
















 家
家AIビデオ生成は完全な制御に向かって移動します
ビデオ基礎モデルであるHunyuanやWan 2.1は大きな進歩を遂げていますが、映画やテレビ制作、特に視覚効果(VFX)の分野で必要とされる詳細な制御に関しては、しばしば不十分です。プロのVFXスタジオでは、これらのモデルや、Stable Diffusion、Kandinsky、Fluxなどの以前の画像ベースのモデルを、特定のクリエイティブな要求を満たすために出力を洗練させるためのツール群と組み合わせて使用しています。監督が「素晴らしい見た目だけど、もう少し[n]にできないか?」と微調整を要求したとき、モデルにそのような調整を行う精度が不足していると単に述べるだけでは十分ではありません。
その代わりに、AI VFXチームは、従来のCGIや合成技術と、カスタム開発されたワークフローを組み合わせて、ビデオ合成の限界をさらに押し広げます。このアプローチは、Chromeのようなデフォルトのウェブブラウザを使用するのに似ています。すぐに使える機能はありますが、ニーズに合わせて完全にカスタマイズするには、プラグインをインストールする必要があります。
コントロールフリーク
拡散ベースの画像合成の分野では、最も重要なサードパーティシステムの一つがControlNetです。この技術は、生成モデルに構造化された制御を導入し、エッジマップ、深度マップ、ポーズ情報などの追加入力を使用して、画像やビデオ生成をガイドすることができます。
 *ControlNetのさまざまな手法により、深度>画像(上段)、セマンティックセグメンテーション>画像(左下)、および人間や動物のポーズガイド付き画像生成(左下)が可能です。*
*ControlNetのさまざまな手法により、深度>画像(上段)、セマンティックセグメンテーション>画像(左下)、および人間や動物のポーズガイド付き画像生成(左下)が可能です。*
ControlNetはテキストプロンプトにのみ依存するのではなく、別々のニューラルネットワークブランチやアダプターを使用してこれらの条件付け信号を処理し、ベースモデルの生成能力を維持します。これにより、ユーザーの仕様に密接に一致する高度にカスタマイズされた出力が可能になり、構図、構造、または動きを正確に制御する必要があるアプリケーションにとって非常に価値があります。
 *ガイドポーズを使用することで、ControlNetを通じてさまざまな正確な出力タイプを得ることができます。* ソース: https://arxiv.org/pdf/2302.05543
*ガイドポーズを使用することで、ControlNetを通じてさまざまな正確な出力タイプを得ることができます。* ソース: https://arxiv.org/pdf/2302.05543
しかし、内部に焦点を当てたニューラルプロセス上で外部的に動作するこれらのアダプターベースのシステムには、いくつかの欠点があります。アダプターは独立してトレーニングされるため、複数のアダプターを組み合わせるとブランチ間の競合が発生し、生成品質が低下することがあります。また、アダプターごとに追加の計算リソースとメモリが必要となり、スケーリングが非効率になります。さらに、その柔軟性にもかかわらず、アダプターはマルチコンディション生成用に完全に微調整されたモデルに比べて、しばしば最適でない結果を生成します。これらの問題により、複数の制御信号をシームレスに統合する必要があるタスクでは、アダプターベースの手法が効果を発揮しにくい場合があります。
理想的には、ControlNetの機能がモジュール形式でモデルにネイティブに統合され、ビデオ/オーディオの同時生成やネイティブなリップシンク機能などの将来のイノベーションが可能になるはずです。現在、追加機能はポストプロダクションのタスクとなったり、基礎モデルの敏感な重みを扱う非ネイティブな手順となったりします。
FullDiT
中国発の新しいアプローチであるFullDiTは、ControlNetスタイルの機能をトレーニング中に直接生成ビデオモデルに統合し、後付けとして扱うのではなく、根本的に組み込みます。
 *新しい論文によると、FullDiTアプローチは、アイデンティティの強制、深度、カメラの動きをネイティブな生成に組み込むことができ、これらを任意に組み合わせることができます。* ソース: https://arxiv.org/pdf/2503.19907
*新しい論文によると、FullDiTアプローチは、アイデンティティの強制、深度、カメラの動きをネイティブな生成に組み込むことができ、これらを任意に組み合わせることができます。* ソース: https://arxiv.org/pdf/2503.19907
論文「FullDiT: Multi-Task Video Generative Foundation Model with Full Attention」に記載されているFullDiTは、アイデンティティ転送、深度マッピング、カメラの動きなどのマルチタスク条件をトレーニングされた生成ビデオモデルのコアに統合します。著者らはプロトタイプモデルと、プロジェクトサイトで利用可能な関連ビデオクリップを開発しました。
**クリックして再生。ControlNetスタイルのユーザー強制の例で、ネイティブにトレーニングされた基礎モデルのみを使用。** ソース: https://fulldit.github.io/
著者らは、FullDiTをテキストからビデオ(T2V)および画像からビデオ(I2V)モデルの概念実証として提示し、画像やテキストプロンプトだけでなく、ユーザーにより多くの制御を提供します。類似のモデルが存在しないため、研究者らはマルチタスクビデオを評価するための新しいベンチマーク「FullBench」を作成し、彼らが設計したテストで最先端のパフォーマンスを主張しています。ただし、著者自身が設計したFullBenchの客観性は検証されておらず、1,400ケースのデータセットは広範な結論には限定的すぎる可能性があります。
FullDiTのアーキテクチャの最も興味深い側面は、新しい制御タイプを組み込む可能性です。著者らは次のように述べています:
**「本研究では、カメラ、アイデンティティ、深度情報の制御条件のみを検討しました。オーディオ、スピーチ、ポイントクラウド、オブジェクトのバウンディングボックス、光学フローなどの他の条件やモダリティはさらに調査していません。FullDiTの設計は、他のモダリティを最小限のアーキテクチャ変更でシームレスに統合できますが、既存のモデルを新しい条件やモダリティに迅速かつコスト効率よく適応させる方法は、引き続き重要な課題であり、さらなる探求が必要です。」**
FullDiTはマルチタスクビデオ生成の前進を象徴していますが、既存のアーキテクチャを基盤としており、新しいパラダイムを導入するものではありません。それでも、ControlNetスタイルの機能をネイティブに統合した唯一のビデオ基礎モデルとして際立っており、そのアーキテクチャは将来のイノベーションに対応するよう設計されています。
**クリックして再生。プロジェクトサイトからのユーザー制御カメラ移動の例。**
この論文は、Kuaishou Technologyと香港中文大学の9人の研究者によって執筆され、タイトルは「FullDiT: Multi-Task Video Generative Foundation Model with Full Attention」です。プロジェクトページと新しいベンチマークデータはHugging Faceで利用可能です。
メソッド
FullDiTの統一アテンション機構は、条件間の空間的および時間的関係を捉えることで、クロスモーダル表現学習を強化するように設計されています。
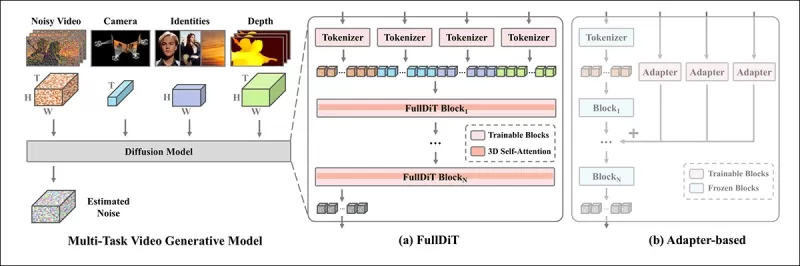 *新しい論文によると、FullDiTはフルセルフアテンションを通じて複数の入力条件を統合し、それらを統一されたシーケンスに変換します。一方、アダプターベースのモデル(最左)は各入力に対して別々のモジュールを使用し、冗長性、競合、弱いパフォーマンスを引き起こします。*
*新しい論文によると、FullDiTはフルセルフアテンションを通じて複数の入力条件を統合し、それらを統一されたシーケンスに変換します。一方、アダプターベースのモデル(最左)は各入力に対して別々のモジュールを使用し、冗長性、競合、弱いパフォーマンスを引き起こします。*
各入力ストリームを個別に処理するアダプターベースの設定とは異なり、FullDiTの共有アテンション構造はブランチ間の競合を回避し、パラメータのオーバーヘッドを削減します。著者らは、このアーキテクチャが大幅な再設計なしに新しい入力タイプにスケールでき、モデルスキーマがトレーニング中に見られなかった条件の組み合わせ(カメラの動きとキャラクターのアイデンティティのリンクなど)に一般化する兆候を示していると主張しています。
**クリックして再生。プロジェクトサイトからのアイデンティティ生成の例。**
FullDiTのアーキテクチャでは、テキスト、カメラの動き、アイデンティティ、深度などのすべての条件付け入力が、まず統一されたトークン形式に変換されます。これらのトークンは単一の長いシーケンスに連結され、フルセルフアテンションを使用してトランスフォーマーレイヤーのスタックを通じて処理されます。このアプローチは、Open-Sora PlanやMovie Genなどの先行研究に従っています。
この設計により、モデルはすべての条件を時間的および空間的に共同で学習できます。各トランスフォーマーブロックはシーケンス全体を操作し、モダリティ間の動的な相互作用を可能にし、各入力に対して別々のモジュールを必要としません。このアーキテクチャは拡張可能に設計されており、将来の追加制御信号を大幅な構造変更なしに容易に組み込むことができます。
3つの力
FullDiTは各制御信号を標準化されたトークン形式に変換し、すべての条件を統一されたアテンション枠組みで一緒に処理できるようにします。カメラの動きについては、モデルは各フレームの位置や向きなどの外部パラメータのシーケンスをエンコードします。これらのパラメータはタイムスタンプ付きで、信号の時間的性質を反映する埋め込みベクトルに投影されます。
アイデンティティ情報は、時間的ではなく本質的に空間的なため、異なる方法で扱われます。モデルは、各フレームのどの部分にどのキャラクターが存在するかを示すアイデンティティマップを使用します。これらのマップはパッチに分割され、各パッチは空間的アイデンティティの手がかりを捉える埋め込みに投影され、モデルはフレームの特定の領域を特定のエンティティと関連付けることができます。
深度は時空間信号であり、モデルは深度ビデオを空間と時間の両方をカバーする3Dパッチに分割して処理します。これらのパッチは、フレーム間で構造を保持する方法で埋め込まれます。
埋め込み後、カメラ、アイデンティティ、深度のすべての条件トークンは単一の長いシーケンスに連結され、FullDiTがフルセルフアテンションを使用してそれらを一緒に処理できるようになります。この共有表現により、モデルはモダリティ間および時間にわたる相互作用を、独立した処理ストリームに依存せずに学習できます。
データとテスト
FullDiTのトレーニングアプローチは、すべての条件が同時に存在することを要求するのではなく、各条件タイプに合わせた選択的に注釈付けされたデータセットに依存していました。
テキスト条件については、MiraDataプロジェクトで概説された構造化キャプションアプローチに従っています。
 *MiraDataプロジェクトからのビデオ収集および注釈パイプライン。* ソース: https://arxiv.org/pdf/2407.06358
*MiraDataプロジェクトからのビデオ収集および注釈パイプライン。* ソース: https://arxiv.org/pdf/2407.06358
カメラの動きについては、カメラパラメータの高品質なグラウンドトゥルース注釈があるため、RealEstate10Kデータセットが主なデータソースでした。しかし、著者らは、RealEstate10Kのような静的シーンカメラデータセットのみでトレーニングすると、生成されたビデオの動的なオブジェクトや人間の動きが減少する傾向があると観察しました。これに対抗するため、より動的なカメラの動きを含む内部データセットを使用して追加の微調整を行いました。
アイデンティティ注釈は、ConceptMasterプロジェクト用に開発されたパイプラインを使用して生成され、細かいアイデンティティ情報の効率的なフィルタリングと抽出を可能にしました。
 *ConceptMasterフレームワークは、カスタマイズされたビデオでアイデンティティの分離問題に対処しながら、コンセプトの忠実度を維持するように設計されています。* ソース: https://arxiv.org/pdf/2501.04698
*ConceptMasterフレームワークは、カスタマイズされたビデオでアイデンティティの分離問題に対処しながら、コンセプトの忠実度を維持するように設計されています。* ソース: https://arxiv.org/pdf/2501.04698
深度注釈は、Panda-70MデータセットからDepth Anythingを使用して取得されました。
データ順序による最適化
著者らは、モデルが簡単なタスクが追加される前に堅牢な表現を獲得するように、より挑戦的な条件をトレーニングの早い段階で導入する進行的なトレーニングスケジュールも実施しました。トレーニングの順序は、テキストからカメラ条件、次にアイデンティティ、最後に深度へと進み、簡単なタスクは一般に後で、より少ない例で導入されました。
著者らは、このようにワークロードを順序付ける価値を強調しています:
**「プレトレーニングフェーズでは、より挑戦的なタスクは長いトレーニング時間を要求し、学習プロセスで早い段階で導入されるべきだと気づきました。これらの挑戦的なタスクは、出力ビデオとは大きく異なる複雑なデータ分布を伴い、モデルがそれらを正確に捉えて表現する十分な能力を持つ必要があります。」**
**「逆に、簡単なタスクをあまりにも早く導入すると、モデルがそれらを優先的に学習する可能性があり、即時の最適化フィードバックを提供するため、より挑戦的なタスクの収束を妨げる可能性があります。」**
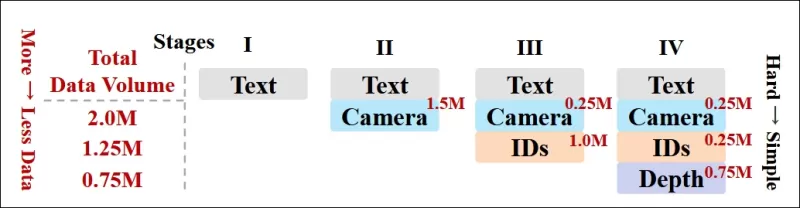 *研究者が採用したデータトレーニング順序の図で、赤はより多くのデータ量を示します。*
*研究者が採用したデータトレーニング順序の図で、赤はより多くのデータ量を示します。*
初期のプレトレーニング後、最終的な微調整段階でモデルをさらに改良し、視覚品質と動きのダイナミクスを改善しました。その後、トレーニングは標準的な拡散フレームワークに従いました:ビデオの潜在空間にノイズを追加し、モデルが埋め込み条件トークンをガイドとして使用してノイズを予測し、除去することを学習します。
FullDiTを効果的に評価し、既存の方法と公平な比較を提供するために、適切な他のベンチマークがない中で、著者らは1,400の異なるテストケースからなるキュレートされたベンチマークスイート「FullBench」を導入しました。
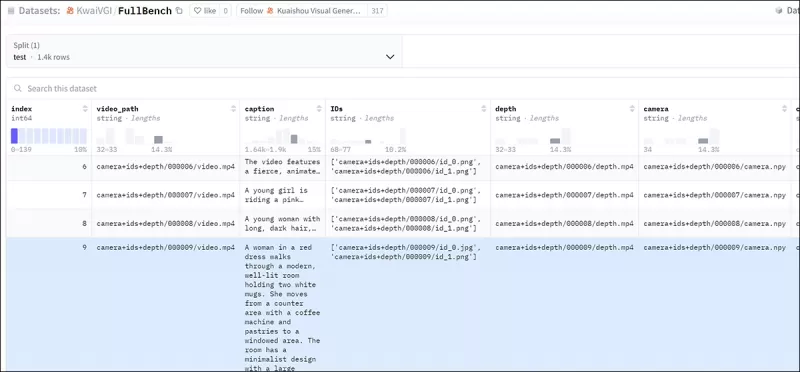 *新しいFullBenchベンチマークのデータエクスプローラインスタンス。* ソース: https://huggingface.co/datasets/KwaiVGI/FullBench
*新しいFullBenchベンチマークのデータエクスプローラインスタンス。* ソース: https://huggingface.co/datasets/KwaiVGI/FullBench
各データポイントは、カメラの動き、アイデンティティ、深度などのさまざまな条件付け信号に対するグラウンドトゥルース注釈を提供しました。
メトリクス
著者らは、テキストの整合性、カメラ制御、アイデンティティの類似性、深度の精度、全体的なビデオ品質の5つの主要なパフォーマンス側面をカバーする10のメトリクスを使用してFullDiTを評価しました。
テキストの整合性はCLIP類似性を使用して測定され、カメラ制御はCameraCtrlプロジェクトのCamI2Vのアプローチに従って、回転エラー(RotErr)、移動エラー(TransErr)、カメラの動きの一貫性(CamMC)を通じて評価されました。
アイデンティティの類似性はDINO-IとCLIP-Iを使用して評価され、深度制御の精度は平均絶対誤差(MAE)で定量化されました。
ビデオ品質は、MiraDataの3つのメトリクスで評価されました:スムーズさのためのフレームレベルのCLIP類似性、ダイナミクスのための光学フローベースの動き距離、視覚的魅力のためのLAION-Aestheticスコアです。
トレーニング
著者らは、約10億のパラメータを含む内部(非公開)のテキストからビデオへの拡散モデルを使用してFullDiTをトレーニングしました。彼らは、以前の方法との比較の公平性を維持し、再現性を確保するために、意図的に適度なパラメータサイズを選択しました。
トレーニングビデオは長さや解像度が異なるため、著者らは各バッチを標準化し、ビデオを共通の解像度にリサイズおよびパディングし、シーケンスごとに77フレームをサンプリングし、アテンションとロスマスクを適用してトレーニングの効果を最適化しました。
Adamオプティマイザは、64台のNVIDIA H800 GPUのクラスタ全体で学習率1×10−5で使用され、合計5,120GBのVRAM(愛好家の合成コミュニティでは、RTX 3090の24GBが依然として豪華な基準と見なされていることを考慮してください)。
モデルは約32,000ステップでトレーニングされ、ビデオごとに最大3つのアイデンティティ、20フレームのカメラ条件、21フレームの深度条件を組み込み、両方とも合計77フレームから均等にサンプリングされました。
推論では、モデルは384×672ピクセルの解像度(15フレーム/秒で約5秒)でビデオを生成し、50の拡散推論ステップと5の分類器なしガイダンススケールを使用しました。
先行方法
カメラからビデオへの評価では、著者らはFullDiTをMotionCtrl、CameraCtrl、CamI2Vと比較し、すべてのモデルは一貫性と公平性を確保するためにRealEstate10kデータセットを使用してトレーニングされました。
アイデンティティ条件付き生成では、比較可能なオープンソースのマルチアイデンティティモデルが存在しないため、モデルは同じトレーニングデータとアーキテクチャを使用して、1BパラメータのConceptMasterモデルとベンチマークされました。
深度からビデオへのタスクでは、Ctrl-AdapterおよびControlVideoと比較されました。
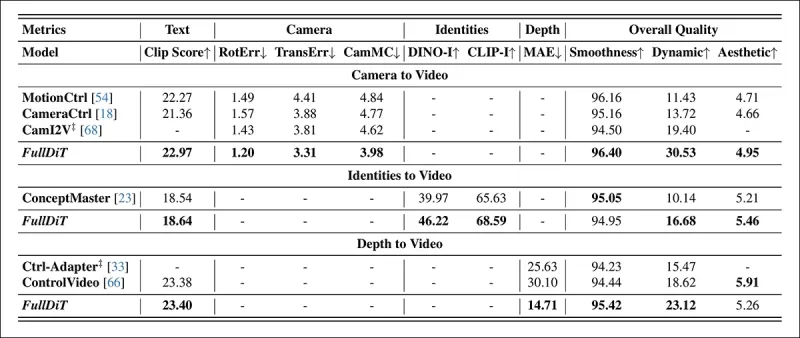 *シングルタスクビデオ生成の定量的結果。FullDiTは、カメラからビデオ生成のためにMotionCtrl、CameraCtrl、CamI2Vと比較され、アイデンティティからビデオのためにConceptMaster(1Bパラメータ版)と比較され、深度からビデオのためにCtrl-AdapterおよびControlVideoと比較されました。すべてのモデルはデフォルト設定で評価されました。一貫性のために、各メソッドから16フレームが均等にサンプリングされ、以前のモデルの出力長に一致しました。*
*シングルタスクビデオ生成の定量的結果。FullDiTは、カメラからビデオ生成のためにMotionCtrl、CameraCtrl、CamI2Vと比較され、アイデンティティからビデオのためにConceptMaster(1Bパラメータ版)と比較され、深度からビデオのためにCtrl-AdapterおよびControlVideoと比較されました。すべてのモデルはデフォルト設定で評価されました。一貫性のために、各メソッドから16フレームが均等にサンプリングされ、以前のモデルの出力長に一致しました。*
結果は、FullDiTが複数の条件付け信号を同時に処理しているにもかかわらず、テキスト、カメラの動き、アイデンティティ、深度制御に関連するメトリクスで最先端のパフォーマンスを達成したことを示しています。
全体的な品質メトリクスでは、システムは一般に他の方法を上回りましたが、スムーズさはConceptMasterに比べてわずかに低かったです。ここで著者らはコメントしています:
**「FullDiTのスムーズさは、隣接フレーム間のCLIP類似性に基づいて計算されるため、ConceptMasterに比べてわずかに低いです。FullDiTはConceptMasterに比べて大幅に高いダイナミクスを示すため、隣接フレーム間の大きな変動がスムーズさのメトリクスに影響を与えます。」**
**「美的スコアについては、評価モデルが絵画スタイルの画像を好むため、ControlVideoが通常このスタイルでビデオを生成し、美的スコアで高い点数を獲得します。」**
定性的な比較については、PDFの例は必然的に静的である(また、ここで完全に再現するには大きすぎる)ため、FullDiTプロジェクトサイトのサンプルビデオを参照する方が良いかもしれません。
 *PDFに再現された定性的結果の最初のセクション。追加の例については、ソース論文を参照してください。ここでは再現するには広範すぎます。*
*PDFに再現された定性的結果の最初のセクション。追加の例については、ソース論文を参照してください。ここでは再現するには広範すぎます。*
著者らはコメントしています:
**「FullDiTは、優れたアイデンティティの保持を示し、[ConceptMaster]に比べてダイナミクスと視覚的品質が優れたビデオを生成します。ConceptMasterとFullDiTは同じバックボーンでトレーニングされているため、フルアテンションによる条件注入の有効性が強調されます。」**
**「…[他の]結果は、既存の深度からビデオおよびカメラからビデオの方法と比較して、FullDiTの優れた制御性と生成品質を示しています。」**
 *PDFのFullDiTの複数信号出力の例のセクション。追加の例については、ソース論文およびプロジェクトサイトを参照してください。*
*PDFのFullDiTの複数信号出力の例のセクション。追加の例については、ソース論文およびプロジェクトサイトを参照してください。*
結論
FullDiTは、より包括的なビデオ基礎モデルに向けたエキサイティングな一歩を表しますが、ControlNetスタイルの機能を大規模に実装する需要が、特にオープンソースプロジェクトにおいて、正当化されるかどうかは疑問です。これらのプロジェクトは、商業的サポートなしでは、必要な膨大なGPU処理能力を確保するのに苦労します。
主な課題は、DepthやPoseなどのシステムを使用するには、ComfyUIのような複雑なユーザーインターフェースに慣れる必要があることです。そのため、この種の機能的なオープンソースモデルは、リソースや動機が不足して独自にモデルをキュレートおよびトレーニングする能力を持たない小さなVFX企業によって開発される可能性が高いです。
一方、API駆動の「AIをレンタルする」システムは、直接トレーニングされた補助制御システムを備えたモデルに対して、よりシンプルでユーザーフレンドリーな解釈方法を開発する強い動機を持つかもしれません。
**クリックして再生。FullDiTを使用してビデオ生成に課されたDepth+Text制御。**
*著者らは、既知のベースモデル(例:SDXLなど)を特定していません。*
**初公開:2025年3月27日(木曜日)**
関連記事
 YouTube、AIを活用した検索機能のテストを開始――ガイド付き回答機能を搭載
多くのユーザーは、レシピや旅行プランを探す際、関連する動画を探そうとYouTubeを利用しています。今回、YouTubeはテキストと動画コンテンツを融合させた、ステップバイステップの検索結果を表示するAI搭載の対話型検索ツールを導入しました。新しい「Ask YouTube」機能を使えば、ユーザーは「サンフランシスコからサンタバーバラまでの3日間のロードトリップを計画して」といった質問を投げかけ、動
独占:Luma AI、『統合インテリジェンス』モデルを搭載したクリエイティブエージェントを発表
木曜日、AI動画生成スタートアップのLumaは、テキスト・画像・動画・音声にまたがる完全なクリエイティブワークフローを管理するシステム「Luma Agents」を発表した。これらのエージェントは、単一のマルチモーダル推論エンジンとして訓練されたアーキテクチャを特徴とするLumaのUnified Intelligenceモデルファミリーによって駆動される。Lumaは、広告代理店、マーケティング部門、
Soraの新アップデートでペットAI動画、ソーシャルツール、Androidアプリが登場
OpenAIは、9月下旬のローンチ後、App Storeのトップに急浮上したブレイク中のAI動画作成アプリ「Sora」の新機能を相次いでプレビューしている。米国とカナダで現在も1位をキープしているこのアプリは、近日中に動画編集機能を追加し、ユーザーがペットやその他のアイテムのキャラクター「カメオ」を作成したり、ソーシャル機能を強化したりする予定だ。同社はまた、Android版が "実際に間もなくリ
関連特集おすすめ
仕事
YouTube、AIを活用した検索機能のテストを開始――ガイド付き回答機能を搭載
多くのユーザーは、レシピや旅行プランを探す際、関連する動画を探そうとYouTubeを利用しています。今回、YouTubeはテキストと動画コンテンツを融合させた、ステップバイステップの検索結果を表示するAI搭載の対話型検索ツールを導入しました。新しい「Ask YouTube」機能を使えば、ユーザーは「サンフランシスコからサンタバーバラまでの3日間のロードトリップを計画して」といった質問を投げかけ、動
独占:Luma AI、『統合インテリジェンス』モデルを搭載したクリエイティブエージェントを発表
木曜日、AI動画生成スタートアップのLumaは、テキスト・画像・動画・音声にまたがる完全なクリエイティブワークフローを管理するシステム「Luma Agents」を発表した。これらのエージェントは、単一のマルチモーダル推論エンジンとして訓練されたアーキテクチャを特徴とするLumaのUnified Intelligenceモデルファミリーによって駆動される。Lumaは、広告代理店、マーケティング部門、
Soraの新アップデートでペットAI動画、ソーシャルツール、Androidアプリが登場
OpenAIは、9月下旬のローンチ後、App Storeのトップに急浮上したブレイク中のAI動画作成アプリ「Sora」の新機能を相次いでプレビューしている。米国とカナダで現在も1位をキープしているこのアプリは、近日中に動画編集機能を追加し、ユーザーがペットやその他のアイテムのキャラクター「カメオ」を作成したり、ソーシャル機能を強化したりする予定だ。同社はまた、Android版が "実際に間もなくリ
関連特集おすすめ
仕事
 おすすめのAI採用ツール:履歴書の選考と候補者の面接スケジュール管理を自動化
おすすめのAI採用ツール:履歴書の選考と候補者の面接スケジュール管理を自動化
XIX.AIで、2026年最新の評価の高いAI採用ツールをチェックしましょう。厳選されたリストには、履歴書のスクリーニングや候補者の面接スケジュール管理を自動化する、強力で画期的なソリューションが揃っています。実際のテスト結果や毎週更新されるランキングを参考に、無料版と有料版の比較が可能です。最適な採用アシスタントを見つけて、今すぐ採用業務を効率化しましょう!
 10 ツール
10 ツール
 xix.ai
生産性
AIパーソナルウェルネス&集中力コーチ:バーンアウトの予防とメンタルエネルギーの向上
xix.ai
生産性
AIパーソナルウェルネス&集中力コーチ:バーンアウトの予防とメンタルエネルギーの向上
XIX.AIで、2026年最高のAIパーソナルウェルネス&集中力向上ツールをご紹介。厳選されたランキングでは、バーンアウトの解消やメンタルエネルギーの向上に役立つ、高評価で画期的なツールを取り上げています。実際のユーザーの声をもとに、無料版と有料版の比較も可能です。今すぐ、最高の生産性とウェルビーイングへの道を開きましょう。
10 ツール
xix.ai
チャットボット
高評価のAI恋愛チャットボット:一貫した個性で長期的な関係を築く
2026年版、本物の長期的なつながりを築くための、高評価のAI恋愛チャットボットをご紹介します。厳選されたリストには、魅力的で一貫性のあるキャラクター、無料版と有料版の比較、そして実地テストの結果が掲載されています。あなたにぴったりのパートナーを見つけて、今すぐXIX.AIで関係を築き始めましょう。
10 ツール
xix.ai
教育と学習
最高のAIデータサイエンスメンター:SQL、Pandas、および機械学習ワークフローをマスターしましょう
2026年に最も優れたAIデータサイエンスのメンターを探して、SQL、Pandas、およびMLワークフローをマスターしましょう。XIX.AIで評価の高い厳選されたメンターたちの指導を受けて、力強く、革新的なアドバイスを得てください。無料オプションと有料オプションを実世界の視点から比較しましょう。今日すぐにデータサイエンスのスキルを向上させましょう。
10 ツール
xix.ai
チャットボット
最高のAIを使ったナンパ&会話トレーニング:社交的な魅力と自信をリアルタイムで高める
XIX.AIで、2026年最高のAIを使った口説き術・会話トレーニングツールを発見しましょう。厳選された高評価のツールが、リアルタイムで社交的な魅力と自信を築くお手伝いをします。無料版と有料版の比較や毎週更新されるランキングを参考に、ぜひ試すべき画期的なツールを探してみてください。今すぐ、あなたの社交力を引き出しましょう。
10 ツール
xix.ai
コード
自動化ユニットテストに最適なAIツール:ワンクリックでJest、PyTest、JUnitのテストケースを生成する
2026年に登場した、自動化ユニットテスト用の最高評価を受けたAIツールを発見してください。当社が厳選したこれらのツールは、Jest、PyTest、JUnitのテストケースを瞬時に生成するための強力で革新的なソリューションです。XIX.AIでは、無料オプションと有料オプションを実際のテストデータと共に比較し、毎週更新されるランキングもご覧いただけます。今すぐAIの力を活用して、開発生産性を向上させましょう。
10 ツール
xix.ai

 コメント (3)
0/500
コメント (3)
0/500
![TimothyMitchell]()
映像の詳細なコントロールって本当に難しいんですね。AIがプロのVFXスタジオで使われる日はまだ先かな?でも技術の進歩にはワクワクする!🔥
![CharlesMartinez]()
Finalmente os vídeos gerados por IA estão evoluindo para algo útil! Mas ainda parece que falta muito pra substituir os efeitos manuais de grandes produções... será que um dia chegaremos lá? 🎥
![DonaldLee]()
The idea of AI taking over VFX in films is wild! I mean, total control over video generation? That’s some sci-fi stuff coming to life. But I wonder if these models like Hunyuan can really nail the tiny details directors obsess over. Exciting times! 🎥
ビデオ基礎モデルであるHunyuanやWan 2.1は大きな進歩を遂げていますが、映画やテレビ制作、特に視覚効果(VFX)の分野で必要とされる詳細な制御に関しては、しばしば不十分です。プロのVFXスタジオでは、これらのモデルや、Stable Diffusion、Kandinsky、Fluxなどの以前の画像ベースのモデルを、特定のクリエイティブな要求を満たすために出力を洗練させるためのツール群と組み合わせて使用しています。監督が「素晴らしい見た目だけど、もう少し[n]にできないか?」と微調整を要求したとき、モデルにそのような調整を行う精度が不足していると単に述べるだけでは十分ではありません。
その代わりに、AI VFXチームは、従来のCGIや合成技術と、カスタム開発されたワークフローを組み合わせて、ビデオ合成の限界をさらに押し広げます。このアプローチは、Chromeのようなデフォルトのウェブブラウザを使用するのに似ています。すぐに使える機能はありますが、ニーズに合わせて完全にカスタマイズするには、プラグインをインストールする必要があります。
コントロールフリーク
拡散ベースの画像合成の分野では、最も重要なサードパーティシステムの一つがControlNetです。この技術は、生成モデルに構造化された制御を導入し、エッジマップ、深度マップ、ポーズ情報などの追加入力を使用して、画像やビデオ生成をガイドすることができます。
*ControlNetのさまざまな手法により、深度>画像(上段)、セマンティックセグメンテーション>画像(左下)、および人間や動物のポーズガイド付き画像生成(左下)が可能です。*
ControlNetはテキストプロンプトにのみ依存するのではなく、別々のニューラルネットワークブランチやアダプターを使用してこれらの条件付け信号を処理し、ベースモデルの生成能力を維持します。これにより、ユーザーの仕様に密接に一致する高度にカスタマイズされた出力が可能になり、構図、構造、または動きを正確に制御する必要があるアプリケーションにとって非常に価値があります。
*ガイドポーズを使用することで、ControlNetを通じてさまざまな正確な出力タイプを得ることができます。* ソース: https://arxiv.org/pdf/2302.05543
しかし、内部に焦点を当てたニューラルプロセス上で外部的に動作するこれらのアダプターベースのシステムには、いくつかの欠点があります。アダプターは独立してトレーニングされるため、複数のアダプターを組み合わせるとブランチ間の競合が発生し、生成品質が低下することがあります。また、アダプターごとに追加の計算リソースとメモリが必要となり、スケーリングが非効率になります。さらに、その柔軟性にもかかわらず、アダプターはマルチコンディション生成用に完全に微調整されたモデルに比べて、しばしば最適でない結果を生成します。これらの問題により、複数の制御信号をシームレスに統合する必要があるタスクでは、アダプターベースの手法が効果を発揮しにくい場合があります。
理想的には、ControlNetの機能がモジュール形式でモデルにネイティブに統合され、ビデオ/オーディオの同時生成やネイティブなリップシンク機能などの将来のイノベーションが可能になるはずです。現在、追加機能はポストプロダクションのタスクとなったり、基礎モデルの敏感な重みを扱う非ネイティブな手順となったりします。
FullDiT
中国発の新しいアプローチであるFullDiTは、ControlNetスタイルの機能をトレーニング中に直接生成ビデオモデルに統合し、後付けとして扱うのではなく、根本的に組み込みます。
*新しい論文によると、FullDiTアプローチは、アイデンティティの強制、深度、カメラの動きをネイティブな生成に組み込むことができ、これらを任意に組み合わせることができます。* ソース: https://arxiv.org/pdf/2503.19907
論文「FullDiT: Multi-Task Video Generative Foundation Model with Full Attention」に記載されているFullDiTは、アイデンティティ転送、深度マッピング、カメラの動きなどのマルチタスク条件をトレーニングされた生成ビデオモデルのコアに統合します。著者らはプロトタイプモデルと、プロジェクトサイトで利用可能な関連ビデオクリップを開発しました。
**クリックして再生。ControlNetスタイルのユーザー強制の例で、ネイティブにトレーニングされた基礎モデルのみを使用。** ソース: https://fulldit.github.io/
著者らは、FullDiTをテキストからビデオ(T2V)および画像からビデオ(I2V)モデルの概念実証として提示し、画像やテキストプロンプトだけでなく、ユーザーにより多くの制御を提供します。類似のモデルが存在しないため、研究者らはマルチタスクビデオを評価するための新しいベンチマーク「FullBench」を作成し、彼らが設計したテストで最先端のパフォーマンスを主張しています。ただし、著者自身が設計したFullBenchの客観性は検証されておらず、1,400ケースのデータセットは広範な結論には限定的すぎる可能性があります。
FullDiTのアーキテクチャの最も興味深い側面は、新しい制御タイプを組み込む可能性です。著者らは次のように述べています:
**「本研究では、カメラ、アイデンティティ、深度情報の制御条件のみを検討しました。オーディオ、スピーチ、ポイントクラウド、オブジェクトのバウンディングボックス、光学フローなどの他の条件やモダリティはさらに調査していません。FullDiTの設計は、他のモダリティを最小限のアーキテクチャ変更でシームレスに統合できますが、既存のモデルを新しい条件やモダリティに迅速かつコスト効率よく適応させる方法は、引き続き重要な課題であり、さらなる探求が必要です。」**
FullDiTはマルチタスクビデオ生成の前進を象徴していますが、既存のアーキテクチャを基盤としており、新しいパラダイムを導入するものではありません。それでも、ControlNetスタイルの機能をネイティブに統合した唯一のビデオ基礎モデルとして際立っており、そのアーキテクチャは将来のイノベーションに対応するよう設計されています。
**クリックして再生。プロジェクトサイトからのユーザー制御カメラ移動の例。**
この論文は、Kuaishou Technologyと香港中文大学の9人の研究者によって執筆され、タイトルは「FullDiT: Multi-Task Video Generative Foundation Model with Full Attention」です。プロジェクトページと新しいベンチマークデータはHugging Faceで利用可能です。
メソッド
FullDiTの統一アテンション機構は、条件間の空間的および時間的関係を捉えることで、クロスモーダル表現学習を強化するように設計されています。
*新しい論文によると、FullDiTはフルセルフアテンションを通じて複数の入力条件を統合し、それらを統一されたシーケンスに変換します。一方、アダプターベースのモデル(最左)は各入力に対して別々のモジュールを使用し、冗長性、競合、弱いパフォーマンスを引き起こします。*
各入力ストリームを個別に処理するアダプターベースの設定とは異なり、FullDiTの共有アテンション構造はブランチ間の競合を回避し、パラメータのオーバーヘッドを削減します。著者らは、このアーキテクチャが大幅な再設計なしに新しい入力タイプにスケールでき、モデルスキーマがトレーニング中に見られなかった条件の組み合わせ(カメラの動きとキャラクターのアイデンティティのリンクなど)に一般化する兆候を示していると主張しています。
**クリックして再生。プロジェクトサイトからのアイデンティティ生成の例。**
FullDiTのアーキテクチャでは、テキスト、カメラの動き、アイデンティティ、深度などのすべての条件付け入力が、まず統一されたトークン形式に変換されます。これらのトークンは単一の長いシーケンスに連結され、フルセルフアテンションを使用してトランスフォーマーレイヤーのスタックを通じて処理されます。このアプローチは、Open-Sora PlanやMovie Genなどの先行研究に従っています。
この設計により、モデルはすべての条件を時間的および空間的に共同で学習できます。各トランスフォーマーブロックはシーケンス全体を操作し、モダリティ間の動的な相互作用を可能にし、各入力に対して別々のモジュールを必要としません。このアーキテクチャは拡張可能に設計されており、将来の追加制御信号を大幅な構造変更なしに容易に組み込むことができます。
3つの力
FullDiTは各制御信号を標準化されたトークン形式に変換し、すべての条件を統一されたアテンション枠組みで一緒に処理できるようにします。カメラの動きについては、モデルは各フレームの位置や向きなどの外部パラメータのシーケンスをエンコードします。これらのパラメータはタイムスタンプ付きで、信号の時間的性質を反映する埋め込みベクトルに投影されます。
アイデンティティ情報は、時間的ではなく本質的に空間的なため、異なる方法で扱われます。モデルは、各フレームのどの部分にどのキャラクターが存在するかを示すアイデンティティマップを使用します。これらのマップはパッチに分割され、各パッチは空間的アイデンティティの手がかりを捉える埋め込みに投影され、モデルはフレームの特定の領域を特定のエンティティと関連付けることができます。
深度は時空間信号であり、モデルは深度ビデオを空間と時間の両方をカバーする3Dパッチに分割して処理します。これらのパッチは、フレーム間で構造を保持する方法で埋め込まれます。
埋め込み後、カメラ、アイデンティティ、深度のすべての条件トークンは単一の長いシーケンスに連結され、FullDiTがフルセルフアテンションを使用してそれらを一緒に処理できるようになります。この共有表現により、モデルはモダリティ間および時間にわたる相互作用を、独立した処理ストリームに依存せずに学習できます。
データとテスト
FullDiTのトレーニングアプローチは、すべての条件が同時に存在することを要求するのではなく、各条件タイプに合わせた選択的に注釈付けされたデータセットに依存していました。
テキスト条件については、MiraDataプロジェクトで概説された構造化キャプションアプローチに従っています。
*MiraDataプロジェクトからのビデオ収集および注釈パイプライン。* ソース: https://arxiv.org/pdf/2407.06358
カメラの動きについては、カメラパラメータの高品質なグラウンドトゥルース注釈があるため、RealEstate10Kデータセットが主なデータソースでした。しかし、著者らは、RealEstate10Kのような静的シーンカメラデータセットのみでトレーニングすると、生成されたビデオの動的なオブジェクトや人間の動きが減少する傾向があると観察しました。これに対抗するため、より動的なカメラの動きを含む内部データセットを使用して追加の微調整を行いました。
アイデンティティ注釈は、ConceptMasterプロジェクト用に開発されたパイプラインを使用して生成され、細かいアイデンティティ情報の効率的なフィルタリングと抽出を可能にしました。
*ConceptMasterフレームワークは、カスタマイズされたビデオでアイデンティティの分離問題に対処しながら、コンセプトの忠実度を維持するように設計されています。* ソース: https://arxiv.org/pdf/2501.04698
深度注釈は、Panda-70MデータセットからDepth Anythingを使用して取得されました。
データ順序による最適化
著者らは、モデルが簡単なタスクが追加される前に堅牢な表現を獲得するように、より挑戦的な条件をトレーニングの早い段階で導入する進行的なトレーニングスケジュールも実施しました。トレーニングの順序は、テキストからカメラ条件、次にアイデンティティ、最後に深度へと進み、簡単なタスクは一般に後で、より少ない例で導入されました。
著者らは、このようにワークロードを順序付ける価値を強調しています:
**「プレトレーニングフェーズでは、より挑戦的なタスクは長いトレーニング時間を要求し、学習プロセスで早い段階で導入されるべきだと気づきました。これらの挑戦的なタスクは、出力ビデオとは大きく異なる複雑なデータ分布を伴い、モデルがそれらを正確に捉えて表現する十分な能力を持つ必要があります。」**
**「逆に、簡単なタスクをあまりにも早く導入すると、モデルがそれらを優先的に学習する可能性があり、即時の最適化フィードバックを提供するため、より挑戦的なタスクの収束を妨げる可能性があります。」**
*研究者が採用したデータトレーニング順序の図で、赤はより多くのデータ量を示します。*
初期のプレトレーニング後、最終的な微調整段階でモデルをさらに改良し、視覚品質と動きのダイナミクスを改善しました。その後、トレーニングは標準的な拡散フレームワークに従いました:ビデオの潜在空間にノイズを追加し、モデルが埋め込み条件トークンをガイドとして使用してノイズを予測し、除去することを学習します。
FullDiTを効果的に評価し、既存の方法と公平な比較を提供するために、適切な他のベンチマークがない中で、著者らは1,400の異なるテストケースからなるキュレートされたベンチマークスイート「FullBench」を導入しました。
*新しいFullBenchベンチマークのデータエクスプローラインスタンス。* ソース: https://huggingface.co/datasets/KwaiVGI/FullBench
各データポイントは、カメラの動き、アイデンティティ、深度などのさまざまな条件付け信号に対するグラウンドトゥルース注釈を提供しました。
メトリクス
著者らは、テキストの整合性、カメラ制御、アイデンティティの類似性、深度の精度、全体的なビデオ品質の5つの主要なパフォーマンス側面をカバーする10のメトリクスを使用してFullDiTを評価しました。
テキストの整合性はCLIP類似性を使用して測定され、カメラ制御はCameraCtrlプロジェクトのCamI2Vのアプローチに従って、回転エラー(RotErr)、移動エラー(TransErr)、カメラの動きの一貫性(CamMC)を通じて評価されました。
アイデンティティの類似性はDINO-IとCLIP-Iを使用して評価され、深度制御の精度は平均絶対誤差(MAE)で定量化されました。
ビデオ品質は、MiraDataの3つのメトリクスで評価されました:スムーズさのためのフレームレベルのCLIP類似性、ダイナミクスのための光学フローベースの動き距離、視覚的魅力のためのLAION-Aestheticスコアです。
トレーニング
著者らは、約10億のパラメータを含む内部(非公開)のテキストからビデオへの拡散モデルを使用してFullDiTをトレーニングしました。彼らは、以前の方法との比較の公平性を維持し、再現性を確保するために、意図的に適度なパラメータサイズを選択しました。
トレーニングビデオは長さや解像度が異なるため、著者らは各バッチを標準化し、ビデオを共通の解像度にリサイズおよびパディングし、シーケンスごとに77フレームをサンプリングし、アテンションとロスマスクを適用してトレーニングの効果を最適化しました。
Adamオプティマイザは、64台のNVIDIA H800 GPUのクラスタ全体で学習率1×10−5で使用され、合計5,120GBのVRAM(愛好家の合成コミュニティでは、RTX 3090の24GBが依然として豪華な基準と見なされていることを考慮してください)。
モデルは約32,000ステップでトレーニングされ、ビデオごとに最大3つのアイデンティティ、20フレームのカメラ条件、21フレームの深度条件を組み込み、両方とも合計77フレームから均等にサンプリングされました。
推論では、モデルは384×672ピクセルの解像度(15フレーム/秒で約5秒)でビデオを生成し、50の拡散推論ステップと5の分類器なしガイダンススケールを使用しました。
先行方法
カメラからビデオへの評価では、著者らはFullDiTをMotionCtrl、CameraCtrl、CamI2Vと比較し、すべてのモデルは一貫性と公平性を確保するためにRealEstate10kデータセットを使用してトレーニングされました。
アイデンティティ条件付き生成では、比較可能なオープンソースのマルチアイデンティティモデルが存在しないため、モデルは同じトレーニングデータとアーキテクチャを使用して、1BパラメータのConceptMasterモデルとベンチマークされました。
深度からビデオへのタスクでは、Ctrl-AdapterおよびControlVideoと比較されました。
*シングルタスクビデオ生成の定量的結果。FullDiTは、カメラからビデオ生成のためにMotionCtrl、CameraCtrl、CamI2Vと比較され、アイデンティティからビデオのためにConceptMaster(1Bパラメータ版)と比較され、深度からビデオのためにCtrl-AdapterおよびControlVideoと比較されました。すべてのモデルはデフォルト設定で評価されました。一貫性のために、各メソッドから16フレームが均等にサンプリングされ、以前のモデルの出力長に一致しました。*
結果は、FullDiTが複数の条件付け信号を同時に処理しているにもかかわらず、テキスト、カメラの動き、アイデンティティ、深度制御に関連するメトリクスで最先端のパフォーマンスを達成したことを示しています。
全体的な品質メトリクスでは、システムは一般に他の方法を上回りましたが、スムーズさはConceptMasterに比べてわずかに低かったです。ここで著者らはコメントしています:
**「FullDiTのスムーズさは、隣接フレーム間のCLIP類似性に基づいて計算されるため、ConceptMasterに比べてわずかに低いです。FullDiTはConceptMasterに比べて大幅に高いダイナミクスを示すため、隣接フレーム間の大きな変動がスムーズさのメトリクスに影響を与えます。」**
**「美的スコアについては、評価モデルが絵画スタイルの画像を好むため、ControlVideoが通常このスタイルでビデオを生成し、美的スコアで高い点数を獲得します。」**
定性的な比較については、PDFの例は必然的に静的である(また、ここで完全に再現するには大きすぎる)ため、FullDiTプロジェクトサイトのサンプルビデオを参照する方が良いかもしれません。
*PDFに再現された定性的結果の最初のセクション。追加の例については、ソース論文を参照してください。ここでは再現するには広範すぎます。*
著者らはコメントしています:
**「FullDiTは、優れたアイデンティティの保持を示し、[ConceptMaster]に比べてダイナミクスと視覚的品質が優れたビデオを生成します。ConceptMasterとFullDiTは同じバックボーンでトレーニングされているため、フルアテンションによる条件注入の有効性が強調されます。」**
**「…[他の]結果は、既存の深度からビデオおよびカメラからビデオの方法と比較して、FullDiTの優れた制御性と生成品質を示しています。」**
*PDFのFullDiTの複数信号出力の例のセクション。追加の例については、ソース論文およびプロジェクトサイトを参照してください。*
結論
FullDiTは、より包括的なビデオ基礎モデルに向けたエキサイティングな一歩を表しますが、ControlNetスタイルの機能を大規模に実装する需要が、特にオープンソースプロジェクトにおいて、正当化されるかどうかは疑問です。これらのプロジェクトは、商業的サポートなしでは、必要な膨大なGPU処理能力を確保するのに苦労します。
主な課題は、DepthやPoseなどのシステムを使用するには、ComfyUIのような複雑なユーザーインターフェースに慣れる必要があることです。そのため、この種の機能的なオープンソースモデルは、リソースや動機が不足して独自にモデルをキュレートおよびトレーニングする能力を持たない小さなVFX企業によって開発される可能性が高いです。
一方、API駆動の「AIをレンタルする」システムは、直接トレーニングされた補助制御システムを備えたモデルに対して、よりシンプルでユーザーフレンドリーな解釈方法を開発する強い動機を持つかもしれません。
**クリックして再生。FullDiTを使用してビデオ生成に課されたDepth+Text制御。**
*著者らは、既知のベースモデル(例:SDXLなど)を特定していません。*
**初公開:2025年3月27日(木曜日)**










 YouTube、AIを活用した検索機能のテストを開始――ガイド付き回答機能を搭載
多くのユーザーは、レシピや旅行プランを探す際、関連する動画を探そうとYouTubeを利用しています。今回、YouTubeはテキストと動画コンテンツを融合させた、ステップバイステップの検索結果を表示するAI搭載の対話型検索ツールを導入しました。新しい「Ask YouTube」機能を使えば、ユーザーは「サンフランシスコからサンタバーバラまでの3日間のロードトリップを計画して」といった質問を投げかけ、動
YouTube、AIを活用した検索機能のテストを開始――ガイド付き回答機能を搭載
多くのユーザーは、レシピや旅行プランを探す際、関連する動画を探そうとYouTubeを利用しています。今回、YouTubeはテキストと動画コンテンツを融合させた、ステップバイステップの検索結果を表示するAI搭載の対話型検索ツールを導入しました。新しい「Ask YouTube」機能を使えば、ユーザーは「サンフランシスコからサンタバーバラまでの3日間のロードトリップを計画して」といった質問を投げかけ、動
 独占:Luma AI、『統合インテリジェンス』モデルを搭載したクリエイティブエージェントを発表
木曜日、AI動画生成スタートアップのLumaは、テキスト・画像・動画・音声にまたがる完全なクリエイティブワークフローを管理するシステム「Luma Agents」を発表した。これらのエージェントは、単一のマルチモーダル推論エンジンとして訓練されたアーキテクチャを特徴とするLumaのUnified Intelligenceモデルファミリーによって駆動される。Lumaは、広告代理店、マーケティング部門、
独占:Luma AI、『統合インテリジェンス』モデルを搭載したクリエイティブエージェントを発表
木曜日、AI動画生成スタートアップのLumaは、テキスト・画像・動画・音声にまたがる完全なクリエイティブワークフローを管理するシステム「Luma Agents」を発表した。これらのエージェントは、単一のマルチモーダル推論エンジンとして訓練されたアーキテクチャを特徴とするLumaのUnified Intelligenceモデルファミリーによって駆動される。Lumaは、広告代理店、マーケティング部門、
 Soraの新アップデートでペットAI動画、ソーシャルツール、Androidアプリが登場
OpenAIは、9月下旬のローンチ後、App Storeのトップに急浮上したブレイク中のAI動画作成アプリ「Sora」の新機能を相次いでプレビューしている。米国とカナダで現在も1位をキープしているこのアプリは、近日中に動画編集機能を追加し、ユーザーがペットやその他のアイテムのキャラクター「カメオ」を作成したり、ソーシャル機能を強化したりする予定だ。同社はまた、Android版が "実際に間もなくリ
Soraの新アップデートでペットAI動画、ソーシャルツール、Androidアプリが登場
OpenAIは、9月下旬のローンチ後、App Storeのトップに急浮上したブレイク中のAI動画作成アプリ「Sora」の新機能を相次いでプレビューしている。米国とカナダで現在も1位をキープしているこのアプリは、近日中に動画編集機能を追加し、ユーザーがペットやその他のアイテムのキャラクター「カメオ」を作成したり、ソーシャル機能を強化したりする予定だ。同社はまた、Android版が "実際に間もなくリ

XIX.AIで、2026年最新の評価の高いAI採用ツールをチェックしましょう。厳選されたリストには、履歴書のスクリーニングや候補者の面接スケジュール管理を自動化する、強力で画期的なソリューションが揃っています。実際のテスト結果や毎週更新されるランキングを参考に、無料版と有料版の比較が可能です。最適な採用アシスタントを見つけて、今すぐ採用業務を効率化しましょう!
10 ツール
xix.ai

XIX.AIで、2026年最高のAIパーソナルウェルネス&集中力向上ツールをご紹介。厳選されたランキングでは、バーンアウトの解消やメンタルエネルギーの向上に役立つ、高評価で画期的なツールを取り上げています。実際のユーザーの声をもとに、無料版と有料版の比較も可能です。今すぐ、最高の生産性とウェルビーイングへの道を開きましょう。
10 ツール
xix.ai

2026年版、本物の長期的なつながりを築くための、高評価のAI恋愛チャットボットをご紹介します。厳選されたリストには、魅力的で一貫性のあるキャラクター、無料版と有料版の比較、そして実地テストの結果が掲載されています。あなたにぴったりのパートナーを見つけて、今すぐXIX.AIで関係を築き始めましょう。
10 ツール
xix.ai

2026年に最も優れたAIデータサイエンスのメンターを探して、SQL、Pandas、およびMLワークフローをマスターしましょう。XIX.AIで評価の高い厳選されたメンターたちの指導を受けて、力強く、革新的なアドバイスを得てください。無料オプションと有料オプションを実世界の視点から比較しましょう。今日すぐにデータサイエンスのスキルを向上させましょう。
10 ツール
xix.ai

XIX.AIで、2026年最高のAIを使った口説き術・会話トレーニングツールを発見しましょう。厳選された高評価のツールが、リアルタイムで社交的な魅力と自信を築くお手伝いをします。無料版と有料版の比較や毎週更新されるランキングを参考に、ぜひ試すべき画期的なツールを探してみてください。今すぐ、あなたの社交力を引き出しましょう。
10 ツール
xix.ai

2026年に登場した、自動化ユニットテスト用の最高評価を受けたAIツールを発見してください。当社が厳選したこれらのツールは、Jest、PyTest、JUnitのテストケースを瞬時に生成するための強力で革新的なソリューションです。XIX.AIでは、無料オプションと有料オプションを実際のテストデータと共に比較し、毎週更新されるランキングもご覧いただけます。今すぐAIの力を活用して、開発生産性を向上させましょう。
10 ツール
xix.ai

映像の詳細なコントロールって本当に難しいんですね。AIがプロのVFXスタジオで使われる日はまだ先かな?でも技術の進歩にはワクワクする!🔥
Finalmente os vídeos gerados por IA estão evoluindo para algo útil! Mas ainda parece que falta muito pra substituir os efeitos manuais de grandes produções... será que um dia chegaremos lá? 🎥
The idea of AI taking over VFX in films is wild! I mean, total control over video generation? That’s some sci-fi stuff coming to life. But I wonder if these models like Hunyuan can really nail the tiny details directors obsess over. Exciting times! 🎥













