
















 Heim
HeimTencent stellt HunyuanCustom für Videoanpassung mit einem einzigen Bild vor
Dieser Artikel beleuchtet die Einführung von HunyuanCustom, einem multimodalen Videogenerierungsmodell von Tencent. Der umfangreiche Umfang des begleitenden Forschungspapiers und die Herausforderungen mit den bereitgestellten Beispielvideos auf der Projektseite erfordern eine breitere Übersicht, mit begrenzter Wiedergabe des umfangreichen Videoinhalts aufgrund von Formatierungs- und Verarbeitungsanforderungen für verbesserte Klarheit.
Beachten Sie, dass das Papier das API-basierte generative System Kling als „Keling“ bezeichnet. Der Konsistenz halber verwendet dieser Artikel durchgehend „Kling“.
Tencent hat eine fortschrittliche Version seines Hunyuan Video-Modells vorgestellt, genannt HunyuanCustom. Diese Veröffentlichung übertrifft Berichten zufolge die Notwendigkeit für Hunyuan LoRA-Modelle, indem sie Nutzern ermöglicht, Deepfake-ähnliche Videoanpassungen mit nur einem einzigen Bild zu erstellen:
Klicken zum Abspielen. Eingabe: „Ein Mann genießt Musik, während er Schneckennudeln in einer Küche zubereitet.“ Im Vergleich zu proprietären und Open-Source-Methoden, einschließlich Kling, einem Hauptkonkurrenten, sticht HunyuanCustom heraus. Quelle: https://hunyuancustom.github.io/ (Hinweis: ressourcenintensive Seite)
Im obigen Video zeigt die linke Spalte das einzelne Quellbild für HunyuanCustom, gefolgt von der Interpretation der Eingabe durch das System in der angrenzenden Spalte. Die verbleibenden Spalten zeigen Ausgaben anderer Systeme: Kling, Vidu, Pika, Hailuo und SkyReels-A2 (Wan-basiert).
Das folgende Video hebt drei Kerneinsatzszenarien dieser Veröffentlichung hervor: Person mit Objekt, Einzelcharakter-Replikation und virtuelles Anprobieren von Kleidung:
Klicken zum Abspielen. Drei kuratierte Beispiele von der Hunyuan Video-Unterstützungsseite.
Diese Beispiele zeigen Einschränkungen, die mit der Verwendung eines einzigen Quellbildes statt mehreren Perspektiven verbunden sind.
Im ersten Clip blickt der Mann direkt in die Kamera mit minimaler Kopfbewegung, die nicht mehr als 20-25 Grad beträgt. Darüber hinaus hat das System Schwierigkeiten, sein Profil präzise aus einem einzigen Frontalbild abzuleiten.
Im zweiten Clip behält das Mädchen einen lächelnden Ausdruck im Video bei, der ihrem statischen Quellbild entspricht. Ohne zusätzliche Referenzen kann HunyuanCustom ihren neutralen Ausdruck nicht zuverlässig darstellen, und ihr Gesicht bleibt größtenteils nach vorne gerichtet, ähnlich wie im vorherigen Beispiel.
Im letzten Clip führt unvollständiges Quellmaterial – eine Frau und virtuelle Kleidung – zu einer beschnittenen Darstellung, eine praktische Lösung für begrenzte Daten.
Während HunyuanCustom mehrere Bild-Eingaben unterstützt (z. B. Person mit Snacks oder Person mit Kleidung), berücksichtigt es keine unterschiedlichen Winkel oder Ausdrücke für einen einzelnen Charakter. Dies könnte seine Fähigkeit einschränken, das wachsende Ökosystem von LoRA-Modellen für HunyuanVideo vollständig zu ersetzen, die 20-60 Bilder verwenden, um konsistente Charakterdarstellungen über verschiedene Winkel und Ausdrücke hinweg zu gewährleisten.
Audiointegration
Für Audio verwendet HunyuanCustom das LatentSync-System, das für Hobbyisten schwierig zu konfigurieren ist, um Lippenbewegungen mit vom Benutzer bereitgestelltem Audio und Text zu synchronisieren:
Enthält Audio. Klicken zum Abspielen. Zusammengestellte Lippensynchronisationsbeispiele von der HunyuanCustom-Zusatzseite.
Derzeit sind keine Beispiele in englischer Sprache verfügbar, aber die Ergebnisse erscheinen vielversprechend, insbesondere wenn der Einrichtungsprozess benutzerfreundlich ist.
Videobearbeitungsfähigkeiten
HunyuanCustom glänzt in der Video-zu-Video (V2V)-Bearbeitung, die gezieltes Ersetzen von Elementen in bestehenden Videos mit einem einzigen Referenzbild ermöglicht. Ein Beispiel aus den Zusatzmaterialien veranschaulicht dies:
Klicken zum Abspielen. Das zentrale Objekt wird modifiziert, wobei umliegende Elemente in einem HunyuanCustom V2V-Prozess subtil verändert werden.
Wie typisch für V2V-Workflows wird das gesamte Video leicht modifiziert, wobei der Fokus auf dem Zielbereich liegt, wie z. B. dem Plüschtier. Fortgeschrittene Pipelines könnten potenziell mehr vom Originalinhalt bewahren, ähnlich wie der Ansatz von Adobe Firefly, was in Open-Source-Communities jedoch wenig erforscht ist.
Weitere Beispiele zeigen verbesserte Präzision bei gezielten Integrationen, wie in dieser Zusammenstellung zu sehen:
Klicken zum Abspielen. Verschiedene Beispiele für V2V-Inhaltseinfügung in HunyuanCustom, die Respekt vor unveränderten Elementen zeigen.
Evolutionäre Verbesserung
HunyuanCustom baut auf dem Hunyuan Video-Projekt auf und führt gezielte architektonische Verbesserungen ein, anstatt eine vollständige Überarbeitung. Diese Upgrades zielen darauf ab, die Charakterkonsistenz über Frames hinweg ohne subjektspezifisches Feintuning, wie LoRA oder textuelle Inversion, zu erhalten.
Diese Veröffentlichung ist eine verfeinerte Version des HunyuanVideo-Modells vom Dezember 2024, kein neu entwickeltes Modell von Grund auf.
Nutzer bestehender HunyuanVideo LoRAs könnten sich fragen, ob diese mit diesem Update kompatibel sind oder ob neue LoRAs entwickelt werden müssen, um die erweiterten Anpassungsfunktionen zu nutzen.
Typischerweise verändert ein signifikantes Feintuning die Modellgewichte so stark, dass vorherige LoRAs inkompatibel werden. Einige Feintunings, wie Pony Diffusion für Stable Diffusion XL, haben jedoch unabhängige Ökosysteme mit dedizierten LoRA-Bibliotheken geschaffen, was auf ein Potenzial für HunyuanCustom hinweist, diesem Beispiel zu folgen.
Veröffentlichungsdetails
Das Forschungspapier, betitelt HunyuanCustom: Eine multimodal getriebene Architektur für angepasste Videogenerierung, verlinkt auf ein GitHub-Repository, das nun mit Code und Gewichten für lokale Bereitstellung aktiv ist, neben einer geplanten ComfyUI-Integration.
Derzeit ist die Hugging Face-Seite des Projekts nicht zugänglich, aber eine API-basierte Demo ist über einen WeChat-Scan-Code verfügbar.
Die Zusammenstellung verschiedener Projekte durch HunyuanCustom ist bemerkenswert umfassend, wahrscheinlich getrieben durch Lizenzanforderungen für vollständige Offenlegung.
Zwei Modellvarianten werden angeboten: eine Version mit 720x1280px, die 80GB GPU-Speicher für optimale Leistung benötigt (mindestens 24GB, aber langsam) und eine Version mit 512x896px, die 60GB erfordert. Tests waren auf Linux beschränkt, aber Community-Bemühungen könnten es bald für Windows und niedrigere VRAM-Konfigurationen anpassen, wie beim vorherigen Hunyuan Video-Modell gesehen.
Aufgrund des Umfangs der begleitenden Materialien verfolgt diese Übersicht einen übergeordneten Ansatz zu den Fähigkeiten von HunyuanCustom.
Technische Einblicke
Die Datenpipeline von HunyuanCustom, DSGVO-konform, integriert synthetisierte und Open-Source-Videodatensätze wie OpenHumanVid, die acht Kategorien abdecken: Menschen, Tiere, Pflanzen, Landschaften, Fahrzeuge, Objekte, Architektur und Anime.
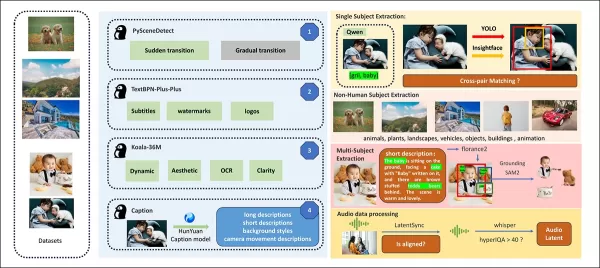
Aus dem Veröffentlichungspapier, eine Übersicht der verschiedenen beitragenden Pakete in der HunyuanCustom-Datenerstellungspipeline. Quelle: https://arxiv.org/pdf/2505.04512
Videos werden mit PySceneDetect in Einzelaufnahme-Clips segmentiert, wobei TextBPN-Plus-Plus Inhalte mit übermäßigem Text, Untertiteln oder Wasserzeichen herausfiltert.
Clips werden auf fünf Sekunden standardisiert und auf 512 oder 720 Pixel an der kurzen Seite skaliert. Ästhetische Qualität wird mit Koala-36M und einem benutzerdefinierten Schwellenwert von 0,06 sichergestellt.
Die Extraktion menschlicher Identitäten nutzt Qwen7B, YOLO11X und InsightFace, während nicht-menschliche Subjekte mit QwenVL und Grounded SAM 2 verarbeitet werden, wobei kleine Bounding-Boxen verworfen werden.

Beispiele für semantische Segmentierung mit Grounded SAM 2, verwendet im Hunyuan Control-Projekt. Quelle: https://github.com/IDEA-Research/Grounded-SAM-2
Die Extraktion mehrerer Subjekte verwendet Florence2 für Annotationen und Grounded SAM 2 für Segmentierung, gefolgt von Clustering und temporaler Rahmensegmentierung.
Clips werden mit proprietärer strukturierter Kennzeichnung durch das Hunyuan-Team verbessert, die Metadaten wie Beschreibungen und Kamerabewegungshinweise hinzufügt.
Masken-Augmentation verhindert Überanpassung und gewährleistet Anpassungsfähigkeit an unterschiedliche Objektformen. Audio-Synchronisation verwendet LatentSync, wobei Clips unterhalb eines Qualitätsschwellenwerts verworfen werden. HyperIQA filtert Videos mit einem Score unter 40 heraus, und Whisper verarbeitet gültiges Audio für nachgelagerte Aufgaben.
Das LLaVA-Modell spielt eine zentrale Rolle, generiert Untertitel und stimmt visuelle und textuelle Inhalte für semantische Konsistenz ab, insbesondere in komplexen oder mehrsubjektiven Szenen.
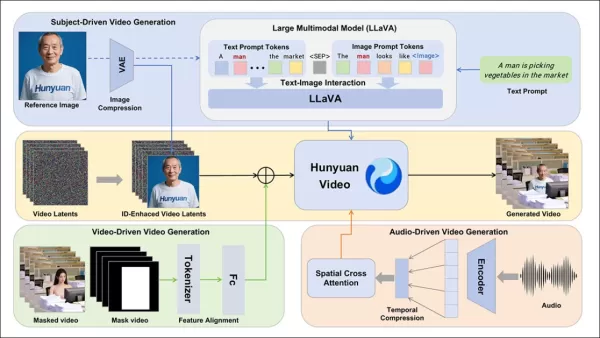
Das HunyuanCustom-Framework unterstützt identitätskonsistente Videogenerierung, die auf Text-, Bild-, Audio- und Videoeingaben basiert.
Videopersonalisierung
Um Videogenerierung aus einem Referenzbild und einer Eingabe zu ermöglichen, wurden zwei LLaVA-basierte Module entwickelt, die die Eingabe von HunyuanVideo anpassen, um sowohl Bild als auch Text zu akzeptieren. Eingaben betten Bilder direkt ein oder markieren sie mit kurzen Identitätsbeschreibungen, unter Verwendung eines Trennzeichens, um den Einfluss von Bild und Text auszubalancieren.
Ein Identitätsverbesserungsmodul adressiert die Tendenz von LLaVA, feinkörnige räumliche Details zu verlieren, die für die Aufrechterhaltung der Subjektkonsistenz in kurzen Videoclips entscheidend sind.
Das Referenzbild wird skaliert und über den kausalen 3D-VAE von HunyuanVideo kodiert, wobei sein Latent über die temporale Achse und mit einem räumlichen Offset eingefügt wird, um die Generierung zu leiten, ohne direkte Replikation.
Das Training verwendete Flow Matching mit Rauschen aus einer logit-normalen Verteilung, wobei LLaVA und der Videogenerator gemeinsam optimiert wurden, um kohärente Bild-Eingabe-Führung und Identitätskonsistenz zu gewährleisten.
Für Eingaben mit mehreren Subjekten wird jedes Bild-Text-Paar separat mit unterschiedlichen temporalen Positionen eingebettet, was Szenen mit mehreren interagierenden Subjekten ermöglicht.
Audio- und visuelle Integration
HunyuanCustom unterstützt audio-gesteuerte Generierung mit vom Benutzer bereitgestelltem Audio und Text, wodurch Charaktere in kontextuell relevanten Umgebungen sprechen können.
Ein identitätsentkoppeltes AudioNet-Modul stimmt Audio-Features mit der Video-Timeline ab, unter Verwendung von räumlicher Cross-Attention, um Frames zu isolieren und die Subjektkonsistenz zu wahren.
Ein temporales Injektionsmodul verfeinert das Bewegungs-Timing, indem Audio über ein Multi-Layer-Perceptron auf latente Sequenzen abgebildet wird, um die Ausrichtung von Gesten mit dem Audio-Rhythmus sicherzustellen.
Für die Videobearbeitung ersetzt HunyuanCustom Subjekte in bestehenden Clips, ohne das gesamte Video neu zu generieren, ideal für gezielte Änderungen an Aussehen oder Bewegung.
Klicken zum Abspielen. Ein weiteres Beispiel von der Zusatzseite.
Das System komprimiert Referenzvideos mit dem vortrainierten kausalen 3D-VAE und richtet sie an die Latenten der Generierungspipeline für eine leichte Verarbeitung aus. Ein neuronales Netzwerk richtet saubere Eingabevideos mit verrauschten Latenten aus, wobei die frameweise Hinzufügung von Features effektiver ist als die Vor-Kompressions-Vers融合。
Leistungsbewertung
Testmetriken umfassten ArcFace für Gesichtsidentitätskonsistenz, YOLO11x und Dino 2 für Subjektähnlichkeit, CLIP-B für Text-Video-Ausrichtung und temporale Konsistenz sowie VBench für Bewegungsintensität.
Konkurrenten umfassten geschlossene Systeme (Hailuo, Vidu 2.0, Kling 1.6, Pika) und Open-Source-Frameworks (VACE, SkyReels-A2).
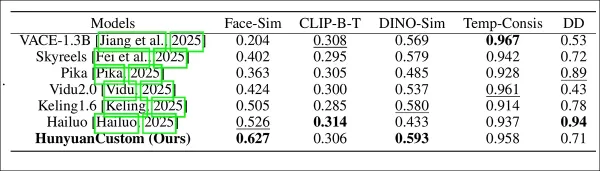
Modellleistungsbewertung, die HunyuanCustom mit führenden Videopersonalisierungsmethoden in Bezug auf ID-Konsistenz (Face-Sim), Subjektähnlichkeit (DINO-Sim), Text-Video-Ausrichtung (CLIP-B-T), temporale Konsistenz (Temp-Consis) und Bewegungsintensität (DD) vergleicht. Optimale und suboptimale Ergebnisse sind in Fettschrift bzw. unterstrichen dargestellt.
Die Autoren bemerken:
„HunyuanCustom glänzt in ID- und Subjektkonsistenz, mit wettbewerbsfähiger Eingabe-Treue und temporaler Stabilität. Hailuo führt beim Clip-Score aufgrund starker Textausrichtung, hat aber Schwierigkeiten mit der Konsistenz nicht-menschlicher Subjekte. Vidu und VACE hinken bei der Bewegungsintensität hinterher, wahrscheinlich aufgrund kleinerer Modellgrößen.“
Während die Projektseite zahlreiche Vergleichsvideos bietet, priorisiert deren Layout Ästhetik über Vergleichsfreundlichkeit. Leser werden ermutigt, die Videos direkt für klarere Einblicke zu überprüfen:
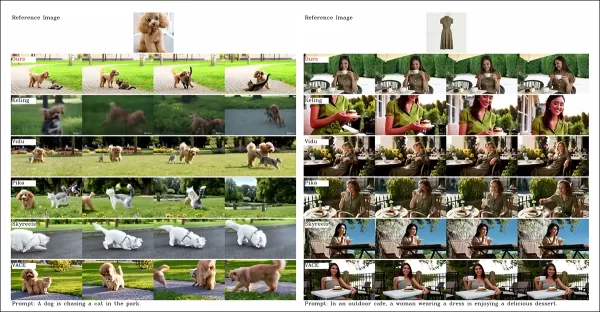
Aus dem Papier, ein Vergleich zur objektzentrierten Videopersonalisierung. Obwohl der Betrachter das Quell-PDF für bessere Auflösung konsultieren sollte, bieten die Videos auf der Projektseite klarere Einblicke.
Die Autoren erklären:
„Vidu, SkyReels A2 und HunyuanCustom erreichen starke Eingabe-Ausrichtung und Subjektkonsistenz, aber unsere Videoqualität übertrifft Vidu und SkyReels, dank der robusten Grundlage von Hunyuanvideo-13B.“
„Unter den kommerziellen Lösungen liefert Kling hochwertige Videos, leidet jedoch unter einem Kopier-Einfüge-Effekt im ersten Frame und gelegentlicher Subjektunschärfe, was das Zuschauererlebnis beeinträchtigt.“
Pika hat Schwierigkeiten mit temporaler Konsistenz und führt Untertitel-Artefakte durch schlechte Datenkuration ein. Hailuo bewahrt die Gesichtsidentität, scheitert jedoch bei der Ganzkörper-Konsistenz. VACE, unter den Open-Source-Methoden, kann die Identitätskonsistenz nicht aufrechterhalten, während HunyuanCustom starke Identitätsbewahrung, Qualität und Vielfalt liefert.
Tests zur Videopersonalisierung mit mehreren Subjekten ergaben ähnliche Ergebnisse:

Vergleiche mit Videopersonalisierungen mit mehreren Subjekten. Bitte konsultieren Sie das PDF für bessere Details und Auflösung.
Das Papier bemerkt:
„Pika generiert spezifizierte Subjekte, zeigt aber Frame-Instabilität, wobei Subjekte verschwinden oder Eingaben nicht folgen. Vidu und VACE erfassen menschliche Identität teilweise, verlieren jedoch Details nicht-menschlicher Objekte. SkyReels A2 leidet unter schwerer Frame-Instabilität und Artefakten. HunyuanCustom erfasst effektiv alle Subjektidentitäten, hält Eingaben ein und bewahrt hohe visuelle Qualität und Stabilität.“
Ein Test für virtuelle menschliche Werbung integrierte Produkte mit Menschen:

Aus der qualitativen Testrunde, Beispiele für neuronale „Produktplatzierung“. Bitte konsultieren Sie das PDF für bessere Details und Auflösung.
Die Autoren erklären:
„HunyuanCustom bewahrt menschliche Identität und Produktdetails, einschließlich Text, mit natürlichen Interaktionen und starker Eingabe-Treue, was sein Potenzial für Werbevideos zeigt.“
Tests zur audio-gesteuerten Personalisierung hoben flexible Szenen- und Haltungskontrolle hervor:
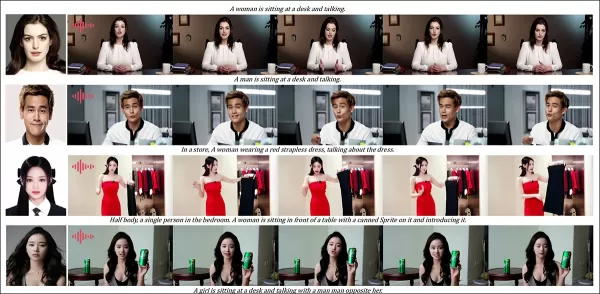
Teilweise Ergebnisse für die Audio-Runde – Videergebnisse wären vorzuziehen. Nur die obere Hälfte der PDF-Abbildung wird aufgrund von Größenbeschränkungen gezeigt. Bitte konsultieren Sie das Quell-PDF für bessere Details.
Die Autoren bemerken:
„Frühere audio-gesteuerte Methoden beschränken Haltung und Umgebung auf das Eingabebild, was Anwendungen einschränkt. HunyuanCustom ermöglicht flexible audio-gesteuerte Animation mit textbeschriebenen Szenen und Haltungen.“
Tests zum Ersetzen von Subjekten in Videos verglichen HunyuanCustom mit VACE und Kling 1.6:

Tests zum Ersetzen von Subjekten im Video-zu-Video-Modus. Bitte konsultieren Sie das Quell-PDF für bessere Details und Auflösung.
Die Forscher erklären:
„VACE erzeugt Randartefakte durch strikte Maskenhaftung, was die Bewegungskontinuität stört. Kling zeigt einen Kopier-Einfüge-Effekt mit schlechter Hintergrundintegration. HunyuanCustom vermeidet Artefakte, gewährleistet nahtlose Integration und bewahrt starke Identität, was in der Videobearbeitung hervorragt.“
Fazit
HunyuanCustom ist eine überzeugende Veröffentlichung, die die wachsende Nachfrage nach Lippensynchronisation in der Videosynthese adressiert und den Realismus in Systemen wie Hunyuan Video verbessert. Trotz Herausforderungen beim Vergleich seiner Fähigkeiten aufgrund des Video-Layouts der Projektseite hält Tencents Modell gegen Top-Konkurrenten wie Kling stand und markiert bedeutende Fortschritte in der personalisierten Videogenerierung.
* Einige Videos sind zu breit, zu kurz oder zu hochauflösend, um in Standardplayern wie VLC oder Windows Media Player abgespielt zu werden und zeigen schwarze Bildschirme.
Erstmals veröffentlicht am Donnerstag, 8. Mai 2025
Verwandter Artikel
 Exklusiv: Luma AI stellt kreative Agenten vor, die auf „Unified Intelligence”-Modellen basieren
Am Donnerstag stellte das Start-up-Unternehmen Luma, das sich mit der Erstellung von KI-Videos befasst, Luma Agents vor, ein System zur Verwaltung kompletter kreativer Workflows, die Text, Bilder, Vid
Das neue Update von Sora bietet KI-Videos für Haustiere, soziale Tools und eine kommende Android-App
OpenAI gibt eine Vorschau auf eine Reihe neuer Funktionen für seine bahnbrechende App zur Erstellung von KI-Videos, Sora, die nach ihrem Start Ende September schnell an die Spitze des App Store geklet
Die KI -Videogenerierung bewegt sich in Richtung vollständiger Kontrolle
Video -Foundation -Modelle wie Hunyuan und Wan 2.1 haben erhebliche Fortschritte gemacht, aber sie fallen häufig in Bezug auf die detaillierte Kontrolle, die für die Film- und Fernsehproduktion erforderlich ist, insbesondere im Bereich der visuellen Effekte (VFX). In professionellen VFX-Studios, diesen Modellen, zusammen mit früheren Bildbas
Empfehlungen zu verwandten Spezialthemen
Text-zu-Sprache
Exklusiv: Luma AI stellt kreative Agenten vor, die auf „Unified Intelligence”-Modellen basieren
Am Donnerstag stellte das Start-up-Unternehmen Luma, das sich mit der Erstellung von KI-Videos befasst, Luma Agents vor, ein System zur Verwaltung kompletter kreativer Workflows, die Text, Bilder, Vid
Das neue Update von Sora bietet KI-Videos für Haustiere, soziale Tools und eine kommende Android-App
OpenAI gibt eine Vorschau auf eine Reihe neuer Funktionen für seine bahnbrechende App zur Erstellung von KI-Videos, Sora, die nach ihrem Start Ende September schnell an die Spitze des App Store geklet
Die KI -Videogenerierung bewegt sich in Richtung vollständiger Kontrolle
Video -Foundation -Modelle wie Hunyuan und Wan 2.1 haben erhebliche Fortschritte gemacht, aber sie fallen häufig in Bezug auf die detaillierte Kontrolle, die für die Film- und Fernsehproduktion erforderlich ist, insbesondere im Bereich der visuellen Effekte (VFX). In professionellen VFX-Studios, diesen Modellen, zusammen mit früheren Bildbas
Empfehlungen zu verwandten Spezialthemen
Text-zu-Sprache
 Die besten KI-Sprachausgabe-Apps für Legasthenie: Unterstützung für das Lernen und effizienteres Lesen bei Schülern
Die besten KI-Sprachausgabe-Apps für Legasthenie: Unterstützung für das Lernen und effizienteres Lesen bei Schülern
Entdecken Sie die besten KI-TTS-Apps des Jahres 2026, die speziell zur Unterstützung bei Legasthenie ausgewählt wurden. In unseren Experten-Rankings vergleichen wir kostenlose und kostenpflichtige Tools und stellen leistungsstarke Funktionen für mehr Leseeffizienz und besseren Lernerfolg vor. Entdecken Sie bahnbrechende Lösungen, die Sie unbedingt ausprobieren sollten, um das Potenzial Ihrer Schüler voll auszuschöpfen. Beginnen Sie Ihre Reise bei XIX.AI.
 10 Tools
10 Tools
 xix.ai
Comic-Erstellung
Die besten KI-Generatoren für Shonen-Manga: Erstelle actiongeladene Sequenzen und dynamische Effekte
xix.ai
Comic-Erstellung
Die besten KI-Generatoren für Shonen-Manga: Erstelle actiongeladene Sequenzen und dynamische Effekte
Entdecken Sie bei XIX.AI die besten KI-Generatoren für Shonen-Manga des Jahres 2026. Unsere sorgfältig zusammengestellte Liste der Top-Anbieter umfasst leistungsstarke Tools zur Erstellung actiongeladener Sequenzen und dynamischer Energieeffekte. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Entfalten Sie Ihr kreatives Potenzial und beginnen Sie noch heute mit der Gestaltung epischer Manga!
15 Tools
xix.ai
Geschäft
Die besten KI-basierten Spesenabrechnungsprogramme: Quittungen scannen und Geschäftsausgaben automatisch kategorisieren
Die besten KI-basierten Spesenmanager 2026: Erstklassige Tools zum Scannen von Belegen und zur automatischen Kategorisierung von Unternehmensausgaben. Entdecken Sie leistungsstarke, bahnbrechende Lösungen für müheloses Spesenmanagement, präzise Finanzüberwachung und optimierte Compliance. Unser sorgfältig zusammengestellter, wöchentlich aktualisierter Vergleich zwischen kostenlosen und kostenpflichtigen Optionen hilft Ihnen dabei, die perfekte Lösung zu finden. Nutzen Sie Ihren KI-Vorteil mit den Expertenempfehlungen von XIX.AI.
10 Tools
xix.ai
Geschäft
Die besten KI-Tools für die Personalbeschaffung: Lebensläufe prüfen und die Terminplanung für Vorstellungsgespräche automatisieren
Entdecken Sie auf XIX.AI die besten KI-Tools für die Personalbeschaffung des Jahres 2026. Unsere sorgfältig zusammengestellte Liste umfasst leistungsstarke, bahnbrechende Lösungen für die Sichtung von Lebensläufen und die automatisierte Terminplanung für Vorstellungsgespräche. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Finden Sie Ihren perfekten Assistenten für die Personalbeschaffung und optimieren Sie noch heute Ihren Rekrutierungsprozess!
10 Tools
xix.ai
Produktivität
KI-Coaches für persönliches Wohlbefinden und Konzentration: Burnout bewältigen und die geistige Energie steigern
Entdecken Sie auf XIX.AI die besten KI-basierten Coaches für persönliches Wohlbefinden und Konzentration des Jahres 2026. Unsere sorgfältig zusammengestellte Rangliste umfasst erstklassige, bahnbrechende Tools zur Bewältigung von Burnout und zur Steigerung der mentalen Energie. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Erfahrungsberichten aus der Praxis. Schlagen Sie noch heute den Weg zu höchster Produktivität und Wohlbefinden ein.
10 Tools
xix.ai
Chatbot
Die besten KI-basierten Romantik-Chatbots: Bauen Sie langfristige Beziehungen mit beständiger Persönlichkeit auf
Entdecken Sie die besten KI-Romantik-Chatbots des Jahres 2026, mit denen Sie echte, langfristige Beziehungen aufbauen können. Unsere sorgfältig zusammengestellte Liste bietet Ihnen überzeugende, konsistente Persönlichkeiten, Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten sowie Tests aus der Praxis. Finden Sie Ihren perfekten Begleiter und legen Sie noch heute bei XIX.AI los.
10 Tools
xix.ai

 Kommentare (1)
Kommentare (1)
![RalphHill]()
Esse exemplo de vídeo parece meio bugado... Mas a ideia de transformar uma imagem estática em vídeo é fascinante. Será que isso poderia ser usado para criar conteúdos educativos ou de forma indevida? A discussão ética sempre fica atrás da tecnologia 🤔.
Dieser Artikel beleuchtet die Einführung von HunyuanCustom, einem multimodalen Videogenerierungsmodell von Tencent. Der umfangreiche Umfang des begleitenden Forschungspapiers und die Herausforderungen mit den bereitgestellten Beispielvideos auf der Projektseite erfordern eine breitere Übersicht, mit begrenzter Wiedergabe des umfangreichen Videoinhalts aufgrund von Formatierungs- und Verarbeitungsanforderungen für verbesserte Klarheit.
Beachten Sie, dass das Papier das API-basierte generative System Kling als „Keling“ bezeichnet. Der Konsistenz halber verwendet dieser Artikel durchgehend „Kling“.
Tencent hat eine fortschrittliche Version seines Hunyuan Video-Modells vorgestellt, genannt HunyuanCustom. Diese Veröffentlichung übertrifft Berichten zufolge die Notwendigkeit für Hunyuan LoRA-Modelle, indem sie Nutzern ermöglicht, Deepfake-ähnliche Videoanpassungen mit nur einem einzigen Bild zu erstellen:
Klicken zum Abspielen. Eingabe: „Ein Mann genießt Musik, während er Schneckennudeln in einer Küche zubereitet.“ Im Vergleich zu proprietären und Open-Source-Methoden, einschließlich Kling, einem Hauptkonkurrenten, sticht HunyuanCustom heraus. Quelle: https://hunyuancustom.github.io/ (Hinweis: ressourcenintensive Seite)
Im obigen Video zeigt die linke Spalte das einzelne Quellbild für HunyuanCustom, gefolgt von der Interpretation der Eingabe durch das System in der angrenzenden Spalte. Die verbleibenden Spalten zeigen Ausgaben anderer Systeme: Kling, Vidu, Pika, Hailuo und SkyReels-A2 (Wan-basiert).
Das folgende Video hebt drei Kerneinsatzszenarien dieser Veröffentlichung hervor: Person mit Objekt, Einzelcharakter-Replikation und virtuelles Anprobieren von Kleidung:
Klicken zum Abspielen. Drei kuratierte Beispiele von der Hunyuan Video-Unterstützungsseite.
Diese Beispiele zeigen Einschränkungen, die mit der Verwendung eines einzigen Quellbildes statt mehreren Perspektiven verbunden sind.
Im ersten Clip blickt der Mann direkt in die Kamera mit minimaler Kopfbewegung, die nicht mehr als 20-25 Grad beträgt. Darüber hinaus hat das System Schwierigkeiten, sein Profil präzise aus einem einzigen Frontalbild abzuleiten.
Im zweiten Clip behält das Mädchen einen lächelnden Ausdruck im Video bei, der ihrem statischen Quellbild entspricht. Ohne zusätzliche Referenzen kann HunyuanCustom ihren neutralen Ausdruck nicht zuverlässig darstellen, und ihr Gesicht bleibt größtenteils nach vorne gerichtet, ähnlich wie im vorherigen Beispiel.
Im letzten Clip führt unvollständiges Quellmaterial – eine Frau und virtuelle Kleidung – zu einer beschnittenen Darstellung, eine praktische Lösung für begrenzte Daten.
Während HunyuanCustom mehrere Bild-Eingaben unterstützt (z. B. Person mit Snacks oder Person mit Kleidung), berücksichtigt es keine unterschiedlichen Winkel oder Ausdrücke für einen einzelnen Charakter. Dies könnte seine Fähigkeit einschränken, das wachsende Ökosystem von LoRA-Modellen für HunyuanVideo vollständig zu ersetzen, die 20-60 Bilder verwenden, um konsistente Charakterdarstellungen über verschiedene Winkel und Ausdrücke hinweg zu gewährleisten.
Audiointegration
Für Audio verwendet HunyuanCustom das LatentSync-System, das für Hobbyisten schwierig zu konfigurieren ist, um Lippenbewegungen mit vom Benutzer bereitgestelltem Audio und Text zu synchronisieren:
Enthält Audio. Klicken zum Abspielen. Zusammengestellte Lippensynchronisationsbeispiele von der HunyuanCustom-Zusatzseite.
Derzeit sind keine Beispiele in englischer Sprache verfügbar, aber die Ergebnisse erscheinen vielversprechend, insbesondere wenn der Einrichtungsprozess benutzerfreundlich ist.
Videobearbeitungsfähigkeiten
HunyuanCustom glänzt in der Video-zu-Video (V2V)-Bearbeitung, die gezieltes Ersetzen von Elementen in bestehenden Videos mit einem einzigen Referenzbild ermöglicht. Ein Beispiel aus den Zusatzmaterialien veranschaulicht dies:
Klicken zum Abspielen. Das zentrale Objekt wird modifiziert, wobei umliegende Elemente in einem HunyuanCustom V2V-Prozess subtil verändert werden.
Wie typisch für V2V-Workflows wird das gesamte Video leicht modifiziert, wobei der Fokus auf dem Zielbereich liegt, wie z. B. dem Plüschtier. Fortgeschrittene Pipelines könnten potenziell mehr vom Originalinhalt bewahren, ähnlich wie der Ansatz von Adobe Firefly, was in Open-Source-Communities jedoch wenig erforscht ist.
Weitere Beispiele zeigen verbesserte Präzision bei gezielten Integrationen, wie in dieser Zusammenstellung zu sehen:
Klicken zum Abspielen. Verschiedene Beispiele für V2V-Inhaltseinfügung in HunyuanCustom, die Respekt vor unveränderten Elementen zeigen.
Evolutionäre Verbesserung
HunyuanCustom baut auf dem Hunyuan Video-Projekt auf und führt gezielte architektonische Verbesserungen ein, anstatt eine vollständige Überarbeitung. Diese Upgrades zielen darauf ab, die Charakterkonsistenz über Frames hinweg ohne subjektspezifisches Feintuning, wie LoRA oder textuelle Inversion, zu erhalten.
Diese Veröffentlichung ist eine verfeinerte Version des HunyuanVideo-Modells vom Dezember 2024, kein neu entwickeltes Modell von Grund auf.
Nutzer bestehender HunyuanVideo LoRAs könnten sich fragen, ob diese mit diesem Update kompatibel sind oder ob neue LoRAs entwickelt werden müssen, um die erweiterten Anpassungsfunktionen zu nutzen.
Typischerweise verändert ein signifikantes Feintuning die Modellgewichte so stark, dass vorherige LoRAs inkompatibel werden. Einige Feintunings, wie Pony Diffusion für Stable Diffusion XL, haben jedoch unabhängige Ökosysteme mit dedizierten LoRA-Bibliotheken geschaffen, was auf ein Potenzial für HunyuanCustom hinweist, diesem Beispiel zu folgen.
Veröffentlichungsdetails
Das Forschungspapier, betitelt HunyuanCustom: Eine multimodal getriebene Architektur für angepasste Videogenerierung, verlinkt auf ein GitHub-Repository, das nun mit Code und Gewichten für lokale Bereitstellung aktiv ist, neben einer geplanten ComfyUI-Integration.
Derzeit ist die Hugging Face-Seite des Projekts nicht zugänglich, aber eine API-basierte Demo ist über einen WeChat-Scan-Code verfügbar.
Die Zusammenstellung verschiedener Projekte durch HunyuanCustom ist bemerkenswert umfassend, wahrscheinlich getrieben durch Lizenzanforderungen für vollständige Offenlegung.
Zwei Modellvarianten werden angeboten: eine Version mit 720x1280px, die 80GB GPU-Speicher für optimale Leistung benötigt (mindestens 24GB, aber langsam) und eine Version mit 512x896px, die 60GB erfordert. Tests waren auf Linux beschränkt, aber Community-Bemühungen könnten es bald für Windows und niedrigere VRAM-Konfigurationen anpassen, wie beim vorherigen Hunyuan Video-Modell gesehen.
Aufgrund des Umfangs der begleitenden Materialien verfolgt diese Übersicht einen übergeordneten Ansatz zu den Fähigkeiten von HunyuanCustom.
Technische Einblicke
Die Datenpipeline von HunyuanCustom, DSGVO-konform, integriert synthetisierte und Open-Source-Videodatensätze wie OpenHumanVid, die acht Kategorien abdecken: Menschen, Tiere, Pflanzen, Landschaften, Fahrzeuge, Objekte, Architektur und Anime.
Aus dem Veröffentlichungspapier, eine Übersicht der verschiedenen beitragenden Pakete in der HunyuanCustom-Datenerstellungspipeline. Quelle: https://arxiv.org/pdf/2505.04512
Videos werden mit PySceneDetect in Einzelaufnahme-Clips segmentiert, wobei TextBPN-Plus-Plus Inhalte mit übermäßigem Text, Untertiteln oder Wasserzeichen herausfiltert.
Clips werden auf fünf Sekunden standardisiert und auf 512 oder 720 Pixel an der kurzen Seite skaliert. Ästhetische Qualität wird mit Koala-36M und einem benutzerdefinierten Schwellenwert von 0,06 sichergestellt.
Die Extraktion menschlicher Identitäten nutzt Qwen7B, YOLO11X und InsightFace, während nicht-menschliche Subjekte mit QwenVL und Grounded SAM 2 verarbeitet werden, wobei kleine Bounding-Boxen verworfen werden.
Beispiele für semantische Segmentierung mit Grounded SAM 2, verwendet im Hunyuan Control-Projekt. Quelle: https://github.com/IDEA-Research/Grounded-SAM-2
Die Extraktion mehrerer Subjekte verwendet Florence2 für Annotationen und Grounded SAM 2 für Segmentierung, gefolgt von Clustering und temporaler Rahmensegmentierung.
Clips werden mit proprietärer strukturierter Kennzeichnung durch das Hunyuan-Team verbessert, die Metadaten wie Beschreibungen und Kamerabewegungshinweise hinzufügt.
Masken-Augmentation verhindert Überanpassung und gewährleistet Anpassungsfähigkeit an unterschiedliche Objektformen. Audio-Synchronisation verwendet LatentSync, wobei Clips unterhalb eines Qualitätsschwellenwerts verworfen werden. HyperIQA filtert Videos mit einem Score unter 40 heraus, und Whisper verarbeitet gültiges Audio für nachgelagerte Aufgaben.
Das LLaVA-Modell spielt eine zentrale Rolle, generiert Untertitel und stimmt visuelle und textuelle Inhalte für semantische Konsistenz ab, insbesondere in komplexen oder mehrsubjektiven Szenen.
Das HunyuanCustom-Framework unterstützt identitätskonsistente Videogenerierung, die auf Text-, Bild-, Audio- und Videoeingaben basiert.
Videopersonalisierung
Um Videogenerierung aus einem Referenzbild und einer Eingabe zu ermöglichen, wurden zwei LLaVA-basierte Module entwickelt, die die Eingabe von HunyuanVideo anpassen, um sowohl Bild als auch Text zu akzeptieren. Eingaben betten Bilder direkt ein oder markieren sie mit kurzen Identitätsbeschreibungen, unter Verwendung eines Trennzeichens, um den Einfluss von Bild und Text auszubalancieren.
Ein Identitätsverbesserungsmodul adressiert die Tendenz von LLaVA, feinkörnige räumliche Details zu verlieren, die für die Aufrechterhaltung der Subjektkonsistenz in kurzen Videoclips entscheidend sind.
Das Referenzbild wird skaliert und über den kausalen 3D-VAE von HunyuanVideo kodiert, wobei sein Latent über die temporale Achse und mit einem räumlichen Offset eingefügt wird, um die Generierung zu leiten, ohne direkte Replikation.
Das Training verwendete Flow Matching mit Rauschen aus einer logit-normalen Verteilung, wobei LLaVA und der Videogenerator gemeinsam optimiert wurden, um kohärente Bild-Eingabe-Führung und Identitätskonsistenz zu gewährleisten.
Für Eingaben mit mehreren Subjekten wird jedes Bild-Text-Paar separat mit unterschiedlichen temporalen Positionen eingebettet, was Szenen mit mehreren interagierenden Subjekten ermöglicht.
Audio- und visuelle Integration
HunyuanCustom unterstützt audio-gesteuerte Generierung mit vom Benutzer bereitgestelltem Audio und Text, wodurch Charaktere in kontextuell relevanten Umgebungen sprechen können.
Ein identitätsentkoppeltes AudioNet-Modul stimmt Audio-Features mit der Video-Timeline ab, unter Verwendung von räumlicher Cross-Attention, um Frames zu isolieren und die Subjektkonsistenz zu wahren.
Ein temporales Injektionsmodul verfeinert das Bewegungs-Timing, indem Audio über ein Multi-Layer-Perceptron auf latente Sequenzen abgebildet wird, um die Ausrichtung von Gesten mit dem Audio-Rhythmus sicherzustellen.
Für die Videobearbeitung ersetzt HunyuanCustom Subjekte in bestehenden Clips, ohne das gesamte Video neu zu generieren, ideal für gezielte Änderungen an Aussehen oder Bewegung.
Klicken zum Abspielen. Ein weiteres Beispiel von der Zusatzseite.
Das System komprimiert Referenzvideos mit dem vortrainierten kausalen 3D-VAE und richtet sie an die Latenten der Generierungspipeline für eine leichte Verarbeitung aus. Ein neuronales Netzwerk richtet saubere Eingabevideos mit verrauschten Latenten aus, wobei die frameweise Hinzufügung von Features effektiver ist als die Vor-Kompressions-Vers融合。
Leistungsbewertung
Testmetriken umfassten ArcFace für Gesichtsidentitätskonsistenz, YOLO11x und Dino 2 für Subjektähnlichkeit, CLIP-B für Text-Video-Ausrichtung und temporale Konsistenz sowie VBench für Bewegungsintensität.
Konkurrenten umfassten geschlossene Systeme (Hailuo, Vidu 2.0, Kling 1.6, Pika) und Open-Source-Frameworks (VACE, SkyReels-A2).
Modellleistungsbewertung, die HunyuanCustom mit führenden Videopersonalisierungsmethoden in Bezug auf ID-Konsistenz (Face-Sim), Subjektähnlichkeit (DINO-Sim), Text-Video-Ausrichtung (CLIP-B-T), temporale Konsistenz (Temp-Consis) und Bewegungsintensität (DD) vergleicht. Optimale und suboptimale Ergebnisse sind in Fettschrift bzw. unterstrichen dargestellt.
Die Autoren bemerken:
„HunyuanCustom glänzt in ID- und Subjektkonsistenz, mit wettbewerbsfähiger Eingabe-Treue und temporaler Stabilität. Hailuo führt beim Clip-Score aufgrund starker Textausrichtung, hat aber Schwierigkeiten mit der Konsistenz nicht-menschlicher Subjekte. Vidu und VACE hinken bei der Bewegungsintensität hinterher, wahrscheinlich aufgrund kleinerer Modellgrößen.“
Während die Projektseite zahlreiche Vergleichsvideos bietet, priorisiert deren Layout Ästhetik über Vergleichsfreundlichkeit. Leser werden ermutigt, die Videos direkt für klarere Einblicke zu überprüfen:
Aus dem Papier, ein Vergleich zur objektzentrierten Videopersonalisierung. Obwohl der Betrachter das Quell-PDF für bessere Auflösung konsultieren sollte, bieten die Videos auf der Projektseite klarere Einblicke.
Die Autoren erklären:
„Vidu, SkyReels A2 und HunyuanCustom erreichen starke Eingabe-Ausrichtung und Subjektkonsistenz, aber unsere Videoqualität übertrifft Vidu und SkyReels, dank der robusten Grundlage von Hunyuanvideo-13B.“
„Unter den kommerziellen Lösungen liefert Kling hochwertige Videos, leidet jedoch unter einem Kopier-Einfüge-Effekt im ersten Frame und gelegentlicher Subjektunschärfe, was das Zuschauererlebnis beeinträchtigt.“
Pika hat Schwierigkeiten mit temporaler Konsistenz und führt Untertitel-Artefakte durch schlechte Datenkuration ein. Hailuo bewahrt die Gesichtsidentität, scheitert jedoch bei der Ganzkörper-Konsistenz. VACE, unter den Open-Source-Methoden, kann die Identitätskonsistenz nicht aufrechterhalten, während HunyuanCustom starke Identitätsbewahrung, Qualität und Vielfalt liefert.
Tests zur Videopersonalisierung mit mehreren Subjekten ergaben ähnliche Ergebnisse:
Vergleiche mit Videopersonalisierungen mit mehreren Subjekten. Bitte konsultieren Sie das PDF für bessere Details und Auflösung.
Das Papier bemerkt:
„Pika generiert spezifizierte Subjekte, zeigt aber Frame-Instabilität, wobei Subjekte verschwinden oder Eingaben nicht folgen. Vidu und VACE erfassen menschliche Identität teilweise, verlieren jedoch Details nicht-menschlicher Objekte. SkyReels A2 leidet unter schwerer Frame-Instabilität und Artefakten. HunyuanCustom erfasst effektiv alle Subjektidentitäten, hält Eingaben ein und bewahrt hohe visuelle Qualität und Stabilität.“
Ein Test für virtuelle menschliche Werbung integrierte Produkte mit Menschen:
Aus der qualitativen Testrunde, Beispiele für neuronale „Produktplatzierung“. Bitte konsultieren Sie das PDF für bessere Details und Auflösung.
Die Autoren erklären:
„HunyuanCustom bewahrt menschliche Identität und Produktdetails, einschließlich Text, mit natürlichen Interaktionen und starker Eingabe-Treue, was sein Potenzial für Werbevideos zeigt.“
Tests zur audio-gesteuerten Personalisierung hoben flexible Szenen- und Haltungskontrolle hervor:
Teilweise Ergebnisse für die Audio-Runde – Videergebnisse wären vorzuziehen. Nur die obere Hälfte der PDF-Abbildung wird aufgrund von Größenbeschränkungen gezeigt. Bitte konsultieren Sie das Quell-PDF für bessere Details.
Die Autoren bemerken:
„Frühere audio-gesteuerte Methoden beschränken Haltung und Umgebung auf das Eingabebild, was Anwendungen einschränkt. HunyuanCustom ermöglicht flexible audio-gesteuerte Animation mit textbeschriebenen Szenen und Haltungen.“
Tests zum Ersetzen von Subjekten in Videos verglichen HunyuanCustom mit VACE und Kling 1.6:
Tests zum Ersetzen von Subjekten im Video-zu-Video-Modus. Bitte konsultieren Sie das Quell-PDF für bessere Details und Auflösung.
Die Forscher erklären:
„VACE erzeugt Randartefakte durch strikte Maskenhaftung, was die Bewegungskontinuität stört. Kling zeigt einen Kopier-Einfüge-Effekt mit schlechter Hintergrundintegration. HunyuanCustom vermeidet Artefakte, gewährleistet nahtlose Integration und bewahrt starke Identität, was in der Videobearbeitung hervorragt.“
Fazit
HunyuanCustom ist eine überzeugende Veröffentlichung, die die wachsende Nachfrage nach Lippensynchronisation in der Videosynthese adressiert und den Realismus in Systemen wie Hunyuan Video verbessert. Trotz Herausforderungen beim Vergleich seiner Fähigkeiten aufgrund des Video-Layouts der Projektseite hält Tencents Modell gegen Top-Konkurrenten wie Kling stand und markiert bedeutende Fortschritte in der personalisierten Videogenerierung.
* Einige Videos sind zu breit, zu kurz oder zu hochauflösend, um in Standardplayern wie VLC oder Windows Media Player abgespielt zu werden und zeigen schwarze Bildschirme.
Erstmals veröffentlicht am Donnerstag, 8. Mai 2025










 Exklusiv: Luma AI stellt kreative Agenten vor, die auf „Unified Intelligence”-Modellen basieren
Am Donnerstag stellte das Start-up-Unternehmen Luma, das sich mit der Erstellung von KI-Videos befasst, Luma Agents vor, ein System zur Verwaltung kompletter kreativer Workflows, die Text, Bilder, Vid
Exklusiv: Luma AI stellt kreative Agenten vor, die auf „Unified Intelligence”-Modellen basieren
Am Donnerstag stellte das Start-up-Unternehmen Luma, das sich mit der Erstellung von KI-Videos befasst, Luma Agents vor, ein System zur Verwaltung kompletter kreativer Workflows, die Text, Bilder, Vid
 Das neue Update von Sora bietet KI-Videos für Haustiere, soziale Tools und eine kommende Android-App
OpenAI gibt eine Vorschau auf eine Reihe neuer Funktionen für seine bahnbrechende App zur Erstellung von KI-Videos, Sora, die nach ihrem Start Ende September schnell an die Spitze des App Store geklet
Das neue Update von Sora bietet KI-Videos für Haustiere, soziale Tools und eine kommende Android-App
OpenAI gibt eine Vorschau auf eine Reihe neuer Funktionen für seine bahnbrechende App zur Erstellung von KI-Videos, Sora, die nach ihrem Start Ende September schnell an die Spitze des App Store geklet
 Die KI -Videogenerierung bewegt sich in Richtung vollständiger Kontrolle
Video -Foundation -Modelle wie Hunyuan und Wan 2.1 haben erhebliche Fortschritte gemacht, aber sie fallen häufig in Bezug auf die detaillierte Kontrolle, die für die Film- und Fernsehproduktion erforderlich ist, insbesondere im Bereich der visuellen Effekte (VFX). In professionellen VFX-Studios, diesen Modellen, zusammen mit früheren Bildbas
Die KI -Videogenerierung bewegt sich in Richtung vollständiger Kontrolle
Video -Foundation -Modelle wie Hunyuan und Wan 2.1 haben erhebliche Fortschritte gemacht, aber sie fallen häufig in Bezug auf die detaillierte Kontrolle, die für die Film- und Fernsehproduktion erforderlich ist, insbesondere im Bereich der visuellen Effekte (VFX). In professionellen VFX-Studios, diesen Modellen, zusammen mit früheren Bildbas

Entdecken Sie die besten KI-TTS-Apps des Jahres 2026, die speziell zur Unterstützung bei Legasthenie ausgewählt wurden. In unseren Experten-Rankings vergleichen wir kostenlose und kostenpflichtige Tools und stellen leistungsstarke Funktionen für mehr Leseeffizienz und besseren Lernerfolg vor. Entdecken Sie bahnbrechende Lösungen, die Sie unbedingt ausprobieren sollten, um das Potenzial Ihrer Schüler voll auszuschöpfen. Beginnen Sie Ihre Reise bei XIX.AI.
10 Tools
xix.ai

Entdecken Sie bei XIX.AI die besten KI-Generatoren für Shonen-Manga des Jahres 2026. Unsere sorgfältig zusammengestellte Liste der Top-Anbieter umfasst leistungsstarke Tools zur Erstellung actiongeladener Sequenzen und dynamischer Energieeffekte. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Entfalten Sie Ihr kreatives Potenzial und beginnen Sie noch heute mit der Gestaltung epischer Manga!
15 Tools
xix.ai

Die besten KI-basierten Spesenmanager 2026: Erstklassige Tools zum Scannen von Belegen und zur automatischen Kategorisierung von Unternehmensausgaben. Entdecken Sie leistungsstarke, bahnbrechende Lösungen für müheloses Spesenmanagement, präzise Finanzüberwachung und optimierte Compliance. Unser sorgfältig zusammengestellter, wöchentlich aktualisierter Vergleich zwischen kostenlosen und kostenpflichtigen Optionen hilft Ihnen dabei, die perfekte Lösung zu finden. Nutzen Sie Ihren KI-Vorteil mit den Expertenempfehlungen von XIX.AI.
10 Tools
xix.ai

Entdecken Sie auf XIX.AI die besten KI-Tools für die Personalbeschaffung des Jahres 2026. Unsere sorgfältig zusammengestellte Liste umfasst leistungsstarke, bahnbrechende Lösungen für die Sichtung von Lebensläufen und die automatisierte Terminplanung für Vorstellungsgespräche. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Finden Sie Ihren perfekten Assistenten für die Personalbeschaffung und optimieren Sie noch heute Ihren Rekrutierungsprozess!
10 Tools
xix.ai

Entdecken Sie auf XIX.AI die besten KI-basierten Coaches für persönliches Wohlbefinden und Konzentration des Jahres 2026. Unsere sorgfältig zusammengestellte Rangliste umfasst erstklassige, bahnbrechende Tools zur Bewältigung von Burnout und zur Steigerung der mentalen Energie. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Erfahrungsberichten aus der Praxis. Schlagen Sie noch heute den Weg zu höchster Produktivität und Wohlbefinden ein.
10 Tools
xix.ai

Entdecken Sie die besten KI-Romantik-Chatbots des Jahres 2026, mit denen Sie echte, langfristige Beziehungen aufbauen können. Unsere sorgfältig zusammengestellte Liste bietet Ihnen überzeugende, konsistente Persönlichkeiten, Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten sowie Tests aus der Praxis. Finden Sie Ihren perfekten Begleiter und legen Sie noch heute bei XIX.AI los.
10 Tools
xix.ai

Esse exemplo de vídeo parece meio bugado... Mas a ideia de transformar uma imagem estática em vídeo é fascinante. Será que isso poderia ser usado para criar conteúdos educativos ou de forma indevida? A discussão ética sempre fica atrás da tecnologia 🤔.













