
















 家
家Cisco警告:微調整されたLLMSが22倍不正になる可能性が高い
# cisco
# LLMs
# APIs
# saas
# csco
# goog-2
# msft-2
# nvda-2
# darkgpt
# darkweb
# fraudgpt
# ghostgpt
# zeroday
武器化された大規模言語モデルがサイバー攻撃を再構築
サイバー攻撃の状況は、武器化された大規模言語モデル(LLMs)の出現によって大きな変革を遂げています。FraudGPT、GhostGPT、DarkGPTなどの先進的なモデルは、サイバー犯罪者の戦略を再構築し、最高情報セキュリティ責任者(CISOs)にセキュリティプロトコルの再考を迫っています。偵察の自動化、身元のなりすまし、検知の回避といった能力を持つこれらのLLMは、前例のない規模でソーシャルエンジニアリング攻撃を加速させています。
月額わずか75ドルで利用可能なこれらのモデルは、攻撃用途に特化しており、フィッシング、悪用コード生成、コード難読化、脆弱性スキャン、クレジットカード検証などのタスクを容易にします。サイバー犯罪グループ、シンジケート、さらには国家までもがこれらのツールを活用し、プラットフォーム、キット、リースサービスとして提供しています。正規のソフトウェア・アズ・ア・サービス(SaaS)アプリケーションと同様に、武器化されたLLMにはダッシュボード、API、定期的なアップデート、さらにはカスタマーサポートが付属しています。
VentureBeatは、これらの武器化されたLLMの急速な進化を注視しています。その洗練度が増すにつれ、開発者プラットフォームとサイバー犯罪キットの境界がますます曖昧になっています。リースやレンタル価格の低下に伴い、さらなる攻撃者がこれらのプラットフォームを探索し、AI駆動の脅威の新時代を告げています。
正規のLLMが脅威にさらされる
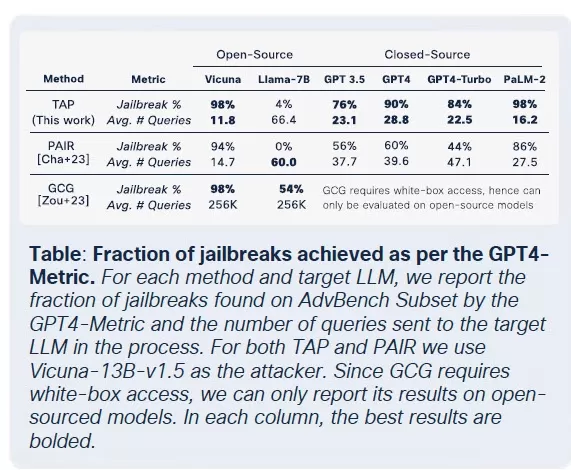
武器化されたLLMの急増は、正規のLLMでさえ犯罪ツールチェーンに組み込まれ、侵害されるリスクに直面する段階に達しています。CiscoのAIセキュリティの現状レポートによると、微調整されたLLMは、ベースモデルに比べて有害な出力を生成する可能性が22倍高いとされています。微調整は文脈の関連性を高めるために重要ですが、安全対策を弱め、モデルをジェイルブレイク、プロンプトインジェクション、モデル反転に対して脆弱にします。
Ciscoの研究では、モデルが本番用に精緻化されるほど脆弱性が増すことが強調されています。微調整に含まれる継続的な調整、サードパーティ統合、コーディング、テスト、エージェントオーケストレーションなどのコアプロセスは、攻撃者に悪用される新たな道を開きます。一旦侵入されると、攻撃者は迅速にデータを汚染し、インフラを乗っ取り、エージェントの動作を変更し、大規模に訓練データを抽出できます。追加のセキュリティ層がなければ、これらの慎重に微調整されたモデルは、攻撃者による悪用に適した負債となり得ます。
LLMの微調整:両刃の剣
Ciscoのセキュリティチームは、Llama-2-7BやMicrosoftのドメイン特化型Adapt LLMなど、複数のモデルに対する微調整の影響について広範な研究を行いました。テストは医療、金融、法律などさまざまな分野に及びました。主な発見は、クリーンデータセットを使用した微調整であっても、特に生物医学や法律などの厳格に規制された分野で、モデルの整合性を不安定にするというものでした。
微調整はタスクのパフォーマンス向上を目指していますが、組み込みの安全制御を意図せず損ないます。基盤モデルに対して通常失敗するジェイルブレイクの試みは、微調整されたバージョン、特に厳格なコンプライアンス要件がある敏感な領域で、はるかに高い成功率で成功します。結果は顕著で、ジェイルブレイクの成功率は3倍になり、悪意のある出力生成は基盤モデルに比べて2,200%増加しました。このトレードオフは、微調整が有用性を高める一方で、攻撃対象領域を大幅に広げることを意味します。
悪意のあるLLMの商品化
Cisco Talosは、ブラックマーケットのLLMの台頭を積極的に追跡し、その運用に関する洞察を提供しています。GhostGPT、DarkGPT、FraudGPTなどのモデルは、Telegramやダークウェブで月額わずか75ドルで入手可能です。これらのツールは、フィッシング、悪用開発、クレジットカード検証、難読化のためのプラグアンドプレイ用途に設計されています。
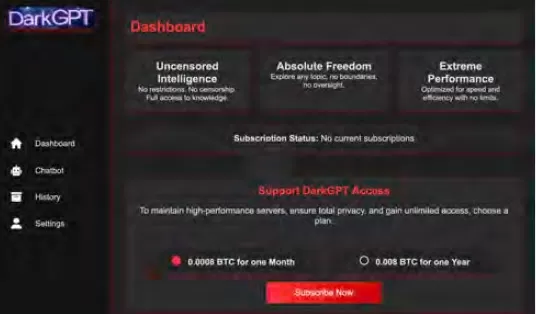
安全機能を備えた主流のモデルとは異なり、これらの悪意のあるLLMは攻撃的な操作用に事前設定されており、商用SaaS製品を模倣したAPI、アップデート、ダッシュボードが付属しています。
データセット汚染:AIサプライチェーンへの60ドルの脅威
Ciscoの研究者たちは、Google、ETH Zurich、Nvidiaと協力して、わずか60ドルで攻撃者がゼロデイ攻撃を必要とせずにAIモデルの基盤データセットを汚染できることを明らかにしました。期限切れのドメインを悪用したり、データセットのアーカイブ中にWikipediaの編集をタイミングよく行うことで、攻撃者はLAION-400MやCOYO-700Mなどのデータセットのわずか0.01%を汚染し、下流のLLMに大きな影響を与えることができます。
スプリットビュー汚染やフロントランニング攻撃などの手法は、ウェブクロールデータへの固有の信頼を悪用します。ほとんどの企業向けLLMがオープンデータに基づいて構築されているため、これらの攻撃は静かにスケールし、推論パイプラインの奥深くまで持続し、AIサプライチェーンに深刻な脅威をもたらします。
分解攻撃:機密データの抽出
Ciscoの研究から最も懸念される発見の一つは、LLMが安全メカニズムをトリガーせずに機密性の高い訓練データを漏洩する能力です。分解プロンプティングと呼ばれる技術を使用し、研究者はThe New York TimesやThe Wall Street Journalから選ばれた記事の20%以上を再構築しました。この手法は、プロンプトをガードレールが安全とみなすサブクエリに分解し、出力結果を再組み立てしてペイウォールや著作権で保護されたコンテンツを再作成します。
この種の攻撃は、独自またはライセンスされたデータセットで訓練されたLLMを使用する企業にとって重大なリスクをもたらします。侵害は入力レベルではなく、モデルの出力を通じて発生するため、検知、監査、封じ込めが困難です。医療、金融、法律などの規制されたセクターの組織にとって、これはGDPR、HIPAA、CCPAのコンプライアンスに関する懸念だけでなく、合法的に取得されたデータが推論を通じて暴露される新たなリスククラスを導入します。
最終的な考察:新たな攻撃対象としてのLLM
Ciscoの継続的な研究とTalosのダークウェブ監視により、武器化されたLLMがますます洗練され、ダークウェブ上で価格とパッケージングの競争が展開されていることが確認されています。この発見は、LLMが企業の端にあるツールにとどまらず、その中核に不可欠であることを強調しています。微調整に伴うリスクからデータセット汚染、モデル出力漏洩に至るまで、攻撃者はLLMを悪用すべき重要なインフラと見なしています。
Ciscoのレポートの主なポイントは明らかです:静的なガードレールはもはや十分ではありません。CISOとセキュリティリーダーは、IT全体でリアルタイムの可視性を獲得し、敵対的テストを強化し、進化する脅威に対応するために技術スタックを合理化する必要があります。LLMとモデルは、微調整されるにつれてますます脆弱になる動的な攻撃対象であることを認識しなければなりません。
関連記事
 ベイン・アンド・カンパニーは、エージェント型AIオートメーションのSaaS市場規模が1,000億米ドルに達すると予測している
ベイン・アンド・カンパニーは、エージェント型AIを活用するSaaS企業向けの米国市場規模を1,000億ドルと推計している。同社によると、この市場は企業システム内の調整業務の自動化によって生まれるという。この推計は、AI時代のソフトウェア業界に関するベインの5回シリーズ第2弾に基づくものである。同レポートでは、エージェント型AIがどのような新たなソフトウェア市場を切り拓く可能性があり、SaaSプロバ
Anthropicの国防総省との契約は、政府との契約を目指すスタートアップ企業にとっての警鐘となる
プレイヤーを読み込んでいます…米国防総省は、自律型兵器や国内での広範な監視への利用可能性を含め、AIモデルに対する軍の統制範囲について両者が合意に至らなかったことを受け、Anthropicをサプライチェーン上のリスクとして正式に指定した。 Anthropicとの2億ドル規模の契約が破談となった後、国防総省はOpenAIに白羽の矢を立てた。OpenAIは契約を受け入れたが、その後ChatGPTのアン
リオ、企業調達業務の自動化に向けアンドリーセン・ホロウィッツから3000万ドルを調達
リオの共同創業者たちは、ベンダーからサービスを購入するプロセスである企業調達がいかに大きなボトルネックになり得るかを直接目撃してきた。共同創業者兼CEOのウラジミール・カイルは、大企業での勤務経験と、その後立ち上げた最初のスタートアップ経営の両方でこの問題に直面した。「エンタープライズソフトウェアを販売していた当時、自ら調達プロセスを経験し、その手作業的で断片化された現状を目の当たりにした」と彼は
関連特集おすすめ
仕事
ベイン・アンド・カンパニーは、エージェント型AIオートメーションのSaaS市場規模が1,000億米ドルに達すると予測している
ベイン・アンド・カンパニーは、エージェント型AIを活用するSaaS企業向けの米国市場規模を1,000億ドルと推計している。同社によると、この市場は企業システム内の調整業務の自動化によって生まれるという。この推計は、AI時代のソフトウェア業界に関するベインの5回シリーズ第2弾に基づくものである。同レポートでは、エージェント型AIがどのような新たなソフトウェア市場を切り拓く可能性があり、SaaSプロバ
Anthropicの国防総省との契約は、政府との契約を目指すスタートアップ企業にとっての警鐘となる
プレイヤーを読み込んでいます…米国防総省は、自律型兵器や国内での広範な監視への利用可能性を含め、AIモデルに対する軍の統制範囲について両者が合意に至らなかったことを受け、Anthropicをサプライチェーン上のリスクとして正式に指定した。 Anthropicとの2億ドル規模の契約が破談となった後、国防総省はOpenAIに白羽の矢を立てた。OpenAIは契約を受け入れたが、その後ChatGPTのアン
リオ、企業調達業務の自動化に向けアンドリーセン・ホロウィッツから3000万ドルを調達
リオの共同創業者たちは、ベンダーからサービスを購入するプロセスである企業調達がいかに大きなボトルネックになり得るかを直接目撃してきた。共同創業者兼CEOのウラジミール・カイルは、大企業での勤務経験と、その後立ち上げた最初のスタートアップ経営の両方でこの問題に直面した。「エンタープライズソフトウェアを販売していた当時、自ら調達プロセスを経験し、その手作業的で断片化された現状を目の当たりにした」と彼は
関連特集おすすめ
仕事
 AIを活用した価格最適化ソフトのトップ選定:競合他社の動向を追跡し、店舗価格を自動調整
AIを活用した価格最適化ソフトのトップ選定:競合他社の動向を追跡し、店舗価格を自動調整
XIX.AIで、2026年最高のAI価格最適化ソフトウェアを見つけましょう。厳選されたリストには、競合他社の動向を追跡し、利益を最大化するために店舗の価格を自動調整する、高評価の画期的なツールが揃っています。実際のテスト結果をもとに、無料版と有料版を比較してください。今すぐ価格設定における優位性を手に入れましょう。
 10 ツール
10 ツール
 xix.ai
コード
最高のAIコードレビューツール:クリーンコードの遵守を自動化し、レガシーリポジトリのファイルをリファクタリング
xix.ai
コード
最高のAIコードレビューツール:クリーンコードの遵守を自動化し、レガシーリポジトリのファイルをリファクタリング
XIX.AIで、2026年最高のAIコードレビューツールを発見しましょう。厳選されたこのリストには、クリーンなコードの遵守を自動化し、レガシーリポジトリのファイルをリファクタリングするための、高評価で画期的なツールが揃っています。実際のテスト結果や毎週更新されるランキングを参考に、無料版と有料版を比較してください。今すぐAIの力を活用しましょう。
10 ツール
xix.ai
テキスト読み上げ
ディスレクシアに最適なAI音声合成アプリ:生徒の学習と読解力の向上をサポート
ディスレクシア支援のために厳選された、2026年最新の最高評価AI TTSアプリをご紹介します。専門家によるランキングでは、無料ツールと有料ツールを比較し、読解効率と学習効果を高める強力な機能を詳しく解説しています。生徒の可能性を引き出す、ぜひ試すべき画期的なソリューションをご覧ください。XIX.AIでその第一歩を踏み出しましょう。
10 ツール
xix.ai
漫画制作
少年漫画向けトップAIジェネレーター:迫力満点のアクションシーンやエネルギーエフェクトを作成
XIX.AIで、2026年のおすすめ少年漫画向けAIジェネレーターをご紹介します。厳選されたトップクラスのリストには、迫力満点のアクションシーンや躍動感あふれるエフェクトを作成できる強力なツールが揃っています。実際のテスト結果をもとに、無料版と有料版の比較も可能です。あなたの創造力を解き放ち、今日から壮大な漫画の制作を始めましょう!
15 ツール
xix.ai
仕事
おすすめのAI経費管理ツール:レシートをスキャンして、業務経費を自動分類
2026年最新・最高のAI経費管理ツール:レシートをスキャンし、法人経費を自動分類する高評価ツールをご紹介。手間いらずの経費管理、正確な財務追跡、コンプライアンス対応の効率化を実現する、画期的なソリューションをご覧ください。無料版と有料版の比較表は厳選され、毎週更新されるため、最適なツール選びにお役立ていただけます。XIX.AIの専門家が厳選したツールで、AIの力を最大限に活用しましょう。
10 ツール
xix.ai
仕事
おすすめのAI採用ツール:履歴書の選考と候補者の面接スケジュール管理を自動化
XIX.AIで、2026年最新の評価の高いAI採用ツールをチェックしましょう。厳選されたリストには、履歴書のスクリーニングや候補者の面接スケジュール管理を自動化する、強力で画期的なソリューションが揃っています。実際のテスト結果や毎週更新されるランキングを参考に、無料版と有料版の比較が可能です。最適な採用アシスタントを見つけて、今すぐ採用業務を効率化しましょう!
10 ツール
xix.ai

 コメント (32)
0/500
コメント (32)
0/500
![WalterHarris]()
Die Vorstellung, dass feinabgestimmte LLMs 22-mal häufiger 'ausrasten' könnten, ist echt gruselig. 😅 Das erinnert mich an diese Sci-Fi-Filme, wo die KI plötzlich die Kontrolle übernimmt. Cisco warnt nicht ohne Grund – aber ich frage mich, ob die Sicherheitsbranche überhaupt mit der rasanten Entwicklung Schritt halten kann. Vielleicht brauchen wir strengere Regulierungen, bevor es zu spät ist. Spannender Artikel auf jeden Fall!
![BillyGreen]()
This article on weaponized LLMs is wild! 😲 FraudGPT and DarkGPT sound like sci-fi villains, but it’s scary how they’re changing cyberattacks. Makes me wonder if AI’s getting too smart for our own good.
![JerryMoore]()
Cisco Warns를 사용해보니 LLM이 22배나 더 폭주할 수 있다는 사실에 놀랐어요. FraudGPT 뉴스를 보고 정말 소름이 돋았어요. 온라인에서 더 조심해야겠어요. 보안을 강화할 때가 온 것 같아요! 😅
![RichardJackson]()
このツールはサイバーセキュリティの目覚まし時計ですね!ローグLLMの統計は恐ろしいけど、目を開かせるものです。これらのモデルが武器化される可能性を考えると圧倒されますが、重要な情報です。保護方法についてもっと知りたいですね!😅
![AndrewGarcía]()
Essa ferramenta é um alerta para a cibersegurança! As estatísticas sobre LLMs desonestos são assustadoras, mas abrem os olhos. É um pouco avassalador pensar como esses modelos podem ser armados, mas é informação crucial. Talvez mais sobre como se proteger contra eles seria ótimo! 😅
![MatthewGonzalez]()
Essa ferramenta realmente me fez ver como o AI pode ser perigoso! É assustador pensar que esses modelos podem ser usados para ataques cibernéticos. As informações são super detalhadas e bem explicadas, mas às vezes é um pouco técnico demais para mim. Ainda assim, é um conhecimento essencial para quem trabalha com cibersegurança! 😱
武器化された大規模言語モデルがサイバー攻撃を再構築
サイバー攻撃の状況は、武器化された大規模言語モデル(LLMs)の出現によって大きな変革を遂げています。FraudGPT、GhostGPT、DarkGPTなどの先進的なモデルは、サイバー犯罪者の戦略を再構築し、最高情報セキュリティ責任者(CISOs)にセキュリティプロトコルの再考を迫っています。偵察の自動化、身元のなりすまし、検知の回避といった能力を持つこれらのLLMは、前例のない規模でソーシャルエンジニアリング攻撃を加速させています。
月額わずか75ドルで利用可能なこれらのモデルは、攻撃用途に特化しており、フィッシング、悪用コード生成、コード難読化、脆弱性スキャン、クレジットカード検証などのタスクを容易にします。サイバー犯罪グループ、シンジケート、さらには国家までもがこれらのツールを活用し、プラットフォーム、キット、リースサービスとして提供しています。正規のソフトウェア・アズ・ア・サービス(SaaS)アプリケーションと同様に、武器化されたLLMにはダッシュボード、API、定期的なアップデート、さらにはカスタマーサポートが付属しています。
VentureBeatは、これらの武器化されたLLMの急速な進化を注視しています。その洗練度が増すにつれ、開発者プラットフォームとサイバー犯罪キットの境界がますます曖昧になっています。リースやレンタル価格の低下に伴い、さらなる攻撃者がこれらのプラットフォームを探索し、AI駆動の脅威の新時代を告げています。
正規のLLMが脅威にさらされる
武器化されたLLMの急増は、正規のLLMでさえ犯罪ツールチェーンに組み込まれ、侵害されるリスクに直面する段階に達しています。CiscoのAIセキュリティの現状レポートによると、微調整されたLLMは、ベースモデルに比べて有害な出力を生成する可能性が22倍高いとされています。微調整は文脈の関連性を高めるために重要ですが、安全対策を弱め、モデルをジェイルブレイク、プロンプトインジェクション、モデル反転に対して脆弱にします。
Ciscoの研究では、モデルが本番用に精緻化されるほど脆弱性が増すことが強調されています。微調整に含まれる継続的な調整、サードパーティ統合、コーディング、テスト、エージェントオーケストレーションなどのコアプロセスは、攻撃者に悪用される新たな道を開きます。一旦侵入されると、攻撃者は迅速にデータを汚染し、インフラを乗っ取り、エージェントの動作を変更し、大規模に訓練データを抽出できます。追加のセキュリティ層がなければ、これらの慎重に微調整されたモデルは、攻撃者による悪用に適した負債となり得ます。
LLMの微調整:両刃の剣
Ciscoのセキュリティチームは、Llama-2-7BやMicrosoftのドメイン特化型Adapt LLMなど、複数のモデルに対する微調整の影響について広範な研究を行いました。テストは医療、金融、法律などさまざまな分野に及びました。主な発見は、クリーンデータセットを使用した微調整であっても、特に生物医学や法律などの厳格に規制された分野で、モデルの整合性を不安定にするというものでした。
微調整はタスクのパフォーマンス向上を目指していますが、組み込みの安全制御を意図せず損ないます。基盤モデルに対して通常失敗するジェイルブレイクの試みは、微調整されたバージョン、特に厳格なコンプライアンス要件がある敏感な領域で、はるかに高い成功率で成功します。結果は顕著で、ジェイルブレイクの成功率は3倍になり、悪意のある出力生成は基盤モデルに比べて2,200%増加しました。このトレードオフは、微調整が有用性を高める一方で、攻撃対象領域を大幅に広げることを意味します。
悪意のあるLLMの商品化
Cisco Talosは、ブラックマーケットのLLMの台頭を積極的に追跡し、その運用に関する洞察を提供しています。GhostGPT、DarkGPT、FraudGPTなどのモデルは、Telegramやダークウェブで月額わずか75ドルで入手可能です。これらのツールは、フィッシング、悪用開発、クレジットカード検証、難読化のためのプラグアンドプレイ用途に設計されています。
安全機能を備えた主流のモデルとは異なり、これらの悪意のあるLLMは攻撃的な操作用に事前設定されており、商用SaaS製品を模倣したAPI、アップデート、ダッシュボードが付属しています。
データセット汚染:AIサプライチェーンへの60ドルの脅威
Ciscoの研究者たちは、Google、ETH Zurich、Nvidiaと協力して、わずか60ドルで攻撃者がゼロデイ攻撃を必要とせずにAIモデルの基盤データセットを汚染できることを明らかにしました。期限切れのドメインを悪用したり、データセットのアーカイブ中にWikipediaの編集をタイミングよく行うことで、攻撃者はLAION-400MやCOYO-700Mなどのデータセットのわずか0.01%を汚染し、下流のLLMに大きな影響を与えることができます。
スプリットビュー汚染やフロントランニング攻撃などの手法は、ウェブクロールデータへの固有の信頼を悪用します。ほとんどの企業向けLLMがオープンデータに基づいて構築されているため、これらの攻撃は静かにスケールし、推論パイプラインの奥深くまで持続し、AIサプライチェーンに深刻な脅威をもたらします。
分解攻撃:機密データの抽出
Ciscoの研究から最も懸念される発見の一つは、LLMが安全メカニズムをトリガーせずに機密性の高い訓練データを漏洩する能力です。分解プロンプティングと呼ばれる技術を使用し、研究者はThe New York TimesやThe Wall Street Journalから選ばれた記事の20%以上を再構築しました。この手法は、プロンプトをガードレールが安全とみなすサブクエリに分解し、出力結果を再組み立てしてペイウォールや著作権で保護されたコンテンツを再作成します。
この種の攻撃は、独自またはライセンスされたデータセットで訓練されたLLMを使用する企業にとって重大なリスクをもたらします。侵害は入力レベルではなく、モデルの出力を通じて発生するため、検知、監査、封じ込めが困難です。医療、金融、法律などの規制されたセクターの組織にとって、これはGDPR、HIPAA、CCPAのコンプライアンスに関する懸念だけでなく、合法的に取得されたデータが推論を通じて暴露される新たなリスククラスを導入します。
最終的な考察:新たな攻撃対象としてのLLM
Ciscoの継続的な研究とTalosのダークウェブ監視により、武器化されたLLMがますます洗練され、ダークウェブ上で価格とパッケージングの競争が展開されていることが確認されています。この発見は、LLMが企業の端にあるツールにとどまらず、その中核に不可欠であることを強調しています。微調整に伴うリスクからデータセット汚染、モデル出力漏洩に至るまで、攻撃者はLLMを悪用すべき重要なインフラと見なしています。
Ciscoのレポートの主なポイントは明らかです:静的なガードレールはもはや十分ではありません。CISOとセキュリティリーダーは、IT全体でリアルタイムの可視性を獲得し、敵対的テストを強化し、進化する脅威に対応するために技術スタックを合理化する必要があります。LLMとモデルは、微調整されるにつれてますます脆弱になる動的な攻撃対象であることを認識しなければなりません。









 ベイン・アンド・カンパニーは、エージェント型AIオートメーションのSaaS市場規模が1,000億米ドルに達すると予測している
ベイン・アンド・カンパニーは、エージェント型AIを活用するSaaS企業向けの米国市場規模を1,000億ドルと推計している。同社によると、この市場は企業システム内の調整業務の自動化によって生まれるという。この推計は、AI時代のソフトウェア業界に関するベインの5回シリーズ第2弾に基づくものである。同レポートでは、エージェント型AIがどのような新たなソフトウェア市場を切り拓く可能性があり、SaaSプロバ
ベイン・アンド・カンパニーは、エージェント型AIオートメーションのSaaS市場規模が1,000億米ドルに達すると予測している
ベイン・アンド・カンパニーは、エージェント型AIを活用するSaaS企業向けの米国市場規模を1,000億ドルと推計している。同社によると、この市場は企業システム内の調整業務の自動化によって生まれるという。この推計は、AI時代のソフトウェア業界に関するベインの5回シリーズ第2弾に基づくものである。同レポートでは、エージェント型AIがどのような新たなソフトウェア市場を切り拓く可能性があり、SaaSプロバ
 Anthropicの国防総省との契約は、政府との契約を目指すスタートアップ企業にとっての警鐘となる
プレイヤーを読み込んでいます…米国防総省は、自律型兵器や国内での広範な監視への利用可能性を含め、AIモデルに対する軍の統制範囲について両者が合意に至らなかったことを受け、Anthropicをサプライチェーン上のリスクとして正式に指定した。 Anthropicとの2億ドル規模の契約が破談となった後、国防総省はOpenAIに白羽の矢を立てた。OpenAIは契約を受け入れたが、その後ChatGPTのアン
Anthropicの国防総省との契約は、政府との契約を目指すスタートアップ企業にとっての警鐘となる
プレイヤーを読み込んでいます…米国防総省は、自律型兵器や国内での広範な監視への利用可能性を含め、AIモデルに対する軍の統制範囲について両者が合意に至らなかったことを受け、Anthropicをサプライチェーン上のリスクとして正式に指定した。 Anthropicとの2億ドル規模の契約が破談となった後、国防総省はOpenAIに白羽の矢を立てた。OpenAIは契約を受け入れたが、その後ChatGPTのアン
 リオ、企業調達業務の自動化に向けアンドリーセン・ホロウィッツから3000万ドルを調達
リオの共同創業者たちは、ベンダーからサービスを購入するプロセスである企業調達がいかに大きなボトルネックになり得るかを直接目撃してきた。共同創業者兼CEOのウラジミール・カイルは、大企業での勤務経験と、その後立ち上げた最初のスタートアップ経営の両方でこの問題に直面した。「エンタープライズソフトウェアを販売していた当時、自ら調達プロセスを経験し、その手作業的で断片化された現状を目の当たりにした」と彼は
リオ、企業調達業務の自動化に向けアンドリーセン・ホロウィッツから3000万ドルを調達
リオの共同創業者たちは、ベンダーからサービスを購入するプロセスである企業調達がいかに大きなボトルネックになり得るかを直接目撃してきた。共同創業者兼CEOのウラジミール・カイルは、大企業での勤務経験と、その後立ち上げた最初のスタートアップ経営の両方でこの問題に直面した。「エンタープライズソフトウェアを販売していた当時、自ら調達プロセスを経験し、その手作業的で断片化された現状を目の当たりにした」と彼は

XIX.AIで、2026年最高のAI価格最適化ソフトウェアを見つけましょう。厳選されたリストには、競合他社の動向を追跡し、利益を最大化するために店舗の価格を自動調整する、高評価の画期的なツールが揃っています。実際のテスト結果をもとに、無料版と有料版を比較してください。今すぐ価格設定における優位性を手に入れましょう。
10 ツール
xix.ai

XIX.AIで、2026年最高のAIコードレビューツールを発見しましょう。厳選されたこのリストには、クリーンなコードの遵守を自動化し、レガシーリポジトリのファイルをリファクタリングするための、高評価で画期的なツールが揃っています。実際のテスト結果や毎週更新されるランキングを参考に、無料版と有料版を比較してください。今すぐAIの力を活用しましょう。
10 ツール
xix.ai

ディスレクシア支援のために厳選された、2026年最新の最高評価AI TTSアプリをご紹介します。専門家によるランキングでは、無料ツールと有料ツールを比較し、読解効率と学習効果を高める強力な機能を詳しく解説しています。生徒の可能性を引き出す、ぜひ試すべき画期的なソリューションをご覧ください。XIX.AIでその第一歩を踏み出しましょう。
10 ツール
xix.ai

XIX.AIで、2026年のおすすめ少年漫画向けAIジェネレーターをご紹介します。厳選されたトップクラスのリストには、迫力満点のアクションシーンや躍動感あふれるエフェクトを作成できる強力なツールが揃っています。実際のテスト結果をもとに、無料版と有料版の比較も可能です。あなたの創造力を解き放ち、今日から壮大な漫画の制作を始めましょう!
15 ツール
xix.ai

2026年最新・最高のAI経費管理ツール:レシートをスキャンし、法人経費を自動分類する高評価ツールをご紹介。手間いらずの経費管理、正確な財務追跡、コンプライアンス対応の効率化を実現する、画期的なソリューションをご覧ください。無料版と有料版の比較表は厳選され、毎週更新されるため、最適なツール選びにお役立ていただけます。XIX.AIの専門家が厳選したツールで、AIの力を最大限に活用しましょう。
10 ツール
xix.ai

XIX.AIで、2026年最新の評価の高いAI採用ツールをチェックしましょう。厳選されたリストには、履歴書のスクリーニングや候補者の面接スケジュール管理を自動化する、強力で画期的なソリューションが揃っています。実際のテスト結果や毎週更新されるランキングを参考に、無料版と有料版の比較が可能です。最適な採用アシスタントを見つけて、今すぐ採用業務を効率化しましょう!
10 ツール
xix.ai

Die Vorstellung, dass feinabgestimmte LLMs 22-mal häufiger 'ausrasten' könnten, ist echt gruselig. 😅 Das erinnert mich an diese Sci-Fi-Filme, wo die KI plötzlich die Kontrolle übernimmt. Cisco warnt nicht ohne Grund – aber ich frage mich, ob die Sicherheitsbranche überhaupt mit der rasanten Entwicklung Schritt halten kann. Vielleicht brauchen wir strengere Regulierungen, bevor es zu spät ist. Spannender Artikel auf jeden Fall!
This article on weaponized LLMs is wild! 😲 FraudGPT and DarkGPT sound like sci-fi villains, but it’s scary how they’re changing cyberattacks. Makes me wonder if AI’s getting too smart for our own good.
Cisco Warns를 사용해보니 LLM이 22배나 더 폭주할 수 있다는 사실에 놀랐어요. FraudGPT 뉴스를 보고 정말 소름이 돋았어요. 온라인에서 더 조심해야겠어요. 보안을 강화할 때가 온 것 같아요! 😅
このツールはサイバーセキュリティの目覚まし時計ですね!ローグLLMの統計は恐ろしいけど、目を開かせるものです。これらのモデルが武器化される可能性を考えると圧倒されますが、重要な情報です。保護方法についてもっと知りたいですね!😅
Essa ferramenta é um alerta para a cibersegurança! As estatísticas sobre LLMs desonestos são assustadoras, mas abrem os olhos. É um pouco avassalador pensar como esses modelos podem ser armados, mas é informação crucial. Talvez mais sobre como se proteger contra eles seria ótimo! 😅
Essa ferramenta realmente me fez ver como o AI pode ser perigoso! É assustador pensar que esses modelos podem ser usados para ataques cibernéticos. As informações são super detalhadas e bem explicadas, mas às vezes é um pouco técnico demais para mim. Ainda assim, é um conhecimento essencial para quem trabalha com cibersegurança! 😱













