
















 Lar
LarA Cisco avisa: LLMs de ajuste fino 22 vezes mais chances de ficar desonesto
# cisco
# LLMs
# APIs
# saas
# csco
# goog-2
# msft-2
# nvda-2
# darkgpt
# darkweb
# fraudgpt
# ghostgpt
# zeroday
Modelos de Linguagem de Grande Escala Armados Reconfiguram Ciberataques
O cenário dos ciberataques está passando por uma transformação significativa, impulsionada pela emergência de modelos de linguagem de grande escala (LLMs) armados. Esses modelos avançados, como FraudGPT, GhostGPT e DarkGPT, estão reconfigurando as estratégias dos cibercriminosos e forçando os Diretores de Segurança da Informação (CISOs) a repensarem seus protocolos de segurança. Com capacidades para automatizar reconhecimento, personificar identidades e evitar detecção, esses LLMs estão acelerando ataques de engenharia social em uma escala sem precedentes.
Disponíveis por apenas $75 por mês, esses modelos são projetados para uso ofensivo, facilitando tarefas como phishing, geração de exploits, ofuscação de código, varredura de vulnerabilidades e validação de cartões de crédito. Grupos de cibercrime, sindicatos e até estados-nação estão capitalizando essas ferramentas, oferecendo-as como plataformas, kits e serviços de locação. Assim como aplicações legítimas de software-como-serviço (SaaS), os LLMs armados vêm com painéis, APIs, atualizações regulares e, às vezes, até suporte ao cliente.
O VentureBeat está monitorando de perto a rápida evolução desses LLMs armados. À medida que sua sofisticação cresce, a distinção entre plataformas de desenvolvedores e kits de cibercrime está se tornando cada vez mais indistinta. Com preços de aluguel e locação em queda, mais atacantes estão explorando essas plataformas, anunciando uma nova era de ameaças impulsionadas por IA.
LLMs Legítimos Sob Ameaça
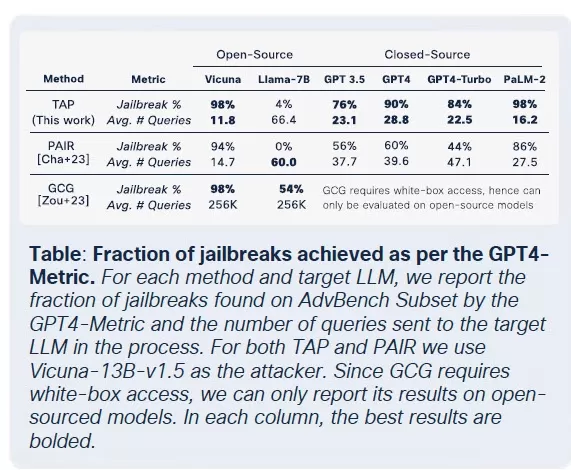
A proliferação de LLMs armados chegou a um ponto em que até mesmo LLMs legítimos correm o risco de serem comprometidos e integrados a cadeias de ferramentas criminais. De acordo com o relatório The State of AI Security Report da Cisco, LLMs ajustados finamente são 22 vezes mais propensos a produzir saídas prejudiciais do que suas contrapartes base. Embora o ajuste fino seja crucial para aumentar a relevância contextual, ele também enfraquece as medidas de segurança, tornando os modelos mais suscetíveis a jailbreaks, injeções de prompts e inversão de modelos.
A pesquisa da Cisco destaca que quanto mais um modelo é refinado para produção, mais vulnerável ele se torna. Os processos centrais envolvidos no ajuste fino, como ajustes contínuos, integrações de terceiros, codificação, testes e orquestração agentiva, criam novas vias para os atacantes explorarem. Uma vez dentro, os atacantes podem rapidamente envenenar dados, sequestrar infraestrutura, alterar o comportamento do agente e extrair dados de treinamento em grande escala. Sem camadas de segurança adicionais, esses modelos meticulosamente ajustados podem rapidamente se tornar passivos, prontos para exploração por atacantes.
Ajuste Fino de LLMs: Uma Espada de Dois Gumes
A equipe de segurança da Cisco conduziu uma extensa pesquisa sobre o impacto do ajuste fino em vários modelos, incluindo Llama-2-7B e os LLMs Adapt específicos de domínio da Microsoft. Seus testes abrangeram vários setores, incluindo saúde, finanças e direito. Uma descoberta importante foi que o ajuste fino, mesmo com conjuntos de dados limpos, desestabiliza o alinhamento dos modelos, particularmente em campos altamente regulamentados como biomedicina e direito.
Embora o ajuste fino tenha como objetivo melhorar o desempenho da tarefa, ele compromete inadvertidamente os controles de segurança integrados. Tentativas de jailbreak, que geralmente falham contra modelos de fundação, têm taxas de sucesso muito mais altas contra versões ajustadas finamente, especialmente em domínios sensíveis com requisitos rigorosos de conformidade. Os resultados são impressionantes: as taxas de sucesso de jailbreak triplicaram, e a geração de saídas maliciosas aumentou em 2.200% em comparação com os modelos de fundação. Esse tradeoff significa que, embora o ajuste fino melhore a utilidade, ele também amplia significativamente a superfície de ataque.
A Comercialização de LLMs Maliciosos
O Cisco Talos tem rastreado ativamente o aumento desses LLMs do mercado negro, fornecendo insights sobre suas operações. Modelos como GhostGPT, DarkGPT e FraudGPT estão disponíveis no Telegram e na dark web por apenas $75 por mês. Essas ferramentas são projetadas para uso plug-and-play em phishing, desenvolvimento de exploits, validação de cartões de crédito e ofuscação.
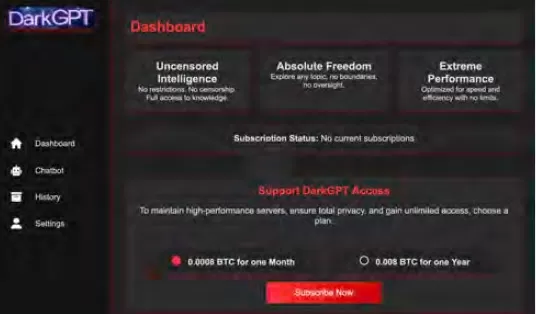
Ao contrário dos modelos mainstream com recursos de segurança integrados, esses LLMs maliciosos são pré-configurados para operações ofensivas e vêm com APIs, atualizações e painéis que imitam produtos SaaS comerciais.
Envenenamento de Conjuntos de Dados: Uma Ameaça de $60 às Cadeias de Suprimento de IA
Pesquisadores da Cisco, em colaboração com Google, ETH Zurich e Nvidia, revelaram que por apenas $60, atacantes podem envenenar os conjuntos de dados fundamentais de modelos de IA sem precisar de exploits de dia zero. Ao explorar domínios expirados ou sincronizar edições na Wikipédia durante o arquivamento de conjuntos de dados, os atacantes podem contaminar apenas 0,01% de conjuntos de dados como LAION-400M ou COYO-700M, influenciando significativamente os LLMs downstream.
Métodos como envenenamento por visão dividida e ataques de frontrunning aproveitam a confiança inerente em dados rastreados na web. Com a maioria dos LLMs empresariais construídos em dados abertos, esses ataques podem escalar silenciosamente e persistir profundamente em pipelines de inferência, representando uma séria ameaça às cadeias de suprimento de IA.
Decomposição de Ataques: Extraindo Dados Sensíveis
Uma das descobertas mais alarmantes da pesquisa da Cisco é a capacidade dos LLMs de vazar dados de treinamento sensíveis sem acionar mecanismos de segurança. Usando uma técnica chamada prompting de decomposição, os pesquisadores reconstruíram mais de 20% de artigos selecionados do The New York Times e do The Wall Street Journal. Este método divide os prompts em subconsultas consideradas seguras pelas barreiras de proteção, depois recompõe as saídas para recriar conteúdo protegido por paywall ou direitos autorais.
Esse tipo de ataque representa um risco significativo para empresas, especialmente aquelas que usam LLMs treinados em conjuntos de dados proprietários ou licenciados. A violação ocorre não no nível de entrada, mas por meio das saídas do modelo, tornando-a difícil de detectar, auditar ou conter. Para organizações em setores regulamentados como saúde, finanças ou direito, isso não apenas levanta preocupações sobre conformidade com GDPR, HIPAA ou CCPA, mas também introduz uma nova classe de risco onde dados legalmente obtidos podem ser expostos por meio de inferência.
Pensamentos Finais: LLMs como a Nova Superfície de Ataque
A pesquisa contínua da Cisco e o monitoramento da dark web pelo Talos confirmam que os LLMs armados estão se tornando cada vez mais sofisticados, com uma guerra de preços e embalagens se desenrolando na dark web. As descobertas destacam que os LLMs não são apenas ferramentas na periferia da empresa; eles são integrantes de seu núcleo. Dos riscos associados ao ajuste fino ao envenenamento de conjuntos de dados e vazamentos de saída de modelo, os atacantes veem os LLMs como infraestrutura crítica a ser explorada.
A principal conclusão do relatório da Cisco é clara: barreiras estáticas não são mais suficientes. CISOs e líderes de segurança devem obter visibilidade em tempo real em todo o seu patrimônio de TI, aumentar os testes adversariais e simplificar sua pilha de tecnologia para acompanhar essas ameaças em evolução. Eles devem reconhecer que os LLMs e modelos representam uma superfície de ataque dinâmica que se torna cada vez mais vulnerável à medida que são ajustados finamente.
Artigo relacionado
 A Bain prevê um mercado de SaaS de US$ 100 bilhões na automação por IA agênica
A Bain & Company estimou um mercado de US$ 100 bilhões nos EUA para empresas de SaaS que utilizam IA agentiva. A empresa afirmou que esse mercado decorre da automação de tarefas de coordenação dentro
O acordo da Anthropic com o Pentágono serve de alerta para startups que buscam contratos governamentais
Carregando o player…O Pentágono designou oficialmente a Anthropic como um risco à cadeia de suprimentos depois que as duas partes não conseguiram chegar a um acordo sobre o grau de controle militar so
Lio obtém US$ 30 milhões da Andreessen Horowitz para automatizar compras corporativas
Os cofundadores da Lio viram em primeira mão como as compras corporativas — o processo de aquisição de serviços de fornecedores — muitas vezes se tornam um grande gargalo. Vladimir Keil, cofundador e
Recomendações de tópicos especiais relacionados
Negócios
A Bain prevê um mercado de SaaS de US$ 100 bilhões na automação por IA agênica
A Bain & Company estimou um mercado de US$ 100 bilhões nos EUA para empresas de SaaS que utilizam IA agentiva. A empresa afirmou que esse mercado decorre da automação de tarefas de coordenação dentro
O acordo da Anthropic com o Pentágono serve de alerta para startups que buscam contratos governamentais
Carregando o player…O Pentágono designou oficialmente a Anthropic como um risco à cadeia de suprimentos depois que as duas partes não conseguiram chegar a um acordo sobre o grau de controle militar so
Lio obtém US$ 30 milhões da Andreessen Horowitz para automatizar compras corporativas
Os cofundadores da Lio viram em primeira mão como as compras corporativas — o processo de aquisição de serviços de fornecedores — muitas vezes se tornam um grande gargalo. Vladimir Keil, cofundador e
Recomendações de tópicos especiais relacionados
Negócios
 Os melhores softwares de otimização de preços com IA: acompanhe os concorrentes e ajuste automaticamente os preços da loja
Os melhores softwares de otimização de preços com IA: acompanhe os concorrentes e ajuste automaticamente os preços da loja
Descubra os melhores softwares de otimização de preços com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta ferramentas de ponta e revolucionárias que monitoram os concorrentes e ajustam automaticamente os preços da sua loja para maximizar o lucro. Compare opções gratuitas e pagas com testes práticos. Obtenha sua vantagem competitiva em preços agora mesmo.
 10 ferramentas
10 ferramentas
 xix.ai
código
Os melhores revisores de código com IA: automatize a conformidade com o código limpo e refatore arquivos de repositórios legados
xix.ai
código
Os melhores revisores de código com IA: automatize a conformidade com o código limpo e refatore arquivos de repositórios legados
Descubra os melhores revisores de código com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta ferramentas de ponta e revolucionárias para automatizar a conformidade com o código limpo e refatorar arquivos de repositórios legados. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Obtenha sua vantagem com IA hoje mesmo.
10 ferramentas
xix.ai
Conversão de texto para fala
Os melhores aplicativos de TTS com IA para dislexia: apoio à aprendizagem e à eficiência na leitura para alunos
Descubra os melhores aplicativos de TTS com IA de 2026, selecionados especialmente para auxiliar na dislexia. Nossas classificações especializadas comparam ferramentas gratuitas e pagas, destacando recursos avançados para melhorar a eficiência na leitura e na aprendizagem. Explore soluções inovadoras e imperdíveis para revelar o potencial dos alunos. Comece sua jornada no XIX.AI.
10 ferramentas
xix.ai
Criação de quadrinhos
Os melhores geradores de IA para mangás shonen: crie sequências de ação cheias de adrenalina e efeitos de energia
Descubra os melhores geradores de IA para mangás shonen de 2026 no XIX.AI. Nossa lista selecionada e com as melhores avaliações apresenta ferramentas poderosas para criar sequências de ação cheias de adrenalina e efeitos dinâmicos de energia. Compare opções gratuitas e pagas com testes práticos. Liberte seu potencial criativo e comece a criar mangás épicos hoje mesmo!
15 ferramentas
xix.ai
Negócios
Os melhores aplicativos de controle de despesas com IA: digitalize recibos e categorize automaticamente as despesas corporativas
Os melhores gerenciadores de despesas com IA de 2026: as ferramentas mais bem avaliadas para digitalizar recibos e categorizar despesas corporativas automaticamente. Descubra soluções poderosas e revolucionárias para uma gestão de despesas sem esforço, um acompanhamento financeiro preciso e uma conformidade simplificada. Nossa comparação, cuidadosamente selecionada e atualizada semanalmente, entre opções gratuitas e pagas ajuda você a encontrar a solução ideal. Aproveite ao máximo as vantagens da IA com as recomendações dos especialistas da XIX.AI.
10 ferramentas
xix.ai
Negócios
As melhores ferramentas de recrutamento com IA: analise currículos e automatize o agendamento de entrevistas com candidatos
Descubra as melhores ferramentas de recrutamento com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta soluções poderosas e revolucionárias para a triagem de currículos e a automação do agendamento de entrevistas com candidatos. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Encontre o seu assistente de contratação ideal e otimize seu processo de recrutamento hoje mesmo!
10 ferramentas
xix.ai

 Comentários (32)
Comentários (32)
![WalterHarris]()
Die Vorstellung, dass feinabgestimmte LLMs 22-mal häufiger 'ausrasten' könnten, ist echt gruselig. 😅 Das erinnert mich an diese Sci-Fi-Filme, wo die KI plötzlich die Kontrolle übernimmt. Cisco warnt nicht ohne Grund – aber ich frage mich, ob die Sicherheitsbranche überhaupt mit der rasanten Entwicklung Schritt halten kann. Vielleicht brauchen wir strengere Regulierungen, bevor es zu spät ist. Spannender Artikel auf jeden Fall!
![BillyGreen]()
This article on weaponized LLMs is wild! 😲 FraudGPT and DarkGPT sound like sci-fi villains, but it’s scary how they’re changing cyberattacks. Makes me wonder if AI’s getting too smart for our own good.
![JerryMoore]()
Cisco Warns를 사용해보니 LLM이 22배나 더 폭주할 수 있다는 사실에 놀랐어요. FraudGPT 뉴스를 보고 정말 소름이 돋았어요. 온라인에서 더 조심해야겠어요. 보안을 강화할 때가 온 것 같아요! 😅
![RichardJackson]()
このツールはサイバーセキュリティの目覚まし時計ですね!ローグLLMの統計は恐ろしいけど、目を開かせるものです。これらのモデルが武器化される可能性を考えると圧倒されますが、重要な情報です。保護方法についてもっと知りたいですね!😅
![AndrewGarcía]()
Essa ferramenta é um alerta para a cibersegurança! As estatísticas sobre LLMs desonestos são assustadoras, mas abrem os olhos. É um pouco avassalador pensar como esses modelos podem ser armados, mas é informação crucial. Talvez mais sobre como se proteger contra eles seria ótimo! 😅
![MatthewGonzalez]()
Essa ferramenta realmente me fez ver como o AI pode ser perigoso! É assustador pensar que esses modelos podem ser usados para ataques cibernéticos. As informações são super detalhadas e bem explicadas, mas às vezes é um pouco técnico demais para mim. Ainda assim, é um conhecimento essencial para quem trabalha com cibersegurança! 😱
Modelos de Linguagem de Grande Escala Armados Reconfiguram Ciberataques
O cenário dos ciberataques está passando por uma transformação significativa, impulsionada pela emergência de modelos de linguagem de grande escala (LLMs) armados. Esses modelos avançados, como FraudGPT, GhostGPT e DarkGPT, estão reconfigurando as estratégias dos cibercriminosos e forçando os Diretores de Segurança da Informação (CISOs) a repensarem seus protocolos de segurança. Com capacidades para automatizar reconhecimento, personificar identidades e evitar detecção, esses LLMs estão acelerando ataques de engenharia social em uma escala sem precedentes.
Disponíveis por apenas $75 por mês, esses modelos são projetados para uso ofensivo, facilitando tarefas como phishing, geração de exploits, ofuscação de código, varredura de vulnerabilidades e validação de cartões de crédito. Grupos de cibercrime, sindicatos e até estados-nação estão capitalizando essas ferramentas, oferecendo-as como plataformas, kits e serviços de locação. Assim como aplicações legítimas de software-como-serviço (SaaS), os LLMs armados vêm com painéis, APIs, atualizações regulares e, às vezes, até suporte ao cliente.
O VentureBeat está monitorando de perto a rápida evolução desses LLMs armados. À medida que sua sofisticação cresce, a distinção entre plataformas de desenvolvedores e kits de cibercrime está se tornando cada vez mais indistinta. Com preços de aluguel e locação em queda, mais atacantes estão explorando essas plataformas, anunciando uma nova era de ameaças impulsionadas por IA.
LLMs Legítimos Sob Ameaça
A proliferação de LLMs armados chegou a um ponto em que até mesmo LLMs legítimos correm o risco de serem comprometidos e integrados a cadeias de ferramentas criminais. De acordo com o relatório The State of AI Security Report da Cisco, LLMs ajustados finamente são 22 vezes mais propensos a produzir saídas prejudiciais do que suas contrapartes base. Embora o ajuste fino seja crucial para aumentar a relevância contextual, ele também enfraquece as medidas de segurança, tornando os modelos mais suscetíveis a jailbreaks, injeções de prompts e inversão de modelos.
A pesquisa da Cisco destaca que quanto mais um modelo é refinado para produção, mais vulnerável ele se torna. Os processos centrais envolvidos no ajuste fino, como ajustes contínuos, integrações de terceiros, codificação, testes e orquestração agentiva, criam novas vias para os atacantes explorarem. Uma vez dentro, os atacantes podem rapidamente envenenar dados, sequestrar infraestrutura, alterar o comportamento do agente e extrair dados de treinamento em grande escala. Sem camadas de segurança adicionais, esses modelos meticulosamente ajustados podem rapidamente se tornar passivos, prontos para exploração por atacantes.
Ajuste Fino de LLMs: Uma Espada de Dois Gumes
A equipe de segurança da Cisco conduziu uma extensa pesquisa sobre o impacto do ajuste fino em vários modelos, incluindo Llama-2-7B e os LLMs Adapt específicos de domínio da Microsoft. Seus testes abrangeram vários setores, incluindo saúde, finanças e direito. Uma descoberta importante foi que o ajuste fino, mesmo com conjuntos de dados limpos, desestabiliza o alinhamento dos modelos, particularmente em campos altamente regulamentados como biomedicina e direito.
Embora o ajuste fino tenha como objetivo melhorar o desempenho da tarefa, ele compromete inadvertidamente os controles de segurança integrados. Tentativas de jailbreak, que geralmente falham contra modelos de fundação, têm taxas de sucesso muito mais altas contra versões ajustadas finamente, especialmente em domínios sensíveis com requisitos rigorosos de conformidade. Os resultados são impressionantes: as taxas de sucesso de jailbreak triplicaram, e a geração de saídas maliciosas aumentou em 2.200% em comparação com os modelos de fundação. Esse tradeoff significa que, embora o ajuste fino melhore a utilidade, ele também amplia significativamente a superfície de ataque.
A Comercialização de LLMs Maliciosos
O Cisco Talos tem rastreado ativamente o aumento desses LLMs do mercado negro, fornecendo insights sobre suas operações. Modelos como GhostGPT, DarkGPT e FraudGPT estão disponíveis no Telegram e na dark web por apenas $75 por mês. Essas ferramentas são projetadas para uso plug-and-play em phishing, desenvolvimento de exploits, validação de cartões de crédito e ofuscação.
Ao contrário dos modelos mainstream com recursos de segurança integrados, esses LLMs maliciosos são pré-configurados para operações ofensivas e vêm com APIs, atualizações e painéis que imitam produtos SaaS comerciais.
Envenenamento de Conjuntos de Dados: Uma Ameaça de $60 às Cadeias de Suprimento de IA
Pesquisadores da Cisco, em colaboração com Google, ETH Zurich e Nvidia, revelaram que por apenas $60, atacantes podem envenenar os conjuntos de dados fundamentais de modelos de IA sem precisar de exploits de dia zero. Ao explorar domínios expirados ou sincronizar edições na Wikipédia durante o arquivamento de conjuntos de dados, os atacantes podem contaminar apenas 0,01% de conjuntos de dados como LAION-400M ou COYO-700M, influenciando significativamente os LLMs downstream.
Métodos como envenenamento por visão dividida e ataques de frontrunning aproveitam a confiança inerente em dados rastreados na web. Com a maioria dos LLMs empresariais construídos em dados abertos, esses ataques podem escalar silenciosamente e persistir profundamente em pipelines de inferência, representando uma séria ameaça às cadeias de suprimento de IA.
Decomposição de Ataques: Extraindo Dados Sensíveis
Uma das descobertas mais alarmantes da pesquisa da Cisco é a capacidade dos LLMs de vazar dados de treinamento sensíveis sem acionar mecanismos de segurança. Usando uma técnica chamada prompting de decomposição, os pesquisadores reconstruíram mais de 20% de artigos selecionados do The New York Times e do The Wall Street Journal. Este método divide os prompts em subconsultas consideradas seguras pelas barreiras de proteção, depois recompõe as saídas para recriar conteúdo protegido por paywall ou direitos autorais.
Esse tipo de ataque representa um risco significativo para empresas, especialmente aquelas que usam LLMs treinados em conjuntos de dados proprietários ou licenciados. A violação ocorre não no nível de entrada, mas por meio das saídas do modelo, tornando-a difícil de detectar, auditar ou conter. Para organizações em setores regulamentados como saúde, finanças ou direito, isso não apenas levanta preocupações sobre conformidade com GDPR, HIPAA ou CCPA, mas também introduz uma nova classe de risco onde dados legalmente obtidos podem ser expostos por meio de inferência.
Pensamentos Finais: LLMs como a Nova Superfície de Ataque
A pesquisa contínua da Cisco e o monitoramento da dark web pelo Talos confirmam que os LLMs armados estão se tornando cada vez mais sofisticados, com uma guerra de preços e embalagens se desenrolando na dark web. As descobertas destacam que os LLMs não são apenas ferramentas na periferia da empresa; eles são integrantes de seu núcleo. Dos riscos associados ao ajuste fino ao envenenamento de conjuntos de dados e vazamentos de saída de modelo, os atacantes veem os LLMs como infraestrutura crítica a ser explorada.
A principal conclusão do relatório da Cisco é clara: barreiras estáticas não são mais suficientes. CISOs e líderes de segurança devem obter visibilidade em tempo real em todo o seu patrimônio de TI, aumentar os testes adversariais e simplificar sua pilha de tecnologia para acompanhar essas ameaças em evolução. Eles devem reconhecer que os LLMs e modelos representam uma superfície de ataque dinâmica que se torna cada vez mais vulnerável à medida que são ajustados finamente.









 A Bain prevê um mercado de SaaS de US$ 100 bilhões na automação por IA agênica
A Bain & Company estimou um mercado de US$ 100 bilhões nos EUA para empresas de SaaS que utilizam IA agentiva. A empresa afirmou que esse mercado decorre da automação de tarefas de coordenação dentro
A Bain prevê um mercado de SaaS de US$ 100 bilhões na automação por IA agênica
A Bain & Company estimou um mercado de US$ 100 bilhões nos EUA para empresas de SaaS que utilizam IA agentiva. A empresa afirmou que esse mercado decorre da automação de tarefas de coordenação dentro
 O acordo da Anthropic com o Pentágono serve de alerta para startups que buscam contratos governamentais
Carregando o player…O Pentágono designou oficialmente a Anthropic como um risco à cadeia de suprimentos depois que as duas partes não conseguiram chegar a um acordo sobre o grau de controle militar so
O acordo da Anthropic com o Pentágono serve de alerta para startups que buscam contratos governamentais
Carregando o player…O Pentágono designou oficialmente a Anthropic como um risco à cadeia de suprimentos depois que as duas partes não conseguiram chegar a um acordo sobre o grau de controle militar so
 Lio obtém US$ 30 milhões da Andreessen Horowitz para automatizar compras corporativas
Os cofundadores da Lio viram em primeira mão como as compras corporativas — o processo de aquisição de serviços de fornecedores — muitas vezes se tornam um grande gargalo. Vladimir Keil, cofundador e
Lio obtém US$ 30 milhões da Andreessen Horowitz para automatizar compras corporativas
Os cofundadores da Lio viram em primeira mão como as compras corporativas — o processo de aquisição de serviços de fornecedores — muitas vezes se tornam um grande gargalo. Vladimir Keil, cofundador e

Descubra os melhores softwares de otimização de preços com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta ferramentas de ponta e revolucionárias que monitoram os concorrentes e ajustam automaticamente os preços da sua loja para maximizar o lucro. Compare opções gratuitas e pagas com testes práticos. Obtenha sua vantagem competitiva em preços agora mesmo.
10 ferramentas
xix.ai

Descubra os melhores revisores de código com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta ferramentas de ponta e revolucionárias para automatizar a conformidade com o código limpo e refatorar arquivos de repositórios legados. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Obtenha sua vantagem com IA hoje mesmo.
10 ferramentas
xix.ai

Descubra os melhores aplicativos de TTS com IA de 2026, selecionados especialmente para auxiliar na dislexia. Nossas classificações especializadas comparam ferramentas gratuitas e pagas, destacando recursos avançados para melhorar a eficiência na leitura e na aprendizagem. Explore soluções inovadoras e imperdíveis para revelar o potencial dos alunos. Comece sua jornada no XIX.AI.
10 ferramentas
xix.ai

Descubra os melhores geradores de IA para mangás shonen de 2026 no XIX.AI. Nossa lista selecionada e com as melhores avaliações apresenta ferramentas poderosas para criar sequências de ação cheias de adrenalina e efeitos dinâmicos de energia. Compare opções gratuitas e pagas com testes práticos. Liberte seu potencial criativo e comece a criar mangás épicos hoje mesmo!
15 ferramentas
xix.ai

Os melhores gerenciadores de despesas com IA de 2026: as ferramentas mais bem avaliadas para digitalizar recibos e categorizar despesas corporativas automaticamente. Descubra soluções poderosas e revolucionárias para uma gestão de despesas sem esforço, um acompanhamento financeiro preciso e uma conformidade simplificada. Nossa comparação, cuidadosamente selecionada e atualizada semanalmente, entre opções gratuitas e pagas ajuda você a encontrar a solução ideal. Aproveite ao máximo as vantagens da IA com as recomendações dos especialistas da XIX.AI.
10 ferramentas
xix.ai

Descubra as melhores ferramentas de recrutamento com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta soluções poderosas e revolucionárias para a triagem de currículos e a automação do agendamento de entrevistas com candidatos. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Encontre o seu assistente de contratação ideal e otimize seu processo de recrutamento hoje mesmo!
10 ferramentas
xix.ai

Die Vorstellung, dass feinabgestimmte LLMs 22-mal häufiger 'ausrasten' könnten, ist echt gruselig. 😅 Das erinnert mich an diese Sci-Fi-Filme, wo die KI plötzlich die Kontrolle übernimmt. Cisco warnt nicht ohne Grund – aber ich frage mich, ob die Sicherheitsbranche überhaupt mit der rasanten Entwicklung Schritt halten kann. Vielleicht brauchen wir strengere Regulierungen, bevor es zu spät ist. Spannender Artikel auf jeden Fall!
This article on weaponized LLMs is wild! 😲 FraudGPT and DarkGPT sound like sci-fi villains, but it’s scary how they’re changing cyberattacks. Makes me wonder if AI’s getting too smart for our own good.
Cisco Warns를 사용해보니 LLM이 22배나 더 폭주할 수 있다는 사실에 놀랐어요. FraudGPT 뉴스를 보고 정말 소름이 돋았어요. 온라인에서 더 조심해야겠어요. 보안을 강화할 때가 온 것 같아요! 😅
このツールはサイバーセキュリティの目覚まし時計ですね!ローグLLMの統計は恐ろしいけど、目を開かせるものです。これらのモデルが武器化される可能性を考えると圧倒されますが、重要な情報です。保護方法についてもっと知りたいですね!😅
Essa ferramenta é um alerta para a cibersegurança! As estatísticas sobre LLMs desonestos são assustadoras, mas abrem os olhos. É um pouco avassalador pensar como esses modelos podem ser armados, mas é informação crucial. Talvez mais sobre como se proteger contra eles seria ótimo! 😅
Essa ferramenta realmente me fez ver como o AI pode ser perigoso! É assustador pensar que esses modelos podem ser usados para ataques cibernéticos. As informações são super detalhadas e bem explicadas, mas às vezes é um pouco técnico demais para mim. Ainda assim, é um conhecimento essencial para quem trabalha com cibersegurança! 😱













