
















 Lar
LarDeepcoder alcança a alta eficiência de codificação com o modelo aberto 14B
Apresentando DeepCoder-14B: Uma Nova Fronteira em Modelos de Codificação de Código Aberto
As equipes da Together AI e Agentica revelaram o DeepCoder-14B, um modelo de codificação revolucionário que se equipara aos melhores modelos proprietários, como o o3-mini da OpenAI. Este desenvolvimento empolgante é baseado no DeepSeek-R1 e oferece maior flexibilidade para integrar geração de código e raciocínio de alto desempenho em aplicações práticas. Além disso, os criadores deram um passo louvável ao disponibilizar completamente o modelo em código aberto, incluindo seus dados de treinamento, código, logs e otimizações de sistema. Essa iniciativa está pronta para catalisar pesquisas e acelerar avanços no campo.
Desempenho Impressionante em um Pacote Compacto
O DeepCoder-14B demonstrou resultados notáveis em vários benchmarks de codificação, como LiveCodeBench (LCB), Codeforces e HumanEval+. Os experimentos da equipe de pesquisa destacaram que o desempenho do modelo é comparável aos principais modelos, como o3-mini (baixo) e o1. "Nosso modelo demonstra forte desempenho em todos os benchmarks de codificação... comparável ao desempenho do o3-mini (baixo) e o1," declararam os pesquisadores orgulhosamente em seu post de blog.
O que é particularmente intrigante é que, apesar de ser treinado principalmente em tarefas de codificação, o DeepCoder-14B também mostrou uma melhoria notável em raciocínio matemático, alcançando uma pontuação de 73,8% no benchmark AIME 2024. Isso marca um aumento de 4,1% em relação ao seu modelo base, DeepSeek-R1-Distill-Qwen-14B, sugerindo que as habilidades de raciocínio aprimoradas por meio de aprendizado por reforço (RL) em código podem ser transferidas eficazmente para outros domínios.
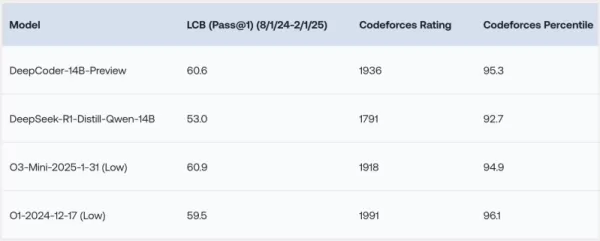
*Crédito: Together AI* Talvez a característica mais empolgante do DeepCoder-14B seja sua eficiência. Com apenas 14 bilhões de parâmetros, ele alcança alto desempenho, sendo significativamente menor e mais eficiente em recursos do que muitos outros modelos líderes.
Inovações por Trás do Sucesso do DeepCoder
Desenvolver o DeepCoder-14B envolveu superar vários desafios, particularmente no treinamento de modelos de codificação usando aprendizado por reforço. Um grande obstáculo foi a curadoria de dados de treinamento. Diferentemente de tarefas matemáticas, onde dados verificáveis e de alta qualidade são abundantes, dados de codificação podem ser escassos. A equipe do DeepCoder abordou isso implementando um pipeline rigoroso para coletar e filtrar exemplos de vários conjuntos de dados, garantindo validade, complexidade e evitando duplicações. Esse processo resultou em 24.000 problemas de alta qualidade, que formaram uma base robusta para o treinamento por RL.
A equipe também criou uma função de recompensa direta que recompensa o modelo apenas se o código gerado passar em todos os testes unitários amostrados dentro de um limite de tempo estabelecido. Essa abordagem, combinada com exemplos de treinamento de alta qualidade, garantiu que o modelo se concentrasse em resolver problemas centrais, em vez de explorar atalhos.
O algoritmo de treinamento do DeepCoder-14B é baseado na Otimização de Política Relativa de Grupo (GRPO), que foi bem-sucedida no DeepSeek-R1. No entanto, a equipe fez modificações significativas para aumentar a estabilidade e permitir durações de treinamento mais longas.
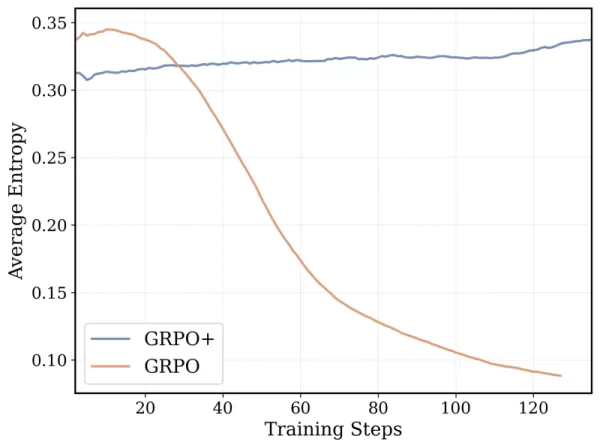
*GRPO+ permite que o DeepCoder-14 continue por durações mais longas sem colapsar Crédito: Together AI* Além disso, a equipe ampliou iterativamente a janela de contexto do modelo, começando com sequências mais curtas e aumentando gradualmente. Eles também introduziram um método de filtragem para evitar penalizar o modelo por exceder os limites de contexto ao resolver prompts complexos.
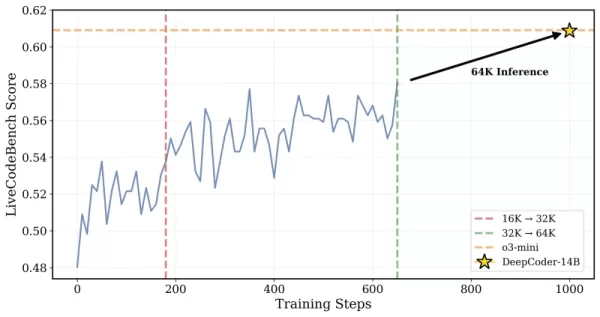
*DeepCoder foi treinado em problemas de contexto de 32K, mas também conseguiu resolver tarefas de 64K Crédito: Together AI* Os pesquisadores explicaram sua abordagem: "Para preservar o raciocínio de contexto longo enquanto possibilitamos um treinamento eficiente, incorporamos filtragem de sequências longas... Essa técnica mascara sequências truncadas durante o treinamento para que os modelos não sejam penalizados por gerar saídas longas e bem pensadas que excedem o limite de contexto atual." O treinamento escalou de uma janela de contexto de 16K para 32K, permitindo que o modelo enfrentasse problemas que exigem até 64K tokens.
Otimizando o Treinamento de RL de Contexto Longo
Treinar modelos grandes com RL, especialmente em tarefas que geram sequências longas como codificação, é notoriamente lento e intensivo em recursos. A etapa de amostragem, onde o modelo gera milhares de tokens por exemplo, frequentemente leva a atrasos significativos devido a comprimentos de resposta variados.
Para enfrentar isso, a equipe desenvolveu o verl-pipeline, uma extensão otimizada da biblioteca de código aberto verl para aprendizado por reforço a partir de feedback humano (RLHF). Sua inovação "One-Off Pipelining" reestruturou a amostragem e as atualizações do modelo para minimizar gargalos e reduzir o tempo ocioso em aceleradores.
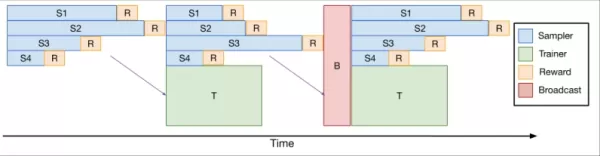
*One-Off Pipelining* Seus experimentos demonstraram que o one-off pipelining poderia acelerar tarefas de RL de codificação em até 2x em comparação com métodos padrão. Essa otimização foi crucial para treinar o DeepCoder-14B em um prazo razoável (2,5 semanas em 32 H100s) e agora está disponível como código aberto como parte do verl-pipeline para a comunidade aproveitar.
Impacto Empresarial e Colaboração de Código Aberto
Os pesquisadores disponibilizaram todos os artefatos de treinamento e operacionais do DeepCoder-14B no GitHub e Hugging Face sob uma licença permissiva. "Ao compartilhar totalmente nosso conjunto de dados, código e receita de treinamento, capacitamos a comunidade a reproduzir nosso trabalho e tornar o treinamento de RL acessível a todos," declararam.
O DeepCoder-14B exemplifica a crescente tendência de modelos eficientes e acessíveis abertamente no cenário da IA. Para empresas, isso significa mais opções e maior acessibilidade a modelos avançados. A geração de código de alto desempenho e o raciocínio não são mais exclusivos de grandes corporações ou daqueles dispostos a pagar altas taxas de API. Organizações de todos os tamanhos agora podem aproveitar essas capacidades, personalizar soluções para suas necessidades específicas e implantá-las de forma segura em seus ambientes.
Essa mudança está pronta para reduzir as barreiras à adoção de IA, fomentando um ecossistema mais competitivo e inovador impulsionado pela colaboração de código aberto.
Artigo relacionado
 Multiverse Computing lança modelo gratuito de IA generativa compactada
Os grandes modelos de linguagem enfrentam um desafio significativo: seu tamanho imenso. A startup espanhola Multiverse Computing está enfrentando esse problema com a criação de modelos compactados, pr
Dados secretos de rastreamento expõem roubo de modelos de IA
Um novo método pode marcar invisivelmente modelos como o ChatGPT em segundos, sem necessidade de retreinamento, sem deixar rastros nas saídas padrão e resistindo a todas as tentativas práticas de remo
Sistemas de IA enganados para aprovar artigos científicos absurdos
Uma nova pesquisa revela que os sistemas de IA agora podem produzir artigos científicos fraudulentos que outros modelos de IA aceitam erroneamente como autênticos. Esses estudos fabricados contornam m
Recomendações de tópicos especiais relacionados
Análise de dados
Multiverse Computing lança modelo gratuito de IA generativa compactada
Os grandes modelos de linguagem enfrentam um desafio significativo: seu tamanho imenso. A startup espanhola Multiverse Computing está enfrentando esse problema com a criação de modelos compactados, pr
Dados secretos de rastreamento expõem roubo de modelos de IA
Um novo método pode marcar invisivelmente modelos como o ChatGPT em segundos, sem necessidade de retreinamento, sem deixar rastros nas saídas padrão e resistindo a todas as tentativas práticas de remo
Sistemas de IA enganados para aprovar artigos científicos absurdos
Uma nova pesquisa revela que os sistemas de IA agora podem produzir artigos científicos fraudulentos que outros modelos de IA aceitam erroneamente como autênticos. Esses estudos fabricados contornam m
Recomendações de tópicos especiais relacionados
Análise de dados
 As melhores ferramentas de visualização de dados com IA: gere automaticamente painéis interativos de BI a partir de arquivos brutos
As melhores ferramentas de visualização de dados com IA: gere automaticamente painéis interativos de BI a partir de arquivos brutos
Descubra as melhores ferramentas de visualização de dados com IA de 2026 no XIX.AI. Nossa seleção cuidadosamente escolhida e com as melhores avaliações ajuda você a gerar automaticamente painéis de BI poderosos e interativos a partir de arquivos brutos, de forma instantânea. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Liberte o potencial dos seus dados hoje mesmo.
 10 ferramentas
10 ferramentas
 xix.ai
Mídias Sociais
Kits de identidade visual com IA para redes sociais: mantenha a identidade visual da marca consistente em todos os canais
xix.ai
Mídias Sociais
Kits de identidade visual com IA para redes sociais: mantenha a identidade visual da marca consistente em todos os canais
Descubra os melhores kits de branding com IA para redes sociais de 2026. A lista selecionada pela XIX.AI apresenta ferramentas de ponta e revolucionárias para manter uma identidade visual de marca perfeitamente consistente em todos os canais. Compare opções gratuitas e pagas com testes práticos. Destaque-se visualmente com sua marca hoje mesmo.
10 ferramentas
xix.ai
chatbot
Os melhores aplicativos de namoradas virtuais com IA e ferramentas de companhia com IA para jogos de interpretação (Guia de 2026)
Descubra as melhores ferramentas de IA para companhia de 2026, idealizadas para uma experiência imersiva de interpretação de papéis e conexão. O guia selecionado pela XIX.AI apresenta aplicativos poderosos e revolucionários, com rankings atualizados semanalmente, comparações entre versões gratuitas e pagas e testes práticos. Encontre a sua combinação perfeita e desfrute hoje mesmo de uma companhia digital significativa.
10 ferramentas
xix.ai
escrita
Os melhores assistentes de IA para Xianxia e Wuxia: crie histórias épicas de evolução no caminho do cultivo e coreografias de artes marciais
Descubra os melhores assistentes de IA de 2026 para criar histórias épicas de xianxia e wuxia. A lista selecionada pela XIX.AI apresenta ferramentas de primeira linha e revolucionárias para dominar a progressão no caminho do cultivo e a coreografia de artes marciais. Compare opções gratuitas e pagas com testes práticos. Liberte seu potencial criativo e comece a escrever hoje mesmo!
10 ferramentas
xix.ai
código
Ferramentas de Codificação para Aplicativos Móveis com IA: Gere código multiplataforma Flutter e React Native a partir de prompts.
Descubra os melhores ferramentas de programação para aplicativos móveis com IA em 2026 para Flutter e React Native. Nossa lista selecionada e altamente avaliada apresenta soluções poderosas que revolucionam o processo de desenvolvimento, gerando código multiplataforma a partir de instruções simples. Compare opções gratuitas e pagas com testes reais. Acelere seu desenvolvimento e crie aplicativos melhores. Explore as classificações no XIX.AI agora mesmo!
10 ferramentas
xix.ai
código
Os melhores geradores de extensões do Chrome com IA: crie complementos personalizados para o navegador sem precisar saber programar
Descubra as melhores extensões do Chrome com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta as ferramentas mais bem avaliadas e imperdíveis, que permitem criar complementos personalizados para o navegador sem precisar programar. Compare as opções gratuitas com as pagas, confira testes práticos e aumente sua produtividade. Explore os rankings mais recentes e encontre a ferramenta perfeita para você hoje mesmo!
10 ferramentas
xix.ai

 Comentários (14)
Comentários (14)
![RyanTaylor]()
Interesting! I've been following the open-source vs. proprietary model race. DeepCoder-14B matching o3-mini is a big deal for accessibility. Hope this pushes the big players to open up more, or at least lower their prices. The compute cost for training these 14B models must be insane though. 🤔
![FrankRodriguez]()
Wow, DeepCoder-14B sounds like a game-changer! I'm stoked to see open-source models catching up to the big players. Can't wait to try it out for my side projects—hope it’s as fast as they claim! 🚀
![GregoryBaker]()
DeepCoder-14B sounds like a game-changer! Can't wait to try it out and see how it stacks up against the big players. 🚀
![BillyLewis]()
Wow, DeepCoder-14B sounds like a game-changer for open-source coding! I'm curious how it stacks up against o3-mini in real-world projects. Anyone tried it yet? 🚀
![RaymondWalker]()
¡DeepCoder-14B es una locura! Un modelo de código abierto que compite con los grandes. ¿Será el fin de los modelos propietarios? 🤔
![RalphGarcia]()
DeepCoder-14B、めっちゃ面白そう!😊 オープンソースでここまでできるなんて、コーディングの未来が楽しみ!
Apresentando DeepCoder-14B: Uma Nova Fronteira em Modelos de Codificação de Código Aberto
As equipes da Together AI e Agentica revelaram o DeepCoder-14B, um modelo de codificação revolucionário que se equipara aos melhores modelos proprietários, como o o3-mini da OpenAI. Este desenvolvimento empolgante é baseado no DeepSeek-R1 e oferece maior flexibilidade para integrar geração de código e raciocínio de alto desempenho em aplicações práticas. Além disso, os criadores deram um passo louvável ao disponibilizar completamente o modelo em código aberto, incluindo seus dados de treinamento, código, logs e otimizações de sistema. Essa iniciativa está pronta para catalisar pesquisas e acelerar avanços no campo.
Desempenho Impressionante em um Pacote Compacto
O DeepCoder-14B demonstrou resultados notáveis em vários benchmarks de codificação, como LiveCodeBench (LCB), Codeforces e HumanEval+. Os experimentos da equipe de pesquisa destacaram que o desempenho do modelo é comparável aos principais modelos, como o3-mini (baixo) e o1. "Nosso modelo demonstra forte desempenho em todos os benchmarks de codificação... comparável ao desempenho do o3-mini (baixo) e o1," declararam os pesquisadores orgulhosamente em seu post de blog.
O que é particularmente intrigante é que, apesar de ser treinado principalmente em tarefas de codificação, o DeepCoder-14B também mostrou uma melhoria notável em raciocínio matemático, alcançando uma pontuação de 73,8% no benchmark AIME 2024. Isso marca um aumento de 4,1% em relação ao seu modelo base, DeepSeek-R1-Distill-Qwen-14B, sugerindo que as habilidades de raciocínio aprimoradas por meio de aprendizado por reforço (RL) em código podem ser transferidas eficazmente para outros domínios.
Talvez a característica mais empolgante do DeepCoder-14B seja sua eficiência. Com apenas 14 bilhões de parâmetros, ele alcança alto desempenho, sendo significativamente menor e mais eficiente em recursos do que muitos outros modelos líderes.
Inovações por Trás do Sucesso do DeepCoder
Desenvolver o DeepCoder-14B envolveu superar vários desafios, particularmente no treinamento de modelos de codificação usando aprendizado por reforço. Um grande obstáculo foi a curadoria de dados de treinamento. Diferentemente de tarefas matemáticas, onde dados verificáveis e de alta qualidade são abundantes, dados de codificação podem ser escassos. A equipe do DeepCoder abordou isso implementando um pipeline rigoroso para coletar e filtrar exemplos de vários conjuntos de dados, garantindo validade, complexidade e evitando duplicações. Esse processo resultou em 24.000 problemas de alta qualidade, que formaram uma base robusta para o treinamento por RL.
A equipe também criou uma função de recompensa direta que recompensa o modelo apenas se o código gerado passar em todos os testes unitários amostrados dentro de um limite de tempo estabelecido. Essa abordagem, combinada com exemplos de treinamento de alta qualidade, garantiu que o modelo se concentrasse em resolver problemas centrais, em vez de explorar atalhos.
O algoritmo de treinamento do DeepCoder-14B é baseado na Otimização de Política Relativa de Grupo (GRPO), que foi bem-sucedida no DeepSeek-R1. No entanto, a equipe fez modificações significativas para aumentar a estabilidade e permitir durações de treinamento mais longas.
Além disso, a equipe ampliou iterativamente a janela de contexto do modelo, começando com sequências mais curtas e aumentando gradualmente. Eles também introduziram um método de filtragem para evitar penalizar o modelo por exceder os limites de contexto ao resolver prompts complexos.
Os pesquisadores explicaram sua abordagem: "Para preservar o raciocínio de contexto longo enquanto possibilitamos um treinamento eficiente, incorporamos filtragem de sequências longas... Essa técnica mascara sequências truncadas durante o treinamento para que os modelos não sejam penalizados por gerar saídas longas e bem pensadas que excedem o limite de contexto atual." O treinamento escalou de uma janela de contexto de 16K para 32K, permitindo que o modelo enfrentasse problemas que exigem até 64K tokens.
Otimizando o Treinamento de RL de Contexto Longo
Treinar modelos grandes com RL, especialmente em tarefas que geram sequências longas como codificação, é notoriamente lento e intensivo em recursos. A etapa de amostragem, onde o modelo gera milhares de tokens por exemplo, frequentemente leva a atrasos significativos devido a comprimentos de resposta variados.
Para enfrentar isso, a equipe desenvolveu o verl-pipeline, uma extensão otimizada da biblioteca de código aberto verl para aprendizado por reforço a partir de feedback humano (RLHF). Sua inovação "One-Off Pipelining" reestruturou a amostragem e as atualizações do modelo para minimizar gargalos e reduzir o tempo ocioso em aceleradores.
Seus experimentos demonstraram que o one-off pipelining poderia acelerar tarefas de RL de codificação em até 2x em comparação com métodos padrão. Essa otimização foi crucial para treinar o DeepCoder-14B em um prazo razoável (2,5 semanas em 32 H100s) e agora está disponível como código aberto como parte do verl-pipeline para a comunidade aproveitar.
Impacto Empresarial e Colaboração de Código Aberto
Os pesquisadores disponibilizaram todos os artefatos de treinamento e operacionais do DeepCoder-14B no GitHub e Hugging Face sob uma licença permissiva. "Ao compartilhar totalmente nosso conjunto de dados, código e receita de treinamento, capacitamos a comunidade a reproduzir nosso trabalho e tornar o treinamento de RL acessível a todos," declararam.
O DeepCoder-14B exemplifica a crescente tendência de modelos eficientes e acessíveis abertamente no cenário da IA. Para empresas, isso significa mais opções e maior acessibilidade a modelos avançados. A geração de código de alto desempenho e o raciocínio não são mais exclusivos de grandes corporações ou daqueles dispostos a pagar altas taxas de API. Organizações de todos os tamanhos agora podem aproveitar essas capacidades, personalizar soluções para suas necessidades específicas e implantá-las de forma segura em seus ambientes.
Essa mudança está pronta para reduzir as barreiras à adoção de IA, fomentando um ecossistema mais competitivo e inovador impulsionado pela colaboração de código aberto.










 Multiverse Computing lança modelo gratuito de IA generativa compactada
Os grandes modelos de linguagem enfrentam um desafio significativo: seu tamanho imenso. A startup espanhola Multiverse Computing está enfrentando esse problema com a criação de modelos compactados, pr
Multiverse Computing lança modelo gratuito de IA generativa compactada
Os grandes modelos de linguagem enfrentam um desafio significativo: seu tamanho imenso. A startup espanhola Multiverse Computing está enfrentando esse problema com a criação de modelos compactados, pr
 Dados secretos de rastreamento expõem roubo de modelos de IA
Um novo método pode marcar invisivelmente modelos como o ChatGPT em segundos, sem necessidade de retreinamento, sem deixar rastros nas saídas padrão e resistindo a todas as tentativas práticas de remo
Dados secretos de rastreamento expõem roubo de modelos de IA
Um novo método pode marcar invisivelmente modelos como o ChatGPT em segundos, sem necessidade de retreinamento, sem deixar rastros nas saídas padrão e resistindo a todas as tentativas práticas de remo
 Sistemas de IA enganados para aprovar artigos científicos absurdos
Uma nova pesquisa revela que os sistemas de IA agora podem produzir artigos científicos fraudulentos que outros modelos de IA aceitam erroneamente como autênticos. Esses estudos fabricados contornam m
Sistemas de IA enganados para aprovar artigos científicos absurdos
Uma nova pesquisa revela que os sistemas de IA agora podem produzir artigos científicos fraudulentos que outros modelos de IA aceitam erroneamente como autênticos. Esses estudos fabricados contornam m

Descubra as melhores ferramentas de visualização de dados com IA de 2026 no XIX.AI. Nossa seleção cuidadosamente escolhida e com as melhores avaliações ajuda você a gerar automaticamente painéis de BI poderosos e interativos a partir de arquivos brutos, de forma instantânea. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Liberte o potencial dos seus dados hoje mesmo.
10 ferramentas
xix.ai

Descubra os melhores kits de branding com IA para redes sociais de 2026. A lista selecionada pela XIX.AI apresenta ferramentas de ponta e revolucionárias para manter uma identidade visual de marca perfeitamente consistente em todos os canais. Compare opções gratuitas e pagas com testes práticos. Destaque-se visualmente com sua marca hoje mesmo.
10 ferramentas
xix.ai

Descubra as melhores ferramentas de IA para companhia de 2026, idealizadas para uma experiência imersiva de interpretação de papéis e conexão. O guia selecionado pela XIX.AI apresenta aplicativos poderosos e revolucionários, com rankings atualizados semanalmente, comparações entre versões gratuitas e pagas e testes práticos. Encontre a sua combinação perfeita e desfrute hoje mesmo de uma companhia digital significativa.
10 ferramentas
xix.ai

Descubra os melhores assistentes de IA de 2026 para criar histórias épicas de xianxia e wuxia. A lista selecionada pela XIX.AI apresenta ferramentas de primeira linha e revolucionárias para dominar a progressão no caminho do cultivo e a coreografia de artes marciais. Compare opções gratuitas e pagas com testes práticos. Liberte seu potencial criativo e comece a escrever hoje mesmo!
10 ferramentas
xix.ai

Descubra os melhores ferramentas de programação para aplicativos móveis com IA em 2026 para Flutter e React Native. Nossa lista selecionada e altamente avaliada apresenta soluções poderosas que revolucionam o processo de desenvolvimento, gerando código multiplataforma a partir de instruções simples. Compare opções gratuitas e pagas com testes reais. Acelere seu desenvolvimento e crie aplicativos melhores. Explore as classificações no XIX.AI agora mesmo!
10 ferramentas
xix.ai

Descubra as melhores extensões do Chrome com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta as ferramentas mais bem avaliadas e imperdíveis, que permitem criar complementos personalizados para o navegador sem precisar programar. Compare as opções gratuitas com as pagas, confira testes práticos e aumente sua produtividade. Explore os rankings mais recentes e encontre a ferramenta perfeita para você hoje mesmo!
10 ferramentas
xix.ai

Interesting! I've been following the open-source vs. proprietary model race. DeepCoder-14B matching o3-mini is a big deal for accessibility. Hope this pushes the big players to open up more, or at least lower their prices. The compute cost for training these 14B models must be insane though. 🤔
Wow, DeepCoder-14B sounds like a game-changer! I'm stoked to see open-source models catching up to the big players. Can't wait to try it out for my side projects—hope it’s as fast as they claim! 🚀
DeepCoder-14B sounds like a game-changer! Can't wait to try it out and see how it stacks up against the big players. 🚀
Wow, DeepCoder-14B sounds like a game-changer for open-source coding! I'm curious how it stacks up against o3-mini in real-world projects. Anyone tried it yet? 🚀
¡DeepCoder-14B es una locura! Un modelo de código abierto que compite con los grandes. ¿Será el fin de los modelos propietarios? 🤔
DeepCoder-14B、めっちゃ面白そう!😊 オープンソースでここまでできるなんて、コーディングの未来が楽しみ!













