
















 首頁
首頁騰訊推出HunyuanCustom用於單圖像視頻定制
本文探討騰訊推出的HunyuanCustom,一款多模態視頻生成模型。隨附研究論文的廣泛範圍及項目頁面提供的示例視頻挑戰,需更廣泛的概述,因格式和處理要求限制了大量視頻內容的再現以提高清晰度。
請注意,論文中將基於API的生成系統Kling稱為“Keling”。為保持一致性,本文全程使用“Kling”。
騰訊推出其Hunyuan Video模型的進階版本,名為HunyuanCustom。據報導,此版本超越了Hunyuan LoRA模型的需求,允許用戶僅用一張單一圖像創建類似深偽的視頻定制:
點擊播放。提示:“一名男子在廚房準備螺螄粉時享受音樂。”與專有和開源方法(包括主要競爭對手Kling)相比,HunyuanCustom表現突出。 來源:https://hunyuancustom.github.io/(注意:資源密集型網站)
在上述視頻中,最左側欄顯示HunyuanCustom的單一來源圖像輸入,旁邊欄顯示系統對提示的解釋。其餘欄展示其他系統的輸出:Kling、Vidu、Pika、Hailuo和SkyReels-A2(基於Wan)。
以下視頻展示了此次發布的三個核心場景:人物與物體、單一角色複製和虛擬服裝試穿:
點擊播放。來自Hunyuan Video支持網站的三個精選示例。
這些示例揭示了依賴單一來源圖像而非多視角的限制。
在第一個片段中,男子面向攝影機,頭部移動幅度不超過20-25度。超出此範圍,系統難以從單一正面圖像準確推斷其側面輪廓。
在第二個片段中,女孩在視頻中保持微笑表情,與其靜態來源圖像一致。在無額外參考的情況下,HunyuanCustom無法可靠描繪其中性表情,其面部仍主要為正面,類似前例。
在最後一個片段中,不完整的來源素材——一名女子和虛擬服裝——導致渲染裁剪,這是應對有限數據的實際解決方案。
雖然HunyuanCustom支持多圖像輸入(例如,人物與零食或人物與服裝),但不支援單一角色的不同角度或表情。這可能限制其完全取代HunyuanVideo的LoRA模型生態系統,後者使用20-60張圖像確保跨角度和表情的角色渲染一致性。
音頻整合
對於音頻,HunyuanCustom採用LatentSync系統,業餘愛好者配置困難,用於同步用戶提供的音頻和文本的唇部動作:
包含音頻。點擊播放。來自HunyuanCustom補充網站的唇部同步示例彙編。
目前無英文示例,但結果看起來很有前景,特別是若設置過程對用戶友好。
視頻編輯能力
HunyuanCustom擅長視頻到視頻(V2V)編輯,允許使用單一參考圖像在現有視頻中針對性替換元素。補充材料中的示例說明了這一點:
點擊播放。中心物體被修改,周圍元素在HunyuanCustom V2V過程中被微妙改變。
與典型的V2V工作流程一致,整個視頻略有修改,焦點主要在目標區域,如毛絨玩具。先進的管道可能保留更多原始內容,類似Adobe Firefly的方法,但這在開源社群中尚未充分探索。
其他示例展示了目標整合的精確度提升,如以下彙編所示:
點擊播放。HunyuanCustom中V2V內容插入的多樣示例,顯示對未更改元素的尊重。
進化升級
HunyuanCustom基於Hunyuan Video項目,引入針對性架構增強,而非徹底改造。這些升級旨在無需特定主題微調(如LoRA或文本反轉)的情況下保持跨幀的角色一致性。
此次發布是2024年12月HunyuanVideo模型的精進版本,而非從頭構建的新模型。
現有HunyuanVideo LoRA用戶可能會疑問其與此次更新的兼容性,或是否需開發新LoRA以利用增強的定制功能。
通常,顯著的微調會改變模型權重,足以使先前LoRA不兼容。然而,像Pony Diffusion for Stable Diffusion XL這樣的微調已創建獨立生態系統,擁有專用LoRA庫,顯示HunyuanCustom可能有類似潛力。
發布詳情
研究論文題為HunyuanCustom:用於定制視頻生成的多模態驅動架構,連結至現已啟用的GitHub儲存庫,包含本地部署的程式碼和權重,並計劃整合ComfyUI。
目前,項目的Hugging Face頁面無法訪問,但可通過微信掃碼使用基於API的演示。
HunyuanCustom整合多樣項目的全面性顯著,可能是因完全披露的許可要求所驅動。
提供兩種模型變體:720x1280px版本需80GB GPU記憶體以達最佳性能(最低24GB,但速度慢),512x896px版本需60GB。測試僅限Linux,但社群努力可能很快適配Windows和較低VRAM配置,如之前的Hunyuan Video模型。
由於隨附材料數量龐大,此概述對HunyuanCustom的能力採取高層次方法。
技術洞察
HunyuanCustom的數據管道符合GDPR,整合合成和開源視頻數據集,如OpenHumanVid,涵蓋八類:人類、動物、植物、風景、車輛、物體、建築和動漫。
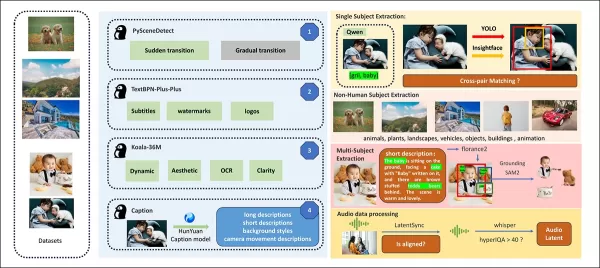
來自發布論文,對HunyuanCustom數據構建管道中多樣貢獻套件的概述。 來源:https://arxiv.org/pdf/2505.04512
使用PySceneDetect將視頻分割為單一鏡頭片段,TextBPN-Plus-Plus過濾掉含過多文本、字幕或水印的內容。
片段標準化為五秒,短邊調整為512或720像素。使用Koala-36M以自訂0.06閾值確保美學品質。
人類身份提取利用Qwen7B、YOLO11X和InsightFace,非人類主體則使用QwenVL和Grounded SAM 2處理,捨棄小型邊界框。

使用Grounded SAM 2進行語義分割的示例,用於Hunyuan Control項目。 來源:https://github.com/IDEA-Research/Grounded-SAM-2
多主體提取使用Florence2進行註釋,Grounded SAM 2進行分割,隨後進行叢集和時間框架分割。
片段由Hunyuan團隊使用專有結構化標籤增強,添加描述和攝影機運動提示等元數據。
遮罩增強防止過擬合,確保適應多樣物體形狀。音頻同步使用LatentSync,捨棄低於品質閾值的片段。HyperIQA過濾得分低於40的視頻,Whisper處理有效音頻以進行後續任務。
LLaVA模型在生成字幕和對齊視覺與文本內容以確保語義一致性中扮演核心角色,特別是在複雜或多主體場景中。
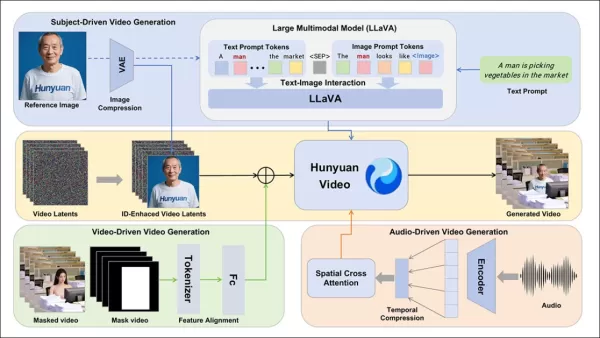
HunyuanCustom框架支持基於文本、圖像、音頻和視頻輸入的身份一致視頻生成。
視頻定制
為實現從參考圖像和提示生成視頻,開發了兩個基於LLaVA的模組,適配HunyuanVideo的輸入以接受圖像和文本。提示直接嵌入圖像或以簡短身份描述標記,使用分隔符號平衡圖像和文本影響。
身份增強模組解決LLaVA在短視頻片段中失去細粒度空間細節的傾向,這對保持主體一致性至關重要。
參考圖像通過HunyuanVideo的因果3D-VAE調整大小並編碼,其潛在表示沿時間軸插入,並帶有空間偏移以指導生成,而非直接複製。
訓練使用來自邏輯正態分佈的噪聲進行Flow Matching,同時微調LLaVA和視頻生成器以實現圖像-提示指導和身份一致性的凝聚力。
對於多主體提示,每個圖像-文本對以不同時間位置單獨嵌入,實現多個互動主體的場景。
音頻與視覺整合
HunyuanCustom支持使用用戶提供的音頻和文本進行音頻驅動生成,使角色在相關情境中說話。
身份解耦AudioNet模組將音頻特徵與視頻時間線對齊,使用空間交叉注意力隔離框架並保持主體一致性。
時間注入模組精細化運動時序,通過多層感知器將音頻映射到潛在序列,確保手勢與音頻節奏對齊。
對於視頻編輯,HunyuanCustom在現有片段中替換主體,而無需重新生成整個視頻,適用於針對性外觀或運動變化。
點擊播放。來自補充網站的另一示例。
系統使用預訓練的因果3D-VAE壓縮參考視頻,將其與生成管道潛在表示對齊以進行輕量處理。神經網絡將乾淨輸入視頻與噪聲潛在表示對齊,逐幀特徵添加比預壓縮合併更有效。
性能評估
測試指標包括ArcFace用於面部身份一致性,YOLO11x和Dino 2用於主體相似性,CLIP-B用於文本-視頻對齊和時間一致性,VBench用於運動強度。
競爭對手包括閉源系統(Hailuo、Vidu 2.0、Kling 1.6、Pika)和開源框架(VACE、SkyReels-A2)。
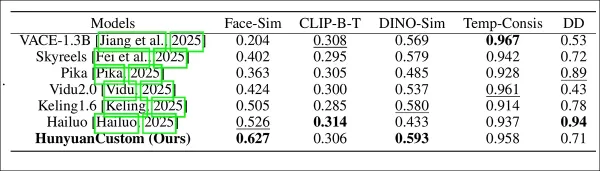
模型性能評估,比較HunyuanCustom與領先視頻定制方法在身份一致性(Face-Sim)、主體相似性(DINO-Sim)、文本-視頻對齊(CLIP-B-T)、時間一致性(Temp-Consis)和運動強度(DD)方面的表現。最佳和次佳結果分別以粗體和底線顯示。
作者指出:
“HunyuanCustom在身份和主體一致性方面表現出色,提示遵循和時間穩定性具有競爭力。Hailuo因強大的文本對齊在剪輯得分上領先,但在非人類主體一致性上表現不佳。Vidu和VACE在運動強度上落後,可能是因模型規模較小。”
雖然項目網站提供許多比較視頻,但其布局注重美學而非比較便利性。建議讀者直接審查視頻以獲得更清晰的見解:
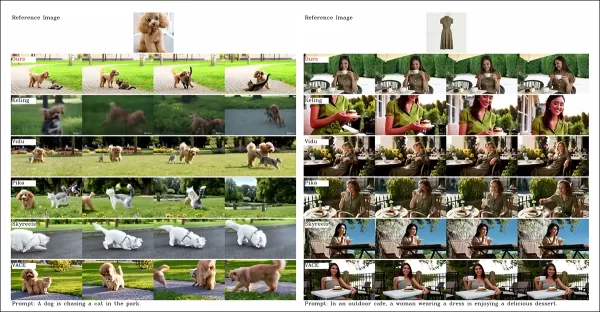
來自論文,關於以物體為中心的視頻定制比較。雖然觀眾應參考來源PDF以獲得更好解析度,但項目網站的視頻提供更清晰的見解。
作者聲明:
“Vidu、SkyReels A2和HunyuanCustom實現強大的提示對齊和主體一致性,但我們的視頻品質超越Vidu和SkyReels,得益於Hunyuanvideo-13B的堅實基礎。”
“在商業解決方案中,Kling提供高品質視頻,但在首幀出現複製黏貼效果,偶爾主體模糊,影響觀眾體驗。”
Pika在時間一致性上掙扎,因數據整理不佳引入字幕偽影。Hailuo保留面部身份,但在全身一致性上表現不佳。VACE在開源方法中無法保持身份一致性,而HunyuanCustom提供強大的身份保留、品質和多樣性。
多主體視頻定制測試產生類似結果:

使用多主體視頻定制的比較。請參考PDF以獲得更好細節和解析度。
論文指出:
“Pika生成指定主體,但顯示框架不穩定,主體消失或無法遵循提示。Vidu和VACE部分捕捉人類身份,但失去非人類物體細節。SkyReels A2遭受嚴重框架不穩定和偽影。HunyuanCustom有效捕捉所有主體身份,遵循提示,保持高視覺品質和穩定性。”
虛擬人類廣告測試整合了產品與人物:

來自定性測試輪次,神經“產品植入”示例。請參考PDF以獲得更好細節和解析度。
作者聲明:
“HunyuanCustom保持人類身份和產品細節,包括文本,具有自然互動和強大的提示遵循,展示其在廣告視頻中的潛力。”
音頻驅動定制測試突顯了靈活的場景和姿態控制:
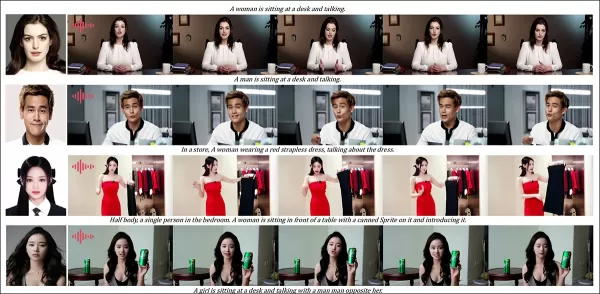
音頻輪次的部份結果——視頻結果可能更佳。由於尺寸限制,僅顯示PDF圖表的上半部分。請參考來源PDF以獲得更好細節。
作者指出:
“之前的音頻驅動方法將姿態和環境限制於輸入圖像,限制應用。HunyuanCustom實現靈活的音頻驅動動畫,支援文本描述的場景和姿態。”
視頻主體替換測試比較了HunyuanCustom與VACE和Kling 1.6:

測試視頻到視頻模式中的主體替換。請參考來源PDF以獲得更好細節和解析度。
研究人員聲明:
“VACE因嚴格遮罩遵循產生邊界偽影,破壞運動連續性。Kling顯示複製黏貼效果,背景整合不佳。HunyuanCustom避免偽影,確保無縫整合,並保持強大的身份保留,擅長視頻編輯。”
結論
HunyuanCustom是一款引人注目的發布,滿足視頻合成中對唇部同步的日益需求,提升了如Hunyuan Video的系統真實性。儘管項目網站的視頻布局帶來比較挑戰,騰訊的模型與頂尖競爭者如Kling競爭,標誌著定制視頻生成的重要進展。
* 部分視頻過寬、過短或解析度過高,無法在VLC或Windows Media Player等標準播放器中播放,顯示黑屏。
首次發布於2025年5月8日,星期四
相關文章
 獨家報導:Luma AI 推出搭載「統一智能」模型的創意代理程式
週四,AI影片生成新創公司Luma推出「Luma Agents」系統,旨在管理涵蓋文字、圖像、影片及音訊的完整創意工作流程。這些代理程式由Luma的統一智能模型家族驅動,其架構經訓練成為單一多模態推理引擎。Luma將其代理程式定位為廣告代理商、行銷部門、設計工作室及企業的變革性工具。據Luma表示,這些代理程式不僅能規劃與製作文字、圖像、影片及音訊內容,還能與其他AI模型協同運作,例如Luma的R
Sora 的新更新提供寵物 AI 影片、社交工具以及即將推出的 Android 應用程式
OpenAI 正在為其爆紅的 AI 視訊創作應用程式 Sora 預覽一大波新功能,該應用程式在 9 月底推出後迅速攀升至 App Store 榜首。該應用程式目前仍在美國和加拿大穩居第一,不久將新增視訊編輯功能,讓使用者可以創造寵物和其他物品的角色「客串」,並加強社交功能等。該公司還確認 Android 版本「實際上即將推出」。Sora 的領導 Bill Peebles 在 X 上宣布了這個消息,
人工智能視頻生成朝著完全控制
諸如Hunyuan和Wan 2.1之類的視頻基礎模型已經取得了長足的進步,但是當涉及電影和電視製作所需的詳細控制時,尤其是在視覺效果領域(VFX)所需的詳細控制。在專業的VFX Studios中,這些模型以及早期的Image-Bas
相關專題推薦
漫畫創作
獨家報導:Luma AI 推出搭載「統一智能」模型的創意代理程式
週四,AI影片生成新創公司Luma推出「Luma Agents」系統,旨在管理涵蓋文字、圖像、影片及音訊的完整創意工作流程。這些代理程式由Luma的統一智能模型家族驅動,其架構經訓練成為單一多模態推理引擎。Luma將其代理程式定位為廣告代理商、行銷部門、設計工作室及企業的變革性工具。據Luma表示,這些代理程式不僅能規劃與製作文字、圖像、影片及音訊內容,還能與其他AI模型協同運作,例如Luma的R
Sora 的新更新提供寵物 AI 影片、社交工具以及即將推出的 Android 應用程式
OpenAI 正在為其爆紅的 AI 視訊創作應用程式 Sora 預覽一大波新功能,該應用程式在 9 月底推出後迅速攀升至 App Store 榜首。該應用程式目前仍在美國和加拿大穩居第一,不久將新增視訊編輯功能,讓使用者可以創造寵物和其他物品的角色「客串」,並加強社交功能等。該公司還確認 Android 版本「實際上即將推出」。Sora 的領導 Bill Peebles 在 X 上宣布了這個消息,
人工智能視頻生成朝著完全控制
諸如Hunyuan和Wan 2.1之類的視頻基礎模型已經取得了長足的進步,但是當涉及電影和電視製作所需的詳細控制時,尤其是在視覺效果領域(VFX)所需的詳細控制。在專業的VFX Studios中,這些模型以及早期的Image-Bas
相關專題推薦
漫畫創作
 漫畫頂尖 AI 自動上色工具:零一致性錯誤地套用平面色彩
漫畫頂尖 AI 自動上色工具:零一致性錯誤地套用平面色彩
立即前往 XIX.AI,探索 2026 年最優秀的漫畫 AI 自動上色工具。我們精心挑選的清單收錄了備受好評、能徹底改變遊戲規則的解決方案,這些工具能以零一致性錯誤的方式套用平面色彩,大幅提升您的工作效率。透過免費與付費版本的比較、實際測試結果,以及每週更新的排行榜,找到最適合您的工具。立即解鎖您的 AI 優勢。
 10 個工具
10 個工具
 xix.ai
寫作
頂尖 AI 角色設定生成工具:創造一致的角色動機與致命弱點
xix.ai
寫作
頂尖 AI 角色設定生成工具:創造一致的角色動機與致命弱點
探索 2026 年最優秀的 AI 角色設定生成工具,打造立體鮮明的角色。XIX.AI 精心整理的清單收錄了備受好評、能徹底改變遊戲規則的工具,這些工具能生成一貫的動機與致命缺陷。透過實際測試,比較免費與付費選項的差異。立即釋放您的說故事潛能。
10 個工具
xix.ai
商業
頂尖 AI 定價優化軟體:追蹤競爭對手並自動調整商店價格
立即在 XIX.AI 探索 2026 年最佳 AI 定價優化軟體。我們精心挑選的清單收錄了備受好評、能徹底改變遊戲規則的工具,這些工具不僅能追蹤競爭對手,還能自動調整您的商店價格,以實現利潤最大化。透過實際測試,比較免費與付費方案的差異。立即掌握您的定價優勢。
10 個工具
xix.ai
代碼
最佳 AI 程式碼審查工具:自動化確保程式碼整潔度,並重構舊版儲存庫檔案
立即在 XIX.AI 探索 2026 年最佳 AI 程式碼審查工具。我們精心挑選的清單收錄了備受好評、能徹底改變遊戲規則的工具,可自動確保程式碼符合規範,並重構舊版儲存庫檔案。透過實際測試與每週更新的排行榜,比較免費與付費選項。立即掌握您的 AI 競爭優勢。
10 個工具
xix.ai
文字轉語音
專為閱讀障礙設計的頂尖 AI 語音合成應用程式:協助學生提升學習與閱讀效率
探索 2026 年最新精選、專為閱讀障礙者設計的頂級 AI 語音合成(TTS)應用程式。我們的專家評比將免費與付費工具進行對照,重點介紹能提升閱讀效率與學習成效的強大功能。發掘這些必試且能帶來革命性改變的解決方案,釋放學生的潛能。立即前往 XIX.AI 展開您的探索之旅。
10 個工具
xix.ai
漫畫創作
少年漫畫頂尖 AI 生成器:打造高張力動作場面與能量特效
立即前往 XIX.AI,探索 2026 年最優秀的少年漫畫 AI 生成工具。我們精心挑選的頂級清單,匯集了能打造高張力動作場面與動態能量特效的強大工具。透過實際測試,比較免費與付費選項的差異。釋放您的創作潛能,今天就開始打造史詩級漫畫吧!
15 個工具
xix.ai

 評論 (1)
0/500
評論 (1)
0/500
![RalphHill]()
Esse exemplo de vídeo parece meio bugado... Mas a ideia de transformar uma imagem estática em vídeo é fascinante. Será que isso poderia ser usado para criar conteúdos educativos ou de forma indevida? A discussão ética sempre fica atrás da tecnologia 🤔.
本文探討騰訊推出的HunyuanCustom,一款多模態視頻生成模型。隨附研究論文的廣泛範圍及項目頁面提供的示例視頻挑戰,需更廣泛的概述,因格式和處理要求限制了大量視頻內容的再現以提高清晰度。
請注意,論文中將基於API的生成系統Kling稱為“Keling”。為保持一致性,本文全程使用“Kling”。
騰訊推出其Hunyuan Video模型的進階版本,名為HunyuanCustom。據報導,此版本超越了Hunyuan LoRA模型的需求,允許用戶僅用一張單一圖像創建類似深偽的視頻定制:
點擊播放。提示:“一名男子在廚房準備螺螄粉時享受音樂。”與專有和開源方法(包括主要競爭對手Kling)相比,HunyuanCustom表現突出。 來源:https://hunyuancustom.github.io/(注意:資源密集型網站)
在上述視頻中,最左側欄顯示HunyuanCustom的單一來源圖像輸入,旁邊欄顯示系統對提示的解釋。其餘欄展示其他系統的輸出:Kling、Vidu、Pika、Hailuo和SkyReels-A2(基於Wan)。
以下視頻展示了此次發布的三個核心場景:人物與物體、單一角色複製和虛擬服裝試穿:
點擊播放。來自Hunyuan Video支持網站的三個精選示例。
這些示例揭示了依賴單一來源圖像而非多視角的限制。
在第一個片段中,男子面向攝影機,頭部移動幅度不超過20-25度。超出此範圍,系統難以從單一正面圖像準確推斷其側面輪廓。
在第二個片段中,女孩在視頻中保持微笑表情,與其靜態來源圖像一致。在無額外參考的情況下,HunyuanCustom無法可靠描繪其中性表情,其面部仍主要為正面,類似前例。
在最後一個片段中,不完整的來源素材——一名女子和虛擬服裝——導致渲染裁剪,這是應對有限數據的實際解決方案。
雖然HunyuanCustom支持多圖像輸入(例如,人物與零食或人物與服裝),但不支援單一角色的不同角度或表情。這可能限制其完全取代HunyuanVideo的LoRA模型生態系統,後者使用20-60張圖像確保跨角度和表情的角色渲染一致性。
音頻整合
對於音頻,HunyuanCustom採用LatentSync系統,業餘愛好者配置困難,用於同步用戶提供的音頻和文本的唇部動作:
包含音頻。點擊播放。來自HunyuanCustom補充網站的唇部同步示例彙編。
目前無英文示例,但結果看起來很有前景,特別是若設置過程對用戶友好。
視頻編輯能力
HunyuanCustom擅長視頻到視頻(V2V)編輯,允許使用單一參考圖像在現有視頻中針對性替換元素。補充材料中的示例說明了這一點:
點擊播放。中心物體被修改,周圍元素在HunyuanCustom V2V過程中被微妙改變。
與典型的V2V工作流程一致,整個視頻略有修改,焦點主要在目標區域,如毛絨玩具。先進的管道可能保留更多原始內容,類似Adobe Firefly的方法,但這在開源社群中尚未充分探索。
其他示例展示了目標整合的精確度提升,如以下彙編所示:
點擊播放。HunyuanCustom中V2V內容插入的多樣示例,顯示對未更改元素的尊重。
進化升級
HunyuanCustom基於Hunyuan Video項目,引入針對性架構增強,而非徹底改造。這些升級旨在無需特定主題微調(如LoRA或文本反轉)的情況下保持跨幀的角色一致性。
此次發布是2024年12月HunyuanVideo模型的精進版本,而非從頭構建的新模型。
現有HunyuanVideo LoRA用戶可能會疑問其與此次更新的兼容性,或是否需開發新LoRA以利用增強的定制功能。
通常,顯著的微調會改變模型權重,足以使先前LoRA不兼容。然而,像Pony Diffusion for Stable Diffusion XL這樣的微調已創建獨立生態系統,擁有專用LoRA庫,顯示HunyuanCustom可能有類似潛力。
發布詳情
研究論文題為HunyuanCustom:用於定制視頻生成的多模態驅動架構,連結至現已啟用的GitHub儲存庫,包含本地部署的程式碼和權重,並計劃整合ComfyUI。
目前,項目的Hugging Face頁面無法訪問,但可通過微信掃碼使用基於API的演示。
HunyuanCustom整合多樣項目的全面性顯著,可能是因完全披露的許可要求所驅動。
提供兩種模型變體:720x1280px版本需80GB GPU記憶體以達最佳性能(最低24GB,但速度慢),512x896px版本需60GB。測試僅限Linux,但社群努力可能很快適配Windows和較低VRAM配置,如之前的Hunyuan Video模型。
由於隨附材料數量龐大,此概述對HunyuanCustom的能力採取高層次方法。
技術洞察
HunyuanCustom的數據管道符合GDPR,整合合成和開源視頻數據集,如OpenHumanVid,涵蓋八類:人類、動物、植物、風景、車輛、物體、建築和動漫。
來自發布論文,對HunyuanCustom數據構建管道中多樣貢獻套件的概述。 來源:https://arxiv.org/pdf/2505.04512
使用PySceneDetect將視頻分割為單一鏡頭片段,TextBPN-Plus-Plus過濾掉含過多文本、字幕或水印的內容。
片段標準化為五秒,短邊調整為512或720像素。使用Koala-36M以自訂0.06閾值確保美學品質。
人類身份提取利用Qwen7B、YOLO11X和InsightFace,非人類主體則使用QwenVL和Grounded SAM 2處理,捨棄小型邊界框。
使用Grounded SAM 2進行語義分割的示例,用於Hunyuan Control項目。 來源:https://github.com/IDEA-Research/Grounded-SAM-2
多主體提取使用Florence2進行註釋,Grounded SAM 2進行分割,隨後進行叢集和時間框架分割。
片段由Hunyuan團隊使用專有結構化標籤增強,添加描述和攝影機運動提示等元數據。
遮罩增強防止過擬合,確保適應多樣物體形狀。音頻同步使用LatentSync,捨棄低於品質閾值的片段。HyperIQA過濾得分低於40的視頻,Whisper處理有效音頻以進行後續任務。
LLaVA模型在生成字幕和對齊視覺與文本內容以確保語義一致性中扮演核心角色,特別是在複雜或多主體場景中。
HunyuanCustom框架支持基於文本、圖像、音頻和視頻輸入的身份一致視頻生成。
視頻定制
為實現從參考圖像和提示生成視頻,開發了兩個基於LLaVA的模組,適配HunyuanVideo的輸入以接受圖像和文本。提示直接嵌入圖像或以簡短身份描述標記,使用分隔符號平衡圖像和文本影響。
身份增強模組解決LLaVA在短視頻片段中失去細粒度空間細節的傾向,這對保持主體一致性至關重要。
參考圖像通過HunyuanVideo的因果3D-VAE調整大小並編碼,其潛在表示沿時間軸插入,並帶有空間偏移以指導生成,而非直接複製。
訓練使用來自邏輯正態分佈的噪聲進行Flow Matching,同時微調LLaVA和視頻生成器以實現圖像-提示指導和身份一致性的凝聚力。
對於多主體提示,每個圖像-文本對以不同時間位置單獨嵌入,實現多個互動主體的場景。
音頻與視覺整合
HunyuanCustom支持使用用戶提供的音頻和文本進行音頻驅動生成,使角色在相關情境中說話。
身份解耦AudioNet模組將音頻特徵與視頻時間線對齊,使用空間交叉注意力隔離框架並保持主體一致性。
時間注入模組精細化運動時序,通過多層感知器將音頻映射到潛在序列,確保手勢與音頻節奏對齊。
對於視頻編輯,HunyuanCustom在現有片段中替換主體,而無需重新生成整個視頻,適用於針對性外觀或運動變化。
點擊播放。來自補充網站的另一示例。
系統使用預訓練的因果3D-VAE壓縮參考視頻,將其與生成管道潛在表示對齊以進行輕量處理。神經網絡將乾淨輸入視頻與噪聲潛在表示對齊,逐幀特徵添加比預壓縮合併更有效。
性能評估
測試指標包括ArcFace用於面部身份一致性,YOLO11x和Dino 2用於主體相似性,CLIP-B用於文本-視頻對齊和時間一致性,VBench用於運動強度。
競爭對手包括閉源系統(Hailuo、Vidu 2.0、Kling 1.6、Pika)和開源框架(VACE、SkyReels-A2)。
模型性能評估,比較HunyuanCustom與領先視頻定制方法在身份一致性(Face-Sim)、主體相似性(DINO-Sim)、文本-視頻對齊(CLIP-B-T)、時間一致性(Temp-Consis)和運動強度(DD)方面的表現。最佳和次佳結果分別以粗體和底線顯示。
作者指出:
“HunyuanCustom在身份和主體一致性方面表現出色,提示遵循和時間穩定性具有競爭力。Hailuo因強大的文本對齊在剪輯得分上領先,但在非人類主體一致性上表現不佳。Vidu和VACE在運動強度上落後,可能是因模型規模較小。”
雖然項目網站提供許多比較視頻,但其布局注重美學而非比較便利性。建議讀者直接審查視頻以獲得更清晰的見解:
來自論文,關於以物體為中心的視頻定制比較。雖然觀眾應參考來源PDF以獲得更好解析度,但項目網站的視頻提供更清晰的見解。
作者聲明:
“Vidu、SkyReels A2和HunyuanCustom實現強大的提示對齊和主體一致性,但我們的視頻品質超越Vidu和SkyReels,得益於Hunyuanvideo-13B的堅實基礎。”
“在商業解決方案中,Kling提供高品質視頻,但在首幀出現複製黏貼效果,偶爾主體模糊,影響觀眾體驗。”
Pika在時間一致性上掙扎,因數據整理不佳引入字幕偽影。Hailuo保留面部身份,但在全身一致性上表現不佳。VACE在開源方法中無法保持身份一致性,而HunyuanCustom提供強大的身份保留、品質和多樣性。
多主體視頻定制測試產生類似結果:
使用多主體視頻定制的比較。請參考PDF以獲得更好細節和解析度。
論文指出:
“Pika生成指定主體,但顯示框架不穩定,主體消失或無法遵循提示。Vidu和VACE部分捕捉人類身份,但失去非人類物體細節。SkyReels A2遭受嚴重框架不穩定和偽影。HunyuanCustom有效捕捉所有主體身份,遵循提示,保持高視覺品質和穩定性。”
虛擬人類廣告測試整合了產品與人物:
來自定性測試輪次,神經“產品植入”示例。請參考PDF以獲得更好細節和解析度。
作者聲明:
“HunyuanCustom保持人類身份和產品細節,包括文本,具有自然互動和強大的提示遵循,展示其在廣告視頻中的潛力。”
音頻驅動定制測試突顯了靈活的場景和姿態控制:
音頻輪次的部份結果——視頻結果可能更佳。由於尺寸限制,僅顯示PDF圖表的上半部分。請參考來源PDF以獲得更好細節。
作者指出:
“之前的音頻驅動方法將姿態和環境限制於輸入圖像,限制應用。HunyuanCustom實現靈活的音頻驅動動畫,支援文本描述的場景和姿態。”
視頻主體替換測試比較了HunyuanCustom與VACE和Kling 1.6:
測試視頻到視頻模式中的主體替換。請參考來源PDF以獲得更好細節和解析度。
研究人員聲明:
“VACE因嚴格遮罩遵循產生邊界偽影,破壞運動連續性。Kling顯示複製黏貼效果,背景整合不佳。HunyuanCustom避免偽影,確保無縫整合,並保持強大的身份保留,擅長視頻編輯。”
結論
HunyuanCustom是一款引人注目的發布,滿足視頻合成中對唇部同步的日益需求,提升了如Hunyuan Video的系統真實性。儘管項目網站的視頻布局帶來比較挑戰,騰訊的模型與頂尖競爭者如Kling競爭,標誌著定制視頻生成的重要進展。
* 部分視頻過寬、過短或解析度過高,無法在VLC或Windows Media Player等標準播放器中播放,顯示黑屏。
首次發布於2025年5月8日,星期四










 獨家報導:Luma AI 推出搭載「統一智能」模型的創意代理程式
週四,AI影片生成新創公司Luma推出「Luma Agents」系統,旨在管理涵蓋文字、圖像、影片及音訊的完整創意工作流程。這些代理程式由Luma的統一智能模型家族驅動,其架構經訓練成為單一多模態推理引擎。Luma將其代理程式定位為廣告代理商、行銷部門、設計工作室及企業的變革性工具。據Luma表示,這些代理程式不僅能規劃與製作文字、圖像、影片及音訊內容,還能與其他AI模型協同運作,例如Luma的R
獨家報導:Luma AI 推出搭載「統一智能」模型的創意代理程式
週四,AI影片生成新創公司Luma推出「Luma Agents」系統,旨在管理涵蓋文字、圖像、影片及音訊的完整創意工作流程。這些代理程式由Luma的統一智能模型家族驅動,其架構經訓練成為單一多模態推理引擎。Luma將其代理程式定位為廣告代理商、行銷部門、設計工作室及企業的變革性工具。據Luma表示,這些代理程式不僅能規劃與製作文字、圖像、影片及音訊內容,還能與其他AI模型協同運作,例如Luma的R
 Sora 的新更新提供寵物 AI 影片、社交工具以及即將推出的 Android 應用程式
OpenAI 正在為其爆紅的 AI 視訊創作應用程式 Sora 預覽一大波新功能,該應用程式在 9 月底推出後迅速攀升至 App Store 榜首。該應用程式目前仍在美國和加拿大穩居第一,不久將新增視訊編輯功能,讓使用者可以創造寵物和其他物品的角色「客串」,並加強社交功能等。該公司還確認 Android 版本「實際上即將推出」。Sora 的領導 Bill Peebles 在 X 上宣布了這個消息,
Sora 的新更新提供寵物 AI 影片、社交工具以及即將推出的 Android 應用程式
OpenAI 正在為其爆紅的 AI 視訊創作應用程式 Sora 預覽一大波新功能,該應用程式在 9 月底推出後迅速攀升至 App Store 榜首。該應用程式目前仍在美國和加拿大穩居第一,不久將新增視訊編輯功能,讓使用者可以創造寵物和其他物品的角色「客串」,並加強社交功能等。該公司還確認 Android 版本「實際上即將推出」。Sora 的領導 Bill Peebles 在 X 上宣布了這個消息,
 人工智能視頻生成朝著完全控制
諸如Hunyuan和Wan 2.1之類的視頻基礎模型已經取得了長足的進步,但是當涉及電影和電視製作所需的詳細控制時,尤其是在視覺效果領域(VFX)所需的詳細控制。在專業的VFX Studios中,這些模型以及早期的Image-Bas
人工智能視頻生成朝著完全控制
諸如Hunyuan和Wan 2.1之類的視頻基礎模型已經取得了長足的進步,但是當涉及電影和電視製作所需的詳細控制時,尤其是在視覺效果領域(VFX)所需的詳細控制。在專業的VFX Studios中,這些模型以及早期的Image-Bas

立即前往 XIX.AI,探索 2026 年最優秀的漫畫 AI 自動上色工具。我們精心挑選的清單收錄了備受好評、能徹底改變遊戲規則的解決方案,這些工具能以零一致性錯誤的方式套用平面色彩,大幅提升您的工作效率。透過免費與付費版本的比較、實際測試結果,以及每週更新的排行榜,找到最適合您的工具。立即解鎖您的 AI 優勢。
10 個工具
xix.ai

探索 2026 年最優秀的 AI 角色設定生成工具,打造立體鮮明的角色。XIX.AI 精心整理的清單收錄了備受好評、能徹底改變遊戲規則的工具,這些工具能生成一貫的動機與致命缺陷。透過實際測試,比較免費與付費選項的差異。立即釋放您的說故事潛能。
10 個工具
xix.ai

立即在 XIX.AI 探索 2026 年最佳 AI 定價優化軟體。我們精心挑選的清單收錄了備受好評、能徹底改變遊戲規則的工具,這些工具不僅能追蹤競爭對手,還能自動調整您的商店價格,以實現利潤最大化。透過實際測試,比較免費與付費方案的差異。立即掌握您的定價優勢。
10 個工具
xix.ai

立即在 XIX.AI 探索 2026 年最佳 AI 程式碼審查工具。我們精心挑選的清單收錄了備受好評、能徹底改變遊戲規則的工具,可自動確保程式碼符合規範,並重構舊版儲存庫檔案。透過實際測試與每週更新的排行榜,比較免費與付費選項。立即掌握您的 AI 競爭優勢。
10 個工具
xix.ai

探索 2026 年最新精選、專為閱讀障礙者設計的頂級 AI 語音合成(TTS)應用程式。我們的專家評比將免費與付費工具進行對照,重點介紹能提升閱讀效率與學習成效的強大功能。發掘這些必試且能帶來革命性改變的解決方案,釋放學生的潛能。立即前往 XIX.AI 展開您的探索之旅。
10 個工具
xix.ai

立即前往 XIX.AI,探索 2026 年最優秀的少年漫畫 AI 生成工具。我們精心挑選的頂級清單,匯集了能打造高張力動作場面與動態能量特效的強大工具。透過實際測試,比較免費與付費選項的差異。釋放您的創作潛能,今天就開始打造史詩級漫畫吧!
15 個工具
xix.ai

Esse exemplo de vídeo parece meio bugado... Mas a ideia de transformar uma imagem estática em vídeo é fascinante. Será que isso poderia ser usado para criar conteúdos educativos ou de forma indevida? A discussão ética sempre fica atrás da tecnologia 🤔.













