
















 집
집DeepCoder는 14B 오픈 모델로 높은 코딩 효율을 달성합니다
DeepCoder-14B 소개: 오픈 소스 코딩 모델의 새로운 지평
Together AI와 Agentica의 팀은 DeepCoder-14B를 공개했습니다. 이는 OpenAI의 o3-mini와 같은 최고 수준의 독점 모델과 어깨를 나란히 하는 획기적인 코딩 모델입니다. 이 흥미로운 개발은 DeepSeek-R1을 기반으로 하며, 고성능 코드 생성 및 추론을 실제 응용 프로그램에 통합할 수 있는 향상된 유연성을 제공합니다. 더욱이, 제작자들은 모델을 완전히 오픈 소스로 공개하며 훈련 데이터, 코드, 로그, 시스템 최적화를 포함하는 훌륭한 조치를 취했습니다. 이 결정은 연구를 촉진하고 해당 분야의 발전을 가속화할 것입니다.
컴팩트한 패키지에서의 인상적인 성능
DeepCoder-14B는 LiveCodeBench(LCB), Codeforces, HumanEval+와 같은 다양한 코딩 벤치마크에서 놀라운 결과를 보여주었습니다. 연구팀의 실험은 이 모델의 성능이 o3-mini(낮음) 및 o1과 같은 선도 모델들과 동등하다는 것을 강조했습니다. 연구진은 블로그 포스트에서 “우리 모델은 모든 코딩 벤치마크에서 강력한 성능을 보여주며… o3-mini(낮음) 및 o1의 성능과 비슷하다”고 자랑스럽게 밝혔습니다.
특히 흥미로운 점은 주로 코딩 작업에 훈련되었음에도 불구하고, DeepCoder-14B는 수학적 추론에서도 주목할 만한 향상을 보여 AIME 2024 벤치마크에서 73.8%의 점수를 달성했습니다. 이는 기본 모델인 DeepSeek-R1-Distill-Qwen-14B보다 4.1% 향상된 결과로, 코드에 대한 강화 학습(RL)을 통해 연마된 추론 기술이 다른 도메인으로 효과적으로 전이될 수 있음을 시사합니다.
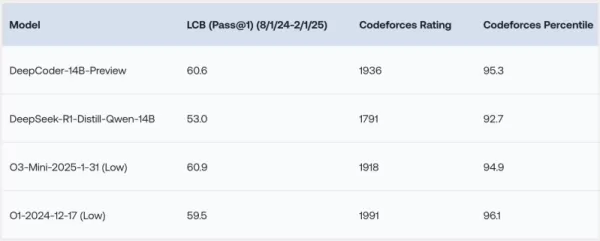
*출처: Together AI* DeepCoder-14B의 가장 흥미로운 특징은 그 효율성입니다. 140억 개의 파라미터만으로도 높은 성능을 달성하며, 다른 많은 선도 모델들보다 훨씬 작고 자원 효율적입니다.
DeepCoder 성공의 이면에 있는 혁신
DeepCoder-14B 개발에는 강화 학습을 사용한 코딩 모델 훈련에서 여러 가지 도전 과제를 극복하는 과정이 포함되었습니다. 주요 장애물 중 하나는 훈련 데이터의 선별이었습니다. 고품질의 검증 가능한 데이터가 풍부한 수학적 작업과 달리, 코딩 데이터는 부족할 수 있습니다. DeepCoder 팀은 다양한 데이터셋에서 예제를 수집하고 필터링하는 엄격한 파이프라인을 구현하여 유효성, 복잡성, 중복 방지를 보장함으로써 이를 해결했습니다. 이 과정은 RL 훈련을 위한 견고한 기반이 되는 24,000개의 고품질 문제를 만들어냈습니다.
팀은 또한 생성된 코드가 설정된 시간 제한 내에서 모든 샘플링된 단위 테스트를 성공적으로 통과할 경우에만 모델에 보상을 주는 간단한 보상 함수를 고안했습니다. 이러한 접근 방식은 고품질 훈련 예제와 결합하여 모델이 단축키를 활용하기보다는 핵심 문제를 해결하는 데 집중하도록 했습니다.
DeepCoder-14B의 훈련 알고리즘은 DeepSeek-R1에서 성공적이었던 Group Relative Policy Optimization(GRPO)을 기반으로 하지만, 팀은 안정성을 높이고 더 긴 훈련 기간을 가능하게 하기 위해 상당한 수정 작업을 수행했습니다.
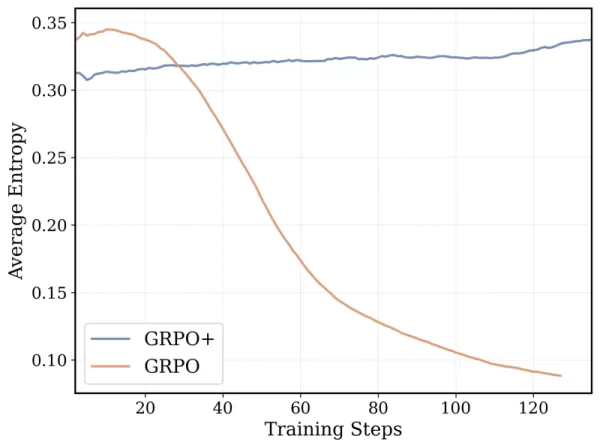
*GRPO+는 DeepCoder-14가 붕괴 없이 더 긴 기간 동안 지속할 수 있도록 합니다 출처: Together AI* 또한, 팀은 모델의 컨텍스트 창을 반복적으로 확장하여 짧은 시퀀스에서 시작해 점진적으로 늘려갔습니다. 또한 복잡한 프롬프트를 해결할 때 컨텍스트 제한을 초과하는 것에 대해 모델이 불이익을 받지 않도록 필터링 방법을 도입했습니다.
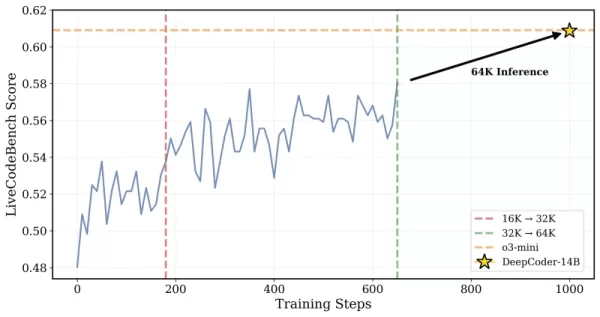
*DeepCoder는 32K 컨텍스트 문제로 훈련되었지만 64K 작업도 해결할 수 있었습니다 출처: Together AI* 연구진은 그들의 접근 방식을 이렇게 설명했습니다: “효율적인 훈련을 가능하게 하면서 장문 컨텍스트 추론을 보존하기 위해, 우리는 과도한 필터링을 포함했습니다… 이 기술은 훈련 중 잘린 시퀀스를 마스킹하여 모델이 현재 컨텍스트 제한을 초과하는 신중하지만 긴 출력을 생성하는 데 불이익을 받지 않도록 합니다.” 훈련은 16K에서 32K 컨텍스트 창으로 확장되어 최대 64K 토큰이 필요한 문제를 해결할 수 있게 했습니다.
장문 컨텍스트 RL 훈련 최적화
코딩과 같이 긴 시퀀스를 생성하는 작업에 RL로 대규모 모델을 훈련시키는 것은 매우 느리고 자원 집약적입니다. 모델이 예제당 수천 개의 토큰을 생성하는 샘플링 단계는 응답 길이의 다양성으로 인해 상당한 지연을 초래합니다.
이를 해결하기 위해 팀은 인간 피드백으로부터의 강화 학습(RLHF)을 위한 오픈 소스 verl 라이브러리의 최적화된 확장인 verl-pipeline을 개발했습니다. 그들의 “One-Off Pipelining” 혁신은 샘플링과 모델 업데이트를 재구성하여 병목 현상을 최소화하고 가속기의 유휴 시간을 줄였습니다.
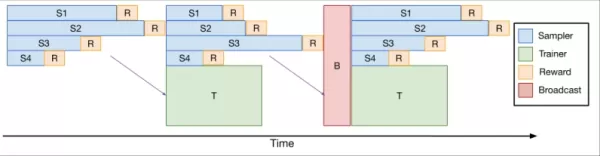
*One-Off Pipelining* 그들의 실험은 one-off pipelining이 표준 방법에 비해 코딩 RL 작업을 최대 2배까지 가속화할 수 있음을 보여주었습니다. 이 최적화는 DeepCoder-14B를 합리적인 시간 내(32개의 H100에서 2.5주)에 훈련시키는 데 결정적이었으며, 이제 커뮤니티가 활용할 수 있도록 verl-pipeline의 일부로 오픈 소스화되었습니다.
기업 영향과 오픈 소스 협업
연구진은 DeepCoder-14B의 모든 훈련 및 운영 아티팩트를 GitHub와 Hugging Face에 허용 라이선스로 공개했습니다. “우리의 데이터셋, 코드, 훈련 레시피를 완전히 공유함으로써, 우리는 커뮤니티가 우리의 작업을 재현하고 RL 훈련을 모두에게 접근 가능하게 할 수 있도록 힘을 실어줍니다”라고 그들은 밝혔습니다.
DeepCoder-14B는 AI 환경에서 효율적이고 공개적으로 접근 가능한 모델의 증가 추세를 잘 보여줍니다. 기업에게 이는 고급 모델에 대한 더 많은 선택지와 더 큰 접근성을 의미합니다. 고성능 코드 생성과 추론은 더 이상 대기업이나 높은 API 비용을 지불하려는 이들에게만 독점적이지 않습니다. 이제 모든 규모의 조직이 이러한 기능을 활용하여 특정 요구에 맞는 솔루션을 맞춤화하고 안전하게 환경 내에서 배포할 수 있습니다.
이러한 변화는 AI 채택의 장벽을 낮추고 오픈 소스 협업에 의해 구동되는 보다 경쟁적이고 혁신적인 생태계를 촉진할 준비가 되어 있습니다.
관련 기사
 멀티버스 컴퓨팅, 무료 압축 생성형 AI 모델 출시
대규모 언어 모델은 상당한 과제에 직면해 있습니다: 바로 그 방대한 규모입니다. 스페인 스타트업 멀티버스 컴퓨팅(Multiverse Computing)은 최첨단 AI의 성능과 기업이 실질적으로 도입할 수 있는 수준 사이의 격차를 해소하기 위해 설계된 압축 모델을 개발함으로써 이 문제를 해결하고 있습니다.핵심 혁신은 양자 컴퓨팅 원리에서 영감을 받은 압축 기
비밀 추적 데이터, AI 모델 도용 사건 폭로
새로운 방법은 재훈련 없이도 ChatGPT와 같은 모델에 몇 초 만에 보이지 않는 워터마크를 적용할 수 있으며, 표준 출력물에 흔적을 남기지 않고 모든 실질적인 제거 시도를 견딥니다. 워터마킹과 '저작권 유인(copyright-baiting)'의 핵심 차이점은 워터마크(가시적이든 숨겨진 것이든)는 일반적으로 이미지 데이터셋과 같은 컬렉션 전체에 걸쳐 나타나
인공지능 시스템, 터무니없는 과학 논문을 승인하도록 속아넘어갔다
새로운 연구에 따르면, 인공지능 시스템이 이제 다른 인공지능 모델들이 진품으로 오인하는 사기성 과학 논문을 생성할 수 있게 되었다. 이러한 조작된 연구들은 기존에 효과적이었던 탐지 방법을 우회하며, 연구 생태계가 봇이 다른 봇을 속이는 악순환으로 붕괴될 위험성을 부각시키고 있다. 아이러니하게도 AI 혁신의 최전선에 있는 학술 연구 분야가 AI에 의해 촉발된
관련 특별 주제 추천
데이터 분석
멀티버스 컴퓨팅, 무료 압축 생성형 AI 모델 출시
대규모 언어 모델은 상당한 과제에 직면해 있습니다: 바로 그 방대한 규모입니다. 스페인 스타트업 멀티버스 컴퓨팅(Multiverse Computing)은 최첨단 AI의 성능과 기업이 실질적으로 도입할 수 있는 수준 사이의 격차를 해소하기 위해 설계된 압축 모델을 개발함으로써 이 문제를 해결하고 있습니다.핵심 혁신은 양자 컴퓨팅 원리에서 영감을 받은 압축 기
비밀 추적 데이터, AI 모델 도용 사건 폭로
새로운 방법은 재훈련 없이도 ChatGPT와 같은 모델에 몇 초 만에 보이지 않는 워터마크를 적용할 수 있으며, 표준 출력물에 흔적을 남기지 않고 모든 실질적인 제거 시도를 견딥니다. 워터마킹과 '저작권 유인(copyright-baiting)'의 핵심 차이점은 워터마크(가시적이든 숨겨진 것이든)는 일반적으로 이미지 데이터셋과 같은 컬렉션 전체에 걸쳐 나타나
인공지능 시스템, 터무니없는 과학 논문을 승인하도록 속아넘어갔다
새로운 연구에 따르면, 인공지능 시스템이 이제 다른 인공지능 모델들이 진품으로 오인하는 사기성 과학 논문을 생성할 수 있게 되었다. 이러한 조작된 연구들은 기존에 효과적이었던 탐지 방법을 우회하며, 연구 생태계가 봇이 다른 봇을 속이는 악순환으로 붕괴될 위험성을 부각시키고 있다. 아이러니하게도 AI 혁신의 최전선에 있는 학술 연구 분야가 AI에 의해 촉발된
관련 특별 주제 추천
데이터 분석
 최고의 AI 데이터 시각화 도구: 원본 파일에서 대화형 BI 대시보드를 자동 생성
최고의 AI 데이터 시각화 도구: 원본 파일에서 대화형 BI 대시보드를 자동 생성
XIX.AI에서 2026년 최고의 AI 데이터 시각화 도구를 만나보세요. 저희가 엄선한 최고 평점의 도구들을 통해 원시 파일에서 강력하고 상호작용이 가능한 BI 대시보드를 즉시 자동 생성할 수 있습니다. 실제 테스트와 매주 업데이트되는 순위를 바탕으로 무료 및 유료 옵션을 비교해 보세요. 지금 바로 데이터의 잠재력을 발휘해 보세요.
 10 도구
10 도구
 xix.ai
소셜 미디어
소셜 미디어용 AI 브랜딩 키트: 모든 채널에서 일관된 브랜드 비주얼 유지
xix.ai
소셜 미디어
소셜 미디어용 AI 브랜딩 키트: 모든 채널에서 일관된 브랜드 비주얼 유지
2026년 최고의 소셜 미디어 AI 브랜딩 툴을 만나보세요. XIX.AI가 엄선한 이 목록에는 모든 채널에서 완벽하게 일관된 브랜드 비주얼을 유지할 수 있는, 최고 평점을 받은 혁신적인 도구들이 포함되어 있습니다. 실제 테스트를 통해 무료 버전과 유료 버전을 비교해 보세요. 지금 바로 브랜드의 시각적 경쟁력을 강화해 보세요.
10 도구
xix.ai
챗봇
역할극을 위한 최고의 AI 여자친구 앱 및 AI 동반자 도구 (2026년 가이드)
몰입감 넘치는 역할극과 소통을 위한 2026년 최신 최고 평점 AI 동반자 도구를 만나보세요. XIX.AI가 엄선한 이 가이드에서는 매주 업데이트되는 순위, 무료 및 유료 버전 비교, 실제 사용 후기를 통해 게임의 판도를 바꿀 만큼 강력한 앱들을 소개합니다. 지금 바로 나에게 딱 맞는 앱을 찾아 의미 있는 디지털 동반자 관계를 시작해 보세요.
10 도구
xix.ai
글쓰기
최고의 AI 선협·무협 조력자: 장대한 수련 성장 스토리와 무술 연출을 작성하세요
2026년 최고의 AI 어시스턴트를 만나보세요. 장대한 선협(仙侠) 및 무협(武侠) 이야기를 창작하는 데 도움을 줄 수 있는 도구들입니다. XIX.AI가 엄선한 이 목록에는 수련 과정과 무술 연출을 완벽하게 구현할 수 있는 최고 평점을 받은 혁신적인 도구들이 포함되어 있습니다. 실제 테스트를 통해 무료 버전과 유료 버전을 비교해 보세요. 창의력을 마음껏 발휘하고 오늘 바로 집필을 시작해 보세요!
10 도구
xix.ai
암호
AI 모바일 앱 코딩 도구: 프롬프트를 기반으로 크로스플랫폼용 Flutter 및 React Native 코드를 생성합니다.
2026년 최고의 AI 모바일 앱 개발 도구를 발견해 보세요. Flutter 및 React Native에 적합한 이 도구들은 강력하며, 사용자의 요청에 따라 크로스플랫폼 코드를 자동으로 생성해 줍니다. 무료 옵션과 유료 옵션을 실제 사용 사례를 통해 비교해 보세요. 더 빠른 개발이 가능해지며, 더 나은 앱을 만들 수 있습니다. 지금 바로 XIX.AI에서 순위를 확인해 보세요!
10 도구
xix.ai
암호
최고의 AI 크롬 확장 프로그램 생성기: 코딩 경험 없이도 나만의 브라우저 확장 프로그램 만들기
XIX.AI에서 2026년 최고의 AI 크롬 확장 프로그램 생성기를 만나보세요. 저희가 엄선한 이 목록에는 코딩 없이도 나만의 브라우저 확장 프로그램을 만들 수 있는, 평점이 높고 꼭 사용해봐야 할 도구들이 포함되어 있습니다. 무료 버전과 유료 버전을 비교하고, 실제 테스트 결과를 확인하며, 업무 효율을 극대화해 보세요. 최신 순위를 살펴보고 오늘 바로 나에게 딱 맞는 도구를 찾아보세요!
10 도구
xix.ai

 의견 (14)
0/500
의견 (14)
0/500
![RyanTaylor]()
Interesting! I've been following the open-source vs. proprietary model race. DeepCoder-14B matching o3-mini is a big deal for accessibility. Hope this pushes the big players to open up more, or at least lower their prices. The compute cost for training these 14B models must be insane though. 🤔
![FrankRodriguez]()
Wow, DeepCoder-14B sounds like a game-changer! I'm stoked to see open-source models catching up to the big players. Can't wait to try it out for my side projects—hope it’s as fast as they claim! 🚀
![GregoryBaker]()
DeepCoder-14B sounds like a game-changer! Can't wait to try it out and see how it stacks up against the big players. 🚀
![BillyLewis]()
Wow, DeepCoder-14B sounds like a game-changer for open-source coding! I'm curious how it stacks up against o3-mini in real-world projects. Anyone tried it yet? 🚀
![RaymondWalker]()
¡DeepCoder-14B es una locura! Un modelo de código abierto que compite con los grandes. ¿Será el fin de los modelos propietarios? 🤔
![RalphGarcia]()
DeepCoder-14B、めっちゃ面白そう!😊 オープンソースでここまでできるなんて、コーディングの未来が楽しみ!
DeepCoder-14B 소개: 오픈 소스 코딩 모델의 새로운 지평
Together AI와 Agentica의 팀은 DeepCoder-14B를 공개했습니다. 이는 OpenAI의 o3-mini와 같은 최고 수준의 독점 모델과 어깨를 나란히 하는 획기적인 코딩 모델입니다. 이 흥미로운 개발은 DeepSeek-R1을 기반으로 하며, 고성능 코드 생성 및 추론을 실제 응용 프로그램에 통합할 수 있는 향상된 유연성을 제공합니다. 더욱이, 제작자들은 모델을 완전히 오픈 소스로 공개하며 훈련 데이터, 코드, 로그, 시스템 최적화를 포함하는 훌륭한 조치를 취했습니다. 이 결정은 연구를 촉진하고 해당 분야의 발전을 가속화할 것입니다.
컴팩트한 패키지에서의 인상적인 성능
DeepCoder-14B는 LiveCodeBench(LCB), Codeforces, HumanEval+와 같은 다양한 코딩 벤치마크에서 놀라운 결과를 보여주었습니다. 연구팀의 실험은 이 모델의 성능이 o3-mini(낮음) 및 o1과 같은 선도 모델들과 동등하다는 것을 강조했습니다. 연구진은 블로그 포스트에서 “우리 모델은 모든 코딩 벤치마크에서 강력한 성능을 보여주며… o3-mini(낮음) 및 o1의 성능과 비슷하다”고 자랑스럽게 밝혔습니다.
특히 흥미로운 점은 주로 코딩 작업에 훈련되었음에도 불구하고, DeepCoder-14B는 수학적 추론에서도 주목할 만한 향상을 보여 AIME 2024 벤치마크에서 73.8%의 점수를 달성했습니다. 이는 기본 모델인 DeepSeek-R1-Distill-Qwen-14B보다 4.1% 향상된 결과로, 코드에 대한 강화 학습(RL)을 통해 연마된 추론 기술이 다른 도메인으로 효과적으로 전이될 수 있음을 시사합니다.
DeepCoder-14B의 가장 흥미로운 특징은 그 효율성입니다. 140억 개의 파라미터만으로도 높은 성능을 달성하며, 다른 많은 선도 모델들보다 훨씬 작고 자원 효율적입니다.
DeepCoder 성공의 이면에 있는 혁신
DeepCoder-14B 개발에는 강화 학습을 사용한 코딩 모델 훈련에서 여러 가지 도전 과제를 극복하는 과정이 포함되었습니다. 주요 장애물 중 하나는 훈련 데이터의 선별이었습니다. 고품질의 검증 가능한 데이터가 풍부한 수학적 작업과 달리, 코딩 데이터는 부족할 수 있습니다. DeepCoder 팀은 다양한 데이터셋에서 예제를 수집하고 필터링하는 엄격한 파이프라인을 구현하여 유효성, 복잡성, 중복 방지를 보장함으로써 이를 해결했습니다. 이 과정은 RL 훈련을 위한 견고한 기반이 되는 24,000개의 고품질 문제를 만들어냈습니다.
팀은 또한 생성된 코드가 설정된 시간 제한 내에서 모든 샘플링된 단위 테스트를 성공적으로 통과할 경우에만 모델에 보상을 주는 간단한 보상 함수를 고안했습니다. 이러한 접근 방식은 고품질 훈련 예제와 결합하여 모델이 단축키를 활용하기보다는 핵심 문제를 해결하는 데 집중하도록 했습니다.
DeepCoder-14B의 훈련 알고리즘은 DeepSeek-R1에서 성공적이었던 Group Relative Policy Optimization(GRPO)을 기반으로 하지만, 팀은 안정성을 높이고 더 긴 훈련 기간을 가능하게 하기 위해 상당한 수정 작업을 수행했습니다.
또한, 팀은 모델의 컨텍스트 창을 반복적으로 확장하여 짧은 시퀀스에서 시작해 점진적으로 늘려갔습니다. 또한 복잡한 프롬프트를 해결할 때 컨텍스트 제한을 초과하는 것에 대해 모델이 불이익을 받지 않도록 필터링 방법을 도입했습니다.
연구진은 그들의 접근 방식을 이렇게 설명했습니다: “효율적인 훈련을 가능하게 하면서 장문 컨텍스트 추론을 보존하기 위해, 우리는 과도한 필터링을 포함했습니다… 이 기술은 훈련 중 잘린 시퀀스를 마스킹하여 모델이 현재 컨텍스트 제한을 초과하는 신중하지만 긴 출력을 생성하는 데 불이익을 받지 않도록 합니다.” 훈련은 16K에서 32K 컨텍스트 창으로 확장되어 최대 64K 토큰이 필요한 문제를 해결할 수 있게 했습니다.
장문 컨텍스트 RL 훈련 최적화
코딩과 같이 긴 시퀀스를 생성하는 작업에 RL로 대규모 모델을 훈련시키는 것은 매우 느리고 자원 집약적입니다. 모델이 예제당 수천 개의 토큰을 생성하는 샘플링 단계는 응답 길이의 다양성으로 인해 상당한 지연을 초래합니다.
이를 해결하기 위해 팀은 인간 피드백으로부터의 강화 학습(RLHF)을 위한 오픈 소스 verl 라이브러리의 최적화된 확장인 verl-pipeline을 개발했습니다. 그들의 “One-Off Pipelining” 혁신은 샘플링과 모델 업데이트를 재구성하여 병목 현상을 최소화하고 가속기의 유휴 시간을 줄였습니다.
그들의 실험은 one-off pipelining이 표준 방법에 비해 코딩 RL 작업을 최대 2배까지 가속화할 수 있음을 보여주었습니다. 이 최적화는 DeepCoder-14B를 합리적인 시간 내(32개의 H100에서 2.5주)에 훈련시키는 데 결정적이었으며, 이제 커뮤니티가 활용할 수 있도록 verl-pipeline의 일부로 오픈 소스화되었습니다.
기업 영향과 오픈 소스 협업
연구진은 DeepCoder-14B의 모든 훈련 및 운영 아티팩트를 GitHub와 Hugging Face에 허용 라이선스로 공개했습니다. “우리의 데이터셋, 코드, 훈련 레시피를 완전히 공유함으로써, 우리는 커뮤니티가 우리의 작업을 재현하고 RL 훈련을 모두에게 접근 가능하게 할 수 있도록 힘을 실어줍니다”라고 그들은 밝혔습니다.
DeepCoder-14B는 AI 환경에서 효율적이고 공개적으로 접근 가능한 모델의 증가 추세를 잘 보여줍니다. 기업에게 이는 고급 모델에 대한 더 많은 선택지와 더 큰 접근성을 의미합니다. 고성능 코드 생성과 추론은 더 이상 대기업이나 높은 API 비용을 지불하려는 이들에게만 독점적이지 않습니다. 이제 모든 규모의 조직이 이러한 기능을 활용하여 특정 요구에 맞는 솔루션을 맞춤화하고 안전하게 환경 내에서 배포할 수 있습니다.
이러한 변화는 AI 채택의 장벽을 낮추고 오픈 소스 협업에 의해 구동되는 보다 경쟁적이고 혁신적인 생태계를 촉진할 준비가 되어 있습니다.










 멀티버스 컴퓨팅, 무료 압축 생성형 AI 모델 출시
대규모 언어 모델은 상당한 과제에 직면해 있습니다: 바로 그 방대한 규모입니다. 스페인 스타트업 멀티버스 컴퓨팅(Multiverse Computing)은 최첨단 AI의 성능과 기업이 실질적으로 도입할 수 있는 수준 사이의 격차를 해소하기 위해 설계된 압축 모델을 개발함으로써 이 문제를 해결하고 있습니다.핵심 혁신은 양자 컴퓨팅 원리에서 영감을 받은 압축 기
멀티버스 컴퓨팅, 무료 압축 생성형 AI 모델 출시
대규모 언어 모델은 상당한 과제에 직면해 있습니다: 바로 그 방대한 규모입니다. 스페인 스타트업 멀티버스 컴퓨팅(Multiverse Computing)은 최첨단 AI의 성능과 기업이 실질적으로 도입할 수 있는 수준 사이의 격차를 해소하기 위해 설계된 압축 모델을 개발함으로써 이 문제를 해결하고 있습니다.핵심 혁신은 양자 컴퓨팅 원리에서 영감을 받은 압축 기
 비밀 추적 데이터, AI 모델 도용 사건 폭로
새로운 방법은 재훈련 없이도 ChatGPT와 같은 모델에 몇 초 만에 보이지 않는 워터마크를 적용할 수 있으며, 표준 출력물에 흔적을 남기지 않고 모든 실질적인 제거 시도를 견딥니다. 워터마킹과 '저작권 유인(copyright-baiting)'의 핵심 차이점은 워터마크(가시적이든 숨겨진 것이든)는 일반적으로 이미지 데이터셋과 같은 컬렉션 전체에 걸쳐 나타나
비밀 추적 데이터, AI 모델 도용 사건 폭로
새로운 방법은 재훈련 없이도 ChatGPT와 같은 모델에 몇 초 만에 보이지 않는 워터마크를 적용할 수 있으며, 표준 출력물에 흔적을 남기지 않고 모든 실질적인 제거 시도를 견딥니다. 워터마킹과 '저작권 유인(copyright-baiting)'의 핵심 차이점은 워터마크(가시적이든 숨겨진 것이든)는 일반적으로 이미지 데이터셋과 같은 컬렉션 전체에 걸쳐 나타나
 인공지능 시스템, 터무니없는 과학 논문을 승인하도록 속아넘어갔다
새로운 연구에 따르면, 인공지능 시스템이 이제 다른 인공지능 모델들이 진품으로 오인하는 사기성 과학 논문을 생성할 수 있게 되었다. 이러한 조작된 연구들은 기존에 효과적이었던 탐지 방법을 우회하며, 연구 생태계가 봇이 다른 봇을 속이는 악순환으로 붕괴될 위험성을 부각시키고 있다. 아이러니하게도 AI 혁신의 최전선에 있는 학술 연구 분야가 AI에 의해 촉발된
인공지능 시스템, 터무니없는 과학 논문을 승인하도록 속아넘어갔다
새로운 연구에 따르면, 인공지능 시스템이 이제 다른 인공지능 모델들이 진품으로 오인하는 사기성 과학 논문을 생성할 수 있게 되었다. 이러한 조작된 연구들은 기존에 효과적이었던 탐지 방법을 우회하며, 연구 생태계가 봇이 다른 봇을 속이는 악순환으로 붕괴될 위험성을 부각시키고 있다. 아이러니하게도 AI 혁신의 최전선에 있는 학술 연구 분야가 AI에 의해 촉발된

XIX.AI에서 2026년 최고의 AI 데이터 시각화 도구를 만나보세요. 저희가 엄선한 최고 평점의 도구들을 통해 원시 파일에서 강력하고 상호작용이 가능한 BI 대시보드를 즉시 자동 생성할 수 있습니다. 실제 테스트와 매주 업데이트되는 순위를 바탕으로 무료 및 유료 옵션을 비교해 보세요. 지금 바로 데이터의 잠재력을 발휘해 보세요.
10 도구
xix.ai

2026년 최고의 소셜 미디어 AI 브랜딩 툴을 만나보세요. XIX.AI가 엄선한 이 목록에는 모든 채널에서 완벽하게 일관된 브랜드 비주얼을 유지할 수 있는, 최고 평점을 받은 혁신적인 도구들이 포함되어 있습니다. 실제 테스트를 통해 무료 버전과 유료 버전을 비교해 보세요. 지금 바로 브랜드의 시각적 경쟁력을 강화해 보세요.
10 도구
xix.ai

몰입감 넘치는 역할극과 소통을 위한 2026년 최신 최고 평점 AI 동반자 도구를 만나보세요. XIX.AI가 엄선한 이 가이드에서는 매주 업데이트되는 순위, 무료 및 유료 버전 비교, 실제 사용 후기를 통해 게임의 판도를 바꿀 만큼 강력한 앱들을 소개합니다. 지금 바로 나에게 딱 맞는 앱을 찾아 의미 있는 디지털 동반자 관계를 시작해 보세요.
10 도구
xix.ai

2026년 최고의 AI 어시스턴트를 만나보세요. 장대한 선협(仙侠) 및 무협(武侠) 이야기를 창작하는 데 도움을 줄 수 있는 도구들입니다. XIX.AI가 엄선한 이 목록에는 수련 과정과 무술 연출을 완벽하게 구현할 수 있는 최고 평점을 받은 혁신적인 도구들이 포함되어 있습니다. 실제 테스트를 통해 무료 버전과 유료 버전을 비교해 보세요. 창의력을 마음껏 발휘하고 오늘 바로 집필을 시작해 보세요!
10 도구
xix.ai

2026년 최고의 AI 모바일 앱 개발 도구를 발견해 보세요. Flutter 및 React Native에 적합한 이 도구들은 강력하며, 사용자의 요청에 따라 크로스플랫폼 코드를 자동으로 생성해 줍니다. 무료 옵션과 유료 옵션을 실제 사용 사례를 통해 비교해 보세요. 더 빠른 개발이 가능해지며, 더 나은 앱을 만들 수 있습니다. 지금 바로 XIX.AI에서 순위를 확인해 보세요!
10 도구
xix.ai

XIX.AI에서 2026년 최고의 AI 크롬 확장 프로그램 생성기를 만나보세요. 저희가 엄선한 이 목록에는 코딩 없이도 나만의 브라우저 확장 프로그램을 만들 수 있는, 평점이 높고 꼭 사용해봐야 할 도구들이 포함되어 있습니다. 무료 버전과 유료 버전을 비교하고, 실제 테스트 결과를 확인하며, 업무 효율을 극대화해 보세요. 최신 순위를 살펴보고 오늘 바로 나에게 딱 맞는 도구를 찾아보세요!
10 도구
xix.ai

Interesting! I've been following the open-source vs. proprietary model race. DeepCoder-14B matching o3-mini is a big deal for accessibility. Hope this pushes the big players to open up more, or at least lower their prices. The compute cost for training these 14B models must be insane though. 🤔
Wow, DeepCoder-14B sounds like a game-changer! I'm stoked to see open-source models catching up to the big players. Can't wait to try it out for my side projects—hope it’s as fast as they claim! 🚀
DeepCoder-14B sounds like a game-changer! Can't wait to try it out and see how it stacks up against the big players. 🚀
Wow, DeepCoder-14B sounds like a game-changer for open-source coding! I'm curious how it stacks up against o3-mini in real-world projects. Anyone tried it yet? 🚀
¡DeepCoder-14B es una locura! Un modelo de código abierto que compite con los grandes. ¿Será el fin de los modelos propietarios? 🤔
DeepCoder-14B、めっちゃ面白そう!😊 オープンソースでここまでできるなんて、コーディングの未来が楽しみ!













