
















 Дом
ДомDeepCoder достигает высокой эффективности кодирования с открытой моделью 14B
Представляем DeepCoder-14B: новая веха в моделях программирования с открытым исходным кодом
Команды Together AI и Agentica представили DeepCoder-14B, революционную модель программирования, которая стоит на одном уровне с ведущими проприетарными моделями, такими как o3-mini от OpenAI. Это захватывающее развитие основано на модели DeepSeek-R1 и предлагает повышенную гибкость для интеграции высокопроизводительной генерации кода и рассуждений в практические приложения. Более того, создатели сделали похвальный шаг, полностью открыв исходный код модели, включая данные для обучения, код, логи и системные оптимизации. Этот шаг призван стимулировать исследования и ускорить прогресс в этой области.
Впечатляющая производительность в компактном формате
DeepCoder-14B показал выдающиеся результаты в различных тестах программирования, таких как LiveCodeBench (LCB), Codeforces и HumanEval+. Эксперименты исследовательской группы показали, что производительность модели сравнима с ведущими моделями, такими как o3-mini (низкий уровень) и o1. «Наша модель демонстрирует высокую производительность во всех тестах программирования... сравнимую с производительностью o3-mini (низкий уровень) и o1», — с гордостью заявили исследователи в своем блоге.
Особенно интригует то, что, несмотря на основное обучение на задачах программирования, DeepCoder-14B также показал заметное улучшение в математических рассуждениях, достигнув результата 73,8% в тесте AIME 2024. Это на 4,1% выше, чем у базовой модели DeepSeek-R1-Distill-Qwen-14B, что свидетельствует о том, что навыки рассуждения, отточенные через обучение с подкреплением (RL) на коде, могут эффективно переноситься на другие области.
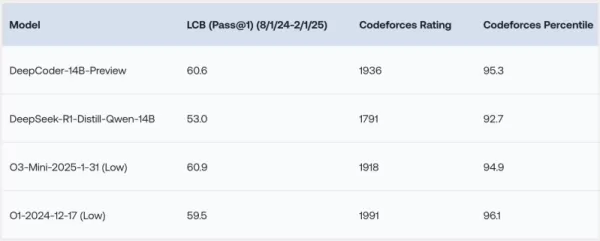
*Источник: Together AI* Пожалуй, наиболее захватывающей особенностью DeepCoder-14B является его эффективность. С всего 14 миллиардами параметров он достигает высокой производительности, будучи значительно меньше и более экономичным по ресурсам, чем многие другие ведущие модели.
Инновации, стоящие за успехом DeepCoder
Разработка DeepCoder-14B включала преодоление нескольких вызовов, особенно в обучении моделей программирования с использованием обучения с подкреплением. Одной из главных проблем была подготовка обучающих данных. В отличие от математических задач, где доступно множество высококачественных и проверяемых данных, данные для программирования могут быть ограничены. Команда DeepCoder решила эту проблему, внедрив строгую систему для сбора и фильтрации примеров из различных наборов данных, обеспечивая их валидность, сложность и отсутствие дублирования. Этот процесс привел к созданию 24 000 высококачественных задач, которые стали прочной основой для обучения с подкреплением.
Команда также разработала простую функцию вознаграждения, которая вознаграждает модель только в случае успешного прохождения всех выборочных модульных тестов в установленный срок. Этот подход, в сочетании с высококачественными обучающими примерами, гарантировал, что модель сосредотачивается на решении основных задач, а не на использовании обходных путей.
Алгоритм обучения DeepCoder-14B основан на Group Relative Policy Optimization (GRPO), который был успешен в DeepSeek-R1. Однако команда внесла значительные изменения для повышения стабильности и возможности более длительного обучения.
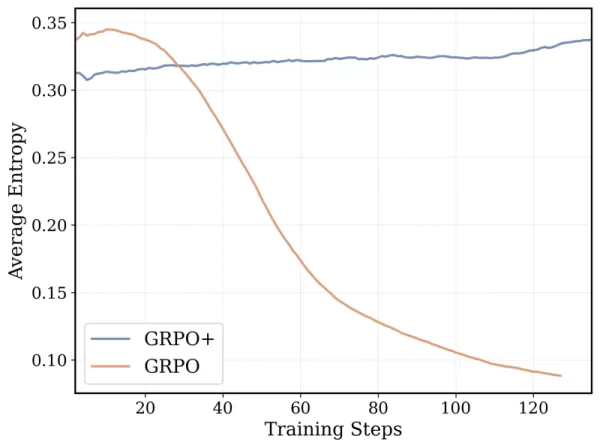
*GRPO+ позволяет DeepCoder-14 продолжать обучение дольше без сбоев Источник: Together AI* Кроме того, команда постепенно расширяла окно контекста модели, начиная с коротких последовательностей и постепенно увеличивая их. Также была введена методика фильтрации, чтобы избежать наказания модели за превышение лимитов контекста при решении сложных задач.
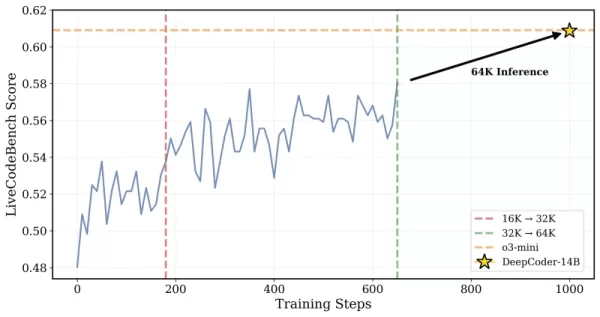
*DeepCoder обучался на задачах с контекстом 32K, но также смог решать задачи на 64K Источник: Together AI* Исследователи объяснили свой подход: «Чтобы сохранить рассуждения на длинных контекстах при эффективном обучении, мы внедрили фильтрацию избыточных последовательностей... Эта техника маскирует обрезанные последовательности во время обучения, чтобы модели не наказывались за генерацию продуманных, но длинных выводов, превышающих текущий лимит контекста». Обучение масштабировалось с контекста 16K до 32K, что позволило модели решать задачи, требующие до 64K токенов.
Оптимизация обучения с подкреплением для длинных контекстов
Обучение больших моделей с использованием RL, особенно на задачах, генерирующих длинные последовательности, таких как программирование, известно своей медлительностью и ресурсоемкостью. Шаг выборки, при котором модель генерирует тысячи токенов на пример, часто приводит к значительным задержкам из-за разной длины ответов.
Для решения этой проблемы команда разработала verl-pipeline, оптимизированное расширение библиотеки с открытым исходным кодом verl для обучения с подкреплением на основе обратной связи от человека (RLHF). Их инновация «One-Off Pipelining» реструктурировала выборку и обновления модели, чтобы минимизировать узкие места и сократить время простоя ускорителей.
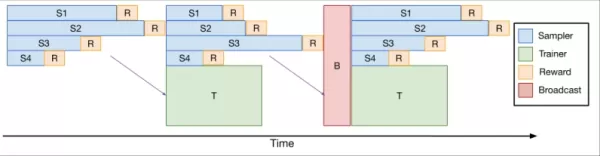
*One-Off Pipelining* Их эксперименты показали, что one-off pipelining может ускорить задачи RL программирования до 2 раз по сравнению со стандартными методами. Эта оптимизация была ключевой для обучения DeepCoder-14B в разумные сроки (2,5 недели на 32 H100) и теперь открыта для сообщества в рамках verl-pipeline.
Влияние на предприятия и сотрудничество с открытым исходным кодом
Исследователи сделали все обучающие и операционные артефакты DeepCoder-14B доступными на GitHub и Hugging Face под разрешительной лицензией. «Полностью делясь нашим набором данных, кодом и рецептом обучения, мы даем сообществу возможность воспроизвести нашу работу и сделать обучение RL доступным для всех», — заявили они.
DeepCoder-14B является примером растущей тенденции к эффективным моделям с открытым доступом в области AI. Для предприятий это означает больше возможностей и большую доступность к продвинутым моделям. Высокопроизводительная генерация кода и рассуждения больше не являются эксклюзивом крупных корпораций или тех, кто готов платить высокие сборы за API. Организации всех размеров теперь могут использовать эти возможности, адаптировать решения под свои конкретные потребности и безопасно развертывать их в своих средах.
Этот сдвиг призван снизить барьеры для внедрения AI, способствуя созданию более конкурентной и инновационной экосистемы, основанной на сотрудничестве с открытым исходным кодом.
Связанная статья
 Multiverse Computing запускает бесплатную сжатую генеративную модель искусственного интеллекта
Крупные языковые модели сталкиваются с серьезной проблемой: их огромный размер. Испанский стартап Multiverse Computing решает эту проблему, создавая сжатые модели, призванные преодолеть разрыв между в
Секретные данные отслеживания раскрывают кражу моделей искусственного интеллекта
Новый метод позволяет за считанные секунды незаметно наносить водяные знаки на модели, такие как ChatGPT, без повторного обучения, не оставляя следов в стандартных выводах и противостоять всем практич
Искусственный интеллект обманом заставили одобрить абсурдные научные статьи
Новые исследования показывают, что системы искусственного интеллекта теперь могут создавать фальшивые научные статьи, которые другие модели искусственного интеллекта ошибочно принимают за подлинные. Э
Рекомендации по связанным специальным темам
код
Multiverse Computing запускает бесплатную сжатую генеративную модель искусственного интеллекта
Крупные языковые модели сталкиваются с серьезной проблемой: их огромный размер. Испанский стартап Multiverse Computing решает эту проблему, создавая сжатые модели, призванные преодолеть разрыв между в
Секретные данные отслеживания раскрывают кражу моделей искусственного интеллекта
Новый метод позволяет за считанные секунды незаметно наносить водяные знаки на модели, такие как ChatGPT, без повторного обучения, не оставляя следов в стандартных выводах и противостоять всем практич
Искусственный интеллект обманом заставили одобрить абсурдные научные статьи
Новые исследования показывают, что системы искусственного интеллекта теперь могут создавать фальшивые научные статьи, которые другие модели искусственного интеллекта ошибочно принимают за подлинные. Э
Рекомендации по связанным специальным темам
код
 Лучшие инструменты ИИ для автоматизированного тестирования модулей: создание случаев тестирования Jest, PyTest и JUnit одним кликом
Лучшие инструменты ИИ для автоматизированного тестирования модулей: создание случаев тестирования Jest, PyTest и JUnit одним кликом
Откройте для себя самые новые и высоко оцененные инструменты ИИ 2026 года для автоматизированного тестирования модулей. Наша тщательно подобранная коллекция включает мощные решения, способные радикально изменить процесс разработки, позволяющие мгновенно генерировать тестовые случаи для Jest, PyTest и JUnit. Сравните бесплатные и платные варианты с результатами реальных тестов, а также еженедельно обновляемыми рейтингами на сайте XIX.AI. Раскройте потенциал ИИ и повысьте эффективность своей работы в области разработки сегодня же.
 10 инструментов
10 инструментов
 xix.ai
Анализ данных
Лучшие инструменты для визуализации данных с помощью ИИ: автоматическое создание интерактивных панелей BI на основе исходных файлов
xix.ai
Анализ данных
Лучшие инструменты для визуализации данных с помощью ИИ: автоматическое создание интерактивных панелей BI на основе исходных файлов
Откройте для себя лучшие инструменты визуализации данных на базе ИИ 2026 года на сайте XIX.AI. Наша тщательно отобранная подборка лидеров рейтинга поможет вам мгновенно создавать мощные интерактивные информационные панели BI на основе необработанных файлов. Сравните бесплатные и платные варианты с помощью реальных тестов и еженедельно обновляемых рейтингов. Раскройте потенциал ваших данных уже сегодня.
10 инструментов
xix.ai
Социальные сети
Наборы материалов для продвижения бренда в социальных сетях с использованием ИИ: обеспечение единообразия визуального стиля бренда во всех каналах
Откройте для себя лучшие наборы материалов для брендинга на базе ИИ в социальных сетях 2026 года. В тщательно подобранном списке XIX.AI представлены самые популярные и революционные инструменты, которые помогут обеспечить идеальную визуальную согласованность бренда во всех каналах. Сравните бесплатные и платные варианты на основе реальных тестов. Раскройте визуальный потенциал вашего бренда уже сегодня.
10 инструментов
xix.ai
чат-бот
Лучшие приложения с виртуальными подругами на базе ИИ и инструменты для ролевых игр с ИИ-компаньонами (руководство 2026 года)
Откройте для себя 2026 лучших инструментов с искусственным интеллектом для увлекательных ролевых игр и общения. В тщательно составленном руководстве XIX.AI представлены мощные приложения, которые кардинально меняют правила игры, с еженедельно обновляемым рейтингом, сравнением бесплатных и платных версий, а также результатами реальных тестов. Найдите идеальный вариант и начните наслаждаться полноценным цифровым общением уже сегодня.
10 инструментов
xix.ai
письмо
Лучшие помощники по жанрам «сянься» и «уся» на базе ИИ: создавайте эпические истории о духовном росте и хореографию боевых искусств
Откройте для себя лучшие ИИ-помощники 2026 года для создания эпических историй в жанрах сянься и уся. В тщательно подобранном списке XIX.AI представлены самые популярные и революционные инструменты, которые помогут вам освоить систему развития персонажей и постановку боевых сцен. Сравните бесплатные и платные варианты на основе реальных тестов. Раскройте свой творческий потенциал и начните писать уже сегодня!
10 инструментов
xix.ai
код
Инструменты для программирования мобильных приложений на основе технологий ИИ: генерация кода для платформFlutter и React Native на основе вводимых пользователем данных
Откройте для себя лучшие инструменты для программирования в области искусственного интеллекта на мобильных устройствах в 2026 году, подходящие для использования с фреймворками Flutter и React Native. Наш отобранный список включает мощные решения, способные изменить ход разработки приложений, позволяющие генерировать код, работающий на различных платформах, на основе предоставленных инструкций. Сравните бесплатные и платные варианты с использованием реальных примеров тестирования. Ускорьте процесс разработки и создавайте качественные приложения. Ознакомьтесь с рейтингом на сайте XIX.AI прямо сейчас!
10 инструментов
xix.ai

 Комментарии (14)
Комментарии (14)
![RyanTaylor]()
Interesting! I've been following the open-source vs. proprietary model race. DeepCoder-14B matching o3-mini is a big deal for accessibility. Hope this pushes the big players to open up more, or at least lower their prices. The compute cost for training these 14B models must be insane though. 🤔
![FrankRodriguez]()
Wow, DeepCoder-14B sounds like a game-changer! I'm stoked to see open-source models catching up to the big players. Can't wait to try it out for my side projects—hope it’s as fast as they claim! 🚀
![GregoryBaker]()
DeepCoder-14B sounds like a game-changer! Can't wait to try it out and see how it stacks up against the big players. 🚀
![BillyLewis]()
Wow, DeepCoder-14B sounds like a game-changer for open-source coding! I'm curious how it stacks up against o3-mini in real-world projects. Anyone tried it yet? 🚀
![RaymondWalker]()
¡DeepCoder-14B es una locura! Un modelo de código abierto que compite con los grandes. ¿Será el fin de los modelos propietarios? 🤔
![RalphGarcia]()
DeepCoder-14B、めっちゃ面白そう!😊 オープンソースでここまでできるなんて、コーディングの未来が楽しみ!
Представляем DeepCoder-14B: новая веха в моделях программирования с открытым исходным кодом
Команды Together AI и Agentica представили DeepCoder-14B, революционную модель программирования, которая стоит на одном уровне с ведущими проприетарными моделями, такими как o3-mini от OpenAI. Это захватывающее развитие основано на модели DeepSeek-R1 и предлагает повышенную гибкость для интеграции высокопроизводительной генерации кода и рассуждений в практические приложения. Более того, создатели сделали похвальный шаг, полностью открыв исходный код модели, включая данные для обучения, код, логи и системные оптимизации. Этот шаг призван стимулировать исследования и ускорить прогресс в этой области.
Впечатляющая производительность в компактном формате
DeepCoder-14B показал выдающиеся результаты в различных тестах программирования, таких как LiveCodeBench (LCB), Codeforces и HumanEval+. Эксперименты исследовательской группы показали, что производительность модели сравнима с ведущими моделями, такими как o3-mini (низкий уровень) и o1. «Наша модель демонстрирует высокую производительность во всех тестах программирования... сравнимую с производительностью o3-mini (низкий уровень) и o1», — с гордостью заявили исследователи в своем блоге.
Особенно интригует то, что, несмотря на основное обучение на задачах программирования, DeepCoder-14B также показал заметное улучшение в математических рассуждениях, достигнув результата 73,8% в тесте AIME 2024. Это на 4,1% выше, чем у базовой модели DeepSeek-R1-Distill-Qwen-14B, что свидетельствует о том, что навыки рассуждения, отточенные через обучение с подкреплением (RL) на коде, могут эффективно переноситься на другие области.
Пожалуй, наиболее захватывающей особенностью DeepCoder-14B является его эффективность. С всего 14 миллиардами параметров он достигает высокой производительности, будучи значительно меньше и более экономичным по ресурсам, чем многие другие ведущие модели.
Инновации, стоящие за успехом DeepCoder
Разработка DeepCoder-14B включала преодоление нескольких вызовов, особенно в обучении моделей программирования с использованием обучения с подкреплением. Одной из главных проблем была подготовка обучающих данных. В отличие от математических задач, где доступно множество высококачественных и проверяемых данных, данные для программирования могут быть ограничены. Команда DeepCoder решила эту проблему, внедрив строгую систему для сбора и фильтрации примеров из различных наборов данных, обеспечивая их валидность, сложность и отсутствие дублирования. Этот процесс привел к созданию 24 000 высококачественных задач, которые стали прочной основой для обучения с подкреплением.
Команда также разработала простую функцию вознаграждения, которая вознаграждает модель только в случае успешного прохождения всех выборочных модульных тестов в установленный срок. Этот подход, в сочетании с высококачественными обучающими примерами, гарантировал, что модель сосредотачивается на решении основных задач, а не на использовании обходных путей.
Алгоритм обучения DeepCoder-14B основан на Group Relative Policy Optimization (GRPO), который был успешен в DeepSeek-R1. Однако команда внесла значительные изменения для повышения стабильности и возможности более длительного обучения.
Кроме того, команда постепенно расширяла окно контекста модели, начиная с коротких последовательностей и постепенно увеличивая их. Также была введена методика фильтрации, чтобы избежать наказания модели за превышение лимитов контекста при решении сложных задач.
Исследователи объяснили свой подход: «Чтобы сохранить рассуждения на длинных контекстах при эффективном обучении, мы внедрили фильтрацию избыточных последовательностей... Эта техника маскирует обрезанные последовательности во время обучения, чтобы модели не наказывались за генерацию продуманных, но длинных выводов, превышающих текущий лимит контекста». Обучение масштабировалось с контекста 16K до 32K, что позволило модели решать задачи, требующие до 64K токенов.
Оптимизация обучения с подкреплением для длинных контекстов
Обучение больших моделей с использованием RL, особенно на задачах, генерирующих длинные последовательности, таких как программирование, известно своей медлительностью и ресурсоемкостью. Шаг выборки, при котором модель генерирует тысячи токенов на пример, часто приводит к значительным задержкам из-за разной длины ответов.
Для решения этой проблемы команда разработала verl-pipeline, оптимизированное расширение библиотеки с открытым исходным кодом verl для обучения с подкреплением на основе обратной связи от человека (RLHF). Их инновация «One-Off Pipelining» реструктурировала выборку и обновления модели, чтобы минимизировать узкие места и сократить время простоя ускорителей.
Их эксперименты показали, что one-off pipelining может ускорить задачи RL программирования до 2 раз по сравнению со стандартными методами. Эта оптимизация была ключевой для обучения DeepCoder-14B в разумные сроки (2,5 недели на 32 H100) и теперь открыта для сообщества в рамках verl-pipeline.
Влияние на предприятия и сотрудничество с открытым исходным кодом
Исследователи сделали все обучающие и операционные артефакты DeepCoder-14B доступными на GitHub и Hugging Face под разрешительной лицензией. «Полностью делясь нашим набором данных, кодом и рецептом обучения, мы даем сообществу возможность воспроизвести нашу работу и сделать обучение RL доступным для всех», — заявили они.
DeepCoder-14B является примером растущей тенденции к эффективным моделям с открытым доступом в области AI. Для предприятий это означает больше возможностей и большую доступность к продвинутым моделям. Высокопроизводительная генерация кода и рассуждения больше не являются эксклюзивом крупных корпораций или тех, кто готов платить высокие сборы за API. Организации всех размеров теперь могут использовать эти возможности, адаптировать решения под свои конкретные потребности и безопасно развертывать их в своих средах.
Этот сдвиг призван снизить барьеры для внедрения AI, способствуя созданию более конкурентной и инновационной экосистемы, основанной на сотрудничестве с открытым исходным кодом.










 Multiverse Computing запускает бесплатную сжатую генеративную модель искусственного интеллекта
Крупные языковые модели сталкиваются с серьезной проблемой: их огромный размер. Испанский стартап Multiverse Computing решает эту проблему, создавая сжатые модели, призванные преодолеть разрыв между в
Multiverse Computing запускает бесплатную сжатую генеративную модель искусственного интеллекта
Крупные языковые модели сталкиваются с серьезной проблемой: их огромный размер. Испанский стартап Multiverse Computing решает эту проблему, создавая сжатые модели, призванные преодолеть разрыв между в
 Секретные данные отслеживания раскрывают кражу моделей искусственного интеллекта
Новый метод позволяет за считанные секунды незаметно наносить водяные знаки на модели, такие как ChatGPT, без повторного обучения, не оставляя следов в стандартных выводах и противостоять всем практич
Секретные данные отслеживания раскрывают кражу моделей искусственного интеллекта
Новый метод позволяет за считанные секунды незаметно наносить водяные знаки на модели, такие как ChatGPT, без повторного обучения, не оставляя следов в стандартных выводах и противостоять всем практич
 Искусственный интеллект обманом заставили одобрить абсурдные научные статьи
Новые исследования показывают, что системы искусственного интеллекта теперь могут создавать фальшивые научные статьи, которые другие модели искусственного интеллекта ошибочно принимают за подлинные. Э
Искусственный интеллект обманом заставили одобрить абсурдные научные статьи
Новые исследования показывают, что системы искусственного интеллекта теперь могут создавать фальшивые научные статьи, которые другие модели искусственного интеллекта ошибочно принимают за подлинные. Э

Откройте для себя самые новые и высоко оцененные инструменты ИИ 2026 года для автоматизированного тестирования модулей. Наша тщательно подобранная коллекция включает мощные решения, способные радикально изменить процесс разработки, позволяющие мгновенно генерировать тестовые случаи для Jest, PyTest и JUnit. Сравните бесплатные и платные варианты с результатами реальных тестов, а также еженедельно обновляемыми рейтингами на сайте XIX.AI. Раскройте потенциал ИИ и повысьте эффективность своей работы в области разработки сегодня же.
10 инструментов
xix.ai

Откройте для себя лучшие инструменты визуализации данных на базе ИИ 2026 года на сайте XIX.AI. Наша тщательно отобранная подборка лидеров рейтинга поможет вам мгновенно создавать мощные интерактивные информационные панели BI на основе необработанных файлов. Сравните бесплатные и платные варианты с помощью реальных тестов и еженедельно обновляемых рейтингов. Раскройте потенциал ваших данных уже сегодня.
10 инструментов
xix.ai

Откройте для себя лучшие наборы материалов для брендинга на базе ИИ в социальных сетях 2026 года. В тщательно подобранном списке XIX.AI представлены самые популярные и революционные инструменты, которые помогут обеспечить идеальную визуальную согласованность бренда во всех каналах. Сравните бесплатные и платные варианты на основе реальных тестов. Раскройте визуальный потенциал вашего бренда уже сегодня.
10 инструментов
xix.ai

Откройте для себя 2026 лучших инструментов с искусственным интеллектом для увлекательных ролевых игр и общения. В тщательно составленном руководстве XIX.AI представлены мощные приложения, которые кардинально меняют правила игры, с еженедельно обновляемым рейтингом, сравнением бесплатных и платных версий, а также результатами реальных тестов. Найдите идеальный вариант и начните наслаждаться полноценным цифровым общением уже сегодня.
10 инструментов
xix.ai

Откройте для себя лучшие ИИ-помощники 2026 года для создания эпических историй в жанрах сянься и уся. В тщательно подобранном списке XIX.AI представлены самые популярные и революционные инструменты, которые помогут вам освоить систему развития персонажей и постановку боевых сцен. Сравните бесплатные и платные варианты на основе реальных тестов. Раскройте свой творческий потенциал и начните писать уже сегодня!
10 инструментов
xix.ai

Откройте для себя лучшие инструменты для программирования в области искусственного интеллекта на мобильных устройствах в 2026 году, подходящие для использования с фреймворками Flutter и React Native. Наш отобранный список включает мощные решения, способные изменить ход разработки приложений, позволяющие генерировать код, работающий на различных платформах, на основе предоставленных инструкций. Сравните бесплатные и платные варианты с использованием реальных примеров тестирования. Ускорьте процесс разработки и создавайте качественные приложения. Ознакомьтесь с рейтингом на сайте XIX.AI прямо сейчас!
10 инструментов
xix.ai

Interesting! I've been following the open-source vs. proprietary model race. DeepCoder-14B matching o3-mini is a big deal for accessibility. Hope this pushes the big players to open up more, or at least lower their prices. The compute cost for training these 14B models must be insane though. 🤔
Wow, DeepCoder-14B sounds like a game-changer! I'm stoked to see open-source models catching up to the big players. Can't wait to try it out for my side projects—hope it’s as fast as they claim! 🚀
DeepCoder-14B sounds like a game-changer! Can't wait to try it out and see how it stacks up against the big players. 🚀
Wow, DeepCoder-14B sounds like a game-changer for open-source coding! I'm curious how it stacks up against o3-mini in real-world projects. Anyone tried it yet? 🚀
¡DeepCoder-14B es una locura! Un modelo de código abierto que compite con los grandes. ¿Será el fin de los modelos propietarios? 🤔
DeepCoder-14B、めっちゃ面白そう!😊 オープンソースでここまでできるなんて、コーディングの未来が楽しみ!













