
















 家
家TencentがHunyuanCustomを発表、単一画像でのビデオカスタマイズが可能
この記事では、Tencentが発表したマルチモーダルビデオ生成モデルであるHunyuanCustomのリリースについて探ります。付随する研究論文の広範な内容とプロジェクトページに提供されたサンプルビデオの課題により、フォーマットと処理の要件により広範な概要が必要であり、広範なビデオコンテンツの再現は限定的です。
なお、論文ではAPIベースの生成システムKlingを「Keling」と記載しています。一貫性を保つため、この記事では「Kling」を使用します。
Tencentは、Hunyuan Videoモデルの進化したバージョンであるHunyuanCustomを導入しました。このリリースは、単一の画像を使用してディープフェイク風のビデオカスタマイズを可能にすることで、Hunyuan LoRAモデルを不要にするとされています:
クリックして再生。プロンプト:「キッチンで男性が音楽を楽しみながらスネイルヌードルを調理する。」Klingを含む独自およびオープンソースの方法と比較して、HunyuanCustomは際立っています。 出典:https://hunyuancustom.github.io/(注意:リソースを多く消費するサイト)
上記のビデオでは、最左列にHunyuanCustomの単一ソース画像入力が表示され、隣の列にはシステムによるプロンプトの解釈が示されています。残りの列には、Kling、Vidu、Pika、Hailuo、SkyReels-A2(Wanベース)の他のシステムの出力が表示されています。
次のビデオでは、このリリースの3つの主要なシナリオが強調されています:人物とオブジェクト、単一キャラクターの再現、仮想試着:
クリックして再生。Hunyuan Videoサポートサイトからの3つの厳選された例。
これらの例は、単一のソース画像に依存することによる限界を示しています。
最初のクリップでは、男性がカメラに向かってほとんど頭を動かさず、20〜25度以上傾けません。それを超えると、システムは単一の正面画像から正確なプロフィールを推測するのに苦労します。
2番目のクリップでは、少女がビデオで笑顔の表情を維持し、静的なソース画像を反映しています。追加の参照がない場合、HunyuanCustomは彼女の無表情を確実に描写できず、顔はほぼ正面を向いたままです。
最後のクリップでは、不完全なソース素材(女性と仮想の衣類)により、限られたデータに対する実際的な回避策として、トリミングされたレンダリングが行われます。
HunyuanCustomは、複数の画像入力(例:スナックを持つ人物や服装を持つ人物)をサポートしますが、単一キャラクターのさまざまな角度や表情には対応していません。これは、HunyuanVideoのLoRAモデルが20〜60枚の画像を使用して角度や表情を一貫してレンダリングするエコシステムを完全に置き換える能力を制限する可能性があります。
オーディオ統合
オーディオについては、HunyuanCustomはLatentSyncシステムを採用し、ユーザーが提供するオーディオとテキストでリップの動きを同期させますが、ホビーストには設定が難しいです:
オーディオ付き。クリックして再生。HunyuanCustom補足サイトからのリップシンク例の編集。
現在、英語の例は利用できませんが、設定プロセスがユーザーフレンドリーであれば、結果は有望に見えます。
ビデオ編集機能
HunyuanCustomは、ビデオからビデオ(V2V)編集に優れており、単一の参照画像を使用して既存のビデオ内の要素を選択的に置き換えることができます。補足資料からの例がこれを示しています:
クリックして再生。中央のオブジェクトが変更され、周辺要素がHunyuanCustomのV2Vプロセスで微妙に変更されています。
V2Vワークフローでは通常、ビデオ全体がわずかに変更され、対象エリア(例:ぬいぐるみ)に主な焦点が当てられます。Adobe Fireflyのような高度なパイプラインは、元のコンテンツをより多く保持する可能性がありますが、これはオープンソースコミュニティではあまり探究されていません。
他の例では、統合の精度が向上していることが示されています:
クリックして再生。HunyuanCustomでのV2Vコンテンツ挿入のさまざまな例で、変更されていない要素を尊重しています。
進化的アップグレード
HunyuanCustomは、Hunyuan Videoプロジェクトを基盤に、完全なオーバーホールではなく、ターゲットを絞ったアーキテクチャの強化を導入しています。これらのアップグレードは、LoRAやテキスト反転などの主題固有の微調整を必要とせずに、フレーム間でキャラクターの一貫性を維持することを目指しています。
このリリースは、2024年12月のHunyuanVideoモデルの改良版であり、ゼロから構築された新しいモデルではありません。
既存のHunyuanVideo LoRAのユーザーは、このアップデートとの互換性や、強化されたカスタマイズ機能を活用するために新しいLoRAを開発する必要があるか疑問に思うかもしれません。
通常、大きな微調整はモデルの重みを十分に変更し、以前のLoRAを互換性のないものにします。しかし、Stable Diffusion XLのPony Diffusionのような一部の微調整は、専用のLoRAライブラリを持つ独立したエコシステムを生み出しており、HunyuanCustomも同様の可能性を示唆しています。
リリース詳細
研究論文「HunyuanCustom: カスタマイズされたビデオ生成のためのマルチモーダル駆動アーキテクチャ」は、GitHubリポジトリにリンクしており、現在コードとウェイトがローカル展開用に公開されており、ComfyUIとの統合も計画されています。
現在、プロジェクトのHugging Faceページにはアクセスできませんが、WeChatスキャンコードを介してAPIベースのデモが利用可能です。
HunyuanCustomの多様なプロジェクトの組み立ては、完全な開示のためのライセンス要件によって駆動されている可能性があり、非常に包括的です。
2つのモデルバリアントが提供されています:最適なパフォーマンスに80GBのGPUメモリを必要とする720x1280pxバージョン(最小24GB、ただし遅い)と、60GBを必要とする512x896pxバージョンです。テストはLinuxに限定されていますが、コミュニティの努力により、以前のHunyuan Videoモデルと同様に、Windowsや低VRAM構成への適応がまもなく行われる可能性があります。
付属資料の量が多いため、この概要はHunyuanCustomの機能を高レベルで取り上げています。
技術的洞察
HunyuanCustomのデータパイプラインは、GDPRに準拠しており、OpenHumanVidなどの合成およびオープンソースのビデオデータセットを統合し、8つのカテゴリをカバーしています:人間、動物、植物、風景、車両、オブジェクト、建築、アニメ。
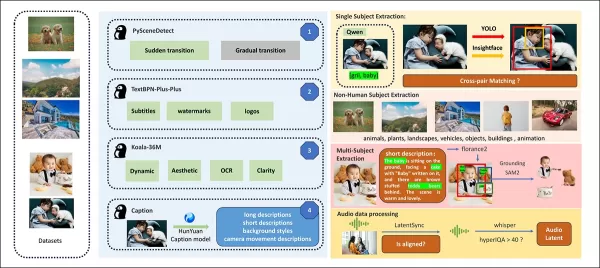
リリース論文からの、HunyuanCustomデータ構築パイプラインにおける多様な貢献パッケージの概要。 出典:https://arxiv.org/pdf/2505.04512
ビデオはPySceneDetectを使用してシングルショットクリップに分割され、TextBPN-Plus-Plusが過剰なテキスト、字幕、または透かしを持つコンテンツをフィルタリングします。
クリップは5秒に標準化され、短辺が512または720ピクセルにリサイズされます。美的品質は、Koala-36Mを使用してカスタム0.06閾値で保証されます。
人間のアイデンティティ抽出は、Qwen7B、YOLO11X、InsightFaceを活用し、非人間の被写体はQwenVLとGrounded SAM 2で処理され、小さなバウンディングボックスは破棄されます。

Hunyuan Controlプロジェクトで使用されたGrounded SAM 2によるセマンティックセグメンテーションの例。 出典:https://github.com/IDEA-Research/Grounded-SAM-2
複数被写体の抽出は、Florence2でアノテーションを行い、Grounded SAM 2でセグメンテーションを行い、クラスタリングと時間的フレームセグメンテーションが続きます。
クリップは、Hunyuanチームによる独自の構造化ラベリングで強化され、説明やカメラモーションの手がかりなどのメタデータが追加されます。
マスク拡張は、さまざまなオブジェクト形状への適応性を確保し、オーバーフィッティングを防ぎます。オーディオ同期はLatentSyncを使用し、品質閾値以下のクリップを破棄します。HyperIQAはスコア40未満のビデオをフィルタリングし、Whisperは有効なオーディオを下流タスクに処理します。
LLaVAモデルは、キャプション生成と視覚的およびテキストコンテンツのセマンティック一貫性の調整に中心的な役割を果たし、特に複雑または複数被写体のシーンで効果的です。
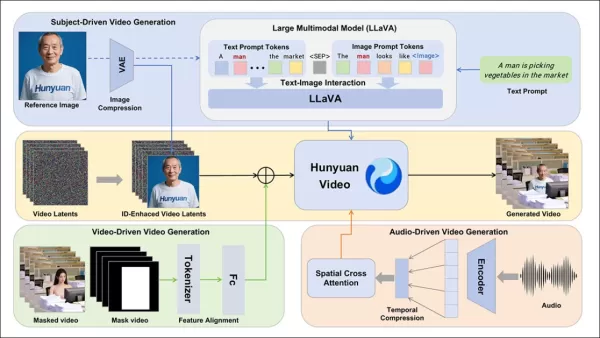
HunyuanCustomフレームワークは、テキスト、画像、オーディオ、ビデオ入力に基づくアイデンティティ一貫性のあるビデオ生成をサポートします。
ビデオカスタマイズ
参照画像とプロンプトからのビデオ生成を可能にするため、HunyuanVideoの入力を画像とテキストの両方を受け入れるように適応させた2つのLLaVAベースのモジュールが開発されました。プロンプトは画像を直接埋め込むか、簡潔なアイデンティティ記述でタグ付けし、セパレータトークンを使用して画像とテキストの影響をバランスさせます。
アイデンティティ強化モジュールは、LLaVAが細かい空間的詳細を失う傾向に対処し、短いビデオクリップで被写体の一貫性を維持するために重要です。
参照画像は、HunyuanVideoの因果3D-VAEを介してリサイズおよびエンコードされ、その潜在表現が時間軸全体に挿入され、直接的な複製なしに生成を導くための空間的オフセットが施されます。
トレーニングでは、Flow Matchingをロジット正規分布からのノイズで使用し、LLaVAとビデオジェネレータを一緒に微調整して、画像プロンプトガイダンスとアイデンティティの一貫性を確保します。
複数被写体のプロンプトの場合、各画像-テキストペアは異なる時間的位置で個別に埋め込まれ、複数の相互作用する被写体を持つシーンを可能にします。
オーディオとビジュアルの統合
HunyuanCustomは、ユーザーが提供するオーディオとテキストを使用したオーディオ駆動の生成をサポートし、キャラクターが文脈的に関連する設定で話すことを可能にします。
アイデンティティ分離型AudioNetモジュールは、オーディオ機能をビデオタイムラインに合わせ、空間クロスアテンションを使用してフレームを分離し、被写体の一貫性を維持します。
時間的注入モジュールは、モーションタイミングを洗練し、マルチレイヤーパーセプトロンを介してオーディオを潜在シーケンスにマッピングし、ジェスチャーがオーディオリズムに一致するようにします。
ビデオ編集では、HunyuanCustomはビデオ全体を再生成せずに既存のクリップ内の被写体を置き換え、外観やモーションのターゲット変更に最適です。
クリックして再生。補足サイトからの別の例。
システムは、事前トレーニングされた因果3D-VAEを使用して参照ビデオを圧縮し、生成パイプラインプロセスに合わせ、軽量な処理を行います。ニューラルネットワークは、クリーンな入力ビデオをノイズ付き潜在表現に合わせ、フレームごとの特徴追加が事前圧縮マージよりも効果的であることが証明されています。
パフォーマンス評価
テスト指標には、顔のアイデンティティ一貫性のためのArcFace、被写体の類似性のためのYOLO11xおよびDino 2、テキスト-ビデオアライメントおよび時間的一貫性のためのCLIP-B、モーション強度ののためのVBenchが含まれます。
競合他社には、クローズドソースシステム(Hailuo、Vidu 2.0、Kling 1.6、Pika)およびオープンソースフレームワーク(VACE、SkyReels-A2)が含まれます。
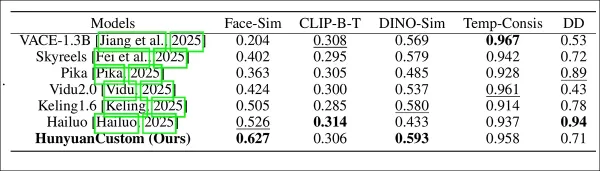
HunyuanCustomと主要なビデオカスタマイズ方法を、ID一貫性(Face-Sim)、被写体類似性(DINO-Sim)、テキスト-ビデオアライメント(CLIP-B-T)、時間的一貫性(Temp-Consis)、モーション強度(DD)で比較したモデルパフォーマンス評価。最適および準最適の結果は、それぞれ太字および下線で示されています。
著者は次のように述べています:
「HunyuanCustomは、IDおよび被写体の一貫性で優れており、プロンプトの順守と時間的安定性でも競争力があります。Hailuoはテキストアライメントの強さによりクリップスコアでリードしていますが、非人間の被写体の一貫性に苦労します。ViduおよびVACEは、モデルサイズが小さいためか、モーション強度で遅れています。」
プロジェクトサイトには多数の比較ビデオがありますが、そのレイアウトは比較のしやすさよりも美観を優先しています。読者は、より明確な洞察を得るためにビデオを直接確認することをお勧めします:
論文からの、オブジェクト中心のビデオカスタマイズの比較。視聴者は、より高い解像度のためにソースPDFを参照する必要がありますが、プロジェクトサイトのビデオはより明確な洞察を提供します。
著者は述べています:
「Vidu、SkyReels A2、HunyuanCustomは、プロンプトアライメントと被写体の一貫性で強い結果を達成していますが、Hunyuanvideo-13Bの強固な基盤のおかげで、ビデオ品質はViduおよびSkyReelsを上回ります。」
「商用ソリューションの中では、Klingは高品質のビデオを提供しますが、最初のフレームでのコピーペースト効果や、時折の被写体のぼやけが視聴体験に影響を与えます。」
Pikaは時間的一貫性に苦労し、データキュレーションの不備による字幕アーティファクトを導入します。Hailuoは顔のアイデンティティを保持しますが、全身の一貫性に欠けます。オープンソースの方法の中では、VACEはアイデンティティの一貫性を維持できず、HunyuanCustomは強いアイデンティティ保持、品質、多様性を提供します。
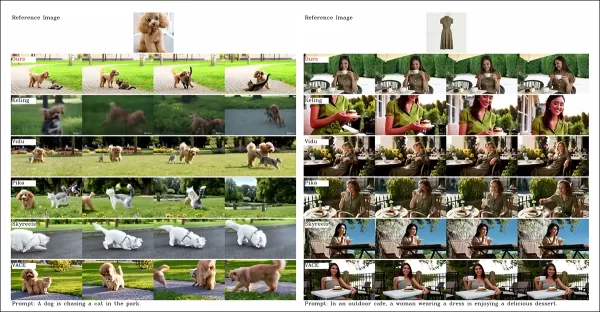
複数被写体のビデオカスタマイズテストでも同様の結果が得られました:

複数被写体を使用したビデオカスタマイズの比較。詳細と解像度のためにPDFを参照してください。
論文は次のように指摘しています:
「Pikaは指定された被写体を生成しますが、フレームの不安定性を示し、被写体が消えたりプロンプトに従わなかったりします。ViduおよびVACEは人間のアイデンティティを部分的に捉えますが、非人間のオブジェクトの詳細を失います。SkyReels A2は深刻なフレームの不安定性とアーティファクトに悩まされます。HunyuanCustomはすべての被写体のアイデンティティを効果的に捉え、プロンプトに準拠し、高い視覚的品質と安定性を維持します。」
仮想人間の広告テストでは、製品と人々を統合しました:

定性的テストラウンドからの、ニューラル「プロダクトプレイスメント」の例。詳細と解像度のためにPDFを参照してください。
著者は述べています:
「HunyuanCustomは、人間のアイデンティティと製品の詳細(テキストを含む)を維持し、自然な相互作用と強いプロンプト順守を示し、広告ビデオの可能性を示しています。」
オーディオ駆動のカスタマイズテストでは、柔軟なシーンと姿勢制御が強調されました:
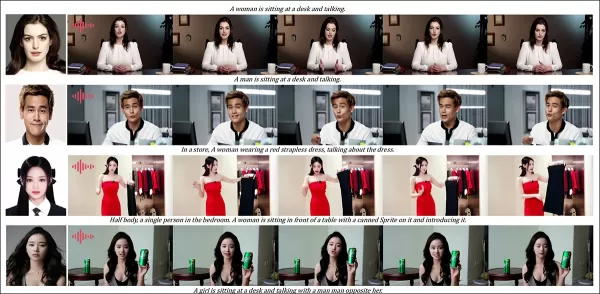
オーディオラウンドの部分的な結果—ビデオ結果が望ましい。サイズの制約により、PDF図の上の半分のみが表示されています。詳細のためにソースPDFを参照してください。
著者は次のように指摘しています:
「従来のオーディオ駆動方法は、姿勢と環境を入力画像に制限し、アプリケーションを制限します。HunyuanCustomは、テキストで記述されたシーンと姿勢で柔軟なオーディオ駆動アニメーションを可能にします。」
ビデオ被写体置換テストでは、HunyuanCustomをVACEおよびKling 1.6と比較しました:

ビデオからビデオモードでの被写体置換のテスト。詳細と解像度のためにソースPDFを参照してください。
研究者は次のように述べています:
「VACEは厳格なマスク順守による境界アーティファクトを生成し、モーションの連続性を乱します。Klingはコピーペースト効果を示し、背景の統合が不十分です。HunyuanCustomはアーティファクトを回避し、シームレスな統合を確保し、強いアイデンティティ保持を提供し、ビデオ編集で優れています。」
結論
HunyuanCustomは、ビデオ合成におけるリップシンクの需要の高まりに対応し、Hunyuan Videoのようなシステムのリアリズムを強化する魅力的なリリースです。プロジェクトサイトのビデオレイアウトによる比較の課題にもかかわらず、TencentのモデルはKlingなどのトップ競合他社と互角に戦い、カスタマイズされたビデオ生成における大きな進歩を示しています。
* 一部のビデオは幅が広すぎたり、短すぎたり、高解像度すぎたりするため、VLCやWindows Media Playerなどの標準プレーヤーで再生できず、黒い画面が表示されます。
初公開:2025年5月8日木曜日
関連記事
 独占:Luma AI、『統合インテリジェンス』モデルを搭載したクリエイティブエージェントを発表
木曜日、AI動画生成スタートアップのLumaは、テキスト・画像・動画・音声にまたがる完全なクリエイティブワークフローを管理するシステム「Luma Agents」を発表した。これらのエージェントは、単一のマルチモーダル推論エンジンとして訓練されたアーキテクチャを特徴とするLumaのUnified Intelligenceモデルファミリーによって駆動される。Lumaは、広告代理店、マーケティング部門、
Soraの新アップデートでペットAI動画、ソーシャルツール、Androidアプリが登場
OpenAIは、9月下旬のローンチ後、App Storeのトップに急浮上したブレイク中のAI動画作成アプリ「Sora」の新機能を相次いでプレビューしている。米国とカナダで現在も1位をキープしているこのアプリは、近日中に動画編集機能を追加し、ユーザーがペットやその他のアイテムのキャラクター「カメオ」を作成したり、ソーシャル機能を強化したりする予定だ。同社はまた、Android版が "実際に間もなくリ
AIビデオ生成は完全な制御に向かって移動します
HunyuanやWAN 2.1のようなビデオファンデーションモデルは大きな進歩を遂げましたが、映画やテレビ制作、特に視覚効果(VFX)で必要な詳細なコントロールに関しては、しばしば不足しています。プロのVFXスタジオでは、これらのモデルと以前の画像バスとともに
関連特集おすすめ
テキスト読み上げ
独占:Luma AI、『統合インテリジェンス』モデルを搭載したクリエイティブエージェントを発表
木曜日、AI動画生成スタートアップのLumaは、テキスト・画像・動画・音声にまたがる完全なクリエイティブワークフローを管理するシステム「Luma Agents」を発表した。これらのエージェントは、単一のマルチモーダル推論エンジンとして訓練されたアーキテクチャを特徴とするLumaのUnified Intelligenceモデルファミリーによって駆動される。Lumaは、広告代理店、マーケティング部門、
Soraの新アップデートでペットAI動画、ソーシャルツール、Androidアプリが登場
OpenAIは、9月下旬のローンチ後、App Storeのトップに急浮上したブレイク中のAI動画作成アプリ「Sora」の新機能を相次いでプレビューしている。米国とカナダで現在も1位をキープしているこのアプリは、近日中に動画編集機能を追加し、ユーザーがペットやその他のアイテムのキャラクター「カメオ」を作成したり、ソーシャル機能を強化したりする予定だ。同社はまた、Android版が "実際に間もなくリ
AIビデオ生成は完全な制御に向かって移動します
HunyuanやWAN 2.1のようなビデオファンデーションモデルは大きな進歩を遂げましたが、映画やテレビ制作、特に視覚効果(VFX)で必要な詳細なコントロールに関しては、しばしば不足しています。プロのVFXスタジオでは、これらのモデルと以前の画像バスとともに
関連特集おすすめ
テキスト読み上げ
 ディスレクシアに最適なAI音声合成アプリ:生徒の学習と読解力の向上をサポート
ディスレクシアに最適なAI音声合成アプリ:生徒の学習と読解力の向上をサポート
ディスレクシア支援のために厳選された、2026年最新の最高評価AI TTSアプリをご紹介します。専門家によるランキングでは、無料ツールと有料ツールを比較し、読解効率と学習効果を高める強力な機能を詳しく解説しています。生徒の可能性を引き出す、ぜひ試すべき画期的なソリューションをご覧ください。XIX.AIでその第一歩を踏み出しましょう。
 10 ツール
10 ツール
 xix.ai
漫画制作
少年漫画向けトップAIジェネレーター:迫力満点のアクションシーンやエネルギーエフェクトを作成
xix.ai
漫画制作
少年漫画向けトップAIジェネレーター:迫力満点のアクションシーンやエネルギーエフェクトを作成
XIX.AIで、2026年のおすすめ少年漫画向けAIジェネレーターをご紹介します。厳選されたトップクラスのリストには、迫力満点のアクションシーンや躍動感あふれるエフェクトを作成できる強力なツールが揃っています。実際のテスト結果をもとに、無料版と有料版の比較も可能です。あなたの創造力を解き放ち、今日から壮大な漫画の制作を始めましょう!
15 ツール
xix.ai
仕事
おすすめのAI経費管理ツール:レシートをスキャンして、業務経費を自動分類
2026年最新・最高のAI経費管理ツール:レシートをスキャンし、法人経費を自動分類する高評価ツールをご紹介。手間いらずの経費管理、正確な財務追跡、コンプライアンス対応の効率化を実現する、画期的なソリューションをご覧ください。無料版と有料版の比較表は厳選され、毎週更新されるため、最適なツール選びにお役立ていただけます。XIX.AIの専門家が厳選したツールで、AIの力を最大限に活用しましょう。
10 ツール
xix.ai
仕事
おすすめのAI採用ツール:履歴書の選考と候補者の面接スケジュール管理を自動化
XIX.AIで、2026年最新の評価の高いAI採用ツールをチェックしましょう。厳選されたリストには、履歴書のスクリーニングや候補者の面接スケジュール管理を自動化する、強力で画期的なソリューションが揃っています。実際のテスト結果や毎週更新されるランキングを参考に、無料版と有料版の比較が可能です。最適な採用アシスタントを見つけて、今すぐ採用業務を効率化しましょう!
10 ツール
xix.ai
生産性
AIパーソナルウェルネス&集中力コーチ:バーンアウトの予防とメンタルエネルギーの向上
XIX.AIで、2026年最高のAIパーソナルウェルネス&集中力向上ツールをご紹介。厳選されたランキングでは、バーンアウトの解消やメンタルエネルギーの向上に役立つ、高評価で画期的なツールを取り上げています。実際のユーザーの声をもとに、無料版と有料版の比較も可能です。今すぐ、最高の生産性とウェルビーイングへの道を開きましょう。
10 ツール
xix.ai
チャットボット
高評価のAI恋愛チャットボット:一貫した個性で長期的な関係を築く
2026年版、本物の長期的なつながりを築くための、高評価のAI恋愛チャットボットをご紹介します。厳選されたリストには、魅力的で一貫性のあるキャラクター、無料版と有料版の比較、そして実地テストの結果が掲載されています。あなたにぴったりのパートナーを見つけて、今すぐXIX.AIで関係を築き始めましょう。
10 ツール
xix.ai

 コメント (1)
0/500
コメント (1)
0/500
![RalphHill]()
Esse exemplo de vídeo parece meio bugado... Mas a ideia de transformar uma imagem estática em vídeo é fascinante. Será que isso poderia ser usado para criar conteúdos educativos ou de forma indevida? A discussão ética sempre fica atrás da tecnologia 🤔.
この記事では、Tencentが発表したマルチモーダルビデオ生成モデルであるHunyuanCustomのリリースについて探ります。付随する研究論文の広範な内容とプロジェクトページに提供されたサンプルビデオの課題により、フォーマットと処理の要件により広範な概要が必要であり、広範なビデオコンテンツの再現は限定的です。
なお、論文ではAPIベースの生成システムKlingを「Keling」と記載しています。一貫性を保つため、この記事では「Kling」を使用します。
Tencentは、Hunyuan Videoモデルの進化したバージョンであるHunyuanCustomを導入しました。このリリースは、単一の画像を使用してディープフェイク風のビデオカスタマイズを可能にすることで、Hunyuan LoRAモデルを不要にするとされています:
クリックして再生。プロンプト:「キッチンで男性が音楽を楽しみながらスネイルヌードルを調理する。」Klingを含む独自およびオープンソースの方法と比較して、HunyuanCustomは際立っています。 出典:https://hunyuancustom.github.io/(注意:リソースを多く消費するサイト)
上記のビデオでは、最左列にHunyuanCustomの単一ソース画像入力が表示され、隣の列にはシステムによるプロンプトの解釈が示されています。残りの列には、Kling、Vidu、Pika、Hailuo、SkyReels-A2(Wanベース)の他のシステムの出力が表示されています。
次のビデオでは、このリリースの3つの主要なシナリオが強調されています:人物とオブジェクト、単一キャラクターの再現、仮想試着:
クリックして再生。Hunyuan Videoサポートサイトからの3つの厳選された例。
これらの例は、単一のソース画像に依存することによる限界を示しています。
最初のクリップでは、男性がカメラに向かってほとんど頭を動かさず、20〜25度以上傾けません。それを超えると、システムは単一の正面画像から正確なプロフィールを推測するのに苦労します。
2番目のクリップでは、少女がビデオで笑顔の表情を維持し、静的なソース画像を反映しています。追加の参照がない場合、HunyuanCustomは彼女の無表情を確実に描写できず、顔はほぼ正面を向いたままです。
最後のクリップでは、不完全なソース素材(女性と仮想の衣類)により、限られたデータに対する実際的な回避策として、トリミングされたレンダリングが行われます。
HunyuanCustomは、複数の画像入力(例:スナックを持つ人物や服装を持つ人物)をサポートしますが、単一キャラクターのさまざまな角度や表情には対応していません。これは、HunyuanVideoのLoRAモデルが20〜60枚の画像を使用して角度や表情を一貫してレンダリングするエコシステムを完全に置き換える能力を制限する可能性があります。
オーディオ統合
オーディオについては、HunyuanCustomはLatentSyncシステムを採用し、ユーザーが提供するオーディオとテキストでリップの動きを同期させますが、ホビーストには設定が難しいです:
オーディオ付き。クリックして再生。HunyuanCustom補足サイトからのリップシンク例の編集。
現在、英語の例は利用できませんが、設定プロセスがユーザーフレンドリーであれば、結果は有望に見えます。
ビデオ編集機能
HunyuanCustomは、ビデオからビデオ(V2V)編集に優れており、単一の参照画像を使用して既存のビデオ内の要素を選択的に置き換えることができます。補足資料からの例がこれを示しています:
クリックして再生。中央のオブジェクトが変更され、周辺要素がHunyuanCustomのV2Vプロセスで微妙に変更されています。
V2Vワークフローでは通常、ビデオ全体がわずかに変更され、対象エリア(例:ぬいぐるみ)に主な焦点が当てられます。Adobe Fireflyのような高度なパイプラインは、元のコンテンツをより多く保持する可能性がありますが、これはオープンソースコミュニティではあまり探究されていません。
他の例では、統合の精度が向上していることが示されています:
クリックして再生。HunyuanCustomでのV2Vコンテンツ挿入のさまざまな例で、変更されていない要素を尊重しています。
進化的アップグレード
HunyuanCustomは、Hunyuan Videoプロジェクトを基盤に、完全なオーバーホールではなく、ターゲットを絞ったアーキテクチャの強化を導入しています。これらのアップグレードは、LoRAやテキスト反転などの主題固有の微調整を必要とせずに、フレーム間でキャラクターの一貫性を維持することを目指しています。
このリリースは、2024年12月のHunyuanVideoモデルの改良版であり、ゼロから構築された新しいモデルではありません。
既存のHunyuanVideo LoRAのユーザーは、このアップデートとの互換性や、強化されたカスタマイズ機能を活用するために新しいLoRAを開発する必要があるか疑問に思うかもしれません。
通常、大きな微調整はモデルの重みを十分に変更し、以前のLoRAを互換性のないものにします。しかし、Stable Diffusion XLのPony Diffusionのような一部の微調整は、専用のLoRAライブラリを持つ独立したエコシステムを生み出しており、HunyuanCustomも同様の可能性を示唆しています。
リリース詳細
研究論文「HunyuanCustom: カスタマイズされたビデオ生成のためのマルチモーダル駆動アーキテクチャ」は、GitHubリポジトリにリンクしており、現在コードとウェイトがローカル展開用に公開されており、ComfyUIとの統合も計画されています。
現在、プロジェクトのHugging Faceページにはアクセスできませんが、WeChatスキャンコードを介してAPIベースのデモが利用可能です。
HunyuanCustomの多様なプロジェクトの組み立ては、完全な開示のためのライセンス要件によって駆動されている可能性があり、非常に包括的です。
2つのモデルバリアントが提供されています:最適なパフォーマンスに80GBのGPUメモリを必要とする720x1280pxバージョン(最小24GB、ただし遅い)と、60GBを必要とする512x896pxバージョンです。テストはLinuxに限定されていますが、コミュニティの努力により、以前のHunyuan Videoモデルと同様に、Windowsや低VRAM構成への適応がまもなく行われる可能性があります。
付属資料の量が多いため、この概要はHunyuanCustomの機能を高レベルで取り上げています。
技術的洞察
HunyuanCustomのデータパイプラインは、GDPRに準拠しており、OpenHumanVidなどの合成およびオープンソースのビデオデータセットを統合し、8つのカテゴリをカバーしています:人間、動物、植物、風景、車両、オブジェクト、建築、アニメ。
リリース論文からの、HunyuanCustomデータ構築パイプラインにおける多様な貢献パッケージの概要。 出典:https://arxiv.org/pdf/2505.04512
ビデオはPySceneDetectを使用してシングルショットクリップに分割され、TextBPN-Plus-Plusが過剰なテキスト、字幕、または透かしを持つコンテンツをフィルタリングします。
クリップは5秒に標準化され、短辺が512または720ピクセルにリサイズされます。美的品質は、Koala-36Mを使用してカスタム0.06閾値で保証されます。
人間のアイデンティティ抽出は、Qwen7B、YOLO11X、InsightFaceを活用し、非人間の被写体はQwenVLとGrounded SAM 2で処理され、小さなバウンディングボックスは破棄されます。
Hunyuan Controlプロジェクトで使用されたGrounded SAM 2によるセマンティックセグメンテーションの例。 出典:https://github.com/IDEA-Research/Grounded-SAM-2
複数被写体の抽出は、Florence2でアノテーションを行い、Grounded SAM 2でセグメンテーションを行い、クラスタリングと時間的フレームセグメンテーションが続きます。
クリップは、Hunyuanチームによる独自の構造化ラベリングで強化され、説明やカメラモーションの手がかりなどのメタデータが追加されます。
マスク拡張は、さまざまなオブジェクト形状への適応性を確保し、オーバーフィッティングを防ぎます。オーディオ同期はLatentSyncを使用し、品質閾値以下のクリップを破棄します。HyperIQAはスコア40未満のビデオをフィルタリングし、Whisperは有効なオーディオを下流タスクに処理します。
LLaVAモデルは、キャプション生成と視覚的およびテキストコンテンツのセマンティック一貫性の調整に中心的な役割を果たし、特に複雑または複数被写体のシーンで効果的です。
HunyuanCustomフレームワークは、テキスト、画像、オーディオ、ビデオ入力に基づくアイデンティティ一貫性のあるビデオ生成をサポートします。
ビデオカスタマイズ
参照画像とプロンプトからのビデオ生成を可能にするため、HunyuanVideoの入力を画像とテキストの両方を受け入れるように適応させた2つのLLaVAベースのモジュールが開発されました。プロンプトは画像を直接埋め込むか、簡潔なアイデンティティ記述でタグ付けし、セパレータトークンを使用して画像とテキストの影響をバランスさせます。
アイデンティティ強化モジュールは、LLaVAが細かい空間的詳細を失う傾向に対処し、短いビデオクリップで被写体の一貫性を維持するために重要です。
参照画像は、HunyuanVideoの因果3D-VAEを介してリサイズおよびエンコードされ、その潜在表現が時間軸全体に挿入され、直接的な複製なしに生成を導くための空間的オフセットが施されます。
トレーニングでは、Flow Matchingをロジット正規分布からのノイズで使用し、LLaVAとビデオジェネレータを一緒に微調整して、画像プロンプトガイダンスとアイデンティティの一貫性を確保します。
複数被写体のプロンプトの場合、各画像-テキストペアは異なる時間的位置で個別に埋め込まれ、複数の相互作用する被写体を持つシーンを可能にします。
オーディオとビジュアルの統合
HunyuanCustomは、ユーザーが提供するオーディオとテキストを使用したオーディオ駆動の生成をサポートし、キャラクターが文脈的に関連する設定で話すことを可能にします。
アイデンティティ分離型AudioNetモジュールは、オーディオ機能をビデオタイムラインに合わせ、空間クロスアテンションを使用してフレームを分離し、被写体の一貫性を維持します。
時間的注入モジュールは、モーションタイミングを洗練し、マルチレイヤーパーセプトロンを介してオーディオを潜在シーケンスにマッピングし、ジェスチャーがオーディオリズムに一致するようにします。
ビデオ編集では、HunyuanCustomはビデオ全体を再生成せずに既存のクリップ内の被写体を置き換え、外観やモーションのターゲット変更に最適です。
クリックして再生。補足サイトからの別の例。
システムは、事前トレーニングされた因果3D-VAEを使用して参照ビデオを圧縮し、生成パイプラインプロセスに合わせ、軽量な処理を行います。ニューラルネットワークは、クリーンな入力ビデオをノイズ付き潜在表現に合わせ、フレームごとの特徴追加が事前圧縮マージよりも効果的であることが証明されています。
パフォーマンス評価
テスト指標には、顔のアイデンティティ一貫性のためのArcFace、被写体の類似性のためのYOLO11xおよびDino 2、テキスト-ビデオアライメントおよび時間的一貫性のためのCLIP-B、モーション強度ののためのVBenchが含まれます。
競合他社には、クローズドソースシステム(Hailuo、Vidu 2.0、Kling 1.6、Pika)およびオープンソースフレームワーク(VACE、SkyReels-A2)が含まれます。
HunyuanCustomと主要なビデオカスタマイズ方法を、ID一貫性(Face-Sim)、被写体類似性(DINO-Sim)、テキスト-ビデオアライメント(CLIP-B-T)、時間的一貫性(Temp-Consis)、モーション強度(DD)で比較したモデルパフォーマンス評価。最適および準最適の結果は、それぞれ太字および下線で示されています。
著者は次のように述べています:
「HunyuanCustomは、IDおよび被写体の一貫性で優れており、プロンプトの順守と時間的安定性でも競争力があります。Hailuoはテキストアライメントの強さによりクリップスコアでリードしていますが、非人間の被写体の一貫性に苦労します。ViduおよびVACEは、モデルサイズが小さいためか、モーション強度で遅れています。」
プロジェクトサイトには多数の比較ビデオがありますが、そのレイアウトは比較のしやすさよりも美観を優先しています。読者は、より明確な洞察を得るためにビデオを直接確認することをお勧めします:
論文からの、オブジェクト中心のビデオカスタマイズの比較。視聴者は、より高い解像度のためにソースPDFを参照する必要がありますが、プロジェクトサイトのビデオはより明確な洞察を提供します。
著者は述べています:
「Vidu、SkyReels A2、HunyuanCustomは、プロンプトアライメントと被写体の一貫性で強い結果を達成していますが、Hunyuanvideo-13Bの強固な基盤のおかげで、ビデオ品質はViduおよびSkyReelsを上回ります。」
「商用ソリューションの中では、Klingは高品質のビデオを提供しますが、最初のフレームでのコピーペースト効果や、時折の被写体のぼやけが視聴体験に影響を与えます。」
Pikaは時間的一貫性に苦労し、データキュレーションの不備による字幕アーティファクトを導入します。Hailuoは顔のアイデンティティを保持しますが、全身の一貫性に欠けます。オープンソースの方法の中では、VACEはアイデンティティの一貫性を維持できず、HunyuanCustomは強いアイデンティティ保持、品質、多様性を提供します。
複数被写体のビデオカスタマイズテストでも同様の結果が得られました:
複数被写体を使用したビデオカスタマイズの比較。詳細と解像度のためにPDFを参照してください。
論文は次のように指摘しています:
「Pikaは指定された被写体を生成しますが、フレームの不安定性を示し、被写体が消えたりプロンプトに従わなかったりします。ViduおよびVACEは人間のアイデンティティを部分的に捉えますが、非人間のオブジェクトの詳細を失います。SkyReels A2は深刻なフレームの不安定性とアーティファクトに悩まされます。HunyuanCustomはすべての被写体のアイデンティティを効果的に捉え、プロンプトに準拠し、高い視覚的品質と安定性を維持します。」
仮想人間の広告テストでは、製品と人々を統合しました:
定性的テストラウンドからの、ニューラル「プロダクトプレイスメント」の例。詳細と解像度のためにPDFを参照してください。
著者は述べています:
「HunyuanCustomは、人間のアイデンティティと製品の詳細(テキストを含む)を維持し、自然な相互作用と強いプロンプト順守を示し、広告ビデオの可能性を示しています。」
オーディオ駆動のカスタマイズテストでは、柔軟なシーンと姿勢制御が強調されました:
オーディオラウンドの部分的な結果—ビデオ結果が望ましい。サイズの制約により、PDF図の上の半分のみが表示されています。詳細のためにソースPDFを参照してください。
著者は次のように指摘しています:
「従来のオーディオ駆動方法は、姿勢と環境を入力画像に制限し、アプリケーションを制限します。HunyuanCustomは、テキストで記述されたシーンと姿勢で柔軟なオーディオ駆動アニメーションを可能にします。」
ビデオ被写体置換テストでは、HunyuanCustomをVACEおよびKling 1.6と比較しました:
ビデオからビデオモードでの被写体置換のテスト。詳細と解像度のためにソースPDFを参照してください。
研究者は次のように述べています:
「VACEは厳格なマスク順守による境界アーティファクトを生成し、モーションの連続性を乱します。Klingはコピーペースト効果を示し、背景の統合が不十分です。HunyuanCustomはアーティファクトを回避し、シームレスな統合を確保し、強いアイデンティティ保持を提供し、ビデオ編集で優れています。」
結論
HunyuanCustomは、ビデオ合成におけるリップシンクの需要の高まりに対応し、Hunyuan Videoのようなシステムのリアリズムを強化する魅力的なリリースです。プロジェクトサイトのビデオレイアウトによる比較の課題にもかかわらず、TencentのモデルはKlingなどのトップ競合他社と互角に戦い、カスタマイズされたビデオ生成における大きな進歩を示しています。
* 一部のビデオは幅が広すぎたり、短すぎたり、高解像度すぎたりするため、VLCやWindows Media Playerなどの標準プレーヤーで再生できず、黒い画面が表示されます。
初公開:2025年5月8日木曜日










 独占:Luma AI、『統合インテリジェンス』モデルを搭載したクリエイティブエージェントを発表
木曜日、AI動画生成スタートアップのLumaは、テキスト・画像・動画・音声にまたがる完全なクリエイティブワークフローを管理するシステム「Luma Agents」を発表した。これらのエージェントは、単一のマルチモーダル推論エンジンとして訓練されたアーキテクチャを特徴とするLumaのUnified Intelligenceモデルファミリーによって駆動される。Lumaは、広告代理店、マーケティング部門、
独占:Luma AI、『統合インテリジェンス』モデルを搭載したクリエイティブエージェントを発表
木曜日、AI動画生成スタートアップのLumaは、テキスト・画像・動画・音声にまたがる完全なクリエイティブワークフローを管理するシステム「Luma Agents」を発表した。これらのエージェントは、単一のマルチモーダル推論エンジンとして訓練されたアーキテクチャを特徴とするLumaのUnified Intelligenceモデルファミリーによって駆動される。Lumaは、広告代理店、マーケティング部門、
 Soraの新アップデートでペットAI動画、ソーシャルツール、Androidアプリが登場
OpenAIは、9月下旬のローンチ後、App Storeのトップに急浮上したブレイク中のAI動画作成アプリ「Sora」の新機能を相次いでプレビューしている。米国とカナダで現在も1位をキープしているこのアプリは、近日中に動画編集機能を追加し、ユーザーがペットやその他のアイテムのキャラクター「カメオ」を作成したり、ソーシャル機能を強化したりする予定だ。同社はまた、Android版が "実際に間もなくリ
Soraの新アップデートでペットAI動画、ソーシャルツール、Androidアプリが登場
OpenAIは、9月下旬のローンチ後、App Storeのトップに急浮上したブレイク中のAI動画作成アプリ「Sora」の新機能を相次いでプレビューしている。米国とカナダで現在も1位をキープしているこのアプリは、近日中に動画編集機能を追加し、ユーザーがペットやその他のアイテムのキャラクター「カメオ」を作成したり、ソーシャル機能を強化したりする予定だ。同社はまた、Android版が "実際に間もなくリ
 AIビデオ生成は完全な制御に向かって移動します
HunyuanやWAN 2.1のようなビデオファンデーションモデルは大きな進歩を遂げましたが、映画やテレビ制作、特に視覚効果(VFX)で必要な詳細なコントロールに関しては、しばしば不足しています。プロのVFXスタジオでは、これらのモデルと以前の画像バスとともに
AIビデオ生成は完全な制御に向かって移動します
HunyuanやWAN 2.1のようなビデオファンデーションモデルは大きな進歩を遂げましたが、映画やテレビ制作、特に視覚効果(VFX)で必要な詳細なコントロールに関しては、しばしば不足しています。プロのVFXスタジオでは、これらのモデルと以前の画像バスとともに

ディスレクシア支援のために厳選された、2026年最新の最高評価AI TTSアプリをご紹介します。専門家によるランキングでは、無料ツールと有料ツールを比較し、読解効率と学習効果を高める強力な機能を詳しく解説しています。生徒の可能性を引き出す、ぜひ試すべき画期的なソリューションをご覧ください。XIX.AIでその第一歩を踏み出しましょう。
10 ツール
xix.ai

XIX.AIで、2026年のおすすめ少年漫画向けAIジェネレーターをご紹介します。厳選されたトップクラスのリストには、迫力満点のアクションシーンや躍動感あふれるエフェクトを作成できる強力なツールが揃っています。実際のテスト結果をもとに、無料版と有料版の比較も可能です。あなたの創造力を解き放ち、今日から壮大な漫画の制作を始めましょう!
15 ツール
xix.ai

2026年最新・最高のAI経費管理ツール:レシートをスキャンし、法人経費を自動分類する高評価ツールをご紹介。手間いらずの経費管理、正確な財務追跡、コンプライアンス対応の効率化を実現する、画期的なソリューションをご覧ください。無料版と有料版の比較表は厳選され、毎週更新されるため、最適なツール選びにお役立ていただけます。XIX.AIの専門家が厳選したツールで、AIの力を最大限に活用しましょう。
10 ツール
xix.ai

XIX.AIで、2026年最新の評価の高いAI採用ツールをチェックしましょう。厳選されたリストには、履歴書のスクリーニングや候補者の面接スケジュール管理を自動化する、強力で画期的なソリューションが揃っています。実際のテスト結果や毎週更新されるランキングを参考に、無料版と有料版の比較が可能です。最適な採用アシスタントを見つけて、今すぐ採用業務を効率化しましょう!
10 ツール
xix.ai

XIX.AIで、2026年最高のAIパーソナルウェルネス&集中力向上ツールをご紹介。厳選されたランキングでは、バーンアウトの解消やメンタルエネルギーの向上に役立つ、高評価で画期的なツールを取り上げています。実際のユーザーの声をもとに、無料版と有料版の比較も可能です。今すぐ、最高の生産性とウェルビーイングへの道を開きましょう。
10 ツール
xix.ai

2026年版、本物の長期的なつながりを築くための、高評価のAI恋愛チャットボットをご紹介します。厳選されたリストには、魅力的で一貫性のあるキャラクター、無料版と有料版の比較、そして実地テストの結果が掲載されています。あなたにぴったりのパートナーを見つけて、今すぐXIX.AIで関係を築き始めましょう。
10 ツール
xix.ai

Esse exemplo de vídeo parece meio bugado... Mas a ideia de transformar uma imagem estática em vídeo é fascinante. Será que isso poderia ser usado para criar conteúdos educativos ou de forma indevida? A discussão ética sempre fica atrás da tecnologia 🤔.













