
















 Home
HomeTencent Unveils HunyuanCustom for Single-Image Video Customization
This article explores the launch of HunyuanCustom, a multimodal video generation model by Tencent. The extensive scope of the accompanying research paper and challenges with the provided example videos on the project page necessitate a broader overview, with limited reproduction of the extensive video content due to formatting and processing requirements for improved clarity.
Note that the paper refers to the API-based generative system Kling as ‘Keling.’ For consistency, this article uses ‘Kling’ throughout.
Tencent has introduced an advanced iteration of its Hunyuan Video model, named HunyuanCustom. This release reportedly surpasses the need for Hunyuan LoRA models by enabling users to create deepfake-style video customizations using just a single image:
Click to play. Prompt: ‘A man enjoys music while preparing snail noodles in a kitchen.’ Compared to both proprietary and open-source methods, including Kling, a key competitor, HunyuanCustom stands out. Source: https://hunyuancustom.github.io/ (note: resource-heavy site)
In the video above, the leftmost column displays the single source image input for HunyuanCustom, followed by the system’s interpretation of the prompt in the adjacent column. The remaining columns showcase outputs from other systems: Kling, Vidu, Pika, Hailuo, and SkyReels-A2 (Wan-based).
The following video highlights three core scenarios for this release: person with object, single-character replication, and virtual clothing try-on:
Click to play. Three curated examples from the Hunyuan Video support site.
These examples reveal limitations tied to relying on a single source image rather than multiple perspectives.
In the first clip, the man faces the camera with minimal head movement, tilting no more than 20-25 degrees. Beyond this, the system struggles to infer his profile accurately from a single frontal image.
In the second clip, the girl maintains a smiling expression in the video, mirroring her static source image. Without additional references, HunyuanCustom cannot reliably depict her neutral expression, and her face remains largely forward-facing, similar to the previous example.
In the final clip, incomplete source material—a woman and virtual clothing—results in a cropped render, a practical workaround for limited data.
While HunyuanCustom supports multiple image inputs (e.g., person with snacks or person with attire), it does not accommodate varied angles or expressions for a single character. This may limit its ability to fully replace the expanding ecosystem of LoRA models for HunyuanVideo, which use 20-60 images to ensure consistent character rendering across angles and expressions.
Audio Integration
For audio, HunyuanCustom employs the LatentSync system, which is challenging for hobbyists to configure, to synchronize lip movements with user-provided audio and text:
Includes audio. Click to play. Compiled lip-sync examples from the HunyuanCustom supplementary site.
Currently, no English-language examples are available, but the results appear promising, particularly if the setup process is user-friendly.
Video Editing Capabilities
HunyuanCustom excels in video-to-video (V2V) editing, allowing targeted replacement of elements in existing videos using a single reference image. An example from the supplementary materials illustrates this:
Click to play. The central object is modified, with surrounding elements subtly altered in a HunyuanCustom V2V process.
As typical in V2V workflows, the entire video is slightly modified, with the primary focus on the targeted area, such as the plush toy. Advanced pipelines could potentially preserve more of the original content, similar to Adobe Firefly’s approach, though this remains underexplored in open-source communities.
Other examples demonstrate improved precision in targeting integrations, as seen in this compilation:
Click to play. Varied examples of V2V content insertion in HunyuanCustom, showing respect for unaltered elements.
Evolutionary Upgrade
HunyuanCustom builds on the Hunyuan Video project, introducing targeted architectural enhancements rather than a complete overhaul. These upgrades aim to maintain character consistency across frames without requiring subject-specific fine-tuning, such as LoRA or textual inversion.
This release is a refined version of the December 2024 HunyuanVideo model, not a new model built from the ground up.
Users of existing HunyuanVideo LoRAs may question their compatibility with this update or whether new LoRAs must be developed to leverage enhanced customization features.
Typically, significant fine-tuning alters model weights enough to render prior LoRAs incompatible. However, some fine-tunes, like Pony Diffusion for Stable Diffusion XL, have created independent ecosystems with dedicated LoRA libraries, suggesting potential for HunyuanCustom to follow suit.
Release Details
The research paper, titled HunyuanCustom: A Multimodal-Driven Architecture for Customized Video Generation, links to a GitHub repository now active with code and weights for local deployment, alongside a planned ComfyUI integration.
Currently, the project’s Hugging Face page is inaccessible, but an API-based demo is available via WeChat scan code.
HunyuanCustom’s assembly of diverse projects is notably comprehensive, likely driven by licensing requirements for full disclosure.
Two model variants are offered: a 720x1280px version needing 80GB of GPU memory for optimal performance (24GB minimum, but slow) and a 512x896px version requiring 60GB. Testing has been limited to Linux, but community efforts may soon adapt it for Windows and lower VRAM configurations, as seen with the prior Hunyuan Video model.
Due to the volume of accompanying materials, this overview takes a high-level approach to HunyuanCustom’s capabilities.
Technical Insights
HunyuanCustom’s data pipeline, GDPR-compliant, integrates synthesized and open-source video datasets like OpenHumanVid, covering eight categories: humans, animals, plants, landscapes, vehicles, objects, architecture, and anime.
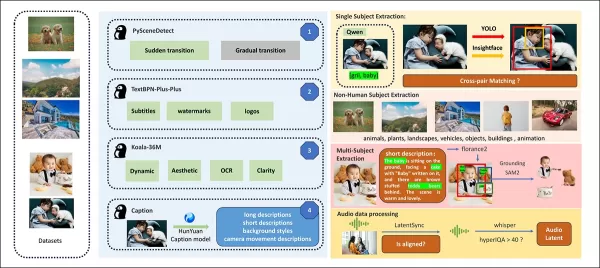
From the release paper, an overview of the diverse contributing packages in the HunyuanCustom data construction pipeline. Source: https://arxiv.org/pdf/2505.04512
Videos are segmented into single-shot clips using PySceneDetect, with TextBPN-Plus-Plus filtering out content with excessive text, subtitles, or watermarks.
Clips are standardized to five seconds and resized to 512 or 720 pixels on the short side. Aesthetic quality is ensured using Koala-36M with a custom 0.06 threshold.
Human identity extraction leverages Qwen7B, YOLO11X, and InsightFace, while non-human subjects are processed with QwenVL and Grounded SAM 2, discarding small bounding boxes.

Examples of semantic segmentation with Grounded SAM 2, used in the Hunyuan Control project. Source: https://github.com/IDEA-Research/Grounded-SAM-2
Multi-subject extraction uses Florence2 for annotation and Grounded SAM 2 for segmentation, followed by clustering and temporal frame segmentation.
Clips are enhanced with proprietary structured-labeling by the Hunyuan team, adding metadata like descriptions and camera motion cues.
Mask augmentation prevents overfitting, ensuring adaptability to varied object shapes. Audio synchronization uses LatentSync, discarding clips below a quality threshold. HyperIQA filters out videos scoring below 40, and Whisper processes valid audio for downstream tasks.
The LLaVA model plays a central role, generating captions and aligning visual and textual content for semantic consistency, especially in complex or multi-subject scenes.
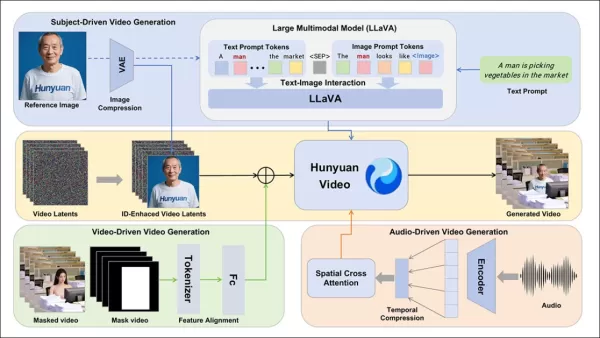
The HunyuanCustom framework supports identity-consistent video generation conditioned on text, image, audio, and video inputs.
Video Customization
To enable video generation from a reference image and prompt, two LLaVA-based modules were developed, adapting HunyuanVideo’s input to accept both image and text. Prompts embed images directly or tag them with brief identity descriptions, using a separator token to balance image and text influence.
An identity enhancement module addresses LLaVA’s tendency to lose fine-grained spatial details, critical for maintaining subject consistency in short video clips.
The reference image is resized and encoded via the causal 3D-VAE from HunyuanVideo, with its latent inserted across the temporal axis and a spatial offset to guide generation without direct replication.
Training used Flow Matching with noise from a logit-normal distribution, fine-tuning LLaVA and the video generator together for cohesive image-prompt guidance and identity consistency.
For multi-subject prompts, each image-text pair is embedded separately with distinct temporal positions, enabling scenes with multiple interacting subjects.
Audio and Visual Integration
HunyuanCustom supports audio-driven generation using user-provided audio and text, enabling characters to speak in contextually relevant settings.
An Identity-disentangled AudioNet module aligns audio features with the video timeline, using spatial cross-attention to isolate frames and maintain subject consistency.
A temporal injection module refines motion timing, mapping audio to latent sequences via a Multi-Layer Perceptron, ensuring gestures align with audio rhythm.
For video editing, HunyuanCustom replaces subjects in existing clips without regenerating the entire video, ideal for targeted appearance or motion changes.
Click to play. Another example from the supplementary site.
The system compresses reference videos using the pretrained causal 3D-VAE, aligning them with generation pipeline latents for lightweight processing. A neural network aligns clean input videos with noisy latents, with frame-by-frame feature addition proving more effective than pre-compression merging.
Performance Evaluation
Testing metrics included ArcFace for facial identity consistency, YOLO11x and Dino 2 for subject similarity, CLIP-B for text-video alignment and temporal consistency, and VBench for motion intensity.
Competitors included closed-source systems (Hailuo, Vidu 2.0, Kling 1.6, Pika) and open-source frameworks (VACE, SkyReels-A2).
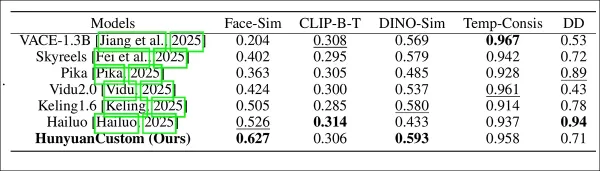
Model performance evaluation comparing HunyuanCustom with leading video customization methods across ID consistency (Face-Sim), subject similarity (DINO-Sim), text-video alignment (CLIP-B-T), temporal consistency (Temp-Consis), and motion intensity (DD). Optimal and sub-optimal results are shown in bold and underlined, respectively.
The authors note:
‘HunyuanCustom excels in ID and subject consistency, with competitive prompt adherence and temporal stability. Hailuo leads in clip score due to strong text alignment but struggles with non-human subject consistency. Vidu and VACE lag in motion intensity, likely due to smaller model sizes.’
While the project site offers numerous comparison videos, their layout prioritizes aesthetics over ease of comparison. Readers are encouraged to review the videos directly for clearer insights:
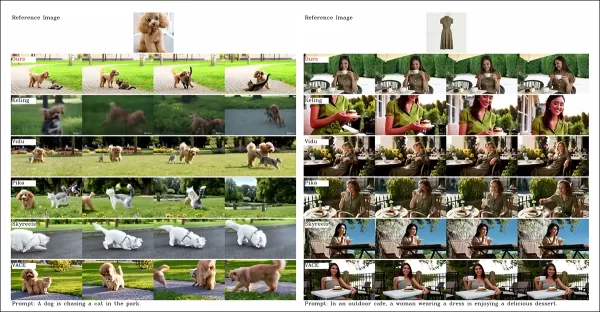
From the paper, a comparison on object-centered video customization. Though the viewer should refer to the source PDF for better resolution, the videos at the project site offer clearer insights.
The authors state:
‘Vidu, SkyReels A2, and HunyuanCustom achieve strong prompt alignment and subject consistency, but our video quality surpasses Vidu and SkyReels, thanks to the robust foundation of Hunyuanvideo-13B.’
‘Among commercial solutions, Kling delivers high-quality video but suffers from a copy-paste effect in the first frame and occasional subject blur, impacting viewer experience.’
Pika struggles with temporal consistency, introducing subtitle artifacts from poor data curation. Hailuo preserves facial identity but falters in full-body consistency. VACE, among open-source methods, fails to maintain identity consistency, while HunyuanCustom delivers strong identity preservation, quality, and diversity.
Multi-subject video customization tests yielded similar results:

Comparisons using multi-subject video customizations. Please see PDF for better detail and resolution.
The paper notes:
‘Pika generates specified subjects but shows frame instability, with subjects disappearing or failing to follow prompts. Vidu and VACE capture human identity partially but lose non-human object details. SkyReels A2 suffers severe frame instability and artifacts. HunyuanCustom effectively captures all subject identities, adheres to prompts, and maintains high visual quality and stability.’
A virtual human advertisement test integrated products with people:

From the qualitative testing round, examples of neural ‘product placement’. Please see PDF for better detail and resolution.
The authors state:
‘HunyuanCustom maintains human identity and product details, including text, with natural interactions and strong prompt adherence, showcasing its potential for advertisement videos.’
Audio-driven customization tests highlighted flexible scene and posture control:
Partial results for the audio round—video results would be preferable. Only the top half of the PDF figure is shown due to size constraints. Refer to the source PDF for better detail.
The authors note:
‘Previous audio-driven methods limit posture and environment to the input image, restricting applications. HunyuanCustom enables flexible audio-driven animation with text-described scenes and postures.’
Video subject replacement tests compared HunyuanCustom against VACE and Kling 1.6:

Testing subject replacement in video-to-video mode. Please refer to source PDF for better detail and resolution.
The researchers state:
‘VACE produces boundary artifacts from strict mask adherence, disrupting motion continuity. Kling shows a copy-paste effect with poor background integration. HunyuanCustom avoids artifacts, ensures seamless integration, and maintains strong identity preservation, excelling in video editing.’
Conclusion
HunyuanCustom is a compelling release, addressing the growing demand for lip-sync in video synthesis, enhancing realism in systems like Hunyuan Video. Despite challenges in comparing its capabilities due to the project site’s video layout, Tencent’s model holds its own against top competitors like Kling, marking significant progress in customized video generation.
* Some videos are too wide, short, or high-resolution to play in standard players like VLC or Windows Media Player, displaying black screens.
First published Thursday, May 8, 2025
Related article
 Exclusive: Luma AI Debuts Creative Agents Fueled by 'Unified Intelligence' Models
On Thursday, AI video generation startup Luma introduced Luma Agents, a system built to manage complete creative workflows spanning text, images, video, and audio. These agents are driven by Luma’s Unified Intelligence model family, featuring an arch
Sora's New Update Delivers Pet AI Videos, Social Tools, and an Upcoming Android App
OpenAI is previewing a wave of new features for its breakout AI video creation app, Sora, which rapidly climbed to the top of the App Store following its launch in late September. The app, still holding the number one spot in the U.S. and Canada, wil
AI Video Generation Moves Towards Complete Control
Video foundation models like Hunyuan and Wan 2.1 have made significant strides, but they often fall short when it comes to the detailed control required in film and TV production, especially in the realm of visual effects (VFX). In professional VFX studios, these models, along with earlier image-bas
Related Special Topic Recommendations
Comic Creation
Exclusive: Luma AI Debuts Creative Agents Fueled by 'Unified Intelligence' Models
On Thursday, AI video generation startup Luma introduced Luma Agents, a system built to manage complete creative workflows spanning text, images, video, and audio. These agents are driven by Luma’s Unified Intelligence model family, featuring an arch
Sora's New Update Delivers Pet AI Videos, Social Tools, and an Upcoming Android App
OpenAI is previewing a wave of new features for its breakout AI video creation app, Sora, which rapidly climbed to the top of the App Store following its launch in late September. The app, still holding the number one spot in the U.S. and Canada, wil
AI Video Generation Moves Towards Complete Control
Video foundation models like Hunyuan and Wan 2.1 have made significant strides, but they often fall short when it comes to the detailed control required in film and TV production, especially in the realm of visual effects (VFX). In professional VFX studios, these models, along with earlier image-bas
Related Special Topic Recommendations
Comic Creation
 Top AI Generators for Shonen Manga: Create High-Octane Action Sequences & Energy Effects
Top AI Generators for Shonen Manga: Create High-Octane Action Sequences & Energy Effects
Discover the 2026 best AI generators for Shonen manga at XIX.AI. Our top-rated, curated list features powerful tools for creating high-octane action sequences and dynamic energy effects. Compare free vs paid options with real-world tests. Unlock your creative potential and start crafting epic manga today!
 15 tools
15 tools
 xix.ai
Business
Best AI Expense Trackers: Scan Receipts & Categorize Corporate Spend Automatically
xix.ai
Business
Best AI Expense Trackers: Scan Receipts & Categorize Corporate Spend Automatically
2026 Latest Best AI Expense Trackers: Top-rated tools to scan receipts & categorize corporate spend automatically. Discover powerful, game-changing solutions for effortless expense management, accurate financial tracking, and streamlined compliance. Our curated, weekly-updated comparison of free vs paid options helps you find the perfect fit. Unlock your AI edge with XIX.AI's expert picks.
10 tools
xix.ai
Business
Best AI Recruiting Tools: Screen Resumes & Automate Candidate Interview Scheduling
Discover the 2026 latest top-rated AI recruiting tools on XIX.AI. Our curated list features powerful, game-changing solutions for screening resumes and automating candidate interview scheduling. Compare free vs paid options with real-world tests and weekly updated rankings. Find your perfect hiring assistant and streamline your recruitment today!
10 tools
xix.ai
Productivity
AI Personal Wellness & Focus Coaches: Manage Burnout & Boost Mental Energy Levels
Discover the 2026 best AI personal wellness and focus coaches on XIX.AI. Our curated rankings feature top-rated, game-changing tools to manage burnout and boost mental energy. Compare free vs paid options with real-world insights. Unlock your path to peak productivity and well-being today.
10 tools
xix.ai
chatbot
Top-Rated AI Romantic Chatbots: Build Long-Term Relationships with Consistent Personalities
Discover the 2026 latest top-rated AI romantic chatbots for building genuine, long-term connections. Our curated list features powerful, consistent personalities, free vs paid comparisons, and real-world tests. Find your perfect companion and start building today at XIX.AI.
10 tools
xix.ai
Education and Learning
Best AI Data Science Mentors: Master SQL, Pandas & Machine Learning Workflows
Discover the 2026 best AI data science mentors to master SQL, Pandas & ML workflows. Explore our top-rated, curated selection at XIX.AI for powerful, game-changing guidance. Compare free vs paid options with real-world insights. Unlock your data science mastery today.
10 tools
xix.ai

 Comments (1)
0/500
Comments (1)
0/500
![RalphHill]()
Esse exemplo de vídeo parece meio bugado... Mas a ideia de transformar uma imagem estática em vídeo é fascinante. Será que isso poderia ser usado para criar conteúdos educativos ou de forma indevida? A discussão ética sempre fica atrás da tecnologia 🤔.
This article explores the launch of HunyuanCustom, a multimodal video generation model by Tencent. The extensive scope of the accompanying research paper and challenges with the provided example videos on the project page necessitate a broader overview, with limited reproduction of the extensive video content due to formatting and processing requirements for improved clarity.
Note that the paper refers to the API-based generative system Kling as ‘Keling.’ For consistency, this article uses ‘Kling’ throughout.
Tencent has introduced an advanced iteration of its Hunyuan Video model, named HunyuanCustom. This release reportedly surpasses the need for Hunyuan LoRA models by enabling users to create deepfake-style video customizations using just a single image:
Click to play. Prompt: ‘A man enjoys music while preparing snail noodles in a kitchen.’ Compared to both proprietary and open-source methods, including Kling, a key competitor, HunyuanCustom stands out. Source: https://hunyuancustom.github.io/ (note: resource-heavy site)
In the video above, the leftmost column displays the single source image input for HunyuanCustom, followed by the system’s interpretation of the prompt in the adjacent column. The remaining columns showcase outputs from other systems: Kling, Vidu, Pika, Hailuo, and SkyReels-A2 (Wan-based).
The following video highlights three core scenarios for this release: person with object, single-character replication, and virtual clothing try-on:
Click to play. Three curated examples from the Hunyuan Video support site.
These examples reveal limitations tied to relying on a single source image rather than multiple perspectives.
In the first clip, the man faces the camera with minimal head movement, tilting no more than 20-25 degrees. Beyond this, the system struggles to infer his profile accurately from a single frontal image.
In the second clip, the girl maintains a smiling expression in the video, mirroring her static source image. Without additional references, HunyuanCustom cannot reliably depict her neutral expression, and her face remains largely forward-facing, similar to the previous example.
In the final clip, incomplete source material—a woman and virtual clothing—results in a cropped render, a practical workaround for limited data.
While HunyuanCustom supports multiple image inputs (e.g., person with snacks or person with attire), it does not accommodate varied angles or expressions for a single character. This may limit its ability to fully replace the expanding ecosystem of LoRA models for HunyuanVideo, which use 20-60 images to ensure consistent character rendering across angles and expressions.
Audio Integration
For audio, HunyuanCustom employs the LatentSync system, which is challenging for hobbyists to configure, to synchronize lip movements with user-provided audio and text:
Includes audio. Click to play. Compiled lip-sync examples from the HunyuanCustom supplementary site.
Currently, no English-language examples are available, but the results appear promising, particularly if the setup process is user-friendly.
Video Editing Capabilities
HunyuanCustom excels in video-to-video (V2V) editing, allowing targeted replacement of elements in existing videos using a single reference image. An example from the supplementary materials illustrates this:
Click to play. The central object is modified, with surrounding elements subtly altered in a HunyuanCustom V2V process.
As typical in V2V workflows, the entire video is slightly modified, with the primary focus on the targeted area, such as the plush toy. Advanced pipelines could potentially preserve more of the original content, similar to Adobe Firefly’s approach, though this remains underexplored in open-source communities.
Other examples demonstrate improved precision in targeting integrations, as seen in this compilation:
Click to play. Varied examples of V2V content insertion in HunyuanCustom, showing respect for unaltered elements.
Evolutionary Upgrade
HunyuanCustom builds on the Hunyuan Video project, introducing targeted architectural enhancements rather than a complete overhaul. These upgrades aim to maintain character consistency across frames without requiring subject-specific fine-tuning, such as LoRA or textual inversion.
This release is a refined version of the December 2024 HunyuanVideo model, not a new model built from the ground up.
Users of existing HunyuanVideo LoRAs may question their compatibility with this update or whether new LoRAs must be developed to leverage enhanced customization features.
Typically, significant fine-tuning alters model weights enough to render prior LoRAs incompatible. However, some fine-tunes, like Pony Diffusion for Stable Diffusion XL, have created independent ecosystems with dedicated LoRA libraries, suggesting potential for HunyuanCustom to follow suit.
Release Details
The research paper, titled HunyuanCustom: A Multimodal-Driven Architecture for Customized Video Generation, links to a GitHub repository now active with code and weights for local deployment, alongside a planned ComfyUI integration.
Currently, the project’s Hugging Face page is inaccessible, but an API-based demo is available via WeChat scan code.
HunyuanCustom’s assembly of diverse projects is notably comprehensive, likely driven by licensing requirements for full disclosure.
Two model variants are offered: a 720x1280px version needing 80GB of GPU memory for optimal performance (24GB minimum, but slow) and a 512x896px version requiring 60GB. Testing has been limited to Linux, but community efforts may soon adapt it for Windows and lower VRAM configurations, as seen with the prior Hunyuan Video model.
Due to the volume of accompanying materials, this overview takes a high-level approach to HunyuanCustom’s capabilities.
Technical Insights
HunyuanCustom’s data pipeline, GDPR-compliant, integrates synthesized and open-source video datasets like OpenHumanVid, covering eight categories: humans, animals, plants, landscapes, vehicles, objects, architecture, and anime.
From the release paper, an overview of the diverse contributing packages in the HunyuanCustom data construction pipeline. Source: https://arxiv.org/pdf/2505.04512
Videos are segmented into single-shot clips using PySceneDetect, with TextBPN-Plus-Plus filtering out content with excessive text, subtitles, or watermarks.
Clips are standardized to five seconds and resized to 512 or 720 pixels on the short side. Aesthetic quality is ensured using Koala-36M with a custom 0.06 threshold.
Human identity extraction leverages Qwen7B, YOLO11X, and InsightFace, while non-human subjects are processed with QwenVL and Grounded SAM 2, discarding small bounding boxes.
Examples of semantic segmentation with Grounded SAM 2, used in the Hunyuan Control project. Source: https://github.com/IDEA-Research/Grounded-SAM-2
Multi-subject extraction uses Florence2 for annotation and Grounded SAM 2 for segmentation, followed by clustering and temporal frame segmentation.
Clips are enhanced with proprietary structured-labeling by the Hunyuan team, adding metadata like descriptions and camera motion cues.
Mask augmentation prevents overfitting, ensuring adaptability to varied object shapes. Audio synchronization uses LatentSync, discarding clips below a quality threshold. HyperIQA filters out videos scoring below 40, and Whisper processes valid audio for downstream tasks.
The LLaVA model plays a central role, generating captions and aligning visual and textual content for semantic consistency, especially in complex or multi-subject scenes.
The HunyuanCustom framework supports identity-consistent video generation conditioned on text, image, audio, and video inputs.
Video Customization
To enable video generation from a reference image and prompt, two LLaVA-based modules were developed, adapting HunyuanVideo’s input to accept both image and text. Prompts embed images directly or tag them with brief identity descriptions, using a separator token to balance image and text influence.
An identity enhancement module addresses LLaVA’s tendency to lose fine-grained spatial details, critical for maintaining subject consistency in short video clips.
The reference image is resized and encoded via the causal 3D-VAE from HunyuanVideo, with its latent inserted across the temporal axis and a spatial offset to guide generation without direct replication.
Training used Flow Matching with noise from a logit-normal distribution, fine-tuning LLaVA and the video generator together for cohesive image-prompt guidance and identity consistency.
For multi-subject prompts, each image-text pair is embedded separately with distinct temporal positions, enabling scenes with multiple interacting subjects.
Audio and Visual Integration
HunyuanCustom supports audio-driven generation using user-provided audio and text, enabling characters to speak in contextually relevant settings.
An Identity-disentangled AudioNet module aligns audio features with the video timeline, using spatial cross-attention to isolate frames and maintain subject consistency.
A temporal injection module refines motion timing, mapping audio to latent sequences via a Multi-Layer Perceptron, ensuring gestures align with audio rhythm.
For video editing, HunyuanCustom replaces subjects in existing clips without regenerating the entire video, ideal for targeted appearance or motion changes.
Click to play. Another example from the supplementary site.
The system compresses reference videos using the pretrained causal 3D-VAE, aligning them with generation pipeline latents for lightweight processing. A neural network aligns clean input videos with noisy latents, with frame-by-frame feature addition proving more effective than pre-compression merging.
Performance Evaluation
Testing metrics included ArcFace for facial identity consistency, YOLO11x and Dino 2 for subject similarity, CLIP-B for text-video alignment and temporal consistency, and VBench for motion intensity.
Competitors included closed-source systems (Hailuo, Vidu 2.0, Kling 1.6, Pika) and open-source frameworks (VACE, SkyReels-A2).
Model performance evaluation comparing HunyuanCustom with leading video customization methods across ID consistency (Face-Sim), subject similarity (DINO-Sim), text-video alignment (CLIP-B-T), temporal consistency (Temp-Consis), and motion intensity (DD). Optimal and sub-optimal results are shown in bold and underlined, respectively.
The authors note:
‘HunyuanCustom excels in ID and subject consistency, with competitive prompt adherence and temporal stability. Hailuo leads in clip score due to strong text alignment but struggles with non-human subject consistency. Vidu and VACE lag in motion intensity, likely due to smaller model sizes.’
While the project site offers numerous comparison videos, their layout prioritizes aesthetics over ease of comparison. Readers are encouraged to review the videos directly for clearer insights:
From the paper, a comparison on object-centered video customization. Though the viewer should refer to the source PDF for better resolution, the videos at the project site offer clearer insights.
The authors state:
‘Vidu, SkyReels A2, and HunyuanCustom achieve strong prompt alignment and subject consistency, but our video quality surpasses Vidu and SkyReels, thanks to the robust foundation of Hunyuanvideo-13B.’
‘Among commercial solutions, Kling delivers high-quality video but suffers from a copy-paste effect in the first frame and occasional subject blur, impacting viewer experience.’
Pika struggles with temporal consistency, introducing subtitle artifacts from poor data curation. Hailuo preserves facial identity but falters in full-body consistency. VACE, among open-source methods, fails to maintain identity consistency, while HunyuanCustom delivers strong identity preservation, quality, and diversity.
Multi-subject video customization tests yielded similar results:
Comparisons using multi-subject video customizations. Please see PDF for better detail and resolution.
The paper notes:
‘Pika generates specified subjects but shows frame instability, with subjects disappearing or failing to follow prompts. Vidu and VACE capture human identity partially but lose non-human object details. SkyReels A2 suffers severe frame instability and artifacts. HunyuanCustom effectively captures all subject identities, adheres to prompts, and maintains high visual quality and stability.’
A virtual human advertisement test integrated products with people:
From the qualitative testing round, examples of neural ‘product placement’. Please see PDF for better detail and resolution.
The authors state:
‘HunyuanCustom maintains human identity and product details, including text, with natural interactions and strong prompt adherence, showcasing its potential for advertisement videos.’
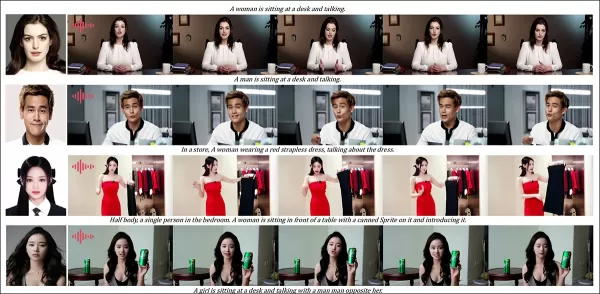
Audio-driven customization tests highlighted flexible scene and posture control:
Partial results for the audio round—video results would be preferable. Only the top half of the PDF figure is shown due to size constraints. Refer to the source PDF for better detail.
The authors note:
‘Previous audio-driven methods limit posture and environment to the input image, restricting applications. HunyuanCustom enables flexible audio-driven animation with text-described scenes and postures.’
Video subject replacement tests compared HunyuanCustom against VACE and Kling 1.6:
Testing subject replacement in video-to-video mode. Please refer to source PDF for better detail and resolution.
The researchers state:
‘VACE produces boundary artifacts from strict mask adherence, disrupting motion continuity. Kling shows a copy-paste effect with poor background integration. HunyuanCustom avoids artifacts, ensures seamless integration, and maintains strong identity preservation, excelling in video editing.’
Conclusion
HunyuanCustom is a compelling release, addressing the growing demand for lip-sync in video synthesis, enhancing realism in systems like Hunyuan Video. Despite challenges in comparing its capabilities due to the project site’s video layout, Tencent’s model holds its own against top competitors like Kling, marking significant progress in customized video generation.
* Some videos are too wide, short, or high-resolution to play in standard players like VLC or Windows Media Player, displaying black screens.
First published Thursday, May 8, 2025










 Exclusive: Luma AI Debuts Creative Agents Fueled by 'Unified Intelligence' Models
On Thursday, AI video generation startup Luma introduced Luma Agents, a system built to manage complete creative workflows spanning text, images, video, and audio. These agents are driven by Luma’s Unified Intelligence model family, featuring an arch
Exclusive: Luma AI Debuts Creative Agents Fueled by 'Unified Intelligence' Models
On Thursday, AI video generation startup Luma introduced Luma Agents, a system built to manage complete creative workflows spanning text, images, video, and audio. These agents are driven by Luma’s Unified Intelligence model family, featuring an arch
 Sora's New Update Delivers Pet AI Videos, Social Tools, and an Upcoming Android App
OpenAI is previewing a wave of new features for its breakout AI video creation app, Sora, which rapidly climbed to the top of the App Store following its launch in late September. The app, still holding the number one spot in the U.S. and Canada, wil
Sora's New Update Delivers Pet AI Videos, Social Tools, and an Upcoming Android App
OpenAI is previewing a wave of new features for its breakout AI video creation app, Sora, which rapidly climbed to the top of the App Store following its launch in late September. The app, still holding the number one spot in the U.S. and Canada, wil
 AI Video Generation Moves Towards Complete Control
Video foundation models like Hunyuan and Wan 2.1 have made significant strides, but they often fall short when it comes to the detailed control required in film and TV production, especially in the realm of visual effects (VFX). In professional VFX studios, these models, along with earlier image-bas
AI Video Generation Moves Towards Complete Control
Video foundation models like Hunyuan and Wan 2.1 have made significant strides, but they often fall short when it comes to the detailed control required in film and TV production, especially in the realm of visual effects (VFX). In professional VFX studios, these models, along with earlier image-bas

Discover the 2026 best AI generators for Shonen manga at XIX.AI. Our top-rated, curated list features powerful tools for creating high-octane action sequences and dynamic energy effects. Compare free vs paid options with real-world tests. Unlock your creative potential and start crafting epic manga today!
15 tools
xix.ai

2026 Latest Best AI Expense Trackers: Top-rated tools to scan receipts & categorize corporate spend automatically. Discover powerful, game-changing solutions for effortless expense management, accurate financial tracking, and streamlined compliance. Our curated, weekly-updated comparison of free vs paid options helps you find the perfect fit. Unlock your AI edge with XIX.AI's expert picks.
10 tools
xix.ai

Discover the 2026 latest top-rated AI recruiting tools on XIX.AI. Our curated list features powerful, game-changing solutions for screening resumes and automating candidate interview scheduling. Compare free vs paid options with real-world tests and weekly updated rankings. Find your perfect hiring assistant and streamline your recruitment today!
10 tools
xix.ai

Discover the 2026 best AI personal wellness and focus coaches on XIX.AI. Our curated rankings feature top-rated, game-changing tools to manage burnout and boost mental energy. Compare free vs paid options with real-world insights. Unlock your path to peak productivity and well-being today.
10 tools
xix.ai

Discover the 2026 latest top-rated AI romantic chatbots for building genuine, long-term connections. Our curated list features powerful, consistent personalities, free vs paid comparisons, and real-world tests. Find your perfect companion and start building today at XIX.AI.
10 tools
xix.ai

Discover the 2026 best AI data science mentors to master SQL, Pandas & ML workflows. Explore our top-rated, curated selection at XIX.AI for powerful, game-changing guidance. Compare free vs paid options with real-world insights. Unlock your data science mastery today.
10 tools
xix.ai

Esse exemplo de vídeo parece meio bugado... Mas a ideia de transformar uma imagem estática em vídeo é fascinante. Será que isso poderia ser usado para criar conteúdos educativos ou de forma indevida? A discussão ética sempre fica atrás da tecnologia 🤔.













