
















 首页
首页思科警告:流氓的微调LLMS的可能性高22倍
# cisco
# LLMs
# APIs
# saas
# csco
# goog-2
# msft-2
# nvda-2
# darkgpt
# darkweb
# fraudgpt
# ghostgpt
# zeroday
武器化大型语言模型重塑网络攻击
网络攻击的格局正在发生重大变革,这主要得益于武器化大型语言模型(LLMs)的出现。这些高级模型,如FraudGPT、GhostGPT和DarkGPT,正在重塑网络犯罪分子的策略,并迫使首席信息安全官(CISOs)重新思考他们的安全协议。这些模型具备自动化侦察、冒充身份和逃避检测的能力,正在以前所未有的规模加速社会工程攻击。
这些模型的月租费低至75美元,专为进攻性用途量身定制,支持的任务包括钓鱼攻击、漏洞生成、代码混淆、漏洞扫描和信用卡验证。网络犯罪集团、财团甚至国家行为者正在利用这些工具,将其作为平台、套件和租赁服务提供。就像合法的软件即服务(SaaS)应用程序一样,武器化LLMs配备了仪表板、API、定期更新,有时甚至还有客户支持。
VentureBeat正在密切关注这些武器化LLMs的快速发展。随着其复杂性的增加,开发者平台与网络犯罪套件之间的界限正变得日益模糊。随着租赁和租用价格的下降,更多攻击者正在探索这些平台,预示着AI驱动威胁的新时代。
合法LLMs面临威胁
武器化LLMs的扩散已达到一个临界点,甚至连合法的LLMs也面临被攻破并整合进犯罪工具链的风险。根据思科的《AI安全状况报告》,经过微调的LLMs产生有害输出的可能性是基础模型的22倍。虽然微调对于增强上下文相关性至关重要,但它也削弱了安全措施,使模型更容易受到越狱、提示注入和模型反转的攻击。
思科的研究表明,模型越是为生产环境优化,就越容易受到攻击。微调涉及的核心过程,如持续调整、第三方集成、编码、测试和代理编排,为攻击者提供了新的可利用途径。一旦入侵,攻击者可以迅速污染数据、劫持基础设施、改变代理行为,并大规模提取训练数据。如果没有额外的安全层,这些精心微调的模型很快就会成为攻击者可利用的漏洞。
微调LLMs:一把双刃剑
思科的安全团队对多个模型进行了广泛研究,包括Llama-2-7B和微软的领域特定Adapt LLMs,研究了微调对其影响。测试覆盖了医疗、金融和法律等多个领域。一个关键发现是,即使使用干净的数据集进行微调,也会破坏模型的对齐,尤其是在生物医学和法律等高度监管的领域。
尽管微调旨在提高任务性能,但它无意中削弱了内置的安全控制。对基础模型通常会失败的越狱尝试,在微调版本上成功率显著提高,特别是在具有严格合规要求的敏感领域。结果触目惊心:越狱成功率提高了三倍,恶意输出生成量比基础模型增加了2200%。这种权衡意味着,虽然微调提升了实用性,但也显著扩大了攻击面。
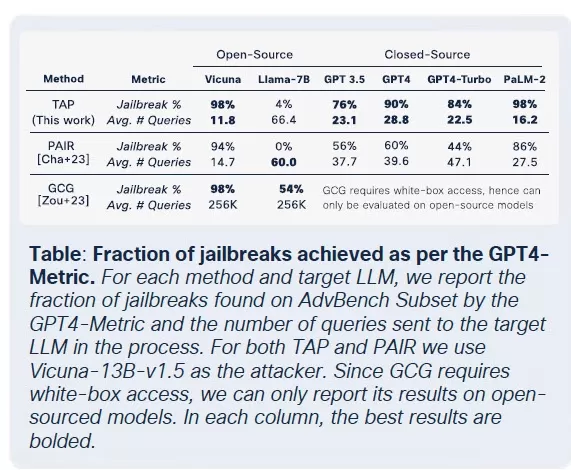
恶意LLMs的商品化
思科Talos一直在积极追踪这些黑市LLMs的崛起,提供了对其运营的洞察。像GhostGPT、DarkGPT和FraudGPT这样的模型在Telegram和暗网上以每月75美元的价格出售。这些工具设计为即插即用,适用于钓鱼攻击、漏洞开发、信用卡验证和混淆。
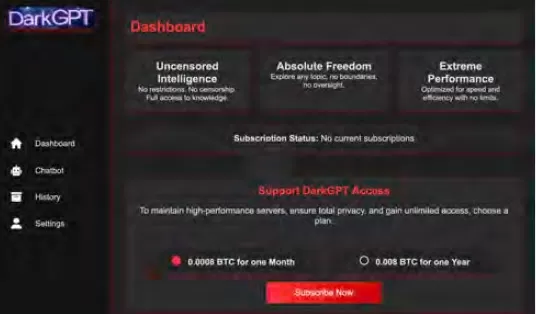
与内置安全功能的主流模型不同,这些恶意LLMs预配置为进攻性操作,并配备了模仿商业SaaS产品的API、更新和仪表板。
数据集污染:对AI供应链的60美元威胁
思科研究人员与Google、ETH Zurich和Nvidia合作揭示,攻击者仅需60美元即可污染AI模型的基础数据集,而无需零日漏洞。通过利用过期域名或在数据集归档期间定时编辑Wikipedia,攻击者可以污染像LAION-400M或COYO-700M这样低至0.01%的数据集,显著影响下游LLMs。
诸如分视图污染和抢先攻击的方法利用了网络爬取数据的固有信任。由于大多数企业LLMs基于开放数据构建,这些攻击可以悄无声息地扩展,并深入推理管道,构成对AI供应链的严重威胁。
分解攻击:提取敏感数据
思科研究中最令人担忧的发现之一是,LLMs能够在不触发安全机制的情况下泄露敏感训练数据。研究人员使用一种称为分解提示的技术,重构了超过20%的《纽约时报》和《华尔街日报》的选定文章。这种方法将提示分解为被护栏视为安全的子查询,然后重新组装输出以重现付费墙或受版权保护的内容。
这种攻击对使用专有或许可数据集训练的LLMs的企业构成了重大风险。漏洞不是发生在输入层面,而是通过模型的输出,使其难以检测、审计或遏制。对于医疗、金融或法律等受监管行业,这不仅引发了关于GDPR、HIPAA或CCPA合规性的担忧,还引入了一种新型风险,即合法来源的数据可能通过推理暴露。
最终思考:LLMs作为新的攻击面
思科的持续研究和Talos的暗网监控证实,武器化LLMs正变得日益复杂,暗网上正在展开价格和包装战。这些发现强调,LLMs不仅是企业的边缘工具,而是其核心组成部分。从微调相关风险到数据集污染和模型输出泄露,攻击者将LLMs视为可利用的关键基础设施。
思科报告的关键结论显而易见:静态护栏已不足以应对威胁。首席信息安全官和安全领导者必须获得整个IT环境的实时可见性,增强对抗性测试,并简化技术堆栈,以跟上这些不断演变的威胁。他们必须认识到,LLMs和模型代表了一个动态攻击面,随着微调的深入,其脆弱性不断增加。
相关文章
 贝恩预测代理式人工智能自动化领域的SaaS市场规模将达1000亿美元
贝恩公司预计,在美国,利用代理式人工智能的SaaS公司将拥有一个价值1000亿美元的市场。该公司表示,这一市场源于企业系统内部协调任务的自动化。这一估算数据来自贝恩公司关于“AI时代软件行业”五部曲系列的第二篇报告。该报告探讨了代理式AI可能开拓哪些新的软件市场,以及SaaS供应商如何抢占这些市场。企业系统中的协调工作贝恩指出,该市场的形成源于员工在不同企业应用程序间执行的手动任务。这些工作流程通
Anthropic与五角大楼达成的协议为寻求政府合同的初创企业敲响了警钟
正在加载播放器……在双方未能就军方对其AI模型的管控范围达成一致——包括这些模型在自主武器及大规模国内监控中的潜在应用——后,五角大楼已正式将Anthropic列为供应链风险。 随着Anthropic价值2亿美元的合同告吹,美国国防部转而寻求OpenAI的合作。OpenAI接受了该协议,随后其ChatGPT的卸载量激增了295%。随着事态持续升级,一个根本性问题仍未得到解答:军方应被赋予多大程度的
Lio公司获安德森·霍洛维茨基金3000万美元投资,用于企业采购自动化
Lio的联合创始人亲眼目睹了企业采购——即从供应商处购买服务的流程——如何常常成为主要瓶颈。公司联合创始人兼首席执行官弗拉基米尔·凯尔(Vladimir Keil)在大型企业任职期间以及后来创办首家初创公司时都遭遇过这个问题。"销售企业软件时,我们不得不亲自经历采购流程,亲眼目睹其仍充满人工操作且支离破碎的现状,"他向TechCrunch透露。凯尔团队开发了基于AI代理(代人执行任务的软件)的自动
相关专题推荐
漫画创作
贝恩预测代理式人工智能自动化领域的SaaS市场规模将达1000亿美元
贝恩公司预计,在美国,利用代理式人工智能的SaaS公司将拥有一个价值1000亿美元的市场。该公司表示,这一市场源于企业系统内部协调任务的自动化。这一估算数据来自贝恩公司关于“AI时代软件行业”五部曲系列的第二篇报告。该报告探讨了代理式AI可能开拓哪些新的软件市场,以及SaaS供应商如何抢占这些市场。企业系统中的协调工作贝恩指出,该市场的形成源于员工在不同企业应用程序间执行的手动任务。这些工作流程通
Anthropic与五角大楼达成的协议为寻求政府合同的初创企业敲响了警钟
正在加载播放器……在双方未能就军方对其AI模型的管控范围达成一致——包括这些模型在自主武器及大规模国内监控中的潜在应用——后,五角大楼已正式将Anthropic列为供应链风险。 随着Anthropic价值2亿美元的合同告吹,美国国防部转而寻求OpenAI的合作。OpenAI接受了该协议,随后其ChatGPT的卸载量激增了295%。随着事态持续升级,一个根本性问题仍未得到解答:军方应被赋予多大程度的
Lio公司获安德森·霍洛维茨基金3000万美元投资,用于企业采购自动化
Lio的联合创始人亲眼目睹了企业采购——即从供应商处购买服务的流程——如何常常成为主要瓶颈。公司联合创始人兼首席执行官弗拉基米尔·凯尔(Vladimir Keil)在大型企业任职期间以及后来创办首家初创公司时都遭遇过这个问题。"销售企业软件时,我们不得不亲自经历采购流程,亲眼目睹其仍充满人工操作且支离破碎的现状,"他向TechCrunch透露。凯尔团队开发了基于AI代理(代人执行任务的软件)的自动
相关专题推荐
漫画创作
 漫画领域顶尖的AI自动上色工具:零一致性错误地应用平涂色彩
漫画领域顶尖的AI自动上色工具:零一致性错误地应用平涂色彩
立即访问 XIX.AI,探索 2026 年最优秀的漫画 AI 自动上色工具。我们精心筛选的清单汇集了广受好评、颠覆行业的解决方案,这些工具能以零一致性错误的方式应用平涂色彩,从而大幅提升您的工作效率。通过免费版与付费版的对比分析、实际测试以及每周更新的排行榜,找到最适合您的工具。立即开启您的 AI 优势。
 10 个工具
10 个工具
 xix.ai
写作
顶尖 AI 角色设定生成器:生成一致的角色动机与致命缺陷
xix.ai
写作
顶尖 AI 角色设定生成器:生成一致的角色动机与致命缺陷
探索2026年最优秀的AI人物设定生成工具,助您塑造鲜活立体的角色。XIX.AI精心筛选的这份清单汇集了广受好评、颠覆传统的工具,能够生成具有内在逻辑的动机和致命缺陷。通过实际测试对比免费与付费选项。立即释放您的叙事潜能。
10 个工具
xix.ai
商业
顶级 AI 定价优化软件:追踪竞争对手并自动调整店铺价格
在 XIX.AI 上探索 2026 年最佳 AI 定价优化软件。我们精心挑选的清单汇集了备受好评、具有颠覆性意义的工具,这些工具不仅能追踪竞争对手,还能自动调整您的店铺价格,从而实现利润最大化。通过实际测试对比免费与付费选项。立即掌握您的定价优势。
10 个工具
xix.ai
代码
最佳 AI 代码审查工具:自动确保代码符合规范,并重构遗留代码库文件
在 XIX.AI 上探索 2026 年最佳 AI 代码审查工具。我们的精选列表汇集了备受好评、具有颠覆性的工具,可自动确保代码规范并重构遗留代码库文件。通过实际测试和每周更新的排行榜,对比免费与付费选项。立即开启您的 AI 优势。
10 个工具
xix.ai
文字转语音
专为阅读障碍设计的顶级AI语音合成应用:助力学生提升学习与阅读效率
探索2026年最新精选的高评分AI语音合成(TTS)应用,专为阅读障碍者提供支持。我们的专家评级对比了免费与付费工具,重点介绍了能够提升阅读效率和学习效果的强大功能。探索这些必试的、具有革命性意义的解决方案,释放学生的潜能。立即访问XIX.AI,开启您的探索之旅。
10 个工具
xix.ai
漫画创作
少年漫画顶级AI生成器:打造高能动作场面与特效
在 XIX.AI 探索 2026 年最优秀的少年漫画 AI 生成工具。我们精心筛选的这份高评分清单汇集了强大的工具,助您创作充满张力的动作场面和动态能量特效。通过实际测试对比免费与付费选项。释放您的创作潜能,立即开始创作史诗级漫画吧!
15 个工具
xix.ai

 评论 (32)
0/500
评论 (32)
0/500
![WalterHarris]()
Die Vorstellung, dass feinabgestimmte LLMs 22-mal häufiger 'ausrasten' könnten, ist echt gruselig. 😅 Das erinnert mich an diese Sci-Fi-Filme, wo die KI plötzlich die Kontrolle übernimmt. Cisco warnt nicht ohne Grund – aber ich frage mich, ob die Sicherheitsbranche überhaupt mit der rasanten Entwicklung Schritt halten kann. Vielleicht brauchen wir strengere Regulierungen, bevor es zu spät ist. Spannender Artikel auf jeden Fall!
![BillyGreen]()
This article on weaponized LLMs is wild! 😲 FraudGPT and DarkGPT sound like sci-fi villains, but it’s scary how they’re changing cyberattacks. Makes me wonder if AI’s getting too smart for our own good.
![JerryMoore]()
Cisco Warns를 사용해보니 LLM이 22배나 더 폭주할 수 있다는 사실에 놀랐어요. FraudGPT 뉴스를 보고 정말 소름이 돋았어요. 온라인에서 더 조심해야겠어요. 보안을 강화할 때가 온 것 같아요! 😅
![RichardJackson]()
このツールはサイバーセキュリティの目覚まし時計ですね!ローグLLMの統計は恐ろしいけど、目を開かせるものです。これらのモデルが武器化される可能性を考えると圧倒されますが、重要な情報です。保護方法についてもっと知りたいですね!😅
![AndrewGarcía]()
Essa ferramenta é um alerta para a cibersegurança! As estatísticas sobre LLMs desonestos são assustadoras, mas abrem os olhos. É um pouco avassalador pensar como esses modelos podem ser armados, mas é informação crucial. Talvez mais sobre como se proteger contra eles seria ótimo! 😅
![MatthewGonzalez]()
Essa ferramenta realmente me fez ver como o AI pode ser perigoso! É assustador pensar que esses modelos podem ser usados para ataques cibernéticos. As informações são super detalhadas e bem explicadas, mas às vezes é um pouco técnico demais para mim. Ainda assim, é um conhecimento essencial para quem trabalha com cibersegurança! 😱
武器化大型语言模型重塑网络攻击
网络攻击的格局正在发生重大变革,这主要得益于武器化大型语言模型(LLMs)的出现。这些高级模型,如FraudGPT、GhostGPT和DarkGPT,正在重塑网络犯罪分子的策略,并迫使首席信息安全官(CISOs)重新思考他们的安全协议。这些模型具备自动化侦察、冒充身份和逃避检测的能力,正在以前所未有的规模加速社会工程攻击。
这些模型的月租费低至75美元,专为进攻性用途量身定制,支持的任务包括钓鱼攻击、漏洞生成、代码混淆、漏洞扫描和信用卡验证。网络犯罪集团、财团甚至国家行为者正在利用这些工具,将其作为平台、套件和租赁服务提供。就像合法的软件即服务(SaaS)应用程序一样,武器化LLMs配备了仪表板、API、定期更新,有时甚至还有客户支持。
VentureBeat正在密切关注这些武器化LLMs的快速发展。随着其复杂性的增加,开发者平台与网络犯罪套件之间的界限正变得日益模糊。随着租赁和租用价格的下降,更多攻击者正在探索这些平台,预示着AI驱动威胁的新时代。
合法LLMs面临威胁
武器化LLMs的扩散已达到一个临界点,甚至连合法的LLMs也面临被攻破并整合进犯罪工具链的风险。根据思科的《AI安全状况报告》,经过微调的LLMs产生有害输出的可能性是基础模型的22倍。虽然微调对于增强上下文相关性至关重要,但它也削弱了安全措施,使模型更容易受到越狱、提示注入和模型反转的攻击。
思科的研究表明,模型越是为生产环境优化,就越容易受到攻击。微调涉及的核心过程,如持续调整、第三方集成、编码、测试和代理编排,为攻击者提供了新的可利用途径。一旦入侵,攻击者可以迅速污染数据、劫持基础设施、改变代理行为,并大规模提取训练数据。如果没有额外的安全层,这些精心微调的模型很快就会成为攻击者可利用的漏洞。
微调LLMs:一把双刃剑
思科的安全团队对多个模型进行了广泛研究,包括Llama-2-7B和微软的领域特定Adapt LLMs,研究了微调对其影响。测试覆盖了医疗、金融和法律等多个领域。一个关键发现是,即使使用干净的数据集进行微调,也会破坏模型的对齐,尤其是在生物医学和法律等高度监管的领域。
尽管微调旨在提高任务性能,但它无意中削弱了内置的安全控制。对基础模型通常会失败的越狱尝试,在微调版本上成功率显著提高,特别是在具有严格合规要求的敏感领域。结果触目惊心:越狱成功率提高了三倍,恶意输出生成量比基础模型增加了2200%。这种权衡意味着,虽然微调提升了实用性,但也显著扩大了攻击面。
恶意LLMs的商品化
思科Talos一直在积极追踪这些黑市LLMs的崛起,提供了对其运营的洞察。像GhostGPT、DarkGPT和FraudGPT这样的模型在Telegram和暗网上以每月75美元的价格出售。这些工具设计为即插即用,适用于钓鱼攻击、漏洞开发、信用卡验证和混淆。
与内置安全功能的主流模型不同,这些恶意LLMs预配置为进攻性操作,并配备了模仿商业SaaS产品的API、更新和仪表板。
数据集污染:对AI供应链的60美元威胁
思科研究人员与Google、ETH Zurich和Nvidia合作揭示,攻击者仅需60美元即可污染AI模型的基础数据集,而无需零日漏洞。通过利用过期域名或在数据集归档期间定时编辑Wikipedia,攻击者可以污染像LAION-400M或COYO-700M这样低至0.01%的数据集,显著影响下游LLMs。
诸如分视图污染和抢先攻击的方法利用了网络爬取数据的固有信任。由于大多数企业LLMs基于开放数据构建,这些攻击可以悄无声息地扩展,并深入推理管道,构成对AI供应链的严重威胁。
分解攻击:提取敏感数据
思科研究中最令人担忧的发现之一是,LLMs能够在不触发安全机制的情况下泄露敏感训练数据。研究人员使用一种称为分解提示的技术,重构了超过20%的《纽约时报》和《华尔街日报》的选定文章。这种方法将提示分解为被护栏视为安全的子查询,然后重新组装输出以重现付费墙或受版权保护的内容。
这种攻击对使用专有或许可数据集训练的LLMs的企业构成了重大风险。漏洞不是发生在输入层面,而是通过模型的输出,使其难以检测、审计或遏制。对于医疗、金融或法律等受监管行业,这不仅引发了关于GDPR、HIPAA或CCPA合规性的担忧,还引入了一种新型风险,即合法来源的数据可能通过推理暴露。
最终思考:LLMs作为新的攻击面
思科的持续研究和Talos的暗网监控证实,武器化LLMs正变得日益复杂,暗网上正在展开价格和包装战。这些发现强调,LLMs不仅是企业的边缘工具,而是其核心组成部分。从微调相关风险到数据集污染和模型输出泄露,攻击者将LLMs视为可利用的关键基础设施。
思科报告的关键结论显而易见:静态护栏已不足以应对威胁。首席信息安全官和安全领导者必须获得整个IT环境的实时可见性,增强对抗性测试,并简化技术堆栈,以跟上这些不断演变的威胁。他们必须认识到,LLMs和模型代表了一个动态攻击面,随着微调的深入,其脆弱性不断增加。









 贝恩预测代理式人工智能自动化领域的SaaS市场规模将达1000亿美元
贝恩公司预计,在美国,利用代理式人工智能的SaaS公司将拥有一个价值1000亿美元的市场。该公司表示,这一市场源于企业系统内部协调任务的自动化。这一估算数据来自贝恩公司关于“AI时代软件行业”五部曲系列的第二篇报告。该报告探讨了代理式AI可能开拓哪些新的软件市场,以及SaaS供应商如何抢占这些市场。企业系统中的协调工作贝恩指出,该市场的形成源于员工在不同企业应用程序间执行的手动任务。这些工作流程通
贝恩预测代理式人工智能自动化领域的SaaS市场规模将达1000亿美元
贝恩公司预计,在美国,利用代理式人工智能的SaaS公司将拥有一个价值1000亿美元的市场。该公司表示,这一市场源于企业系统内部协调任务的自动化。这一估算数据来自贝恩公司关于“AI时代软件行业”五部曲系列的第二篇报告。该报告探讨了代理式AI可能开拓哪些新的软件市场,以及SaaS供应商如何抢占这些市场。企业系统中的协调工作贝恩指出,该市场的形成源于员工在不同企业应用程序间执行的手动任务。这些工作流程通
 Anthropic与五角大楼达成的协议为寻求政府合同的初创企业敲响了警钟
正在加载播放器……在双方未能就军方对其AI模型的管控范围达成一致——包括这些模型在自主武器及大规模国内监控中的潜在应用——后,五角大楼已正式将Anthropic列为供应链风险。 随着Anthropic价值2亿美元的合同告吹,美国国防部转而寻求OpenAI的合作。OpenAI接受了该协议,随后其ChatGPT的卸载量激增了295%。随着事态持续升级,一个根本性问题仍未得到解答:军方应被赋予多大程度的
Anthropic与五角大楼达成的协议为寻求政府合同的初创企业敲响了警钟
正在加载播放器……在双方未能就军方对其AI模型的管控范围达成一致——包括这些模型在自主武器及大规模国内监控中的潜在应用——后,五角大楼已正式将Anthropic列为供应链风险。 随着Anthropic价值2亿美元的合同告吹,美国国防部转而寻求OpenAI的合作。OpenAI接受了该协议,随后其ChatGPT的卸载量激增了295%。随着事态持续升级,一个根本性问题仍未得到解答:军方应被赋予多大程度的
 Lio公司获安德森·霍洛维茨基金3000万美元投资,用于企业采购自动化
Lio的联合创始人亲眼目睹了企业采购——即从供应商处购买服务的流程——如何常常成为主要瓶颈。公司联合创始人兼首席执行官弗拉基米尔·凯尔(Vladimir Keil)在大型企业任职期间以及后来创办首家初创公司时都遭遇过这个问题。"销售企业软件时,我们不得不亲自经历采购流程,亲眼目睹其仍充满人工操作且支离破碎的现状,"他向TechCrunch透露。凯尔团队开发了基于AI代理(代人执行任务的软件)的自动
Lio公司获安德森·霍洛维茨基金3000万美元投资,用于企业采购自动化
Lio的联合创始人亲眼目睹了企业采购——即从供应商处购买服务的流程——如何常常成为主要瓶颈。公司联合创始人兼首席执行官弗拉基米尔·凯尔(Vladimir Keil)在大型企业任职期间以及后来创办首家初创公司时都遭遇过这个问题。"销售企业软件时,我们不得不亲自经历采购流程,亲眼目睹其仍充满人工操作且支离破碎的现状,"他向TechCrunch透露。凯尔团队开发了基于AI代理(代人执行任务的软件)的自动

立即访问 XIX.AI,探索 2026 年最优秀的漫画 AI 自动上色工具。我们精心筛选的清单汇集了广受好评、颠覆行业的解决方案,这些工具能以零一致性错误的方式应用平涂色彩,从而大幅提升您的工作效率。通过免费版与付费版的对比分析、实际测试以及每周更新的排行榜,找到最适合您的工具。立即开启您的 AI 优势。
10 个工具
xix.ai

探索2026年最优秀的AI人物设定生成工具,助您塑造鲜活立体的角色。XIX.AI精心筛选的这份清单汇集了广受好评、颠覆传统的工具,能够生成具有内在逻辑的动机和致命缺陷。通过实际测试对比免费与付费选项。立即释放您的叙事潜能。
10 个工具
xix.ai

在 XIX.AI 上探索 2026 年最佳 AI 定价优化软件。我们精心挑选的清单汇集了备受好评、具有颠覆性意义的工具,这些工具不仅能追踪竞争对手,还能自动调整您的店铺价格,从而实现利润最大化。通过实际测试对比免费与付费选项。立即掌握您的定价优势。
10 个工具
xix.ai

在 XIX.AI 上探索 2026 年最佳 AI 代码审查工具。我们的精选列表汇集了备受好评、具有颠覆性的工具,可自动确保代码规范并重构遗留代码库文件。通过实际测试和每周更新的排行榜,对比免费与付费选项。立即开启您的 AI 优势。
10 个工具
xix.ai

探索2026年最新精选的高评分AI语音合成(TTS)应用,专为阅读障碍者提供支持。我们的专家评级对比了免费与付费工具,重点介绍了能够提升阅读效率和学习效果的强大功能。探索这些必试的、具有革命性意义的解决方案,释放学生的潜能。立即访问XIX.AI,开启您的探索之旅。
10 个工具
xix.ai

在 XIX.AI 探索 2026 年最优秀的少年漫画 AI 生成工具。我们精心筛选的这份高评分清单汇集了强大的工具,助您创作充满张力的动作场面和动态能量特效。通过实际测试对比免费与付费选项。释放您的创作潜能,立即开始创作史诗级漫画吧!
15 个工具
xix.ai

Die Vorstellung, dass feinabgestimmte LLMs 22-mal häufiger 'ausrasten' könnten, ist echt gruselig. 😅 Das erinnert mich an diese Sci-Fi-Filme, wo die KI plötzlich die Kontrolle übernimmt. Cisco warnt nicht ohne Grund – aber ich frage mich, ob die Sicherheitsbranche überhaupt mit der rasanten Entwicklung Schritt halten kann. Vielleicht brauchen wir strengere Regulierungen, bevor es zu spät ist. Spannender Artikel auf jeden Fall!
This article on weaponized LLMs is wild! 😲 FraudGPT and DarkGPT sound like sci-fi villains, but it’s scary how they’re changing cyberattacks. Makes me wonder if AI’s getting too smart for our own good.
Cisco Warns를 사용해보니 LLM이 22배나 더 폭주할 수 있다는 사실에 놀랐어요. FraudGPT 뉴스를 보고 정말 소름이 돋았어요. 온라인에서 더 조심해야겠어요. 보안을 강화할 때가 온 것 같아요! 😅
このツールはサイバーセキュリティの目覚まし時計ですね!ローグLLMの統計は恐ろしいけど、目を開かせるものです。これらのモデルが武器化される可能性を考えると圧倒されますが、重要な情報です。保護方法についてもっと知りたいですね!😅
Essa ferramenta é um alerta para a cibersegurança! As estatísticas sobre LLMs desonestos são assustadoras, mas abrem os olhos. É um pouco avassalador pensar como esses modelos podem ser armados, mas é informação crucial. Talvez mais sobre como se proteger contra eles seria ótimo! 😅
Essa ferramenta realmente me fez ver como o AI pode ser perigoso! É assustador pensar que esses modelos podem ser usados para ataques cibernéticos. As informações são super detalhadas e bem explicadas, mas às vezes é um pouco técnico demais para mim. Ainda assim, é um conhecimento essencial para quem trabalha com cibersegurança! 😱













