
















 집
집Tencent, HunyuanCustom 단일 이미지 비디오 커스터마이제이션 공개
이 기사는 Tencent의 멀티모달 비디오 생성 모델 HunyuanCustom의 출시를 탐구합니다. 동반된 연구 논문의 광범위한 범위와 프로젝트 페이지에 제공된 예시 비디오의 문제로 인해 포맷팅 및 처리 요구사항으로 인해 명확성을 높이기 위해 광범위한 비디오 콘텐츠의 재생산이 제한된 개요가 필요합니다.
논문은 API 기반 생성 시스템 Kling을 ‘Keling’으로 언급합니다. 일관성을 위해 이 기사에서는 ‘Kling’을 사용합니다.
Tencent는 Hunyuan Video 모델의 고급 버전인 HunyuanCustom을 소개했습니다. 이 릴리스는 단일 이미지만 사용하여 딥페이크 스타일의 비디오 커스터마이제이션을 가능하게 함으로써 Hunyuan LoRA 모델의 필요성을 초월한 것으로 알려져 있습니다:
재생하려면 클릭하세요. 프롬프트: ‘남자가 주방에서 달팽이 국수를 준비하며 음악을 즐긴다.’ 독점 및 오픈소스 방법, 특히 주요 경쟁자인 Kling과 비교했을 때 HunyuanCustom은 두드러집니다. 출처: https://hunyuancustom.github.io/ (참고: 리소스 집약적 사이트)
위 비디오에서 가장 왼쪽 열은 HunyuanCustom의 단일 소스 이미지 입력을 표시하고, 옆 열은 시스템의 프롬프트 해석을 보여줍니다. 나머지 열은 Kling, Vidu, Pika, Hailuo, SkyReels-A2 (Wan 기반)의 출력을 보여줍니다.
다음 비디오는 이번 릴리스의 세 가지 핵심 시나리오를 강조합니다: 객체와 함께한 사람, 단일 캐릭터 복제, 가상 의류 착용:
재생하려면 클릭하세요. Hunyuan Video 지원 사이트에서 선별된 세 가지 예시.
이 예시는 단일 소스 이미지에 의존하는 것과 관련된 한계를 드러냅니다.
첫 번째 클립에서 남자는 카메라를 향하며 머리 움직임이 최소화되고 20-25도를 넘지 않습니다. 이 범위를 벗어나면 시스템은 단일 정면 이미지에서 정확한 프로필을 추론하는 데 어려움을 겪습니다.
두 번째 클립에서 소녀는 비디오에서 미소 표정을 유지하며 정적 소스 이미지를 반영합니다. 추가 참조 없이 HunyuanCustom은 그녀의 중립적인 표정을 신뢰할 수 있게 묘사하지 못하며, 얼굴은 이전 예시와 유사하게 대부분 정면을 향합니다.
마지막 클립에서는 불완전한 소스 자료—여성과 가상 의류—로 인해 제한된 데이터에 대한 실용적인 해결책으로 잘린 렌더링이 발생합니다.
HunyuanCustom은 다중 이미지 입력(예: 스낵과 함께한 사람 또는 의류를 입은 사람)을 지원하지만, 단일 캐릭터에 대한 다양한 각도나 표정을 수용하지 않습니다. 이는 각도와 표정에 걸쳐 일관된 캐릭터 렌더링을 보장하기 위해 20-60개의 이미지를 사용하는 HunyuanVideo의 LoRA 모델 생태계를 완전히 대체하는 능력을 제한할 수 있습니다.
오디오 통합
오디오의 경우, HunyuanCustom은 취미자가 구성하기 어려운 LatentSync 시스템을 사용하여 사용자가 제공한 오디오와 텍스트로 입술 움직임을 동기화합니다:
오디오 포함. 재생하려면 클릭하세요. HunyuanCustom 보조 사이트에서 컴파일된 입술 동기화 예시.
현재 영어 예시는 없지만, 설정 프로세스가 사용자 친화적이라면 결과는 유망해 보입니다.
비디오 편집 기능
HunyuanCustom은 비디오-투-비디오(V2V) 편집에서 탁월하며, 단일 참조 이미지를 사용하여 기존 비디오의 요소를 타겟팅하여 교체할 수 있습니다. 보조 자료의 예시가 이를 보여줍니다:
재생하려면 클릭하세요. 중심 객체가 수정되고 주변 요소가 HunyuanCustom V2V 프로세스에서 미묘하게 변경됩니다.
V2V 워크플로우에서 일반적으로 전체 비디오가 약간 수정되며, 주요 초점은 봉제 인형과 같은 타겟 영역에 있습니다. Adobe Firefly의 접근 방식과 유사하게 고급 파이프라인은 원본 콘텐츠를 더 많이 보존할 가능성이 있지만, 이는 오픈소스 커뮤니티에서 아직 충분히 탐구되지 않았습니다.
다른 예시는 통합의 정밀도가 향상되었음을 보여줍니다:
재생하려면 클릭하세요. HunyuanCustom에서 V2V 콘텐츠 삽입의 다양한 예시로, 변경되지 않은 요소를 존중합니다.
진화적 업그레이드
HunyuanCustom은 Hunyuan Video 프로젝트를 기반으로 하여 전체적인 재구성 대신 타겟팅된 아키텍처 개선을 도입합니다. 이러한 업그레이드는 LoRA 또는 텍스트 반전을 필요로 하지 않고 프레임 간 캐릭터 일관성을 유지하는 것을 목표로 합니다.
이 릴리스는 2024년 12월 HunyuanVideo 모델의 정제된 버전이며, 처음부터 새로 구축된 모델이 아닙니다.
기존 HunyuanVideo LoRA 사용자들은 이 업데이트와의 호환성 또는 향상된 커스터마이제이션 기능을 활용하기 위해 새로운 LoRA를 개발해야 하는지 의문을 가질 수 있습니다.
일반적으로 상당한 미세 조정은 모델 가중치를 충분히 변경하여 이전 LoRA와 호환되지 않게 만듭니다. 그러나 Stable Diffusion XL용 Pony Diffusion과 같은 일부 미세 조정은 전용 LoRA 라이브러리가 있는 독립적인 생태계를 만들어 HunyuanCustom이 이를 따를 가능성을 시사합니다.
릴리스 세부 정보
연구 논문, 제목 HunyuanCustom: 맞춤형 비디오 생성을 위한 멀티모달 기반 아키텍처,는 로컬 배포를 위한 코드와 가중치가 포함된 GitHub 리포지토리와 ComfyUI 통합 계획에 연결됩니다.
현재 프로젝트의 Hugging Face 페이지는 접근할 수 없지만, WeChat 스캔 코드를 통해 API 기반 데모를 이용할 수 있습니다.
HunyuanCustom의 다양한 프로젝트 조립은 완전한 공개를 위한 라이선스 요구사항에 의해 주도된 것으로 보입니다.
두 가지 모델 변형이 제공됩니다: 최적 성능을 위해 80GB GPU 메모리가 필요한 720x1280px 버전(최소 24GB, 느림)과 60GB가 필요한 512x896px 버전. 테스트는 Linux에 국한되었지만, 이전 Hunyuan Video 모델과 같이 커뮤니티 노력을 통해 Windows 및 낮은 VRAM 구성에 곧 적응할 수 있습니다.
동반 자료의 양으로 인해 이 개요는 HunyuanCustom의 기능에 대해 고급 접근 방식을 취합니다.
기술적 통찰
HunyuanCustom의 데이터 파이프라인은 GDPR을 준수하며, OpenHumanVid와 같은 합성 및 오픈소스 비디오 데이터셋을 통합하여 인간, 동물, 식물, 풍경, 차량, 객체, 건축, 애니메이션의 8개 카테고리를 다룹니다.
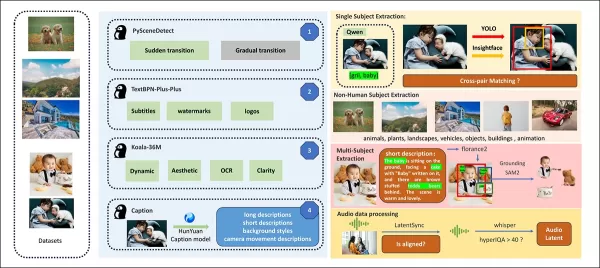
릴리스 논문에서 HunyuanCustom 데이터 구축 파이프라인의 다양한 기여 패키지에 대한 개요. 출처: https://arxiv.org/pdf/2505.04512
비디오는 PySceneDetect를 사용하여 단일 샷 클립으로 분할되며, TextBPN-Plus-Plus는 과도한 텍스트, 자막 또는 워터마크가 있는 콘텐츠를 필터링합니다.
클립은 5초로 표준화되고 짧은 쪽이 512 또는 720 픽셀로 크기가 조정됩니다. 미적 품질은 Koala-36M을 사용한 사용자 정의 0.06 임계값으로 보장됩니다.
인간 신원 추출은 Qwen7B, YOLO11X, InsightFace를 활용하며, 비인간 주제는 QwenVL과 Grounded SAM 2로 처리되며 작은 경계 상자는 폐기됩니다.

Hunyuan Control 프로젝트에 사용된 Grounded SAM 2의 시맨틱 분할 예시. 출처: https://github.com/IDEA-Research/Grounded-SAM-2
다중 주제 추출은 Florence2로 주석을 달고 Grounded SAM 2로 분할하며, 클러스터링 및 시간적 프레임 분할이 뒤따릅니다.
클립은 Hunyuan 팀의 독점 구조적 라벨링으로 향상되며, 설명 및 카메라 모션 단서와 같은 메타데이터가 추가됩니다.
마스크 증강은 다양한 객체 형태에 대한 적응력을 보장하여 과적합을 방지합니다. 오디오 동기화는 LatentSync를 사용하며 품질 임계값 이하의 클립은 폐기됩니다. HyperIQA는 40점 미만의 비디오를 필터링하며, Whisper는 유효한 오디오를 처리하여 다운스트림 작업을 수행합니다.
LLaVA 모델은 캡션 생성과 시각 및 텍스트 콘텐츠 정렬에서 중심 역할을 하며, 특히 복잡하거나 다중 주제 장면에서 시맨틱 일관성을 보장합니다.
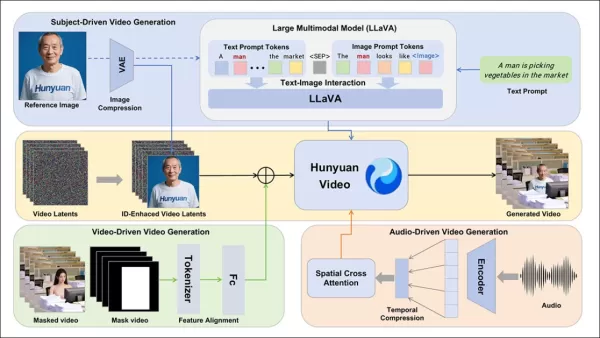
HunyuanCustom 프레임워크는 텍스트, 이미지, 오디오, 비디오 입력에 따라 신원 일관성 있는 비디오 생성을 지원합니다.
비디오 커스터마이제이션
참조 이미지와 프롬프트에서 비디오 생성을 가능하게 하기 위해 LLaVA 기반 두 모듈이 개발되어 HunyuanVideo의 입력이 이미지와 텍스트를 모두 수용하도록 조정되었습니다. 프롬프트는 이미지를 직접 삽입하거나 간단한 신원 설명으로 태그하며, 이미지와 텍스트의 영향을 균형 있게 유지하기 위해 분리자 토큰을 사용합니다.
신원 강화 모듈은 짧은 비디오 클립에서 주제 일관성을 유지하는 데 중요한 LLaVA의 세밀한 공간적 세부 정보 손실 문제를 해결합니다.
참조 이미지는 HunyuanVideo의 인과적 3D-VAE를 통해 크기가 조정되고 인코딩되며, 그 잠재는 시간 축을 따라 삽입되고 공간적 오프셋으로 생성을 안내하여 직접 복제를 피합니다.
로짓-정규 분포의 노이즈를 사용한 Flow Matching으로 훈련하여 LLaVA와 비디오 생성기를 함께 미세 조정하여 이미지-프롬프트 안내와 신원 일관성을 통합했습니다.
다중 주제 프롬프트의 경우, 각 이미지-텍스트 쌍은 별도의 시간 위치로 개별적으로 임베딩되어 다중 상호작용 주제가 있는 장면을 가능하게 합니다.
오디오 및 시각 통합
HunyuanCustom은 사용자가 제공한 오디오와 텍스트를 사용한 오디오 기반 생성을 지원하여 캐릭터가 맥락적으로 관련 있는 환경에서 말할 수 있게 합니다.
Identity-disentangled AudioNet 모듈은 오디오 기능을 비디오 타임라인과 정렬하며, 공간적 교차 주의를 사용하여 프레임을 분리하고 주제 일관성을 유지합니다.
시간적 주입 모듈은 오디오를 잠재 시퀀스에 매핑하여 Multi-Layer Perceptron을 통해 동작 타이밍을 정제하며, 제스처가 오디오 리듬과 정렬되도록 합니다.
비디오 편집의 경우, HunyuanCustom은 전체 비디오를 재생성하지 않고 기존 클립에서 주제를 교체하여 외관이나 동작 변경에 이상적입니다.
재생하려면 클릭하세요. 보조 사이트의 또 다른 예시.
시스템은 사전 훈련된 인과적 3D-VAE를 사용하여 참조 비디오를 압축하며, 생성 파이프라인 잠재와 정렬하여 경량 처리를 합니다. 신경망은 깨끗한 입력 비디오를 노이즈가 있는 잠재와 정렬하며, 프레임별 기능 추가는 사전 압축 병합보다 효과적임이 입증되었습니다.
성능 평가
테스트 메트릭에는 얼굴 신원 일관성을 위한 ArcFace, 주제 유사성을 위한 YOLO11x 및 Dino 2, 텍스트-비디오 정렬 및 시간적 일관성을 위한 CLIP-B, 동작 강도를 위한 VBench가 포함되었습니다.
경쟁자는 폐쇄 소스 시스템(Hailuo, Vidu 2.0, Kling 1.6, Pika)과 오픈소스 프레임워크(VACE, SkyReels-A2)를 포함했습니다.
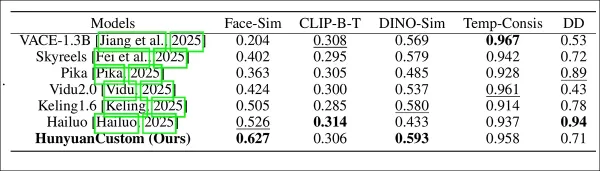
HunyuanCustom과 선도적인 비디오 커스터마이제이션 방법을 신원 일관성(Face-Sim), 주제 유사성(DINO-Sim), 텍스트-비디오 정렬(CLIP-B-T), 시간적 일관성(Temp-Consis), 동작 강도(DD)에서 비교한 모델 성능 평가. 최적 및 차선 결과는 각각 굵은 글씨와 밑줄로 표시됩니다.
저자들은 다음과 같이 언급합니다:
‘HunyuanCustom은 신원 및 주제 일관성에서 탁월하며, 프롬프트 준수와 시간적 안정성에서 경쟁력 있습니다. Hailuo는 강력한 텍스트 정렬로 인해 클립 점수에서 선두를 달리지만 비인간 주제 일관성에서 어려움을 겪습니다. Vidu와 VACE는 모델 크기가 작아 동작 강도가 뒤떨어집니다.’
프로젝트 사이트는 수많은 비교 비디오를 제공하지만, 레이아웃은 비교의 용이성보다 미학을 우선시합니다. 더 명확한 통찰을 위해 비디오를 직접 검토하는 것이 좋습니다:
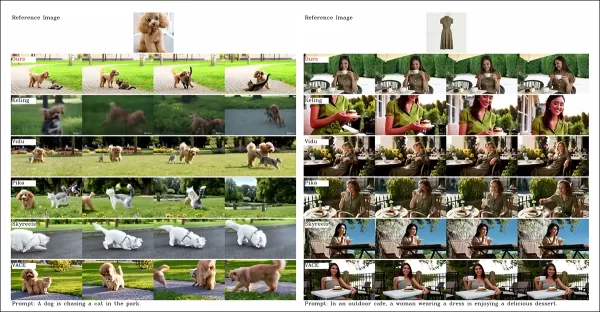
논문에서 객체 중심 비디오 커스터마이제이션 비교. 더 나은 해상도를 위해 소스 PDF를 참조해야 하지만, 프로젝트 사이트의 비디오가 더 명확한 통찰을 제공합니다.
저자들은 다음과 같이 말합니다:
‘Vidu, SkyReels A2, HunyuanCustom은 강력한 프롬프트 정렬과 주제 일관성을 달성하지만, Hunyuanvideo-13B의 견고한 기반 덕분에 우리의 비디오 품질은 Vidu와 SkyReels를 능가합니다.’
‘상용 솔루션 중 Kling은 고품질 비디오를 제공하지만 첫 프레임에서 복사-붙여넣기 효과와 가끔 주제 흐림으로 인해 시청 경험에 영향을 미칩니다.’
Pika는 데이터 큐레이션 부족으로 자막 아티팩트를 도입하며 시간적 일관성에서 어려움을 겪습니다. Hailuo는 얼굴 신원을 유지하지만 전신 일관성에서 실패합니다. 오픈소스 방법 중 VACE는 신원 일관성을 유지하지 못하며, HunyuanCustom은 강력한 신원 보존, 품질, 다양성을 제공합니다.
다중 주제 비디오 커스터마이제이션 테스트는 유사한 결과를 보였습니다:

다중 주제 비디오 커스터마이제이션 비교. 더 나은 세부 정보와 해상도를 위해 PDF를 참조하세요.
논문은 다음과 같이 언급합니다:
‘Pika는 지정된 주제를 생성하지만 프레임 불안정성을 보여주며, 주제가 사라지거나 프롬프트를 따르지 못합니다. Vidu와 VACE는 인간 신원을 부분적으로 포착하지만 비인간 객체 세부 정보를 잃습니다. SkyReels A2는 심각한 프레임 불안정성과 아티팩트를 겪습니다. HunyuanCustom은 모든 주제 신원을 효과적으로 포착하고, 프롬프트를 준수하며, 높은 시각 품질과 안정성을 유지합니다.’
가상 인간 광고 테스트는 제품과 사람을 통합했습니다:

정성적 테스트 라운드에서 신경망 ‘제품 배치’ 예시. 더 나은 세부 정보와 해상도를 위해 PDF를 참조하세요.
저자들은 다음과 같이 말합니다:
‘HunyuanCustom은 인간 신원과 제품 세부 정보(텍스트 포함)를 유지하며, 자연스러운 상호작용과 강력한 프롬프트 준수로 광고 비디오에 대한 잠재력을 보여줍니다.’
오디오 기반 커스터마이제이션 테스트는 유연한 장면 및 자세 제어를 강조했습니다:
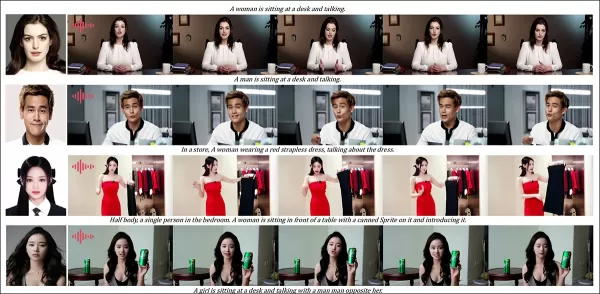
오디오 라운드에 대한 부분 결과—비디오 결과가 더 바람직했을 수 있습니다. 크기 제약으로 인해 PDF 그림의 상단 절반만 표시됩니다. 더 나은 세부 정보를 위해 소스 PDF를 참조하세요.
저자들은 다음과 같이 언급합니다:
‘이전 오디오 기반 방법은 입력 이미지에 자세와 환경을 제한하여 응용 프로그램을 제한했습니다. HunyuanCustom은 텍스트로 설명된 장면과 자세로 유연한 오디오 기반 애니메이션을 가능하게 합니다.’
비디오 주제 교체 테스트는 HunyuanCustom을 VACE 및 Kling 1.6과 비교했습니다:

비디오-투-비디오 모드에서 주제 교체 테스트. 더 나은 세부 정보와 해상도를 위해 소스 PDF를 참조하세요.
연구자들은 다음과 같이 말합니다:
‘VACE는 엄격한 마스크 준수로 인해 경계 아티팩트를 생성하여 동작 연속성을 방해합니다. Kling은 배경 통합이 약한 복사-붙여넣기 효과를 보여줍니다. HunyuanCustom은 아티팩트를 피하고, 원활한 통합을 보장하며, 강력한 신원 보존을 유지하여 비디오 편집에서 탁월합니다.’
결론
HunyuanCustom은 비디오 합성에서 입술 동기화에 대한 증가하는 수요를 해결하여 Hunyuan Video와 같은 시스템의 리얼리즘을 향상시키는 매력적인 릴리스입니다. 프로젝트 사이트의 비디오 레이아웃으로 인해 기능을 비교하는 데 어려움이 있지만, Tencent의 모델은 Kling과 같은 주요 경쟁자와 견줄 수 있으며, 맞춤형 비디오 생성에서 상당한 진전을 이루었습니다.
* 일부 비디오는 VLC 또는 Windows Media Player와 같은 표준 플레이어에서 재생하기에 너무 넓거나, 짧거나, 고해상도여서 검은 화면이 표시됩니다.
2025년 5월 8일 목요일에 처음 게시됨
관련 기사
 독점: 루마 AI, '통합 지능' 모델로 구동되는 크리에이티브 에이전트 선보여
목요일, AI 영상 생성 스타트업 루마(Luma)는 텍스트, 이미지, 영상, 오디오에 걸친 완전한 크리에이티브 워크플로우를 관리하기 위해 구축된 시스템인 '루마 에이전트(Luma Agents)'를 공개했다. 이 에이전트들은 단일 다중 모달 추론 엔진으로 훈련된 아키텍처를 특징으로 하는 루마의 통합 인텔리전스 모델 패밀리(Unified In
반려동물 AI 동영상, 소셜 도구, 곧 출시될 안드로이드 앱을 제공하는 Sora의 새로운 업데이트
지난 9월 말 출시 후 단숨에 App Store 인기 앱 1위에 오른 인기 AI 동영상 제작 앱 Sora에 새로운 기능이 추가될 예정입니다. 미국과 캐나다에서 여전히 1위를 차지하고 있는 이 앱은 곧 동영상 편집 기능을 추가하고, 사용자가 애완동물과 기타 아이템의 캐릭터 '카메오'를 만들 수 있도록 하며, 소셜 기능을 강화하는 등의 기능을 추가할 예정입니다
AI 비디오 생성은 완전한 제어로 이동합니다
Hunyuan 및 WAN 2.1과 같은 비디오 파운데이션 모델은 상당한 진전을 이루었지만 영화 및 TV 제작, 특히 VFX (Visual Effects) 영역에서 필요한 세부 제어에있어 종종 부족합니다. 전문적인 VFX 스튜디오에서는이 모델과 이전 이미지 바와 함께
관련 특별 주제 추천
텍스트 음성 변환
독점: 루마 AI, '통합 지능' 모델로 구동되는 크리에이티브 에이전트 선보여
목요일, AI 영상 생성 스타트업 루마(Luma)는 텍스트, 이미지, 영상, 오디오에 걸친 완전한 크리에이티브 워크플로우를 관리하기 위해 구축된 시스템인 '루마 에이전트(Luma Agents)'를 공개했다. 이 에이전트들은 단일 다중 모달 추론 엔진으로 훈련된 아키텍처를 특징으로 하는 루마의 통합 인텔리전스 모델 패밀리(Unified In
반려동물 AI 동영상, 소셜 도구, 곧 출시될 안드로이드 앱을 제공하는 Sora의 새로운 업데이트
지난 9월 말 출시 후 단숨에 App Store 인기 앱 1위에 오른 인기 AI 동영상 제작 앱 Sora에 새로운 기능이 추가될 예정입니다. 미국과 캐나다에서 여전히 1위를 차지하고 있는 이 앱은 곧 동영상 편집 기능을 추가하고, 사용자가 애완동물과 기타 아이템의 캐릭터 '카메오'를 만들 수 있도록 하며, 소셜 기능을 강화하는 등의 기능을 추가할 예정입니다
AI 비디오 생성은 완전한 제어로 이동합니다
Hunyuan 및 WAN 2.1과 같은 비디오 파운데이션 모델은 상당한 진전을 이루었지만 영화 및 TV 제작, 특히 VFX (Visual Effects) 영역에서 필요한 세부 제어에있어 종종 부족합니다. 전문적인 VFX 스튜디오에서는이 모델과 이전 이미지 바와 함께
관련 특별 주제 추천
텍스트 음성 변환
 난독증 환자를 위한 최고의 AI 음성 합성 앱: 학생들의 학습 및 독서 효율성 향상
난독증 환자를 위한 최고의 AI 음성 합성 앱: 학생들의 학습 및 독서 효율성 향상
난독증 지원을 위해 엄선된 2026년 최신 최고 평점 AI TTS 앱을 만나보세요. 전문가들이 선정한 이 순위는 무료 및 유료 도구를 비교 분석하여, 읽기 효율과 학습 효과를 높여주는 강력한 기능들을 소개합니다. 학생들의 잠재력을 최대한 발휘할 수 있도록 도와줄, 꼭 사용해봐야 할 혁신적인 솔루션을 확인해 보세요. XIX.AI에서 여정을 시작해 보세요.
 10 도구
10 도구
 xix.ai
만화 창작
소년 만화를 위한 최고의 AI 생성기: 박진감 넘치는 액션 장면과 에너지 효과 만들기
xix.ai
만화 창작
소년 만화를 위한 최고의 AI 생성기: 박진감 넘치는 액션 장면과 에너지 효과 만들기
XIX.AI에서 2026년 최고의 소년 만화 AI 생성기를 만나보세요. 엄선된 최고 평점 목록에는 박진감 넘치는 액션 장면과 역동적인 에너지 효과를 연출할 수 있는 강력한 도구들이 포함되어 있습니다. 실제 테스트를 통해 무료 버전과 유료 버전을 비교해 보세요. 여러분의 창의력을 마음껏 발휘하여 오늘 바로 장대한 만화를 만들어 보세요!
15 도구
xix.ai
사업
최고의 AI 경비 관리 앱: 영수증을 스캔하고 기업 경비를 자동으로 분류하세요
2026년 최신 최고의 AI 경비 관리 도구: 영수증을 스캔하고 기업 경비를 자동으로 분류해 주는 최고 평점의 도구들. 손쉬운 경비 관리, 정확한 재무 추적, 효율적인 규정 준수를 위한 강력하고 혁신적인 솔루션을 만나보세요. 무료 및 유료 옵션을 엄선하여 매주 업데이트되는 비교 자료를 통해 귀사에 딱 맞는 도구를 찾으실 수 있습니다. XIX.AI의 전문가 추천 목록으로 AI의 장점을 최대한 활용하세요.
10 도구
xix.ai
사업
최고의 AI 채용 도구: 이력서 심사 및 후보자 면접 일정 자동화
XIX.AI에서 2026년 최신 최고 평점을 받은 AI 채용 도구를 확인해 보세요. 저희가 엄선한 이 목록에는 이력서 심사 및 후보자 면접 일정 자동화를 위한 강력하고 혁신적인 솔루션이 포함되어 있습니다. 실제 테스트 결과와 매주 업데이트되는 순위를 바탕으로 무료 및 유료 옵션을 비교해 보세요. 지금 바로 귀사에 딱 맞는 채용 도우미를 찾아 채용 프로세스를 효율화하세요!
10 도구
xix.ai
생산력
AI 개인 웰니스 및 집중력 코치: 번아웃 관리 및 정신적 에너지 수준 향상
XIX.AI에서 2026년 최고의 AI 기반 개인 웰니스 및 집중력 코치들을 만나보세요. 저희가 엄선한 순위 목록에는 번아웃을 관리하고 정신적 에너지를 높여주는 최고 평점을 받은 혁신적인 도구들이 소개되어 있습니다. 실제 사용 후기를 바탕으로 무료 버전과 유료 버전을 비교해 보세요. 지금 바로 최고의 생산성과 웰빙을 향한 길을 열어보세요.
10 도구
xix.ai
챗봇
최고 평점을 받은 AI 로맨틱 챗봇: 일관된 성격으로 장기적인 관계를 구축하세요
진정성 있는 장기적인 관계를 형성할 수 있는 2026년 최신 최고 평점 AI 로맨틱 챗봇을 만나보세요. 저희가 엄선한 이 목록에는 강력하고 일관된 캐릭터, 무료 및 유료 버전 비교, 실제 사용 후기가 담겨 있습니다. XIX.AI에서 나에게 딱 맞는 파트너를 찾아 오늘 바로 관계를 시작해 보세요.
10 도구
xix.ai

 의견 (1)
0/500
의견 (1)
0/500
![RalphHill]()
Esse exemplo de vídeo parece meio bugado... Mas a ideia de transformar uma imagem estática em vídeo é fascinante. Será que isso poderia ser usado para criar conteúdos educativos ou de forma indevida? A discussão ética sempre fica atrás da tecnologia 🤔.
이 기사는 Tencent의 멀티모달 비디오 생성 모델 HunyuanCustom의 출시를 탐구합니다. 동반된 연구 논문의 광범위한 범위와 프로젝트 페이지에 제공된 예시 비디오의 문제로 인해 포맷팅 및 처리 요구사항으로 인해 명확성을 높이기 위해 광범위한 비디오 콘텐츠의 재생산이 제한된 개요가 필요합니다.
논문은 API 기반 생성 시스템 Kling을 ‘Keling’으로 언급합니다. 일관성을 위해 이 기사에서는 ‘Kling’을 사용합니다.
Tencent는 Hunyuan Video 모델의 고급 버전인 HunyuanCustom을 소개했습니다. 이 릴리스는 단일 이미지만 사용하여 딥페이크 스타일의 비디오 커스터마이제이션을 가능하게 함으로써 Hunyuan LoRA 모델의 필요성을 초월한 것으로 알려져 있습니다:
재생하려면 클릭하세요. 프롬프트: ‘남자가 주방에서 달팽이 국수를 준비하며 음악을 즐긴다.’ 독점 및 오픈소스 방법, 특히 주요 경쟁자인 Kling과 비교했을 때 HunyuanCustom은 두드러집니다. 출처: https://hunyuancustom.github.io/ (참고: 리소스 집약적 사이트)
위 비디오에서 가장 왼쪽 열은 HunyuanCustom의 단일 소스 이미지 입력을 표시하고, 옆 열은 시스템의 프롬프트 해석을 보여줍니다. 나머지 열은 Kling, Vidu, Pika, Hailuo, SkyReels-A2 (Wan 기반)의 출력을 보여줍니다.
다음 비디오는 이번 릴리스의 세 가지 핵심 시나리오를 강조합니다: 객체와 함께한 사람, 단일 캐릭터 복제, 가상 의류 착용:
재생하려면 클릭하세요. Hunyuan Video 지원 사이트에서 선별된 세 가지 예시.
이 예시는 단일 소스 이미지에 의존하는 것과 관련된 한계를 드러냅니다.
첫 번째 클립에서 남자는 카메라를 향하며 머리 움직임이 최소화되고 20-25도를 넘지 않습니다. 이 범위를 벗어나면 시스템은 단일 정면 이미지에서 정확한 프로필을 추론하는 데 어려움을 겪습니다.
두 번째 클립에서 소녀는 비디오에서 미소 표정을 유지하며 정적 소스 이미지를 반영합니다. 추가 참조 없이 HunyuanCustom은 그녀의 중립적인 표정을 신뢰할 수 있게 묘사하지 못하며, 얼굴은 이전 예시와 유사하게 대부분 정면을 향합니다.
마지막 클립에서는 불완전한 소스 자료—여성과 가상 의류—로 인해 제한된 데이터에 대한 실용적인 해결책으로 잘린 렌더링이 발생합니다.
HunyuanCustom은 다중 이미지 입력(예: 스낵과 함께한 사람 또는 의류를 입은 사람)을 지원하지만, 단일 캐릭터에 대한 다양한 각도나 표정을 수용하지 않습니다. 이는 각도와 표정에 걸쳐 일관된 캐릭터 렌더링을 보장하기 위해 20-60개의 이미지를 사용하는 HunyuanVideo의 LoRA 모델 생태계를 완전히 대체하는 능력을 제한할 수 있습니다.
오디오 통합
오디오의 경우, HunyuanCustom은 취미자가 구성하기 어려운 LatentSync 시스템을 사용하여 사용자가 제공한 오디오와 텍스트로 입술 움직임을 동기화합니다:
오디오 포함. 재생하려면 클릭하세요. HunyuanCustom 보조 사이트에서 컴파일된 입술 동기화 예시.
현재 영어 예시는 없지만, 설정 프로세스가 사용자 친화적이라면 결과는 유망해 보입니다.
비디오 편집 기능
HunyuanCustom은 비디오-투-비디오(V2V) 편집에서 탁월하며, 단일 참조 이미지를 사용하여 기존 비디오의 요소를 타겟팅하여 교체할 수 있습니다. 보조 자료의 예시가 이를 보여줍니다:
재생하려면 클릭하세요. 중심 객체가 수정되고 주변 요소가 HunyuanCustom V2V 프로세스에서 미묘하게 변경됩니다.
V2V 워크플로우에서 일반적으로 전체 비디오가 약간 수정되며, 주요 초점은 봉제 인형과 같은 타겟 영역에 있습니다. Adobe Firefly의 접근 방식과 유사하게 고급 파이프라인은 원본 콘텐츠를 더 많이 보존할 가능성이 있지만, 이는 오픈소스 커뮤니티에서 아직 충분히 탐구되지 않았습니다.
다른 예시는 통합의 정밀도가 향상되었음을 보여줍니다:
재생하려면 클릭하세요. HunyuanCustom에서 V2V 콘텐츠 삽입의 다양한 예시로, 변경되지 않은 요소를 존중합니다.
진화적 업그레이드
HunyuanCustom은 Hunyuan Video 프로젝트를 기반으로 하여 전체적인 재구성 대신 타겟팅된 아키텍처 개선을 도입합니다. 이러한 업그레이드는 LoRA 또는 텍스트 반전을 필요로 하지 않고 프레임 간 캐릭터 일관성을 유지하는 것을 목표로 합니다.
이 릴리스는 2024년 12월 HunyuanVideo 모델의 정제된 버전이며, 처음부터 새로 구축된 모델이 아닙니다.
기존 HunyuanVideo LoRA 사용자들은 이 업데이트와의 호환성 또는 향상된 커스터마이제이션 기능을 활용하기 위해 새로운 LoRA를 개발해야 하는지 의문을 가질 수 있습니다.
일반적으로 상당한 미세 조정은 모델 가중치를 충분히 변경하여 이전 LoRA와 호환되지 않게 만듭니다. 그러나 Stable Diffusion XL용 Pony Diffusion과 같은 일부 미세 조정은 전용 LoRA 라이브러리가 있는 독립적인 생태계를 만들어 HunyuanCustom이 이를 따를 가능성을 시사합니다.
릴리스 세부 정보
연구 논문, 제목 HunyuanCustom: 맞춤형 비디오 생성을 위한 멀티모달 기반 아키텍처,는 로컬 배포를 위한 코드와 가중치가 포함된 GitHub 리포지토리와 ComfyUI 통합 계획에 연결됩니다.
현재 프로젝트의 Hugging Face 페이지는 접근할 수 없지만, WeChat 스캔 코드를 통해 API 기반 데모를 이용할 수 있습니다.
HunyuanCustom의 다양한 프로젝트 조립은 완전한 공개를 위한 라이선스 요구사항에 의해 주도된 것으로 보입니다.
두 가지 모델 변형이 제공됩니다: 최적 성능을 위해 80GB GPU 메모리가 필요한 720x1280px 버전(최소 24GB, 느림)과 60GB가 필요한 512x896px 버전. 테스트는 Linux에 국한되었지만, 이전 Hunyuan Video 모델과 같이 커뮤니티 노력을 통해 Windows 및 낮은 VRAM 구성에 곧 적응할 수 있습니다.
동반 자료의 양으로 인해 이 개요는 HunyuanCustom의 기능에 대해 고급 접근 방식을 취합니다.
기술적 통찰
HunyuanCustom의 데이터 파이프라인은 GDPR을 준수하며, OpenHumanVid와 같은 합성 및 오픈소스 비디오 데이터셋을 통합하여 인간, 동물, 식물, 풍경, 차량, 객체, 건축, 애니메이션의 8개 카테고리를 다룹니다.
릴리스 논문에서 HunyuanCustom 데이터 구축 파이프라인의 다양한 기여 패키지에 대한 개요. 출처: https://arxiv.org/pdf/2505.04512
비디오는 PySceneDetect를 사용하여 단일 샷 클립으로 분할되며, TextBPN-Plus-Plus는 과도한 텍스트, 자막 또는 워터마크가 있는 콘텐츠를 필터링합니다.
클립은 5초로 표준화되고 짧은 쪽이 512 또는 720 픽셀로 크기가 조정됩니다. 미적 품질은 Koala-36M을 사용한 사용자 정의 0.06 임계값으로 보장됩니다.
인간 신원 추출은 Qwen7B, YOLO11X, InsightFace를 활용하며, 비인간 주제는 QwenVL과 Grounded SAM 2로 처리되며 작은 경계 상자는 폐기됩니다.
Hunyuan Control 프로젝트에 사용된 Grounded SAM 2의 시맨틱 분할 예시. 출처: https://github.com/IDEA-Research/Grounded-SAM-2
다중 주제 추출은 Florence2로 주석을 달고 Grounded SAM 2로 분할하며, 클러스터링 및 시간적 프레임 분할이 뒤따릅니다.
클립은 Hunyuan 팀의 독점 구조적 라벨링으로 향상되며, 설명 및 카메라 모션 단서와 같은 메타데이터가 추가됩니다.
마스크 증강은 다양한 객체 형태에 대한 적응력을 보장하여 과적합을 방지합니다. 오디오 동기화는 LatentSync를 사용하며 품질 임계값 이하의 클립은 폐기됩니다. HyperIQA는 40점 미만의 비디오를 필터링하며, Whisper는 유효한 오디오를 처리하여 다운스트림 작업을 수행합니다.
LLaVA 모델은 캡션 생성과 시각 및 텍스트 콘텐츠 정렬에서 중심 역할을 하며, 특히 복잡하거나 다중 주제 장면에서 시맨틱 일관성을 보장합니다.
HunyuanCustom 프레임워크는 텍스트, 이미지, 오디오, 비디오 입력에 따라 신원 일관성 있는 비디오 생성을 지원합니다.
비디오 커스터마이제이션
참조 이미지와 프롬프트에서 비디오 생성을 가능하게 하기 위해 LLaVA 기반 두 모듈이 개발되어 HunyuanVideo의 입력이 이미지와 텍스트를 모두 수용하도록 조정되었습니다. 프롬프트는 이미지를 직접 삽입하거나 간단한 신원 설명으로 태그하며, 이미지와 텍스트의 영향을 균형 있게 유지하기 위해 분리자 토큰을 사용합니다.
신원 강화 모듈은 짧은 비디오 클립에서 주제 일관성을 유지하는 데 중요한 LLaVA의 세밀한 공간적 세부 정보 손실 문제를 해결합니다.
참조 이미지는 HunyuanVideo의 인과적 3D-VAE를 통해 크기가 조정되고 인코딩되며, 그 잠재는 시간 축을 따라 삽입되고 공간적 오프셋으로 생성을 안내하여 직접 복제를 피합니다.
로짓-정규 분포의 노이즈를 사용한 Flow Matching으로 훈련하여 LLaVA와 비디오 생성기를 함께 미세 조정하여 이미지-프롬프트 안내와 신원 일관성을 통합했습니다.
다중 주제 프롬프트의 경우, 각 이미지-텍스트 쌍은 별도의 시간 위치로 개별적으로 임베딩되어 다중 상호작용 주제가 있는 장면을 가능하게 합니다.
오디오 및 시각 통합
HunyuanCustom은 사용자가 제공한 오디오와 텍스트를 사용한 오디오 기반 생성을 지원하여 캐릭터가 맥락적으로 관련 있는 환경에서 말할 수 있게 합니다.
Identity-disentangled AudioNet 모듈은 오디오 기능을 비디오 타임라인과 정렬하며, 공간적 교차 주의를 사용하여 프레임을 분리하고 주제 일관성을 유지합니다.
시간적 주입 모듈은 오디오를 잠재 시퀀스에 매핑하여 Multi-Layer Perceptron을 통해 동작 타이밍을 정제하며, 제스처가 오디오 리듬과 정렬되도록 합니다.
비디오 편집의 경우, HunyuanCustom은 전체 비디오를 재생성하지 않고 기존 클립에서 주제를 교체하여 외관이나 동작 변경에 이상적입니다.
재생하려면 클릭하세요. 보조 사이트의 또 다른 예시.
시스템은 사전 훈련된 인과적 3D-VAE를 사용하여 참조 비디오를 압축하며, 생성 파이프라인 잠재와 정렬하여 경량 처리를 합니다. 신경망은 깨끗한 입력 비디오를 노이즈가 있는 잠재와 정렬하며, 프레임별 기능 추가는 사전 압축 병합보다 효과적임이 입증되었습니다.
성능 평가
테스트 메트릭에는 얼굴 신원 일관성을 위한 ArcFace, 주제 유사성을 위한 YOLO11x 및 Dino 2, 텍스트-비디오 정렬 및 시간적 일관성을 위한 CLIP-B, 동작 강도를 위한 VBench가 포함되었습니다.
경쟁자는 폐쇄 소스 시스템(Hailuo, Vidu 2.0, Kling 1.6, Pika)과 오픈소스 프레임워크(VACE, SkyReels-A2)를 포함했습니다.
HunyuanCustom과 선도적인 비디오 커스터마이제이션 방법을 신원 일관성(Face-Sim), 주제 유사성(DINO-Sim), 텍스트-비디오 정렬(CLIP-B-T), 시간적 일관성(Temp-Consis), 동작 강도(DD)에서 비교한 모델 성능 평가. 최적 및 차선 결과는 각각 굵은 글씨와 밑줄로 표시됩니다.
저자들은 다음과 같이 언급합니다:
‘HunyuanCustom은 신원 및 주제 일관성에서 탁월하며, 프롬프트 준수와 시간적 안정성에서 경쟁력 있습니다. Hailuo는 강력한 텍스트 정렬로 인해 클립 점수에서 선두를 달리지만 비인간 주제 일관성에서 어려움을 겪습니다. Vidu와 VACE는 모델 크기가 작아 동작 강도가 뒤떨어집니다.’
프로젝트 사이트는 수많은 비교 비디오를 제공하지만, 레이아웃은 비교의 용이성보다 미학을 우선시합니다. 더 명확한 통찰을 위해 비디오를 직접 검토하는 것이 좋습니다:
논문에서 객체 중심 비디오 커스터마이제이션 비교. 더 나은 해상도를 위해 소스 PDF를 참조해야 하지만, 프로젝트 사이트의 비디오가 더 명확한 통찰을 제공합니다.
저자들은 다음과 같이 말합니다:
‘Vidu, SkyReels A2, HunyuanCustom은 강력한 프롬프트 정렬과 주제 일관성을 달성하지만, Hunyuanvideo-13B의 견고한 기반 덕분에 우리의 비디오 품질은 Vidu와 SkyReels를 능가합니다.’
‘상용 솔루션 중 Kling은 고품질 비디오를 제공하지만 첫 프레임에서 복사-붙여넣기 효과와 가끔 주제 흐림으로 인해 시청 경험에 영향을 미칩니다.’
Pika는 데이터 큐레이션 부족으로 자막 아티팩트를 도입하며 시간적 일관성에서 어려움을 겪습니다. Hailuo는 얼굴 신원을 유지하지만 전신 일관성에서 실패합니다. 오픈소스 방법 중 VACE는 신원 일관성을 유지하지 못하며, HunyuanCustom은 강력한 신원 보존, 품질, 다양성을 제공합니다.
다중 주제 비디오 커스터마이제이션 테스트는 유사한 결과를 보였습니다:
다중 주제 비디오 커스터마이제이션 비교. 더 나은 세부 정보와 해상도를 위해 PDF를 참조하세요.
논문은 다음과 같이 언급합니다:
‘Pika는 지정된 주제를 생성하지만 프레임 불안정성을 보여주며, 주제가 사라지거나 프롬프트를 따르지 못합니다. Vidu와 VACE는 인간 신원을 부분적으로 포착하지만 비인간 객체 세부 정보를 잃습니다. SkyReels A2는 심각한 프레임 불안정성과 아티팩트를 겪습니다. HunyuanCustom은 모든 주제 신원을 효과적으로 포착하고, 프롬프트를 준수하며, 높은 시각 품질과 안정성을 유지합니다.’
가상 인간 광고 테스트는 제품과 사람을 통합했습니다:
정성적 테스트 라운드에서 신경망 ‘제품 배치’ 예시. 더 나은 세부 정보와 해상도를 위해 PDF를 참조하세요.
저자들은 다음과 같이 말합니다:
‘HunyuanCustom은 인간 신원과 제품 세부 정보(텍스트 포함)를 유지하며, 자연스러운 상호작용과 강력한 프롬프트 준수로 광고 비디오에 대한 잠재력을 보여줍니다.’
오디오 기반 커스터마이제이션 테스트는 유연한 장면 및 자세 제어를 강조했습니다:
오디오 라운드에 대한 부분 결과—비디오 결과가 더 바람직했을 수 있습니다. 크기 제약으로 인해 PDF 그림의 상단 절반만 표시됩니다. 더 나은 세부 정보를 위해 소스 PDF를 참조하세요.
저자들은 다음과 같이 언급합니다:
‘이전 오디오 기반 방법은 입력 이미지에 자세와 환경을 제한하여 응용 프로그램을 제한했습니다. HunyuanCustom은 텍스트로 설명된 장면과 자세로 유연한 오디오 기반 애니메이션을 가능하게 합니다.’
비디오 주제 교체 테스트는 HunyuanCustom을 VACE 및 Kling 1.6과 비교했습니다:
비디오-투-비디오 모드에서 주제 교체 테스트. 더 나은 세부 정보와 해상도를 위해 소스 PDF를 참조하세요.
연구자들은 다음과 같이 말합니다:
‘VACE는 엄격한 마스크 준수로 인해 경계 아티팩트를 생성하여 동작 연속성을 방해합니다. Kling은 배경 통합이 약한 복사-붙여넣기 효과를 보여줍니다. HunyuanCustom은 아티팩트를 피하고, 원활한 통합을 보장하며, 강력한 신원 보존을 유지하여 비디오 편집에서 탁월합니다.’
결론
HunyuanCustom은 비디오 합성에서 입술 동기화에 대한 증가하는 수요를 해결하여 Hunyuan Video와 같은 시스템의 리얼리즘을 향상시키는 매력적인 릴리스입니다. 프로젝트 사이트의 비디오 레이아웃으로 인해 기능을 비교하는 데 어려움이 있지만, Tencent의 모델은 Kling과 같은 주요 경쟁자와 견줄 수 있으며, 맞춤형 비디오 생성에서 상당한 진전을 이루었습니다.
* 일부 비디오는 VLC 또는 Windows Media Player와 같은 표준 플레이어에서 재생하기에 너무 넓거나, 짧거나, 고해상도여서 검은 화면이 표시됩니다.
2025년 5월 8일 목요일에 처음 게시됨










 독점: 루마 AI, '통합 지능' 모델로 구동되는 크리에이티브 에이전트 선보여
목요일, AI 영상 생성 스타트업 루마(Luma)는 텍스트, 이미지, 영상, 오디오에 걸친 완전한 크리에이티브 워크플로우를 관리하기 위해 구축된 시스템인 '루마 에이전트(Luma Agents)'를 공개했다. 이 에이전트들은 단일 다중 모달 추론 엔진으로 훈련된 아키텍처를 특징으로 하는 루마의 통합 인텔리전스 모델 패밀리(Unified In
독점: 루마 AI, '통합 지능' 모델로 구동되는 크리에이티브 에이전트 선보여
목요일, AI 영상 생성 스타트업 루마(Luma)는 텍스트, 이미지, 영상, 오디오에 걸친 완전한 크리에이티브 워크플로우를 관리하기 위해 구축된 시스템인 '루마 에이전트(Luma Agents)'를 공개했다. 이 에이전트들은 단일 다중 모달 추론 엔진으로 훈련된 아키텍처를 특징으로 하는 루마의 통합 인텔리전스 모델 패밀리(Unified In
 반려동물 AI 동영상, 소셜 도구, 곧 출시될 안드로이드 앱을 제공하는 Sora의 새로운 업데이트
지난 9월 말 출시 후 단숨에 App Store 인기 앱 1위에 오른 인기 AI 동영상 제작 앱 Sora에 새로운 기능이 추가될 예정입니다. 미국과 캐나다에서 여전히 1위를 차지하고 있는 이 앱은 곧 동영상 편집 기능을 추가하고, 사용자가 애완동물과 기타 아이템의 캐릭터 '카메오'를 만들 수 있도록 하며, 소셜 기능을 강화하는 등의 기능을 추가할 예정입니다
반려동물 AI 동영상, 소셜 도구, 곧 출시될 안드로이드 앱을 제공하는 Sora의 새로운 업데이트
지난 9월 말 출시 후 단숨에 App Store 인기 앱 1위에 오른 인기 AI 동영상 제작 앱 Sora에 새로운 기능이 추가될 예정입니다. 미국과 캐나다에서 여전히 1위를 차지하고 있는 이 앱은 곧 동영상 편집 기능을 추가하고, 사용자가 애완동물과 기타 아이템의 캐릭터 '카메오'를 만들 수 있도록 하며, 소셜 기능을 강화하는 등의 기능을 추가할 예정입니다
 AI 비디오 생성은 완전한 제어로 이동합니다
Hunyuan 및 WAN 2.1과 같은 비디오 파운데이션 모델은 상당한 진전을 이루었지만 영화 및 TV 제작, 특히 VFX (Visual Effects) 영역에서 필요한 세부 제어에있어 종종 부족합니다. 전문적인 VFX 스튜디오에서는이 모델과 이전 이미지 바와 함께
AI 비디오 생성은 완전한 제어로 이동합니다
Hunyuan 및 WAN 2.1과 같은 비디오 파운데이션 모델은 상당한 진전을 이루었지만 영화 및 TV 제작, 특히 VFX (Visual Effects) 영역에서 필요한 세부 제어에있어 종종 부족합니다. 전문적인 VFX 스튜디오에서는이 모델과 이전 이미지 바와 함께

난독증 지원을 위해 엄선된 2026년 최신 최고 평점 AI TTS 앱을 만나보세요. 전문가들이 선정한 이 순위는 무료 및 유료 도구를 비교 분석하여, 읽기 효율과 학습 효과를 높여주는 강력한 기능들을 소개합니다. 학생들의 잠재력을 최대한 발휘할 수 있도록 도와줄, 꼭 사용해봐야 할 혁신적인 솔루션을 확인해 보세요. XIX.AI에서 여정을 시작해 보세요.
10 도구
xix.ai

XIX.AI에서 2026년 최고의 소년 만화 AI 생성기를 만나보세요. 엄선된 최고 평점 목록에는 박진감 넘치는 액션 장면과 역동적인 에너지 효과를 연출할 수 있는 강력한 도구들이 포함되어 있습니다. 실제 테스트를 통해 무료 버전과 유료 버전을 비교해 보세요. 여러분의 창의력을 마음껏 발휘하여 오늘 바로 장대한 만화를 만들어 보세요!
15 도구
xix.ai

2026년 최신 최고의 AI 경비 관리 도구: 영수증을 스캔하고 기업 경비를 자동으로 분류해 주는 최고 평점의 도구들. 손쉬운 경비 관리, 정확한 재무 추적, 효율적인 규정 준수를 위한 강력하고 혁신적인 솔루션을 만나보세요. 무료 및 유료 옵션을 엄선하여 매주 업데이트되는 비교 자료를 통해 귀사에 딱 맞는 도구를 찾으실 수 있습니다. XIX.AI의 전문가 추천 목록으로 AI의 장점을 최대한 활용하세요.
10 도구
xix.ai

XIX.AI에서 2026년 최신 최고 평점을 받은 AI 채용 도구를 확인해 보세요. 저희가 엄선한 이 목록에는 이력서 심사 및 후보자 면접 일정 자동화를 위한 강력하고 혁신적인 솔루션이 포함되어 있습니다. 실제 테스트 결과와 매주 업데이트되는 순위를 바탕으로 무료 및 유료 옵션을 비교해 보세요. 지금 바로 귀사에 딱 맞는 채용 도우미를 찾아 채용 프로세스를 효율화하세요!
10 도구
xix.ai

XIX.AI에서 2026년 최고의 AI 기반 개인 웰니스 및 집중력 코치들을 만나보세요. 저희가 엄선한 순위 목록에는 번아웃을 관리하고 정신적 에너지를 높여주는 최고 평점을 받은 혁신적인 도구들이 소개되어 있습니다. 실제 사용 후기를 바탕으로 무료 버전과 유료 버전을 비교해 보세요. 지금 바로 최고의 생산성과 웰빙을 향한 길을 열어보세요.
10 도구
xix.ai

진정성 있는 장기적인 관계를 형성할 수 있는 2026년 최신 최고 평점 AI 로맨틱 챗봇을 만나보세요. 저희가 엄선한 이 목록에는 강력하고 일관된 캐릭터, 무료 및 유료 버전 비교, 실제 사용 후기가 담겨 있습니다. XIX.AI에서 나에게 딱 맞는 파트너를 찾아 오늘 바로 관계를 시작해 보세요.
10 도구
xix.ai

Esse exemplo de vídeo parece meio bugado... Mas a ideia de transformar uma imagem estática em vídeo é fascinante. Será que isso poderia ser usado para criar conteúdos educativos ou de forma indevida? A discussão ética sempre fica atrás da tecnologia 🤔.













