
















 Heim
HeimDie KI -Videogenerierung bewegt sich in Richtung vollständiger Kontrolle
Videogrundmodelle wie Hunyuan und Wan 2.1 haben bedeutende Fortschritte gemacht, aber sie stoßen oft an ihre Grenzen, wenn es um die detaillierte Steuerung geht, die in der Film- und Fernsehproduktion, insbesondere im Bereich visueller Effekte (VFX), erforderlich ist. In professionellen VFX-Studios werden diese Modelle zusammen mit früheren bildbasierten Modellen wie Stable Diffusion, Kandinsky und Flux in Verbindung mit einer Reihe von Werkzeugen verwendet, die entwickelt wurden, um ihre Ausgabe an spezifische kreative Anforderungen anzupassen. Wenn ein Regisseur eine Anpassung fordert und sagt: „Das sieht toll aus, aber können wir es etwas mehr [n] gestalten?“, reicht es nicht aus, einfach zu erklären, dass dem Modell die Präzision für solche Anpassungen fehlt.
Stattdessen setzt ein AI-VFX-Team eine Kombination aus traditionellem CGI und Kompositionstechniken sowie speziell entwickelten Arbeitsabläufen ein, um die Grenzen der Videosynthese weiter zu verschieben. Dieser Ansatz ähnelt der Verwendung eines Standard-Webbrowsers wie Chrome; er ist direkt einsatzbereit, aber um ihn wirklich an Ihre Bedürfnisse anzupassen, müssen Sie einige Plugins installieren.
Kontrollfanatiker
Im Bereich der diffusionsbasierten Bildsynthese ist eines der wichtigsten Drittanbietersysteme ControlNet. Diese Technik führt strukturierte Kontrolle in generative Modelle ein, sodass Benutzer die Bild- oder Videogenerierung mithilfe zusätzlicher Eingaben wie Kantenmappen, Tiefenkarten oder Poseninformationen steuern können.
 *Die verschiedenen Methoden von ControlNet ermöglichen Tiefen>Image (obere Reihe), semantische Segmentierung>Image (unten links) und posengesteuerte Bildgenerierung von Menschen und Tieren (unten links).*
*Die verschiedenen Methoden von ControlNet ermöglichen Tiefen>Image (obere Reihe), semantische Segmentierung>Image (unten links) und posengesteuerte Bildgenerierung von Menschen und Tieren (unten links).*
ControlNet verlässt sich nicht ausschließlich auf Textprompts; es verwendet separate neuronale Netzwerkzweige oder Adapter, um diese Konditionierungssignale zu verarbeiten, während die generativen Fähigkeiten des Basismodells erhalten bleiben. Dies ermöglicht hochgradig angepasste Ausgaben, die eng an die Benutzerspezifikationen angelehnt sind, was es für Anwendungen unverzichtbar macht, die eine präzise Kontrolle über Komposition, Struktur oder Bewegung erfordern.
 *Mit einer steuernden Pose können durch ControlNet eine Vielzahl präziser Ausgabetypen erzielt werden.* Quelle: https://arxiv.org/pdf/2302.05543
*Mit einer steuernden Pose können durch ControlNet eine Vielzahl präziser Ausgabetypen erzielt werden.* Quelle: https://arxiv.org/pdf/2302.05543
Diese adapterbasierten Systeme, die extern auf einer Reihe intern fokussierter neuronaler Prozesse arbeiten, bringen jedoch mehrere Nachteile mit sich. Adapter werden unabhängig trainiert, was zu Konflikten zwischen den Zweigen führen kann, wenn mehrere Adapter kombiniert werden, was oft zu minderwertigen Generierungen führt. Sie führen auch Parameterredundanz ein, die zusätzliche Rechenressourcen und Speicher für jeden Adapter erfordern, was die Skalierung ineffizient macht. Zudem liefern Adapter trotz ihrer Flexibilität oft suboptimale Ergebnisse im Vergleich zu Modellen, die vollständig für die Generierung mit mehreren Bedingungen optimiert wurden. Diese Probleme können adapterbasierte Methoden für Aufgaben weniger effektiv machen, die eine nahtlose Integration mehrerer Steuerungssignale erfordern.
Idealerweise wären die Fähigkeiten von ControlNet modular in das Modell integriert, um zukünftige Innovationen wie gleichzeitige Video-/Audiogenerierung oder native Lippensynchronisationsfähigkeiten zu ermöglichen. Derzeit ist jede zusätzliche Funktion entweder eine Nachbearbeitungsaufgabe oder ein nicht-nativer Prozess, der die empfindlichen Gewichte des Grundmodells navigieren muss.
FullDiT
Hier kommt FullDiT ins Spiel, ein neuer Ansatz aus China, der ControlNet-ähnliche Funktionen direkt während des Trainings in ein generatives Videomodell integriert, anstatt sie nachträglich hinzuzufügen.
 *Aus dem neuen Paper: Der FullDiT-Ansatz kann Identitätsauferlegung, Tiefe und Kamerabewegung in eine native Generierung integrieren und jede Kombination davon gleichzeitig abrufen.* Quelle: https://arxiv.org/pdf/2503.19907
*Aus dem neuen Paper: Der FullDiT-Ansatz kann Identitätsauferlegung, Tiefe und Kamerabewegung in eine native Generierung integrieren und jede Kombination davon gleichzeitig abrufen.* Quelle: https://arxiv.org/pdf/2503.19907
FullDiT, wie im Paper mit dem Titel **FullDiT: Multi-Task Video Generative Foundation Model with Full Attention** beschrieben, integriert Multi-Task-Bedingungen wie Identitätsübertragung, Tiefenabbildung und Kamerabewegung in den Kern eines trainierten generativen Videomodells. Die Autoren haben ein Prototypmodell und begleitende Videoclips entwickelt, die auf einer Projektseite verfügbar sind.
**Klicken Sie zum Abspielen. Beispiele für ControlNet-ähnliche Benutzerauferlegung mit ausschließlich einem nativ trainierten Grundmodell.** Quelle: https://fulldit.github.io/
Die Autoren stellen FullDiT als Proof-of-Concept für native Text-zu-Video (T2V) und Bild-zu-Video (I2V) Modelle vor, die Benutzern mehr Kontrolle bieten als nur ein Bild- oder Textprompt. Da keine ähnlichen Modelle existieren, haben die Forscher einen neuen Benchmark namens **FullBench** für die Bewertung von Multi-Task-Videos erstellt und behaupten, in ihren entwickelten Tests eine erstklassige Leistung zu erzielen. Die Objektivität von FullBench, das von den Autoren selbst entworfen wurde, bleibt jedoch ungetestet, und der Datensatz mit 1.400 Fällen könnte für breitere Schlussfolgerungen zu begrenzt sein.
Der faszinierendste Aspekt der FullDiT-Architektur ist ihr Potenzial, neue Arten von Steuerung zu integrieren. Die Autoren stellen fest:
**„In dieser Arbeit untersuchen wir nur Steuerungsbedingungen der Kamera, Identitäten und Tiefeninformationen. Wir haben keine weiteren Bedingungen und Modalitäten wie Audio, Sprache, Punktwolken, Objektbegrenzungsrahmen, optischen Fluss usw. weiter untersucht. Obwohl das Design von FullDiT andere Modalitäten mit minimalen Architekturänderungen nahtlos integrieren kann, bleibt die Frage, wie bestehende Modelle schnell und kosteneffizient an neue Bedingungen und Modalitäten angepasst werden können, eine wichtige Frage, die weitere Untersuchungen erfordert.“**
Während FullDiT einen Schritt nach vorne in der Multi-Task-Videogenerierung darstellt, baut es auf bestehenden Architekturen auf, anstatt ein neues Paradigma einzuführen. Dennoch sticht es als einziges Videogrundmodell mit nativ integrierten ControlNet-ähnlichen Funktionen hervor, und seine Architektur ist darauf ausgelegt, zukünftige Innovationen zu unterstützen.
**Klicken Sie zum Abspielen. Beispiele für benutzergesteuerte Kamerabewegungen von der Projektseite.**
Das Paper, verfasst von neun Forschern der Kuaishou Technology und der Chinese University of Hong Kong, trägt den Titel **FullDiT: Multi-Task Video Generative Foundation Model with Full Attention**. Die Projektseite und die neuen Benchmark-Daten sind auf Hugging Face verfügbar.
Methode
Der vereinheitlichte Aufmerksamkeitsmechanismus von FullDiT ist darauf ausgelegt, das Lernen von cross-modalen Repräsentationen zu verbessern, indem sowohl räumliche als auch zeitliche Beziehungen über die Bedingungen hinweg erfasst werden.
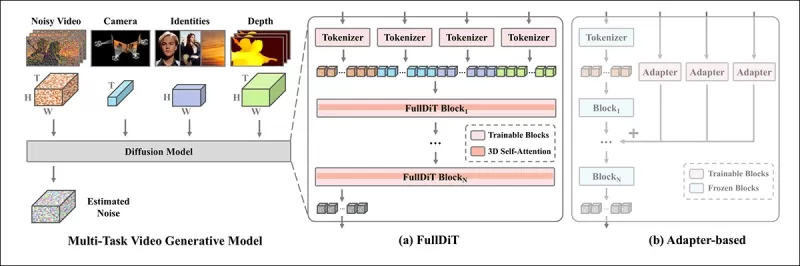 *Laut dem neuen Paper integriert FullDiT mehrere Eingabebedingungen durch vollständige Selbstaufmerksamkeit, indem sie in eine einheitliche Sequenz umgewandelt werden. Im Gegensatz dazu verwenden adapterbasierte Modelle (ganz links oben) separate Module für jede Eingabe, was zu Redundanz, Konflikten und schwächerer Leistung führt.*
*Laut dem neuen Paper integriert FullDiT mehrere Eingabebedingungen durch vollständige Selbstaufmerksamkeit, indem sie in eine einheitliche Sequenz umgewandelt werden. Im Gegensatz dazu verwenden adapterbasierte Modelle (ganz links oben) separate Module für jede Eingabe, was zu Redundanz, Konflikten und schwächerer Leistung führt.*
Im Gegensatz zu adapterbasierten Setups, die jeden Eingabestrom separat verarbeiten, vermeidet die gemeinsame Aufmerksamkeitsstruktur von FullDiT Konflikte zwischen den Zweigen und reduziert den Parameteraufwand. Die Autoren behaupten, dass die Architektur auf neue Eingabetypen skaliert werden kann, ohne wesentliche Neugestaltung, und dass das Modellschema Anzeichen dafür zeigt, auf Kombinationen von Bedingungen zu verallgemeinern, die während des Trainings nicht gesehen wurden, wie etwa die Verknüpfung von Kamerabewegung mit Charakteridentität.
**Klicken Sie zum Abspielen. Beispiele für Identitätsgenerierung von der Projektseite.**
In der Architektur von FullDiT werden alle Konditionierungseingaben – wie Text, Kamerabewegung, Identität und Tiefe – zunächst in ein einheitliches Token-Format umgewandelt. Diese Token werden dann zu einer einzigen langen Sequenz verkettet, die durch einen Stapel von Transformer-Schichten mit vollständiger Selbstaufmerksamkeit verarbeitet wird. Dieser Ansatz folgt früheren Arbeiten wie Open-Sora Plan und Movie Gen.
Dieses Design ermöglicht es dem Modell, zeitliche und räumliche Beziehungen gemeinsam über alle Bedingungen hinweg zu lernen. Jeder Transformer-Block arbeitet über die gesamte Sequenz, was dynamische Interaktionen zwischen Modalitäten ermöglicht, ohne auf separate Module für jede Eingabe angewiesen zu sein. Die Architektur ist erweiterbar gestaltet, was die Integration zusätzlicher Steuerungssignale in der Zukunft ohne größere strukturelle Änderungen erleichtert.
Die Kraft der Drei
FullDiT wandelt jedes Steuerungssignal in ein standardisiertes Token-Format um, sodass alle Bedingungen gemeinsam in einem einheitlichen Aufmerksamkeitsrahmen verarbeitet werden können. Für Kamerabewegung kodiert das Modell eine Sequenz extrinsischer Parameter – wie Position und Ausrichtung – für jedes Frame. Diese Parameter sind zeitgestempelt und werden in Einbettungsvektoren projiziert, die die zeitliche Natur des Signals widerspiegeln.
Identitätsinformationen werden anders behandelt, da sie von Natur aus räumlich und nicht zeitlich sind. Das Modell verwendet Identitätskarten, die anzeigen, welche Charaktere in welchen Teilen jedes Frames vorhanden sind. Diese Karten werden in Patches unterteilt, wobei jedes Patch in eine Einbettung projiziert wird, die räumliche Identitätshinweise erfasst, sodass das Modell bestimmte Bereiche des Frames mit bestimmten Entitäten verknüpfen kann.
Tiefe ist ein raumzeitliches Signal, und das Modell behandelt es, indem Tiefenvideos in 3D-Patches unterteilt werden, die sowohl Raum als auch Zeit umfassen. Diese Patches werden dann so eingebettet, dass ihre Struktur über die Frames hinweg erhalten bleibt.
Nach der Einbettung werden alle diese Bedingungstoken (Kamera, Identität und Tiefe) zu einer einzigen langen Sequenz verkettet, sodass FullDiT sie gemeinsam mit vollständiger Selbstaufmerksamkeit verarbeiten kann. Diese gemeinsame Repräsentation ermöglicht es dem Modell, Interaktionen über Modalitäten und über die Zeit hinweg zu lernen, ohne auf isolierte Verarbeitungsströme angewiesen zu sein.
Daten und Tests
Der Trainingsansatz von FullDiT stützte sich auf selektiv annotierte Datensätze, die auf jeden Bedingungstyp zugeschnitten waren, anstatt zu verlangen, dass alle Bedingungen gleichzeitig vorhanden sind.
Für textuelle Bedingungen folgt die Initiative dem strukturierten Beschriftungsansatz, der im MiraData-Projekt beschrieben ist.
 *Pipeline zur Videosammlung und -annotation aus dem MiraData-Projekt.* Quelle: https://arxiv.org/pdf/2407.06358
*Pipeline zur Videosammlung und -annotation aus dem MiraData-Projekt.* Quelle: https://arxiv.org/pdf/2407.06358
Für Kamerabewegung war der RealEstate10K-Datensatz die Hauptquelle, aufgrund seiner hochwertigen Ground-Truth-Annotationen von Kameraparametern. Die Autoren stellten jedoch fest, dass das Training ausschließlich auf statischen Szenen-Kameradatensätzen wie RealEstate10K die Bewegungen dynamischer Objekte und Menschen in generierten Videos reduzierte. Um dem entgegenzuwirken, führten sie zusätzliches Feintuning mit internen Datensätzen durch, die dynamischere Kamerabewegungen enthielten.
Identitätsannotationen wurden mithilfe der Pipeline generiert, die für das ConceptMaster-Projekt entwickelt wurde, was eine effiziente Filterung und Extraktion feinkörniger Identitätsinformationen ermöglichte.
 *Das ConceptMaster-Framework ist darauf ausgelegt, Identitätsentkopplungsprobleme zu adressieren, während die Konzepttreue in angepassten Videos erhalten bleibt.* Quelle: https://arxiv.org/pdf/2501.04698
*Das ConceptMaster-Framework ist darauf ausgelegt, Identitätsentkopplungsprobleme zu adressieren, während die Konzepttreue in angepassten Videos erhalten bleibt.* Quelle: https://arxiv.org/pdf/2501.04698
Tiefenannotationen wurden aus dem Panda-70M-Datensatz mit Depth Anything gewonnen.
Optimierung durch Datenreihenfolge
Die Autoren implementierten auch einen progressiven Trainingsplan, indem sie anspruchsvollere Bedingungen früher im Training einführten, um sicherzustellen, dass das Modell robuste Repräsentationen erwarb, bevor einfachere Aufgaben hinzugefügt wurden. Die Trainingsreihenfolge verlief von Text zu Kamerabedingungen, dann Identitäten und schließlich Tiefe, wobei einfachere Aufgaben im Allgemeinen später und mit weniger Beispielen eingeführt wurden.
Die Autoren betonen den Wert dieser Reihenfolge der Arbeitslast:
**„Während der Pre-Training-Phase stellten wir fest, dass anspruchsvollere Aufgaben eine längere Trainingszeit erfordern und früher im Lernprozess eingeführt werden sollten. Diese anspruchsvollen Aufgaben beinhalten komplexe Datenverteilungen, die sich erheblich vom Ausgabevideo unterscheiden, was erfordert, dass das Modell ausreichende Kapazität besitzt, um sie genau zu erfassen und darzustellen.**
**„Umgekehrt kann die zu frühe Einführung einfacherer Aufgaben dazu führen, dass das Modell diese zuerst lernt, da sie sofortigeres Optimierungsfeedback bieten, was die Konvergenz anspruchsvollerer Aufgaben behindern kann.“**
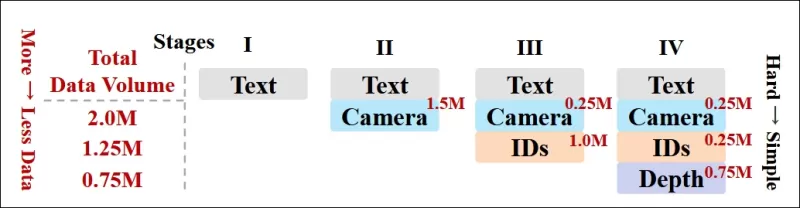 *Eine Illustration der von den Forschern übernommenen Daten-Trainingsreihenfolge, wobei Rot ein größeres Datenvolumen anzeigt.*
*Eine Illustration der von den Forschern übernommenen Daten-Trainingsreihenfolge, wobei Rot ein größeres Datenvolumen anzeigt.*
Nach dem anfänglichen Pre-Training verfeinerte eine abschließende Feintuning-Phase das Modell weiter, um die visuelle Qualität und Bewegungsdyamik zu verbessern. Danach folgte das Training dem eines standardmäßigen Diffusionsrahmens: Rauschen wurde zu Videolatenzen hinzugefügt, und das Modell lernte, dieses zu prognostizieren und zu entfernen, indem es die eingebetteten Bedingungstoken als Leitlinie nutzte.
Um FullDiT effektiv zu bewerten und einen fairen Vergleich mit bestehenden Methoden zu ermöglichen, führten die Autoren in Ermangelung eines anderen passenden Benchmarks **FullBench** ein, eine kuratierte Benchmark-Suite, die aus 1.400 unterschiedlichen Testfällen besteht.
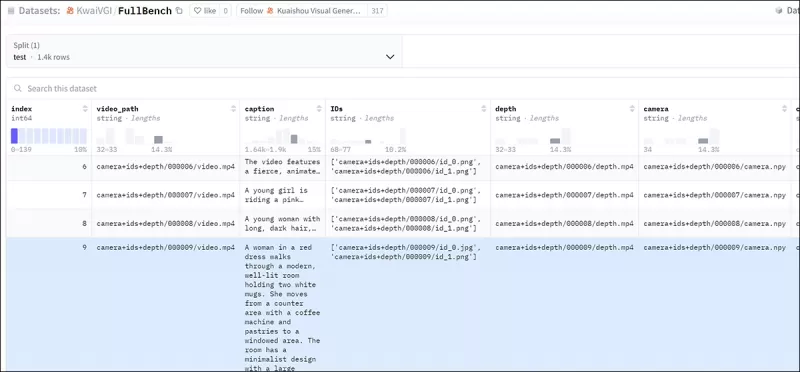 *Eine Datenexplorer-Instanz für den neuen FullBench-Benchmark.* Quelle: https://huggingface.co/datasets/KwaiVGI/FullBench
*Eine Datenexplorer-Instanz für den neuen FullBench-Benchmark.* Quelle: https://huggingface.co/datasets/KwaiVGI/FullBench
Jeder Datenpunkt lieferte Ground-Truth-Annotationen für verschiedene Konditionierungssignale, einschließlich Kamerabewegung, Identität und Tiefe.
Metriken
Die Autoren bewerteten FullDiT anhand von zehn Metriken, die fünf Hauptaspekte der Leistung abdecken: Textausrichtung, Kamerakontrolle, Identitätsähnlichkeit, Tiefengenauigkeit und allgemeine Videoqualität.
Die Textausrichtung wurde mit CLIP-Ähnlichkeit gemessen, während die Kamerakontrolle durch Rotationsfehler (RotErr), Translationsfehler (TransErr) und Kamerabewegungskonsistenz (CamMC) bewertet wurde, nach dem Ansatz von CamI2V (im CameraCtrl-Projekt).
Die Identitätsähnlichkeit wurde mit DINO-I und CLIP-I bewertet, und die Genauigkeit der Tiefenkontrolle wurde mit dem Mean Absolute Error (MAE) quantifiziert.
Die Videoqualität wurde mit drei Metriken aus MiraData beurteilt: CLIP-Ähnlichkeit auf Frame-Ebene für Glätte; optische Fluss-basierte Bewegungsentfernung für Dynamik; und LAION-Ästhetik-Scores für visuelle Anziehungskraft.
Training
Die Autoren trainierten FullDiT mit einem internen (nicht offengelegten) Text-zu-Video-Diffusionsmodell mit etwa einer Milliarde Parametern. Sie wählten absichtlich eine moderate Parametergröße, um Fairness im Vergleich mit früheren Methoden zu gewährleisten und die Reproduzierbarkeit sicherzustellen.
Da die Trainingsvideos in Länge und Auflösung variierten, standardisierten die Autoren jeden Batch, indem sie die Videos auf eine gemeinsame Auflösung skalierten und auffüllten, 77 Frames pro Sequenz sampelten und angewandte Aufmerksamkeits- und Verlustmasken verwendeten, um die Trainingseffektivität zu optimieren.
Der Adam-Optimierer wurde mit einer Lernrate von 1×10−5 auf einem Cluster von 64 NVIDIA H800 GPUs verwendet, für insgesamt 5.120 GB VRAM (bedenken Sie, dass in Enthusiasten-Synthese-Communities 24 GB auf einer RTX 3090 immer noch als luxuriöser Standard gilt).
Das Modell wurde für etwa 32.000 Schritte trainiert, wobei bis zu drei Identitäten pro Video einbezogen wurden, zusammen mit 20 Frames von Kamerabedingungen und 21 Frames von Tiefenbedingungen, beide gleichmäßig aus den insgesamt 77 Frames gesampelt.
Für die Inferenz generierte das Modell Videos mit einer Auflösung von 384×672 Pixeln (etwa fünf Sekunden bei 15 Frames pro Sekunde) mit 50 Diffusions-Inferenzschritten und einer klassifikatorfreien Führungsskala von fünf.
Frühere Methoden
Für die Kamera-zu-Video-Bewertung verglichen die Autoren FullDiT mit MotionCtrl, CameraCtrl und CamI2V, wobei alle Modelle mit dem RealEstate10k-Datensatz trainiert wurden, um Konsistenz und Fairness zu gewährleisten.
In der identitätsbedingten Generierung, da keine vergleichbaren Open-Source-Multi-Identitätsmodelle verfügbar waren, wurde das Modell gegen das 1B-Parameter-ConceptMaster-Modell benchmarked, unter Verwendung derselben Trainingsdaten und Architektur.
Für Tiefen-zu-Video-Aufgaben wurden Vergleiche mit Ctrl-Adapter und ControlVideo angestellt.
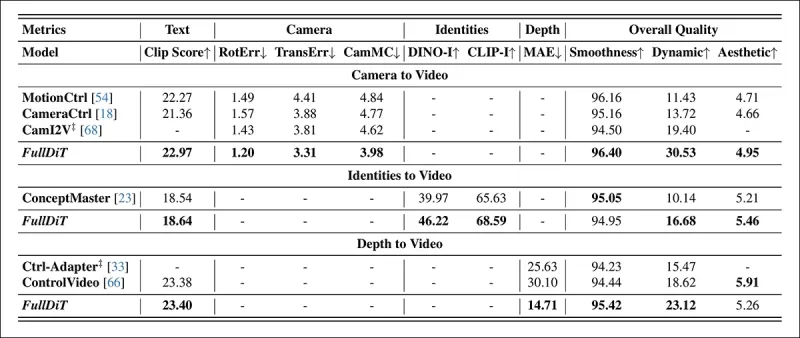 *Quantitative Ergebnisse für die Generierung von Einzelaufgabenvideos. FullDiT wurde mit MotionCtrl, CameraCtrl und CamI2V für die Kamera-zu-Video-Generierung verglichen; ConceptMaster (1B-Parameter-Version) für Identität-zu-Video; und Ctrl-Adapter und ControlVideo für Tiefe-zu-Video. Alle Modelle wurden mit ihren Standardeinstellungen bewertet. Für Konsistenz wurden 16 Frames gleichmäßig von jeder Methode gesampelt, passend zur Ausgabelänge früherer Modelle.*
*Quantitative Ergebnisse für die Generierung von Einzelaufgabenvideos. FullDiT wurde mit MotionCtrl, CameraCtrl und CamI2V für die Kamera-zu-Video-Generierung verglichen; ConceptMaster (1B-Parameter-Version) für Identität-zu-Video; und Ctrl-Adapter und ControlVideo für Tiefe-zu-Video. Alle Modelle wurden mit ihren Standardeinstellungen bewertet. Für Konsistenz wurden 16 Frames gleichmäßig von jeder Methode gesampelt, passend zur Ausgabelänge früherer Modelle.*
Die Ergebnisse zeigen, dass FullDiT, obwohl es mehrere Konditionierungssignale gleichzeitig verarbeitet, in Metriken bezüglich Text, Kamerabewegung, Identität und Tiefenkontrollen eine erstklassige Leistung erzielte.
In den allgemeinen Qualitätsmetriken übertraf das System im Allgemeinen andere Methoden, obwohl seine Glätte etwas niedriger war als die von ConceptMaster. Hier kommentieren die Autoren:
**„Die Glätte von FullDiT ist etwas niedriger als die von ConceptMaster, da die Berechnung der Glätte auf der CLIP-Ähnlichkeit zwischen benachbarten Frames basiert. Da FullDiT deutlich größere Dynamiken im Vergleich zu ConceptMaster aufweist, wird die Glättemetrik durch die großen Variationen zwischen benachbarten Frames beeinflusst.**
**„Für die Ästhetikbewertung, da das Bewertungsmodell Bilder im Malstil bevorzugt und ControlVideo typischerweise Videos in diesem Stil generiert, erzielt es eine hohe Bewertung in der Ästhetik.“**
In Bezug auf den qualitativen Vergleich wäre es vorzuziehen, die Beispielvideos auf der FullDiT-Projektseite anzusehen, da die PDF-Beispiele zwangsläufig statisch sind (und auch zu umfangreich, um hier vollständig wiedergegeben zu werden).
 *Der erste Abschnitt der reproduzierten qualitativen Ergebnisse im PDF. Bitte beziehen Sie sich auf das Quellenpaper für die zusätzlichen Beispiele, die hier zu umfangreich sind, um reproduziert zu werden.*
*Der erste Abschnitt der reproduzierten qualitativen Ergebnisse im PDF. Bitte beziehen Sie sich auf das Quellenpaper für die zusätzlichen Beispiele, die hier zu umfangreich sind, um reproduziert zu werden.*
Die Autoren kommentieren:
**„FullDiT zeigt eine überlegene Identitätserhaltung und generiert Videos mit besserer Dynamik und visueller Qualität im Vergleich zu [ConceptMaster]. Da ConceptMaster und FullDiT auf demselben Rückgrat trainiert wurden, hebt dies die Wirksamkeit der Bedingungsinjektion mit vollständiger Aufmerksamkeit hervor.**
**„…Die [anderen] Ergebnisse demonstrieren die überlegene Steuerbarkeit und Generierungsqualität von FullDiT im Vergleich zu bestehenden Tiefe-zu-Video- und Kamera-zu-Video-Methoden.“**
 *Ein Abschnitt der PDF-Beispiele von FullDiT’s Ausgabe mit mehreren Signalen. Bitte beziehen Sie sich auf das Quellenpaper und die Projektseite für zusätzliche Beispiele.*
*Ein Abschnitt der PDF-Beispiele von FullDiT’s Ausgabe mit mehreren Signalen. Bitte beziehen Sie sich auf das Quellenpaper und die Projektseite für zusätzliche Beispiele.*
Fazit
FullDiT stellt einen spannenden Schritt hin zu einem umfassenderen Videogrundmodell dar, aber die Frage bleibt, ob die Nachfrage nach ControlNet-ähnlichen Funktionen ihre Implementierung im großen Maßstab rechtfertigt, insbesondere für Open-Source-Projekte. Diese Projekte hätten Schwierigkeiten, die enorme GPU-Rechenleistung zu beschaffen, die ohne kommerzielle Unterstützung erforderlich ist.
Die Hauptherausforderung besteht darin, dass die Verwendung von Systemen wie Tiefe und Pose im Allgemeinen eine nicht-triviale Vertrautheit mit komplexen Benutzeroberflächen wie ComfyUI erfordert. Daher ist ein funktionales Open-Source-Modell dieser Art am ehesten von kleineren VFX-Unternehmen zu erwarten, denen die Ressourcen oder die Motivation fehlen, ein solches Modell privat zu kuratieren und zu trainieren.
Auf der anderen Seite könnten API-gesteuerte „Rent-an-AI“-Systeme gut motiviert sein, einfachere und benutzerfreundlichere Interpretationsmethoden für Modelle mit direkt trainierten zusätzlichen Steuerungssystemen zu entwickeln.
**Klicken Sie zum Abspielen. Tiefen+Text-Steuerungen, die auf eine Videogenerierung mit FullDiT angewendet werden.**
*Die Autoren geben kein bekanntes Basismodell an (z.B. SDXL, etc.)*
**Erstmals veröffentlicht am Donnerstag, 27. März 2025**
Verwandter Artikel
 YouTube testet eine KI-gestützte Suchfunktion mit geführten Antworten
Viele Nutzer greifen auf YouTube zurück, wenn sie nach Rezepten oder Reiseplänen suchen, um relevante Videos zu finden. Nun führt die Plattform ein KI-gestütztes interaktives Suchtool ein, das Schritt
Exklusiv: Luma AI stellt kreative Agenten vor, die auf „Unified Intelligence”-Modellen basieren
Am Donnerstag stellte das Start-up-Unternehmen Luma, das sich mit der Erstellung von KI-Videos befasst, Luma Agents vor, ein System zur Verwaltung kompletter kreativer Workflows, die Text, Bilder, Vid
Das neue Update von Sora bietet KI-Videos für Haustiere, soziale Tools und eine kommende Android-App
OpenAI gibt eine Vorschau auf eine Reihe neuer Funktionen für seine bahnbrechende App zur Erstellung von KI-Videos, Sora, die nach ihrem Start Ende September schnell an die Spitze des App Store geklet
Empfehlungen zu verwandten Spezialthemen
Geschäft
YouTube testet eine KI-gestützte Suchfunktion mit geführten Antworten
Viele Nutzer greifen auf YouTube zurück, wenn sie nach Rezepten oder Reiseplänen suchen, um relevante Videos zu finden. Nun führt die Plattform ein KI-gestütztes interaktives Suchtool ein, das Schritt
Exklusiv: Luma AI stellt kreative Agenten vor, die auf „Unified Intelligence”-Modellen basieren
Am Donnerstag stellte das Start-up-Unternehmen Luma, das sich mit der Erstellung von KI-Videos befasst, Luma Agents vor, ein System zur Verwaltung kompletter kreativer Workflows, die Text, Bilder, Vid
Das neue Update von Sora bietet KI-Videos für Haustiere, soziale Tools und eine kommende Android-App
OpenAI gibt eine Vorschau auf eine Reihe neuer Funktionen für seine bahnbrechende App zur Erstellung von KI-Videos, Sora, die nach ihrem Start Ende September schnell an die Spitze des App Store geklet
Empfehlungen zu verwandten Spezialthemen
Geschäft
 Die besten KI-Tools für die Personalbeschaffung: Lebensläufe prüfen und die Terminplanung für Vorstellungsgespräche automatisieren
Die besten KI-Tools für die Personalbeschaffung: Lebensläufe prüfen und die Terminplanung für Vorstellungsgespräche automatisieren
Entdecken Sie auf XIX.AI die besten KI-Tools für die Personalbeschaffung des Jahres 2026. Unsere sorgfältig zusammengestellte Liste umfasst leistungsstarke, bahnbrechende Lösungen für die Sichtung von Lebensläufen und die automatisierte Terminplanung für Vorstellungsgespräche. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Finden Sie Ihren perfekten Assistenten für die Personalbeschaffung und optimieren Sie noch heute Ihren Rekrutierungsprozess!
 10 Tools
10 Tools
 xix.ai
Produktivität
KI-Coaches für persönliches Wohlbefinden und Konzentration: Burnout bewältigen und die geistige Energie steigern
xix.ai
Produktivität
KI-Coaches für persönliches Wohlbefinden und Konzentration: Burnout bewältigen und die geistige Energie steigern
Entdecken Sie auf XIX.AI die besten KI-basierten Coaches für persönliches Wohlbefinden und Konzentration des Jahres 2026. Unsere sorgfältig zusammengestellte Rangliste umfasst erstklassige, bahnbrechende Tools zur Bewältigung von Burnout und zur Steigerung der mentalen Energie. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Erfahrungsberichten aus der Praxis. Schlagen Sie noch heute den Weg zu höchster Produktivität und Wohlbefinden ein.
10 Tools
xix.ai
Chatbot
Die besten KI-basierten Romantik-Chatbots: Bauen Sie langfristige Beziehungen mit beständiger Persönlichkeit auf
Entdecken Sie die besten KI-Romantik-Chatbots des Jahres 2026, mit denen Sie echte, langfristige Beziehungen aufbauen können. Unsere sorgfältig zusammengestellte Liste bietet Ihnen überzeugende, konsistente Persönlichkeiten, Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten sowie Tests aus der Praxis. Finden Sie Ihren perfekten Begleiter und legen Sie noch heute bei XIX.AI los.
10 Tools
xix.ai
Bildung und Lernen
Die besten AI-Datenwissenschafts-Mentoren: Beherrschen Sie SQL, Pandas und Arbeitsabläufe für maschinelles Lernen.
Entdecken Sie die besten AI-Data-Science-Mentoren von 2026, um SQL, Pandas und ML-Arbeitsabläufe zu meistern. Erfahren Sie mehr über unsere hochbewerteten, sorgfältig ausgewählten Angebote bei XIX.AI – für effektive und bahnbrechende Anleitung. Vergleichen Sie kostenlose und bezahlte Optionen mit praktischen Einblicken aus der Praxis. Entfalten Sie Ihr Potenzial in der Data Science noch heute.
10 Tools
xix.ai
Chatbot
Die besten KI-Flirt- und Konversationstrainer: Steigere dein soziales Charisma und dein Selbstvertrauen in Echtzeit
Entdecken Sie auf XIX.AI die besten KI-Flirt- und Konversationstrainer des Jahres 2026. Unsere sorgfältig zusammengestellte, erstklassige Auswahl hilft Ihnen dabei, Ihr soziales Charisma und Ihr Selbstvertrauen in Echtzeit zu stärken. Entdecken Sie unverzichtbare, bahnbrechende Tools mit Vergleichen zwischen kostenlosen und kostenpflichtigen Angeboten sowie wöchentlich aktualisierten Rankings. Schaffen Sie sich noch heute einen sozialen Vorsprung.
10 Tools
xix.ai
Code
Die besten KI-Tools für automatisierte Einheitstests: Generieren Sie mit nur einem Klick Jest-, PyTest- und JUnit-Testfälle.
Entdecken Sie die neuesten, hochbewerteten KI-Tools von 2026 für den automatisierten Unit-Testing-Prozess. Unsere sorgfältig ausgewählten Lösungen bieten leistungsstarke und bahnbrechende Funktionen, um sofort Jest-, PyTest- und JUnit-Testfälle zu generieren. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von tatsächlichen Tests sowie wöchentlich aktualisierten Rankings auf XIX.AI. Entfalten Sie Ihr KI-Potenzial und steigern Sie noch heute die Produktivität Ihrer Entwicklungstätigkeit.
10 Tools
xix.ai

 Kommentare (3)
Kommentare (3)
![TimothyMitchell]()
映像の詳細なコントロールって本当に難しいんですね。AIがプロのVFXスタジオで使われる日はまだ先かな?でも技術の進歩にはワクワクする!🔥
![CharlesMartinez]()
Finalmente os vídeos gerados por IA estão evoluindo para algo útil! Mas ainda parece que falta muito pra substituir os efeitos manuais de grandes produções... será que um dia chegaremos lá? 🎥
![DonaldLee]()
The idea of AI taking over VFX in films is wild! I mean, total control over video generation? That’s some sci-fi stuff coming to life. But I wonder if these models like Hunyuan can really nail the tiny details directors obsess over. Exciting times! 🎥
Videogrundmodelle wie Hunyuan und Wan 2.1 haben bedeutende Fortschritte gemacht, aber sie stoßen oft an ihre Grenzen, wenn es um die detaillierte Steuerung geht, die in der Film- und Fernsehproduktion, insbesondere im Bereich visueller Effekte (VFX), erforderlich ist. In professionellen VFX-Studios werden diese Modelle zusammen mit früheren bildbasierten Modellen wie Stable Diffusion, Kandinsky und Flux in Verbindung mit einer Reihe von Werkzeugen verwendet, die entwickelt wurden, um ihre Ausgabe an spezifische kreative Anforderungen anzupassen. Wenn ein Regisseur eine Anpassung fordert und sagt: „Das sieht toll aus, aber können wir es etwas mehr [n] gestalten?“, reicht es nicht aus, einfach zu erklären, dass dem Modell die Präzision für solche Anpassungen fehlt.
Stattdessen setzt ein AI-VFX-Team eine Kombination aus traditionellem CGI und Kompositionstechniken sowie speziell entwickelten Arbeitsabläufen ein, um die Grenzen der Videosynthese weiter zu verschieben. Dieser Ansatz ähnelt der Verwendung eines Standard-Webbrowsers wie Chrome; er ist direkt einsatzbereit, aber um ihn wirklich an Ihre Bedürfnisse anzupassen, müssen Sie einige Plugins installieren.
Kontrollfanatiker
Im Bereich der diffusionsbasierten Bildsynthese ist eines der wichtigsten Drittanbietersysteme ControlNet. Diese Technik führt strukturierte Kontrolle in generative Modelle ein, sodass Benutzer die Bild- oder Videogenerierung mithilfe zusätzlicher Eingaben wie Kantenmappen, Tiefenkarten oder Poseninformationen steuern können.
*Die verschiedenen Methoden von ControlNet ermöglichen Tiefen>Image (obere Reihe), semantische Segmentierung>Image (unten links) und posengesteuerte Bildgenerierung von Menschen und Tieren (unten links).*
ControlNet verlässt sich nicht ausschließlich auf Textprompts; es verwendet separate neuronale Netzwerkzweige oder Adapter, um diese Konditionierungssignale zu verarbeiten, während die generativen Fähigkeiten des Basismodells erhalten bleiben. Dies ermöglicht hochgradig angepasste Ausgaben, die eng an die Benutzerspezifikationen angelehnt sind, was es für Anwendungen unverzichtbar macht, die eine präzise Kontrolle über Komposition, Struktur oder Bewegung erfordern.
*Mit einer steuernden Pose können durch ControlNet eine Vielzahl präziser Ausgabetypen erzielt werden.* Quelle: https://arxiv.org/pdf/2302.05543
Diese adapterbasierten Systeme, die extern auf einer Reihe intern fokussierter neuronaler Prozesse arbeiten, bringen jedoch mehrere Nachteile mit sich. Adapter werden unabhängig trainiert, was zu Konflikten zwischen den Zweigen führen kann, wenn mehrere Adapter kombiniert werden, was oft zu minderwertigen Generierungen führt. Sie führen auch Parameterredundanz ein, die zusätzliche Rechenressourcen und Speicher für jeden Adapter erfordern, was die Skalierung ineffizient macht. Zudem liefern Adapter trotz ihrer Flexibilität oft suboptimale Ergebnisse im Vergleich zu Modellen, die vollständig für die Generierung mit mehreren Bedingungen optimiert wurden. Diese Probleme können adapterbasierte Methoden für Aufgaben weniger effektiv machen, die eine nahtlose Integration mehrerer Steuerungssignale erfordern.
Idealerweise wären die Fähigkeiten von ControlNet modular in das Modell integriert, um zukünftige Innovationen wie gleichzeitige Video-/Audiogenerierung oder native Lippensynchronisationsfähigkeiten zu ermöglichen. Derzeit ist jede zusätzliche Funktion entweder eine Nachbearbeitungsaufgabe oder ein nicht-nativer Prozess, der die empfindlichen Gewichte des Grundmodells navigieren muss.
FullDiT
Hier kommt FullDiT ins Spiel, ein neuer Ansatz aus China, der ControlNet-ähnliche Funktionen direkt während des Trainings in ein generatives Videomodell integriert, anstatt sie nachträglich hinzuzufügen.
*Aus dem neuen Paper: Der FullDiT-Ansatz kann Identitätsauferlegung, Tiefe und Kamerabewegung in eine native Generierung integrieren und jede Kombination davon gleichzeitig abrufen.* Quelle: https://arxiv.org/pdf/2503.19907
FullDiT, wie im Paper mit dem Titel **FullDiT: Multi-Task Video Generative Foundation Model with Full Attention** beschrieben, integriert Multi-Task-Bedingungen wie Identitätsübertragung, Tiefenabbildung und Kamerabewegung in den Kern eines trainierten generativen Videomodells. Die Autoren haben ein Prototypmodell und begleitende Videoclips entwickelt, die auf einer Projektseite verfügbar sind.
**Klicken Sie zum Abspielen. Beispiele für ControlNet-ähnliche Benutzerauferlegung mit ausschließlich einem nativ trainierten Grundmodell.** Quelle: https://fulldit.github.io/
Die Autoren stellen FullDiT als Proof-of-Concept für native Text-zu-Video (T2V) und Bild-zu-Video (I2V) Modelle vor, die Benutzern mehr Kontrolle bieten als nur ein Bild- oder Textprompt. Da keine ähnlichen Modelle existieren, haben die Forscher einen neuen Benchmark namens **FullBench** für die Bewertung von Multi-Task-Videos erstellt und behaupten, in ihren entwickelten Tests eine erstklassige Leistung zu erzielen. Die Objektivität von FullBench, das von den Autoren selbst entworfen wurde, bleibt jedoch ungetestet, und der Datensatz mit 1.400 Fällen könnte für breitere Schlussfolgerungen zu begrenzt sein.
Der faszinierendste Aspekt der FullDiT-Architektur ist ihr Potenzial, neue Arten von Steuerung zu integrieren. Die Autoren stellen fest:
**„In dieser Arbeit untersuchen wir nur Steuerungsbedingungen der Kamera, Identitäten und Tiefeninformationen. Wir haben keine weiteren Bedingungen und Modalitäten wie Audio, Sprache, Punktwolken, Objektbegrenzungsrahmen, optischen Fluss usw. weiter untersucht. Obwohl das Design von FullDiT andere Modalitäten mit minimalen Architekturänderungen nahtlos integrieren kann, bleibt die Frage, wie bestehende Modelle schnell und kosteneffizient an neue Bedingungen und Modalitäten angepasst werden können, eine wichtige Frage, die weitere Untersuchungen erfordert.“**
Während FullDiT einen Schritt nach vorne in der Multi-Task-Videogenerierung darstellt, baut es auf bestehenden Architekturen auf, anstatt ein neues Paradigma einzuführen. Dennoch sticht es als einziges Videogrundmodell mit nativ integrierten ControlNet-ähnlichen Funktionen hervor, und seine Architektur ist darauf ausgelegt, zukünftige Innovationen zu unterstützen.
**Klicken Sie zum Abspielen. Beispiele für benutzergesteuerte Kamerabewegungen von der Projektseite.**
Das Paper, verfasst von neun Forschern der Kuaishou Technology und der Chinese University of Hong Kong, trägt den Titel **FullDiT: Multi-Task Video Generative Foundation Model with Full Attention**. Die Projektseite und die neuen Benchmark-Daten sind auf Hugging Face verfügbar.
Methode
Der vereinheitlichte Aufmerksamkeitsmechanismus von FullDiT ist darauf ausgelegt, das Lernen von cross-modalen Repräsentationen zu verbessern, indem sowohl räumliche als auch zeitliche Beziehungen über die Bedingungen hinweg erfasst werden.
*Laut dem neuen Paper integriert FullDiT mehrere Eingabebedingungen durch vollständige Selbstaufmerksamkeit, indem sie in eine einheitliche Sequenz umgewandelt werden. Im Gegensatz dazu verwenden adapterbasierte Modelle (ganz links oben) separate Module für jede Eingabe, was zu Redundanz, Konflikten und schwächerer Leistung führt.*
Im Gegensatz zu adapterbasierten Setups, die jeden Eingabestrom separat verarbeiten, vermeidet die gemeinsame Aufmerksamkeitsstruktur von FullDiT Konflikte zwischen den Zweigen und reduziert den Parameteraufwand. Die Autoren behaupten, dass die Architektur auf neue Eingabetypen skaliert werden kann, ohne wesentliche Neugestaltung, und dass das Modellschema Anzeichen dafür zeigt, auf Kombinationen von Bedingungen zu verallgemeinern, die während des Trainings nicht gesehen wurden, wie etwa die Verknüpfung von Kamerabewegung mit Charakteridentität.
**Klicken Sie zum Abspielen. Beispiele für Identitätsgenerierung von der Projektseite.**
In der Architektur von FullDiT werden alle Konditionierungseingaben – wie Text, Kamerabewegung, Identität und Tiefe – zunächst in ein einheitliches Token-Format umgewandelt. Diese Token werden dann zu einer einzigen langen Sequenz verkettet, die durch einen Stapel von Transformer-Schichten mit vollständiger Selbstaufmerksamkeit verarbeitet wird. Dieser Ansatz folgt früheren Arbeiten wie Open-Sora Plan und Movie Gen.
Dieses Design ermöglicht es dem Modell, zeitliche und räumliche Beziehungen gemeinsam über alle Bedingungen hinweg zu lernen. Jeder Transformer-Block arbeitet über die gesamte Sequenz, was dynamische Interaktionen zwischen Modalitäten ermöglicht, ohne auf separate Module für jede Eingabe angewiesen zu sein. Die Architektur ist erweiterbar gestaltet, was die Integration zusätzlicher Steuerungssignale in der Zukunft ohne größere strukturelle Änderungen erleichtert.
Die Kraft der Drei
FullDiT wandelt jedes Steuerungssignal in ein standardisiertes Token-Format um, sodass alle Bedingungen gemeinsam in einem einheitlichen Aufmerksamkeitsrahmen verarbeitet werden können. Für Kamerabewegung kodiert das Modell eine Sequenz extrinsischer Parameter – wie Position und Ausrichtung – für jedes Frame. Diese Parameter sind zeitgestempelt und werden in Einbettungsvektoren projiziert, die die zeitliche Natur des Signals widerspiegeln.
Identitätsinformationen werden anders behandelt, da sie von Natur aus räumlich und nicht zeitlich sind. Das Modell verwendet Identitätskarten, die anzeigen, welche Charaktere in welchen Teilen jedes Frames vorhanden sind. Diese Karten werden in Patches unterteilt, wobei jedes Patch in eine Einbettung projiziert wird, die räumliche Identitätshinweise erfasst, sodass das Modell bestimmte Bereiche des Frames mit bestimmten Entitäten verknüpfen kann.
Tiefe ist ein raumzeitliches Signal, und das Modell behandelt es, indem Tiefenvideos in 3D-Patches unterteilt werden, die sowohl Raum als auch Zeit umfassen. Diese Patches werden dann so eingebettet, dass ihre Struktur über die Frames hinweg erhalten bleibt.
Nach der Einbettung werden alle diese Bedingungstoken (Kamera, Identität und Tiefe) zu einer einzigen langen Sequenz verkettet, sodass FullDiT sie gemeinsam mit vollständiger Selbstaufmerksamkeit verarbeiten kann. Diese gemeinsame Repräsentation ermöglicht es dem Modell, Interaktionen über Modalitäten und über die Zeit hinweg zu lernen, ohne auf isolierte Verarbeitungsströme angewiesen zu sein.
Daten und Tests
Der Trainingsansatz von FullDiT stützte sich auf selektiv annotierte Datensätze, die auf jeden Bedingungstyp zugeschnitten waren, anstatt zu verlangen, dass alle Bedingungen gleichzeitig vorhanden sind.
Für textuelle Bedingungen folgt die Initiative dem strukturierten Beschriftungsansatz, der im MiraData-Projekt beschrieben ist.
*Pipeline zur Videosammlung und -annotation aus dem MiraData-Projekt.* Quelle: https://arxiv.org/pdf/2407.06358
Für Kamerabewegung war der RealEstate10K-Datensatz die Hauptquelle, aufgrund seiner hochwertigen Ground-Truth-Annotationen von Kameraparametern. Die Autoren stellten jedoch fest, dass das Training ausschließlich auf statischen Szenen-Kameradatensätzen wie RealEstate10K die Bewegungen dynamischer Objekte und Menschen in generierten Videos reduzierte. Um dem entgegenzuwirken, führten sie zusätzliches Feintuning mit internen Datensätzen durch, die dynamischere Kamerabewegungen enthielten.
Identitätsannotationen wurden mithilfe der Pipeline generiert, die für das ConceptMaster-Projekt entwickelt wurde, was eine effiziente Filterung und Extraktion feinkörniger Identitätsinformationen ermöglichte.
*Das ConceptMaster-Framework ist darauf ausgelegt, Identitätsentkopplungsprobleme zu adressieren, während die Konzepttreue in angepassten Videos erhalten bleibt.* Quelle: https://arxiv.org/pdf/2501.04698
Tiefenannotationen wurden aus dem Panda-70M-Datensatz mit Depth Anything gewonnen.
Optimierung durch Datenreihenfolge
Die Autoren implementierten auch einen progressiven Trainingsplan, indem sie anspruchsvollere Bedingungen früher im Training einführten, um sicherzustellen, dass das Modell robuste Repräsentationen erwarb, bevor einfachere Aufgaben hinzugefügt wurden. Die Trainingsreihenfolge verlief von Text zu Kamerabedingungen, dann Identitäten und schließlich Tiefe, wobei einfachere Aufgaben im Allgemeinen später und mit weniger Beispielen eingeführt wurden.
Die Autoren betonen den Wert dieser Reihenfolge der Arbeitslast:
**„Während der Pre-Training-Phase stellten wir fest, dass anspruchsvollere Aufgaben eine längere Trainingszeit erfordern und früher im Lernprozess eingeführt werden sollten. Diese anspruchsvollen Aufgaben beinhalten komplexe Datenverteilungen, die sich erheblich vom Ausgabevideo unterscheiden, was erfordert, dass das Modell ausreichende Kapazität besitzt, um sie genau zu erfassen und darzustellen.**
**„Umgekehrt kann die zu frühe Einführung einfacherer Aufgaben dazu führen, dass das Modell diese zuerst lernt, da sie sofortigeres Optimierungsfeedback bieten, was die Konvergenz anspruchsvollerer Aufgaben behindern kann.“**
*Eine Illustration der von den Forschern übernommenen Daten-Trainingsreihenfolge, wobei Rot ein größeres Datenvolumen anzeigt.*
Nach dem anfänglichen Pre-Training verfeinerte eine abschließende Feintuning-Phase das Modell weiter, um die visuelle Qualität und Bewegungsdyamik zu verbessern. Danach folgte das Training dem eines standardmäßigen Diffusionsrahmens: Rauschen wurde zu Videolatenzen hinzugefügt, und das Modell lernte, dieses zu prognostizieren und zu entfernen, indem es die eingebetteten Bedingungstoken als Leitlinie nutzte.
Um FullDiT effektiv zu bewerten und einen fairen Vergleich mit bestehenden Methoden zu ermöglichen, führten die Autoren in Ermangelung eines anderen passenden Benchmarks **FullBench** ein, eine kuratierte Benchmark-Suite, die aus 1.400 unterschiedlichen Testfällen besteht.
*Eine Datenexplorer-Instanz für den neuen FullBench-Benchmark.* Quelle: https://huggingface.co/datasets/KwaiVGI/FullBench
Jeder Datenpunkt lieferte Ground-Truth-Annotationen für verschiedene Konditionierungssignale, einschließlich Kamerabewegung, Identität und Tiefe.
Metriken
Die Autoren bewerteten FullDiT anhand von zehn Metriken, die fünf Hauptaspekte der Leistung abdecken: Textausrichtung, Kamerakontrolle, Identitätsähnlichkeit, Tiefengenauigkeit und allgemeine Videoqualität.
Die Textausrichtung wurde mit CLIP-Ähnlichkeit gemessen, während die Kamerakontrolle durch Rotationsfehler (RotErr), Translationsfehler (TransErr) und Kamerabewegungskonsistenz (CamMC) bewertet wurde, nach dem Ansatz von CamI2V (im CameraCtrl-Projekt).
Die Identitätsähnlichkeit wurde mit DINO-I und CLIP-I bewertet, und die Genauigkeit der Tiefenkontrolle wurde mit dem Mean Absolute Error (MAE) quantifiziert.
Die Videoqualität wurde mit drei Metriken aus MiraData beurteilt: CLIP-Ähnlichkeit auf Frame-Ebene für Glätte; optische Fluss-basierte Bewegungsentfernung für Dynamik; und LAION-Ästhetik-Scores für visuelle Anziehungskraft.
Training
Die Autoren trainierten FullDiT mit einem internen (nicht offengelegten) Text-zu-Video-Diffusionsmodell mit etwa einer Milliarde Parametern. Sie wählten absichtlich eine moderate Parametergröße, um Fairness im Vergleich mit früheren Methoden zu gewährleisten und die Reproduzierbarkeit sicherzustellen.
Da die Trainingsvideos in Länge und Auflösung variierten, standardisierten die Autoren jeden Batch, indem sie die Videos auf eine gemeinsame Auflösung skalierten und auffüllten, 77 Frames pro Sequenz sampelten und angewandte Aufmerksamkeits- und Verlustmasken verwendeten, um die Trainingseffektivität zu optimieren.
Der Adam-Optimierer wurde mit einer Lernrate von 1×10−5 auf einem Cluster von 64 NVIDIA H800 GPUs verwendet, für insgesamt 5.120 GB VRAM (bedenken Sie, dass in Enthusiasten-Synthese-Communities 24 GB auf einer RTX 3090 immer noch als luxuriöser Standard gilt).
Das Modell wurde für etwa 32.000 Schritte trainiert, wobei bis zu drei Identitäten pro Video einbezogen wurden, zusammen mit 20 Frames von Kamerabedingungen und 21 Frames von Tiefenbedingungen, beide gleichmäßig aus den insgesamt 77 Frames gesampelt.
Für die Inferenz generierte das Modell Videos mit einer Auflösung von 384×672 Pixeln (etwa fünf Sekunden bei 15 Frames pro Sekunde) mit 50 Diffusions-Inferenzschritten und einer klassifikatorfreien Führungsskala von fünf.
Frühere Methoden
Für die Kamera-zu-Video-Bewertung verglichen die Autoren FullDiT mit MotionCtrl, CameraCtrl und CamI2V, wobei alle Modelle mit dem RealEstate10k-Datensatz trainiert wurden, um Konsistenz und Fairness zu gewährleisten.
In der identitätsbedingten Generierung, da keine vergleichbaren Open-Source-Multi-Identitätsmodelle verfügbar waren, wurde das Modell gegen das 1B-Parameter-ConceptMaster-Modell benchmarked, unter Verwendung derselben Trainingsdaten und Architektur.
Für Tiefen-zu-Video-Aufgaben wurden Vergleiche mit Ctrl-Adapter und ControlVideo angestellt.
*Quantitative Ergebnisse für die Generierung von Einzelaufgabenvideos. FullDiT wurde mit MotionCtrl, CameraCtrl und CamI2V für die Kamera-zu-Video-Generierung verglichen; ConceptMaster (1B-Parameter-Version) für Identität-zu-Video; und Ctrl-Adapter und ControlVideo für Tiefe-zu-Video. Alle Modelle wurden mit ihren Standardeinstellungen bewertet. Für Konsistenz wurden 16 Frames gleichmäßig von jeder Methode gesampelt, passend zur Ausgabelänge früherer Modelle.*
Die Ergebnisse zeigen, dass FullDiT, obwohl es mehrere Konditionierungssignale gleichzeitig verarbeitet, in Metriken bezüglich Text, Kamerabewegung, Identität und Tiefenkontrollen eine erstklassige Leistung erzielte.
In den allgemeinen Qualitätsmetriken übertraf das System im Allgemeinen andere Methoden, obwohl seine Glätte etwas niedriger war als die von ConceptMaster. Hier kommentieren die Autoren:
**„Die Glätte von FullDiT ist etwas niedriger als die von ConceptMaster, da die Berechnung der Glätte auf der CLIP-Ähnlichkeit zwischen benachbarten Frames basiert. Da FullDiT deutlich größere Dynamiken im Vergleich zu ConceptMaster aufweist, wird die Glättemetrik durch die großen Variationen zwischen benachbarten Frames beeinflusst.**
**„Für die Ästhetikbewertung, da das Bewertungsmodell Bilder im Malstil bevorzugt und ControlVideo typischerweise Videos in diesem Stil generiert, erzielt es eine hohe Bewertung in der Ästhetik.“**
In Bezug auf den qualitativen Vergleich wäre es vorzuziehen, die Beispielvideos auf der FullDiT-Projektseite anzusehen, da die PDF-Beispiele zwangsläufig statisch sind (und auch zu umfangreich, um hier vollständig wiedergegeben zu werden).
*Der erste Abschnitt der reproduzierten qualitativen Ergebnisse im PDF. Bitte beziehen Sie sich auf das Quellenpaper für die zusätzlichen Beispiele, die hier zu umfangreich sind, um reproduziert zu werden.*
Die Autoren kommentieren:
**„FullDiT zeigt eine überlegene Identitätserhaltung und generiert Videos mit besserer Dynamik und visueller Qualität im Vergleich zu [ConceptMaster]. Da ConceptMaster und FullDiT auf demselben Rückgrat trainiert wurden, hebt dies die Wirksamkeit der Bedingungsinjektion mit vollständiger Aufmerksamkeit hervor.**
**„…Die [anderen] Ergebnisse demonstrieren die überlegene Steuerbarkeit und Generierungsqualität von FullDiT im Vergleich zu bestehenden Tiefe-zu-Video- und Kamera-zu-Video-Methoden.“**
*Ein Abschnitt der PDF-Beispiele von FullDiT’s Ausgabe mit mehreren Signalen. Bitte beziehen Sie sich auf das Quellenpaper und die Projektseite für zusätzliche Beispiele.*
Fazit
FullDiT stellt einen spannenden Schritt hin zu einem umfassenderen Videogrundmodell dar, aber die Frage bleibt, ob die Nachfrage nach ControlNet-ähnlichen Funktionen ihre Implementierung im großen Maßstab rechtfertigt, insbesondere für Open-Source-Projekte. Diese Projekte hätten Schwierigkeiten, die enorme GPU-Rechenleistung zu beschaffen, die ohne kommerzielle Unterstützung erforderlich ist.
Die Hauptherausforderung besteht darin, dass die Verwendung von Systemen wie Tiefe und Pose im Allgemeinen eine nicht-triviale Vertrautheit mit komplexen Benutzeroberflächen wie ComfyUI erfordert. Daher ist ein funktionales Open-Source-Modell dieser Art am ehesten von kleineren VFX-Unternehmen zu erwarten, denen die Ressourcen oder die Motivation fehlen, ein solches Modell privat zu kuratieren und zu trainieren.
Auf der anderen Seite könnten API-gesteuerte „Rent-an-AI“-Systeme gut motiviert sein, einfachere und benutzerfreundlichere Interpretationsmethoden für Modelle mit direkt trainierten zusätzlichen Steuerungssystemen zu entwickeln.
**Klicken Sie zum Abspielen. Tiefen+Text-Steuerungen, die auf eine Videogenerierung mit FullDiT angewendet werden.**
*Die Autoren geben kein bekanntes Basismodell an (z.B. SDXL, etc.)*
**Erstmals veröffentlicht am Donnerstag, 27. März 2025**










 YouTube testet eine KI-gestützte Suchfunktion mit geführten Antworten
Viele Nutzer greifen auf YouTube zurück, wenn sie nach Rezepten oder Reiseplänen suchen, um relevante Videos zu finden. Nun führt die Plattform ein KI-gestütztes interaktives Suchtool ein, das Schritt
YouTube testet eine KI-gestützte Suchfunktion mit geführten Antworten
Viele Nutzer greifen auf YouTube zurück, wenn sie nach Rezepten oder Reiseplänen suchen, um relevante Videos zu finden. Nun führt die Plattform ein KI-gestütztes interaktives Suchtool ein, das Schritt
 Exklusiv: Luma AI stellt kreative Agenten vor, die auf „Unified Intelligence”-Modellen basieren
Am Donnerstag stellte das Start-up-Unternehmen Luma, das sich mit der Erstellung von KI-Videos befasst, Luma Agents vor, ein System zur Verwaltung kompletter kreativer Workflows, die Text, Bilder, Vid
Exklusiv: Luma AI stellt kreative Agenten vor, die auf „Unified Intelligence”-Modellen basieren
Am Donnerstag stellte das Start-up-Unternehmen Luma, das sich mit der Erstellung von KI-Videos befasst, Luma Agents vor, ein System zur Verwaltung kompletter kreativer Workflows, die Text, Bilder, Vid
 Das neue Update von Sora bietet KI-Videos für Haustiere, soziale Tools und eine kommende Android-App
OpenAI gibt eine Vorschau auf eine Reihe neuer Funktionen für seine bahnbrechende App zur Erstellung von KI-Videos, Sora, die nach ihrem Start Ende September schnell an die Spitze des App Store geklet
Das neue Update von Sora bietet KI-Videos für Haustiere, soziale Tools und eine kommende Android-App
OpenAI gibt eine Vorschau auf eine Reihe neuer Funktionen für seine bahnbrechende App zur Erstellung von KI-Videos, Sora, die nach ihrem Start Ende September schnell an die Spitze des App Store geklet

Entdecken Sie auf XIX.AI die besten KI-Tools für die Personalbeschaffung des Jahres 2026. Unsere sorgfältig zusammengestellte Liste umfasst leistungsstarke, bahnbrechende Lösungen für die Sichtung von Lebensläufen und die automatisierte Terminplanung für Vorstellungsgespräche. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Finden Sie Ihren perfekten Assistenten für die Personalbeschaffung und optimieren Sie noch heute Ihren Rekrutierungsprozess!
10 Tools
xix.ai

Entdecken Sie auf XIX.AI die besten KI-basierten Coaches für persönliches Wohlbefinden und Konzentration des Jahres 2026. Unsere sorgfältig zusammengestellte Rangliste umfasst erstklassige, bahnbrechende Tools zur Bewältigung von Burnout und zur Steigerung der mentalen Energie. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Erfahrungsberichten aus der Praxis. Schlagen Sie noch heute den Weg zu höchster Produktivität und Wohlbefinden ein.
10 Tools
xix.ai

Entdecken Sie die besten KI-Romantik-Chatbots des Jahres 2026, mit denen Sie echte, langfristige Beziehungen aufbauen können. Unsere sorgfältig zusammengestellte Liste bietet Ihnen überzeugende, konsistente Persönlichkeiten, Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten sowie Tests aus der Praxis. Finden Sie Ihren perfekten Begleiter und legen Sie noch heute bei XIX.AI los.
10 Tools
xix.ai

Entdecken Sie die besten AI-Data-Science-Mentoren von 2026, um SQL, Pandas und ML-Arbeitsabläufe zu meistern. Erfahren Sie mehr über unsere hochbewerteten, sorgfältig ausgewählten Angebote bei XIX.AI – für effektive und bahnbrechende Anleitung. Vergleichen Sie kostenlose und bezahlte Optionen mit praktischen Einblicken aus der Praxis. Entfalten Sie Ihr Potenzial in der Data Science noch heute.
10 Tools
xix.ai

Entdecken Sie auf XIX.AI die besten KI-Flirt- und Konversationstrainer des Jahres 2026. Unsere sorgfältig zusammengestellte, erstklassige Auswahl hilft Ihnen dabei, Ihr soziales Charisma und Ihr Selbstvertrauen in Echtzeit zu stärken. Entdecken Sie unverzichtbare, bahnbrechende Tools mit Vergleichen zwischen kostenlosen und kostenpflichtigen Angeboten sowie wöchentlich aktualisierten Rankings. Schaffen Sie sich noch heute einen sozialen Vorsprung.
10 Tools
xix.ai

Entdecken Sie die neuesten, hochbewerteten KI-Tools von 2026 für den automatisierten Unit-Testing-Prozess. Unsere sorgfältig ausgewählten Lösungen bieten leistungsstarke und bahnbrechende Funktionen, um sofort Jest-, PyTest- und JUnit-Testfälle zu generieren. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von tatsächlichen Tests sowie wöchentlich aktualisierten Rankings auf XIX.AI. Entfalten Sie Ihr KI-Potenzial und steigern Sie noch heute die Produktivität Ihrer Entwicklungstätigkeit.
10 Tools
xix.ai

映像の詳細なコントロールって本当に難しいんですね。AIがプロのVFXスタジオで使われる日はまだ先かな?でも技術の進歩にはワクワクする!🔥
Finalmente os vídeos gerados por IA estão evoluindo para algo útil! Mas ainda parece que falta muito pra substituir os efeitos manuais de grandes produções... será que um dia chegaremos lá? 🎥
The idea of AI taking over VFX in films is wild! I mean, total control over video generation? That’s some sci-fi stuff coming to life. But I wonder if these models like Hunyuan can really nail the tiny details directors obsess over. Exciting times! 🎥













