
















 首頁
首頁人工智能視頻生成朝著完全控制
像Hunyuan和Wan 2.1這樣的視頻基礎模型已取得顯著進展,但在電影和電視製作中所需的精細控制方面,特別是在視覺效果(VFX)領域,常常表現不足。在專業VFX工作室中,這些模型與早期的基於圖像的模型,如Stable Diffusion、Kandinsky和Flux,結合一系列專為滿足特定創意需求而設計的工具一起使用。當導演要求進行微調,例如說「這看起來很棒,但可以再稍微[n]一點嗎?」,僅僅聲稱模型缺乏精確調整的能力是不夠的。
相反,AI VFX團隊會結合傳統CGI和合成技術,以及自定義開發的工作流程,進一步推動視頻合成的邊界。這種方法類似於使用像Chrome這樣的預設網頁瀏覽器;它開箱即用,但要真正滿足你的需求,你需要安裝一些插件。
控制狂熱者
在基於擴散的圖像合成領域中,最關鍵的第三方系統之一是ControlNet。這項技術為生成模型引入結構化控制,允許用戶通過額外的輸入(如邊緣圖、深度圖或姿態信息)來引導圖像或視頻生成。
 *ControlNet的多種方法允許深度>圖像(頂行)、語義分割>圖像(左下)以及人類和動物的姿態引導圖像生成(左下)。*
*ControlNet的多種方法允許深度>圖像(頂行)、語義分割>圖像(左下)以及人類和動物的姿態引導圖像生成(左下)。*
ControlNet不僅依賴文本提示;它使用獨立的神經網絡分支或適配器來處理這些條件信號,同時保持基礎模型的生成能力。這使得高度定制的輸出能夠與用戶規格緊密對齊,對於需要精確控制構圖、結構或運動的應用來說極其寶貴。
 *通過引導姿態,ControlNet可以獲得多種精確的輸出類型。* 來源:https://arxiv.org/pdf/2302.05543
*通過引導姿態,ControlNet可以獲得多種精確的輸出類型。* 來源:https://arxiv.org/pdf/2302.05543
然而,這些基於適配器的系統,通過外部操作一組內部聚焦的神經過程,存在幾個缺點。適配器是獨立訓練的,當多個適配器組合時可能導致分支衝突,通常會導致生成質量下降。它們還引入了參數冗餘,每個適配器都需要額外的計算資源和內存,使得擴展效率低下。此外,儘管適配器靈活,但與專為多條件生成完全微調的模型相比,它們的結果往往不夠理想。這些問題可能使基於適配器的方法在需要無縫整合多個控制信號的任務中效果不佳。
理想情況下,ControlNet的功能應以模組化方式原生整合到模型中,允許未來創新,如同時生成視頻/音頻或原生唇部同步功能。目前,每個額外功能要麼成為後期製作任務,要麼是必須在基礎模型敏感權重中導航的非原生程序。
FullDiT
來自中國的新方法FullDiT,將ControlNet風格的功能直接整合到生成視頻模型的訓練過程中,而不是將其視為事後補充。
 *來自新論文:FullDiT方法可以將身份強加、深度和攝影機運動融入原生生成,並能同時調用這些功能的任意組合。* 來源:https://arxiv.org/pdf/2503.19907
*來自新論文:FullDiT方法可以將身份強加、深度和攝影機運動融入原生生成,並能同時調用這些功能的任意組合。* 來源:https://arxiv.org/pdf/2503.19907
FullDiT,如論文《FullDiT:具有完全注意力的多任務視頻生成基礎模型》中所述,將多任務條件(如身份轉移、深度映射和攝影機運動)整合到訓練好的生成視頻模型的核心中。作者開發了一個原型模型及相關視頻片段,可在項目網站上查看。
**點擊播放。僅使用原生訓練基礎模型的ControlNet風格用戶強加示例。** 來源:https://fulldit.github.io/
作者將FullDiT作為原生文本到視頻(T2V)和圖像到視頻(I2V)模型的概念驗證,這些模型為用戶提供比僅圖像或文本提示更多的控制。由於不存在類似模型,研究人員創建了一個名為**FullBench**的新基準,用於評估多任務視頻,聲稱在他們設計的測試中達到最先進的性能。然而,由作者自行設計的FullBench的客觀性尚未經過測試,其1,400個案例的數據集可能對於更廣泛的結論來說過於有限。
FullDiT架構最引人注目的方面是其整合新型控制的潛力。作者指出:
**‘在這項工作中,我們僅探索了攝影機、身份和深度信息的控制條件。我們尚未進一步研究其他條件和模態,如音頻、語音、點雲、物體邊界框、光流等。雖然FullDiT的設計可以以最小的架構修改無縫整合其他模態,但如何快速且成本效益高地適應現有模型以應對新條件和模態仍是一個值得進一步探索的重要問題。’**
雖然FullDiT代表了多任務視頻生成的一步進展,但它建立在現有架構之上,而不是引入全新範式。儘管如此,它作為唯一具有原生整合ControlNet風格功能的視頻基礎模型脫穎而出,其架構設計也能適應未來的創新。
**點擊播放。來自項目網站的用戶控制攝影機運動示例。**
該論文由來自快手科技和香港中文大學的九位研究人員撰寫,題為**FullDiT:具有完全注意力的多任務視頻生成基礎模型**。項目頁面和新基準數據可在Hugging Face上獲取。
方法
FullDiT的統一注意力機制旨在通過捕捉條件間的空間和時間關係來增強跨模態表示學習。
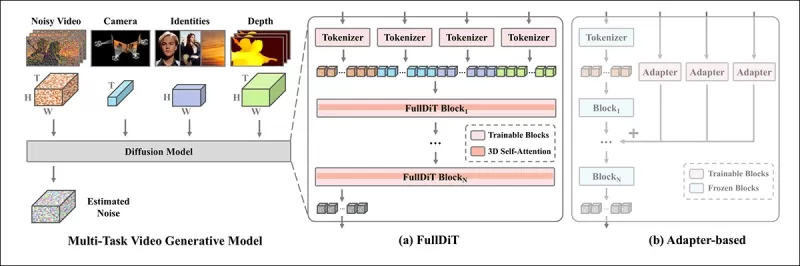 *根據新論文,FullDiT通過完全自注意力整合多個輸入條件,將其轉換為統一序列。相比之下,基於適配器的模型(上方最左側)為每個輸入使用獨立模組,導致冗餘、衝突和較弱的性能。*
*根據新論文,FullDiT通過完全自注意力整合多個輸入條件,將其轉換為統一序列。相比之下,基於適配器的模型(上方最左側)為每個輸入使用獨立模組,導致冗餘、衝突和較弱的性能。*
與分別處理每個輸入流的基於適配器設置不同,FullDiT的共享注意力結構避免了分支衝突並減少了參數開銷。作者聲稱該架構可以擴展到新型輸入類型而無需重大重新設計,且模型結構顯示出對訓練中未見過的條件組合的泛化跡象,例如將攝影機運動與角色身份連結。
**點擊播放。來自項目網站的身份生成示例。**
在FullDiT的架構中,所有條件輸入(如文本、攝影機運動、身份和深度)首先被轉換為統一的標記格式。這些標記隨後被拼接成一個長序列,通過一組變換器層使用完全自注意力進行處理。這種方法遵循了Open-Sora Plan和Movie Gen等先前工作的做法。
這種設計使模型能夠聯合學習所有條件的時間和空間關係。每個變換器塊對整個序列進行操作,實現模態間的動態交互,而無需依賴每個輸入的獨立模組。該架構設計為可擴展,使得未來無需重大結構更改即可輕鬆整合額外的控制信號。
三者之力
FullDiT將每個控制信號轉換為標準化標記格式,以便所有條件可以在統一的注意力框架中一起處理。對於攝影機運動,模型為每幀編碼一系列外在參數(如位置和方向)。這些參數帶有時間戳並投影到嵌入向量中,反映信號的時間特性。
身份信息因其本質上是空間而非時間的而被不同處理。模型使用身份圖,指示每個幀的哪些部分存在哪些角色。這些圖被分成小塊,每個小塊投影到一個捕捉空間身份線索的嵌入中,使模型能夠將幀的特定區域與特定實體關聯。
深度是一個時空信號,模型通過將深度視頻分成跨越空間和時間的3D小塊來處理。這些小塊隨後以保留其跨幀結構的方式嵌入。
一旦嵌入,所有這些條件標記(攝影機、身份和深度)被拼接成一個長序列,使FullDiT能夠使用完全自注意力一起處理它們。這種共享表示使模型能夠學習跨模態和跨時間的交互,而無需依賴獨立的處理流。
數據與測試
FullDiT的訓練方法依賴於為每種條件類型量身定制的選擇性註釋數據集,而非要求所有條件同時存在。
對於文本條件,該計劃遵循MiraData項目中概述的結構化標籤方法。
 *來自MiraData項目的視頻收集和註釋流程。* 來源:https://arxiv.org/pdf/2407.06358
*來自MiraData項目的視頻收集和註釋流程。* 來源:https://arxiv.org/pdf/2407.06358
對於攝影機運動,RealEstate10K數據集是主要數據來源,因其高質量的攝影機參數真值註釋。然而,作者觀察到僅在像RealEstate10K這樣的靜態場景攝影機數據集上訓練,傾向於減少生成視頻中的動態物體和人類運動。為了解決這個問題,他們使用包含更多動態攝影機運動的內部數據集進行了額外的微調。
身份註釋使用為ConceptMaster項目開發的流程生成,該流程允許高效過濾和提取細粒度的身份信息。
 *ConceptMaster框架旨在解決身份解耦問題,同時保留自定義視頻中的概念忠實度。* 來源:https://arxiv.org/pdf/2501.04698
*ConceptMaster框架旨在解決身份解耦問題,同時保留自定義視頻中的概念忠實度。* 來源:https://arxiv.org/pdf/2501.04698
深度註釋從Panda-70M數據集使用Depth Anything獲得。
通過數據排序優化
作者還實施了漸進式訓練計劃,在訓練早期引入更具挑戰性的條件,以確保模型在添加較簡單任務之前獲得穩健的表示。訓練順序從文本到攝影機條件,然後是身份,最後是深度,較簡單的任務通常在後期引入並使用較少的示例。
作者強調了以這種方式安排工作量的價值:
**‘在預訓練階段,我們注意到更具挑戰性的任務需要更長的訓練時間,並應在學習過程中較早引入。這些具挑戰性的任務涉及與輸出視頻顯著不同的複雜數據分佈,要求模型具備足夠的能力來準確捕捉和表示它們。’**
**‘相反,過早引入較簡單的任務可能導致模型優先學習它們,因為它們提供更即時的優化反饋,這會阻礙更具挑戰性任務的收斂。’**
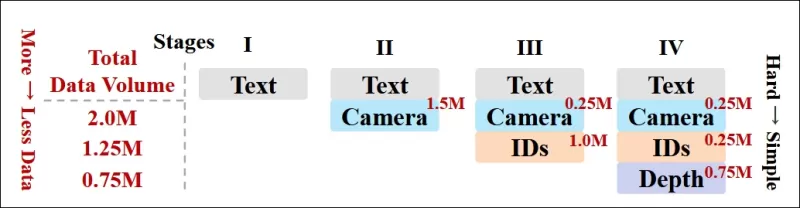 *研究人員採用的數據訓練順序示意圖,紅色表示更大的數據量。*
*研究人員採用的數據訓練順序示意圖,紅色表示更大的數據量。*
在初始預訓練後,最終的微調階段進一步完善了模型,以提高視覺質量和運動動態。此後,訓練遵循標準擴散框架:向視頻潛在變量添加噪聲,模型學習預測並移除噪聲,使用嵌入的條件標記作為指導。
為了有效評估FullDiT並與現有方法進行公平比較,在沒有其他合適基準的情況下,作者引入了**FullBench**,一個包含1,400個獨特測試案例的精選基準套件。
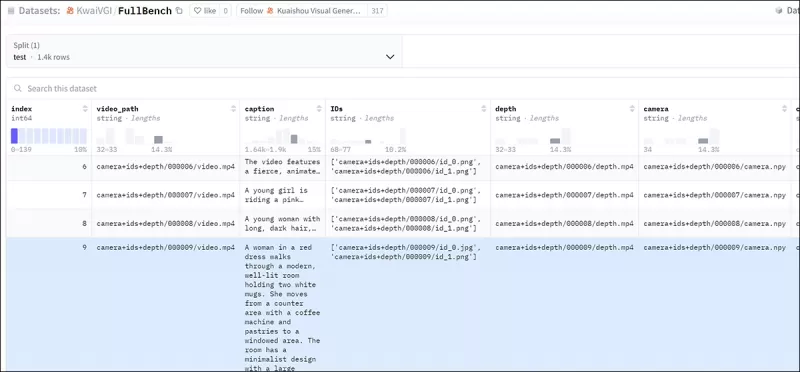 *新FullBench基準的數據瀏覽器實例。* 來源:https://huggingface.co/datasets/KwaiVGI/FullBench
*新FullBench基準的數據瀏覽器實例。* 來源:https://huggingface.co/datasets/KwaiVGI/FullBench
每個數據點為各種條件信號提供真值註釋,包括攝影機運動、身份和深度。
指標
作者使用十個指標評估FullDiT,涵蓋五個主要性能方面:文本對齊、攝影機控制、身份相似性、深度準確性和一般視頻質量。
文本對齊使用CLIP相似性測量,攝影機控制通過旋轉誤差(RotErr)、平移誤差(TransErr)和攝影機運動一致性(CamMC)進行評估,遵循CameraCtrl項目中的CamI2V方法。
身份相似性使用DINO-I和CLIP-I進行評估,深度控制準確性使用平均絕對誤差(MAE)進行量化。
視頻質量使用MiraData的三個指標進行判斷:平滑度的幀級CLIP相似性;動態的光流基運動距離;以及視覺吸引力的LAION-Aesthetic分數。
訓練
作者使用一個內部(未公開)文本到視頻擴散模型訓練FullDiT,該模型包含大約十億個參數。他們有意選擇了適中的參數規模,以保持與先前方法的比較公平性並確保可重現性。
由於訓練視頻的長度和分辨率不同,作者通過調整和填充視頻到統一分辨率、每個序列採樣77幀,並使用應用注意力和損失掩碼來優化訓練效果,從而標準化每個批次。
使用Adam優化器,學習率為1×10−5,在64個NVIDIA H800 GPU集群上進行訓練,總計5,120GB的VRAM(考慮到在愛好者合成社區中,RTX 3090上的24GB仍被認為是豪華標準)。
模型訓練約32,000步,每個視頻最多包含三個身份,以及20幀攝影機條件和21幀深度條件,均從總計77幀中均勻採樣。
對於推理,模型以384×672像素的分辨率生成視頻(大約5秒,15幀每秒),使用50個擴散推理步驟和無分類器指導尺度為5。
先前方法
對於攝影機到視頻評估,作者將FullDiT與MotionCtrl、CameraCtrl和CamI2V進行比較,所有模型均使用RealEstate10k數據集訓練,以確保一致性和公平性。
在身份條件生成中,由於沒有可比較的開源多身份模型,該模型與1B參數的ConceptMaster模型進行基準比較,使用相同的訓練數據和架構。
對於深度到視頻任務,與Ctrl-Adapter和ControlVideo進行比較。
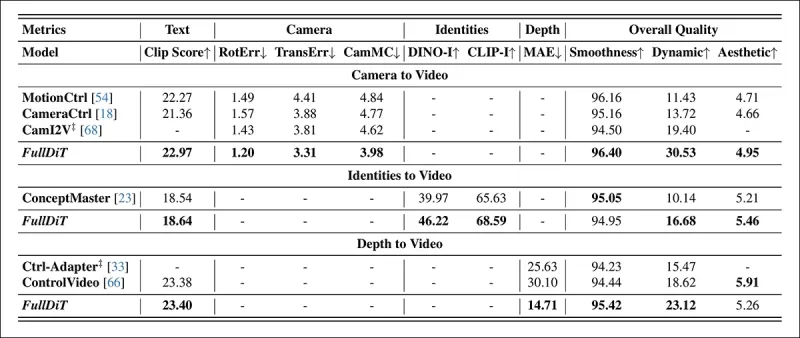 *單任務視頻生成的定量結果。FullDiT與MotionCtrl、CameraCtrl和CamI2V進行攝影機到視頻生成比較;與ConceptMaster(1B參數版本)進行身份到視頻比較;與Ctrl-Adapter和ControlVideo進行深度到視頻比較。所有模型均使用其默認設置進行評估。為保持一致性,從每種方法中均勻採樣16幀,與先前模型的輸出長度匹配。*
*單任務視頻生成的定量結果。FullDiT與MotionCtrl、CameraCtrl和CamI2V進行攝影機到視頻生成比較;與ConceptMaster(1B參數版本)進行身份到視頻比較;與Ctrl-Adapter和ControlVideo進行深度到視頻比較。所有模型均使用其默認設置進行評估。為保持一致性,從每種方法中均勻採樣16幀,與先前模型的輸出長度匹配。*
結果表明,儘管FullDiT同時處理多個條件信號,但在與文本、攝影機運動、身份和深度控制相關的指標中實現了最先進的性能。
在總體質量指標中,該系統通常優於其他方法,儘管其平滑度略低於ConceptMaster。作者評論道:
**‘FullDiT的平滑度略低於ConceptMaster,因為平滑度的計算基於相鄰幀之間的CLIP相似性。由於FullDiT表現出比ConceptMaster顯著更大的動態性,相鄰幀之間的較大變化影響了平滑度指標。’**
**‘對於美學分數,由於評分模型偏好繪畫風格的圖像,而ControlVideo通常生成這種風格的視頻,因此在美學方面獲得高分。’**
關於定性比較,參考FullDiT項目網站的樣本視頻可能更可取,因為PDF示例不可避免是靜態的(而且也太大,無法在此完全重現)。
 *PDF中重現的定性結果的第一部分。請參閱源論文以獲取額外示例,這些示例過於廣泛,無法在此重現。*
*PDF中重現的定性結果的第一部分。請參閱源論文以獲取額外示例,這些示例過於廣泛,無法在此重現。*
作者評論道:
**‘FullDiT展示了卓越的身份保留能力,並生成比[ConceptMaster]具有更好動態性和視覺質量的視頻。由於ConceptMaster和FullDiT在同一骨架上訓練,這突顯了使用完全注意力進行條件注入的有效性。’**
**‘…[其他]結果展示了FullDiT與現有深度到視頻和攝影機到視頻方法相比的優越可控性和生成質量。’**
 *PDF中FullDiT多信號輸出的示例部分。請參閱源論文和項目網站以獲取額外示例。*
*PDF中FullDiT多信號輸出的示例部分。請參閱源論文和項目網站以獲取額外示例。*
結論
FullDiT代表了朝向更全面的視頻基礎模型的激動人心的一步,但問題仍然在於對ControlNet風格功能的需求是否足以證明其大規模實現的合理性,特別是對於開源項目。這些項目在沒有商業支持的情況下很難獲得所需的龐大GPU處理能力。
主要挑戰在於使用像Depth和Pose這樣的系統通常需要對像ComfyUI這樣複雜的用戶界面有非平凡的熟悉度。因此,這種功能性開源模型最有可能由缺乏資源或動機私下策劃和訓練此類模型的小型VFX公司開發。
另一方面,API驅動的“租用AI”系統可能有充分的動機開發更簡單、更用戶友好的解釋方法,適用於具有直接訓練輔助控制系統的模型。
**點擊播放。使用FullDiT對視頻生成施加的深度+文本控制。**
*作者未指定任何已知基礎模型(如SDXL等)。*
**首次發布於2025年3月27日,星期四**
相關文章
 YouTube 測試由人工智慧驅動的搜尋功能,提供引導式答案
許多用戶在搜尋食譜或旅遊計畫時,都會轉向 YouTube 尋找相關影片。如今,該平台推出了一款由人工智慧驅動的互動式搜尋工具,能提供結合文字與影片內容的逐步指引結果。透過全新的「Ask YouTube」功能,使用者可以提出諸如「規劃從舊金山到聖塔芭芭拉的 3 天自駕遊」這類問題,並獲得結合文字、短片片段及較長影片的逐步指引結果——而非僅顯示影片結果。YouTube 表示,系統將同時顯示影片、相關片
獨家報導:Luma AI 推出搭載「統一智能」模型的創意代理程式
週四,AI影片生成新創公司Luma推出「Luma Agents」系統,旨在管理涵蓋文字、圖像、影片及音訊的完整創意工作流程。這些代理程式由Luma的統一智能模型家族驅動,其架構經訓練成為單一多模態推理引擎。Luma將其代理程式定位為廣告代理商、行銷部門、設計工作室及企業的變革性工具。據Luma表示,這些代理程式不僅能規劃與製作文字、圖像、影片及音訊內容,還能與其他AI模型協同運作,例如Luma的R
Sora 的新更新提供寵物 AI 影片、社交工具以及即將推出的 Android 應用程式
OpenAI 正在為其爆紅的 AI 視訊創作應用程式 Sora 預覽一大波新功能,該應用程式在 9 月底推出後迅速攀升至 App Store 榜首。該應用程式目前仍在美國和加拿大穩居第一,不久將新增視訊編輯功能,讓使用者可以創造寵物和其他物品的角色「客串」,並加強社交功能等。該公司還確認 Android 版本「實際上即將推出」。Sora 的領導 Bill Peebles 在 X 上宣布了這個消息,
相關專題推薦
商業
YouTube 測試由人工智慧驅動的搜尋功能,提供引導式答案
許多用戶在搜尋食譜或旅遊計畫時,都會轉向 YouTube 尋找相關影片。如今,該平台推出了一款由人工智慧驅動的互動式搜尋工具,能提供結合文字與影片內容的逐步指引結果。透過全新的「Ask YouTube」功能,使用者可以提出諸如「規劃從舊金山到聖塔芭芭拉的 3 天自駕遊」這類問題,並獲得結合文字、短片片段及較長影片的逐步指引結果——而非僅顯示影片結果。YouTube 表示,系統將同時顯示影片、相關片
獨家報導:Luma AI 推出搭載「統一智能」模型的創意代理程式
週四,AI影片生成新創公司Luma推出「Luma Agents」系統,旨在管理涵蓋文字、圖像、影片及音訊的完整創意工作流程。這些代理程式由Luma的統一智能模型家族驅動,其架構經訓練成為單一多模態推理引擎。Luma將其代理程式定位為廣告代理商、行銷部門、設計工作室及企業的變革性工具。據Luma表示,這些代理程式不僅能規劃與製作文字、圖像、影片及音訊內容,還能與其他AI模型協同運作,例如Luma的R
Sora 的新更新提供寵物 AI 影片、社交工具以及即將推出的 Android 應用程式
OpenAI 正在為其爆紅的 AI 視訊創作應用程式 Sora 預覽一大波新功能,該應用程式在 9 月底推出後迅速攀升至 App Store 榜首。該應用程式目前仍在美國和加拿大穩居第一,不久將新增視訊編輯功能,讓使用者可以創造寵物和其他物品的角色「客串」,並加強社交功能等。該公司還確認 Android 版本「實際上即將推出」。Sora 的領導 Bill Peebles 在 X 上宣布了這個消息,
相關專題推薦
商業
 最佳 AI 支出追蹤工具:掃描收據並自動分類公司開支
最佳 AI 支出追蹤工具:掃描收據並自動分類公司開支
2026 年最新最佳 AI 報銷管理工具:備受好評的解決方案,可自動掃描收據並分類企業支出。探索強大且顛覆傳統的解決方案,助您輕鬆管理報銷、精準追蹤財務,並簡化合規流程。我們精心整理並每週更新的免費與付費方案比較指南,將協助您找到最合適的選擇。透過 XIX.AI 的專家精選,釋放您的 AI 優勢。
 10 個工具
10 個工具
 xix.ai
商業
最佳 AI 招聘工具:篩選履歷與自動化安排候選人面試
xix.ai
商業
最佳 AI 招聘工具:篩選履歷與自動化安排候選人面試
在 XIX.AI 探索 2026 年最新且評價最高的 AI 招聘工具。我們精心挑選的清單收錄了強大且具顛覆性的解決方案,可協助篩選履歷並自動化安排候選人面試。透過實際測試與每週更新的排行榜,比較免費與付費選項。立即找到最適合您的招聘助手,並優化您的招聘流程!
10 個工具
xix.ai
生產率
AI 個人健康與專注力教練:管理倦怠感並提升精神能量
立即在 XIX.AI 探索 2026 年最佳 AI 個人健康與專注力教練。我們精心策劃的排行榜收錄了備受好評、能帶來革命性改變的工具,助您管理倦怠感並提升精神能量。透過實際使用心得,比較免費與付費方案的差異。立即開啟通往巔峰生產力與身心健康的道路。
10 個工具
xix.ai
聊天機器人
最受好評的 AI 浪漫聊天機器人:透過一貫的個性建立長期關係
探索 2026 年最新、評價最高的 AI 浪漫聊天機器人,助您建立真摯且長久的連結。我們精心整理的清單包含功能強大且性格鮮明的聊天機器人、免費與付費版本的比較,以及實際測試結果。立即前往 XIX.AI 尋找您的完美伴侶,並開始建立這段關係吧。
10 個工具
xix.ai
教育與學習
最佳AI資料科學導師:精通SQL、Pandas及機器學習工作流程
探索2026年最優秀的人工智慧資料科學導師,幫助他們掌握SQL、Pandas以及機器學習工作流程。在XIX.AI上檢視我們精心挑選的頂級導師名單,獲得強大而具有變革性的指導。透過對比免費和付費選項,並結合實際應用案例進行了解,今天就開啟你的資料科學精通之路吧。
10 個工具
xix.ai
聊天機器人
最佳 AI 調情與對話訓練工具:即時提升社交魅力與自信
在 XIX.AI 探索 2026 年最頂尖的 AI 調情與對話訓練工具。我們精心挑選、評價最高的精選清單,能助您即時建立社交魅力與自信。探索這些必試且能徹底改變遊戲規則的工具,並透過免費與付費版本的比較,以及每週更新的排行榜,立即解鎖您的社交優勢。
10 個工具
xix.ai

 評論 (3)
0/500
評論 (3)
0/500
![TimothyMitchell]()
映像の詳細なコントロールって本当に難しいんですね。AIがプロのVFXスタジオで使われる日はまだ先かな?でも技術の進歩にはワクワクする!🔥
![CharlesMartinez]()
Finalmente os vídeos gerados por IA estão evoluindo para algo útil! Mas ainda parece que falta muito pra substituir os efeitos manuais de grandes produções... será que um dia chegaremos lá? 🎥
![DonaldLee]()
The idea of AI taking over VFX in films is wild! I mean, total control over video generation? That’s some sci-fi stuff coming to life. But I wonder if these models like Hunyuan can really nail the tiny details directors obsess over. Exciting times! 🎥
像Hunyuan和Wan 2.1這樣的視頻基礎模型已取得顯著進展,但在電影和電視製作中所需的精細控制方面,特別是在視覺效果(VFX)領域,常常表現不足。在專業VFX工作室中,這些模型與早期的基於圖像的模型,如Stable Diffusion、Kandinsky和Flux,結合一系列專為滿足特定創意需求而設計的工具一起使用。當導演要求進行微調,例如說「這看起來很棒,但可以再稍微[n]一點嗎?」,僅僅聲稱模型缺乏精確調整的能力是不夠的。
相反,AI VFX團隊會結合傳統CGI和合成技術,以及自定義開發的工作流程,進一步推動視頻合成的邊界。這種方法類似於使用像Chrome這樣的預設網頁瀏覽器;它開箱即用,但要真正滿足你的需求,你需要安裝一些插件。
控制狂熱者
在基於擴散的圖像合成領域中,最關鍵的第三方系統之一是ControlNet。這項技術為生成模型引入結構化控制,允許用戶通過額外的輸入(如邊緣圖、深度圖或姿態信息)來引導圖像或視頻生成。
*ControlNet的多種方法允許深度>圖像(頂行)、語義分割>圖像(左下)以及人類和動物的姿態引導圖像生成(左下)。*
ControlNet不僅依賴文本提示;它使用獨立的神經網絡分支或適配器來處理這些條件信號,同時保持基礎模型的生成能力。這使得高度定制的輸出能夠與用戶規格緊密對齊,對於需要精確控制構圖、結構或運動的應用來說極其寶貴。
*通過引導姿態,ControlNet可以獲得多種精確的輸出類型。* 來源:https://arxiv.org/pdf/2302.05543
然而,這些基於適配器的系統,通過外部操作一組內部聚焦的神經過程,存在幾個缺點。適配器是獨立訓練的,當多個適配器組合時可能導致分支衝突,通常會導致生成質量下降。它們還引入了參數冗餘,每個適配器都需要額外的計算資源和內存,使得擴展效率低下。此外,儘管適配器靈活,但與專為多條件生成完全微調的模型相比,它們的結果往往不夠理想。這些問題可能使基於適配器的方法在需要無縫整合多個控制信號的任務中效果不佳。
理想情況下,ControlNet的功能應以模組化方式原生整合到模型中,允許未來創新,如同時生成視頻/音頻或原生唇部同步功能。目前,每個額外功能要麼成為後期製作任務,要麼是必須在基礎模型敏感權重中導航的非原生程序。
FullDiT
來自中國的新方法FullDiT,將ControlNet風格的功能直接整合到生成視頻模型的訓練過程中,而不是將其視為事後補充。
*來自新論文:FullDiT方法可以將身份強加、深度和攝影機運動融入原生生成,並能同時調用這些功能的任意組合。* 來源:https://arxiv.org/pdf/2503.19907
FullDiT,如論文《FullDiT:具有完全注意力的多任務視頻生成基礎模型》中所述,將多任務條件(如身份轉移、深度映射和攝影機運動)整合到訓練好的生成視頻模型的核心中。作者開發了一個原型模型及相關視頻片段,可在項目網站上查看。
**點擊播放。僅使用原生訓練基礎模型的ControlNet風格用戶強加示例。** 來源:https://fulldit.github.io/
作者將FullDiT作為原生文本到視頻(T2V)和圖像到視頻(I2V)模型的概念驗證,這些模型為用戶提供比僅圖像或文本提示更多的控制。由於不存在類似模型,研究人員創建了一個名為**FullBench**的新基準,用於評估多任務視頻,聲稱在他們設計的測試中達到最先進的性能。然而,由作者自行設計的FullBench的客觀性尚未經過測試,其1,400個案例的數據集可能對於更廣泛的結論來說過於有限。
FullDiT架構最引人注目的方面是其整合新型控制的潛力。作者指出:
**‘在這項工作中,我們僅探索了攝影機、身份和深度信息的控制條件。我們尚未進一步研究其他條件和模態,如音頻、語音、點雲、物體邊界框、光流等。雖然FullDiT的設計可以以最小的架構修改無縫整合其他模態,但如何快速且成本效益高地適應現有模型以應對新條件和模態仍是一個值得進一步探索的重要問題。’**
雖然FullDiT代表了多任務視頻生成的一步進展,但它建立在現有架構之上,而不是引入全新範式。儘管如此,它作為唯一具有原生整合ControlNet風格功能的視頻基礎模型脫穎而出,其架構設計也能適應未來的創新。
**點擊播放。來自項目網站的用戶控制攝影機運動示例。**
該論文由來自快手科技和香港中文大學的九位研究人員撰寫,題為**FullDiT:具有完全注意力的多任務視頻生成基礎模型**。項目頁面和新基準數據可在Hugging Face上獲取。
方法
FullDiT的統一注意力機制旨在通過捕捉條件間的空間和時間關係來增強跨模態表示學習。
*根據新論文,FullDiT通過完全自注意力整合多個輸入條件,將其轉換為統一序列。相比之下,基於適配器的模型(上方最左側)為每個輸入使用獨立模組,導致冗餘、衝突和較弱的性能。*
與分別處理每個輸入流的基於適配器設置不同,FullDiT的共享注意力結構避免了分支衝突並減少了參數開銷。作者聲稱該架構可以擴展到新型輸入類型而無需重大重新設計,且模型結構顯示出對訓練中未見過的條件組合的泛化跡象,例如將攝影機運動與角色身份連結。
**點擊播放。來自項目網站的身份生成示例。**
在FullDiT的架構中,所有條件輸入(如文本、攝影機運動、身份和深度)首先被轉換為統一的標記格式。這些標記隨後被拼接成一個長序列,通過一組變換器層使用完全自注意力進行處理。這種方法遵循了Open-Sora Plan和Movie Gen等先前工作的做法。
這種設計使模型能夠聯合學習所有條件的時間和空間關係。每個變換器塊對整個序列進行操作,實現模態間的動態交互,而無需依賴每個輸入的獨立模組。該架構設計為可擴展,使得未來無需重大結構更改即可輕鬆整合額外的控制信號。
三者之力
FullDiT將每個控制信號轉換為標準化標記格式,以便所有條件可以在統一的注意力框架中一起處理。對於攝影機運動,模型為每幀編碼一系列外在參數(如位置和方向)。這些參數帶有時間戳並投影到嵌入向量中,反映信號的時間特性。
身份信息因其本質上是空間而非時間的而被不同處理。模型使用身份圖,指示每個幀的哪些部分存在哪些角色。這些圖被分成小塊,每個小塊投影到一個捕捉空間身份線索的嵌入中,使模型能夠將幀的特定區域與特定實體關聯。
深度是一個時空信號,模型通過將深度視頻分成跨越空間和時間的3D小塊來處理。這些小塊隨後以保留其跨幀結構的方式嵌入。
一旦嵌入,所有這些條件標記(攝影機、身份和深度)被拼接成一個長序列,使FullDiT能夠使用完全自注意力一起處理它們。這種共享表示使模型能夠學習跨模態和跨時間的交互,而無需依賴獨立的處理流。
數據與測試
FullDiT的訓練方法依賴於為每種條件類型量身定制的選擇性註釋數據集,而非要求所有條件同時存在。
對於文本條件,該計劃遵循MiraData項目中概述的結構化標籤方法。
*來自MiraData項目的視頻收集和註釋流程。* 來源:https://arxiv.org/pdf/2407.06358
對於攝影機運動,RealEstate10K數據集是主要數據來源,因其高質量的攝影機參數真值註釋。然而,作者觀察到僅在像RealEstate10K這樣的靜態場景攝影機數據集上訓練,傾向於減少生成視頻中的動態物體和人類運動。為了解決這個問題,他們使用包含更多動態攝影機運動的內部數據集進行了額外的微調。
身份註釋使用為ConceptMaster項目開發的流程生成,該流程允許高效過濾和提取細粒度的身份信息。
*ConceptMaster框架旨在解決身份解耦問題,同時保留自定義視頻中的概念忠實度。* 來源:https://arxiv.org/pdf/2501.04698
深度註釋從Panda-70M數據集使用Depth Anything獲得。
通過數據排序優化
作者還實施了漸進式訓練計劃,在訓練早期引入更具挑戰性的條件,以確保模型在添加較簡單任務之前獲得穩健的表示。訓練順序從文本到攝影機條件,然後是身份,最後是深度,較簡單的任務通常在後期引入並使用較少的示例。
作者強調了以這種方式安排工作量的價值:
**‘在預訓練階段,我們注意到更具挑戰性的任務需要更長的訓練時間,並應在學習過程中較早引入。這些具挑戰性的任務涉及與輸出視頻顯著不同的複雜數據分佈,要求模型具備足夠的能力來準確捕捉和表示它們。’**
**‘相反,過早引入較簡單的任務可能導致模型優先學習它們,因為它們提供更即時的優化反饋,這會阻礙更具挑戰性任務的收斂。’**
*研究人員採用的數據訓練順序示意圖,紅色表示更大的數據量。*
在初始預訓練後,最終的微調階段進一步完善了模型,以提高視覺質量和運動動態。此後,訓練遵循標準擴散框架:向視頻潛在變量添加噪聲,模型學習預測並移除噪聲,使用嵌入的條件標記作為指導。
為了有效評估FullDiT並與現有方法進行公平比較,在沒有其他合適基準的情況下,作者引入了**FullBench**,一個包含1,400個獨特測試案例的精選基準套件。
*新FullBench基準的數據瀏覽器實例。* 來源:https://huggingface.co/datasets/KwaiVGI/FullBench
每個數據點為各種條件信號提供真值註釋,包括攝影機運動、身份和深度。
指標
作者使用十個指標評估FullDiT,涵蓋五個主要性能方面:文本對齊、攝影機控制、身份相似性、深度準確性和一般視頻質量。
文本對齊使用CLIP相似性測量,攝影機控制通過旋轉誤差(RotErr)、平移誤差(TransErr)和攝影機運動一致性(CamMC)進行評估,遵循CameraCtrl項目中的CamI2V方法。
身份相似性使用DINO-I和CLIP-I進行評估,深度控制準確性使用平均絕對誤差(MAE)進行量化。
視頻質量使用MiraData的三個指標進行判斷:平滑度的幀級CLIP相似性;動態的光流基運動距離;以及視覺吸引力的LAION-Aesthetic分數。
訓練
作者使用一個內部(未公開)文本到視頻擴散模型訓練FullDiT,該模型包含大約十億個參數。他們有意選擇了適中的參數規模,以保持與先前方法的比較公平性並確保可重現性。
由於訓練視頻的長度和分辨率不同,作者通過調整和填充視頻到統一分辨率、每個序列採樣77幀,並使用應用注意力和損失掩碼來優化訓練效果,從而標準化每個批次。
使用Adam優化器,學習率為1×10−5,在64個NVIDIA H800 GPU集群上進行訓練,總計5,120GB的VRAM(考慮到在愛好者合成社區中,RTX 3090上的24GB仍被認為是豪華標準)。
模型訓練約32,000步,每個視頻最多包含三個身份,以及20幀攝影機條件和21幀深度條件,均從總計77幀中均勻採樣。
對於推理,模型以384×672像素的分辨率生成視頻(大約5秒,15幀每秒),使用50個擴散推理步驟和無分類器指導尺度為5。
先前方法
對於攝影機到視頻評估,作者將FullDiT與MotionCtrl、CameraCtrl和CamI2V進行比較,所有模型均使用RealEstate10k數據集訓練,以確保一致性和公平性。
在身份條件生成中,由於沒有可比較的開源多身份模型,該模型與1B參數的ConceptMaster模型進行基準比較,使用相同的訓練數據和架構。
對於深度到視頻任務,與Ctrl-Adapter和ControlVideo進行比較。
*單任務視頻生成的定量結果。FullDiT與MotionCtrl、CameraCtrl和CamI2V進行攝影機到視頻生成比較;與ConceptMaster(1B參數版本)進行身份到視頻比較;與Ctrl-Adapter和ControlVideo進行深度到視頻比較。所有模型均使用其默認設置進行評估。為保持一致性,從每種方法中均勻採樣16幀,與先前模型的輸出長度匹配。*
結果表明,儘管FullDiT同時處理多個條件信號,但在與文本、攝影機運動、身份和深度控制相關的指標中實現了最先進的性能。
在總體質量指標中,該系統通常優於其他方法,儘管其平滑度略低於ConceptMaster。作者評論道:
**‘FullDiT的平滑度略低於ConceptMaster,因為平滑度的計算基於相鄰幀之間的CLIP相似性。由於FullDiT表現出比ConceptMaster顯著更大的動態性,相鄰幀之間的較大變化影響了平滑度指標。’**
**‘對於美學分數,由於評分模型偏好繪畫風格的圖像,而ControlVideo通常生成這種風格的視頻,因此在美學方面獲得高分。’**
關於定性比較,參考FullDiT項目網站的樣本視頻可能更可取,因為PDF示例不可避免是靜態的(而且也太大,無法在此完全重現)。
*PDF中重現的定性結果的第一部分。請參閱源論文以獲取額外示例,這些示例過於廣泛,無法在此重現。*
作者評論道:
**‘FullDiT展示了卓越的身份保留能力,並生成比[ConceptMaster]具有更好動態性和視覺質量的視頻。由於ConceptMaster和FullDiT在同一骨架上訓練,這突顯了使用完全注意力進行條件注入的有效性。’**
**‘…[其他]結果展示了FullDiT與現有深度到視頻和攝影機到視頻方法相比的優越可控性和生成質量。’**
*PDF中FullDiT多信號輸出的示例部分。請參閱源論文和項目網站以獲取額外示例。*
結論
FullDiT代表了朝向更全面的視頻基礎模型的激動人心的一步,但問題仍然在於對ControlNet風格功能的需求是否足以證明其大規模實現的合理性,特別是對於開源項目。這些項目在沒有商業支持的情況下很難獲得所需的龐大GPU處理能力。
主要挑戰在於使用像Depth和Pose這樣的系統通常需要對像ComfyUI這樣複雜的用戶界面有非平凡的熟悉度。因此,這種功能性開源模型最有可能由缺乏資源或動機私下策劃和訓練此類模型的小型VFX公司開發。
另一方面,API驅動的“租用AI”系統可能有充分的動機開發更簡單、更用戶友好的解釋方法,適用於具有直接訓練輔助控制系統的模型。
**點擊播放。使用FullDiT對視頻生成施加的深度+文本控制。**
*作者未指定任何已知基礎模型(如SDXL等)。*
**首次發布於2025年3月27日,星期四**










 YouTube 測試由人工智慧驅動的搜尋功能,提供引導式答案
許多用戶在搜尋食譜或旅遊計畫時,都會轉向 YouTube 尋找相關影片。如今,該平台推出了一款由人工智慧驅動的互動式搜尋工具,能提供結合文字與影片內容的逐步指引結果。透過全新的「Ask YouTube」功能,使用者可以提出諸如「規劃從舊金山到聖塔芭芭拉的 3 天自駕遊」這類問題,並獲得結合文字、短片片段及較長影片的逐步指引結果——而非僅顯示影片結果。YouTube 表示,系統將同時顯示影片、相關片
YouTube 測試由人工智慧驅動的搜尋功能,提供引導式答案
許多用戶在搜尋食譜或旅遊計畫時,都會轉向 YouTube 尋找相關影片。如今,該平台推出了一款由人工智慧驅動的互動式搜尋工具,能提供結合文字與影片內容的逐步指引結果。透過全新的「Ask YouTube」功能,使用者可以提出諸如「規劃從舊金山到聖塔芭芭拉的 3 天自駕遊」這類問題,並獲得結合文字、短片片段及較長影片的逐步指引結果——而非僅顯示影片結果。YouTube 表示,系統將同時顯示影片、相關片
 獨家報導:Luma AI 推出搭載「統一智能」模型的創意代理程式
週四,AI影片生成新創公司Luma推出「Luma Agents」系統,旨在管理涵蓋文字、圖像、影片及音訊的完整創意工作流程。這些代理程式由Luma的統一智能模型家族驅動,其架構經訓練成為單一多模態推理引擎。Luma將其代理程式定位為廣告代理商、行銷部門、設計工作室及企業的變革性工具。據Luma表示,這些代理程式不僅能規劃與製作文字、圖像、影片及音訊內容,還能與其他AI模型協同運作,例如Luma的R
獨家報導:Luma AI 推出搭載「統一智能」模型的創意代理程式
週四,AI影片生成新創公司Luma推出「Luma Agents」系統,旨在管理涵蓋文字、圖像、影片及音訊的完整創意工作流程。這些代理程式由Luma的統一智能模型家族驅動,其架構經訓練成為單一多模態推理引擎。Luma將其代理程式定位為廣告代理商、行銷部門、設計工作室及企業的變革性工具。據Luma表示,這些代理程式不僅能規劃與製作文字、圖像、影片及音訊內容,還能與其他AI模型協同運作,例如Luma的R
 Sora 的新更新提供寵物 AI 影片、社交工具以及即將推出的 Android 應用程式
OpenAI 正在為其爆紅的 AI 視訊創作應用程式 Sora 預覽一大波新功能,該應用程式在 9 月底推出後迅速攀升至 App Store 榜首。該應用程式目前仍在美國和加拿大穩居第一,不久將新增視訊編輯功能,讓使用者可以創造寵物和其他物品的角色「客串」,並加強社交功能等。該公司還確認 Android 版本「實際上即將推出」。Sora 的領導 Bill Peebles 在 X 上宣布了這個消息,
Sora 的新更新提供寵物 AI 影片、社交工具以及即將推出的 Android 應用程式
OpenAI 正在為其爆紅的 AI 視訊創作應用程式 Sora 預覽一大波新功能,該應用程式在 9 月底推出後迅速攀升至 App Store 榜首。該應用程式目前仍在美國和加拿大穩居第一,不久將新增視訊編輯功能,讓使用者可以創造寵物和其他物品的角色「客串」,並加強社交功能等。該公司還確認 Android 版本「實際上即將推出」。Sora 的領導 Bill Peebles 在 X 上宣布了這個消息,

2026 年最新最佳 AI 報銷管理工具:備受好評的解決方案,可自動掃描收據並分類企業支出。探索強大且顛覆傳統的解決方案,助您輕鬆管理報銷、精準追蹤財務,並簡化合規流程。我們精心整理並每週更新的免費與付費方案比較指南,將協助您找到最合適的選擇。透過 XIX.AI 的專家精選,釋放您的 AI 優勢。
10 個工具
xix.ai

在 XIX.AI 探索 2026 年最新且評價最高的 AI 招聘工具。我們精心挑選的清單收錄了強大且具顛覆性的解決方案,可協助篩選履歷並自動化安排候選人面試。透過實際測試與每週更新的排行榜,比較免費與付費選項。立即找到最適合您的招聘助手,並優化您的招聘流程!
10 個工具
xix.ai

立即在 XIX.AI 探索 2026 年最佳 AI 個人健康與專注力教練。我們精心策劃的排行榜收錄了備受好評、能帶來革命性改變的工具,助您管理倦怠感並提升精神能量。透過實際使用心得,比較免費與付費方案的差異。立即開啟通往巔峰生產力與身心健康的道路。
10 個工具
xix.ai

探索 2026 年最新、評價最高的 AI 浪漫聊天機器人,助您建立真摯且長久的連結。我們精心整理的清單包含功能強大且性格鮮明的聊天機器人、免費與付費版本的比較,以及實際測試結果。立即前往 XIX.AI 尋找您的完美伴侶,並開始建立這段關係吧。
10 個工具
xix.ai

探索2026年最優秀的人工智慧資料科學導師,幫助他們掌握SQL、Pandas以及機器學習工作流程。在XIX.AI上檢視我們精心挑選的頂級導師名單,獲得強大而具有變革性的指導。透過對比免費和付費選項,並結合實際應用案例進行了解,今天就開啟你的資料科學精通之路吧。
10 個工具
xix.ai

在 XIX.AI 探索 2026 年最頂尖的 AI 調情與對話訓練工具。我們精心挑選、評價最高的精選清單,能助您即時建立社交魅力與自信。探索這些必試且能徹底改變遊戲規則的工具,並透過免費與付費版本的比較,以及每週更新的排行榜,立即解鎖您的社交優勢。
10 個工具
xix.ai

映像の詳細なコントロールって本当に難しいんですね。AIがプロのVFXスタジオで使われる日はまだ先かな?でも技術の進歩にはワクワクする!🔥
Finalmente os vídeos gerados por IA estão evoluindo para algo útil! Mas ainda parece que falta muito pra substituir os efeitos manuais de grandes produções... será que um dia chegaremos lá? 🎥
The idea of AI taking over VFX in films is wild! I mean, total control over video generation? That’s some sci-fi stuff coming to life. But I wonder if these models like Hunyuan can really nail the tiny details directors obsess over. Exciting times! 🎥













