
















 Maison
Maison
Tencent dévoile HunyuanCustom pour la personnalisation vidéo à partir d'une seule image
Cet article explore le lancement de HunyuanCustom, un modèle de génération vidéo multimodal par Tencent. L'ampleur considérable du document de recherche accompagnant et les défis posés par les vidéos d'exemple fournies sur la page du projet nécessitent une vue d'ensemble plus large, avec une reproduction limitée du contenu vidéo extensif en raison des exigences de formatage et de traitement pour une clarté améliorée.
Notez que le document fait référence au système génératif basé sur API Kling sous le nom de ‘Keling.’ Pour des raisons de cohérence, cet article utilise ‘Kling’ tout au long.
Tencent a introduit une itération avancée de son modèle Hunyuan Video, nommé HunyuanCustom. Cette version surpasserait le besoin des modèles Hunyuan LoRA en permettant aux utilisateurs de créer des personnalisations vidéo de type deepfake en utilisant une seule image :
Cliquez pour jouer. Prompt : ‘Un homme écoute de la musique tout en préparant des nouilles d'escargot dans une cuisine.’ Comparé aux méthodes propriétaires et open-source, y compris Kling, un concurrent clé, HunyuanCustom se distingue. Source : https://hunyuancustom.github.io/ (note : site à forte consommation de ressources)
Dans la vidéo ci-dessus, la colonne la plus à gauche affiche l'image source unique pour HunyuanCustom, suivie de l'interprétation du prompt par le système dans la colonne adjacente. Les colonnes restantes présentent les sorties d'autres systèmes : Kling, Vidu, Pika, Hailuo et SkyReels-A2 (basé sur Wan).
La vidéo suivante met en lumière trois scénarios principaux pour cette version : personne avec objet, réplication d'un personnage unique, et essayage virtuel de vêtements :
Cliquez pour jouer. Trois exemples sélectionnés à partir du site de support Hunyuan Video.
Ces exemples révèlent des limitations liées à l'utilisation d'une image source unique plutôt que de multiples perspectives.
Dans le premier clip, l'homme fait face à la caméra avec un mouvement minimal de la tête, ne s'inclinant pas au-delà de 20-25 degrés. Au-delà de cela, le système peine à déduire précisément son profil à partir d'une seule image frontale.
Dans le deuxième clip, la fille conserve une expression souriante dans la vidéo, reflétant son image source statique. Sans références supplémentaires, HunyuanCustom ne peut pas représenter de manière fiable une expression neutre, et son visage reste largement orienté vers l'avant, similaire à l'exemple précédent.
Dans le clip final, un matériel source incomplet—une femme et des vêtements virtuels—entraîne un rendu tronqué, une solution pratique pour des données limitées.
Bien que HunyuanCustom prenne en charge plusieurs entrées d'images (par exemple, personne avec des collations ou personne avec des vêtements), il ne prend pas en charge des angles ou expressions variés pour un seul personnage. Cela peut limiter sa capacité à remplacer complètement l'écosystème en expansion des modèles LoRA pour HunyuanVideo, qui utilisent 20 à 60 images pour garantir un rendu cohérent du personnage à travers différents angles et expressions.
Intégration audio
Pour l'audio, HunyuanCustom utilise le système LatentSync, difficile à configurer pour les amateurs, pour synchroniser les mouvements des lèvres avec l'audio et le texte fournis par l'utilisateur :
Inclut l'audio. Cliquez pour jouer. Exemples compilés de synchronisation labiale à partir du site supplémentaire de HunyuanCustom.
Actuellement, aucun exemple en langue anglaise n'est disponible, mais les résultats semblent prometteurs, en particulier si le processus de configuration est convivial.
Capacités d'édition vidéo
HunyuanCustom excelle dans l'édition vidéo à vidéo (V2V), permettant le remplacement ciblé d'éléments dans des vidéos existantes à l'aide d'une seule image de référence. Un exemple tiré des matériaux supplémentaires illustre cela :
Cliquez pour jouer. L'objet central est modifié, avec les éléments environnants subtilement altérés dans un processus V2V de HunyuanCustom.
Comme typique dans les flux de travail V2V, l'ensemble de la vidéo est légèrement modifié, avec un accent principal sur la zone ciblée, comme le jouet en peluche. Des pipelines avancés pourraient potentiellement préserver davantage du contenu original, à l'image de l'approche d'Adobe Firefly, bien que cela reste peu exploré dans les communautés open-source.
D'autres exemples démontrent une précision améliorée dans les intégrations ciblées, comme vu dans cette compilation :
Cliquez pour jouer. Exemples variés d'insertion de contenu V2V dans HunyuanCustom, montrant du respect pour les éléments non modifiés.
Mise à niveau évolutive
HunyuanCustom s'appuie sur le projet Hunyuan Video, introduisant des améliorations architecturales ciblées plutôt qu'une refonte complète. Ces mises à jour visent à maintenir la cohérence des personnages à travers les images sans nécessiter d'ajustement spécifique au sujet, comme LoRA ou l'inversion textuelle.
Cette version est une version affinée du modèle HunyuanVideo de décembre 2024, et non un nouveau modèle construit de toutes pièces.
Les utilisateurs des LoRAs existants de HunyuanVideo peuvent se demander si ceux-ci sont compatibles avec cette mise à jour ou si de nouveaux LoRAs doivent être développés pour tirer parti des fonctionnalités de personnalisation améliorées.
En général, un réglage fin important modifie suffisamment les poids du modèle pour rendre les LoRAs précédents incompatibles. Cependant, certains réglages fins, comme Pony Diffusion pour Stable Diffusion XL, ont créé des écosystèmes indépendants avec des bibliothèques LoRA dédiées, suggérant un potentiel pour HunyuanCustom de suivre cette voie.
Détails de la sortie
Le document de recherche, intitulé HunyuanCustom : Une architecture pilotée par le multimodal pour la génération vidéo personnalisée, renvoie à un dépôt GitHub désormais actif avec du code et des poids pour un déploiement local, ainsi qu'une intégration prévue avec ComfyUI.
Actuellement, la page Hugging Face du projet est inaccessible, mais une démo basée sur API est disponible via un code de scan WeChat.
L'assemblage par HunyuanCustom de divers projets est particulièrement complet, probablement motivé par les exigences de licence pour une divulgation complète.
Deux variantes du modèle sont proposées : une version 720x1280px nécessitant 80 Go de mémoire GPU pour des performances optimales (24 Go minimum, mais lente) et une version 512x896px nécessitant 60 Go. Les tests ont été limités à Linux, mais des efforts communautaires pourraient bientôt l'adapter pour Windows et des configurations VRAM plus faibles, comme vu avec le modèle Hunyuan Video précédent.
En raison du volume des matériaux accompagnants, cette vue d'ensemble adopte une approche de haut niveau des capacités de HunyuanCustom.
Perspectives techniques
Le pipeline de données de HunyuanCustom, conforme au RGPD, intègre des ensembles de données vidéo synthétisées et open-source comme OpenHumanVid, couvrant huit catégories : humains, animaux, plantes, paysages, véhicules, objets, architecture, et anime.
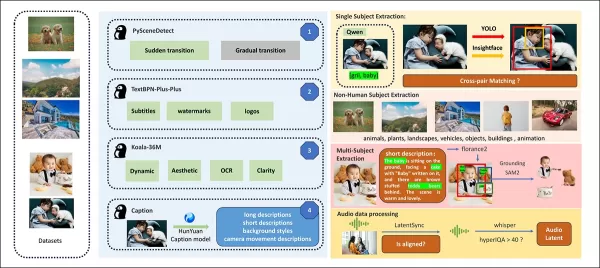
À partir du document de sortie, une vue d'ensemble des divers packages contributeurs dans le pipeline de construction de données de HunyuanCustom. Source : https://arxiv.org/pdf/2505.04512
Les vidéos sont segmentées en clips à plan unique à l'aide de PySceneDetect, avec TextBPN-Plus-Plus filtrant le contenu avec trop de texte, sous-titres ou filigranes.
Les clips sont standardisés à cinq secondes et redimensionnés à 512 ou 720 pixels sur le côté court. La qualité esthétique est assurée à l'aide de Koala-36M avec un seuil personnalisé de 0,06.
L'extraction d'identité humaine s'appuie sur Qwen7B, YOLO11X et InsightFace, tandis que les sujets non humains sont traités avec QwenVL et Grounded SAM 2, éliminant les petites boîtes englobantes.

Exemples de segmentation sémantique avec Grounded SAM 2, utilisé dans le projet Hunyuan Control. Source : https://github.com/IDEA-Research/Grounded-SAM-2
L'extraction multi-sujets utilise Florence2 pour l'annotation et Grounded SAM 2 pour la segmentation, suivie d'un regroupement et d'une segmentation temporelle des images.
Les clips sont enrichis avec un étiquetage structuré exclusif par l'équipe Hunyuan, ajoutant des métadonnées comme des descriptions et des indices de mouvement de caméra.
L'augmentation de masque empêche le surajustement, assurant une adaptabilité à des formes d'objets variées. La synchronisation audio utilise LatentSync, éliminant les clips en dessous d'un seuil de qualité. HyperIQA filtre les vidéos scoring en dessous de 40, et Whisper traite l'audio valide pour les tâches en aval.
Le modèle LLaVA joue un rôle central, générant des légendes et alignant le contenu visuel et textuel pour une cohérence sémantique, en particulier dans les scènes complexes ou multi-sujets.
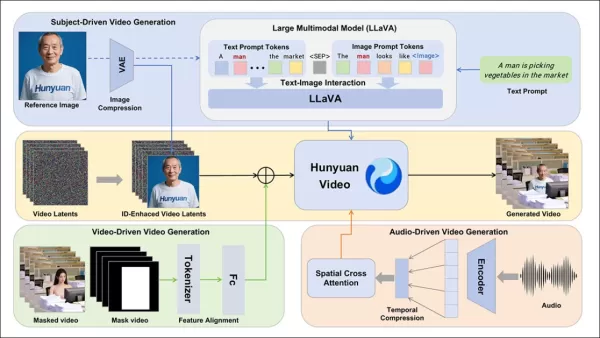
Le cadre HunyuanCustom prend en charge la génération vidéo cohérente avec l'identité, conditionnée par des entrées de texte, d'image, d'audio et de vidéo.
Personnalisation vidéo
Pour permettre la génération vidéo à partir d'une image de référence et d'un prompt, deux modules basés sur LLaVA ont été développés, adaptant l'entrée de HunyuanVideo pour accepter à la fois l'image et le texte. Les prompts intègrent les images directement ou les étiquettent avec de brèves descriptions d'identité, utilisant un jeton séparateur pour équilibrer l'influence de l'image et du texte.
Un module d'amélioration d'identité corrige la tendance de LLaVA à perdre des détails spatiaux fins, cruciaux pour maintenir la cohérence du sujet dans les clips vidéo courts.
L'image de référence est redimensionnée et encodée via le 3D-VAE causal de HunyuanVideo, avec son latent inséré à travers l'axe temporel et un décalage spatial pour guider la génération sans réplication directe.
L'entraînement a utilisé Flow Matching avec du bruit provenant d'une distribution normale logit, ajustant finement LLaVA et le générateur vidéo ensemble pour une guidance cohérente image-prompt et une cohérence d'identité.
Pour les prompts multi-sujets, chaque paire image-texte est intégrée séparément avec des positions temporelles distinctes, permettant des scènes avec plusieurs sujets en interaction.
Intégration audio et visuelle
HunyuanCustom prend en charge la génération pilotée par l'audio en utilisant l'audio et le texte fournis par l'utilisateur, permettant aux personnages de parler dans des contextes pertinents.
Un module AudioNet désentrelacé d'identité aligne les caractéristiques audio avec la chronologie vidéo, utilisant une attention croisée spatiale pour isoler les images et maintenir la cohérence du sujet.
Un module d'injection temporelle affine le timing du mouvement, mappant l'audio sur des séquences latentes via un perceptron multicouche, assurant l'alignement des gestes avec le rythme audio.
Pour l'édition vidéo, HunyuanCustom remplace les sujets dans les clips existants sans régénérer la vidéo entière, idéal pour des changements ciblés d'apparence ou de mouvement.
Cliquez pour jouer. Un autre exemple du site supplémentaire.
Le système compresse les vidéos de référence à l'aide du 3D-VAE causal pré-entraîné, les alignant avec les latents du pipeline de génération pour un traitement léger. Un réseau neuronal aligne les vidéos d'entrée propres avec des latents bruités, l'ajout de caractéristiques image par image s'avérant plus efficace que la fusion pré-compression.
Évaluation des performances
Les métriques de test incluaient ArcFace pour la cohérence d'identité faciale, YOLO11x et Dino 2 pour la similarité des sujets, CLIP-B pour l'alignement texte-vidéo et la cohérence temporelle, et VBench pour l'intensité du mouvement.
Les concurrents incluaient des systèmes fermés (Hailuo, Vidu 2.0, Kling 1.6, Pika) et des cadres open-source (VACE, SkyReels-A2).
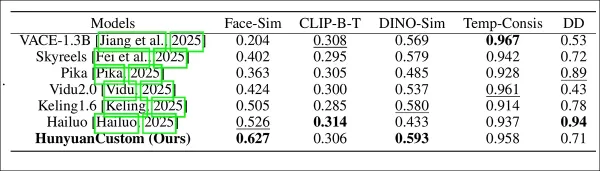
Évaluation des performances du modèle comparant HunyuanCustom avec les principales méthodes de personnalisation vidéo à travers la cohérence d'identité (Face-Sim), la similarité des sujets (DINO-Sim), l'alignement texte-vidéo (CLIP-B-T), la cohérence temporelle (Temp-Consis), et l'intensité du mouvement (DD). Les résultats optimaux et sous-optimaux sont affichés en gras et soulignés, respectivement.
Les auteurs notent :
‘HunyuanCustom excelle dans la cohérence d'identité et de sujet, avec une adhérence compétitive au prompt et une stabilité temporelle. Hailuo mène en score de clip grâce à un fort alignement textuel mais lutte avec la cohérence des sujets non humains. Vidu et VACE sont à la traîne en intensité de mouvement, probablement en raison de tailles de modèle plus petites.’
Bien que le site du projet propose de nombreuses vidéos de comparaison, leur disposition privilégie l'esthétique à la facilité de comparaison. Les lecteurs sont encouragés à consulter directement les vidéos pour des idées plus claires :
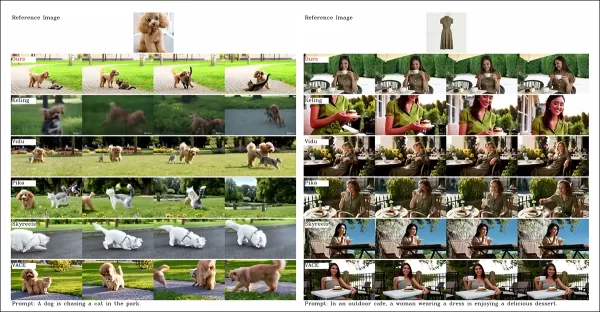
À partir du document, une comparaison sur la personnalisation vidéo centrée sur les objets. Bien que le spectateur devrait se référer au PDF source pour une meilleure résolution, les vidéos sur le site du projet offrent des idées plus claires.
Les auteurs déclarent :
‘Vidu, SkyReels A2 et HunyuanCustom réalisent un fort alignement au prompt et une cohérence des sujets, mais notre qualité vidéo surpasse Vidu et SkyReels, grâce à la base robuste de Hunyuanvideo-13B.’
‘Parmi les solutions commerciales, Kling offre une vidéo de haute qualité mais souffre d’un effet de copier-coller dans la première image et d’un flou occasionnel du sujet, impactant l’expérience du spectateur.’
Pika lutte avec la cohérence temporelle, introduisant des artefacts de sous-titres dus à une mauvaise curation des données. Hailuo préserve l’identité faciale mais échoue dans la cohérence du corps entier. VACE, parmi les méthodes open-source, ne parvient pas à maintenir la cohérence d’identité, tandis que HunyuanCustom offre une forte préservation d’identité, une qualité et une diversité.
Les tests de personnalisation vidéo multi-sujets ont donné des résultats similaires :

Comparaisons utilisant des personnalisations vidéo multi-sujets. Veuillez consulter le PDF pour plus de détails et de résolution.
Le document note :
‘Pika génère les sujets spécifiés mais montre une instabilité des images, avec des sujets disparaissant ou ne suivant pas les prompts. Vidu et VACE capturent partiellement l’identité humaine mais perdent les détails des objets non humains. SkyReels A2 souffre d’une instabilité sévère des images et d’artefacts. HunyuanCustom capture efficacement toutes les identités des sujets, adhère aux prompts et maintient une haute qualité visuelle et une stabilité.’
Un test de publicité humaine virtuelle a intégré des produits avec des personnes :

À partir du tour de test qualitatif, exemples de placement de produit neuronal. Veuillez consulter le PDF pour plus de détails et de résolution.
Les auteurs déclarent :
‘HunyuanCustom maintient l’identité humaine et les détails du produit, y compris le texte, avec des interactions naturelles et une forte adhérence au prompt, démontrant son potentiel pour les vidéos publicitaires.’
Les tests de personnalisation pilotée par l’audio ont mis en évidence un contrôle flexible des scènes et des postures :
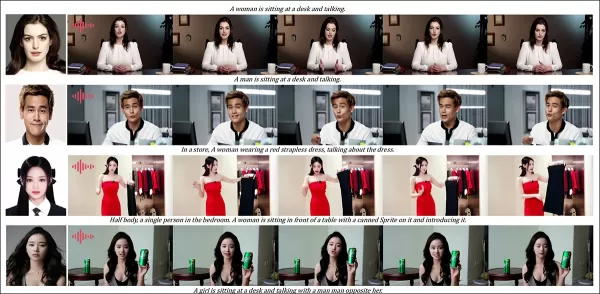
Résultats partiels pour le tour audio – des résultats vidéo seraient préférables. Seule la moitié supérieure de la figure PDF est montrée en raison de contraintes de taille. Veuillez consulter le PDF source pour plus de détails.
Les auteurs notent :
‘Les méthodes pilotées par l’audio précédentes limitent la posture et l’environnement à l’image d’entrée, restreignant les applications. HunyuanCustom permet une animation pilotée par l’audio flexible avec des scènes et des postures décrites par texte.’
Les tests de remplacement de sujet vidéo ont comparé HunyuanCustom à VACE et Kling 1.6 :

Test de remplacement de sujet en mode vidéo à vidéo. Veuillez consulter le PDF source pour plus de détails et de résolution.
Les chercheurs déclarent :
‘VACE produit des artefacts de frontière en raison d’une adhérence stricte au masque, perturbant la continuité du mouvement. Kling montre un effet de copier-coller avec une mauvaise intégration de l’arrière-plan. HunyuanCustom évite les artefacts, assure une intégration fluide et maintient une forte préservation de l’identité, excellant dans l’édition vidéo.’
Conclusion
HunyuanCustom est une version convaincante, répondant à la demande croissante de synchronisation labiale dans la synthèse vidéo, améliorant le réalisme dans des systèmes comme Hunyuan Video. Malgré les défis pour comparer ses capacités en raison de la disposition des vidéos sur le site du projet, le modèle de Tencent tient tête aux principaux concurrents comme Kling, marquant des progrès significatifs dans la génération vidéo personnalisée.
* Certaines vidéos sont trop larges, courtes ou en haute résolution pour être lues dans des lecteurs standards comme VLC ou Windows Media Player, affichant des écrans noirs.
Première publication le jeudi 8 mai 2025
Article connexe
 Exclusivité : Luma AI lance des agents créatifs alimentés par des modèles d'« intelligence unifiée »
Jeudi, la start-up spécialisée dans la génération de vidéos par IA Luma a présenté Luma Agents, un système conçu pour gérer l'ensemble des workflows créatifs, qu'il s'agisse de texte, d
La nouvelle mise à jour de Sora propose des vidéos sur l'intelligence artificielle des animaux de compagnie, des outils sociaux et une nouvelle application Android.
OpenAI présente en avant-première une vague de nouvelles fonctionnalités pour Sora, son application de création vidéo par l'IA, qui s'est rapidement hissée au sommet de l'App Store après son lancement
La génération de vidéos AI se déplace vers un contrôle complet
Des modèles de fondations vidéo comme Hunyuan et WAN 2.1 ont fait des progrès importants, mais ils échouent souvent en ce qui concerne le contrôle détaillé requis dans la production de films et de télévision, en particulier dans le domaine des effets visuels (VFX). Dans les studios VFX professionnels, ces modèles, ainsi que des bas d'images antérieurs
Recommandations de sujets spéciaux liés
code
Exclusivité : Luma AI lance des agents créatifs alimentés par des modèles d'« intelligence unifiée »
Jeudi, la start-up spécialisée dans la génération de vidéos par IA Luma a présenté Luma Agents, un système conçu pour gérer l'ensemble des workflows créatifs, qu'il s'agisse de texte, d
La nouvelle mise à jour de Sora propose des vidéos sur l'intelligence artificielle des animaux de compagnie, des outils sociaux et une nouvelle application Android.
OpenAI présente en avant-première une vague de nouvelles fonctionnalités pour Sora, son application de création vidéo par l'IA, qui s'est rapidement hissée au sommet de l'App Store après son lancement
La génération de vidéos AI se déplace vers un contrôle complet
Des modèles de fondations vidéo comme Hunyuan et WAN 2.1 ont fait des progrès importants, mais ils échouent souvent en ce qui concerne le contrôle détaillé requis dans la production de films et de télévision, en particulier dans le domaine des effets visuels (VFX). Dans les studios VFX professionnels, ces modèles, ainsi que des bas d'images antérieurs
Recommandations de sujets spéciaux liés
code
 Les meilleurs outils d'analyse de code basés sur l'IA : automatisez la conformité au code propre et refactorisez les fichiers des dépôts hérités
Les meilleurs outils d'analyse de code basés sur l'IA : automatisez la conformité au code propre et refactorisez les fichiers des dépôts hérités
Découvrez les meilleurs outils d'analyse de code par IA de 2026 sur XIX.AI. Notre sélection comprend des outils de premier plan, véritables révolutionnaires, permettant d'automatiser la conformité au code propre et de refactoriser les fichiers de dépôts hérités. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Prenez dès aujourd'hui une longueur d'avance grâce à l'IA.
 10 outils
10 outils
 xix.ai
Synthèse vocale
Les meilleures applications de synthèse vocale basées sur l'IA pour la dyslexie : un soutien à l'apprentissage et à l'efficacité en lecture pour les élèves
xix.ai
Synthèse vocale
Les meilleures applications de synthèse vocale basées sur l'IA pour la dyslexie : un soutien à l'apprentissage et à l'efficacité en lecture pour les élèves
Découvrez les meilleures applications de synthèse vocale par IA de 2026, spécialement sélectionnées pour aider les personnes dyslexiques. Notre classement d'experts compare les outils gratuits et payants, en mettant en avant des fonctionnalités performantes qui améliorent l'efficacité de la lecture et l'apprentissage. Découvrez des solutions révolutionnaires à ne pas manquer pour libérer le potentiel des élèves. Commencez votre parcours sur XIX.AI.
10 outils
xix.ai
Création de bande dessinée
Les meilleurs générateurs IA pour les mangas shonen : créez des séquences d'action survoltées et des effets d'énergie
Découvrez les meilleurs générateurs IA de mangas shonen de 2026 sur XIX.AI. Notre sélection triée sur le volet comprend des outils performants pour créer des séquences d'action à couper le souffle et des effets d'énergie dynamiques. Comparez les options gratuites et payantes grâce à des tests concrets. Libérez votre potentiel créatif et commencez dès aujourd'hui à créer des mangas épiques !
15 outils
xix.ai
Entreprise
Les meilleurs outils de suivi des dépenses basés sur l'IA : numérisez vos reçus et classez automatiquement les dépenses de l'entreprise
Les meilleurs outils de gestion des dépenses basés sur l'IA en 2026 : les outils les mieux notés pour numériser vos reçus et classer automatiquement les dépenses de votre entreprise. Découvrez des solutions puissantes et révolutionnaires pour une gestion des dépenses sans effort, un suivi financier précis et une conformité simplifiée. Notre comparatif, mis à jour chaque semaine, qui oppose les options gratuites aux options payantes, vous aide à trouver la solution qui vous convient le mieux. Tirez pleinement parti de l'IA grâce aux recommandations d'experts de XIX.AI.
10 outils
xix.ai
Entreprise
Les meilleurs outils de recrutement basés sur l'IA : triez les CV et automatisez la planification des entretiens avec les candidats
Découvrez les meilleurs outils de recrutement basés sur l'IA de 2026 sur XIX.AI. Notre sélection propose des solutions performantes et révolutionnaires pour l'analyse des CV et l'automatisation de la planification des entretiens avec les candidats. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Trouvez l'assistant de recrutement idéal et optimisez votre processus de recrutement dès aujourd'hui !
10 outils
xix.ai
Productivité
Coaches IA dédiés au bien-être et à la concentration : gérer l'épuisement professionnel et booster son énergie mentale
Découvrez sur XIX.AI les meilleurs coachs IA de 2026 spécialisés dans le bien-être personnel et la concentration. Notre classement, soigneusement établi, présente les outils les mieux notés et les plus innovants pour gérer le surmenage et booster votre énergie mentale. Comparez les options gratuites et payantes grâce à des avis concrets. Ouvrez-vous dès aujourd’hui la voie vers une productivité et un bien-être optimaux.
10 outils
xix.ai

 commentaires (1)
commentaires (1)
![RalphHill]()
Esse exemplo de vídeo parece meio bugado... Mas a ideia de transformar uma imagem estática em vídeo é fascinante. Será que isso poderia ser usado para criar conteúdos educativos ou de forma indevida? A discussão ética sempre fica atrás da tecnologia 🤔.
Cet article explore le lancement de HunyuanCustom, un modèle de génération vidéo multimodal par Tencent. L'ampleur considérable du document de recherche accompagnant et les défis posés par les vidéos d'exemple fournies sur la page du projet nécessitent une vue d'ensemble plus large, avec une reproduction limitée du contenu vidéo extensif en raison des exigences de formatage et de traitement pour une clarté améliorée.
Notez que le document fait référence au système génératif basé sur API Kling sous le nom de ‘Keling.’ Pour des raisons de cohérence, cet article utilise ‘Kling’ tout au long.
Tencent a introduit une itération avancée de son modèle Hunyuan Video, nommé HunyuanCustom. Cette version surpasserait le besoin des modèles Hunyuan LoRA en permettant aux utilisateurs de créer des personnalisations vidéo de type deepfake en utilisant une seule image :
Cliquez pour jouer. Prompt : ‘Un homme écoute de la musique tout en préparant des nouilles d'escargot dans une cuisine.’ Comparé aux méthodes propriétaires et open-source, y compris Kling, un concurrent clé, HunyuanCustom se distingue. Source : https://hunyuancustom.github.io/ (note : site à forte consommation de ressources)
Dans la vidéo ci-dessus, la colonne la plus à gauche affiche l'image source unique pour HunyuanCustom, suivie de l'interprétation du prompt par le système dans la colonne adjacente. Les colonnes restantes présentent les sorties d'autres systèmes : Kling, Vidu, Pika, Hailuo et SkyReels-A2 (basé sur Wan).
La vidéo suivante met en lumière trois scénarios principaux pour cette version : personne avec objet, réplication d'un personnage unique, et essayage virtuel de vêtements :
Cliquez pour jouer. Trois exemples sélectionnés à partir du site de support Hunyuan Video.
Ces exemples révèlent des limitations liées à l'utilisation d'une image source unique plutôt que de multiples perspectives.
Dans le premier clip, l'homme fait face à la caméra avec un mouvement minimal de la tête, ne s'inclinant pas au-delà de 20-25 degrés. Au-delà de cela, le système peine à déduire précisément son profil à partir d'une seule image frontale.
Dans le deuxième clip, la fille conserve une expression souriante dans la vidéo, reflétant son image source statique. Sans références supplémentaires, HunyuanCustom ne peut pas représenter de manière fiable une expression neutre, et son visage reste largement orienté vers l'avant, similaire à l'exemple précédent.
Dans le clip final, un matériel source incomplet—une femme et des vêtements virtuels—entraîne un rendu tronqué, une solution pratique pour des données limitées.
Bien que HunyuanCustom prenne en charge plusieurs entrées d'images (par exemple, personne avec des collations ou personne avec des vêtements), il ne prend pas en charge des angles ou expressions variés pour un seul personnage. Cela peut limiter sa capacité à remplacer complètement l'écosystème en expansion des modèles LoRA pour HunyuanVideo, qui utilisent 20 à 60 images pour garantir un rendu cohérent du personnage à travers différents angles et expressions.
Intégration audio
Pour l'audio, HunyuanCustom utilise le système LatentSync, difficile à configurer pour les amateurs, pour synchroniser les mouvements des lèvres avec l'audio et le texte fournis par l'utilisateur :
Inclut l'audio. Cliquez pour jouer. Exemples compilés de synchronisation labiale à partir du site supplémentaire de HunyuanCustom.
Actuellement, aucun exemple en langue anglaise n'est disponible, mais les résultats semblent prometteurs, en particulier si le processus de configuration est convivial.
Capacités d'édition vidéo
HunyuanCustom excelle dans l'édition vidéo à vidéo (V2V), permettant le remplacement ciblé d'éléments dans des vidéos existantes à l'aide d'une seule image de référence. Un exemple tiré des matériaux supplémentaires illustre cela :
Cliquez pour jouer. L'objet central est modifié, avec les éléments environnants subtilement altérés dans un processus V2V de HunyuanCustom.
Comme typique dans les flux de travail V2V, l'ensemble de la vidéo est légèrement modifié, avec un accent principal sur la zone ciblée, comme le jouet en peluche. Des pipelines avancés pourraient potentiellement préserver davantage du contenu original, à l'image de l'approche d'Adobe Firefly, bien que cela reste peu exploré dans les communautés open-source.
D'autres exemples démontrent une précision améliorée dans les intégrations ciblées, comme vu dans cette compilation :
Cliquez pour jouer. Exemples variés d'insertion de contenu V2V dans HunyuanCustom, montrant du respect pour les éléments non modifiés.
Mise à niveau évolutive
HunyuanCustom s'appuie sur le projet Hunyuan Video, introduisant des améliorations architecturales ciblées plutôt qu'une refonte complète. Ces mises à jour visent à maintenir la cohérence des personnages à travers les images sans nécessiter d'ajustement spécifique au sujet, comme LoRA ou l'inversion textuelle.
Cette version est une version affinée du modèle HunyuanVideo de décembre 2024, et non un nouveau modèle construit de toutes pièces.
Les utilisateurs des LoRAs existants de HunyuanVideo peuvent se demander si ceux-ci sont compatibles avec cette mise à jour ou si de nouveaux LoRAs doivent être développés pour tirer parti des fonctionnalités de personnalisation améliorées.
En général, un réglage fin important modifie suffisamment les poids du modèle pour rendre les LoRAs précédents incompatibles. Cependant, certains réglages fins, comme Pony Diffusion pour Stable Diffusion XL, ont créé des écosystèmes indépendants avec des bibliothèques LoRA dédiées, suggérant un potentiel pour HunyuanCustom de suivre cette voie.
Détails de la sortie
Le document de recherche, intitulé HunyuanCustom : Une architecture pilotée par le multimodal pour la génération vidéo personnalisée, renvoie à un dépôt GitHub désormais actif avec du code et des poids pour un déploiement local, ainsi qu'une intégration prévue avec ComfyUI.
Actuellement, la page Hugging Face du projet est inaccessible, mais une démo basée sur API est disponible via un code de scan WeChat.
L'assemblage par HunyuanCustom de divers projets est particulièrement complet, probablement motivé par les exigences de licence pour une divulgation complète.
Deux variantes du modèle sont proposées : une version 720x1280px nécessitant 80 Go de mémoire GPU pour des performances optimales (24 Go minimum, mais lente) et une version 512x896px nécessitant 60 Go. Les tests ont été limités à Linux, mais des efforts communautaires pourraient bientôt l'adapter pour Windows et des configurations VRAM plus faibles, comme vu avec le modèle Hunyuan Video précédent.
En raison du volume des matériaux accompagnants, cette vue d'ensemble adopte une approche de haut niveau des capacités de HunyuanCustom.
Perspectives techniques
Le pipeline de données de HunyuanCustom, conforme au RGPD, intègre des ensembles de données vidéo synthétisées et open-source comme OpenHumanVid, couvrant huit catégories : humains, animaux, plantes, paysages, véhicules, objets, architecture, et anime.
À partir du document de sortie, une vue d'ensemble des divers packages contributeurs dans le pipeline de construction de données de HunyuanCustom. Source : https://arxiv.org/pdf/2505.04512
Les vidéos sont segmentées en clips à plan unique à l'aide de PySceneDetect, avec TextBPN-Plus-Plus filtrant le contenu avec trop de texte, sous-titres ou filigranes.
Les clips sont standardisés à cinq secondes et redimensionnés à 512 ou 720 pixels sur le côté court. La qualité esthétique est assurée à l'aide de Koala-36M avec un seuil personnalisé de 0,06.
L'extraction d'identité humaine s'appuie sur Qwen7B, YOLO11X et InsightFace, tandis que les sujets non humains sont traités avec QwenVL et Grounded SAM 2, éliminant les petites boîtes englobantes.
Exemples de segmentation sémantique avec Grounded SAM 2, utilisé dans le projet Hunyuan Control. Source : https://github.com/IDEA-Research/Grounded-SAM-2
L'extraction multi-sujets utilise Florence2 pour l'annotation et Grounded SAM 2 pour la segmentation, suivie d'un regroupement et d'une segmentation temporelle des images.
Les clips sont enrichis avec un étiquetage structuré exclusif par l'équipe Hunyuan, ajoutant des métadonnées comme des descriptions et des indices de mouvement de caméra.
L'augmentation de masque empêche le surajustement, assurant une adaptabilité à des formes d'objets variées. La synchronisation audio utilise LatentSync, éliminant les clips en dessous d'un seuil de qualité. HyperIQA filtre les vidéos scoring en dessous de 40, et Whisper traite l'audio valide pour les tâches en aval.
Le modèle LLaVA joue un rôle central, générant des légendes et alignant le contenu visuel et textuel pour une cohérence sémantique, en particulier dans les scènes complexes ou multi-sujets.
Le cadre HunyuanCustom prend en charge la génération vidéo cohérente avec l'identité, conditionnée par des entrées de texte, d'image, d'audio et de vidéo.
Personnalisation vidéo
Pour permettre la génération vidéo à partir d'une image de référence et d'un prompt, deux modules basés sur LLaVA ont été développés, adaptant l'entrée de HunyuanVideo pour accepter à la fois l'image et le texte. Les prompts intègrent les images directement ou les étiquettent avec de brèves descriptions d'identité, utilisant un jeton séparateur pour équilibrer l'influence de l'image et du texte.
Un module d'amélioration d'identité corrige la tendance de LLaVA à perdre des détails spatiaux fins, cruciaux pour maintenir la cohérence du sujet dans les clips vidéo courts.
L'image de référence est redimensionnée et encodée via le 3D-VAE causal de HunyuanVideo, avec son latent inséré à travers l'axe temporel et un décalage spatial pour guider la génération sans réplication directe.
L'entraînement a utilisé Flow Matching avec du bruit provenant d'une distribution normale logit, ajustant finement LLaVA et le générateur vidéo ensemble pour une guidance cohérente image-prompt et une cohérence d'identité.
Pour les prompts multi-sujets, chaque paire image-texte est intégrée séparément avec des positions temporelles distinctes, permettant des scènes avec plusieurs sujets en interaction.
Intégration audio et visuelle
HunyuanCustom prend en charge la génération pilotée par l'audio en utilisant l'audio et le texte fournis par l'utilisateur, permettant aux personnages de parler dans des contextes pertinents.
Un module AudioNet désentrelacé d'identité aligne les caractéristiques audio avec la chronologie vidéo, utilisant une attention croisée spatiale pour isoler les images et maintenir la cohérence du sujet.
Un module d'injection temporelle affine le timing du mouvement, mappant l'audio sur des séquences latentes via un perceptron multicouche, assurant l'alignement des gestes avec le rythme audio.
Pour l'édition vidéo, HunyuanCustom remplace les sujets dans les clips existants sans régénérer la vidéo entière, idéal pour des changements ciblés d'apparence ou de mouvement.
Cliquez pour jouer. Un autre exemple du site supplémentaire.
Le système compresse les vidéos de référence à l'aide du 3D-VAE causal pré-entraîné, les alignant avec les latents du pipeline de génération pour un traitement léger. Un réseau neuronal aligne les vidéos d'entrée propres avec des latents bruités, l'ajout de caractéristiques image par image s'avérant plus efficace que la fusion pré-compression.
Évaluation des performances
Les métriques de test incluaient ArcFace pour la cohérence d'identité faciale, YOLO11x et Dino 2 pour la similarité des sujets, CLIP-B pour l'alignement texte-vidéo et la cohérence temporelle, et VBench pour l'intensité du mouvement.
Les concurrents incluaient des systèmes fermés (Hailuo, Vidu 2.0, Kling 1.6, Pika) et des cadres open-source (VACE, SkyReels-A2).
Évaluation des performances du modèle comparant HunyuanCustom avec les principales méthodes de personnalisation vidéo à travers la cohérence d'identité (Face-Sim), la similarité des sujets (DINO-Sim), l'alignement texte-vidéo (CLIP-B-T), la cohérence temporelle (Temp-Consis), et l'intensité du mouvement (DD). Les résultats optimaux et sous-optimaux sont affichés en gras et soulignés, respectivement.
Les auteurs notent :
‘HunyuanCustom excelle dans la cohérence d'identité et de sujet, avec une adhérence compétitive au prompt et une stabilité temporelle. Hailuo mène en score de clip grâce à un fort alignement textuel mais lutte avec la cohérence des sujets non humains. Vidu et VACE sont à la traîne en intensité de mouvement, probablement en raison de tailles de modèle plus petites.’
Bien que le site du projet propose de nombreuses vidéos de comparaison, leur disposition privilégie l'esthétique à la facilité de comparaison. Les lecteurs sont encouragés à consulter directement les vidéos pour des idées plus claires :
À partir du document, une comparaison sur la personnalisation vidéo centrée sur les objets. Bien que le spectateur devrait se référer au PDF source pour une meilleure résolution, les vidéos sur le site du projet offrent des idées plus claires.
Les auteurs déclarent :
‘Vidu, SkyReels A2 et HunyuanCustom réalisent un fort alignement au prompt et une cohérence des sujets, mais notre qualité vidéo surpasse Vidu et SkyReels, grâce à la base robuste de Hunyuanvideo-13B.’
‘Parmi les solutions commerciales, Kling offre une vidéo de haute qualité mais souffre d’un effet de copier-coller dans la première image et d’un flou occasionnel du sujet, impactant l’expérience du spectateur.’
Pika lutte avec la cohérence temporelle, introduisant des artefacts de sous-titres dus à une mauvaise curation des données. Hailuo préserve l’identité faciale mais échoue dans la cohérence du corps entier. VACE, parmi les méthodes open-source, ne parvient pas à maintenir la cohérence d’identité, tandis que HunyuanCustom offre une forte préservation d’identité, une qualité et une diversité.
Les tests de personnalisation vidéo multi-sujets ont donné des résultats similaires :
Comparaisons utilisant des personnalisations vidéo multi-sujets. Veuillez consulter le PDF pour plus de détails et de résolution.
Le document note :
‘Pika génère les sujets spécifiés mais montre une instabilité des images, avec des sujets disparaissant ou ne suivant pas les prompts. Vidu et VACE capturent partiellement l’identité humaine mais perdent les détails des objets non humains. SkyReels A2 souffre d’une instabilité sévère des images et d’artefacts. HunyuanCustom capture efficacement toutes les identités des sujets, adhère aux prompts et maintient une haute qualité visuelle et une stabilité.’
Un test de publicité humaine virtuelle a intégré des produits avec des personnes :
À partir du tour de test qualitatif, exemples de placement de produit neuronal. Veuillez consulter le PDF pour plus de détails et de résolution.
Les auteurs déclarent :
‘HunyuanCustom maintient l’identité humaine et les détails du produit, y compris le texte, avec des interactions naturelles et une forte adhérence au prompt, démontrant son potentiel pour les vidéos publicitaires.’
Les tests de personnalisation pilotée par l’audio ont mis en évidence un contrôle flexible des scènes et des postures :
Résultats partiels pour le tour audio – des résultats vidéo seraient préférables. Seule la moitié supérieure de la figure PDF est montrée en raison de contraintes de taille. Veuillez consulter le PDF source pour plus de détails.
Les auteurs notent :
‘Les méthodes pilotées par l’audio précédentes limitent la posture et l’environnement à l’image d’entrée, restreignant les applications. HunyuanCustom permet une animation pilotée par l’audio flexible avec des scènes et des postures décrites par texte.’
Les tests de remplacement de sujet vidéo ont comparé HunyuanCustom à VACE et Kling 1.6 :
Test de remplacement de sujet en mode vidéo à vidéo. Veuillez consulter le PDF source pour plus de détails et de résolution.
Les chercheurs déclarent :
‘VACE produit des artefacts de frontière en raison d’une adhérence stricte au masque, perturbant la continuité du mouvement. Kling montre un effet de copier-coller avec une mauvaise intégration de l’arrière-plan. HunyuanCustom évite les artefacts, assure une intégration fluide et maintient une forte préservation de l’identité, excellant dans l’édition vidéo.’
Conclusion
HunyuanCustom est une version convaincante, répondant à la demande croissante de synchronisation labiale dans la synthèse vidéo, améliorant le réalisme dans des systèmes comme Hunyuan Video. Malgré les défis pour comparer ses capacités en raison de la disposition des vidéos sur le site du projet, le modèle de Tencent tient tête aux principaux concurrents comme Kling, marquant des progrès significatifs dans la génération vidéo personnalisée.
* Certaines vidéos sont trop larges, courtes ou en haute résolution pour être lues dans des lecteurs standards comme VLC ou Windows Media Player, affichant des écrans noirs.
Première publication le jeudi 8 mai 2025










 Exclusivité : Luma AI lance des agents créatifs alimentés par des modèles d'« intelligence unifiée »
Jeudi, la start-up spécialisée dans la génération de vidéos par IA Luma a présenté Luma Agents, un système conçu pour gérer l'ensemble des workflows créatifs, qu'il s'agisse de texte, d
Exclusivité : Luma AI lance des agents créatifs alimentés par des modèles d'« intelligence unifiée »
Jeudi, la start-up spécialisée dans la génération de vidéos par IA Luma a présenté Luma Agents, un système conçu pour gérer l'ensemble des workflows créatifs, qu'il s'agisse de texte, d
 La nouvelle mise à jour de Sora propose des vidéos sur l'intelligence artificielle des animaux de compagnie, des outils sociaux et une nouvelle application Android.
OpenAI présente en avant-première une vague de nouvelles fonctionnalités pour Sora, son application de création vidéo par l'IA, qui s'est rapidement hissée au sommet de l'App Store après son lancement
La nouvelle mise à jour de Sora propose des vidéos sur l'intelligence artificielle des animaux de compagnie, des outils sociaux et une nouvelle application Android.
OpenAI présente en avant-première une vague de nouvelles fonctionnalités pour Sora, son application de création vidéo par l'IA, qui s'est rapidement hissée au sommet de l'App Store après son lancement
 La génération de vidéos AI se déplace vers un contrôle complet
Des modèles de fondations vidéo comme Hunyuan et WAN 2.1 ont fait des progrès importants, mais ils échouent souvent en ce qui concerne le contrôle détaillé requis dans la production de films et de télévision, en particulier dans le domaine des effets visuels (VFX). Dans les studios VFX professionnels, ces modèles, ainsi que des bas d'images antérieurs
La génération de vidéos AI se déplace vers un contrôle complet
Des modèles de fondations vidéo comme Hunyuan et WAN 2.1 ont fait des progrès importants, mais ils échouent souvent en ce qui concerne le contrôle détaillé requis dans la production de films et de télévision, en particulier dans le domaine des effets visuels (VFX). Dans les studios VFX professionnels, ces modèles, ainsi que des bas d'images antérieurs

Découvrez les meilleurs outils d'analyse de code par IA de 2026 sur XIX.AI. Notre sélection comprend des outils de premier plan, véritables révolutionnaires, permettant d'automatiser la conformité au code propre et de refactoriser les fichiers de dépôts hérités. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Prenez dès aujourd'hui une longueur d'avance grâce à l'IA.
10 outils
xix.ai

Découvrez les meilleures applications de synthèse vocale par IA de 2026, spécialement sélectionnées pour aider les personnes dyslexiques. Notre classement d'experts compare les outils gratuits et payants, en mettant en avant des fonctionnalités performantes qui améliorent l'efficacité de la lecture et l'apprentissage. Découvrez des solutions révolutionnaires à ne pas manquer pour libérer le potentiel des élèves. Commencez votre parcours sur XIX.AI.
10 outils
xix.ai

Découvrez les meilleurs générateurs IA de mangas shonen de 2026 sur XIX.AI. Notre sélection triée sur le volet comprend des outils performants pour créer des séquences d'action à couper le souffle et des effets d'énergie dynamiques. Comparez les options gratuites et payantes grâce à des tests concrets. Libérez votre potentiel créatif et commencez dès aujourd'hui à créer des mangas épiques !
15 outils
xix.ai

Les meilleurs outils de gestion des dépenses basés sur l'IA en 2026 : les outils les mieux notés pour numériser vos reçus et classer automatiquement les dépenses de votre entreprise. Découvrez des solutions puissantes et révolutionnaires pour une gestion des dépenses sans effort, un suivi financier précis et une conformité simplifiée. Notre comparatif, mis à jour chaque semaine, qui oppose les options gratuites aux options payantes, vous aide à trouver la solution qui vous convient le mieux. Tirez pleinement parti de l'IA grâce aux recommandations d'experts de XIX.AI.
10 outils
xix.ai

Découvrez les meilleurs outils de recrutement basés sur l'IA de 2026 sur XIX.AI. Notre sélection propose des solutions performantes et révolutionnaires pour l'analyse des CV et l'automatisation de la planification des entretiens avec les candidats. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Trouvez l'assistant de recrutement idéal et optimisez votre processus de recrutement dès aujourd'hui !
10 outils
xix.ai

Découvrez sur XIX.AI les meilleurs coachs IA de 2026 spécialisés dans le bien-être personnel et la concentration. Notre classement, soigneusement établi, présente les outils les mieux notés et les plus innovants pour gérer le surmenage et booster votre énergie mentale. Comparez les options gratuites et payantes grâce à des avis concrets. Ouvrez-vous dès aujourd’hui la voie vers une productivité et un bien-être optimaux.
10 outils
xix.ai

Esse exemplo de vídeo parece meio bugado... Mas a ideia de transformar uma imagem estática em vídeo é fascinante. Será que isso poderia ser usado para criar conteúdos educativos ou de forma indevida? A discussão ética sempre fica atrás da tecnologia 🤔.













