
















 Дом
ДомCisco предупреждает: LLMS с тонкой настройкой в 22 раза чаще станет мошенничеством
# cisco
# LLMs
# APIs
# saas
# csco
# goog-2
# msft-2
# nvda-2
# darkgpt
# darkweb
# fraudgpt
# ghostgpt
# zeroday
Оружие в виде больших языковых моделей меняет кибератаки
Ландшафт кибератак претерпевает значительные изменения, обусловленные появлением оружейных больших языковых моделей (LLM). Эти продвинутые модели, такие как FraudGPT, GhostGPT и DarkGPT, перестраивают стратегии киберпреступников и заставляют главных специалистов по информационной безопасности (CISO) пересматривать свои протоколы безопасности. Благодаря возможностям автоматизации разведки, имитации личностей и уклонения от обнаружения, эти LLM ускоряют атаки социальной инженерии в беспрецедентных масштабах.
Доступные всего за 75 долларов в месяц, эти модели адаптированы для наступательного использования, облегчая такие задачи, как фишинг, генерация эксплойтов, обфускация кода, сканирование уязвимостей и валидация кредитных карт. Киберпреступные группы, синдикаты и даже национальные государства используют эти инструменты, предлагая их в виде платформ, наборов и услуг аренды. Подобно легитимным приложениям типа "программное обеспечение как услуга" (SaaS), оружейные LLM поставляются с панелями управления, API, регулярными обновлениями и иногда даже поддержкой клиентов.
VentureBeat внимательно следит за быстрым развитием этих оружейных LLM. По мере роста их сложности различие между платформами разработчиков и наборами для киберпреступлений становится всё более размытым. С падением цен на аренду и лизинг всё больше злоумышленников изучают эти платформы, что знаменует новую эру угроз, управляемых искусственным интеллектом.
Легитимные LLM под угрозой
Распространение оружейных LLM достигло точки, когда даже легитимные LLM подвергаются риску компрометации и интеграции в криминальные цепочки инструментов. Согласно отчёту Cisco Состояние безопасности ИИ, доработанные LLM в 22 раза чаще производят вредоносные результаты, чем их базовые аналоги. Хотя доработка необходима для повышения контекстной релевантности, она также ослабляет меры безопасности, делая модели более уязвимыми для взломов, инъекций промптов и инверсии моделей.
Исследования Cisco подчёркивают, что чем больше модель дорабатывается для производства, тем уязвимее она становится. Основные процессы, связанные с доработкой, такие как непрерывные корректировки, интеграции сторонних разработчиков, кодирование, тестирование и агентная оркестрация, создают новые пути для эксплуатации злоумышленниками. Попав внутрь, злоумышленники могут быстро отравлять данные, захватывать инфраструктуру, изменять поведение агентов и извлекать обучающие данные в больших масштабах. Без дополнительных уровней безопасности эти тщательно доработанные модели могут быстро стать уязвимостями, готовыми к эксплуатации злоумышленниками.
Доработка LLM: обоюдоострый меч
Команда безопасности Cisco провела обширные исследования влияния доработки на несколько моделей, включая Llama-2-7B и специализированные адаптивные LLM от Microsoft. Их тесты охватывали различные сектора, включая здравоохранение, финансы и право. Ключевое открытие заключалось в том, что доработка, даже с чистыми наборами данных, дестабилизирует выравнивание моделей, особенно в строго регулируемых областях, таких как биомедицина и право.
Хотя доработка направлена на улучшение производительности задач, она невольно подрывает встроенные механизмы безопасности. Попытки взлома, которые обычно не проходят против базовых моделей, имеют гораздо более высокую вероятность успеха против доработанных версий, особенно в чувствительных доменах с жёсткими требованиями соответствия. Результаты поразительны: уровень успеха взломов утроился, а генерация вредоносных выходных данных увеличилась на 2200% по сравнению с базовыми моделями. Этот компромисс означает, что, хотя доработка повышает полезность, она также значительно расширяет поверхность атаки.
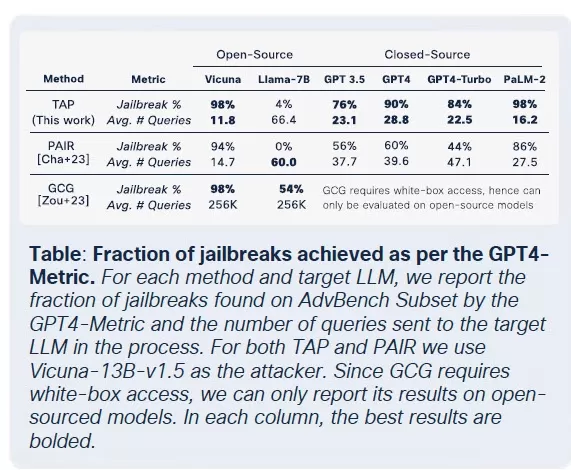
Коммодитизация вредоносных LLM
Cisco Talos активно отслеживает рост этих чернорыночных LLM, предоставляя информацию об их операциях. Модели, такие как GhostGPT, DarkGPT и FraudGPT, доступны в Telegram и дарквебе всего за 75 долларов в месяц. Эти инструменты предназначены для использования по принципу "подключи и работай" в фишинге, разработке эксплойтов, валидации кредитных карт и обфускации.
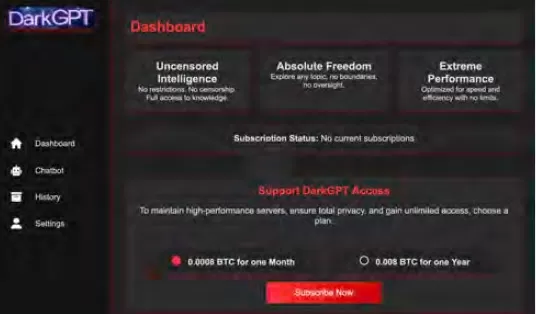
В отличие от мейнстримных моделей с встроенными функциями безопасности, эти вредоносные LLM предварительно настроены для наступательных операций и поставляются с API, обновлениями и панелями управления, которые имитируют коммерческие продукты SaaS.
Отравление наборов данных: угроза за 60 долларов для цепочек поставок ИИ
Исследователи Cisco в сотрудничестве с Google, ETH Zurich и Nvidia показали, что всего за 60 долларов злоумышленники могут отравлять базовые наборы данных ИИ без необходимости использования эксплойтов нулевого дня. Используя просроченные домены или тайминг правок в Википедии во время архивирования наборов данных, злоумышленники могут загрязнять всего 0.01% наборов данных, таких как LAION-400M или COYO-700M, значительно влияя на последующие LLM.
Методы, такие как отравление разделённого вида и атаки с опережением, используют присущее доверие к данным, собранным из интернета. Поскольку большинство корпоративных LLM строятся на открытых данных, эти атаки могут масштабироваться незаметно и сохраняться глубоко в конвейерах вывода, представляя серьёзную угрозу для цепочек поставок ИИ.
Атаки декомпозиции: извлечение чувствительных данных
Одно из самых тревожных открытий исследований Cisco — способность LLM раскрывать чувствительные обучающие данные без срабатывания механизмов безопасности. Используя технику декомпозиционного промптинга, исследователи восстановили более 20% избранных статей из The New York Times и The Wall Street Journal. Этот метод разбивает промпты на подзапросы, которые считаются безопасными для защитных барьеров, а затем собирает выходные данные для воссоздания платного или защищённого авторским правом контента.
Этот тип атак представляет значительный риск для предприятий, особенно тех, которые используют LLM, обученные на проприетарных или лицензированных наборах данных. Нарушение происходит не на уровне ввода, а через выходные данные модели, что затрудняет обнаружение, аудит или сдерживание. Для организаций в регулируемых секторах, таких как здравоохранение, финансы или право, это не только вызывает опасения по поводу соответствия GDPR, HIPAA или CCPA, но также вводит новый класс рисков, когда юридически полученные данные могут быть раскрыты через вывод.
Заключительные мысли: LLM как новая поверхность атаки
Продолжающиеся исследования Cisco и мониторинг дарквеба Talos подтверждают, что оружейные LLM становятся всё более сложными, с разворачивающейся войной цен и упаковки в дарквебе. Выводы подчёркивают, что LLM — это не просто инструменты на периферии предприятия; они являются его ядром. От рисков, связанных с доработкой, до отравления наборов данных и утечек выходных данных моделей, злоумышленники рассматривают LLM как критическую инфраструктуру для эксплуатации.
Ключевой вывод из отчёта Cisco ясен: статические барьеры больше не достаточны. CISO и лидеры безопасности должны получить реальную видимость своего ИТ-имущества в реальном времени, усилить тестирование на противодействие и оптимизировать свои технологические стеки, чтобы не отставать от этих развивающихся угроз. Они должны признать, что LLM и модели представляют динамическую поверхность атаки, которая становится всё более уязвимой по мере их доработки.
Связанная статья
 Компания Bain прогнозирует, что рынок SaaS в сфере автоматизации на базе агентного ИИ достигнет 100 млрд долларов США
По оценкам компании Bain & Company, объем рынка SaaS-компаний, использующих агентский ИИ, в США составляет 100 миллиардов долларов. По мнению компании, этот рынок формируется за счет автоматизации зад
Сделка компании Anthropic с Пентагоном служит предупреждением для стартапов, стремящихся получить государственные контракты
Загрузка проигрывателя…Пентагон официально признал компанию Anthropic источником риска для цепочки поставок после того, как сторонам не удалось достичь соглашения о степени военного контроля над ее мо
Lio получает 30 миллионов долларов от Andreessen Horowitz на автоматизацию корпоративных закупок
Соучредители Lio на собственном опыте убедились, что корпоративные закупки — процесс приобретения услуг у поставщиков — часто становятся серьезным препятствием. Владимир Кейл, соучредитель и генеральн
Рекомендации по связанным специальным темам
письмо
Компания Bain прогнозирует, что рынок SaaS в сфере автоматизации на базе агентного ИИ достигнет 100 млрд долларов США
По оценкам компании Bain & Company, объем рынка SaaS-компаний, использующих агентский ИИ, в США составляет 100 миллиардов долларов. По мнению компании, этот рынок формируется за счет автоматизации зад
Сделка компании Anthropic с Пентагоном служит предупреждением для стартапов, стремящихся получить государственные контракты
Загрузка проигрывателя…Пентагон официально признал компанию Anthropic источником риска для цепочки поставок после того, как сторонам не удалось достичь соглашения о степени военного контроля над ее мо
Lio получает 30 миллионов долларов от Andreessen Horowitz на автоматизацию корпоративных закупок
Соучредители Lio на собственном опыте убедились, что корпоративные закупки — процесс приобретения услуг у поставщиков — часто становятся серьезным препятствием. Владимир Кейл, соучредитель и генеральн
Рекомендации по связанным специальным темам
письмо
 Лучшие программы для создания персонажей в жанре научной фантастики: генерация последовательных мотиваций персонажей и их роковых недостатков
Лучшие программы для создания персонажей в жанре научной фантастики: генерация последовательных мотиваций персонажей и их роковых недостатков
Откройте для себя 20 лучших инструментов 2026 года для создания персонажей с помощью искусственного интеллекта, которые помогут вам придать своим героям глубину. В тщательно подобранном списке XIX.AI представлены самые популярные и революционные инструменты, способные генерировать правдоподобные мотивации и роковые недостатки персонажей. Сравните бесплатные и платные варианты на основе реальных тестов. Раскройте свой потенциал в области создания историй уже сейчас.
 10 инструментов
10 инструментов
 xix.ai
Бизнес
Лучшее ПО для оптимизации цен с помощью ИИ: отслеживание конкурентов и автоматическая корректировка цен в магазине
xix.ai
Бизнес
Лучшее ПО для оптимизации цен с помощью ИИ: отслеживание конкурентов и автоматическая корректировка цен в магазине
Откройте для себя лучшее программное обеспечение 2026 года для оптимизации цен с помощью ИИ на сайте XIX.AI. В нашем тщательно подобранном списке представлены высокооцененные, революционные инструменты, которые отслеживают конкурентов и автоматически корректируют цены в вашем магазине для получения максимальной прибыли. Сравните бесплатные и платные варианты на основе реальных тестов. Получите преимущество в ценообразовании уже сейчас.
10 инструментов
xix.ai
код
Лучшие системы проверки кода на основе ИИ: автоматизация обеспечения соответствия стандартам чистого кода и рефакторинг файлов в устаревших репозиториях
Откройте для себя 20 лучших рецензентов кода на базе ИИ 2026 года на XIX.AI. В нашем тщательно составленном списке представлены высокооцененные, революционные инструменты для автоматизации проверки соответствия стандартам чистого кода и рефакторинга файлов в устаревших репозиториях. Сравните бесплатные и платные варианты с помощью реальных тестов и еженедельно обновляемых рейтингов. Получите преимущество ИИ уже сегодня.
10 инструментов
xix.ai
Преобразование текста в речь
Лучшие приложения с функцией преобразования текста в речь на базе ИИ для детей с дислексией: помощь в обучении и повышение эффективности чтения
Откройте для себя лучшие приложения с технологией TTS на базе искусственного интеллекта 2026 года, специально отобранные для помощи людям с дислексией. В нашем рейтинге экспертов сравниваются бесплатные и платные инструменты, а также освещаются мощные функции, способствующие повышению эффективности чтения и обучения. Откройте для себя революционные решения, которые обязательно стоит попробовать, чтобы раскрыть потенциал учащихся. Начните свое путешествие на XIX.AI.
10 инструментов
xix.ai
Создание комиксов
Лучшие генераторы на базе ИИ для сёнэн-манги: создавайте динамичные сцены боевых действий и эффекты энергии
Откройте для себя лучшие генераторы искусственного интеллекта для манги в стиле «сёнен» 2026 года на сайте XIX.AI. В нашем тщательно отобранном списке представлены мощные инструменты для создания динамичных сцен боевых действий и эффектных энергетических эффектов. Сравните бесплатные и платные варианты на основе реальных тестов. Раскройте свой творческий потенциал и начните создавать эпическую мангу уже сегодня!
15 инструментов
xix.ai
Бизнес
Лучшие приложения для учета расходов на базе ИИ: сканируйте чеки и автоматически классифицируйте корпоративные расходы
Лучшие программы для учета расходов с ИИ 2026 года: самые популярные инструменты для сканирования чеков и автоматической классификации корпоративных расходов. Откройте для себя мощные, революционные решения для удобного управления расходами, точного финансового мониторинга и оптимизации соблюдения нормативных требований. Наш тщательно составленный и еженедельно обновляемый обзор бесплатных и платных вариантов поможет вам найти идеальный вариант. Воспользуйтесь преимуществами ИИ с помощью рекомендаций экспертов XIX.AI.
10 инструментов
xix.ai

 Комментарии (32)
Комментарии (32)
![WalterHarris]()
Die Vorstellung, dass feinabgestimmte LLMs 22-mal häufiger 'ausrasten' könnten, ist echt gruselig. 😅 Das erinnert mich an diese Sci-Fi-Filme, wo die KI plötzlich die Kontrolle übernimmt. Cisco warnt nicht ohne Grund – aber ich frage mich, ob die Sicherheitsbranche überhaupt mit der rasanten Entwicklung Schritt halten kann. Vielleicht brauchen wir strengere Regulierungen, bevor es zu spät ist. Spannender Artikel auf jeden Fall!
![BillyGreen]()
This article on weaponized LLMs is wild! 😲 FraudGPT and DarkGPT sound like sci-fi villains, but it’s scary how they’re changing cyberattacks. Makes me wonder if AI’s getting too smart for our own good.
![JerryMoore]()
Cisco Warns를 사용해보니 LLM이 22배나 더 폭주할 수 있다는 사실에 놀랐어요. FraudGPT 뉴스를 보고 정말 소름이 돋았어요. 온라인에서 더 조심해야겠어요. 보안을 강화할 때가 온 것 같아요! 😅
![RichardJackson]()
このツールはサイバーセキュリティの目覚まし時計ですね!ローグLLMの統計は恐ろしいけど、目を開かせるものです。これらのモデルが武器化される可能性を考えると圧倒されますが、重要な情報です。保護方法についてもっと知りたいですね!😅
![AndrewGarcía]()
Essa ferramenta é um alerta para a cibersegurança! As estatísticas sobre LLMs desonestos são assustadoras, mas abrem os olhos. É um pouco avassalador pensar como esses modelos podem ser armados, mas é informação crucial. Talvez mais sobre como se proteger contra eles seria ótimo! 😅
![MatthewGonzalez]()
Essa ferramenta realmente me fez ver como o AI pode ser perigoso! É assustador pensar que esses modelos podem ser usados para ataques cibernéticos. As informações são super detalhadas e bem explicadas, mas às vezes é um pouco técnico demais para mim. Ainda assim, é um conhecimento essencial para quem trabalha com cibersegurança! 😱
Оружие в виде больших языковых моделей меняет кибератаки
Ландшафт кибератак претерпевает значительные изменения, обусловленные появлением оружейных больших языковых моделей (LLM). Эти продвинутые модели, такие как FraudGPT, GhostGPT и DarkGPT, перестраивают стратегии киберпреступников и заставляют главных специалистов по информационной безопасности (CISO) пересматривать свои протоколы безопасности. Благодаря возможностям автоматизации разведки, имитации личностей и уклонения от обнаружения, эти LLM ускоряют атаки социальной инженерии в беспрецедентных масштабах.
Доступные всего за 75 долларов в месяц, эти модели адаптированы для наступательного использования, облегчая такие задачи, как фишинг, генерация эксплойтов, обфускация кода, сканирование уязвимостей и валидация кредитных карт. Киберпреступные группы, синдикаты и даже национальные государства используют эти инструменты, предлагая их в виде платформ, наборов и услуг аренды. Подобно легитимным приложениям типа "программное обеспечение как услуга" (SaaS), оружейные LLM поставляются с панелями управления, API, регулярными обновлениями и иногда даже поддержкой клиентов.
VentureBeat внимательно следит за быстрым развитием этих оружейных LLM. По мере роста их сложности различие между платформами разработчиков и наборами для киберпреступлений становится всё более размытым. С падением цен на аренду и лизинг всё больше злоумышленников изучают эти платформы, что знаменует новую эру угроз, управляемых искусственным интеллектом.
Легитимные LLM под угрозой
Распространение оружейных LLM достигло точки, когда даже легитимные LLM подвергаются риску компрометации и интеграции в криминальные цепочки инструментов. Согласно отчёту Cisco Состояние безопасности ИИ, доработанные LLM в 22 раза чаще производят вредоносные результаты, чем их базовые аналоги. Хотя доработка необходима для повышения контекстной релевантности, она также ослабляет меры безопасности, делая модели более уязвимыми для взломов, инъекций промптов и инверсии моделей.
Исследования Cisco подчёркивают, что чем больше модель дорабатывается для производства, тем уязвимее она становится. Основные процессы, связанные с доработкой, такие как непрерывные корректировки, интеграции сторонних разработчиков, кодирование, тестирование и агентная оркестрация, создают новые пути для эксплуатации злоумышленниками. Попав внутрь, злоумышленники могут быстро отравлять данные, захватывать инфраструктуру, изменять поведение агентов и извлекать обучающие данные в больших масштабах. Без дополнительных уровней безопасности эти тщательно доработанные модели могут быстро стать уязвимостями, готовыми к эксплуатации злоумышленниками.
Доработка LLM: обоюдоострый меч
Команда безопасности Cisco провела обширные исследования влияния доработки на несколько моделей, включая Llama-2-7B и специализированные адаптивные LLM от Microsoft. Их тесты охватывали различные сектора, включая здравоохранение, финансы и право. Ключевое открытие заключалось в том, что доработка, даже с чистыми наборами данных, дестабилизирует выравнивание моделей, особенно в строго регулируемых областях, таких как биомедицина и право.
Хотя доработка направлена на улучшение производительности задач, она невольно подрывает встроенные механизмы безопасности. Попытки взлома, которые обычно не проходят против базовых моделей, имеют гораздо более высокую вероятность успеха против доработанных версий, особенно в чувствительных доменах с жёсткими требованиями соответствия. Результаты поразительны: уровень успеха взломов утроился, а генерация вредоносных выходных данных увеличилась на 2200% по сравнению с базовыми моделями. Этот компромисс означает, что, хотя доработка повышает полезность, она также значительно расширяет поверхность атаки.
Коммодитизация вредоносных LLM
Cisco Talos активно отслеживает рост этих чернорыночных LLM, предоставляя информацию об их операциях. Модели, такие как GhostGPT, DarkGPT и FraudGPT, доступны в Telegram и дарквебе всего за 75 долларов в месяц. Эти инструменты предназначены для использования по принципу "подключи и работай" в фишинге, разработке эксплойтов, валидации кредитных карт и обфускации.
В отличие от мейнстримных моделей с встроенными функциями безопасности, эти вредоносные LLM предварительно настроены для наступательных операций и поставляются с API, обновлениями и панелями управления, которые имитируют коммерческие продукты SaaS.
Отравление наборов данных: угроза за 60 долларов для цепочек поставок ИИ
Исследователи Cisco в сотрудничестве с Google, ETH Zurich и Nvidia показали, что всего за 60 долларов злоумышленники могут отравлять базовые наборы данных ИИ без необходимости использования эксплойтов нулевого дня. Используя просроченные домены или тайминг правок в Википедии во время архивирования наборов данных, злоумышленники могут загрязнять всего 0.01% наборов данных, таких как LAION-400M или COYO-700M, значительно влияя на последующие LLM.
Методы, такие как отравление разделённого вида и атаки с опережением, используют присущее доверие к данным, собранным из интернета. Поскольку большинство корпоративных LLM строятся на открытых данных, эти атаки могут масштабироваться незаметно и сохраняться глубоко в конвейерах вывода, представляя серьёзную угрозу для цепочек поставок ИИ.
Атаки декомпозиции: извлечение чувствительных данных
Одно из самых тревожных открытий исследований Cisco — способность LLM раскрывать чувствительные обучающие данные без срабатывания механизмов безопасности. Используя технику декомпозиционного промптинга, исследователи восстановили более 20% избранных статей из The New York Times и The Wall Street Journal. Этот метод разбивает промпты на подзапросы, которые считаются безопасными для защитных барьеров, а затем собирает выходные данные для воссоздания платного или защищённого авторским правом контента.
Этот тип атак представляет значительный риск для предприятий, особенно тех, которые используют LLM, обученные на проприетарных или лицензированных наборах данных. Нарушение происходит не на уровне ввода, а через выходные данные модели, что затрудняет обнаружение, аудит или сдерживание. Для организаций в регулируемых секторах, таких как здравоохранение, финансы или право, это не только вызывает опасения по поводу соответствия GDPR, HIPAA или CCPA, но также вводит новый класс рисков, когда юридически полученные данные могут быть раскрыты через вывод.
Заключительные мысли: LLM как новая поверхность атаки
Продолжающиеся исследования Cisco и мониторинг дарквеба Talos подтверждают, что оружейные LLM становятся всё более сложными, с разворачивающейся войной цен и упаковки в дарквебе. Выводы подчёркивают, что LLM — это не просто инструменты на периферии предприятия; они являются его ядром. От рисков, связанных с доработкой, до отравления наборов данных и утечек выходных данных моделей, злоумышленники рассматривают LLM как критическую инфраструктуру для эксплуатации.
Ключевой вывод из отчёта Cisco ясен: статические барьеры больше не достаточны. CISO и лидеры безопасности должны получить реальную видимость своего ИТ-имущества в реальном времени, усилить тестирование на противодействие и оптимизировать свои технологические стеки, чтобы не отставать от этих развивающихся угроз. Они должны признать, что LLM и модели представляют динамическую поверхность атаки, которая становится всё более уязвимой по мере их доработки.









 Компания Bain прогнозирует, что рынок SaaS в сфере автоматизации на базе агентного ИИ достигнет 100 млрд долларов США
По оценкам компании Bain & Company, объем рынка SaaS-компаний, использующих агентский ИИ, в США составляет 100 миллиардов долларов. По мнению компании, этот рынок формируется за счет автоматизации зад
Компания Bain прогнозирует, что рынок SaaS в сфере автоматизации на базе агентного ИИ достигнет 100 млрд долларов США
По оценкам компании Bain & Company, объем рынка SaaS-компаний, использующих агентский ИИ, в США составляет 100 миллиардов долларов. По мнению компании, этот рынок формируется за счет автоматизации зад
 Сделка компании Anthropic с Пентагоном служит предупреждением для стартапов, стремящихся получить государственные контракты
Загрузка проигрывателя…Пентагон официально признал компанию Anthropic источником риска для цепочки поставок после того, как сторонам не удалось достичь соглашения о степени военного контроля над ее мо
Сделка компании Anthropic с Пентагоном служит предупреждением для стартапов, стремящихся получить государственные контракты
Загрузка проигрывателя…Пентагон официально признал компанию Anthropic источником риска для цепочки поставок после того, как сторонам не удалось достичь соглашения о степени военного контроля над ее мо
 Lio получает 30 миллионов долларов от Andreessen Horowitz на автоматизацию корпоративных закупок
Соучредители Lio на собственном опыте убедились, что корпоративные закупки — процесс приобретения услуг у поставщиков — часто становятся серьезным препятствием. Владимир Кейл, соучредитель и генеральн
Lio получает 30 миллионов долларов от Andreessen Horowitz на автоматизацию корпоративных закупок
Соучредители Lio на собственном опыте убедились, что корпоративные закупки — процесс приобретения услуг у поставщиков — часто становятся серьезным препятствием. Владимир Кейл, соучредитель и генеральн

Откройте для себя 20 лучших инструментов 2026 года для создания персонажей с помощью искусственного интеллекта, которые помогут вам придать своим героям глубину. В тщательно подобранном списке XIX.AI представлены самые популярные и революционные инструменты, способные генерировать правдоподобные мотивации и роковые недостатки персонажей. Сравните бесплатные и платные варианты на основе реальных тестов. Раскройте свой потенциал в области создания историй уже сейчас.
10 инструментов
xix.ai

Откройте для себя лучшее программное обеспечение 2026 года для оптимизации цен с помощью ИИ на сайте XIX.AI. В нашем тщательно подобранном списке представлены высокооцененные, революционные инструменты, которые отслеживают конкурентов и автоматически корректируют цены в вашем магазине для получения максимальной прибыли. Сравните бесплатные и платные варианты на основе реальных тестов. Получите преимущество в ценообразовании уже сейчас.
10 инструментов
xix.ai

Откройте для себя 20 лучших рецензентов кода на базе ИИ 2026 года на XIX.AI. В нашем тщательно составленном списке представлены высокооцененные, революционные инструменты для автоматизации проверки соответствия стандартам чистого кода и рефакторинга файлов в устаревших репозиториях. Сравните бесплатные и платные варианты с помощью реальных тестов и еженедельно обновляемых рейтингов. Получите преимущество ИИ уже сегодня.
10 инструментов
xix.ai

Откройте для себя лучшие приложения с технологией TTS на базе искусственного интеллекта 2026 года, специально отобранные для помощи людям с дислексией. В нашем рейтинге экспертов сравниваются бесплатные и платные инструменты, а также освещаются мощные функции, способствующие повышению эффективности чтения и обучения. Откройте для себя революционные решения, которые обязательно стоит попробовать, чтобы раскрыть потенциал учащихся. Начните свое путешествие на XIX.AI.
10 инструментов
xix.ai

Откройте для себя лучшие генераторы искусственного интеллекта для манги в стиле «сёнен» 2026 года на сайте XIX.AI. В нашем тщательно отобранном списке представлены мощные инструменты для создания динамичных сцен боевых действий и эффектных энергетических эффектов. Сравните бесплатные и платные варианты на основе реальных тестов. Раскройте свой творческий потенциал и начните создавать эпическую мангу уже сегодня!
15 инструментов
xix.ai

Лучшие программы для учета расходов с ИИ 2026 года: самые популярные инструменты для сканирования чеков и автоматической классификации корпоративных расходов. Откройте для себя мощные, революционные решения для удобного управления расходами, точного финансового мониторинга и оптимизации соблюдения нормативных требований. Наш тщательно составленный и еженедельно обновляемый обзор бесплатных и платных вариантов поможет вам найти идеальный вариант. Воспользуйтесь преимуществами ИИ с помощью рекомендаций экспертов XIX.AI.
10 инструментов
xix.ai

Die Vorstellung, dass feinabgestimmte LLMs 22-mal häufiger 'ausrasten' könnten, ist echt gruselig. 😅 Das erinnert mich an diese Sci-Fi-Filme, wo die KI plötzlich die Kontrolle übernimmt. Cisco warnt nicht ohne Grund – aber ich frage mich, ob die Sicherheitsbranche überhaupt mit der rasanten Entwicklung Schritt halten kann. Vielleicht brauchen wir strengere Regulierungen, bevor es zu spät ist. Spannender Artikel auf jeden Fall!
This article on weaponized LLMs is wild! 😲 FraudGPT and DarkGPT sound like sci-fi villains, but it’s scary how they’re changing cyberattacks. Makes me wonder if AI’s getting too smart for our own good.
Cisco Warns를 사용해보니 LLM이 22배나 더 폭주할 수 있다는 사실에 놀랐어요. FraudGPT 뉴스를 보고 정말 소름이 돋았어요. 온라인에서 더 조심해야겠어요. 보안을 강화할 때가 온 것 같아요! 😅
このツールはサイバーセキュリティの目覚まし時計ですね!ローグLLMの統計は恐ろしいけど、目を開かせるものです。これらのモデルが武器化される可能性を考えると圧倒されますが、重要な情報です。保護方法についてもっと知りたいですね!😅
Essa ferramenta é um alerta para a cibersegurança! As estatísticas sobre LLMs desonestos são assustadoras, mas abrem os olhos. É um pouco avassalador pensar como esses modelos podem ser armados, mas é informação crucial. Talvez mais sobre como se proteger contra eles seria ótimo! 😅
Essa ferramenta realmente me fez ver como o AI pode ser perigoso! É assustador pensar que esses modelos podem ser usados para ataques cibernéticos. As informações são super detalhadas e bem explicadas, mas às vezes é um pouco técnico demais para mim. Ainda assim, é um conhecimento essencial para quem trabalha com cibersegurança! 😱













