
















 Hogar
HogarCisco advierte: LLMS ajustados 22 veces más probabilidades de volverse pícaros
# cisco
# LLMs
# APIs
# saas
# csco
# goog-2
# msft-2
# nvda-2
# darkgpt
# darkweb
# fraudgpt
# ghostgpt
# zeroday
Modelos de Lenguaje de Gran Escala Armados Transforman los Ciberataques
El panorama de los ciberataques está experimentando una transformación significativa, impulsada por la aparición de modelos de lenguaje de gran escala (LLMs) armados. Estos modelos avanzados, como FraudGPT, GhostGPT y DarkGPT, están reformulando las estrategias de los ciberdelincuentes y obligando a los Directores de Seguridad de la Información (CISOs) a repensar sus protocolos de seguridad. Con capacidades para automatizar el reconocimiento, suplantar identidades y evadir la detección, estos LLMs están acelerando los ataques de ingeniería social a una escala sin precedentes.
Disponibles por tan solo $75 al mes, estos modelos están diseñados para un uso ofensivo, facilitando tareas como phishing, generación de exploits, ofuscación de código, escaneo de vulnerabilidades y validación de tarjetas de crédito. Grupos de ciberdelincuencia, sindicatos e incluso estados-nación están capitalizando estas herramientas, ofreciéndolas como plataformas, kits y servicios de alquiler. Al igual que las aplicaciones legítimas de software como servicio (SaaS), los LLMs armados vienen con paneles de control, APIs, actualizaciones regulares y, en ocasiones, incluso soporte al cliente.
VentureBeat está monitoreando de cerca la rápida evolución de estos LLMs armados. A medida que su sofisticación crece, la distinción entre plataformas de desarrolladores y kits de ciberdelincuencia se está volviendo cada vez más difusa. Con precios de alquiler y arrendamiento en descenso, más atacantes están explorando estas plataformas, anunciando una nueva era de amenazas impulsadas por IA.
LLMs Legítimos Bajo Amenaza
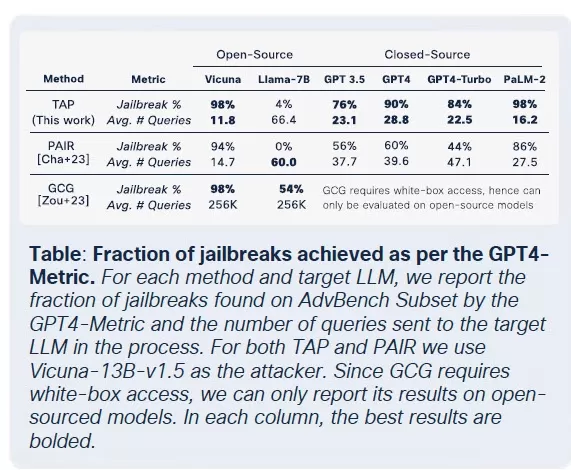
La proliferación de LLMs armados ha alcanzado un punto en el que incluso los LLMs legítimos corren el riesgo de ser comprometidos e integrados en cadenas de herramientas criminales. Según el informe El Estado de la Seguridad de la IA de Cisco, los LLMs afinados son 22 veces más propensos a producir resultados dañinos que sus contrapartes base. Aunque el afinamiento es crucial para mejorar la relevancia contextual, también debilita las medidas de seguridad, haciendo que los modelos sean más susceptibles a jailbreaks, inyecciones de prompts e inversión de modelos.
La investigación de Cisco destaca que cuanto más se refina un modelo para producción, más vulnerable se vuelve. Los procesos centrales involucrados en el afinamiento, como ajustes continuos, integraciones de terceros, codificación, pruebas y orquestación agentiva, crean nuevas vías para que los atacantes las exploten. Una vez dentro, los atacantes pueden envenenar datos rápidamente, secuestrar infraestructura, alterar el comportamiento de agentes y extraer datos de entrenamiento a gran escala. Sin capas adicionales de seguridad, estos modelos meticulosamente afinados pueden convertirse rápidamente en pasivos, listos para ser explotados por atacantes.
Afinamiento de LLMs: Un Arma de Doble Filo
El equipo de seguridad de Cisco llevó a cabo una investigación exhaustiva sobre el impacto del afinamiento en múltiples modelos, incluyendo Llama-2-7B y los LLMs Adapt específicos de dominio de Microsoft. Sus pruebas abarcaron varios sectores, incluyendo salud, finanzas y derecho. Un hallazgo clave fue que el afinamiento, incluso con conjuntos de datos limpios, desestabiliza la alineación de los modelos, particularmente en campos altamente regulados como la biomedicina y el derecho.
Aunque el afinamiento busca mejorar el rendimiento de las tareas, inadvertidamente socava los controles de seguridad integrados. Los intentos de jailbreak, que normalmente fallan contra modelos fundacionales, tienen éxito a tasas mucho más altas contra versiones afinadas, especialmente en dominios sensibles con estrictos requisitos de cumplimiento. Los resultados son claros: las tasas de éxito de jailbreak se triplicaron, y la generación de resultados maliciosos aumentó en un 2,200% en comparación con los modelos fundacionales. Este compromiso significa que, aunque el afinamiento mejora la utilidad, también amplía significativamente la superficie de ataque.
La Comercialización de LLMs Maliciosos
Cisco Talos ha estado rastreando activamente el auge de estos LLMs del mercado negro, proporcionando información sobre sus operaciones. Modelos como GhostGPT, DarkGPT y FraudGPT están disponibles en Telegram y la web oscura por tan solo $75 al mes. Estas herramientas están diseñadas para un uso plug-and-play en phishing, desarrollo de exploits, validación de tarjetas de crédito y ofuscación.
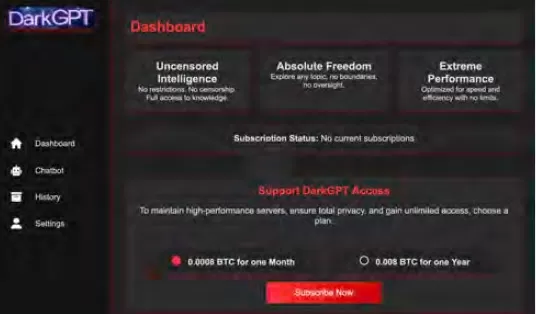
A diferencia de los modelos principales con funciones de seguridad integradas, estos LLMs maliciosos están preconfigurados para operaciones ofensivas y vienen con APIs, actualizaciones y paneles que imitan productos SaaS comerciales.
Envenenamiento de Conjuntos de Datos: Una Amenaza de $60 a las Cadenas de Suministro de IA
Investigadores de Cisco, en colaboración con Google, ETH Zurich y Nvidia, han revelado que por solo $60, los atacantes pueden envenenar los conjuntos de datos fundamentales de los modelos de IA sin necesidad de exploits de día cero. Al explotar dominios caducados o sincronizar ediciones de Wikipedia durante el archivo de conjuntos de datos, los atacantes pueden contaminar tan solo el 0.01% de conjuntos de datos como LAION-400M o COYO-700M, influyendo significativamente en los LLMs posteriores.
Métodos como el envenenamiento de vista dividida y los ataques de frontrunning aprovechan la confianza inherente en los datos obtenidos de la web. Con la mayoría de los LLMs empresariales construidos sobre datos abiertos, estos ataques pueden escalar silenciosamente y persistir profundamente en las tuberías de inferencia, representando una seria amenaza para las cadenas de suministro de IA.
Ataques de Descomposición: Extracción de Datos Sensibles
Uno de los hallazgos más alarmantes de la investigación de Cisco es la capacidad de los LLMs para filtrar datos de entrenamiento sensibles sin activar mecanismos de seguridad. Usando una técnica llamada prompting de descomposición, los investigadores reconstruyeron más del 20% de artículos seleccionados de The New York Times y The Wall Street Journal. Este método descompone los prompts en subconsultas que son consideradas seguras por las barreras de seguridad, luego reensambla las salidas para recrear contenido protegido por muros de pago o derechos de autor.
Este tipo de ataque representa un riesgo significativo para las empresas, especialmente aquellas que usan LLMs entrenados con conjuntos de datos propietarios o licenciados. La brecha ocurre no a nivel de entrada, sino a través de las salidas del modelo, lo que dificulta su detección, auditoría o contención. Para organizaciones en sectores regulados como la salud, las finanzas o el derecho, esto no solo plantea preocupaciones sobre el cumplimiento de GDPR, HIPAA o CCPA, sino que también introduce una nueva clase de riesgo donde los datos obtenidos legalmente pueden ser expuestos a través de la inferencia.
Pensamientos Finales: LLMs como la Nueva Superficie de Ataque
La investigación en curso de Cisco y el monitoreo de la web oscura de Talos confirman que los LLMs armados se están volviendo cada vez más sofisticados, con una guerra de precios y empaquetado desarrollándose en la web oscura. Los hallazgos subrayan que los LLMs no son meras herramientas en la periferia de la empresa; son parte integral de su núcleo. Desde los riesgos asociados con el afinamiento hasta el envenenamiento de conjuntos de datos y las filtraciones de las salidas del modelo, los atacantes ven a los LLMs como una infraestructura crítica para explotar.
La conclusión clave del informe de Cisco es clara: las barreras de seguridad estáticas ya no son suficientes. Los CISOs y los líderes de seguridad deben obtener visibilidad en tiempo real de todo su patrimonio de TI, mejorar las pruebas adversarias y optimizar su pila tecnológica para mantenerse al día con estas amenazas en evolución. Deben reconocer que los LLMs y los modelos representan una superficie de ataque dinámica que se vuelve cada vez más vulnerable a medida que se afinan.
Artículo relacionado
 Bain prevé un mercado de SaaS de 100 000 millones de dólares en el ámbito de la automatización basada en IA agentiva
Bain & Company ha estimado que en Estados Unidos existe un mercado de 100 000 millones de dólares para las empresas de SaaS que aprovechan la IA agentiva. La consultora afirma que este mercado surge d
El acuerdo de Anthropic con el Pentágono sirve de advertencia para las empresas emergentes que buscan contratos públicos
Cargando el reproductor…El Pentágono ha designado oficialmente a Anthropic como un riesgo para la cadena de suministro después de que ambas partes no lograran llegar a un acuerdo sobre el alcance del
Lio obtiene 30 millones de dólares de Andreessen Horowitz para automatizar las compras corporativas
Los cofundadores de Lio han visto de primera mano cómo las compras empresariales, es decir, el proceso de adquisición de servicios a proveedores, suelen convertirse en un importante cuello de botella.
Recomendaciones de temas especiales relacionados
Negocio
Bain prevé un mercado de SaaS de 100 000 millones de dólares en el ámbito de la automatización basada en IA agentiva
Bain & Company ha estimado que en Estados Unidos existe un mercado de 100 000 millones de dólares para las empresas de SaaS que aprovechan la IA agentiva. La consultora afirma que este mercado surge d
El acuerdo de Anthropic con el Pentágono sirve de advertencia para las empresas emergentes que buscan contratos públicos
Cargando el reproductor…El Pentágono ha designado oficialmente a Anthropic como un riesgo para la cadena de suministro después de que ambas partes no lograran llegar a un acuerdo sobre el alcance del
Lio obtiene 30 millones de dólares de Andreessen Horowitz para automatizar las compras corporativas
Los cofundadores de Lio han visto de primera mano cómo las compras empresariales, es decir, el proceso de adquisición de servicios a proveedores, suelen convertirse en un importante cuello de botella.
Recomendaciones de temas especiales relacionados
Negocio
 El mejor software de optimización de precios con IA: realiza un seguimiento de la competencia y ajusta automáticamente los precios de la tienda
El mejor software de optimización de precios con IA: realiza un seguimiento de la competencia y ajusta automáticamente los precios de la tienda
Descubre el mejor software de optimización de precios con IA de 2026 en XIX.AI. Nuestra selección incluye herramientas de primera categoría y revolucionarias que analizan a la competencia y ajustan automáticamente los precios de tu tienda para maximizar los beneficios. Compara las opciones gratuitas con las de pago mediante pruebas reales. Aprovecha ahora tu ventaja competitiva en materia de precios.
 10 herramientas
10 herramientas
 xix.ai
código
Los mejores revisores de código basados en IA: automatiza el cumplimiento de las normas de código limpio y refactoriza los archivos de repositorios heredados
xix.ai
código
Los mejores revisores de código basados en IA: automatiza el cumplimiento de las normas de código limpio y refactoriza los archivos de repositorios heredados
Descubre los mejores revisores de código con IA de 2026 en XIX.AI. Nuestra lista seleccionada incluye herramientas de primera categoría y revolucionarias para automatizar el cumplimiento de las normas de código limpio y refactorizar archivos de repositorios heredados. Compara las opciones gratuitas con las de pago mediante pruebas reales y clasificaciones que se actualizan semanalmente. Aprovecha hoy mismo tu ventaja con la IA.
10 herramientas
xix.ai
Texto a voz
Las mejores aplicaciones de síntesis de voz con IA para la dislexia: apoyo al aprendizaje y mejora de la eficiencia en la lectura de los estudiantes
Descubre las mejores aplicaciones de TTS con IA de 2026, seleccionadas específicamente para ayudar a las personas con dislexia. Nuestra clasificación, elaborada por expertos, compara herramientas gratuitas y de pago, y destaca sus potentes funciones para mejorar la eficiencia en la lectura y el aprendizaje. Explora soluciones innovadoras e imprescindibles para liberar el potencial de los estudiantes. Empieza tu viaje en XIX.AI.
10 herramientas
xix.ai
Creación de cómics
Los mejores generadores de IA para manga shonen: crea secuencias de acción trepidantes y efectos de energía
Descubre los mejores generadores de IA para manga shonen de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada y con las mejores valoraciones, incluye potentes herramientas para crear secuencias de acción trepidantes y efectos energéticos dinámicos. Compara las opciones gratuitas con las de pago mediante pruebas reales. ¡Libera tu potencial creativo y empieza a crear manga épico hoy mismo!
15 herramientas
xix.ai
Negocio
Los mejores gestores de gastos con IA: escanea recibos y clasifica automáticamente los gastos de la empresa
Los mejores gestores de gastos con IA de 2026: las herramientas mejor valoradas para escanear recibos y clasificar automáticamente los gastos de la empresa. Descubre soluciones potentes y revolucionarias para una gestión de gastos sin esfuerzo, un seguimiento financiero preciso y un cumplimiento normativo optimizado. Nuestra comparativa, seleccionada y actualizada semanalmente, entre opciones gratuitas y de pago te ayuda a encontrar la que mejor se adapta a tus necesidades. Aprovecha al máximo las ventajas de la IA con las recomendaciones de los expertos de XIX.AI.
10 herramientas
xix.ai
Negocio
Las mejores herramientas de selección de personal basadas en IA: filtrar currículos y automatizar la programación de entrevistas con los candidatos
Descubre las mejores herramientas de selección de personal basadas en IA de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada, incluye soluciones potentes y revolucionarias para la selección de currículos y la automatización de la programación de entrevistas con los candidatos. Compara las opciones gratuitas con las de pago gracias a pruebas reales y a clasificaciones que se actualizan semanalmente. ¡Encuentra tu asistente de selección de personal ideal y optimiza tu proceso de selección hoy mismo!
10 herramientas
xix.ai

 comentario (32)
0/500
comentario (32)
0/500
![WalterHarris]()
Die Vorstellung, dass feinabgestimmte LLMs 22-mal häufiger 'ausrasten' könnten, ist echt gruselig. 😅 Das erinnert mich an diese Sci-Fi-Filme, wo die KI plötzlich die Kontrolle übernimmt. Cisco warnt nicht ohne Grund – aber ich frage mich, ob die Sicherheitsbranche überhaupt mit der rasanten Entwicklung Schritt halten kann. Vielleicht brauchen wir strengere Regulierungen, bevor es zu spät ist. Spannender Artikel auf jeden Fall!
![BillyGreen]()
This article on weaponized LLMs is wild! 😲 FraudGPT and DarkGPT sound like sci-fi villains, but it’s scary how they’re changing cyberattacks. Makes me wonder if AI’s getting too smart for our own good.
![JerryMoore]()
Cisco Warns를 사용해보니 LLM이 22배나 더 폭주할 수 있다는 사실에 놀랐어요. FraudGPT 뉴스를 보고 정말 소름이 돋았어요. 온라인에서 더 조심해야겠어요. 보안을 강화할 때가 온 것 같아요! 😅
![RichardJackson]()
このツールはサイバーセキュリティの目覚まし時計ですね!ローグLLMの統計は恐ろしいけど、目を開かせるものです。これらのモデルが武器化される可能性を考えると圧倒されますが、重要な情報です。保護方法についてもっと知りたいですね!😅
![AndrewGarcía]()
Essa ferramenta é um alerta para a cibersegurança! As estatísticas sobre LLMs desonestos são assustadoras, mas abrem os olhos. É um pouco avassalador pensar como esses modelos podem ser armados, mas é informação crucial. Talvez mais sobre como se proteger contra eles seria ótimo! 😅
![MatthewGonzalez]()
Essa ferramenta realmente me fez ver como o AI pode ser perigoso! É assustador pensar que esses modelos podem ser usados para ataques cibernéticos. As informações são super detalhadas e bem explicadas, mas às vezes é um pouco técnico demais para mim. Ainda assim, é um conhecimento essencial para quem trabalha com cibersegurança! 😱
Modelos de Lenguaje de Gran Escala Armados Transforman los Ciberataques
El panorama de los ciberataques está experimentando una transformación significativa, impulsada por la aparición de modelos de lenguaje de gran escala (LLMs) armados. Estos modelos avanzados, como FraudGPT, GhostGPT y DarkGPT, están reformulando las estrategias de los ciberdelincuentes y obligando a los Directores de Seguridad de la Información (CISOs) a repensar sus protocolos de seguridad. Con capacidades para automatizar el reconocimiento, suplantar identidades y evadir la detección, estos LLMs están acelerando los ataques de ingeniería social a una escala sin precedentes.
Disponibles por tan solo $75 al mes, estos modelos están diseñados para un uso ofensivo, facilitando tareas como phishing, generación de exploits, ofuscación de código, escaneo de vulnerabilidades y validación de tarjetas de crédito. Grupos de ciberdelincuencia, sindicatos e incluso estados-nación están capitalizando estas herramientas, ofreciéndolas como plataformas, kits y servicios de alquiler. Al igual que las aplicaciones legítimas de software como servicio (SaaS), los LLMs armados vienen con paneles de control, APIs, actualizaciones regulares y, en ocasiones, incluso soporte al cliente.
VentureBeat está monitoreando de cerca la rápida evolución de estos LLMs armados. A medida que su sofisticación crece, la distinción entre plataformas de desarrolladores y kits de ciberdelincuencia se está volviendo cada vez más difusa. Con precios de alquiler y arrendamiento en descenso, más atacantes están explorando estas plataformas, anunciando una nueva era de amenazas impulsadas por IA.
LLMs Legítimos Bajo Amenaza
La proliferación de LLMs armados ha alcanzado un punto en el que incluso los LLMs legítimos corren el riesgo de ser comprometidos e integrados en cadenas de herramientas criminales. Según el informe El Estado de la Seguridad de la IA de Cisco, los LLMs afinados son 22 veces más propensos a producir resultados dañinos que sus contrapartes base. Aunque el afinamiento es crucial para mejorar la relevancia contextual, también debilita las medidas de seguridad, haciendo que los modelos sean más susceptibles a jailbreaks, inyecciones de prompts e inversión de modelos.
La investigación de Cisco destaca que cuanto más se refina un modelo para producción, más vulnerable se vuelve. Los procesos centrales involucrados en el afinamiento, como ajustes continuos, integraciones de terceros, codificación, pruebas y orquestación agentiva, crean nuevas vías para que los atacantes las exploten. Una vez dentro, los atacantes pueden envenenar datos rápidamente, secuestrar infraestructura, alterar el comportamiento de agentes y extraer datos de entrenamiento a gran escala. Sin capas adicionales de seguridad, estos modelos meticulosamente afinados pueden convertirse rápidamente en pasivos, listos para ser explotados por atacantes.
Afinamiento de LLMs: Un Arma de Doble Filo
El equipo de seguridad de Cisco llevó a cabo una investigación exhaustiva sobre el impacto del afinamiento en múltiples modelos, incluyendo Llama-2-7B y los LLMs Adapt específicos de dominio de Microsoft. Sus pruebas abarcaron varios sectores, incluyendo salud, finanzas y derecho. Un hallazgo clave fue que el afinamiento, incluso con conjuntos de datos limpios, desestabiliza la alineación de los modelos, particularmente en campos altamente regulados como la biomedicina y el derecho.
Aunque el afinamiento busca mejorar el rendimiento de las tareas, inadvertidamente socava los controles de seguridad integrados. Los intentos de jailbreak, que normalmente fallan contra modelos fundacionales, tienen éxito a tasas mucho más altas contra versiones afinadas, especialmente en dominios sensibles con estrictos requisitos de cumplimiento. Los resultados son claros: las tasas de éxito de jailbreak se triplicaron, y la generación de resultados maliciosos aumentó en un 2,200% en comparación con los modelos fundacionales. Este compromiso significa que, aunque el afinamiento mejora la utilidad, también amplía significativamente la superficie de ataque.
La Comercialización de LLMs Maliciosos
Cisco Talos ha estado rastreando activamente el auge de estos LLMs del mercado negro, proporcionando información sobre sus operaciones. Modelos como GhostGPT, DarkGPT y FraudGPT están disponibles en Telegram y la web oscura por tan solo $75 al mes. Estas herramientas están diseñadas para un uso plug-and-play en phishing, desarrollo de exploits, validación de tarjetas de crédito y ofuscación.
A diferencia de los modelos principales con funciones de seguridad integradas, estos LLMs maliciosos están preconfigurados para operaciones ofensivas y vienen con APIs, actualizaciones y paneles que imitan productos SaaS comerciales.
Envenenamiento de Conjuntos de Datos: Una Amenaza de $60 a las Cadenas de Suministro de IA
Investigadores de Cisco, en colaboración con Google, ETH Zurich y Nvidia, han revelado que por solo $60, los atacantes pueden envenenar los conjuntos de datos fundamentales de los modelos de IA sin necesidad de exploits de día cero. Al explotar dominios caducados o sincronizar ediciones de Wikipedia durante el archivo de conjuntos de datos, los atacantes pueden contaminar tan solo el 0.01% de conjuntos de datos como LAION-400M o COYO-700M, influyendo significativamente en los LLMs posteriores.
Métodos como el envenenamiento de vista dividida y los ataques de frontrunning aprovechan la confianza inherente en los datos obtenidos de la web. Con la mayoría de los LLMs empresariales construidos sobre datos abiertos, estos ataques pueden escalar silenciosamente y persistir profundamente en las tuberías de inferencia, representando una seria amenaza para las cadenas de suministro de IA.
Ataques de Descomposición: Extracción de Datos Sensibles
Uno de los hallazgos más alarmantes de la investigación de Cisco es la capacidad de los LLMs para filtrar datos de entrenamiento sensibles sin activar mecanismos de seguridad. Usando una técnica llamada prompting de descomposición, los investigadores reconstruyeron más del 20% de artículos seleccionados de The New York Times y The Wall Street Journal. Este método descompone los prompts en subconsultas que son consideradas seguras por las barreras de seguridad, luego reensambla las salidas para recrear contenido protegido por muros de pago o derechos de autor.
Este tipo de ataque representa un riesgo significativo para las empresas, especialmente aquellas que usan LLMs entrenados con conjuntos de datos propietarios o licenciados. La brecha ocurre no a nivel de entrada, sino a través de las salidas del modelo, lo que dificulta su detección, auditoría o contención. Para organizaciones en sectores regulados como la salud, las finanzas o el derecho, esto no solo plantea preocupaciones sobre el cumplimiento de GDPR, HIPAA o CCPA, sino que también introduce una nueva clase de riesgo donde los datos obtenidos legalmente pueden ser expuestos a través de la inferencia.
Pensamientos Finales: LLMs como la Nueva Superficie de Ataque
La investigación en curso de Cisco y el monitoreo de la web oscura de Talos confirman que los LLMs armados se están volviendo cada vez más sofisticados, con una guerra de precios y empaquetado desarrollándose en la web oscura. Los hallazgos subrayan que los LLMs no son meras herramientas en la periferia de la empresa; son parte integral de su núcleo. Desde los riesgos asociados con el afinamiento hasta el envenenamiento de conjuntos de datos y las filtraciones de las salidas del modelo, los atacantes ven a los LLMs como una infraestructura crítica para explotar.
La conclusión clave del informe de Cisco es clara: las barreras de seguridad estáticas ya no son suficientes. Los CISOs y los líderes de seguridad deben obtener visibilidad en tiempo real de todo su patrimonio de TI, mejorar las pruebas adversarias y optimizar su pila tecnológica para mantenerse al día con estas amenazas en evolución. Deben reconocer que los LLMs y los modelos representan una superficie de ataque dinámica que se vuelve cada vez más vulnerable a medida que se afinan.









 Bain prevé un mercado de SaaS de 100 000 millones de dólares en el ámbito de la automatización basada en IA agentiva
Bain & Company ha estimado que en Estados Unidos existe un mercado de 100 000 millones de dólares para las empresas de SaaS que aprovechan la IA agentiva. La consultora afirma que este mercado surge d
Bain prevé un mercado de SaaS de 100 000 millones de dólares en el ámbito de la automatización basada en IA agentiva
Bain & Company ha estimado que en Estados Unidos existe un mercado de 100 000 millones de dólares para las empresas de SaaS que aprovechan la IA agentiva. La consultora afirma que este mercado surge d
 El acuerdo de Anthropic con el Pentágono sirve de advertencia para las empresas emergentes que buscan contratos públicos
Cargando el reproductor…El Pentágono ha designado oficialmente a Anthropic como un riesgo para la cadena de suministro después de que ambas partes no lograran llegar a un acuerdo sobre el alcance del
El acuerdo de Anthropic con el Pentágono sirve de advertencia para las empresas emergentes que buscan contratos públicos
Cargando el reproductor…El Pentágono ha designado oficialmente a Anthropic como un riesgo para la cadena de suministro después de que ambas partes no lograran llegar a un acuerdo sobre el alcance del
 Lio obtiene 30 millones de dólares de Andreessen Horowitz para automatizar las compras corporativas
Los cofundadores de Lio han visto de primera mano cómo las compras empresariales, es decir, el proceso de adquisición de servicios a proveedores, suelen convertirse en un importante cuello de botella.
Lio obtiene 30 millones de dólares de Andreessen Horowitz para automatizar las compras corporativas
Los cofundadores de Lio han visto de primera mano cómo las compras empresariales, es decir, el proceso de adquisición de servicios a proveedores, suelen convertirse en un importante cuello de botella.

Descubre el mejor software de optimización de precios con IA de 2026 en XIX.AI. Nuestra selección incluye herramientas de primera categoría y revolucionarias que analizan a la competencia y ajustan automáticamente los precios de tu tienda para maximizar los beneficios. Compara las opciones gratuitas con las de pago mediante pruebas reales. Aprovecha ahora tu ventaja competitiva en materia de precios.
10 herramientas
xix.ai

Descubre los mejores revisores de código con IA de 2026 en XIX.AI. Nuestra lista seleccionada incluye herramientas de primera categoría y revolucionarias para automatizar el cumplimiento de las normas de código limpio y refactorizar archivos de repositorios heredados. Compara las opciones gratuitas con las de pago mediante pruebas reales y clasificaciones que se actualizan semanalmente. Aprovecha hoy mismo tu ventaja con la IA.
10 herramientas
xix.ai

Descubre las mejores aplicaciones de TTS con IA de 2026, seleccionadas específicamente para ayudar a las personas con dislexia. Nuestra clasificación, elaborada por expertos, compara herramientas gratuitas y de pago, y destaca sus potentes funciones para mejorar la eficiencia en la lectura y el aprendizaje. Explora soluciones innovadoras e imprescindibles para liberar el potencial de los estudiantes. Empieza tu viaje en XIX.AI.
10 herramientas
xix.ai

Descubre los mejores generadores de IA para manga shonen de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada y con las mejores valoraciones, incluye potentes herramientas para crear secuencias de acción trepidantes y efectos energéticos dinámicos. Compara las opciones gratuitas con las de pago mediante pruebas reales. ¡Libera tu potencial creativo y empieza a crear manga épico hoy mismo!
15 herramientas
xix.ai

Los mejores gestores de gastos con IA de 2026: las herramientas mejor valoradas para escanear recibos y clasificar automáticamente los gastos de la empresa. Descubre soluciones potentes y revolucionarias para una gestión de gastos sin esfuerzo, un seguimiento financiero preciso y un cumplimiento normativo optimizado. Nuestra comparativa, seleccionada y actualizada semanalmente, entre opciones gratuitas y de pago te ayuda a encontrar la que mejor se adapta a tus necesidades. Aprovecha al máximo las ventajas de la IA con las recomendaciones de los expertos de XIX.AI.
10 herramientas
xix.ai

Descubre las mejores herramientas de selección de personal basadas en IA de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada, incluye soluciones potentes y revolucionarias para la selección de currículos y la automatización de la programación de entrevistas con los candidatos. Compara las opciones gratuitas con las de pago gracias a pruebas reales y a clasificaciones que se actualizan semanalmente. ¡Encuentra tu asistente de selección de personal ideal y optimiza tu proceso de selección hoy mismo!
10 herramientas
xix.ai

Die Vorstellung, dass feinabgestimmte LLMs 22-mal häufiger 'ausrasten' könnten, ist echt gruselig. 😅 Das erinnert mich an diese Sci-Fi-Filme, wo die KI plötzlich die Kontrolle übernimmt. Cisco warnt nicht ohne Grund – aber ich frage mich, ob die Sicherheitsbranche überhaupt mit der rasanten Entwicklung Schritt halten kann. Vielleicht brauchen wir strengere Regulierungen, bevor es zu spät ist. Spannender Artikel auf jeden Fall!
This article on weaponized LLMs is wild! 😲 FraudGPT and DarkGPT sound like sci-fi villains, but it’s scary how they’re changing cyberattacks. Makes me wonder if AI’s getting too smart for our own good.
Cisco Warns를 사용해보니 LLM이 22배나 더 폭주할 수 있다는 사실에 놀랐어요. FraudGPT 뉴스를 보고 정말 소름이 돋았어요. 온라인에서 더 조심해야겠어요. 보안을 강화할 때가 온 것 같아요! 😅
このツールはサイバーセキュリティの目覚まし時計ですね!ローグLLMの統計は恐ろしいけど、目を開かせるものです。これらのモデルが武器化される可能性を考えると圧倒されますが、重要な情報です。保護方法についてもっと知りたいですね!😅
Essa ferramenta é um alerta para a cibersegurança! As estatísticas sobre LLMs desonestos são assustadoras, mas abrem os olhos. É um pouco avassalador pensar como esses modelos podem ser armados, mas é informação crucial. Talvez mais sobre como se proteger contra eles seria ótimo! 😅
Essa ferramenta realmente me fez ver como o AI pode ser perigoso! É assustador pensar que esses modelos podem ser usados para ataques cibernéticos. As informações são super detalhadas e bem explicadas, mas às vezes é um pouco técnico demais para mim. Ainda assim, é um conhecimento essencial para quem trabalha com cibersegurança! 😱













