
















 Heim
HeimDeepCoder erreicht eine hohe Codierungseffizienz mit 14B Open -Modell
Einführung von DeepCoder-14B: Eine neue Grenze in Open-Source-Coding-Modellen
Die Teams bei Together AI und Agentica haben DeepCoder-14B vorgestellt, ein bahnbrechendes Coding-Modell, das mit erstklassigen proprietären Modellen wie OpenAI's o3-mini gleichzieht. Diese spannende Entwicklung basiert auf DeepSeek-R1 und bietet verbesserte Flexibilität für die Integration von leistungsstarker Codegenerierung und -logik in praktische Anwendungen. Darüber hinaus haben die Entwickler einen lobenswerten Schritt unternommen, indem sie das Modell vollständig open-source gemacht haben, einschließlich Trainingsdaten, Code, Logs und Systemoptimierungen. Dieser Schritt wird die Forschung katalysieren und Fortschritte im Bereich beschleunigen.
Beeindruckende Leistung in einem kompakten Paket
DeepCoder-14B hat bemerkenswerte Ergebnisse bei verschiedenen Coding-Benchmarks wie LiveCodeBench (LCB), Codeforces und HumanEval+ gezeigt. Die Experimente des Forschungsteams haben gezeigt, dass die Leistung des Modells mit führenden Modellen wie o3-mini (low) und o1 vergleichbar ist. „Unser Modell zeigt starke Leistungen bei allen Coding-Benchmarks... vergleichbar mit der Leistung von o3-mini (low) und o1“, erklärten die Forscher stolz in ihrem Blogbeitrag.
Besonders faszinierend ist, dass DeepCoder-14B, obwohl hauptsächlich auf Coding-Aufgaben trainiert, auch eine bemerkenswerte Verbesserung im mathematischen Denken gezeigt hat und eine Punktzahl von 73,8 % beim AIME 2024 Benchmark erreichte. Dies markiert eine Steigerung von 4,1 % gegenüber seinem Basismodell DeepSeek-R1-Distill-Qwen-14B, was darauf hindeutet, dass die durch Reinforcement Learning (RL) an Code geschulten Denkfähigkeiten effektiv auf andere Domänen übertragen werden können.
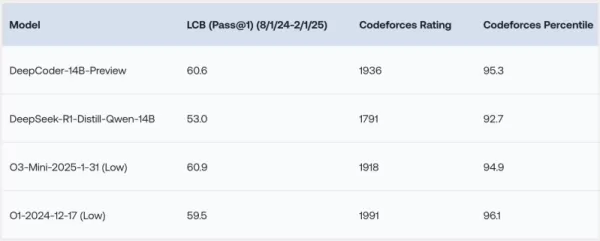
*Quelle: Together AI* Die vielleicht spannendste Eigenschaft von DeepCoder-14B ist seine Effizienz. Mit nur 14 Milliarden Parametern erreicht es hohe Leistung, während es deutlich kleiner und ressourcenschonender ist als viele andere führende Modelle.
Innovationen hinter DeepCoders Erfolg
Die Entwicklung von DeepCoder-14B erforderte die Überwindung mehrerer Herausforderungen, insbesondere beim Training von Coding-Modellen mit Reinforcement Learning. Eine große Hürde war die Kuratierung der Trainingsdaten. Im Gegensatz zu mathematischen Aufgaben, bei denen hochwertige, verifizierbare Daten reichlich vorhanden sind, können Coding-Daten knapp sein. Das DeepCoder-Team löste dies durch die Implementierung einer strengen Pipeline zur Sammlung und Filterung von Beispielen aus verschiedenen Datensätzen, um Gültigkeit, Komplexität und Vermeidung von Duplikaten zu gewährleisten. Dieses Verfahren führte zu 24.000 hochwertigen Problemen, die eine robuste Grundlage für das RL-Training bildeten.
Das Team entwickelte auch eine einfache Belohnungsfunktion, die das Modell nur belohnt, wenn der generierte Code alle gesampelten Unit-Tests innerhalb einer festgelegten Zeitgrenze erfolgreich besteht. Dieser Ansatz, gepaart mit hochwertigen Trainingsbeispielen, stellte sicher, dass das Modell sich auf die Lösung zentraler Probleme konzentrierte, anstatt Abkürzungen auszunutzen.
Der Trainingsalgorithmus von DeepCoder-14B basiert auf Group Relative Policy Optimization (GRPO), das in DeepSeek-R1 erfolgreich war. Das Team nahm jedoch bedeutende Änderungen vor, um die Stabilität zu verbessern und längere Trainingsdauern zu ermöglichen.
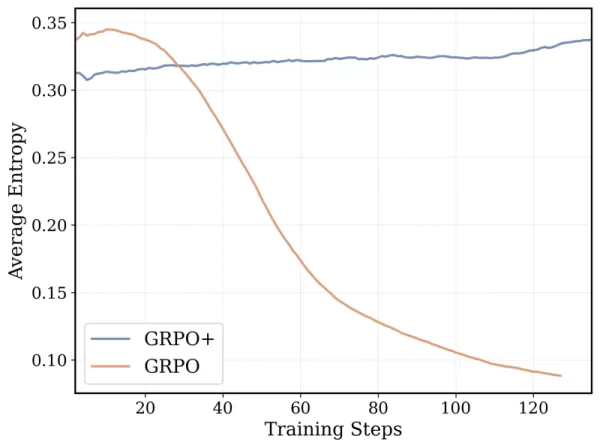
*GRPO+ ermöglicht DeepCoder-14 längere Laufzeiten ohne Zusammenbruch Quelle: Together AI* Zusätzlich erweiterte das Team iterativ das Kontextfenster des Modells, beginnend mit kürzeren Sequenzen und diese schrittweise erhöhend. Sie führten auch eine Filtermethode ein, um zu vermeiden, dass das Modell für das Überschreiten von Kontextgrenzen bei der Lösung komplexer Prompts bestraft wird.
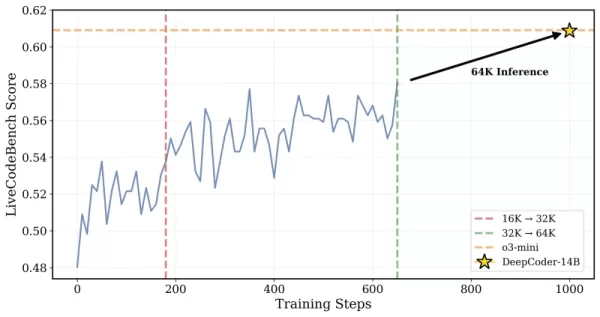
*DeepCoder wurde auf 32K-Kontextprobleme trainiert, konnte aber auch 64K-Aufgaben lösen Quelle: Together AI* Die Forscher erläuterten ihren Ansatz: „Um langkontextuelles Denken zu bewahren und gleichzeitig effizientes Training zu ermöglichen, haben wir überlange Filterung integriert... Diese Technik maskiert abgeschnittene Sequenzen während des Trainings, sodass Modelle nicht für das Generieren durchdachter, aber langer Ausgaben bestraft werden, die die aktuelle Kontextgrenze überschreiten.“ Das Training skalierte von einem 16K- zu einem 32K-Kontextfenster, was dem Modell ermöglichte, Probleme mit bis zu 64K Token anzugehen.
Optimierung des Langkontext-RL-Trainings
Das Training großer Modelle mit RL, insbesondere bei Aufgaben, die lange Sequenzen wie Coding generieren, ist notorisch langsam und ressourcenintensiv. Der Sampling-Schritt, bei dem das Modell Tausende von Token pro Beispiel generiert, führt oft zu erheblichen Verzögerungen aufgrund variierender Antwortlängen.
Um dies anzugehen, entwickelte das Team verl-pipeline, eine optimierte Erweiterung der Open-Source-verl-Bibliothek für Reinforcement Learning von menschlichem Feedback (RLHF). Ihre „One-Off Pipelining“-Innovation restrukturierte das Sampling und die Modellaktualisierungen, um Engpässe zu minimieren und Leerlaufzeiten auf Beschleunigern zu reduzieren.
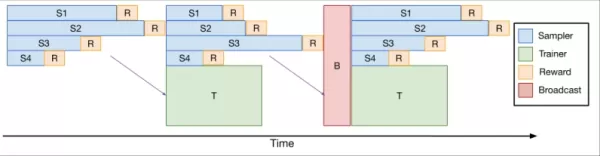
*One-Off Pipelining* Ihre Experimente zeigten, dass One-Off Pipelining Coding-RL-Aufgaben im Vergleich zu Standardmethoden um bis zu 2x beschleunigen konnte. Diese Optimierung war entscheidend, um DeepCoder-14B in einem angemessenen Zeitrahmen (2,5 Wochen auf 32 H100s) zu trainieren und ist nun als Teil von verl-pipeline für die Community open-source verfügbar.
Unternehmensauswirkungen und Open-Source-Zusammenarbeit
Die Forscher haben alle Trainings- und Betriebsartefakte für DeepCoder-14B auf GitHub und Hugging Face unter einer permissiven Lizenz verfügbar gemacht. „Durch das vollständige Teilen unseres Datensatzes, Codes und Trainingsrezepts befähigen wir die Community, unsere Arbeit zu reproduzieren und RL-Training für alle zugänglich zu machen“, erklärten sie.
DeepCoder-14B ist ein Beispiel für den wachsenden Trend effizienter, offen zugänglicher Modelle in der AI-Landschaft. Für Unternehmen bedeutet dies mehr Optionen und größere Zugänglichkeit zu fortschrittlichen Modellen. Hochleistungsfähige Codegenerierung und -logik sind nicht länger exklusiv für große Konzerne oder jene, die bereit sind, hohe API-Gebühren zu zahlen. Organisationen aller Größen können diese Fähigkeiten nun nutzen, Lösungen an ihre spezifischen Bedürfnisse anpassen und sie sicher in ihren Umgebungen einsetzen.
Dieser Wandel wird die Barrieren für die Einführung von AI senken und ein wettbewerbsfähigeres und innovativeres Ökosystem fördern, das von Open-Source-Zusammenarbeit angetrieben wird.
Verwandter Artikel
 Multiverse Computing bringt kostenloses komprimiertes generatives KI-Modell auf den Markt
Große Sprachmodelle stehen vor einer großen Herausforderung: ihrer immensen Größe. Das spanische Start-up Multiverse Computing geht dieses Problem an, indem es komprimierte Modelle entwickelt, die die
Geheime Tracking-Daten enthüllen Diebstahl von KI-Modellen
Eine neue Methode kann Modelle wie ChatGPT innerhalb von Sekunden unsichtbar mit einem Wasserzeichen versehen, ohne dass ein erneutes Training erforderlich ist. Dabei hinterlässt sie keine Spuren in d
KI-Systeme dazu gebracht, absurde wissenschaftliche Arbeiten zu genehmigen
Neue Forschungsergebnisse zeigen, dass KI-Systeme mittlerweile gefälschte wissenschaftliche Arbeiten erstellen können, die andere KI-Modelle fälschlicherweise als authentisch akzeptieren. Diese gefäls
Empfehlungen zu verwandten Spezialthemen
Code
Multiverse Computing bringt kostenloses komprimiertes generatives KI-Modell auf den Markt
Große Sprachmodelle stehen vor einer großen Herausforderung: ihrer immensen Größe. Das spanische Start-up Multiverse Computing geht dieses Problem an, indem es komprimierte Modelle entwickelt, die die
Geheime Tracking-Daten enthüllen Diebstahl von KI-Modellen
Eine neue Methode kann Modelle wie ChatGPT innerhalb von Sekunden unsichtbar mit einem Wasserzeichen versehen, ohne dass ein erneutes Training erforderlich ist. Dabei hinterlässt sie keine Spuren in d
KI-Systeme dazu gebracht, absurde wissenschaftliche Arbeiten zu genehmigen
Neue Forschungsergebnisse zeigen, dass KI-Systeme mittlerweile gefälschte wissenschaftliche Arbeiten erstellen können, die andere KI-Modelle fälschlicherweise als authentisch akzeptieren. Diese gefäls
Empfehlungen zu verwandten Spezialthemen
Code
 Die besten KI-Tools für automatisierte Einheitstests: Generieren Sie mit nur einem Klick Jest-, PyTest- und JUnit-Testfälle.
Die besten KI-Tools für automatisierte Einheitstests: Generieren Sie mit nur einem Klick Jest-, PyTest- und JUnit-Testfälle.
Entdecken Sie die neuesten, hochbewerteten KI-Tools von 2026 für den automatisierten Unit-Testing-Prozess. Unsere sorgfältig ausgewählten Lösungen bieten leistungsstarke und bahnbrechende Funktionen, um sofort Jest-, PyTest- und JUnit-Testfälle zu generieren. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von tatsächlichen Tests sowie wöchentlich aktualisierten Rankings auf XIX.AI. Entfalten Sie Ihr KI-Potenzial und steigern Sie noch heute die Produktivität Ihrer Entwicklungstätigkeit.
 10 Tools
10 Tools
 xix.ai
Datenanalyse
Die besten KI-Tools zur Datenvisualisierung: Interaktive BI-Dashboards automatisch aus Rohdaten generieren
xix.ai
Datenanalyse
Die besten KI-Tools zur Datenvisualisierung: Interaktive BI-Dashboards automatisch aus Rohdaten generieren
Entdecken Sie bei XIX.AI die besten KI-Tools zur Datenvisualisierung für 2026. Unsere sorgfältig zusammengestellte Auswahl der besten Tools hilft Ihnen dabei, leistungsstarke, interaktive BI-Dashboards sofort aus Rohdaten automatisch zu erstellen. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Schöpfen Sie noch heute das Potenzial Ihrer Daten aus.
10 Tools
xix.ai
Soziale Medien
KI-Branding-Kits für soziale Medien: Sorgen Sie für ein einheitliches Markenbild auf allen Kanälen
Entdecken Sie die besten KI-Branding-Kits für Social Media im Jahr 2026. Die von XIX.AI zusammengestellte Liste enthält erstklassige, bahnbrechende Tools, mit denen Sie ein einheitliches Markenbild auf allen Kanälen gewährleisten können. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Verschaffen Sie Ihrer Marke noch heute einen visuellen Vorsprung.
10 Tools
xix.ai
Chatbot
Die besten KI-Freundinnen-Apps und KI-Begleit-Tools für Rollenspiele (Leitfaden 2026)
Entdecken Sie die besten KI-Begleit-Tools des Jahres 2026 für ein fesselndes Rollenspiel und echte Verbundenheit. Der von XIX.AI zusammengestellte Leitfaden präsentiert leistungsstarke, bahnbrechende Apps mit wöchentlich aktualisierten Rankings, Vergleichen zwischen kostenlosen und kostenpflichtigen Angeboten sowie Tests aus der Praxis. Finden Sie noch heute Ihren perfekten Partner und erleben Sie eine bereichernde digitale Begleitung.
10 Tools
xix.ai
Schreiben
Die besten KI-Assistenten für Xianxia und Wuxia: Verfassen Sie epische Kultivierungsgeschichten und Kampfkunst-Choreografien
Entdecken Sie die besten KI-Assistenten des Jahres 2026 für das Verfassen epischer Xianxia- und Wuxia-Geschichten. Die von XIX.AI zusammengestellte Liste enthält erstklassige, bahnbrechende Tools, mit denen Sie den Fortschritt der Kultivierung und die Choreografie von Kampfkünsten meistern können. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Entfalten Sie Ihr kreatives Potenzial und beginnen Sie noch heute mit dem Schreiben!
10 Tools
xix.ai
Code
AI-Mobilanwendungsentwicklungstools: Erstellen Sie plattformübergreifenden Flutter- und React Native-Code auf Basis von Eingaben.
Entdecken Sie die besten AI-Programmierwerkzeuge für mobile Anwendungen im Jahr 2026 – geeignet für Flutter und React Native. Unsere sorgfältig ausgewählte, hochbewertete Liste bietet leistungsstarke Lösungen, die es ermöglichen, plattformübergreifenden Code auf Basis von Vorgaben zu generieren. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand realer Tests – beschleunigen Sie Ihre Entwicklung und erstellen Sie bessere Anwendungen. Erfahren Sie mehr über die Rangliste auf XIX.AI!
10 Tools
xix.ai

 Kommentare (14)
Kommentare (14)
![RyanTaylor]()
Interesting! I've been following the open-source vs. proprietary model race. DeepCoder-14B matching o3-mini is a big deal for accessibility. Hope this pushes the big players to open up more, or at least lower their prices. The compute cost for training these 14B models must be insane though. 🤔
![FrankRodriguez]()
Wow, DeepCoder-14B sounds like a game-changer! I'm stoked to see open-source models catching up to the big players. Can't wait to try it out for my side projects—hope it’s as fast as they claim! 🚀
![GregoryBaker]()
DeepCoder-14B sounds like a game-changer! Can't wait to try it out and see how it stacks up against the big players. 🚀
![BillyLewis]()
Wow, DeepCoder-14B sounds like a game-changer for open-source coding! I'm curious how it stacks up against o3-mini in real-world projects. Anyone tried it yet? 🚀
![RaymondWalker]()
¡DeepCoder-14B es una locura! Un modelo de código abierto que compite con los grandes. ¿Será el fin de los modelos propietarios? 🤔
![RalphGarcia]()
DeepCoder-14B、めっちゃ面白そう!😊 オープンソースでここまでできるなんて、コーディングの未来が楽しみ!
Einführung von DeepCoder-14B: Eine neue Grenze in Open-Source-Coding-Modellen
Die Teams bei Together AI und Agentica haben DeepCoder-14B vorgestellt, ein bahnbrechendes Coding-Modell, das mit erstklassigen proprietären Modellen wie OpenAI's o3-mini gleichzieht. Diese spannende Entwicklung basiert auf DeepSeek-R1 und bietet verbesserte Flexibilität für die Integration von leistungsstarker Codegenerierung und -logik in praktische Anwendungen. Darüber hinaus haben die Entwickler einen lobenswerten Schritt unternommen, indem sie das Modell vollständig open-source gemacht haben, einschließlich Trainingsdaten, Code, Logs und Systemoptimierungen. Dieser Schritt wird die Forschung katalysieren und Fortschritte im Bereich beschleunigen.
Beeindruckende Leistung in einem kompakten Paket
DeepCoder-14B hat bemerkenswerte Ergebnisse bei verschiedenen Coding-Benchmarks wie LiveCodeBench (LCB), Codeforces und HumanEval+ gezeigt. Die Experimente des Forschungsteams haben gezeigt, dass die Leistung des Modells mit führenden Modellen wie o3-mini (low) und o1 vergleichbar ist. „Unser Modell zeigt starke Leistungen bei allen Coding-Benchmarks... vergleichbar mit der Leistung von o3-mini (low) und o1“, erklärten die Forscher stolz in ihrem Blogbeitrag.
Besonders faszinierend ist, dass DeepCoder-14B, obwohl hauptsächlich auf Coding-Aufgaben trainiert, auch eine bemerkenswerte Verbesserung im mathematischen Denken gezeigt hat und eine Punktzahl von 73,8 % beim AIME 2024 Benchmark erreichte. Dies markiert eine Steigerung von 4,1 % gegenüber seinem Basismodell DeepSeek-R1-Distill-Qwen-14B, was darauf hindeutet, dass die durch Reinforcement Learning (RL) an Code geschulten Denkfähigkeiten effektiv auf andere Domänen übertragen werden können.
Die vielleicht spannendste Eigenschaft von DeepCoder-14B ist seine Effizienz. Mit nur 14 Milliarden Parametern erreicht es hohe Leistung, während es deutlich kleiner und ressourcenschonender ist als viele andere führende Modelle.
Innovationen hinter DeepCoders Erfolg
Die Entwicklung von DeepCoder-14B erforderte die Überwindung mehrerer Herausforderungen, insbesondere beim Training von Coding-Modellen mit Reinforcement Learning. Eine große Hürde war die Kuratierung der Trainingsdaten. Im Gegensatz zu mathematischen Aufgaben, bei denen hochwertige, verifizierbare Daten reichlich vorhanden sind, können Coding-Daten knapp sein. Das DeepCoder-Team löste dies durch die Implementierung einer strengen Pipeline zur Sammlung und Filterung von Beispielen aus verschiedenen Datensätzen, um Gültigkeit, Komplexität und Vermeidung von Duplikaten zu gewährleisten. Dieses Verfahren führte zu 24.000 hochwertigen Problemen, die eine robuste Grundlage für das RL-Training bildeten.
Das Team entwickelte auch eine einfache Belohnungsfunktion, die das Modell nur belohnt, wenn der generierte Code alle gesampelten Unit-Tests innerhalb einer festgelegten Zeitgrenze erfolgreich besteht. Dieser Ansatz, gepaart mit hochwertigen Trainingsbeispielen, stellte sicher, dass das Modell sich auf die Lösung zentraler Probleme konzentrierte, anstatt Abkürzungen auszunutzen.
Der Trainingsalgorithmus von DeepCoder-14B basiert auf Group Relative Policy Optimization (GRPO), das in DeepSeek-R1 erfolgreich war. Das Team nahm jedoch bedeutende Änderungen vor, um die Stabilität zu verbessern und längere Trainingsdauern zu ermöglichen.
Zusätzlich erweiterte das Team iterativ das Kontextfenster des Modells, beginnend mit kürzeren Sequenzen und diese schrittweise erhöhend. Sie führten auch eine Filtermethode ein, um zu vermeiden, dass das Modell für das Überschreiten von Kontextgrenzen bei der Lösung komplexer Prompts bestraft wird.
Die Forscher erläuterten ihren Ansatz: „Um langkontextuelles Denken zu bewahren und gleichzeitig effizientes Training zu ermöglichen, haben wir überlange Filterung integriert... Diese Technik maskiert abgeschnittene Sequenzen während des Trainings, sodass Modelle nicht für das Generieren durchdachter, aber langer Ausgaben bestraft werden, die die aktuelle Kontextgrenze überschreiten.“ Das Training skalierte von einem 16K- zu einem 32K-Kontextfenster, was dem Modell ermöglichte, Probleme mit bis zu 64K Token anzugehen.
Optimierung des Langkontext-RL-Trainings
Das Training großer Modelle mit RL, insbesondere bei Aufgaben, die lange Sequenzen wie Coding generieren, ist notorisch langsam und ressourcenintensiv. Der Sampling-Schritt, bei dem das Modell Tausende von Token pro Beispiel generiert, führt oft zu erheblichen Verzögerungen aufgrund variierender Antwortlängen.
Um dies anzugehen, entwickelte das Team verl-pipeline, eine optimierte Erweiterung der Open-Source-verl-Bibliothek für Reinforcement Learning von menschlichem Feedback (RLHF). Ihre „One-Off Pipelining“-Innovation restrukturierte das Sampling und die Modellaktualisierungen, um Engpässe zu minimieren und Leerlaufzeiten auf Beschleunigern zu reduzieren.
Ihre Experimente zeigten, dass One-Off Pipelining Coding-RL-Aufgaben im Vergleich zu Standardmethoden um bis zu 2x beschleunigen konnte. Diese Optimierung war entscheidend, um DeepCoder-14B in einem angemessenen Zeitrahmen (2,5 Wochen auf 32 H100s) zu trainieren und ist nun als Teil von verl-pipeline für die Community open-source verfügbar.
Unternehmensauswirkungen und Open-Source-Zusammenarbeit
Die Forscher haben alle Trainings- und Betriebsartefakte für DeepCoder-14B auf GitHub und Hugging Face unter einer permissiven Lizenz verfügbar gemacht. „Durch das vollständige Teilen unseres Datensatzes, Codes und Trainingsrezepts befähigen wir die Community, unsere Arbeit zu reproduzieren und RL-Training für alle zugänglich zu machen“, erklärten sie.
DeepCoder-14B ist ein Beispiel für den wachsenden Trend effizienter, offen zugänglicher Modelle in der AI-Landschaft. Für Unternehmen bedeutet dies mehr Optionen und größere Zugänglichkeit zu fortschrittlichen Modellen. Hochleistungsfähige Codegenerierung und -logik sind nicht länger exklusiv für große Konzerne oder jene, die bereit sind, hohe API-Gebühren zu zahlen. Organisationen aller Größen können diese Fähigkeiten nun nutzen, Lösungen an ihre spezifischen Bedürfnisse anpassen und sie sicher in ihren Umgebungen einsetzen.
Dieser Wandel wird die Barrieren für die Einführung von AI senken und ein wettbewerbsfähigeres und innovativeres Ökosystem fördern, das von Open-Source-Zusammenarbeit angetrieben wird.










 Multiverse Computing bringt kostenloses komprimiertes generatives KI-Modell auf den Markt
Große Sprachmodelle stehen vor einer großen Herausforderung: ihrer immensen Größe. Das spanische Start-up Multiverse Computing geht dieses Problem an, indem es komprimierte Modelle entwickelt, die die
Multiverse Computing bringt kostenloses komprimiertes generatives KI-Modell auf den Markt
Große Sprachmodelle stehen vor einer großen Herausforderung: ihrer immensen Größe. Das spanische Start-up Multiverse Computing geht dieses Problem an, indem es komprimierte Modelle entwickelt, die die
 Geheime Tracking-Daten enthüllen Diebstahl von KI-Modellen
Eine neue Methode kann Modelle wie ChatGPT innerhalb von Sekunden unsichtbar mit einem Wasserzeichen versehen, ohne dass ein erneutes Training erforderlich ist. Dabei hinterlässt sie keine Spuren in d
Geheime Tracking-Daten enthüllen Diebstahl von KI-Modellen
Eine neue Methode kann Modelle wie ChatGPT innerhalb von Sekunden unsichtbar mit einem Wasserzeichen versehen, ohne dass ein erneutes Training erforderlich ist. Dabei hinterlässt sie keine Spuren in d
 KI-Systeme dazu gebracht, absurde wissenschaftliche Arbeiten zu genehmigen
Neue Forschungsergebnisse zeigen, dass KI-Systeme mittlerweile gefälschte wissenschaftliche Arbeiten erstellen können, die andere KI-Modelle fälschlicherweise als authentisch akzeptieren. Diese gefäls
KI-Systeme dazu gebracht, absurde wissenschaftliche Arbeiten zu genehmigen
Neue Forschungsergebnisse zeigen, dass KI-Systeme mittlerweile gefälschte wissenschaftliche Arbeiten erstellen können, die andere KI-Modelle fälschlicherweise als authentisch akzeptieren. Diese gefäls

Entdecken Sie die neuesten, hochbewerteten KI-Tools von 2026 für den automatisierten Unit-Testing-Prozess. Unsere sorgfältig ausgewählten Lösungen bieten leistungsstarke und bahnbrechende Funktionen, um sofort Jest-, PyTest- und JUnit-Testfälle zu generieren. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von tatsächlichen Tests sowie wöchentlich aktualisierten Rankings auf XIX.AI. Entfalten Sie Ihr KI-Potenzial und steigern Sie noch heute die Produktivität Ihrer Entwicklungstätigkeit.
10 Tools
xix.ai

Entdecken Sie bei XIX.AI die besten KI-Tools zur Datenvisualisierung für 2026. Unsere sorgfältig zusammengestellte Auswahl der besten Tools hilft Ihnen dabei, leistungsstarke, interaktive BI-Dashboards sofort aus Rohdaten automatisch zu erstellen. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Schöpfen Sie noch heute das Potenzial Ihrer Daten aus.
10 Tools
xix.ai

Entdecken Sie die besten KI-Branding-Kits für Social Media im Jahr 2026. Die von XIX.AI zusammengestellte Liste enthält erstklassige, bahnbrechende Tools, mit denen Sie ein einheitliches Markenbild auf allen Kanälen gewährleisten können. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Verschaffen Sie Ihrer Marke noch heute einen visuellen Vorsprung.
10 Tools
xix.ai

Entdecken Sie die besten KI-Begleit-Tools des Jahres 2026 für ein fesselndes Rollenspiel und echte Verbundenheit. Der von XIX.AI zusammengestellte Leitfaden präsentiert leistungsstarke, bahnbrechende Apps mit wöchentlich aktualisierten Rankings, Vergleichen zwischen kostenlosen und kostenpflichtigen Angeboten sowie Tests aus der Praxis. Finden Sie noch heute Ihren perfekten Partner und erleben Sie eine bereichernde digitale Begleitung.
10 Tools
xix.ai

Entdecken Sie die besten KI-Assistenten des Jahres 2026 für das Verfassen epischer Xianxia- und Wuxia-Geschichten. Die von XIX.AI zusammengestellte Liste enthält erstklassige, bahnbrechende Tools, mit denen Sie den Fortschritt der Kultivierung und die Choreografie von Kampfkünsten meistern können. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Entfalten Sie Ihr kreatives Potenzial und beginnen Sie noch heute mit dem Schreiben!
10 Tools
xix.ai

Entdecken Sie die besten AI-Programmierwerkzeuge für mobile Anwendungen im Jahr 2026 – geeignet für Flutter und React Native. Unsere sorgfältig ausgewählte, hochbewertete Liste bietet leistungsstarke Lösungen, die es ermöglichen, plattformübergreifenden Code auf Basis von Vorgaben zu generieren. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand realer Tests – beschleunigen Sie Ihre Entwicklung und erstellen Sie bessere Anwendungen. Erfahren Sie mehr über die Rangliste auf XIX.AI!
10 Tools
xix.ai

Interesting! I've been following the open-source vs. proprietary model race. DeepCoder-14B matching o3-mini is a big deal for accessibility. Hope this pushes the big players to open up more, or at least lower their prices. The compute cost for training these 14B models must be insane though. 🤔
Wow, DeepCoder-14B sounds like a game-changer! I'm stoked to see open-source models catching up to the big players. Can't wait to try it out for my side projects—hope it’s as fast as they claim! 🚀
DeepCoder-14B sounds like a game-changer! Can't wait to try it out and see how it stacks up against the big players. 🚀
Wow, DeepCoder-14B sounds like a game-changer for open-source coding! I'm curious how it stacks up against o3-mini in real-world projects. Anyone tried it yet? 🚀
¡DeepCoder-14B es una locura! Un modelo de código abierto que compite con los grandes. ¿Será el fin de los modelos propietarios? 🤔
DeepCoder-14B、めっちゃ面白そう!😊 オープンソースでここまでできるなんて、コーディングの未来が楽しみ!













