
















 首页
首页人工智能视频生成朝着完全控制
视频基础模型如Hunyuan和Wan 2.1已取得显著进展,但在电影和电视制作中,尤其是在视觉特效(VFX)领域,它们往往无法满足所需的精细控制。在专业VFX工作室中,这些模型与早期基于图像的模型如Stable Diffusion、Kandinsky和Flux一起,与一系列专为满足特定创意需求而设计的工具结合使用。当导演要求调整时,比如说“这看起来很好,但能再稍微[n]一点吗?”,仅仅声称模型缺乏精确调整能力是不够的。
相反,AI VFX团队会结合传统CGI和合成技术,以及定制开发的工作流程,进一步推动视频合成的边界。这种方法类似于使用默认浏览器如Chrome;它开箱即用,但要真正满足你的需求,你需要安装一些插件。
控制狂
在基于扩散的图像合成领域,最关键的第三方系统之一是ControlNet。这种技术为生成模型引入了结构化控制,允许用户通过额外的输入(如边缘图、深度图或姿态信息)来引导图像或视频生成。
 *ControlNet的多种方法允许进行深度>图像(上行)、语义分割>图像(左下)和人类及动物的姿态引导图像生成(左下)。*
*ControlNet的多种方法允许进行深度>图像(上行)、语义分割>图像(左下)和人类及动物的姿态引导图像生成(左下)。*
ControlNet不完全依赖文本提示;它使用独立的神经网络分支或适配器来处理这些条件信号,同时保持基础模型的生成能力。这能够生成高度定制化的输出,紧密符合用户规格,对于需要精确控制构图、结构或运动的应用来说尤为宝贵。
 *通过引导姿态,ControlNet可以获得多种精确的输出类型。* 来源:https://arxiv.org/pdf/2302.05543
*通过引导姿态,ControlNet可以获得多种精确的输出类型。* 来源:https://arxiv.org/pdf/2302.05543
然而,这些基于适配器的系统在内部聚焦的神经过程集上外部操作,存在几个缺点。适配器是独立训练的,当多个适配器结合时可能导致分支冲突,通常导致生成质量较低。它们还引入了参数冗余,每个适配器都需要额外的计算资源和内存,使得扩展效率低下。此外,尽管适配器具有灵活性,但与为多条件生成完全微调的模型相比,其结果往往次优。这些问题可能使基于适配器的方法在需要无缝整合多种控制信号的任务中效果较差。
理想情况下,ControlNet的功能应以模块化方式原生集成到模型中,允许未来创新,如同步视频/音频生成或原生唇部同步功能。目前,每增加一个功能要么成为后期制作任务,要么成为必须处理基础模型敏感权重的非原生程序。
FullDiT
来自中国的新方法FullDiT在训练期间将ControlNet风格的功能直接集成到生成视频模型中,而不是将其作为事后考虑。
 *来自新论文:FullDiT方法可以将身份强制、深度和相机运动融入原生生成,并能同时调用这些的任意组合。* 来源:https://arxiv.org/pdf/2503.19907
*来自新论文:FullDiT方法可以将身份强制、深度和相机运动融入原生生成,并能同时调用这些的任意组合。* 来源:https://arxiv.org/pdf/2503.19907
FullDiT在题为**FullDiT:全注意力多任务视频生成基础模型**的论文中概述,将多任务条件(如身份转移、深度映射和相机运动)集成到训练好的生成视频模型核心中。作者开发了一个原型模型,并提供了可在项目网站上访问的视频片段。
**点击播放。仅使用原生训练的基础模型实现ControlNet风格的用户强制示例。** 来源:https://fulldit.github.io/
作者将FullDiT作为原生文本到视频(T2V)和图像到视频(I2V)模型的概念验证,为用户提供比仅图像或文本提示更多的控制。由于没有类似的模型存在,研究人员创建了一个名为**FullBench**的新基准,用于评估多任务视频,声称在他们设计的测试中表现最佳。然而,由作者自己设计的FullBench的客观性尚未得到验证,其1,400个案例的数据集可能对于更广泛的结论来说过于有限。
FullDiT架构最引人注目的方面是其融入新型控制的潜力。作者指出:
**‘在这项工作中,我们仅探索了相机、身份和深度信息的控制条件。我们没有进一步研究其他条件和模态,如音频、语音、点云、对象边界框、光流等。尽管FullDiT的设计可以以最小的架构修改无缝整合其他模态,如何快速且成本效益高地适应现有模型以应对新条件和模态仍是一个值得进一步探索的重要问题。’**
虽然FullDiT在多任务视频生成方面迈出了重要一步,但它基于现有架构,而不是引入新范式。尽管如此,它作为唯一具有原生集成ControlNet风格功能的视频基础模型脱颖而出,其架构设计能够适应未来的创新。
**点击播放。来自项目网站的用户控制相机移动示例。**
由快手科技和香港中文大学九位研究人员撰写的论文题为**FullDiT:全注意力多任务视频生成基础模型**。项目页面和新基准数据可在Hugging Face上获取。
方法
FullDiT的统一注意力机制旨在通过捕捉跨条件的空间和时间关系来增强跨模态表示学习。
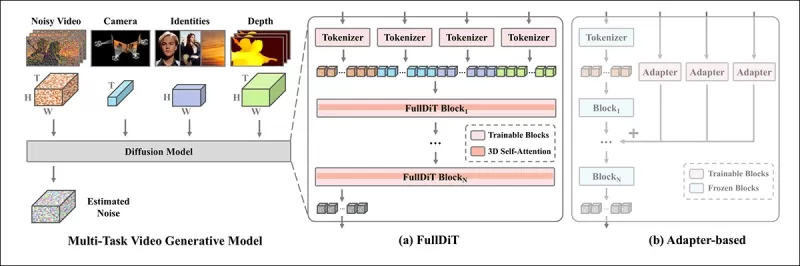 *根据新论文,FullDiT通过全自注意力整合多种输入条件,将其转换为统一序列。相比之下,基于适配器的模型(上图最左侧)为每个输入使用单独模块,导致冗余、冲突和性能较弱。*
*根据新论文,FullDiT通过全自注意力整合多种输入条件,将其转换为统一序列。相比之下,基于适配器的模型(上图最左侧)为每个输入使用单独模块,导致冗余、冲突和性能较弱。*
与分别处理每个输入流的基于适配器的设置不同,FullDiT的共享注意力结构避免了分支冲突并减少了参数开销。作者声称该架构可以扩展到新的输入类型而无需重大重新设计,模型架构显示出泛化到训练期间未见条件组合的迹象,如将相机运动与角色身份关联。
**点击播放。来自项目网站的身份生成示例。**
在FullDiT的架构中,所有条件输入(如文本、相机运动、身份和深度)首先被转换为统一的令牌格式。然后这些令牌被连接成一个单一的长序列,通过一组使用全自注意力的转换器层进行处理。这种方法遵循了Open-Sora Plan和Movie Gen等先前工作。
这种设计使模型能够跨所有条件共同学习时间和空间关系。每个转换器块在整个序列上操作,使模态之间的动态交互成为可能,而无需为每个输入依赖单独的模块。该架构设计具有扩展性,便于未来融入额外的控制信号而无需重大结构更改。
三者之力
FullDiT将每个控制信号转换为标准化令牌格式,以便所有条件可以在统一的注意力框架中一起处理。对于相机运动,模型为每帧编码一系列外部参数(如位置和方向)。这些参数被加时间戳并投影到反映信号时间性质的嵌入向量中。
身份信息处理方式不同,因为它本质上是空间性的而非时间性的。模型使用身份映射来指示每个帧中哪些部分存在哪些角色。这些映射被分为补丁,每个补丁投影到捕获空间身份线索的嵌入中,使模型能够将帧的特定区域与特定实体关联起来。
深度是一种时空信号,模型通过将深度视频分为跨越空间和时间的3D补丁来处理。这些补丁随后以保留其跨帧结构的方式嵌入。
一旦嵌入,所有这些条件令牌(相机、身份和深度)被连接成一个单一的长序列,使FullDiT能够使用全自注意力一起处理它们。这种共享表示使模型能够学习跨模态和跨时间的交互,而无需依赖隔离的处理流。
数据与测试
FullDiT的训练方法依赖于为每种条件类型量身定制的选择性注释数据集,而无需所有条件同时存在。
对于文本条件,该项目遵循MiraData项目中概述的结构化字幕方法。
 *来自MiraData项目的视频收集和注释流程。* 来源:https://arxiv.org/pdf/2407.06358
*来自MiraData项目的视频收集和注释流程。* 来源:https://arxiv.org/pdf/2407.06358
对于相机运动,RealEstate10K数据集是主要数据来源,因其高质量的相机参数地面实况注释。然而,作者观察到,仅在RealEstate10K等静态场景相机数据集上训练往往会减少生成视频中的动态对象和人物运动。为此,他们使用包含更多动态相机运动的内部数据集进行了额外的微调。
身份注释使用为ConceptMaster项目开发的流程生成,该流程允许高效过滤和提取细粒度身份信息。
 *ConceptMaster框架旨在解决身份解耦问题,同时在定制视频中保留概念保真度。* 来源:https://arxiv.org/pdf/2501.04698
*ConceptMaster框架旨在解决身份解耦问题,同时在定制视频中保留概念保真度。* 来源:https://arxiv.org/pdf/2501.04698
深度注释使用Depth Anything从Panda-70M数据集中获得。
通过数据排序优化
作者还实施了渐进式训练计划,在训练早期引入更具挑战性的条件,以确保模型在添加较简单任务之前获得稳健的表示。训练顺序从文本到相机条件,然后是身份,最后是深度,较简单的任务通常在后期引入且示例较少。
作者强调了以这种方式排序工作负载的价值:
**‘在预训练阶段,我们注意到,更具挑战性的任务需要更长的训练时间,并应在学习过程的早期引入。这些挑战性任务涉及与输出视频显著不同的复杂数据分布,要求模型具备足够的能力来准确捕获和表示它们。’**
**‘相反,过早引入较简单的任务可能导致模型优先学习它们,因为它们提供了更即时的优化反馈,这会阻碍更具挑战性任务的收敛。’**
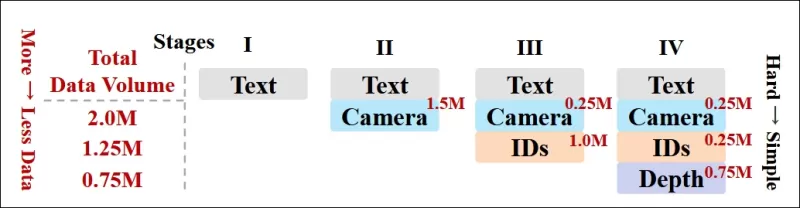 *研究人员采用的数据训练顺序示意图,红色表示更大的数据量。*
*研究人员采用的数据训练顺序示意图,红色表示更大的数据量。*
在初始预训练后,最终微调阶段进一步优化了模型,以提高视觉质量和运动动态。此后,训练遵循标准扩散框架:将噪声添加到视频潜在表示中,模型学习预测和移除噪声,使用嵌入的条件令牌作为指导。
为了有效评估FullDiT并与其他现有方法进行公平比较,在没有任何其他适用基准的情况下,作者引入了**FullBench**,一个包含1,400个不同测试用例的精选基准套件。
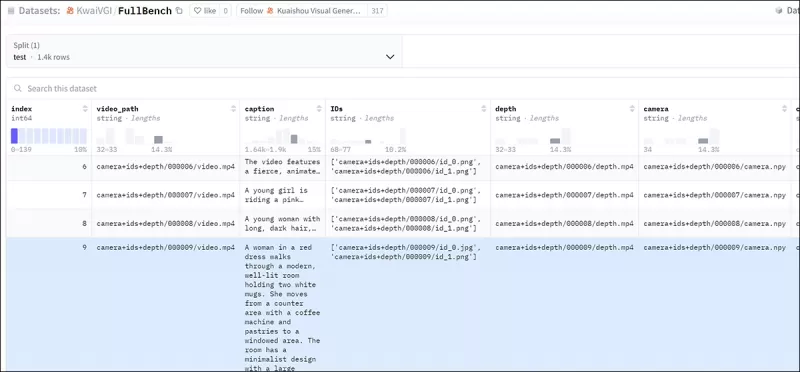 *新FullBench基准的数据探索器实例。* 来源:https://huggingface.co/datasets/KwaiVGI/FullBench
*新FullBench基准的数据探索器实例。* 来源:https://huggingface.co/datasets/KwaiVGI/FullBench
每个数据点为各种条件信号提供了地面实况注释,包括相机运动、身份和深度。
指标
作者使用十个指标评估FullDiT,涵盖五个主要性能方面:文本对齐、相机控制、身份相似性、深度准确性和总体视频质量。
文本对齐使用CLIP相似性测量,而相机控制通过旋转误差(RotErr)、平移误差(TransErr)和相机运动一致性(CamMC)进行评估,遵循CameraCtrl项目中的CamI2V方法。
身份相似性使用DINO-I和CLIP-I进行评估,深度控制准确性使用平均绝对误差(MAE)量化。
视频质量使用MiraData的三个指标进行判断:帧级CLIP相似性用于平滑度;基于光流的运动距离用于动态性;LAION-Aesthetic分数用于视觉吸引力。
训练
作者使用内部(未公开)文本到视频扩散模型训练FullDiT,参数规模约为10亿。他们有意选择适中的参数规模,以保持与先前方法的比较公平性并确保可重现性。
由于训练视频的长度和分辨率不同,作者通过调整和填充视频到统一分辨率、每序列采样77帧,并使用应用注意力机制和损失掩码来优化训练效果,标准化了每个批次。
使用Adam优化器,学习率为1×10−5,在一组64个NVIDIA H800 GPU上进行训练,总共5,120GB的显存(考虑在爱好者合成社区中,RTX 3090上的24GB仍被认为是豪华标准)。
模型训练约32,000步,每视频包含最多三个身份,20帧相机条件和21帧深度条件,均从总共77帧中均匀采样。
在推理时,模型以384×672像素的分辨率生成视频(约5秒,15帧每秒),使用50个扩散推理步骤和无分类器指导尺度为5。
先前方法
对于相机到视频评估,作者将FullDiT与MotionCtrl、CameraCtrl和CamI2V进行比较,所有模型使用RealEstate10k数据集训练,以确保一致性和公平性。
在身份条件生成中,由于没有可比较的开源多身份模型,模型与1B参数的ConceptMaster模型进行基准比较,使用相同的训练数据和架构。
对于深度到视频任务,与Ctrl-Adapter和ControlVideo进行比较。
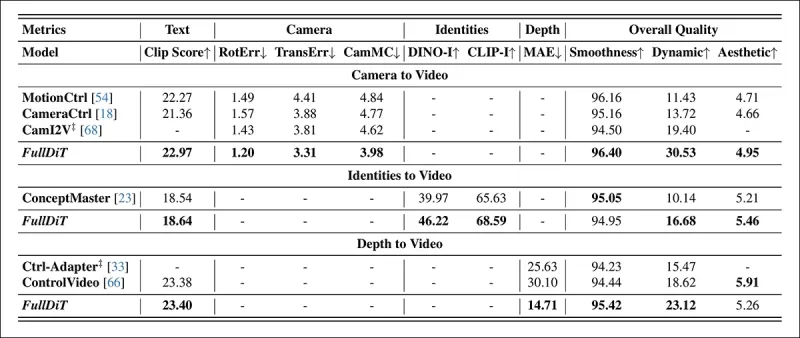 *单任务视频生成的定量结果。FullDiT与MotionCtrl、CameraCtrl和CamI2V在相机到视频生成上进行比较;与ConceptMaster(1B参数版本)在身份到视频上进行比较;与Ctrl-Adapter和ControlVideo在深度到视频上进行比较。所有模型使用其默认设置进行评估。为保持一致性,从每种方法中均匀采样16帧,与先前模型的输出长度匹配。*
*单任务视频生成的定量结果。FullDiT与MotionCtrl、CameraCtrl和CamI2V在相机到视频生成上进行比较;与ConceptMaster(1B参数版本)在身份到视频上进行比较;与Ctrl-Adapter和ControlVideo在深度到视频上进行比较。所有模型使用其默认设置进行评估。为保持一致性,从每种方法中均匀采样16帧,与先前模型的输出长度匹配。*
结果表明,尽管FullDiT同时处理多个条件信号,但在与文本、相机运动、身份和深度控制相关的指标中取得了最佳性能。
在总体质量指标中,该系统通常优于其他方法,尽管其平滑度略低于ConceptMaster。作者对此评论道:
**‘FullDiT的平滑度略低于ConceptMaster,因为平滑度的计算基于相邻帧之间的CLIP相似性。由于FullDiT表现出比ConceptMaster明显更大的动态性,平滑度指标受到相邻帧之间较大变化的影响。’**
**‘对于美学评分,由于评分模型偏好绘画风格的图像,而ControlVideo通常生成这种风格的视频,因此其在美学方面得分较高。’**
关于定性比较,建议参考FullDiT项目网站上的示例视频,因为PDF示例不可避免是静态的(且内容过大,无法在此完全重现)。
 *PDF中重现的定性结果的第一部分。请参阅源论文以获取更多示例,因内容过多无法在此完全重现。*
*PDF中重现的定性结果的第一部分。请参阅源论文以获取更多示例,因内容过多无法在此完全重现。*
作者评论道:
**‘FullDiT展示出优越的身份保持能力,并生成具有更好动态性和视觉质量的视频,与[ConceptMaster]相比。由于ConceptMaster和FullDiT在同一骨干上训练,这凸显了全注意力条件注入的有效性。’**
**‘…[其他]结果表明,与现有的深度到视频和相机到视频方法相比,FullDiT具有卓越的可控性和生成质量。’**
 *PDF中FullDiT多信号输出的示例部分。请参阅源论文和项目网站以获取更多示例。*
*PDF中FullDiT多信号输出的示例部分。请参阅源论文和项目网站以获取更多示例。*
结论
FullDiT代表了迈向更全面的视频基础模型的激动人心的一步,但问题在于,对ControlNet风格功能的需求是否足以证明其大规模实施的合理性,特别是对于开源项目。这些项目在没有商业支持的情况下难以获得所需的大量GPU处理能力。
主要挑战在于,使用深度和姿态等系统通常需要熟悉复杂的用户界面,如ComfyUI。因此,这种功能性开源模型最有可能由缺乏资源或动力私下开发和训练此类模型的小型VFX公司开发。
另一方面,API驱动的“租用AI”系统可能有充分的动力开发更简单、更用户友好的解释方法,用于具有直接训练辅助控制系统的模型。
**点击播放。使用FullDiT对视频生成施加的深度+文本控制。**
*作者未指定任何已知的基础模型(即SDXL等)。*
**首次发布于2025年3月27日,星期四**
相关文章
 YouTube 测试基于人工智能的搜索功能,提供引导式答案
许多用户在搜索食谱或旅行计划时会转向YouTube,寻找相关视频。如今,该平台推出了一款由人工智能驱动的交互式搜索工具,能够提供融合文字和视频内容的分步搜索结果。借助全新的“Ask YouTube”功能,用户可以提出诸如“规划从旧金山到圣巴巴拉的3天自驾游”之类的问题,并获得结合了文字、短视频片段和长视频的分步结果——而非仅显示视频结果。YouTube表示,该功能将展示视频及相关片段,同时提供标题
独家报道:Luma AI推出基于"统一智能"模型的创意智能助手
周四,人工智能视频生成初创公司Luma推出了Luma Agents系统,该系统旨在管理涵盖文本、图像、视频和音频的完整创意工作流程。这些智能代理由Luma的统一智能模型家族驱动,其架构经过训练成为单一的多模态推理引擎。Luma将该代理定位为广告公司、营销部门、设计工作室及企业的变革性工具。据称,这些代理不仅能规划并生成文本、图像、视频和音频内容,还能协同其他AI模型运作,包括Luma的Ray 3.
索拉的最新更新提供了宠物人工智能视频、社交工具和即将推出的安卓应用程序
OpenAI 正在预览其爆款人工智能视频创作应用 Sora 的一系列新功能,该应用在 9 月底推出后迅速攀升至 App Store 榜首。该应用在美国和加拿大仍保持着第一的位置,不久将增加视频编辑功能,让用户创建宠物和其他物品的角色 "浮雕",增强社交功能等。该公司还确认 Android 版本 "即将推出"。Sora 的负责人比尔-皮布尔斯(Bill Peebles)在 X 上宣布了这一消息,称这
相关专题推荐
商业
YouTube 测试基于人工智能的搜索功能,提供引导式答案
许多用户在搜索食谱或旅行计划时会转向YouTube,寻找相关视频。如今,该平台推出了一款由人工智能驱动的交互式搜索工具,能够提供融合文字和视频内容的分步搜索结果。借助全新的“Ask YouTube”功能,用户可以提出诸如“规划从旧金山到圣巴巴拉的3天自驾游”之类的问题,并获得结合了文字、短视频片段和长视频的分步结果——而非仅显示视频结果。YouTube表示,该功能将展示视频及相关片段,同时提供标题
独家报道:Luma AI推出基于"统一智能"模型的创意智能助手
周四,人工智能视频生成初创公司Luma推出了Luma Agents系统,该系统旨在管理涵盖文本、图像、视频和音频的完整创意工作流程。这些智能代理由Luma的统一智能模型家族驱动,其架构经过训练成为单一的多模态推理引擎。Luma将该代理定位为广告公司、营销部门、设计工作室及企业的变革性工具。据称,这些代理不仅能规划并生成文本、图像、视频和音频内容,还能协同其他AI模型运作,包括Luma的Ray 3.
索拉的最新更新提供了宠物人工智能视频、社交工具和即将推出的安卓应用程序
OpenAI 正在预览其爆款人工智能视频创作应用 Sora 的一系列新功能,该应用在 9 月底推出后迅速攀升至 App Store 榜首。该应用在美国和加拿大仍保持着第一的位置,不久将增加视频编辑功能,让用户创建宠物和其他物品的角色 "浮雕",增强社交功能等。该公司还确认 Android 版本 "即将推出"。Sora 的负责人比尔-皮布尔斯(Bill Peebles)在 X 上宣布了这一消息,称这
相关专题推荐
商业
 最佳人工智能招聘工具:筛选简历并自动安排候选人面试
最佳人工智能招聘工具:筛选简历并自动安排候选人面试
在 XIX.AI 上探索 2026 年最新、评价最高的人工智能招聘工具。我们精心筛选的清单汇集了功能强大、颠覆传统的解决方案,可帮助您筛选简历并自动安排候选人面试。通过实际测试和每周更新的排名,对比免费与付费选项。立即找到最适合您的招聘助手,优化您的招聘流程!
 10 个工具
10 个工具
 xix.ai
生产率
AI个人健康与专注力教练:缓解倦怠,提升精神能量
xix.ai
生产率
AI个人健康与专注力教练:缓解倦怠,提升精神能量
立即访问 XIX.AI,探索 2026 年最优秀的 AI 个人健康与专注力教练。我们的精选排行榜汇集了广受好评、具有颠覆性意义的工具,助您缓解倦怠、提升精神能量。通过真实案例分析,对比免费与付费选项。立即开启通往巅峰生产力和身心健康的道路。
10 个工具
xix.ai
聊天机器人
备受好评的AI浪漫聊天机器人:凭借稳定的个性建立长期关系
探索2026年最新、评价最高的人工智能浪漫聊天机器人,助您建立真实而长久的联系。我们的精选清单涵盖了功能强大且性格鲜明的聊天机器人,并提供了免费与付费版本的对比分析以及实际测试结果。在XIX.AI上找到您的完美伴侣,立即开始建立联系吧。
10 个工具
xix.ai
教育与学习
最佳AI数据科学导师:精通SQL、Pandas及机器学习工作流程
探索2026年最优秀的人工智能数据科学导师,帮助他们掌握SQL、Pandas以及机器学习工作流程。在XIX.AI上查看我们精心挑选的顶级导师名单,获得强大而具有变革性的指导。通过对比免费和付费选项,并结合实际应用案例进行了解,今天就开启你的数据科学精通之路吧。
10 个工具
xix.ai
聊天机器人
最佳AI调情与对话训练工具:实时提升社交魅力与自信
在 XIX.AI 上探索 2026 年最优秀的 AI 调情与对话训练工具。我们精心挑选的高评分工具助您实时提升社交魅力与自信。探索这些必试的、颠覆性的工具,查看免费版与付费版的对比,并了解每周更新的排行榜。立即开启您的社交优势。
10 个工具
xix.ai
代码
最适合自动化单元测试的最佳AI工具:一键生成Jest、PyTest和JUnit测试用例
探索2026年最新评选出的顶级AI工具,这些工具专为自动化单元测试而设计。我们精心挑选了那些功能强大、能够改变开发流程的工具,它们能够帮助您快速生成Jest、PyTest和JUnit测试用例。在XIX.AI平台上,您可以免费查看各种选项,并通过实际测试结果以及每周更新的排名来了解它们的优劣。立即利用这些AI工具,提升您的开发效率吧!
10 个工具
xix.ai

 评论 (3)
0/500
评论 (3)
0/500
![TimothyMitchell]()
映像の詳細なコントロールって本当に難しいんですね。AIがプロのVFXスタジオで使われる日はまだ先かな?でも技術の進歩にはワクワクする!🔥
![CharlesMartinez]()
Finalmente os vídeos gerados por IA estão evoluindo para algo útil! Mas ainda parece que falta muito pra substituir os efeitos manuais de grandes produções... será que um dia chegaremos lá? 🎥
![DonaldLee]()
The idea of AI taking over VFX in films is wild! I mean, total control over video generation? That’s some sci-fi stuff coming to life. But I wonder if these models like Hunyuan can really nail the tiny details directors obsess over. Exciting times! 🎥
视频基础模型如Hunyuan和Wan 2.1已取得显著进展,但在电影和电视制作中,尤其是在视觉特效(VFX)领域,它们往往无法满足所需的精细控制。在专业VFX工作室中,这些模型与早期基于图像的模型如Stable Diffusion、Kandinsky和Flux一起,与一系列专为满足特定创意需求而设计的工具结合使用。当导演要求调整时,比如说“这看起来很好,但能再稍微[n]一点吗?”,仅仅声称模型缺乏精确调整能力是不够的。
相反,AI VFX团队会结合传统CGI和合成技术,以及定制开发的工作流程,进一步推动视频合成的边界。这种方法类似于使用默认浏览器如Chrome;它开箱即用,但要真正满足你的需求,你需要安装一些插件。
控制狂
在基于扩散的图像合成领域,最关键的第三方系统之一是ControlNet。这种技术为生成模型引入了结构化控制,允许用户通过额外的输入(如边缘图、深度图或姿态信息)来引导图像或视频生成。
*ControlNet的多种方法允许进行深度>图像(上行)、语义分割>图像(左下)和人类及动物的姿态引导图像生成(左下)。*
ControlNet不完全依赖文本提示;它使用独立的神经网络分支或适配器来处理这些条件信号,同时保持基础模型的生成能力。这能够生成高度定制化的输出,紧密符合用户规格,对于需要精确控制构图、结构或运动的应用来说尤为宝贵。
*通过引导姿态,ControlNet可以获得多种精确的输出类型。* 来源:https://arxiv.org/pdf/2302.05543
然而,这些基于适配器的系统在内部聚焦的神经过程集上外部操作,存在几个缺点。适配器是独立训练的,当多个适配器结合时可能导致分支冲突,通常导致生成质量较低。它们还引入了参数冗余,每个适配器都需要额外的计算资源和内存,使得扩展效率低下。此外,尽管适配器具有灵活性,但与为多条件生成完全微调的模型相比,其结果往往次优。这些问题可能使基于适配器的方法在需要无缝整合多种控制信号的任务中效果较差。
理想情况下,ControlNet的功能应以模块化方式原生集成到模型中,允许未来创新,如同步视频/音频生成或原生唇部同步功能。目前,每增加一个功能要么成为后期制作任务,要么成为必须处理基础模型敏感权重的非原生程序。
FullDiT
来自中国的新方法FullDiT在训练期间将ControlNet风格的功能直接集成到生成视频模型中,而不是将其作为事后考虑。
*来自新论文:FullDiT方法可以将身份强制、深度和相机运动融入原生生成,并能同时调用这些的任意组合。* 来源:https://arxiv.org/pdf/2503.19907
FullDiT在题为**FullDiT:全注意力多任务视频生成基础模型**的论文中概述,将多任务条件(如身份转移、深度映射和相机运动)集成到训练好的生成视频模型核心中。作者开发了一个原型模型,并提供了可在项目网站上访问的视频片段。
**点击播放。仅使用原生训练的基础模型实现ControlNet风格的用户强制示例。** 来源:https://fulldit.github.io/
作者将FullDiT作为原生文本到视频(T2V)和图像到视频(I2V)模型的概念验证,为用户提供比仅图像或文本提示更多的控制。由于没有类似的模型存在,研究人员创建了一个名为**FullBench**的新基准,用于评估多任务视频,声称在他们设计的测试中表现最佳。然而,由作者自己设计的FullBench的客观性尚未得到验证,其1,400个案例的数据集可能对于更广泛的结论来说过于有限。
FullDiT架构最引人注目的方面是其融入新型控制的潜力。作者指出:
**‘在这项工作中,我们仅探索了相机、身份和深度信息的控制条件。我们没有进一步研究其他条件和模态,如音频、语音、点云、对象边界框、光流等。尽管FullDiT的设计可以以最小的架构修改无缝整合其他模态,如何快速且成本效益高地适应现有模型以应对新条件和模态仍是一个值得进一步探索的重要问题。’**
虽然FullDiT在多任务视频生成方面迈出了重要一步,但它基于现有架构,而不是引入新范式。尽管如此,它作为唯一具有原生集成ControlNet风格功能的视频基础模型脱颖而出,其架构设计能够适应未来的创新。
**点击播放。来自项目网站的用户控制相机移动示例。**
由快手科技和香港中文大学九位研究人员撰写的论文题为**FullDiT:全注意力多任务视频生成基础模型**。项目页面和新基准数据可在Hugging Face上获取。
方法
FullDiT的统一注意力机制旨在通过捕捉跨条件的空间和时间关系来增强跨模态表示学习。
*根据新论文,FullDiT通过全自注意力整合多种输入条件,将其转换为统一序列。相比之下,基于适配器的模型(上图最左侧)为每个输入使用单独模块,导致冗余、冲突和性能较弱。*
与分别处理每个输入流的基于适配器的设置不同,FullDiT的共享注意力结构避免了分支冲突并减少了参数开销。作者声称该架构可以扩展到新的输入类型而无需重大重新设计,模型架构显示出泛化到训练期间未见条件组合的迹象,如将相机运动与角色身份关联。
**点击播放。来自项目网站的身份生成示例。**
在FullDiT的架构中,所有条件输入(如文本、相机运动、身份和深度)首先被转换为统一的令牌格式。然后这些令牌被连接成一个单一的长序列,通过一组使用全自注意力的转换器层进行处理。这种方法遵循了Open-Sora Plan和Movie Gen等先前工作。
这种设计使模型能够跨所有条件共同学习时间和空间关系。每个转换器块在整个序列上操作,使模态之间的动态交互成为可能,而无需为每个输入依赖单独的模块。该架构设计具有扩展性,便于未来融入额外的控制信号而无需重大结构更改。
三者之力
FullDiT将每个控制信号转换为标准化令牌格式,以便所有条件可以在统一的注意力框架中一起处理。对于相机运动,模型为每帧编码一系列外部参数(如位置和方向)。这些参数被加时间戳并投影到反映信号时间性质的嵌入向量中。
身份信息处理方式不同,因为它本质上是空间性的而非时间性的。模型使用身份映射来指示每个帧中哪些部分存在哪些角色。这些映射被分为补丁,每个补丁投影到捕获空间身份线索的嵌入中,使模型能够将帧的特定区域与特定实体关联起来。
深度是一种时空信号,模型通过将深度视频分为跨越空间和时间的3D补丁来处理。这些补丁随后以保留其跨帧结构的方式嵌入。
一旦嵌入,所有这些条件令牌(相机、身份和深度)被连接成一个单一的长序列,使FullDiT能够使用全自注意力一起处理它们。这种共享表示使模型能够学习跨模态和跨时间的交互,而无需依赖隔离的处理流。
数据与测试
FullDiT的训练方法依赖于为每种条件类型量身定制的选择性注释数据集,而无需所有条件同时存在。
对于文本条件,该项目遵循MiraData项目中概述的结构化字幕方法。
*来自MiraData项目的视频收集和注释流程。* 来源:https://arxiv.org/pdf/2407.06358
对于相机运动,RealEstate10K数据集是主要数据来源,因其高质量的相机参数地面实况注释。然而,作者观察到,仅在RealEstate10K等静态场景相机数据集上训练往往会减少生成视频中的动态对象和人物运动。为此,他们使用包含更多动态相机运动的内部数据集进行了额外的微调。
身份注释使用为ConceptMaster项目开发的流程生成,该流程允许高效过滤和提取细粒度身份信息。
*ConceptMaster框架旨在解决身份解耦问题,同时在定制视频中保留概念保真度。* 来源:https://arxiv.org/pdf/2501.04698
深度注释使用Depth Anything从Panda-70M数据集中获得。
通过数据排序优化
作者还实施了渐进式训练计划,在训练早期引入更具挑战性的条件,以确保模型在添加较简单任务之前获得稳健的表示。训练顺序从文本到相机条件,然后是身份,最后是深度,较简单的任务通常在后期引入且示例较少。
作者强调了以这种方式排序工作负载的价值:
**‘在预训练阶段,我们注意到,更具挑战性的任务需要更长的训练时间,并应在学习过程的早期引入。这些挑战性任务涉及与输出视频显著不同的复杂数据分布,要求模型具备足够的能力来准确捕获和表示它们。’**
**‘相反,过早引入较简单的任务可能导致模型优先学习它们,因为它们提供了更即时的优化反馈,这会阻碍更具挑战性任务的收敛。’**
*研究人员采用的数据训练顺序示意图,红色表示更大的数据量。*
在初始预训练后,最终微调阶段进一步优化了模型,以提高视觉质量和运动动态。此后,训练遵循标准扩散框架:将噪声添加到视频潜在表示中,模型学习预测和移除噪声,使用嵌入的条件令牌作为指导。
为了有效评估FullDiT并与其他现有方法进行公平比较,在没有任何其他适用基准的情况下,作者引入了**FullBench**,一个包含1,400个不同测试用例的精选基准套件。
*新FullBench基准的数据探索器实例。* 来源:https://huggingface.co/datasets/KwaiVGI/FullBench
每个数据点为各种条件信号提供了地面实况注释,包括相机运动、身份和深度。
指标
作者使用十个指标评估FullDiT,涵盖五个主要性能方面:文本对齐、相机控制、身份相似性、深度准确性和总体视频质量。
文本对齐使用CLIP相似性测量,而相机控制通过旋转误差(RotErr)、平移误差(TransErr)和相机运动一致性(CamMC)进行评估,遵循CameraCtrl项目中的CamI2V方法。
身份相似性使用DINO-I和CLIP-I进行评估,深度控制准确性使用平均绝对误差(MAE)量化。
视频质量使用MiraData的三个指标进行判断:帧级CLIP相似性用于平滑度;基于光流的运动距离用于动态性;LAION-Aesthetic分数用于视觉吸引力。
训练
作者使用内部(未公开)文本到视频扩散模型训练FullDiT,参数规模约为10亿。他们有意选择适中的参数规模,以保持与先前方法的比较公平性并确保可重现性。
由于训练视频的长度和分辨率不同,作者通过调整和填充视频到统一分辨率、每序列采样77帧,并使用应用注意力机制和损失掩码来优化训练效果,标准化了每个批次。
使用Adam优化器,学习率为1×10−5,在一组64个NVIDIA H800 GPU上进行训练,总共5,120GB的显存(考虑在爱好者合成社区中,RTX 3090上的24GB仍被认为是豪华标准)。
模型训练约32,000步,每视频包含最多三个身份,20帧相机条件和21帧深度条件,均从总共77帧中均匀采样。
在推理时,模型以384×672像素的分辨率生成视频(约5秒,15帧每秒),使用50个扩散推理步骤和无分类器指导尺度为5。
先前方法
对于相机到视频评估,作者将FullDiT与MotionCtrl、CameraCtrl和CamI2V进行比较,所有模型使用RealEstate10k数据集训练,以确保一致性和公平性。
在身份条件生成中,由于没有可比较的开源多身份模型,模型与1B参数的ConceptMaster模型进行基准比较,使用相同的训练数据和架构。
对于深度到视频任务,与Ctrl-Adapter和ControlVideo进行比较。
*单任务视频生成的定量结果。FullDiT与MotionCtrl、CameraCtrl和CamI2V在相机到视频生成上进行比较;与ConceptMaster(1B参数版本)在身份到视频上进行比较;与Ctrl-Adapter和ControlVideo在深度到视频上进行比较。所有模型使用其默认设置进行评估。为保持一致性,从每种方法中均匀采样16帧,与先前模型的输出长度匹配。*
结果表明,尽管FullDiT同时处理多个条件信号,但在与文本、相机运动、身份和深度控制相关的指标中取得了最佳性能。
在总体质量指标中,该系统通常优于其他方法,尽管其平滑度略低于ConceptMaster。作者对此评论道:
**‘FullDiT的平滑度略低于ConceptMaster,因为平滑度的计算基于相邻帧之间的CLIP相似性。由于FullDiT表现出比ConceptMaster明显更大的动态性,平滑度指标受到相邻帧之间较大变化的影响。’**
**‘对于美学评分,由于评分模型偏好绘画风格的图像,而ControlVideo通常生成这种风格的视频,因此其在美学方面得分较高。’**
关于定性比较,建议参考FullDiT项目网站上的示例视频,因为PDF示例不可避免是静态的(且内容过大,无法在此完全重现)。
*PDF中重现的定性结果的第一部分。请参阅源论文以获取更多示例,因内容过多无法在此完全重现。*
作者评论道:
**‘FullDiT展示出优越的身份保持能力,并生成具有更好动态性和视觉质量的视频,与[ConceptMaster]相比。由于ConceptMaster和FullDiT在同一骨干上训练,这凸显了全注意力条件注入的有效性。’**
**‘…[其他]结果表明,与现有的深度到视频和相机到视频方法相比,FullDiT具有卓越的可控性和生成质量。’**
*PDF中FullDiT多信号输出的示例部分。请参阅源论文和项目网站以获取更多示例。*
结论
FullDiT代表了迈向更全面的视频基础模型的激动人心的一步,但问题在于,对ControlNet风格功能的需求是否足以证明其大规模实施的合理性,特别是对于开源项目。这些项目在没有商业支持的情况下难以获得所需的大量GPU处理能力。
主要挑战在于,使用深度和姿态等系统通常需要熟悉复杂的用户界面,如ComfyUI。因此,这种功能性开源模型最有可能由缺乏资源或动力私下开发和训练此类模型的小型VFX公司开发。
另一方面,API驱动的“租用AI”系统可能有充分的动力开发更简单、更用户友好的解释方法,用于具有直接训练辅助控制系统的模型。
**点击播放。使用FullDiT对视频生成施加的深度+文本控制。**
*作者未指定任何已知的基础模型(即SDXL等)。*
**首次发布于2025年3月27日,星期四**










 YouTube 测试基于人工智能的搜索功能,提供引导式答案
许多用户在搜索食谱或旅行计划时会转向YouTube,寻找相关视频。如今,该平台推出了一款由人工智能驱动的交互式搜索工具,能够提供融合文字和视频内容的分步搜索结果。借助全新的“Ask YouTube”功能,用户可以提出诸如“规划从旧金山到圣巴巴拉的3天自驾游”之类的问题,并获得结合了文字、短视频片段和长视频的分步结果——而非仅显示视频结果。YouTube表示,该功能将展示视频及相关片段,同时提供标题
YouTube 测试基于人工智能的搜索功能,提供引导式答案
许多用户在搜索食谱或旅行计划时会转向YouTube,寻找相关视频。如今,该平台推出了一款由人工智能驱动的交互式搜索工具,能够提供融合文字和视频内容的分步搜索结果。借助全新的“Ask YouTube”功能,用户可以提出诸如“规划从旧金山到圣巴巴拉的3天自驾游”之类的问题,并获得结合了文字、短视频片段和长视频的分步结果——而非仅显示视频结果。YouTube表示,该功能将展示视频及相关片段,同时提供标题
 独家报道:Luma AI推出基于"统一智能"模型的创意智能助手
周四,人工智能视频生成初创公司Luma推出了Luma Agents系统,该系统旨在管理涵盖文本、图像、视频和音频的完整创意工作流程。这些智能代理由Luma的统一智能模型家族驱动,其架构经过训练成为单一的多模态推理引擎。Luma将该代理定位为广告公司、营销部门、设计工作室及企业的变革性工具。据称,这些代理不仅能规划并生成文本、图像、视频和音频内容,还能协同其他AI模型运作,包括Luma的Ray 3.
独家报道:Luma AI推出基于"统一智能"模型的创意智能助手
周四,人工智能视频生成初创公司Luma推出了Luma Agents系统,该系统旨在管理涵盖文本、图像、视频和音频的完整创意工作流程。这些智能代理由Luma的统一智能模型家族驱动,其架构经过训练成为单一的多模态推理引擎。Luma将该代理定位为广告公司、营销部门、设计工作室及企业的变革性工具。据称,这些代理不仅能规划并生成文本、图像、视频和音频内容,还能协同其他AI模型运作,包括Luma的Ray 3.
 索拉的最新更新提供了宠物人工智能视频、社交工具和即将推出的安卓应用程序
OpenAI 正在预览其爆款人工智能视频创作应用 Sora 的一系列新功能,该应用在 9 月底推出后迅速攀升至 App Store 榜首。该应用在美国和加拿大仍保持着第一的位置,不久将增加视频编辑功能,让用户创建宠物和其他物品的角色 "浮雕",增强社交功能等。该公司还确认 Android 版本 "即将推出"。Sora 的负责人比尔-皮布尔斯(Bill Peebles)在 X 上宣布了这一消息,称这
索拉的最新更新提供了宠物人工智能视频、社交工具和即将推出的安卓应用程序
OpenAI 正在预览其爆款人工智能视频创作应用 Sora 的一系列新功能,该应用在 9 月底推出后迅速攀升至 App Store 榜首。该应用在美国和加拿大仍保持着第一的位置,不久将增加视频编辑功能,让用户创建宠物和其他物品的角色 "浮雕",增强社交功能等。该公司还确认 Android 版本 "即将推出"。Sora 的负责人比尔-皮布尔斯(Bill Peebles)在 X 上宣布了这一消息,称这

在 XIX.AI 上探索 2026 年最新、评价最高的人工智能招聘工具。我们精心筛选的清单汇集了功能强大、颠覆传统的解决方案,可帮助您筛选简历并自动安排候选人面试。通过实际测试和每周更新的排名,对比免费与付费选项。立即找到最适合您的招聘助手,优化您的招聘流程!
10 个工具
xix.ai

立即访问 XIX.AI,探索 2026 年最优秀的 AI 个人健康与专注力教练。我们的精选排行榜汇集了广受好评、具有颠覆性意义的工具,助您缓解倦怠、提升精神能量。通过真实案例分析,对比免费与付费选项。立即开启通往巅峰生产力和身心健康的道路。
10 个工具
xix.ai

探索2026年最新、评价最高的人工智能浪漫聊天机器人,助您建立真实而长久的联系。我们的精选清单涵盖了功能强大且性格鲜明的聊天机器人,并提供了免费与付费版本的对比分析以及实际测试结果。在XIX.AI上找到您的完美伴侣,立即开始建立联系吧。
10 个工具
xix.ai

探索2026年最优秀的人工智能数据科学导师,帮助他们掌握SQL、Pandas以及机器学习工作流程。在XIX.AI上查看我们精心挑选的顶级导师名单,获得强大而具有变革性的指导。通过对比免费和付费选项,并结合实际应用案例进行了解,今天就开启你的数据科学精通之路吧。
10 个工具
xix.ai

在 XIX.AI 上探索 2026 年最优秀的 AI 调情与对话训练工具。我们精心挑选的高评分工具助您实时提升社交魅力与自信。探索这些必试的、颠覆性的工具,查看免费版与付费版的对比,并了解每周更新的排行榜。立即开启您的社交优势。
10 个工具
xix.ai

探索2026年最新评选出的顶级AI工具,这些工具专为自动化单元测试而设计。我们精心挑选了那些功能强大、能够改变开发流程的工具,它们能够帮助您快速生成Jest、PyTest和JUnit测试用例。在XIX.AI平台上,您可以免费查看各种选项,并通过实际测试结果以及每周更新的排名来了解它们的优劣。立即利用这些AI工具,提升您的开发效率吧!
10 个工具
xix.ai

映像の詳細なコントロールって本当に難しいんですね。AIがプロのVFXスタジオで使われる日はまだ先かな?でも技術の進歩にはワクワクする!🔥
Finalmente os vídeos gerados por IA estão evoluindo para algo útil! Mas ainda parece que falta muito pra substituir os efeitos manuais de grandes produções... será que um dia chegaremos lá? 🎥
The idea of AI taking over VFX in films is wild! I mean, total control over video generation? That’s some sci-fi stuff coming to life. But I wonder if these models like Hunyuan can really nail the tiny details directors obsess over. Exciting times! 🎥













