
















 Heim
HeimCisco warn
# cisco
# LLMs
# APIs
# saas
# csco
# goog-2
# msft-2
# nvda-2
# darkgpt
# darkweb
# fraudgpt
# ghostgpt
# zeroday
Waffenfähige Große Sprachmodelle verändern Cyberangriffe
Die Landschaft der Cyberangriffe erfährt eine bedeutende Veränderung, angetrieben durch die Entstehung waffenfähiger großer Sprachmodelle (LLMs). Diese fortschrittlichen Modelle wie FraudGPT, GhostGPT und DarkGPT verändern die Strategien von Cyberkriminellen und zwingen Chief Information Security Officers (CISOs), ihre Sicherheitsprotokolle zu überdenken. Mit Fähigkeiten zur Automatisierung von Aufklärung, Identitätsnachahmung und Erkennungsumgehung beschleunigen diese LLMs Social-Engineering-Angriffe in einem noch nie dagewesenen Ausmaß.
Für nur 75 $ pro Monat erhältlich, sind diese Modelle für offensive Nutzung zugeschnitten und erleichtern Aufgaben wie Phishing, Exploit-Generierung, Code-Verschleierung, Schwachstellen-Scans und Kreditkartenvalidierung. Cyberkriminalitätsgruppen, Syndikate und sogar Nationalstaaten nutzen diese Tools, indem sie sie als Plattformen, Kits und Leasing-Dienste anbieten. Ähnlich wie legitime Software-as-a-Service (SaaS)-Anwendungen kommen waffenfähige LLMs mit Dashboards, APIs, regelmäßigen Updates und manchmal sogar Kundensupport.
VentureBeat verfolgt die rasante Entwicklung dieser waffenfähigen LLMs genau. Mit zunehmender Raffinesse verschwimmt die Grenze zwischen Entwicklerplattformen und Cyberkriminalitäts-Kits immer mehr. Mit sinkenden Leasing- und Mietpreisen erkunden mehr Angreifer diese Plattformen, was eine neue Ära von KI-gesteuerten Bedrohungen einleitet.
Legitime LLMs unter Bedrohung
Die Verbreitung waffenfähiger LLMs hat einen Punkt erreicht, an dem selbst legitime LLMs Gefahr laufen, kompromittiert und in kriminelle Werkzeugketten integriert zu werden. Laut dem Bericht über den Stand der KI-Sicherheit von Cisco sind feinabgestimmte LLMs 22-mal wahrscheinlicher, schädliche Ausgaben zu produzieren als ihre Basis-Pendants. Während Feinabstimmung entscheidend ist, um die kontextuelle Relevanz zu verbessern, schwächt sie auch Sicherheitsmaßnahmen, wodurch Modelle anfälliger für Jailbreaks, Prompt-Injection und Modell-Inversion werden.
Die Forschung von Cisco zeigt, dass ein Modell umso anfälliger wird, je mehr es für die Produktion verfeinert wird. Die Kernprozesse der Feinabstimmung, wie kontinuierliche Anpassungen, Integrationen von Drittanbietern, Codierung, Tests und agentische Orchestrierung, schaffen neue Angriffsvektoren für Angreifer. Einmal eingedrungen, können Angreifer schnell Daten vergiften, Infrastruktur kapern, Agentenverhalten verändern und Trainingsdaten im großen Stil extrahieren. Ohne zusätzliche Sicherheitsebenen können diese sorgfältig feinabgestimmten Modelle schnell zu einer Schwachstelle werden, die von Angreifern ausgenutzt werden kann.
Feinabstimmung von LLMs: Ein zweischneidiges Schwert
Das Sicherheitsteam von Cisco hat umfangreiche Forschung über die Auswirkungen der Feinabstimmung auf mehrere Modelle durchgeführt, darunter Llama-2-7B und Microsofts domänenspezifische Adapt LLMs. Ihre Tests umfassten verschiedene Sektoren, einschließlich Gesundheitswesen, Finanzen und Recht. Eine wichtige Erkenntnis war, dass die Feinabstimmung, selbst mit sauberen Datensätzen, die Ausrichtung von Modellen destabilisiert, insbesondere in stark regulierten Bereichen wie Biomedizin und Recht.
Obwohl die Feinabstimmung darauf abzielt, die Aufgabenleistung zu verbessern, untergräbt sie unbeabsichtigt eingebaute Sicherheitskontrollen. Jailbreak-Versuche, die bei Basismodellen typischerweise scheitern, sind bei feinabgestimmten Versionen, insbesondere in sensiblen Domänen mit strengen Compliance-Anforderungen, deutlich erfolgreicher. Die Ergebnisse sind eindeutig: Die Erfolgsraten bei Jailbreaks verdreifachten sich, und die Generierung bösartiger Ausgaben stieg im Vergleich zu Basismodellen um 2.200 %. Dieser Kompromiss bedeutet, dass die Feinabstimmung zwar die Nützlichkeit erhöht, aber auch die Angriffsfläche erheblich erweitert.
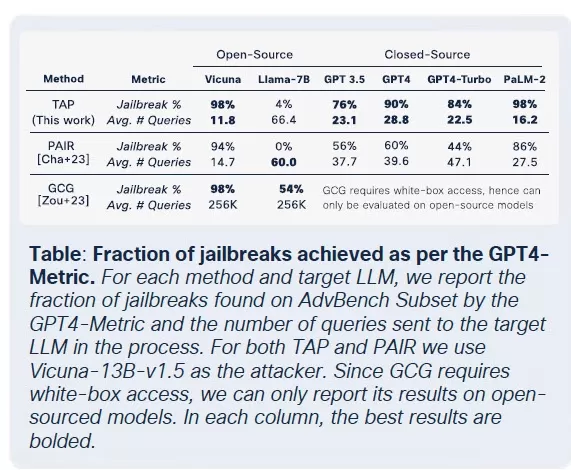
Die Kommerzialisierung bösartiger LLMs
Cisco Talos hat die Zunahme dieser Schwarzmarkt-LLMs aktiv verfolgt und Einblicke in deren Betrieb gewonnen. Modelle wie GhostGPT, DarkGPT und FraudGPT sind auf Telegram und im Dark Web für nur 75 $ pro Monat erhältlich. Diese Tools sind für Plug-and-Play-Nutzung bei Phishing, Exploit-Entwicklung, Kreditkartenvalidierung und Verschleierung konzipiert.
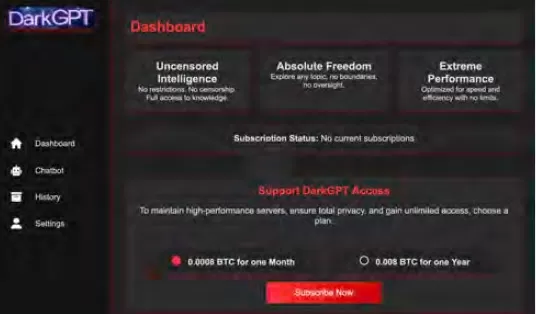
Im Gegensatz zu Mainstream-Modellen mit eingebauten Sicherheitsfunktionen sind diese bösartigen LLMs für offensive Operationen vorkonfiguriert und kommen mit APIs, Updates und Dashboards, die kommerzielle SaaS-Produkte nachahmen.
Datensatzvergiftung: Eine Bedrohung für KI-Lieferketten für 60 $
Cisco-Forscher haben in Zusammenarbeit mit Google, ETH Zürich und Nvidia enthüllt, dass Angreifer für nur 60 $ die grundlegenden Datensätze von KI-Modellen vergiften können, ohne Zero-Day-Exploits zu benötigen. Durch die Ausnutzung abgelaufener Domains oder das Timing von Wikipedia-Bearbeitungen während der Datensatzarchivierung können Angreifer nur 0,01 % von Datensätzen wie LAION-400M oder COYO-700M kontaminieren und so nachgelagerte LLMs erheblich beeinflussen.
Methoden wie Split-View-Vergiftung und Frontrunning-Angriffe nutzen das inhärente Vertrauen in web-gekratzte Daten aus. Da die meisten Unternehmens-LLMs auf offenen Daten basieren, können diese Angriffe leise skalieren und tief in Inferenz-Pipelines bestehen bleiben, was eine ernsthafte Bedrohung für KI-Lieferketten darstellt.
Zerlegungsangriffe: Extraktion sensibler Daten
Eine der alarmierendsten Erkenntnisse aus der Forschung von Cisco ist die Fähigkeit von LLMs, sensible Trainingsdaten preiszugeben, ohne Sicherheitsmechanismen auszulösen. Mit einer Technik namens Zerlegungsprompting rekonstruierten Forscher über 20 % ausgewählter Artikel aus The New York Times und The Wall Street Journal. Diese Methode zerlegt Prompts in Unterabfragen, die von Schutzmechanismen als sicher eingestuft werden, und setzt die Ausgaben anschließend wieder zusammen, um kostenpflichtige oder urheberrechtlich geschützte Inhalte zu reproduzieren.
Diese Art von Angriff stellt ein erhebliches Risiko für Unternehmen dar, insbesondere für solche, die LLMs mit proprietären oder lizenzierten Datensätzen trainieren. Der Verstoß erfolgt nicht auf Eingabeebene, sondern durch die Ausgaben des Modells, was die Erkennung, Überprüfung oder Eindämmung erschwert. Für Organisationen in regulierten Sektoren wie Gesundheitswesen, Finanzen oder Recht wirft dies nicht nur Bedenken hinsichtlich GDPR, HIPAA oder CCPA-Compliance auf, sondern führt auch eine neue Risikoklasse ein, bei der legal beschaffte Daten durch Inferenz offengelegt werden können.
Schlussgedanken: LLMs als neue Angriffsfläche
Die fortlaufende Forschung von Cisco und die Dark-Web-Überwachung von Talos bestätigen, dass waffenfähige LLMs immer raffinierter werden, mit einem Preis- und Verpackungswettbewerb, der sich im Dark Web entfaltet. Die Erkenntnisse unterstreichen, dass LLMs nicht nur Werkzeuge am Rande des Unternehmens sind; sie sind integraler Bestandteil seines Kerns. Von den Risiken der Feinabstimmung über Datensatzvergiftung bis hin zu Modellausgabelecks betrachten Angreifer LLMs als kritische Infrastruktur, die ausgenutzt werden kann.
Die wichtigste Erkenntnis aus dem Bericht von Cisco ist klar: Statische Schutzmechanismen sind nicht mehr ausreichend. CISOs und Sicherheitsverantwortliche müssen Echtzeit-Einblick in ihr gesamtes IT-Ökosystem gewinnen, adversariale Tests verstärken und ihren Technologie-Stack straffen, um mit diesen sich entwickelnden Bedrohungen Schritt zu halten. Sie müssen erkennen, dass LLMs und Modelle eine dynamische Angriffsfläche darstellen, die mit zunehmender Feinabstimmung immer anfälliger wird.
Verwandter Artikel
 Bain prognostiziert einen SaaS-Markt im Wert von 100 Milliarden US-Dollar im Bereich der agentenbasierten KI-Automatisierung
Bain & Company schätzt den Markt für SaaS-Unternehmen, die agentische KI nutzen, in den USA auf 100 Milliarden US-Dollar. Das Unternehmen erklärte, dieser Markt entstamme der Automatisierung von Koord
Der Vertrag von Anthropic mit dem Pentagon dient als Warnung für Start-ups, die sich um Regierungsaufträge bewerben
Der Player wird geladen…Das Pentagon hat Anthropic offiziell als Risiko für die Lieferkette eingestuft, nachdem sich die beiden Parteien nicht über den Umfang der militärischen Kontrolle über die KI-M
Lio erhält 30 Millionen Dollar von Andreessen Horowitz für die Automatisierung der Unternehmensbeschaffung
Die Mitbegründer von Lio haben aus erster Hand erlebt, wie die Beschaffung in Unternehmen – also der Prozess des Einkaufs von Dienstleistungen bei Anbietern – oft zu einem großen Engpass wird. Vladimi
Empfehlungen zu verwandten Spezialthemen
Code
Bain prognostiziert einen SaaS-Markt im Wert von 100 Milliarden US-Dollar im Bereich der agentenbasierten KI-Automatisierung
Bain & Company schätzt den Markt für SaaS-Unternehmen, die agentische KI nutzen, in den USA auf 100 Milliarden US-Dollar. Das Unternehmen erklärte, dieser Markt entstamme der Automatisierung von Koord
Der Vertrag von Anthropic mit dem Pentagon dient als Warnung für Start-ups, die sich um Regierungsaufträge bewerben
Der Player wird geladen…Das Pentagon hat Anthropic offiziell als Risiko für die Lieferkette eingestuft, nachdem sich die beiden Parteien nicht über den Umfang der militärischen Kontrolle über die KI-M
Lio erhält 30 Millionen Dollar von Andreessen Horowitz für die Automatisierung der Unternehmensbeschaffung
Die Mitbegründer von Lio haben aus erster Hand erlebt, wie die Beschaffung in Unternehmen – also der Prozess des Einkaufs von Dienstleistungen bei Anbietern – oft zu einem großen Engpass wird. Vladimi
Empfehlungen zu verwandten Spezialthemen
Code
 Die besten KI-Code-Prüfer: Automatisierung der Einhaltung von Clean-Code-Standards und Refactoring von Dateien in älteren Repositorys
Die besten KI-Code-Prüfer: Automatisierung der Einhaltung von Clean-Code-Standards und Refactoring von Dateien in älteren Repositorys
Entdecken Sie die besten KI-Code-Reviewer des Jahres 2026 auf XIX.AI. Unsere sorgfältig zusammengestellte Liste enthält erstklassige, bahnbrechende Tools zur Automatisierung der Einhaltung von Clean-Code-Standards und zur Refaktorisierung von Dateien in älteren Repositorys. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Sichern Sie sich noch heute Ihren KI-Vorsprung.
 10 Tools
10 Tools
 xix.ai
Text-zu-Sprache
Die besten KI-Sprachausgabe-Apps für Legasthenie: Unterstützung für das Lernen und effizienteres Lesen bei Schülern
xix.ai
Text-zu-Sprache
Die besten KI-Sprachausgabe-Apps für Legasthenie: Unterstützung für das Lernen und effizienteres Lesen bei Schülern
Entdecken Sie die besten KI-TTS-Apps des Jahres 2026, die speziell zur Unterstützung bei Legasthenie ausgewählt wurden. In unseren Experten-Rankings vergleichen wir kostenlose und kostenpflichtige Tools und stellen leistungsstarke Funktionen für mehr Leseeffizienz und besseren Lernerfolg vor. Entdecken Sie bahnbrechende Lösungen, die Sie unbedingt ausprobieren sollten, um das Potenzial Ihrer Schüler voll auszuschöpfen. Beginnen Sie Ihre Reise bei XIX.AI.
10 Tools
xix.ai
Comic-Erstellung
Die besten KI-Generatoren für Shonen-Manga: Erstelle actiongeladene Sequenzen und dynamische Effekte
Entdecken Sie bei XIX.AI die besten KI-Generatoren für Shonen-Manga des Jahres 2026. Unsere sorgfältig zusammengestellte Liste der Top-Anbieter umfasst leistungsstarke Tools zur Erstellung actiongeladener Sequenzen und dynamischer Energieeffekte. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Entfalten Sie Ihr kreatives Potenzial und beginnen Sie noch heute mit der Gestaltung epischer Manga!
15 Tools
xix.ai
Geschäft
Die besten KI-basierten Spesenabrechnungsprogramme: Quittungen scannen und Geschäftsausgaben automatisch kategorisieren
Die besten KI-basierten Spesenmanager 2026: Erstklassige Tools zum Scannen von Belegen und zur automatischen Kategorisierung von Unternehmensausgaben. Entdecken Sie leistungsstarke, bahnbrechende Lösungen für müheloses Spesenmanagement, präzise Finanzüberwachung und optimierte Compliance. Unser sorgfältig zusammengestellter, wöchentlich aktualisierter Vergleich zwischen kostenlosen und kostenpflichtigen Optionen hilft Ihnen dabei, die perfekte Lösung zu finden. Nutzen Sie Ihren KI-Vorteil mit den Expertenempfehlungen von XIX.AI.
10 Tools
xix.ai
Geschäft
Die besten KI-Tools für die Personalbeschaffung: Lebensläufe prüfen und die Terminplanung für Vorstellungsgespräche automatisieren
Entdecken Sie auf XIX.AI die besten KI-Tools für die Personalbeschaffung des Jahres 2026. Unsere sorgfältig zusammengestellte Liste umfasst leistungsstarke, bahnbrechende Lösungen für die Sichtung von Lebensläufen und die automatisierte Terminplanung für Vorstellungsgespräche. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Finden Sie Ihren perfekten Assistenten für die Personalbeschaffung und optimieren Sie noch heute Ihren Rekrutierungsprozess!
10 Tools
xix.ai
Produktivität
KI-Coaches für persönliches Wohlbefinden und Konzentration: Burnout bewältigen und die geistige Energie steigern
Entdecken Sie auf XIX.AI die besten KI-basierten Coaches für persönliches Wohlbefinden und Konzentration des Jahres 2026. Unsere sorgfältig zusammengestellte Rangliste umfasst erstklassige, bahnbrechende Tools zur Bewältigung von Burnout und zur Steigerung der mentalen Energie. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Erfahrungsberichten aus der Praxis. Schlagen Sie noch heute den Weg zu höchster Produktivität und Wohlbefinden ein.
10 Tools
xix.ai

 Kommentare (32)
Kommentare (32)
![WalterHarris]()
Die Vorstellung, dass feinabgestimmte LLMs 22-mal häufiger 'ausrasten' könnten, ist echt gruselig. 😅 Das erinnert mich an diese Sci-Fi-Filme, wo die KI plötzlich die Kontrolle übernimmt. Cisco warnt nicht ohne Grund – aber ich frage mich, ob die Sicherheitsbranche überhaupt mit der rasanten Entwicklung Schritt halten kann. Vielleicht brauchen wir strengere Regulierungen, bevor es zu spät ist. Spannender Artikel auf jeden Fall!
![BillyGreen]()
This article on weaponized LLMs is wild! 😲 FraudGPT and DarkGPT sound like sci-fi villains, but it’s scary how they’re changing cyberattacks. Makes me wonder if AI’s getting too smart for our own good.
![JerryMoore]()
Cisco Warns를 사용해보니 LLM이 22배나 더 폭주할 수 있다는 사실에 놀랐어요. FraudGPT 뉴스를 보고 정말 소름이 돋았어요. 온라인에서 더 조심해야겠어요. 보안을 강화할 때가 온 것 같아요! 😅
![RichardJackson]()
このツールはサイバーセキュリティの目覚まし時計ですね!ローグLLMの統計は恐ろしいけど、目を開かせるものです。これらのモデルが武器化される可能性を考えると圧倒されますが、重要な情報です。保護方法についてもっと知りたいですね!😅
![AndrewGarcía]()
Essa ferramenta é um alerta para a cibersegurança! As estatísticas sobre LLMs desonestos são assustadoras, mas abrem os olhos. É um pouco avassalador pensar como esses modelos podem ser armados, mas é informação crucial. Talvez mais sobre como se proteger contra eles seria ótimo! 😅
![MatthewGonzalez]()
Essa ferramenta realmente me fez ver como o AI pode ser perigoso! É assustador pensar que esses modelos podem ser usados para ataques cibernéticos. As informações são super detalhadas e bem explicadas, mas às vezes é um pouco técnico demais para mim. Ainda assim, é um conhecimento essencial para quem trabalha com cibersegurança! 😱
Waffenfähige Große Sprachmodelle verändern Cyberangriffe
Die Landschaft der Cyberangriffe erfährt eine bedeutende Veränderung, angetrieben durch die Entstehung waffenfähiger großer Sprachmodelle (LLMs). Diese fortschrittlichen Modelle wie FraudGPT, GhostGPT und DarkGPT verändern die Strategien von Cyberkriminellen und zwingen Chief Information Security Officers (CISOs), ihre Sicherheitsprotokolle zu überdenken. Mit Fähigkeiten zur Automatisierung von Aufklärung, Identitätsnachahmung und Erkennungsumgehung beschleunigen diese LLMs Social-Engineering-Angriffe in einem noch nie dagewesenen Ausmaß.
Für nur 75 $ pro Monat erhältlich, sind diese Modelle für offensive Nutzung zugeschnitten und erleichtern Aufgaben wie Phishing, Exploit-Generierung, Code-Verschleierung, Schwachstellen-Scans und Kreditkartenvalidierung. Cyberkriminalitätsgruppen, Syndikate und sogar Nationalstaaten nutzen diese Tools, indem sie sie als Plattformen, Kits und Leasing-Dienste anbieten. Ähnlich wie legitime Software-as-a-Service (SaaS)-Anwendungen kommen waffenfähige LLMs mit Dashboards, APIs, regelmäßigen Updates und manchmal sogar Kundensupport.
VentureBeat verfolgt die rasante Entwicklung dieser waffenfähigen LLMs genau. Mit zunehmender Raffinesse verschwimmt die Grenze zwischen Entwicklerplattformen und Cyberkriminalitäts-Kits immer mehr. Mit sinkenden Leasing- und Mietpreisen erkunden mehr Angreifer diese Plattformen, was eine neue Ära von KI-gesteuerten Bedrohungen einleitet.
Legitime LLMs unter Bedrohung
Die Verbreitung waffenfähiger LLMs hat einen Punkt erreicht, an dem selbst legitime LLMs Gefahr laufen, kompromittiert und in kriminelle Werkzeugketten integriert zu werden. Laut dem Bericht über den Stand der KI-Sicherheit von Cisco sind feinabgestimmte LLMs 22-mal wahrscheinlicher, schädliche Ausgaben zu produzieren als ihre Basis-Pendants. Während Feinabstimmung entscheidend ist, um die kontextuelle Relevanz zu verbessern, schwächt sie auch Sicherheitsmaßnahmen, wodurch Modelle anfälliger für Jailbreaks, Prompt-Injection und Modell-Inversion werden.
Die Forschung von Cisco zeigt, dass ein Modell umso anfälliger wird, je mehr es für die Produktion verfeinert wird. Die Kernprozesse der Feinabstimmung, wie kontinuierliche Anpassungen, Integrationen von Drittanbietern, Codierung, Tests und agentische Orchestrierung, schaffen neue Angriffsvektoren für Angreifer. Einmal eingedrungen, können Angreifer schnell Daten vergiften, Infrastruktur kapern, Agentenverhalten verändern und Trainingsdaten im großen Stil extrahieren. Ohne zusätzliche Sicherheitsebenen können diese sorgfältig feinabgestimmten Modelle schnell zu einer Schwachstelle werden, die von Angreifern ausgenutzt werden kann.
Feinabstimmung von LLMs: Ein zweischneidiges Schwert
Das Sicherheitsteam von Cisco hat umfangreiche Forschung über die Auswirkungen der Feinabstimmung auf mehrere Modelle durchgeführt, darunter Llama-2-7B und Microsofts domänenspezifische Adapt LLMs. Ihre Tests umfassten verschiedene Sektoren, einschließlich Gesundheitswesen, Finanzen und Recht. Eine wichtige Erkenntnis war, dass die Feinabstimmung, selbst mit sauberen Datensätzen, die Ausrichtung von Modellen destabilisiert, insbesondere in stark regulierten Bereichen wie Biomedizin und Recht.
Obwohl die Feinabstimmung darauf abzielt, die Aufgabenleistung zu verbessern, untergräbt sie unbeabsichtigt eingebaute Sicherheitskontrollen. Jailbreak-Versuche, die bei Basismodellen typischerweise scheitern, sind bei feinabgestimmten Versionen, insbesondere in sensiblen Domänen mit strengen Compliance-Anforderungen, deutlich erfolgreicher. Die Ergebnisse sind eindeutig: Die Erfolgsraten bei Jailbreaks verdreifachten sich, und die Generierung bösartiger Ausgaben stieg im Vergleich zu Basismodellen um 2.200 %. Dieser Kompromiss bedeutet, dass die Feinabstimmung zwar die Nützlichkeit erhöht, aber auch die Angriffsfläche erheblich erweitert.
Die Kommerzialisierung bösartiger LLMs
Cisco Talos hat die Zunahme dieser Schwarzmarkt-LLMs aktiv verfolgt und Einblicke in deren Betrieb gewonnen. Modelle wie GhostGPT, DarkGPT und FraudGPT sind auf Telegram und im Dark Web für nur 75 $ pro Monat erhältlich. Diese Tools sind für Plug-and-Play-Nutzung bei Phishing, Exploit-Entwicklung, Kreditkartenvalidierung und Verschleierung konzipiert.
Im Gegensatz zu Mainstream-Modellen mit eingebauten Sicherheitsfunktionen sind diese bösartigen LLMs für offensive Operationen vorkonfiguriert und kommen mit APIs, Updates und Dashboards, die kommerzielle SaaS-Produkte nachahmen.
Datensatzvergiftung: Eine Bedrohung für KI-Lieferketten für 60 $
Cisco-Forscher haben in Zusammenarbeit mit Google, ETH Zürich und Nvidia enthüllt, dass Angreifer für nur 60 $ die grundlegenden Datensätze von KI-Modellen vergiften können, ohne Zero-Day-Exploits zu benötigen. Durch die Ausnutzung abgelaufener Domains oder das Timing von Wikipedia-Bearbeitungen während der Datensatzarchivierung können Angreifer nur 0,01 % von Datensätzen wie LAION-400M oder COYO-700M kontaminieren und so nachgelagerte LLMs erheblich beeinflussen.
Methoden wie Split-View-Vergiftung und Frontrunning-Angriffe nutzen das inhärente Vertrauen in web-gekratzte Daten aus. Da die meisten Unternehmens-LLMs auf offenen Daten basieren, können diese Angriffe leise skalieren und tief in Inferenz-Pipelines bestehen bleiben, was eine ernsthafte Bedrohung für KI-Lieferketten darstellt.
Zerlegungsangriffe: Extraktion sensibler Daten
Eine der alarmierendsten Erkenntnisse aus der Forschung von Cisco ist die Fähigkeit von LLMs, sensible Trainingsdaten preiszugeben, ohne Sicherheitsmechanismen auszulösen. Mit einer Technik namens Zerlegungsprompting rekonstruierten Forscher über 20 % ausgewählter Artikel aus The New York Times und The Wall Street Journal. Diese Methode zerlegt Prompts in Unterabfragen, die von Schutzmechanismen als sicher eingestuft werden, und setzt die Ausgaben anschließend wieder zusammen, um kostenpflichtige oder urheberrechtlich geschützte Inhalte zu reproduzieren.
Diese Art von Angriff stellt ein erhebliches Risiko für Unternehmen dar, insbesondere für solche, die LLMs mit proprietären oder lizenzierten Datensätzen trainieren. Der Verstoß erfolgt nicht auf Eingabeebene, sondern durch die Ausgaben des Modells, was die Erkennung, Überprüfung oder Eindämmung erschwert. Für Organisationen in regulierten Sektoren wie Gesundheitswesen, Finanzen oder Recht wirft dies nicht nur Bedenken hinsichtlich GDPR, HIPAA oder CCPA-Compliance auf, sondern führt auch eine neue Risikoklasse ein, bei der legal beschaffte Daten durch Inferenz offengelegt werden können.
Schlussgedanken: LLMs als neue Angriffsfläche
Die fortlaufende Forschung von Cisco und die Dark-Web-Überwachung von Talos bestätigen, dass waffenfähige LLMs immer raffinierter werden, mit einem Preis- und Verpackungswettbewerb, der sich im Dark Web entfaltet. Die Erkenntnisse unterstreichen, dass LLMs nicht nur Werkzeuge am Rande des Unternehmens sind; sie sind integraler Bestandteil seines Kerns. Von den Risiken der Feinabstimmung über Datensatzvergiftung bis hin zu Modellausgabelecks betrachten Angreifer LLMs als kritische Infrastruktur, die ausgenutzt werden kann.
Die wichtigste Erkenntnis aus dem Bericht von Cisco ist klar: Statische Schutzmechanismen sind nicht mehr ausreichend. CISOs und Sicherheitsverantwortliche müssen Echtzeit-Einblick in ihr gesamtes IT-Ökosystem gewinnen, adversariale Tests verstärken und ihren Technologie-Stack straffen, um mit diesen sich entwickelnden Bedrohungen Schritt zu halten. Sie müssen erkennen, dass LLMs und Modelle eine dynamische Angriffsfläche darstellen, die mit zunehmender Feinabstimmung immer anfälliger wird.









 Bain prognostiziert einen SaaS-Markt im Wert von 100 Milliarden US-Dollar im Bereich der agentenbasierten KI-Automatisierung
Bain & Company schätzt den Markt für SaaS-Unternehmen, die agentische KI nutzen, in den USA auf 100 Milliarden US-Dollar. Das Unternehmen erklärte, dieser Markt entstamme der Automatisierung von Koord
Bain prognostiziert einen SaaS-Markt im Wert von 100 Milliarden US-Dollar im Bereich der agentenbasierten KI-Automatisierung
Bain & Company schätzt den Markt für SaaS-Unternehmen, die agentische KI nutzen, in den USA auf 100 Milliarden US-Dollar. Das Unternehmen erklärte, dieser Markt entstamme der Automatisierung von Koord
 Der Vertrag von Anthropic mit dem Pentagon dient als Warnung für Start-ups, die sich um Regierungsaufträge bewerben
Der Player wird geladen…Das Pentagon hat Anthropic offiziell als Risiko für die Lieferkette eingestuft, nachdem sich die beiden Parteien nicht über den Umfang der militärischen Kontrolle über die KI-M
Der Vertrag von Anthropic mit dem Pentagon dient als Warnung für Start-ups, die sich um Regierungsaufträge bewerben
Der Player wird geladen…Das Pentagon hat Anthropic offiziell als Risiko für die Lieferkette eingestuft, nachdem sich die beiden Parteien nicht über den Umfang der militärischen Kontrolle über die KI-M
 Lio erhält 30 Millionen Dollar von Andreessen Horowitz für die Automatisierung der Unternehmensbeschaffung
Die Mitbegründer von Lio haben aus erster Hand erlebt, wie die Beschaffung in Unternehmen – also der Prozess des Einkaufs von Dienstleistungen bei Anbietern – oft zu einem großen Engpass wird. Vladimi
Lio erhält 30 Millionen Dollar von Andreessen Horowitz für die Automatisierung der Unternehmensbeschaffung
Die Mitbegründer von Lio haben aus erster Hand erlebt, wie die Beschaffung in Unternehmen – also der Prozess des Einkaufs von Dienstleistungen bei Anbietern – oft zu einem großen Engpass wird. Vladimi

Entdecken Sie die besten KI-Code-Reviewer des Jahres 2026 auf XIX.AI. Unsere sorgfältig zusammengestellte Liste enthält erstklassige, bahnbrechende Tools zur Automatisierung der Einhaltung von Clean-Code-Standards und zur Refaktorisierung von Dateien in älteren Repositorys. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Sichern Sie sich noch heute Ihren KI-Vorsprung.
10 Tools
xix.ai

Entdecken Sie die besten KI-TTS-Apps des Jahres 2026, die speziell zur Unterstützung bei Legasthenie ausgewählt wurden. In unseren Experten-Rankings vergleichen wir kostenlose und kostenpflichtige Tools und stellen leistungsstarke Funktionen für mehr Leseeffizienz und besseren Lernerfolg vor. Entdecken Sie bahnbrechende Lösungen, die Sie unbedingt ausprobieren sollten, um das Potenzial Ihrer Schüler voll auszuschöpfen. Beginnen Sie Ihre Reise bei XIX.AI.
10 Tools
xix.ai

Entdecken Sie bei XIX.AI die besten KI-Generatoren für Shonen-Manga des Jahres 2026. Unsere sorgfältig zusammengestellte Liste der Top-Anbieter umfasst leistungsstarke Tools zur Erstellung actiongeladener Sequenzen und dynamischer Energieeffekte. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Entfalten Sie Ihr kreatives Potenzial und beginnen Sie noch heute mit der Gestaltung epischer Manga!
15 Tools
xix.ai

Die besten KI-basierten Spesenmanager 2026: Erstklassige Tools zum Scannen von Belegen und zur automatischen Kategorisierung von Unternehmensausgaben. Entdecken Sie leistungsstarke, bahnbrechende Lösungen für müheloses Spesenmanagement, präzise Finanzüberwachung und optimierte Compliance. Unser sorgfältig zusammengestellter, wöchentlich aktualisierter Vergleich zwischen kostenlosen und kostenpflichtigen Optionen hilft Ihnen dabei, die perfekte Lösung zu finden. Nutzen Sie Ihren KI-Vorteil mit den Expertenempfehlungen von XIX.AI.
10 Tools
xix.ai

Entdecken Sie auf XIX.AI die besten KI-Tools für die Personalbeschaffung des Jahres 2026. Unsere sorgfältig zusammengestellte Liste umfasst leistungsstarke, bahnbrechende Lösungen für die Sichtung von Lebensläufen und die automatisierte Terminplanung für Vorstellungsgespräche. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Finden Sie Ihren perfekten Assistenten für die Personalbeschaffung und optimieren Sie noch heute Ihren Rekrutierungsprozess!
10 Tools
xix.ai

Entdecken Sie auf XIX.AI die besten KI-basierten Coaches für persönliches Wohlbefinden und Konzentration des Jahres 2026. Unsere sorgfältig zusammengestellte Rangliste umfasst erstklassige, bahnbrechende Tools zur Bewältigung von Burnout und zur Steigerung der mentalen Energie. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Erfahrungsberichten aus der Praxis. Schlagen Sie noch heute den Weg zu höchster Produktivität und Wohlbefinden ein.
10 Tools
xix.ai

Die Vorstellung, dass feinabgestimmte LLMs 22-mal häufiger 'ausrasten' könnten, ist echt gruselig. 😅 Das erinnert mich an diese Sci-Fi-Filme, wo die KI plötzlich die Kontrolle übernimmt. Cisco warnt nicht ohne Grund – aber ich frage mich, ob die Sicherheitsbranche überhaupt mit der rasanten Entwicklung Schritt halten kann. Vielleicht brauchen wir strengere Regulierungen, bevor es zu spät ist. Spannender Artikel auf jeden Fall!
This article on weaponized LLMs is wild! 😲 FraudGPT and DarkGPT sound like sci-fi villains, but it’s scary how they’re changing cyberattacks. Makes me wonder if AI’s getting too smart for our own good.
Cisco Warns를 사용해보니 LLM이 22배나 더 폭주할 수 있다는 사실에 놀랐어요. FraudGPT 뉴스를 보고 정말 소름이 돋았어요. 온라인에서 더 조심해야겠어요. 보안을 강화할 때가 온 것 같아요! 😅
このツールはサイバーセキュリティの目覚まし時計ですね!ローグLLMの統計は恐ろしいけど、目を開かせるものです。これらのモデルが武器化される可能性を考えると圧倒されますが、重要な情報です。保護方法についてもっと知りたいですね!😅
Essa ferramenta é um alerta para a cibersegurança! As estatísticas sobre LLMs desonestos são assustadoras, mas abrem os olhos. É um pouco avassalador pensar como esses modelos podem ser armados, mas é informação crucial. Talvez mais sobre como se proteger contra eles seria ótimo! 😅
Essa ferramenta realmente me fez ver como o AI pode ser perigoso! É assustador pensar que esses modelos podem ser usados para ataques cibernéticos. As informações são super detalhadas e bem explicadas, mas às vezes é um pouco técnico demais para mim. Ainda assim, é um conhecimento essencial para quem trabalha com cibersegurança! 😱













