




Deepcoder logra una alta eficiencia de codificación con un modelo abierto de 14b
Presentando DeepCoder-14B: Una Nueva Frontera en Modelos de Codificación de Código Abierto
Los equipos de Together AI y Agentica han presentado DeepCoder-14B, un modelo de codificación revolucionario que compite codo a codo con los mejores modelos propietarios como el o3-mini de OpenAI. Este emocionante desarrollo se basa en DeepSeek-R1 y ofrece mayor flexibilidad para integrar generación de código y razonamiento de alto rendimiento en aplicaciones prácticas. Además, los creadores han dado un paso admirable al abrir completamente el modelo, incluyendo sus datos de entrenamiento, código, registros y optimizaciones del sistema. Esta medida está destinada a catalizar la investigación y acelerar los avances en el campo.
Rendimiento Impresionante en un Paquete Compacto
DeepCoder-14B ha mostrado resultados notables en varios puntos de referencia de codificación como LiveCodeBench (LCB), Codeforces y HumanEval+. Los experimentos del equipo de investigación han destacado que el rendimiento del modelo está a la par con modelos líderes como o3-mini (bajo) y o1. "Nuestro modelo demuestra un fuerte rendimiento en todos los puntos de referencia de codificación... comparable al rendimiento de o3-mini (bajo) y o1," declararon orgullosamente los investigadores en su publicación de blog.
Lo que es particularmente intrigante es que, a pesar de estar principalmente entrenado en tareas de codificación, DeepCoder-14B también ha mostrado una notable mejora en el razonamiento matemático, logrando un puntaje del 73.8% en el punto de referencia AIME 2024. Esto marca un aumento del 4.1% sobre su modelo base, DeepSeek-R1-Distill-Qwen-14B, sugiriendo que las habilidades de razonamiento perfeccionadas a través del aprendizaje por refuerzo (RL) en código pueden transferirse eficazmente a otros dominios.
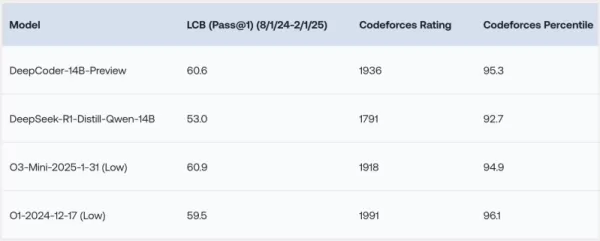
*Crédito: Together AI* Quizás la característica más emocionante de DeepCoder-14B es su eficiencia. Con solo 14 mil millones de parámetros, logra un alto rendimiento mientras es significativamente más pequeño y eficiente en recursos que muchos otros modelos líderes.
Innovaciones Detrás del Éxito de DeepCoder
Desarrollar DeepCoder-14B implicó superar varios desafíos, particularmente en el entrenamiento de modelos de codificación usando aprendizaje por refuerzo. Un obstáculo importante fue la curación de los datos de entrenamiento. A diferencia de las tareas matemáticas, donde los datos verificables de alta calidad son abundantes, los datos de codificación pueden ser escasos. El equipo de DeepCoder abordó esto implementando un proceso riguroso para recopilar y filtrar ejemplos de varios conjuntos de datos, asegurando validez, complejidad y evitando duplicaciones. Este proceso resultó en 24,000 problemas de alta calidad, que formaron una base sólida para el entrenamiento de RL.
El equipo también diseñó una función de recompensa directa que solo premia al modelo si el código generado pasa con éxito todas las pruebas unitarias muestreadas dentro de un límite de tiempo establecido. Este enfoque, junto con ejemplos de entrenamiento de alta calidad, aseguró que el modelo se enfocara en resolver problemas centrales en lugar de explotar atajos.
El algoritmo de entrenamiento de DeepCoder-14B se basa en la Optimización de Políticas Relativas de Grupo (GRPO), que tuvo éxito en DeepSeek-R1. Sin embargo, el equipo realizó modificaciones significativas para mejorar la estabilidad y permitir duraciones de entrenamiento más largas.
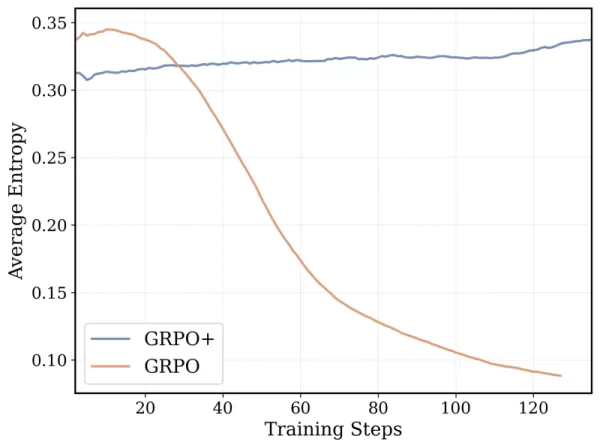
*GRPO+ permite a DeepCoder-14 continuar por más tiempo sin colapsar Crédito: Together AI* Además, el equipo extendió iterativamente la ventana de contexto del modelo, comenzando con secuencias más cortas y aumentándolas gradualmente. También introdujeron un método de filtrado para evitar penalizar al modelo por exceder los límites de contexto al resolver prompts complejos.
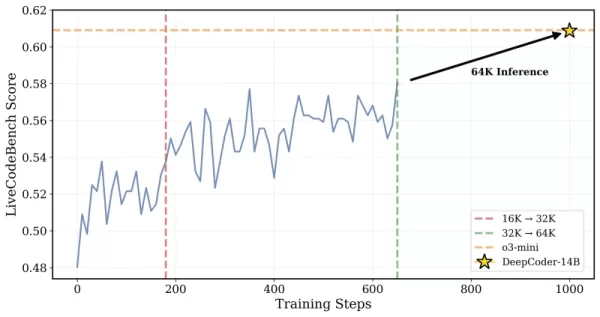
*DeepCoder fue entrenado en problemas de contexto de 32K pero también pudo resolver tareas de 64K Crédito: Together AI* Los investigadores explicaron su enfoque: "Para preservar el razonamiento de contexto largo mientras se permite un entrenamiento eficiente, incorporamos un filtrado de exceso de longitud... Esta técnica enmascara secuencias truncadas durante el entrenamiento para que los modelos no sean penalizados por generar resultados reflexivos pero extensos que excedan el límite de contexto actual." El entrenamiento escaló de una ventana de contexto de 16K a 32K, permitiendo al modelo abordar problemas que requieren hasta 64K tokens.
Optimizando el Entrenamiento de RL de Contexto Largo
Entrenar modelos grandes con RL, especialmente en tareas que generan secuencias largas como la codificación, es notoriamente lento y consume muchos recursos. El paso de muestreo, donde el modelo genera miles de tokens por ejemplo, a menudo lleva a retrasos significativos debido a las longitudes de respuesta variables.
Para abordar esto, el equipo desarrolló verl-pipeline, una extensión optimizada de la biblioteca de código abierto verl para el aprendizaje por refuerzo desde retroalimentación humana (RLHF). Su innovación "One-Off Pipelining" reestructuró el muestreo y las actualizaciones del modelo para minimizar cuellos de botella y reducir el tiempo de inactividad en los aceleradores.
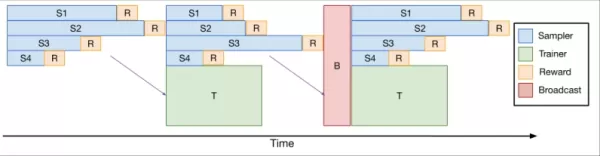
*One-Off Pipelining* Sus experimentos demostraron que el one-off pipelining podía acelerar las tareas de RL de codificación hasta 2 veces en comparación con los métodos estándar. Esta optimización fue crucial para entrenar DeepCoder-14B en un plazo razonable (2.5 semanas en 32 H100s) y ahora está disponible como código abierto como parte de verl-pipeline para que la comunidad lo aproveche.
Impacto Empresarial y Colaboración de Código Abierto
Los investigadores han puesto a disposición todos los artefactos de entrenamiento y operación de DeepCoder-14B en GitHub y Hugging Face bajo una licencia permisiva. "Al compartir completamente nuestro conjunto de datos, código y receta de entrenamiento, empoderamos a la comunidad para reproducir nuestro trabajo y hacer que el entrenamiento de RL sea accesible para todos," afirmaron.
DeepCoder-14B ejemplifica la creciente tendencia de modelos eficientes y de acceso abierto en el panorama de la IA. Para las empresas, esto significa más opciones y mayor accesibilidad a modelos avanzados. La generación de código y el razonamiento de alto rendimiento ya no son exclusivos de grandes corporaciones o aquellos dispuestos a pagar altas tarifas de API. Organizaciones de todos los tamaños ahora pueden aprovechar estas capacidades, adaptar soluciones a sus necesidades específicas e implementarlas de manera segura en sus entornos.
Este cambio está preparado para reducir las barreras a la adopción de la IA, fomentando un ecosistema más competitivo e innovador impulsado por la colaboración de código abierto.
Artículo relacionado
 Google Cloud impulsa grandes avances en la investigación y el descubrimiento científicos
La revolución digital está transformando las metodologías científicas gracias a unas capacidades computacionales sin precedentes. Las tecnologías de vanguardia aumentan ahora tanto los marcos teóricos
La IA acelera la investigación científica para lograr un mayor impacto en el mundo real
Google ha aprovechado constantemente la IA como catalizador del progreso científico, y el ritmo actual de los descubrimientos ha alcanzado niveles extraordinarios. Esta aceleración ha transformado el
La IA "ZeroSearch" de Alibaba reduce los costes de formación en un 88% gracias al aprendizaje autónomo
ZeroSearch de Alibaba: Un cambio en la eficiencia del entrenamiento de IALos investigadores del Grupo Alibaba han sido pioneros en un método innovador que podría revolucionar la forma en que los siste
comentario (13)
0/200
Google Cloud impulsa grandes avances en la investigación y el descubrimiento científicos
La revolución digital está transformando las metodologías científicas gracias a unas capacidades computacionales sin precedentes. Las tecnologías de vanguardia aumentan ahora tanto los marcos teóricos
La IA acelera la investigación científica para lograr un mayor impacto en el mundo real
Google ha aprovechado constantemente la IA como catalizador del progreso científico, y el ritmo actual de los descubrimientos ha alcanzado niveles extraordinarios. Esta aceleración ha transformado el
La IA "ZeroSearch" de Alibaba reduce los costes de formación en un 88% gracias al aprendizaje autónomo
ZeroSearch de Alibaba: Un cambio en la eficiencia del entrenamiento de IALos investigadores del Grupo Alibaba han sido pioneros en un método innovador que podría revolucionar la forma en que los siste
comentario (13)
0/200
![FrankRodriguez]() FrankRodriguez
FrankRodriguez
 26 de agosto de 2025 07:25:25 GMT+02:00
26 de agosto de 2025 07:25:25 GMT+02:00
Wow, DeepCoder-14B sounds like a game-changer! I'm stoked to see open-source models catching up to the big players. Can't wait to try it out for my side projects—hope it’s as fast as they claim! 🚀


 0
0
![GregoryBaker]() GregoryBaker
11 de agosto de 2025 08:20:39 GMT+02:00
GregoryBaker
11 de agosto de 2025 08:20:39 GMT+02:00
DeepCoder-14B sounds like a game-changer! Can't wait to try it out and see how it stacks up against the big players. 🚀
0
![BillyLewis]() BillyLewis
6 de agosto de 2025 09:01:06 GMT+02:00
BillyLewis
6 de agosto de 2025 09:01:06 GMT+02:00
Wow, DeepCoder-14B sounds like a game-changer for open-source coding! I'm curious how it stacks up against o3-mini in real-world projects. Anyone tried it yet? 🚀
0
![RaymondWalker]() RaymondWalker
25 de abril de 2025 05:21:57 GMT+02:00
RaymondWalker
25 de abril de 2025 05:21:57 GMT+02:00
¡DeepCoder-14B es una locura! Un modelo de código abierto que compite con los grandes. ¿Será el fin de los modelos propietarios? 🤔
0
![RalphGarcia]() RalphGarcia
24 de abril de 2025 18:21:21 GMT+02:00
RalphGarcia
24 de abril de 2025 18:21:21 GMT+02:00
DeepCoder-14B、めっちゃ面白そう!😊 オープンソースでここまでできるなんて、コーディングの未来が楽しみ!
0
![SebastianAnderson]() SebastianAnderson
24 de abril de 2025 09:46:12 GMT+02:00
SebastianAnderson
24 de abril de 2025 09:46:12 GMT+02:00
¡DeepCoder-14B es una bestia! Es increíble cómo puede codificar tan eficientemente, casi como tener a un programador de primera a mano. Lo he usado en proyectos complejos y ha acertado cada vez. Lo único es que puede ser un poco lento en mi vieja laptop. Aún así, una herramienta sólida para cualquier programador! 🤓💻
0
Presentando DeepCoder-14B: Una Nueva Frontera en Modelos de Codificación de Código Abierto
Los equipos de Together AI y Agentica han presentado DeepCoder-14B, un modelo de codificación revolucionario que compite codo a codo con los mejores modelos propietarios como el o3-mini de OpenAI. Este emocionante desarrollo se basa en DeepSeek-R1 y ofrece mayor flexibilidad para integrar generación de código y razonamiento de alto rendimiento en aplicaciones prácticas. Además, los creadores han dado un paso admirable al abrir completamente el modelo, incluyendo sus datos de entrenamiento, código, registros y optimizaciones del sistema. Esta medida está destinada a catalizar la investigación y acelerar los avances en el campo.
Rendimiento Impresionante en un Paquete Compacto
DeepCoder-14B ha mostrado resultados notables en varios puntos de referencia de codificación como LiveCodeBench (LCB), Codeforces y HumanEval+. Los experimentos del equipo de investigación han destacado que el rendimiento del modelo está a la par con modelos líderes como o3-mini (bajo) y o1. "Nuestro modelo demuestra un fuerte rendimiento en todos los puntos de referencia de codificación... comparable al rendimiento de o3-mini (bajo) y o1," declararon orgullosamente los investigadores en su publicación de blog.
Lo que es particularmente intrigante es que, a pesar de estar principalmente entrenado en tareas de codificación, DeepCoder-14B también ha mostrado una notable mejora en el razonamiento matemático, logrando un puntaje del 73.8% en el punto de referencia AIME 2024. Esto marca un aumento del 4.1% sobre su modelo base, DeepSeek-R1-Distill-Qwen-14B, sugiriendo que las habilidades de razonamiento perfeccionadas a través del aprendizaje por refuerzo (RL) en código pueden transferirse eficazmente a otros dominios.
Quizás la característica más emocionante de DeepCoder-14B es su eficiencia. Con solo 14 mil millones de parámetros, logra un alto rendimiento mientras es significativamente más pequeño y eficiente en recursos que muchos otros modelos líderes.
Innovaciones Detrás del Éxito de DeepCoder
Desarrollar DeepCoder-14B implicó superar varios desafíos, particularmente en el entrenamiento de modelos de codificación usando aprendizaje por refuerzo. Un obstáculo importante fue la curación de los datos de entrenamiento. A diferencia de las tareas matemáticas, donde los datos verificables de alta calidad son abundantes, los datos de codificación pueden ser escasos. El equipo de DeepCoder abordó esto implementando un proceso riguroso para recopilar y filtrar ejemplos de varios conjuntos de datos, asegurando validez, complejidad y evitando duplicaciones. Este proceso resultó en 24,000 problemas de alta calidad, que formaron una base sólida para el entrenamiento de RL.
El equipo también diseñó una función de recompensa directa que solo premia al modelo si el código generado pasa con éxito todas las pruebas unitarias muestreadas dentro de un límite de tiempo establecido. Este enfoque, junto con ejemplos de entrenamiento de alta calidad, aseguró que el modelo se enfocara en resolver problemas centrales en lugar de explotar atajos.
El algoritmo de entrenamiento de DeepCoder-14B se basa en la Optimización de Políticas Relativas de Grupo (GRPO), que tuvo éxito en DeepSeek-R1. Sin embargo, el equipo realizó modificaciones significativas para mejorar la estabilidad y permitir duraciones de entrenamiento más largas.
Además, el equipo extendió iterativamente la ventana de contexto del modelo, comenzando con secuencias más cortas y aumentándolas gradualmente. También introdujeron un método de filtrado para evitar penalizar al modelo por exceder los límites de contexto al resolver prompts complejos.
Los investigadores explicaron su enfoque: "Para preservar el razonamiento de contexto largo mientras se permite un entrenamiento eficiente, incorporamos un filtrado de exceso de longitud... Esta técnica enmascara secuencias truncadas durante el entrenamiento para que los modelos no sean penalizados por generar resultados reflexivos pero extensos que excedan el límite de contexto actual." El entrenamiento escaló de una ventana de contexto de 16K a 32K, permitiendo al modelo abordar problemas que requieren hasta 64K tokens.
Optimizando el Entrenamiento de RL de Contexto Largo
Entrenar modelos grandes con RL, especialmente en tareas que generan secuencias largas como la codificación, es notoriamente lento y consume muchos recursos. El paso de muestreo, donde el modelo genera miles de tokens por ejemplo, a menudo lleva a retrasos significativos debido a las longitudes de respuesta variables.
Para abordar esto, el equipo desarrolló verl-pipeline, una extensión optimizada de la biblioteca de código abierto verl para el aprendizaje por refuerzo desde retroalimentación humana (RLHF). Su innovación "One-Off Pipelining" reestructuró el muestreo y las actualizaciones del modelo para minimizar cuellos de botella y reducir el tiempo de inactividad en los aceleradores.
Sus experimentos demostraron que el one-off pipelining podía acelerar las tareas de RL de codificación hasta 2 veces en comparación con los métodos estándar. Esta optimización fue crucial para entrenar DeepCoder-14B en un plazo razonable (2.5 semanas en 32 H100s) y ahora está disponible como código abierto como parte de verl-pipeline para que la comunidad lo aproveche.
Impacto Empresarial y Colaboración de Código Abierto
Los investigadores han puesto a disposición todos los artefactos de entrenamiento y operación de DeepCoder-14B en GitHub y Hugging Face bajo una licencia permisiva. "Al compartir completamente nuestro conjunto de datos, código y receta de entrenamiento, empoderamos a la comunidad para reproducir nuestro trabajo y hacer que el entrenamiento de RL sea accesible para todos," afirmaron.
DeepCoder-14B ejemplifica la creciente tendencia de modelos eficientes y de acceso abierto en el panorama de la IA. Para las empresas, esto significa más opciones y mayor accesibilidad a modelos avanzados. La generación de código y el razonamiento de alto rendimiento ya no son exclusivos de grandes corporaciones o aquellos dispuestos a pagar altas tarifas de API. Organizaciones de todos los tamaños ahora pueden aprovechar estas capacidades, adaptar soluciones a sus necesidades específicas e implementarlas de manera segura en sus entornos.
Este cambio está preparado para reducir las barreras a la adopción de la IA, fomentando un ecosistema más competitivo e innovador impulsado por la colaboración de código abierto.










 Google Cloud impulsa grandes avances en la investigación y el descubrimiento científicos
La revolución digital está transformando las metodologías científicas gracias a unas capacidades computacionales sin precedentes. Las tecnologías de vanguardia aumentan ahora tanto los marcos teóricos
Google Cloud impulsa grandes avances en la investigación y el descubrimiento científicos
La revolución digital está transformando las metodologías científicas gracias a unas capacidades computacionales sin precedentes. Las tecnologías de vanguardia aumentan ahora tanto los marcos teóricos
 La IA acelera la investigación científica para lograr un mayor impacto en el mundo real
Google ha aprovechado constantemente la IA como catalizador del progreso científico, y el ritmo actual de los descubrimientos ha alcanzado niveles extraordinarios. Esta aceleración ha transformado el
La IA acelera la investigación científica para lograr un mayor impacto en el mundo real
Google ha aprovechado constantemente la IA como catalizador del progreso científico, y el ritmo actual de los descubrimientos ha alcanzado niveles extraordinarios. Esta aceleración ha transformado el
 La IA "ZeroSearch" de Alibaba reduce los costes de formación en un 88% gracias al aprendizaje autónomo
ZeroSearch de Alibaba: Un cambio en la eficiencia del entrenamiento de IALos investigadores del Grupo Alibaba han sido pioneros en un método innovador que podría revolucionar la forma en que los siste
26 de agosto de 2025 07:25:25 GMT+02:00
La IA "ZeroSearch" de Alibaba reduce los costes de formación en un 88% gracias al aprendizaje autónomo
ZeroSearch de Alibaba: Un cambio en la eficiencia del entrenamiento de IALos investigadores del Grupo Alibaba han sido pioneros en un método innovador que podría revolucionar la forma en que los siste
26 de agosto de 2025 07:25:25 GMT+02:00
Wow, DeepCoder-14B sounds like a game-changer! I'm stoked to see open-source models catching up to the big players. Can't wait to try it out for my side projects—hope it’s as fast as they claim! 🚀
0
11 de agosto de 2025 08:20:39 GMT+02:00
DeepCoder-14B sounds like a game-changer! Can't wait to try it out and see how it stacks up against the big players. 🚀
0
6 de agosto de 2025 09:01:06 GMT+02:00
Wow, DeepCoder-14B sounds like a game-changer for open-source coding! I'm curious how it stacks up against o3-mini in real-world projects. Anyone tried it yet? 🚀
0
25 de abril de 2025 05:21:57 GMT+02:00
¡DeepCoder-14B es una locura! Un modelo de código abierto que compite con los grandes. ¿Será el fin de los modelos propietarios? 🤔
0
24 de abril de 2025 18:21:21 GMT+02:00
DeepCoder-14B、めっちゃ面白そう!😊 オープンソースでここまでできるなんて、コーディングの未来が楽しみ!
0
24 de abril de 2025 09:46:12 GMT+02:00
¡DeepCoder-14B es una bestia! Es increíble cómo puede codificar tan eficientemente, casi como tener a un programador de primera a mano. Lo he usado en proyectos complejos y ha acertado cada vez. Lo único es que puede ser un poco lento en mi vieja laptop. Aún así, una herramienta sólida para cualquier programador! 🤓💻
0













