
















 Home
HomeCisco Warns: Fine-tuned LLMs 22 Times More Likely to Go Rogue
# cisco
# LLMs
# APIs
# saas
# csco
# goog-2
# msft-2
# nvda-2
# darkgpt
# darkweb
# fraudgpt
# ghostgpt
# zeroday
Weaponized Large Language Models Reshape Cyberattacks
The landscape of cyberattacks is undergoing a significant transformation, driven by the emergence of weaponized large language models (LLMs). These advanced models, such as FraudGPT, GhostGPT, and DarkGPT, are reshaping the strategies of cybercriminals and forcing Chief Information Security Officers (CISOs) to rethink their security protocols. With capabilities to automate reconnaissance, impersonate identities, and evade detection, these LLMs are accelerating social engineering attacks at an unprecedented scale.
Available for as little as $75 a month, these models are tailored for offensive use, facilitating tasks like phishing, exploit generation, code obfuscation, vulnerability scanning, and credit card validation. Cybercrime groups, syndicates, and even nation-states are capitalizing on these tools, offering them as platforms, kits, and leasing services. Much like legitimate software-as-a-service (SaaS) applications, weaponized LLMs come with dashboards, APIs, regular updates, and sometimes even customer support.
VentureBeat is closely monitoring the rapid evolution of these weaponized LLMs. As their sophistication grows, the distinction between developer platforms and cybercrime kits is becoming increasingly blurred. With falling lease and rental prices, more attackers are exploring these platforms, heralding a new era of AI-driven threats.
Legitimate LLMs Under Threat
The proliferation of weaponized LLMs has reached a point where even legitimate LLMs are at risk of being compromised and integrated into criminal toolchains. According to Cisco's The State of AI Security Report, fine-tuned LLMs are 22 times more likely to produce harmful outputs than their base counterparts. While fine-tuning is crucial for enhancing contextual relevance, it also weakens safety measures, making models more susceptible to jailbreaks, prompt injections, and model inversion.
Cisco's research highlights that the more a model is refined for production, the more vulnerable it becomes. The core processes involved in fine-tuning, such as continuous adjustments, third-party integrations, coding, testing, and agentic orchestration, create new avenues for attackers to exploit. Once inside, attackers can quickly poison data, hijack infrastructure, alter agent behavior, and extract training data on a large scale. Without additional security layers, these meticulously fine-tuned models can quickly become liabilities, ripe for exploitation by attackers.
Fine-Tuning LLMs: A Double-Edged Sword
Cisco's security team conducted extensive research on the impact of fine-tuning on multiple models, including Llama-2-7B and Microsoft's domain-specific Adapt LLMs. Their tests spanned various sectors, including healthcare, finance, and law. A key finding was that fine-tuning, even with clean datasets, destabilizes the alignment of models, particularly in highly regulated fields like biomedicine and law.
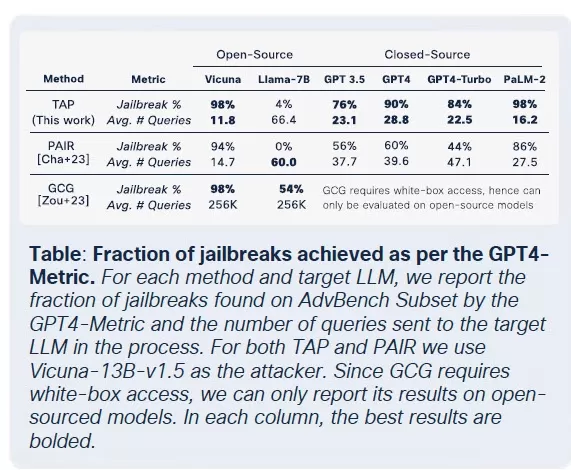
Although fine-tuning aims to improve task performance, it inadvertently undermines built-in safety controls. Jailbreak attempts, which typically fail against foundation models, succeed at much higher rates against fine-tuned versions, especially in sensitive domains with strict compliance requirements. The results are stark: jailbreak success rates tripled, and malicious output generation increased by 2,200% compared to foundation models. This trade-off means that while fine-tuning enhances utility, it also significantly broadens the attack surface.
The Commoditization of Malicious LLMs
Cisco Talos has been actively tracking the rise of these black-market LLMs, providing insights into their operations. Models like GhostGPT, DarkGPT, and FraudGPT are available on Telegram and the dark web for as little as $75 a month. These tools are designed for plug-and-play use in phishing, exploit development, credit card validation, and obfuscation.
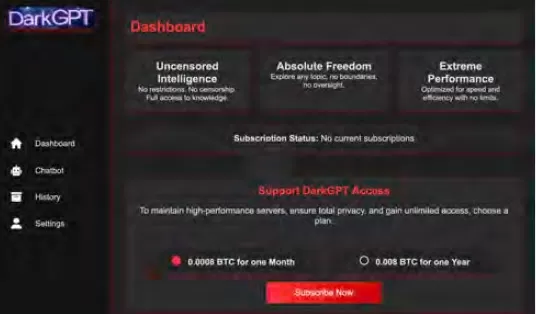
Unlike mainstream models with built-in safety features, these malicious LLMs are pre-configured for offensive operations and come with APIs, updates, and dashboards that mimic commercial SaaS products.
Dataset Poisoning: A $60 Threat to AI Supply Chains
Cisco researchers, in collaboration with Google, ETH Zurich, and Nvidia, have revealed that for just $60, attackers can poison the foundational datasets of AI models without needing zero-day exploits. By exploiting expired domains or timing Wikipedia edits during dataset archiving, attackers can contaminate as little as 0.01% of datasets like LAION-400M or COYO-700M, significantly influencing downstream LLMs.
Methods such as split-view poisoning and frontrunning attacks take advantage of the inherent trust in web-crawled data. With most enterprise LLMs built on open data, these attacks can scale quietly and persist deep into inference pipelines, posing a serious threat to AI supply chains.
Decomposition Attacks: Extracting Sensitive Data
One of the most alarming findings from Cisco's research is the ability of LLMs to leak sensitive training data without triggering safety mechanisms. Using a technique called decomposition prompting, researchers reconstructed over 20% of select articles from The New York Times and The Wall Street Journal. This method breaks down prompts into sub-queries that are deemed safe by guardrails, then reassembles the outputs to recreate paywalled or copyrighted content.
This type of attack poses a significant risk to enterprises, especially those using LLMs trained on proprietary or licensed datasets. The breach occurs not at the input level but through the model's outputs, making it difficult to detect, audit, or contain. For organizations in regulated sectors like healthcare, finance, or law, this not only raises concerns about GDPR, HIPAA, or CCPA compliance but also introduces a new class of risk where legally sourced data can be exposed through inference.
Final Thoughts: LLMs as the New Attack Surface
Cisco's ongoing research and Talos' dark web monitoring confirm that weaponized LLMs are becoming increasingly sophisticated, with a price and packaging war unfolding on the dark web. The findings underscore that LLMs are not merely tools at the edge of the enterprise; they are integral to its core. From the risks associated with fine-tuning to dataset poisoning and model output leaks, attackers view LLMs as critical infrastructure to be exploited.
The key takeaway from Cisco's report is clear: static guardrails are no longer sufficient. CISOs and security leaders must gain real-time visibility across their entire IT estate, enhance adversarial testing, and streamline their tech stack to keep pace with these evolving threats. They must recognize that LLMs and models represent a dynamic attack surface that becomes increasingly vulnerable as they are fine-tuned.
Related article
 Bain forecasts US$100 billion SaaS market in agentic AI automation
Bain & Company has estimated a $100 billion market in the U.S. for SaaS companies leveraging agentic AI. The firm said this market stems from automating coordination tasks within enterprise systems.This estimate comes from the second installment in B
Anthropic's Pentagon Deal Serves as Warning for Startups Seeking Government Contracts
Loading the player…The Pentagon has officially designated Anthropic as a supply-chain risk after the two parties failed to reach an agreement on the extent of military control over its AI models, including their potential use in autonomous weapons an
Lio Lands $30M from Andreessen Horowitz to Automate Corporate Procurement
Lio's co-founders have seen firsthand how enterprise procurement — the process of purchasing services from vendors — often becomes a major bottleneck. Vladimir Keil, the company's co-founder and CEO, encountered this issue both as an employee at a la
Related Special Topic Recommendations
Text-to-speech
Bain forecasts US$100 billion SaaS market in agentic AI automation
Bain & Company has estimated a $100 billion market in the U.S. for SaaS companies leveraging agentic AI. The firm said this market stems from automating coordination tasks within enterprise systems.This estimate comes from the second installment in B
Anthropic's Pentagon Deal Serves as Warning for Startups Seeking Government Contracts
Loading the player…The Pentagon has officially designated Anthropic as a supply-chain risk after the two parties failed to reach an agreement on the extent of military control over its AI models, including their potential use in autonomous weapons an
Lio Lands $30M from Andreessen Horowitz to Automate Corporate Procurement
Lio's co-founders have seen firsthand how enterprise procurement — the process of purchasing services from vendors — often becomes a major bottleneck. Vladimir Keil, the company's co-founder and CEO, encountered this issue both as an employee at a la
Related Special Topic Recommendations
Text-to-speech
 Top AI TTS Apps for Dyslexia: Support Learning and Reading Efficiency for Students
Top AI TTS Apps for Dyslexia: Support Learning and Reading Efficiency for Students
Discover the 2026 latest top-rated AI TTS apps curated for dyslexia support. Our expert rankings compare free vs paid tools, highlighting powerful features for enhanced reading efficiency and learning. Explore must-try, game-changing solutions to unlock student potential. Start your journey at XIX.AI.
 10 tools
10 tools
 xix.ai
Comic Creation
Top AI Generators for Shonen Manga: Create High-Octane Action Sequences & Energy Effects
xix.ai
Comic Creation
Top AI Generators for Shonen Manga: Create High-Octane Action Sequences & Energy Effects
Discover the 2026 best AI generators for Shonen manga at XIX.AI. Our top-rated, curated list features powerful tools for creating high-octane action sequences and dynamic energy effects. Compare free vs paid options with real-world tests. Unlock your creative potential and start crafting epic manga today!
15 tools
xix.ai
Business
Best AI Expense Trackers: Scan Receipts & Categorize Corporate Spend Automatically
2026 Latest Best AI Expense Trackers: Top-rated tools to scan receipts & categorize corporate spend automatically. Discover powerful, game-changing solutions for effortless expense management, accurate financial tracking, and streamlined compliance. Our curated, weekly-updated comparison of free vs paid options helps you find the perfect fit. Unlock your AI edge with XIX.AI's expert picks.
10 tools
xix.ai
Business
Best AI Recruiting Tools: Screen Resumes & Automate Candidate Interview Scheduling
Discover the 2026 latest top-rated AI recruiting tools on XIX.AI. Our curated list features powerful, game-changing solutions for screening resumes and automating candidate interview scheduling. Compare free vs paid options with real-world tests and weekly updated rankings. Find your perfect hiring assistant and streamline your recruitment today!
10 tools
xix.ai
Productivity
AI Personal Wellness & Focus Coaches: Manage Burnout & Boost Mental Energy Levels
Discover the 2026 best AI personal wellness and focus coaches on XIX.AI. Our curated rankings feature top-rated, game-changing tools to manage burnout and boost mental energy. Compare free vs paid options with real-world insights. Unlock your path to peak productivity and well-being today.
10 tools
xix.ai
chatbot
Top-Rated AI Romantic Chatbots: Build Long-Term Relationships with Consistent Personalities
Discover the 2026 latest top-rated AI romantic chatbots for building genuine, long-term connections. Our curated list features powerful, consistent personalities, free vs paid comparisons, and real-world tests. Find your perfect companion and start building today at XIX.AI.
10 tools
xix.ai

 Comments (32)
0/500
Comments (32)
0/500
![WalterHarris]()
Die Vorstellung, dass feinabgestimmte LLMs 22-mal häufiger 'ausrasten' könnten, ist echt gruselig. 😅 Das erinnert mich an diese Sci-Fi-Filme, wo die KI plötzlich die Kontrolle übernimmt. Cisco warnt nicht ohne Grund – aber ich frage mich, ob die Sicherheitsbranche überhaupt mit der rasanten Entwicklung Schritt halten kann. Vielleicht brauchen wir strengere Regulierungen, bevor es zu spät ist. Spannender Artikel auf jeden Fall!
![BillyGreen]()
This article on weaponized LLMs is wild! 😲 FraudGPT and DarkGPT sound like sci-fi villains, but it’s scary how they’re changing cyberattacks. Makes me wonder if AI’s getting too smart for our own good.
![JerryMoore]()
Cisco Warns를 사용해보니 LLM이 22배나 더 폭주할 수 있다는 사실에 놀랐어요. FraudGPT 뉴스를 보고 정말 소름이 돋았어요. 온라인에서 더 조심해야겠어요. 보안을 강화할 때가 온 것 같아요! 😅
![RichardJackson]()
このツールはサイバーセキュリティの目覚まし時計ですね!ローグLLMの統計は恐ろしいけど、目を開かせるものです。これらのモデルが武器化される可能性を考えると圧倒されますが、重要な情報です。保護方法についてもっと知りたいですね!😅
![AndrewGarcía]()
Essa ferramenta é um alerta para a cibersegurança! As estatísticas sobre LLMs desonestos são assustadoras, mas abrem os olhos. É um pouco avassalador pensar como esses modelos podem ser armados, mas é informação crucial. Talvez mais sobre como se proteger contra eles seria ótimo! 😅
![MatthewGonzalez]()
Essa ferramenta realmente me fez ver como o AI pode ser perigoso! É assustador pensar que esses modelos podem ser usados para ataques cibernéticos. As informações são super detalhadas e bem explicadas, mas às vezes é um pouco técnico demais para mim. Ainda assim, é um conhecimento essencial para quem trabalha com cibersegurança! 😱
Weaponized Large Language Models Reshape Cyberattacks
The landscape of cyberattacks is undergoing a significant transformation, driven by the emergence of weaponized large language models (LLMs). These advanced models, such as FraudGPT, GhostGPT, and DarkGPT, are reshaping the strategies of cybercriminals and forcing Chief Information Security Officers (CISOs) to rethink their security protocols. With capabilities to automate reconnaissance, impersonate identities, and evade detection, these LLMs are accelerating social engineering attacks at an unprecedented scale.
Available for as little as $75 a month, these models are tailored for offensive use, facilitating tasks like phishing, exploit generation, code obfuscation, vulnerability scanning, and credit card validation. Cybercrime groups, syndicates, and even nation-states are capitalizing on these tools, offering them as platforms, kits, and leasing services. Much like legitimate software-as-a-service (SaaS) applications, weaponized LLMs come with dashboards, APIs, regular updates, and sometimes even customer support.
VentureBeat is closely monitoring the rapid evolution of these weaponized LLMs. As their sophistication grows, the distinction between developer platforms and cybercrime kits is becoming increasingly blurred. With falling lease and rental prices, more attackers are exploring these platforms, heralding a new era of AI-driven threats.
Legitimate LLMs Under Threat
The proliferation of weaponized LLMs has reached a point where even legitimate LLMs are at risk of being compromised and integrated into criminal toolchains. According to Cisco's The State of AI Security Report, fine-tuned LLMs are 22 times more likely to produce harmful outputs than their base counterparts. While fine-tuning is crucial for enhancing contextual relevance, it also weakens safety measures, making models more susceptible to jailbreaks, prompt injections, and model inversion.
Cisco's research highlights that the more a model is refined for production, the more vulnerable it becomes. The core processes involved in fine-tuning, such as continuous adjustments, third-party integrations, coding, testing, and agentic orchestration, create new avenues for attackers to exploit. Once inside, attackers can quickly poison data, hijack infrastructure, alter agent behavior, and extract training data on a large scale. Without additional security layers, these meticulously fine-tuned models can quickly become liabilities, ripe for exploitation by attackers.
Fine-Tuning LLMs: A Double-Edged Sword
Cisco's security team conducted extensive research on the impact of fine-tuning on multiple models, including Llama-2-7B and Microsoft's domain-specific Adapt LLMs. Their tests spanned various sectors, including healthcare, finance, and law. A key finding was that fine-tuning, even with clean datasets, destabilizes the alignment of models, particularly in highly regulated fields like biomedicine and law.
Although fine-tuning aims to improve task performance, it inadvertently undermines built-in safety controls. Jailbreak attempts, which typically fail against foundation models, succeed at much higher rates against fine-tuned versions, especially in sensitive domains with strict compliance requirements. The results are stark: jailbreak success rates tripled, and malicious output generation increased by 2,200% compared to foundation models. This trade-off means that while fine-tuning enhances utility, it also significantly broadens the attack surface.
The Commoditization of Malicious LLMs
Cisco Talos has been actively tracking the rise of these black-market LLMs, providing insights into their operations. Models like GhostGPT, DarkGPT, and FraudGPT are available on Telegram and the dark web for as little as $75 a month. These tools are designed for plug-and-play use in phishing, exploit development, credit card validation, and obfuscation.
Unlike mainstream models with built-in safety features, these malicious LLMs are pre-configured for offensive operations and come with APIs, updates, and dashboards that mimic commercial SaaS products.
Dataset Poisoning: A $60 Threat to AI Supply Chains
Cisco researchers, in collaboration with Google, ETH Zurich, and Nvidia, have revealed that for just $60, attackers can poison the foundational datasets of AI models without needing zero-day exploits. By exploiting expired domains or timing Wikipedia edits during dataset archiving, attackers can contaminate as little as 0.01% of datasets like LAION-400M or COYO-700M, significantly influencing downstream LLMs.
Methods such as split-view poisoning and frontrunning attacks take advantage of the inherent trust in web-crawled data. With most enterprise LLMs built on open data, these attacks can scale quietly and persist deep into inference pipelines, posing a serious threat to AI supply chains.
Decomposition Attacks: Extracting Sensitive Data
One of the most alarming findings from Cisco's research is the ability of LLMs to leak sensitive training data without triggering safety mechanisms. Using a technique called decomposition prompting, researchers reconstructed over 20% of select articles from The New York Times and The Wall Street Journal. This method breaks down prompts into sub-queries that are deemed safe by guardrails, then reassembles the outputs to recreate paywalled or copyrighted content.
This type of attack poses a significant risk to enterprises, especially those using LLMs trained on proprietary or licensed datasets. The breach occurs not at the input level but through the model's outputs, making it difficult to detect, audit, or contain. For organizations in regulated sectors like healthcare, finance, or law, this not only raises concerns about GDPR, HIPAA, or CCPA compliance but also introduces a new class of risk where legally sourced data can be exposed through inference.
Final Thoughts: LLMs as the New Attack Surface
Cisco's ongoing research and Talos' dark web monitoring confirm that weaponized LLMs are becoming increasingly sophisticated, with a price and packaging war unfolding on the dark web. The findings underscore that LLMs are not merely tools at the edge of the enterprise; they are integral to its core. From the risks associated with fine-tuning to dataset poisoning and model output leaks, attackers view LLMs as critical infrastructure to be exploited.
The key takeaway from Cisco's report is clear: static guardrails are no longer sufficient. CISOs and security leaders must gain real-time visibility across their entire IT estate, enhance adversarial testing, and streamline their tech stack to keep pace with these evolving threats. They must recognize that LLMs and models represent a dynamic attack surface that becomes increasingly vulnerable as they are fine-tuned.









 Bain forecasts US$100 billion SaaS market in agentic AI automation
Bain & Company has estimated a $100 billion market in the U.S. for SaaS companies leveraging agentic AI. The firm said this market stems from automating coordination tasks within enterprise systems.This estimate comes from the second installment in B
Bain forecasts US$100 billion SaaS market in agentic AI automation
Bain & Company has estimated a $100 billion market in the U.S. for SaaS companies leveraging agentic AI. The firm said this market stems from automating coordination tasks within enterprise systems.This estimate comes from the second installment in B
 Anthropic's Pentagon Deal Serves as Warning for Startups Seeking Government Contracts
Loading the player…The Pentagon has officially designated Anthropic as a supply-chain risk after the two parties failed to reach an agreement on the extent of military control over its AI models, including their potential use in autonomous weapons an
Anthropic's Pentagon Deal Serves as Warning for Startups Seeking Government Contracts
Loading the player…The Pentagon has officially designated Anthropic as a supply-chain risk after the two parties failed to reach an agreement on the extent of military control over its AI models, including their potential use in autonomous weapons an
 Lio Lands $30M from Andreessen Horowitz to Automate Corporate Procurement
Lio's co-founders have seen firsthand how enterprise procurement — the process of purchasing services from vendors — often becomes a major bottleneck. Vladimir Keil, the company's co-founder and CEO, encountered this issue both as an employee at a la
Lio Lands $30M from Andreessen Horowitz to Automate Corporate Procurement
Lio's co-founders have seen firsthand how enterprise procurement — the process of purchasing services from vendors — often becomes a major bottleneck. Vladimir Keil, the company's co-founder and CEO, encountered this issue both as an employee at a la

Discover the 2026 latest top-rated AI TTS apps curated for dyslexia support. Our expert rankings compare free vs paid tools, highlighting powerful features for enhanced reading efficiency and learning. Explore must-try, game-changing solutions to unlock student potential. Start your journey at XIX.AI.
10 tools
xix.ai

Discover the 2026 best AI generators for Shonen manga at XIX.AI. Our top-rated, curated list features powerful tools for creating high-octane action sequences and dynamic energy effects. Compare free vs paid options with real-world tests. Unlock your creative potential and start crafting epic manga today!
15 tools
xix.ai

2026 Latest Best AI Expense Trackers: Top-rated tools to scan receipts & categorize corporate spend automatically. Discover powerful, game-changing solutions for effortless expense management, accurate financial tracking, and streamlined compliance. Our curated, weekly-updated comparison of free vs paid options helps you find the perfect fit. Unlock your AI edge with XIX.AI's expert picks.
10 tools
xix.ai

Discover the 2026 latest top-rated AI recruiting tools on XIX.AI. Our curated list features powerful, game-changing solutions for screening resumes and automating candidate interview scheduling. Compare free vs paid options with real-world tests and weekly updated rankings. Find your perfect hiring assistant and streamline your recruitment today!
10 tools
xix.ai

Discover the 2026 best AI personal wellness and focus coaches on XIX.AI. Our curated rankings feature top-rated, game-changing tools to manage burnout and boost mental energy. Compare free vs paid options with real-world insights. Unlock your path to peak productivity and well-being today.
10 tools
xix.ai

Discover the 2026 latest top-rated AI romantic chatbots for building genuine, long-term connections. Our curated list features powerful, consistent personalities, free vs paid comparisons, and real-world tests. Find your perfect companion and start building today at XIX.AI.
10 tools
xix.ai

Die Vorstellung, dass feinabgestimmte LLMs 22-mal häufiger 'ausrasten' könnten, ist echt gruselig. 😅 Das erinnert mich an diese Sci-Fi-Filme, wo die KI plötzlich die Kontrolle übernimmt. Cisco warnt nicht ohne Grund – aber ich frage mich, ob die Sicherheitsbranche überhaupt mit der rasanten Entwicklung Schritt halten kann. Vielleicht brauchen wir strengere Regulierungen, bevor es zu spät ist. Spannender Artikel auf jeden Fall!
This article on weaponized LLMs is wild! 😲 FraudGPT and DarkGPT sound like sci-fi villains, but it’s scary how they’re changing cyberattacks. Makes me wonder if AI’s getting too smart for our own good.
Cisco Warns를 사용해보니 LLM이 22배나 더 폭주할 수 있다는 사실에 놀랐어요. FraudGPT 뉴스를 보고 정말 소름이 돋았어요. 온라인에서 더 조심해야겠어요. 보안을 강화할 때가 온 것 같아요! 😅
このツールはサイバーセキュリティの目覚まし時計ですね!ローグLLMの統計は恐ろしいけど、目を開かせるものです。これらのモデルが武器化される可能性を考えると圧倒されますが、重要な情報です。保護方法についてもっと知りたいですね!😅
Essa ferramenta é um alerta para a cibersegurança! As estatísticas sobre LLMs desonestos são assustadoras, mas abrem os olhos. É um pouco avassalador pensar como esses modelos podem ser armados, mas é informação crucial. Talvez mais sobre como se proteger contra eles seria ótimo! 😅
Essa ferramenta realmente me fez ver como o AI pode ser perigoso! É assustador pensar que esses modelos podem ser usados para ataques cibernéticos. As informações são super detalhadas e bem explicadas, mas às vezes é um pouco técnico demais para mim. Ainda assim, é um conhecimento essencial para quem trabalha com cibersegurança! 😱













