




AI Video Generation Moves Towards Complete Control
Video foundation models like Hunyuan and Wan 2.1 have made significant strides, but they often fall short when it comes to the detailed control required in film and TV production, especially in the realm of visual effects (VFX). In professional VFX studios, these models, along with earlier image-based models like Stable Diffusion, Kandinsky, and Flux, are used in conjunction with a suite of tools designed to refine their output to meet specific creative demands. When a director requests a tweak, saying something like, "That looks great, but can we make it a little more [n]?", it's not enough to simply state that the model lacks the precision to make such adjustments.
Instead, an AI VFX team will employ a combination of traditional CGI and compositional techniques, along with custom-developed workflows, to push the boundaries of video synthesis further. This approach is akin to using a default web browser like Chrome; it's functional out of the box, but to truly tailor it to your needs, you'll need to install some plugins.
Control Freaks
In the field of diffusion-based image synthesis, one of the most crucial third-party systems is ControlNet. This technique introduces structured control to generative models, allowing users to guide image or video generation using additional inputs such as edge maps, depth maps, or pose information.
 *ControlNet's various methods allow for depth>image (top row), semantic segmentation>image (lower left) and pose-guided image generation of humans and animals (lower left).*
*ControlNet's various methods allow for depth>image (top row), semantic segmentation>image (lower left) and pose-guided image generation of humans and animals (lower left).*
ControlNet doesn't rely solely on text prompts; it employs separate neural network branches, or adapters, to process these conditioning signals while maintaining the generative capabilities of the base model. This enables highly customized outputs that closely align with user specifications, making it invaluable for applications requiring precise control over composition, structure, or motion.
 *With a guiding pose, a variety of accurate output types can be obtained via ControlNet.* Source: https://arxiv.org/pdf/2302.05543
*With a guiding pose, a variety of accurate output types can be obtained via ControlNet.* Source: https://arxiv.org/pdf/2302.05543
However, these adapter-based systems, which operate externally on a set of internally-focused neural processes, come with several drawbacks. Adapters are trained independently, which can lead to branch conflicts when multiple adapters are combined, often resulting in lower quality generations. They also introduce parameter redundancy, requiring additional computational resources and memory for each adapter, making scaling inefficient. Moreover, despite their flexibility, adapters often yield sub-optimal results compared to models fully fine-tuned for multi-condition generation. These issues can make adapter-based methods less effective for tasks that require the seamless integration of multiple control signals.
Ideally, ControlNet's capabilities would be natively integrated into the model in a modular fashion, allowing for future innovations like simultaneous video/audio generation or native lip-sync capabilities. Currently, each additional feature either becomes a post-production task or a non-native procedure that must navigate the sensitive weights of the foundation model.
FullDiT
Enter FullDiT, a new approach from China that integrates ControlNet-style features directly into a generative video model during training, rather than treating them as an afterthought.
 *From the new paper: the FullDiT approach can incorporate identity imposition, depth and camera movement into a native generation, and can summon up any combination of these at once.* Source: https://arxiv.org/pdf/2503.19907
*From the new paper: the FullDiT approach can incorporate identity imposition, depth and camera movement into a native generation, and can summon up any combination of these at once.* Source: https://arxiv.org/pdf/2503.19907
FullDiT, as outlined in the paper titled **FullDiT: Multi-Task Video Generative Foundation Model with Full Attention**, integrates multi-task conditions such as identity transfer, depth-mapping, and camera movement into the core of a trained generative video model. The authors have developed a prototype model and accompanying video clips available at a project site.
**Click to play. Examples of ControlNet-style user imposition with only a native trained foundation model.** Source: https://fulldit.github.io/
The authors present FullDiT as a proof-of-concept for native text-to-video (T2V) and image-to-video (I2V) models that offer users more control than just an image or text prompt. Since no similar models exist, the researchers created a new benchmark called **FullBench** for evaluating multi-task videos, claiming state-of-the-art performance in their devised tests. However, the objectivity of FullBench, designed by the authors themselves, remains untested, and its dataset of 1,400 cases may be too limited for broader conclusions.
The most intriguing aspect of FullDiT's architecture is its potential to incorporate new types of control. The authors note:
**‘In this work, we only explore control conditions of the camera, identities, and depth information. We did not further investigate other conditions and modalities such as audio, speech, point cloud, object bounding boxes, optical flow, etc. Although the design of FullDiT can seamlessly integrate other modalities with minimal architecture modification, how to quickly and cost-effectively adapt existing models to new conditions and modalities is still an important question that warrants further exploration.'**
While FullDiT represents a step forward in multi-task video generation, it builds on existing architectures rather than introducing a new paradigm. Nonetheless, it stands out as the only video foundation model with natively integrated ControlNet-style features, and its architecture is designed to accommodate future innovations.
**Click to play. Examples of user-controlled camera moves, from the project site.**
The paper, authored by nine researchers from Kuaishou Technology and The Chinese University of Hong Kong, is titled **FullDiT: Multi-Task Video Generative Foundation Model with Full Attention**. The project page and new benchmark data are available at Hugging Face.
Method
FullDiT's unified attention mechanism is designed to enhance cross-modal representation learning by capturing both spatial and temporal relationships across conditions.
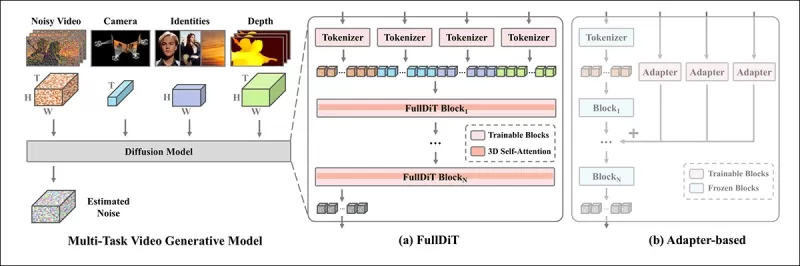 *According to the new paper, FullDiT integrates multiple input conditions through full self-attention, converting them into a unified sequence. By contrast, adapter-based models (leftmost above) use separate modules for each input, leading to redundancy, conflicts, and weaker performance.*
*According to the new paper, FullDiT integrates multiple input conditions through full self-attention, converting them into a unified sequence. By contrast, adapter-based models (leftmost above) use separate modules for each input, leading to redundancy, conflicts, and weaker performance.*
Unlike adapter-based setups that process each input stream separately, FullDiT's shared attention structure avoids branch conflicts and reduces parameter overhead. The authors claim that the architecture can scale to new input types without major redesign and that the model schema shows signs of generalizing to condition combinations not seen during training, such as linking camera motion with character identity.
**Click to play. Examples of identity generation from the project site**.
In FullDiT's architecture, all conditioning inputs—such as text, camera motion, identity, and depth—are first converted into a unified token format. These tokens are then concatenated into a single long sequence, processed through a stack of transformer layers using full self-attention. This approach follows prior works like Open-Sora Plan and Movie Gen.
This design allows the model to learn temporal and spatial relationships jointly across all conditions. Each transformer block operates over the entire sequence, enabling dynamic interactions between modalities without relying on separate modules for each input. The architecture is designed to be extensible, making it easier to incorporate additional control signals in the future without major structural changes.
The Power of Three
FullDiT converts each control signal into a standardized token format so that all conditions can be processed together in a unified attention framework. For camera motion, the model encodes a sequence of extrinsic parameters—such as position and orientation—for each frame. These parameters are timestamped and projected into embedding vectors that reflect the temporal nature of the signal.
Identity information is treated differently, as it is inherently spatial rather than temporal. The model uses identity maps that indicate which characters are present in which parts of each frame. These maps are divided into patches, with each patch projected into an embedding that captures spatial identity cues, allowing the model to associate specific regions of the frame with specific entities.
Depth is a spatiotemporal signal, and the model handles it by dividing depth videos into 3D patches that span both space and time. These patches are then embedded in a way that preserves their structure across frames.
Once embedded, all of these condition tokens (camera, identity, and depth) are concatenated into a single long sequence, allowing FullDiT to process them together using full self-attention. This shared representation enables the model to learn interactions across modalities and across time without relying on isolated processing streams.
Data and Tests
FullDiT's training approach relied on selectively annotated datasets tailored to each conditioning type, rather than requiring all conditions to be present simultaneously.
For textual conditions, the initiative follows the structured captioning approach outlined in the MiraData project.
 *Video collection and annotation pipeline from the MiraData project.* Source: https://arxiv.org/pdf/2407.06358
*Video collection and annotation pipeline from the MiraData project.* Source: https://arxiv.org/pdf/2407.06358
For camera motion, the RealEstate10K dataset was the main data source, due to its high-quality ground-truth annotations of camera parameters. However, the authors observed that training exclusively on static-scene camera datasets like RealEstate10K tended to reduce dynamic object and human movements in generated videos. To counteract this, they conducted additional fine-tuning using internal datasets that included more dynamic camera motions.
Identity annotations were generated using the pipeline developed for the ConceptMaster project, which allowed efficient filtering and extraction of fine-grained identity information.
 *The ConceptMaster framework is designed to address identity decoupling issues while preserving concept fidelity in customized videos.* Source: https://arxiv.org/pdf/2501.04698
*The ConceptMaster framework is designed to address identity decoupling issues while preserving concept fidelity in customized videos.* Source: https://arxiv.org/pdf/2501.04698
Depth annotations were obtained from the Panda-70M dataset using Depth Anything.
Optimization Through Data-Ordering
The authors also implemented a progressive training schedule, introducing more challenging conditions earlier in training to ensure the model acquired robust representations before simpler tasks were added. The training order proceeded from text to camera conditions, then identities, and finally depth, with easier tasks generally introduced later and with fewer examples.
The authors emphasize the value of ordering the workload in this way:
**‘During the pre-training phase, we noted that more challenging tasks demand extended training time and should be introduced earlier in the learning process. These challenging tasks involve complex data distributions that differ significantly from the output video, requiring the model to possess sufficient capacity to accurately capture and represent them.**
**‘Conversely, introducing easier tasks too early may lead the model to prioritize learning them first, since they provide more immediate optimization feedback, which hinder the convergence of more challenging tasks.'**
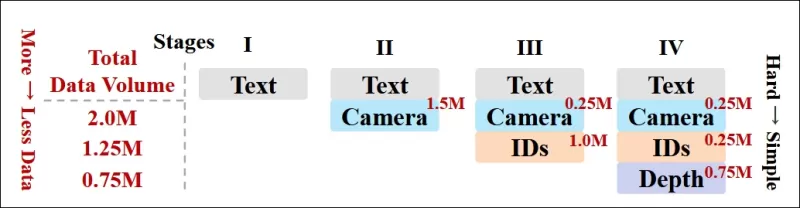 *An illustration of the data training order adopted by the researchers, with red indicating greater data volume.*
*An illustration of the data training order adopted by the researchers, with red indicating greater data volume.*
After initial pre-training, a final fine-tuning stage further refined the model to improve visual quality and motion dynamics. Thereafter, the training followed that of a standard diffusion framework: noise added to video latents, and the model learning to predict and remove it, using the embedded condition tokens as guidance.
To effectively evaluate FullDiT and provide a fair comparison against existing methods, and in the absence of any other apposite benchmark, the authors introduced **FullBench**, a curated benchmark suite consisting of 1,400 distinct test cases.
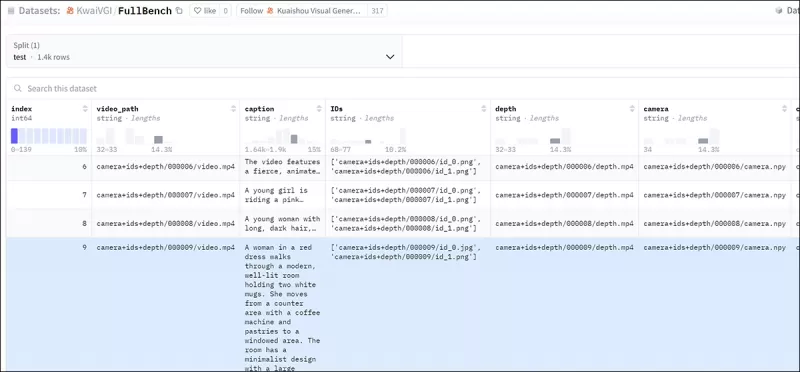 *A data explorer instance for the new FullBench benchmark.* Source: https://huggingface.co/datasets/KwaiVGI/FullBench
*A data explorer instance for the new FullBench benchmark.* Source: https://huggingface.co/datasets/KwaiVGI/FullBench
Each data point provided ground truth annotations for various conditioning signals, including camera motion, identity, and depth.
Metrics
The authors evaluated FullDiT using ten metrics covering five main aspects of performance: text alignment, camera control, identity similarity, depth accuracy, and general video quality.
Text alignment was measured using CLIP similarity, while camera control was assessed through rotation error (RotErr), translation error (TransErr), and camera motion consistency (CamMC), following the approach of CamI2V (in the CameraCtrl project).
Identity similarity was evaluated using DINO-I and CLIP-I, and depth control accuracy was quantified using Mean Absolute Error (MAE).
Video quality was judged with three metrics from MiraData: frame-level CLIP similarity for smoothness; optical flow-based motion distance for dynamics; and LAION-Aesthetic scores for visual appeal.
Training
The authors trained FullDiT using an internal (undisclosed) text-to-video diffusion model containing roughly one billion parameters. They intentionally chose a modest parameter size to maintain fairness in comparisons with prior methods and ensure reproducibility.
Since training videos differed in length and resolution, the authors standardized each batch by resizing and padding videos to a common resolution, sampling 77 frames per sequence, and using applied attention and loss masks to optimize training effectiveness.
The Adam optimizer was used at a learning rate of 1×10−5 across a cluster of 64 NVIDIA H800 GPUs, for a combined total of 5,120GB of VRAM (consider that in the enthusiast synthesis communities, 24GB on an RTX 3090 is still considered a luxurious standard).
The model was trained for around 32,000 steps, incorporating up to three identities per video, along with 20 frames of camera conditions and 21 frames of depth conditions, both evenly sampled from the total 77 frames.
For inference, the model generated videos at a resolution of 384×672 pixels (roughly five seconds at 15 frames per second) with 50 diffusion inference steps and a classifier-free guidance scale of five.
Prior Methods
For camera-to-video evaluation, the authors compared FullDiT against MotionCtrl, CameraCtrl, and CamI2V, with all models trained using the RealEstate10k dataset to ensure consistency and fairness.
In identity-conditioned generation, since no comparable open-source multi-identity models were available, the model was benchmarked against the 1B-parameter ConceptMaster model, using the same training data and architecture.
For depth-to-video tasks, comparisons were made with Ctrl-Adapter and ControlVideo.
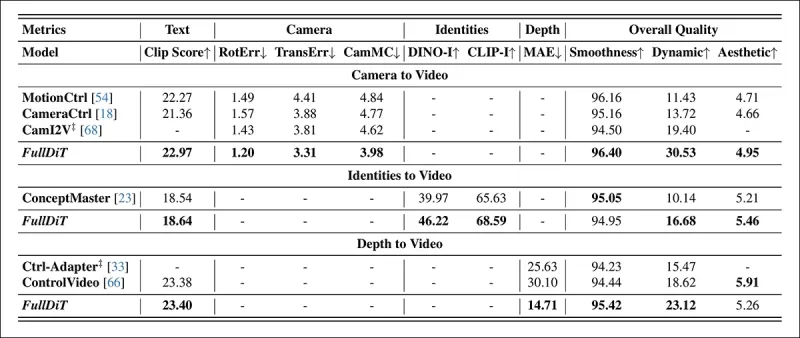 *Quantitative results for single-task video generation. FullDiT was compared to MotionCtrl, CameraCtrl, and CamI2V for camera-to-video generation; ConceptMaster (1B parameter version) for identity-to-video; and Ctrl-Adapter and ControlVideo for depth-to-video. All models were evaluated using their default settings. For consistency, 16 frames were uniformly sampled from each method, matching the output length of prior models.*
*Quantitative results for single-task video generation. FullDiT was compared to MotionCtrl, CameraCtrl, and CamI2V for camera-to-video generation; ConceptMaster (1B parameter version) for identity-to-video; and Ctrl-Adapter and ControlVideo for depth-to-video. All models were evaluated using their default settings. For consistency, 16 frames were uniformly sampled from each method, matching the output length of prior models.*
The results indicate that FullDiT, despite handling multiple conditioning signals simultaneously, achieved state-of-the-art performance in metrics related to text, camera motion, identity, and depth controls.
In overall quality metrics, the system generally outperformed other methods, although its smoothness was slightly lower than ConceptMaster's. Here the authors comment:
**‘The smoothness of FullDiT is slightly lower than that of ConceptMaster since the calculation of smoothness is based on CLIP similarity between adjacent frames. As FullDiT exhibits significantly greater dynamics compared to ConceptMaster, the smoothness metric is impacted by the large variations between adjacent frames.**
**‘For the aesthetic score, since the rating model favors images in painting style and ControlVideo typically generates videos in this style, it achieves a high score in aesthetics.'**
Regarding the qualitative comparison, it might be preferable to refer to the sample videos at the FullDiT project site, since the PDF examples are inevitably static (and also too large to entirely reproduce here).
 *The first section of the qualitative results in the PDF. Please refer to the source paper for the additional examples, which are too extensive to reproduce here.*
*The first section of the qualitative results in the PDF. Please refer to the source paper for the additional examples, which are too extensive to reproduce here.*
The authors comment:
**‘FullDiT demonstrates superior identity preservation and generates videos with better dynamics and visual quality compared to [ConceptMaster]. Since ConceptMaster and FullDiT are trained on the same backbone, this highlights the effectiveness of condition injection with full attention.**
**‘…The [other] results demonstrate the superior controllability and generation quality of FullDiT compared to existing depth-to-video and camera-to-video methods.'**
 *A section of the PDF's examples of FullDiT's output with multiple signals. Please refer to the source paper and the project site for additional examples.*
*A section of the PDF's examples of FullDiT's output with multiple signals. Please refer to the source paper and the project site for additional examples.*
Conclusion
FullDiT represents an exciting step towards a more comprehensive video foundation model, but the question remains whether the demand for ControlNet-style features justifies their implementation at scale, especially for open-source projects. These projects would struggle to obtain the vast GPU processing power required without commercial support.
The primary challenge is that using systems like Depth and Pose generally requires a non-trivial familiarity with complex user interfaces like ComfyUI. Therefore, a functional open-source model of this kind is most likely to be developed by smaller VFX companies that lack the resources or motivation to curate and train such a model privately.
On the other hand, API-driven 'rent-an-AI' systems may be well-motivated to develop simpler and more user-friendly interpretive methods for models with directly trained ancillary control systems.
**Click to play. Depth+Text controls imposed on a video generation using FullDiT.**
*The authors do not specify any known base model (i.e., SDXL, etc.)*
**First published Thursday, March 27, 2025**
Related article
 Tencent Unveils HunyuanCustom for Single-Image Video Customization
This article explores the launch of HunyuanCustom, a multimodal video generation model by Tencent. The extensive scope of the accompanying research paper and challenges with the provided example video
Unveiling Subtle Yet Impactful AI Modifications in Authentic Video Content
In 2019, a deceptive video of Nancy Pelosi, then Speaker of the US House of Representatives, circulated widely. The video, which was edited to make her appear intoxicated, was a stark reminder of how easily manipulated media can mislead the public. Despite its simplicity, this incident highlighted t
OpenAI plans to bring Sora’s video generator to ChatGPT
OpenAI plans to integrate its AI video generation tool, Sora, into its popular consumer chatbot, ChatGPT. This was revealed by company leaders during a recent office hours session on Discord. Currently, Sora is accessible only through a dedicated web app launched by OpenAI in December, allowing user
Comments (2)
0/200
Tencent Unveils HunyuanCustom for Single-Image Video Customization
This article explores the launch of HunyuanCustom, a multimodal video generation model by Tencent. The extensive scope of the accompanying research paper and challenges with the provided example video
Unveiling Subtle Yet Impactful AI Modifications in Authentic Video Content
In 2019, a deceptive video of Nancy Pelosi, then Speaker of the US House of Representatives, circulated widely. The video, which was edited to make her appear intoxicated, was a stark reminder of how easily manipulated media can mislead the public. Despite its simplicity, this incident highlighted t
OpenAI plans to bring Sora’s video generator to ChatGPT
OpenAI plans to integrate its AI video generation tool, Sora, into its popular consumer chatbot, ChatGPT. This was revealed by company leaders during a recent office hours session on Discord. Currently, Sora is accessible only through a dedicated web app launched by OpenAI in December, allowing user
Comments (2)
0/200
![CharlesMartinez]() CharlesMartinez
CharlesMartinez
 September 3, 2025 at 12:30:37 PM EDT
September 3, 2025 at 12:30:37 PM EDT
Finalmente os vídeos gerados por IA estão evoluindo para algo útil! Mas ainda parece que falta muito pra substituir os efeitos manuais de grandes produções... será que um dia chegaremos lá? 🎥


 0
0
![DonaldLee]() DonaldLee
July 27, 2025 at 9:20:02 PM EDT
DonaldLee
July 27, 2025 at 9:20:02 PM EDT
The idea of AI taking over VFX in films is wild! I mean, total control over video generation? That’s some sci-fi stuff coming to life. But I wonder if these models like Hunyuan can really nail the tiny details directors obsess over. Exciting times! 🎥
0
Video foundation models like Hunyuan and Wan 2.1 have made significant strides, but they often fall short when it comes to the detailed control required in film and TV production, especially in the realm of visual effects (VFX). In professional VFX studios, these models, along with earlier image-based models like Stable Diffusion, Kandinsky, and Flux, are used in conjunction with a suite of tools designed to refine their output to meet specific creative demands. When a director requests a tweak, saying something like, "That looks great, but can we make it a little more [n]?", it's not enough to simply state that the model lacks the precision to make such adjustments.
Instead, an AI VFX team will employ a combination of traditional CGI and compositional techniques, along with custom-developed workflows, to push the boundaries of video synthesis further. This approach is akin to using a default web browser like Chrome; it's functional out of the box, but to truly tailor it to your needs, you'll need to install some plugins.
Control Freaks
In the field of diffusion-based image synthesis, one of the most crucial third-party systems is ControlNet. This technique introduces structured control to generative models, allowing users to guide image or video generation using additional inputs such as edge maps, depth maps, or pose information.
*ControlNet's various methods allow for depth>image (top row), semantic segmentation>image (lower left) and pose-guided image generation of humans and animals (lower left).*
ControlNet doesn't rely solely on text prompts; it employs separate neural network branches, or adapters, to process these conditioning signals while maintaining the generative capabilities of the base model. This enables highly customized outputs that closely align with user specifications, making it invaluable for applications requiring precise control over composition, structure, or motion.
*With a guiding pose, a variety of accurate output types can be obtained via ControlNet.* Source: https://arxiv.org/pdf/2302.05543
However, these adapter-based systems, which operate externally on a set of internally-focused neural processes, come with several drawbacks. Adapters are trained independently, which can lead to branch conflicts when multiple adapters are combined, often resulting in lower quality generations. They also introduce parameter redundancy, requiring additional computational resources and memory for each adapter, making scaling inefficient. Moreover, despite their flexibility, adapters often yield sub-optimal results compared to models fully fine-tuned for multi-condition generation. These issues can make adapter-based methods less effective for tasks that require the seamless integration of multiple control signals.
Ideally, ControlNet's capabilities would be natively integrated into the model in a modular fashion, allowing for future innovations like simultaneous video/audio generation or native lip-sync capabilities. Currently, each additional feature either becomes a post-production task or a non-native procedure that must navigate the sensitive weights of the foundation model.
FullDiT
Enter FullDiT, a new approach from China that integrates ControlNet-style features directly into a generative video model during training, rather than treating them as an afterthought.
*From the new paper: the FullDiT approach can incorporate identity imposition, depth and camera movement into a native generation, and can summon up any combination of these at once.* Source: https://arxiv.org/pdf/2503.19907
FullDiT, as outlined in the paper titled **FullDiT: Multi-Task Video Generative Foundation Model with Full Attention**, integrates multi-task conditions such as identity transfer, depth-mapping, and camera movement into the core of a trained generative video model. The authors have developed a prototype model and accompanying video clips available at a project site.
**Click to play. Examples of ControlNet-style user imposition with only a native trained foundation model.** Source: https://fulldit.github.io/
The authors present FullDiT as a proof-of-concept for native text-to-video (T2V) and image-to-video (I2V) models that offer users more control than just an image or text prompt. Since no similar models exist, the researchers created a new benchmark called **FullBench** for evaluating multi-task videos, claiming state-of-the-art performance in their devised tests. However, the objectivity of FullBench, designed by the authors themselves, remains untested, and its dataset of 1,400 cases may be too limited for broader conclusions.
The most intriguing aspect of FullDiT's architecture is its potential to incorporate new types of control. The authors note:
**‘In this work, we only explore control conditions of the camera, identities, and depth information. We did not further investigate other conditions and modalities such as audio, speech, point cloud, object bounding boxes, optical flow, etc. Although the design of FullDiT can seamlessly integrate other modalities with minimal architecture modification, how to quickly and cost-effectively adapt existing models to new conditions and modalities is still an important question that warrants further exploration.'**
While FullDiT represents a step forward in multi-task video generation, it builds on existing architectures rather than introducing a new paradigm. Nonetheless, it stands out as the only video foundation model with natively integrated ControlNet-style features, and its architecture is designed to accommodate future innovations.
**Click to play. Examples of user-controlled camera moves, from the project site.**
The paper, authored by nine researchers from Kuaishou Technology and The Chinese University of Hong Kong, is titled **FullDiT: Multi-Task Video Generative Foundation Model with Full Attention**. The project page and new benchmark data are available at Hugging Face.
Method
FullDiT's unified attention mechanism is designed to enhance cross-modal representation learning by capturing both spatial and temporal relationships across conditions.
*According to the new paper, FullDiT integrates multiple input conditions through full self-attention, converting them into a unified sequence. By contrast, adapter-based models (leftmost above) use separate modules for each input, leading to redundancy, conflicts, and weaker performance.*
Unlike adapter-based setups that process each input stream separately, FullDiT's shared attention structure avoids branch conflicts and reduces parameter overhead. The authors claim that the architecture can scale to new input types without major redesign and that the model schema shows signs of generalizing to condition combinations not seen during training, such as linking camera motion with character identity.
**Click to play. Examples of identity generation from the project site**.
In FullDiT's architecture, all conditioning inputs—such as text, camera motion, identity, and depth—are first converted into a unified token format. These tokens are then concatenated into a single long sequence, processed through a stack of transformer layers using full self-attention. This approach follows prior works like Open-Sora Plan and Movie Gen.
This design allows the model to learn temporal and spatial relationships jointly across all conditions. Each transformer block operates over the entire sequence, enabling dynamic interactions between modalities without relying on separate modules for each input. The architecture is designed to be extensible, making it easier to incorporate additional control signals in the future without major structural changes.
The Power of Three
FullDiT converts each control signal into a standardized token format so that all conditions can be processed together in a unified attention framework. For camera motion, the model encodes a sequence of extrinsic parameters—such as position and orientation—for each frame. These parameters are timestamped and projected into embedding vectors that reflect the temporal nature of the signal.
Identity information is treated differently, as it is inherently spatial rather than temporal. The model uses identity maps that indicate which characters are present in which parts of each frame. These maps are divided into patches, with each patch projected into an embedding that captures spatial identity cues, allowing the model to associate specific regions of the frame with specific entities.
Depth is a spatiotemporal signal, and the model handles it by dividing depth videos into 3D patches that span both space and time. These patches are then embedded in a way that preserves their structure across frames.
Once embedded, all of these condition tokens (camera, identity, and depth) are concatenated into a single long sequence, allowing FullDiT to process them together using full self-attention. This shared representation enables the model to learn interactions across modalities and across time without relying on isolated processing streams.
Data and Tests
FullDiT's training approach relied on selectively annotated datasets tailored to each conditioning type, rather than requiring all conditions to be present simultaneously.
For textual conditions, the initiative follows the structured captioning approach outlined in the MiraData project.
*Video collection and annotation pipeline from the MiraData project.* Source: https://arxiv.org/pdf/2407.06358
For camera motion, the RealEstate10K dataset was the main data source, due to its high-quality ground-truth annotations of camera parameters. However, the authors observed that training exclusively on static-scene camera datasets like RealEstate10K tended to reduce dynamic object and human movements in generated videos. To counteract this, they conducted additional fine-tuning using internal datasets that included more dynamic camera motions.
Identity annotations were generated using the pipeline developed for the ConceptMaster project, which allowed efficient filtering and extraction of fine-grained identity information.
*The ConceptMaster framework is designed to address identity decoupling issues while preserving concept fidelity in customized videos.* Source: https://arxiv.org/pdf/2501.04698
Depth annotations were obtained from the Panda-70M dataset using Depth Anything.
Optimization Through Data-Ordering
The authors also implemented a progressive training schedule, introducing more challenging conditions earlier in training to ensure the model acquired robust representations before simpler tasks were added. The training order proceeded from text to camera conditions, then identities, and finally depth, with easier tasks generally introduced later and with fewer examples.
The authors emphasize the value of ordering the workload in this way:
**‘During the pre-training phase, we noted that more challenging tasks demand extended training time and should be introduced earlier in the learning process. These challenging tasks involve complex data distributions that differ significantly from the output video, requiring the model to possess sufficient capacity to accurately capture and represent them.**
**‘Conversely, introducing easier tasks too early may lead the model to prioritize learning them first, since they provide more immediate optimization feedback, which hinder the convergence of more challenging tasks.'**
*An illustration of the data training order adopted by the researchers, with red indicating greater data volume.*
After initial pre-training, a final fine-tuning stage further refined the model to improve visual quality and motion dynamics. Thereafter, the training followed that of a standard diffusion framework: noise added to video latents, and the model learning to predict and remove it, using the embedded condition tokens as guidance.
To effectively evaluate FullDiT and provide a fair comparison against existing methods, and in the absence of any other apposite benchmark, the authors introduced **FullBench**, a curated benchmark suite consisting of 1,400 distinct test cases.
*A data explorer instance for the new FullBench benchmark.* Source: https://huggingface.co/datasets/KwaiVGI/FullBench
Each data point provided ground truth annotations for various conditioning signals, including camera motion, identity, and depth.
Metrics
The authors evaluated FullDiT using ten metrics covering five main aspects of performance: text alignment, camera control, identity similarity, depth accuracy, and general video quality.
Text alignment was measured using CLIP similarity, while camera control was assessed through rotation error (RotErr), translation error (TransErr), and camera motion consistency (CamMC), following the approach of CamI2V (in the CameraCtrl project).
Identity similarity was evaluated using DINO-I and CLIP-I, and depth control accuracy was quantified using Mean Absolute Error (MAE).
Video quality was judged with three metrics from MiraData: frame-level CLIP similarity for smoothness; optical flow-based motion distance for dynamics; and LAION-Aesthetic scores for visual appeal.
Training
The authors trained FullDiT using an internal (undisclosed) text-to-video diffusion model containing roughly one billion parameters. They intentionally chose a modest parameter size to maintain fairness in comparisons with prior methods and ensure reproducibility.
Since training videos differed in length and resolution, the authors standardized each batch by resizing and padding videos to a common resolution, sampling 77 frames per sequence, and using applied attention and loss masks to optimize training effectiveness.
The Adam optimizer was used at a learning rate of 1×10−5 across a cluster of 64 NVIDIA H800 GPUs, for a combined total of 5,120GB of VRAM (consider that in the enthusiast synthesis communities, 24GB on an RTX 3090 is still considered a luxurious standard).
The model was trained for around 32,000 steps, incorporating up to three identities per video, along with 20 frames of camera conditions and 21 frames of depth conditions, both evenly sampled from the total 77 frames.
For inference, the model generated videos at a resolution of 384×672 pixels (roughly five seconds at 15 frames per second) with 50 diffusion inference steps and a classifier-free guidance scale of five.
Prior Methods
For camera-to-video evaluation, the authors compared FullDiT against MotionCtrl, CameraCtrl, and CamI2V, with all models trained using the RealEstate10k dataset to ensure consistency and fairness.
In identity-conditioned generation, since no comparable open-source multi-identity models were available, the model was benchmarked against the 1B-parameter ConceptMaster model, using the same training data and architecture.
For depth-to-video tasks, comparisons were made with Ctrl-Adapter and ControlVideo.
*Quantitative results for single-task video generation. FullDiT was compared to MotionCtrl, CameraCtrl, and CamI2V for camera-to-video generation; ConceptMaster (1B parameter version) for identity-to-video; and Ctrl-Adapter and ControlVideo for depth-to-video. All models were evaluated using their default settings. For consistency, 16 frames were uniformly sampled from each method, matching the output length of prior models.*
The results indicate that FullDiT, despite handling multiple conditioning signals simultaneously, achieved state-of-the-art performance in metrics related to text, camera motion, identity, and depth controls.
In overall quality metrics, the system generally outperformed other methods, although its smoothness was slightly lower than ConceptMaster's. Here the authors comment:
**‘The smoothness of FullDiT is slightly lower than that of ConceptMaster since the calculation of smoothness is based on CLIP similarity between adjacent frames. As FullDiT exhibits significantly greater dynamics compared to ConceptMaster, the smoothness metric is impacted by the large variations between adjacent frames.**
**‘For the aesthetic score, since the rating model favors images in painting style and ControlVideo typically generates videos in this style, it achieves a high score in aesthetics.'**
Regarding the qualitative comparison, it might be preferable to refer to the sample videos at the FullDiT project site, since the PDF examples are inevitably static (and also too large to entirely reproduce here).
*The first section of the qualitative results in the PDF. Please refer to the source paper for the additional examples, which are too extensive to reproduce here.*
The authors comment:
**‘FullDiT demonstrates superior identity preservation and generates videos with better dynamics and visual quality compared to [ConceptMaster]. Since ConceptMaster and FullDiT are trained on the same backbone, this highlights the effectiveness of condition injection with full attention.**
**‘…The [other] results demonstrate the superior controllability and generation quality of FullDiT compared to existing depth-to-video and camera-to-video methods.'**
*A section of the PDF's examples of FullDiT's output with multiple signals. Please refer to the source paper and the project site for additional examples.*
Conclusion
FullDiT represents an exciting step towards a more comprehensive video foundation model, but the question remains whether the demand for ControlNet-style features justifies their implementation at scale, especially for open-source projects. These projects would struggle to obtain the vast GPU processing power required without commercial support.
The primary challenge is that using systems like Depth and Pose generally requires a non-trivial familiarity with complex user interfaces like ComfyUI. Therefore, a functional open-source model of this kind is most likely to be developed by smaller VFX companies that lack the resources or motivation to curate and train such a model privately.
On the other hand, API-driven 'rent-an-AI' systems may be well-motivated to develop simpler and more user-friendly interpretive methods for models with directly trained ancillary control systems.
**Click to play. Depth+Text controls imposed on a video generation using FullDiT.**
*The authors do not specify any known base model (i.e., SDXL, etc.)*
**First published Thursday, March 27, 2025**










 Tencent Unveils HunyuanCustom for Single-Image Video Customization
This article explores the launch of HunyuanCustom, a multimodal video generation model by Tencent. The extensive scope of the accompanying research paper and challenges with the provided example video
Tencent Unveils HunyuanCustom for Single-Image Video Customization
This article explores the launch of HunyuanCustom, a multimodal video generation model by Tencent. The extensive scope of the accompanying research paper and challenges with the provided example video
 Unveiling Subtle Yet Impactful AI Modifications in Authentic Video Content
In 2019, a deceptive video of Nancy Pelosi, then Speaker of the US House of Representatives, circulated widely. The video, which was edited to make her appear intoxicated, was a stark reminder of how easily manipulated media can mislead the public. Despite its simplicity, this incident highlighted t
Unveiling Subtle Yet Impactful AI Modifications in Authentic Video Content
In 2019, a deceptive video of Nancy Pelosi, then Speaker of the US House of Representatives, circulated widely. The video, which was edited to make her appear intoxicated, was a stark reminder of how easily manipulated media can mislead the public. Despite its simplicity, this incident highlighted t
 OpenAI plans to bring Sora’s video generator to ChatGPT
OpenAI plans to integrate its AI video generation tool, Sora, into its popular consumer chatbot, ChatGPT. This was revealed by company leaders during a recent office hours session on Discord. Currently, Sora is accessible only through a dedicated web app launched by OpenAI in December, allowing user
September 3, 2025 at 12:30:37 PM EDT
OpenAI plans to bring Sora’s video generator to ChatGPT
OpenAI plans to integrate its AI video generation tool, Sora, into its popular consumer chatbot, ChatGPT. This was revealed by company leaders during a recent office hours session on Discord. Currently, Sora is accessible only through a dedicated web app launched by OpenAI in December, allowing user
September 3, 2025 at 12:30:37 PM EDT
Finalmente os vídeos gerados por IA estão evoluindo para algo útil! Mas ainda parece que falta muito pra substituir os efeitos manuais de grandes produções... será que um dia chegaremos lá? 🎥
0
July 27, 2025 at 9:20:02 PM EDT
The idea of AI taking over VFX in films is wild! I mean, total control over video generation? That’s some sci-fi stuff coming to life. But I wonder if these models like Hunyuan can really nail the tiny details directors obsess over. Exciting times! 🎥
0













