
















 Maison
Maison
Étude de Microsoft révèle les limites des modèles d'IA dans le débogage de logiciels
Les modèles d'IA d'OpenAI, Anthropic et d'autres laboratoires d'IA de pointe sont de plus en plus utilisés pour les tâches de codage. Le PDG de Google, Sundar Pichai, a noté en octobre que l'IA génère 25 % du nouveau code dans l'entreprise, tandis que le PDG de Meta, Mark Zuckerberg, vise à implémenter largement des outils de codage par IA au sein du géant des réseaux sociaux.
Cependant, même les modèles les plus performants peinent à corriger les bogues logiciels que les développeurs expérimentés gèrent avec aisance.
Une récente étude de Microsoft Research, menée par la division R&D de Microsoft, montre que des modèles comme Claude 3.7 Sonnet d'Anthropic et o3-mini d'OpenAI ont du mal à résoudre de nombreux problèmes dans le benchmark de développement logiciel SWE-bench Lite. Les résultats soulignent que, malgré les revendications ambitieuses d'entreprises comme OpenAI, l'IA reste en deçà de l'expertise humaine dans des domaines comme le codage.
Les chercheurs de l'étude ont testé neuf modèles comme base pour un « agent basé sur une seule invite » équipé d'outils de débogage, y compris un débogueur Python. L'agent a été chargé de relever 300 défis de débogage logiciel soigneusement sélectionnés dans SWE-bench Lite.
Les résultats ont montré que même avec des modèles avancés, l'agent a rarement réussi à résoudre plus de la moitié des tâches avec succès. Claude 3.7 Sonnet a dominé avec un taux de réussite de 48,4 %, suivi par o1 d'OpenAI à 30,2 %, et o3-mini à 22,1 %.
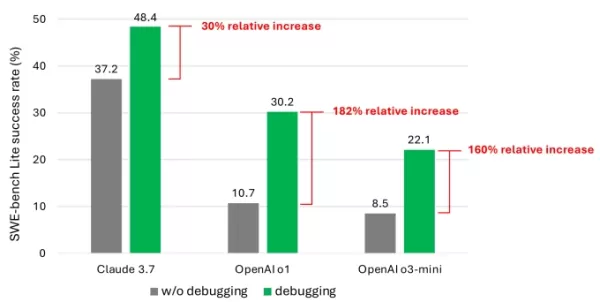
Un graphique de l'étude montrant l'amélioration des performances des modèles grâce aux outils de débogage. Crédits image : Microsoft Qu'explique ces résultats décevants ? Certains modèles ont eu du mal à utiliser efficacement les outils de débogage disponibles ou à identifier quels outils convenaient à des problèmes spécifiques. Le principal problème, selon les chercheurs, était un manque de données d'entraînement suffisantes, en particulier des données capturant les « processus de prise de décision séquentielle » comme les traces de débogage humain.
« Nous pensons que l'entraînement ou l'ajustement fin de ces modèles peut améliorer leurs capacités de débogage », ont écrit les chercheurs. « Cependant, cela nécessite des données spécialisées, telles que des données de trajectoire capturant les interactions des agents avec un débogueur pour recueillir des informations avant de proposer des corrections. »
Participez aux sessions TechCrunch : IA
Réservez votre place à notre événement phare de l'industrie de l'IA, avec des conférenciers d'OpenAI, Anthropic et Cohere. Pour une durée limitée, les billets coûtent seulement 292 $ pour une journée complète de conférences d'experts, d'ateliers et d'opportunités de réseautage.
Exposez aux sessions TechCrunch : IA
Réservez votre place aux sessions TC : IA pour présenter votre travail à plus de 1 200 décideurs. Des opportunités d'exposition sont disponibles jusqu'au 9 mai ou jusqu'à ce que les stands soient entièrement réservés.
Les résultats ne sont pas surprenants. De nombreuses études ont montré que le code généré par l'IA introduit souvent des failles de sécurité et des erreurs en raison de faiblesses dans la compréhension de la logique de programmation. Un test récent de Devin, un outil de codage IA bien connu, a révélé qu'il ne pouvait accomplir que trois des 20 tâches de programmation.
L'étude de Microsoft offre l'un des examens les plus approfondis de ce défi persistant pour les modèles d'IA. Bien qu'il soit peu probable que cela freine l'intérêt des investisseurs pour les outils de codage alimentés par l'IA, cela pourrait inciter les développeurs et leurs dirigeants à reconsidérer une dépendance excessive envers l'IA pour les tâches de codage.
Notamment, plusieurs leaders technologiques ont repoussé l'idée que l'IA éliminera les emplois de codage. Le cofondateur de Microsoft, Bill Gates, le PDG de Replit, Amjad Masad, le PDG d'Okta, Todd McKinnon, et le PDG d'IBM, Arvind Krishna, ont tous exprimé leur confiance dans la pérennité de la profession de programmeur.
Article connexe
 Kakao Mobility présente sa feuille de route pour la conduite autonome de niveau 4 basée sur l'IA physique
Kakao Mobility prévoit de développer en interne des technologies de conduite autonome de niveau 4 dans le cadre de sa stratégie d'IA physique.Lors de la conférence World IT Show 2026 qui s'est tenue
Barry Diller : la confiance en Sam Altman n'a plus d'importance à l'approche de l'IA générale
Barry Diller, le magnat milliardaire des médias, ne considère pas que Sam Altman, PDG d’OpenAI, soit indigne de confiance, malgré des informations récentes suggérant le contraire. S’exprimant cette se
YouTube étend sa détection des deepfakes par IA aux personnalités politiques, aux responsables gouvernementaux et aux journalistes
Mardi, YouTube a annoncé qu’il étendait sa technologie de détection des deepfakes à un groupe restreint de responsables gouvernementaux, de candidats politiques et de journalistes. Cet outil identifie
Recommandations de sujets spéciaux liés
chatbot
Kakao Mobility présente sa feuille de route pour la conduite autonome de niveau 4 basée sur l'IA physique
Kakao Mobility prévoit de développer en interne des technologies de conduite autonome de niveau 4 dans le cadre de sa stratégie d'IA physique.Lors de la conférence World IT Show 2026 qui s'est tenue
Barry Diller : la confiance en Sam Altman n'a plus d'importance à l'approche de l'IA générale
Barry Diller, le magnat milliardaire des médias, ne considère pas que Sam Altman, PDG d’OpenAI, soit indigne de confiance, malgré des informations récentes suggérant le contraire. S’exprimant cette se
YouTube étend sa détection des deepfakes par IA aux personnalités politiques, aux responsables gouvernementaux et aux journalistes
Mardi, YouTube a annoncé qu’il étendait sa technologie de détection des deepfakes à un groupe restreint de responsables gouvernementaux, de candidats politiques et de journalistes. Cet outil identifie
Recommandations de sujets spéciaux liés
chatbot
 Les meilleurs outils d'IA pour apprendre à flirter et à converser : renforcez votre charisme social et votre confiance en vous en temps réel
Les meilleurs outils d'IA pour apprendre à flirter et à converser : renforcez votre charisme social et votre confiance en vous en temps réel
Découvrez les meilleurs outils d'entraînement au flirt et à la conversation basés sur l'IA de 2026 sur XIX.AI. Notre sélection triée sur le volet et très bien notée vous aide à développer votre charisme social et votre confiance en vous en temps réel. Découvrez des outils incontournables qui changent la donne, avec des comparaisons entre versions gratuites et payantes ainsi que des classements mis à jour chaque semaine. Développez dès aujourd'hui vos compétences sociales.
 10 outils
10 outils
 xix.ai
code
Meilleurs outils d'IA pour les tests unitaires automatisés : générer des cas de test Jest, PyTest et JUnit en un clic
xix.ai
code
Meilleurs outils d'IA pour les tests unitaires automatisés : générer des cas de test Jest, PyTest et JUnit en un clic
Découvrez les derniers outils d'IA hautement réputés de 2026 pour les tests unitaires automatisés. Notre sélection rigoureusement élaborée vous propose des solutions puissantes et révolutionnaires pour générer instantanément des cas de test Jest, PyTest et JUnit. Comparez les options gratuites et payantes à l'aide de tests réels et des classements mises à jour chaque semaine sur XIX.AI. Développez un avantage concurrentiel grâce à l'IA et améliorez rapidement votre productivité en développement.
10 outils
xix.ai
Analyse des données
Les meilleurs outils de visualisation de données basés sur l'IA : générez automatiquement des tableaux de bord BI interactifs à partir de fichiers bruts
Découvrez les meilleurs outils de visualisation de données par IA de 2026 sur XIX.AI. Notre sélection rigoureuse et hautement notée vous aide à générer instantanément et automatiquement des tableaux de bord BI puissants et interactifs à partir de fichiers bruts. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Libérez dès aujourd'hui le potentiel de vos données.
10 outils
xix.ai
Réseaux sociaux
Kits de marque basés sur l'IA pour les réseaux sociaux : assurez la cohérence visuelle de votre marque sur tous les canaux
Découvrez les meilleurs kits de branding IA pour les réseaux sociaux en 2026. La sélection de XIX.AI regroupe des outils de premier plan qui changent la donne et vous permettent de garantir une cohérence visuelle parfaite de votre marque sur tous les canaux. Comparez les options gratuites et payantes grâce à des tests concrets. Donnez dès aujourd'hui un coup de pouce visuel à votre marque.
10 outils
xix.ai
chatbot
Les meilleures applications de petite amie virtuelle et outils d'accompagnement IA pour les jeux de rôle (Guide 2026)
Découvrez les meilleurs outils d'IA de 2026 pour des jeux de rôle immersifs et des interactions enrichissantes. Le guide sélectionné par XIX.AI présente des applications puissantes et révolutionnaires, avec des classements mis à jour chaque semaine, des comparaisons entre versions gratuites et payantes, ainsi que des tests en conditions réelles. Trouvez le partenaire idéal et profitez dès aujourd'hui d'une compagnie numérique enrichissante.
10 outils
xix.ai
en écrivant
Les meilleurs assistants IA pour les genres xianxia et wuxia : rédigez des récits épiques de progression spirituelle et des chorégraphies d'arts martiaux
Découvrez les meilleurs assistants IA de 2026 pour créer des récits épiques de xianxia et de wuxia. La sélection de XIX.AI regroupe les outils les mieux notés et les plus innovants pour maîtriser la progression dans la voie de la cultivation et la chorégraphie des arts martiaux. Comparez les options gratuites et payantes grâce à des tests concrets. Libérez votre potentiel créatif et commencez à écrire dès aujourd'hui !
10 outils
xix.ai

 commentaires (6)
commentaires (6)
![ThomasScott]()
微软这个研究结果太真实了😂 前几天用Copilot改bug,它居然把正确代码改得更错了…看来AI写代码还是得人工把关,至少现阶段别太依赖它们debug。
![HenryWalker]()
It's wild that AI is pumping out 25% of Google's code, but this Microsoft study shows it's not perfect at debugging. Kinda makes you wonder if we're trusting these models a bit too much too soon. 😅 Anyone else worried about buggy AI code sneaking into big projects?
![BrianRoberts]()
It's wild that AI is cranking out 25% of Google's code, but the debugging struggles are real. Makes me wonder if we're leaning too hard on AI without fixing its blind spots first. 🧑💻
![KevinDavis]()
It's wild that AI is pumping out 25% of Google's code, but the debugging limitations in this study make me wonder if we're leaning too hard on these models without enough human oversight. 🤔
![PeterThomas]()
Interesting read! AI generating 25% of Google's code is wild, but I'm not surprised it struggles with debugging. Machines can churn out code fast, but catching tricky bugs? That’s still a human’s game. 🧑💻
![JuanWhite]()
AI coding sounds cool, but if it can't debug properly, what's the point? 🤔 Feels like we're hyping up half-baked tools while devs still clean up the mess.
Les modèles d'IA d'OpenAI, Anthropic et d'autres laboratoires d'IA de pointe sont de plus en plus utilisés pour les tâches de codage. Le PDG de Google, Sundar Pichai, a noté en octobre que l'IA génère 25 % du nouveau code dans l'entreprise, tandis que le PDG de Meta, Mark Zuckerberg, vise à implémenter largement des outils de codage par IA au sein du géant des réseaux sociaux.
Cependant, même les modèles les plus performants peinent à corriger les bogues logiciels que les développeurs expérimentés gèrent avec aisance.
Une récente étude de Microsoft Research, menée par la division R&D de Microsoft, montre que des modèles comme Claude 3.7 Sonnet d'Anthropic et o3-mini d'OpenAI ont du mal à résoudre de nombreux problèmes dans le benchmark de développement logiciel SWE-bench Lite. Les résultats soulignent que, malgré les revendications ambitieuses d'entreprises comme OpenAI, l'IA reste en deçà de l'expertise humaine dans des domaines comme le codage.
Les chercheurs de l'étude ont testé neuf modèles comme base pour un « agent basé sur une seule invite » équipé d'outils de débogage, y compris un débogueur Python. L'agent a été chargé de relever 300 défis de débogage logiciel soigneusement sélectionnés dans SWE-bench Lite.
Les résultats ont montré que même avec des modèles avancés, l'agent a rarement réussi à résoudre plus de la moitié des tâches avec succès. Claude 3.7 Sonnet a dominé avec un taux de réussite de 48,4 %, suivi par o1 d'OpenAI à 30,2 %, et o3-mini à 22,1 %.
Qu'explique ces résultats décevants ? Certains modèles ont eu du mal à utiliser efficacement les outils de débogage disponibles ou à identifier quels outils convenaient à des problèmes spécifiques. Le principal problème, selon les chercheurs, était un manque de données d'entraînement suffisantes, en particulier des données capturant les « processus de prise de décision séquentielle » comme les traces de débogage humain.
« Nous pensons que l'entraînement ou l'ajustement fin de ces modèles peut améliorer leurs capacités de débogage », ont écrit les chercheurs. « Cependant, cela nécessite des données spécialisées, telles que des données de trajectoire capturant les interactions des agents avec un débogueur pour recueillir des informations avant de proposer des corrections. »
Participez aux sessions TechCrunch : IA
Réservez votre place à notre événement phare de l'industrie de l'IA, avec des conférenciers d'OpenAI, Anthropic et Cohere. Pour une durée limitée, les billets coûtent seulement 292 $ pour une journée complète de conférences d'experts, d'ateliers et d'opportunités de réseautage.
Exposez aux sessions TechCrunch : IA
Réservez votre place aux sessions TC : IA pour présenter votre travail à plus de 1 200 décideurs. Des opportunités d'exposition sont disponibles jusqu'au 9 mai ou jusqu'à ce que les stands soient entièrement réservés.
Les résultats ne sont pas surprenants. De nombreuses études ont montré que le code généré par l'IA introduit souvent des failles de sécurité et des erreurs en raison de faiblesses dans la compréhension de la logique de programmation. Un test récent de Devin, un outil de codage IA bien connu, a révélé qu'il ne pouvait accomplir que trois des 20 tâches de programmation.
L'étude de Microsoft offre l'un des examens les plus approfondis de ce défi persistant pour les modèles d'IA. Bien qu'il soit peu probable que cela freine l'intérêt des investisseurs pour les outils de codage alimentés par l'IA, cela pourrait inciter les développeurs et leurs dirigeants à reconsidérer une dépendance excessive envers l'IA pour les tâches de codage.
Notamment, plusieurs leaders technologiques ont repoussé l'idée que l'IA éliminera les emplois de codage. Le cofondateur de Microsoft, Bill Gates, le PDG de Replit, Amjad Masad, le PDG d'Okta, Todd McKinnon, et le PDG d'IBM, Arvind Krishna, ont tous exprimé leur confiance dans la pérennité de la profession de programmeur.









 Kakao Mobility présente sa feuille de route pour la conduite autonome de niveau 4 basée sur l'IA physique
Kakao Mobility prévoit de développer en interne des technologies de conduite autonome de niveau 4 dans le cadre de sa stratégie d'IA physique.Lors de la conférence World IT Show 2026 qui s'est tenue
Kakao Mobility présente sa feuille de route pour la conduite autonome de niveau 4 basée sur l'IA physique
Kakao Mobility prévoit de développer en interne des technologies de conduite autonome de niveau 4 dans le cadre de sa stratégie d'IA physique.Lors de la conférence World IT Show 2026 qui s'est tenue
 Barry Diller : la confiance en Sam Altman n'a plus d'importance à l'approche de l'IA générale
Barry Diller, le magnat milliardaire des médias, ne considère pas que Sam Altman, PDG d’OpenAI, soit indigne de confiance, malgré des informations récentes suggérant le contraire. S’exprimant cette se
Barry Diller : la confiance en Sam Altman n'a plus d'importance à l'approche de l'IA générale
Barry Diller, le magnat milliardaire des médias, ne considère pas que Sam Altman, PDG d’OpenAI, soit indigne de confiance, malgré des informations récentes suggérant le contraire. S’exprimant cette se
 YouTube étend sa détection des deepfakes par IA aux personnalités politiques, aux responsables gouvernementaux et aux journalistes
Mardi, YouTube a annoncé qu’il étendait sa technologie de détection des deepfakes à un groupe restreint de responsables gouvernementaux, de candidats politiques et de journalistes. Cet outil identifie
YouTube étend sa détection des deepfakes par IA aux personnalités politiques, aux responsables gouvernementaux et aux journalistes
Mardi, YouTube a annoncé qu’il étendait sa technologie de détection des deepfakes à un groupe restreint de responsables gouvernementaux, de candidats politiques et de journalistes. Cet outil identifie

Découvrez les meilleurs outils d'entraînement au flirt et à la conversation basés sur l'IA de 2026 sur XIX.AI. Notre sélection triée sur le volet et très bien notée vous aide à développer votre charisme social et votre confiance en vous en temps réel. Découvrez des outils incontournables qui changent la donne, avec des comparaisons entre versions gratuites et payantes ainsi que des classements mis à jour chaque semaine. Développez dès aujourd'hui vos compétences sociales.
10 outils
xix.ai

Découvrez les derniers outils d'IA hautement réputés de 2026 pour les tests unitaires automatisés. Notre sélection rigoureusement élaborée vous propose des solutions puissantes et révolutionnaires pour générer instantanément des cas de test Jest, PyTest et JUnit. Comparez les options gratuites et payantes à l'aide de tests réels et des classements mises à jour chaque semaine sur XIX.AI. Développez un avantage concurrentiel grâce à l'IA et améliorez rapidement votre productivité en développement.
10 outils
xix.ai

Découvrez les meilleurs outils de visualisation de données par IA de 2026 sur XIX.AI. Notre sélection rigoureuse et hautement notée vous aide à générer instantanément et automatiquement des tableaux de bord BI puissants et interactifs à partir de fichiers bruts. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Libérez dès aujourd'hui le potentiel de vos données.
10 outils
xix.ai

Découvrez les meilleurs kits de branding IA pour les réseaux sociaux en 2026. La sélection de XIX.AI regroupe des outils de premier plan qui changent la donne et vous permettent de garantir une cohérence visuelle parfaite de votre marque sur tous les canaux. Comparez les options gratuites et payantes grâce à des tests concrets. Donnez dès aujourd'hui un coup de pouce visuel à votre marque.
10 outils
xix.ai

Découvrez les meilleurs outils d'IA de 2026 pour des jeux de rôle immersifs et des interactions enrichissantes. Le guide sélectionné par XIX.AI présente des applications puissantes et révolutionnaires, avec des classements mis à jour chaque semaine, des comparaisons entre versions gratuites et payantes, ainsi que des tests en conditions réelles. Trouvez le partenaire idéal et profitez dès aujourd'hui d'une compagnie numérique enrichissante.
10 outils
xix.ai

Découvrez les meilleurs assistants IA de 2026 pour créer des récits épiques de xianxia et de wuxia. La sélection de XIX.AI regroupe les outils les mieux notés et les plus innovants pour maîtriser la progression dans la voie de la cultivation et la chorégraphie des arts martiaux. Comparez les options gratuites et payantes grâce à des tests concrets. Libérez votre potentiel créatif et commencez à écrire dès aujourd'hui !
10 outils
xix.ai

微软这个研究结果太真实了😂 前几天用Copilot改bug,它居然把正确代码改得更错了…看来AI写代码还是得人工把关,至少现阶段别太依赖它们debug。
It's wild that AI is pumping out 25% of Google's code, but this Microsoft study shows it's not perfect at debugging. Kinda makes you wonder if we're trusting these models a bit too much too soon. 😅 Anyone else worried about buggy AI code sneaking into big projects?
It's wild that AI is cranking out 25% of Google's code, but the debugging struggles are real. Makes me wonder if we're leaning too hard on AI without fixing its blind spots first. 🧑💻
It's wild that AI is pumping out 25% of Google's code, but the debugging limitations in this study make me wonder if we're leaning too hard on these models without enough human oversight. 🤔
Interesting read! AI generating 25% of Google's code is wild, but I'm not surprised it struggles with debugging. Machines can churn out code fast, but catching tricky bugs? That’s still a human’s game. 🧑💻
AI coding sounds cool, but if it can't debug properly, what's the point? 🤔 Feels like we're hyping up half-baked tools while devs still clean up the mess.













