
















 家
家DeepCoderは、14Bオープンモデルで高いコーディング効率を実現します
DeepCoder-14Bの紹介:オープンソースコーディングモデルの新たなフロンティア
Together AIとAgenticaのチームは、DeepCoder-14Bを発表しました。これは、OpenAIのo3-miniのようなトップレベルのプロプライエタリモデルと肩を並べる画期的なコーディングモデルです。このエキサイティングな開発は、DeepSeek-R1を基盤としており、高性能なコード生成と推論を実際のアプリケーションに統合するための柔軟性を向上させています。さらに、開発者はモデルを完全にオープンソース化し、トレーニングデータ、コード、ログ、システム最適化を含めるという称賛すべきステップを踏みました。この動きは、研究を加速し、分野の進歩を促進するでしょう。
コンパクトなパッケージでの驚異的なパフォーマンス
DeepCoder-14Bは、LiveCodeBench(LCB)、Codeforces、HumanEval+などのさまざまなコーディングベンチマークで驚くべき結果を示しています。研究チームの実験では、モデルのパフォーマンスがo3-mini(低)やo1といったリーディングモデルと同等であることが強調されています。「私たちのモデルは、すべてのコーディングベンチマークで強力なパフォーマンスを示し…o3-mini(低)やo1のパフォーマンスに匹敵します」と、研究者たちはブログ投稿で誇らしげに述べています。
特に興味深いのは、主にコーディングタスクでトレーニングされているにもかかわらず、DeepCoder-14Bが数学的推論でも顕著な向上を示し、AIME 2024ベンチマークで73.8%のスコアを達成した点です。これは、ベースモデルであるDeepSeek-R1-Distill-Qwen-14Bに比べて4.1%の向上を示しており、コードに対する強化学習(RL)で磨かれた推論スキルが他の領域にも効果的に転移することを示唆しています。
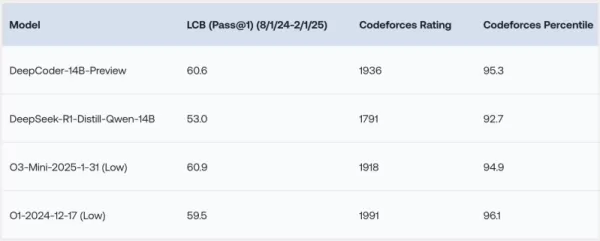
*クレジット:Together AI* DeepCoder-14Bの最もエキサイティングな特徴は、その効率性です。140億のパラメータしか持たないにもかかわらず、他の多くのリーディングモデルよりも大幅に小さく、リソース効率が高いながらも高いパフォーマンスを達成しています。
DeepCoderの成功の背後にある革新
DeepCoder-14Bの開発には、強化学習を使用したコーディングモデルのトレーニングにおけるいくつかの課題を克服する必要がありました。主なハードルの一つは、トレーニングデータのキュレーションでした。数学的タスクとは異なり、高品質で検証可能なデータが豊富にある一方で、コーディングデータは不足しがちです。DeepCoderチームは、さまざまなデータセットから例を収集しフィルタリングする厳格なパイプラインを実装し、有効性、複雑さ、重複の回避を確保することでこれに対処しました。このプロセスにより、24,000の高品質な問題が得られ、RLトレーニングのための強固な基盤が形成されました。
チームはまた、生成されたコードが設定された時間内にすべてのサンプリングされたユニットテストを正常に通過した場合にのみモデルに報酬を与える、シンプルな報酬関数を考案しました。このアプローチは、高品質なトレーニング例と組み合わせることで、モデルが近道を利用するのではなく、核心的な問題解決に焦点を当てることを保証しました。
DeepCoder-14Bのトレーニングアルゴリズムは、DeepSeek-R1で成功したGroup Relative Policy Optimization(GRPO)を基盤としていますが、チームは安定性を高め、より長いトレーニング期間を可能にするために大幅な改良を加えました。
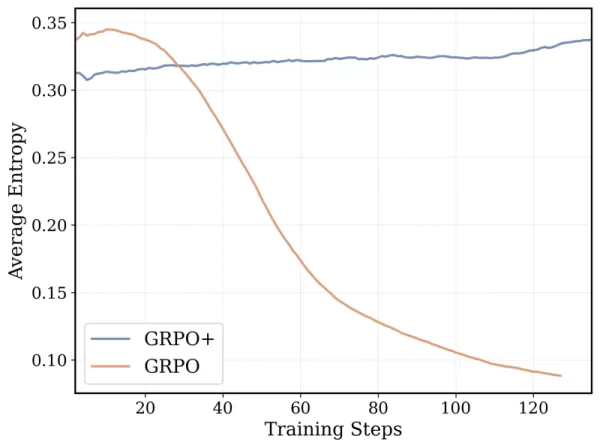
*GRPO+により、DeepCoder-14は崩壊せずに長期間継続可能 クレジット:Together AI* さらに、チームはモデルのコンテキストウィンドウを段階的に拡張し、短いシーケンスから始めて徐々に増やしました。また、複雑なプロンプトを解決する際にコンテキスト制限を超えることに対してモデルがペナルティを受けないようにするフィルタリング手法も導入しました。
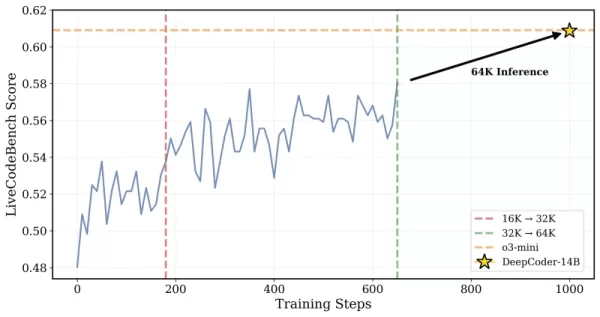
*DeepCoderは32Kコンテキストの問題でトレーニングされましたが、64Kタスクも解決可能 クレジット:Together AI* 研究者たちはそのアプローチを次のように説明しています:「長コンテキスト推論を維持しながら効率的なトレーニングを可能にするために、オーバーロングフィルタリングを導入しました…この手法は、トレーニング中に切り捨てられたシーケンスをマスクすることで、現在のコンテキスト制限を超える思慮深いが長い出力を生成することに対してモデルがペナルティを受けないようにします。」トレーニングは16Kから32Kのコンテキストウィンドウにスケールアップし、最大64Kトークンが必要な問題に取り組むことができるようになりました。
長コンテキストRLトレーニングの最適化
コーディングのような長いシーケンスを生成するタスクで、RLを使用して大規模モデルをトレーニングすることは、非常に遅く、リソースを大量に消費します。モデルが例ごとに数千のトークンを生成するサンプリングステップは、応答の長さが異なるため、しばしば大きな遅延を引き起こします。
これに対処するために、チームは、人間からのフィードバックによる強化学習(RLHF)のためのオープンソースverlライブラリの最適化された拡張であるverl-pipelineを開発しました。彼らの「One-Off Pipelining」イノベーションは、サンプリングとモデル更新を再構築してボトルネックを最小限に抑え、アクセラレータのアイドル時間を削減しました。
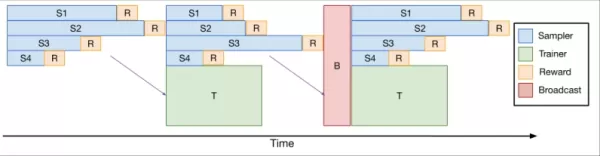
*One-Off Pipelining* 彼らの実験では、ワンオフパイプラインが標準的な方法に比べてコーディングRLタスクを最大2倍高速化できることが示されました。この最適化は、DeepCoder-14Bを合理的な時間枠(32 H100で2.5週間)でトレーニングする上で重要であり、コミュニティが活用できるようにverl-pipelineの一部としてオープンソース化されています。
企業への影響とオープンソースコラボレーション
研究者は、DeepCoder-14Bのすべてのトレーニングおよび運用アーティファクトを、GitHubおよびHugging Faceで寛容なライセンスの下で公開しました。「私たちのデータセット、コード、トレーニングレシピを完全に共有することで、コミュニティが私たちの成果を再現し、RLトレーニングをすべての人にアクセス可能にすることを可能にします」と彼らは述べています。
DeepCoder-14Bは、AIランドスケープにおける効率的でオープンにアクセス可能なモデルの成長トレンドを象徴しています。企業にとって、これはより多くの選択肢と高度なモデルへのアクセシビリティの向上を意味します。高性能なコード生成と推論は、もはや大企業や高額なAPI料金を支払う意欲のある者に限定されません。あらゆる規模の組織がこれらの能力を活用し、特定のニーズに合わせたソリューションをカスタマイズし、環境内で安全に展開することができます。
このシフトは、AIの採用障壁を下げ、オープンソースコラボレーションによって推進されるより競争力のある革新的なエコシステムを育む準備ができています。
関連記事
 マルチバース・コンピューティング、無料圧縮生成AIモデルを発表
大規模言語モデルは重大な課題に直面している:その膨大なサイズである。スペインのスタートアップMultiverse Computingは、最先端AIの能力と企業が実用的に導入できる範囲とのギャップを埋めるべく設計された圧縮モデルを開発することでこの問題に取り組んでいる。同社の革新的な技術「CompactifAI」は量子コンピューティング原理に着想を得た圧縮技術であり、バスク地方のこの企業はOpenA
秘密の追跡データがAIモデルの盗難を暴露
新たな手法により、ChatGPTのようなモデルに再学習なしで数秒で目に見えない透かしを埋め込める。標準出力に痕跡を残さず、あらゆる実用的な除去試みを耐えうる。 透かしと「著作権侵害の誘引」の主な違いは、透かし(可視・不可視を問わず)が通常、画像データセットなどのコレクション全体に一貫して配置され、軽率な複製に対する抑止力として設計されている点である。これに対し、偽装エントリとは、大規模な汎用コレク
AIシステムが騙され、荒唐無稽な科学論文を承認
新たな研究により、AIシステムが偽の科学論文を生成し、他のAIモデルが誤って本物と認識することが明らかになった。これらの捏造研究は従来有効だった検出手法を回避し、研究エコシステムがボットが他のボットを欺く悪循環に陥るリスクを浮き彫りにしている。 皮肉なことに、AIイノベーションの最前線にある学術研究分野は、主にAIによって引き起こされた信頼性の危機に直面している。機械学習の可能性が明らかになってか
関連特集おすすめ
チャットボット
マルチバース・コンピューティング、無料圧縮生成AIモデルを発表
大規模言語モデルは重大な課題に直面している:その膨大なサイズである。スペインのスタートアップMultiverse Computingは、最先端AIの能力と企業が実用的に導入できる範囲とのギャップを埋めるべく設計された圧縮モデルを開発することでこの問題に取り組んでいる。同社の革新的な技術「CompactifAI」は量子コンピューティング原理に着想を得た圧縮技術であり、バスク地方のこの企業はOpenA
秘密の追跡データがAIモデルの盗難を暴露
新たな手法により、ChatGPTのようなモデルに再学習なしで数秒で目に見えない透かしを埋め込める。標準出力に痕跡を残さず、あらゆる実用的な除去試みを耐えうる。 透かしと「著作権侵害の誘引」の主な違いは、透かし(可視・不可視を問わず)が通常、画像データセットなどのコレクション全体に一貫して配置され、軽率な複製に対する抑止力として設計されている点である。これに対し、偽装エントリとは、大規模な汎用コレク
AIシステムが騙され、荒唐無稽な科学論文を承認
新たな研究により、AIシステムが偽の科学論文を生成し、他のAIモデルが誤って本物と認識することが明らかになった。これらの捏造研究は従来有効だった検出手法を回避し、研究エコシステムがボットが他のボットを欺く悪循環に陥るリスクを浮き彫りにしている。 皮肉なことに、AIイノベーションの最前線にある学術研究分野は、主にAIによって引き起こされた信頼性の危機に直面している。機械学習の可能性が明らかになってか
関連特集おすすめ
チャットボット
 最高のAIを使ったナンパ&会話トレーニング:社交的な魅力と自信をリアルタイムで高める
最高のAIを使ったナンパ&会話トレーニング:社交的な魅力と自信をリアルタイムで高める
XIX.AIで、2026年最高のAIを使った口説き術・会話トレーニングツールを発見しましょう。厳選された高評価のツールが、リアルタイムで社交的な魅力と自信を築くお手伝いをします。無料版と有料版の比較や毎週更新されるランキングを参考に、ぜひ試すべき画期的なツールを探してみてください。今すぐ、あなたの社交力を引き出しましょう。
 10 ツール
10 ツール
 xix.ai
コード
自動化ユニットテストに最適なAIツール:ワンクリックでJest、PyTest、JUnitのテストケースを生成する
xix.ai
コード
自動化ユニットテストに最適なAIツール:ワンクリックでJest、PyTest、JUnitのテストケースを生成する
2026年に登場した、自動化ユニットテスト用の最高評価を受けたAIツールを発見してください。当社が厳選したこれらのツールは、Jest、PyTest、JUnitのテストケースを瞬時に生成するための強力で革新的なソリューションです。XIX.AIでは、無料オプションと有料オプションを実際のテストデータと共に比較し、毎週更新されるランキングもご覧いただけます。今すぐAIの力を活用して、開発生産性を向上させましょう。
10 ツール
xix.ai
データ分析
最高のAIデータ可視化ツール:生データからインタラクティブなBIダッシュボードを自動生成
XIX.AIで、2026年最高のAIデータ可視化ツールをご覧ください。厳選された高評価のツール群を活用すれば、生データから強力でインタラクティブなBIダッシュボードを瞬時に自動生成できます。実環境でのテスト結果や毎週更新されるランキングをもとに、無料版と有料版の比較も可能です。今すぐデータの可能性を引き出しましょう。
10 ツール
xix.ai
ソーシャルメディア
ソーシャルメディア向けAIブランディングキット:すべてのチャネルで一貫したブランドビジュアルを維持
2026年版、ソーシャルメディア向けAIブランディングキットベストセレクションをご紹介。XIX.AIが厳選したこのリストには、あらゆるチャネルでブランドビジュアルの統一感を完璧に保つ、高評価で画期的なツールが揃っています。実際のテスト結果をもとに、無料版と有料版を比較しましょう。今すぐ、ブランドのビジュアル面での優位性を手に入れましょう。
10 ツール
xix.ai
チャットボット
ロールプレイに最適なAIガールフレンドアプリ&AIコンパニオンツール(2026年版ガイド)
没入感のあるロールプレイとつながりを実現する、2026年最新の最高評価AIコンパニオンツールを発見しましょう。XIX.AIが厳選したガイドでは、業界に革新をもたらす強力なアプリを紹介しています。ランキングは毎週更新され、無料版と有料版の比較や実地テストの結果も掲載されています。あなたにぴったりのツールを見つけて、今日から有意義なデジタルコンパニオン体験を始めましょう。
10 ツール
xix.ai
書き込み
最高のAI仙侠・武侠アシスタント:壮大な修練の物語と武術の演出を執筆
2026年版、壮大な仙侠・武侠物語を創作するための最高のAIアシスタントをご紹介。XIX.AIが厳選したこのリストには、修練の進捗管理や武術の演出を完璧にこなす、高評価で画期的なツールが揃っています。無料版と有料版を実際のテスト結果で比較。あなたの創造力を解き放ち、今すぐ執筆を始めましょう!
10 ツール
xix.ai

 コメント (14)
0/500
コメント (14)
0/500
![RyanTaylor]()
Interesting! I've been following the open-source vs. proprietary model race. DeepCoder-14B matching o3-mini is a big deal for accessibility. Hope this pushes the big players to open up more, or at least lower their prices. The compute cost for training these 14B models must be insane though. 🤔
![FrankRodriguez]()
Wow, DeepCoder-14B sounds like a game-changer! I'm stoked to see open-source models catching up to the big players. Can't wait to try it out for my side projects—hope it’s as fast as they claim! 🚀
![GregoryBaker]()
DeepCoder-14B sounds like a game-changer! Can't wait to try it out and see how it stacks up against the big players. 🚀
![BillyLewis]()
Wow, DeepCoder-14B sounds like a game-changer for open-source coding! I'm curious how it stacks up against o3-mini in real-world projects. Anyone tried it yet? 🚀
![RaymondWalker]()
¡DeepCoder-14B es una locura! Un modelo de código abierto que compite con los grandes. ¿Será el fin de los modelos propietarios? 🤔
![RalphGarcia]()
DeepCoder-14B、めっちゃ面白そう!😊 オープンソースでここまでできるなんて、コーディングの未来が楽しみ!
DeepCoder-14Bの紹介:オープンソースコーディングモデルの新たなフロンティア
Together AIとAgenticaのチームは、DeepCoder-14Bを発表しました。これは、OpenAIのo3-miniのようなトップレベルのプロプライエタリモデルと肩を並べる画期的なコーディングモデルです。このエキサイティングな開発は、DeepSeek-R1を基盤としており、高性能なコード生成と推論を実際のアプリケーションに統合するための柔軟性を向上させています。さらに、開発者はモデルを完全にオープンソース化し、トレーニングデータ、コード、ログ、システム最適化を含めるという称賛すべきステップを踏みました。この動きは、研究を加速し、分野の進歩を促進するでしょう。
コンパクトなパッケージでの驚異的なパフォーマンス
DeepCoder-14Bは、LiveCodeBench(LCB)、Codeforces、HumanEval+などのさまざまなコーディングベンチマークで驚くべき結果を示しています。研究チームの実験では、モデルのパフォーマンスがo3-mini(低)やo1といったリーディングモデルと同等であることが強調されています。「私たちのモデルは、すべてのコーディングベンチマークで強力なパフォーマンスを示し…o3-mini(低)やo1のパフォーマンスに匹敵します」と、研究者たちはブログ投稿で誇らしげに述べています。
特に興味深いのは、主にコーディングタスクでトレーニングされているにもかかわらず、DeepCoder-14Bが数学的推論でも顕著な向上を示し、AIME 2024ベンチマークで73.8%のスコアを達成した点です。これは、ベースモデルであるDeepSeek-R1-Distill-Qwen-14Bに比べて4.1%の向上を示しており、コードに対する強化学習(RL)で磨かれた推論スキルが他の領域にも効果的に転移することを示唆しています。
DeepCoder-14Bの最もエキサイティングな特徴は、その効率性です。140億のパラメータしか持たないにもかかわらず、他の多くのリーディングモデルよりも大幅に小さく、リソース効率が高いながらも高いパフォーマンスを達成しています。
DeepCoderの成功の背後にある革新
DeepCoder-14Bの開発には、強化学習を使用したコーディングモデルのトレーニングにおけるいくつかの課題を克服する必要がありました。主なハードルの一つは、トレーニングデータのキュレーションでした。数学的タスクとは異なり、高品質で検証可能なデータが豊富にある一方で、コーディングデータは不足しがちです。DeepCoderチームは、さまざまなデータセットから例を収集しフィルタリングする厳格なパイプラインを実装し、有効性、複雑さ、重複の回避を確保することでこれに対処しました。このプロセスにより、24,000の高品質な問題が得られ、RLトレーニングのための強固な基盤が形成されました。
チームはまた、生成されたコードが設定された時間内にすべてのサンプリングされたユニットテストを正常に通過した場合にのみモデルに報酬を与える、シンプルな報酬関数を考案しました。このアプローチは、高品質なトレーニング例と組み合わせることで、モデルが近道を利用するのではなく、核心的な問題解決に焦点を当てることを保証しました。
DeepCoder-14Bのトレーニングアルゴリズムは、DeepSeek-R1で成功したGroup Relative Policy Optimization(GRPO)を基盤としていますが、チームは安定性を高め、より長いトレーニング期間を可能にするために大幅な改良を加えました。
さらに、チームはモデルのコンテキストウィンドウを段階的に拡張し、短いシーケンスから始めて徐々に増やしました。また、複雑なプロンプトを解決する際にコンテキスト制限を超えることに対してモデルがペナルティを受けないようにするフィルタリング手法も導入しました。
研究者たちはそのアプローチを次のように説明しています:「長コンテキスト推論を維持しながら効率的なトレーニングを可能にするために、オーバーロングフィルタリングを導入しました…この手法は、トレーニング中に切り捨てられたシーケンスをマスクすることで、現在のコンテキスト制限を超える思慮深いが長い出力を生成することに対してモデルがペナルティを受けないようにします。」トレーニングは16Kから32Kのコンテキストウィンドウにスケールアップし、最大64Kトークンが必要な問題に取り組むことができるようになりました。
長コンテキストRLトレーニングの最適化
コーディングのような長いシーケンスを生成するタスクで、RLを使用して大規模モデルをトレーニングすることは、非常に遅く、リソースを大量に消費します。モデルが例ごとに数千のトークンを生成するサンプリングステップは、応答の長さが異なるため、しばしば大きな遅延を引き起こします。
これに対処するために、チームは、人間からのフィードバックによる強化学習(RLHF)のためのオープンソースverlライブラリの最適化された拡張であるverl-pipelineを開発しました。彼らの「One-Off Pipelining」イノベーションは、サンプリングとモデル更新を再構築してボトルネックを最小限に抑え、アクセラレータのアイドル時間を削減しました。
彼らの実験では、ワンオフパイプラインが標準的な方法に比べてコーディングRLタスクを最大2倍高速化できることが示されました。この最適化は、DeepCoder-14Bを合理的な時間枠(32 H100で2.5週間)でトレーニングする上で重要であり、コミュニティが活用できるようにverl-pipelineの一部としてオープンソース化されています。
企業への影響とオープンソースコラボレーション
研究者は、DeepCoder-14Bのすべてのトレーニングおよび運用アーティファクトを、GitHubおよびHugging Faceで寛容なライセンスの下で公開しました。「私たちのデータセット、コード、トレーニングレシピを完全に共有することで、コミュニティが私たちの成果を再現し、RLトレーニングをすべての人にアクセス可能にすることを可能にします」と彼らは述べています。
DeepCoder-14Bは、AIランドスケープにおける効率的でオープンにアクセス可能なモデルの成長トレンドを象徴しています。企業にとって、これはより多くの選択肢と高度なモデルへのアクセシビリティの向上を意味します。高性能なコード生成と推論は、もはや大企業や高額なAPI料金を支払う意欲のある者に限定されません。あらゆる規模の組織がこれらの能力を活用し、特定のニーズに合わせたソリューションをカスタマイズし、環境内で安全に展開することができます。
このシフトは、AIの採用障壁を下げ、オープンソースコラボレーションによって推進されるより競争力のある革新的なエコシステムを育む準備ができています。










 マルチバース・コンピューティング、無料圧縮生成AIモデルを発表
大規模言語モデルは重大な課題に直面している:その膨大なサイズである。スペインのスタートアップMultiverse Computingは、最先端AIの能力と企業が実用的に導入できる範囲とのギャップを埋めるべく設計された圧縮モデルを開発することでこの問題に取り組んでいる。同社の革新的な技術「CompactifAI」は量子コンピューティング原理に着想を得た圧縮技術であり、バスク地方のこの企業はOpenA
マルチバース・コンピューティング、無料圧縮生成AIモデルを発表
大規模言語モデルは重大な課題に直面している:その膨大なサイズである。スペインのスタートアップMultiverse Computingは、最先端AIの能力と企業が実用的に導入できる範囲とのギャップを埋めるべく設計された圧縮モデルを開発することでこの問題に取り組んでいる。同社の革新的な技術「CompactifAI」は量子コンピューティング原理に着想を得た圧縮技術であり、バスク地方のこの企業はOpenA
 秘密の追跡データがAIモデルの盗難を暴露
新たな手法により、ChatGPTのようなモデルに再学習なしで数秒で目に見えない透かしを埋め込める。標準出力に痕跡を残さず、あらゆる実用的な除去試みを耐えうる。 透かしと「著作権侵害の誘引」の主な違いは、透かし(可視・不可視を問わず)が通常、画像データセットなどのコレクション全体に一貫して配置され、軽率な複製に対する抑止力として設計されている点である。これに対し、偽装エントリとは、大規模な汎用コレク
秘密の追跡データがAIモデルの盗難を暴露
新たな手法により、ChatGPTのようなモデルに再学習なしで数秒で目に見えない透かしを埋め込める。標準出力に痕跡を残さず、あらゆる実用的な除去試みを耐えうる。 透かしと「著作権侵害の誘引」の主な違いは、透かし(可視・不可視を問わず)が通常、画像データセットなどのコレクション全体に一貫して配置され、軽率な複製に対する抑止力として設計されている点である。これに対し、偽装エントリとは、大規模な汎用コレク
 AIシステムが騙され、荒唐無稽な科学論文を承認
新たな研究により、AIシステムが偽の科学論文を生成し、他のAIモデルが誤って本物と認識することが明らかになった。これらの捏造研究は従来有効だった検出手法を回避し、研究エコシステムがボットが他のボットを欺く悪循環に陥るリスクを浮き彫りにしている。 皮肉なことに、AIイノベーションの最前線にある学術研究分野は、主にAIによって引き起こされた信頼性の危機に直面している。機械学習の可能性が明らかになってか
AIシステムが騙され、荒唐無稽な科学論文を承認
新たな研究により、AIシステムが偽の科学論文を生成し、他のAIモデルが誤って本物と認識することが明らかになった。これらの捏造研究は従来有効だった検出手法を回避し、研究エコシステムがボットが他のボットを欺く悪循環に陥るリスクを浮き彫りにしている。 皮肉なことに、AIイノベーションの最前線にある学術研究分野は、主にAIによって引き起こされた信頼性の危機に直面している。機械学習の可能性が明らかになってか

XIX.AIで、2026年最高のAIを使った口説き術・会話トレーニングツールを発見しましょう。厳選された高評価のツールが、リアルタイムで社交的な魅力と自信を築くお手伝いをします。無料版と有料版の比較や毎週更新されるランキングを参考に、ぜひ試すべき画期的なツールを探してみてください。今すぐ、あなたの社交力を引き出しましょう。
10 ツール
xix.ai

2026年に登場した、自動化ユニットテスト用の最高評価を受けたAIツールを発見してください。当社が厳選したこれらのツールは、Jest、PyTest、JUnitのテストケースを瞬時に生成するための強力で革新的なソリューションです。XIX.AIでは、無料オプションと有料オプションを実際のテストデータと共に比較し、毎週更新されるランキングもご覧いただけます。今すぐAIの力を活用して、開発生産性を向上させましょう。
10 ツール
xix.ai

XIX.AIで、2026年最高のAIデータ可視化ツールをご覧ください。厳選された高評価のツール群を活用すれば、生データから強力でインタラクティブなBIダッシュボードを瞬時に自動生成できます。実環境でのテスト結果や毎週更新されるランキングをもとに、無料版と有料版の比較も可能です。今すぐデータの可能性を引き出しましょう。
10 ツール
xix.ai

2026年版、ソーシャルメディア向けAIブランディングキットベストセレクションをご紹介。XIX.AIが厳選したこのリストには、あらゆるチャネルでブランドビジュアルの統一感を完璧に保つ、高評価で画期的なツールが揃っています。実際のテスト結果をもとに、無料版と有料版を比較しましょう。今すぐ、ブランドのビジュアル面での優位性を手に入れましょう。
10 ツール
xix.ai

没入感のあるロールプレイとつながりを実現する、2026年最新の最高評価AIコンパニオンツールを発見しましょう。XIX.AIが厳選したガイドでは、業界に革新をもたらす強力なアプリを紹介しています。ランキングは毎週更新され、無料版と有料版の比較や実地テストの結果も掲載されています。あなたにぴったりのツールを見つけて、今日から有意義なデジタルコンパニオン体験を始めましょう。
10 ツール
xix.ai

2026年版、壮大な仙侠・武侠物語を創作するための最高のAIアシスタントをご紹介。XIX.AIが厳選したこのリストには、修練の進捗管理や武術の演出を完璧にこなす、高評価で画期的なツールが揃っています。無料版と有料版を実際のテスト結果で比較。あなたの創造力を解き放ち、今すぐ執筆を始めましょう!
10 ツール
xix.ai

Interesting! I've been following the open-source vs. proprietary model race. DeepCoder-14B matching o3-mini is a big deal for accessibility. Hope this pushes the big players to open up more, or at least lower their prices. The compute cost for training these 14B models must be insane though. 🤔
Wow, DeepCoder-14B sounds like a game-changer! I'm stoked to see open-source models catching up to the big players. Can't wait to try it out for my side projects—hope it’s as fast as they claim! 🚀
DeepCoder-14B sounds like a game-changer! Can't wait to try it out and see how it stacks up against the big players. 🚀
Wow, DeepCoder-14B sounds like a game-changer for open-source coding! I'm curious how it stacks up against o3-mini in real-world projects. Anyone tried it yet? 🚀
¡DeepCoder-14B es una locura! Un modelo de código abierto que compite con los grandes. ¿Será el fin de los modelos propietarios? 🤔
DeepCoder-14B、めっちゃ面白そう!😊 オープンソースでここまでできるなんて、コーディングの未来が楽しみ!













