
















 Maison
MaisonDeepcoder atteint une efficacité de codage élevée avec un modèle ouvert 14B
Présentation de DeepCoder-14B : Une nouvelle frontière dans les modèles de codage open-source
Les équipes de Together AI et Agentica ont dévoilé DeepCoder-14B, un modèle de codage révolutionnaire qui rivalise avec les modèles propriétaires de premier plan comme l'o3-mini d'OpenAI. Ce développement passionnant repose sur les bases de DeepSeek-R1 et offre une flexibilité accrue pour intégrer la génération de code et le raisonnement de haute performance dans des applications pratiques. De plus, les créateurs ont pris une initiative louable en rendant le modèle entièrement open-source, y compris ses données d'entraînement, son code, ses journaux et ses optimisations système. Cette démarche est destinée à catalyser la recherche et à accélérer les progrès dans le domaine.
Performance impressionnante dans un format compact
DeepCoder-14B a montré des résultats remarquables sur divers benchmarks de codage tels que LiveCodeBench (LCB), Codeforces et HumanEval+. Les expériences de l'équipe de recherche ont souligné que les performances du modèle sont comparables à celles des modèles leaders comme l'o3-mini (bas) et l'o1. « Notre modèle démontre une forte performance sur tous les benchmarks de codage... comparable aux performances de l'o3-mini (bas) et de l'o1 », ont fièrement déclaré les chercheurs dans leur billet de blog.
Ce qui est particulièrement intrigant, c'est que, bien qu'entraîné principalement sur des tâches de codage, DeepCoder-14B a également montré une amélioration notable dans le raisonnement mathématique, atteignant un score de 73,8 % sur le benchmark AIME 2024. Cela représente une augmentation de 4,1 % par rapport à son modèle de base, DeepSeek-R1-Distill-Qwen-14B, suggérant que les compétences de raisonnement développées grâce à l'apprentissage par renforcement (RL) sur le code peuvent être efficacement transférées à d'autres domaines.
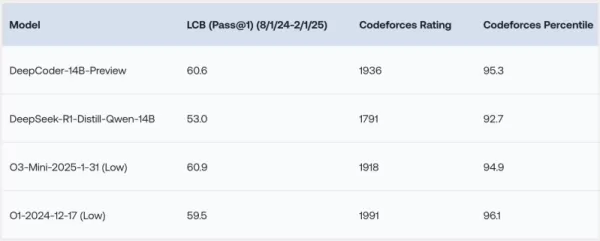
*Crédit : Together AI* La caractéristique peut-être la plus excitante de DeepCoder-14B est son efficacité. Avec seulement 14 milliards de paramètres, il atteint des performances élevées tout en étant significativement plus petit et plus économe en ressources que de nombreux autres modèles leaders.
Innovations derrière le succès de DeepCoder
Le développement de DeepCoder-14B a impliqué de surmonter plusieurs défis, notamment dans l'entraînement des modèles de codage à l'aide de l'apprentissage par renforcement. Un obstacle majeur était la curation des données d'entraînement. Contrairement aux tâches mathématiques, où les données de haute qualité et vérifiables sont abondantes, les données de codage peuvent être rares. L'équipe de DeepCoder a résolu ce problème en mettant en place un pipeline rigoureux pour collecter et filtrer des exemples provenant de divers ensembles de données, garantissant leur validité, leur complexité et évitant les duplications. Ce processus a abouti à 24 000 problèmes de haute qualité, qui ont constitué une base solide pour l'entraînement RL.
L'équipe a également conçu une fonction de récompense simple qui ne récompense le modèle que si le code généré passe avec succès tous les tests unitaires échantillonnés dans une limite de temps définie. Cette approche, couplée à des exemples d'entraînement de haute qualité, a garanti que le modèle se concentrait sur la résolution des problèmes centraux plutôt que d'exploiter des raccourcis.
L'algorithme d'entraînement de DeepCoder-14B est basé sur l'Optimisation de la Politique Relative de Groupe (GRPO), qui a réussi dans DeepSeek-R1. Cependant, l'équipe a apporté des modifications significatives pour améliorer la stabilité et permettre des durées d'entraînement plus longues.
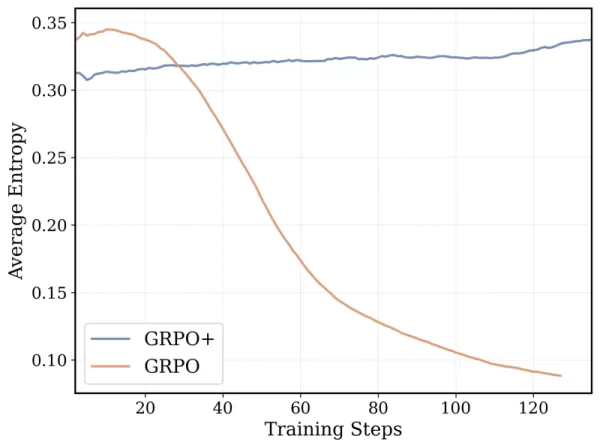
*GRPO+ permet à DeepCoder-14 de continuer sur de plus longues durées sans s'effondrer Crédit : Together AI* De plus, l'équipe a progressivement étendu la fenêtre de contexte du modèle, commençant par des séquences plus courtes et les augmentant graduellement. Ils ont également introduit une méthode de filtrage pour éviter de pénaliser le modèle lorsqu'il dépasse les limites de contexte en résolvant des prompts complexes.
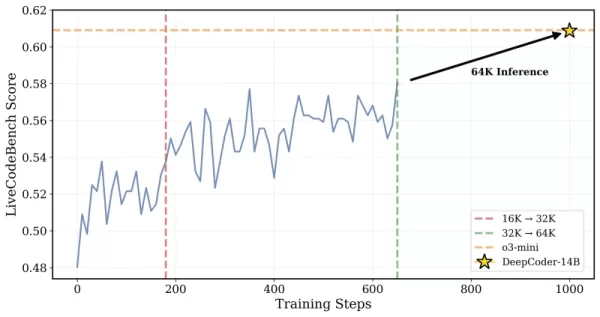
*DeepCoder a été entraîné sur des problèmes de contexte de 32K mais a également pu résoudre des tâches de 64K Crédit : Together AI* Les chercheurs ont expliqué leur approche : « Pour préserver le raisonnement sur de longs contextes tout en permettant un entraînement efficace, nous avons incorporé un filtrage des séquences trop longues... Cette technique masque les séquences tronquées pendant l'entraînement afin que les modèles ne soient pas pénalisés pour générer des sorties réfléchies mais longues qui dépassent la limite de contexte actuelle. » L'entraînement a évolué d'une fenêtre de contexte de 16K à 32K, permettant au modèle de s'attaquer à des problèmes nécessitant jusqu'à 64K tokens.
Optimisation de l'entraînement RL à long contexte
L'entraînement de grands modèles avec RL, en particulier sur des tâches qui génèrent de longues séquences comme le codage, est notoirement lent et gourmand en ressources. L'étape d'échantillonnage, où le modèle génère des milliers de tokens par exemple, entraîne souvent des retards significatifs en raison des longueurs de réponse variables.
Pour y remédier, l'équipe a développé verl-pipeline, une extension optimisée de la bibliothèque open-source verl pour l'apprentissage par renforcement à partir des retours humains (RLHF). Leur innovation « One-Off Pipelining » a restructuré l'échantillonnage et les mises à jour du modèle pour minimiser les goulots d'étranglement et réduire le temps d'inactivité des accélérateurs.
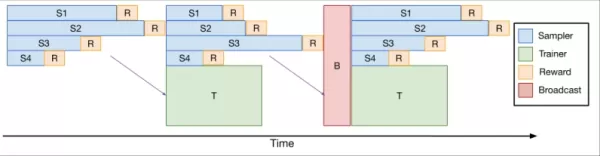
*One-Off Pipelining* Leurs expériences ont démontré que le pipelining one-off pouvait accélérer les tâches de codage RL jusqu'à 2 fois par rapport aux méthodes standard. Cette optimisation a été cruciale pour entraîner DeepCoder-14B dans un délai raisonnable (2,5 semaines sur 32 H100) et est maintenant open-source dans le cadre de verl-pipeline pour que la communauté puisse en tirer parti.
Impact sur les entreprises et collaboration open-source
Les chercheurs ont rendu tous les artefacts d'entraînement et opérationnels de DeepCoder-14B disponibles sur GitHub et Hugging Face sous une licence permissive. « En partageant entièrement notre ensemble de données, notre code et notre recette d'entraînement, nous permettons à la communauté de reproduire notre travail et de rendre l'entraînement RL accessible à tous », ont-ils déclaré.
DeepCoder-14B illustre la tendance croissante des modèles efficaces et accessibles publiquement dans le paysage de l'IA. Pour les entreprises, cela signifie plus d'options et une meilleure accessibilité aux modèles avancés. La génération de code et le raisonnement de haute performance ne sont plus exclusifs aux grandes entreprises ou à ceux prêts à payer des frais d'API élevés. Les organisations de toutes tailles peuvent désormais exploiter ces capacités, adapter des solutions à leurs besoins spécifiques et les déployer en toute sécurité dans leurs environnements.
Ce changement est prêt à abaisser les barrières à l'adoption de l'IA, favorisant un écosystème plus compétitif et innovant, stimulé par la collaboration open-source.
Article connexe
 Multiverse Computing lance un modèle d'IA générative compressé gratuit
Les grands modèles linguistiques sont confrontés à un défi de taille : leur taille immense. La start-up espagnole Multiverse Computing s'attaque à ce problème en créant des modèles compressés con
Des données de suivi secrètes révèlent le vol de modèles d'IA
Une nouvelle méthode permet d'apposer un filigrane invisible sur des modèles tels que ChatGPT en quelques secondes sans nécessiter de réentraînement, sans laisser de trace dans les sorties standard et
Des systèmes d'IA trompés pour approuver des articles scientifiques absurdes
De nouvelles recherches révèlent que les systèmes d'IA sont désormais capables de produire des articles scientifiques frauduleux que d'autres modèles d'IA acceptent à tort comme authentiques. Ces étud
Recommandations de sujets spéciaux liés
code
Multiverse Computing lance un modèle d'IA générative compressé gratuit
Les grands modèles linguistiques sont confrontés à un défi de taille : leur taille immense. La start-up espagnole Multiverse Computing s'attaque à ce problème en créant des modèles compressés con
Des données de suivi secrètes révèlent le vol de modèles d'IA
Une nouvelle méthode permet d'apposer un filigrane invisible sur des modèles tels que ChatGPT en quelques secondes sans nécessiter de réentraînement, sans laisser de trace dans les sorties standard et
Des systèmes d'IA trompés pour approuver des articles scientifiques absurdes
De nouvelles recherches révèlent que les systèmes d'IA sont désormais capables de produire des articles scientifiques frauduleux que d'autres modèles d'IA acceptent à tort comme authentiques. Ces étud
Recommandations de sujets spéciaux liés
code
 Meilleurs outils d'IA pour les tests unitaires automatisés : générer des cas de test Jest, PyTest et JUnit en un clic
Meilleurs outils d'IA pour les tests unitaires automatisés : générer des cas de test Jest, PyTest et JUnit en un clic
Découvrez les derniers outils d'IA hautement réputés de 2026 pour les tests unitaires automatisés. Notre sélection rigoureusement élaborée vous propose des solutions puissantes et révolutionnaires pour générer instantanément des cas de test Jest, PyTest et JUnit. Comparez les options gratuites et payantes à l'aide de tests réels et des classements mises à jour chaque semaine sur XIX.AI. Développez un avantage concurrentiel grâce à l'IA et améliorez rapidement votre productivité en développement.
 10 outils
10 outils
 xix.ai
Analyse des données
Les meilleurs outils de visualisation de données basés sur l'IA : générez automatiquement des tableaux de bord BI interactifs à partir de fichiers bruts
xix.ai
Analyse des données
Les meilleurs outils de visualisation de données basés sur l'IA : générez automatiquement des tableaux de bord BI interactifs à partir de fichiers bruts
Découvrez les meilleurs outils de visualisation de données par IA de 2026 sur XIX.AI. Notre sélection rigoureuse et hautement notée vous aide à générer instantanément et automatiquement des tableaux de bord BI puissants et interactifs à partir de fichiers bruts. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Libérez dès aujourd'hui le potentiel de vos données.
10 outils
xix.ai
Réseaux sociaux
Kits de marque basés sur l'IA pour les réseaux sociaux : assurez la cohérence visuelle de votre marque sur tous les canaux
Découvrez les meilleurs kits de branding IA pour les réseaux sociaux en 2026. La sélection de XIX.AI regroupe des outils de premier plan qui changent la donne et vous permettent de garantir une cohérence visuelle parfaite de votre marque sur tous les canaux. Comparez les options gratuites et payantes grâce à des tests concrets. Donnez dès aujourd'hui un coup de pouce visuel à votre marque.
10 outils
xix.ai
chatbot
Les meilleures applications de petite amie virtuelle et outils d'accompagnement IA pour les jeux de rôle (Guide 2026)
Découvrez les meilleurs outils d'IA de 2026 pour des jeux de rôle immersifs et des interactions enrichissantes. Le guide sélectionné par XIX.AI présente des applications puissantes et révolutionnaires, avec des classements mis à jour chaque semaine, des comparaisons entre versions gratuites et payantes, ainsi que des tests en conditions réelles. Trouvez le partenaire idéal et profitez dès aujourd'hui d'une compagnie numérique enrichissante.
10 outils
xix.ai
en écrivant
Les meilleurs assistants IA pour les genres xianxia et wuxia : rédigez des récits épiques de progression spirituelle et des chorégraphies d'arts martiaux
Découvrez les meilleurs assistants IA de 2026 pour créer des récits épiques de xianxia et de wuxia. La sélection de XIX.AI regroupe les outils les mieux notés et les plus innovants pour maîtriser la progression dans la voie de la cultivation et la chorégraphie des arts martiaux. Comparez les options gratuites et payantes grâce à des tests concrets. Libérez votre potentiel créatif et commencez à écrire dès aujourd'hui !
10 outils
xix.ai
code
Outils de codage pour applications mobiles AI : générer du code Flutter et React Native multiplateforme à partir de commandes.
Découvrez les 20 meilleurs outils de codage pour applications mobiles basées sur l'IA en 2026, conçus pour Flutter et React Native. Notre liste, soigneusement sélectionnée et hautement réputée, met en avant des solutions puissantes qui permettent de générer du code multiplateforme à partir de simples instructions. Comparez les options gratuites et payantes grâce à des tests pratiques. Accélérez votre développement et créez de meilleures applications. Consultez le classement sur XIX.AI dès maintenant !
10 outils
xix.ai

 commentaires (14)
commentaires (14)
![RyanTaylor]()
Interesting! I've been following the open-source vs. proprietary model race. DeepCoder-14B matching o3-mini is a big deal for accessibility. Hope this pushes the big players to open up more, or at least lower their prices. The compute cost for training these 14B models must be insane though. 🤔
![FrankRodriguez]()
Wow, DeepCoder-14B sounds like a game-changer! I'm stoked to see open-source models catching up to the big players. Can't wait to try it out for my side projects—hope it’s as fast as they claim! 🚀
![GregoryBaker]()
DeepCoder-14B sounds like a game-changer! Can't wait to try it out and see how it stacks up against the big players. 🚀
![BillyLewis]()
Wow, DeepCoder-14B sounds like a game-changer for open-source coding! I'm curious how it stacks up against o3-mini in real-world projects. Anyone tried it yet? 🚀
![RaymondWalker]()
¡DeepCoder-14B es una locura! Un modelo de código abierto que compite con los grandes. ¿Será el fin de los modelos propietarios? 🤔
![RalphGarcia]()
DeepCoder-14B、めっちゃ面白そう!😊 オープンソースでここまでできるなんて、コーディングの未来が楽しみ!
Présentation de DeepCoder-14B : Une nouvelle frontière dans les modèles de codage open-source
Les équipes de Together AI et Agentica ont dévoilé DeepCoder-14B, un modèle de codage révolutionnaire qui rivalise avec les modèles propriétaires de premier plan comme l'o3-mini d'OpenAI. Ce développement passionnant repose sur les bases de DeepSeek-R1 et offre une flexibilité accrue pour intégrer la génération de code et le raisonnement de haute performance dans des applications pratiques. De plus, les créateurs ont pris une initiative louable en rendant le modèle entièrement open-source, y compris ses données d'entraînement, son code, ses journaux et ses optimisations système. Cette démarche est destinée à catalyser la recherche et à accélérer les progrès dans le domaine.
Performance impressionnante dans un format compact
DeepCoder-14B a montré des résultats remarquables sur divers benchmarks de codage tels que LiveCodeBench (LCB), Codeforces et HumanEval+. Les expériences de l'équipe de recherche ont souligné que les performances du modèle sont comparables à celles des modèles leaders comme l'o3-mini (bas) et l'o1. « Notre modèle démontre une forte performance sur tous les benchmarks de codage... comparable aux performances de l'o3-mini (bas) et de l'o1 », ont fièrement déclaré les chercheurs dans leur billet de blog.
Ce qui est particulièrement intrigant, c'est que, bien qu'entraîné principalement sur des tâches de codage, DeepCoder-14B a également montré une amélioration notable dans le raisonnement mathématique, atteignant un score de 73,8 % sur le benchmark AIME 2024. Cela représente une augmentation de 4,1 % par rapport à son modèle de base, DeepSeek-R1-Distill-Qwen-14B, suggérant que les compétences de raisonnement développées grâce à l'apprentissage par renforcement (RL) sur le code peuvent être efficacement transférées à d'autres domaines.
La caractéristique peut-être la plus excitante de DeepCoder-14B est son efficacité. Avec seulement 14 milliards de paramètres, il atteint des performances élevées tout en étant significativement plus petit et plus économe en ressources que de nombreux autres modèles leaders.
Innovations derrière le succès de DeepCoder
Le développement de DeepCoder-14B a impliqué de surmonter plusieurs défis, notamment dans l'entraînement des modèles de codage à l'aide de l'apprentissage par renforcement. Un obstacle majeur était la curation des données d'entraînement. Contrairement aux tâches mathématiques, où les données de haute qualité et vérifiables sont abondantes, les données de codage peuvent être rares. L'équipe de DeepCoder a résolu ce problème en mettant en place un pipeline rigoureux pour collecter et filtrer des exemples provenant de divers ensembles de données, garantissant leur validité, leur complexité et évitant les duplications. Ce processus a abouti à 24 000 problèmes de haute qualité, qui ont constitué une base solide pour l'entraînement RL.
L'équipe a également conçu une fonction de récompense simple qui ne récompense le modèle que si le code généré passe avec succès tous les tests unitaires échantillonnés dans une limite de temps définie. Cette approche, couplée à des exemples d'entraînement de haute qualité, a garanti que le modèle se concentrait sur la résolution des problèmes centraux plutôt que d'exploiter des raccourcis.
L'algorithme d'entraînement de DeepCoder-14B est basé sur l'Optimisation de la Politique Relative de Groupe (GRPO), qui a réussi dans DeepSeek-R1. Cependant, l'équipe a apporté des modifications significatives pour améliorer la stabilité et permettre des durées d'entraînement plus longues.
De plus, l'équipe a progressivement étendu la fenêtre de contexte du modèle, commençant par des séquences plus courtes et les augmentant graduellement. Ils ont également introduit une méthode de filtrage pour éviter de pénaliser le modèle lorsqu'il dépasse les limites de contexte en résolvant des prompts complexes.
Les chercheurs ont expliqué leur approche : « Pour préserver le raisonnement sur de longs contextes tout en permettant un entraînement efficace, nous avons incorporé un filtrage des séquences trop longues... Cette technique masque les séquences tronquées pendant l'entraînement afin que les modèles ne soient pas pénalisés pour générer des sorties réfléchies mais longues qui dépassent la limite de contexte actuelle. » L'entraînement a évolué d'une fenêtre de contexte de 16K à 32K, permettant au modèle de s'attaquer à des problèmes nécessitant jusqu'à 64K tokens.
Optimisation de l'entraînement RL à long contexte
L'entraînement de grands modèles avec RL, en particulier sur des tâches qui génèrent de longues séquences comme le codage, est notoirement lent et gourmand en ressources. L'étape d'échantillonnage, où le modèle génère des milliers de tokens par exemple, entraîne souvent des retards significatifs en raison des longueurs de réponse variables.
Pour y remédier, l'équipe a développé verl-pipeline, une extension optimisée de la bibliothèque open-source verl pour l'apprentissage par renforcement à partir des retours humains (RLHF). Leur innovation « One-Off Pipelining » a restructuré l'échantillonnage et les mises à jour du modèle pour minimiser les goulots d'étranglement et réduire le temps d'inactivité des accélérateurs.
Leurs expériences ont démontré que le pipelining one-off pouvait accélérer les tâches de codage RL jusqu'à 2 fois par rapport aux méthodes standard. Cette optimisation a été cruciale pour entraîner DeepCoder-14B dans un délai raisonnable (2,5 semaines sur 32 H100) et est maintenant open-source dans le cadre de verl-pipeline pour que la communauté puisse en tirer parti.
Impact sur les entreprises et collaboration open-source
Les chercheurs ont rendu tous les artefacts d'entraînement et opérationnels de DeepCoder-14B disponibles sur GitHub et Hugging Face sous une licence permissive. « En partageant entièrement notre ensemble de données, notre code et notre recette d'entraînement, nous permettons à la communauté de reproduire notre travail et de rendre l'entraînement RL accessible à tous », ont-ils déclaré.
DeepCoder-14B illustre la tendance croissante des modèles efficaces et accessibles publiquement dans le paysage de l'IA. Pour les entreprises, cela signifie plus d'options et une meilleure accessibilité aux modèles avancés. La génération de code et le raisonnement de haute performance ne sont plus exclusifs aux grandes entreprises ou à ceux prêts à payer des frais d'API élevés. Les organisations de toutes tailles peuvent désormais exploiter ces capacités, adapter des solutions à leurs besoins spécifiques et les déployer en toute sécurité dans leurs environnements.
Ce changement est prêt à abaisser les barrières à l'adoption de l'IA, favorisant un écosystème plus compétitif et innovant, stimulé par la collaboration open-source.










 Multiverse Computing lance un modèle d'IA générative compressé gratuit
Les grands modèles linguistiques sont confrontés à un défi de taille : leur taille immense. La start-up espagnole Multiverse Computing s'attaque à ce problème en créant des modèles compressés con
Multiverse Computing lance un modèle d'IA générative compressé gratuit
Les grands modèles linguistiques sont confrontés à un défi de taille : leur taille immense. La start-up espagnole Multiverse Computing s'attaque à ce problème en créant des modèles compressés con
 Des données de suivi secrètes révèlent le vol de modèles d'IA
Une nouvelle méthode permet d'apposer un filigrane invisible sur des modèles tels que ChatGPT en quelques secondes sans nécessiter de réentraînement, sans laisser de trace dans les sorties standard et
Des données de suivi secrètes révèlent le vol de modèles d'IA
Une nouvelle méthode permet d'apposer un filigrane invisible sur des modèles tels que ChatGPT en quelques secondes sans nécessiter de réentraînement, sans laisser de trace dans les sorties standard et
 Des systèmes d'IA trompés pour approuver des articles scientifiques absurdes
De nouvelles recherches révèlent que les systèmes d'IA sont désormais capables de produire des articles scientifiques frauduleux que d'autres modèles d'IA acceptent à tort comme authentiques. Ces étud
Des systèmes d'IA trompés pour approuver des articles scientifiques absurdes
De nouvelles recherches révèlent que les systèmes d'IA sont désormais capables de produire des articles scientifiques frauduleux que d'autres modèles d'IA acceptent à tort comme authentiques. Ces étud

Découvrez les derniers outils d'IA hautement réputés de 2026 pour les tests unitaires automatisés. Notre sélection rigoureusement élaborée vous propose des solutions puissantes et révolutionnaires pour générer instantanément des cas de test Jest, PyTest et JUnit. Comparez les options gratuites et payantes à l'aide de tests réels et des classements mises à jour chaque semaine sur XIX.AI. Développez un avantage concurrentiel grâce à l'IA et améliorez rapidement votre productivité en développement.
10 outils
xix.ai

Découvrez les meilleurs outils de visualisation de données par IA de 2026 sur XIX.AI. Notre sélection rigoureuse et hautement notée vous aide à générer instantanément et automatiquement des tableaux de bord BI puissants et interactifs à partir de fichiers bruts. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Libérez dès aujourd'hui le potentiel de vos données.
10 outils
xix.ai

Découvrez les meilleurs kits de branding IA pour les réseaux sociaux en 2026. La sélection de XIX.AI regroupe des outils de premier plan qui changent la donne et vous permettent de garantir une cohérence visuelle parfaite de votre marque sur tous les canaux. Comparez les options gratuites et payantes grâce à des tests concrets. Donnez dès aujourd'hui un coup de pouce visuel à votre marque.
10 outils
xix.ai

Découvrez les meilleurs outils d'IA de 2026 pour des jeux de rôle immersifs et des interactions enrichissantes. Le guide sélectionné par XIX.AI présente des applications puissantes et révolutionnaires, avec des classements mis à jour chaque semaine, des comparaisons entre versions gratuites et payantes, ainsi que des tests en conditions réelles. Trouvez le partenaire idéal et profitez dès aujourd'hui d'une compagnie numérique enrichissante.
10 outils
xix.ai

Découvrez les meilleurs assistants IA de 2026 pour créer des récits épiques de xianxia et de wuxia. La sélection de XIX.AI regroupe les outils les mieux notés et les plus innovants pour maîtriser la progression dans la voie de la cultivation et la chorégraphie des arts martiaux. Comparez les options gratuites et payantes grâce à des tests concrets. Libérez votre potentiel créatif et commencez à écrire dès aujourd'hui !
10 outils
xix.ai

Découvrez les 20 meilleurs outils de codage pour applications mobiles basées sur l'IA en 2026, conçus pour Flutter et React Native. Notre liste, soigneusement sélectionnée et hautement réputée, met en avant des solutions puissantes qui permettent de générer du code multiplateforme à partir de simples instructions. Comparez les options gratuites et payantes grâce à des tests pratiques. Accélérez votre développement et créez de meilleures applications. Consultez le classement sur XIX.AI dès maintenant !
10 outils
xix.ai

Interesting! I've been following the open-source vs. proprietary model race. DeepCoder-14B matching o3-mini is a big deal for accessibility. Hope this pushes the big players to open up more, or at least lower their prices. The compute cost for training these 14B models must be insane though. 🤔
Wow, DeepCoder-14B sounds like a game-changer! I'm stoked to see open-source models catching up to the big players. Can't wait to try it out for my side projects—hope it’s as fast as they claim! 🚀
DeepCoder-14B sounds like a game-changer! Can't wait to try it out and see how it stacks up against the big players. 🚀
Wow, DeepCoder-14B sounds like a game-changer for open-source coding! I'm curious how it stacks up against o3-mini in real-world projects. Anyone tried it yet? 🚀
¡DeepCoder-14B es una locura! Un modelo de código abierto que compite con los grandes. ¿Será el fin de los modelos propietarios? 🤔
DeepCoder-14B、めっちゃ面白そう!😊 オープンソースでここまでできるなんて、コーディングの未来が楽しみ!













