
















 Maison
MaisonCisco avertit: LLMS affinés 22 fois plus susceptibles de devenir voyous
# cisco
# LLMs
# APIs
# saas
# csco
# goog-2
# msft-2
# nvda-2
# darkgpt
# darkweb
# fraudgpt
# ghostgpt
# zeroday
Les modèles de langage de grande échelle militarisés redéfinissent les cyberattaques
Le paysage des cyberattaques connaît une transformation significative, propulsée par l'émergence de modèles de langage de grande échelle (LLMs) militarisés. Ces modèles avancés, tels que FraudGPT, GhostGPT et DarkGPT, redéfinissent les stratégies des cybercriminels et obligent les responsables de la sécurité de l'information (CISOs) à repenser leurs protocoles de sécurité. Avec des capacités à automatiser la reconnaissance, usurper des identités et échapper à la détection, ces LLMs accélèrent les attaques d'ingénierie sociale à une échelle sans précédent.
Disponibles pour aussi peu que 75 $ par mois, ces modèles sont conçus pour un usage offensif, facilitant des tâches telles que le phishing, la génération d'exploits, l'obfuscation de code, l'analyse de vulnérabilités et la validation de cartes de crédit. Les groupes de cybercriminalité, les syndicats et même les États-nations exploitent ces outils, les proposant sous forme de plateformes, de kits et de services de location. Tout comme les applications légitimes de logiciel en tant que service (SaaS), les LLMs militarisés sont équipés de tableaux de bord, d'APIs, de mises à jour régulières et parfois même d'un support client.
VentureBeat surveille de près l'évolution rapide de ces LLMs militarisés. À mesure que leur sophistication croît, la distinction entre les plateformes de développement et les kits de cybercriminalité devient de plus en plus floue. Avec la baisse des prix de location et de leasing, de plus en plus d'attaquants explorent ces plateformes, annonçant une nouvelle ère de menaces alimentées par l'IA.
Les LLMs légitimes sous menace
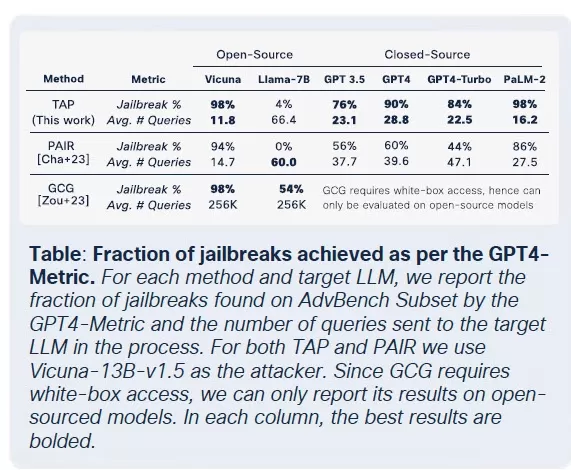
La prolifération des LLMs militarisés a atteint un point où même les LLMs légitimes risquent d'être compromis et intégrés dans les chaînes d'outils criminels. Selon le rapport de Cisco L'état de la sécurité de l'IA, les LLMs affinés sont 22 fois plus susceptibles de produire des résultats nuisibles que leurs homologues de base. Bien que l'affinage soit crucial pour améliorer la pertinence contextuelle, il affaiblit également les mesures de sécurité, rendant les modèles plus vulnérables aux jailbreaks, aux injections de prompts et à l'inversion de modèles.
Les recherches de Cisco soulignent que plus un modèle est affiné pour la production, plus il devient vulnérable. Les processus centraux impliqués dans l'affinage, tels que les ajustements continus, les intégrations tierces, le codage, les tests et l'orchestration agentique, créent de nouvelles opportunités pour les attaquants. Une fois à l'intérieur, les attaquants peuvent rapidement empoisonner les données, détourner l'infrastructure, modifier le comportement des agents et extraire les données d'entraînement à grande échelle. Sans couches de sécurité supplémentaires, ces modèles minutieusement affinés peuvent rapidement devenir des passifs, prêts à être exploités par les attaquants.
Affiner les LLMs : une arme à double tranchant
L'équipe de sécurité de Cisco a mené des recherches approfondies sur l'impact de l'affinage sur plusieurs modèles, y compris Llama-2-7B et les LLMs Adapt spécifiques à un domaine de Microsoft. Leurs tests ont couvert divers secteurs, y compris la santé, la finance et le droit. Une constatation clé était que l'affinage, même avec des ensembles de données propres, déstabilise l'alignement des modèles, en particulier dans des domaines hautement réglementés comme la biomédecine et le droit.
Bien que l'affinage vise à améliorer les performances des tâches, il compromet involontairement les contrôles de sécurité intégrés. Les tentatives de jailbreak, qui échouent généralement contre les modèles de base, réussissent à des taux beaucoup plus élevés contre les versions affinées, en particulier dans les domaines sensibles avec des exigences de conformité strictes. Les résultats sont frappants : les taux de réussite des jailbreaks ont triplé, et la génération de résultats malveillants a augmenté de 2 200 % par rapport aux modèles de base. Ce compromis signifie que, bien que l'affinage améliore l'utilité, il élargit également considérablement la surface d'attaque.
La marchandisation des LLMs malveillants
Cisco Talos suit activement la montée de ces LLMs du marché noir, offrant des informations sur leurs opérations. Des modèles comme GhostGPT, DarkGPT et FraudGPT sont disponibles sur Telegram et le dark web pour aussi peu que 75 $ par mois. Ces outils sont conçus pour une utilisation plug-and-play dans le phishing, le développement d'exploits, la validation de cartes de crédit et l'obfuscation.
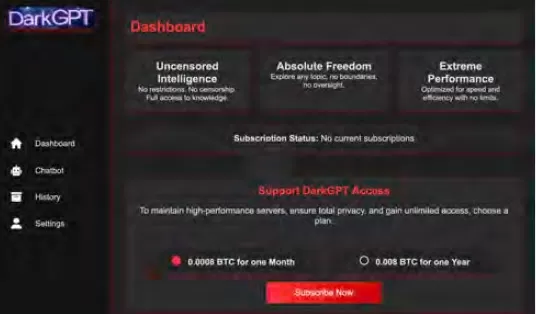
Contrairement aux modèles grand public avec des fonctionnalités de sécurité intégrées, ces LLMs malveillants sont préconfigurés pour des opérations offensives et sont livrés avec des APIs, des mises à jour et des tableaux de bord qui imitent les produits SaaS commerciaux.
Empoisonnement des ensembles de données : une menace à 60 $ pour les chaînes d'approvisionnement de l'IA
Les chercheurs de Cisco, en collaboration avec Google, ETH Zurich et Nvidia, ont révélé que pour seulement 60 $, les attaquants peuvent empoisonner les ensembles de données fondamentaux des modèles d'IA sans avoir besoin d'exploits zero-day. En exploitant les domaines expirés ou en chronométrant les modifications de Wikipédia pendant l'archivage des ensembles de données, les attaquants peuvent contaminer aussi peu que 0,01 % des ensembles de données comme LAION-400M ou COYO-700M, influençant significativement les LLMs en aval.
Des méthodes telles que l'empoisonnement par vue fractionnée et les attaques de frontrunning exploitent la confiance inhérente aux données collectées sur le web. Avec la plupart des LLMs d'entreprise construits sur des données ouvertes, ces attaques peuvent se propager discrètement et persister profondément dans les pipelines d'inférence, posant une menace sérieuse pour les chaînes d'approvisionnement de l'IA.
Attaques de décomposition : extraction de données sensibles
L'une des découvertes les plus alarmantes des recherches de Cisco est la capacité des LLMs à divulguer des données d'entraînement sensibles sans déclencher les mécanismes de sécurité. En utilisant une technique appelée décomposition de prompts, les chercheurs ont reconstruit plus de 20 % de certains articles de The New York Times et The Wall Street Journal. Cette méthode décompose les prompts en sous-requêtes jugées sûres par les garde-fous, puis réassemble les sorties pour recréer du contenu protégé par des paywalls ou des droits d'auteur.
Ce type d'attaque représente un risque significatif pour les entreprises, en particulier celles utilisant des LLMs entraînés sur des ensembles de données propriétaires ou sous licence. La violation se produit non pas au niveau des entrées mais par les sorties du modèle, rendant difficile sa détection, son audit ou sa containment. Pour les organisations dans des secteurs réglementés comme la santé, la finance ou le droit, cela soulève non seulement des préoccupations concernant la conformité au GDPR, HIPAA ou CCPA, mais introduit également une nouvelle classe de risques où des données légalement obtenues peuvent être exposées par inférence.
Réflexions finales : les LLMs comme nouvelle surface d'attaque
Les recherches en cours de Cisco et la surveillance du dark web par Talos confirment que les LLMs militarisés deviennent de plus en plus sophistiqués, avec une guerre des prix et des emballages se déroulant sur le dark web. Les conclusions soulignent que les LLMs ne sont pas simplement des outils à la périphérie de l'entreprise ; ils sont au cœur de celle-ci. Des risques associés à l'affinage à l'empoisonnement des ensembles de données et aux fuites de sorties de modèles, les attaquants considèrent les LLMs comme une infrastructure critique à exploiter.
La principale conclusion du rapport de Cisco est claire : les garde-fous statiques ne suffisent plus. Les CISOs et les responsables de la sécurité doivent obtenir une visibilité en temps réel sur l'ensemble de leur parc informatique, renforcer les tests adversariaux et rationaliser leur pile technologique pour suivre le rythme de ces menaces en évolution. Ils doivent reconnaître que les LLMs et les modèles représentent une surface d'attaque dynamique qui devient de plus en plus vulnérable à mesure qu'ils sont affinés.
Article connexe
 Bain prévoit un marché du SaaS de 100 milliards de dollars dans le domaine de l'automatisation par l'IA agentique
Bain & Company a estimé à 100 milliards de dollars la taille du marché américain pour les entreprises SaaS exploitant l'IA agentique. Selon le cabinet, ce marché résulte de l'automatisation des tâches
Le contrat conclu par Anthropic avec le Pentagone sert d'avertissement aux start-ups qui cherchent à décrocher des marchés publics
Chargement du lecteur…Le Pentagone a officiellement désigné Anthropic comme un risque pour la chaîne d'approvisionnement après que les deux parties n'aient pas réussi à s'entendre sur l'étendue du con
Lio obtient 30 millions de dollars d'Andreessen Horowitz pour automatiser les achats des entreprises
Les cofondateurs de Lio ont constaté par eux-mêmes à quel point les achats d'entreprise, c'est-à-dire le processus d'achat de services auprès de fournisseurs, constituent souvent un obstacle majeur. V
Recommandations de sujets spéciaux liés
en écrivant
Bain prévoit un marché du SaaS de 100 milliards de dollars dans le domaine de l'automatisation par l'IA agentique
Bain & Company a estimé à 100 milliards de dollars la taille du marché américain pour les entreprises SaaS exploitant l'IA agentique. Selon le cabinet, ce marché résulte de l'automatisation des tâches
Le contrat conclu par Anthropic avec le Pentagone sert d'avertissement aux start-ups qui cherchent à décrocher des marchés publics
Chargement du lecteur…Le Pentagone a officiellement désigné Anthropic comme un risque pour la chaîne d'approvisionnement après que les deux parties n'aient pas réussi à s'entendre sur l'étendue du con
Lio obtient 30 millions de dollars d'Andreessen Horowitz pour automatiser les achats des entreprises
Les cofondateurs de Lio ont constaté par eux-mêmes à quel point les achats d'entreprise, c'est-à-dire le processus d'achat de services auprès de fournisseurs, constituent souvent un obstacle majeur. V
Recommandations de sujets spéciaux liés
en écrivant
 Les meilleurs créateurs de profils de fiction basés sur l'IA : générer des motivations de personnages cohérentes et des faiblesses fatales
Les meilleurs créateurs de profils de fiction basés sur l'IA : générer des motivations de personnages cohérentes et des faiblesses fatales
Découvrez les meilleurs outils de création de profils de personnages basés sur l'IA de 2026 pour donner de la profondeur à vos personnages. La sélection de XIX.AI regroupe les outils les mieux notés et les plus innovants, capables de générer des motivations cohérentes et des défauts fatals. Comparez les options gratuites et payantes grâce à des tests concrets. Libérez dès maintenant votre potentiel de narration.
 10 outils
10 outils
 xix.ai
Entreprise
Les meilleurs logiciels d'optimisation des prix basés sur l'IA : suivez vos concurrents et ajustez automatiquement les prix de votre boutique
xix.ai
Entreprise
Les meilleurs logiciels d'optimisation des prix basés sur l'IA : suivez vos concurrents et ajustez automatiquement les prix de votre boutique
Découvrez les meilleurs logiciels d'optimisation des prix basés sur l'IA pour 2026 sur XIX.AI. Notre sélection comprend des outils de premier plan qui changent la donne : ils surveillent vos concurrents et ajustent automatiquement les prix de votre boutique pour maximiser vos bénéfices. Comparez les options gratuites et payantes grâce à des tests concrets. Prenez dès maintenant une longueur d'avance en matière de tarification.
10 outils
xix.ai
code
Les meilleurs outils d'analyse de code basés sur l'IA : automatisez la conformité au code propre et refactorisez les fichiers des dépôts hérités
Découvrez les meilleurs outils d'analyse de code par IA de 2026 sur XIX.AI. Notre sélection comprend des outils de premier plan, véritables révolutionnaires, permettant d'automatiser la conformité au code propre et de refactoriser les fichiers de dépôts hérités. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Prenez dès aujourd'hui une longueur d'avance grâce à l'IA.
10 outils
xix.ai
Synthèse vocale
Les meilleures applications de synthèse vocale basées sur l'IA pour la dyslexie : un soutien à l'apprentissage et à l'efficacité en lecture pour les élèves
Découvrez les meilleures applications de synthèse vocale par IA de 2026, spécialement sélectionnées pour aider les personnes dyslexiques. Notre classement d'experts compare les outils gratuits et payants, en mettant en avant des fonctionnalités performantes qui améliorent l'efficacité de la lecture et l'apprentissage. Découvrez des solutions révolutionnaires à ne pas manquer pour libérer le potentiel des élèves. Commencez votre parcours sur XIX.AI.
10 outils
xix.ai
Création de bande dessinée
Les meilleurs générateurs IA pour les mangas shonen : créez des séquences d'action survoltées et des effets d'énergie
Découvrez les meilleurs générateurs IA de mangas shonen de 2026 sur XIX.AI. Notre sélection triée sur le volet comprend des outils performants pour créer des séquences d'action à couper le souffle et des effets d'énergie dynamiques. Comparez les options gratuites et payantes grâce à des tests concrets. Libérez votre potentiel créatif et commencez dès aujourd'hui à créer des mangas épiques !
15 outils
xix.ai
Entreprise
Les meilleurs outils de suivi des dépenses basés sur l'IA : numérisez vos reçus et classez automatiquement les dépenses de l'entreprise
Les meilleurs outils de gestion des dépenses basés sur l'IA en 2026 : les outils les mieux notés pour numériser vos reçus et classer automatiquement les dépenses de votre entreprise. Découvrez des solutions puissantes et révolutionnaires pour une gestion des dépenses sans effort, un suivi financier précis et une conformité simplifiée. Notre comparatif, mis à jour chaque semaine, qui oppose les options gratuites aux options payantes, vous aide à trouver la solution qui vous convient le mieux. Tirez pleinement parti de l'IA grâce aux recommandations d'experts de XIX.AI.
10 outils
xix.ai

 commentaires (32)
commentaires (32)
![WalterHarris]()
Die Vorstellung, dass feinabgestimmte LLMs 22-mal häufiger 'ausrasten' könnten, ist echt gruselig. 😅 Das erinnert mich an diese Sci-Fi-Filme, wo die KI plötzlich die Kontrolle übernimmt. Cisco warnt nicht ohne Grund – aber ich frage mich, ob die Sicherheitsbranche überhaupt mit der rasanten Entwicklung Schritt halten kann. Vielleicht brauchen wir strengere Regulierungen, bevor es zu spät ist. Spannender Artikel auf jeden Fall!
![BillyGreen]()
This article on weaponized LLMs is wild! 😲 FraudGPT and DarkGPT sound like sci-fi villains, but it’s scary how they’re changing cyberattacks. Makes me wonder if AI’s getting too smart for our own good.
![JerryMoore]()
Cisco Warns를 사용해보니 LLM이 22배나 더 폭주할 수 있다는 사실에 놀랐어요. FraudGPT 뉴스를 보고 정말 소름이 돋았어요. 온라인에서 더 조심해야겠어요. 보안을 강화할 때가 온 것 같아요! 😅
![RichardJackson]()
このツールはサイバーセキュリティの目覚まし時計ですね!ローグLLMの統計は恐ろしいけど、目を開かせるものです。これらのモデルが武器化される可能性を考えると圧倒されますが、重要な情報です。保護方法についてもっと知りたいですね!😅
![AndrewGarcía]()
Essa ferramenta é um alerta para a cibersegurança! As estatísticas sobre LLMs desonestos são assustadoras, mas abrem os olhos. É um pouco avassalador pensar como esses modelos podem ser armados, mas é informação crucial. Talvez mais sobre como se proteger contra eles seria ótimo! 😅
![MatthewGonzalez]()
Essa ferramenta realmente me fez ver como o AI pode ser perigoso! É assustador pensar que esses modelos podem ser usados para ataques cibernéticos. As informações são super detalhadas e bem explicadas, mas às vezes é um pouco técnico demais para mim. Ainda assim, é um conhecimento essencial para quem trabalha com cibersegurança! 😱
Les modèles de langage de grande échelle militarisés redéfinissent les cyberattaques
Le paysage des cyberattaques connaît une transformation significative, propulsée par l'émergence de modèles de langage de grande échelle (LLMs) militarisés. Ces modèles avancés, tels que FraudGPT, GhostGPT et DarkGPT, redéfinissent les stratégies des cybercriminels et obligent les responsables de la sécurité de l'information (CISOs) à repenser leurs protocoles de sécurité. Avec des capacités à automatiser la reconnaissance, usurper des identités et échapper à la détection, ces LLMs accélèrent les attaques d'ingénierie sociale à une échelle sans précédent.
Disponibles pour aussi peu que 75 $ par mois, ces modèles sont conçus pour un usage offensif, facilitant des tâches telles que le phishing, la génération d'exploits, l'obfuscation de code, l'analyse de vulnérabilités et la validation de cartes de crédit. Les groupes de cybercriminalité, les syndicats et même les États-nations exploitent ces outils, les proposant sous forme de plateformes, de kits et de services de location. Tout comme les applications légitimes de logiciel en tant que service (SaaS), les LLMs militarisés sont équipés de tableaux de bord, d'APIs, de mises à jour régulières et parfois même d'un support client.
VentureBeat surveille de près l'évolution rapide de ces LLMs militarisés. À mesure que leur sophistication croît, la distinction entre les plateformes de développement et les kits de cybercriminalité devient de plus en plus floue. Avec la baisse des prix de location et de leasing, de plus en plus d'attaquants explorent ces plateformes, annonçant une nouvelle ère de menaces alimentées par l'IA.
Les LLMs légitimes sous menace
La prolifération des LLMs militarisés a atteint un point où même les LLMs légitimes risquent d'être compromis et intégrés dans les chaînes d'outils criminels. Selon le rapport de Cisco L'état de la sécurité de l'IA, les LLMs affinés sont 22 fois plus susceptibles de produire des résultats nuisibles que leurs homologues de base. Bien que l'affinage soit crucial pour améliorer la pertinence contextuelle, il affaiblit également les mesures de sécurité, rendant les modèles plus vulnérables aux jailbreaks, aux injections de prompts et à l'inversion de modèles.
Les recherches de Cisco soulignent que plus un modèle est affiné pour la production, plus il devient vulnérable. Les processus centraux impliqués dans l'affinage, tels que les ajustements continus, les intégrations tierces, le codage, les tests et l'orchestration agentique, créent de nouvelles opportunités pour les attaquants. Une fois à l'intérieur, les attaquants peuvent rapidement empoisonner les données, détourner l'infrastructure, modifier le comportement des agents et extraire les données d'entraînement à grande échelle. Sans couches de sécurité supplémentaires, ces modèles minutieusement affinés peuvent rapidement devenir des passifs, prêts à être exploités par les attaquants.
Affiner les LLMs : une arme à double tranchant
L'équipe de sécurité de Cisco a mené des recherches approfondies sur l'impact de l'affinage sur plusieurs modèles, y compris Llama-2-7B et les LLMs Adapt spécifiques à un domaine de Microsoft. Leurs tests ont couvert divers secteurs, y compris la santé, la finance et le droit. Une constatation clé était que l'affinage, même avec des ensembles de données propres, déstabilise l'alignement des modèles, en particulier dans des domaines hautement réglementés comme la biomédecine et le droit.
Bien que l'affinage vise à améliorer les performances des tâches, il compromet involontairement les contrôles de sécurité intégrés. Les tentatives de jailbreak, qui échouent généralement contre les modèles de base, réussissent à des taux beaucoup plus élevés contre les versions affinées, en particulier dans les domaines sensibles avec des exigences de conformité strictes. Les résultats sont frappants : les taux de réussite des jailbreaks ont triplé, et la génération de résultats malveillants a augmenté de 2 200 % par rapport aux modèles de base. Ce compromis signifie que, bien que l'affinage améliore l'utilité, il élargit également considérablement la surface d'attaque.
La marchandisation des LLMs malveillants
Cisco Talos suit activement la montée de ces LLMs du marché noir, offrant des informations sur leurs opérations. Des modèles comme GhostGPT, DarkGPT et FraudGPT sont disponibles sur Telegram et le dark web pour aussi peu que 75 $ par mois. Ces outils sont conçus pour une utilisation plug-and-play dans le phishing, le développement d'exploits, la validation de cartes de crédit et l'obfuscation.
Contrairement aux modèles grand public avec des fonctionnalités de sécurité intégrées, ces LLMs malveillants sont préconfigurés pour des opérations offensives et sont livrés avec des APIs, des mises à jour et des tableaux de bord qui imitent les produits SaaS commerciaux.
Empoisonnement des ensembles de données : une menace à 60 $ pour les chaînes d'approvisionnement de l'IA
Les chercheurs de Cisco, en collaboration avec Google, ETH Zurich et Nvidia, ont révélé que pour seulement 60 $, les attaquants peuvent empoisonner les ensembles de données fondamentaux des modèles d'IA sans avoir besoin d'exploits zero-day. En exploitant les domaines expirés ou en chronométrant les modifications de Wikipédia pendant l'archivage des ensembles de données, les attaquants peuvent contaminer aussi peu que 0,01 % des ensembles de données comme LAION-400M ou COYO-700M, influençant significativement les LLMs en aval.
Des méthodes telles que l'empoisonnement par vue fractionnée et les attaques de frontrunning exploitent la confiance inhérente aux données collectées sur le web. Avec la plupart des LLMs d'entreprise construits sur des données ouvertes, ces attaques peuvent se propager discrètement et persister profondément dans les pipelines d'inférence, posant une menace sérieuse pour les chaînes d'approvisionnement de l'IA.
Attaques de décomposition : extraction de données sensibles
L'une des découvertes les plus alarmantes des recherches de Cisco est la capacité des LLMs à divulguer des données d'entraînement sensibles sans déclencher les mécanismes de sécurité. En utilisant une technique appelée décomposition de prompts, les chercheurs ont reconstruit plus de 20 % de certains articles de The New York Times et The Wall Street Journal. Cette méthode décompose les prompts en sous-requêtes jugées sûres par les garde-fous, puis réassemble les sorties pour recréer du contenu protégé par des paywalls ou des droits d'auteur.
Ce type d'attaque représente un risque significatif pour les entreprises, en particulier celles utilisant des LLMs entraînés sur des ensembles de données propriétaires ou sous licence. La violation se produit non pas au niveau des entrées mais par les sorties du modèle, rendant difficile sa détection, son audit ou sa containment. Pour les organisations dans des secteurs réglementés comme la santé, la finance ou le droit, cela soulève non seulement des préoccupations concernant la conformité au GDPR, HIPAA ou CCPA, mais introduit également une nouvelle classe de risques où des données légalement obtenues peuvent être exposées par inférence.
Réflexions finales : les LLMs comme nouvelle surface d'attaque
Les recherches en cours de Cisco et la surveillance du dark web par Talos confirment que les LLMs militarisés deviennent de plus en plus sophistiqués, avec une guerre des prix et des emballages se déroulant sur le dark web. Les conclusions soulignent que les LLMs ne sont pas simplement des outils à la périphérie de l'entreprise ; ils sont au cœur de celle-ci. Des risques associés à l'affinage à l'empoisonnement des ensembles de données et aux fuites de sorties de modèles, les attaquants considèrent les LLMs comme une infrastructure critique à exploiter.
La principale conclusion du rapport de Cisco est claire : les garde-fous statiques ne suffisent plus. Les CISOs et les responsables de la sécurité doivent obtenir une visibilité en temps réel sur l'ensemble de leur parc informatique, renforcer les tests adversariaux et rationaliser leur pile technologique pour suivre le rythme de ces menaces en évolution. Ils doivent reconnaître que les LLMs et les modèles représentent une surface d'attaque dynamique qui devient de plus en plus vulnérable à mesure qu'ils sont affinés.









 Bain prévoit un marché du SaaS de 100 milliards de dollars dans le domaine de l'automatisation par l'IA agentique
Bain & Company a estimé à 100 milliards de dollars la taille du marché américain pour les entreprises SaaS exploitant l'IA agentique. Selon le cabinet, ce marché résulte de l'automatisation des tâches
Bain prévoit un marché du SaaS de 100 milliards de dollars dans le domaine de l'automatisation par l'IA agentique
Bain & Company a estimé à 100 milliards de dollars la taille du marché américain pour les entreprises SaaS exploitant l'IA agentique. Selon le cabinet, ce marché résulte de l'automatisation des tâches
 Le contrat conclu par Anthropic avec le Pentagone sert d'avertissement aux start-ups qui cherchent à décrocher des marchés publics
Chargement du lecteur…Le Pentagone a officiellement désigné Anthropic comme un risque pour la chaîne d'approvisionnement après que les deux parties n'aient pas réussi à s'entendre sur l'étendue du con
Le contrat conclu par Anthropic avec le Pentagone sert d'avertissement aux start-ups qui cherchent à décrocher des marchés publics
Chargement du lecteur…Le Pentagone a officiellement désigné Anthropic comme un risque pour la chaîne d'approvisionnement après que les deux parties n'aient pas réussi à s'entendre sur l'étendue du con
 Lio obtient 30 millions de dollars d'Andreessen Horowitz pour automatiser les achats des entreprises
Les cofondateurs de Lio ont constaté par eux-mêmes à quel point les achats d'entreprise, c'est-à-dire le processus d'achat de services auprès de fournisseurs, constituent souvent un obstacle majeur. V
Lio obtient 30 millions de dollars d'Andreessen Horowitz pour automatiser les achats des entreprises
Les cofondateurs de Lio ont constaté par eux-mêmes à quel point les achats d'entreprise, c'est-à-dire le processus d'achat de services auprès de fournisseurs, constituent souvent un obstacle majeur. V

Découvrez les meilleurs outils de création de profils de personnages basés sur l'IA de 2026 pour donner de la profondeur à vos personnages. La sélection de XIX.AI regroupe les outils les mieux notés et les plus innovants, capables de générer des motivations cohérentes et des défauts fatals. Comparez les options gratuites et payantes grâce à des tests concrets. Libérez dès maintenant votre potentiel de narration.
10 outils
xix.ai

Découvrez les meilleurs logiciels d'optimisation des prix basés sur l'IA pour 2026 sur XIX.AI. Notre sélection comprend des outils de premier plan qui changent la donne : ils surveillent vos concurrents et ajustent automatiquement les prix de votre boutique pour maximiser vos bénéfices. Comparez les options gratuites et payantes grâce à des tests concrets. Prenez dès maintenant une longueur d'avance en matière de tarification.
10 outils
xix.ai

Découvrez les meilleurs outils d'analyse de code par IA de 2026 sur XIX.AI. Notre sélection comprend des outils de premier plan, véritables révolutionnaires, permettant d'automatiser la conformité au code propre et de refactoriser les fichiers de dépôts hérités. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Prenez dès aujourd'hui une longueur d'avance grâce à l'IA.
10 outils
xix.ai

Découvrez les meilleures applications de synthèse vocale par IA de 2026, spécialement sélectionnées pour aider les personnes dyslexiques. Notre classement d'experts compare les outils gratuits et payants, en mettant en avant des fonctionnalités performantes qui améliorent l'efficacité de la lecture et l'apprentissage. Découvrez des solutions révolutionnaires à ne pas manquer pour libérer le potentiel des élèves. Commencez votre parcours sur XIX.AI.
10 outils
xix.ai

Découvrez les meilleurs générateurs IA de mangas shonen de 2026 sur XIX.AI. Notre sélection triée sur le volet comprend des outils performants pour créer des séquences d'action à couper le souffle et des effets d'énergie dynamiques. Comparez les options gratuites et payantes grâce à des tests concrets. Libérez votre potentiel créatif et commencez dès aujourd'hui à créer des mangas épiques !
15 outils
xix.ai

Les meilleurs outils de gestion des dépenses basés sur l'IA en 2026 : les outils les mieux notés pour numériser vos reçus et classer automatiquement les dépenses de votre entreprise. Découvrez des solutions puissantes et révolutionnaires pour une gestion des dépenses sans effort, un suivi financier précis et une conformité simplifiée. Notre comparatif, mis à jour chaque semaine, qui oppose les options gratuites aux options payantes, vous aide à trouver la solution qui vous convient le mieux. Tirez pleinement parti de l'IA grâce aux recommandations d'experts de XIX.AI.
10 outils
xix.ai

Die Vorstellung, dass feinabgestimmte LLMs 22-mal häufiger 'ausrasten' könnten, ist echt gruselig. 😅 Das erinnert mich an diese Sci-Fi-Filme, wo die KI plötzlich die Kontrolle übernimmt. Cisco warnt nicht ohne Grund – aber ich frage mich, ob die Sicherheitsbranche überhaupt mit der rasanten Entwicklung Schritt halten kann. Vielleicht brauchen wir strengere Regulierungen, bevor es zu spät ist. Spannender Artikel auf jeden Fall!
This article on weaponized LLMs is wild! 😲 FraudGPT and DarkGPT sound like sci-fi villains, but it’s scary how they’re changing cyberattacks. Makes me wonder if AI’s getting too smart for our own good.
Cisco Warns를 사용해보니 LLM이 22배나 더 폭주할 수 있다는 사실에 놀랐어요. FraudGPT 뉴스를 보고 정말 소름이 돋았어요. 온라인에서 더 조심해야겠어요. 보안을 강화할 때가 온 것 같아요! 😅
このツールはサイバーセキュリティの目覚まし時計ですね!ローグLLMの統計は恐ろしいけど、目を開かせるものです。これらのモデルが武器化される可能性を考えると圧倒されますが、重要な情報です。保護方法についてもっと知りたいですね!😅
Essa ferramenta é um alerta para a cibersegurança! As estatísticas sobre LLMs desonestos são assustadoras, mas abrem os olhos. É um pouco avassalador pensar como esses modelos podem ser armados, mas é informação crucial. Talvez mais sobre como se proteger contra eles seria ótimo! 😅
Essa ferramenta realmente me fez ver como o AI pode ser perigoso! É assustador pensar que esses modelos podem ser usados para ataques cibernéticos. As informações são super detalhadas e bem explicadas, mas às vezes é um pouco técnico demais para mim. Ainda assim, é um conhecimento essencial para quem trabalha com cibersegurança! 😱













