
















 Lar
LarTencent Revela HunyuanCustom para Personalização de Vídeo com Imagem Única
Este artigo explora o lançamento do HunyuanCustom, um modelo de geração de vídeo multimodal da Tencent. O amplo escopo do artigo de pesquisa acompanhante e os desafios com os vídeos de exemplo fornecidos na página do projeto requerem uma visão geral mais ampla, com reprodução limitada do extenso conteúdo de vídeo devido a requisitos de formatação e processamento para maior clareza.
Observe que o artigo se refere ao sistema generativo baseado em API Kling como ‘Keling.’ Para consistência, este artigo usa ‘Kling’ em todo o texto.
A Tencent apresentou uma iteração avançada de seu modelo Hunyuan Video, chamada HunyuanCustom. Este lançamento supostamente elimina a necessidade de modelos Hunyuan LoRA, permitindo que os usuários criem personalizações de vídeo estilo deepfake usando apenas uma única imagem:
Clique para reproduzir. Prompt: ‘Um homem curte música enquanto prepara macarrão de caracol em uma cozinha.’ Comparado a métodos proprietários e de código aberto, incluindo o Kling, um concorrente importante, o HunyuanCustom se destaca. Fonte: https://hunyuancustom.github.io/ (nota: site com alto consumo de recursos)
No vídeo acima, a coluna mais à esquerda exibe a imagem de origem única para o HunyuanCustom, seguida pela interpretação do sistema do prompt na coluna adjacente. As colunas restantes mostram saídas de outros sistemas: Kling, Vidu, Pika, Hailuo e SkyReels-A2 (baseado em Wan).
O vídeo a seguir destaca três cenários principais para este lançamento: pessoa com objeto, replicação de personagem único e prova virtual de roupas:
Clique para reproduzir. Três exemplos selecionados do site de suporte do Hunyuan Video.
Esses exemplos revelam limitações relacionadas à dependência de uma única imagem de origem em vez de múltiplas perspectivas.
No primeiro clipe, o homem enfrenta a câmera com movimento mínimo da cabeça, inclinando não mais que 20-25 graus. Além disso, o sistema tem dificuldade em inferir seu perfil com precisão a partir de uma única imagem frontal.
No segundo clipe, a garota mantém uma expressão sorridente no vídeo, espelhando sua imagem de origem estática. Sem referências adicionais, o HunyuanCustom não pode retratar de forma confiável sua expressão neutra, e seu rosto permanece voltado para frente, semelhante ao exemplo anterior.
No clipe final, material de origem incompleto—uma mulher e roupas virtuais—resulta em uma renderização recortada, uma solução prática para dados limitados.
Embora o HunyuanCustom suporte múltiplas entradas de imagem (por exemplo, pessoa com lanches ou pessoa com vestimenta), ele não acomoda ângulos ou expressões variadas para um único personagem. Isso pode limitar sua capacidade de substituir completamente o ecossistema em expansão de modelos LoRA para o HunyuanVideo, que usam 20-60 imagens para garantir a renderização consistente de personagens em diferentes ângulos e expressões.
Integração de Áudio
Para áudio, o HunyuanCustom utiliza o sistema LatentSync, que é desafiador para amadores configurarem, para sincronizar movimentos labiais com áudio e texto fornecidos pelo usuário:
Inclui áudio. Clique para reproduzir. Exemplos compilados de sincronização labial do site suplementar do HunyuanCustom.
Atualmente, não há exemplos em língua inglesa disponíveis, mas os resultados parecem promissores, especialmente se o processo de configuração for amigável ao usuário.
Capacidades de Edição de Vídeo
O HunyuanCustom se destaca na edição de vídeo para vídeo (V2V), permitindo a substituição direcionada de elementos em vídeos existentes usando uma única imagem de referência. Um exemplo dos materiais suplementares ilustra isso:
Clique para reproduzir. O objeto central é modificado, com elementos ao redor alterados sutilmente em um processo V2V do HunyuanCustom.
Como típico em fluxos de trabalho V2V, o vídeo inteiro é ligeiramente modificado, com foco principal na área direcionada, como o brinquedo de pelúcia. Pipelines avançados poderiam potencialmente preservar mais do conteúdo original, semelhante à abordagem do Adobe Firefly, embora isso permaneça pouco explorado em comunidades de código aberto.
Outros exemplos demonstram maior precisão em integrações direcionadas, como visto nesta compilação:
Clique para reproduzir. Exemplos variados de inserção de conteúdo V2V no HunyuanCustom, mostrando respeito pelos elementos inalterados.
Atualização Evolutiva
O HunyuanCustom é construído sobre o projeto Hunyuan Video, introduzindo melhorias arquiteturais direcionadas em vez de uma reformulação completa. Essas atualizações visam manter a consistência do personagem entre quadros sem exigir ajustes específicos ao sujeito, como LoRA ou inversão textual.
Este lançamento é uma versão refinada do modelo HunyuanVideo de dezembro de 2024, não um novo modelo construído do zero.
Usuários de LoRAs existentes do HunyuanVideo podem questionar sua compatibilidade com esta atualização ou se novos LoRAs devem ser desenvolvidos para aproveitar os recursos de personalização aprimorados.
Tipicamente, ajustes significativos alteram os pesos do modelo o suficiente para tornar LoRAs anteriores incompatíveis. No entanto, alguns ajustes, como o Pony Diffusion para o Stable Diffusion XL, criaram ecossistemas independentes com bibliotecas LoRA dedicadas, sugerindo potencial para o HunyuanCustom seguir o mesmo caminho.
Detalhes do Lançamento
O artigo de pesquisa, intitulado HunyuanCustom: Uma Arquitetura Multimodal para Geração de Vídeo Personalizado, vincula-se a um repositório GitHub agora ativo com código e pesos para implantação local, juntamente com uma integração planejada com o ComfyUI.
Atualmente, a página do projeto no Hugging Face está inacessível, mas uma demonstração baseada em API está disponível via código de escaneamento do WeChat.
A montagem de projetos diversos do HunyuanCustom é notavelmente abrangente, provavelmente impulsionada por requisitos de licenciamento para divulgação completa.
Duas variantes do modelo são oferecidas: uma versão de 720x1280px que precisa de 80GB de memória GPU para desempenho ideal (24GB no mínimo, mas lenta) e uma versão de 512x896px que requer 60GB. Os testes foram limitados ao Linux, mas esforços da comunidade podem em breve adaptá-lo para Windows e configurações de VRAM mais baixas, como visto com o modelo anterior Hunyuan Video.
Devido ao volume de materiais acompanhantes, esta visão geral adota uma abordagem de alto nível sobre as capacidades do HunyuanCustom.
Insights Técnicos
O pipeline de dados do HunyuanCustom, compatível com o GDPR, integra conjuntos de dados de vídeo sintetizados e de código aberto como o OpenHumanVid, cobrindo oito categorias: humanos, animais, plantas, paisagens, veículos, objetos, arquitetura e anime.
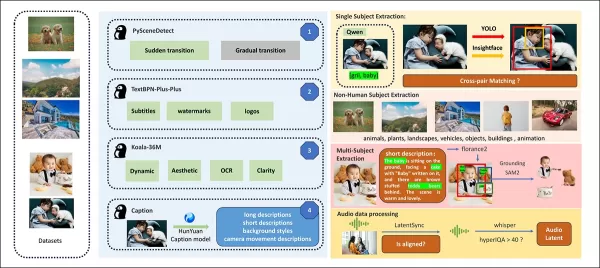
Do artigo de lançamento, uma visão geral dos diversos pacotes contribuintes no pipeline de construção de dados do HunyuanCustom. Fonte: https://arxiv.org/pdf/2505.04512
Os vídeos são segmentados em clipes de tomada única usando o PySceneDetect, com o TextBPN-Plus-Plus filtrando conteúdos com texto excessivo, legendas ou marcas d’água.
Os clipes são padronizados para cinco segundos e redimensionados para 512 ou 720 pixels no lado mais curto. A qualidade estética é garantida usando o Koala-36M com um limiar personalizado de 0,06.
A extração de identidade humana utiliza Qwen7B, YOLO11X e InsightFace, enquanto sujeitos não humanos são processados com QwenVL e Grounded SAM 2, descartando caixas delimitadoras pequenas.

Exemplos de segmentação semântica com Grounded SAM 2, usado no projeto Hunyuan Control. Fonte: https://github.com/IDEA-Research/Grounded-SAM-2
A extração de múltiplos sujeitos usa o Florence2 para anotações e o Grounded SAM 2 para segmentação, seguida por clustering e segmentação de quadros temporais.
Os clipes são aprimorados com rotulagem estruturada proprietária pela equipe Hunyuan, adicionando metadados como descrições e dicas de movimento da câmera.
A ampliação de máscaras previne o overfitting, garantindo adaptabilidade a formas de objetos variadas. A sincronização de áudio usa o LatentSync, descartando clipes abaixo de um limiar de qualidade. O HyperIQA filtra vídeos com pontuação abaixo de 40, e o Whisper processa áudio válido para tarefas subsequentes.
O modelo LLaVA desempenha um papel central, gerando legendas e alinhando conteúdo visual e textual para consistência semântica, especialmente em cenas complexas ou com múltiplos sujeitos.
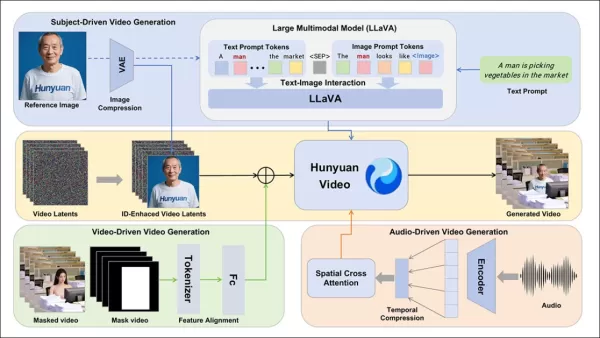
O framework HunyuanCustom suporta geração de vídeo consistente com identidade condicionada por texto, imagem, áudio e entradas de vídeo.
Personalização de Vídeo
Para possibilitar a geração de vídeo a partir de uma imagem de referência e prompt, dois módulos baseados em LLaVA foram desenvolvidos, adaptando a entrada do HunyuanVideo para aceitar imagem e texto. Os prompts incorporam imagens diretamente ou as marcam com descrições breves de identidade, usando um token separador para equilibrar a influência de imagem e texto.
Um módulo de aprimoramento de identidade aborda a tendência do LLaVA de perder detalhes espaciais refinados, críticos para manter a consistência do sujeito em clipes de vídeo curtos.
A imagem de referência é redimensionada e codificada via causal 3D-VAE do HunyuanVideo, com seu latente inserido ao longo do eixo temporal e um deslocamento espacial para guiar a geração sem replicação direta.
O treinamento usou Flow Matching com ruído de uma distribuição logit-normal, ajustando o LLaVA e o gerador de vídeo juntos para orientação coesa de imagem-prompt e consistência de identidade.
Para prompts com múltiplos sujeitos, cada par imagem-texto é incorporado separadamente com posições temporais distintas, possibilitando cenas com múltiplos sujeitos interagindo.
Integração de Áudio e Visual
O HunyuanCustom suporta geração orientada por áudio usando áudio e texto fornecidos pelo usuário, permitindo que personagens falem em cenários contextualmente relevantes.
Um módulo Identity-disentangled AudioNet alinha recursos de áudio com a linha do tempo do vídeo, usando atenção cruzada espacial para isolar quadros e manter a consistência do sujeito.
Um módulo de injeção temporal refina o tempo de movimento, mapeando áudio para sequências latentes via Perceptron Multi-Camadas, garantindo que gestos se alinhem com o ritmo do áudio.
Para edição de vídeo, o HunyuanCustom substitui sujeitos em clipes existentes sem regenerar o vídeo inteiro, ideal para alterações direcionadas de aparência ou movimento.
Clique para reproduzir. Outro exemplo do site suplementar.
O sistema comprime vídeos de referência usando o causal 3D-VAE pré-treinado, alinhando-os com os latentes do pipeline de geração para processamento leve. Uma rede neural alinha vídeos de entrada limpos com latentes ruidosos, com adição de recursos quadro a quadro provando ser mais eficaz do que a fusão pré-compressão.
Avaliação de Desempenho
As métricas de teste incluíram ArcFace para consistência de identidade facial, YOLO11x e Dino 2 para similaridade de sujeito, CLIP-B para alinhamento de texto-vídeo e consistência temporal, e VBench para intensidade de movimento.
Os concorrentes incluíram sistemas de código fechado (Hailuo, Vidu 2.0, Kling 1.6, Pika) e frameworks de código aberto (VACE, SkyReels-A2).
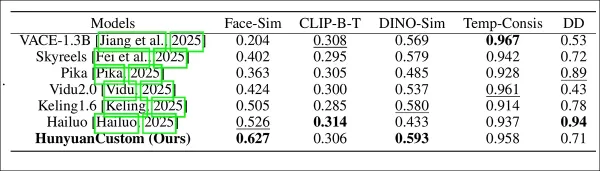
Avaliação de desempenho do modelo comparando o HunyuanCustom com métodos líderes de personalização de vídeo em consistência de ID (Face-Sim), similaridade de sujeito (DINO-Sim), alinhamento de texto-vídeo (CLIP-B-T), consistência temporal (Temp-Consis) e intensidade de movimento (DD). Resultados ótimos e subótimos são mostrados em negrito e sublinhado, respectivamente.
Os autores observam:
‘O HunyuanCustom se destaca em consistência de ID e sujeito, com aderência competitiva ao prompt e estabilidade temporal. O Hailuo lidera em pontuação de clipe devido ao forte alinhamento de texto, mas enfrenta dificuldades com consistência de sujeitos não humanos. Vidu e VACE ficam atrás em intensidade de movimento, provavelmente devido a tamanhos de modelo menores.’
Embora o site do projeto ofereça numerosos vídeos de comparação, seu layout prioriza a estética em vez da facilidade de comparação. Os leitores são incentivados a revisar os vídeos diretamente para obter insights mais claros:
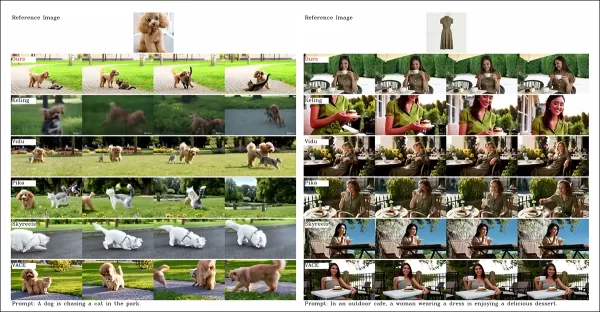
Do artigo, uma comparação sobre personalização de vídeo centrada em objetos. Embora o espectador deva consultar o PDF de origem para melhor resolução, os vídeos no site do projeto oferecem insights mais claros.
Os autores afirmam:
‘Vidu, SkyReels A2 e HunyuanCustom alcançam forte alinhamento de prompt e consistência de sujeito, mas nossa qualidade de vídeo supera Vidu e SkyReels, graças à base robusta do Hunyuanvideo-13B.’
‘Entre as soluções comerciais, o Kling entrega vídeo de alta qualidade, mas sofre com um efeito de copiar-colar no primeiro quadro e borrões ocasionais do sujeito, impactando a experiência do espectador.’
O Pika enfrenta dificuldades com consistência temporal, introduzindo artefatos de legenda devido à má curadoria de dados. O Hailuo preserva a identidade facial, mas falha na consistência de corpo inteiro. O VACE, entre os métodos de código aberto, não mantém a consistência de identidade, enquanto o HunyuanCustom entrega forte preservação de identidade, qualidade e diversidade.
Testes de personalização de vídeo com múltiplos sujeitos produziram resultados semelhantes:

Comparações usando personalizações de vídeo com múltiplos sujeitos. Consulte o PDF para melhores detalhes e resolução.
O artigo observa:
‘O Pika gera sujeitos especificados, mas mostra instabilidade de quadros, com sujeitos desaparecendo ou não seguindo os prompts. Vidu e VACE capturam a identidade humana parcialmente, mas perdem detalhes de objetos não humanos. SkyReels A2 sofre com instabilidade severa de quadros e artefatos. O HunyuanCustom captura eficazmente todas as identidades dos sujeitos, adere aos prompts e mantém alta qualidade visual e estabilidade.’
Um teste de anúncio de humano virtual integrou produtos com pessoas:

Da rodada de testes qualitativos, exemplos de colocação de produtos neurais. Consulte o PDF para melhores detalhes e resolução.
Os autores afirmam:
‘O HunyuanCustom mantém a identidade humana e detalhes do produto, incluindo texto, com interações naturais e forte aderência ao prompt, mostrando seu potencial para vídeos de publicidade.’
Testes de personalização orientada por áudio destacaram controle flexível de cena e postura:
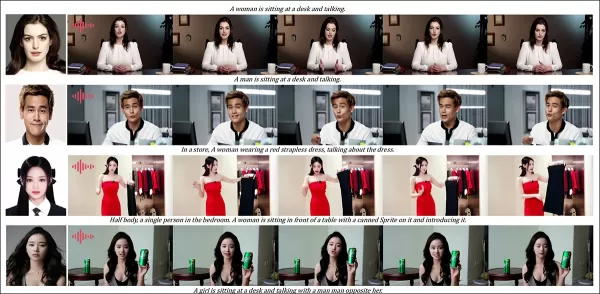
Resultados parciais para a rodada de áudio—resultados de vídeo seriam preferíveis. Apenas a metade superior da figura do PDF é mostrada devido a restrições de tamanho. Consulte o PDF de origem para melhores detalhes.
Os autores observam:
‘Métodos anteriores orientados por áudio limitam postura e ambiente à imagem de entrada, restringindo aplicações. O HunyuanCustom permite animação orientada por áudio flexível com cenas e posturas descritas por texto.’
Testes de substituição de sujeito em vídeo compararam o HunyuanCustom contra VACE e Kling 1.6:

Teste de substituição de sujeito no modo vídeo para vídeo. Consulte o PDF de origem para melhores detalhes e resolução.
Os pesquisadores afirmam:
‘O VACE produz artefatos de borda devido à aderência estrita à máscara, interrompendo a continuidade do movimento. O Kling mostra um efeito de copiar-colar com má integração de fundo. O HunyuanCustom evita artefatos, garante integração perfeita e mantém forte preservação de identidade, destacando-se na edição de vídeo.’
Conclusão
O HunyuanCustom é um lançamento atraente, atendendo à crescente demanda por sincronização labial na síntese de vídeo, aprimorando o realismo em sistemas como o Hunyuan Video. Apesar dos desafios em comparar suas capacidades devido ao layout de vídeos do site do projeto, o modelo da Tencent se mantém firme contra os principais concorrentes como o Kling, marcando um progresso significativo na geração de vídeos personalizados.
* Alguns vídeos são muito largos, curtos ou de alta resolução para serem reproduzidos em players padrão como VLC ou Windows Media Player, exibindo telas pretas.
Publicado pela primeira vez na quinta-feira, 8 de maio de 2025
Artigo relacionado
 Exclusivo: Luma AI lança agentes criativos alimentados por modelos de “inteligência unificada”
Na quinta-feira, a startup de geração de vídeo com IA Luma apresentou o Luma Agents, um sistema criado para gerenciar fluxos de trabalho criativos completos, abrangendo texto, imagens, vídeo e áudio.
A nova atualização do Sora oferece vídeos de IA para animais de estimação, ferramentas sociais e um aplicativo para Android que será lançado em breve
A OpenAI está prevendo uma onda de novos recursos para seu aplicativo de criação de vídeos com IA, o Sora, que rapidamente alcançou o topo da App Store após seu lançamento no final de setembro. O apli
A geração de vídeo da IA se move para o controle completo
Modelos de fundação em vídeo como Hunyuan e Wan 2.1 fizeram avanços significativos, mas geralmente ficam aquém do controle detalhado necessário na produção de filmes e TV, especialmente no campo dos efeitos visuais (VFX). Nos estúdios profissionais de VFX, esses modelos, juntamente com as base de imagens anteriores
Recomendações de tópicos especiais relacionados
código
Exclusivo: Luma AI lança agentes criativos alimentados por modelos de “inteligência unificada”
Na quinta-feira, a startup de geração de vídeo com IA Luma apresentou o Luma Agents, um sistema criado para gerenciar fluxos de trabalho criativos completos, abrangendo texto, imagens, vídeo e áudio.
A nova atualização do Sora oferece vídeos de IA para animais de estimação, ferramentas sociais e um aplicativo para Android que será lançado em breve
A OpenAI está prevendo uma onda de novos recursos para seu aplicativo de criação de vídeos com IA, o Sora, que rapidamente alcançou o topo da App Store após seu lançamento no final de setembro. O apli
A geração de vídeo da IA se move para o controle completo
Modelos de fundação em vídeo como Hunyuan e Wan 2.1 fizeram avanços significativos, mas geralmente ficam aquém do controle detalhado necessário na produção de filmes e TV, especialmente no campo dos efeitos visuais (VFX). Nos estúdios profissionais de VFX, esses modelos, juntamente com as base de imagens anteriores
Recomendações de tópicos especiais relacionados
código
 Os melhores revisores de código com IA: automatize a conformidade com o código limpo e refatore arquivos de repositórios legados
Os melhores revisores de código com IA: automatize a conformidade com o código limpo e refatore arquivos de repositórios legados
Descubra os melhores revisores de código com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta ferramentas de ponta e revolucionárias para automatizar a conformidade com o código limpo e refatorar arquivos de repositórios legados. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Obtenha sua vantagem com IA hoje mesmo.
 10 ferramentas
10 ferramentas
 xix.ai
Conversão de texto para fala
Os melhores aplicativos de TTS com IA para dislexia: apoio à aprendizagem e à eficiência na leitura para alunos
xix.ai
Conversão de texto para fala
Os melhores aplicativos de TTS com IA para dislexia: apoio à aprendizagem e à eficiência na leitura para alunos
Descubra os melhores aplicativos de TTS com IA de 2026, selecionados especialmente para auxiliar na dislexia. Nossas classificações especializadas comparam ferramentas gratuitas e pagas, destacando recursos avançados para melhorar a eficiência na leitura e na aprendizagem. Explore soluções inovadoras e imperdíveis para revelar o potencial dos alunos. Comece sua jornada no XIX.AI.
10 ferramentas
xix.ai
Criação de quadrinhos
Os melhores geradores de IA para mangás shonen: crie sequências de ação cheias de adrenalina e efeitos de energia
Descubra os melhores geradores de IA para mangás shonen de 2026 no XIX.AI. Nossa lista selecionada e com as melhores avaliações apresenta ferramentas poderosas para criar sequências de ação cheias de adrenalina e efeitos dinâmicos de energia. Compare opções gratuitas e pagas com testes práticos. Liberte seu potencial criativo e comece a criar mangás épicos hoje mesmo!
15 ferramentas
xix.ai
Negócios
Os melhores aplicativos de controle de despesas com IA: digitalize recibos e categorize automaticamente as despesas corporativas
Os melhores gerenciadores de despesas com IA de 2026: as ferramentas mais bem avaliadas para digitalizar recibos e categorizar despesas corporativas automaticamente. Descubra soluções poderosas e revolucionárias para uma gestão de despesas sem esforço, um acompanhamento financeiro preciso e uma conformidade simplificada. Nossa comparação, cuidadosamente selecionada e atualizada semanalmente, entre opções gratuitas e pagas ajuda você a encontrar a solução ideal. Aproveite ao máximo as vantagens da IA com as recomendações dos especialistas da XIX.AI.
10 ferramentas
xix.ai
Negócios
As melhores ferramentas de recrutamento com IA: analise currículos e automatize o agendamento de entrevistas com candidatos
Descubra as melhores ferramentas de recrutamento com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta soluções poderosas e revolucionárias para a triagem de currículos e a automação do agendamento de entrevistas com candidatos. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Encontre o seu assistente de contratação ideal e otimize seu processo de recrutamento hoje mesmo!
10 ferramentas
xix.ai
Produtividade
Treinadores de bem-estar e concentração com IA: controle o esgotamento e aumente os níveis de energia mental
Descubra os melhores coaches de bem-estar pessoal e concentração com IA de 2026 no XIX.AI. Nossos rankings selecionados apresentam ferramentas de ponta e revolucionárias para lidar com o esgotamento e aumentar a energia mental. Compare opções gratuitas e pagas com informações reais. Descubra hoje mesmo o caminho para atingir o máximo de produtividade e bem-estar.
10 ferramentas
xix.ai

 Comentários (1)
Comentários (1)
![RalphHill]()
Esse exemplo de vídeo parece meio bugado... Mas a ideia de transformar uma imagem estática em vídeo é fascinante. Será que isso poderia ser usado para criar conteúdos educativos ou de forma indevida? A discussão ética sempre fica atrás da tecnologia 🤔.
Este artigo explora o lançamento do HunyuanCustom, um modelo de geração de vídeo multimodal da Tencent. O amplo escopo do artigo de pesquisa acompanhante e os desafios com os vídeos de exemplo fornecidos na página do projeto requerem uma visão geral mais ampla, com reprodução limitada do extenso conteúdo de vídeo devido a requisitos de formatação e processamento para maior clareza.
Observe que o artigo se refere ao sistema generativo baseado em API Kling como ‘Keling.’ Para consistência, este artigo usa ‘Kling’ em todo o texto.
A Tencent apresentou uma iteração avançada de seu modelo Hunyuan Video, chamada HunyuanCustom. Este lançamento supostamente elimina a necessidade de modelos Hunyuan LoRA, permitindo que os usuários criem personalizações de vídeo estilo deepfake usando apenas uma única imagem:
Clique para reproduzir. Prompt: ‘Um homem curte música enquanto prepara macarrão de caracol em uma cozinha.’ Comparado a métodos proprietários e de código aberto, incluindo o Kling, um concorrente importante, o HunyuanCustom se destaca. Fonte: https://hunyuancustom.github.io/ (nota: site com alto consumo de recursos)
No vídeo acima, a coluna mais à esquerda exibe a imagem de origem única para o HunyuanCustom, seguida pela interpretação do sistema do prompt na coluna adjacente. As colunas restantes mostram saídas de outros sistemas: Kling, Vidu, Pika, Hailuo e SkyReels-A2 (baseado em Wan).
O vídeo a seguir destaca três cenários principais para este lançamento: pessoa com objeto, replicação de personagem único e prova virtual de roupas:
Clique para reproduzir. Três exemplos selecionados do site de suporte do Hunyuan Video.
Esses exemplos revelam limitações relacionadas à dependência de uma única imagem de origem em vez de múltiplas perspectivas.
No primeiro clipe, o homem enfrenta a câmera com movimento mínimo da cabeça, inclinando não mais que 20-25 graus. Além disso, o sistema tem dificuldade em inferir seu perfil com precisão a partir de uma única imagem frontal.
No segundo clipe, a garota mantém uma expressão sorridente no vídeo, espelhando sua imagem de origem estática. Sem referências adicionais, o HunyuanCustom não pode retratar de forma confiável sua expressão neutra, e seu rosto permanece voltado para frente, semelhante ao exemplo anterior.
No clipe final, material de origem incompleto—uma mulher e roupas virtuais—resulta em uma renderização recortada, uma solução prática para dados limitados.
Embora o HunyuanCustom suporte múltiplas entradas de imagem (por exemplo, pessoa com lanches ou pessoa com vestimenta), ele não acomoda ângulos ou expressões variadas para um único personagem. Isso pode limitar sua capacidade de substituir completamente o ecossistema em expansão de modelos LoRA para o HunyuanVideo, que usam 20-60 imagens para garantir a renderização consistente de personagens em diferentes ângulos e expressões.
Integração de Áudio
Para áudio, o HunyuanCustom utiliza o sistema LatentSync, que é desafiador para amadores configurarem, para sincronizar movimentos labiais com áudio e texto fornecidos pelo usuário:
Inclui áudio. Clique para reproduzir. Exemplos compilados de sincronização labial do site suplementar do HunyuanCustom.
Atualmente, não há exemplos em língua inglesa disponíveis, mas os resultados parecem promissores, especialmente se o processo de configuração for amigável ao usuário.
Capacidades de Edição de Vídeo
O HunyuanCustom se destaca na edição de vídeo para vídeo (V2V), permitindo a substituição direcionada de elementos em vídeos existentes usando uma única imagem de referência. Um exemplo dos materiais suplementares ilustra isso:
Clique para reproduzir. O objeto central é modificado, com elementos ao redor alterados sutilmente em um processo V2V do HunyuanCustom.
Como típico em fluxos de trabalho V2V, o vídeo inteiro é ligeiramente modificado, com foco principal na área direcionada, como o brinquedo de pelúcia. Pipelines avançados poderiam potencialmente preservar mais do conteúdo original, semelhante à abordagem do Adobe Firefly, embora isso permaneça pouco explorado em comunidades de código aberto.
Outros exemplos demonstram maior precisão em integrações direcionadas, como visto nesta compilação:
Clique para reproduzir. Exemplos variados de inserção de conteúdo V2V no HunyuanCustom, mostrando respeito pelos elementos inalterados.
Atualização Evolutiva
O HunyuanCustom é construído sobre o projeto Hunyuan Video, introduzindo melhorias arquiteturais direcionadas em vez de uma reformulação completa. Essas atualizações visam manter a consistência do personagem entre quadros sem exigir ajustes específicos ao sujeito, como LoRA ou inversão textual.
Este lançamento é uma versão refinada do modelo HunyuanVideo de dezembro de 2024, não um novo modelo construído do zero.
Usuários de LoRAs existentes do HunyuanVideo podem questionar sua compatibilidade com esta atualização ou se novos LoRAs devem ser desenvolvidos para aproveitar os recursos de personalização aprimorados.
Tipicamente, ajustes significativos alteram os pesos do modelo o suficiente para tornar LoRAs anteriores incompatíveis. No entanto, alguns ajustes, como o Pony Diffusion para o Stable Diffusion XL, criaram ecossistemas independentes com bibliotecas LoRA dedicadas, sugerindo potencial para o HunyuanCustom seguir o mesmo caminho.
Detalhes do Lançamento
O artigo de pesquisa, intitulado HunyuanCustom: Uma Arquitetura Multimodal para Geração de Vídeo Personalizado, vincula-se a um repositório GitHub agora ativo com código e pesos para implantação local, juntamente com uma integração planejada com o ComfyUI.
Atualmente, a página do projeto no Hugging Face está inacessível, mas uma demonstração baseada em API está disponível via código de escaneamento do WeChat.
A montagem de projetos diversos do HunyuanCustom é notavelmente abrangente, provavelmente impulsionada por requisitos de licenciamento para divulgação completa.
Duas variantes do modelo são oferecidas: uma versão de 720x1280px que precisa de 80GB de memória GPU para desempenho ideal (24GB no mínimo, mas lenta) e uma versão de 512x896px que requer 60GB. Os testes foram limitados ao Linux, mas esforços da comunidade podem em breve adaptá-lo para Windows e configurações de VRAM mais baixas, como visto com o modelo anterior Hunyuan Video.
Devido ao volume de materiais acompanhantes, esta visão geral adota uma abordagem de alto nível sobre as capacidades do HunyuanCustom.
Insights Técnicos
O pipeline de dados do HunyuanCustom, compatível com o GDPR, integra conjuntos de dados de vídeo sintetizados e de código aberto como o OpenHumanVid, cobrindo oito categorias: humanos, animais, plantas, paisagens, veículos, objetos, arquitetura e anime.
Do artigo de lançamento, uma visão geral dos diversos pacotes contribuintes no pipeline de construção de dados do HunyuanCustom. Fonte: https://arxiv.org/pdf/2505.04512
Os vídeos são segmentados em clipes de tomada única usando o PySceneDetect, com o TextBPN-Plus-Plus filtrando conteúdos com texto excessivo, legendas ou marcas d’água.
Os clipes são padronizados para cinco segundos e redimensionados para 512 ou 720 pixels no lado mais curto. A qualidade estética é garantida usando o Koala-36M com um limiar personalizado de 0,06.
A extração de identidade humana utiliza Qwen7B, YOLO11X e InsightFace, enquanto sujeitos não humanos são processados com QwenVL e Grounded SAM 2, descartando caixas delimitadoras pequenas.
Exemplos de segmentação semântica com Grounded SAM 2, usado no projeto Hunyuan Control. Fonte: https://github.com/IDEA-Research/Grounded-SAM-2
A extração de múltiplos sujeitos usa o Florence2 para anotações e o Grounded SAM 2 para segmentação, seguida por clustering e segmentação de quadros temporais.
Os clipes são aprimorados com rotulagem estruturada proprietária pela equipe Hunyuan, adicionando metadados como descrições e dicas de movimento da câmera.
A ampliação de máscaras previne o overfitting, garantindo adaptabilidade a formas de objetos variadas. A sincronização de áudio usa o LatentSync, descartando clipes abaixo de um limiar de qualidade. O HyperIQA filtra vídeos com pontuação abaixo de 40, e o Whisper processa áudio válido para tarefas subsequentes.
O modelo LLaVA desempenha um papel central, gerando legendas e alinhando conteúdo visual e textual para consistência semântica, especialmente em cenas complexas ou com múltiplos sujeitos.
O framework HunyuanCustom suporta geração de vídeo consistente com identidade condicionada por texto, imagem, áudio e entradas de vídeo.
Personalização de Vídeo
Para possibilitar a geração de vídeo a partir de uma imagem de referência e prompt, dois módulos baseados em LLaVA foram desenvolvidos, adaptando a entrada do HunyuanVideo para aceitar imagem e texto. Os prompts incorporam imagens diretamente ou as marcam com descrições breves de identidade, usando um token separador para equilibrar a influência de imagem e texto.
Um módulo de aprimoramento de identidade aborda a tendência do LLaVA de perder detalhes espaciais refinados, críticos para manter a consistência do sujeito em clipes de vídeo curtos.
A imagem de referência é redimensionada e codificada via causal 3D-VAE do HunyuanVideo, com seu latente inserido ao longo do eixo temporal e um deslocamento espacial para guiar a geração sem replicação direta.
O treinamento usou Flow Matching com ruído de uma distribuição logit-normal, ajustando o LLaVA e o gerador de vídeo juntos para orientação coesa de imagem-prompt e consistência de identidade.
Para prompts com múltiplos sujeitos, cada par imagem-texto é incorporado separadamente com posições temporais distintas, possibilitando cenas com múltiplos sujeitos interagindo.
Integração de Áudio e Visual
O HunyuanCustom suporta geração orientada por áudio usando áudio e texto fornecidos pelo usuário, permitindo que personagens falem em cenários contextualmente relevantes.
Um módulo Identity-disentangled AudioNet alinha recursos de áudio com a linha do tempo do vídeo, usando atenção cruzada espacial para isolar quadros e manter a consistência do sujeito.
Um módulo de injeção temporal refina o tempo de movimento, mapeando áudio para sequências latentes via Perceptron Multi-Camadas, garantindo que gestos se alinhem com o ritmo do áudio.
Para edição de vídeo, o HunyuanCustom substitui sujeitos em clipes existentes sem regenerar o vídeo inteiro, ideal para alterações direcionadas de aparência ou movimento.
Clique para reproduzir. Outro exemplo do site suplementar.
O sistema comprime vídeos de referência usando o causal 3D-VAE pré-treinado, alinhando-os com os latentes do pipeline de geração para processamento leve. Uma rede neural alinha vídeos de entrada limpos com latentes ruidosos, com adição de recursos quadro a quadro provando ser mais eficaz do que a fusão pré-compressão.
Avaliação de Desempenho
As métricas de teste incluíram ArcFace para consistência de identidade facial, YOLO11x e Dino 2 para similaridade de sujeito, CLIP-B para alinhamento de texto-vídeo e consistência temporal, e VBench para intensidade de movimento.
Os concorrentes incluíram sistemas de código fechado (Hailuo, Vidu 2.0, Kling 1.6, Pika) e frameworks de código aberto (VACE, SkyReels-A2).
Avaliação de desempenho do modelo comparando o HunyuanCustom com métodos líderes de personalização de vídeo em consistência de ID (Face-Sim), similaridade de sujeito (DINO-Sim), alinhamento de texto-vídeo (CLIP-B-T), consistência temporal (Temp-Consis) e intensidade de movimento (DD). Resultados ótimos e subótimos são mostrados em negrito e sublinhado, respectivamente.
Os autores observam:
‘O HunyuanCustom se destaca em consistência de ID e sujeito, com aderência competitiva ao prompt e estabilidade temporal. O Hailuo lidera em pontuação de clipe devido ao forte alinhamento de texto, mas enfrenta dificuldades com consistência de sujeitos não humanos. Vidu e VACE ficam atrás em intensidade de movimento, provavelmente devido a tamanhos de modelo menores.’
Embora o site do projeto ofereça numerosos vídeos de comparação, seu layout prioriza a estética em vez da facilidade de comparação. Os leitores são incentivados a revisar os vídeos diretamente para obter insights mais claros:
Do artigo, uma comparação sobre personalização de vídeo centrada em objetos. Embora o espectador deva consultar o PDF de origem para melhor resolução, os vídeos no site do projeto oferecem insights mais claros.
Os autores afirmam:
‘Vidu, SkyReels A2 e HunyuanCustom alcançam forte alinhamento de prompt e consistência de sujeito, mas nossa qualidade de vídeo supera Vidu e SkyReels, graças à base robusta do Hunyuanvideo-13B.’
‘Entre as soluções comerciais, o Kling entrega vídeo de alta qualidade, mas sofre com um efeito de copiar-colar no primeiro quadro e borrões ocasionais do sujeito, impactando a experiência do espectador.’
O Pika enfrenta dificuldades com consistência temporal, introduzindo artefatos de legenda devido à má curadoria de dados. O Hailuo preserva a identidade facial, mas falha na consistência de corpo inteiro. O VACE, entre os métodos de código aberto, não mantém a consistência de identidade, enquanto o HunyuanCustom entrega forte preservação de identidade, qualidade e diversidade.
Testes de personalização de vídeo com múltiplos sujeitos produziram resultados semelhantes:
Comparações usando personalizações de vídeo com múltiplos sujeitos. Consulte o PDF para melhores detalhes e resolução.
O artigo observa:
‘O Pika gera sujeitos especificados, mas mostra instabilidade de quadros, com sujeitos desaparecendo ou não seguindo os prompts. Vidu e VACE capturam a identidade humana parcialmente, mas perdem detalhes de objetos não humanos. SkyReels A2 sofre com instabilidade severa de quadros e artefatos. O HunyuanCustom captura eficazmente todas as identidades dos sujeitos, adere aos prompts e mantém alta qualidade visual e estabilidade.’
Um teste de anúncio de humano virtual integrou produtos com pessoas:
Da rodada de testes qualitativos, exemplos de colocação de produtos neurais. Consulte o PDF para melhores detalhes e resolução.
Os autores afirmam:
‘O HunyuanCustom mantém a identidade humana e detalhes do produto, incluindo texto, com interações naturais e forte aderência ao prompt, mostrando seu potencial para vídeos de publicidade.’
Testes de personalização orientada por áudio destacaram controle flexível de cena e postura:
Resultados parciais para a rodada de áudio—resultados de vídeo seriam preferíveis. Apenas a metade superior da figura do PDF é mostrada devido a restrições de tamanho. Consulte o PDF de origem para melhores detalhes.
Os autores observam:
‘Métodos anteriores orientados por áudio limitam postura e ambiente à imagem de entrada, restringindo aplicações. O HunyuanCustom permite animação orientada por áudio flexível com cenas e posturas descritas por texto.’
Testes de substituição de sujeito em vídeo compararam o HunyuanCustom contra VACE e Kling 1.6:
Teste de substituição de sujeito no modo vídeo para vídeo. Consulte o PDF de origem para melhores detalhes e resolução.
Os pesquisadores afirmam:
‘O VACE produz artefatos de borda devido à aderência estrita à máscara, interrompendo a continuidade do movimento. O Kling mostra um efeito de copiar-colar com má integração de fundo. O HunyuanCustom evita artefatos, garante integração perfeita e mantém forte preservação de identidade, destacando-se na edição de vídeo.’
Conclusão
O HunyuanCustom é um lançamento atraente, atendendo à crescente demanda por sincronização labial na síntese de vídeo, aprimorando o realismo em sistemas como o Hunyuan Video. Apesar dos desafios em comparar suas capacidades devido ao layout de vídeos do site do projeto, o modelo da Tencent se mantém firme contra os principais concorrentes como o Kling, marcando um progresso significativo na geração de vídeos personalizados.
* Alguns vídeos são muito largos, curtos ou de alta resolução para serem reproduzidos em players padrão como VLC ou Windows Media Player, exibindo telas pretas.
Publicado pela primeira vez na quinta-feira, 8 de maio de 2025










 Exclusivo: Luma AI lança agentes criativos alimentados por modelos de “inteligência unificada”
Na quinta-feira, a startup de geração de vídeo com IA Luma apresentou o Luma Agents, um sistema criado para gerenciar fluxos de trabalho criativos completos, abrangendo texto, imagens, vídeo e áudio.
Exclusivo: Luma AI lança agentes criativos alimentados por modelos de “inteligência unificada”
Na quinta-feira, a startup de geração de vídeo com IA Luma apresentou o Luma Agents, um sistema criado para gerenciar fluxos de trabalho criativos completos, abrangendo texto, imagens, vídeo e áudio.
 A nova atualização do Sora oferece vídeos de IA para animais de estimação, ferramentas sociais e um aplicativo para Android que será lançado em breve
A OpenAI está prevendo uma onda de novos recursos para seu aplicativo de criação de vídeos com IA, o Sora, que rapidamente alcançou o topo da App Store após seu lançamento no final de setembro. O apli
A nova atualização do Sora oferece vídeos de IA para animais de estimação, ferramentas sociais e um aplicativo para Android que será lançado em breve
A OpenAI está prevendo uma onda de novos recursos para seu aplicativo de criação de vídeos com IA, o Sora, que rapidamente alcançou o topo da App Store após seu lançamento no final de setembro. O apli
 A geração de vídeo da IA se move para o controle completo
Modelos de fundação em vídeo como Hunyuan e Wan 2.1 fizeram avanços significativos, mas geralmente ficam aquém do controle detalhado necessário na produção de filmes e TV, especialmente no campo dos efeitos visuais (VFX). Nos estúdios profissionais de VFX, esses modelos, juntamente com as base de imagens anteriores
A geração de vídeo da IA se move para o controle completo
Modelos de fundação em vídeo como Hunyuan e Wan 2.1 fizeram avanços significativos, mas geralmente ficam aquém do controle detalhado necessário na produção de filmes e TV, especialmente no campo dos efeitos visuais (VFX). Nos estúdios profissionais de VFX, esses modelos, juntamente com as base de imagens anteriores

Descubra os melhores revisores de código com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta ferramentas de ponta e revolucionárias para automatizar a conformidade com o código limpo e refatorar arquivos de repositórios legados. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Obtenha sua vantagem com IA hoje mesmo.
10 ferramentas
xix.ai

Descubra os melhores aplicativos de TTS com IA de 2026, selecionados especialmente para auxiliar na dislexia. Nossas classificações especializadas comparam ferramentas gratuitas e pagas, destacando recursos avançados para melhorar a eficiência na leitura e na aprendizagem. Explore soluções inovadoras e imperdíveis para revelar o potencial dos alunos. Comece sua jornada no XIX.AI.
10 ferramentas
xix.ai

Descubra os melhores geradores de IA para mangás shonen de 2026 no XIX.AI. Nossa lista selecionada e com as melhores avaliações apresenta ferramentas poderosas para criar sequências de ação cheias de adrenalina e efeitos dinâmicos de energia. Compare opções gratuitas e pagas com testes práticos. Liberte seu potencial criativo e comece a criar mangás épicos hoje mesmo!
15 ferramentas
xix.ai

Os melhores gerenciadores de despesas com IA de 2026: as ferramentas mais bem avaliadas para digitalizar recibos e categorizar despesas corporativas automaticamente. Descubra soluções poderosas e revolucionárias para uma gestão de despesas sem esforço, um acompanhamento financeiro preciso e uma conformidade simplificada. Nossa comparação, cuidadosamente selecionada e atualizada semanalmente, entre opções gratuitas e pagas ajuda você a encontrar a solução ideal. Aproveite ao máximo as vantagens da IA com as recomendações dos especialistas da XIX.AI.
10 ferramentas
xix.ai

Descubra as melhores ferramentas de recrutamento com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta soluções poderosas e revolucionárias para a triagem de currículos e a automação do agendamento de entrevistas com candidatos. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Encontre o seu assistente de contratação ideal e otimize seu processo de recrutamento hoje mesmo!
10 ferramentas
xix.ai

Descubra os melhores coaches de bem-estar pessoal e concentração com IA de 2026 no XIX.AI. Nossos rankings selecionados apresentam ferramentas de ponta e revolucionárias para lidar com o esgotamento e aumentar a energia mental. Compare opções gratuitas e pagas com informações reais. Descubra hoje mesmo o caminho para atingir o máximo de produtividade e bem-estar.
10 ferramentas
xix.ai

Esse exemplo de vídeo parece meio bugado... Mas a ideia de transformar uma imagem estática em vídeo é fascinante. Será que isso poderia ser usado para criar conteúdos educativos ou de forma indevida? A discussão ética sempre fica atrás da tecnologia 🤔.













