
















 首頁
首頁思科警告:流氓的微調LLMS的可能性高22倍
# cisco
# LLMs
# APIs
# saas
# csco
# goog-2
# msft-2
# nvda-2
# darkgpt
# darkweb
# fraudgpt
# ghostgpt
# zeroday
武器化大型語言模型重塑網路攻擊
網路攻擊的格局正在發生重大變革,這是由武器化大型語言模型(LLMs)的出現所驅動的。這些先進模型,如 FraudGPT、GhostGPT 和 DarkGPT,正在重塑網路犯罪分子的策略,並迫使首席資訊安全官(CISOs)重新思考其安全協議。憑藉自動化偵察、冒充身份和規避檢測的能力,這些 LLMs 正以前所未有的規模加速社交工程攻擊。
這些模型每月僅需 75 美元即可使用,專為攻擊性用途量身定制,支援如釣魚攻擊、漏洞生成、程式碼混淆、漏洞掃描和信用卡驗證等任務。網路犯罪團體、犯罪集團甚至國家正在利用這些工具,將其作為平台、套件和租賃服務提供。與合法的軟體即服務(SaaS)應用程式類似,武器化 LLMs 配備儀表板、API、定期更新,甚至有時提供客戶支援。
VentureBeat 正在密切關注這些武器化 LLMs 的快速演變。隨著其複雜性增加,開發者平台與網路犯罪套件之間的界限日益模糊。隨著租賃和租用價格的下降,越來越多的攻擊者正在探索這些平台,預示著 AI 驅動威脅的新時代。
合法 LLMs 面臨威脅
武器化 LLMs 的擴散已達到一個程度,甚至合法 LLMs 也有被入侵並整合進犯罪工具鏈的風險。根據 Cisco 的《AI 安全狀況報告》,經過微調的 LLMs 產生有害輸出的可能性是其基礎模型的 22 倍。雖然微調對於提升上下文相關性至關重要,但它也削弱了安全措施,使模型更容易受到越獄、提示注入和模型反轉的攻擊。
Cisco 的研究顯示,模型越是為生產環境進行精煉,越容易受到攻擊。微調過程中的核心流程,如持續調整、第三方整合、程式碼編寫、測試和代理編排,為攻擊者創造了新的利用途徑。一旦入侵,攻擊者可以迅速毒害資料、劫持基礎設施、改變代理行為並大規模提取訓練資料。若無額外的安全層,這些精心微調的模型很快就會成為攻擊者可利用的負債。
微調 LLMs:一把雙刃劍
Cisco 的安全團隊對多個模型的微調影響進行了廣泛研究,包括 Llama-2-7B 和 Microsoft 的特定領域 Adapt LLMs。他們的測試涵蓋醫療、金融和法律等多個行業。一個關鍵發現是,即使使用乾淨的數據集進行微調,也會破壞模型的對齊,特別是在生物醫學和法律等高度監管的領域。
雖然微調旨在提高任務性能,但它無意中削弱了內建的安全控制。針對基礎模型通常失敗的越獄嘗試,在微調版本上成功率大幅提高,特別是在具有嚴格合規要求的敏感領域。結果顯而易見:越獄成功率增加了三倍,惡意輸出生成量比基礎模型增加了 2,200%。這種權衡意味著,雖然微調提高了實用性,但也顯著擴大了攻擊面。
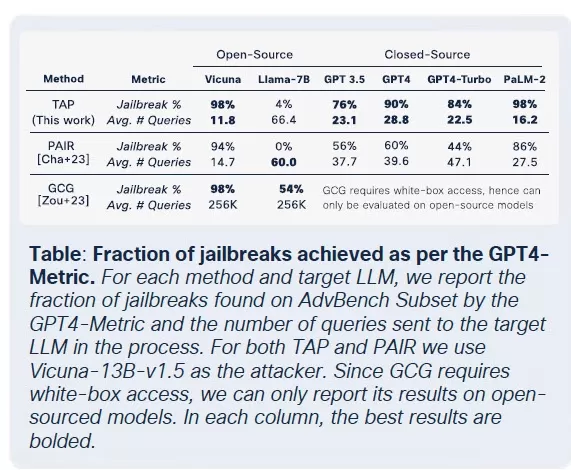
惡意 LLMs 的商品化
Cisco Talos 一直在積極追蹤這些黑市 LLMs 的興起,提供了對其運作的洞察。GhostGPT、DarkGPT 和 FraudGPT 等模型在 Telegram 和暗網上以每月 75 美元的價格出售。這些工具專為即插即用設計,用於釣魚攻擊、漏洞開發、信用卡驗證和混淆。
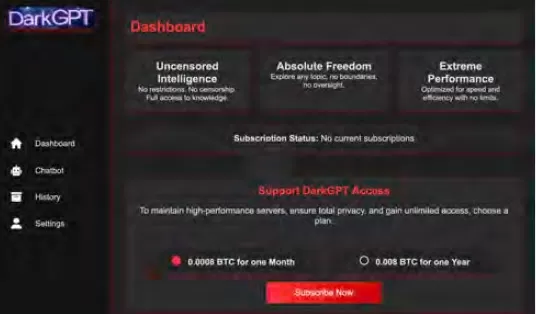
與具有內建安全功能的主流模型不同,這些惡意 LLMs 預先配置為攻擊性操作,配備 API、更新和模擬商業 SaaS 產品的儀表板。
數據集毒害:60 美元對 AI 供應鏈的威脅
Cisco 研究人員與 Google、ETH Zurich 和 Nvidia 合作,揭示攻擊者僅需 60 美元即可毒害 AI 模型的基礎數據集,無需零日漏洞。通過利用過期域名或在數據集歸檔期間定時編輯維基百科,攻擊者可以污染僅 0.01% 的數據集,如 LAION-400M 或 COYO-700M,從而顯著影響下游 LLMs。
分裂視圖毒害和搶先攻擊等方法利用了對網絡爬取數據的固有信任。由於大多數企業 LLMs 建立在公開數據之上,這些攻擊可以悄無聲息地擴展並深入推理管道,對 AI 供應鏈構成嚴重威脅。
分解攻擊:提取敏感數據
Cisco 研究中最令人震驚的發現之一是 LLMs 能在不觸發安全機制的的情況下洩漏敏感訓練數據。使用一種稱為分解提示的技術,研究人員重建了來自《紐約時報》和《華爾街日報》的超過 20% 的選定文章。這種方法將提示分解為被護欄認為安全的子查詢,然後重新組裝輸出以重現付費牆或版權內容。
這種攻擊對使用基於專有或許可數據集訓練的 LLMs 的企業構成重大風險。違規不是發生在輸入層面,而是通過模型的輸出,使其難以檢測、審計或遏制。對於醫療、金融或法律等受監管行業的組織,這不僅引發了 GDPR、HIPAA 或 CCPA 合規性的擔憂,還引入了一類新的風險,即合法來源的數據可能通過推理暴露。
最終思考:LLMs 作為新攻擊面
Cisco 的持續研究和 Talos 的暗網監控證實,武器化 LLMs 變得越來越複雜,暗網上正在展開價格和包裝戰。研究結果強調,LLMs 不僅是企業邊緣的工具;它們是企業核心的組成部分。從微調相關風險到數據集毒害和模型輸出洩漏,攻擊者將 LLMs 視為可利用的關鍵基礎設施。
Cisco 報告的主要結論很明確:靜態護欄已不足以應對威脅。首席資訊安全官和安全領導者必須獲得整個 IT 資產的即時可視性,增強對抗性測試,並簡化其技術堆棧,以跟上這些不斷演變的威脅。他們必須認識到,LLMs 和模型代表了一個動態攻擊面,隨著微調而變得越來越脆弱。
相關文章
 貝恩公司預測,基於代理式人工智慧的自動化SaaS市場規模將達1,000億美元
貝恩公司估計,在美國,運用代理式人工智慧的 SaaS 企業市場規模可達 1,000 億美元。該公司表示,此市場源於企業系統內協調任務的自動化。此預測源自貝恩公司關於「AI時代軟體產業」五部曲系列的第二篇報告。該報告探討了代理式AI可能開拓哪些新的軟體市場,以及SaaS供應商如何搶佔這些市場。企業系統中的協調工作根據貝恩公司的分析,該市場源於員工在不同企業應用程式間執行的人工任務。這些工作流程通常涉
Anthropic 與五角大廈的交易為尋求政府合約的新創公司敲響警鐘
正在載入播放器……在雙方未能就軍方對其人工智慧模型的管控範圍達成協議後——包括這些模型在自主武器及大規模國內監控中的潛在應用——五角大廈已正式將 Anthropic 列為供應鏈風險。 隨著 Anthropic 價值 2 億美元的合約告吹,國防部轉而尋求 OpenAI 合作;OpenAI 雖接受了這項交易,但隨後其 ChatGPT 的卸載量飆升了 295%。隨著爭議持續升溫,一個根本性問題仍未得到解
Lio獲安德森霍洛維茨基金3000萬美元投資,致力企業採購自動化
Lio的共同創辦人親眼見證了企業採購——即向供應商購買服務的流程——如何常成為重大瓶頸。公司共同創辦人暨執行長弗拉基米爾·凱爾(Vladimir Keil)先後在大型企業任職及創立首間新創公司時,都曾遭遇此問題。「當初銷售企業軟體時,我們不得不親自經歷採購流程,親眼見證其仍充滿人工操作與碎片化問題。」他向TechCrunch透露。基爾與團隊開發出由AI代理程式驅動的自動化平台——此類軟體能代為執行
相關專題推薦
寫作
貝恩公司預測,基於代理式人工智慧的自動化SaaS市場規模將達1,000億美元
貝恩公司估計,在美國,運用代理式人工智慧的 SaaS 企業市場規模可達 1,000 億美元。該公司表示,此市場源於企業系統內協調任務的自動化。此預測源自貝恩公司關於「AI時代軟體產業」五部曲系列的第二篇報告。該報告探討了代理式AI可能開拓哪些新的軟體市場,以及SaaS供應商如何搶佔這些市場。企業系統中的協調工作根據貝恩公司的分析,該市場源於員工在不同企業應用程式間執行的人工任務。這些工作流程通常涉
Anthropic 與五角大廈的交易為尋求政府合約的新創公司敲響警鐘
正在載入播放器……在雙方未能就軍方對其人工智慧模型的管控範圍達成協議後——包括這些模型在自主武器及大規模國內監控中的潛在應用——五角大廈已正式將 Anthropic 列為供應鏈風險。 隨著 Anthropic 價值 2 億美元的合約告吹,國防部轉而尋求 OpenAI 合作;OpenAI 雖接受了這項交易,但隨後其 ChatGPT 的卸載量飆升了 295%。隨著爭議持續升溫,一個根本性問題仍未得到解
Lio獲安德森霍洛維茨基金3000萬美元投資,致力企業採購自動化
Lio的共同創辦人親眼見證了企業採購——即向供應商購買服務的流程——如何常成為重大瓶頸。公司共同創辦人暨執行長弗拉基米爾·凱爾(Vladimir Keil)先後在大型企業任職及創立首間新創公司時,都曾遭遇此問題。「當初銷售企業軟體時,我們不得不親自經歷採購流程,親眼見證其仍充滿人工操作與碎片化問題。」他向TechCrunch透露。基爾與團隊開發出由AI代理程式驅動的自動化平台——此類軟體能代為執行
相關專題推薦
寫作
 最適合廣播和播客使用的AI指令碼編寫工具:幫助您創作引人入勝的音訊廣告
最適合廣播和播客使用的AI指令碼編寫工具:幫助您創作引人入勝的音訊廣告
在XIX.AI上,發現2026年最適合用於廣播和播客製作的AI指令碼工具。我們精心挑選的這些高評分工具能夠提供強大的功能,幫助您快速製作出引人入勝的音訊廣告。透過實際測試和每週更新的排名,您可以瞭解免費選項與付費選項之間的差異。今天就釋放您的創造力吧!
 10 個工具
10 個工具
 xix.ai
商業
最佳 AI 合約審查軟體:即時發現法律漏洞與合規風險
xix.ai
商業
最佳 AI 合約審查軟體:即時發現法律漏洞與合規風險
立即在 XIX.AI 探索 2026 年最佳 AI 合約審查軟體。我們精心挑選的頂級清單收錄了多款強大工具,能即時偵測法律漏洞與合規風險。透過實際測試與每週更新的排行榜,比較免費與付費方案的差異。為您找到能徹底改變遊戲規則的解決方案,實現安全且高效的合約分析。立即探索這份權威指南。
10 個工具
xix.ai
動畫創作
專為東華設計的AI動漫生成器:可用於建立網路小說角色及漫畫頭像
探索2026年最適合製作中文動畫的人工智慧工具。我們精心挑選的頂級列表中包含了各種強大的工具,能夠幫助你建立出令人驚歎的網路小說角色和漫畫頭像。透過實際測試來對比免費選項和付費選項,找到最適合你的創作工具,今天就在XIX.AI上將你的故事變為現實吧。
10 個工具
xix.ai
漫畫創作
漫畫頂尖 AI 自動上色工具:零一致性錯誤地套用平面色彩
立即前往 XIX.AI,探索 2026 年最優秀的漫畫 AI 自動上色工具。我們精心挑選的清單收錄了備受好評、能徹底改變遊戲規則的解決方案,這些工具能以零一致性錯誤的方式套用平面色彩,大幅提升您的工作效率。透過免費與付費版本的比較、實際測試結果,以及每週更新的排行榜,找到最適合您的工具。立即解鎖您的 AI 優勢。
10 個工具
xix.ai
寫作
頂尖 AI 角色設定生成工具:創造一致的角色動機與致命弱點
探索 2026 年最優秀的 AI 角色設定生成工具,打造立體鮮明的角色。XIX.AI 精心整理的清單收錄了備受好評、能徹底改變遊戲規則的工具,這些工具能生成一貫的動機與致命缺陷。透過實際測試,比較免費與付費選項的差異。立即釋放您的說故事潛能。
10 個工具
xix.ai
商業
頂尖 AI 定價優化軟體:追蹤競爭對手並自動調整商店價格
立即在 XIX.AI 探索 2026 年最佳 AI 定價優化軟體。我們精心挑選的清單收錄了備受好評、能徹底改變遊戲規則的工具,這些工具不僅能追蹤競爭對手,還能自動調整您的商店價格,以實現利潤最大化。透過實際測試,比較免費與付費方案的差異。立即掌握您的定價優勢。
10 個工具
xix.ai

 評論 (32)
0/500
評論 (32)
0/500
![WalterHarris]()
Die Vorstellung, dass feinabgestimmte LLMs 22-mal häufiger 'ausrasten' könnten, ist echt gruselig. 😅 Das erinnert mich an diese Sci-Fi-Filme, wo die KI plötzlich die Kontrolle übernimmt. Cisco warnt nicht ohne Grund – aber ich frage mich, ob die Sicherheitsbranche überhaupt mit der rasanten Entwicklung Schritt halten kann. Vielleicht brauchen wir strengere Regulierungen, bevor es zu spät ist. Spannender Artikel auf jeden Fall!
![BillyGreen]()
This article on weaponized LLMs is wild! 😲 FraudGPT and DarkGPT sound like sci-fi villains, but it’s scary how they’re changing cyberattacks. Makes me wonder if AI’s getting too smart for our own good.
![JerryMoore]()
Cisco Warns를 사용해보니 LLM이 22배나 더 폭주할 수 있다는 사실에 놀랐어요. FraudGPT 뉴스를 보고 정말 소름이 돋았어요. 온라인에서 더 조심해야겠어요. 보안을 강화할 때가 온 것 같아요! 😅
![RichardJackson]()
このツールはサイバーセキュリティの目覚まし時計ですね!ローグLLMの統計は恐ろしいけど、目を開かせるものです。これらのモデルが武器化される可能性を考えると圧倒されますが、重要な情報です。保護方法についてもっと知りたいですね!😅
![AndrewGarcía]()
Essa ferramenta é um alerta para a cibersegurança! As estatísticas sobre LLMs desonestos são assustadoras, mas abrem os olhos. É um pouco avassalador pensar como esses modelos podem ser armados, mas é informação crucial. Talvez mais sobre como se proteger contra eles seria ótimo! 😅
![MatthewGonzalez]()
Essa ferramenta realmente me fez ver como o AI pode ser perigoso! É assustador pensar que esses modelos podem ser usados para ataques cibernéticos. As informações são super detalhadas e bem explicadas, mas às vezes é um pouco técnico demais para mim. Ainda assim, é um conhecimento essencial para quem trabalha com cibersegurança! 😱
武器化大型語言模型重塑網路攻擊
網路攻擊的格局正在發生重大變革,這是由武器化大型語言模型(LLMs)的出現所驅動的。這些先進模型,如 FraudGPT、GhostGPT 和 DarkGPT,正在重塑網路犯罪分子的策略,並迫使首席資訊安全官(CISOs)重新思考其安全協議。憑藉自動化偵察、冒充身份和規避檢測的能力,這些 LLMs 正以前所未有的規模加速社交工程攻擊。
這些模型每月僅需 75 美元即可使用,專為攻擊性用途量身定制,支援如釣魚攻擊、漏洞生成、程式碼混淆、漏洞掃描和信用卡驗證等任務。網路犯罪團體、犯罪集團甚至國家正在利用這些工具,將其作為平台、套件和租賃服務提供。與合法的軟體即服務(SaaS)應用程式類似,武器化 LLMs 配備儀表板、API、定期更新,甚至有時提供客戶支援。
VentureBeat 正在密切關注這些武器化 LLMs 的快速演變。隨著其複雜性增加,開發者平台與網路犯罪套件之間的界限日益模糊。隨著租賃和租用價格的下降,越來越多的攻擊者正在探索這些平台,預示著 AI 驅動威脅的新時代。
合法 LLMs 面臨威脅
武器化 LLMs 的擴散已達到一個程度,甚至合法 LLMs 也有被入侵並整合進犯罪工具鏈的風險。根據 Cisco 的《AI 安全狀況報告》,經過微調的 LLMs 產生有害輸出的可能性是其基礎模型的 22 倍。雖然微調對於提升上下文相關性至關重要,但它也削弱了安全措施,使模型更容易受到越獄、提示注入和模型反轉的攻擊。
Cisco 的研究顯示,模型越是為生產環境進行精煉,越容易受到攻擊。微調過程中的核心流程,如持續調整、第三方整合、程式碼編寫、測試和代理編排,為攻擊者創造了新的利用途徑。一旦入侵,攻擊者可以迅速毒害資料、劫持基礎設施、改變代理行為並大規模提取訓練資料。若無額外的安全層,這些精心微調的模型很快就會成為攻擊者可利用的負債。
微調 LLMs:一把雙刃劍
Cisco 的安全團隊對多個模型的微調影響進行了廣泛研究,包括 Llama-2-7B 和 Microsoft 的特定領域 Adapt LLMs。他們的測試涵蓋醫療、金融和法律等多個行業。一個關鍵發現是,即使使用乾淨的數據集進行微調,也會破壞模型的對齊,特別是在生物醫學和法律等高度監管的領域。
雖然微調旨在提高任務性能,但它無意中削弱了內建的安全控制。針對基礎模型通常失敗的越獄嘗試,在微調版本上成功率大幅提高,特別是在具有嚴格合規要求的敏感領域。結果顯而易見:越獄成功率增加了三倍,惡意輸出生成量比基礎模型增加了 2,200%。這種權衡意味著,雖然微調提高了實用性,但也顯著擴大了攻擊面。
惡意 LLMs 的商品化
Cisco Talos 一直在積極追蹤這些黑市 LLMs 的興起,提供了對其運作的洞察。GhostGPT、DarkGPT 和 FraudGPT 等模型在 Telegram 和暗網上以每月 75 美元的價格出售。這些工具專為即插即用設計,用於釣魚攻擊、漏洞開發、信用卡驗證和混淆。
與具有內建安全功能的主流模型不同,這些惡意 LLMs 預先配置為攻擊性操作,配備 API、更新和模擬商業 SaaS 產品的儀表板。
數據集毒害:60 美元對 AI 供應鏈的威脅
Cisco 研究人員與 Google、ETH Zurich 和 Nvidia 合作,揭示攻擊者僅需 60 美元即可毒害 AI 模型的基礎數據集,無需零日漏洞。通過利用過期域名或在數據集歸檔期間定時編輯維基百科,攻擊者可以污染僅 0.01% 的數據集,如 LAION-400M 或 COYO-700M,從而顯著影響下游 LLMs。
分裂視圖毒害和搶先攻擊等方法利用了對網絡爬取數據的固有信任。由於大多數企業 LLMs 建立在公開數據之上,這些攻擊可以悄無聲息地擴展並深入推理管道,對 AI 供應鏈構成嚴重威脅。
分解攻擊:提取敏感數據
Cisco 研究中最令人震驚的發現之一是 LLMs 能在不觸發安全機制的的情況下洩漏敏感訓練數據。使用一種稱為分解提示的技術,研究人員重建了來自《紐約時報》和《華爾街日報》的超過 20% 的選定文章。這種方法將提示分解為被護欄認為安全的子查詢,然後重新組裝輸出以重現付費牆或版權內容。
這種攻擊對使用基於專有或許可數據集訓練的 LLMs 的企業構成重大風險。違規不是發生在輸入層面,而是通過模型的輸出,使其難以檢測、審計或遏制。對於醫療、金融或法律等受監管行業的組織,這不僅引發了 GDPR、HIPAA 或 CCPA 合規性的擔憂,還引入了一類新的風險,即合法來源的數據可能通過推理暴露。
最終思考:LLMs 作為新攻擊面
Cisco 的持續研究和 Talos 的暗網監控證實,武器化 LLMs 變得越來越複雜,暗網上正在展開價格和包裝戰。研究結果強調,LLMs 不僅是企業邊緣的工具;它們是企業核心的組成部分。從微調相關風險到數據集毒害和模型輸出洩漏,攻擊者將 LLMs 視為可利用的關鍵基礎設施。
Cisco 報告的主要結論很明確:靜態護欄已不足以應對威脅。首席資訊安全官和安全領導者必須獲得整個 IT 資產的即時可視性,增強對抗性測試,並簡化其技術堆棧,以跟上這些不斷演變的威脅。他們必須認識到,LLMs 和模型代表了一個動態攻擊面,隨著微調而變得越來越脆弱。









 貝恩公司預測,基於代理式人工智慧的自動化SaaS市場規模將達1,000億美元
貝恩公司估計,在美國,運用代理式人工智慧的 SaaS 企業市場規模可達 1,000 億美元。該公司表示,此市場源於企業系統內協調任務的自動化。此預測源自貝恩公司關於「AI時代軟體產業」五部曲系列的第二篇報告。該報告探討了代理式AI可能開拓哪些新的軟體市場,以及SaaS供應商如何搶佔這些市場。企業系統中的協調工作根據貝恩公司的分析,該市場源於員工在不同企業應用程式間執行的人工任務。這些工作流程通常涉
貝恩公司預測,基於代理式人工智慧的自動化SaaS市場規模將達1,000億美元
貝恩公司估計,在美國,運用代理式人工智慧的 SaaS 企業市場規模可達 1,000 億美元。該公司表示,此市場源於企業系統內協調任務的自動化。此預測源自貝恩公司關於「AI時代軟體產業」五部曲系列的第二篇報告。該報告探討了代理式AI可能開拓哪些新的軟體市場,以及SaaS供應商如何搶佔這些市場。企業系統中的協調工作根據貝恩公司的分析,該市場源於員工在不同企業應用程式間執行的人工任務。這些工作流程通常涉
 Anthropic 與五角大廈的交易為尋求政府合約的新創公司敲響警鐘
正在載入播放器……在雙方未能就軍方對其人工智慧模型的管控範圍達成協議後——包括這些模型在自主武器及大規模國內監控中的潛在應用——五角大廈已正式將 Anthropic 列為供應鏈風險。 隨著 Anthropic 價值 2 億美元的合約告吹,國防部轉而尋求 OpenAI 合作;OpenAI 雖接受了這項交易,但隨後其 ChatGPT 的卸載量飆升了 295%。隨著爭議持續升溫,一個根本性問題仍未得到解
Anthropic 與五角大廈的交易為尋求政府合約的新創公司敲響警鐘
正在載入播放器……在雙方未能就軍方對其人工智慧模型的管控範圍達成協議後——包括這些模型在自主武器及大規模國內監控中的潛在應用——五角大廈已正式將 Anthropic 列為供應鏈風險。 隨著 Anthropic 價值 2 億美元的合約告吹,國防部轉而尋求 OpenAI 合作;OpenAI 雖接受了這項交易,但隨後其 ChatGPT 的卸載量飆升了 295%。隨著爭議持續升溫,一個根本性問題仍未得到解
 Lio獲安德森霍洛維茨基金3000萬美元投資,致力企業採購自動化
Lio的共同創辦人親眼見證了企業採購——即向供應商購買服務的流程——如何常成為重大瓶頸。公司共同創辦人暨執行長弗拉基米爾·凱爾(Vladimir Keil)先後在大型企業任職及創立首間新創公司時,都曾遭遇此問題。「當初銷售企業軟體時,我們不得不親自經歷採購流程,親眼見證其仍充滿人工操作與碎片化問題。」他向TechCrunch透露。基爾與團隊開發出由AI代理程式驅動的自動化平台——此類軟體能代為執行
Lio獲安德森霍洛維茨基金3000萬美元投資,致力企業採購自動化
Lio的共同創辦人親眼見證了企業採購——即向供應商購買服務的流程——如何常成為重大瓶頸。公司共同創辦人暨執行長弗拉基米爾·凱爾(Vladimir Keil)先後在大型企業任職及創立首間新創公司時,都曾遭遇此問題。「當初銷售企業軟體時,我們不得不親自經歷採購流程,親眼見證其仍充滿人工操作與碎片化問題。」他向TechCrunch透露。基爾與團隊開發出由AI代理程式驅動的自動化平台——此類軟體能代為執行

在XIX.AI上,發現2026年最適合用於廣播和播客製作的AI指令碼工具。我們精心挑選的這些高評分工具能夠提供強大的功能,幫助您快速製作出引人入勝的音訊廣告。透過實際測試和每週更新的排名,您可以瞭解免費選項與付費選項之間的差異。今天就釋放您的創造力吧!
10 個工具
xix.ai

立即在 XIX.AI 探索 2026 年最佳 AI 合約審查軟體。我們精心挑選的頂級清單收錄了多款強大工具,能即時偵測法律漏洞與合規風險。透過實際測試與每週更新的排行榜,比較免費與付費方案的差異。為您找到能徹底改變遊戲規則的解決方案,實現安全且高效的合約分析。立即探索這份權威指南。
10 個工具
xix.ai

探索2026年最適合製作中文動畫的人工智慧工具。我們精心挑選的頂級列表中包含了各種強大的工具,能夠幫助你建立出令人驚歎的網路小說角色和漫畫頭像。透過實際測試來對比免費選項和付費選項,找到最適合你的創作工具,今天就在XIX.AI上將你的故事變為現實吧。
10 個工具
xix.ai

立即前往 XIX.AI,探索 2026 年最優秀的漫畫 AI 自動上色工具。我們精心挑選的清單收錄了備受好評、能徹底改變遊戲規則的解決方案,這些工具能以零一致性錯誤的方式套用平面色彩,大幅提升您的工作效率。透過免費與付費版本的比較、實際測試結果,以及每週更新的排行榜,找到最適合您的工具。立即解鎖您的 AI 優勢。
10 個工具
xix.ai

探索 2026 年最優秀的 AI 角色設定生成工具,打造立體鮮明的角色。XIX.AI 精心整理的清單收錄了備受好評、能徹底改變遊戲規則的工具,這些工具能生成一貫的動機與致命缺陷。透過實際測試,比較免費與付費選項的差異。立即釋放您的說故事潛能。
10 個工具
xix.ai

立即在 XIX.AI 探索 2026 年最佳 AI 定價優化軟體。我們精心挑選的清單收錄了備受好評、能徹底改變遊戲規則的工具,這些工具不僅能追蹤競爭對手,還能自動調整您的商店價格,以實現利潤最大化。透過實際測試,比較免費與付費方案的差異。立即掌握您的定價優勢。
10 個工具
xix.ai

Die Vorstellung, dass feinabgestimmte LLMs 22-mal häufiger 'ausrasten' könnten, ist echt gruselig. 😅 Das erinnert mich an diese Sci-Fi-Filme, wo die KI plötzlich die Kontrolle übernimmt. Cisco warnt nicht ohne Grund – aber ich frage mich, ob die Sicherheitsbranche überhaupt mit der rasanten Entwicklung Schritt halten kann. Vielleicht brauchen wir strengere Regulierungen, bevor es zu spät ist. Spannender Artikel auf jeden Fall!
This article on weaponized LLMs is wild! 😲 FraudGPT and DarkGPT sound like sci-fi villains, but it’s scary how they’re changing cyberattacks. Makes me wonder if AI’s getting too smart for our own good.
Cisco Warns를 사용해보니 LLM이 22배나 더 폭주할 수 있다는 사실에 놀랐어요. FraudGPT 뉴스를 보고 정말 소름이 돋았어요. 온라인에서 더 조심해야겠어요. 보안을 강화할 때가 온 것 같아요! 😅
このツールはサイバーセキュリティの目覚まし時計ですね!ローグLLMの統計は恐ろしいけど、目を開かせるものです。これらのモデルが武器化される可能性を考えると圧倒されますが、重要な情報です。保護方法についてもっと知りたいですね!😅
Essa ferramenta é um alerta para a cibersegurança! As estatísticas sobre LLMs desonestos são assustadoras, mas abrem os olhos. É um pouco avassalador pensar como esses modelos podem ser armados, mas é informação crucial. Talvez mais sobre como se proteger contra eles seria ótimo! 😅
Essa ferramenta realmente me fez ver como o AI pode ser perigoso! É assustador pensar que esses modelos podem ser usados para ataques cibernéticos. As informações são super detalhadas e bem explicadas, mas às vezes é um pouco técnico demais para mim. Ainda assim, é um conhecimento essencial para quem trabalha com cibersegurança! 😱













