




Công bố sửa đổi AI tinh tế nhưng có tác động trong nội dung video đích thực
Vào năm 2019, một video lừa đảo về Nancy Pelosi, khi đó là Chủ tịch Hạ viện Hoa Kỳ, đã lan truyền rộng rãi. Video này, được chỉnh sửa để khiến bà trông như say xỉn, là một lời nhắc nhở rõ ràng về việc truyền thông bị thao túng dễ dàng như thế nào có thể đánh lừa công chúng. Mặc dù đơn giản, sự việc này đã làm nổi bật thiệt hại tiềm tàng của các chỉnh sửa âm thanh-hình ảnh cơ bản.
Vào thời điểm đó, bối cảnh deepfake phần lớn bị chi phối bởi các công nghệ thay thế khuôn mặt dựa trên autoencoder, đã xuất hiện từ cuối năm 2017. Những hệ thống ban đầu này gặp khó khăn trong việc tạo ra các thay đổi tinh tế như trong video Pelosi, thay vào đó tập trung vào các hoán đổi khuôn mặt rõ rệt hơn.
 Khung công tác ‘Neural Emotion Director’ năm 2022 thay đổi tâm trạng của một khuôn mặt nổi tiếng. Nguồn: https://www.youtube.com/watch?v=Li6W8pRDMJQ
Khung công tác ‘Neural Emotion Director’ năm 2022 thay đổi tâm trạng của một khuôn mặt nổi tiếng. Nguồn: https://www.youtube.com/watch?v=Li6W8pRDMJQ
Nhanh chóng đến hiện tại, ngành công nghiệp phim và truyền hình ngày càng khám phá các chỉnh sửa hậu kỳ dựa trên AI. Xu hướng này đã gây ra cả sự quan tâm lẫn chỉ trích, khi AI cho phép đạt được mức độ hoàn hảo trước đây không thể đạt được. Để đáp ứng, cộng đồng nghiên cứu đã phát triển nhiều dự án tập trung vào các chỉnh sửa cục bộ của các bản ghi hình khuôn mặt, như Diffusion Video Autoencoders, Stitch it in Time, ChatFace, MagicFace và DISCO.
 Chỉnh sửa biểu cảm với dự án MagicFace tháng 1 năm 2025. Nguồn: https://arxiv.org/pdf/2501.02260
Chỉnh sửa biểu cảm với dự án MagicFace tháng 1 năm 2025. Nguồn: https://arxiv.org/pdf/2501.02260
Khuôn mặt mới, nếp nhăn mới
Tuy nhiên, công nghệ để tạo ra các chỉnh sửa tinh tế này đang tiến bộ nhanh hơn nhiều so với khả năng phát hiện chúng của chúng ta. Hầu hết các phương pháp phát hiện deepfake đã lỗi thời, tập trung vào các kỹ thuật và bộ dữ liệu cũ hơn. Điều đó kéo dài cho đến khi có một bước đột phá gần đây từ các nhà nghiên cứu ở Ấn Độ.
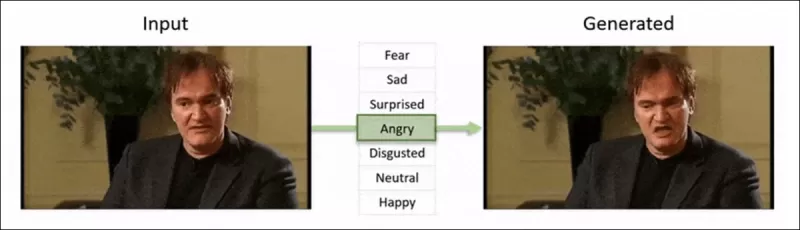
 Phát hiện các chỉnh sửa cục bộ tinh tế trong Deepfake: Một video thật được thay đổi để tạo ra các video giả với các thay đổi tinh tế như nâng lông mày, thay đổi đặc điểm giới tính, và chuyển đổi biểu cảm sang sự ghê tởm (được minh họa ở đây bằng một khung hình duy nhất). Nguồn: https://arxiv.org/pdf/2503.22121
Phát hiện các chỉnh sửa cục bộ tinh tế trong Deepfake: Một video thật được thay đổi để tạo ra các video giả với các thay đổi tinh tế như nâng lông mày, thay đổi đặc điểm giới tính, và chuyển đổi biểu cảm sang sự ghê tởm (được minh họa ở đây bằng một khung hình duy nhất). Nguồn: https://arxiv.org/pdf/2503.22121
Nghiên cứu mới này nhắm đến việc phát hiện các thao túng khuôn mặt cục bộ tinh tế, một loại giả mạo thường bị bỏ qua. Thay vì tìm kiếm các mâu thuẫn rộng lớn hoặc sự không khớp về danh tính, phương pháp này tập trung vào các chi tiết nhỏ như sự thay đổi biểu cảm nhẹ hoặc các chỉnh sửa nhỏ cho các đặc điểm khuôn mặt cụ thể. Nó tận dụng Hệ thống Mã hóa Hành động Khuôn mặt (FACS), phân tích biểu cảm khuôn mặt thành 64 khu vực có thể thay đổi.
 Một số thành phần của 64 phần biểu cảm trong FACS. Nguồn: https://www.cs.cmu.edu/~face/facs.htm
Một số thành phần của 64 phần biểu cảm trong FACS. Nguồn: https://www.cs.cmu.edu/~face/facs.htm
Các nhà nghiên cứu đã thử nghiệm phương pháp của họ với nhiều phương pháp chỉnh sửa gần đây và nhận thấy nó liên tục vượt trội so với các giải pháp hiện có, ngay cả với các bộ dữ liệu cũ hơn và các vector tấn công mới hơn.
‘Bằng cách sử dụng các đặc trưng dựa trên AU để hướng dẫn các biểu diễn video được học qua Masked Autoencoders (MAE), phương pháp của chúng tôi nắm bắt hiệu quả các thay đổi cục bộ quan trọng để phát hiện các chỉnh sửa khuôn mặt tinh tế.
‘Phương pháp này cho phép chúng tôi xây dựng một biểu diễn ẩn thống nhất mã hóa cả các chỉnh sửa cục bộ và các thay đổi rộng hơn trong các video tập trung vào khuôn mặt, cung cấp một giải pháp toàn diện và thích nghi cho việc phát hiện deepfake.’
Bài báo, có tựa đề Phát hiện các thao túng Deepfake cục bộ bằng các biểu diễn video được dẫn dắt bởi đơn vị hành động, được viết bởi các nhà nghiên cứu tại Viện Công nghệ Ấn Độ tại Madras.
Phương pháp
Phương pháp bắt đầu bằng cách phát hiện khuôn mặt trong video và lấy mẫu các khung hình cách đều nhau tập trung vào các khuôn mặt này. Các khung hình này sau đó được chia thành các mảnh 3D nhỏ, nắm bắt các chi tiết không gian và thời gian cục bộ.
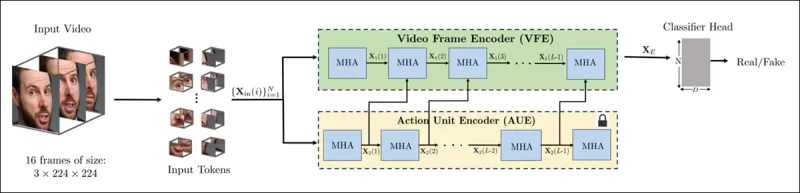 Sơ đồ cho phương pháp mới. Video đầu vào được xử lý với phát hiện khuôn mặt để trích xuất các khung hình cách đều nhau, tập trung vào khuôn mặt, sau đó được chia thành các mảnh ‘ống’ và truyền qua một bộ mã hóa kết hợp các biểu diễn ẩn từ hai nhiệm vụ tiền xử lý được huấn luyện trước. Vector kết quả sau đó được sử dụng bởi một bộ phân loại để xác định video là thật hay giả.
Sơ đồ cho phương pháp mới. Video đầu vào được xử lý với phát hiện khuôn mặt để trích xuất các khung hình cách đều nhau, tập trung vào khuôn mặt, sau đó được chia thành các mảnh ‘ống’ và truyền qua một bộ mã hóa kết hợp các biểu diễn ẩn từ hai nhiệm vụ tiền xử lý được huấn luyện trước. Vector kết quả sau đó được sử dụng bởi một bộ phân loại để xác định video là thật hay giả.
Mỗi mảnh chứa một cửa sổ pixel nhỏ từ một vài khung hình liên tiếp, cho phép mô hình học các chuyển động ngắn hạn và thay đổi biểu cảm. Các mảnh này được nhúng và mã hóa vị trí trước khi được đưa vào một bộ mã hóa được thiết kế để phân biệt video thật và giả.
Thách thức trong việc phát hiện các thao túng tinh tế được giải quyết bằng cách sử dụng một bộ mã hóa kết hợp hai loại biểu diễn đã học thông qua cơ chế chú ý chéo, nhằm tạo ra một không gian đặc trưng nhạy hơn và tổng quát hơn.
Nhiệm vụ tiền xử lý
Biểu diễn đầu tiên đến từ một bộ mã hóa được huấn luyện với nhiệm vụ mã hóa tự động có che chắn. Bằng cách che giấu phần lớn các mảnh 3D của video, bộ mã hóa học cách tái tạo các phần bị thiếu, nắm bắt các mẫu không gian-thời gian quan trọng như chuyển động khuôn mặt.
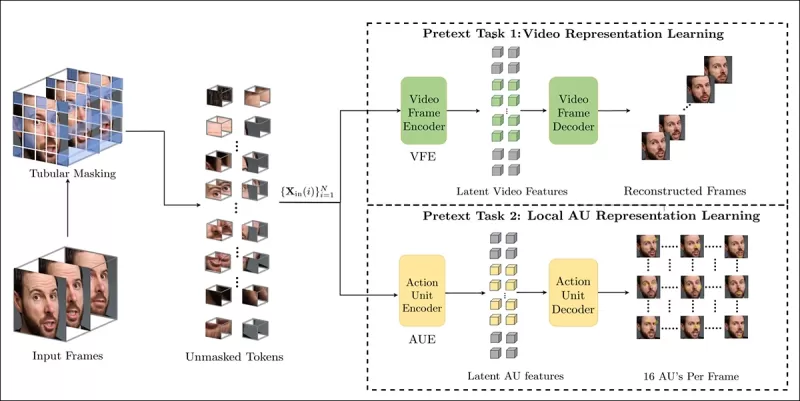 Huấn luyện nhiệm vụ tiền xử lý liên quan đến việc che giấu một phần đầu vào video và sử dụng thiết lập mã hóa-giải mã để tái tạo các khung hình gốc hoặc bản đồ đơn vị hành động cho mỗi khung hình, tùy thuộc vào nhiệm vụ.
Huấn luyện nhiệm vụ tiền xử lý liên quan đến việc che giấu một phần đầu vào video và sử dụng thiết lập mã hóa-giải mã để tái tạo các khung hình gốc hoặc bản đồ đơn vị hành động cho mỗi khung hình, tùy thuộc vào nhiệm vụ.
Tuy nhiên, điều này chưa đủ để phát hiện các chỉnh sửa chi tiết. Các nhà nghiên cứu đã giới thiệu một bộ mã hóa thứ hai được huấn luyện để phát hiện các đơn vị hành động khuôn mặt (AUs), khuyến khích nó tập trung vào hoạt động cơ cục bộ nơi các chỉnh sửa deepfake tinh tế thường xảy ra.
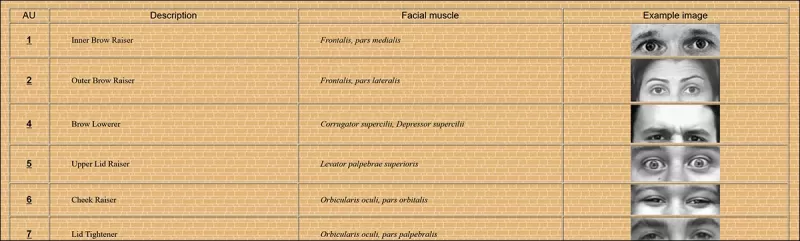
 Các ví dụ khác về Đơn vị Hành động Khuôn mặt (FAUs, hoặc AUs). Nguồn: https://www.eiagroup.com/the-facial-action-coding-system/
Các ví dụ khác về Đơn vị Hành động Khuôn mặt (FAUs, hoặc AUs). Nguồn: https://www.eiagroup.com/the-facial-action-coding-system/
Sau khi huấn luyện trước, đầu ra của cả hai bộ mã hóa được kết hợp bằng chú ý chéo, với các đặc trưng dựa trên AU dẫn dắt sự chú ý lên các đặc trưng không gian-thời gian. Điều này dẫn đến một biểu diễn ẩn kết hợp nắm bắt cả bối cảnh chuyển động rộng hơn và chi tiết biểu cảm cục bộ, được sử dụng cho nhiệm vụ phân loại cuối cùng.
Dữ liệu và Thử nghiệm
Thực hiện
Hệ thống được triển khai bằng khung công tác phát hiện khuôn mặt dựa trên PyTorch FaceXZoo, trích xuất 16 khung hình tập trung vào khuôn mặt từ mỗi đoạn video. Các nhiệm vụ tiền xử lý được huấn luyện trên bộ dữ liệu CelebV-HQ, bao gồm 35,000 video khuôn mặt chất lượng cao.
 Từ bài báo nguồn, các ví dụ từ bộ dữ liệu CelebV-HQ được sử dụng trong dự án mới. Nguồn: https://arxiv.org/pdf/2207.12393
Từ bài báo nguồn, các ví dụ từ bộ dữ liệu CelebV-HQ được sử dụng trong dự án mới. Nguồn: https://arxiv.org/pdf/2207.12393
Một nửa dữ liệu được che giấu để ngăn chặn quá khớp. Đối với nhiệm vụ tái tạo khung hình bị che giấu, mô hình được huấn luyện để dự đoán các vùng bị thiếu bằng cách sử dụng mất mát L1. Đối với nhiệm vụ thứ hai, nó được huấn luyện để tạo ra các bản đồ cho 16 đơn vị hành động khuôn mặt, được giám sát bởi mất mát L1.
Sau khi huấn luyện trước, các bộ mã hóa được kết hợp và tinh chỉnh để phát hiện deepfake bằng bộ dữ liệu FaceForensics++, bao gồm cả video thật và video đã bị thao túng.
 Bộ dữ liệu FaceForensics++ đã là nền tảng của việc phát hiện deepfake từ năm 2017, mặc dù hiện nay nó đã khá lỗi thời liên quan đến các kỹ thuật tổng hợp khuôn mặt mới nhất. Nguồn: https://www.youtube.com/watch?v=x2g48Q2I2ZQ
Bộ dữ liệu FaceForensics++ đã là nền tảng của việc phát hiện deepfake từ năm 2017, mặc dù hiện nay nó đã khá lỗi thời liên quan đến các kỹ thuật tổng hợp khuôn mặt mới nhất. Nguồn: https://www.youtube.com/watch?v=x2g48Q2I2ZQ
Để giải quyết vấn đề mất cân bằng lớp, các tác giả đã sử dụng Mất mát Tiêu điểm, nhấn mạnh vào các ví dụ khó hơn trong quá trình huấn luyện. Tất cả quá trình huấn luyện được thực hiện trên một GPU RTX 4090 duy nhất với 24Gb VRAM, sử dụng các điểm kiểm tra được huấn luyện trước từ VideoMAE.
Thử nghiệm
Phương pháp này được đánh giá so với nhiều kỹ thuật phát hiện deepfake khác nhau, tập trung vào các deepfake được chỉnh sửa cục bộ. Các thử nghiệm bao gồm một loạt các phương pháp chỉnh sửa và các bộ dữ liệu deepfake cũ hơn, sử dụng các chỉ số như Diện tích Dưới Đường Cong (AUC), Độ chính xác Trung bình và Điểm F1 Trung bình.
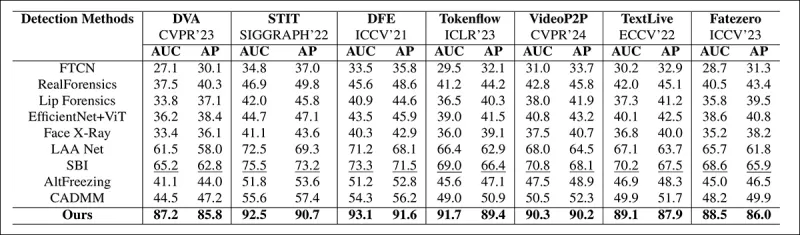 Từ bài báo: so sánh trên các deepfake cục bộ gần đây cho thấy phương pháp được đề xuất vượt trội so với tất cả các phương pháp khác, với mức tăng từ 15 đến 20 phần trăm về cả AUC và độ chính xác trung bình so với phương pháp tốt thứ hai.
Từ bài báo: so sánh trên các deepfake cục bộ gần đây cho thấy phương pháp được đề xuất vượt trội so với tất cả các phương pháp khác, với mức tăng từ 15 đến 20 phần trăm về cả AUC và độ chính xác trung bình so với phương pháp tốt thứ hai.
Các tác giả đã cung cấp các so sánh trực quan về các video bị thao túng cục bộ, cho thấy độ nhạy vượt trội của phương pháp đối với các chỉnh sửa tinh tế.
 Một video thật được thay đổi bằng ba thao túng cục bộ khác nhau để tạo ra các video giả vẫn giống với bản gốc về mặt hình ảnh. Các khung hình đại diện được hiển thị ở đây cùng với điểm phát hiện giả trung bình cho mỗi phương pháp. Trong khi các bộ phát hiện hiện tại gặp khó khăn với các chỉnh sửa tinh tế này, mô hình được đề xuất liên tục gán xác suất giả cao, cho thấy độ nhạy cao hơn đối với các thay đổi cục bộ.
Một video thật được thay đổi bằng ba thao túng cục bộ khác nhau để tạo ra các video giả vẫn giống với bản gốc về mặt hình ảnh. Các khung hình đại diện được hiển thị ở đây cùng với điểm phát hiện giả trung bình cho mỗi phương pháp. Trong khi các bộ phát hiện hiện tại gặp khó khăn với các chỉnh sửa tinh tế này, mô hình được đề xuất liên tục gán xác suất giả cao, cho thấy độ nhạy cao hơn đối với các thay đổi cục bộ.
Các nhà nghiên cứu lưu ý rằng các phương pháp phát hiện tiên tiến hiện tại gặp khó khăn với các kỹ thuật tạo deepfake mới nhất, trong khi phương pháp của họ cho thấy khả năng tổng quát hóa mạnh mẽ, đạt được điểm AUC và độ chính xác trung bình cao.
 Hiệu suất trên các bộ dữ liệu deepfake truyền thống cho thấy phương pháp được đề xuất vẫn cạnh tranh với các phương pháp hàng đầu, thể hiện khả năng tổng quát hóa mạnh mẽ trên nhiều loại thao túng.
Hiệu suất trên các bộ dữ liệu deepfake truyền thống cho thấy phương pháp được đề xuất vẫn cạnh tranh với các phương pháp hàng đầu, thể hiện khả năng tổng quát hóa mạnh mẽ trên nhiều loại thao túng.
Các tác giả cũng đã thử nghiệm độ tin cậy của mô hình trong các điều kiện thực tế, nhận thấy nó bền vững với các biến dạng video phổ biến như điều chỉnh độ bão hòa, làm mờ Gaussian và pixelation.
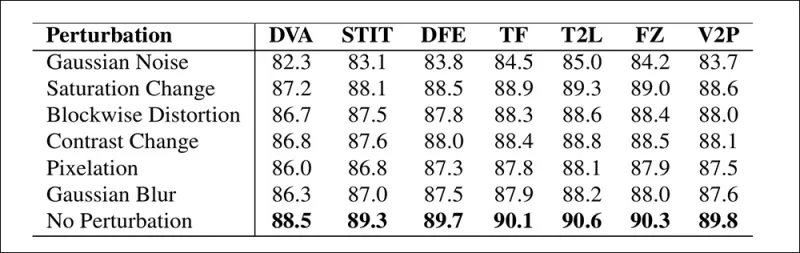 Hình minh họa về cách độ chính xác phát hiện thay đổi dưới các biến dạng video khác nhau. Phương pháp mới vẫn bền vững trong hầu hết các trường hợp, chỉ giảm nhẹ về AUC. Sự sụt giảm đáng kể nhất xảy ra khi nhiễu Gaussian được giới thiệu.
Hình minh họa về cách độ chính xác phát hiện thay đổi dưới các biến dạng video khác nhau. Phương pháp mới vẫn bền vững trong hầu hết các trường hợp, chỉ giảm nhẹ về AUC. Sự sụt giảm đáng kể nhất xảy ra khi nhiễu Gaussian được giới thiệu.
Kết luận
Mặc dù công chúng thường nghĩ về deepfake như các hoán đổi danh tính, thực tế của thao túng AI phức tạp hơn và có khả năng nguy hiểm hơn. Loại chỉnh sửa cục bộ được thảo luận trong nghiên cứu mới này có thể không thu hút sự chú ý của công chúng cho đến khi xảy ra một sự cố nổi bật khác. Tuy nhiên, như diễn viên Nic Cage đã chỉ ra, tiềm năng của các chỉnh sửa hậu kỳ để thay đổi diễn xuất là một mối quan ngại mà tất cả chúng ta nên nhận thức được. Chúng ta tự nhiên nhạy cảm với ngay cả những thay đổi nhỏ nhất trong biểu cảm khuôn mặt, và bối cảnh có thể làm thay đổi đáng kể tác động của chúng.
Được xuất bản lần đầu vào thứ Tư, ngày 2 tháng 4 năm 2025
Bài viết liên quan
 Civitai tăng cường các quy định của Deepfake trong bối cảnh áp lực từ Thẻ Mastercard và Visa
Civitai, một trong những kho lưu trữ mô hình AI nổi bật nhất trên Internet, gần đây đã thực hiện những thay đổi đáng kể đối với các chính sách của mình về nội dung NSFW, đặc biệt liên quan đến người nổi tiếng Loras. Những thay đổi này đã được thúc đẩy bởi áp lực từ MasterCard và Visa của người hỗ trợ thanh toán. Người nổi tiếng Loras, đó là bạn
Google sử dụng AI để đình chỉ hơn 39 triệu tài khoản AD vì bị nghi ngờ gian lận
Google đã công bố vào thứ Tư rằng họ đã có một bước quan trọng trong việc chống gian lận quảng cáo bằng cách đình chỉ một tài khoản nhà quảng cáo đáng kinh ngạc 39,2 triệu trên nền tảng của mình vào năm 2024.
Tạo video AI chuyển sang kiểm soát hoàn toàn
Các mô hình nền tảng video như Hunyuan và WAN 2.1 đã có những bước tiến đáng kể, nhưng chúng thường bị thiếu hụt khi nói đến điều khiển chi tiết cần thiết trong sản xuất phim và TV, đặc biệt là trong lĩnh vực hiệu ứng hình ảnh (VFX). Trong VFX Studios chuyên nghiệp, những mô hình này, cùng với hình ảnh trước đó
Nhận xét (41)
0/200
Civitai tăng cường các quy định của Deepfake trong bối cảnh áp lực từ Thẻ Mastercard và Visa
Civitai, một trong những kho lưu trữ mô hình AI nổi bật nhất trên Internet, gần đây đã thực hiện những thay đổi đáng kể đối với các chính sách của mình về nội dung NSFW, đặc biệt liên quan đến người nổi tiếng Loras. Những thay đổi này đã được thúc đẩy bởi áp lực từ MasterCard và Visa của người hỗ trợ thanh toán. Người nổi tiếng Loras, đó là bạn
Google sử dụng AI để đình chỉ hơn 39 triệu tài khoản AD vì bị nghi ngờ gian lận
Google đã công bố vào thứ Tư rằng họ đã có một bước quan trọng trong việc chống gian lận quảng cáo bằng cách đình chỉ một tài khoản nhà quảng cáo đáng kinh ngạc 39,2 triệu trên nền tảng của mình vào năm 2024.
Tạo video AI chuyển sang kiểm soát hoàn toàn
Các mô hình nền tảng video như Hunyuan và WAN 2.1 đã có những bước tiến đáng kể, nhưng chúng thường bị thiếu hụt khi nói đến điều khiển chi tiết cần thiết trong sản xuất phim và TV, đặc biệt là trong lĩnh vực hiệu ứng hình ảnh (VFX). Trong VFX Studios chuyên nghiệp, những mô hình này, cùng với hình ảnh trước đó
Nhận xét (41)
0/200
![RyanPerez]() RyanPerez
RyanPerez
 19:25:16 GMT+07:00 Ngày 29 tháng 7 năm 2025
19:25:16 GMT+07:00 Ngày 29 tháng 7 năm 2025
That Pelosi video from 2019 is wild! It’s scary how a few tweaks can make someone look totally out of it. AI’s power to mess with reality is no joke—makes you wonder what’s real anymore. 🫣


 0
0
![MarkRoberts]() MarkRoberts
09:24:54 GMT+07:00 Ngày 24 tháng 4 năm 2025
MarkRoberts
09:24:54 GMT+07:00 Ngày 24 tháng 4 năm 2025
Este herramienta de IA me mostró lo fácil que es manipular videos. El incidente de Nancy Pelosi fue un recordatorio impactante. Es aterrador pensar en cuántas noticias falsas pueden existir. Ahora estoy más atento a lo que creo en línea. ¡Cuidado, amigos! 👀
0
![RobertMartin]() RobertMartin
03:42:51 GMT+07:00 Ngày 21 tháng 4 năm 2025
RobertMartin
03:42:51 GMT+07:00 Ngày 21 tháng 4 năm 2025
このAIツールは、ビデオを操作するのがどれほど簡単かを教えてくれました。ナンシー・ペロシの事件は衝撃的でした。偽ニュースがどれだけあるかと思うと恐ろしいです。オンラインで何を信じるかについて、今はもっと注意しています。みなさんも気をつけてくださいね!👀
0
![PaulMartínez]() PaulMartínez
17:25:50 GMT+07:00 Ngày 19 tháng 4 năm 2025
PaulMartínez
17:25:50 GMT+07:00 Ngày 19 tháng 4 năm 2025
Dieses KI-Tool hat mir gezeigt, wie einfach es ist, Videos zu manipulieren! Der Vorfall mit Nancy Pelosi war ein Weckruf. Es ist beängstigend, wie viele gefälschte Nachrichten es geben könnte. Ich bin jetzt vorsichtiger mit dem, was ich online glaube. Seid wachsam, Leute! 👀
0
![HarryWilliams]() HarryWilliams
17:17:36 GMT+07:00 Ngày 19 tháng 4 năm 2025
HarryWilliams
17:17:36 GMT+07:00 Ngày 19 tháng 4 năm 2025
This AI tool really opened my eyes to how easy it is to manipulate videos! The Nancy Pelosi incident was a wake-up call. It's scary to think how much fake news could be out there. Definitely makes me more cautious about what I believe online. Keep an eye out, folks! 👀
0
![EricRoberts]() EricRoberts
17:05:37 GMT+07:00 Ngày 15 tháng 4 năm 2025
EricRoberts
17:05:37 GMT+07:00 Ngày 15 tháng 4 năm 2025
이 앱은 눈을 뜨게 합니다! AI의 미묘한 변화가 비디오의 진위성을 어떻게 망칠 수 있는지를 보여줍니다. 낸시 펠로시의 예는 경고였어요. 하지만 설명이 때때로 나에게는 너무 기술적이어서요. 더 간단하게 설명해주면 좋겠어요! 그래도 AI의 영향을 이해하는 데는 좋은 도구입니다. 👀
0
Vào năm 2019, một video lừa đảo về Nancy Pelosi, khi đó là Chủ tịch Hạ viện Hoa Kỳ, đã lan truyền rộng rãi. Video này, được chỉnh sửa để khiến bà trông như say xỉn, là một lời nhắc nhở rõ ràng về việc truyền thông bị thao túng dễ dàng như thế nào có thể đánh lừa công chúng. Mặc dù đơn giản, sự việc này đã làm nổi bật thiệt hại tiềm tàng của các chỉnh sửa âm thanh-hình ảnh cơ bản.
Vào thời điểm đó, bối cảnh deepfake phần lớn bị chi phối bởi các công nghệ thay thế khuôn mặt dựa trên autoencoder, đã xuất hiện từ cuối năm 2017. Những hệ thống ban đầu này gặp khó khăn trong việc tạo ra các thay đổi tinh tế như trong video Pelosi, thay vào đó tập trung vào các hoán đổi khuôn mặt rõ rệt hơn.
Khung công tác ‘Neural Emotion Director’ năm 2022 thay đổi tâm trạng của một khuôn mặt nổi tiếng. Nguồn: https://www.youtube.com/watch?v=Li6W8pRDMJQ
Nhanh chóng đến hiện tại, ngành công nghiệp phim và truyền hình ngày càng khám phá các chỉnh sửa hậu kỳ dựa trên AI. Xu hướng này đã gây ra cả sự quan tâm lẫn chỉ trích, khi AI cho phép đạt được mức độ hoàn hảo trước đây không thể đạt được. Để đáp ứng, cộng đồng nghiên cứu đã phát triển nhiều dự án tập trung vào các chỉnh sửa cục bộ của các bản ghi hình khuôn mặt, như Diffusion Video Autoencoders, Stitch it in Time, ChatFace, MagicFace và DISCO.
Chỉnh sửa biểu cảm với dự án MagicFace tháng 1 năm 2025. Nguồn: https://arxiv.org/pdf/2501.02260
Khuôn mặt mới, nếp nhăn mới
Tuy nhiên, công nghệ để tạo ra các chỉnh sửa tinh tế này đang tiến bộ nhanh hơn nhiều so với khả năng phát hiện chúng của chúng ta. Hầu hết các phương pháp phát hiện deepfake đã lỗi thời, tập trung vào các kỹ thuật và bộ dữ liệu cũ hơn. Điều đó kéo dài cho đến khi có một bước đột phá gần đây từ các nhà nghiên cứu ở Ấn Độ.
Phát hiện các chỉnh sửa cục bộ tinh tế trong Deepfake: Một video thật được thay đổi để tạo ra các video giả với các thay đổi tinh tế như nâng lông mày, thay đổi đặc điểm giới tính, và chuyển đổi biểu cảm sang sự ghê tởm (được minh họa ở đây bằng một khung hình duy nhất). Nguồn: https://arxiv.org/pdf/2503.22121
Nghiên cứu mới này nhắm đến việc phát hiện các thao túng khuôn mặt cục bộ tinh tế, một loại giả mạo thường bị bỏ qua. Thay vì tìm kiếm các mâu thuẫn rộng lớn hoặc sự không khớp về danh tính, phương pháp này tập trung vào các chi tiết nhỏ như sự thay đổi biểu cảm nhẹ hoặc các chỉnh sửa nhỏ cho các đặc điểm khuôn mặt cụ thể. Nó tận dụng Hệ thống Mã hóa Hành động Khuôn mặt (FACS), phân tích biểu cảm khuôn mặt thành 64 khu vực có thể thay đổi.
Một số thành phần của 64 phần biểu cảm trong FACS. Nguồn: https://www.cs.cmu.edu/~face/facs.htm
Các nhà nghiên cứu đã thử nghiệm phương pháp của họ với nhiều phương pháp chỉnh sửa gần đây và nhận thấy nó liên tục vượt trội so với các giải pháp hiện có, ngay cả với các bộ dữ liệu cũ hơn và các vector tấn công mới hơn.
‘Bằng cách sử dụng các đặc trưng dựa trên AU để hướng dẫn các biểu diễn video được học qua Masked Autoencoders (MAE), phương pháp của chúng tôi nắm bắt hiệu quả các thay đổi cục bộ quan trọng để phát hiện các chỉnh sửa khuôn mặt tinh tế.
‘Phương pháp này cho phép chúng tôi xây dựng một biểu diễn ẩn thống nhất mã hóa cả các chỉnh sửa cục bộ và các thay đổi rộng hơn trong các video tập trung vào khuôn mặt, cung cấp một giải pháp toàn diện và thích nghi cho việc phát hiện deepfake.’
Bài báo, có tựa đề Phát hiện các thao túng Deepfake cục bộ bằng các biểu diễn video được dẫn dắt bởi đơn vị hành động, được viết bởi các nhà nghiên cứu tại Viện Công nghệ Ấn Độ tại Madras.
Phương pháp
Phương pháp bắt đầu bằng cách phát hiện khuôn mặt trong video và lấy mẫu các khung hình cách đều nhau tập trung vào các khuôn mặt này. Các khung hình này sau đó được chia thành các mảnh 3D nhỏ, nắm bắt các chi tiết không gian và thời gian cục bộ.
Sơ đồ cho phương pháp mới. Video đầu vào được xử lý với phát hiện khuôn mặt để trích xuất các khung hình cách đều nhau, tập trung vào khuôn mặt, sau đó được chia thành các mảnh ‘ống’ và truyền qua một bộ mã hóa kết hợp các biểu diễn ẩn từ hai nhiệm vụ tiền xử lý được huấn luyện trước. Vector kết quả sau đó được sử dụng bởi một bộ phân loại để xác định video là thật hay giả.
Mỗi mảnh chứa một cửa sổ pixel nhỏ từ một vài khung hình liên tiếp, cho phép mô hình học các chuyển động ngắn hạn và thay đổi biểu cảm. Các mảnh này được nhúng và mã hóa vị trí trước khi được đưa vào một bộ mã hóa được thiết kế để phân biệt video thật và giả.
Thách thức trong việc phát hiện các thao túng tinh tế được giải quyết bằng cách sử dụng một bộ mã hóa kết hợp hai loại biểu diễn đã học thông qua cơ chế chú ý chéo, nhằm tạo ra một không gian đặc trưng nhạy hơn và tổng quát hơn.
Nhiệm vụ tiền xử lý
Biểu diễn đầu tiên đến từ một bộ mã hóa được huấn luyện với nhiệm vụ mã hóa tự động có che chắn. Bằng cách che giấu phần lớn các mảnh 3D của video, bộ mã hóa học cách tái tạo các phần bị thiếu, nắm bắt các mẫu không gian-thời gian quan trọng như chuyển động khuôn mặt.
Huấn luyện nhiệm vụ tiền xử lý liên quan đến việc che giấu một phần đầu vào video và sử dụng thiết lập mã hóa-giải mã để tái tạo các khung hình gốc hoặc bản đồ đơn vị hành động cho mỗi khung hình, tùy thuộc vào nhiệm vụ.
Tuy nhiên, điều này chưa đủ để phát hiện các chỉnh sửa chi tiết. Các nhà nghiên cứu đã giới thiệu một bộ mã hóa thứ hai được huấn luyện để phát hiện các đơn vị hành động khuôn mặt (AUs), khuyến khích nó tập trung vào hoạt động cơ cục bộ nơi các chỉnh sửa deepfake tinh tế thường xảy ra.
Các ví dụ khác về Đơn vị Hành động Khuôn mặt (FAUs, hoặc AUs). Nguồn: https://www.eiagroup.com/the-facial-action-coding-system/
Sau khi huấn luyện trước, đầu ra của cả hai bộ mã hóa được kết hợp bằng chú ý chéo, với các đặc trưng dựa trên AU dẫn dắt sự chú ý lên các đặc trưng không gian-thời gian. Điều này dẫn đến một biểu diễn ẩn kết hợp nắm bắt cả bối cảnh chuyển động rộng hơn và chi tiết biểu cảm cục bộ, được sử dụng cho nhiệm vụ phân loại cuối cùng.
Dữ liệu và Thử nghiệm
Thực hiện
Hệ thống được triển khai bằng khung công tác phát hiện khuôn mặt dựa trên PyTorch FaceXZoo, trích xuất 16 khung hình tập trung vào khuôn mặt từ mỗi đoạn video. Các nhiệm vụ tiền xử lý được huấn luyện trên bộ dữ liệu CelebV-HQ, bao gồm 35,000 video khuôn mặt chất lượng cao.
Từ bài báo nguồn, các ví dụ từ bộ dữ liệu CelebV-HQ được sử dụng trong dự án mới. Nguồn: https://arxiv.org/pdf/2207.12393
Một nửa dữ liệu được che giấu để ngăn chặn quá khớp. Đối với nhiệm vụ tái tạo khung hình bị che giấu, mô hình được huấn luyện để dự đoán các vùng bị thiếu bằng cách sử dụng mất mát L1. Đối với nhiệm vụ thứ hai, nó được huấn luyện để tạo ra các bản đồ cho 16 đơn vị hành động khuôn mặt, được giám sát bởi mất mát L1.
Sau khi huấn luyện trước, các bộ mã hóa được kết hợp và tinh chỉnh để phát hiện deepfake bằng bộ dữ liệu FaceForensics++, bao gồm cả video thật và video đã bị thao túng.
Bộ dữ liệu FaceForensics++ đã là nền tảng của việc phát hiện deepfake từ năm 2017, mặc dù hiện nay nó đã khá lỗi thời liên quan đến các kỹ thuật tổng hợp khuôn mặt mới nhất. Nguồn: https://www.youtube.com/watch?v=x2g48Q2I2ZQ
Để giải quyết vấn đề mất cân bằng lớp, các tác giả đã sử dụng Mất mát Tiêu điểm, nhấn mạnh vào các ví dụ khó hơn trong quá trình huấn luyện. Tất cả quá trình huấn luyện được thực hiện trên một GPU RTX 4090 duy nhất với 24Gb VRAM, sử dụng các điểm kiểm tra được huấn luyện trước từ VideoMAE.
Thử nghiệm
Phương pháp này được đánh giá so với nhiều kỹ thuật phát hiện deepfake khác nhau, tập trung vào các deepfake được chỉnh sửa cục bộ. Các thử nghiệm bao gồm một loạt các phương pháp chỉnh sửa và các bộ dữ liệu deepfake cũ hơn, sử dụng các chỉ số như Diện tích Dưới Đường Cong (AUC), Độ chính xác Trung bình và Điểm F1 Trung bình.
Từ bài báo: so sánh trên các deepfake cục bộ gần đây cho thấy phương pháp được đề xuất vượt trội so với tất cả các phương pháp khác, với mức tăng từ 15 đến 20 phần trăm về cả AUC và độ chính xác trung bình so với phương pháp tốt thứ hai.
Các tác giả đã cung cấp các so sánh trực quan về các video bị thao túng cục bộ, cho thấy độ nhạy vượt trội của phương pháp đối với các chỉnh sửa tinh tế.
Một video thật được thay đổi bằng ba thao túng cục bộ khác nhau để tạo ra các video giả vẫn giống với bản gốc về mặt hình ảnh. Các khung hình đại diện được hiển thị ở đây cùng với điểm phát hiện giả trung bình cho mỗi phương pháp. Trong khi các bộ phát hiện hiện tại gặp khó khăn với các chỉnh sửa tinh tế này, mô hình được đề xuất liên tục gán xác suất giả cao, cho thấy độ nhạy cao hơn đối với các thay đổi cục bộ.
Các nhà nghiên cứu lưu ý rằng các phương pháp phát hiện tiên tiến hiện tại gặp khó khăn với các kỹ thuật tạo deepfake mới nhất, trong khi phương pháp của họ cho thấy khả năng tổng quát hóa mạnh mẽ, đạt được điểm AUC và độ chính xác trung bình cao.
Hiệu suất trên các bộ dữ liệu deepfake truyền thống cho thấy phương pháp được đề xuất vẫn cạnh tranh với các phương pháp hàng đầu, thể hiện khả năng tổng quát hóa mạnh mẽ trên nhiều loại thao túng.
Các tác giả cũng đã thử nghiệm độ tin cậy của mô hình trong các điều kiện thực tế, nhận thấy nó bền vững với các biến dạng video phổ biến như điều chỉnh độ bão hòa, làm mờ Gaussian và pixelation.
Hình minh họa về cách độ chính xác phát hiện thay đổi dưới các biến dạng video khác nhau. Phương pháp mới vẫn bền vững trong hầu hết các trường hợp, chỉ giảm nhẹ về AUC. Sự sụt giảm đáng kể nhất xảy ra khi nhiễu Gaussian được giới thiệu.
Kết luận
Mặc dù công chúng thường nghĩ về deepfake như các hoán đổi danh tính, thực tế của thao túng AI phức tạp hơn và có khả năng nguy hiểm hơn. Loại chỉnh sửa cục bộ được thảo luận trong nghiên cứu mới này có thể không thu hút sự chú ý của công chúng cho đến khi xảy ra một sự cố nổi bật khác. Tuy nhiên, như diễn viên Nic Cage đã chỉ ra, tiềm năng của các chỉnh sửa hậu kỳ để thay đổi diễn xuất là một mối quan ngại mà tất cả chúng ta nên nhận thức được. Chúng ta tự nhiên nhạy cảm với ngay cả những thay đổi nhỏ nhất trong biểu cảm khuôn mặt, và bối cảnh có thể làm thay đổi đáng kể tác động của chúng.
Được xuất bản lần đầu vào thứ Tư, ngày 2 tháng 4 năm 2025









 Civitai tăng cường các quy định của Deepfake trong bối cảnh áp lực từ Thẻ Mastercard và Visa
Civitai, một trong những kho lưu trữ mô hình AI nổi bật nhất trên Internet, gần đây đã thực hiện những thay đổi đáng kể đối với các chính sách của mình về nội dung NSFW, đặc biệt liên quan đến người nổi tiếng Loras. Những thay đổi này đã được thúc đẩy bởi áp lực từ MasterCard và Visa của người hỗ trợ thanh toán. Người nổi tiếng Loras, đó là bạn
Civitai tăng cường các quy định của Deepfake trong bối cảnh áp lực từ Thẻ Mastercard và Visa
Civitai, một trong những kho lưu trữ mô hình AI nổi bật nhất trên Internet, gần đây đã thực hiện những thay đổi đáng kể đối với các chính sách của mình về nội dung NSFW, đặc biệt liên quan đến người nổi tiếng Loras. Những thay đổi này đã được thúc đẩy bởi áp lực từ MasterCard và Visa của người hỗ trợ thanh toán. Người nổi tiếng Loras, đó là bạn
 Google sử dụng AI để đình chỉ hơn 39 triệu tài khoản AD vì bị nghi ngờ gian lận
Google đã công bố vào thứ Tư rằng họ đã có một bước quan trọng trong việc chống gian lận quảng cáo bằng cách đình chỉ một tài khoản nhà quảng cáo đáng kinh ngạc 39,2 triệu trên nền tảng của mình vào năm 2024.
Google sử dụng AI để đình chỉ hơn 39 triệu tài khoản AD vì bị nghi ngờ gian lận
Google đã công bố vào thứ Tư rằng họ đã có một bước quan trọng trong việc chống gian lận quảng cáo bằng cách đình chỉ một tài khoản nhà quảng cáo đáng kinh ngạc 39,2 triệu trên nền tảng của mình vào năm 2024.
 Tạo video AI chuyển sang kiểm soát hoàn toàn
Các mô hình nền tảng video như Hunyuan và WAN 2.1 đã có những bước tiến đáng kể, nhưng chúng thường bị thiếu hụt khi nói đến điều khiển chi tiết cần thiết trong sản xuất phim và TV, đặc biệt là trong lĩnh vực hiệu ứng hình ảnh (VFX). Trong VFX Studios chuyên nghiệp, những mô hình này, cùng với hình ảnh trước đó
19:25:16 GMT+07:00 Ngày 29 tháng 7 năm 2025
Tạo video AI chuyển sang kiểm soát hoàn toàn
Các mô hình nền tảng video như Hunyuan và WAN 2.1 đã có những bước tiến đáng kể, nhưng chúng thường bị thiếu hụt khi nói đến điều khiển chi tiết cần thiết trong sản xuất phim và TV, đặc biệt là trong lĩnh vực hiệu ứng hình ảnh (VFX). Trong VFX Studios chuyên nghiệp, những mô hình này, cùng với hình ảnh trước đó
19:25:16 GMT+07:00 Ngày 29 tháng 7 năm 2025
That Pelosi video from 2019 is wild! It’s scary how a few tweaks can make someone look totally out of it. AI’s power to mess with reality is no joke—makes you wonder what’s real anymore. 🫣
0
09:24:54 GMT+07:00 Ngày 24 tháng 4 năm 2025
Este herramienta de IA me mostró lo fácil que es manipular videos. El incidente de Nancy Pelosi fue un recordatorio impactante. Es aterrador pensar en cuántas noticias falsas pueden existir. Ahora estoy más atento a lo que creo en línea. ¡Cuidado, amigos! 👀
0
03:42:51 GMT+07:00 Ngày 21 tháng 4 năm 2025
このAIツールは、ビデオを操作するのがどれほど簡単かを教えてくれました。ナンシー・ペロシの事件は衝撃的でした。偽ニュースがどれだけあるかと思うと恐ろしいです。オンラインで何を信じるかについて、今はもっと注意しています。みなさんも気をつけてくださいね!👀
0
17:25:50 GMT+07:00 Ngày 19 tháng 4 năm 2025
Dieses KI-Tool hat mir gezeigt, wie einfach es ist, Videos zu manipulieren! Der Vorfall mit Nancy Pelosi war ein Weckruf. Es ist beängstigend, wie viele gefälschte Nachrichten es geben könnte. Ich bin jetzt vorsichtiger mit dem, was ich online glaube. Seid wachsam, Leute! 👀
0
17:17:36 GMT+07:00 Ngày 19 tháng 4 năm 2025
This AI tool really opened my eyes to how easy it is to manipulate videos! The Nancy Pelosi incident was a wake-up call. It's scary to think how much fake news could be out there. Definitely makes me more cautious about what I believe online. Keep an eye out, folks! 👀
0
17:05:37 GMT+07:00 Ngày 15 tháng 4 năm 2025
이 앱은 눈을 뜨게 합니다! AI의 미묘한 변화가 비디오의 진위성을 어떻게 망칠 수 있는지를 보여줍니다. 낸시 펠로시의 예는 경고였어요. 하지만 설명이 때때로 나에게는 너무 기술적이어서요. 더 간단하게 설명해주면 좋겠어요! 그래도 AI의 영향을 이해하는 데는 좋은 도구입니다. 👀
0













