
















 首页
首页DeepCoder通过14B开放模型实现高编码效率
介绍DeepCoder-14B:开源编码模型的新前沿
Together AI和Agentica的团队推出了DeepCoder-14B,这是一个突破性的编码模型,与OpenAI的o3-mini等顶级专有模型不相上下。这一激动人心的发展基于DeepSeek-R1,提供了更高的灵活性,用于将高性能代码生成和推理集成到实际应用中。更令人称赞的是,创建者完全开源了该模型,包括其训练数据、代码、日志和系统优化。这一举措将催化研究并加速该领域的进步。
小巧包装中的出色性能
DeepCoder-14B在LiveCodeBench (LCB)、Codeforces和HumanEval+等多种编码基准测试中表现出色。研究团队的实验表明,该模型的性能与o3-mini(低配版)和o1等领先模型相当。研究人员在博客文章中自豪地表示:“我们的模型在所有编码基准测试中表现出色……与o3-mini(低配版)和o1的性能相当。”
特别引人注目的是,尽管主要针对编码任务进行训练,DeepCoder-14B在数学推理方面也显示出显著提升,在AIME 2024基准测试中取得了73.8%的得分。这比其基础模型DeepSeek-R1-Distill-Qwen-14B提高了4.1%,表明通过强化学习(RL)在代码上培养的推理技能可以有效转移到其他领域。
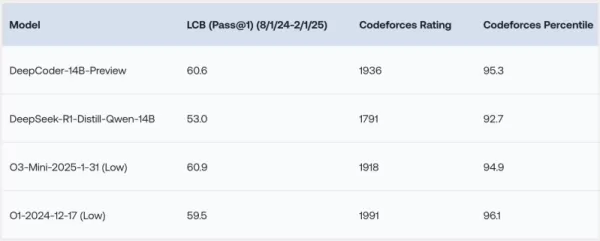
*来源:Together AI* DeepCoder-14B最激动人心的特点或许是其效率。仅拥有140亿个参数,它实现了高性能,同时比许多其他领先模型更小巧、更节省资源。
DeepCoder成功的创新
开发DeepCoder-14B涉及克服多个挑战,特别是在使用强化学习训练编码模型时。一个主要障碍是训练数据的筛选。与数学任务不同,高品质、可验证的编码数据较为稀缺。DeepCoder团队通过实施严格的流程,从各种数据集中收集和过滤示例,确保有效性、复杂性和避免重复,解决了这一问题。这一过程产生了24,000个高质量问题,为强化学习训练奠定了坚实基础。
团队还设计了一个简单的奖励函数,仅在生成代码成功通过所有采样单元测试并在设定时间限制内完成时奖励模型。这种方法结合高质量训练示例,确保模型专注于解决核心问题,而不是利用捷径。
DeepCoder-14B的训练算法基于Group Relative Policy Optimization (GRPO),这在DeepSeek-R1中已取得成功。然而,团队进行了重大修改,以增强稳定性和支持更长时间的训练。
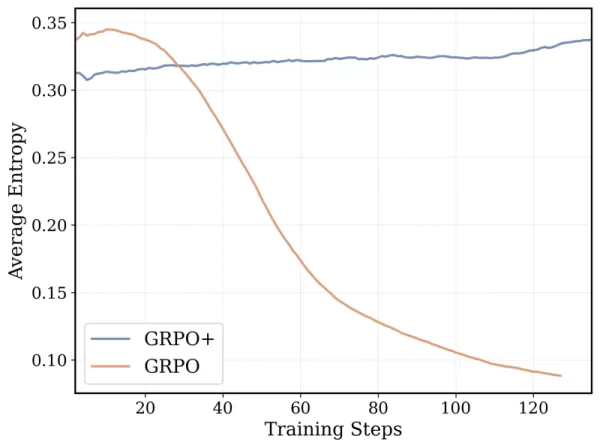
*GRPO+使DeepCoder-14能够持续更长时间而不崩溃 来源:Together AI* 此外,团队逐步扩展了模型的上下文窗口,从较短的序列开始,逐渐增加长度。他们还引入了一种过滤方法,以避免在解决复杂提示时因超出上下文限制而惩罚模型。
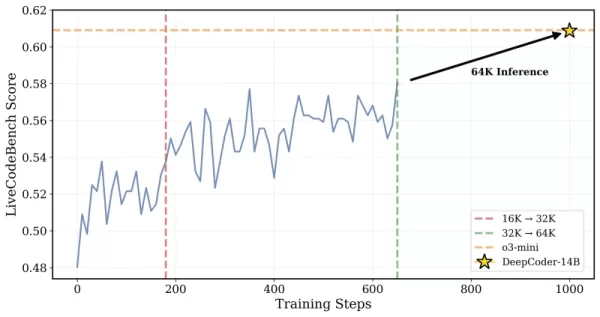
*DeepCoder在32K上下文问题上训练,但也能解决64K任务 来源:Together AI* 研究人员解释了他们的方法:“为了在保持长上下文推理的同时实现高效训练,我们引入了超长过滤……这种技术在训练期间屏蔽截断序列,使模型不会因生成深思熟虑但超出当前上下文限制的冗长输出而受到惩罚。”训练从16K扩展到32K上下文窗口,使模型能够处理需要高达64K令牌的问题。
优化长上下文强化学习训练
使用强化学习训练大型模型,尤其是在生成长序列的任务(如编码)时,速度慢且资源密集。采样步骤中,模型为每个示例生成数千个令牌,因响应长度不同常导致显著延迟。
为此,团队开发了verl-pipeline,这是开源verl库的优化扩展,用于基于人类反馈的强化学习(RLHF)。他们的“One-Off Pipelining”创新重构了采样和模型更新,以最小化瓶颈并减少加速器的空闲时间。
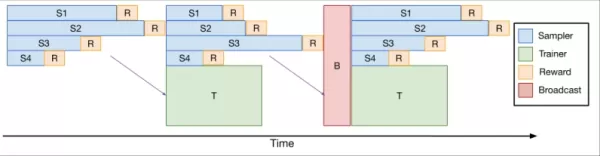
*One-Off Pipelining* 他们的实验表明,one-off pipelining可以将编码强化学习任务的速度提高至标准方法的两倍。这种优化对于在合理时间内(32个H100上2.5周)训练DeepCoder-14B至关重要,现已作为verl-pipeline的一部分开源,供社区使用。
企业影响与开源协作
研究人员已在GitHub和Hugging Face上以宽松许可公开了DeepCoder-14B的所有训练和操作工件。他们表示:“通过完全共享我们的数据集、代码和训练配方,我们赋予社区重现我们工作的能力,并使强化学习训练对所有人可及。”
DeepCoder-14B体现了AI领域高效、开放可访问模型的增长趋势。对于企业而言,这意味着更多选择和对高级模型的更大可访问性。高性能代码生成和推理不再是大公司或愿意支付高昂API费用的组织的专属。各种规模的组织现在都可以利用这些能力,定制适合其特定需求的解决方案,并在其环境中安全部署。
这一转变有望降低AI采用的门槛,促进由开源协作驱动的更具竞争力和创新性的生态系统。
相关文章
 Multiverse Computing推出免费压缩生成式AI模型
大型语言模型面临着一个重大挑战:其庞大的体量。西班牙初创公司Multiverse Computing正通过创建压缩模型来解决这一问题,旨在弥合尖端人工智能能力与企业实际可负担实施能力之间的差距。其核心创新在于CompactifAI压缩技术——这项受量子计算原理启发的技术已被这家巴斯克公司用于优化OpenAI的模型。从今天起,开发者可在Hugging Face平台免费获取Multiverse增强版H
秘密追踪数据揭露人工智能模型被盗事件
一种新方法能在数秒内对ChatGPT等模型进行隐形水印处理,无需重新训练,既不会在标准输出中留下痕迹,又能抵御所有实际的去除尝试。 水印技术与"版权诱饵"的关键区别在于:无论可见或隐形的水印,通常都设计为贯穿整个集合(如图像数据集)的持续性威慑手段,以防范随意复制。而虚构条目则是将一小段文本(通常为单词或定义)植入大型通用集合中,旨在证明盗用行为。其原理在于:当作品被直接盗用或作为衍生作品基础时,
人工智能系统被诱骗批准荒谬的科学论文
最新研究表明,人工智能系统现已能够生成虚假科学论文,且其他AI模型会将其误认为真实研究。这些伪造的研究绕过了以往有效的检测方法,凸显出科研生态系统可能陷入机器人欺骗机器人的循环漩涡,面临崩溃风险。 具有讽刺意味的是,作为人工智能创新前沿的学术研究领域,正面临着主要由人工智能引发的可信度危机。自四年前机器学习的潜在影响显现以来,其已深刻重塑了研究、投稿和同行评审流程。最新争议涉及低质量调查论文的批量
相关专题推荐
代码
Multiverse Computing推出免费压缩生成式AI模型
大型语言模型面临着一个重大挑战:其庞大的体量。西班牙初创公司Multiverse Computing正通过创建压缩模型来解决这一问题,旨在弥合尖端人工智能能力与企业实际可负担实施能力之间的差距。其核心创新在于CompactifAI压缩技术——这项受量子计算原理启发的技术已被这家巴斯克公司用于优化OpenAI的模型。从今天起,开发者可在Hugging Face平台免费获取Multiverse增强版H
秘密追踪数据揭露人工智能模型被盗事件
一种新方法能在数秒内对ChatGPT等模型进行隐形水印处理,无需重新训练,既不会在标准输出中留下痕迹,又能抵御所有实际的去除尝试。 水印技术与"版权诱饵"的关键区别在于:无论可见或隐形的水印,通常都设计为贯穿整个集合(如图像数据集)的持续性威慑手段,以防范随意复制。而虚构条目则是将一小段文本(通常为单词或定义)植入大型通用集合中,旨在证明盗用行为。其原理在于:当作品被直接盗用或作为衍生作品基础时,
人工智能系统被诱骗批准荒谬的科学论文
最新研究表明,人工智能系统现已能够生成虚假科学论文,且其他AI模型会将其误认为真实研究。这些伪造的研究绕过了以往有效的检测方法,凸显出科研生态系统可能陷入机器人欺骗机器人的循环漩涡,面临崩溃风险。 具有讽刺意味的是,作为人工智能创新前沿的学术研究领域,正面临着主要由人工智能引发的可信度危机。自四年前机器学习的潜在影响显现以来,其已深刻重塑了研究、投稿和同行评审流程。最新争议涉及低质量调查论文的批量
相关专题推荐
代码
 最适合自动化单元测试的最佳AI工具:一键生成Jest、PyTest和JUnit测试用例
最适合自动化单元测试的最佳AI工具:一键生成Jest、PyTest和JUnit测试用例
探索2026年最新评选出的顶级AI工具,这些工具专为自动化单元测试而设计。我们精心挑选了那些功能强大、能够改变开发流程的工具,它们能够帮助您快速生成Jest、PyTest和JUnit测试用例。在XIX.AI平台上,您可以免费查看各种选项,并通过实际测试结果以及每周更新的排名来了解它们的优劣。立即利用这些AI工具,提升您的开发效率吧!
 10 个工具
10 个工具
 xix.ai
数据分析
最佳 AI 数据可视化工具:从原始文件自动生成交互式 BI 仪表盘
xix.ai
数据分析
最佳 AI 数据可视化工具:从原始文件自动生成交互式 BI 仪表盘
在 XIX.AI 探索 2026 年最佳 AI 数据可视化工具。我们精心挑选的顶级工具助您即时从原始文件中自动生成功能强大且交互式的商业智能仪表盘。通过实际测试和每周更新的排行榜,对比免费与付费选项。立即释放您数据的潜力。
10 个工具
xix.ai
社交媒体
适用于社交媒体的 AI 品牌工具包:在所有渠道保持品牌视觉形象的一致性
探索2026年最优秀的社交媒体AI品牌设计套件。XIX.AI精心整理的这份清单汇集了广受好评、具有颠覆性的工具,助您在所有渠道上保持品牌视觉形象的完美一致性。通过实际测试对比免费与付费选项。立即为您的品牌解锁视觉优势。
10 个工具
xix.ai
聊天机器人
最佳AI女友应用与角色扮演用AI伴侣工具(2026年指南)
探索2026年最新、最受好评的AI伴侣工具,体验沉浸式角色扮演与情感联结。XIX.AI精心编纂的指南汇集了功能强大、颠覆传统的应用程序,提供每周更新的排行榜、免费与付费版本对比,以及真实场景测试。立即找到您的理想伴侣,开启有意义的数字陪伴之旅。
10 个工具
xix.ai
写作
最佳AI仙侠与武侠助手:创作史诗般的修仙历程与武打场面
探索2026年最优秀的AI助手,助您创作史诗级的仙侠与武侠故事。XIX.AI精心整理的这份清单汇集了广受好评、能彻底改变创作格局的工具,助您驾驭修仙进阶与武术动作设计。通过实际测试对比免费与付费选项。释放您的创作潜能,今天就开始写作吧!
10 个工具
xix.ai
代码
AI移动应用开发工具:根据提示生成跨平台的Flutter与React Native代码
探索2026年最适合Flutter和React Native的最佳AI移动应用开发工具。我们精心挑选的这些高评分工具能够提供强大的功能,帮助您根据提示生成跨平台代码。通过实际测试来对比免费选项和付费选项,让开发更加高效,从而打造出更出色的应用程序。现在就访问XIX.AI查看排名吧!
10 个工具
xix.ai

 评论 (14)
0/500
评论 (14)
0/500
![RyanTaylor]()
Interesting! I've been following the open-source vs. proprietary model race. DeepCoder-14B matching o3-mini is a big deal for accessibility. Hope this pushes the big players to open up more, or at least lower their prices. The compute cost for training these 14B models must be insane though. 🤔
![FrankRodriguez]()
Wow, DeepCoder-14B sounds like a game-changer! I'm stoked to see open-source models catching up to the big players. Can't wait to try it out for my side projects—hope it’s as fast as they claim! 🚀
![GregoryBaker]()
DeepCoder-14B sounds like a game-changer! Can't wait to try it out and see how it stacks up against the big players. 🚀
![BillyLewis]()
Wow, DeepCoder-14B sounds like a game-changer for open-source coding! I'm curious how it stacks up against o3-mini in real-world projects. Anyone tried it yet? 🚀
![RaymondWalker]()
¡DeepCoder-14B es una locura! Un modelo de código abierto que compite con los grandes. ¿Será el fin de los modelos propietarios? 🤔
![RalphGarcia]()
DeepCoder-14B、めっちゃ面白そう!😊 オープンソースでここまでできるなんて、コーディングの未来が楽しみ!
介绍DeepCoder-14B:开源编码模型的新前沿
Together AI和Agentica的团队推出了DeepCoder-14B,这是一个突破性的编码模型,与OpenAI的o3-mini等顶级专有模型不相上下。这一激动人心的发展基于DeepSeek-R1,提供了更高的灵活性,用于将高性能代码生成和推理集成到实际应用中。更令人称赞的是,创建者完全开源了该模型,包括其训练数据、代码、日志和系统优化。这一举措将催化研究并加速该领域的进步。
小巧包装中的出色性能
DeepCoder-14B在LiveCodeBench (LCB)、Codeforces和HumanEval+等多种编码基准测试中表现出色。研究团队的实验表明,该模型的性能与o3-mini(低配版)和o1等领先模型相当。研究人员在博客文章中自豪地表示:“我们的模型在所有编码基准测试中表现出色……与o3-mini(低配版)和o1的性能相当。”
特别引人注目的是,尽管主要针对编码任务进行训练,DeepCoder-14B在数学推理方面也显示出显著提升,在AIME 2024基准测试中取得了73.8%的得分。这比其基础模型DeepSeek-R1-Distill-Qwen-14B提高了4.1%,表明通过强化学习(RL)在代码上培养的推理技能可以有效转移到其他领域。
DeepCoder-14B最激动人心的特点或许是其效率。仅拥有140亿个参数,它实现了高性能,同时比许多其他领先模型更小巧、更节省资源。
DeepCoder成功的创新
开发DeepCoder-14B涉及克服多个挑战,特别是在使用强化学习训练编码模型时。一个主要障碍是训练数据的筛选。与数学任务不同,高品质、可验证的编码数据较为稀缺。DeepCoder团队通过实施严格的流程,从各种数据集中收集和过滤示例,确保有效性、复杂性和避免重复,解决了这一问题。这一过程产生了24,000个高质量问题,为强化学习训练奠定了坚实基础。
团队还设计了一个简单的奖励函数,仅在生成代码成功通过所有采样单元测试并在设定时间限制内完成时奖励模型。这种方法结合高质量训练示例,确保模型专注于解决核心问题,而不是利用捷径。
DeepCoder-14B的训练算法基于Group Relative Policy Optimization (GRPO),这在DeepSeek-R1中已取得成功。然而,团队进行了重大修改,以增强稳定性和支持更长时间的训练。
此外,团队逐步扩展了模型的上下文窗口,从较短的序列开始,逐渐增加长度。他们还引入了一种过滤方法,以避免在解决复杂提示时因超出上下文限制而惩罚模型。
研究人员解释了他们的方法:“为了在保持长上下文推理的同时实现高效训练,我们引入了超长过滤……这种技术在训练期间屏蔽截断序列,使模型不会因生成深思熟虑但超出当前上下文限制的冗长输出而受到惩罚。”训练从16K扩展到32K上下文窗口,使模型能够处理需要高达64K令牌的问题。
优化长上下文强化学习训练
使用强化学习训练大型模型,尤其是在生成长序列的任务(如编码)时,速度慢且资源密集。采样步骤中,模型为每个示例生成数千个令牌,因响应长度不同常导致显著延迟。
为此,团队开发了verl-pipeline,这是开源verl库的优化扩展,用于基于人类反馈的强化学习(RLHF)。他们的“One-Off Pipelining”创新重构了采样和模型更新,以最小化瓶颈并减少加速器的空闲时间。
他们的实验表明,one-off pipelining可以将编码强化学习任务的速度提高至标准方法的两倍。这种优化对于在合理时间内(32个H100上2.5周)训练DeepCoder-14B至关重要,现已作为verl-pipeline的一部分开源,供社区使用。
企业影响与开源协作
研究人员已在GitHub和Hugging Face上以宽松许可公开了DeepCoder-14B的所有训练和操作工件。他们表示:“通过完全共享我们的数据集、代码和训练配方,我们赋予社区重现我们工作的能力,并使强化学习训练对所有人可及。”
DeepCoder-14B体现了AI领域高效、开放可访问模型的增长趋势。对于企业而言,这意味着更多选择和对高级模型的更大可访问性。高性能代码生成和推理不再是大公司或愿意支付高昂API费用的组织的专属。各种规模的组织现在都可以利用这些能力,定制适合其特定需求的解决方案,并在其环境中安全部署。
这一转变有望降低AI采用的门槛,促进由开源协作驱动的更具竞争力和创新性的生态系统。










 Multiverse Computing推出免费压缩生成式AI模型
大型语言模型面临着一个重大挑战:其庞大的体量。西班牙初创公司Multiverse Computing正通过创建压缩模型来解决这一问题,旨在弥合尖端人工智能能力与企业实际可负担实施能力之间的差距。其核心创新在于CompactifAI压缩技术——这项受量子计算原理启发的技术已被这家巴斯克公司用于优化OpenAI的模型。从今天起,开发者可在Hugging Face平台免费获取Multiverse增强版H
Multiverse Computing推出免费压缩生成式AI模型
大型语言模型面临着一个重大挑战:其庞大的体量。西班牙初创公司Multiverse Computing正通过创建压缩模型来解决这一问题,旨在弥合尖端人工智能能力与企业实际可负担实施能力之间的差距。其核心创新在于CompactifAI压缩技术——这项受量子计算原理启发的技术已被这家巴斯克公司用于优化OpenAI的模型。从今天起,开发者可在Hugging Face平台免费获取Multiverse增强版H
 秘密追踪数据揭露人工智能模型被盗事件
一种新方法能在数秒内对ChatGPT等模型进行隐形水印处理,无需重新训练,既不会在标准输出中留下痕迹,又能抵御所有实际的去除尝试。 水印技术与"版权诱饵"的关键区别在于:无论可见或隐形的水印,通常都设计为贯穿整个集合(如图像数据集)的持续性威慑手段,以防范随意复制。而虚构条目则是将一小段文本(通常为单词或定义)植入大型通用集合中,旨在证明盗用行为。其原理在于:当作品被直接盗用或作为衍生作品基础时,
秘密追踪数据揭露人工智能模型被盗事件
一种新方法能在数秒内对ChatGPT等模型进行隐形水印处理,无需重新训练,既不会在标准输出中留下痕迹,又能抵御所有实际的去除尝试。 水印技术与"版权诱饵"的关键区别在于:无论可见或隐形的水印,通常都设计为贯穿整个集合(如图像数据集)的持续性威慑手段,以防范随意复制。而虚构条目则是将一小段文本(通常为单词或定义)植入大型通用集合中,旨在证明盗用行为。其原理在于:当作品被直接盗用或作为衍生作品基础时,
 人工智能系统被诱骗批准荒谬的科学论文
最新研究表明,人工智能系统现已能够生成虚假科学论文,且其他AI模型会将其误认为真实研究。这些伪造的研究绕过了以往有效的检测方法,凸显出科研生态系统可能陷入机器人欺骗机器人的循环漩涡,面临崩溃风险。 具有讽刺意味的是,作为人工智能创新前沿的学术研究领域,正面临着主要由人工智能引发的可信度危机。自四年前机器学习的潜在影响显现以来,其已深刻重塑了研究、投稿和同行评审流程。最新争议涉及低质量调查论文的批量
人工智能系统被诱骗批准荒谬的科学论文
最新研究表明,人工智能系统现已能够生成虚假科学论文,且其他AI模型会将其误认为真实研究。这些伪造的研究绕过了以往有效的检测方法,凸显出科研生态系统可能陷入机器人欺骗机器人的循环漩涡,面临崩溃风险。 具有讽刺意味的是,作为人工智能创新前沿的学术研究领域,正面临着主要由人工智能引发的可信度危机。自四年前机器学习的潜在影响显现以来,其已深刻重塑了研究、投稿和同行评审流程。最新争议涉及低质量调查论文的批量

探索2026年最新评选出的顶级AI工具,这些工具专为自动化单元测试而设计。我们精心挑选了那些功能强大、能够改变开发流程的工具,它们能够帮助您快速生成Jest、PyTest和JUnit测试用例。在XIX.AI平台上,您可以免费查看各种选项,并通过实际测试结果以及每周更新的排名来了解它们的优劣。立即利用这些AI工具,提升您的开发效率吧!
10 个工具
xix.ai

在 XIX.AI 探索 2026 年最佳 AI 数据可视化工具。我们精心挑选的顶级工具助您即时从原始文件中自动生成功能强大且交互式的商业智能仪表盘。通过实际测试和每周更新的排行榜,对比免费与付费选项。立即释放您数据的潜力。
10 个工具
xix.ai

探索2026年最优秀的社交媒体AI品牌设计套件。XIX.AI精心整理的这份清单汇集了广受好评、具有颠覆性的工具,助您在所有渠道上保持品牌视觉形象的完美一致性。通过实际测试对比免费与付费选项。立即为您的品牌解锁视觉优势。
10 个工具
xix.ai

探索2026年最新、最受好评的AI伴侣工具,体验沉浸式角色扮演与情感联结。XIX.AI精心编纂的指南汇集了功能强大、颠覆传统的应用程序,提供每周更新的排行榜、免费与付费版本对比,以及真实场景测试。立即找到您的理想伴侣,开启有意义的数字陪伴之旅。
10 个工具
xix.ai

探索2026年最优秀的AI助手,助您创作史诗级的仙侠与武侠故事。XIX.AI精心整理的这份清单汇集了广受好评、能彻底改变创作格局的工具,助您驾驭修仙进阶与武术动作设计。通过实际测试对比免费与付费选项。释放您的创作潜能,今天就开始写作吧!
10 个工具
xix.ai

探索2026年最适合Flutter和React Native的最佳AI移动应用开发工具。我们精心挑选的这些高评分工具能够提供强大的功能,帮助您根据提示生成跨平台代码。通过实际测试来对比免费选项和付费选项,让开发更加高效,从而打造出更出色的应用程序。现在就访问XIX.AI查看排名吧!
10 个工具
xix.ai

Interesting! I've been following the open-source vs. proprietary model race. DeepCoder-14B matching o3-mini is a big deal for accessibility. Hope this pushes the big players to open up more, or at least lower their prices. The compute cost for training these 14B models must be insane though. 🤔
Wow, DeepCoder-14B sounds like a game-changer! I'm stoked to see open-source models catching up to the big players. Can't wait to try it out for my side projects—hope it’s as fast as they claim! 🚀
DeepCoder-14B sounds like a game-changer! Can't wait to try it out and see how it stacks up against the big players. 🚀
Wow, DeepCoder-14B sounds like a game-changer for open-source coding! I'm curious how it stacks up against o3-mini in real-world projects. Anyone tried it yet? 🚀
¡DeepCoder-14B es una locura! Un modelo de código abierto que compite con los grandes. ¿Será el fin de los modelos propietarios? 🤔
DeepCoder-14B、めっちゃ面白そう!😊 オープンソースでここまでできるなんて、コーディングの未来が楽しみ!













