




DeepCoder đạt được hiệu quả mã hóa cao với mô hình mở 14b
Giới thiệu DeepCoder-14B: Một Biên giới Mới trong Các Mô hình Lập trình Mã nguồn Mở
Các nhóm tại Together AI và Agentica đã công bố DeepCoder-14B, một mô hình lập trình đột phá ngang tầm với các mô hình độc quyền hàng đầu như o3-mini của OpenAI. Sự phát triển thú vị này được xây dựng dựa trên nền tảng DeepSeek-R1 và mang lại sự linh hoạt cao hơn để tích hợp khả năng tạo mã hiệu suất cao và suy luận vào các ứng dụng thực tế. Hơn nữa, các nhà phát triển đã thực hiện một bước đi đáng khen ngợi bằng cách mở hoàn toàn mã nguồn của mô hình, bao gồm dữ liệu huấn luyện, mã, nhật ký và các tối ưu hóa hệ thống. Động thái này được kỳ vọng sẽ thúc đẩy nghiên cứu và đẩy nhanh các tiến bộ trong lĩnh vực.
Hiệu suất Ấn tượng trong một Gói Gọn
DeepCoder-14B đã cho thấy kết quả đáng chú ý trên nhiều điểm chuẩn lập trình như LiveCodeBench (LCB), Codeforces và HumanEval+. Các thí nghiệm của nhóm nghiên cứu đã chỉ ra rằng hiệu suất của mô hình này ngang ngửa với các mô hình hàng đầu như o3-mini (thấp) và o1. "Mô hình của chúng tôi thể hiện hiệu suất mạnh mẽ trên tất cả các điểm chuẩn lập trình... tương đương với hiệu suất của o3-mini (thấp) và o1," các nhà nghiên cứu tự hào tuyên bố trong bài đăng blog của họ.
Điều đặc biệt hấp dẫn là, mặc dù được huấn luyện chủ yếu cho các tác vụ lập trình, DeepCoder-14B cũng cho thấy sự cải thiện đáng kể trong suy luận toán học, đạt điểm 73,8% trên điểm chuẩn AIME 2024. Điều này đánh dấu mức tăng 4,1% so với mô hình cơ sở, DeepSeek-R1-Distill-Qwen-14B, cho thấy các kỹ năng suy luận được rèn giũa thông qua học tăng cường (RL) trên mã có thể chuyển giao hiệu quả sang các lĩnh vực khác.
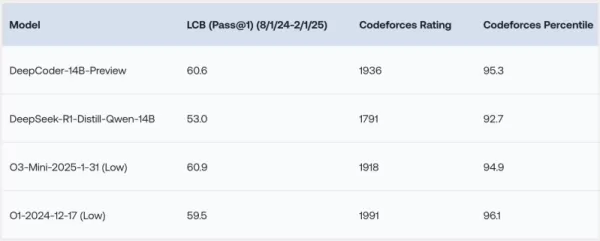
*Nguồn: Together AI* Có lẽ tính năng thú vị nhất của DeepCoder-14B là hiệu quả của nó. Với chỉ 14 tỷ tham số, nó đạt được hiệu suất cao trong khi nhỏ gọn hơn và tiết kiệm tài nguyên hơn nhiều so với các mô hình hàng đầu khác.
Những Đổi mới Đằng sau Thành công của DeepCoder
Việc phát triển DeepCoder-14B đòi hỏi vượt qua nhiều thách thức, đặc biệt trong việc huấn luyện các mô hình lập trình bằng học tăng cường. Một trở ngại lớn là việc thu thập dữ liệu huấn luyện. Không giống như các tác vụ toán học, nơi dữ liệu chất lượng cao, có thể xác minh dễ dàng có sẵn, dữ liệu lập trình có thể khan hiếm. Nhóm DeepCoder đã giải quyết vấn đề này bằng cách triển khai một quy trình nghiêm ngặt để thu thập và lọc các ví dụ từ nhiều bộ dữ liệu, đảm bảo tính hợp lệ, độ phức tạp và tránh trùng lặp. Quá trình này đã tạo ra 24.000 bài toán chất lượng cao, hình thành một nền tảng vững chắc cho huấn luyện RL.
Nhóm cũng thiết kế một hàm thưởng đơn giản chỉ thưởng cho mô hình nếu mã được tạo ra vượt qua tất cả các bài kiểm tra đơn vị được lấy mẫu trong một giới hạn thời gian nhất định. Phương pháp này, kết hợp với các ví dụ huấn luyện chất lượng cao, đảm bảo rằng mô hình tập trung vào việc giải quyết các vấn đề cốt lõi thay vì khai thác các lối tắt.
Thuật toán huấn luyện của DeepCoder-14B dựa trên Tối ưu hóa Chính sách Tương đối Nhóm (GRPO), vốn đã thành công trong DeepSeek-R1. Tuy nhiên, nhóm đã thực hiện các sửa đổi đáng kể để tăng cường sự ổn định và cho phép thời gian huấn luyện lâu hơn.
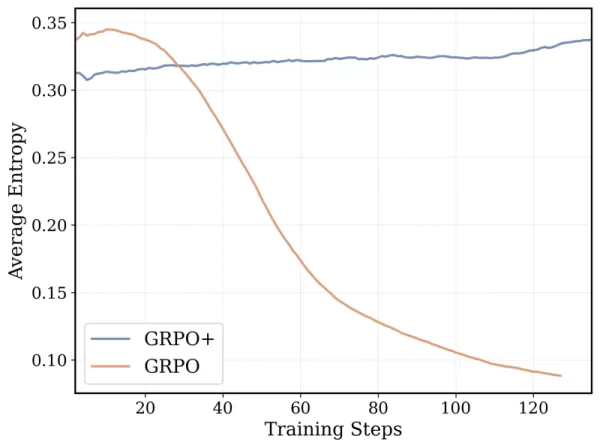
*GRPO+ cho phép DeepCoder-14 tiếp tục hoạt động lâu hơn mà không bị sụp đổ Nguồn: Together AI* Ngoài ra, nhóm đã mở rộng cửa sổ ngữ cảnh của mô hình một cách lặp đi lặp lại, bắt đầu với các chuỗi ngắn hơn và dần dần tăng lên. Họ cũng giới thiệu một phương pháp lọc để tránh phạt mô hình khi vượt quá giới hạn ngữ cảnh khi giải quyết các lời nhắc phức tạp.
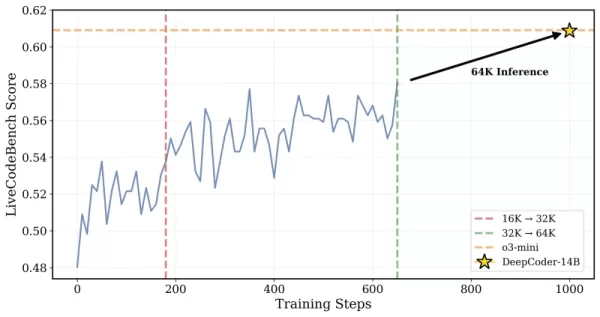
*DeepCoder được huấn luyện trên các bài toán ngữ cảnh 32K nhưng cũng có khả năng giải quyết các nhiệm vụ 64K Nguồn: Together AI* Các nhà nghiên cứu giải thích cách tiếp cận của họ: "Để duy trì khả năng suy luận ngữ cảnh dài trong khi cho phép huấn luyện hiệu quả, chúng tôi đã áp dụng lọc quá dài... Kỹ thuật này che giấu các chuỗi bị cắt ngắn trong quá trình huấn luyện để các mô hình không bị phạt vì tạo ra các đầu ra chu đáo nhưng dài vượt quá giới hạn ngữ cảnh hiện tại." Quá trình huấn luyện được mở rộng từ cửa sổ ngữ cảnh 16K lên 32K, cho phép mô hình giải quyết các bài toán yêu cầu lên đến 64K token.
Tối ưu hóa Huấn luyện RL Ngữ cảnh Dài
Huấn luyện các mô hình lớn với RL, đặc biệt trên các tác vụ tạo ra chuỗi dài như lập trình, là một quá trình chậm và tiêu tốn tài nguyên. Bước lấy mẫu, nơi mô hình tạo ra hàng nghìn token cho mỗi ví dụ, thường dẫn đến sự chậm trễ đáng kể do độ dài phản hồi thay đổi.
Để giải quyết vấn đề này, nhóm đã phát triển verl-pipeline, một phần mở rộng tối ưu hóa của thư viện mã nguồn mở verl để học tăng cường từ phản hồi của con người (RLHF). Đổi mới "One-Off Pipelining" của họ đã tái cấu trúc việc lấy mẫu và cập nhật mô hình để giảm thiểu tắc nghẽn và giảm thời gian nhàn rỗi trên các bộ tăng tốc.
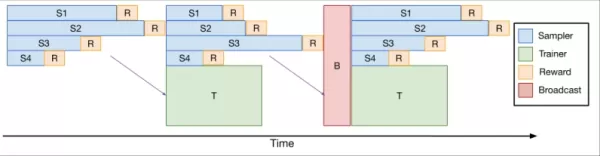
*One-Off Pipelining* Các thí nghiệm của họ chứng minh rằng one-off pipelining có thể tăng tốc các tác vụ RL lập trình lên đến 2 lần so với các phương pháp tiêu chuẩn. Tối ưu hóa này rất quan trọng trong việc huấn luyện DeepCoder-14B trong một khoảng thời gian hợp lý (2,5 tuần trên 32 H100) và hiện đã được mở mã nguồn như một phần của verl-pipeline để cộng đồng tận dụng.
Ảnh hưởng Doanh nghiệp và Hợp tác Mã nguồn Mở
Các nhà nghiên cứu đã công khai tất cả các tài liệu huấn luyện và vận hành cho DeepCoder-14B trên GitHub và Hugging Face dưới giấy phép cho phép. "Bằng cách chia sẻ hoàn toàn bộ dữ liệu, mã và công thức huấn luyện của chúng tôi, chúng tôi trao quyền cho cộng đồng tái tạo công việc của chúng tôi và làm cho huấn luyện RL trở nên dễ tiếp cận với tất cả," họ tuyên bố.
DeepCoder-14B là ví dụ cho xu hướng ngày càng tăng của các mô hình hiệu quả, dễ tiếp cận công khai trong cảnh quan AI. Đối với các doanh nghiệp, điều này có nghĩa là có nhiều lựa chọn hơn và khả năng tiếp cận cao hơn đến các mô hình tiên tiến. Tạo mã hiệu suất cao và suy luận không còn là độc quyền của các tập đoàn lớn hoặc những người sẵn sàng trả phí API cao. Các tổ chức ở mọi quy mô giờ đây có thể khai thác các khả năng này, tùy chỉnh giải pháp theo nhu cầu cụ thể của họ và triển khai chúng một cách an toàn trong môi trường của họ.
Sự thay đổi này được kỳ vọng sẽ hạ thấp rào cản đối với việc áp dụng AI, thúc đẩy một hệ sinh thái cạnh tranh và sáng tạo hơn được dẫn dắt bởi sự hợp tác mã nguồn mở.
Bài viết liên quan
 Nghiên cứu của Microsoft tiết lộ giới hạn của các mô hình AI trong việc gỡ lỗi phần mềm
Các mô hình AI từ OpenAI, Anthropic và các phòng thí nghiệm AI hàng đầu khác ngày càng được sử dụng cho các nhiệm vụ lập trình. Giám đốc điều hành Google Sundar Pichai đã lưu ý vào tháng 10 rằng AI tạ
Giải pháp được hỗ trợ bởi AI có thể giảm đáng kể lượng phát thải carbon toàn cầu
Một nghiên cứu gần đây của Trường Kinh tế London và Systemiq cho thấy trí tuệ nhân tạo có thể giảm đáng kể lượng phát thải carbon toàn cầu mà không làm mất đi các tiện nghi hiện đại, định vị AI như mộ
Cách Bệnh viện Ottawa sử dụng công nghệ thu âm giọng nói AI để giảm kiệt sức cho bác sĩ 70%, đạt 97% sự hài lòng của bệnh nhân
Cách AI đang chuyển đổi chăm sóc sức khỏe: Giảm kiệt sức và cải thiện chăm sóc bệnh nhânThách thức: Quá tải cho bác sĩ và khó khăn trong tiếp cận của bệnh nhânCác hệ thống y tế trên toàn thế giới đối
Nhận xét (11)
0/200
Nghiên cứu của Microsoft tiết lộ giới hạn của các mô hình AI trong việc gỡ lỗi phần mềm
Các mô hình AI từ OpenAI, Anthropic và các phòng thí nghiệm AI hàng đầu khác ngày càng được sử dụng cho các nhiệm vụ lập trình. Giám đốc điều hành Google Sundar Pichai đã lưu ý vào tháng 10 rằng AI tạ
Giải pháp được hỗ trợ bởi AI có thể giảm đáng kể lượng phát thải carbon toàn cầu
Một nghiên cứu gần đây của Trường Kinh tế London và Systemiq cho thấy trí tuệ nhân tạo có thể giảm đáng kể lượng phát thải carbon toàn cầu mà không làm mất đi các tiện nghi hiện đại, định vị AI như mộ
Cách Bệnh viện Ottawa sử dụng công nghệ thu âm giọng nói AI để giảm kiệt sức cho bác sĩ 70%, đạt 97% sự hài lòng của bệnh nhân
Cách AI đang chuyển đổi chăm sóc sức khỏe: Giảm kiệt sức và cải thiện chăm sóc bệnh nhânThách thức: Quá tải cho bác sĩ và khó khăn trong tiếp cận của bệnh nhânCác hệ thống y tế trên toàn thế giới đối
Nhận xét (11)
0/200
![BillyLewis]() BillyLewis
BillyLewis
 14:01:06 GMT+07:00 Ngày 06 tháng 8 năm 2025
14:01:06 GMT+07:00 Ngày 06 tháng 8 năm 2025
Wow, DeepCoder-14B sounds like a game-changer for open-source coding! I'm curious how it stacks up against o3-mini in real-world projects. Anyone tried it yet? 🚀


 0
0
![RaymondWalker]() RaymondWalker
10:21:57 GMT+07:00 Ngày 25 tháng 4 năm 2025
RaymondWalker
10:21:57 GMT+07:00 Ngày 25 tháng 4 năm 2025
¡DeepCoder-14B es una locura! Un modelo de código abierto que compite con los grandes. ¿Será el fin de los modelos propietarios? 🤔
0
![RalphGarcia]() RalphGarcia
23:21:21 GMT+07:00 Ngày 24 tháng 4 năm 2025
RalphGarcia
23:21:21 GMT+07:00 Ngày 24 tháng 4 năm 2025
DeepCoder-14B、めっちゃ面白そう!😊 オープンソースでここまでできるなんて、コーディングの未来が楽しみ!
0
![SebastianAnderson]() SebastianAnderson
14:46:12 GMT+07:00 Ngày 24 tháng 4 năm 2025
SebastianAnderson
14:46:12 GMT+07:00 Ngày 24 tháng 4 năm 2025
¡DeepCoder-14B es una bestia! Es increíble cómo puede codificar tan eficientemente, casi como tener a un programador de primera a mano. Lo he usado en proyectos complejos y ha acertado cada vez. Lo único es que puede ser un poco lento en mi vieja laptop. Aún así, una herramienta sólida para cualquier programador! 🤓💻
0
![TerryAdams]() TerryAdams
14:38:28 GMT+07:00 Ngày 24 tháng 4 năm 2025
TerryAdams
14:38:28 GMT+07:00 Ngày 24 tháng 4 năm 2025
DeepCoder-14B, c’est impressionnant ! Un modèle open-source qui rivalise avec les géants, ça donne envie de tester. 🖥️
0
![JimmyJohnson]() JimmyJohnson
14:06:50 GMT+07:00 Ngày 24 tháng 4 năm 2025
JimmyJohnson
14:06:50 GMT+07:00 Ngày 24 tháng 4 năm 2025
DeepCoder-14B é uma fera! É incrível como ele consegue codificar tão eficientemente, quase como ter um programador de primeira linha à disposição. Usei em projetos complexos e ele acertou em cheio todas as vezes. A única coisa é que pode ser um pouco lento no meu velho laptop. Ainda assim, uma ferramenta sólida para qualquer programador! 🤓💻
0
Giới thiệu DeepCoder-14B: Một Biên giới Mới trong Các Mô hình Lập trình Mã nguồn Mở
Các nhóm tại Together AI và Agentica đã công bố DeepCoder-14B, một mô hình lập trình đột phá ngang tầm với các mô hình độc quyền hàng đầu như o3-mini của OpenAI. Sự phát triển thú vị này được xây dựng dựa trên nền tảng DeepSeek-R1 và mang lại sự linh hoạt cao hơn để tích hợp khả năng tạo mã hiệu suất cao và suy luận vào các ứng dụng thực tế. Hơn nữa, các nhà phát triển đã thực hiện một bước đi đáng khen ngợi bằng cách mở hoàn toàn mã nguồn của mô hình, bao gồm dữ liệu huấn luyện, mã, nhật ký và các tối ưu hóa hệ thống. Động thái này được kỳ vọng sẽ thúc đẩy nghiên cứu và đẩy nhanh các tiến bộ trong lĩnh vực.
Hiệu suất Ấn tượng trong một Gói Gọn
DeepCoder-14B đã cho thấy kết quả đáng chú ý trên nhiều điểm chuẩn lập trình như LiveCodeBench (LCB), Codeforces và HumanEval+. Các thí nghiệm của nhóm nghiên cứu đã chỉ ra rằng hiệu suất của mô hình này ngang ngửa với các mô hình hàng đầu như o3-mini (thấp) và o1. "Mô hình của chúng tôi thể hiện hiệu suất mạnh mẽ trên tất cả các điểm chuẩn lập trình... tương đương với hiệu suất của o3-mini (thấp) và o1," các nhà nghiên cứu tự hào tuyên bố trong bài đăng blog của họ.
Điều đặc biệt hấp dẫn là, mặc dù được huấn luyện chủ yếu cho các tác vụ lập trình, DeepCoder-14B cũng cho thấy sự cải thiện đáng kể trong suy luận toán học, đạt điểm 73,8% trên điểm chuẩn AIME 2024. Điều này đánh dấu mức tăng 4,1% so với mô hình cơ sở, DeepSeek-R1-Distill-Qwen-14B, cho thấy các kỹ năng suy luận được rèn giũa thông qua học tăng cường (RL) trên mã có thể chuyển giao hiệu quả sang các lĩnh vực khác.
Có lẽ tính năng thú vị nhất của DeepCoder-14B là hiệu quả của nó. Với chỉ 14 tỷ tham số, nó đạt được hiệu suất cao trong khi nhỏ gọn hơn và tiết kiệm tài nguyên hơn nhiều so với các mô hình hàng đầu khác.
Những Đổi mới Đằng sau Thành công của DeepCoder
Việc phát triển DeepCoder-14B đòi hỏi vượt qua nhiều thách thức, đặc biệt trong việc huấn luyện các mô hình lập trình bằng học tăng cường. Một trở ngại lớn là việc thu thập dữ liệu huấn luyện. Không giống như các tác vụ toán học, nơi dữ liệu chất lượng cao, có thể xác minh dễ dàng có sẵn, dữ liệu lập trình có thể khan hiếm. Nhóm DeepCoder đã giải quyết vấn đề này bằng cách triển khai một quy trình nghiêm ngặt để thu thập và lọc các ví dụ từ nhiều bộ dữ liệu, đảm bảo tính hợp lệ, độ phức tạp và tránh trùng lặp. Quá trình này đã tạo ra 24.000 bài toán chất lượng cao, hình thành một nền tảng vững chắc cho huấn luyện RL.
Nhóm cũng thiết kế một hàm thưởng đơn giản chỉ thưởng cho mô hình nếu mã được tạo ra vượt qua tất cả các bài kiểm tra đơn vị được lấy mẫu trong một giới hạn thời gian nhất định. Phương pháp này, kết hợp với các ví dụ huấn luyện chất lượng cao, đảm bảo rằng mô hình tập trung vào việc giải quyết các vấn đề cốt lõi thay vì khai thác các lối tắt.
Thuật toán huấn luyện của DeepCoder-14B dựa trên Tối ưu hóa Chính sách Tương đối Nhóm (GRPO), vốn đã thành công trong DeepSeek-R1. Tuy nhiên, nhóm đã thực hiện các sửa đổi đáng kể để tăng cường sự ổn định và cho phép thời gian huấn luyện lâu hơn.
Ngoài ra, nhóm đã mở rộng cửa sổ ngữ cảnh của mô hình một cách lặp đi lặp lại, bắt đầu với các chuỗi ngắn hơn và dần dần tăng lên. Họ cũng giới thiệu một phương pháp lọc để tránh phạt mô hình khi vượt quá giới hạn ngữ cảnh khi giải quyết các lời nhắc phức tạp.
Các nhà nghiên cứu giải thích cách tiếp cận của họ: "Để duy trì khả năng suy luận ngữ cảnh dài trong khi cho phép huấn luyện hiệu quả, chúng tôi đã áp dụng lọc quá dài... Kỹ thuật này che giấu các chuỗi bị cắt ngắn trong quá trình huấn luyện để các mô hình không bị phạt vì tạo ra các đầu ra chu đáo nhưng dài vượt quá giới hạn ngữ cảnh hiện tại." Quá trình huấn luyện được mở rộng từ cửa sổ ngữ cảnh 16K lên 32K, cho phép mô hình giải quyết các bài toán yêu cầu lên đến 64K token.
Tối ưu hóa Huấn luyện RL Ngữ cảnh Dài
Huấn luyện các mô hình lớn với RL, đặc biệt trên các tác vụ tạo ra chuỗi dài như lập trình, là một quá trình chậm và tiêu tốn tài nguyên. Bước lấy mẫu, nơi mô hình tạo ra hàng nghìn token cho mỗi ví dụ, thường dẫn đến sự chậm trễ đáng kể do độ dài phản hồi thay đổi.
Để giải quyết vấn đề này, nhóm đã phát triển verl-pipeline, một phần mở rộng tối ưu hóa của thư viện mã nguồn mở verl để học tăng cường từ phản hồi của con người (RLHF). Đổi mới "One-Off Pipelining" của họ đã tái cấu trúc việc lấy mẫu và cập nhật mô hình để giảm thiểu tắc nghẽn và giảm thời gian nhàn rỗi trên các bộ tăng tốc.
Các thí nghiệm của họ chứng minh rằng one-off pipelining có thể tăng tốc các tác vụ RL lập trình lên đến 2 lần so với các phương pháp tiêu chuẩn. Tối ưu hóa này rất quan trọng trong việc huấn luyện DeepCoder-14B trong một khoảng thời gian hợp lý (2,5 tuần trên 32 H100) và hiện đã được mở mã nguồn như một phần của verl-pipeline để cộng đồng tận dụng.
Ảnh hưởng Doanh nghiệp và Hợp tác Mã nguồn Mở
Các nhà nghiên cứu đã công khai tất cả các tài liệu huấn luyện và vận hành cho DeepCoder-14B trên GitHub và Hugging Face dưới giấy phép cho phép. "Bằng cách chia sẻ hoàn toàn bộ dữ liệu, mã và công thức huấn luyện của chúng tôi, chúng tôi trao quyền cho cộng đồng tái tạo công việc của chúng tôi và làm cho huấn luyện RL trở nên dễ tiếp cận với tất cả," họ tuyên bố.
DeepCoder-14B là ví dụ cho xu hướng ngày càng tăng của các mô hình hiệu quả, dễ tiếp cận công khai trong cảnh quan AI. Đối với các doanh nghiệp, điều này có nghĩa là có nhiều lựa chọn hơn và khả năng tiếp cận cao hơn đến các mô hình tiên tiến. Tạo mã hiệu suất cao và suy luận không còn là độc quyền của các tập đoàn lớn hoặc những người sẵn sàng trả phí API cao. Các tổ chức ở mọi quy mô giờ đây có thể khai thác các khả năng này, tùy chỉnh giải pháp theo nhu cầu cụ thể của họ và triển khai chúng một cách an toàn trong môi trường của họ.
Sự thay đổi này được kỳ vọng sẽ hạ thấp rào cản đối với việc áp dụng AI, thúc đẩy một hệ sinh thái cạnh tranh và sáng tạo hơn được dẫn dắt bởi sự hợp tác mã nguồn mở.










 Nghiên cứu của Microsoft tiết lộ giới hạn của các mô hình AI trong việc gỡ lỗi phần mềm
Các mô hình AI từ OpenAI, Anthropic và các phòng thí nghiệm AI hàng đầu khác ngày càng được sử dụng cho các nhiệm vụ lập trình. Giám đốc điều hành Google Sundar Pichai đã lưu ý vào tháng 10 rằng AI tạ
Giải pháp được hỗ trợ bởi AI có thể giảm đáng kể lượng phát thải carbon toàn cầu
Một nghiên cứu gần đây của Trường Kinh tế London và Systemiq cho thấy trí tuệ nhân tạo có thể giảm đáng kể lượng phát thải carbon toàn cầu mà không làm mất đi các tiện nghi hiện đại, định vị AI như mộ
Nghiên cứu của Microsoft tiết lộ giới hạn của các mô hình AI trong việc gỡ lỗi phần mềm
Các mô hình AI từ OpenAI, Anthropic và các phòng thí nghiệm AI hàng đầu khác ngày càng được sử dụng cho các nhiệm vụ lập trình. Giám đốc điều hành Google Sundar Pichai đã lưu ý vào tháng 10 rằng AI tạ
Giải pháp được hỗ trợ bởi AI có thể giảm đáng kể lượng phát thải carbon toàn cầu
Một nghiên cứu gần đây của Trường Kinh tế London và Systemiq cho thấy trí tuệ nhân tạo có thể giảm đáng kể lượng phát thải carbon toàn cầu mà không làm mất đi các tiện nghi hiện đại, định vị AI như mộ
 Cách Bệnh viện Ottawa sử dụng công nghệ thu âm giọng nói AI để giảm kiệt sức cho bác sĩ 70%, đạt 97% sự hài lòng của bệnh nhân
Cách AI đang chuyển đổi chăm sóc sức khỏe: Giảm kiệt sức và cải thiện chăm sóc bệnh nhânThách thức: Quá tải cho bác sĩ và khó khăn trong tiếp cận của bệnh nhânCác hệ thống y tế trên toàn thế giới đối
14:01:06 GMT+07:00 Ngày 06 tháng 8 năm 2025
Cách Bệnh viện Ottawa sử dụng công nghệ thu âm giọng nói AI để giảm kiệt sức cho bác sĩ 70%, đạt 97% sự hài lòng của bệnh nhân
Cách AI đang chuyển đổi chăm sóc sức khỏe: Giảm kiệt sức và cải thiện chăm sóc bệnh nhânThách thức: Quá tải cho bác sĩ và khó khăn trong tiếp cận của bệnh nhânCác hệ thống y tế trên toàn thế giới đối
14:01:06 GMT+07:00 Ngày 06 tháng 8 năm 2025
Wow, DeepCoder-14B sounds like a game-changer for open-source coding! I'm curious how it stacks up against o3-mini in real-world projects. Anyone tried it yet? 🚀
0
10:21:57 GMT+07:00 Ngày 25 tháng 4 năm 2025
¡DeepCoder-14B es una locura! Un modelo de código abierto que compite con los grandes. ¿Será el fin de los modelos propietarios? 🤔
0
23:21:21 GMT+07:00 Ngày 24 tháng 4 năm 2025
DeepCoder-14B、めっちゃ面白そう!😊 オープンソースでここまでできるなんて、コーディングの未来が楽しみ!
0
14:46:12 GMT+07:00 Ngày 24 tháng 4 năm 2025
¡DeepCoder-14B es una bestia! Es increíble cómo puede codificar tan eficientemente, casi como tener a un programador de primera a mano. Lo he usado en proyectos complejos y ha acertado cada vez. Lo único es que puede ser un poco lento en mi vieja laptop. Aún así, una herramienta sólida para cualquier programador! 🤓💻
0
14:38:28 GMT+07:00 Ngày 24 tháng 4 năm 2025
DeepCoder-14B, c’est impressionnant ! Un modèle open-source qui rivalise avec les géants, ça donne envie de tester. 🖥️
0
14:06:50 GMT+07:00 Ngày 24 tháng 4 năm 2025
DeepCoder-14B é uma fera! É incrível como ele consegue codificar tão eficientemente, quase como ter um programador de primeira linha à disposição. Usei em projetos complexos e ele acertou em cheio todas as vezes. A única coisa é que pode ser um pouco lento no meu velho laptop. Ainda assim, uma ferramenta sólida para qualquer programador! 🤓💻
0













