
















 Дом
ДомTencent представляет HunyuanCustom для видеонастройки на основе одного изображения
Эта статья посвящена запуску HunyuanCustom, мультимодальной модели генерации видео от Tencent. Обширный объем сопроводительной исследовательской статьи и проблемы с предоставленными примерами видео на странице проекта требуют более общего обзора, с ограниченным воспроизведением обширного видеоконтента из-за требований форматирования и обработки для повышения четкости.
Обратите внимание, что в статье API-генеративная система Kling называется ‘Keling’. Для единообразия в этой статье используется ‘Kling’.
Tencent представил продвинутую версию своей модели Hunyuan Video, названную HunyuanCustom. Сообщается, что эта версия превосходит необходимость в моделях Hunyuan LoRA, позволяя пользователям создавать видеонастройки в стиле дипфейк, используя только одно изображение:
Нажмите для воспроизведения. Запрос: ‘Мужчина наслаждается музыкой, готовя лапшу из улиток на кухне.’ По сравнению с проприетарными и открытыми методами, включая Kling, ключевого конкурента, HunyuanCustom выделяется. Источник: https://hunyuancustom.github.io/ (примечание: сайт с высокой нагрузкой)
В видео выше левая колонка показывает исходное изображение для HunyuanCustom, за которым следует интерпретация системой запроса в соседней колонке. Остальные колонки демонстрируют результаты других систем: Kling, Vidu, Pika, Hailuo и SkyReels-A2 (на базе Wan).
Следующее видео выделяет три основных сценария для этого релиза: человек с объектом, репликация одного персонажа и виртуальная примерка одежды:
Нажмите для воспроизведения. Три отобранных примера с сайта поддержки Hunyuan Video.
Эти примеры показывают ограничения, связанные с использованием одного исходного изображения вместо нескольких ракурсов.
В первом клипе мужчина смотрит в камеру с минимальным движением головы, наклоняясь не более чем на 20-25 градусов. За пределами этого система не может точно воспроизвести его профиль из одного фронтального изображения.
Во втором клипе девушка сохраняет улыбающееся выражение в видео, отражая её статичное исходное изображение. Без дополнительных референсов HunyuanCustom не может достоверно показать её нейтральное выражение, и её лицо остаётся преимущественно фронтальным, как в предыдущем примере.
В последнем клипе неполный исходный материал — женщина и виртуальная одежда — приводит к обрезанному рендеру, что является практичным решением для ограниченных данных.
Хотя HunyuanCustom поддерживает ввод нескольких изображений (например, человек с закусками или человек с одеждой), он не учитывает различные ракурсы или выражения для одного персонажа. Это может ограничить его способность полностью заменить расширяющуюся экосистему моделей LoRA для HunyuanVideo, которые используют 20-60 изображений для обеспечения согласованного отображения персонажа с разных ракурсов и выражений.
Интеграция аудио
Для аудио HunyuanCustom использует систему LatentSync, которую сложно настроить любителям, для синхронизации движений губ с предоставленным пользователем аудио и текстом:
Включает аудио. Нажмите для воспроизведения. Скомпилированные примеры синхронизации губ с дополнительного сайта HunyuanCustom.
На данный момент примеры на английском языке недоступны, но результаты кажутся многообещающими, особенно если процесс настройки удобен для пользователя.
Возможности редактирования видео
HunyuanCustom выделяется в редактировании видео-видео (V2V), позволяя целенаправленно заменять элементы в существующих видео с использованием одного референсного изображения. Пример из дополнительных материалов иллюстрирует это:
Нажмите для воспроизведения. Центральный объект изменён, с тонким изменением окружающих элементов в процессе V2V HunyuanCustom.
Как типично для рабочих процессов V2V, всё видео слегка модифицируется, с основным акцентом на целевую область, например, плюшевую игрушку. Продвинутые конвейеры могли бы потенциально сохранить больше оригинального контента, подобно подходу Adobe Firefly, хотя это остаётся малоизученным в сообществах с открытым кодом.
Другие примеры демонстрируют повышенную точность в целевых интеграциях, как видно в этой подборке:
Нажмите для воспроизведения. Разнообразные примеры вставки контента V2V в HunyuanCustom, с уважением к неизменённым элементам.
Эволюционное обновление
HunyuanCustom основывается на проекте Hunyuan Video, внедряя целевые архитектурные улучшения, а не полную переработку. Эти улучшения направлены на поддержание согласованности персонажа между кадрами без необходимости специфической настройки для объекта, например, LoRA или текстового инвертирования.
Этот релиз является усовершенствованной версией модели HunyuanVideo от декабря 2024 года, а не новой моделью, созданной с нуля.
Пользователи существующих LoRA для HunyuanVideo могут задаться вопросом о их совместимости с этим обновлением или о необходимости разработки новых LoRA для использования улучшенных функций настройки.
Обычно значительная тонкая настройка достаточно изменяет веса модели, чтобы сделать предыдущие LoRA несовместимыми. Однако некоторые тонкие настройки, такие как Pony Diffusion для Stable Diffusion XL, создали независимые экосистемы с выделенными библиотеками LoRA, что указывает на потенциал HunyuanCustom последовать этому примеру.
Детали выпуска
Исследовательская статья, озаглавленная HunyuanCustom: Мультимодальная архитектура для настройки видео, ссылается на репозиторий GitHub, теперь активный с кодом и весами для локального развертывания, а также запланированную интеграцию с ComfyUI.
В настоящее время страница проекта на Hugging Face недоступна, но демонстрация на основе API доступна через сканирование кода WeChat.
Сборка HunyuanCustom из различных проектов примечательно всеобъемлюща, вероятно, обусловлена требованиями лицензирования для полного раскрытия.
Предлагаются две версии модели: версия 720x1280px, требующая 80 ГБ памяти GPU для оптимальной производительности (24 ГБ минимум, но медленно) и версия 512x896px, требующая 60 ГБ. Тестирование ограничено Linux, но усилия сообщества могут скоро адаптировать её для Windows и конфигураций с меньшим объёмом VRAM, как это было с предыдущей моделью Hunyuan Video.
Из-за объёма сопроводительных материалов этот обзор принимает высокоуровневый подход к возможностям HunyuanCustom.
Технические детали
Конвейер данных HunyuanCustom, соответствующий GDPR, интегрирует синтезированные и открытые видеодатасеты, такие как OpenHumanVid, охватывающие восемь категорий: люди, животные, растения, пейзажи, транспорт, объекты, архитектура и аниме.
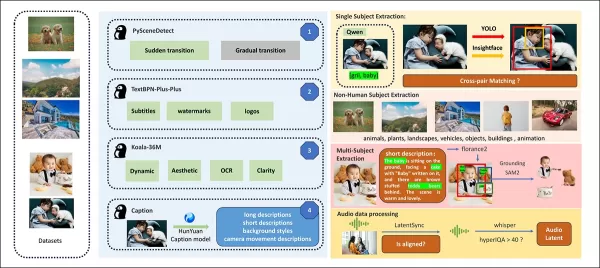
Из статьи о выпуске, обзор различных пакетов, участвующих в конвейере построения данных HunyuanCustom. Источник: https://arxiv.org/pdf/2505.04512
Видео сегментируются на однотипные клипы с помощью PySceneDetect, при этом TextBPN-Plus-Plus отфильтровывает контент с избыточным текстом, субтитрами или водяными знаками.
Клипы стандартизируются до пяти секунд и масштабируются до 512 или 720 пикселей по короткой стороне. Эстетическое качество обеспечивается с помощью Koala-36M с пользовательским порогом 0.06.
Извлечение человеческой идентичности использует Qwen7B, YOLO11X и InsightFace, тогда как нечеловеческие объекты обрабатываются с помощью QwenVL и Grounded SAM 2, отбрасывая маленькие ограничивающие рамки.

Примеры семантической сегментации с Grounded SAM 2, используемые в проекте Hunyuan Control. Источник: https://github.com/IDEA-Research/Grounded-SAM-2
Извлечение нескольких объектов использует Florence2 для аннотаций и Grounded SAM 2 для сегментации, с последующим кластерингом и временной сегментацией кадров.
Клипы улучшаются с помощью проприетарной структурированной разметки от команды Hunyuan, добавляя метаданные, такие как описания и подсказки о движении камеры.
Аугментация масок предотвращает переобучение, обеспечивая адаптивность к различным формам объектов. Синхронизация аудио использует LatentSync, отбрасывая клипы ниже порога качества. HyperIQA отфильтровывает видео с оценкой ниже 40, а Whisper обрабатывает валидное аудио для последующих задач.
Модель LLaVA играет центральную роль, генерируя подписи и выравнивая визуальный и текстовый контент для семантической согласованности, особенно в сложных или многосубъектных сценах.
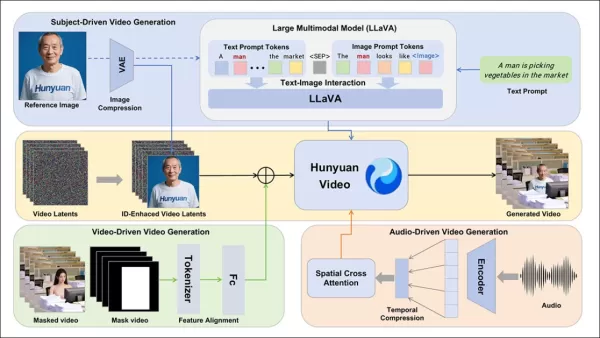
Фреймворк HunyuanCustom поддерживает генерацию видео с сохранением идентичности, обусловленную текстом, изображением, аудио и видео входами.
Настройка видео
Для генерации видео из референсного изображения и запроса были разработаны два модуля на базе LLaVA, адаптирующие вход HunyuanVideo для принятия изображения и текста. Запросы встраивают изображения напрямую или помечают их краткими описаниями идентичности, используя разделительный токен для баланса влияния изображения и текста.
Модуль улучшения идентичности решает проблему потери LLaVA мелких пространственных деталей, критически важных для поддержания согласованности субъекта в коротких видеоклипах.
Референсное изображение масштабируется и кодируется через причинный 3D-VAE от HunyuanVideo, с его латентным вставленным по временной оси и пространственным смещением для управления генерацией без прямого копирования.
Обучение использовало Flow Matching с шумом из логит-нормального распределения, тонко настраивая LLaVA и видеогенератор вместе для согласованного управления изображением-запросом и сохранения идентичности.
Для многосубъектных запросов каждая пара изображение-текст встраивается отдельно с различными временными позициями, позволяя создавать сцены с несколькими взаимодействующими субъектами.
Интеграция аудио и визуала
HunyuanCustom поддерживает генерацию, управляемую аудио, с использованием предоставленного пользователем аудио и текста, позволяя персонажам говорить в контекстно релевантных условиях.
Модуль Identity-disentangled AudioNet выравнивает аудиофункции с временной шкалой видео, используя пространственное кросс-внимание для изоляции кадров и поддержания согласованности субъекта.
Модуль временного внедрения уточняет синхронизацию движений, отображая аудио на латентные последовательности через многослойный перцептрон, обеспечивая соответствие жестов ритму аудио.
Для редактирования видео HunyuanCustom заменяет субъекты в существующих клипах без перегенерации всего видео, что идеально для целевых изменений внешнего вида или движений.
Нажмите для воспроизведения. Ещё один пример с дополнительного сайта.
Система сжимает референсные видео с использованием предварительно обученного причинного 3D-VAE, выравнивая их с латентами конвейера генерации для лёгкой обработки. Нейронная сеть выравнивает чистые входные видео с шумными латентами, причём добавление функций покадрово оказалось более эффективным, чем предварительное слияние.
Оценка производительности
Метрики тестирования включали ArcFace для согласованности идентичности лица, YOLO11x и Dino 2 для сходства субъекта, CLIP-B для выравнивания текста и видео и временной согласованности, и VBench для интенсивности движения.
Конкуренты включали закрытые системы (Hailuo, Vidu 2.0, Kling 1.6, Pika) и фреймворки с открытым кодом (VACE, SkyReels-A2).
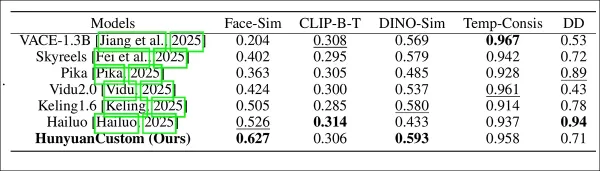
Оценка производительности модели, сравнивающая HunyuanCustom с ведущими методами настройки видео по согласованности идентичности (Face-Sim), сходству субъекта (DINO-Sim), выравниванию текста и видео (CLIP-B-T), временной согласованности (Temp-Consis) и интенсивности движения (DD). Оптимальные и субоптимальные результаты показаны жирным и подчёркнутым соответственно.
Авторы отмечают:
‘HunyuanCustom превосходит в согласованности идентичности и субъекта, с конкурентоспособным следованием запросам и временной стабильностью. Hailuo лидирует по клиповому счёту благодаря сильному выравниванию текста, но испытывает трудности с согласованностью нечеловеческих субъектов. Vidu и VACE отстают в интенсивности движения, вероятно, из-за меньших размеров моделей.’
Хотя сайт проекта предлагает множество сравнительных видео, их расположение приоритетно эстетике, а не удобству сравнения. Читателям рекомендуется напрямую просматривать видео для более ясных выводов:
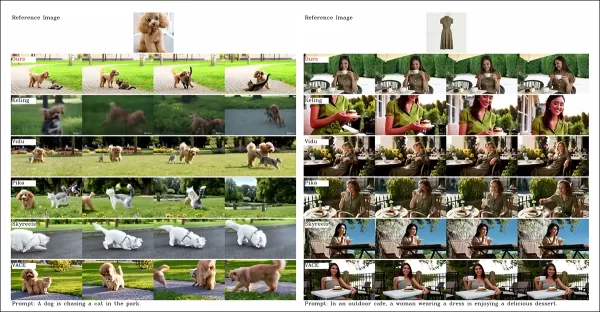
Из статьи, сравнение по настройке видео, ориентированной на объект. Хотя зритель должен обратиться к исходному PDF для лучшего разрешения, видео на сайте проекта предлагают более ясные выводы.
Авторы заявляют:
‘Vidu, SkyReels A2 и HunyuanCustom достигают сильного выравнивания запросов и согласованности субъекта, но качество нашего видео превосходит Vidu и SkyReels благодаря прочной основе Hunyuanvideo-13B.’
‘Среди коммерческих решений Kling обеспечивает высокое качество видео, но страдает от эффекта копирования-вставки в первом кадре и случайного размытия субъекта, влияющего на восприятие зрителя.’
Pika испытывает трудности с временной согласованностью, вводя артефакты субтитров из-за плохой курации данных. Hailuo сохраняет идентичность лица, но ошибается в согласованности всего тела. VACE, среди методов с открытым кодом, не поддерживает идентичность, тогда как HunyuanCustom обеспечивает сильное сохранение идентичности, качество и разнообразие.
Тесты на настройку многосубъектного видео дали схожие результаты:

Сравнения с использованием многосубъектной настройки видео. Пожалуйста, обратитесь к PDF для лучшей детализации и разрешения.
В статье отмечается:
‘Pika генерирует указанных субъектов, но показывает нестабильность кадров, с исчезновением субъектов или несоблюдением запросов. Vidu и VACE частично фиксируют человеческую идентичность, но теряют детали нечеловеческих объектов. SkyReels A2 страдает от сильной нестабильности кадров и артефактов. HunyuanCustom эффективно фиксирует все идентичности субъектов, следует запросам и поддерживает высокое визуальное качество и стабильность.’
Тест рекламы с виртуальным человеком интегрировал продукты с людьми:

Из раунда качественного тестирования, примеры нейронного ‘размещения продукта’. Пожалуйста, обратитесь к PDF для лучшей детализации и разрешения.
Авторы заявляют:
‘HunyuanCustom сохраняет человеческую идентичность и детали продукта, включая текст, с естественными взаимодействиями и сильным следованием запросам, демонстрируя потенциал для рекламных видео.’
Тесты настройки, управляемой аудио, выделили гибкое управление сценой и позой:
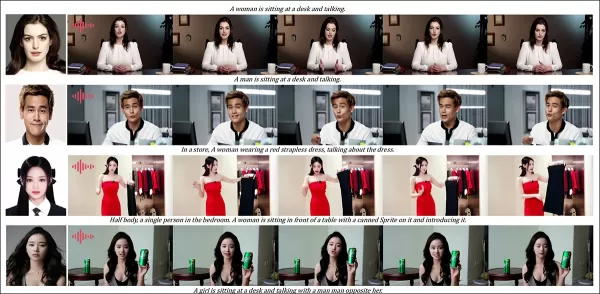
Частичные результаты для аудио-раунда — видео результаты были бы предпочтительнее. Показана только верхняя половина фигуры PDF из-за ограничений по размеру. Обратитесь к исходному PDF для лучшей детализации.
Авторы отмечают:
‘Предыдущие методы, управляемые аудио, ограничивают позу и окружение входным изображением, ограничивая приложения. HunyuanCustom позволяет гибкую анимацию, управляемую аудио, с текстовым описанием сцен и поз.’
Тесты замены субъекта в видео сравнивали HunyuanCustom с VACE и Kling 1.6:

Тестирование замены субъекта в режиме видео-видео. Пожалуйста, обратитесь к исходному PDF для лучшей детализации и разрешения.
Исследователи заявляют:
‘VACE создаёт артефакты границ из-за строгого соблюдения маски, нарушая непрерывность движения. Kling показывает эффект копирования-вставки с плохой интеграцией фона. HunyuanCustom избегает артефактов, обеспечивает бесшовную интеграцию и поддерживает сильное сохранение идентичности, выделяясь в редактировании видео.’
Заключение
HunyuanCustom — это впечатляющий релиз, отвечающий на растущий спрос на синхронизацию губ в видеосинтезе, повышая реализм в системах, таких как Hunyuan Video. Несмотря на трудности в сравнении его возможностей из-за компоновки видео на сайте проекта, модель Tencent держится наравне с ведущими конкурентами, такими как Kling, знаменуя значительный прогресс в настройке видео.
* Некоторые видео слишком широкие, короткие или с высоким разрешением для воспроизведения в стандартных плеерах, таких как VLC или Windows Media Player, отображая чёрные экраны.
Впервые опубликовано в четверг, 8 мая 2025 года
Связанная статья
 Эксклюзив: Luma AI представляет творческих агентов, основанных на моделях «унифицированного интеллекта»
В четверг стартап Luma, занимающийся созданием видео с помощью искусственного интеллекта, представил Luma Agents — систему, созданную для управления полным циклом творческого процесса, включая текст,
В новом обновлении Sora появились видеоролики с искусственным интеллектом домашних животных, социальные инструменты и грядущее приложение для Android.
Компания OpenAI анонсирует ряд новых функций для своего популярного приложения для создания видео с помощью искусственного интеллекта Sora, которое после запуска в конце сентября стремительно взлетело
Генерация видео ИИ движется к полному управлению
Модели видео фонда, такие как Hunyuan и WAN 2.1, добились значительных успехов, но они часто терпят неудачу, когда речь заходит о детальном управлении, необходимым для производства пленки и телевидения, особенно в сфере визуальных эффектов (VFX). В Professional VFX Studios эти модели, наряду с более ранними изображениями BAS
Рекомендации по связанным специальным темам
код
Эксклюзив: Luma AI представляет творческих агентов, основанных на моделях «унифицированного интеллекта»
В четверг стартап Luma, занимающийся созданием видео с помощью искусственного интеллекта, представил Luma Agents — систему, созданную для управления полным циклом творческого процесса, включая текст,
В новом обновлении Sora появились видеоролики с искусственным интеллектом домашних животных, социальные инструменты и грядущее приложение для Android.
Компания OpenAI анонсирует ряд новых функций для своего популярного приложения для создания видео с помощью искусственного интеллекта Sora, которое после запуска в конце сентября стремительно взлетело
Генерация видео ИИ движется к полному управлению
Модели видео фонда, такие как Hunyuan и WAN 2.1, добились значительных успехов, но они часто терпят неудачу, когда речь заходит о детальном управлении, необходимым для производства пленки и телевидения, особенно в сфере визуальных эффектов (VFX). В Professional VFX Studios эти модели, наряду с более ранними изображениями BAS
Рекомендации по связанным специальным темам
код
 Лучшие системы проверки кода на основе ИИ: автоматизация обеспечения соответствия стандартам чистого кода и рефакторинг файлов в устаревших репозиториях
Лучшие системы проверки кода на основе ИИ: автоматизация обеспечения соответствия стандартам чистого кода и рефакторинг файлов в устаревших репозиториях
Откройте для себя 20 лучших рецензентов кода на базе ИИ 2026 года на XIX.AI. В нашем тщательно составленном списке представлены высокооцененные, революционные инструменты для автоматизации проверки соответствия стандартам чистого кода и рефакторинга файлов в устаревших репозиториях. Сравните бесплатные и платные варианты с помощью реальных тестов и еженедельно обновляемых рейтингов. Получите преимущество ИИ уже сегодня.
 10 инструментов
10 инструментов
 xix.ai
Преобразование текста в речь
Лучшие приложения с функцией преобразования текста в речь на базе ИИ для детей с дислексией: помощь в обучении и повышение эффективности чтения
xix.ai
Преобразование текста в речь
Лучшие приложения с функцией преобразования текста в речь на базе ИИ для детей с дислексией: помощь в обучении и повышение эффективности чтения
Откройте для себя лучшие приложения с технологией TTS на базе искусственного интеллекта 2026 года, специально отобранные для помощи людям с дислексией. В нашем рейтинге экспертов сравниваются бесплатные и платные инструменты, а также освещаются мощные функции, способствующие повышению эффективности чтения и обучения. Откройте для себя революционные решения, которые обязательно стоит попробовать, чтобы раскрыть потенциал учащихся. Начните свое путешествие на XIX.AI.
10 инструментов
xix.ai
Создание комиксов
Лучшие генераторы на базе ИИ для сёнэн-манги: создавайте динамичные сцены боевых действий и эффекты энергии
Откройте для себя лучшие генераторы искусственного интеллекта для манги в стиле «сёнен» 2026 года на сайте XIX.AI. В нашем тщательно отобранном списке представлены мощные инструменты для создания динамичных сцен боевых действий и эффектных энергетических эффектов. Сравните бесплатные и платные варианты на основе реальных тестов. Раскройте свой творческий потенциал и начните создавать эпическую мангу уже сегодня!
15 инструментов
xix.ai
Бизнес
Лучшие приложения для учета расходов на базе ИИ: сканируйте чеки и автоматически классифицируйте корпоративные расходы
Лучшие программы для учета расходов с ИИ 2026 года: самые популярные инструменты для сканирования чеков и автоматической классификации корпоративных расходов. Откройте для себя мощные, революционные решения для удобного управления расходами, точного финансового мониторинга и оптимизации соблюдения нормативных требований. Наш тщательно составленный и еженедельно обновляемый обзор бесплатных и платных вариантов поможет вам найти идеальный вариант. Воспользуйтесь преимуществами ИИ с помощью рекомендаций экспертов XIX.AI.
10 инструментов
xix.ai
Бизнес
Лучшие инструменты для подбора персонала с помощью ИИ: отбор резюме и автоматизация планирования собеседований с кандидатами
Откройте для себя 20 лучших инструментов для рекрутинга на базе ИИ 2026 года на сайте XIX.AI. В нашем тщательно составленном списке представлены мощные, революционные решения для отбора резюме и автоматизации планирования собеседований с кандидатами. Сравните бесплатные и платные варианты с помощью реальных тестов и еженедельно обновляемого рейтинга. Найдите своего идеального помощника по подбору персонала и оптимизируйте процесс рекрутинга уже сегодня!
10 инструментов
xix.ai
Производительность
Персональные тренеры по благополучию и концентрации на базе ИИ: борьба с выгоранием и повышение уровня умственной энергии
Откройте для себя лучших в 2026 году ИИ-тренеров по личному благополучию и концентрации внимания на сайте XIX.AI. В нашем тщательно составленном рейтинге представлены высокооцененные, революционные инструменты для борьбы с выгоранием и повышения умственной энергии. Сравните бесплатные и платные варианты с помощью реальных отзывов. Откройте для себя путь к максимальной продуктивности и благополучию уже сегодня.
10 инструментов
xix.ai

 Комментарии (1)
Комментарии (1)
![RalphHill]()
Esse exemplo de vídeo parece meio bugado... Mas a ideia de transformar uma imagem estática em vídeo é fascinante. Será que isso poderia ser usado para criar conteúdos educativos ou de forma indevida? A discussão ética sempre fica atrás da tecnologia 🤔.
Эта статья посвящена запуску HunyuanCustom, мультимодальной модели генерации видео от Tencent. Обширный объем сопроводительной исследовательской статьи и проблемы с предоставленными примерами видео на странице проекта требуют более общего обзора, с ограниченным воспроизведением обширного видеоконтента из-за требований форматирования и обработки для повышения четкости.
Обратите внимание, что в статье API-генеративная система Kling называется ‘Keling’. Для единообразия в этой статье используется ‘Kling’.
Tencent представил продвинутую версию своей модели Hunyuan Video, названную HunyuanCustom. Сообщается, что эта версия превосходит необходимость в моделях Hunyuan LoRA, позволяя пользователям создавать видеонастройки в стиле дипфейк, используя только одно изображение:
Нажмите для воспроизведения. Запрос: ‘Мужчина наслаждается музыкой, готовя лапшу из улиток на кухне.’ По сравнению с проприетарными и открытыми методами, включая Kling, ключевого конкурента, HunyuanCustom выделяется. Источник: https://hunyuancustom.github.io/ (примечание: сайт с высокой нагрузкой)
В видео выше левая колонка показывает исходное изображение для HunyuanCustom, за которым следует интерпретация системой запроса в соседней колонке. Остальные колонки демонстрируют результаты других систем: Kling, Vidu, Pika, Hailuo и SkyReels-A2 (на базе Wan).
Следующее видео выделяет три основных сценария для этого релиза: человек с объектом, репликация одного персонажа и виртуальная примерка одежды:
Нажмите для воспроизведения. Три отобранных примера с сайта поддержки Hunyuan Video.
Эти примеры показывают ограничения, связанные с использованием одного исходного изображения вместо нескольких ракурсов.
В первом клипе мужчина смотрит в камеру с минимальным движением головы, наклоняясь не более чем на 20-25 градусов. За пределами этого система не может точно воспроизвести его профиль из одного фронтального изображения.
Во втором клипе девушка сохраняет улыбающееся выражение в видео, отражая её статичное исходное изображение. Без дополнительных референсов HunyuanCustom не может достоверно показать её нейтральное выражение, и её лицо остаётся преимущественно фронтальным, как в предыдущем примере.
В последнем клипе неполный исходный материал — женщина и виртуальная одежда — приводит к обрезанному рендеру, что является практичным решением для ограниченных данных.
Хотя HunyuanCustom поддерживает ввод нескольких изображений (например, человек с закусками или человек с одеждой), он не учитывает различные ракурсы или выражения для одного персонажа. Это может ограничить его способность полностью заменить расширяющуюся экосистему моделей LoRA для HunyuanVideo, которые используют 20-60 изображений для обеспечения согласованного отображения персонажа с разных ракурсов и выражений.
Интеграция аудио
Для аудио HunyuanCustom использует систему LatentSync, которую сложно настроить любителям, для синхронизации движений губ с предоставленным пользователем аудио и текстом:
Включает аудио. Нажмите для воспроизведения. Скомпилированные примеры синхронизации губ с дополнительного сайта HunyuanCustom.
На данный момент примеры на английском языке недоступны, но результаты кажутся многообещающими, особенно если процесс настройки удобен для пользователя.
Возможности редактирования видео
HunyuanCustom выделяется в редактировании видео-видео (V2V), позволяя целенаправленно заменять элементы в существующих видео с использованием одного референсного изображения. Пример из дополнительных материалов иллюстрирует это:
Нажмите для воспроизведения. Центральный объект изменён, с тонким изменением окружающих элементов в процессе V2V HunyuanCustom.
Как типично для рабочих процессов V2V, всё видео слегка модифицируется, с основным акцентом на целевую область, например, плюшевую игрушку. Продвинутые конвейеры могли бы потенциально сохранить больше оригинального контента, подобно подходу Adobe Firefly, хотя это остаётся малоизученным в сообществах с открытым кодом.
Другие примеры демонстрируют повышенную точность в целевых интеграциях, как видно в этой подборке:
Нажмите для воспроизведения. Разнообразные примеры вставки контента V2V в HunyuanCustom, с уважением к неизменённым элементам.
Эволюционное обновление
HunyuanCustom основывается на проекте Hunyuan Video, внедряя целевые архитектурные улучшения, а не полную переработку. Эти улучшения направлены на поддержание согласованности персонажа между кадрами без необходимости специфической настройки для объекта, например, LoRA или текстового инвертирования.
Этот релиз является усовершенствованной версией модели HunyuanVideo от декабря 2024 года, а не новой моделью, созданной с нуля.
Пользователи существующих LoRA для HunyuanVideo могут задаться вопросом о их совместимости с этим обновлением или о необходимости разработки новых LoRA для использования улучшенных функций настройки.
Обычно значительная тонкая настройка достаточно изменяет веса модели, чтобы сделать предыдущие LoRA несовместимыми. Однако некоторые тонкие настройки, такие как Pony Diffusion для Stable Diffusion XL, создали независимые экосистемы с выделенными библиотеками LoRA, что указывает на потенциал HunyuanCustom последовать этому примеру.
Детали выпуска
Исследовательская статья, озаглавленная HunyuanCustom: Мультимодальная архитектура для настройки видео, ссылается на репозиторий GitHub, теперь активный с кодом и весами для локального развертывания, а также запланированную интеграцию с ComfyUI.
В настоящее время страница проекта на Hugging Face недоступна, но демонстрация на основе API доступна через сканирование кода WeChat.
Сборка HunyuanCustom из различных проектов примечательно всеобъемлюща, вероятно, обусловлена требованиями лицензирования для полного раскрытия.
Предлагаются две версии модели: версия 720x1280px, требующая 80 ГБ памяти GPU для оптимальной производительности (24 ГБ минимум, но медленно) и версия 512x896px, требующая 60 ГБ. Тестирование ограничено Linux, но усилия сообщества могут скоро адаптировать её для Windows и конфигураций с меньшим объёмом VRAM, как это было с предыдущей моделью Hunyuan Video.
Из-за объёма сопроводительных материалов этот обзор принимает высокоуровневый подход к возможностям HunyuanCustom.
Технические детали
Конвейер данных HunyuanCustom, соответствующий GDPR, интегрирует синтезированные и открытые видеодатасеты, такие как OpenHumanVid, охватывающие восемь категорий: люди, животные, растения, пейзажи, транспорт, объекты, архитектура и аниме.
Из статьи о выпуске, обзор различных пакетов, участвующих в конвейере построения данных HunyuanCustom. Источник: https://arxiv.org/pdf/2505.04512
Видео сегментируются на однотипные клипы с помощью PySceneDetect, при этом TextBPN-Plus-Plus отфильтровывает контент с избыточным текстом, субтитрами или водяными знаками.
Клипы стандартизируются до пяти секунд и масштабируются до 512 или 720 пикселей по короткой стороне. Эстетическое качество обеспечивается с помощью Koala-36M с пользовательским порогом 0.06.
Извлечение человеческой идентичности использует Qwen7B, YOLO11X и InsightFace, тогда как нечеловеческие объекты обрабатываются с помощью QwenVL и Grounded SAM 2, отбрасывая маленькие ограничивающие рамки.
Примеры семантической сегментации с Grounded SAM 2, используемые в проекте Hunyuan Control. Источник: https://github.com/IDEA-Research/Grounded-SAM-2
Извлечение нескольких объектов использует Florence2 для аннотаций и Grounded SAM 2 для сегментации, с последующим кластерингом и временной сегментацией кадров.
Клипы улучшаются с помощью проприетарной структурированной разметки от команды Hunyuan, добавляя метаданные, такие как описания и подсказки о движении камеры.
Аугментация масок предотвращает переобучение, обеспечивая адаптивность к различным формам объектов. Синхронизация аудио использует LatentSync, отбрасывая клипы ниже порога качества. HyperIQA отфильтровывает видео с оценкой ниже 40, а Whisper обрабатывает валидное аудио для последующих задач.
Модель LLaVA играет центральную роль, генерируя подписи и выравнивая визуальный и текстовый контент для семантической согласованности, особенно в сложных или многосубъектных сценах.
Фреймворк HunyuanCustom поддерживает генерацию видео с сохранением идентичности, обусловленную текстом, изображением, аудио и видео входами.
Настройка видео
Для генерации видео из референсного изображения и запроса были разработаны два модуля на базе LLaVA, адаптирующие вход HunyuanVideo для принятия изображения и текста. Запросы встраивают изображения напрямую или помечают их краткими описаниями идентичности, используя разделительный токен для баланса влияния изображения и текста.
Модуль улучшения идентичности решает проблему потери LLaVA мелких пространственных деталей, критически важных для поддержания согласованности субъекта в коротких видеоклипах.
Референсное изображение масштабируется и кодируется через причинный 3D-VAE от HunyuanVideo, с его латентным вставленным по временной оси и пространственным смещением для управления генерацией без прямого копирования.
Обучение использовало Flow Matching с шумом из логит-нормального распределения, тонко настраивая LLaVA и видеогенератор вместе для согласованного управления изображением-запросом и сохранения идентичности.
Для многосубъектных запросов каждая пара изображение-текст встраивается отдельно с различными временными позициями, позволяя создавать сцены с несколькими взаимодействующими субъектами.
Интеграция аудио и визуала
HunyuanCustom поддерживает генерацию, управляемую аудио, с использованием предоставленного пользователем аудио и текста, позволяя персонажам говорить в контекстно релевантных условиях.
Модуль Identity-disentangled AudioNet выравнивает аудиофункции с временной шкалой видео, используя пространственное кросс-внимание для изоляции кадров и поддержания согласованности субъекта.
Модуль временного внедрения уточняет синхронизацию движений, отображая аудио на латентные последовательности через многослойный перцептрон, обеспечивая соответствие жестов ритму аудио.
Для редактирования видео HunyuanCustom заменяет субъекты в существующих клипах без перегенерации всего видео, что идеально для целевых изменений внешнего вида или движений.
Нажмите для воспроизведения. Ещё один пример с дополнительного сайта.
Система сжимает референсные видео с использованием предварительно обученного причинного 3D-VAE, выравнивая их с латентами конвейера генерации для лёгкой обработки. Нейронная сеть выравнивает чистые входные видео с шумными латентами, причём добавление функций покадрово оказалось более эффективным, чем предварительное слияние.
Оценка производительности
Метрики тестирования включали ArcFace для согласованности идентичности лица, YOLO11x и Dino 2 для сходства субъекта, CLIP-B для выравнивания текста и видео и временной согласованности, и VBench для интенсивности движения.
Конкуренты включали закрытые системы (Hailuo, Vidu 2.0, Kling 1.6, Pika) и фреймворки с открытым кодом (VACE, SkyReels-A2).
Оценка производительности модели, сравнивающая HunyuanCustom с ведущими методами настройки видео по согласованности идентичности (Face-Sim), сходству субъекта (DINO-Sim), выравниванию текста и видео (CLIP-B-T), временной согласованности (Temp-Consis) и интенсивности движения (DD). Оптимальные и субоптимальные результаты показаны жирным и подчёркнутым соответственно.
Авторы отмечают:
‘HunyuanCustom превосходит в согласованности идентичности и субъекта, с конкурентоспособным следованием запросам и временной стабильностью. Hailuo лидирует по клиповому счёту благодаря сильному выравниванию текста, но испытывает трудности с согласованностью нечеловеческих субъектов. Vidu и VACE отстают в интенсивности движения, вероятно, из-за меньших размеров моделей.’
Хотя сайт проекта предлагает множество сравнительных видео, их расположение приоритетно эстетике, а не удобству сравнения. Читателям рекомендуется напрямую просматривать видео для более ясных выводов:
Из статьи, сравнение по настройке видео, ориентированной на объект. Хотя зритель должен обратиться к исходному PDF для лучшего разрешения, видео на сайте проекта предлагают более ясные выводы.
Авторы заявляют:
‘Vidu, SkyReels A2 и HunyuanCustom достигают сильного выравнивания запросов и согласованности субъекта, но качество нашего видео превосходит Vidu и SkyReels благодаря прочной основе Hunyuanvideo-13B.’
‘Среди коммерческих решений Kling обеспечивает высокое качество видео, но страдает от эффекта копирования-вставки в первом кадре и случайного размытия субъекта, влияющего на восприятие зрителя.’
Pika испытывает трудности с временной согласованностью, вводя артефакты субтитров из-за плохой курации данных. Hailuo сохраняет идентичность лица, но ошибается в согласованности всего тела. VACE, среди методов с открытым кодом, не поддерживает идентичность, тогда как HunyuanCustom обеспечивает сильное сохранение идентичности, качество и разнообразие.
Тесты на настройку многосубъектного видео дали схожие результаты:
Сравнения с использованием многосубъектной настройки видео. Пожалуйста, обратитесь к PDF для лучшей детализации и разрешения.
В статье отмечается:
‘Pika генерирует указанных субъектов, но показывает нестабильность кадров, с исчезновением субъектов или несоблюдением запросов. Vidu и VACE частично фиксируют человеческую идентичность, но теряют детали нечеловеческих объектов. SkyReels A2 страдает от сильной нестабильности кадров и артефактов. HunyuanCustom эффективно фиксирует все идентичности субъектов, следует запросам и поддерживает высокое визуальное качество и стабильность.’
Тест рекламы с виртуальным человеком интегрировал продукты с людьми:
Из раунда качественного тестирования, примеры нейронного ‘размещения продукта’. Пожалуйста, обратитесь к PDF для лучшей детализации и разрешения.
Авторы заявляют:
‘HunyuanCustom сохраняет человеческую идентичность и детали продукта, включая текст, с естественными взаимодействиями и сильным следованием запросам, демонстрируя потенциал для рекламных видео.’
Тесты настройки, управляемой аудио, выделили гибкое управление сценой и позой:
Частичные результаты для аудио-раунда — видео результаты были бы предпочтительнее. Показана только верхняя половина фигуры PDF из-за ограничений по размеру. Обратитесь к исходному PDF для лучшей детализации.
Авторы отмечают:
‘Предыдущие методы, управляемые аудио, ограничивают позу и окружение входным изображением, ограничивая приложения. HunyuanCustom позволяет гибкую анимацию, управляемую аудио, с текстовым описанием сцен и поз.’
Тесты замены субъекта в видео сравнивали HunyuanCustom с VACE и Kling 1.6:
Тестирование замены субъекта в режиме видео-видео. Пожалуйста, обратитесь к исходному PDF для лучшей детализации и разрешения.
Исследователи заявляют:
‘VACE создаёт артефакты границ из-за строгого соблюдения маски, нарушая непрерывность движения. Kling показывает эффект копирования-вставки с плохой интеграцией фона. HunyuanCustom избегает артефактов, обеспечивает бесшовную интеграцию и поддерживает сильное сохранение идентичности, выделяясь в редактировании видео.’
Заключение
HunyuanCustom — это впечатляющий релиз, отвечающий на растущий спрос на синхронизацию губ в видеосинтезе, повышая реализм в системах, таких как Hunyuan Video. Несмотря на трудности в сравнении его возможностей из-за компоновки видео на сайте проекта, модель Tencent держится наравне с ведущими конкурентами, такими как Kling, знаменуя значительный прогресс в настройке видео.
* Некоторые видео слишком широкие, короткие или с высоким разрешением для воспроизведения в стандартных плеерах, таких как VLC или Windows Media Player, отображая чёрные экраны.
Впервые опубликовано в четверг, 8 мая 2025 года










 Эксклюзив: Luma AI представляет творческих агентов, основанных на моделях «унифицированного интеллекта»
В четверг стартап Luma, занимающийся созданием видео с помощью искусственного интеллекта, представил Luma Agents — систему, созданную для управления полным циклом творческого процесса, включая текст,
Эксклюзив: Luma AI представляет творческих агентов, основанных на моделях «унифицированного интеллекта»
В четверг стартап Luma, занимающийся созданием видео с помощью искусственного интеллекта, представил Luma Agents — систему, созданную для управления полным циклом творческого процесса, включая текст,
 В новом обновлении Sora появились видеоролики с искусственным интеллектом домашних животных, социальные инструменты и грядущее приложение для Android.
Компания OpenAI анонсирует ряд новых функций для своего популярного приложения для создания видео с помощью искусственного интеллекта Sora, которое после запуска в конце сентября стремительно взлетело
В новом обновлении Sora появились видеоролики с искусственным интеллектом домашних животных, социальные инструменты и грядущее приложение для Android.
Компания OpenAI анонсирует ряд новых функций для своего популярного приложения для создания видео с помощью искусственного интеллекта Sora, которое после запуска в конце сентября стремительно взлетело
 Генерация видео ИИ движется к полному управлению
Модели видео фонда, такие как Hunyuan и WAN 2.1, добились значительных успехов, но они часто терпят неудачу, когда речь заходит о детальном управлении, необходимым для производства пленки и телевидения, особенно в сфере визуальных эффектов (VFX). В Professional VFX Studios эти модели, наряду с более ранними изображениями BAS
Генерация видео ИИ движется к полному управлению
Модели видео фонда, такие как Hunyuan и WAN 2.1, добились значительных успехов, но они часто терпят неудачу, когда речь заходит о детальном управлении, необходимым для производства пленки и телевидения, особенно в сфере визуальных эффектов (VFX). В Professional VFX Studios эти модели, наряду с более ранними изображениями BAS

Откройте для себя 20 лучших рецензентов кода на базе ИИ 2026 года на XIX.AI. В нашем тщательно составленном списке представлены высокооцененные, революционные инструменты для автоматизации проверки соответствия стандартам чистого кода и рефакторинга файлов в устаревших репозиториях. Сравните бесплатные и платные варианты с помощью реальных тестов и еженедельно обновляемых рейтингов. Получите преимущество ИИ уже сегодня.
10 инструментов
xix.ai

Откройте для себя лучшие приложения с технологией TTS на базе искусственного интеллекта 2026 года, специально отобранные для помощи людям с дислексией. В нашем рейтинге экспертов сравниваются бесплатные и платные инструменты, а также освещаются мощные функции, способствующие повышению эффективности чтения и обучения. Откройте для себя революционные решения, которые обязательно стоит попробовать, чтобы раскрыть потенциал учащихся. Начните свое путешествие на XIX.AI.
10 инструментов
xix.ai

Откройте для себя лучшие генераторы искусственного интеллекта для манги в стиле «сёнен» 2026 года на сайте XIX.AI. В нашем тщательно отобранном списке представлены мощные инструменты для создания динамичных сцен боевых действий и эффектных энергетических эффектов. Сравните бесплатные и платные варианты на основе реальных тестов. Раскройте свой творческий потенциал и начните создавать эпическую мангу уже сегодня!
15 инструментов
xix.ai

Лучшие программы для учета расходов с ИИ 2026 года: самые популярные инструменты для сканирования чеков и автоматической классификации корпоративных расходов. Откройте для себя мощные, революционные решения для удобного управления расходами, точного финансового мониторинга и оптимизации соблюдения нормативных требований. Наш тщательно составленный и еженедельно обновляемый обзор бесплатных и платных вариантов поможет вам найти идеальный вариант. Воспользуйтесь преимуществами ИИ с помощью рекомендаций экспертов XIX.AI.
10 инструментов
xix.ai

Откройте для себя 20 лучших инструментов для рекрутинга на базе ИИ 2026 года на сайте XIX.AI. В нашем тщательно составленном списке представлены мощные, революционные решения для отбора резюме и автоматизации планирования собеседований с кандидатами. Сравните бесплатные и платные варианты с помощью реальных тестов и еженедельно обновляемого рейтинга. Найдите своего идеального помощника по подбору персонала и оптимизируйте процесс рекрутинга уже сегодня!
10 инструментов
xix.ai

Откройте для себя лучших в 2026 году ИИ-тренеров по личному благополучию и концентрации внимания на сайте XIX.AI. В нашем тщательно составленном рейтинге представлены высокооцененные, революционные инструменты для борьбы с выгоранием и повышения умственной энергии. Сравните бесплатные и платные варианты с помощью реальных отзывов. Откройте для себя путь к максимальной продуктивности и благополучию уже сегодня.
10 инструментов
xix.ai

Esse exemplo de vídeo parece meio bugado... Mas a ideia de transformar uma imagem estática em vídeo é fascinante. Será que isso poderia ser usado para criar conteúdos educativos ou de forma indevida? A discussão ética sempre fica atrás da tecnologia 🤔.













