
















 Maison
MaisonLa génération de vidéos AI se déplace vers un contrôle complet
Les modèles de fondation vidéo comme Hunyuan et Wan 2.1 ont réalisé des progrès significatifs, mais ils sont souvent insuffisants lorsqu'il s'agit du contrôle détaillé requis dans la production de films et de séries télévisées, en particulier dans le domaine des effets visuels (VFX). Dans les studios professionnels de VFX, ces modèles, ainsi que les modèles antérieurs basés sur l'image comme Stable Diffusion, Kandinsky et Flux, sont utilisés en conjonction avec une suite d'outils conçus pour affiner leur sortie afin de répondre à des exigences créatives spécifiques. Lorsqu'un réalisateur demande une modification, en disant quelque chose comme : « Ça a l'air super, mais peut-on le rendre un peu plus [n] ? », il ne suffit pas de simplement déclarer que le modèle manque de précision pour effectuer de tels ajustements.
Au lieu de cela, une équipe d'IA VFX utilisera une combinaison de CGI traditionnel et de techniques de composition, ainsi que des flux de travail développés sur mesure, pour repousser les limites de la synthèse vidéo. Cette approche est comparable à l'utilisation d'un navigateur web par défaut comme Chrome ; il est fonctionnel dès son installation, mais pour le personnaliser vraiment selon vos besoins, vous devrez installer quelques plugins.
Les maniaques du contrôle
Dans le domaine de la synthèse d'images basée sur la diffusion, l'un des systèmes tiers les plus cruciaux est ControlNet. Cette technique introduit un contrôle structuré aux modèles génératifs, permettant aux utilisateurs de guider la génération d'images ou de vidéos en utilisant des entrées supplémentaires telles que des cartes de contours, des cartes de profondeur ou des informations de pose.
 *Les différentes méthodes de ControlNet permettent la conversion profondeur>image (rangée supérieure), segmentation sémantique>image (en bas à gauche) et la génération d'images guidée par la pose d'humains et d'animaux (en bas à gauche).*
*Les différentes méthodes de ControlNet permettent la conversion profondeur>image (rangée supérieure), segmentation sémantique>image (en bas à gauche) et la génération d'images guidée par la pose d'humains et d'animaux (en bas à gauche).*
ControlNet ne repose pas uniquement sur des invites textuelles ; il utilise des branches de réseaux neuronaux séparées, ou adaptateurs, pour traiter ces signaux de conditionnement tout en maintenant les capacités génératives du modèle de base. Cela permet des sorties hautement personnalisées qui correspondent étroitement aux spécifications des utilisateurs, ce qui est inestimable pour les applications nécessitant un contrôle précis sur la composition, la structure ou le mouvement.
 *Avec une pose guide, une variété de types de sorties précises peut être obtenue via ControlNet.* Source : https://arxiv.org/pdf/2302.05543
*Avec une pose guide, une variété de types de sorties précises peut être obtenue via ControlNet.* Source : https://arxiv.org/pdf/2302.05543
Cependant, ces systèmes basés sur des adaptateurs, qui opèrent de manière externe sur un ensemble de processus neuronaux internes, présentent plusieurs inconvénients. Les adaptateurs sont entraînés indépendamment, ce qui peut entraîner des conflits de branches lorsque plusieurs adaptateurs sont combinés, souvent en résultant des générations de moindre qualité. Ils introduisent également une redondance de paramètres, nécessitant des ressources computationnelles et une mémoire supplémentaires pour chaque adaptateur, rendant l'évolutivité inefficace. De plus, malgré leur flexibilité, les adaptateurs produisent souvent des résultats sous-optimaux par rapport aux modèles entièrement affinés pour la génération multi-conditionnelle. Ces problèmes peuvent rendre les méthodes basées sur les adaptateurs moins efficaces pour les tâches nécessitant l'intégration transparente de multiples signaux de contrôle.
Idéalement, les capacités de ControlNet seraient intégrées de manière native dans le modèle de façon modulaire, permettant des innovations futures comme la génération simultanée de vidéo/audio ou des capacités de synchronisation labiale native. Actuellement, chaque fonctionnalité supplémentaire devient soit une tâche de post-production, soit une procédure non native qui doit naviguer dans les poids sensibles du modèle de fondation.
FullDiT
Voici FullDiT, une nouvelle approche venue de Chine qui intègre des fonctionnalités de type ControlNet directement dans un modèle vidéo génératif pendant l'entraînement, plutôt que de les traiter comme une réflexion après coup.
 *D'après le nouvel article : l'approche FullDiT peut intégrer l'imposition d'identité, la profondeur et le mouvement de la caméra dans une génération native, et peut invoquer n'importe quelle combinaison de ces éléments à la fois.* Source : https://arxiv.org/pdf/2503.19907
*D'après le nouvel article : l'approche FullDiT peut intégrer l'imposition d'identité, la profondeur et le mouvement de la caméra dans une génération native, et peut invoquer n'importe quelle combinaison de ces éléments à la fois.* Source : https://arxiv.org/pdf/2503.19907
FullDiT, tel que décrit dans l'article intitulé **FullDiT : Modèle de fondation vidéo multi-tâches avec attention complète**, intègre des conditions multi-tâches telles que le transfert d'identité, la cartographie de profondeur et le mouvement de la caméra dans le cœur d'un modèle vidéo génératif entraîné. Les auteurs ont développé un modèle prototype et des clips vidéo associés disponibles sur un site de projet.
**Cliquez pour jouer. Exemples d'imposition utilisateur de style ControlNet avec uniquement un modèle de fondation entraîné nativement.** Source : https://fulldit.github.io/
Les auteurs présentent FullDiT comme une preuve de concept pour les modèles texte-à-vidéo (T2V) et image-à-vidéo (I2V) natifs qui offrent aux utilisateurs plus de contrôle qu'une simple invite d'image ou de texte. Puisqu'aucun modèle similaire n'existe, les chercheurs ont créé un nouveau benchmark appelé **FullBench** pour évaluer les vidéos multi-tâches, revendiquant des performances de pointe dans leurs tests conçus. Cependant, l'objectivité de FullBench, conçu par les auteurs eux-mêmes, reste non testée, et son ensemble de données de 1 400 cas peut être trop limité pour des conclusions plus larges.
L'aspect le plus intrigant de l'architecture de FullDiT est son potentiel à incorporer de nouveaux types de contrôle. Les auteurs notent :
**‘Dans ce travail, nous explorons uniquement les conditions de contrôle de la caméra, des identités et des informations de profondeur. Nous n'avons pas approfondi d'autres conditions et modalités telles que l'audio, la parole, le nuage de points, les boîtes englobantes d'objets, le flux optique, etc. Bien que la conception de FullDiT puisse intégrer de manière transparente d'autres modalités avec une modification minimale de l'architecture, la question de savoir comment adapter rapidement et de manière économique les modèles existants à de nouvelles conditions et modalités reste une question importante qui mérite une exploration plus approfondie.'**
Bien que FullDiT représente une avancée dans la génération vidéo multi-tâches, il s'appuie sur des architectures existantes plutôt que d'introduire un nouveau paradigme. Néanmoins, il se distingue comme le seul modèle de fondation vidéo avec des fonctionnalités de style ControlNet intégrées nativement, et son architecture est conçue pour accueillir les innovations futures.
**Cliquez pour jouer. Exemples de mouvements de caméra contrôlés par l'utilisateur, depuis le site du projet.**
L'article, rédigé par neuf chercheurs de Kuaishou Technology et de l'Université chinoise de Hong Kong, est intitulé **FullDiT : Modèle de fondation vidéo multi-tâches avec attention complète**. La page du projet et les données du nouveau benchmark sont disponibles sur Hugging Face.
Méthode
Le mécanisme d'attention unifié de FullDiT est conçu pour améliorer l'apprentissage de représentation multi-modale en capturant les relations spatiales et temporelles entre les conditions.
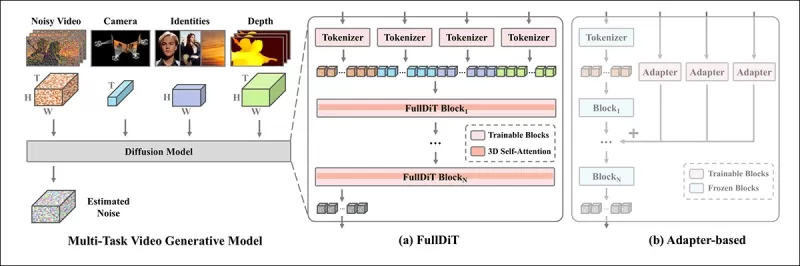 *D'après le nouvel article, FullDiT intègre de multiples conditions d'entrée grâce à une attention complète, les convertissant en une séquence unifiée. En revanche, les modèles basés sur des adaptateurs (à gauche ci-dessus) utilisent des modules séparés pour chaque entrée, entraînant une redondance, des conflits et des performances plus faibles.*
*D'après le nouvel article, FullDiT intègre de multiples conditions d'entrée grâce à une attention complète, les convertissant en une séquence unifiée. En revanche, les modèles basés sur des adaptateurs (à gauche ci-dessus) utilisent des modules séparés pour chaque entrée, entraînant une redondance, des conflits et des performances plus faibles.*
Contrairement aux configurations basées sur des adaptateurs qui traitent chaque flux d'entrée séparément, la structure d'attention partagée de FullDiT évite les conflits de branches et réduit la surcharge des paramètres. Les auteurs affirment que l'architecture peut s'adapter à de nouveaux types d'entrée sans refonte majeure et que le schéma du modèle montre des signes de généralisation à des combinaisons de conditions non vues pendant l'entraînement, telles que la liaison du mouvement de la caméra avec l'identité des personnages.
**Cliquez pour jouer. Exemples de génération d'identité depuis le site du projet.**
Dans l'architecture de FullDiT, toutes les entrées de conditionnement — telles que le texte, le mouvement de la caméra, l'identité et la profondeur — sont d'abord converties en un format de jeton unifié. Ces jetons sont ensuite concaténés en une seule longue séquence, traitée à travers une pile de couches de transformateurs utilisant une attention complète. Cette approche suit les travaux antérieurs comme Open-Sora Plan et Movie Gen.
Cette conception permet au modèle d'apprendre conjointement les relations temporelles et spatiales à travers toutes les conditions. Chaque bloc de transformateur opère sur l'ensemble de la séquence, permettant des interactions dynamiques entre les modalités sans dépendre de modules séparés pour chaque entrée. L'architecture est conçue pour être extensible, facilitant l'incorporation de signaux de contrôle supplémentaires à l'avenir sans changements structurels majeurs.
La puissance du trois
FullDiT convertit chaque signal de contrôle en un format de jeton standardisé afin que toutes les conditions puissent être traitées ensemble dans un cadre d'attention unifié. Pour le mouvement de la caméra, le modèle encode une séquence de paramètres extrinsèques — tels que la position et l'orientation — pour chaque image. Ces paramètres sont horodatés et projetés dans des vecteurs d'intégration qui reflètent la nature temporelle du signal.
L'information d'identité est traitée différemment, car elle est intrinsèquement spatiale plutôt que temporelle. Le modèle utilise des cartes d'identité qui indiquent quels personnages sont présents dans quelles parties de chaque image. Ces cartes sont divisées en patches, chaque patch étant projeté dans une intégration qui capture des indices d'identité spatiale, permettant au modèle d'associer des régions spécifiques de l'image à des entités spécifiques.
La profondeur est un signal spatiotemporel, et le modèle le gère en divisant les vidéos de profondeur en patches 3D qui englobent à la fois l'espace et le temps. Ces patches sont ensuite intégrés de manière à préserver leur structure à travers les images.
Une fois intégrés, tous ces jetons de condition (caméra, identité et profondeur) sont concaténés en une seule longue séquence, permettant à FullDiT de les traiter ensemble à l'aide d'une attention complète. Cette représentation partagée permet au modèle d'apprendre les interactions entre les modalités et à travers le temps sans dépendre de flux de traitement isolés.
Données et tests
L'approche d'entraînement de FullDiT s'appuie sur des ensembles de données annotées sélectivement, adaptés à chaque type de conditionnement, plutôt que de nécessiter la présence simultanée de toutes les conditions.
Pour les conditions textuelles, l'initiative suit l'approche de sous-titrage structuré décrite dans le projet MiraData.
 *Pipeline de collecte et d'annotation de vidéos du projet MiraData.* Source : https://arxiv.org/pdf/2407.06358
*Pipeline de collecte et d'annotation de vidéos du projet MiraData.* Source : https://arxiv.org/pdf/2407.06358
Pour le mouvement de la caméra, l'ensemble de données RealEstate10K a été la principale source de données, en raison de ses annotations de vérité terrain de haute qualité des paramètres de caméra. Cependant, les auteurs ont observé que l'entraînement exclusivement sur des ensembles de données de caméras à scènes statiques comme RealEstate10K tendait à réduire les mouvements dynamiques d'objets et d'humains dans les vidéos générées. Pour contrer cela, ils ont effectué un réglage fin supplémentaire en utilisant des ensembles de données internes qui incluaient des mouvements de caméra plus dynamiques.
Les annotations d'identité ont été générées à l'aide du pipeline développé pour le projet ConceptMaster, qui a permis un filtrage et une extraction efficaces des informations d'identité détaillées.
 *Le cadre ConceptMaster est conçu pour résoudre les problèmes de découplage d'identité tout en préservant la fidélité des concepts dans les vidéos personnalisées.* Source : https://arxiv.org/pdf/2501.04698
*Le cadre ConceptMaster est conçu pour résoudre les problèmes de découplage d'identité tout en préservant la fidélité des concepts dans les vidéos personnalisées.* Source : https://arxiv.org/pdf/2501.04698
Les annotations de profondeur ont été obtenues à partir de l'ensemble de données Panda-70M en utilisant Depth Anything.
Optimisation par ordonnancement des données
Les auteurs ont également mis en œuvre un calendrier d'entraînement progressif, introduisant des conditions plus difficiles plus tôt dans l'entraînement pour s'assurer que le modèle acquiert des représentations robustes avant que des tâches plus simples ne soient ajoutées. L'ordre d'entraînement a progressé du texte aux conditions de caméra, puis aux identités, et enfin à la profondeur, les tâches plus faciles étant généralement introduites plus tard et avec moins d'exemples.
Les auteurs soulignent la valeur de l'ordonnancement de la charge de travail de cette manière :
**‘Au cours de la phase de pré-entraînement, nous avons noté que les tâches plus difficiles exigent un temps d'entraînement prolongé et doivent être introduites plus tôt dans le processus d'apprentissage. Ces tâches difficiles impliquent des distributions de données complexes qui diffèrent considérablement de la vidéo de sortie, exigeant que le modèle ait une capacité suffisante pour les capturer et les représenter avec précision.**
**‘À l'inverse, introduire des tâches plus faciles trop tôt peut amener le modèle à privilégier leur apprentissage en premier, car elles fournissent un retour d'optimisation plus immédiat, ce qui entrave la convergence des tâches plus difficiles.'**
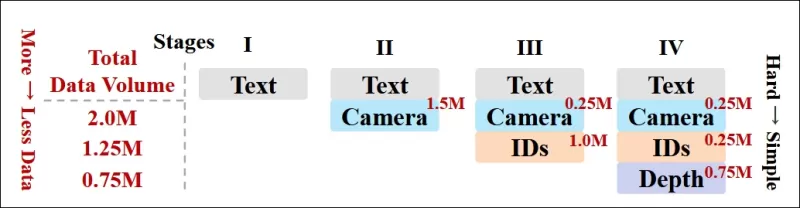 *Une illustration de l'ordre d'entraînement des données adopté par les chercheurs, avec le rouge indiquant un plus grand volume de données.*
*Une illustration de l'ordre d'entraînement des données adopté par les chercheurs, avec le rouge indiquant un plus grand volume de données.*
Après un pré-entraînement initial, une phase finale de réglage fin a encore affiné le modèle pour améliorer la qualité visuelle et la dynamique du mouvement. Par la suite, l'entraînement a suivi celui d'un cadre de diffusion standard : du bruit ajouté aux latents vidéo, et le modèle apprenant à prédire et à supprimer ce bruit, en utilisant les jetons de condition intégrés comme guide.
Pour évaluer efficacement FullDiT et fournir une comparaison équitable avec les méthodes existantes, et en l'absence d'un autre benchmark pertinent, les auteurs ont introduit **FullBench**, une suite de benchmarks organisée composée de 1 400 cas de test distincts.
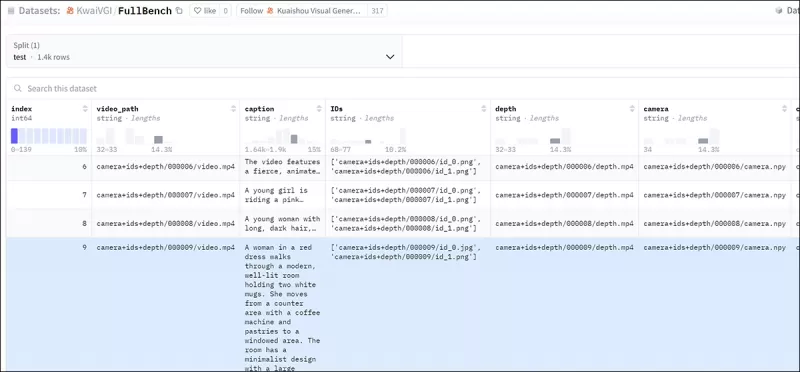 *Une instance d'explorateur de données pour le nouveau benchmark FullBench.* Source : https://huggingface.co/datasets/KwaiVGI/FullBench
*Une instance d'explorateur de données pour le nouveau benchmark FullBench.* Source : https://huggingface.co/datasets/KwaiVGI/FullBench
Chaque point de données fournissait des annotations de vérité terrain pour divers signaux de conditionnement, y compris le mouvement de la caméra, l'identité et la profondeur.
Métriques
Les auteurs ont évalué FullDiT en utilisant dix métriques couvrant cinq aspects principaux de la performance : l'alignement du texte, le contrôle de la caméra, la similarité d'identité, la précision de la profondeur et la qualité générale de la vidéo.
L'alignement du texte a été mesuré à l'aide de la similarité CLIP, tandis que le contrôle de la caméra a été évalué à travers l'erreur de rotation (RotErr), l'erreur de translation (TransErr) et la cohérence du mouvement de la caméra (CamMC), suivant l'approche de CamI2V (dans le projet CameraCtrl).
La similarité d'identité a été évaluée à l'aide de DINO-I et CLIP-I, et la précision du contrôle de la profondeur a été quantifiée à l'aide de l'erreur absolue moyenne (MAE).
La qualité de la vidéo a été jugée avec trois métriques de MiraData : la similarité CLIP au niveau des images pour la fluidité ; la distance de mouvement basée sur le flux optique pour la dynamique ; et les scores esthétiques LAION pour l'attrait visuel.
Entraînement
Les auteurs ont entraîné FullDiT en utilisant un modèle de diffusion texte-à-vidéo interne (non divulgué) contenant environ un milliard de paramètres. Ils ont intentionnellement choisi une taille de paramètres modeste pour maintenir l'équité dans les comparaisons avec les méthodes antérieures et assurer la reproductibilité.
Puisque les vidéos d'entraînement variaient en longueur et en résolution, les auteurs ont standardisé chaque lot en redimensionnant et en rembourrant les vidéos à une résolution commune, en échantillonnant 77 images par séquence, et en utilisant une attention appliquée et des masques de perte pour optimiser l'efficacité de l'entraînement.
L'optimiseur Adam a été utilisé à un taux d'apprentissage de 1×10−5 sur un cluster de 64 GPU NVIDIA H800, pour un total combiné de 5 120 Go de VRAM (considérez que dans les communautés de synthèse enthousiastes, 24 Go sur un RTX 3090 est encore considéré comme une norme luxueuse).
Le modèle a été entraîné pendant environ 32 000 étapes, incorporant jusqu'à trois identités par vidéo, ainsi que 20 images de conditions de caméra et 21 images de conditions de profondeur, toutes deux échantillonnées uniformément à partir des 77 images totales.
Pour l'inférence, le modèle a généré des vidéos à une résolution de 384×672 pixels (environ cinq secondes à 15 images par seconde) avec 50 étapes d'inférence de diffusion et une échelle de guidage sans classificateur de cinq.
Méthodes antérieures
Pour l'évaluation caméra-à-vidéo, les auteurs ont comparé FullDiT à MotionCtrl, CameraCtrl et CamI2V, tous les modèles étant entraînés à l'aide de l'ensemble de données RealEstate10k pour assurer la cohérence et l'équité.
Dans la génération conditionnée par l'identité, comme aucun modèle multi-identité open-source comparable n'était disponible, le modèle a été comparé au modèle ConceptMaster à 1 milliard de paramètres, en utilisant les mêmes données d'entraînement et la même architecture.
Pour les tâches profondeur-à-vidéo, des comparaisons ont été faites avec Ctrl-Adapter et ControlVideo.
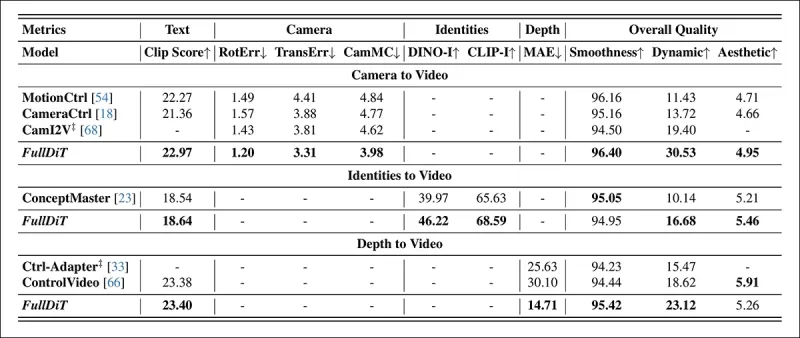 *Résultats quantitatifs pour la génération vidéo à tâche unique. FullDiT a été comparé à MotionCtrl, CameraCtrl et CamI2V pour la génération caméra-à-vidéo ; ConceptMaster (version à 1 milliard de paramètres) pour l'identité-à-vidéo ; et Ctrl-Adapter et ControlVideo pour la profondeur-à-vidéo. Tous les modèles ont été évalués en utilisant leurs paramètres par défaut. Pour la cohérence, 16 images ont été uniformément échantillonnées pour chaque méthode, correspondant à la longueur de sortie des modèles antérieurs.*
*Résultats quantitatifs pour la génération vidéo à tâche unique. FullDiT a été comparé à MotionCtrl, CameraCtrl et CamI2V pour la génération caméra-à-vidéo ; ConceptMaster (version à 1 milliard de paramètres) pour l'identité-à-vidéo ; et Ctrl-Adapter et ControlVideo pour la profondeur-à-vidéo. Tous les modèles ont été évalués en utilisant leurs paramètres par défaut. Pour la cohérence, 16 images ont été uniformément échantillonnées pour chaque méthode, correspondant à la longueur de sortie des modèles antérieurs.*
Les résultats indiquent que FullDiT, bien qu'il gère simultanément plusieurs signaux de conditionnement, a atteint des performances de pointe dans les métriques liées au texte, au mouvement de la caméra, à l'identité et aux contrôles de profondeur.
Dans les métriques de qualité globale, le système a généralement surpassé les autres méthodes, bien que sa fluidité soit légèrement inférieure à celle de ConceptMaster. Ici, les auteurs commentent :
**‘La fluidité de FullDiT est légèrement inférieure à celle de ConceptMaster car le calcul de la fluidité est basé sur la similarité CLIP entre les images adjacentes. Comme FullDiT présente une dynamique nettement plus importante par rapport à ConceptMaster, la métrique de fluidité est affectée par les grandes variations entre les images adjacentes.**
**‘Pour le score esthétique, comme le modèle d'évaluation privilégie les images de style peinture et que ControlVideo génère généralement des vidéos dans ce style, il obtient un score élevé en esthétique.'**
En ce qui concerne la comparaison qualitative, il pourrait être préférable de se référer aux vidéos d'exemple sur le site du projet FullDiT, car les exemples PDF sont inévitablement statiques (et aussi trop volumineux pour être entièrement reproduits ici).
 *La première section des résultats qualitatifs reproduits dans le PDF. Veuillez vous référer à l'article source pour les exemples supplémentaires, qui sont trop nombreux pour être reproduits ici.*
*La première section des résultats qualitatifs reproduits dans le PDF. Veuillez vous référer à l'article source pour les exemples supplémentaires, qui sont trop nombreux pour être reproduits ici.*
Les auteurs commentent :
**‘FullDiT démontre une préservation supérieure de l'identité et génère des vidéos avec une meilleure dynamique et qualité visuelle par rapport à [ConceptMaster]. Puisque ConceptMaster et FullDiT sont entraînés sur la même base, cela met en évidence l'efficacité de l'injection de conditions avec une attention complète.**
**‘…Les [autres] résultats démontrent la contrôlabilité et la qualité de génération supérieures de FullDiT par rapport aux méthodes existantes de profondeur-à-vidéo et caméra-à-vidéo.'**
 *Une section des exemples du PDF des sorties de FullDiT avec plusieurs signaux. Veuillez vous référer à l'article source et au site du projet pour des exemples supplémentaires.*
*Une section des exemples du PDF des sorties de FullDiT avec plusieurs signaux. Veuillez vous référer à l'article source et au site du projet pour des exemples supplémentaires.*
Conclusion
FullDiT représente une étape excitante vers un modèle de fondation vidéo plus complet, mais la question demeure de savoir si la demande pour des fonctionnalités de style ControlNet justifie leur mise en œuvre à grande échelle, en particulier pour les projets open-source. Ces projets auraient du mal à obtenir la puissance de traitement GPU massive requise sans soutien commercial.
Le principal défi est que l'utilisation de systèmes comme Depth et Pose nécessite généralement une familiarité non négligeable avec des interfaces utilisateur complexes comme ComfyUI. Par conséquent, un modèle open-source fonctionnel de ce type est le plus susceptible d'être développé par de petites entreprises de VFX qui manquent de ressources ou de motivation pour organiser et entraîner un tel modèle en privé.
D'un autre côté, les systèmes d'IA basés sur des API de type "location d'IA" peuvent être fortement motivés pour développer des méthodes interprétatives plus simples et conviviales pour les modèles avec des systèmes de contrôle auxiliaires directement entraînés.
**Cliquez pour jouer. Contrôles de profondeur + texte imposés sur une génération vidéo utilisant FullDiT.**
*Les auteurs ne spécifient aucun modèle de base connu (c.-à-d. SDXL, etc.)*
**Première publication jeudi 27 mars 2025**
Article connexe
 YouTube teste une fonctionnalité de recherche basée sur l'IA proposant des réponses guidées
De nombreux utilisateurs se tournent vers YouTube lorsqu'ils recherchent des recettes ou des itinéraires de voyage, à la recherche de vidéos pertinentes. Aujourd'hui, la plateforme lance un outil de r
Exclusivité : Luma AI lance des agents créatifs alimentés par des modèles d'« intelligence unifiée »
Jeudi, la start-up spécialisée dans la génération de vidéos par IA Luma a présenté Luma Agents, un système conçu pour gérer l'ensemble des workflows créatifs, qu'il s'agisse de texte, d
La nouvelle mise à jour de Sora propose des vidéos sur l'intelligence artificielle des animaux de compagnie, des outils sociaux et une nouvelle application Android.
OpenAI présente en avant-première une vague de nouvelles fonctionnalités pour Sora, son application de création vidéo par l'IA, qui s'est rapidement hissée au sommet de l'App Store après son lancement
Recommandations de sujets spéciaux liés
Entreprise
YouTube teste une fonctionnalité de recherche basée sur l'IA proposant des réponses guidées
De nombreux utilisateurs se tournent vers YouTube lorsqu'ils recherchent des recettes ou des itinéraires de voyage, à la recherche de vidéos pertinentes. Aujourd'hui, la plateforme lance un outil de r
Exclusivité : Luma AI lance des agents créatifs alimentés par des modèles d'« intelligence unifiée »
Jeudi, la start-up spécialisée dans la génération de vidéos par IA Luma a présenté Luma Agents, un système conçu pour gérer l'ensemble des workflows créatifs, qu'il s'agisse de texte, d
La nouvelle mise à jour de Sora propose des vidéos sur l'intelligence artificielle des animaux de compagnie, des outils sociaux et une nouvelle application Android.
OpenAI présente en avant-première une vague de nouvelles fonctionnalités pour Sora, son application de création vidéo par l'IA, qui s'est rapidement hissée au sommet de l'App Store après son lancement
Recommandations de sujets spéciaux liés
Entreprise
 Les meilleurs outils de suivi des dépenses basés sur l'IA : numérisez vos reçus et classez automatiquement les dépenses de l'entreprise
Les meilleurs outils de suivi des dépenses basés sur l'IA : numérisez vos reçus et classez automatiquement les dépenses de l'entreprise
Les meilleurs outils de gestion des dépenses basés sur l'IA en 2026 : les outils les mieux notés pour numériser vos reçus et classer automatiquement les dépenses de votre entreprise. Découvrez des solutions puissantes et révolutionnaires pour une gestion des dépenses sans effort, un suivi financier précis et une conformité simplifiée. Notre comparatif, mis à jour chaque semaine, qui oppose les options gratuites aux options payantes, vous aide à trouver la solution qui vous convient le mieux. Tirez pleinement parti de l'IA grâce aux recommandations d'experts de XIX.AI.
 10 outils
10 outils
 xix.ai
Entreprise
Les meilleurs outils de recrutement basés sur l'IA : triez les CV et automatisez la planification des entretiens avec les candidats
xix.ai
Entreprise
Les meilleurs outils de recrutement basés sur l'IA : triez les CV et automatisez la planification des entretiens avec les candidats
Découvrez les meilleurs outils de recrutement basés sur l'IA de 2026 sur XIX.AI. Notre sélection propose des solutions performantes et révolutionnaires pour l'analyse des CV et l'automatisation de la planification des entretiens avec les candidats. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Trouvez l'assistant de recrutement idéal et optimisez votre processus de recrutement dès aujourd'hui !
10 outils
xix.ai
Productivité
Coaches IA dédiés au bien-être et à la concentration : gérer l'épuisement professionnel et booster son énergie mentale
Découvrez sur XIX.AI les meilleurs coachs IA de 2026 spécialisés dans le bien-être personnel et la concentration. Notre classement, soigneusement établi, présente les outils les mieux notés et les plus innovants pour gérer le surmenage et booster votre énergie mentale. Comparez les options gratuites et payantes grâce à des avis concrets. Ouvrez-vous dès aujourd’hui la voie vers une productivité et un bien-être optimaux.
10 outils
xix.ai
chatbot
Les meilleurs chatbots romantiques basés sur l'IA : nouez des relations durables grâce à des personnalités cohérentes
Découvrez les meilleurs chatbots romantiques basés sur l'IA de 2026, sélectionnés pour vous aider à nouer des relations authentiques et durables. Notre sélection comprend des personnalités fortes et cohérentes, des comparaisons entre versions gratuites et payantes, ainsi que des tests en conditions réelles. Trouvez le compagnon idéal et commencez dès aujourd'hui sur XIX.AI.
10 outils
xix.ai
Éducation et apprentissage
Meilleurs mentors en science des données et intelligence artificielle : maîtrise de SQL, Pandas et des workflows d'apprentissage automatique
Découvrez les meilleurs mentors en sciences des données et en intelligence artificielle pour 2026 afin de maîtriser SQL, Pandas et les workflows d'apprentissage automatique. Explorez notre sélection soigneusement élaborée sur XIX.AI pour bénéficier d'une guidance puissante et révolutionnaire. Comparez les options gratuites et payantes en tenant compte de perspectives pratiques. Développez rapidement vos compétences en sciences des données.
10 outils
xix.ai
chatbot
Les meilleurs outils d'IA pour apprendre à flirter et à converser : renforcez votre charisme social et votre confiance en vous en temps réel
Découvrez les meilleurs outils d'entraînement au flirt et à la conversation basés sur l'IA de 2026 sur XIX.AI. Notre sélection triée sur le volet et très bien notée vous aide à développer votre charisme social et votre confiance en vous en temps réel. Découvrez des outils incontournables qui changent la donne, avec des comparaisons entre versions gratuites et payantes ainsi que des classements mis à jour chaque semaine. Développez dès aujourd'hui vos compétences sociales.
10 outils
xix.ai

 commentaires (3)
commentaires (3)
![TimothyMitchell]()
映像の詳細なコントロールって本当に難しいんですね。AIがプロのVFXスタジオで使われる日はまだ先かな?でも技術の進歩にはワクワクする!🔥
![CharlesMartinez]()
Finalmente os vídeos gerados por IA estão evoluindo para algo útil! Mas ainda parece que falta muito pra substituir os efeitos manuais de grandes produções... será que um dia chegaremos lá? 🎥
![DonaldLee]()
The idea of AI taking over VFX in films is wild! I mean, total control over video generation? That’s some sci-fi stuff coming to life. But I wonder if these models like Hunyuan can really nail the tiny details directors obsess over. Exciting times! 🎥
Les modèles de fondation vidéo comme Hunyuan et Wan 2.1 ont réalisé des progrès significatifs, mais ils sont souvent insuffisants lorsqu'il s'agit du contrôle détaillé requis dans la production de films et de séries télévisées, en particulier dans le domaine des effets visuels (VFX). Dans les studios professionnels de VFX, ces modèles, ainsi que les modèles antérieurs basés sur l'image comme Stable Diffusion, Kandinsky et Flux, sont utilisés en conjonction avec une suite d'outils conçus pour affiner leur sortie afin de répondre à des exigences créatives spécifiques. Lorsqu'un réalisateur demande une modification, en disant quelque chose comme : « Ça a l'air super, mais peut-on le rendre un peu plus [n] ? », il ne suffit pas de simplement déclarer que le modèle manque de précision pour effectuer de tels ajustements.
Au lieu de cela, une équipe d'IA VFX utilisera une combinaison de CGI traditionnel et de techniques de composition, ainsi que des flux de travail développés sur mesure, pour repousser les limites de la synthèse vidéo. Cette approche est comparable à l'utilisation d'un navigateur web par défaut comme Chrome ; il est fonctionnel dès son installation, mais pour le personnaliser vraiment selon vos besoins, vous devrez installer quelques plugins.
Les maniaques du contrôle
Dans le domaine de la synthèse d'images basée sur la diffusion, l'un des systèmes tiers les plus cruciaux est ControlNet. Cette technique introduit un contrôle structuré aux modèles génératifs, permettant aux utilisateurs de guider la génération d'images ou de vidéos en utilisant des entrées supplémentaires telles que des cartes de contours, des cartes de profondeur ou des informations de pose.
*Les différentes méthodes de ControlNet permettent la conversion profondeur>image (rangée supérieure), segmentation sémantique>image (en bas à gauche) et la génération d'images guidée par la pose d'humains et d'animaux (en bas à gauche).*
ControlNet ne repose pas uniquement sur des invites textuelles ; il utilise des branches de réseaux neuronaux séparées, ou adaptateurs, pour traiter ces signaux de conditionnement tout en maintenant les capacités génératives du modèle de base. Cela permet des sorties hautement personnalisées qui correspondent étroitement aux spécifications des utilisateurs, ce qui est inestimable pour les applications nécessitant un contrôle précis sur la composition, la structure ou le mouvement.
*Avec une pose guide, une variété de types de sorties précises peut être obtenue via ControlNet.* Source : https://arxiv.org/pdf/2302.05543
Cependant, ces systèmes basés sur des adaptateurs, qui opèrent de manière externe sur un ensemble de processus neuronaux internes, présentent plusieurs inconvénients. Les adaptateurs sont entraînés indépendamment, ce qui peut entraîner des conflits de branches lorsque plusieurs adaptateurs sont combinés, souvent en résultant des générations de moindre qualité. Ils introduisent également une redondance de paramètres, nécessitant des ressources computationnelles et une mémoire supplémentaires pour chaque adaptateur, rendant l'évolutivité inefficace. De plus, malgré leur flexibilité, les adaptateurs produisent souvent des résultats sous-optimaux par rapport aux modèles entièrement affinés pour la génération multi-conditionnelle. Ces problèmes peuvent rendre les méthodes basées sur les adaptateurs moins efficaces pour les tâches nécessitant l'intégration transparente de multiples signaux de contrôle.
Idéalement, les capacités de ControlNet seraient intégrées de manière native dans le modèle de façon modulaire, permettant des innovations futures comme la génération simultanée de vidéo/audio ou des capacités de synchronisation labiale native. Actuellement, chaque fonctionnalité supplémentaire devient soit une tâche de post-production, soit une procédure non native qui doit naviguer dans les poids sensibles du modèle de fondation.
FullDiT
Voici FullDiT, une nouvelle approche venue de Chine qui intègre des fonctionnalités de type ControlNet directement dans un modèle vidéo génératif pendant l'entraînement, plutôt que de les traiter comme une réflexion après coup.
*D'après le nouvel article : l'approche FullDiT peut intégrer l'imposition d'identité, la profondeur et le mouvement de la caméra dans une génération native, et peut invoquer n'importe quelle combinaison de ces éléments à la fois.* Source : https://arxiv.org/pdf/2503.19907
FullDiT, tel que décrit dans l'article intitulé **FullDiT : Modèle de fondation vidéo multi-tâches avec attention complète**, intègre des conditions multi-tâches telles que le transfert d'identité, la cartographie de profondeur et le mouvement de la caméra dans le cœur d'un modèle vidéo génératif entraîné. Les auteurs ont développé un modèle prototype et des clips vidéo associés disponibles sur un site de projet.
**Cliquez pour jouer. Exemples d'imposition utilisateur de style ControlNet avec uniquement un modèle de fondation entraîné nativement.** Source : https://fulldit.github.io/
Les auteurs présentent FullDiT comme une preuve de concept pour les modèles texte-à-vidéo (T2V) et image-à-vidéo (I2V) natifs qui offrent aux utilisateurs plus de contrôle qu'une simple invite d'image ou de texte. Puisqu'aucun modèle similaire n'existe, les chercheurs ont créé un nouveau benchmark appelé **FullBench** pour évaluer les vidéos multi-tâches, revendiquant des performances de pointe dans leurs tests conçus. Cependant, l'objectivité de FullBench, conçu par les auteurs eux-mêmes, reste non testée, et son ensemble de données de 1 400 cas peut être trop limité pour des conclusions plus larges.
L'aspect le plus intrigant de l'architecture de FullDiT est son potentiel à incorporer de nouveaux types de contrôle. Les auteurs notent :
**‘Dans ce travail, nous explorons uniquement les conditions de contrôle de la caméra, des identités et des informations de profondeur. Nous n'avons pas approfondi d'autres conditions et modalités telles que l'audio, la parole, le nuage de points, les boîtes englobantes d'objets, le flux optique, etc. Bien que la conception de FullDiT puisse intégrer de manière transparente d'autres modalités avec une modification minimale de l'architecture, la question de savoir comment adapter rapidement et de manière économique les modèles existants à de nouvelles conditions et modalités reste une question importante qui mérite une exploration plus approfondie.'**
Bien que FullDiT représente une avancée dans la génération vidéo multi-tâches, il s'appuie sur des architectures existantes plutôt que d'introduire un nouveau paradigme. Néanmoins, il se distingue comme le seul modèle de fondation vidéo avec des fonctionnalités de style ControlNet intégrées nativement, et son architecture est conçue pour accueillir les innovations futures.
**Cliquez pour jouer. Exemples de mouvements de caméra contrôlés par l'utilisateur, depuis le site du projet.**
L'article, rédigé par neuf chercheurs de Kuaishou Technology et de l'Université chinoise de Hong Kong, est intitulé **FullDiT : Modèle de fondation vidéo multi-tâches avec attention complète**. La page du projet et les données du nouveau benchmark sont disponibles sur Hugging Face.
Méthode
Le mécanisme d'attention unifié de FullDiT est conçu pour améliorer l'apprentissage de représentation multi-modale en capturant les relations spatiales et temporelles entre les conditions.
*D'après le nouvel article, FullDiT intègre de multiples conditions d'entrée grâce à une attention complète, les convertissant en une séquence unifiée. En revanche, les modèles basés sur des adaptateurs (à gauche ci-dessus) utilisent des modules séparés pour chaque entrée, entraînant une redondance, des conflits et des performances plus faibles.*
Contrairement aux configurations basées sur des adaptateurs qui traitent chaque flux d'entrée séparément, la structure d'attention partagée de FullDiT évite les conflits de branches et réduit la surcharge des paramètres. Les auteurs affirment que l'architecture peut s'adapter à de nouveaux types d'entrée sans refonte majeure et que le schéma du modèle montre des signes de généralisation à des combinaisons de conditions non vues pendant l'entraînement, telles que la liaison du mouvement de la caméra avec l'identité des personnages.
**Cliquez pour jouer. Exemples de génération d'identité depuis le site du projet.**
Dans l'architecture de FullDiT, toutes les entrées de conditionnement — telles que le texte, le mouvement de la caméra, l'identité et la profondeur — sont d'abord converties en un format de jeton unifié. Ces jetons sont ensuite concaténés en une seule longue séquence, traitée à travers une pile de couches de transformateurs utilisant une attention complète. Cette approche suit les travaux antérieurs comme Open-Sora Plan et Movie Gen.
Cette conception permet au modèle d'apprendre conjointement les relations temporelles et spatiales à travers toutes les conditions. Chaque bloc de transformateur opère sur l'ensemble de la séquence, permettant des interactions dynamiques entre les modalités sans dépendre de modules séparés pour chaque entrée. L'architecture est conçue pour être extensible, facilitant l'incorporation de signaux de contrôle supplémentaires à l'avenir sans changements structurels majeurs.
La puissance du trois
FullDiT convertit chaque signal de contrôle en un format de jeton standardisé afin que toutes les conditions puissent être traitées ensemble dans un cadre d'attention unifié. Pour le mouvement de la caméra, le modèle encode une séquence de paramètres extrinsèques — tels que la position et l'orientation — pour chaque image. Ces paramètres sont horodatés et projetés dans des vecteurs d'intégration qui reflètent la nature temporelle du signal.
L'information d'identité est traitée différemment, car elle est intrinsèquement spatiale plutôt que temporelle. Le modèle utilise des cartes d'identité qui indiquent quels personnages sont présents dans quelles parties de chaque image. Ces cartes sont divisées en patches, chaque patch étant projeté dans une intégration qui capture des indices d'identité spatiale, permettant au modèle d'associer des régions spécifiques de l'image à des entités spécifiques.
La profondeur est un signal spatiotemporel, et le modèle le gère en divisant les vidéos de profondeur en patches 3D qui englobent à la fois l'espace et le temps. Ces patches sont ensuite intégrés de manière à préserver leur structure à travers les images.
Une fois intégrés, tous ces jetons de condition (caméra, identité et profondeur) sont concaténés en une seule longue séquence, permettant à FullDiT de les traiter ensemble à l'aide d'une attention complète. Cette représentation partagée permet au modèle d'apprendre les interactions entre les modalités et à travers le temps sans dépendre de flux de traitement isolés.
Données et tests
L'approche d'entraînement de FullDiT s'appuie sur des ensembles de données annotées sélectivement, adaptés à chaque type de conditionnement, plutôt que de nécessiter la présence simultanée de toutes les conditions.
Pour les conditions textuelles, l'initiative suit l'approche de sous-titrage structuré décrite dans le projet MiraData.
*Pipeline de collecte et d'annotation de vidéos du projet MiraData.* Source : https://arxiv.org/pdf/2407.06358
Pour le mouvement de la caméra, l'ensemble de données RealEstate10K a été la principale source de données, en raison de ses annotations de vérité terrain de haute qualité des paramètres de caméra. Cependant, les auteurs ont observé que l'entraînement exclusivement sur des ensembles de données de caméras à scènes statiques comme RealEstate10K tendait à réduire les mouvements dynamiques d'objets et d'humains dans les vidéos générées. Pour contrer cela, ils ont effectué un réglage fin supplémentaire en utilisant des ensembles de données internes qui incluaient des mouvements de caméra plus dynamiques.
Les annotations d'identité ont été générées à l'aide du pipeline développé pour le projet ConceptMaster, qui a permis un filtrage et une extraction efficaces des informations d'identité détaillées.
*Le cadre ConceptMaster est conçu pour résoudre les problèmes de découplage d'identité tout en préservant la fidélité des concepts dans les vidéos personnalisées.* Source : https://arxiv.org/pdf/2501.04698
Les annotations de profondeur ont été obtenues à partir de l'ensemble de données Panda-70M en utilisant Depth Anything.
Optimisation par ordonnancement des données
Les auteurs ont également mis en œuvre un calendrier d'entraînement progressif, introduisant des conditions plus difficiles plus tôt dans l'entraînement pour s'assurer que le modèle acquiert des représentations robustes avant que des tâches plus simples ne soient ajoutées. L'ordre d'entraînement a progressé du texte aux conditions de caméra, puis aux identités, et enfin à la profondeur, les tâches plus faciles étant généralement introduites plus tard et avec moins d'exemples.
Les auteurs soulignent la valeur de l'ordonnancement de la charge de travail de cette manière :
**‘Au cours de la phase de pré-entraînement, nous avons noté que les tâches plus difficiles exigent un temps d'entraînement prolongé et doivent être introduites plus tôt dans le processus d'apprentissage. Ces tâches difficiles impliquent des distributions de données complexes qui diffèrent considérablement de la vidéo de sortie, exigeant que le modèle ait une capacité suffisante pour les capturer et les représenter avec précision.**
**‘À l'inverse, introduire des tâches plus faciles trop tôt peut amener le modèle à privilégier leur apprentissage en premier, car elles fournissent un retour d'optimisation plus immédiat, ce qui entrave la convergence des tâches plus difficiles.'**
*Une illustration de l'ordre d'entraînement des données adopté par les chercheurs, avec le rouge indiquant un plus grand volume de données.*
Après un pré-entraînement initial, une phase finale de réglage fin a encore affiné le modèle pour améliorer la qualité visuelle et la dynamique du mouvement. Par la suite, l'entraînement a suivi celui d'un cadre de diffusion standard : du bruit ajouté aux latents vidéo, et le modèle apprenant à prédire et à supprimer ce bruit, en utilisant les jetons de condition intégrés comme guide.
Pour évaluer efficacement FullDiT et fournir une comparaison équitable avec les méthodes existantes, et en l'absence d'un autre benchmark pertinent, les auteurs ont introduit **FullBench**, une suite de benchmarks organisée composée de 1 400 cas de test distincts.
*Une instance d'explorateur de données pour le nouveau benchmark FullBench.* Source : https://huggingface.co/datasets/KwaiVGI/FullBench
Chaque point de données fournissait des annotations de vérité terrain pour divers signaux de conditionnement, y compris le mouvement de la caméra, l'identité et la profondeur.
Métriques
Les auteurs ont évalué FullDiT en utilisant dix métriques couvrant cinq aspects principaux de la performance : l'alignement du texte, le contrôle de la caméra, la similarité d'identité, la précision de la profondeur et la qualité générale de la vidéo.
L'alignement du texte a été mesuré à l'aide de la similarité CLIP, tandis que le contrôle de la caméra a été évalué à travers l'erreur de rotation (RotErr), l'erreur de translation (TransErr) et la cohérence du mouvement de la caméra (CamMC), suivant l'approche de CamI2V (dans le projet CameraCtrl).
La similarité d'identité a été évaluée à l'aide de DINO-I et CLIP-I, et la précision du contrôle de la profondeur a été quantifiée à l'aide de l'erreur absolue moyenne (MAE).
La qualité de la vidéo a été jugée avec trois métriques de MiraData : la similarité CLIP au niveau des images pour la fluidité ; la distance de mouvement basée sur le flux optique pour la dynamique ; et les scores esthétiques LAION pour l'attrait visuel.
Entraînement
Les auteurs ont entraîné FullDiT en utilisant un modèle de diffusion texte-à-vidéo interne (non divulgué) contenant environ un milliard de paramètres. Ils ont intentionnellement choisi une taille de paramètres modeste pour maintenir l'équité dans les comparaisons avec les méthodes antérieures et assurer la reproductibilité.
Puisque les vidéos d'entraînement variaient en longueur et en résolution, les auteurs ont standardisé chaque lot en redimensionnant et en rembourrant les vidéos à une résolution commune, en échantillonnant 77 images par séquence, et en utilisant une attention appliquée et des masques de perte pour optimiser l'efficacité de l'entraînement.
L'optimiseur Adam a été utilisé à un taux d'apprentissage de 1×10−5 sur un cluster de 64 GPU NVIDIA H800, pour un total combiné de 5 120 Go de VRAM (considérez que dans les communautés de synthèse enthousiastes, 24 Go sur un RTX 3090 est encore considéré comme une norme luxueuse).
Le modèle a été entraîné pendant environ 32 000 étapes, incorporant jusqu'à trois identités par vidéo, ainsi que 20 images de conditions de caméra et 21 images de conditions de profondeur, toutes deux échantillonnées uniformément à partir des 77 images totales.
Pour l'inférence, le modèle a généré des vidéos à une résolution de 384×672 pixels (environ cinq secondes à 15 images par seconde) avec 50 étapes d'inférence de diffusion et une échelle de guidage sans classificateur de cinq.
Méthodes antérieures
Pour l'évaluation caméra-à-vidéo, les auteurs ont comparé FullDiT à MotionCtrl, CameraCtrl et CamI2V, tous les modèles étant entraînés à l'aide de l'ensemble de données RealEstate10k pour assurer la cohérence et l'équité.
Dans la génération conditionnée par l'identité, comme aucun modèle multi-identité open-source comparable n'était disponible, le modèle a été comparé au modèle ConceptMaster à 1 milliard de paramètres, en utilisant les mêmes données d'entraînement et la même architecture.
Pour les tâches profondeur-à-vidéo, des comparaisons ont été faites avec Ctrl-Adapter et ControlVideo.
*Résultats quantitatifs pour la génération vidéo à tâche unique. FullDiT a été comparé à MotionCtrl, CameraCtrl et CamI2V pour la génération caméra-à-vidéo ; ConceptMaster (version à 1 milliard de paramètres) pour l'identité-à-vidéo ; et Ctrl-Adapter et ControlVideo pour la profondeur-à-vidéo. Tous les modèles ont été évalués en utilisant leurs paramètres par défaut. Pour la cohérence, 16 images ont été uniformément échantillonnées pour chaque méthode, correspondant à la longueur de sortie des modèles antérieurs.*
Les résultats indiquent que FullDiT, bien qu'il gère simultanément plusieurs signaux de conditionnement, a atteint des performances de pointe dans les métriques liées au texte, au mouvement de la caméra, à l'identité et aux contrôles de profondeur.
Dans les métriques de qualité globale, le système a généralement surpassé les autres méthodes, bien que sa fluidité soit légèrement inférieure à celle de ConceptMaster. Ici, les auteurs commentent :
**‘La fluidité de FullDiT est légèrement inférieure à celle de ConceptMaster car le calcul de la fluidité est basé sur la similarité CLIP entre les images adjacentes. Comme FullDiT présente une dynamique nettement plus importante par rapport à ConceptMaster, la métrique de fluidité est affectée par les grandes variations entre les images adjacentes.**
**‘Pour le score esthétique, comme le modèle d'évaluation privilégie les images de style peinture et que ControlVideo génère généralement des vidéos dans ce style, il obtient un score élevé en esthétique.'**
En ce qui concerne la comparaison qualitative, il pourrait être préférable de se référer aux vidéos d'exemple sur le site du projet FullDiT, car les exemples PDF sont inévitablement statiques (et aussi trop volumineux pour être entièrement reproduits ici).
*La première section des résultats qualitatifs reproduits dans le PDF. Veuillez vous référer à l'article source pour les exemples supplémentaires, qui sont trop nombreux pour être reproduits ici.*
Les auteurs commentent :
**‘FullDiT démontre une préservation supérieure de l'identité et génère des vidéos avec une meilleure dynamique et qualité visuelle par rapport à [ConceptMaster]. Puisque ConceptMaster et FullDiT sont entraînés sur la même base, cela met en évidence l'efficacité de l'injection de conditions avec une attention complète.**
**‘…Les [autres] résultats démontrent la contrôlabilité et la qualité de génération supérieures de FullDiT par rapport aux méthodes existantes de profondeur-à-vidéo et caméra-à-vidéo.'**
*Une section des exemples du PDF des sorties de FullDiT avec plusieurs signaux. Veuillez vous référer à l'article source et au site du projet pour des exemples supplémentaires.*
Conclusion
FullDiT représente une étape excitante vers un modèle de fondation vidéo plus complet, mais la question demeure de savoir si la demande pour des fonctionnalités de style ControlNet justifie leur mise en œuvre à grande échelle, en particulier pour les projets open-source. Ces projets auraient du mal à obtenir la puissance de traitement GPU massive requise sans soutien commercial.
Le principal défi est que l'utilisation de systèmes comme Depth et Pose nécessite généralement une familiarité non négligeable avec des interfaces utilisateur complexes comme ComfyUI. Par conséquent, un modèle open-source fonctionnel de ce type est le plus susceptible d'être développé par de petites entreprises de VFX qui manquent de ressources ou de motivation pour organiser et entraîner un tel modèle en privé.
D'un autre côté, les systèmes d'IA basés sur des API de type "location d'IA" peuvent être fortement motivés pour développer des méthodes interprétatives plus simples et conviviales pour les modèles avec des systèmes de contrôle auxiliaires directement entraînés.
**Cliquez pour jouer. Contrôles de profondeur + texte imposés sur une génération vidéo utilisant FullDiT.**
*Les auteurs ne spécifient aucun modèle de base connu (c.-à-d. SDXL, etc.)*
**Première publication jeudi 27 mars 2025**










 YouTube teste une fonctionnalité de recherche basée sur l'IA proposant des réponses guidées
De nombreux utilisateurs se tournent vers YouTube lorsqu'ils recherchent des recettes ou des itinéraires de voyage, à la recherche de vidéos pertinentes. Aujourd'hui, la plateforme lance un outil de r
YouTube teste une fonctionnalité de recherche basée sur l'IA proposant des réponses guidées
De nombreux utilisateurs se tournent vers YouTube lorsqu'ils recherchent des recettes ou des itinéraires de voyage, à la recherche de vidéos pertinentes. Aujourd'hui, la plateforme lance un outil de r
 Exclusivité : Luma AI lance des agents créatifs alimentés par des modèles d'« intelligence unifiée »
Jeudi, la start-up spécialisée dans la génération de vidéos par IA Luma a présenté Luma Agents, un système conçu pour gérer l'ensemble des workflows créatifs, qu'il s'agisse de texte, d
Exclusivité : Luma AI lance des agents créatifs alimentés par des modèles d'« intelligence unifiée »
Jeudi, la start-up spécialisée dans la génération de vidéos par IA Luma a présenté Luma Agents, un système conçu pour gérer l'ensemble des workflows créatifs, qu'il s'agisse de texte, d
 La nouvelle mise à jour de Sora propose des vidéos sur l'intelligence artificielle des animaux de compagnie, des outils sociaux et une nouvelle application Android.
OpenAI présente en avant-première une vague de nouvelles fonctionnalités pour Sora, son application de création vidéo par l'IA, qui s'est rapidement hissée au sommet de l'App Store après son lancement
La nouvelle mise à jour de Sora propose des vidéos sur l'intelligence artificielle des animaux de compagnie, des outils sociaux et une nouvelle application Android.
OpenAI présente en avant-première une vague de nouvelles fonctionnalités pour Sora, son application de création vidéo par l'IA, qui s'est rapidement hissée au sommet de l'App Store après son lancement

Les meilleurs outils de gestion des dépenses basés sur l'IA en 2026 : les outils les mieux notés pour numériser vos reçus et classer automatiquement les dépenses de votre entreprise. Découvrez des solutions puissantes et révolutionnaires pour une gestion des dépenses sans effort, un suivi financier précis et une conformité simplifiée. Notre comparatif, mis à jour chaque semaine, qui oppose les options gratuites aux options payantes, vous aide à trouver la solution qui vous convient le mieux. Tirez pleinement parti de l'IA grâce aux recommandations d'experts de XIX.AI.
10 outils
xix.ai

Découvrez les meilleurs outils de recrutement basés sur l'IA de 2026 sur XIX.AI. Notre sélection propose des solutions performantes et révolutionnaires pour l'analyse des CV et l'automatisation de la planification des entretiens avec les candidats. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Trouvez l'assistant de recrutement idéal et optimisez votre processus de recrutement dès aujourd'hui !
10 outils
xix.ai

Découvrez sur XIX.AI les meilleurs coachs IA de 2026 spécialisés dans le bien-être personnel et la concentration. Notre classement, soigneusement établi, présente les outils les mieux notés et les plus innovants pour gérer le surmenage et booster votre énergie mentale. Comparez les options gratuites et payantes grâce à des avis concrets. Ouvrez-vous dès aujourd’hui la voie vers une productivité et un bien-être optimaux.
10 outils
xix.ai

Découvrez les meilleurs chatbots romantiques basés sur l'IA de 2026, sélectionnés pour vous aider à nouer des relations authentiques et durables. Notre sélection comprend des personnalités fortes et cohérentes, des comparaisons entre versions gratuites et payantes, ainsi que des tests en conditions réelles. Trouvez le compagnon idéal et commencez dès aujourd'hui sur XIX.AI.
10 outils
xix.ai

Découvrez les meilleurs mentors en sciences des données et en intelligence artificielle pour 2026 afin de maîtriser SQL, Pandas et les workflows d'apprentissage automatique. Explorez notre sélection soigneusement élaborée sur XIX.AI pour bénéficier d'une guidance puissante et révolutionnaire. Comparez les options gratuites et payantes en tenant compte de perspectives pratiques. Développez rapidement vos compétences en sciences des données.
10 outils
xix.ai

Découvrez les meilleurs outils d'entraînement au flirt et à la conversation basés sur l'IA de 2026 sur XIX.AI. Notre sélection triée sur le volet et très bien notée vous aide à développer votre charisme social et votre confiance en vous en temps réel. Découvrez des outils incontournables qui changent la donne, avec des comparaisons entre versions gratuites et payantes ainsi que des classements mis à jour chaque semaine. Développez dès aujourd'hui vos compétences sociales.
10 outils
xix.ai

映像の詳細なコントロールって本当に難しいんですね。AIがプロのVFXスタジオで使われる日はまだ先かな?でも技術の進歩にはワクワクする!🔥
Finalmente os vídeos gerados por IA estão evoluindo para algo útil! Mas ainda parece que falta muito pra substituir os efeitos manuais de grandes produções... será que um dia chegaremos lá? 🎥
The idea of AI taking over VFX in films is wild! I mean, total control over video generation? That’s some sci-fi stuff coming to life. But I wonder if these models like Hunyuan can really nail the tiny details directors obsess over. Exciting times! 🎥













