
















 Hogar
HogarTencent presenta HunyuanCustom para personalización de videos con una sola imagen
Este artículo explora el lanzamiento de HunyuanCustom, un modelo de generación de videos multimodal de Tencent. El amplio alcance del artículo de investigación adjunto y los desafíos con los videos de ejemplo proporcionados en la página del proyecto requieren una visión general más amplia, con una reproducción limitada del extenso contenido de video debido a los requisitos de formato y procesamiento para una mayor claridad.
Ten en cuenta que el artículo se refiere al sistema generativo basado en API Kling como ‘Keling’. Para mantener la consistencia, este artículo utiliza ‘Kling’ en todo momento.
Tencent ha presentado una iteración avanzada de su modelo Hunyuan Video, denominado HunyuanCustom. Este lanzamiento, según se informa, supera la necesidad de los modelos Hunyuan LoRA al permitir a los usuarios crear personalizaciones de video estilo deepfake usando solo una única imagen:
Haz clic para reproducir. Instrucción: ‘Un hombre disfruta de la música mientras prepara fideos de caracol en una cocina.’ En comparación con métodos propietarios y de código abierto, incluido Kling, un competidor clave, HunyuanCustom destaca. Fuente: https://hunyuancustom.github.io/ (nota: sitio con alto consumo de recursos)
En el video anterior, la columna más a la izquierda muestra la imagen de origen única para HunyuanCustom, seguida de la interpretación del sistema de la instrucción en la columna adyacente. Las columnas restantes muestran resultados de otros sistemas: Kling, Vidu, Pika, Hailuo y SkyReels-A2 (basado en Wan).
El siguiente video destaca tres escenarios principales para este lanzamiento: persona con objeto, replicación de un solo personaje y prueba virtual de ropa:
Haz clic para reproducir. Tres ejemplos seleccionados del sitio de soporte de Hunyuan Video.
Estos ejemplos revelan limitaciones relacionadas con depender de una única imagen de origen en lugar de múltiples perspectivas.
En el primer clip, el hombre mira a la cámara con un movimiento mínimo de la cabeza, inclinándose no más de 20-25 grados. Más allá de esto, el sistema tiene dificultades para inferir su perfil con precisión a partir de una sola imagen frontal.
En el segundo clip, la chica mantiene una expresión sonriente en el video, reflejando su imagen de origen estática. Sin referencias adicionales, HunyuanCustom no puede representar de manera confiable su expresión neutral, y su rostro permanece mayormente de frente, similar al ejemplo anterior.
En el clip final, un material de origen incompleto—una mujer y ropa virtual—resulta en un renderizado recortado, una solución práctica para datos limitados.
Aunque HunyuanCustom admite múltiples entradas de imágenes (por ejemplo, persona con snacks o persona con atuendo), no permite ángulos o expresiones variadas para un solo personaje. Esto puede limitar su capacidad para reemplazar completamente el ecosistema en expansión de modelos LoRA para HunyuanVideo, que usan de 20 a 60 imágenes para garantizar una representación consistente del personaje en diferentes ángulos y expresiones.
Integración de audio
Para el audio, HunyuanCustom emplea el sistema LatentSync, que es desafiante para aficionados configurar, para sincronizar los movimientos de los labios con el audio y texto proporcionados por el usuario:
Incluye audio. Haz clic para reproducir. Ejemplos compilados de sincronización de labios del sitio suplementario de HunyuanCustom.
Actualmente, no hay ejemplos en inglés disponibles, pero los resultados parecen prometedores, particularmente si el proceso de configuración es amigable para el usuario.
Capacidades de edición de video
HunyuanCustom destaca en la edición de video a video (V2V), permitiendo el reemplazo dirigido de elementos en videos existentes usando una sola imagen de referencia. Un ejemplo de los materiales suplementarios ilustra esto:
Haz clic para reproducir. El objeto central se modifica, con los elementos circundantes alterados sutilmente en un proceso V2V de HunyuanCustom.
Como es típico en los flujos de trabajo V2V, todo el video se modifica ligeramente, con un enfoque principal en el área objetivo, como el peluche. Las tuberías avanzadas podrían preservar más del contenido original, similar al enfoque de Adobe Firefly, aunque esto sigue siendo poco explorado en las comunidades de código abierto.
Otros ejemplos demuestran una precisión mejorada en integraciones dirigidas, como se ve en esta compilación:
Haz clic para reproducir. Ejemplos variados de inserción de contenido V2V en HunyuanCustom, mostrando respeto por los elementos no alterados.
Actualización evolutiva
HunyuanCustom se basa en el proyecto Hunyuan Video, introduciendo mejoras arquitectónicas específicas en lugar de una revisión completa. Estas actualizaciones buscan mantener la consistencia del personaje entre fotogramas sin requerir ajustes específicos del sujeto, como LoRA o inversión textual.
Este lanzamiento es una versión refinada del modelo HunyuanVideo de diciembre de 2024, no un modelo nuevo construido desde cero.
Los usuarios de LoRAs existentes de HunyuanVideo pueden preguntarse sobre su compatibilidad con esta actualización o si deben desarrollarse nuevos LoRAs para aprovechar las funciones de personalización mejoradas.
Por lo general, un ajuste significativo altera los pesos del modelo lo suficiente como para hacer incompatibles los LoRAs anteriores. Sin embargo, algunos ajustes, como Pony Diffusion para Stable Diffusion XL, han creado ecosistemas independientes con bibliotecas de LoRA dedicadas, lo que sugiere un potencial para que HunyuanCustom siga un camino similar.
Detalles del lanzamiento
El artículo de investigación, titulado HunyuanCustom: Una arquitectura impulsada por multimodalidad para la generación de videos personalizados, enlaza con un repositorio de GitHub ahora activo con código y pesos para implementación local, junto con una integración planificada con ComfyUI.
Actualmente, la página de Hugging Face del proyecto no está accesible, pero una demostración basada en API está disponible mediante un código de escaneo de WeChat.
El ensamblaje de diversos proyectos de HunyuanCustom es notablemente completo, probablemente impulsado por los requisitos de licencia para una divulgación completa.
Se ofrecen dos variantes del modelo: una versión de 720x1280px que necesita 80GB de memoria GPU para un rendimiento óptimo (24GB mínimo, pero lento) y una versión de 512x896px que requiere 60GB. Las pruebas se han limitado a Linux, pero los esfuerzos de la comunidad pueden adaptar pronto el modelo para Windows y configuraciones de VRAM más bajas, como se vio con el modelo anterior de Hunyuan Video.
Debido al volumen de materiales adjuntos, esta visión general adopta un enfoque de alto nivel sobre las capacidades de HunyuanCustom.
Perspectivas técnicas
El pipeline de datos de HunyuanCustom, compatible con GDPR, integra conjuntos de datos de video sintetizados y de código abierto como OpenHumanVid, cubriendo ocho categorías: humanos, animales, plantas, paisajes, vehículos, objetos, arquitectura y anime.
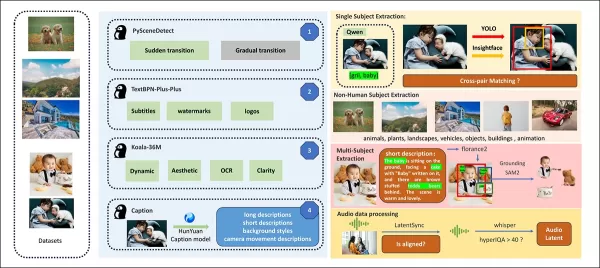
Del artículo de lanzamiento, una visión general de los diversos paquetes contribuyentes en el pipeline de construcción de datos de HunyuanCustom. Fuente: https://arxiv.org/pdf/2505.04512
Los videos se segmentan en clips de una sola toma usando PySceneDetect, con TextBPN-Plus-Plus filtrando contenido con texto excesivo, subtítulos o marcas de agua.
Los clips se estandarizan a cinco segundos y se redimensionan a 512 o 720 píxeles en el lado corto. La calidad estética se asegura utilizando Koala-36M con un umbral personalizado de 0.06.
La extracción de identidad humana utiliza Qwen7B, YOLO11X e InsightFace, mientras que los sujetos no humanos se procesan con QwenVL y Grounded SAM 2, descartando cajas delimitadoras pequeñas.

Ejemplos de segmentación semántica con Grounded SAM 2, utilizado en el proyecto Hunyuan Control. Fuente: https://github.com/IDEA-Research/Grounded-SAM-2
La extracción de múltiples sujetos utiliza Florence2 para la anotación y Grounded SAM 2 para la segmentación, seguida de clustering y segmentación temporal de fotogramas.
Los clips se mejoran con un etiquetado estructurado propietario por el equipo de Hunyuan, añadiendo metadatos como descripciones y señales de movimiento de cámara.
El aumento de máscaras evita el sobreajuste, asegurando adaptabilidad a formas de objetos variadas. La sincronización de audio utiliza LatentSync, descartando clips por debajo de un umbral de calidad. HyperIQA filtra videos con puntajes inferiores a 40, y Whisper procesa audio válido para tareas posteriores.
El modelo LLaVA juega un papel central, generando subtítulos y alineando contenido visual y textual para una consistencia semántica, especialmente en escenas complejas o con múltiples sujetos.
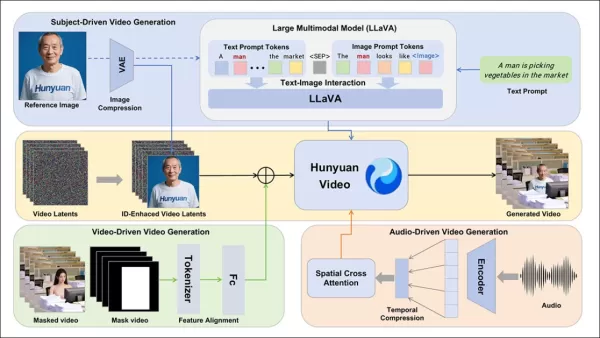
El marco de HunyuanCustom soporta la generación de videos consistente con la identidad condicionada por texto, imagen, audio y entradas de video.
Personalización de video
Para permitir la generación de videos a partir de una imagen de referencia y una instrucción, se desarrollaron dos módulos basados en LLaVA, adaptando la entrada de HunyuanVideo para aceptar tanto imagen como texto. Las instrucciones incrustan imágenes directamente o las etiquetan con breves descripciones de identidad, usando un token separador para equilibrar la influencia de la imagen y el texto.
Un módulo de mejora de identidad aborda la tendencia de LLaVA a perder detalles espaciales finos, cruciales para mantener la consistencia del sujeto en clips de video cortos.
La imagen de referencia se redimensiona y codifica mediante el 3D-VAE causal de HunyuanVideo, con su latente insertado a lo largo del eje temporal y un desplazamiento espacial para guiar la generación sin replicación directa.
El entrenamiento utilizó Flow Matching con ruido de una distribución logit-normal, ajustando LLaVA y el generador de video juntos para una guía cohesiva de imagen-instrucción y consistencia de identidad.
Para instrucciones con múltiples sujetos, cada par imagen-texto se incrusta por separado con posiciones temporales distintas, permitiendo escenas con múltiples sujetos interactuando.
Integración de audio y visual
HunyuanCustom soporta la generación impulsada por audio usando audio y texto proporcionados por el usuario, permitiendo que los personajes hablen en entornos contextualmente relevantes.
Un módulo AudioNet desenredado de identidad alinea las características de audio con la línea temporal del video, usando atención cruzada espacial para aislar fotogramas y mantener la consistencia del sujeto.
Un módulo de inyección temporal refina el tiempo de movimiento, mapeando audio a secuencias latentes mediante un perceptrón multicapa, asegurando que los gestos se alineen con el ritmo del audio.
Para la edición de video, HunyuanCustom reemplaza sujetos en clips existentes sin regenerar todo el video, ideal para cambios dirigidos de apariencia o movimiento.
Haz clic para reproducir. Otro ejemplo del sitio suplementario.
El sistema comprime videos de referencia usando el 3D-VAE causal preentrenado, alineándolos con los latentes del pipeline de generación para un procesamiento ligero. Una red neuronal alinea videos de entrada limpios con latentes ruidosos, con la adición de características fotograma por fotograma demostrando ser más efectiva que la fusión previa a la compresión.
Evaluación de rendimiento
Las métricas de prueba incluyeron ArcFace para la consistencia de identidad facial, YOLO11x y Dino 2 para la similitud de sujetos, CLIP-B para la alineación de texto-video y consistencia temporal, y VBench para la intensidad de movimiento.
Los competidores incluyeron sistemas de código cerrado (Hailuo, Vidu 2.0, Kling 1.6, Pika) y marcos de código abierto (VACE, SkyReels-A2).
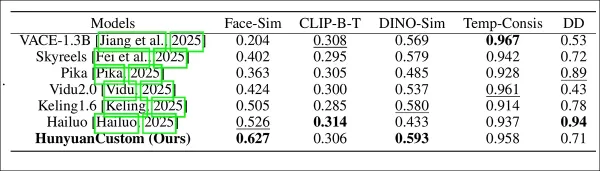
Evaluación del rendimiento del modelo comparando HunyuanCustom con métodos líderes de personalización de videos en consistencia de ID (Face-Sim), similitud de sujetos (DINO-Sim), alineación de texto-video (CLIP-B-T), consistencia temporal (Temp-Consis) e intensidad de movimiento (DD). Los resultados óptimos y subóptimos se muestran en negrita y subrayados, respectivamente.
Los autores señalan:
‘HunyuanCustom destaca en consistencia de ID y sujetos, con una adherencia competitiva a las instrucciones y estabilidad temporal. Hailuo lidera en puntaje de clip debido a una fuerte alineación de texto, pero tiene dificultades con la consistencia de sujetos no humanos. Vidu y VACE se quedan atrás en intensidad de movimiento, probablemente debido a tamaños de modelo más pequeños.’
Aunque el sitio del proyecto ofrece numerosos videos de comparación, su diseño prioriza la estética sobre la facilidad de comparación. Se anima a los lectores a revisar los videos directamente para obtener información más clara:
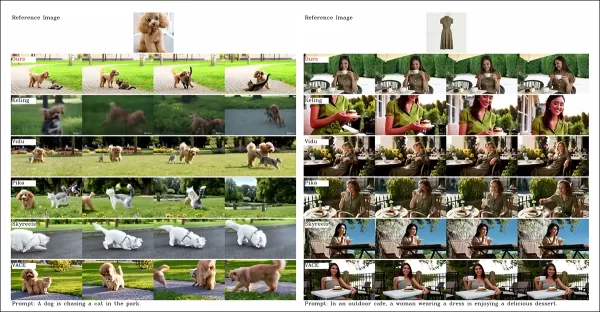
Del artículo, una comparación sobre personalización de videos centrada en objetos. Aunque el espectador debería consultar el PDF fuente para una mejor resolución, los videos en el sitio del proyecto ofrecen información más clara.
Los autores afirman:
‘Vidu, SkyReels A2 y HunyuanCustom logran una fuerte alineación con las instrucciones y consistencia de sujetos, pero nuestra calidad de video supera a Vidu y SkyReels, gracias a la robusta base de Hunyuanvideo-13B.’
‘Entre las soluciones comerciales, Kling ofrece videos de alta calidad, pero sufre un efecto de copia-pega en el primer fotograma y un desenfoque ocasional del sujeto, afectando la experiencia del espectador.’
Pika tiene problemas con la consistencia temporal, introduciendo artefactos de subtítulos por una mala curación de datos. Hailuo preserva la identidad facial, pero falla en la consistencia de cuerpo completo. VACE, entre los métodos de código abierto, no logra mantener la consistencia de identidad, mientras que HunyuanCustom ofrece una fuerte preservación de identidad, calidad y diversidad.
Las pruebas de personalización de videos con múltiples sujetos arrojaron resultados similares:

Comparaciones usando personalizaciones de videos con múltiples sujetos. Consulta el PDF para obtener mejores detalles y resolución.
El artículo señala:
‘Pika genera sujetos especificados, pero muestra inestabilidad en los fotogramas, con sujetos que desaparecen o no siguen las instrucciones. Vidu y VACE capturan parcialmente la identidad humana, pero pierden detalles de objetos no humanos. SkyReels A2 sufre una grave inestabilidad de fotogramas y artefactos. HunyuanCustom captura efectivamente todas las identidades de los sujetos, se adhiere a las instrucciones y mantiene una alta calidad visual y estabilidad.’
Una prueba de publicidad con humanos virtuales integró productos con personas:

De la ronda de pruebas cualitativas, ejemplos de colocación de productos neuronal. Consulta el PDF para obtener mejores detalles y resolución.
Los autores afirman:
‘HunyuanCustom mantiene la identidad humana y los detalles del producto, incluido el texto, con interacciones naturales y una fuerte adherencia a las instrucciones, mostrando su potencial para videos publicitarios.’
Las pruebas de personalización impulsada por audio destacaron un control flexible de escenas y posturas:
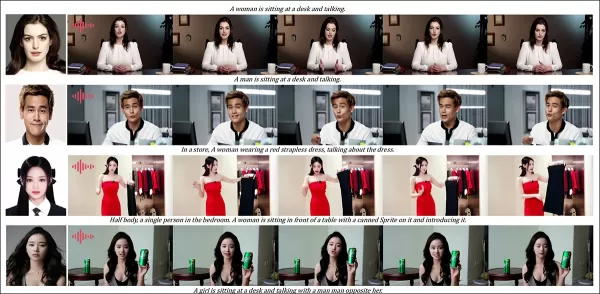
Resultados parciales para la ronda de audio—los resultados en video serían preferibles. Solo se muestra la mitad superior de la figura del PDF debido a restricciones de tamaño. Consulta el PDF fuente para obtener mejores detalles.
Los autores señalan:
‘Los métodos anteriores impulsados por audio limitan la postura y el entorno a la imagen de entrada, restringiendo las aplicaciones. HunyuanCustom permite una animación impulsada por audio flexible con escenas y posturas descritas por texto.’
Las pruebas de reemplazo de sujetos en video compararon HunyuanCustom contra VACE y Kling 1.6:

Pruebas de reemplazo de sujetos en modo video a video. Consulta el PDF fuente para obtener mejores detalles y resolución.
Los investigadores afirman:
‘VACE produce artefactos de borde por una adherencia estricta a la máscara, interrumpiendo la continuidad del movimiento. Kling muestra un efecto de copia-pega con una pobre integración del fondo. HunyuanCustom evita artefactos, asegura una integración fluida y mantiene una fuerte preservación de identidad, destacando en la edición de video.’
Conclusión
HunyuanCustom es un lanzamiento convincente, que aborda la creciente demanda de sincronización de labios en la síntesis de video, mejorando el realismo en sistemas como Hunyuan Video. A pesar de los desafíos para comparar sus capacidades debido al diseño de videos del sitio del proyecto, el modelo de Tencent se mantiene firme frente a los principales competidores como Kling, marcando un progreso significativo en la generación de videos personalizados.
* Algunos videos son demasiado anchos, cortos o de alta resolución para reproducirse en reproductores estándar como VLC o Windows Media Player, mostrando pantallas negras.
Publicado por primera vez el jueves, 8 de mayo de 2025
Artículo relacionado
 Exclusiva: Luma AI presenta agentes creativos impulsados por modelos de «inteligencia unificada»
El jueves, la startup de generación de vídeo mediante IA Luma presentó Luma Agents, un sistema creado para gestionar flujos de trabajo creativos completos que abarcan texto, imágenes, vídeo y audio. E
La nueva actualización de Sora incluye vídeos de inteligencia artificial de mascotas, herramientas sociales y una próxima aplicación para Android.
OpenAI presenta una serie de nuevas funciones para Sora, su aplicación de creación de vídeos con inteligencia artificial, que alcanzó rápidamente el primer puesto de la App Store tras su lanzamiento a
La generación de videos de IA se mueve hacia el control completo
Los modelos de Foundation de Video como Hunyuan y WAN 2.1 han hecho avances significativos, pero a menudo se quedan cortos cuando se trata del control detallado requerido en la producción de cine y televisión, especialmente en el ámbito de los efectos visuales (VFX). En los estudios profesionales de VFX, estos modelos, junto con la imagen de imagen anterior
Recomendaciones de temas especiales relacionados
Texto a voz
Exclusiva: Luma AI presenta agentes creativos impulsados por modelos de «inteligencia unificada»
El jueves, la startup de generación de vídeo mediante IA Luma presentó Luma Agents, un sistema creado para gestionar flujos de trabajo creativos completos que abarcan texto, imágenes, vídeo y audio. E
La nueva actualización de Sora incluye vídeos de inteligencia artificial de mascotas, herramientas sociales y una próxima aplicación para Android.
OpenAI presenta una serie de nuevas funciones para Sora, su aplicación de creación de vídeos con inteligencia artificial, que alcanzó rápidamente el primer puesto de la App Store tras su lanzamiento a
La generación de videos de IA se mueve hacia el control completo
Los modelos de Foundation de Video como Hunyuan y WAN 2.1 han hecho avances significativos, pero a menudo se quedan cortos cuando se trata del control detallado requerido en la producción de cine y televisión, especialmente en el ámbito de los efectos visuales (VFX). En los estudios profesionales de VFX, estos modelos, junto con la imagen de imagen anterior
Recomendaciones de temas especiales relacionados
Texto a voz
 Las mejores aplicaciones de síntesis de voz con IA para la dislexia: apoyo al aprendizaje y mejora de la eficiencia en la lectura de los estudiantes
Las mejores aplicaciones de síntesis de voz con IA para la dislexia: apoyo al aprendizaje y mejora de la eficiencia en la lectura de los estudiantes
Descubre las mejores aplicaciones de TTS con IA de 2026, seleccionadas específicamente para ayudar a las personas con dislexia. Nuestra clasificación, elaborada por expertos, compara herramientas gratuitas y de pago, y destaca sus potentes funciones para mejorar la eficiencia en la lectura y el aprendizaje. Explora soluciones innovadoras e imprescindibles para liberar el potencial de los estudiantes. Empieza tu viaje en XIX.AI.
 10 herramientas
10 herramientas
 xix.ai
Creación de cómics
Los mejores generadores de IA para manga shonen: crea secuencias de acción trepidantes y efectos de energía
xix.ai
Creación de cómics
Los mejores generadores de IA para manga shonen: crea secuencias de acción trepidantes y efectos de energía
Descubre los mejores generadores de IA para manga shonen de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada y con las mejores valoraciones, incluye potentes herramientas para crear secuencias de acción trepidantes y efectos energéticos dinámicos. Compara las opciones gratuitas con las de pago mediante pruebas reales. ¡Libera tu potencial creativo y empieza a crear manga épico hoy mismo!
15 herramientas
xix.ai
Negocio
Los mejores gestores de gastos con IA: escanea recibos y clasifica automáticamente los gastos de la empresa
Los mejores gestores de gastos con IA de 2026: las herramientas mejor valoradas para escanear recibos y clasificar automáticamente los gastos de la empresa. Descubre soluciones potentes y revolucionarias para una gestión de gastos sin esfuerzo, un seguimiento financiero preciso y un cumplimiento normativo optimizado. Nuestra comparativa, seleccionada y actualizada semanalmente, entre opciones gratuitas y de pago te ayuda a encontrar la que mejor se adapta a tus necesidades. Aprovecha al máximo las ventajas de la IA con las recomendaciones de los expertos de XIX.AI.
10 herramientas
xix.ai
Negocio
Las mejores herramientas de selección de personal basadas en IA: filtrar currículos y automatizar la programación de entrevistas con los candidatos
Descubre las mejores herramientas de selección de personal basadas en IA de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada, incluye soluciones potentes y revolucionarias para la selección de currículos y la automatización de la programación de entrevistas con los candidatos. Compara las opciones gratuitas con las de pago gracias a pruebas reales y a clasificaciones que se actualizan semanalmente. ¡Encuentra tu asistente de selección de personal ideal y optimiza tu proceso de selección hoy mismo!
10 herramientas
xix.ai
Productividad
Entrenadores personales de bienestar y concentración basados en IA: controla el agotamiento y aumenta tus niveles de energía mental
Descubre los mejores entrenadores personales de bienestar y concentración basados en IA de 2026 en XIX.AI. Nuestras clasificaciones, cuidadosamente seleccionadas, incluyen herramientas revolucionarias y de primera categoría para gestionar el agotamiento y potenciar la energía mental. Compara las opciones gratuitas con las de pago gracias a información basada en casos reales. Descubre hoy mismo el camino hacia la máxima productividad y el bienestar.
10 herramientas
xix.ai
chatbot
Los mejores chatbots románticos con IA: crea relaciones duraderas con personalidades coherentes
Descubre los mejores chatbots románticos con IA de 2026 para establecer relaciones auténticas y duraderas. Nuestra lista seleccionada incluye personalidades sólidas y coherentes, comparativas entre versiones gratuitas y de pago, y pruebas en situaciones reales. Encuentra a tu compañero ideal y empieza a construir tu relación hoy mismo en XIX.AI.
10 herramientas
xix.ai

 comentario (1)
0/500
comentario (1)
0/500
![RalphHill]()
Esse exemplo de vídeo parece meio bugado... Mas a ideia de transformar uma imagem estática em vídeo é fascinante. Será que isso poderia ser usado para criar conteúdos educativos ou de forma indevida? A discussão ética sempre fica atrás da tecnologia 🤔.
Este artículo explora el lanzamiento de HunyuanCustom, un modelo de generación de videos multimodal de Tencent. El amplio alcance del artículo de investigación adjunto y los desafíos con los videos de ejemplo proporcionados en la página del proyecto requieren una visión general más amplia, con una reproducción limitada del extenso contenido de video debido a los requisitos de formato y procesamiento para una mayor claridad.
Ten en cuenta que el artículo se refiere al sistema generativo basado en API Kling como ‘Keling’. Para mantener la consistencia, este artículo utiliza ‘Kling’ en todo momento.
Tencent ha presentado una iteración avanzada de su modelo Hunyuan Video, denominado HunyuanCustom. Este lanzamiento, según se informa, supera la necesidad de los modelos Hunyuan LoRA al permitir a los usuarios crear personalizaciones de video estilo deepfake usando solo una única imagen:
Haz clic para reproducir. Instrucción: ‘Un hombre disfruta de la música mientras prepara fideos de caracol en una cocina.’ En comparación con métodos propietarios y de código abierto, incluido Kling, un competidor clave, HunyuanCustom destaca. Fuente: https://hunyuancustom.github.io/ (nota: sitio con alto consumo de recursos)
En el video anterior, la columna más a la izquierda muestra la imagen de origen única para HunyuanCustom, seguida de la interpretación del sistema de la instrucción en la columna adyacente. Las columnas restantes muestran resultados de otros sistemas: Kling, Vidu, Pika, Hailuo y SkyReels-A2 (basado en Wan).
El siguiente video destaca tres escenarios principales para este lanzamiento: persona con objeto, replicación de un solo personaje y prueba virtual de ropa:
Haz clic para reproducir. Tres ejemplos seleccionados del sitio de soporte de Hunyuan Video.
Estos ejemplos revelan limitaciones relacionadas con depender de una única imagen de origen en lugar de múltiples perspectivas.
En el primer clip, el hombre mira a la cámara con un movimiento mínimo de la cabeza, inclinándose no más de 20-25 grados. Más allá de esto, el sistema tiene dificultades para inferir su perfil con precisión a partir de una sola imagen frontal.
En el segundo clip, la chica mantiene una expresión sonriente en el video, reflejando su imagen de origen estática. Sin referencias adicionales, HunyuanCustom no puede representar de manera confiable su expresión neutral, y su rostro permanece mayormente de frente, similar al ejemplo anterior.
En el clip final, un material de origen incompleto—una mujer y ropa virtual—resulta en un renderizado recortado, una solución práctica para datos limitados.
Aunque HunyuanCustom admite múltiples entradas de imágenes (por ejemplo, persona con snacks o persona con atuendo), no permite ángulos o expresiones variadas para un solo personaje. Esto puede limitar su capacidad para reemplazar completamente el ecosistema en expansión de modelos LoRA para HunyuanVideo, que usan de 20 a 60 imágenes para garantizar una representación consistente del personaje en diferentes ángulos y expresiones.
Integración de audio
Para el audio, HunyuanCustom emplea el sistema LatentSync, que es desafiante para aficionados configurar, para sincronizar los movimientos de los labios con el audio y texto proporcionados por el usuario:
Incluye audio. Haz clic para reproducir. Ejemplos compilados de sincronización de labios del sitio suplementario de HunyuanCustom.
Actualmente, no hay ejemplos en inglés disponibles, pero los resultados parecen prometedores, particularmente si el proceso de configuración es amigable para el usuario.
Capacidades de edición de video
HunyuanCustom destaca en la edición de video a video (V2V), permitiendo el reemplazo dirigido de elementos en videos existentes usando una sola imagen de referencia. Un ejemplo de los materiales suplementarios ilustra esto:
Haz clic para reproducir. El objeto central se modifica, con los elementos circundantes alterados sutilmente en un proceso V2V de HunyuanCustom.
Como es típico en los flujos de trabajo V2V, todo el video se modifica ligeramente, con un enfoque principal en el área objetivo, como el peluche. Las tuberías avanzadas podrían preservar más del contenido original, similar al enfoque de Adobe Firefly, aunque esto sigue siendo poco explorado en las comunidades de código abierto.
Otros ejemplos demuestran una precisión mejorada en integraciones dirigidas, como se ve en esta compilación:
Haz clic para reproducir. Ejemplos variados de inserción de contenido V2V en HunyuanCustom, mostrando respeto por los elementos no alterados.
Actualización evolutiva
HunyuanCustom se basa en el proyecto Hunyuan Video, introduciendo mejoras arquitectónicas específicas en lugar de una revisión completa. Estas actualizaciones buscan mantener la consistencia del personaje entre fotogramas sin requerir ajustes específicos del sujeto, como LoRA o inversión textual.
Este lanzamiento es una versión refinada del modelo HunyuanVideo de diciembre de 2024, no un modelo nuevo construido desde cero.
Los usuarios de LoRAs existentes de HunyuanVideo pueden preguntarse sobre su compatibilidad con esta actualización o si deben desarrollarse nuevos LoRAs para aprovechar las funciones de personalización mejoradas.
Por lo general, un ajuste significativo altera los pesos del modelo lo suficiente como para hacer incompatibles los LoRAs anteriores. Sin embargo, algunos ajustes, como Pony Diffusion para Stable Diffusion XL, han creado ecosistemas independientes con bibliotecas de LoRA dedicadas, lo que sugiere un potencial para que HunyuanCustom siga un camino similar.
Detalles del lanzamiento
El artículo de investigación, titulado HunyuanCustom: Una arquitectura impulsada por multimodalidad para la generación de videos personalizados, enlaza con un repositorio de GitHub ahora activo con código y pesos para implementación local, junto con una integración planificada con ComfyUI.
Actualmente, la página de Hugging Face del proyecto no está accesible, pero una demostración basada en API está disponible mediante un código de escaneo de WeChat.
El ensamblaje de diversos proyectos de HunyuanCustom es notablemente completo, probablemente impulsado por los requisitos de licencia para una divulgación completa.
Se ofrecen dos variantes del modelo: una versión de 720x1280px que necesita 80GB de memoria GPU para un rendimiento óptimo (24GB mínimo, pero lento) y una versión de 512x896px que requiere 60GB. Las pruebas se han limitado a Linux, pero los esfuerzos de la comunidad pueden adaptar pronto el modelo para Windows y configuraciones de VRAM más bajas, como se vio con el modelo anterior de Hunyuan Video.
Debido al volumen de materiales adjuntos, esta visión general adopta un enfoque de alto nivel sobre las capacidades de HunyuanCustom.
Perspectivas técnicas
El pipeline de datos de HunyuanCustom, compatible con GDPR, integra conjuntos de datos de video sintetizados y de código abierto como OpenHumanVid, cubriendo ocho categorías: humanos, animales, plantas, paisajes, vehículos, objetos, arquitectura y anime.
Del artículo de lanzamiento, una visión general de los diversos paquetes contribuyentes en el pipeline de construcción de datos de HunyuanCustom. Fuente: https://arxiv.org/pdf/2505.04512
Los videos se segmentan en clips de una sola toma usando PySceneDetect, con TextBPN-Plus-Plus filtrando contenido con texto excesivo, subtítulos o marcas de agua.
Los clips se estandarizan a cinco segundos y se redimensionan a 512 o 720 píxeles en el lado corto. La calidad estética se asegura utilizando Koala-36M con un umbral personalizado de 0.06.
La extracción de identidad humana utiliza Qwen7B, YOLO11X e InsightFace, mientras que los sujetos no humanos se procesan con QwenVL y Grounded SAM 2, descartando cajas delimitadoras pequeñas.
Ejemplos de segmentación semántica con Grounded SAM 2, utilizado en el proyecto Hunyuan Control. Fuente: https://github.com/IDEA-Research/Grounded-SAM-2
La extracción de múltiples sujetos utiliza Florence2 para la anotación y Grounded SAM 2 para la segmentación, seguida de clustering y segmentación temporal de fotogramas.
Los clips se mejoran con un etiquetado estructurado propietario por el equipo de Hunyuan, añadiendo metadatos como descripciones y señales de movimiento de cámara.
El aumento de máscaras evita el sobreajuste, asegurando adaptabilidad a formas de objetos variadas. La sincronización de audio utiliza LatentSync, descartando clips por debajo de un umbral de calidad. HyperIQA filtra videos con puntajes inferiores a 40, y Whisper procesa audio válido para tareas posteriores.
El modelo LLaVA juega un papel central, generando subtítulos y alineando contenido visual y textual para una consistencia semántica, especialmente en escenas complejas o con múltiples sujetos.
El marco de HunyuanCustom soporta la generación de videos consistente con la identidad condicionada por texto, imagen, audio y entradas de video.
Personalización de video
Para permitir la generación de videos a partir de una imagen de referencia y una instrucción, se desarrollaron dos módulos basados en LLaVA, adaptando la entrada de HunyuanVideo para aceptar tanto imagen como texto. Las instrucciones incrustan imágenes directamente o las etiquetan con breves descripciones de identidad, usando un token separador para equilibrar la influencia de la imagen y el texto.
Un módulo de mejora de identidad aborda la tendencia de LLaVA a perder detalles espaciales finos, cruciales para mantener la consistencia del sujeto en clips de video cortos.
La imagen de referencia se redimensiona y codifica mediante el 3D-VAE causal de HunyuanVideo, con su latente insertado a lo largo del eje temporal y un desplazamiento espacial para guiar la generación sin replicación directa.
El entrenamiento utilizó Flow Matching con ruido de una distribución logit-normal, ajustando LLaVA y el generador de video juntos para una guía cohesiva de imagen-instrucción y consistencia de identidad.
Para instrucciones con múltiples sujetos, cada par imagen-texto se incrusta por separado con posiciones temporales distintas, permitiendo escenas con múltiples sujetos interactuando.
Integración de audio y visual
HunyuanCustom soporta la generación impulsada por audio usando audio y texto proporcionados por el usuario, permitiendo que los personajes hablen en entornos contextualmente relevantes.
Un módulo AudioNet desenredado de identidad alinea las características de audio con la línea temporal del video, usando atención cruzada espacial para aislar fotogramas y mantener la consistencia del sujeto.
Un módulo de inyección temporal refina el tiempo de movimiento, mapeando audio a secuencias latentes mediante un perceptrón multicapa, asegurando que los gestos se alineen con el ritmo del audio.
Para la edición de video, HunyuanCustom reemplaza sujetos en clips existentes sin regenerar todo el video, ideal para cambios dirigidos de apariencia o movimiento.
Haz clic para reproducir. Otro ejemplo del sitio suplementario.
El sistema comprime videos de referencia usando el 3D-VAE causal preentrenado, alineándolos con los latentes del pipeline de generación para un procesamiento ligero. Una red neuronal alinea videos de entrada limpios con latentes ruidosos, con la adición de características fotograma por fotograma demostrando ser más efectiva que la fusión previa a la compresión.
Evaluación de rendimiento
Las métricas de prueba incluyeron ArcFace para la consistencia de identidad facial, YOLO11x y Dino 2 para la similitud de sujetos, CLIP-B para la alineación de texto-video y consistencia temporal, y VBench para la intensidad de movimiento.
Los competidores incluyeron sistemas de código cerrado (Hailuo, Vidu 2.0, Kling 1.6, Pika) y marcos de código abierto (VACE, SkyReels-A2).
Evaluación del rendimiento del modelo comparando HunyuanCustom con métodos líderes de personalización de videos en consistencia de ID (Face-Sim), similitud de sujetos (DINO-Sim), alineación de texto-video (CLIP-B-T), consistencia temporal (Temp-Consis) e intensidad de movimiento (DD). Los resultados óptimos y subóptimos se muestran en negrita y subrayados, respectivamente.
Los autores señalan:
‘HunyuanCustom destaca en consistencia de ID y sujetos, con una adherencia competitiva a las instrucciones y estabilidad temporal. Hailuo lidera en puntaje de clip debido a una fuerte alineación de texto, pero tiene dificultades con la consistencia de sujetos no humanos. Vidu y VACE se quedan atrás en intensidad de movimiento, probablemente debido a tamaños de modelo más pequeños.’
Aunque el sitio del proyecto ofrece numerosos videos de comparación, su diseño prioriza la estética sobre la facilidad de comparación. Se anima a los lectores a revisar los videos directamente para obtener información más clara:
Del artículo, una comparación sobre personalización de videos centrada en objetos. Aunque el espectador debería consultar el PDF fuente para una mejor resolución, los videos en el sitio del proyecto ofrecen información más clara.
Los autores afirman:
‘Vidu, SkyReels A2 y HunyuanCustom logran una fuerte alineación con las instrucciones y consistencia de sujetos, pero nuestra calidad de video supera a Vidu y SkyReels, gracias a la robusta base de Hunyuanvideo-13B.’
‘Entre las soluciones comerciales, Kling ofrece videos de alta calidad, pero sufre un efecto de copia-pega en el primer fotograma y un desenfoque ocasional del sujeto, afectando la experiencia del espectador.’
Pika tiene problemas con la consistencia temporal, introduciendo artefactos de subtítulos por una mala curación de datos. Hailuo preserva la identidad facial, pero falla en la consistencia de cuerpo completo. VACE, entre los métodos de código abierto, no logra mantener la consistencia de identidad, mientras que HunyuanCustom ofrece una fuerte preservación de identidad, calidad y diversidad.
Las pruebas de personalización de videos con múltiples sujetos arrojaron resultados similares:
Comparaciones usando personalizaciones de videos con múltiples sujetos. Consulta el PDF para obtener mejores detalles y resolución.
El artículo señala:
‘Pika genera sujetos especificados, pero muestra inestabilidad en los fotogramas, con sujetos que desaparecen o no siguen las instrucciones. Vidu y VACE capturan parcialmente la identidad humana, pero pierden detalles de objetos no humanos. SkyReels A2 sufre una grave inestabilidad de fotogramas y artefactos. HunyuanCustom captura efectivamente todas las identidades de los sujetos, se adhiere a las instrucciones y mantiene una alta calidad visual y estabilidad.’
Una prueba de publicidad con humanos virtuales integró productos con personas:
De la ronda de pruebas cualitativas, ejemplos de colocación de productos neuronal. Consulta el PDF para obtener mejores detalles y resolución.
Los autores afirman:
‘HunyuanCustom mantiene la identidad humana y los detalles del producto, incluido el texto, con interacciones naturales y una fuerte adherencia a las instrucciones, mostrando su potencial para videos publicitarios.’
Las pruebas de personalización impulsada por audio destacaron un control flexible de escenas y posturas:
Resultados parciales para la ronda de audio—los resultados en video serían preferibles. Solo se muestra la mitad superior de la figura del PDF debido a restricciones de tamaño. Consulta el PDF fuente para obtener mejores detalles.
Los autores señalan:
‘Los métodos anteriores impulsados por audio limitan la postura y el entorno a la imagen de entrada, restringiendo las aplicaciones. HunyuanCustom permite una animación impulsada por audio flexible con escenas y posturas descritas por texto.’
Las pruebas de reemplazo de sujetos en video compararon HunyuanCustom contra VACE y Kling 1.6:
Pruebas de reemplazo de sujetos en modo video a video. Consulta el PDF fuente para obtener mejores detalles y resolución.
Los investigadores afirman:
‘VACE produce artefactos de borde por una adherencia estricta a la máscara, interrumpiendo la continuidad del movimiento. Kling muestra un efecto de copia-pega con una pobre integración del fondo. HunyuanCustom evita artefactos, asegura una integración fluida y mantiene una fuerte preservación de identidad, destacando en la edición de video.’
Conclusión
HunyuanCustom es un lanzamiento convincente, que aborda la creciente demanda de sincronización de labios en la síntesis de video, mejorando el realismo en sistemas como Hunyuan Video. A pesar de los desafíos para comparar sus capacidades debido al diseño de videos del sitio del proyecto, el modelo de Tencent se mantiene firme frente a los principales competidores como Kling, marcando un progreso significativo en la generación de videos personalizados.
* Algunos videos son demasiado anchos, cortos o de alta resolución para reproducirse en reproductores estándar como VLC o Windows Media Player, mostrando pantallas negras.
Publicado por primera vez el jueves, 8 de mayo de 2025










 Exclusiva: Luma AI presenta agentes creativos impulsados por modelos de «inteligencia unificada»
El jueves, la startup de generación de vídeo mediante IA Luma presentó Luma Agents, un sistema creado para gestionar flujos de trabajo creativos completos que abarcan texto, imágenes, vídeo y audio. E
Exclusiva: Luma AI presenta agentes creativos impulsados por modelos de «inteligencia unificada»
El jueves, la startup de generación de vídeo mediante IA Luma presentó Luma Agents, un sistema creado para gestionar flujos de trabajo creativos completos que abarcan texto, imágenes, vídeo y audio. E
 La nueva actualización de Sora incluye vídeos de inteligencia artificial de mascotas, herramientas sociales y una próxima aplicación para Android.
OpenAI presenta una serie de nuevas funciones para Sora, su aplicación de creación de vídeos con inteligencia artificial, que alcanzó rápidamente el primer puesto de la App Store tras su lanzamiento a
La nueva actualización de Sora incluye vídeos de inteligencia artificial de mascotas, herramientas sociales y una próxima aplicación para Android.
OpenAI presenta una serie de nuevas funciones para Sora, su aplicación de creación de vídeos con inteligencia artificial, que alcanzó rápidamente el primer puesto de la App Store tras su lanzamiento a
 La generación de videos de IA se mueve hacia el control completo
Los modelos de Foundation de Video como Hunyuan y WAN 2.1 han hecho avances significativos, pero a menudo se quedan cortos cuando se trata del control detallado requerido en la producción de cine y televisión, especialmente en el ámbito de los efectos visuales (VFX). En los estudios profesionales de VFX, estos modelos, junto con la imagen de imagen anterior
La generación de videos de IA se mueve hacia el control completo
Los modelos de Foundation de Video como Hunyuan y WAN 2.1 han hecho avances significativos, pero a menudo se quedan cortos cuando se trata del control detallado requerido en la producción de cine y televisión, especialmente en el ámbito de los efectos visuales (VFX). En los estudios profesionales de VFX, estos modelos, junto con la imagen de imagen anterior

Descubre las mejores aplicaciones de TTS con IA de 2026, seleccionadas específicamente para ayudar a las personas con dislexia. Nuestra clasificación, elaborada por expertos, compara herramientas gratuitas y de pago, y destaca sus potentes funciones para mejorar la eficiencia en la lectura y el aprendizaje. Explora soluciones innovadoras e imprescindibles para liberar el potencial de los estudiantes. Empieza tu viaje en XIX.AI.
10 herramientas
xix.ai

Descubre los mejores generadores de IA para manga shonen de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada y con las mejores valoraciones, incluye potentes herramientas para crear secuencias de acción trepidantes y efectos energéticos dinámicos. Compara las opciones gratuitas con las de pago mediante pruebas reales. ¡Libera tu potencial creativo y empieza a crear manga épico hoy mismo!
15 herramientas
xix.ai

Los mejores gestores de gastos con IA de 2026: las herramientas mejor valoradas para escanear recibos y clasificar automáticamente los gastos de la empresa. Descubre soluciones potentes y revolucionarias para una gestión de gastos sin esfuerzo, un seguimiento financiero preciso y un cumplimiento normativo optimizado. Nuestra comparativa, seleccionada y actualizada semanalmente, entre opciones gratuitas y de pago te ayuda a encontrar la que mejor se adapta a tus necesidades. Aprovecha al máximo las ventajas de la IA con las recomendaciones de los expertos de XIX.AI.
10 herramientas
xix.ai

Descubre las mejores herramientas de selección de personal basadas en IA de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada, incluye soluciones potentes y revolucionarias para la selección de currículos y la automatización de la programación de entrevistas con los candidatos. Compara las opciones gratuitas con las de pago gracias a pruebas reales y a clasificaciones que se actualizan semanalmente. ¡Encuentra tu asistente de selección de personal ideal y optimiza tu proceso de selección hoy mismo!
10 herramientas
xix.ai

Descubre los mejores entrenadores personales de bienestar y concentración basados en IA de 2026 en XIX.AI. Nuestras clasificaciones, cuidadosamente seleccionadas, incluyen herramientas revolucionarias y de primera categoría para gestionar el agotamiento y potenciar la energía mental. Compara las opciones gratuitas con las de pago gracias a información basada en casos reales. Descubre hoy mismo el camino hacia la máxima productividad y el bienestar.
10 herramientas
xix.ai

Descubre los mejores chatbots románticos con IA de 2026 para establecer relaciones auténticas y duraderas. Nuestra lista seleccionada incluye personalidades sólidas y coherentes, comparativas entre versiones gratuitas y de pago, y pruebas en situaciones reales. Encuentra a tu compañero ideal y empieza a construir tu relación hoy mismo en XIX.AI.
10 herramientas
xix.ai

Esse exemplo de vídeo parece meio bugado... Mas a ideia de transformar uma imagem estática em vídeo é fascinante. Será que isso poderia ser usado para criar conteúdos educativos ou de forma indevida? A discussão ética sempre fica atrás da tecnologia 🤔.













