




Генерация видео ИИ движется к полному управлению
Модели видеооснов, такие как Hunyuan и Wan 2.1, достигли значительных успехов, но часто оказываются недостаточно точными, когда речь идет о детальном контроле, необходимом в производстве фильмов и телепрограмм, особенно в области визуальных эффектов (VFX). В профессиональных студиях VFX эти модели, наряду с более ранними моделями на основе изображений, такими как Stable Diffusion, Kandinsky и Flux, используются в сочетании с набором инструментов, предназначенных для доработки их результатов в соответствии с конкретными творческими требованиями. Когда режиссер просит внести изменения, говоря что-то вроде: «Это выглядит здорово, но можно ли сделать это немного более [n]?», недостаточно просто заявить, что модели не хватает точности для таких корректировок.
Вместо этого команда AI VFX применяет комбинацию традиционных методов CGI и композиционных техник, а также специально разработанные рабочие процессы, чтобы расширить границы видеосинтеза. Этот подход схож с использованием стандартного веб-браузера, такого как Chrome; он функционален из коробки, но для настоящей настройки под ваши потребности потребуется установить несколько плагинов.
Контрольные фанаты
В области синтеза изображений на основе диффузии одной из самых важных сторонних систем является ControlNet. Эта техника вводит структурированный контроль в генеративные модели, позволяя пользователям направлять генерацию изображений или видео с использованием дополнительных входных данных, таких как карты краев, карты глубины или информация о позах.
 *Различные методы ControlNet позволяют выполнять преобразование глубины в изображение (верхний ряд), семантическую сегментацию в изображение (нижний левый угол) и генерацию изображений людей и животных с учетом поз (нижний левый угол).*
*Различные методы ControlNet позволяют выполнять преобразование глубины в изображение (верхний ряд), семантическую сегментацию в изображение (нижний левый угол) и генерацию изображений людей и животных с учетом поз (нижний левый угол).*
ControlNet не полагается исключительно на текстовые подсказки; он использует отдельные ветви нейронных сетей, или адаптеры, для обработки этих условных сигналов, сохраняя при этом генеративные способности базовой модели. Это позволяет получать высококастомизированные результаты, которые точно соответствуют спецификациям пользователя, что делает его незаменимым для приложений, требующих точного контроля над композицией, структурой или движением.
 *С направляющей позой через ControlNet можно получить множество точных типов выходных данных.* Источник: https://arxiv.org/pdf/2302.05543
*С направляющей позой через ControlNet можно получить множество точных типов выходных данных.* Источник: https://arxiv.org/pdf/2302.05543
Однако системы на основе адаптеров, которые работают внешне на наборе внутренних нейронных процессов, имеют несколько недостатков. Адаптеры обучаются независимо, что может приводить к конфликтам ветвей при комбинировании нескольких адаптеров, часто приводя к генерациям более низкого качества. Они также вносят избыточность параметров, требуя дополнительных вычислительных ресурсов и памяти для каждого адаптера, что делает масштабирование неэффективным. Более того, несмотря на их гибкость, адаптеры часто дают субоптимальные результаты по сравнению с моделями, полностью настроенными для генерации с несколькими условиями. Эти проблемы могут делать методы на основе адаптеров менее эффективными для задач, требующих бесшовной интеграции нескольких управляющих сигналов.
В идеале возможности ControlNet были бы встроены в модель нативно, модульным образом, что позволило бы в будущем внедрять инновации, такие как одновременная генерация видео/аудио или нативные возможности синхронизации губ. В настоящее время каждая дополнительная функция либо становится задачей постпродакшна, либо ненативной процедурой, которая должна учитывать чувствительные веса базовой модели.
FullDiT
Представляем FullDiT, новый подход из Китая, который интегрирует функции в стиле ControlNet непосредственно в генеративную видеомодель во время обучения, вместо того чтобы рассматривать их как дополнение.
 *Из новой статьи: подход FullDiT может включать наложение идентичности, глубину и движение камеры в нативную генерацию и способен вызывать любую комбинацию этих элементов одновременно.* Источник: https://arxiv.org/pdf/2503.19907
*Из новой статьи: подход FullDiT может включать наложение идентичности, глубину и движение камеры в нативную генерацию и способен вызывать любую комбинацию этих элементов одновременно.* Источник: https://arxiv.org/pdf/2503.19907
FullDiT, как описано в статье под названием **FullDiT: Мультитасковая генеративная видеомодель с полным вниманием**, интегрирует мультитасковые условия, такие как перенос идентичности, отображение глубины и движение камеры, в ядро обученной генеративной видеомодели. Авторы разработали прототип модели и сопровождающие видеоклипы, доступные на сайте проекта.
**Нажмите, чтобы воспроизвести. Примеры наложения пользователя в стиле ControlNet только с нативно обученной базовой моделью.** Источник: https://fulldit.github.io/
Авторы представляют FullDiT как доказательство концепции для нативных моделей текст-в-видео (T2V) и изображение-в-видео (I2V), которые предлагают пользователям больше контроля, чем просто изображение или текстовая подсказка. Поскольку подобных моделей не существует, исследователи создали новый эталон под названием **FullBench** для оценки мультитасковых видео, заявляя о лучшей в своем классе производительности в разработанных ими тестах. Однако объективность FullBench, разработанного самими авторами, остается непроверенной, а его набор данных из 1400 случаев может быть слишком ограниченным для более широких выводов.
Наиболее интригующий аспект архитектуры FullDiT — это ее потенциал для включения новых типов контроля. Авторы отмечают:
**«В этой работе мы исследовали только условия контроля камеры, идентичности и информации о глубине. Мы не изучали дальше другие условия и модальности, такие как аудио, речь, облако точек, ограничивающие рамки объектов, оптический поток и т. д. Хотя дизайн FullDiT позволяет бесшовно интегрировать другие модальности с минимальными изменениями архитектуры, вопрос о том, как быстро и экономично адаптировать существующие модели к новым условиям и модальностям, остается важным и требует дальнейшего изучения.»**
Хотя FullDiT представляет собой шаг вперед в мультитасковой генерации видео, он основывается на существующих архитектурах, а не вводит новую парадигму. Тем не менее, он выделяется как единственная видеобазовая модель с нативно интегрированными функциями в стиле ControlNet, а его архитектура разработана для поддержки будущих инноваций.
**Нажмите, чтобы воспроизвести. Примеры управляемых пользователем движений камеры с сайта проекта.**
Статья, написанная девятью исследователями из Kuaishou Technology и Китайского университета Гонконга, называется **FullDiT: Мультитасковая генеративная видеомодель с полным вниманием**. Страница проекта и данные нового эталона доступны на Hugging Face.
Метод
Единый механизм внимания FullDiT разработан для улучшения кросс-модального обучения представлений путем захвата как пространственных, так и временных отношений между условиями.
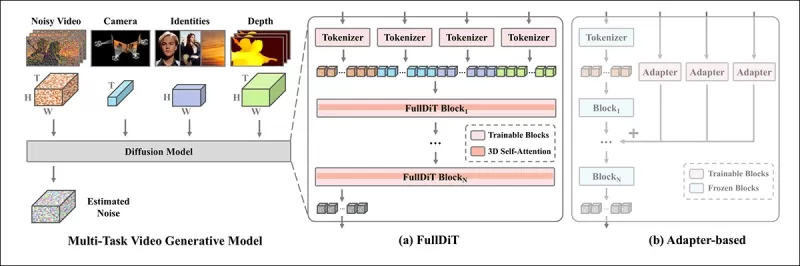 *Согласно новой статье, FullDiT интегрирует множество входных условий через полное самовнимание, преобразуя их в единую последовательность. В отличие от этого, модели на основе адаптеров (крайние слева) используют отдельные модули для каждого входа, что приводит к избыточности, конфликтам и более слабой производительности.*
*Согласно новой статье, FullDiT интегрирует множество входных условий через полное самовнимание, преобразуя их в единую последовательность. В отличие от этого, модели на основе адаптеров (крайние слева) используют отдельные модули для каждого входа, что приводит к избыточности, конфликтам и более слабой производительности.*
В отличие от установок на основе адаптеров, которые обрабатывают каждый входной поток отдельно, структура общего внимания FullDiT избегает конфликтов ветвей и снижает избыточность параметров. Авторы утверждают, что архитектура может масштабироваться на новые типы входных данных без значительных изменений дизайна, а схема модели показывает признаки обобщения на комбинации условий, не виденные во время обучения, такие как связывание движения камеры с идентичностью персонажа.
**Нажмите, чтобы воспроизвести. Примеры генерации идентичности с сайта проекта.**
В архитектуре FullDiT все условные входные данные — такие как текст, движение камеры, идентичность и глубина — сначала преобразуются в единый формат токенов. Эти токены затем объединяются в одну длинную последовательность, обрабатываемую через стек трансформерных слоев с использованием полного самовнимания. Этот подход следует предыдущим работам, таким как Open-Sora Plan и Movie Gen.
Этот дизайн позволяет модели совместно изучать временные и пространственные отношения между всеми условиями. Каждый блок трансформера работает над всей последовательностью, обеспечивая динамическое взаимодействие между модальностями без использования отдельных модулей для каждого входа. Архитектура разработана как расширяемая, что упрощает включение дополнительных управляющих сигналов в будущем без значительных структурных изменений.
Сила трех
FullDiT преобразует каждый управляющий сигнал в стандартизированный формат токенов, чтобы все условия могли обрабатываться вместе в единой системе внимания. Для движения камеры модель кодирует последовательность внешних параметров — таких как положение и ориентация — для каждого кадра. Эти параметры помечены временными метками и проецируются в векторы встраивания, отражающие временную природу сигнала.
Информация об идентичности обрабатывается иначе, поскольку она по своей природе является пространственной, а не временной. Модель использует карты идентичности, которые указывают, какие персонажи присутствуют в каких частях каждого кадра. Эти карты разделяются на патчи, каждый из которых проецируется в встраивание, которое фиксирует пространственные сигналы идентичности, позволяя модели ассоциировать определенные области кадра с конкретными сущностями.
Глубина — это пространственно-временной сигнал, и модель обрабатывает его, разделяя видео глубины на 3D-патчи, охватывающие как пространство, так и время. Эти патчи затем встраиваются таким образом, чтобы сохранять их структуру между кадрами.
После встраивания все эти условные токены (камера, идентичность и глубина) объединяются в одну длинную последовательность, что позволяет FullDiT обрабатывать их вместе с использованием полного самовнимания. Это общее представление позволяет модели изучать взаимодействия между модальностями и во времени без использования изолированных потоков обработки.
Данные и тесты
Подход к обучению FullDiT опирался на выборочно аннотированные наборы данных, адаптированные к каждому типу условий, вместо того чтобы требовать одновременного присутствия всех условий.
Для текстовых условий инициатива следует структурированному подходу к созданию подписей, описанному в проекте MiraData.
 *Конвейер сбора и аннотирования видео из проекта MiraData.* Источник: https://arxiv.org/pdf/2407.06358
*Конвейер сбора и аннотирования видео из проекта MiraData.* Источник: https://arxiv.org/pdf/2407.06358
Для движения камеры основным источником данных был набор данных RealEstate10K, благодаря его высококачественным аннотациям параметров камеры. Однако авторы заметили, что обучение исключительно на наборах данных камеры со статическими сценами, таких как RealEstate10K, имеет тенденцию к снижению движений динамических объектов и людей в сгенерированных видео. Чтобы противодействовать этому, они провели дополнительную тонкую настройку с использованием внутренних наборов данных, которые включали более динамичные движения камеры.
Аннотации идентичности были сгенерированы с использованием конвейера, разработанного для проекта ConceptMaster, который позволил эффективно фильтровать и извлекать детализированную информацию об идентичности.
 *Фреймворк ConceptMaster разработан для решения проблем разделения идентичности при сохранении верности концепции в кастомизированных видео.* Источник: https://arxiv.org/pdf/2501.04698
*Фреймворк ConceptMaster разработан для решения проблем разделения идентичности при сохранении верности концепции в кастомизированных видео.* Источник: https://arxiv.org/pdf/2501.04698
Аннотации глубины были получены из набора данных Panda-70M с использованием Depth Anything.
Оптимизация через упорядочивание данных
Авторы также внедрили прогрессивный график обучения, вводя более сложные условия на ранних этапах обучения, чтобы модель приобрела устойчивые представления до добавления более простых задач. Порядок обучения шел от текста к условиям камеры, затем к идентичностям и, наконец, к глубине, причем более простые задачи обычно вводились позже и с меньшим количеством примеров.
Авторы подчеркивают ценность упорядочивания рабочей нагрузки таким образом:
**«На этапе предварительного обучения мы заметили, что более сложные задачи требуют больше времени на обучение и должны быть введены раньше в процессе обучения. Эти сложные задачи включают сложные распределения данных, которые значительно отличаются от выходного видео, требуя от модели достаточной способности точно захватывать и представлять их.**
**«Напротив, слишком раннее введение более простых задач может привести к тому, что модель будет отдавать приоритет их изучению в первую очередь, поскольку они обеспечивают более немедленную обратную связь по оптимизации, что затрудняет сходимость более сложных задач.»**
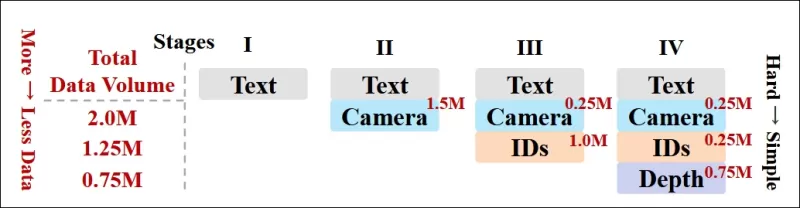 *Иллюстрация порядка обучения данных, принятого исследователями, где красный цвет указывает на больший объем данных.*
*Иллюстрация порядка обучения данных, принятого исследователями, где красный цвет указывает на больший объем данных.*
После начального предварительного обучения финальный этап тонкой настройки дополнительно улучшил модель для повышения визуального качества и динамики движения. После этого обучение следовало стандартной диффузионной схеме: шум добавлялся к видеолатентам, а модель училась предсказывать и удалять его, используя встроенные условные токены в качестве руководства.
Для эффективной оценки FullDiT и обеспечения справедливого сравнения с существующими методами, при отсутствии других подходящих эталонов, авторы представили **FullBench**, курируемый набор эталонов, состоящий из 1400 различных тестовых случаев.
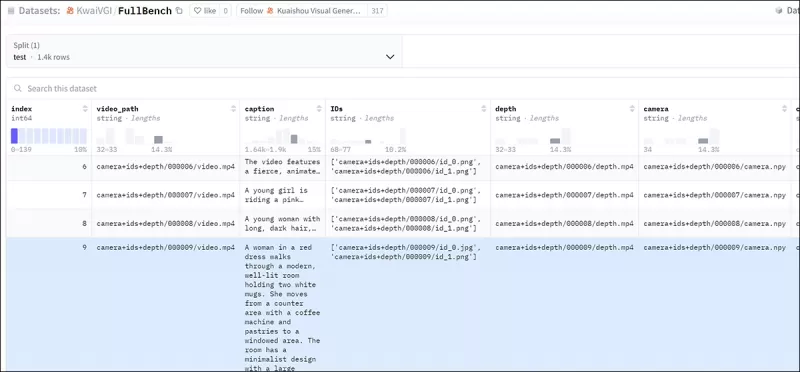 *Экземпляр исследователя данных для нового эталона FullBench.* Источник: https://huggingface.co/datasets/KwaiVGI/FullBench
*Экземпляр исследователя данных для нового эталона FullBench.* Источник: https://huggingface.co/datasets/KwaiVGI/FullBench
Каждая точка данных предоставляла аннотации истинности для различных условных сигналов, включая движение камеры, идентичность и глубину.
Метрики
Авторы оценивали FullDiT с использованием десяти метрик, охватывающих пять основных аспектов производительности: соответствие текста, контроль камеры, сходство идентичности, точность глубины и общее качество видео.
Соответствие текста измерялось с использованием сходства CLIP, в то время как контроль камеры оценивался через ошибку вращения (RotErr), ошибку трансляции (TransErr) и согласованность движения камеры (CamMC), следуя подходу CamI2V (в проекте CameraCtrl).
Сходство идентичности оценивалось с использованием DINO-I и CLIP-I, а точность контроля глубины количественно определялась с использованием средней абсолютной ошибки (MAE).
Качество видео оценивалось с использованием трех метрик из MiraData: сходство CLIP на уровне кадров для плавности; расстояние движения на основе оптического потока для динамики; и оценки LAION-Aesthetic для визуальной привлекательности.
Обучение
Авторы обучали FullDiT с использованием внутренней (неразглашенной) диффузионной модели текст-в-видео, содержащей примерно один миллиард параметров. Они намеренно выбрали скромный размер параметров, чтобы обеспечить справедливость в сравнениях с предыдущими методами и гарантировать воспроизводимость.
Поскольку обучающие видео различались по длине и разрешению, авторы стандартизировали каждую партию, изменяя размер и дополняя видео до общего разрешения, отбирая 77 кадров на последовательность и используя примененные маски внимания и потерь для оптимизации эффективности обучения.
Оптимизатор Adam использовался со скоростью обучения 1×10−5 на кластере из 64 графических процессоров NVIDIA H800, с общим объемом видеопамяти 5120 ГБ (учтите, что в сообществах энтузиастов синтеза 24 ГБ на RTX 3090 все еще считается роскошным стандартом).
Модель обучалась примерно в течение 32 000 шагов, включая до трех идентичностей на видео, а также 20 кадров условий камеры и 21 кадр условий глубины, оба равномерно отобранные из общего числа 77 кадров.
Для вывода модель генерировала видео с разрешением 384×672 пикселей (примерно пять секунд при 15 кадрах в секунду) с 50 шагами диффузионного вывода и шкалой свободного от классификатора руководства, равной пяти.
Предыдущие методы
Для оценки камера-в-видео авторы сравнивали FullDiT с MotionCtrl, CameraCtrl и CamI2V, причем все модели обучались на наборе данных RealEstate10k для обеспечения согласованности и справедливости.
В генерации с условием идентичности, поскольку не было доступных сопоставимых моделей с несколькими идентичностями с открытым исходным кодом, модель сравнивалась с моделью ConceptMaster с 1 миллиардом параметров, используя те же обучающие данные и архитектуру.
Для задач глубина-в-видео сравнения проводились с Ctrl-Adapter и ControlVideo.
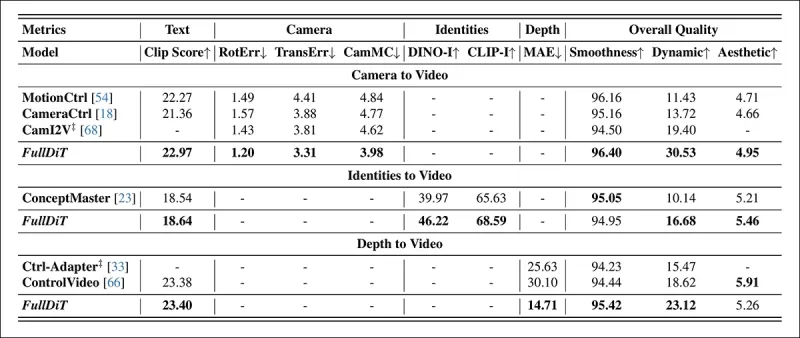 *Количественные результаты для генерации видео с одной задачей. FullDiT сравнивался с MotionCtrl, CameraCtrl и CamI2V для генерации камера-в-видео; ConceptMaster (версия с 1 миллиардом параметров) для генерации идентичность-в-видео; и Ctrl-Adapter и ControlVideo для генерации глубина-в-видео. Все модели оценивались с использованием их настроек по умолчанию. Для согласованности из каждого метода равномерно отбиралось 16 кадров, что соответствует длине вывода предыдущих моделей.*
*Количественные результаты для генерации видео с одной задачей. FullDiT сравнивался с MotionCtrl, CameraCtrl и CamI2V для генерации камера-в-видео; ConceptMaster (версия с 1 миллиардом параметров) для генерации идентичность-в-видео; и Ctrl-Adapter и ControlVideo для генерации глубина-в-видео. Все модели оценивались с использованием их настроек по умолчанию. Для согласованности из каждого метода равномерно отбиралось 16 кадров, что соответствует длине вывода предыдущих моделей.*
Результаты показывают, что FullDiT, несмотря на одновременную обработку нескольких условных сигналов, достиг лучшей в своем классе производительности по метрикам, связанным с текстом, движением камеры, идентичностью и контролем глубины.
По общим метрикам качества система в целом превосходила другие методы, хотя ее плавность была немного ниже, чем у ConceptMaster. Здесь авторы комментируют:
**«Плавность FullDiT немного ниже, чем у ConceptMaster, поскольку расчет плавности основан на сходстве CLIP между соседними кадрами. Поскольку FullDiT демонстрирует значительно большую динамику по сравнению с ConceptMaster, метрика плавности страдает из-за больших вариаций между соседними кадрами.**
**«Что касается эстетической оценки, поскольку модель рейтинга предпочитает изображения в стиле живописи, а ControlVideo обычно генерирует видео в этом стиле, она достигает высокого балла по эстетике.»**
Что касается качественного сравнения, предпочтительнее обратиться к образцам видео на сайте проекта FullDiT, поскольку примеры в PDF неизбежно статичны (и также слишком велики, чтобы полностью воспроизвести здесь).
 *Первая секция воспроизведенных качественных результатов в PDF. Пожалуйста, обратитесь к исходной статье для дополнительных примеров, которые слишком обширны для воспроизведения здесь.*
*Первая секция воспроизведенных качественных результатов в PDF. Пожалуйста, обратитесь к исходной статье для дополнительных примеров, которые слишком обширны для воспроизведения здесь.*
Авторы комментируют:
**«FullDiT демонстрирует превосходное сохранение идентичности и генерирует видео с лучшей динамикой и визуальным качеством по сравнению с [ConceptMaster]. Поскольку ConceptMaster и FullDiT обучены на одной и той же основе, это подчеркивает эффективность инъекции условий с полным вниманием.**
**«…[Другие] результаты демонстрируют превосходную управляемость и качество генерации FullDiT по сравнению с существующими методами глубина-в-видео и камера-в-видео.»**
 *Секция примеров вывода FullDiT с несколькими сигналами в PDF. Пожалуйста, обратитесь к исходной статье и сайту проекта для дополнительных примеров.*
*Секция примеров вывода FullDiT с несколькими сигналами в PDF. Пожалуйста, обратитесь к исходной статье и сайту проекта для дополнительных примеров.*
Заключение
FullDiT представляет собой захватывающий шаг к более всесторонней видеобазовой модели, но остается вопрос, оправдывает ли спрос на функции в стиле ControlNet их реализацию в масштабе, особенно для проектов с открытым исходным кодом. Эти проекты столкнутся с трудностями в получении огромной вычислительной мощности GPU, необходимой без коммерческой поддержки.
Основная проблема заключается в том, что использование систем, таких как Depth и Pose, обычно требует нетривиального знакомства с сложными пользовательскими интерфейсами, такими как ComfyUI. Поэтому функциональная модель с открытым исходным кодом такого рода, скорее всего, будет разработана небольшими компаниями VFX, которым не хватает ресурсов или мотивации для создания и обучения такой модели в частном порядке.
С другой стороны, системы «аренды AI», управляемые через API, могут быть хорошо мотивированы для разработки более простых и удобных для пользователя методов интерпретации для моделей с прямо обученными дополнительными системами управления.
**Нажмите, чтобы воспроизвести. Управление глубиной и текстом, наложенное на генерацию видео с использованием FullDiT.**
*Авторы не указывают известную базовую модель (например, SDXL и т. д.)*
**Впервые опубликовано в четверг, 27 марта 2025 года**
Связанная статья
 Tencent представляет HunyuanCustom для видеонастройки на основе одного изображения
Эта статья посвящена запуску HunyuanCustom, мультимодальной модели генерации видео от Tencent. Обширный объем сопроводительной исследовательской статьи и проблемы с предоставленными примерами видео на
Открытие тонких, но эффективных модификаций ИИ в аутентичном видеоконтенте
В 2019 году в обманчивом видео о Нэнси Пелоси, тогдашней спикере Палаты представителей США, широко распространено. Видео, которое было отредактировано, чтобы она появилась в состоянии алкогольного опьянения, было резким напоминанием о том, как легко манипулируемые средства массовой информации могут ввести в заблуждение общественности. Несмотря на свою простоту, этот инцидент подчеркнул t
OpenAI планирует доставить видео генератор соры в CHATGPT
OpenAI планирует интегрировать свой инструмент генерации видео, Sora, в свой популярный потребительский чат -бот, Chatgpt. Это было раскрыто руководителями компаний во время недавней сессии рабочего дня по Discord. В настоящее время SORA доступна только через выделенное веб -приложение, запущенное OpenAI в декабре, позволяющее пользователю
Комментарии (2)
Tencent представляет HunyuanCustom для видеонастройки на основе одного изображения
Эта статья посвящена запуску HunyuanCustom, мультимодальной модели генерации видео от Tencent. Обширный объем сопроводительной исследовательской статьи и проблемы с предоставленными примерами видео на
Открытие тонких, но эффективных модификаций ИИ в аутентичном видеоконтенте
В 2019 году в обманчивом видео о Нэнси Пелоси, тогдашней спикере Палаты представителей США, широко распространено. Видео, которое было отредактировано, чтобы она появилась в состоянии алкогольного опьянения, было резким напоминанием о том, как легко манипулируемые средства массовой информации могут ввести в заблуждение общественности. Несмотря на свою простоту, этот инцидент подчеркнул t
OpenAI планирует доставить видео генератор соры в CHATGPT
OpenAI планирует интегрировать свой инструмент генерации видео, Sora, в свой популярный потребительский чат -бот, Chatgpt. Это было раскрыто руководителями компаний во время недавней сессии рабочего дня по Discord. В настоящее время SORA доступна только через выделенное веб -приложение, запущенное OpenAI в декабре, позволяющее пользователю
Комментарии (2)
![CharlesMartinez]() CharlesMartinez
CharlesMartinez
 3 сентября 2025 г., 19:30:37 GMT+03:00
3 сентября 2025 г., 19:30:37 GMT+03:00
Finalmente os vídeos gerados por IA estão evoluindo para algo útil! Mas ainda parece que falta muito pra substituir os efeitos manuais de grandes produções... será que um dia chegaremos lá? 🎥


 0
0
![DonaldLee]() DonaldLee
28 июля 2025 г., 4:20:02 GMT+03:00
DonaldLee
28 июля 2025 г., 4:20:02 GMT+03:00
The idea of AI taking over VFX in films is wild! I mean, total control over video generation? That’s some sci-fi stuff coming to life. But I wonder if these models like Hunyuan can really nail the tiny details directors obsess over. Exciting times! 🎥
0
Модели видеооснов, такие как Hunyuan и Wan 2.1, достигли значительных успехов, но часто оказываются недостаточно точными, когда речь идет о детальном контроле, необходимом в производстве фильмов и телепрограмм, особенно в области визуальных эффектов (VFX). В профессиональных студиях VFX эти модели, наряду с более ранними моделями на основе изображений, такими как Stable Diffusion, Kandinsky и Flux, используются в сочетании с набором инструментов, предназначенных для доработки их результатов в соответствии с конкретными творческими требованиями. Когда режиссер просит внести изменения, говоря что-то вроде: «Это выглядит здорово, но можно ли сделать это немного более [n]?», недостаточно просто заявить, что модели не хватает точности для таких корректировок.
Вместо этого команда AI VFX применяет комбинацию традиционных методов CGI и композиционных техник, а также специально разработанные рабочие процессы, чтобы расширить границы видеосинтеза. Этот подход схож с использованием стандартного веб-браузера, такого как Chrome; он функционален из коробки, но для настоящей настройки под ваши потребности потребуется установить несколько плагинов.
Контрольные фанаты
В области синтеза изображений на основе диффузии одной из самых важных сторонних систем является ControlNet. Эта техника вводит структурированный контроль в генеративные модели, позволяя пользователям направлять генерацию изображений или видео с использованием дополнительных входных данных, таких как карты краев, карты глубины или информация о позах.
*Различные методы ControlNet позволяют выполнять преобразование глубины в изображение (верхний ряд), семантическую сегментацию в изображение (нижний левый угол) и генерацию изображений людей и животных с учетом поз (нижний левый угол).*
ControlNet не полагается исключительно на текстовые подсказки; он использует отдельные ветви нейронных сетей, или адаптеры, для обработки этих условных сигналов, сохраняя при этом генеративные способности базовой модели. Это позволяет получать высококастомизированные результаты, которые точно соответствуют спецификациям пользователя, что делает его незаменимым для приложений, требующих точного контроля над композицией, структурой или движением.
*С направляющей позой через ControlNet можно получить множество точных типов выходных данных.* Источник: https://arxiv.org/pdf/2302.05543
Однако системы на основе адаптеров, которые работают внешне на наборе внутренних нейронных процессов, имеют несколько недостатков. Адаптеры обучаются независимо, что может приводить к конфликтам ветвей при комбинировании нескольких адаптеров, часто приводя к генерациям более низкого качества. Они также вносят избыточность параметров, требуя дополнительных вычислительных ресурсов и памяти для каждого адаптера, что делает масштабирование неэффективным. Более того, несмотря на их гибкость, адаптеры часто дают субоптимальные результаты по сравнению с моделями, полностью настроенными для генерации с несколькими условиями. Эти проблемы могут делать методы на основе адаптеров менее эффективными для задач, требующих бесшовной интеграции нескольких управляющих сигналов.
В идеале возможности ControlNet были бы встроены в модель нативно, модульным образом, что позволило бы в будущем внедрять инновации, такие как одновременная генерация видео/аудио или нативные возможности синхронизации губ. В настоящее время каждая дополнительная функция либо становится задачей постпродакшна, либо ненативной процедурой, которая должна учитывать чувствительные веса базовой модели.
FullDiT
Представляем FullDiT, новый подход из Китая, который интегрирует функции в стиле ControlNet непосредственно в генеративную видеомодель во время обучения, вместо того чтобы рассматривать их как дополнение.
*Из новой статьи: подход FullDiT может включать наложение идентичности, глубину и движение камеры в нативную генерацию и способен вызывать любую комбинацию этих элементов одновременно.* Источник: https://arxiv.org/pdf/2503.19907
FullDiT, как описано в статье под названием **FullDiT: Мультитасковая генеративная видеомодель с полным вниманием**, интегрирует мультитасковые условия, такие как перенос идентичности, отображение глубины и движение камеры, в ядро обученной генеративной видеомодели. Авторы разработали прототип модели и сопровождающие видеоклипы, доступные на сайте проекта.
**Нажмите, чтобы воспроизвести. Примеры наложения пользователя в стиле ControlNet только с нативно обученной базовой моделью.** Источник: https://fulldit.github.io/
Авторы представляют FullDiT как доказательство концепции для нативных моделей текст-в-видео (T2V) и изображение-в-видео (I2V), которые предлагают пользователям больше контроля, чем просто изображение или текстовая подсказка. Поскольку подобных моделей не существует, исследователи создали новый эталон под названием **FullBench** для оценки мультитасковых видео, заявляя о лучшей в своем классе производительности в разработанных ими тестах. Однако объективность FullBench, разработанного самими авторами, остается непроверенной, а его набор данных из 1400 случаев может быть слишком ограниченным для более широких выводов.
Наиболее интригующий аспект архитектуры FullDiT — это ее потенциал для включения новых типов контроля. Авторы отмечают:
**«В этой работе мы исследовали только условия контроля камеры, идентичности и информации о глубине. Мы не изучали дальше другие условия и модальности, такие как аудио, речь, облако точек, ограничивающие рамки объектов, оптический поток и т. д. Хотя дизайн FullDiT позволяет бесшовно интегрировать другие модальности с минимальными изменениями архитектуры, вопрос о том, как быстро и экономично адаптировать существующие модели к новым условиям и модальностям, остается важным и требует дальнейшего изучения.»**
Хотя FullDiT представляет собой шаг вперед в мультитасковой генерации видео, он основывается на существующих архитектурах, а не вводит новую парадигму. Тем не менее, он выделяется как единственная видеобазовая модель с нативно интегрированными функциями в стиле ControlNet, а его архитектура разработана для поддержки будущих инноваций.
**Нажмите, чтобы воспроизвести. Примеры управляемых пользователем движений камеры с сайта проекта.**
Статья, написанная девятью исследователями из Kuaishou Technology и Китайского университета Гонконга, называется **FullDiT: Мультитасковая генеративная видеомодель с полным вниманием**. Страница проекта и данные нового эталона доступны на Hugging Face.
Метод
Единый механизм внимания FullDiT разработан для улучшения кросс-модального обучения представлений путем захвата как пространственных, так и временных отношений между условиями.
*Согласно новой статье, FullDiT интегрирует множество входных условий через полное самовнимание, преобразуя их в единую последовательность. В отличие от этого, модели на основе адаптеров (крайние слева) используют отдельные модули для каждого входа, что приводит к избыточности, конфликтам и более слабой производительности.*
В отличие от установок на основе адаптеров, которые обрабатывают каждый входной поток отдельно, структура общего внимания FullDiT избегает конфликтов ветвей и снижает избыточность параметров. Авторы утверждают, что архитектура может масштабироваться на новые типы входных данных без значительных изменений дизайна, а схема модели показывает признаки обобщения на комбинации условий, не виденные во время обучения, такие как связывание движения камеры с идентичностью персонажа.
**Нажмите, чтобы воспроизвести. Примеры генерации идентичности с сайта проекта.**
В архитектуре FullDiT все условные входные данные — такие как текст, движение камеры, идентичность и глубина — сначала преобразуются в единый формат токенов. Эти токены затем объединяются в одну длинную последовательность, обрабатываемую через стек трансформерных слоев с использованием полного самовнимания. Этот подход следует предыдущим работам, таким как Open-Sora Plan и Movie Gen.
Этот дизайн позволяет модели совместно изучать временные и пространственные отношения между всеми условиями. Каждый блок трансформера работает над всей последовательностью, обеспечивая динамическое взаимодействие между модальностями без использования отдельных модулей для каждого входа. Архитектура разработана как расширяемая, что упрощает включение дополнительных управляющих сигналов в будущем без значительных структурных изменений.
Сила трех
FullDiT преобразует каждый управляющий сигнал в стандартизированный формат токенов, чтобы все условия могли обрабатываться вместе в единой системе внимания. Для движения камеры модель кодирует последовательность внешних параметров — таких как положение и ориентация — для каждого кадра. Эти параметры помечены временными метками и проецируются в векторы встраивания, отражающие временную природу сигнала.
Информация об идентичности обрабатывается иначе, поскольку она по своей природе является пространственной, а не временной. Модель использует карты идентичности, которые указывают, какие персонажи присутствуют в каких частях каждого кадра. Эти карты разделяются на патчи, каждый из которых проецируется в встраивание, которое фиксирует пространственные сигналы идентичности, позволяя модели ассоциировать определенные области кадра с конкретными сущностями.
Глубина — это пространственно-временной сигнал, и модель обрабатывает его, разделяя видео глубины на 3D-патчи, охватывающие как пространство, так и время. Эти патчи затем встраиваются таким образом, чтобы сохранять их структуру между кадрами.
После встраивания все эти условные токены (камера, идентичность и глубина) объединяются в одну длинную последовательность, что позволяет FullDiT обрабатывать их вместе с использованием полного самовнимания. Это общее представление позволяет модели изучать взаимодействия между модальностями и во времени без использования изолированных потоков обработки.
Данные и тесты
Подход к обучению FullDiT опирался на выборочно аннотированные наборы данных, адаптированные к каждому типу условий, вместо того чтобы требовать одновременного присутствия всех условий.
Для текстовых условий инициатива следует структурированному подходу к созданию подписей, описанному в проекте MiraData.
*Конвейер сбора и аннотирования видео из проекта MiraData.* Источник: https://arxiv.org/pdf/2407.06358
Для движения камеры основным источником данных был набор данных RealEstate10K, благодаря его высококачественным аннотациям параметров камеры. Однако авторы заметили, что обучение исключительно на наборах данных камеры со статическими сценами, таких как RealEstate10K, имеет тенденцию к снижению движений динамических объектов и людей в сгенерированных видео. Чтобы противодействовать этому, они провели дополнительную тонкую настройку с использованием внутренних наборов данных, которые включали более динамичные движения камеры.
Аннотации идентичности были сгенерированы с использованием конвейера, разработанного для проекта ConceptMaster, который позволил эффективно фильтровать и извлекать детализированную информацию об идентичности.
*Фреймворк ConceptMaster разработан для решения проблем разделения идентичности при сохранении верности концепции в кастомизированных видео.* Источник: https://arxiv.org/pdf/2501.04698
Аннотации глубины были получены из набора данных Panda-70M с использованием Depth Anything.
Оптимизация через упорядочивание данных
Авторы также внедрили прогрессивный график обучения, вводя более сложные условия на ранних этапах обучения, чтобы модель приобрела устойчивые представления до добавления более простых задач. Порядок обучения шел от текста к условиям камеры, затем к идентичностям и, наконец, к глубине, причем более простые задачи обычно вводились позже и с меньшим количеством примеров.
Авторы подчеркивают ценность упорядочивания рабочей нагрузки таким образом:
**«На этапе предварительного обучения мы заметили, что более сложные задачи требуют больше времени на обучение и должны быть введены раньше в процессе обучения. Эти сложные задачи включают сложные распределения данных, которые значительно отличаются от выходного видео, требуя от модели достаточной способности точно захватывать и представлять их.**
**«Напротив, слишком раннее введение более простых задач может привести к тому, что модель будет отдавать приоритет их изучению в первую очередь, поскольку они обеспечивают более немедленную обратную связь по оптимизации, что затрудняет сходимость более сложных задач.»**
*Иллюстрация порядка обучения данных, принятого исследователями, где красный цвет указывает на больший объем данных.*
После начального предварительного обучения финальный этап тонкой настройки дополнительно улучшил модель для повышения визуального качества и динамики движения. После этого обучение следовало стандартной диффузионной схеме: шум добавлялся к видеолатентам, а модель училась предсказывать и удалять его, используя встроенные условные токены в качестве руководства.
Для эффективной оценки FullDiT и обеспечения справедливого сравнения с существующими методами, при отсутствии других подходящих эталонов, авторы представили **FullBench**, курируемый набор эталонов, состоящий из 1400 различных тестовых случаев.
*Экземпляр исследователя данных для нового эталона FullBench.* Источник: https://huggingface.co/datasets/KwaiVGI/FullBench
Каждая точка данных предоставляла аннотации истинности для различных условных сигналов, включая движение камеры, идентичность и глубину.
Метрики
Авторы оценивали FullDiT с использованием десяти метрик, охватывающих пять основных аспектов производительности: соответствие текста, контроль камеры, сходство идентичности, точность глубины и общее качество видео.
Соответствие текста измерялось с использованием сходства CLIP, в то время как контроль камеры оценивался через ошибку вращения (RotErr), ошибку трансляции (TransErr) и согласованность движения камеры (CamMC), следуя подходу CamI2V (в проекте CameraCtrl).
Сходство идентичности оценивалось с использованием DINO-I и CLIP-I, а точность контроля глубины количественно определялась с использованием средней абсолютной ошибки (MAE).
Качество видео оценивалось с использованием трех метрик из MiraData: сходство CLIP на уровне кадров для плавности; расстояние движения на основе оптического потока для динамики; и оценки LAION-Aesthetic для визуальной привлекательности.
Обучение
Авторы обучали FullDiT с использованием внутренней (неразглашенной) диффузионной модели текст-в-видео, содержащей примерно один миллиард параметров. Они намеренно выбрали скромный размер параметров, чтобы обеспечить справедливость в сравнениях с предыдущими методами и гарантировать воспроизводимость.
Поскольку обучающие видео различались по длине и разрешению, авторы стандартизировали каждую партию, изменяя размер и дополняя видео до общего разрешения, отбирая 77 кадров на последовательность и используя примененные маски внимания и потерь для оптимизации эффективности обучения.
Оптимизатор Adam использовался со скоростью обучения 1×10−5 на кластере из 64 графических процессоров NVIDIA H800, с общим объемом видеопамяти 5120 ГБ (учтите, что в сообществах энтузиастов синтеза 24 ГБ на RTX 3090 все еще считается роскошным стандартом).
Модель обучалась примерно в течение 32 000 шагов, включая до трех идентичностей на видео, а также 20 кадров условий камеры и 21 кадр условий глубины, оба равномерно отобранные из общего числа 77 кадров.
Для вывода модель генерировала видео с разрешением 384×672 пикселей (примерно пять секунд при 15 кадрах в секунду) с 50 шагами диффузионного вывода и шкалой свободного от классификатора руководства, равной пяти.
Предыдущие методы
Для оценки камера-в-видео авторы сравнивали FullDiT с MotionCtrl, CameraCtrl и CamI2V, причем все модели обучались на наборе данных RealEstate10k для обеспечения согласованности и справедливости.
В генерации с условием идентичности, поскольку не было доступных сопоставимых моделей с несколькими идентичностями с открытым исходным кодом, модель сравнивалась с моделью ConceptMaster с 1 миллиардом параметров, используя те же обучающие данные и архитектуру.
Для задач глубина-в-видео сравнения проводились с Ctrl-Adapter и ControlVideo.
*Количественные результаты для генерации видео с одной задачей. FullDiT сравнивался с MotionCtrl, CameraCtrl и CamI2V для генерации камера-в-видео; ConceptMaster (версия с 1 миллиардом параметров) для генерации идентичность-в-видео; и Ctrl-Adapter и ControlVideo для генерации глубина-в-видео. Все модели оценивались с использованием их настроек по умолчанию. Для согласованности из каждого метода равномерно отбиралось 16 кадров, что соответствует длине вывода предыдущих моделей.*
Результаты показывают, что FullDiT, несмотря на одновременную обработку нескольких условных сигналов, достиг лучшей в своем классе производительности по метрикам, связанным с текстом, движением камеры, идентичностью и контролем глубины.
По общим метрикам качества система в целом превосходила другие методы, хотя ее плавность была немного ниже, чем у ConceptMaster. Здесь авторы комментируют:
**«Плавность FullDiT немного ниже, чем у ConceptMaster, поскольку расчет плавности основан на сходстве CLIP между соседними кадрами. Поскольку FullDiT демонстрирует значительно большую динамику по сравнению с ConceptMaster, метрика плавности страдает из-за больших вариаций между соседними кадрами.**
**«Что касается эстетической оценки, поскольку модель рейтинга предпочитает изображения в стиле живописи, а ControlVideo обычно генерирует видео в этом стиле, она достигает высокого балла по эстетике.»**
Что касается качественного сравнения, предпочтительнее обратиться к образцам видео на сайте проекта FullDiT, поскольку примеры в PDF неизбежно статичны (и также слишком велики, чтобы полностью воспроизвести здесь).
*Первая секция воспроизведенных качественных результатов в PDF. Пожалуйста, обратитесь к исходной статье для дополнительных примеров, которые слишком обширны для воспроизведения здесь.*
Авторы комментируют:
**«FullDiT демонстрирует превосходное сохранение идентичности и генерирует видео с лучшей динамикой и визуальным качеством по сравнению с [ConceptMaster]. Поскольку ConceptMaster и FullDiT обучены на одной и той же основе, это подчеркивает эффективность инъекции условий с полным вниманием.**
**«…[Другие] результаты демонстрируют превосходную управляемость и качество генерации FullDiT по сравнению с существующими методами глубина-в-видео и камера-в-видео.»**
*Секция примеров вывода FullDiT с несколькими сигналами в PDF. Пожалуйста, обратитесь к исходной статье и сайту проекта для дополнительных примеров.*
Заключение
FullDiT представляет собой захватывающий шаг к более всесторонней видеобазовой модели, но остается вопрос, оправдывает ли спрос на функции в стиле ControlNet их реализацию в масштабе, особенно для проектов с открытым исходным кодом. Эти проекты столкнутся с трудностями в получении огромной вычислительной мощности GPU, необходимой без коммерческой поддержки.
Основная проблема заключается в том, что использование систем, таких как Depth и Pose, обычно требует нетривиального знакомства с сложными пользовательскими интерфейсами, такими как ComfyUI. Поэтому функциональная модель с открытым исходным кодом такого рода, скорее всего, будет разработана небольшими компаниями VFX, которым не хватает ресурсов или мотивации для создания и обучения такой модели в частном порядке.
С другой стороны, системы «аренды AI», управляемые через API, могут быть хорошо мотивированы для разработки более простых и удобных для пользователя методов интерпретации для моделей с прямо обученными дополнительными системами управления.
**Нажмите, чтобы воспроизвести. Управление глубиной и текстом, наложенное на генерацию видео с использованием FullDiT.**
*Авторы не указывают известную базовую модель (например, SDXL и т. д.)*
**Впервые опубликовано в четверг, 27 марта 2025 года**










 Tencent представляет HunyuanCustom для видеонастройки на основе одного изображения
Эта статья посвящена запуску HunyuanCustom, мультимодальной модели генерации видео от Tencent. Обширный объем сопроводительной исследовательской статьи и проблемы с предоставленными примерами видео на
Tencent представляет HunyuanCustom для видеонастройки на основе одного изображения
Эта статья посвящена запуску HunyuanCustom, мультимодальной модели генерации видео от Tencent. Обширный объем сопроводительной исследовательской статьи и проблемы с предоставленными примерами видео на
 Открытие тонких, но эффективных модификаций ИИ в аутентичном видеоконтенте
В 2019 году в обманчивом видео о Нэнси Пелоси, тогдашней спикере Палаты представителей США, широко распространено. Видео, которое было отредактировано, чтобы она появилась в состоянии алкогольного опьянения, было резким напоминанием о том, как легко манипулируемые средства массовой информации могут ввести в заблуждение общественности. Несмотря на свою простоту, этот инцидент подчеркнул t
Открытие тонких, но эффективных модификаций ИИ в аутентичном видеоконтенте
В 2019 году в обманчивом видео о Нэнси Пелоси, тогдашней спикере Палаты представителей США, широко распространено. Видео, которое было отредактировано, чтобы она появилась в состоянии алкогольного опьянения, было резким напоминанием о том, как легко манипулируемые средства массовой информации могут ввести в заблуждение общественности. Несмотря на свою простоту, этот инцидент подчеркнул t
 OpenAI планирует доставить видео генератор соры в CHATGPT
OpenAI планирует интегрировать свой инструмент генерации видео, Sora, в свой популярный потребительский чат -бот, Chatgpt. Это было раскрыто руководителями компаний во время недавней сессии рабочего дня по Discord. В настоящее время SORA доступна только через выделенное веб -приложение, запущенное OpenAI в декабре, позволяющее пользователю
3 сентября 2025 г., 19:30:37 GMT+03:00
OpenAI планирует доставить видео генератор соры в CHATGPT
OpenAI планирует интегрировать свой инструмент генерации видео, Sora, в свой популярный потребительский чат -бот, Chatgpt. Это было раскрыто руководителями компаний во время недавней сессии рабочего дня по Discord. В настоящее время SORA доступна только через выделенное веб -приложение, запущенное OpenAI в декабре, позволяющее пользователю
3 сентября 2025 г., 19:30:37 GMT+03:00
Finalmente os vídeos gerados por IA estão evoluindo para algo útil! Mas ainda parece que falta muito pra substituir os efeitos manuais de grandes produções... será que um dia chegaremos lá? 🎥
0
28 июля 2025 г., 4:20:02 GMT+03:00
The idea of AI taking over VFX in films is wild! I mean, total control over video generation? That’s some sci-fi stuff coming to life. But I wonder if these models like Hunyuan can really nail the tiny details directors obsess over. Exciting times! 🎥
0













