISCO.
Редактирование выражений с проектом MagicFace января 2025 года. Источник: https://arxiv.org/pdf/2501.02260
Новые лица, новые морщины
Однако технологии для создания таких тонких правок развиваются гораздо быстрее, чем наша способность их обнаруживать. Большинство методов обнаружения дипфейков устарели, сосредотачиваясь на старых техниках и наборах данных. Это продолжалось до недавнего прорыва от исследователей из Индии.
Обнаружение тонких локальных правок в дипфейках: реальное видео изменяется для создания подделок с нюансными изменениями, такими как поднятые брови, изменённые гендерные черты и сдвиги в выражении в сторону отвращения (показано здесь на одном кадре). Источник: https://arxiv.org/pdf/2503.22121
Это новое исследование направлено на обнаружение тонких, локализованных манипуляций с лицами, тип подделки, который часто игнорируется. Вместо поиска широких несоответствий или несовпадений идентичности метод сосредотачивается на мелких деталях, таких как лёгкие сдвиги в выражении или незначительные правки отдельных черт лица. Он использует систему кодирования лицевых движений (FACS), которая разбивает выражения лица на 64 изменяемые области.
Некоторые из 64 составных частей выражений в FACS. Источник: https://www.cs.cmu.edu/~face/facs.htm
Исследователи протестировали свой подход против различных недавних методов редактирования и обнаружили, что он стабильно превосходит существующие решения, даже с более старыми наборами данных и новыми векторами атак.
«Используя функции на основе AU для управления видеоизображениями, изученными через маскированные автоэнкодеры (MAE), наш метод эффективно фиксирует локализованные изменения, критически важные для обнаружения тонких правок лица.»
«Этот подход позволяет нам создать единое скрытое представление, которое кодирует как локализованные правки, так и более широкие изменения в видео, сосредоточенных на лице, предоставляя всестороннее и адаптируемое решение для обнаружения дипфейков.»
Статья, озаглавленная Обнаружение локализованных манипуляций дипфейков с использованием видеоизображений, управляемых единицами действия, была написана исследователями из Индийского института технологий в Мадрасе.
Метод
Метод начинается с обнаружения лиц в видео и выборки равномерно распределённых кадров, центрированных на этих лицах. Эти кадры затем разбиваются на небольшие 3D-патчи, фиксирующие локальные пространственные и временные детали.
Схема нового метода. Входное видео обрабатывается с обнаружением лиц для извлечения равномерно распределённых, центрированных на лице кадров, которые затем делятся на «трубчатые» патчи и проходят через энкодер, который объединяет скрытые представления из двух предварительно обученных задач. Получившийся вектор затем используется классификатором для определения, является ли видео реальным или поддельным.
Каждый патч содержит небольшое окно пикселей из нескольких последовательных кадров, позволяя модели изучать краткосрочные движения и изменения выражений. Эти патчи встраиваются и позиционно кодируются перед подачей в энкодер, предназначенный для различения реальных и поддельных видео.
Задача обнаружения тонких манипуляций решается с использованием энкодера, который объединяет два типа изученных представлений через механизм перекрестного внимания, стремясь создать более чувствительное и обобщающее пространство признаков.
Предварительные задачи
Первое представление исходит от энкодера, обученного задаче маскированного автоэнкодирования. Скрывая большую часть 3D-патчей видео, энкодер учится восстанавливать недостающие части, фиксируя важные пространственно-временные шаблоны, такие как движения лица.
Обучение предварительной задаче включает маскирование частей входного видео и использование конфигурации энкодер-декодер для восстановления либо исходных кадров, либо карт единиц действия по кадрам, в зависимости от задачи.
Однако этого недостаточно для обнаружения мелкозернистых правок. Исследователи ввели второй энкодер, обученный обнаружению единиц лицевых действий (AUs), побуждая его сосредотачиваться на локализованной мышечной активности, где часто происходят тонкие правки дипфейков.
Дополнительные примеры единиц лицевых действий (FAUs, или AUs). Источник: https://www.eiagroup.com/the-facial-action-coding-system/
После предварительного обучения выходы обоих энкодеров объединяются с использованием перекрестного внимания, при этом функции на основе AU направляют внимание на пространственно-временные признаки. Это приводит к объединённому скрытому представлению, которое фиксирует как более широкий контекст движения, так и локализованные детали выражений, используемые для финальной задачи классификации.
Данные и тесты
Реализация
Система была реализована с использованием фреймворка обнаружения лиц FaceXZoo на базе PyTorch, извлекая 16 центрированных на лице кадров из каждого видеоклипа. Предварительные задачи обучались на наборе данных CelebV-HQ, который включает 35 000 высококачественных видеороликов с лицами.
Из исходной статьи, примеры из набора данных CelebV-HQ, использованного в новом проекте. Источник: https://arxiv.org/pdf/2207.12393
Половина данных была замаскирована для предотвращения переобучения. Для задачи восстановления маскированных кадров модель обучалась предсказывать недостающие области с использованием функции потерь L1. Для второй задачи она обучалась генерировать карты для 16 единиц лицевых действий, контролируемых функцией потерь L1.
После предварительного обучения энкодеры были объединены и тонко настроены для обнаружения дипфейков с использованием набора данных FaceForensics++, который включает как реальные, так и манипулированные видео.
Набор данных FaceForensics++ является основой для обнаружения дипфейков с 2017 года, хотя он теперь значительно устарел в отношении новейших техник синтеза лиц. Источник: https://www.youtube.com/watch?v=x2g48Q2I2ZQ
Для решения проблемы дисбаланса классов авторы использовали функцию потерь Focal Loss, акцентируя внимание на более сложных примерах во время обучения. Всё обучение проводилось на одном GPU RTX 4090 с 24 ГБ видеопамяти, используя предварительно обученные контрольные точки от VideoMAE.
Тесты
Метод был протестирован против различных техник обнаружения дипфейков, сосредоточившись на локально отредактированных дипфейках. Тесты включали ряд методов редактирования и более старые наборы данных дипфейков, используя метрики, такие как площадь под кривой (AUC), средняя точность и средний F1-показатель.
Из статьи: сравнение на недавних локализованных дипфейках показывает, что предложенный метод превзошёл все остальные, с приростом на 15–20 процентов как в AUC, так и в средней точности по сравнению с ближайшим подходом.
Авторы предоставили визуальные сравнения локально манипулированных видео, демонстрируя превосходную чувствительность их метода к тонким правкам.
Реальное видео было изменено с использованием трёх различных локализованных манипуляций для создания подделок, которые оставались визуально похожими на оригинал. Показаны здесь представительские кадры вместе со средними оценками обнаружения подделок для каждого метода. В то время как существующие детекторы испытывали трудности с этими тонкими правками, предложенная модель стабильно присваивала высокие вероятности подделки, указывая на большую чувствительность к локализованным изменениям.
Исследователи отметили, что существующие современные методы обнаружения испытывали трудности с новейшими техниками генерации дипфейков, в то время как их метод показал устойчивую обобщающую способность, достигая высоких показателей AUC и средней точности.
Производительность на традиционных наборах данных дипфейков показывает, что предложенный метод оставался конкурентоспособным с ведущими подходами, указывая на сильную обобщающую способность для различных типов манипуляций.
Авторы также протестировали надёжность модели в реальных условиях, обнаружив, что она устойчива к обычным искажениям видео, таким как корректировка насыщенности, гауссово размытие и пикселизация.
Иллюстрация того, как точность обнаружения изменяется при различных искажениях видео. Новый метод оставался устойчивым в большинстве случаев, с лишь небольшим снижением AUC. Наиболее значительное падение произошло при введении гауссова шума.
Заключение
Хотя общественность часто ассоциирует дипфейки с заменой идентичности, реальность манипуляций ИИ более тонкая и потенциально более коварная. Тип локального редактирования, обсуждаемый в этом новом исследовании, может не привлечь внимания общественности до очередного громкого инцидента. Однако, как отметил актёр Ник Кейдж, потенциал правок постпроизводства для изменения актёрских выступлений — это проблема, о которой мы все должны знать. Мы естественно чувствительны даже к малейшим изменениям в выражениях лица, и контекст может кардинально изменить их воздействие.
Впервые опубликовано в среду, 2 апреля 2025 года










 Tencent представляет HunyuanCustom для видеонастройки на основе одного изображения
Эта статья посвящена запуску HunyuanCustom, мультимодальной модели генерации видео от Tencent. Обширный объем сопроводительной исследовательской статьи и проблемы с предоставленными примерами видео на
Civitai укрепляет правила глубоких положений на фоне давления со стороны MasterCard и Visa
Civitai, один из самых выдающихся репозиториев моделей искусственного интеллекта в Интернете, недавно внесла значительные изменения в свои политики в отношении содержания NSFW, особенно в отношении знаменитостей Лораса. Эти изменения были подкреплены давлением со стороны платежных фасилитаторов MasterCard и Visa. Знаменитости Лорас, которые ты
Tencent представляет HunyuanCustom для видеонастройки на основе одного изображения
Эта статья посвящена запуску HunyuanCustom, мультимодальной модели генерации видео от Tencent. Обширный объем сопроводительной исследовательской статьи и проблемы с предоставленными примерами видео на
Civitai укрепляет правила глубоких положений на фоне давления со стороны MasterCard и Visa
Civitai, один из самых выдающихся репозиториев моделей искусственного интеллекта в Интернете, недавно внесла значительные изменения в свои политики в отношении содержания NSFW, особенно в отношении знаменитостей Лораса. Эти изменения были подкреплены давлением со стороны платежных фасилитаторов MasterCard и Visa. Знаменитости Лорас, которые ты
 Google использует ИИ для приостановки более 39 миллионов счетов объявлений о подозрении на мошенничество
Google объявил в среду, что он сделал серьезный шаг в борьбе с мошенничеством с рекламой, приостановив ошеломляющие 39,2 миллиона рекламодателей на своей платформе в 2024 году. Этот номер более чем в три раза, о чем сообщалось в предыдущем году, демонстрируя усиленные усилия Google по очистке своей рекламной экосии
20 августа 2025 г., 0:01:13 GMT+03:00
Google использует ИИ для приостановки более 39 миллионов счетов объявлений о подозрении на мошенничество
Google объявил в среду, что он сделал серьезный шаг в борьбе с мошенничеством с рекламой, приостановив ошеломляющие 39,2 миллиона рекламодателей на своей платформе в 2024 году. Этот номер более чем в три раза, о чем сообщалось в предыдущем году, демонстрируя усиленные усилия Google по очистке своей рекламной экосии
20 августа 2025 г., 0:01:13 GMT+03:00
That Pelosi video from 2019 is wild! It’s scary how a few tweaks can make someone look totally drunk. AI’s power to mess with videos is both cool and creepy—makes you wonder what’s real anymore. 😬
0
19 августа 2025 г., 20:01:10 GMT+03:00
This Pelosi video incident is wild! 🤯 It’s scary how a few tweaks can make someone look totally out of it. Makes me wonder how much of what we see online is real anymore. AI’s cool, but this kind of stuff could mess with trust big time.
0
29 июля 2025 г., 15:25:16 GMT+03:00
That Pelosi video from 2019 is wild! It’s scary how a few tweaks can make someone look totally out of it. AI’s power to mess with reality is no joke—makes you wonder what’s real anymore. 🫣
0
24 апреля 2025 г., 5:24:54 GMT+03:00
Este herramienta de IA me mostró lo fácil que es manipular videos. El incidente de Nancy Pelosi fue un recordatorio impactante. Es aterrador pensar en cuántas noticias falsas pueden existir. Ahora estoy más atento a lo que creo en línea. ¡Cuidado, amigos! 👀
0
20 апреля 2025 г., 23:42:51 GMT+03:00
このAIツールは、ビデオを操作するのがどれほど簡単かを教えてくれました。ナンシー・ペロシの事件は衝撃的でした。偽ニュースがどれだけあるかと思うと恐ろしいです。オンラインで何を信じるかについて、今はもっと注意しています。みなさんも気をつけてくださいね!👀
0
19 апреля 2025 г., 13:25:50 GMT+03:00
Dieses KI-Tool hat mir gezeigt, wie einfach es ist, Videos zu manipulieren! Der Vorfall mit Nancy Pelosi war ein Weckruf. Es ist beängstigend, wie viele gefälschte Nachrichten es geben könnte. Ich bin jetzt vorsichtiger mit dem, was ich online glaube. Seid wachsam, Leute! 👀
0













