




डीपकोडर 14 बी ओपन मॉडल के साथ उच्च कोडिंग दक्षता प्राप्त करता है
डीपकोडर-14B का परिचय: ओपन-सोर्स कोडिंग मॉडल में नया मोर्चा
टूगेदर AI और एजेंटिका की टीमों ने डीपकोडर-14B का अनावरण किया है, जो एक क्रांतिकारी कोडिंग मॉडल है जो OpenAI के o3-mini जैसे शीर्ष-स्तरीय मालिकाना मॉडलों के साथ कंधे से कंधा मिलाकर चलता है। यह रोमांचक विकास डीपसीक-R1 की नींव पर बनाया गया है और उच्च-प्रदर्शन कोड जनरेशन और तर्क को व्यावहारिक अनुप्रयोगों में एकीकृत करने के लिए बेहतर लचीलापन प्रदान करता है। इसके अलावा, निर्माताओं ने मॉडल को पूरी तरह से ओपन-सोर्स करने का सराहनीय कदम उठाया है, जिसमें इसके प्रशिक्षण डेटा, कोड, लॉग और सिस्टम अनुकूलन शामिल हैं। यह कदम अनुसंधान को उत्प्रेरित करने और क्षेत्र में प्रगति को तेज करने के लिए तैयार है।
कॉम्पैक्ट पैकेज में प्रभावशाली प्रदर्शन
डीपकोडर-14B ने लाइवकोडबेंच (LCB), कोडफोर्सेस, और ह्यूमनएवैल+ जैसे विभिन्न कोडिंग बेंचमार्क में उल्लेखनीय परिणाम दिखाए हैं। शोध टीम के प्रयोगों ने उजागर किया है कि मॉडल का प्रदर्शन o3-mini (लो) और o1 जैसे अग्रणी मॉडलों के बराबर है। "हमारा मॉडल सभी कोडिंग बेंचमार्क में मजबूत प्रदर्शन प्रदर्शित करता है... o3-mini (लो) और o1 के प्रदर्शन के बराबर," शोधकर्ताओं ने अपने ब्लॉग पोस्ट में गर्व से कहा।
विशेष रूप से दिलचस्प बात यह है कि, मुख्य रूप से कोडिंग कार्यों पर प्रशिक्षित होने के बावजूद, डीपकोडर-14B ने गणितीय तर्क में भी उल्लेखनीय सुधार दिखाया है, जो AIME 2024 बेंचमार्क में 73.8% स्कोर प्राप्त करता है। यह इसके आधार मॉडल, डीपसीक-R1-डिस्टिल-क्वेन-14B, से 4.1% की वृद्धि को दर्शाता है, जो सुझाव देता है कि कोड पर रीइन्फोर्समेंट लर्निंग (RL) के माध्यम से विकसित तर्क कौशल अन्य डोमेन में प्रभावी ढंग से स्थानांतरित हो सकते हैं।
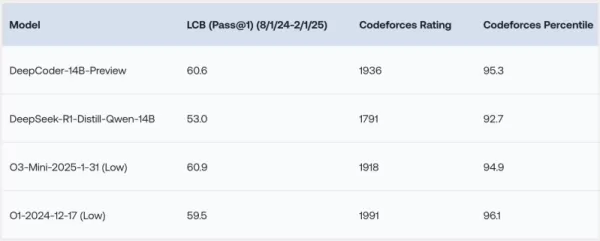
*क्रेडिट: टूगेदर AI* शायद डीपकोडर-14B की सबसे रोमांचक विशेषता इसकी दक्षता है। केवल 14 बिलियन पैरामीटर के साथ, यह कई अन्य अग्रणी मॉडलों की तुलना में काफी छोटा और अधिक संसाधन-कुशल होने के बावजूद उच्च प्रदर्शन प्राप्त करता है।
डीपकोडर की सफलता के पीछे नवाचार
डीपकोडर-14B को विकसित करने में कई चुनौतियों को पार करना शामिल था, विशेष रूप से रीइन्फोर्समेंट लर्निंग का उपयोग करके कोडिंग मॉडल को प्रशिक्षित करने में। एक प्रमुख बाधा प्रशिक्षण डेटा का संग्रह था। गणितीय कार्यों के विपरीत, जहां उच्च-गुणवत्ता, सत्यापनीय डेटा प्रचुर मात्रा में है, कोडिंग डेटा दुर्लभ हो सकता है। डीपकोडर टीम ने विभिन्न डेटासेट से उदाहरण एकत्र करने और फ़िल्टर करने के लिए एक कठोर पाइपलाइन लागू करके इस समस्या का समाधान किया, जिससे वैधता, जटिलता और दोहराव से बचाव सुनिश्चित हुआ। इस प्रक्रिया के परिणामस्वरूप 24,000 उच्च-गुणवत्ता वाले समस्याएं प्राप्त हुईं, जो RL प्रशिक्षण के लिए एक मजबूत नींव बनीं।
टीम ने एक सीधी पुरस्कार फ़ंक्शन भी तैयार की जो मॉडल को केवल तभी पुरस्कृत करती है जब जनरेट किया गया कोड निर्धारित समय सीमा के भीतर सभी नमूना यूनिट टेस्ट पास करता है। इस दृष्टिकोण ने, उच्च-गुणवत्ता वाले प्रशिक्षण उदाहरणों के साथ मिलकर, यह सुनिश्चित किया कि मॉडल शॉर्टकट का दुरुपयोग करने के बजाय मुख्य समस्याओं को हल करने पर केंद्रित रहे।
डीपकोडर-14B का प्रशिक्षण एल्गोरिदम ग्रुप रिलेटिव पॉलिसी ऑप्टिमाइज़ेशन (GRPO) पर आधारित है, जो डीपसीक-R1 में सफल रहा था। हालांकि, टीम ने स्थिरता बढ़ाने और लंबे प्रशिक्षण अवधि को सक्षम करने के लिए महत्वपूर्ण संशोधन किए।
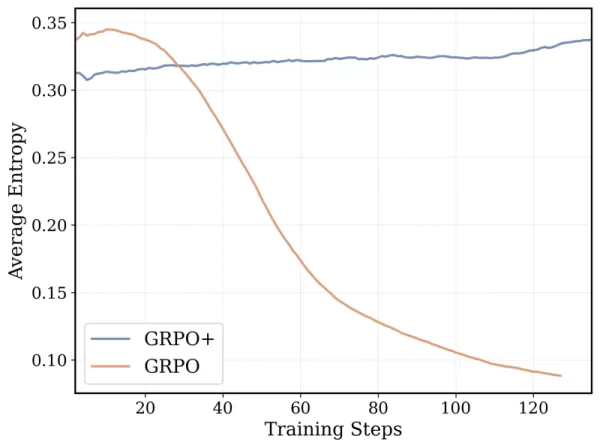
*GRPO+ डीपकोडर-14 को बिना ढहने के लिए लंबी अवधि तक चलने में सक्षम बनाता है क्रेडिट: टूगेदर AI* इसके अतिरिक्त, टीम ने मॉडल के संदर्भ खिड़की को पुनरावृत्त रूप से विस्तारित किया, छोटे अनुक्रमों से शुरू करके और धीरे-धीरे उन्हें बढ़ाया। उन्होंने जटिल संकेतों को हल करते समय संदर्भ सीमा से अधिक होने के लिए मॉडल को दंडित करने से बचने के लिए एक फ़िल्टरिंग विधि भी शुरू की।
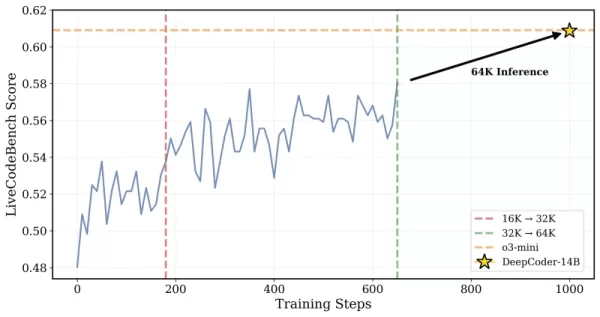
*डीपकोडर को 32K संदर्भ समस्याओं पर प्रशिक्षित किया गया था लेकिन यह 64K कार्यों को भी हल करने में सक्षम था क्रेडिट: टूगेदर AI* शोधकर्ताओं ने अपने दृष्टिकोण को समझाया: "लंबे-संदर्भ तर्क को संरक्षित करने के लिए, जबकि कुशल प्रशिक्षण को सक्षम करने के लिए, हमने ओवरलॉन्ग फ़िल्टरिंग को शामिल किया... यह तकनीक प्रशिक्षण के दौरान कटे हुए अनुक्रमों को मास्क करती है ताकि मॉडल को विचारशील लेकिन लंबे आउटपुट जनरेट करने के लिए दंडित न किया जाए जो वर्तमान संदर्भ सीमा से अधिक हो।" प्रशिक्षण 16K से 32K संदर्भ खिड़की तक स्केल किया गया, जिससे मॉडल 64K टोकन तक की आवश्यकता वाली समस्याओं से निपटने में सक्षम हुआ।
लंबे-संदर्भ RL प्रशिक्षण का अनुकूलन
लंबे अनुक्रम उत्पन्न करने वाले कार्यों, जैसे कोडिंग, पर RL के साथ बड़े मॉडलों को प्रशिक्षित करना कुख्यात रूप से धीमा और संसाधन-गहन है। नमूना चरण, जहां मॉडल प्रत्येक उदाहरण के लिए हजारों टोकन उत्पन्न करता है, अक्सर विभिन्न प्रतिक्रिया लंबाई के कारण महत्वपूर्ण देरी का कारण बनता है।
इसका समाधान करने के लिए, टीम ने verl-pipeline विकसित की, जो मानव प्रतिक्रिया से रीइन्फोर्समेंट लर्निंग (RLHF) के लिए ओपन-सोर्स verl लाइब्रेरी का एक अनुकूलित विस्तार है। उनकी "वन-ऑफ पाइपलाइनिंग" नवाचार ने नमूना और मॉडल अपडेट को पुनर्गठित किया ताकि बाधाओं को कम किया जा सके और एक्सेलेरेटर पर निष्क्रिय समय को कम किया जा सके।
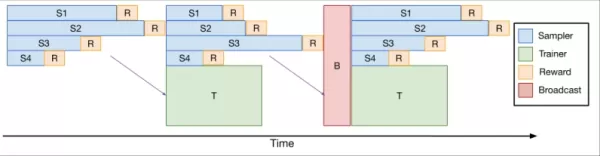
*वन-ऑफ पाइपलाइनिंग* उनके प्रयोगों ने प्रदर्शित किया कि वन-ऑफ पाइपलाइनिंग मानक विधियों की तुलना में कोडिंग RL कार्यों को 2 गुना तक तेज कर सकती है। यह अनुकूलन डीपकोडर-14B को उचित समयसीमा (32 H100 पर 2.5 सप्ताह) में प्रशिक्षित करने में महत्वपूर्ण था और अब इसे verl-pipeline के हिस्से के रूप में समुदाय के लिए ओपन-सोर्स किया गया है।
उद्यम प्रभाव और ओपन-सोर्स सहयोग
शोधकर्ताओं ने डीपकोडर-14B के सभी प्रशिक्षण और परिचालन आर्टिफैक्ट्स को GitHub और Hugging Face पर एक उदार लाइसेंस के तहत उपलब्ध कराया है। "हमारे डेटासेट, कोड, और प्रशिक्षण रेसिपी को पूरी तरह से साझा करके, हम समुदाय को हमारे काम को पुन: उत्पन्न करने और RL प्रशिक्षण को सभी के लिए सुलभ बनाने के लिए सशक्त करते हैं," उन्होंने कहा।
डीपकोडर-14B AI परिदृश्य में कुशल, खुले तौर पर सुलभ मॉडलों की बढ़ती प्रवृत्ति का उदाहरण देता है। उद्यमों के लिए, इसका मतलब है अधिक विकल्प और उन्नत मॉडलों तक अधिक पहुंच। उच्च-प्रदर्शन कोड जनरेशन और तर्क अब बड़े निगमों या भारी API शुल्क देने वालों तक सीमित नहीं हैं। सभी आकार के संगठन अब इन क्षमताओं का उपयोग कर सकते हैं, अपनी विशिष्ट आवश्यकताओं के लिए समाधान तैयार कर सकते हैं, और उन्हें अपने परिवेश में सुरक्षित रूप से तैनात कर सकते हैं।
यह बदलाव AI को अपनाने की बाधाओं को कम करने के लिए तैयार है, जो ओपन-सोर्स सहयोग द्वारा संचालित एक अधिक प्रतिस्पर्धी और नवाचारपूर्ण पारिस्थितिकी तंत्र को बढ़ावा देता है।
संबंधित लेख
 Microsoft Study Reveals AI Models' Limitations in Software Debugging
OpenAI, Anthropic और अन्य प्रमुख AI लैब्स के AI मॉडल कोडिंग कार्यों के लिए तेजी से उपयोग किए जा रहे हैं। Google CEO Sundar Pichai ने अक्टूबर में नोट किया कि AI कंपनी में 25% नए कोड जनरेट करता है, जबकि
AI-चालित समाधान वैश्विक कार्बन उत्सर्जन को काफी हद तक कम कर सकते हैं
लंदन स्कूल ऑफ इकोनॉमिक्स और सिस्टमिक के एक हालिया अध्ययन से पता चलता है कि कृत्रिम बुद्धिमत्ता (AI) आधुनिक सुविधाओं को त्यागे बिना वैश्विक कार्बन उत्सर्जन को काफी हद तक कम कर सकती है, जिससे AI जलवायु
ओटावा अस्पताल AI एम्बिएंट वॉयस कैप्चर का उपयोग कैसे करता है ताकि चिकित्सकों का बर्नआउट 70% कम हो और 97% रोगी संतुष्टि प्राप्त हो
AI कैसे बदल रहा है स्वास्थ्य सेवा: बर्नआउट कम करना और रोगी देखभाल में सुधारचुनौती: चिकित्सक अधिभार और रोगी पहुंचविश्व भर में स्वास्थ्य सेवा प्रणालियां दोहरी चुनौती का सामना कर रही हैं: चिकित्सक बर्नआउ
सूचना (11)
0/200
Microsoft Study Reveals AI Models' Limitations in Software Debugging
OpenAI, Anthropic और अन्य प्रमुख AI लैब्स के AI मॉडल कोडिंग कार्यों के लिए तेजी से उपयोग किए जा रहे हैं। Google CEO Sundar Pichai ने अक्टूबर में नोट किया कि AI कंपनी में 25% नए कोड जनरेट करता है, जबकि
AI-चालित समाधान वैश्विक कार्बन उत्सर्जन को काफी हद तक कम कर सकते हैं
लंदन स्कूल ऑफ इकोनॉमिक्स और सिस्टमिक के एक हालिया अध्ययन से पता चलता है कि कृत्रिम बुद्धिमत्ता (AI) आधुनिक सुविधाओं को त्यागे बिना वैश्विक कार्बन उत्सर्जन को काफी हद तक कम कर सकती है, जिससे AI जलवायु
ओटावा अस्पताल AI एम्बिएंट वॉयस कैप्चर का उपयोग कैसे करता है ताकि चिकित्सकों का बर्नआउट 70% कम हो और 97% रोगी संतुष्टि प्राप्त हो
AI कैसे बदल रहा है स्वास्थ्य सेवा: बर्नआउट कम करना और रोगी देखभाल में सुधारचुनौती: चिकित्सक अधिभार और रोगी पहुंचविश्व भर में स्वास्थ्य सेवा प्रणालियां दोहरी चुनौती का सामना कर रही हैं: चिकित्सक बर्नआउ
सूचना (11)
0/200
![BillyLewis]() BillyLewis
BillyLewis
 6 अगस्त 2025 12:31:06 अपराह्न IST
6 अगस्त 2025 12:31:06 अपराह्न IST
Wow, DeepCoder-14B sounds like a game-changer for open-source coding! I'm curious how it stacks up against o3-mini in real-world projects. Anyone tried it yet? 🚀


 0
0
![RaymondWalker]() RaymondWalker
25 अप्रैल 2025 8:51:57 पूर्वाह्न IST
RaymondWalker
25 अप्रैल 2025 8:51:57 पूर्वाह्न IST
¡DeepCoder-14B es una locura! Un modelo de código abierto que compite con los grandes. ¿Será el fin de los modelos propietarios? 🤔
0
![RalphGarcia]() RalphGarcia
24 अप्रैल 2025 9:51:21 अपराह्न IST
RalphGarcia
24 अप्रैल 2025 9:51:21 अपराह्न IST
DeepCoder-14B、めっちゃ面白そう!😊 オープンソースでここまでできるなんて、コーディングの未来が楽しみ!
0
![SebastianAnderson]() SebastianAnderson
24 अप्रैल 2025 1:16:12 अपराह्न IST
SebastianAnderson
24 अप्रैल 2025 1:16:12 अपराह्न IST
¡DeepCoder-14B es una bestia! Es increíble cómo puede codificar tan eficientemente, casi como tener a un programador de primera a mano. Lo he usado en proyectos complejos y ha acertado cada vez. Lo único es que puede ser un poco lento en mi vieja laptop. Aún así, una herramienta sólida para cualquier programador! 🤓💻
0
![TerryAdams]() TerryAdams
24 अप्रैल 2025 1:08:28 अपराह्न IST
TerryAdams
24 अप्रैल 2025 1:08:28 अपराह्न IST
DeepCoder-14B, c’est impressionnant ! Un modèle open-source qui rivalise avec les géants, ça donne envie de tester. 🖥️
0
![JimmyJohnson]() JimmyJohnson
24 अप्रैल 2025 12:36:50 अपराह्न IST
JimmyJohnson
24 अप्रैल 2025 12:36:50 अपराह्न IST
DeepCoder-14B é uma fera! É incrível como ele consegue codificar tão eficientemente, quase como ter um programador de primeira linha à disposição. Usei em projetos complexos e ele acertou em cheio todas as vezes. A única coisa é que pode ser um pouco lento no meu velho laptop. Ainda assim, uma ferramenta sólida para qualquer programador! 🤓💻
0
डीपकोडर-14B का परिचय: ओपन-सोर्स कोडिंग मॉडल में नया मोर्चा
टूगेदर AI और एजेंटिका की टीमों ने डीपकोडर-14B का अनावरण किया है, जो एक क्रांतिकारी कोडिंग मॉडल है जो OpenAI के o3-mini जैसे शीर्ष-स्तरीय मालिकाना मॉडलों के साथ कंधे से कंधा मिलाकर चलता है। यह रोमांचक विकास डीपसीक-R1 की नींव पर बनाया गया है और उच्च-प्रदर्शन कोड जनरेशन और तर्क को व्यावहारिक अनुप्रयोगों में एकीकृत करने के लिए बेहतर लचीलापन प्रदान करता है। इसके अलावा, निर्माताओं ने मॉडल को पूरी तरह से ओपन-सोर्स करने का सराहनीय कदम उठाया है, जिसमें इसके प्रशिक्षण डेटा, कोड, लॉग और सिस्टम अनुकूलन शामिल हैं। यह कदम अनुसंधान को उत्प्रेरित करने और क्षेत्र में प्रगति को तेज करने के लिए तैयार है।
कॉम्पैक्ट पैकेज में प्रभावशाली प्रदर्शन
डीपकोडर-14B ने लाइवकोडबेंच (LCB), कोडफोर्सेस, और ह्यूमनएवैल+ जैसे विभिन्न कोडिंग बेंचमार्क में उल्लेखनीय परिणाम दिखाए हैं। शोध टीम के प्रयोगों ने उजागर किया है कि मॉडल का प्रदर्शन o3-mini (लो) और o1 जैसे अग्रणी मॉडलों के बराबर है। "हमारा मॉडल सभी कोडिंग बेंचमार्क में मजबूत प्रदर्शन प्रदर्शित करता है... o3-mini (लो) और o1 के प्रदर्शन के बराबर," शोधकर्ताओं ने अपने ब्लॉग पोस्ट में गर्व से कहा।
विशेष रूप से दिलचस्प बात यह है कि, मुख्य रूप से कोडिंग कार्यों पर प्रशिक्षित होने के बावजूद, डीपकोडर-14B ने गणितीय तर्क में भी उल्लेखनीय सुधार दिखाया है, जो AIME 2024 बेंचमार्क में 73.8% स्कोर प्राप्त करता है। यह इसके आधार मॉडल, डीपसीक-R1-डिस्टिल-क्वेन-14B, से 4.1% की वृद्धि को दर्शाता है, जो सुझाव देता है कि कोड पर रीइन्फोर्समेंट लर्निंग (RL) के माध्यम से विकसित तर्क कौशल अन्य डोमेन में प्रभावी ढंग से स्थानांतरित हो सकते हैं।
शायद डीपकोडर-14B की सबसे रोमांचक विशेषता इसकी दक्षता है। केवल 14 बिलियन पैरामीटर के साथ, यह कई अन्य अग्रणी मॉडलों की तुलना में काफी छोटा और अधिक संसाधन-कुशल होने के बावजूद उच्च प्रदर्शन प्राप्त करता है।
डीपकोडर की सफलता के पीछे नवाचार
डीपकोडर-14B को विकसित करने में कई चुनौतियों को पार करना शामिल था, विशेष रूप से रीइन्फोर्समेंट लर्निंग का उपयोग करके कोडिंग मॉडल को प्रशिक्षित करने में। एक प्रमुख बाधा प्रशिक्षण डेटा का संग्रह था। गणितीय कार्यों के विपरीत, जहां उच्च-गुणवत्ता, सत्यापनीय डेटा प्रचुर मात्रा में है, कोडिंग डेटा दुर्लभ हो सकता है। डीपकोडर टीम ने विभिन्न डेटासेट से उदाहरण एकत्र करने और फ़िल्टर करने के लिए एक कठोर पाइपलाइन लागू करके इस समस्या का समाधान किया, जिससे वैधता, जटिलता और दोहराव से बचाव सुनिश्चित हुआ। इस प्रक्रिया के परिणामस्वरूप 24,000 उच्च-गुणवत्ता वाले समस्याएं प्राप्त हुईं, जो RL प्रशिक्षण के लिए एक मजबूत नींव बनीं।
टीम ने एक सीधी पुरस्कार फ़ंक्शन भी तैयार की जो मॉडल को केवल तभी पुरस्कृत करती है जब जनरेट किया गया कोड निर्धारित समय सीमा के भीतर सभी नमूना यूनिट टेस्ट पास करता है। इस दृष्टिकोण ने, उच्च-गुणवत्ता वाले प्रशिक्षण उदाहरणों के साथ मिलकर, यह सुनिश्चित किया कि मॉडल शॉर्टकट का दुरुपयोग करने के बजाय मुख्य समस्याओं को हल करने पर केंद्रित रहे।
डीपकोडर-14B का प्रशिक्षण एल्गोरिदम ग्रुप रिलेटिव पॉलिसी ऑप्टिमाइज़ेशन (GRPO) पर आधारित है, जो डीपसीक-R1 में सफल रहा था। हालांकि, टीम ने स्थिरता बढ़ाने और लंबे प्रशिक्षण अवधि को सक्षम करने के लिए महत्वपूर्ण संशोधन किए।
इसके अतिरिक्त, टीम ने मॉडल के संदर्भ खिड़की को पुनरावृत्त रूप से विस्तारित किया, छोटे अनुक्रमों से शुरू करके और धीरे-धीरे उन्हें बढ़ाया। उन्होंने जटिल संकेतों को हल करते समय संदर्भ सीमा से अधिक होने के लिए मॉडल को दंडित करने से बचने के लिए एक फ़िल्टरिंग विधि भी शुरू की।
शोधकर्ताओं ने अपने दृष्टिकोण को समझाया: "लंबे-संदर्भ तर्क को संरक्षित करने के लिए, जबकि कुशल प्रशिक्षण को सक्षम करने के लिए, हमने ओवरलॉन्ग फ़िल्टरिंग को शामिल किया... यह तकनीक प्रशिक्षण के दौरान कटे हुए अनुक्रमों को मास्क करती है ताकि मॉडल को विचारशील लेकिन लंबे आउटपुट जनरेट करने के लिए दंडित न किया जाए जो वर्तमान संदर्भ सीमा से अधिक हो।" प्रशिक्षण 16K से 32K संदर्भ खिड़की तक स्केल किया गया, जिससे मॉडल 64K टोकन तक की आवश्यकता वाली समस्याओं से निपटने में सक्षम हुआ।
लंबे-संदर्भ RL प्रशिक्षण का अनुकूलन
लंबे अनुक्रम उत्पन्न करने वाले कार्यों, जैसे कोडिंग, पर RL के साथ बड़े मॉडलों को प्रशिक्षित करना कुख्यात रूप से धीमा और संसाधन-गहन है। नमूना चरण, जहां मॉडल प्रत्येक उदाहरण के लिए हजारों टोकन उत्पन्न करता है, अक्सर विभिन्न प्रतिक्रिया लंबाई के कारण महत्वपूर्ण देरी का कारण बनता है।
इसका समाधान करने के लिए, टीम ने verl-pipeline विकसित की, जो मानव प्रतिक्रिया से रीइन्फोर्समेंट लर्निंग (RLHF) के लिए ओपन-सोर्स verl लाइब्रेरी का एक अनुकूलित विस्तार है। उनकी "वन-ऑफ पाइपलाइनिंग" नवाचार ने नमूना और मॉडल अपडेट को पुनर्गठित किया ताकि बाधाओं को कम किया जा सके और एक्सेलेरेटर पर निष्क्रिय समय को कम किया जा सके।
उनके प्रयोगों ने प्रदर्शित किया कि वन-ऑफ पाइपलाइनिंग मानक विधियों की तुलना में कोडिंग RL कार्यों को 2 गुना तक तेज कर सकती है। यह अनुकूलन डीपकोडर-14B को उचित समयसीमा (32 H100 पर 2.5 सप्ताह) में प्रशिक्षित करने में महत्वपूर्ण था और अब इसे verl-pipeline के हिस्से के रूप में समुदाय के लिए ओपन-सोर्स किया गया है।
उद्यम प्रभाव और ओपन-सोर्स सहयोग
शोधकर्ताओं ने डीपकोडर-14B के सभी प्रशिक्षण और परिचालन आर्टिफैक्ट्स को GitHub और Hugging Face पर एक उदार लाइसेंस के तहत उपलब्ध कराया है। "हमारे डेटासेट, कोड, और प्रशिक्षण रेसिपी को पूरी तरह से साझा करके, हम समुदाय को हमारे काम को पुन: उत्पन्न करने और RL प्रशिक्षण को सभी के लिए सुलभ बनाने के लिए सशक्त करते हैं," उन्होंने कहा।
डीपकोडर-14B AI परिदृश्य में कुशल, खुले तौर पर सुलभ मॉडलों की बढ़ती प्रवृत्ति का उदाहरण देता है। उद्यमों के लिए, इसका मतलब है अधिक विकल्प और उन्नत मॉडलों तक अधिक पहुंच। उच्च-प्रदर्शन कोड जनरेशन और तर्क अब बड़े निगमों या भारी API शुल्क देने वालों तक सीमित नहीं हैं। सभी आकार के संगठन अब इन क्षमताओं का उपयोग कर सकते हैं, अपनी विशिष्ट आवश्यकताओं के लिए समाधान तैयार कर सकते हैं, और उन्हें अपने परिवेश में सुरक्षित रूप से तैनात कर सकते हैं।
यह बदलाव AI को अपनाने की बाधाओं को कम करने के लिए तैयार है, जो ओपन-सोर्स सहयोग द्वारा संचालित एक अधिक प्रतिस्पर्धी और नवाचारपूर्ण पारिस्थितिकी तंत्र को बढ़ावा देता है।










 Microsoft Study Reveals AI Models' Limitations in Software Debugging
OpenAI, Anthropic और अन्य प्रमुख AI लैब्स के AI मॉडल कोडिंग कार्यों के लिए तेजी से उपयोग किए जा रहे हैं। Google CEO Sundar Pichai ने अक्टूबर में नोट किया कि AI कंपनी में 25% नए कोड जनरेट करता है, जबकि
AI-चालित समाधान वैश्विक कार्बन उत्सर्जन को काफी हद तक कम कर सकते हैं
लंदन स्कूल ऑफ इकोनॉमिक्स और सिस्टमिक के एक हालिया अध्ययन से पता चलता है कि कृत्रिम बुद्धिमत्ता (AI) आधुनिक सुविधाओं को त्यागे बिना वैश्विक कार्बन उत्सर्जन को काफी हद तक कम कर सकती है, जिससे AI जलवायु
Microsoft Study Reveals AI Models' Limitations in Software Debugging
OpenAI, Anthropic और अन्य प्रमुख AI लैब्स के AI मॉडल कोडिंग कार्यों के लिए तेजी से उपयोग किए जा रहे हैं। Google CEO Sundar Pichai ने अक्टूबर में नोट किया कि AI कंपनी में 25% नए कोड जनरेट करता है, जबकि
AI-चालित समाधान वैश्विक कार्बन उत्सर्जन को काफी हद तक कम कर सकते हैं
लंदन स्कूल ऑफ इकोनॉमिक्स और सिस्टमिक के एक हालिया अध्ययन से पता चलता है कि कृत्रिम बुद्धिमत्ता (AI) आधुनिक सुविधाओं को त्यागे बिना वैश्विक कार्बन उत्सर्जन को काफी हद तक कम कर सकती है, जिससे AI जलवायु
 ओटावा अस्पताल AI एम्बिएंट वॉयस कैप्चर का उपयोग कैसे करता है ताकि चिकित्सकों का बर्नआउट 70% कम हो और 97% रोगी संतुष्टि प्राप्त हो
AI कैसे बदल रहा है स्वास्थ्य सेवा: बर्नआउट कम करना और रोगी देखभाल में सुधारचुनौती: चिकित्सक अधिभार और रोगी पहुंचविश्व भर में स्वास्थ्य सेवा प्रणालियां दोहरी चुनौती का सामना कर रही हैं: चिकित्सक बर्नआउ
6 अगस्त 2025 12:31:06 अपराह्न IST
ओटावा अस्पताल AI एम्बिएंट वॉयस कैप्चर का उपयोग कैसे करता है ताकि चिकित्सकों का बर्नआउट 70% कम हो और 97% रोगी संतुष्टि प्राप्त हो
AI कैसे बदल रहा है स्वास्थ्य सेवा: बर्नआउट कम करना और रोगी देखभाल में सुधारचुनौती: चिकित्सक अधिभार और रोगी पहुंचविश्व भर में स्वास्थ्य सेवा प्रणालियां दोहरी चुनौती का सामना कर रही हैं: चिकित्सक बर्नआउ
6 अगस्त 2025 12:31:06 अपराह्न IST
Wow, DeepCoder-14B sounds like a game-changer for open-source coding! I'm curious how it stacks up against o3-mini in real-world projects. Anyone tried it yet? 🚀
0
25 अप्रैल 2025 8:51:57 पूर्वाह्न IST
¡DeepCoder-14B es una locura! Un modelo de código abierto que compite con los grandes. ¿Será el fin de los modelos propietarios? 🤔
0
24 अप्रैल 2025 9:51:21 अपराह्न IST
DeepCoder-14B、めっちゃ面白そう!😊 オープンソースでここまでできるなんて、コーディングの未来が楽しみ!
0
24 अप्रैल 2025 1:16:12 अपराह्न IST
¡DeepCoder-14B es una bestia! Es increíble cómo puede codificar tan eficientemente, casi como tener a un programador de primera a mano. Lo he usado en proyectos complejos y ha acertado cada vez. Lo único es que puede ser un poco lento en mi vieja laptop. Aún así, una herramienta sólida para cualquier programador! 🤓💻
0
24 अप्रैल 2025 1:08:28 अपराह्न IST
DeepCoder-14B, c’est impressionnant ! Un modèle open-source qui rivalise avec les géants, ça donne envie de tester. 🖥️
0
24 अप्रैल 2025 12:36:50 अपराह्न IST
DeepCoder-14B é uma fera! É incrível como ele consegue codificar tão eficientemente, quase como ter um programador de primeira linha à disposição. Usei em projetos complexos e ele acertou em cheio todas as vezes. A única coisa é que pode ser um pouco lento no meu velho laptop. Ainda assim, uma ferramenta sólida para qualquer programador! 🤓💻
0













