
















 Maison
Maison
ByteDance Dévoile le Modèle d'IA Seed-Thinking-v1.5 pour Améliorer les Capacités de Raisonnement
La course à l'IA avancée en raisonnement a commencé avec le modèle o1 d'OpenAI en septembre 2024, gagnant en élan avec le lancement de R1 par DeepSeek en janvier 2025.
Les principaux développeurs d'IA rivalisent maintenant pour créer des modèles d'IA de raisonnement plus rapides et plus économiques, offrant des réponses précises et bien réfléchies grâce à des processus de chaîne de pensée, garantissant l'exactitude avant de répondre.
ByteDance, la société mère de TikTok, entre dans la compétition avec Seed-Thinking-v1.5, un nouveau grand modèle de langage (LLM) décrit dans un article technique, visant à améliorer le raisonnement dans les domaines STEM et généraux.
Le modèle n'est pas encore disponible, et sa licence — qu'elle soit propriétaire, open-source ou hybride — reste non divulguée. L'article offre cependant des perspectives clés à explorer avant sa sortie.
Exploiter le Cadre Mixture-of-Experts (MoE)
Suivant Llama 4 de Meta et Mixtral de Mistral, Seed-Thinking-v1.5 adopte l'architecture Mixture-of-Experts (MoE).
Cette approche améliore l'efficacité en intégrant plusieurs modèles spécialisés dans un seul, chacun se concentrant sur des domaines distincts.
Seed-Thinking-v1.5 utilise seulement 20 milliards de ses 200 milliards de paramètres à la fois, optimisant les performances.
L'article publié sur GitHub par ByteDance met en avant l'accent du modèle sur le raisonnement structuré et la génération de réponses délibérées.
Il surpasse DeepSeek R1 et rivalise avec Gemini 2.5 Pro de Google et o3-mini-high d'OpenAI dans les benchmarks tiers, dépassant même ces derniers sur le benchmark ARC-AGI, une mesure clé du progrès vers l'intelligence artificielle générale, dépassant les performances humaines dans des tâches économiquement précieuses, selon les normes d'OpenAI.
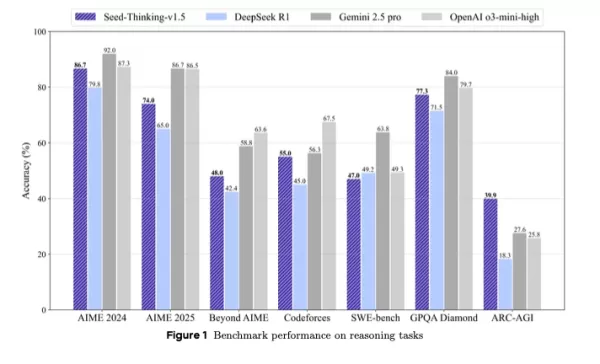
Positionné comme une alternative compacte mais puissante aux modèles plus grands, Seed-Thinking-v1.5 offre de solides résultats de benchmark grâce à un apprentissage par renforcement innovant, des données d'entraînement soigneusement sélectionnées et une infrastructure d'IA avancée.
Performance des Benchmarks et Forces Principales
Seed-Thinking-v1.5 excelle dans les tâches difficiles, obtenant 86,7 % sur AIME 2024, 55,0 % de pass@8 sur Codeforces, et 77,3 % sur le benchmark scientifique GPQA, se rapprochant ou dépassant des modèles comme o3-mini-high d'OpenAI et Gemini 2.5 Pro de Google dans les métriques de raisonnement.
Dans les tâches non liées au raisonnement, il a atteint un taux de préférence humaine 8,0 % supérieur à DeepSeek R1, montrant une polyvalence au-delà de la logique et des mathématiques.
Pour contrer la saturation des benchmarks, ByteDance a créé BeyondAIME, un benchmark mathématique plus difficile pour résister à la mémorisation et mieux évaluer les performances du modèle. Celui-ci, ainsi que l'ensemble Codeforces, sera publié pour aider la recherche future.
Approche des Données d'Entraînement
La qualité des données a été cruciale dans le développement de Seed-Thinking-v1.5. Pour l'ajustement supervisé, 400 000 échantillons ont été soigneusement sélectionnés : 300 000 tâches STEM, logiques et de codage vérifiables, et 100 000 tâches non vérifiables comme l'écriture créative.
Pour l'apprentissage par renforcement, les données ont été divisées en :
- Problèmes vérifiables : 100 000 questions STEM et puzzles logiques soigneusement sélectionnés issus de compétitions d'élite, validés par des experts.
- Tâches non vérifiables : Ensembles de données de préférence humaine pour des prompts ouverts, évalués via des modèles de récompense par paires.
Plus de 80 % des données STEM se concentraient sur les mathématiques avancées, avec des tâches logiques comme le Sudoku et les puzzles de 24 points adaptés pour correspondre aux progrès du modèle.
Innovations en Apprentissage par Renforcement
Seed-Thinking-v1.5 utilise des cadres personnalisés actor-critic (VAPO) et de gradient de politique (DAPO) pour stabiliser l'apprentissage par renforcement, résolvant les problèmes dans les scénarios de chaîne de pensée longue.
Deux modèles de récompense améliorent la supervision RL :
- Seed-Verifier : Un LLM basé sur des règles assurant l'équivalence mathématique entre les réponses générées et les références.
- Seed-Thinking-Verifier : Un juge basé sur le raisonnement pour une évaluation cohérente, résistant à la manipulation des récompenses.
Ce système dual soutient une évaluation précise pour les tâches simples et complexes.
Conception d'Infrastructure Évolutive
Le cadre HybridFlow de ByteDance, alimenté par des clusters Ray, soutient un entraînement à grande échelle efficace avec un entraînement et une inférence co-localisés pour minimiser le temps d'inactivité des GPU.
Le Streaming Rollout System (SRS) sépare l'évolution du modèle de l'exécution, accélérant les itérations jusqu'à trois fois grâce à une gestion asynchrone des générations partielles.
Les techniques supplémentaires incluent :
- Précision mixte (FP8) pour l'efficacité de la mémoire
- Parallélisme d'experts et auto-ajustement de kernel pour l'optimisation MoE
- ByteCheckpoint pour un point de contrôle robuste
- AutoTuner pour des paramètres optimisés de parallélisme et de mémoire
Évaluation Centrée sur l'Humain et Applications
Les tests humains sur l'écriture créative, les humanités et la conversation générale ont montré que Seed-Thinking-v1.5 surpasse DeepSeek R1, prouvant sa pertinence dans le monde réel.
L'équipe note que l'entraînement sur des tâches vérifiables a amélioré la généralisation aux domaines créatifs, grâce à des flux de travail mathématiques rigoureux.
Implications pour les Équipes Techniques et les Entreprises
Pour les leaders techniques supervisant les cycles de vie des LLM, Seed-Thinking-v1.5 offre un modèle pour intégrer un raisonnement avancé dans les systèmes d'IA d'entreprise.
Son entraînement modulaire, avec des ensembles de données vérifiables et un apprentissage par renforcement multi-phases, convient aux équipes qui développent des LLM avec un contrôle précis.
Seed-Verifier et Seed-Thinking-Verifier améliorent la modélisation de récompenses fiables, essentielle pour les environnements orientés clients ou réglementés.
Pour les équipes aux plannings serrés, VAPO et l'échantillonnage dynamique réduisent les cycles d'itération, simplifiant l'ajustement spécifique aux tâches.
L'infrastructure hybride, incluant SRS et l'optimisation FP8, augmente le débit d'entraînement et l'efficacité matérielle, idéale pour les systèmes cloud et sur site.
La rétroaction adaptative des récompenses du modèle répond aux défis de la gestion de pipelines de données divers, assurant une cohérence entre les domaines.
Pour les ingénieurs de données, l'accent sur le filtrage rigoureux des données et la vérification par des experts souligne l'importance des ensembles de données de haute qualité pour améliorer les performances du modèle.
Perspectives Futures
Développé par l'équipe Seed LLM Systems de ByteDance, dirigée par Yonghui Wu et représentée publiquement par Haibin Lin, Seed-Thinking-v1.5 s'appuie sur des efforts comme Doubao 1.5 Pro, utilisant des techniques partagées de RLHF et de curation de données.
L'équipe vise à affiner l'apprentissage par renforcement, en se concentrant sur l'efficacité de l'entraînement et la modélisation des récompenses pour les tâches non vérifiables. La publication de benchmarks comme BeyondAIME favorisera les progrès dans la recherche sur l'IA axée sur le raisonnement.
Article connexe
 Google I/O 2026 dévoile l'interaction vocale avec la boîte de réception Gmail
Google continue d'intégrer l'IA à votre boîte de réception. Lors de la conférence des développeurs IO 2026 qui s'est tenue mardi, l'entreprise a enrichi sa fonctionnalité « AI Inbox » de Gmail d'une I
Satya Nadella est prêt à tirer parti du nouvel accord avec OpenAI
Mercredi, un analyste de Wall Street a demandé directement au PDG de Microsoft, Satya Nadella, en quoi le nouveau partenariat avec OpenAI affecterait les résultats financiers de l’entreprise.Nadella a décrit ce nouvel accord comme une victoire pour
OpenAI présente les grandes lignes d'une économie de l'IA fondée sur des fonds de richesse publique, une taxe sur les robots et la semaine de quatre jours
Alors que les gouvernements peinent à gérer l’impact économique des machines superintelligentes, OpenAI a publié une série de propositions politiques décrivant comment la richesse et le travail pourra
Recommandations de sujets spéciaux liés
code
Google I/O 2026 dévoile l'interaction vocale avec la boîte de réception Gmail
Google continue d'intégrer l'IA à votre boîte de réception. Lors de la conférence des développeurs IO 2026 qui s'est tenue mardi, l'entreprise a enrichi sa fonctionnalité « AI Inbox » de Gmail d'une I
Satya Nadella est prêt à tirer parti du nouvel accord avec OpenAI
Mercredi, un analyste de Wall Street a demandé directement au PDG de Microsoft, Satya Nadella, en quoi le nouveau partenariat avec OpenAI affecterait les résultats financiers de l’entreprise.Nadella a décrit ce nouvel accord comme une victoire pour
OpenAI présente les grandes lignes d'une économie de l'IA fondée sur des fonds de richesse publique, une taxe sur les robots et la semaine de quatre jours
Alors que les gouvernements peinent à gérer l’impact économique des machines superintelligentes, OpenAI a publié une série de propositions politiques décrivant comment la richesse et le travail pourra
Recommandations de sujets spéciaux liés
code
 Les meilleurs outils d'analyse de code basés sur l'IA : automatisez la conformité au code propre et refactorisez les fichiers des dépôts hérités
Les meilleurs outils d'analyse de code basés sur l'IA : automatisez la conformité au code propre et refactorisez les fichiers des dépôts hérités
Découvrez les meilleurs outils d'analyse de code par IA de 2026 sur XIX.AI. Notre sélection comprend des outils de premier plan, véritables révolutionnaires, permettant d'automatiser la conformité au code propre et de refactoriser les fichiers de dépôts hérités. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Prenez dès aujourd'hui une longueur d'avance grâce à l'IA.
 10 outils
10 outils
 xix.ai
Synthèse vocale
Les meilleures applications de synthèse vocale basées sur l'IA pour la dyslexie : un soutien à l'apprentissage et à l'efficacité en lecture pour les élèves
xix.ai
Synthèse vocale
Les meilleures applications de synthèse vocale basées sur l'IA pour la dyslexie : un soutien à l'apprentissage et à l'efficacité en lecture pour les élèves
Découvrez les meilleures applications de synthèse vocale par IA de 2026, spécialement sélectionnées pour aider les personnes dyslexiques. Notre classement d'experts compare les outils gratuits et payants, en mettant en avant des fonctionnalités performantes qui améliorent l'efficacité de la lecture et l'apprentissage. Découvrez des solutions révolutionnaires à ne pas manquer pour libérer le potentiel des élèves. Commencez votre parcours sur XIX.AI.
10 outils
xix.ai
Création de bande dessinée
Les meilleurs générateurs IA pour les mangas shonen : créez des séquences d'action survoltées et des effets d'énergie
Découvrez les meilleurs générateurs IA de mangas shonen de 2026 sur XIX.AI. Notre sélection triée sur le volet comprend des outils performants pour créer des séquences d'action à couper le souffle et des effets d'énergie dynamiques. Comparez les options gratuites et payantes grâce à des tests concrets. Libérez votre potentiel créatif et commencez dès aujourd'hui à créer des mangas épiques !
15 outils
xix.ai
Entreprise
Les meilleurs outils de suivi des dépenses basés sur l'IA : numérisez vos reçus et classez automatiquement les dépenses de l'entreprise
Les meilleurs outils de gestion des dépenses basés sur l'IA en 2026 : les outils les mieux notés pour numériser vos reçus et classer automatiquement les dépenses de votre entreprise. Découvrez des solutions puissantes et révolutionnaires pour une gestion des dépenses sans effort, un suivi financier précis et une conformité simplifiée. Notre comparatif, mis à jour chaque semaine, qui oppose les options gratuites aux options payantes, vous aide à trouver la solution qui vous convient le mieux. Tirez pleinement parti de l'IA grâce aux recommandations d'experts de XIX.AI.
10 outils
xix.ai
Entreprise
Les meilleurs outils de recrutement basés sur l'IA : triez les CV et automatisez la planification des entretiens avec les candidats
Découvrez les meilleurs outils de recrutement basés sur l'IA de 2026 sur XIX.AI. Notre sélection propose des solutions performantes et révolutionnaires pour l'analyse des CV et l'automatisation de la planification des entretiens avec les candidats. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Trouvez l'assistant de recrutement idéal et optimisez votre processus de recrutement dès aujourd'hui !
10 outils
xix.ai
Productivité
Coaches IA dédiés au bien-être et à la concentration : gérer l'épuisement professionnel et booster son énergie mentale
Découvrez sur XIX.AI les meilleurs coachs IA de 2026 spécialisés dans le bien-être personnel et la concentration. Notre classement, soigneusement établi, présente les outils les mieux notés et les plus innovants pour gérer le surmenage et booster votre énergie mentale. Comparez les options gratuites et payantes grâce à des avis concrets. Ouvrez-vous dès aujourd’hui la voie vers une productivité et un bien-être optimaux.
10 outils
xix.ai

 commentaires (1)
commentaires (1)
![ChristopherDavis]()
Cette accélération dans la course au raisonnement avancé me donne un peu le vertige 😅. D'un côté c'est fascinant de voir comment les modèles deviennent de plus en plus 'intelligents', mais d'un autre... on est certains que tout ce développement est sous contrôle ? Pas sûr que les entreprises pensent beaucoup aux implications éthiques quand elles sont lancées dans cette bataille commerciale ultra-compétitive.
La course à l'IA avancée en raisonnement a commencé avec le modèle o1 d'OpenAI en septembre 2024, gagnant en élan avec le lancement de R1 par DeepSeek en janvier 2025.
Les principaux développeurs d'IA rivalisent maintenant pour créer des modèles d'IA de raisonnement plus rapides et plus économiques, offrant des réponses précises et bien réfléchies grâce à des processus de chaîne de pensée, garantissant l'exactitude avant de répondre.
ByteDance, la société mère de TikTok, entre dans la compétition avec Seed-Thinking-v1.5, un nouveau grand modèle de langage (LLM) décrit dans un article technique, visant à améliorer le raisonnement dans les domaines STEM et généraux.
Le modèle n'est pas encore disponible, et sa licence — qu'elle soit propriétaire, open-source ou hybride — reste non divulguée. L'article offre cependant des perspectives clés à explorer avant sa sortie.
Exploiter le Cadre Mixture-of-Experts (MoE)
Suivant Llama 4 de Meta et Mixtral de Mistral, Seed-Thinking-v1.5 adopte l'architecture Mixture-of-Experts (MoE).
Cette approche améliore l'efficacité en intégrant plusieurs modèles spécialisés dans un seul, chacun se concentrant sur des domaines distincts.
Seed-Thinking-v1.5 utilise seulement 20 milliards de ses 200 milliards de paramètres à la fois, optimisant les performances.
L'article publié sur GitHub par ByteDance met en avant l'accent du modèle sur le raisonnement structuré et la génération de réponses délibérées.
Il surpasse DeepSeek R1 et rivalise avec Gemini 2.5 Pro de Google et o3-mini-high d'OpenAI dans les benchmarks tiers, dépassant même ces derniers sur le benchmark ARC-AGI, une mesure clé du progrès vers l'intelligence artificielle générale, dépassant les performances humaines dans des tâches économiquement précieuses, selon les normes d'OpenAI.
Positionné comme une alternative compacte mais puissante aux modèles plus grands, Seed-Thinking-v1.5 offre de solides résultats de benchmark grâce à un apprentissage par renforcement innovant, des données d'entraînement soigneusement sélectionnées et une infrastructure d'IA avancée.
Performance des Benchmarks et Forces Principales
Seed-Thinking-v1.5 excelle dans les tâches difficiles, obtenant 86,7 % sur AIME 2024, 55,0 % de pass@8 sur Codeforces, et 77,3 % sur le benchmark scientifique GPQA, se rapprochant ou dépassant des modèles comme o3-mini-high d'OpenAI et Gemini 2.5 Pro de Google dans les métriques de raisonnement.
Dans les tâches non liées au raisonnement, il a atteint un taux de préférence humaine 8,0 % supérieur à DeepSeek R1, montrant une polyvalence au-delà de la logique et des mathématiques.
Pour contrer la saturation des benchmarks, ByteDance a créé BeyondAIME, un benchmark mathématique plus difficile pour résister à la mémorisation et mieux évaluer les performances du modèle. Celui-ci, ainsi que l'ensemble Codeforces, sera publié pour aider la recherche future.
Approche des Données d'Entraînement
La qualité des données a été cruciale dans le développement de Seed-Thinking-v1.5. Pour l'ajustement supervisé, 400 000 échantillons ont été soigneusement sélectionnés : 300 000 tâches STEM, logiques et de codage vérifiables, et 100 000 tâches non vérifiables comme l'écriture créative.
Pour l'apprentissage par renforcement, les données ont été divisées en :
- Problèmes vérifiables : 100 000 questions STEM et puzzles logiques soigneusement sélectionnés issus de compétitions d'élite, validés par des experts.
- Tâches non vérifiables : Ensembles de données de préférence humaine pour des prompts ouverts, évalués via des modèles de récompense par paires.
Plus de 80 % des données STEM se concentraient sur les mathématiques avancées, avec des tâches logiques comme le Sudoku et les puzzles de 24 points adaptés pour correspondre aux progrès du modèle.
Innovations en Apprentissage par Renforcement
Seed-Thinking-v1.5 utilise des cadres personnalisés actor-critic (VAPO) et de gradient de politique (DAPO) pour stabiliser l'apprentissage par renforcement, résolvant les problèmes dans les scénarios de chaîne de pensée longue.
Deux modèles de récompense améliorent la supervision RL :
- Seed-Verifier : Un LLM basé sur des règles assurant l'équivalence mathématique entre les réponses générées et les références.
- Seed-Thinking-Verifier : Un juge basé sur le raisonnement pour une évaluation cohérente, résistant à la manipulation des récompenses.
Ce système dual soutient une évaluation précise pour les tâches simples et complexes.
Conception d'Infrastructure Évolutive
Le cadre HybridFlow de ByteDance, alimenté par des clusters Ray, soutient un entraînement à grande échelle efficace avec un entraînement et une inférence co-localisés pour minimiser le temps d'inactivité des GPU.
Le Streaming Rollout System (SRS) sépare l'évolution du modèle de l'exécution, accélérant les itérations jusqu'à trois fois grâce à une gestion asynchrone des générations partielles.
Les techniques supplémentaires incluent :
- Précision mixte (FP8) pour l'efficacité de la mémoire
- Parallélisme d'experts et auto-ajustement de kernel pour l'optimisation MoE
- ByteCheckpoint pour un point de contrôle robuste
- AutoTuner pour des paramètres optimisés de parallélisme et de mémoire
Évaluation Centrée sur l'Humain et Applications
Les tests humains sur l'écriture créative, les humanités et la conversation générale ont montré que Seed-Thinking-v1.5 surpasse DeepSeek R1, prouvant sa pertinence dans le monde réel.
L'équipe note que l'entraînement sur des tâches vérifiables a amélioré la généralisation aux domaines créatifs, grâce à des flux de travail mathématiques rigoureux.
Implications pour les Équipes Techniques et les Entreprises
Pour les leaders techniques supervisant les cycles de vie des LLM, Seed-Thinking-v1.5 offre un modèle pour intégrer un raisonnement avancé dans les systèmes d'IA d'entreprise.
Son entraînement modulaire, avec des ensembles de données vérifiables et un apprentissage par renforcement multi-phases, convient aux équipes qui développent des LLM avec un contrôle précis.
Seed-Verifier et Seed-Thinking-Verifier améliorent la modélisation de récompenses fiables, essentielle pour les environnements orientés clients ou réglementés.
Pour les équipes aux plannings serrés, VAPO et l'échantillonnage dynamique réduisent les cycles d'itération, simplifiant l'ajustement spécifique aux tâches.
L'infrastructure hybride, incluant SRS et l'optimisation FP8, augmente le débit d'entraînement et l'efficacité matérielle, idéale pour les systèmes cloud et sur site.
La rétroaction adaptative des récompenses du modèle répond aux défis de la gestion de pipelines de données divers, assurant une cohérence entre les domaines.
Pour les ingénieurs de données, l'accent sur le filtrage rigoureux des données et la vérification par des experts souligne l'importance des ensembles de données de haute qualité pour améliorer les performances du modèle.
Perspectives Futures
Développé par l'équipe Seed LLM Systems de ByteDance, dirigée par Yonghui Wu et représentée publiquement par Haibin Lin, Seed-Thinking-v1.5 s'appuie sur des efforts comme Doubao 1.5 Pro, utilisant des techniques partagées de RLHF et de curation de données.
L'équipe vise à affiner l'apprentissage par renforcement, en se concentrant sur l'efficacité de l'entraînement et la modélisation des récompenses pour les tâches non vérifiables. La publication de benchmarks comme BeyondAIME favorisera les progrès dans la recherche sur l'IA axée sur le raisonnement.










 Google I/O 2026 dévoile l'interaction vocale avec la boîte de réception Gmail
Google continue d'intégrer l'IA à votre boîte de réception. Lors de la conférence des développeurs IO 2026 qui s'est tenue mardi, l'entreprise a enrichi sa fonctionnalité « AI Inbox » de Gmail d'une I
Google I/O 2026 dévoile l'interaction vocale avec la boîte de réception Gmail
Google continue d'intégrer l'IA à votre boîte de réception. Lors de la conférence des développeurs IO 2026 qui s'est tenue mardi, l'entreprise a enrichi sa fonctionnalité « AI Inbox » de Gmail d'une I
 Satya Nadella est prêt à tirer parti du nouvel accord avec OpenAI
Mercredi, un analyste de Wall Street a demandé directement au PDG de Microsoft, Satya Nadella, en quoi le nouveau partenariat avec OpenAI affecterait les résultats financiers de l’entreprise.Nadella a décrit ce nouvel accord comme une victoire pour
Satya Nadella est prêt à tirer parti du nouvel accord avec OpenAI
Mercredi, un analyste de Wall Street a demandé directement au PDG de Microsoft, Satya Nadella, en quoi le nouveau partenariat avec OpenAI affecterait les résultats financiers de l’entreprise.Nadella a décrit ce nouvel accord comme une victoire pour
 OpenAI présente les grandes lignes d'une économie de l'IA fondée sur des fonds de richesse publique, une taxe sur les robots et la semaine de quatre jours
Alors que les gouvernements peinent à gérer l’impact économique des machines superintelligentes, OpenAI a publié une série de propositions politiques décrivant comment la richesse et le travail pourra
OpenAI présente les grandes lignes d'une économie de l'IA fondée sur des fonds de richesse publique, une taxe sur les robots et la semaine de quatre jours
Alors que les gouvernements peinent à gérer l’impact économique des machines superintelligentes, OpenAI a publié une série de propositions politiques décrivant comment la richesse et le travail pourra

Découvrez les meilleurs outils d'analyse de code par IA de 2026 sur XIX.AI. Notre sélection comprend des outils de premier plan, véritables révolutionnaires, permettant d'automatiser la conformité au code propre et de refactoriser les fichiers de dépôts hérités. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Prenez dès aujourd'hui une longueur d'avance grâce à l'IA.
10 outils
xix.ai

Découvrez les meilleures applications de synthèse vocale par IA de 2026, spécialement sélectionnées pour aider les personnes dyslexiques. Notre classement d'experts compare les outils gratuits et payants, en mettant en avant des fonctionnalités performantes qui améliorent l'efficacité de la lecture et l'apprentissage. Découvrez des solutions révolutionnaires à ne pas manquer pour libérer le potentiel des élèves. Commencez votre parcours sur XIX.AI.
10 outils
xix.ai

Découvrez les meilleurs générateurs IA de mangas shonen de 2026 sur XIX.AI. Notre sélection triée sur le volet comprend des outils performants pour créer des séquences d'action à couper le souffle et des effets d'énergie dynamiques. Comparez les options gratuites et payantes grâce à des tests concrets. Libérez votre potentiel créatif et commencez dès aujourd'hui à créer des mangas épiques !
15 outils
xix.ai

Les meilleurs outils de gestion des dépenses basés sur l'IA en 2026 : les outils les mieux notés pour numériser vos reçus et classer automatiquement les dépenses de votre entreprise. Découvrez des solutions puissantes et révolutionnaires pour une gestion des dépenses sans effort, un suivi financier précis et une conformité simplifiée. Notre comparatif, mis à jour chaque semaine, qui oppose les options gratuites aux options payantes, vous aide à trouver la solution qui vous convient le mieux. Tirez pleinement parti de l'IA grâce aux recommandations d'experts de XIX.AI.
10 outils
xix.ai

Découvrez les meilleurs outils de recrutement basés sur l'IA de 2026 sur XIX.AI. Notre sélection propose des solutions performantes et révolutionnaires pour l'analyse des CV et l'automatisation de la planification des entretiens avec les candidats. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Trouvez l'assistant de recrutement idéal et optimisez votre processus de recrutement dès aujourd'hui !
10 outils
xix.ai

Découvrez sur XIX.AI les meilleurs coachs IA de 2026 spécialisés dans le bien-être personnel et la concentration. Notre classement, soigneusement établi, présente les outils les mieux notés et les plus innovants pour gérer le surmenage et booster votre énergie mentale. Comparez les options gratuites et payantes grâce à des avis concrets. Ouvrez-vous dès aujourd’hui la voie vers une productivité et un bien-être optimaux.
10 outils
xix.ai

Cette accélération dans la course au raisonnement avancé me donne un peu le vertige 😅. D'un côté c'est fascinant de voir comment les modèles deviennent de plus en plus 'intelligents', mais d'un autre... on est certains que tout ce développement est sous contrôle ? Pas sûr que les entreprises pensent beaucoup aux implications éthiques quand elles sont lancées dans cette bataille commerciale ultra-compétitive.













