
















 Hogar
HogarLa generación de videos de IA se mueve hacia el control completo
Los modelos de fundación de video como Hunyuan y Wan 2.1 han logrado avances significativos, pero a menudo se quedan cortos cuando se trata del control detallado requerido en la producción de cine y televisión, especialmente en el ámbito de los efectos visuales (VFX). En los estudios profesionales de VFX, estos modelos, junto con modelos anteriores basados en imágenes como Stable Diffusion, Kandinsky y Flux, se utilizan en conjunto con una suite de herramientas diseñadas para refinar su salida y satisfacer demandas creativas específicas. Cuando un director solicita un ajuste, diciendo algo como, "Eso se ve genial, pero ¿podemos hacerlo un poco más [n]?", no es suficiente simplemente afirmar que el modelo carece de la precisión para realizar dichos ajustes.
En cambio, un equipo de VFX de IA empleará una combinación de CGI tradicional y técnicas de composición, junto con flujos de trabajo desarrollados a medida, para empujar los límites de la síntesis de video aún más. Este enfoque es similar a usar un navegador web predeterminado como Chrome; es funcional de inmediato, pero para adaptarlo realmente a tus necesidades, necesitarás instalar algunos complementos.
Control Freaks
En el campo de la síntesis de imágenes basada en difusión, uno de los sistemas de terceros más cruciales es ControlNet. Esta técnica introduce un control estructurado a los modelos generativos, permitiendo a los usuarios guiar la generación de imágenes o videos utilizando entradas adicionales como mapas de bordes, mapas de profundidad o información de poses.
 *Los diversos métodos de ControlNet permiten la generación de imágenes a partir de profundidad (fila superior), segmentación semántica a imagen (inferior izquierda) y generación de imágenes guiadas por poses de humanos y animales (inferior izquierda).*
*Los diversos métodos de ControlNet permiten la generación de imágenes a partir de profundidad (fila superior), segmentación semántica a imagen (inferior izquierda) y generación de imágenes guiadas por poses de humanos y animales (inferior izquierda).*
ControlNet no depende únicamente de prompts de texto; emplea ramas de redes neuronales separadas, o adaptadores, para procesar estas señales de condicionamiento mientras mantiene las capacidades generativas del modelo base. Esto permite salidas altamente personalizadas que se alinean estrechamente con las especificaciones del usuario, lo que lo hace invaluable para aplicaciones que requieren un control preciso sobre la composición, la estructura o el movimiento.
 *Con una pose guía, se pueden obtener una variedad de tipos de salida precisos a través de ControlNet.* Fuente: https://arxiv.org/pdf/2302.05543
*Con una pose guía, se pueden obtener una variedad de tipos de salida precisos a través de ControlNet.* Fuente: https://arxiv.org/pdf/2302.05543
Sin embargo, estos sistemas basados en adaptadores, que operan externamente sobre un conjunto de procesos neuronales enfocados internamente, presentan varios inconvenientes. Los adaptadores se entrenan de forma independiente, lo que puede llevar a conflictos de ramas cuando se combinan múltiples adaptadores, lo que a menudo resulta en generaciones de menor calidad. También introducen redundancia de parámetros, requiriendo recursos computacionales y memoria adicionales para cada adaptador, lo que hace que la escalabilidad sea ineficiente. Además, a pesar de su flexibilidad, los adaptadores a menudo producen resultados subóptimos en comparación con modelos completamente afinados para la generación con múltiples condiciones. Estos problemas pueden hacer que los métodos basados en adaptadores sean menos efectivos para tareas que requieren la integración fluida de múltiples señales de control.
Idealmente, las capacidades de ControlNet se integrarían de forma nativa en el modelo de manera modular, permitiendo innovaciones futuras como la generación simultánea de video/audio o capacidades nativas de sincronización labial. Actualmente, cada característica adicional se convierte en una tarea de posproducción o en un procedimiento no nativo que debe navegar por los pesos sensibles del modelo de fundación.
FullDiT
Entra FullDiT, un nuevo enfoque desde China que integra características de estilo ControlNet directamente en un modelo generativo de video durante el entrenamiento, en lugar de tratarlas como una ocurrencia tardía.
 *Del nuevo artículo: el enfoque FullDiT puede incorporar la imposición de identidad, profundidad y movimiento de cámara en una generación nativa, y puede invocar cualquier combinación de estos a la vez.* Fuente: https://arxiv.org/pdf/2503.19907
*Del nuevo artículo: el enfoque FullDiT puede incorporar la imposición de identidad, profundidad y movimiento de cámara en una generación nativa, y puede invocar cualquier combinación de estos a la vez.* Fuente: https://arxiv.org/pdf/2503.19907
FullDiT, como se describe en el artículo titulado **FullDiT: Modelo de Fundación Generativo de Video Multi-Tarea con Atención Completa**, integra condiciones multi-tarea como transferencia de identidad, mapeo de profundidad y movimiento de cámara en el núcleo de un modelo generativo de video entrenado. Los autores han desarrollado un modelo prototipo y clips de video acompañantes disponibles en un sitio de proyecto.
**Haz clic para reproducir. Ejemplos de imposición de usuario de estilo ControlNet con solo un modelo de fundación entrenado de forma nativa.** Fuente: https://fulldit.github.io/
Los autores presentan FullDiT como una prueba de concepto para modelos de texto a video (T2V) e imagen a video (I2V) que ofrecen a los usuarios más control que solo un prompt de imagen o texto. Dado que no existen modelos similares, los investigadores crearon un nuevo punto de referencia llamado **FullBench** para evaluar videos multi-tarea, afirmando un rendimiento de vanguardia en sus pruebas diseñadas. Sin embargo, la objetividad de FullBench, diseñado por los propios autores, no ha sido probada, y su conjunto de datos de 1,400 casos puede ser demasiado limitado para conclusiones más amplias.
El aspecto más intrigante de la arquitectura de FullDiT es su potencial para incorporar nuevos tipos de control. Los autores señalan:
**‘En este trabajo, solo exploramos condiciones de control de la cámara, identidades e información de profundidad. No investigamos más a fondo otras condiciones y modalidades como audio, voz, nube de puntos, cajas delimitadoras de objetos, flujo óptico, etc. Aunque el diseño de FullDiT puede integrar otras modalidades con modificaciones mínimas en la arquitectura, cómo adaptar rápidamente y de manera rentable los modelos existentes a nuevas condiciones y modalidades sigue siendo una pregunta importante que merece una exploración adicional.’**
Aunque FullDiT representa un paso adelante en la generación de videos multi-tarea, se basa en arquitecturas existentes en lugar de introducir un nuevo paradigma. Sin embargo, se destaca como el único modelo de fundación de video con características de estilo ControlNet integradas de forma nativa, y su arquitectura está diseñada para acomodar innovaciones futuras.
**Haz clic para reproducir. Ejemplos de movimientos de cámara controlados por el usuario, desde el sitio del proyecto.**
El artículo, escrito por nueve investigadores de Kuaishou Technology y The Chinese University of Hong Kong, se titula **FullDiT: Modelo de Fundación Generativo de Video Multi-Tarea con Atención Completa**. La página del proyecto y los datos del nuevo punto de referencia están disponibles en Hugging Face.
Método
El mecanismo de atención unificada de FullDiT está diseñado para mejorar el aprendizaje de representación intermodal al capturar relaciones espaciales y temporales entre las condiciones.
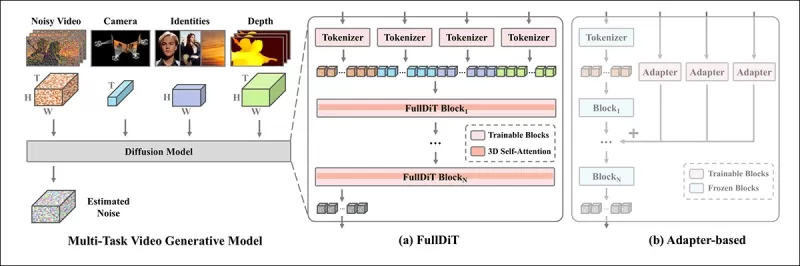 *Según el nuevo artículo, FullDiT integra múltiples condiciones deja entrada a través de una atención propia completa, convirtiéndolas en una secuencia unificada. En contraste, los modelos basados en adaptadores (el más a la izquierda) usan módulos separados para cada entrada, lo que lleva a redundancia, conflictos y un rendimiento más débil.*
*Según el nuevo artículo, FullDiT integra múltiples condiciones deja entrada a través de una atención propia completa, convirtiéndolas en una secuencia unificada. En contraste, los modelos basados en adaptadores (el más a la izquierda) usan módulos separados para cada entrada, lo que lleva a redundancia, conflictos y un rendimiento más débil.*
A diferencia de las configuraciones basadas en adaptadores que procesan cada flujo de entrada por separado, la estructura de atención compartida de FullDiT evita conflictos de ramas y reduce la sobrecarga de parámetros. Los autores afirman que la arquitectura puede escalar a nuevos tipos de entrada sin un rediseño importante y que el esquema del modelo muestra signos de generalización a combinaciones de condiciones no vistas durante el entrenamiento, como vincular el movimiento de la cámara con la identidad del personaje.
**Haz clic para reproducir. Ejemplos de generación de identidad desde el sitio del proyecto.**
En la arquitectura de FullDiT, todas las entradas de condicionamiento —como texto, movimiento de cámara, identidad y profundidad— se convierten primero en un formato de token unificado. Estos tokens se concatenan en una sola secuencia larga, procesada a través de una pila de capas transformadoras utilizando atención propia completa. Este enfoque sigue trabajos anteriores como Open-Sora Plan y Movie Gen.
Este diseño permite al modelo aprender relaciones temporales y espaciales conjuntamente entre todas las condiciones. Cada bloque transformador opera sobre la secuencia completa, habilitando interacciones dinámicas entre modalidades sin depender de módulos separados para cada entrada. La arquitectura está diseñada para ser extensible, facilitando la incorporación de señales de control adicionales en el futuro sin cambios estructurales importantes.
El poder de tres
FullDiT convierte cada señal de control en un formato de token estandarizado para que todas las condiciones puedan procesarse juntas en un marco de atención unificado. Para el movimiento de la cámara, el modelo codifica una secuencia de parámetros extrínsecos —como posición y orientación— para cada cuadro. Estos parámetros se marcan con sello de tiempo y se proyectan en vectores incrustados que reflejan la naturaleza temporal de la señal.
La información de identidad se trata de manera diferente, ya que es inherentemente espacial en lugar de temporal. El modelo utiliza mapas de identidad que indican qué personajes están presentes en qué partes de cada cuadro. Estos mapas se dividen en parches, con cada parche proyectado en un incrustado que captura señales de identidad espacial, permitiendo al modelo asociar regiones específicas del cuadro con entidades específicas.
La profundidad es una señal espaciotemporal, y el modelo la maneja dividiendo los videos de profundidad en parches 3D que abarcan tanto el espacio como el tiempo. Estos parches se incrustan de manera que preservan su estructura a través de los cuadros.
Una vez incrustados, todos estos tokens de condición (cámara, identidad y profundidad) se concatenan en una sola secuencia larga, permitiendo a FullDiT procesarlos juntos usando atención propia completa. Esta representación compartida permite al modelo aprender interacciones entre modalidades y a través del tiempo sin depender de flujos de procesamiento aislados.
Datos y pruebas
El enfoque de entrenamiento de FullDiT se basó en conjuntos de datos anotados selectivamente adaptados a cada tipo de condicionamiento, en lugar de requerir que todas las condiciones estén presentes simultáneamente.
Para las condiciones textuales, la iniciativa sigue el enfoque de subtitulado estructurado descrito en el proyecto MiraData.
 *Tubería de recolección y anotación de videos del proyecto MiraData.* Fuente: https://arxiv.org/pdf/2407.06358
*Tubería de recolección y anotación de videos del proyecto MiraData.* Fuente: https://arxiv.org/pdf/2407.06358
Para el movimiento de la cámara, el conjunto de datos RealEstate10K fue la principal fuente de datos, debido a sus anotaciones de alta calidad de los parámetros de la cámara. Sin embargo, los autores observaron que entrenar exclusivamente con conjuntos de datos de cámaras de escenas estáticas como RealEstate10K tendía a reducir los movimientos de objetos y humanos dinámicos en los videos generados. Para contrarrestar esto, realizaron un ajuste fino adicional utilizando conjuntos de datos internos que incluían movimientos de cámara más dinámicos.
Las anotaciones de identidad se generaron utilizando la tubería desarrollada para el proyecto ConceptMaster, que permitió un filtrado y extracción eficiente de información de identidad detallada.
 *El marco ConceptMaster está diseñado para abordar problemas de desacoplamiento de identidad mientras preserva la fidelidad del concepto en videos personalizados.* Fuente: https://arxiv.org/pdf/2501.04698
*El marco ConceptMaster está diseñado para abordar problemas de desacoplamiento de identidad mientras preserva la fidelidad del concepto en videos personalizados.* Fuente: https://arxiv.org/pdf/2501.04698
Las anotaciones de profundidad se obtuvieron del conjunto de datos Panda-70M utilizando Depth Anything.
Optimización a través del ordenamiento de datos
Los autores también implementaron un programa de entrenamiento progresivo, introduciendo condiciones más desafiantes al principio del entrenamiento para asegurar que el modelo adquiriera representaciones robustas antes de que se añadieran tareas más simples. El orden de entrenamiento pasó de texto a condiciones de cámara, luego identidades y finalmente profundidad, con tareas más fáciles generalmente introducidas más tarde y con menos ejemplos.
Los autores enfatizan el valor de ordenar la carga de trabajo de esta manera:
**‘Durante la fase de pre-entrenamiento, notamos que las tareas más desafiantes requieren un tiempo de entrenamiento prolongado y deben introducirse antes en el proceso de aprendizaje. Estas tareas desafiantes involucran distribuciones de datos complejas que difieren significativamente del video de salida, requiriendo que el modelo tenga suficiente capacidad para capturarlas y representarlas con precisión.’**
**‘Por el contrario, introducir tareas más fáciles demasiado pronto puede llevar al modelo a priorizar su aprendizaje primero, ya que proporcionan retroalimentación de optimización más inmediata, lo que dificulta la convergencia de las tareas más desafiantes.’**
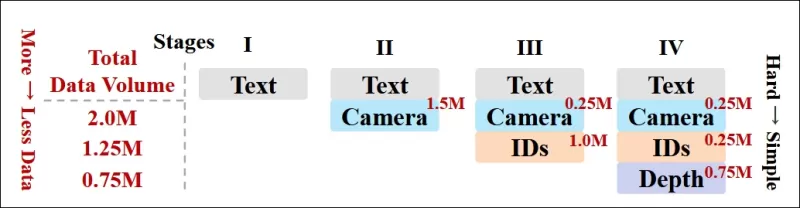 *Una ilustración del orden de entrenamiento de datos adoptado por los investigadores, con rojo indicando un mayor volumen de datos.*
*Una ilustración del orden de entrenamiento de datos adoptado por los investigadores, con rojo indicando un mayor volumen de datos.*
Tras el pre-entrenamiento inicial, una etapa final de ajuste fino refinó aún más el modelo para mejorar la calidad visual y la dinámica del movimiento. A partir de entonces, el entrenamiento siguió el de un marco de difusión estándar: se añadió ruido a los latentes de video, y el modelo aprendió a predecir y eliminarlo, utilizando los tokens de condición incrustados como guía.
Para evaluar eficazmente FullDiT y proporcionar una comparación justa contra los métodos existentes, y en ausencia de cualquier otro punto de referencia apropiado, los autores introdujeron **FullBench**, una suite de evaluación curada que consta de 1,400 casos de prueba distintos.
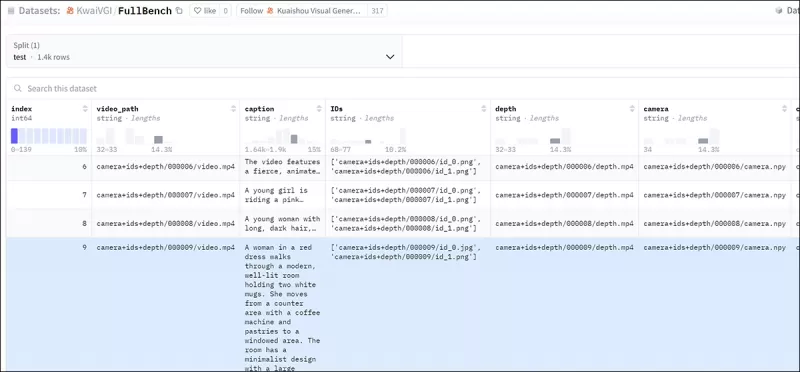 *Una instancia de explorador de datos para el nuevo punto de referencia FullBench.* Fuente: https://huggingface.co/datasets/KwaiVGI/FullBench
*Una instancia de explorador de datos para el nuevo punto de referencia FullBench.* Fuente: https://huggingface.co/datasets/KwaiVGI/FullBench
Cada punto de datos proporcionó anotaciones de verdad de campo para varias señales de condicionamiento, incluyendo movimiento de cámara, identidad y profundidad.
Métricas
Los autores evaluaron FullDiT utilizando diez métricas que cubren cinco aspectos principales del rendimiento: alineación de texto, control de cámara, similitud de identidad, precisión de profundidad y calidad general del video.
La alineación de texto se midió utilizando la similitud CLIP, mientras que el control de cámara se evaluó mediante el error de rotación (RotErr), el error de traslación (TransErr) y la consistencia del movimiento de la cámara (CamMC), siguiendo el enfoque de CamI2V (en el proyecto CameraCtrl).
La similitud de identidad se evaluó utilizando DINO-I y CLIP-I, y la precisión del control de profundidad se cuantificó utilizando el Error Absoluto Medio (MAE).
La calidad del video se juzgó con tres métricas de MiraData: similitud CLIP a nivel de cuadro para suavidad; distancia de movimiento basada en flujo óptico para dinámica; y puntuaciones estéticas de LAION para atractivo visual.
Entrenamiento
Los autores entrenaron FullDiT utilizando un modelo de difusión de texto a video interno (no revelado) que contiene aproximadamente mil millones de parámetros. Eligieron intencionalmente un tamaño de parámetros modesto para mantener la equidad en las comparaciones con métodos anteriores y asegurar la reproducibilidad.
Dado que los videos de entrenamiento diferían en longitud y resolución, los autores estandarizaron cada lote redimensionando y rellenando los videos a una resolución común, muestreando 77 cuadros por secuencia, y utilizando máscaras de atención y pérdida aplicadas para optimizar la efectividad del entrenamiento.
El optimizador Adam se utilizó a una tasa de aprendizaje de 1×10−5 en un clúster de 64 GPUs NVIDIA H800, para un total combinado de 5,120GB de VRAM (considera que en las comunidades de síntesis entusiastas, 24GB en una RTX 3090 aún se considera un estándar lujoso).
El modelo se entrenó durante aproximadamente 32,000 pasos, incorporando hasta tres identidades por video, junto con 20 cuadros de condiciones de cámara y 21 cuadros de condiciones de profundidad, ambos muestreados uniformemente de los 77 cuadros totales.
Para la inferencia, el modelo generó videos a una resolución de 384×672 píxeles (aproximadamente cinco segundos a 15 cuadros por segundo) con 50 pasos de inferencia de difusión y una escala de guía sin clasificador de cinco.
Métodos anteriores
Para la evaluación de cámara a video, los autores compararon FullDiT contra MotionCtrl, CameraCtrl y CamI2V, con todos los modelos entrenados usando el conjunto de datos RealEstate10k para asegurar consistencia y equidad.
En la generación condicionada por identidad, dado que no había modelos de múltiples identidades de código abierto comparables disponibles, el modelo se comparó con el modelo ConceptMaster de 1B parámetros, utilizando los mismos datos de entrenamiento y arquitectura.
Para tareas de profundidad a video, se realizaron comparaciones con Ctrl-Adapter y ControlVideo.
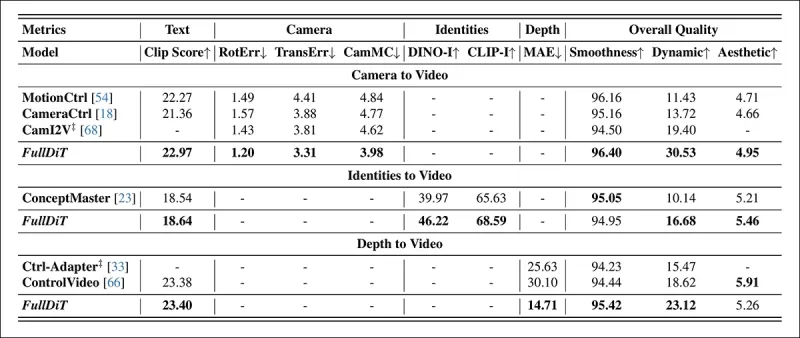 *Resultados cuantitativos para la generación de video de tarea única. FullDiT se comparó con MotionCtrl, CameraCtrl y CamI2V para la generación de cámara a video; ConceptMaster (versión de 1B parámetros) para identidad a video; y Ctrl-Adapter y ControlVideo para profundidad a video. Todos los modelos se evaluaron utilizando sus configuraciones predeterminadas. Para la consistencia, se muestrearon uniformemente 16 cuadros de cada método, igualando la longitud de salida de los modelos anteriores.*
*Resultados cuantitativos para la generación de video de tarea única. FullDiT se comparó con MotionCtrl, CameraCtrl y CamI2V para la generación de cámara a video; ConceptMaster (versión de 1B parámetros) para identidad a video; y Ctrl-Adapter y ControlVideo para profundidad a video. Todos los modelos se evaluaron utilizando sus configuraciones predeterminadas. Para la consistencia, se muestrearon uniformemente 16 cuadros de cada método, igualando la longitud de salida de los modelos anteriores.*
Los resultados indican que FullDiT, a pesar de manejar múltiples señales de condicionamiento simultáneamente, logró un rendimiento de vanguardia en métricas relacionadas con texto, movimiento de cámara, identidad y controles de profundidad.
En las métricas de calidad general, el sistema generalmente superó a otros métodos, aunque su suavidad fue ligeramente inferior a la de ConceptMaster. Aquí los autores comentan:
**‘La suavidad de FullDiT es ligeramente inferior a la de ConceptMaster, ya que el cálculo de la suavidad se basa en la similitud CLIP entre cuadros adyacentes. Como FullDiT exhibe una dinámica significativamente mayor en comparación con ConceptMaster, la métrica de suavidad se ve afectada por las grandes variaciones entre cuadros adyacentes.’**
**‘Para la puntuación estética, dado que el modelo de calificación favorece imágenes en estilo de pintura y ControlVideo típicamente genera videos en este estilo, logra una alta puntuación en estética.’**
Con respecto a la comparación cualitativa, podría ser preferible referirse a los videos de muestra en el sitio del proyecto FullDiT, ya que los ejemplos en PDF son inevitablemente estáticos (y también demasiado extensos para reproducirlos completamente aquí).
 *La primera sección de los resultados cualitativos reproducidos en el PDF. Por favor, consulta el artículo fuente para los ejemplos adicionales, que son demasiado extensos para reproducir aquí.*
*La primera sección de los resultados cualitativos reproducidos en el PDF. Por favor, consulta el artículo fuente para los ejemplos adicionales, que son demasiado extensos para reproducir aquí.*
Los autores comentan:
**‘FullDiT demuestra una preservación de identidad superior y genera videos con mejor dinámica y calidad visual en comparación con [ConceptMaster]. Dado que ConceptMaster y FullDiT están entrenados en el mismo backbone, esto destaca la efectividad de la inyección de condiciones con atención completa.’**
**‘…Los [otros] resultados demuestran la controlabilidad y calidad de generación superiores de FullDiT en comparación con los métodos existentes de profundidad a video y cámara a video.’**
 *Una sección de los ejemplos del PDF de la salida de FullDiT con múltiples señales. Por favor, consulta el artículo fuente y el sitio del proyecto para ejemplos adicionales.*
*Una sección de los ejemplos del PDF de la salida de FullDiT con múltiples señales. Por favor, consulta el artículo fuente y el sitio del proyecto para ejemplos adicionales.*
Conclusión
FullDiT representa un paso emocionante hacia un modelo de fundación de video más completo, pero la pregunta sigue siendo si la demanda de características de estilo ControlNet justifica su implementación a gran escala, especialmente para proyectos de código abierto. Estos proyectos tendrían dificultades para obtener el vasto poder de procesamiento de GPU requerido sin apoyo comercial.
El desafío principal es que usar sistemas como Depth y Pose generalmente requiere una familiaridad no trivial con interfaces de usuario complejas como ComfyUI. Por lo tanto, es más probable que un modelo de código abierto funcional de este tipo sea desarrollado por pequeñas empresas de VFX que carecen de los recursos o la motivación para curar y entrenar un modelo de este tipo de forma privada.
Por otro lado, los sistemas de "alquiler de IA" basados en API pueden estar bien motivados para desarrollar métodos interpretativos más simples y amigables para el usuario para modelos con sistemas de control auxiliares entrenados directamente.
**Haz clic para reproducir. Controles de profundidad+texto impuestos en una generación de video usando FullDiT.**
*Los autores no especifican ningún modelo base conocido (es decir, SDXL, etc.)*
**Publicado por primera vez el jueves, 27 de marzo de 2025**
Artículo relacionado
 YouTube prueba una función de búsqueda basada en inteligencia artificial con respuestas guiadas
Muchos usuarios recurren a YouTube cuando buscan recetas o planes de viaje, en busca de vídeos relevantes. Ahora, la plataforma presenta una herramienta de búsqueda interactiva basada en inteligencia
Exclusiva: Luma AI presenta agentes creativos impulsados por modelos de «inteligencia unificada»
El jueves, la startup de generación de vídeo mediante IA Luma presentó Luma Agents, un sistema creado para gestionar flujos de trabajo creativos completos que abarcan texto, imágenes, vídeo y audio. E
La nueva actualización de Sora incluye vídeos de inteligencia artificial de mascotas, herramientas sociales y una próxima aplicación para Android.
OpenAI presenta una serie de nuevas funciones para Sora, su aplicación de creación de vídeos con inteligencia artificial, que alcanzó rápidamente el primer puesto de la App Store tras su lanzamiento a
Recomendaciones de temas especiales relacionados
Negocio
YouTube prueba una función de búsqueda basada en inteligencia artificial con respuestas guiadas
Muchos usuarios recurren a YouTube cuando buscan recetas o planes de viaje, en busca de vídeos relevantes. Ahora, la plataforma presenta una herramienta de búsqueda interactiva basada en inteligencia
Exclusiva: Luma AI presenta agentes creativos impulsados por modelos de «inteligencia unificada»
El jueves, la startup de generación de vídeo mediante IA Luma presentó Luma Agents, un sistema creado para gestionar flujos de trabajo creativos completos que abarcan texto, imágenes, vídeo y audio. E
La nueva actualización de Sora incluye vídeos de inteligencia artificial de mascotas, herramientas sociales y una próxima aplicación para Android.
OpenAI presenta una serie de nuevas funciones para Sora, su aplicación de creación de vídeos con inteligencia artificial, que alcanzó rápidamente el primer puesto de la App Store tras su lanzamiento a
Recomendaciones de temas especiales relacionados
Negocio
 Las mejores herramientas de selección de personal basadas en IA: filtrar currículos y automatizar la programación de entrevistas con los candidatos
Las mejores herramientas de selección de personal basadas en IA: filtrar currículos y automatizar la programación de entrevistas con los candidatos
Descubre las mejores herramientas de selección de personal basadas en IA de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada, incluye soluciones potentes y revolucionarias para la selección de currículos y la automatización de la programación de entrevistas con los candidatos. Compara las opciones gratuitas con las de pago gracias a pruebas reales y a clasificaciones que se actualizan semanalmente. ¡Encuentra tu asistente de selección de personal ideal y optimiza tu proceso de selección hoy mismo!
 10 herramientas
10 herramientas
 xix.ai
Productividad
Entrenadores personales de bienestar y concentración basados en IA: controla el agotamiento y aumenta tus niveles de energía mental
xix.ai
Productividad
Entrenadores personales de bienestar y concentración basados en IA: controla el agotamiento y aumenta tus niveles de energía mental
Descubre los mejores entrenadores personales de bienestar y concentración basados en IA de 2026 en XIX.AI. Nuestras clasificaciones, cuidadosamente seleccionadas, incluyen herramientas revolucionarias y de primera categoría para gestionar el agotamiento y potenciar la energía mental. Compara las opciones gratuitas con las de pago gracias a información basada en casos reales. Descubre hoy mismo el camino hacia la máxima productividad y el bienestar.
10 herramientas
xix.ai
chatbot
Los mejores chatbots románticos con IA: crea relaciones duraderas con personalidades coherentes
Descubre los mejores chatbots románticos con IA de 2026 para establecer relaciones auténticas y duraderas. Nuestra lista seleccionada incluye personalidades sólidas y coherentes, comparativas entre versiones gratuitas y de pago, y pruebas en situaciones reales. Encuentra a tu compañero ideal y empieza a construir tu relación hoy mismo en XIX.AI.
10 herramientas
xix.ai
Educación y aprendizaje
Los mejores mentores en ciencia de datos y IA: dominan SQL, Pandas y flujos de trabajo de aprendizaje automático.
Descubra a los mejores mentores en ciencia de datos y AI de 2026 para dominar SQL, Pandas y flujos de trabajo de aprendizaje automático. Explore nuestra selección cuidadosamente seleccionada y altamente valorada en XIX.AI para obtener orientación poderosa que cambie completamente la situación. Compare las opciones gratuitas con las pagadas y obtenga información basada en casos reales. Desbloquee su dominio de la ciencia de datos hoy mismo.
10 herramientas
xix.ai
chatbot
Los mejores entrenadores de IA para ligar y conversar: mejora tu carisma social y tu confianza en tiempo real
Descubre los mejores cursos de 2026 sobre coqueteo y conversación con IA en XIX.AI. Nuestra selección, cuidadosamente seleccionada y con las mejores valoraciones, te ayuda a desarrollar tu carisma social y tu confianza en tiempo real. Explora herramientas imprescindibles y revolucionarias con comparativas entre versiones gratuitas y de pago, y clasificaciones que se actualizan semanalmente. Potencia hoy mismo tus habilidades sociales.
10 herramientas
xix.ai
código
Las mejores herramientas de IA para pruebas unitarias automatizadas: genera casos de prueba con Jest, PyTest y JUnit con un solo clic
Descubre las mejores herramientas de IA de 2026 para la automatización de pruebas unitarias. Nuestra selección incluye potentes soluciones revolucionarias que permiten generar casos de prueba para Jest, PyTest y JUnit al instante. Compara las opciones gratuitas con las de pago mediante pruebas reales y clasificaciones actualizadas semanalmente en XIX.AI. Aprovecha las ventajas de la IA y aumenta la productividad de tu desarrollo hoy mismo.
10 herramientas
xix.ai

 comentario (3)
0/500
comentario (3)
0/500
![TimothyMitchell]()
映像の詳細なコントロールって本当に難しいんですね。AIがプロのVFXスタジオで使われる日はまだ先かな?でも技術の進歩にはワクワクする!🔥
![CharlesMartinez]()
Finalmente os vídeos gerados por IA estão evoluindo para algo útil! Mas ainda parece que falta muito pra substituir os efeitos manuais de grandes produções... será que um dia chegaremos lá? 🎥
![DonaldLee]()
The idea of AI taking over VFX in films is wild! I mean, total control over video generation? That’s some sci-fi stuff coming to life. But I wonder if these models like Hunyuan can really nail the tiny details directors obsess over. Exciting times! 🎥
Los modelos de fundación de video como Hunyuan y Wan 2.1 han logrado avances significativos, pero a menudo se quedan cortos cuando se trata del control detallado requerido en la producción de cine y televisión, especialmente en el ámbito de los efectos visuales (VFX). En los estudios profesionales de VFX, estos modelos, junto con modelos anteriores basados en imágenes como Stable Diffusion, Kandinsky y Flux, se utilizan en conjunto con una suite de herramientas diseñadas para refinar su salida y satisfacer demandas creativas específicas. Cuando un director solicita un ajuste, diciendo algo como, "Eso se ve genial, pero ¿podemos hacerlo un poco más [n]?", no es suficiente simplemente afirmar que el modelo carece de la precisión para realizar dichos ajustes.
En cambio, un equipo de VFX de IA empleará una combinación de CGI tradicional y técnicas de composición, junto con flujos de trabajo desarrollados a medida, para empujar los límites de la síntesis de video aún más. Este enfoque es similar a usar un navegador web predeterminado como Chrome; es funcional de inmediato, pero para adaptarlo realmente a tus necesidades, necesitarás instalar algunos complementos.
Control Freaks
En el campo de la síntesis de imágenes basada en difusión, uno de los sistemas de terceros más cruciales es ControlNet. Esta técnica introduce un control estructurado a los modelos generativos, permitiendo a los usuarios guiar la generación de imágenes o videos utilizando entradas adicionales como mapas de bordes, mapas de profundidad o información de poses.
*Los diversos métodos de ControlNet permiten la generación de imágenes a partir de profundidad (fila superior), segmentación semántica a imagen (inferior izquierda) y generación de imágenes guiadas por poses de humanos y animales (inferior izquierda).*
ControlNet no depende únicamente de prompts de texto; emplea ramas de redes neuronales separadas, o adaptadores, para procesar estas señales de condicionamiento mientras mantiene las capacidades generativas del modelo base. Esto permite salidas altamente personalizadas que se alinean estrechamente con las especificaciones del usuario, lo que lo hace invaluable para aplicaciones que requieren un control preciso sobre la composición, la estructura o el movimiento.
*Con una pose guía, se pueden obtener una variedad de tipos de salida precisos a través de ControlNet.* Fuente: https://arxiv.org/pdf/2302.05543
Sin embargo, estos sistemas basados en adaptadores, que operan externamente sobre un conjunto de procesos neuronales enfocados internamente, presentan varios inconvenientes. Los adaptadores se entrenan de forma independiente, lo que puede llevar a conflictos de ramas cuando se combinan múltiples adaptadores, lo que a menudo resulta en generaciones de menor calidad. También introducen redundancia de parámetros, requiriendo recursos computacionales y memoria adicionales para cada adaptador, lo que hace que la escalabilidad sea ineficiente. Además, a pesar de su flexibilidad, los adaptadores a menudo producen resultados subóptimos en comparación con modelos completamente afinados para la generación con múltiples condiciones. Estos problemas pueden hacer que los métodos basados en adaptadores sean menos efectivos para tareas que requieren la integración fluida de múltiples señales de control.
Idealmente, las capacidades de ControlNet se integrarían de forma nativa en el modelo de manera modular, permitiendo innovaciones futuras como la generación simultánea de video/audio o capacidades nativas de sincronización labial. Actualmente, cada característica adicional se convierte en una tarea de posproducción o en un procedimiento no nativo que debe navegar por los pesos sensibles del modelo de fundación.
FullDiT
Entra FullDiT, un nuevo enfoque desde China que integra características de estilo ControlNet directamente en un modelo generativo de video durante el entrenamiento, en lugar de tratarlas como una ocurrencia tardía.
*Del nuevo artículo: el enfoque FullDiT puede incorporar la imposición de identidad, profundidad y movimiento de cámara en una generación nativa, y puede invocar cualquier combinación de estos a la vez.* Fuente: https://arxiv.org/pdf/2503.19907
FullDiT, como se describe en el artículo titulado **FullDiT: Modelo de Fundación Generativo de Video Multi-Tarea con Atención Completa**, integra condiciones multi-tarea como transferencia de identidad, mapeo de profundidad y movimiento de cámara en el núcleo de un modelo generativo de video entrenado. Los autores han desarrollado un modelo prototipo y clips de video acompañantes disponibles en un sitio de proyecto.
**Haz clic para reproducir. Ejemplos de imposición de usuario de estilo ControlNet con solo un modelo de fundación entrenado de forma nativa.** Fuente: https://fulldit.github.io/
Los autores presentan FullDiT como una prueba de concepto para modelos de texto a video (T2V) e imagen a video (I2V) que ofrecen a los usuarios más control que solo un prompt de imagen o texto. Dado que no existen modelos similares, los investigadores crearon un nuevo punto de referencia llamado **FullBench** para evaluar videos multi-tarea, afirmando un rendimiento de vanguardia en sus pruebas diseñadas. Sin embargo, la objetividad de FullBench, diseñado por los propios autores, no ha sido probada, y su conjunto de datos de 1,400 casos puede ser demasiado limitado para conclusiones más amplias.
El aspecto más intrigante de la arquitectura de FullDiT es su potencial para incorporar nuevos tipos de control. Los autores señalan:
**‘En este trabajo, solo exploramos condiciones de control de la cámara, identidades e información de profundidad. No investigamos más a fondo otras condiciones y modalidades como audio, voz, nube de puntos, cajas delimitadoras de objetos, flujo óptico, etc. Aunque el diseño de FullDiT puede integrar otras modalidades con modificaciones mínimas en la arquitectura, cómo adaptar rápidamente y de manera rentable los modelos existentes a nuevas condiciones y modalidades sigue siendo una pregunta importante que merece una exploración adicional.’**
Aunque FullDiT representa un paso adelante en la generación de videos multi-tarea, se basa en arquitecturas existentes en lugar de introducir un nuevo paradigma. Sin embargo, se destaca como el único modelo de fundación de video con características de estilo ControlNet integradas de forma nativa, y su arquitectura está diseñada para acomodar innovaciones futuras.
**Haz clic para reproducir. Ejemplos de movimientos de cámara controlados por el usuario, desde el sitio del proyecto.**
El artículo, escrito por nueve investigadores de Kuaishou Technology y The Chinese University of Hong Kong, se titula **FullDiT: Modelo de Fundación Generativo de Video Multi-Tarea con Atención Completa**. La página del proyecto y los datos del nuevo punto de referencia están disponibles en Hugging Face.
Método
El mecanismo de atención unificada de FullDiT está diseñado para mejorar el aprendizaje de representación intermodal al capturar relaciones espaciales y temporales entre las condiciones.
*Según el nuevo artículo, FullDiT integra múltiples condiciones deja entrada a través de una atención propia completa, convirtiéndolas en una secuencia unificada. En contraste, los modelos basados en adaptadores (el más a la izquierda) usan módulos separados para cada entrada, lo que lleva a redundancia, conflictos y un rendimiento más débil.*
A diferencia de las configuraciones basadas en adaptadores que procesan cada flujo de entrada por separado, la estructura de atención compartida de FullDiT evita conflictos de ramas y reduce la sobrecarga de parámetros. Los autores afirman que la arquitectura puede escalar a nuevos tipos de entrada sin un rediseño importante y que el esquema del modelo muestra signos de generalización a combinaciones de condiciones no vistas durante el entrenamiento, como vincular el movimiento de la cámara con la identidad del personaje.
**Haz clic para reproducir. Ejemplos de generación de identidad desde el sitio del proyecto.**
En la arquitectura de FullDiT, todas las entradas de condicionamiento —como texto, movimiento de cámara, identidad y profundidad— se convierten primero en un formato de token unificado. Estos tokens se concatenan en una sola secuencia larga, procesada a través de una pila de capas transformadoras utilizando atención propia completa. Este enfoque sigue trabajos anteriores como Open-Sora Plan y Movie Gen.
Este diseño permite al modelo aprender relaciones temporales y espaciales conjuntamente entre todas las condiciones. Cada bloque transformador opera sobre la secuencia completa, habilitando interacciones dinámicas entre modalidades sin depender de módulos separados para cada entrada. La arquitectura está diseñada para ser extensible, facilitando la incorporación de señales de control adicionales en el futuro sin cambios estructurales importantes.
El poder de tres
FullDiT convierte cada señal de control en un formato de token estandarizado para que todas las condiciones puedan procesarse juntas en un marco de atención unificado. Para el movimiento de la cámara, el modelo codifica una secuencia de parámetros extrínsecos —como posición y orientación— para cada cuadro. Estos parámetros se marcan con sello de tiempo y se proyectan en vectores incrustados que reflejan la naturaleza temporal de la señal.
La información de identidad se trata de manera diferente, ya que es inherentemente espacial en lugar de temporal. El modelo utiliza mapas de identidad que indican qué personajes están presentes en qué partes de cada cuadro. Estos mapas se dividen en parches, con cada parche proyectado en un incrustado que captura señales de identidad espacial, permitiendo al modelo asociar regiones específicas del cuadro con entidades específicas.
La profundidad es una señal espaciotemporal, y el modelo la maneja dividiendo los videos de profundidad en parches 3D que abarcan tanto el espacio como el tiempo. Estos parches se incrustan de manera que preservan su estructura a través de los cuadros.
Una vez incrustados, todos estos tokens de condición (cámara, identidad y profundidad) se concatenan en una sola secuencia larga, permitiendo a FullDiT procesarlos juntos usando atención propia completa. Esta representación compartida permite al modelo aprender interacciones entre modalidades y a través del tiempo sin depender de flujos de procesamiento aislados.
Datos y pruebas
El enfoque de entrenamiento de FullDiT se basó en conjuntos de datos anotados selectivamente adaptados a cada tipo de condicionamiento, en lugar de requerir que todas las condiciones estén presentes simultáneamente.
Para las condiciones textuales, la iniciativa sigue el enfoque de subtitulado estructurado descrito en el proyecto MiraData.
*Tubería de recolección y anotación de videos del proyecto MiraData.* Fuente: https://arxiv.org/pdf/2407.06358
Para el movimiento de la cámara, el conjunto de datos RealEstate10K fue la principal fuente de datos, debido a sus anotaciones de alta calidad de los parámetros de la cámara. Sin embargo, los autores observaron que entrenar exclusivamente con conjuntos de datos de cámaras de escenas estáticas como RealEstate10K tendía a reducir los movimientos de objetos y humanos dinámicos en los videos generados. Para contrarrestar esto, realizaron un ajuste fino adicional utilizando conjuntos de datos internos que incluían movimientos de cámara más dinámicos.
Las anotaciones de identidad se generaron utilizando la tubería desarrollada para el proyecto ConceptMaster, que permitió un filtrado y extracción eficiente de información de identidad detallada.
*El marco ConceptMaster está diseñado para abordar problemas de desacoplamiento de identidad mientras preserva la fidelidad del concepto en videos personalizados.* Fuente: https://arxiv.org/pdf/2501.04698
Las anotaciones de profundidad se obtuvieron del conjunto de datos Panda-70M utilizando Depth Anything.
Optimización a través del ordenamiento de datos
Los autores también implementaron un programa de entrenamiento progresivo, introduciendo condiciones más desafiantes al principio del entrenamiento para asegurar que el modelo adquiriera representaciones robustas antes de que se añadieran tareas más simples. El orden de entrenamiento pasó de texto a condiciones de cámara, luego identidades y finalmente profundidad, con tareas más fáciles generalmente introducidas más tarde y con menos ejemplos.
Los autores enfatizan el valor de ordenar la carga de trabajo de esta manera:
**‘Durante la fase de pre-entrenamiento, notamos que las tareas más desafiantes requieren un tiempo de entrenamiento prolongado y deben introducirse antes en el proceso de aprendizaje. Estas tareas desafiantes involucran distribuciones de datos complejas que difieren significativamente del video de salida, requiriendo que el modelo tenga suficiente capacidad para capturarlas y representarlas con precisión.’**
**‘Por el contrario, introducir tareas más fáciles demasiado pronto puede llevar al modelo a priorizar su aprendizaje primero, ya que proporcionan retroalimentación de optimización más inmediata, lo que dificulta la convergencia de las tareas más desafiantes.’**
*Una ilustración del orden de entrenamiento de datos adoptado por los investigadores, con rojo indicando un mayor volumen de datos.*
Tras el pre-entrenamiento inicial, una etapa final de ajuste fino refinó aún más el modelo para mejorar la calidad visual y la dinámica del movimiento. A partir de entonces, el entrenamiento siguió el de un marco de difusión estándar: se añadió ruido a los latentes de video, y el modelo aprendió a predecir y eliminarlo, utilizando los tokens de condición incrustados como guía.
Para evaluar eficazmente FullDiT y proporcionar una comparación justa contra los métodos existentes, y en ausencia de cualquier otro punto de referencia apropiado, los autores introdujeron **FullBench**, una suite de evaluación curada que consta de 1,400 casos de prueba distintos.
*Una instancia de explorador de datos para el nuevo punto de referencia FullBench.* Fuente: https://huggingface.co/datasets/KwaiVGI/FullBench
Cada punto de datos proporcionó anotaciones de verdad de campo para varias señales de condicionamiento, incluyendo movimiento de cámara, identidad y profundidad.
Métricas
Los autores evaluaron FullDiT utilizando diez métricas que cubren cinco aspectos principales del rendimiento: alineación de texto, control de cámara, similitud de identidad, precisión de profundidad y calidad general del video.
La alineación de texto se midió utilizando la similitud CLIP, mientras que el control de cámara se evaluó mediante el error de rotación (RotErr), el error de traslación (TransErr) y la consistencia del movimiento de la cámara (CamMC), siguiendo el enfoque de CamI2V (en el proyecto CameraCtrl).
La similitud de identidad se evaluó utilizando DINO-I y CLIP-I, y la precisión del control de profundidad se cuantificó utilizando el Error Absoluto Medio (MAE).
La calidad del video se juzgó con tres métricas de MiraData: similitud CLIP a nivel de cuadro para suavidad; distancia de movimiento basada en flujo óptico para dinámica; y puntuaciones estéticas de LAION para atractivo visual.
Entrenamiento
Los autores entrenaron FullDiT utilizando un modelo de difusión de texto a video interno (no revelado) que contiene aproximadamente mil millones de parámetros. Eligieron intencionalmente un tamaño de parámetros modesto para mantener la equidad en las comparaciones con métodos anteriores y asegurar la reproducibilidad.
Dado que los videos de entrenamiento diferían en longitud y resolución, los autores estandarizaron cada lote redimensionando y rellenando los videos a una resolución común, muestreando 77 cuadros por secuencia, y utilizando máscaras de atención y pérdida aplicadas para optimizar la efectividad del entrenamiento.
El optimizador Adam se utilizó a una tasa de aprendizaje de 1×10−5 en un clúster de 64 GPUs NVIDIA H800, para un total combinado de 5,120GB de VRAM (considera que en las comunidades de síntesis entusiastas, 24GB en una RTX 3090 aún se considera un estándar lujoso).
El modelo se entrenó durante aproximadamente 32,000 pasos, incorporando hasta tres identidades por video, junto con 20 cuadros de condiciones de cámara y 21 cuadros de condiciones de profundidad, ambos muestreados uniformemente de los 77 cuadros totales.
Para la inferencia, el modelo generó videos a una resolución de 384×672 píxeles (aproximadamente cinco segundos a 15 cuadros por segundo) con 50 pasos de inferencia de difusión y una escala de guía sin clasificador de cinco.
Métodos anteriores
Para la evaluación de cámara a video, los autores compararon FullDiT contra MotionCtrl, CameraCtrl y CamI2V, con todos los modelos entrenados usando el conjunto de datos RealEstate10k para asegurar consistencia y equidad.
En la generación condicionada por identidad, dado que no había modelos de múltiples identidades de código abierto comparables disponibles, el modelo se comparó con el modelo ConceptMaster de 1B parámetros, utilizando los mismos datos de entrenamiento y arquitectura.
Para tareas de profundidad a video, se realizaron comparaciones con Ctrl-Adapter y ControlVideo.
*Resultados cuantitativos para la generación de video de tarea única. FullDiT se comparó con MotionCtrl, CameraCtrl y CamI2V para la generación de cámara a video; ConceptMaster (versión de 1B parámetros) para identidad a video; y Ctrl-Adapter y ControlVideo para profundidad a video. Todos los modelos se evaluaron utilizando sus configuraciones predeterminadas. Para la consistencia, se muestrearon uniformemente 16 cuadros de cada método, igualando la longitud de salida de los modelos anteriores.*
Los resultados indican que FullDiT, a pesar de manejar múltiples señales de condicionamiento simultáneamente, logró un rendimiento de vanguardia en métricas relacionadas con texto, movimiento de cámara, identidad y controles de profundidad.
En las métricas de calidad general, el sistema generalmente superó a otros métodos, aunque su suavidad fue ligeramente inferior a la de ConceptMaster. Aquí los autores comentan:
**‘La suavidad de FullDiT es ligeramente inferior a la de ConceptMaster, ya que el cálculo de la suavidad se basa en la similitud CLIP entre cuadros adyacentes. Como FullDiT exhibe una dinámica significativamente mayor en comparación con ConceptMaster, la métrica de suavidad se ve afectada por las grandes variaciones entre cuadros adyacentes.’**
**‘Para la puntuación estética, dado que el modelo de calificación favorece imágenes en estilo de pintura y ControlVideo típicamente genera videos en este estilo, logra una alta puntuación en estética.’**
Con respecto a la comparación cualitativa, podría ser preferible referirse a los videos de muestra en el sitio del proyecto FullDiT, ya que los ejemplos en PDF son inevitablemente estáticos (y también demasiado extensos para reproducirlos completamente aquí).
*La primera sección de los resultados cualitativos reproducidos en el PDF. Por favor, consulta el artículo fuente para los ejemplos adicionales, que son demasiado extensos para reproducir aquí.*
Los autores comentan:
**‘FullDiT demuestra una preservación de identidad superior y genera videos con mejor dinámica y calidad visual en comparación con [ConceptMaster]. Dado que ConceptMaster y FullDiT están entrenados en el mismo backbone, esto destaca la efectividad de la inyección de condiciones con atención completa.’**
**‘…Los [otros] resultados demuestran la controlabilidad y calidad de generación superiores de FullDiT en comparación con los métodos existentes de profundidad a video y cámara a video.’**
*Una sección de los ejemplos del PDF de la salida de FullDiT con múltiples señales. Por favor, consulta el artículo fuente y el sitio del proyecto para ejemplos adicionales.*
Conclusión
FullDiT representa un paso emocionante hacia un modelo de fundación de video más completo, pero la pregunta sigue siendo si la demanda de características de estilo ControlNet justifica su implementación a gran escala, especialmente para proyectos de código abierto. Estos proyectos tendrían dificultades para obtener el vasto poder de procesamiento de GPU requerido sin apoyo comercial.
El desafío principal es que usar sistemas como Depth y Pose generalmente requiere una familiaridad no trivial con interfaces de usuario complejas como ComfyUI. Por lo tanto, es más probable que un modelo de código abierto funcional de este tipo sea desarrollado por pequeñas empresas de VFX que carecen de los recursos o la motivación para curar y entrenar un modelo de este tipo de forma privada.
Por otro lado, los sistemas de "alquiler de IA" basados en API pueden estar bien motivados para desarrollar métodos interpretativos más simples y amigables para el usuario para modelos con sistemas de control auxiliares entrenados directamente.
**Haz clic para reproducir. Controles de profundidad+texto impuestos en una generación de video usando FullDiT.**
*Los autores no especifican ningún modelo base conocido (es decir, SDXL, etc.)*
**Publicado por primera vez el jueves, 27 de marzo de 2025**










 YouTube prueba una función de búsqueda basada en inteligencia artificial con respuestas guiadas
Muchos usuarios recurren a YouTube cuando buscan recetas o planes de viaje, en busca de vídeos relevantes. Ahora, la plataforma presenta una herramienta de búsqueda interactiva basada en inteligencia
YouTube prueba una función de búsqueda basada en inteligencia artificial con respuestas guiadas
Muchos usuarios recurren a YouTube cuando buscan recetas o planes de viaje, en busca de vídeos relevantes. Ahora, la plataforma presenta una herramienta de búsqueda interactiva basada en inteligencia
 Exclusiva: Luma AI presenta agentes creativos impulsados por modelos de «inteligencia unificada»
El jueves, la startup de generación de vídeo mediante IA Luma presentó Luma Agents, un sistema creado para gestionar flujos de trabajo creativos completos que abarcan texto, imágenes, vídeo y audio. E
Exclusiva: Luma AI presenta agentes creativos impulsados por modelos de «inteligencia unificada»
El jueves, la startup de generación de vídeo mediante IA Luma presentó Luma Agents, un sistema creado para gestionar flujos de trabajo creativos completos que abarcan texto, imágenes, vídeo y audio. E
 La nueva actualización de Sora incluye vídeos de inteligencia artificial de mascotas, herramientas sociales y una próxima aplicación para Android.
OpenAI presenta una serie de nuevas funciones para Sora, su aplicación de creación de vídeos con inteligencia artificial, que alcanzó rápidamente el primer puesto de la App Store tras su lanzamiento a
La nueva actualización de Sora incluye vídeos de inteligencia artificial de mascotas, herramientas sociales y una próxima aplicación para Android.
OpenAI presenta una serie de nuevas funciones para Sora, su aplicación de creación de vídeos con inteligencia artificial, que alcanzó rápidamente el primer puesto de la App Store tras su lanzamiento a

Descubre las mejores herramientas de selección de personal basadas en IA de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada, incluye soluciones potentes y revolucionarias para la selección de currículos y la automatización de la programación de entrevistas con los candidatos. Compara las opciones gratuitas con las de pago gracias a pruebas reales y a clasificaciones que se actualizan semanalmente. ¡Encuentra tu asistente de selección de personal ideal y optimiza tu proceso de selección hoy mismo!
10 herramientas
xix.ai

Descubre los mejores entrenadores personales de bienestar y concentración basados en IA de 2026 en XIX.AI. Nuestras clasificaciones, cuidadosamente seleccionadas, incluyen herramientas revolucionarias y de primera categoría para gestionar el agotamiento y potenciar la energía mental. Compara las opciones gratuitas con las de pago gracias a información basada en casos reales. Descubre hoy mismo el camino hacia la máxima productividad y el bienestar.
10 herramientas
xix.ai

Descubre los mejores chatbots románticos con IA de 2026 para establecer relaciones auténticas y duraderas. Nuestra lista seleccionada incluye personalidades sólidas y coherentes, comparativas entre versiones gratuitas y de pago, y pruebas en situaciones reales. Encuentra a tu compañero ideal y empieza a construir tu relación hoy mismo en XIX.AI.
10 herramientas
xix.ai

Descubra a los mejores mentores en ciencia de datos y AI de 2026 para dominar SQL, Pandas y flujos de trabajo de aprendizaje automático. Explore nuestra selección cuidadosamente seleccionada y altamente valorada en XIX.AI para obtener orientación poderosa que cambie completamente la situación. Compare las opciones gratuitas con las pagadas y obtenga información basada en casos reales. Desbloquee su dominio de la ciencia de datos hoy mismo.
10 herramientas
xix.ai

Descubre los mejores cursos de 2026 sobre coqueteo y conversación con IA en XIX.AI. Nuestra selección, cuidadosamente seleccionada y con las mejores valoraciones, te ayuda a desarrollar tu carisma social y tu confianza en tiempo real. Explora herramientas imprescindibles y revolucionarias con comparativas entre versiones gratuitas y de pago, y clasificaciones que se actualizan semanalmente. Potencia hoy mismo tus habilidades sociales.
10 herramientas
xix.ai

Descubre las mejores herramientas de IA de 2026 para la automatización de pruebas unitarias. Nuestra selección incluye potentes soluciones revolucionarias que permiten generar casos de prueba para Jest, PyTest y JUnit al instante. Compara las opciones gratuitas con las de pago mediante pruebas reales y clasificaciones actualizadas semanalmente en XIX.AI. Aprovecha las ventajas de la IA y aumenta la productividad de tu desarrollo hoy mismo.
10 herramientas
xix.ai

映像の詳細なコントロールって本当に難しいんですね。AIがプロのVFXスタジオで使われる日はまだ先かな?でも技術の進歩にはワクワクする!🔥
Finalmente os vídeos gerados por IA estão evoluindo para algo útil! Mas ainda parece que falta muito pra substituir os efeitos manuais de grandes produções... será que um dia chegaremos lá? 🎥
The idea of AI taking over VFX in films is wild! I mean, total control over video generation? That’s some sci-fi stuff coming to life. But I wonder if these models like Hunyuan can really nail the tiny details directors obsess over. Exciting times! 🎥













