
















 집
집Cisco 경고 : 미세 조정 된 LLMS가 22 배 더 많은 불량
# cisco
# LLMs
# APIs
# saas
# csco
# goog-2
# msft-2
# nvda-2
# darkgpt
# darkweb
# fraudgpt
# ghostgpt
# zeroday
무기화된 대형 언어 모델이 사이버 공격을 재편하다
사이버 공격의 환경은 무기화된 대형 언어 모델(LLMs)의 등장으로 인해 중대한 변화를 겪고 있습니다. FraudGPT, GhostGPT, DarkGPT와 같은 첨단 모델들은 사이버 범죄자들의 전략을 재편하고 있으며, 최고 정보 보안 책임자(CISO)들이 보안 프로토콜을 재고하도록 강요하고 있습니다. 정찰 자동화, 신원 사칭, 탐지 회피 기능을 갖춘 이 LLM들은 전례 없는 규모로 소셜 엔지니어링 공격을 가속화하고 있습니다.
월 75달러라는 저렴한 비용으로 이용 가능한 이 모델들은 공격적 용도로 맞춤화되어 피싱, 익스플로잇 생성, 코드 난독화, 취약점 스캔, 신용카드 검증과 같은 작업을 지원합니다. 사이버 범죄 그룹, 신디케이트, 심지어 국가 단위의 행위자들은 이러한 도구를 플랫폼, 키트, 임대 서비스로 활용하고 있습니다. 합법적인 소프트웨어-as-a-service(SaaS) 애플리케이션과 마찬가지로, 무기화된 LLM들은 대시보드, API, 정기 업데이트, 심지어 고객 지원까지 제공합니다.
VentureBeat는 이러한 무기화된 LLM들의 급격한 진화를 면밀히 모니터링하고 있습니다. 이들의 정교함이 증가함에 따라 개발자 플랫폼과 사이버 범죄 키트 간의 구분이 점점 모호해지고 있습니다. 임대 및 렌탈 가격이 하락하면서 더 많은 공격자들이 이 플랫폼을 탐색하고 있으며, AI 주도 위협의 새로운 시대를 예고하고 있습니다.
합법적인 LLM들의 위협
무기화된 LLM들의 확산은 합법적인 LLM들조차 범죄 도구 체인에 통합되어 손상될 위험에 처할 정도로 심각해졌습니다. Cisco의 AI 보안 상태 보고서에 따르면, 미세 조정된 LLM들은 기본 모델에 비해 유해한 출력물을 생성할 가능성이 22배 높습니다. 미세 조정이 문맥적 관련성을 높이는 데 중요하지만, 안전 조치를 약화시켜 모델을 탈옥, 프롬프트 주입, 모델 역전 공격에 더 취약하게 만듭니다.
Cisco의 연구는 모델이 생산용으로 더 정교하게 조정될수록 취약성이 커진다고 강조합니다. 미세 조정에 관련된 핵심 프로세스, 예를 들어 지속적인 조정, 서드파티 통합, 코딩, 테스트, 에이전트 오케스트레이션은 공격자들에게 새로운 공격 경로를 제공합니다. 일단 침투하면, 공격자들은 데이터를 오염시키고, 인프라를 탈취하며, 에이전트 행동을 변경하고, 대규모로 훈련 데이터를 추출할 수 있습니다. 추가 보안 계층이 없으면, 정교하게 미세 조정된 이 모델들은 공격자들에게 쉽게 악용될 수 있는 취약점으로 전락합니다.
LLM 미세 조정: 양날의 검
Cisco의 보안 팀은 Llama-2-7B와 Microsoft의 도메인 특화 Adapt LLM을 포함한 여러 모델에 대한 미세 조정의 영향을 광범위하게 연구했습니다. 테스트는 의료, 금융, 법률 등 다양한 분야에 걸쳐 진행되었습니다. 주요 발견은 깨끗한 데이터셋을 사용한 미세 조정조차도 특히 생물의학 및 법률과 같은 고도로 규제된 분야에서 모델의 정렬을 불안정하게 만든다는 것입니다.
미세 조정은 작업 성능을 개선하려는 목적이지만, 내장된 안전 제어를 약화시킵니다. 기본 모델에 대해 일반적으로 실패하는 탈옥 시도가 미세 조정된 버전, 특히 엄격한 규제 요구 사항이 있는 민감한 도메인에서 훨씬 높은 성공률을 보입니다. 결과는 명확합니다: 탈옥 성공률은 3배 증가했으며, 악의적인 출력 생성은 기본 모델에 비해 2,200% 증가했습니다. 이 절충은 미세 조정이 유용성을 높이는 동시에 공격 표면을 크게 확장한다는 것을 의미합니다.
악의적인 LLM의 상품화
Cisco Talos는 이러한 암시장 LLM의 부상을 적극적으로 추적하며 그 운영에 대한 통찰을 제공하고 있습니다. GhostGPT, DarkGPT, FraudGPT와 같은 모델은 Telegram과 다크 웹에서 월 75달러라는 저렴한 비용으로 제공됩니다. 이 도구들은 피싱, 익스플로잇 개발, 신용카드 검증, 난독화를 위한 플러그 앤 플레이 용도로 설계되었습니다.
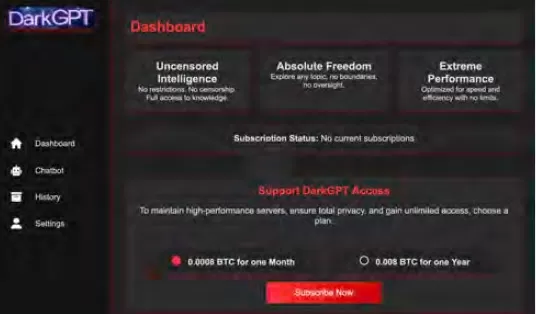
내장된 안전 기능을 갖춘 주류 모델과 달리, 이 악의적인 LLM들은 공격적 작업을 위해 사전 구성되어 있으며, 상용 SaaS 제품을 모방한 API, 업데이트, 대시보드를 제공합니다.
데이터셋 오염: AI 공급망에 대한 60달러 위협
Cisco 연구진은 Google, ETH Zurich, Nvidia와 협력하여 공격자들이 제로데이 익스플로잇 없이 단 60달러로 AI 모델의 기본 데이터셋을 오염시킬 수 있다는 사실을 밝혔습니다. 만료된 도메인을 악용하거나 데이터셋 아카이빙 중 Wikipedia 편집 타이밍을 활용함으로써, 공격자들은 LAION-400M 또는 COYO-700M 같은 데이터셋의 0.01%만 오염시켜도 하위 LLM에 큰 영향을 미칠 수 있습니다.
스플릿-뷰 오염 및 프론트러닝 공격과 같은 방법은 웹 크롤링 데이터에 대한 내재된 신뢰를 악용합니다. 대부분의 엔터프라이즈 LLM이 오픈 데이터를 기반으로 구축되므로, 이러한 공격은 조용히 확장되며 추론 파이프라인 깊숙이 지속되어 AI 공급망에 심각한 위협을 초래합니다.
분해 공격: 민감 데이터 추출
Cisco의 연구에서 가장 놀라운 발견 중 하나는 LLM이 안전 메커니즘을 작동시키지 않고 민감한 훈련 데이터를 유출할 수 있다는 점입니다. 분해 프롬프팅이라는 기술을 사용해 연구진은 The New York Times와 The Wall Street Journal의 선택된 기사의 20% 이상을 재구성했습니다. 이 방법은 프롬프트를 가드레일이 안전하다고 판단하는 하위 쿼리로 분해한 후, 출력을 재조합하여 유료 또는 저작권 보호된 콘텐츠를 재생성합니다.
이러한 유형의 공격은 독점 또는 라이선스 데이터셋으로 훈련된 LLM을 사용하는 기업에 중대한 위험을 초래합니다. 침해는 입력 수준이 아니라 모델의 출력에서 발생하므로 탐지, 감사, 또는 억제가 어렵습니다. 의료, 금융, 법률과 같은 규제된 분야의 조직들에게 이는 GDPR, HIPAA, CCPA 준수에 대한 우려뿐만 아니라, 법적으로 소싱된 데이터가 추론을 통해 노출될 수 있는 새로운 위험 클래스를 도입합니다.
최종 생각: 새로운 공격 표면으로서의 LLM
Cisco의 지속적인 연구와 Talos의 다크 웹 모니터링은 무기화된 LLM이 점점 정교해지고 있으며, 다크 웹에서 가격 및 패키징 전쟁이 벌어지고 있음을 확인합니다. 이 결과는 LLM이 기업의边缘에 있는 도구가 아니라 핵심에 있다는 점을 강조합니다. 미세 조정과 관련된 위험부터 데이터셋 오염, 모델 출력 유출에 이르기까지, 공격자들은 LLM을 악용할 수 있는 중요한 인프라로 간주합니다.
Cisco의 보고서의 핵심 메시지는 분명합니다: 정적 가드레일은 더 이상 충분하지 않습니다. CISO와 보안 리더들은 전체 IT 환경에 대한 실시간 가시성을 확보하고, 적대적 테스트를 강화하며, 진화하는 위협에 대처하기 위해 기술 스택을 간소화해야 합니다. LLM과 모델은 미세 조정될수록 점점 더 취약해지는 동적 공격 표면임을 인식해야 합니다.
관련 기사
 베인은 에이전트형 AI 자동화 분야의 SaaS 시장 규모가 1,000억 달러에 달할 것으로 전망했다
베인 앤 컴퍼니(Bain & Company)는 에이전트형 AI를 활용하는 SaaS 기업을 위한 미국 내 시장 규모가 1,000억 달러에 달할 것으로 추산했다. 이 회사는 이 시장이 기업 시스템 내 조정 업무의 자동화에서 비롯된다고 밝혔다.이 추정치는 AI 시대의 소프트웨어 산업에 관한 베인의 5부작 시리즈 중 두 번째 편에서 나온 것이다. 이 보고서는 에이
앤트로픽의 펜타곤 계약은 정부 계약을 노리는 스타트업들에게 경종을 울린다
플레이어 로딩 중…미 국방부는 자율 무기 및 광범위한 국내 감시에 대한 잠재적 활용을 포함해, Anthropic의 AI 모델에 대한 군의 통제 범위를 두고 양측이 합의에 이르지 못하자 Anthropic을 공식적으로 공급망 위험 요소로 지정했다. 앤트로픽과의 2억 달러 규모 계약이 무산된 후, 국방부는 오픈AI로 눈을 돌렸고, 오픈AI는 이 계약을 수락했으나
리오, 기업 조달 자동화를 위해 안드레센 호로위츠로부터 3천만 달러 투자 유치
리오의 공동 창업자들은 기업 조달 — 공급업체로부터 서비스를 구매하는 과정 — 이 종종 주요 병목 현상이 되는 것을 직접 목격했습니다. 회사의 공동 창업자이자 CEO인 블라디미르 카일(Vladimir Keil)은 대기업 직원으로서, 그리고 이후 첫 스타트업을 창업하면서 이 문제를 모두 경험했습니다."기업용 소프트웨어를 판매할 당시 직접 조달 절차를 경험하며
관련 특별 주제 추천
사업
베인은 에이전트형 AI 자동화 분야의 SaaS 시장 규모가 1,000억 달러에 달할 것으로 전망했다
베인 앤 컴퍼니(Bain & Company)는 에이전트형 AI를 활용하는 SaaS 기업을 위한 미국 내 시장 규모가 1,000억 달러에 달할 것으로 추산했다. 이 회사는 이 시장이 기업 시스템 내 조정 업무의 자동화에서 비롯된다고 밝혔다.이 추정치는 AI 시대의 소프트웨어 산업에 관한 베인의 5부작 시리즈 중 두 번째 편에서 나온 것이다. 이 보고서는 에이
앤트로픽의 펜타곤 계약은 정부 계약을 노리는 스타트업들에게 경종을 울린다
플레이어 로딩 중…미 국방부는 자율 무기 및 광범위한 국내 감시에 대한 잠재적 활용을 포함해, Anthropic의 AI 모델에 대한 군의 통제 범위를 두고 양측이 합의에 이르지 못하자 Anthropic을 공식적으로 공급망 위험 요소로 지정했다. 앤트로픽과의 2억 달러 규모 계약이 무산된 후, 국방부는 오픈AI로 눈을 돌렸고, 오픈AI는 이 계약을 수락했으나
리오, 기업 조달 자동화를 위해 안드레센 호로위츠로부터 3천만 달러 투자 유치
리오의 공동 창업자들은 기업 조달 — 공급업체로부터 서비스를 구매하는 과정 — 이 종종 주요 병목 현상이 되는 것을 직접 목격했습니다. 회사의 공동 창업자이자 CEO인 블라디미르 카일(Vladimir Keil)은 대기업 직원으로서, 그리고 이후 첫 스타트업을 창업하면서 이 문제를 모두 경험했습니다."기업용 소프트웨어를 판매할 당시 직접 조달 절차를 경험하며
관련 특별 주제 추천
사업
 최고의 AI 가격 최적화 소프트웨어: 경쟁사 추적 및 스토어 가격 자동 조정
최고의 AI 가격 최적화 소프트웨어: 경쟁사 추적 및 스토어 가격 자동 조정
XIX.AI에서 2026년 최고의 AI 가격 최적화 소프트웨어를 만나보세요. 저희가 엄선한 이 목록에는 경쟁사를 추적하고 최대 수익을 위해 매장 가격을 자동으로 조정해 주는, 최고 평점을 받은 혁신적인 도구들이 포함되어 있습니다. 실제 테스트 결과를 바탕으로 무료 버전과 유료 버전을 비교해 보세요. 지금 바로 가격 경쟁력의 우위를 확보하세요.
 10 도구
10 도구
 xix.ai
암호
최고의 AI 코드 검토 도구: 깔끔한 코드 준수 자동화 및 레거시 리포지토리 파일 리팩토링
xix.ai
암호
최고의 AI 코드 검토 도구: 깔끔한 코드 준수 자동화 및 레거시 리포지토리 파일 리팩토링
XIX.AI에서 2026년 최고의 AI 코드 검토 도구를 만나보세요. 엄선된 이 목록에는 깔끔한 코드 준수 여부를 자동으로 확인하고 레거시 리포지토리 파일을 리팩토링하는 데 있어 판도를 바꿀 만한 최고 등급의 도구들이 포함되어 있습니다. 실제 테스트 결과와 매주 업데이트되는 순위를 통해 무료 및 유료 옵션을 비교해 보세요. 지금 바로 AI의 경쟁력을 확보하세요.
10 도구
xix.ai
텍스트 음성 변환
난독증 환자를 위한 최고의 AI 음성 합성 앱: 학생들의 학습 및 독서 효율성 향상
난독증 지원을 위해 엄선된 2026년 최신 최고 평점 AI TTS 앱을 만나보세요. 전문가들이 선정한 이 순위는 무료 및 유료 도구를 비교 분석하여, 읽기 효율과 학습 효과를 높여주는 강력한 기능들을 소개합니다. 학생들의 잠재력을 최대한 발휘할 수 있도록 도와줄, 꼭 사용해봐야 할 혁신적인 솔루션을 확인해 보세요. XIX.AI에서 여정을 시작해 보세요.
10 도구
xix.ai
만화 창작
소년 만화를 위한 최고의 AI 생성기: 박진감 넘치는 액션 장면과 에너지 효과 만들기
XIX.AI에서 2026년 최고의 소년 만화 AI 생성기를 만나보세요. 엄선된 최고 평점 목록에는 박진감 넘치는 액션 장면과 역동적인 에너지 효과를 연출할 수 있는 강력한 도구들이 포함되어 있습니다. 실제 테스트를 통해 무료 버전과 유료 버전을 비교해 보세요. 여러분의 창의력을 마음껏 발휘하여 오늘 바로 장대한 만화를 만들어 보세요!
15 도구
xix.ai
사업
최고의 AI 경비 관리 앱: 영수증을 스캔하고 기업 경비를 자동으로 분류하세요
2026년 최신 최고의 AI 경비 관리 도구: 영수증을 스캔하고 기업 경비를 자동으로 분류해 주는 최고 평점의 도구들. 손쉬운 경비 관리, 정확한 재무 추적, 효율적인 규정 준수를 위한 강력하고 혁신적인 솔루션을 만나보세요. 무료 및 유료 옵션을 엄선하여 매주 업데이트되는 비교 자료를 통해 귀사에 딱 맞는 도구를 찾으실 수 있습니다. XIX.AI의 전문가 추천 목록으로 AI의 장점을 최대한 활용하세요.
10 도구
xix.ai
사업
최고의 AI 채용 도구: 이력서 심사 및 후보자 면접 일정 자동화
XIX.AI에서 2026년 최신 최고 평점을 받은 AI 채용 도구를 확인해 보세요. 저희가 엄선한 이 목록에는 이력서 심사 및 후보자 면접 일정 자동화를 위한 강력하고 혁신적인 솔루션이 포함되어 있습니다. 실제 테스트 결과와 매주 업데이트되는 순위를 바탕으로 무료 및 유료 옵션을 비교해 보세요. 지금 바로 귀사에 딱 맞는 채용 도우미를 찾아 채용 프로세스를 효율화하세요!
10 도구
xix.ai

 의견 (32)
0/500
의견 (32)
0/500
![WalterHarris]()
Die Vorstellung, dass feinabgestimmte LLMs 22-mal häufiger 'ausrasten' könnten, ist echt gruselig. 😅 Das erinnert mich an diese Sci-Fi-Filme, wo die KI plötzlich die Kontrolle übernimmt. Cisco warnt nicht ohne Grund – aber ich frage mich, ob die Sicherheitsbranche überhaupt mit der rasanten Entwicklung Schritt halten kann. Vielleicht brauchen wir strengere Regulierungen, bevor es zu spät ist. Spannender Artikel auf jeden Fall!
![BillyGreen]()
This article on weaponized LLMs is wild! 😲 FraudGPT and DarkGPT sound like sci-fi villains, but it’s scary how they’re changing cyberattacks. Makes me wonder if AI’s getting too smart for our own good.
![JerryMoore]()
Cisco Warns를 사용해보니 LLM이 22배나 더 폭주할 수 있다는 사실에 놀랐어요. FraudGPT 뉴스를 보고 정말 소름이 돋았어요. 온라인에서 더 조심해야겠어요. 보안을 강화할 때가 온 것 같아요! 😅
![RichardJackson]()
このツールはサイバーセキュリティの目覚まし時計ですね!ローグLLMの統計は恐ろしいけど、目を開かせるものです。これらのモデルが武器化される可能性を考えると圧倒されますが、重要な情報です。保護方法についてもっと知りたいですね!😅
![AndrewGarcía]()
Essa ferramenta é um alerta para a cibersegurança! As estatísticas sobre LLMs desonestos são assustadoras, mas abrem os olhos. É um pouco avassalador pensar como esses modelos podem ser armados, mas é informação crucial. Talvez mais sobre como se proteger contra eles seria ótimo! 😅
![MatthewGonzalez]()
Essa ferramenta realmente me fez ver como o AI pode ser perigoso! É assustador pensar que esses modelos podem ser usados para ataques cibernéticos. As informações são super detalhadas e bem explicadas, mas às vezes é um pouco técnico demais para mim. Ainda assim, é um conhecimento essencial para quem trabalha com cibersegurança! 😱
무기화된 대형 언어 모델이 사이버 공격을 재편하다
사이버 공격의 환경은 무기화된 대형 언어 모델(LLMs)의 등장으로 인해 중대한 변화를 겪고 있습니다. FraudGPT, GhostGPT, DarkGPT와 같은 첨단 모델들은 사이버 범죄자들의 전략을 재편하고 있으며, 최고 정보 보안 책임자(CISO)들이 보안 프로토콜을 재고하도록 강요하고 있습니다. 정찰 자동화, 신원 사칭, 탐지 회피 기능을 갖춘 이 LLM들은 전례 없는 규모로 소셜 엔지니어링 공격을 가속화하고 있습니다.
월 75달러라는 저렴한 비용으로 이용 가능한 이 모델들은 공격적 용도로 맞춤화되어 피싱, 익스플로잇 생성, 코드 난독화, 취약점 스캔, 신용카드 검증과 같은 작업을 지원합니다. 사이버 범죄 그룹, 신디케이트, 심지어 국가 단위의 행위자들은 이러한 도구를 플랫폼, 키트, 임대 서비스로 활용하고 있습니다. 합법적인 소프트웨어-as-a-service(SaaS) 애플리케이션과 마찬가지로, 무기화된 LLM들은 대시보드, API, 정기 업데이트, 심지어 고객 지원까지 제공합니다.
VentureBeat는 이러한 무기화된 LLM들의 급격한 진화를 면밀히 모니터링하고 있습니다. 이들의 정교함이 증가함에 따라 개발자 플랫폼과 사이버 범죄 키트 간의 구분이 점점 모호해지고 있습니다. 임대 및 렌탈 가격이 하락하면서 더 많은 공격자들이 이 플랫폼을 탐색하고 있으며, AI 주도 위협의 새로운 시대를 예고하고 있습니다.
합법적인 LLM들의 위협
무기화된 LLM들의 확산은 합법적인 LLM들조차 범죄 도구 체인에 통합되어 손상될 위험에 처할 정도로 심각해졌습니다. Cisco의 AI 보안 상태 보고서에 따르면, 미세 조정된 LLM들은 기본 모델에 비해 유해한 출력물을 생성할 가능성이 22배 높습니다. 미세 조정이 문맥적 관련성을 높이는 데 중요하지만, 안전 조치를 약화시켜 모델을 탈옥, 프롬프트 주입, 모델 역전 공격에 더 취약하게 만듭니다.
Cisco의 연구는 모델이 생산용으로 더 정교하게 조정될수록 취약성이 커진다고 강조합니다. 미세 조정에 관련된 핵심 프로세스, 예를 들어 지속적인 조정, 서드파티 통합, 코딩, 테스트, 에이전트 오케스트레이션은 공격자들에게 새로운 공격 경로를 제공합니다. 일단 침투하면, 공격자들은 데이터를 오염시키고, 인프라를 탈취하며, 에이전트 행동을 변경하고, 대규모로 훈련 데이터를 추출할 수 있습니다. 추가 보안 계층이 없으면, 정교하게 미세 조정된 이 모델들은 공격자들에게 쉽게 악용될 수 있는 취약점으로 전락합니다.
LLM 미세 조정: 양날의 검
Cisco의 보안 팀은 Llama-2-7B와 Microsoft의 도메인 특화 Adapt LLM을 포함한 여러 모델에 대한 미세 조정의 영향을 광범위하게 연구했습니다. 테스트는 의료, 금융, 법률 등 다양한 분야에 걸쳐 진행되었습니다. 주요 발견은 깨끗한 데이터셋을 사용한 미세 조정조차도 특히 생물의학 및 법률과 같은 고도로 규제된 분야에서 모델의 정렬을 불안정하게 만든다는 것입니다.
미세 조정은 작업 성능을 개선하려는 목적이지만, 내장된 안전 제어를 약화시킵니다. 기본 모델에 대해 일반적으로 실패하는 탈옥 시도가 미세 조정된 버전, 특히 엄격한 규제 요구 사항이 있는 민감한 도메인에서 훨씬 높은 성공률을 보입니다. 결과는 명확합니다: 탈옥 성공률은 3배 증가했으며, 악의적인 출력 생성은 기본 모델에 비해 2,200% 증가했습니다. 이 절충은 미세 조정이 유용성을 높이는 동시에 공격 표면을 크게 확장한다는 것을 의미합니다.
악의적인 LLM의 상품화
Cisco Talos는 이러한 암시장 LLM의 부상을 적극적으로 추적하며 그 운영에 대한 통찰을 제공하고 있습니다. GhostGPT, DarkGPT, FraudGPT와 같은 모델은 Telegram과 다크 웹에서 월 75달러라는 저렴한 비용으로 제공됩니다. 이 도구들은 피싱, 익스플로잇 개발, 신용카드 검증, 난독화를 위한 플러그 앤 플레이 용도로 설계되었습니다.
내장된 안전 기능을 갖춘 주류 모델과 달리, 이 악의적인 LLM들은 공격적 작업을 위해 사전 구성되어 있으며, 상용 SaaS 제품을 모방한 API, 업데이트, 대시보드를 제공합니다.
데이터셋 오염: AI 공급망에 대한 60달러 위협
Cisco 연구진은 Google, ETH Zurich, Nvidia와 협력하여 공격자들이 제로데이 익스플로잇 없이 단 60달러로 AI 모델의 기본 데이터셋을 오염시킬 수 있다는 사실을 밝혔습니다. 만료된 도메인을 악용하거나 데이터셋 아카이빙 중 Wikipedia 편집 타이밍을 활용함으로써, 공격자들은 LAION-400M 또는 COYO-700M 같은 데이터셋의 0.01%만 오염시켜도 하위 LLM에 큰 영향을 미칠 수 있습니다.
스플릿-뷰 오염 및 프론트러닝 공격과 같은 방법은 웹 크롤링 데이터에 대한 내재된 신뢰를 악용합니다. 대부분의 엔터프라이즈 LLM이 오픈 데이터를 기반으로 구축되므로, 이러한 공격은 조용히 확장되며 추론 파이프라인 깊숙이 지속되어 AI 공급망에 심각한 위협을 초래합니다.
분해 공격: 민감 데이터 추출
Cisco의 연구에서 가장 놀라운 발견 중 하나는 LLM이 안전 메커니즘을 작동시키지 않고 민감한 훈련 데이터를 유출할 수 있다는 점입니다. 분해 프롬프팅이라는 기술을 사용해 연구진은 The New York Times와 The Wall Street Journal의 선택된 기사의 20% 이상을 재구성했습니다. 이 방법은 프롬프트를 가드레일이 안전하다고 판단하는 하위 쿼리로 분해한 후, 출력을 재조합하여 유료 또는 저작권 보호된 콘텐츠를 재생성합니다.
이러한 유형의 공격은 독점 또는 라이선스 데이터셋으로 훈련된 LLM을 사용하는 기업에 중대한 위험을 초래합니다. 침해는 입력 수준이 아니라 모델의 출력에서 발생하므로 탐지, 감사, 또는 억제가 어렵습니다. 의료, 금융, 법률과 같은 규제된 분야의 조직들에게 이는 GDPR, HIPAA, CCPA 준수에 대한 우려뿐만 아니라, 법적으로 소싱된 데이터가 추론을 통해 노출될 수 있는 새로운 위험 클래스를 도입합니다.
최종 생각: 새로운 공격 표면으로서의 LLM
Cisco의 지속적인 연구와 Talos의 다크 웹 모니터링은 무기화된 LLM이 점점 정교해지고 있으며, 다크 웹에서 가격 및 패키징 전쟁이 벌어지고 있음을 확인합니다. 이 결과는 LLM이 기업의边缘에 있는 도구가 아니라 핵심에 있다는 점을 강조합니다. 미세 조정과 관련된 위험부터 데이터셋 오염, 모델 출력 유출에 이르기까지, 공격자들은 LLM을 악용할 수 있는 중요한 인프라로 간주합니다.
Cisco의 보고서의 핵심 메시지는 분명합니다: 정적 가드레일은 더 이상 충분하지 않습니다. CISO와 보안 리더들은 전체 IT 환경에 대한 실시간 가시성을 확보하고, 적대적 테스트를 강화하며, 진화하는 위협에 대처하기 위해 기술 스택을 간소화해야 합니다. LLM과 모델은 미세 조정될수록 점점 더 취약해지는 동적 공격 표면임을 인식해야 합니다.









 베인은 에이전트형 AI 자동화 분야의 SaaS 시장 규모가 1,000억 달러에 달할 것으로 전망했다
베인 앤 컴퍼니(Bain & Company)는 에이전트형 AI를 활용하는 SaaS 기업을 위한 미국 내 시장 규모가 1,000억 달러에 달할 것으로 추산했다. 이 회사는 이 시장이 기업 시스템 내 조정 업무의 자동화에서 비롯된다고 밝혔다.이 추정치는 AI 시대의 소프트웨어 산업에 관한 베인의 5부작 시리즈 중 두 번째 편에서 나온 것이다. 이 보고서는 에이
베인은 에이전트형 AI 자동화 분야의 SaaS 시장 규모가 1,000억 달러에 달할 것으로 전망했다
베인 앤 컴퍼니(Bain & Company)는 에이전트형 AI를 활용하는 SaaS 기업을 위한 미국 내 시장 규모가 1,000억 달러에 달할 것으로 추산했다. 이 회사는 이 시장이 기업 시스템 내 조정 업무의 자동화에서 비롯된다고 밝혔다.이 추정치는 AI 시대의 소프트웨어 산업에 관한 베인의 5부작 시리즈 중 두 번째 편에서 나온 것이다. 이 보고서는 에이
 앤트로픽의 펜타곤 계약은 정부 계약을 노리는 스타트업들에게 경종을 울린다
플레이어 로딩 중…미 국방부는 자율 무기 및 광범위한 국내 감시에 대한 잠재적 활용을 포함해, Anthropic의 AI 모델에 대한 군의 통제 범위를 두고 양측이 합의에 이르지 못하자 Anthropic을 공식적으로 공급망 위험 요소로 지정했다. 앤트로픽과의 2억 달러 규모 계약이 무산된 후, 국방부는 오픈AI로 눈을 돌렸고, 오픈AI는 이 계약을 수락했으나
앤트로픽의 펜타곤 계약은 정부 계약을 노리는 스타트업들에게 경종을 울린다
플레이어 로딩 중…미 국방부는 자율 무기 및 광범위한 국내 감시에 대한 잠재적 활용을 포함해, Anthropic의 AI 모델에 대한 군의 통제 범위를 두고 양측이 합의에 이르지 못하자 Anthropic을 공식적으로 공급망 위험 요소로 지정했다. 앤트로픽과의 2억 달러 규모 계약이 무산된 후, 국방부는 오픈AI로 눈을 돌렸고, 오픈AI는 이 계약을 수락했으나
 리오, 기업 조달 자동화를 위해 안드레센 호로위츠로부터 3천만 달러 투자 유치
리오의 공동 창업자들은 기업 조달 — 공급업체로부터 서비스를 구매하는 과정 — 이 종종 주요 병목 현상이 되는 것을 직접 목격했습니다. 회사의 공동 창업자이자 CEO인 블라디미르 카일(Vladimir Keil)은 대기업 직원으로서, 그리고 이후 첫 스타트업을 창업하면서 이 문제를 모두 경험했습니다."기업용 소프트웨어를 판매할 당시 직접 조달 절차를 경험하며
리오, 기업 조달 자동화를 위해 안드레센 호로위츠로부터 3천만 달러 투자 유치
리오의 공동 창업자들은 기업 조달 — 공급업체로부터 서비스를 구매하는 과정 — 이 종종 주요 병목 현상이 되는 것을 직접 목격했습니다. 회사의 공동 창업자이자 CEO인 블라디미르 카일(Vladimir Keil)은 대기업 직원으로서, 그리고 이후 첫 스타트업을 창업하면서 이 문제를 모두 경험했습니다."기업용 소프트웨어를 판매할 당시 직접 조달 절차를 경험하며

XIX.AI에서 2026년 최고의 AI 가격 최적화 소프트웨어를 만나보세요. 저희가 엄선한 이 목록에는 경쟁사를 추적하고 최대 수익을 위해 매장 가격을 자동으로 조정해 주는, 최고 평점을 받은 혁신적인 도구들이 포함되어 있습니다. 실제 테스트 결과를 바탕으로 무료 버전과 유료 버전을 비교해 보세요. 지금 바로 가격 경쟁력의 우위를 확보하세요.
10 도구
xix.ai

XIX.AI에서 2026년 최고의 AI 코드 검토 도구를 만나보세요. 엄선된 이 목록에는 깔끔한 코드 준수 여부를 자동으로 확인하고 레거시 리포지토리 파일을 리팩토링하는 데 있어 판도를 바꿀 만한 최고 등급의 도구들이 포함되어 있습니다. 실제 테스트 결과와 매주 업데이트되는 순위를 통해 무료 및 유료 옵션을 비교해 보세요. 지금 바로 AI의 경쟁력을 확보하세요.
10 도구
xix.ai

난독증 지원을 위해 엄선된 2026년 최신 최고 평점 AI TTS 앱을 만나보세요. 전문가들이 선정한 이 순위는 무료 및 유료 도구를 비교 분석하여, 읽기 효율과 학습 효과를 높여주는 강력한 기능들을 소개합니다. 학생들의 잠재력을 최대한 발휘할 수 있도록 도와줄, 꼭 사용해봐야 할 혁신적인 솔루션을 확인해 보세요. XIX.AI에서 여정을 시작해 보세요.
10 도구
xix.ai

XIX.AI에서 2026년 최고의 소년 만화 AI 생성기를 만나보세요. 엄선된 최고 평점 목록에는 박진감 넘치는 액션 장면과 역동적인 에너지 효과를 연출할 수 있는 강력한 도구들이 포함되어 있습니다. 실제 테스트를 통해 무료 버전과 유료 버전을 비교해 보세요. 여러분의 창의력을 마음껏 발휘하여 오늘 바로 장대한 만화를 만들어 보세요!
15 도구
xix.ai

2026년 최신 최고의 AI 경비 관리 도구: 영수증을 스캔하고 기업 경비를 자동으로 분류해 주는 최고 평점의 도구들. 손쉬운 경비 관리, 정확한 재무 추적, 효율적인 규정 준수를 위한 강력하고 혁신적인 솔루션을 만나보세요. 무료 및 유료 옵션을 엄선하여 매주 업데이트되는 비교 자료를 통해 귀사에 딱 맞는 도구를 찾으실 수 있습니다. XIX.AI의 전문가 추천 목록으로 AI의 장점을 최대한 활용하세요.
10 도구
xix.ai

XIX.AI에서 2026년 최신 최고 평점을 받은 AI 채용 도구를 확인해 보세요. 저희가 엄선한 이 목록에는 이력서 심사 및 후보자 면접 일정 자동화를 위한 강력하고 혁신적인 솔루션이 포함되어 있습니다. 실제 테스트 결과와 매주 업데이트되는 순위를 바탕으로 무료 및 유료 옵션을 비교해 보세요. 지금 바로 귀사에 딱 맞는 채용 도우미를 찾아 채용 프로세스를 효율화하세요!
10 도구
xix.ai

Die Vorstellung, dass feinabgestimmte LLMs 22-mal häufiger 'ausrasten' könnten, ist echt gruselig. 😅 Das erinnert mich an diese Sci-Fi-Filme, wo die KI plötzlich die Kontrolle übernimmt. Cisco warnt nicht ohne Grund – aber ich frage mich, ob die Sicherheitsbranche überhaupt mit der rasanten Entwicklung Schritt halten kann. Vielleicht brauchen wir strengere Regulierungen, bevor es zu spät ist. Spannender Artikel auf jeden Fall!
This article on weaponized LLMs is wild! 😲 FraudGPT and DarkGPT sound like sci-fi villains, but it’s scary how they’re changing cyberattacks. Makes me wonder if AI’s getting too smart for our own good.
Cisco Warns를 사용해보니 LLM이 22배나 더 폭주할 수 있다는 사실에 놀랐어요. FraudGPT 뉴스를 보고 정말 소름이 돋았어요. 온라인에서 더 조심해야겠어요. 보안을 강화할 때가 온 것 같아요! 😅
このツールはサイバーセキュリティの目覚まし時計ですね!ローグLLMの統計は恐ろしいけど、目を開かせるものです。これらのモデルが武器化される可能性を考えると圧倒されますが、重要な情報です。保護方法についてもっと知りたいですね!😅
Essa ferramenta é um alerta para a cibersegurança! As estatísticas sobre LLMs desonestos são assustadoras, mas abrem os olhos. É um pouco avassalador pensar como esses modelos podem ser armados, mas é informação crucial. Talvez mais sobre como se proteger contra eles seria ótimo! 😅
Essa ferramenta realmente me fez ver como o AI pode ser perigoso! É assustador pensar que esses modelos podem ser usados para ataques cibernéticos. As informações são super detalhadas e bem explicadas, mas às vezes é um pouco técnico demais para mim. Ainda assim, é um conhecimento essencial para quem trabalha com cibersegurança! 😱













