
















 Home
HomeDeepCoder Achieves High Coding Efficiency with 14B Open Model
Introducing DeepCoder-14B: A New Frontier in Open-Source Coding Models
The teams at Together AI and Agentica have unveiled DeepCoder-14B, a groundbreaking coding model that stands shoulder-to-shoulder with top-tier proprietary models like OpenAI's o3-mini. This exciting development is built on the foundation of DeepSeek-R1 and offers enhanced flexibility for integrating high-performance code generation and reasoning into practical applications. What's more, the creators have taken a commendable step by fully open-sourcing the model, including its training data, code, logs, and system optimizations. This move is set to catalyze research and accelerate advancements in the field.
Impressive Performance in a Compact Package
DeepCoder-14B has shown remarkable results across various coding benchmarks such as LiveCodeBench (LCB), Codeforces, and HumanEval+. The research team's experiments have highlighted that the model's performance is on par with leading models like o3-mini (low) and o1. "Our model demonstrates strong performance across all coding benchmarks... comparable to the performance of o3-mini (low) and o1," the researchers proudly stated in their blog post.
What's particularly intriguing is that, despite being primarily trained on coding tasks, DeepCoder-14B has also shown a notable improvement in mathematical reasoning, achieving a 73.8% score on the AIME 2024 benchmark. This marks a 4.1% increase over its base model, DeepSeek-R1-Distill-Qwen-14B, suggesting that the reasoning skills honed through reinforcement learning (RL) on code can effectively transfer to other domains.
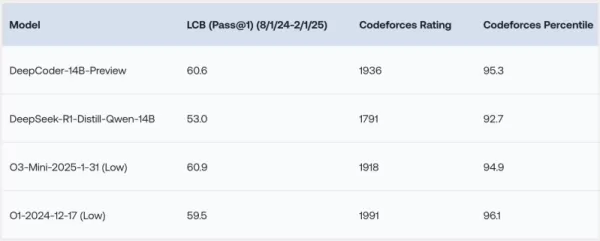
*Credit: Together AI*
Perhaps the most exciting feature of DeepCoder-14B is its efficiency. With only 14 billion parameters, it achieves high performance while being significantly smaller and more resource-efficient than many other leading models.
Innovations Behind DeepCoder’s Success
Developing DeepCoder-14B involved overcoming several challenges, particularly in training coding models using reinforcement learning. One major hurdle was the curation of training data. Unlike mathematical tasks, where high-quality, verifiable data is plentiful, coding data can be scarce. The DeepCoder team addressed this by implementing a rigorous pipeline to gather and filter examples from various datasets, ensuring validity, complexity, and avoiding duplication. This process resulted in 24,000 high-quality problems, which formed a robust foundation for RL training.
The team also devised a straightforward reward function that only rewards the model if the generated code successfully passes all sampled unit tests within a set time limit. This approach, coupled with high-quality training examples, ensured that the model focused on solving core problems rather than exploiting shortcuts.
DeepCoder-14B's training algorithm is based on Group Relative Policy Optimization (GRPO), which was successful in DeepSeek-R1. However, the team made significant modifications to enhance stability and enable longer training durations.
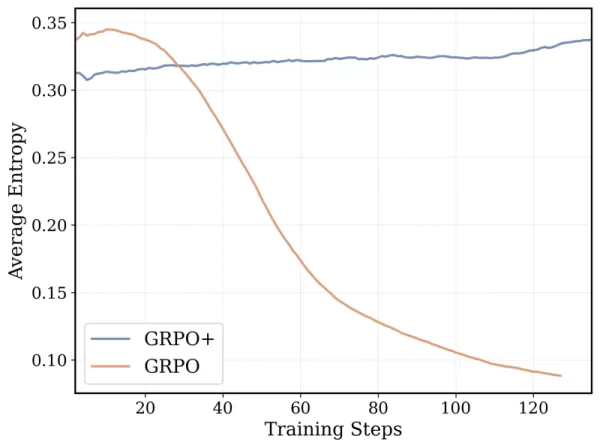
*GRPO+ enables DeepCoder-14 to continue for longer durations without collapsing Credit: Together AI*
Additionally, the team iteratively extended the model's context window, starting with shorter sequences and gradually increasing them. They also introduced a filtering method to avoid penalizing the model for exceeding context limits when solving complex prompts.
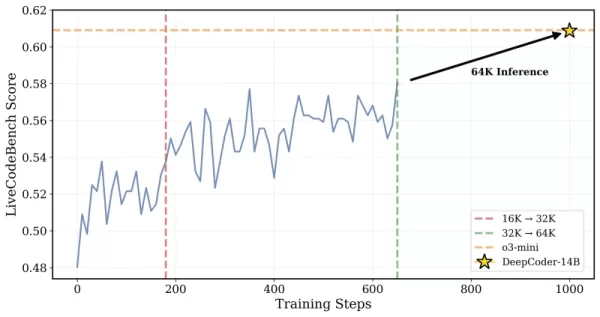
*DeepCoder was trained on 32K context problems but was also able to solve 64K tasks Credit: Together AI*
The researchers explained their approach: "To preserve long-context reasoning while enabling efficient training, we incorporated overlong filtering... This technique masks out truncated sequences during training so that models aren’t penalized for generating thoughtful but lengthy outputs that exceed the current context limit." The training scaled from a 16K to a 32K context window, enabling the model to tackle problems requiring up to 64K tokens.
Optimizing Long-Context RL Training
Training large models with RL, especially on tasks that generate long sequences like coding, is notoriously slow and resource-intensive. The sampling step, where the model generates thousands of tokens per example, often leads to significant delays due to varying response lengths.
To tackle this, the team developed verl-pipeline, an optimized extension of the open-source verl library for reinforcement learning from human feedback (RLHF). Their "One-Off Pipelining" innovation restructured the sampling and model updates to minimize bottlenecks and reduce idle time on accelerators.
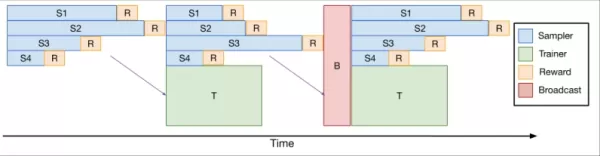
*One-Off Pipelining*
Their experiments demonstrated that one-off pipelining could speed up coding RL tasks by up to 2x compared to standard methods. This optimization was crucial in training DeepCoder-14B within a reasonable timeframe (2.5 weeks on 32 H100s) and is now open-sourced as part of verl-pipeline for the community to leverage.
Enterprise Impact and Open-Source Collaboration
The researchers have made all training and operational artifacts for DeepCoder-14B available on GitHub and Hugging Face under a permissive license. "By fully sharing our dataset, code, and training recipe, we empower the community to reproduce our work and make RL training accessible to all," they stated.
DeepCoder-14B exemplifies the growing trend of efficient, openly accessible models in the AI landscape. For enterprises, this means more options and greater accessibility to advanced models. High-performance code generation and reasoning are no longer exclusive to large corporations or those willing to pay hefty API fees. Organizations of all sizes can now harness these capabilities, tailor solutions to their specific needs, and deploy them securely within their environments.
This shift is poised to lower the barriers to AI adoption, fostering a more competitive and innovative ecosystem driven by open-source collaboration.
Related article
 Multiverse Computing Launches Free Compressed Generative AI Model
Large language models face a significant challenge: their immense size. Spanish startup Multiverse Computing is tackling this problem by creating compressed models designed to bridge the gap between the capabilities of cutting-edge AI and what busine
Secret Tracking Data Exposes Theft of AI Models
A new method can invisibly watermark models like ChatGPT in seconds without retraining, leaving no trace in standard outputs and resisting all practical removal attempts. The key distinction between watermarking and 'copyright-baiting' is that waterm
AI Systems Tricked into Approving Absurd Scientific Papers
New research reveals that AI systems can now produce fraudulent scientific papers that other AI models mistakenly accept as authentic. These fabricated studies bypass detection methods that were previously effective, highlighting the risk of research
Related Special Topic Recommendations
writing
Multiverse Computing Launches Free Compressed Generative AI Model
Large language models face a significant challenge: their immense size. Spanish startup Multiverse Computing is tackling this problem by creating compressed models designed to bridge the gap between the capabilities of cutting-edge AI and what busine
Secret Tracking Data Exposes Theft of AI Models
A new method can invisibly watermark models like ChatGPT in seconds without retraining, leaving no trace in standard outputs and resisting all practical removal attempts. The key distinction between watermarking and 'copyright-baiting' is that waterm
AI Systems Tricked into Approving Absurd Scientific Papers
New research reveals that AI systems can now produce fraudulent scientific papers that other AI models mistakenly accept as authentic. These fabricated studies bypass detection methods that were previously effective, highlighting the risk of research
Related Special Topic Recommendations
writing
 Best AI Xianxia & Wuxia Assistants: Write Epic Cultivation Progression & Martial Arts Choreography
Best AI Xianxia & Wuxia Assistants: Write Epic Cultivation Progression & Martial Arts Choreography
Discover the 2026 best AI assistants for crafting epic xianxia & wuxia tales. XIX.AI's curated list features top-rated, game-changing tools to master cultivation progression and martial arts choreography. Compare free vs paid options with real-world tests. Unlock your creative potential and start writing today!
 10 tools
10 tools
 xix.ai
code
AI Mobile App Coding Tools: Generate Cross-Platform Flutter & React Native Code from Prompts
xix.ai
code
AI Mobile App Coding Tools: Generate Cross-Platform Flutter & React Native Code from Prompts
Discover the 2026 best AI mobile app coding tools for Flutter & React Native. Our curated, top-rated list features powerful, game-changing solutions that generate cross-platform code from prompts. Compare free vs paid options with real-world tests. Unlock faster development and build better apps. Explore the rankings on XIX.AI now!
10 tools
xix.ai
code
Best AI Chrome Extension Generators: Create Custom Browser Add-ons with Zero Coding Experience
Discover the 2026 best AI Chrome extension generators on XIX.AI. Our curated list features top-rated, must-try tools that let you create custom browser add-ons with zero coding. Compare free vs paid options, see real-world tests, and unlock your productivity. Explore the latest rankings and find your perfect tool today!
10 tools
xix.ai
Text-to-speech
Best AI Multilingual TTS: Generate Authentic Native-Accent Speech in 50+ Languages
Discover the 2026 best AI multilingual TTS tools for authentic native-accent speech in 50+ languages. Explore our top-rated, curated rankings with free vs paid comparisons and real-world tests. Find your perfect voice tool on XIX.AI and unlock global communication today.
10 tools
xix.ai
Meeting Assistant
Best AI Meeting Automation Tools for Smarter and Faster Collaboration
Discover the 2026 latest top-rated AI meeting automation tools for smarter, faster collaboration. Our curated list features powerful, game-changing solutions to automate notes, summaries, and action items. Compare free vs paid options with real-world tests and weekly updated rankings. Unlock peak team productivity. Explore the best picks now at XIX.AI.
10 tools
xix.ai
Prompt
AI Prompts for Infrastructure-as-Code: Deploy Terraform & Docker Configurations Safely
Discover the 2026 latest top-rated AI prompts for Infrastructure-as-Code. XIX.AI's curated selection helps you safely deploy Terraform & Docker configurations, automate cloud setups, and boost DevOps productivity. Compare free vs paid options with real-world tests. Explore now and unlock your AI edge.
10 tools
xix.ai

 Comments (14)
0/500
Comments (14)
0/500
![RyanTaylor]()
Interesting! I've been following the open-source vs. proprietary model race. DeepCoder-14B matching o3-mini is a big deal for accessibility. Hope this pushes the big players to open up more, or at least lower their prices. The compute cost for training these 14B models must be insane though. 🤔
![FrankRodriguez]()
Wow, DeepCoder-14B sounds like a game-changer! I'm stoked to see open-source models catching up to the big players. Can't wait to try it out for my side projects—hope it’s as fast as they claim! 🚀
![GregoryBaker]()
DeepCoder-14B sounds like a game-changer! Can't wait to try it out and see how it stacks up against the big players. 🚀
![BillyLewis]()
Wow, DeepCoder-14B sounds like a game-changer for open-source coding! I'm curious how it stacks up against o3-mini in real-world projects. Anyone tried it yet? 🚀
![RaymondWalker]()
¡DeepCoder-14B es una locura! Un modelo de código abierto que compite con los grandes. ¿Será el fin de los modelos propietarios? 🤔
![RalphGarcia]()
DeepCoder-14B、めっちゃ面白そう!😊 オープンソースでここまでできるなんて、コーディングの未来が楽しみ!
Introducing DeepCoder-14B: A New Frontier in Open-Source Coding Models
The teams at Together AI and Agentica have unveiled DeepCoder-14B, a groundbreaking coding model that stands shoulder-to-shoulder with top-tier proprietary models like OpenAI's o3-mini. This exciting development is built on the foundation of DeepSeek-R1 and offers enhanced flexibility for integrating high-performance code generation and reasoning into practical applications. What's more, the creators have taken a commendable step by fully open-sourcing the model, including its training data, code, logs, and system optimizations. This move is set to catalyze research and accelerate advancements in the field.
Impressive Performance in a Compact Package
DeepCoder-14B has shown remarkable results across various coding benchmarks such as LiveCodeBench (LCB), Codeforces, and HumanEval+. The research team's experiments have highlighted that the model's performance is on par with leading models like o3-mini (low) and o1. "Our model demonstrates strong performance across all coding benchmarks... comparable to the performance of o3-mini (low) and o1," the researchers proudly stated in their blog post.
What's particularly intriguing is that, despite being primarily trained on coding tasks, DeepCoder-14B has also shown a notable improvement in mathematical reasoning, achieving a 73.8% score on the AIME 2024 benchmark. This marks a 4.1% increase over its base model, DeepSeek-R1-Distill-Qwen-14B, suggesting that the reasoning skills honed through reinforcement learning (RL) on code can effectively transfer to other domains.
Perhaps the most exciting feature of DeepCoder-14B is its efficiency. With only 14 billion parameters, it achieves high performance while being significantly smaller and more resource-efficient than many other leading models.
Innovations Behind DeepCoder’s Success
Developing DeepCoder-14B involved overcoming several challenges, particularly in training coding models using reinforcement learning. One major hurdle was the curation of training data. Unlike mathematical tasks, where high-quality, verifiable data is plentiful, coding data can be scarce. The DeepCoder team addressed this by implementing a rigorous pipeline to gather and filter examples from various datasets, ensuring validity, complexity, and avoiding duplication. This process resulted in 24,000 high-quality problems, which formed a robust foundation for RL training.
The team also devised a straightforward reward function that only rewards the model if the generated code successfully passes all sampled unit tests within a set time limit. This approach, coupled with high-quality training examples, ensured that the model focused on solving core problems rather than exploiting shortcuts.
DeepCoder-14B's training algorithm is based on Group Relative Policy Optimization (GRPO), which was successful in DeepSeek-R1. However, the team made significant modifications to enhance stability and enable longer training durations.
Additionally, the team iteratively extended the model's context window, starting with shorter sequences and gradually increasing them. They also introduced a filtering method to avoid penalizing the model for exceeding context limits when solving complex prompts.
The researchers explained their approach: "To preserve long-context reasoning while enabling efficient training, we incorporated overlong filtering... This technique masks out truncated sequences during training so that models aren’t penalized for generating thoughtful but lengthy outputs that exceed the current context limit." The training scaled from a 16K to a 32K context window, enabling the model to tackle problems requiring up to 64K tokens.
Optimizing Long-Context RL Training
Training large models with RL, especially on tasks that generate long sequences like coding, is notoriously slow and resource-intensive. The sampling step, where the model generates thousands of tokens per example, often leads to significant delays due to varying response lengths.
To tackle this, the team developed verl-pipeline, an optimized extension of the open-source verl library for reinforcement learning from human feedback (RLHF). Their "One-Off Pipelining" innovation restructured the sampling and model updates to minimize bottlenecks and reduce idle time on accelerators.
Their experiments demonstrated that one-off pipelining could speed up coding RL tasks by up to 2x compared to standard methods. This optimization was crucial in training DeepCoder-14B within a reasonable timeframe (2.5 weeks on 32 H100s) and is now open-sourced as part of verl-pipeline for the community to leverage.
Enterprise Impact and Open-Source Collaboration
The researchers have made all training and operational artifacts for DeepCoder-14B available on GitHub and Hugging Face under a permissive license. "By fully sharing our dataset, code, and training recipe, we empower the community to reproduce our work and make RL training accessible to all," they stated.
DeepCoder-14B exemplifies the growing trend of efficient, openly accessible models in the AI landscape. For enterprises, this means more options and greater accessibility to advanced models. High-performance code generation and reasoning are no longer exclusive to large corporations or those willing to pay hefty API fees. Organizations of all sizes can now harness these capabilities, tailor solutions to their specific needs, and deploy them securely within their environments.
This shift is poised to lower the barriers to AI adoption, fostering a more competitive and innovative ecosystem driven by open-source collaboration.










 Multiverse Computing Launches Free Compressed Generative AI Model
Large language models face a significant challenge: their immense size. Spanish startup Multiverse Computing is tackling this problem by creating compressed models designed to bridge the gap between the capabilities of cutting-edge AI and what busine
Multiverse Computing Launches Free Compressed Generative AI Model
Large language models face a significant challenge: their immense size. Spanish startup Multiverse Computing is tackling this problem by creating compressed models designed to bridge the gap between the capabilities of cutting-edge AI and what busine
 Secret Tracking Data Exposes Theft of AI Models
A new method can invisibly watermark models like ChatGPT in seconds without retraining, leaving no trace in standard outputs and resisting all practical removal attempts. The key distinction between watermarking and 'copyright-baiting' is that waterm
Secret Tracking Data Exposes Theft of AI Models
A new method can invisibly watermark models like ChatGPT in seconds without retraining, leaving no trace in standard outputs and resisting all practical removal attempts. The key distinction between watermarking and 'copyright-baiting' is that waterm
 AI Systems Tricked into Approving Absurd Scientific Papers
New research reveals that AI systems can now produce fraudulent scientific papers that other AI models mistakenly accept as authentic. These fabricated studies bypass detection methods that were previously effective, highlighting the risk of research
AI Systems Tricked into Approving Absurd Scientific Papers
New research reveals that AI systems can now produce fraudulent scientific papers that other AI models mistakenly accept as authentic. These fabricated studies bypass detection methods that were previously effective, highlighting the risk of research

Discover the 2026 best AI assistants for crafting epic xianxia & wuxia tales. XIX.AI's curated list features top-rated, game-changing tools to master cultivation progression and martial arts choreography. Compare free vs paid options with real-world tests. Unlock your creative potential and start writing today!
10 tools
xix.ai

Discover the 2026 best AI mobile app coding tools for Flutter & React Native. Our curated, top-rated list features powerful, game-changing solutions that generate cross-platform code from prompts. Compare free vs paid options with real-world tests. Unlock faster development and build better apps. Explore the rankings on XIX.AI now!
10 tools
xix.ai

Discover the 2026 best AI Chrome extension generators on XIX.AI. Our curated list features top-rated, must-try tools that let you create custom browser add-ons with zero coding. Compare free vs paid options, see real-world tests, and unlock your productivity. Explore the latest rankings and find your perfect tool today!
10 tools
xix.ai

Discover the 2026 best AI multilingual TTS tools for authentic native-accent speech in 50+ languages. Explore our top-rated, curated rankings with free vs paid comparisons and real-world tests. Find your perfect voice tool on XIX.AI and unlock global communication today.
10 tools
xix.ai

Discover the 2026 latest top-rated AI meeting automation tools for smarter, faster collaboration. Our curated list features powerful, game-changing solutions to automate notes, summaries, and action items. Compare free vs paid options with real-world tests and weekly updated rankings. Unlock peak team productivity. Explore the best picks now at XIX.AI.
10 tools
xix.ai

Discover the 2026 latest top-rated AI prompts for Infrastructure-as-Code. XIX.AI's curated selection helps you safely deploy Terraform & Docker configurations, automate cloud setups, and boost DevOps productivity. Compare free vs paid options with real-world tests. Explore now and unlock your AI edge.
10 tools
xix.ai

Interesting! I've been following the open-source vs. proprietary model race. DeepCoder-14B matching o3-mini is a big deal for accessibility. Hope this pushes the big players to open up more, or at least lower their prices. The compute cost for training these 14B models must be insane though. 🤔
Wow, DeepCoder-14B sounds like a game-changer! I'm stoked to see open-source models catching up to the big players. Can't wait to try it out for my side projects—hope it’s as fast as they claim! 🚀
DeepCoder-14B sounds like a game-changer! Can't wait to try it out and see how it stacks up against the big players. 🚀
Wow, DeepCoder-14B sounds like a game-changer for open-source coding! I'm curious how it stacks up against o3-mini in real-world projects. Anyone tried it yet? 🚀
¡DeepCoder-14B es una locura! Un modelo de código abierto que compite con los grandes. ¿Será el fin de los modelos propietarios? 🤔
DeepCoder-14B、めっちゃ面白そう!😊 オープンソースでここまでできるなんて、コーディングの未来が楽しみ!













