




एआई वीडियो पीढ़ी पूर्ण नियंत्रण की ओर बढ़ती है
हुनयुआन और वान 2.1 जैसे वीडियो फाउंडेशन मॉडल्स ने महत्वपूर्ण प्रगति की है, लेकिन फिल्म और टीवी प्रोडक्शन में आवश्यक विस्तृत नियंत्रण, विशेष रूप से विजुअल इफेक्ट्स (VFX) के क्षेत्र में, वे अक्सर कमी महसूस करते हैं। पेशेवर VFX स्टूडियोज में, इन मॉडल्स को, स्टेबल डिफ्यूजन, कंडिंस्की और फ्लक्स जैसे पहले के इमेज-आधारित मॉडल्स के साथ, विशिष्ट रचनात्मक मांगों को पूरा करने के लिए उनके आउटपुट को परिष्कृत करने के लिए डिज़ाइन किए गए टूल्स के सुइट के साथ उपयोग किया जाता है। जब कोई डायरेक्टर बदलाव की मांग करता है, जैसे कि, "यह बहुत अच्छा लग रहा है, लेकिन क्या हम इसे थोड़ा और [n] कर सकते हैं?", तो यह कहना पर्याप्त नहीं है कि मॉडल में ऐसे समायोजन करने की सटीकता की कमी है।
इसके बजाय, एक AI VFX टीम पारंपरिक CGI और कम्पोजिशनल तकनीकों के संयोजन का उपयोग करेगी, साथ ही कस्टम-विकसित वर्कफ्लोज़ के साथ, वीडियो संश्लेषण की सीमाओं को और आगे बढ़ाने के लिए। यह दृष्टिकोण क्रोम जैसे डिफॉल्ट वेब ब्राउज़र का उपयोग करने के समान है; यह बॉक्स से बाहर कार्यात्मक है, लेकिन इसे अपनी आवश्यकताओं के अनुरूप बनाने के लिए, आपको कुछ प्लगइन्स इंस्टॉल करने होंगे।
नियंत्रण प्रेमी
डिफ्यूजन-आधारित इमेज संश्लेषण के क्षेत्र में, सबसे महत्वपूर्ण तृतीय-पक्ष सिस्टम्स में से एक है ControlNet। यह तकनीक जेनरेटिव मॉडल्स में संरचित नियंत्रण लाती है, जिससे उपयोगकर्ता एज मैप्स, डेप्थ मैप्स, या पोज़ जानकारी जैसे अतिरिक्त इनपुट्स का उपयोग करके इमेज या वीडियो जनरेशन को गाइड कर सकते हैं।
 *ControlNet के विभिन्न तरीके डेप्थ>इमेज (शीर्ष पंक्ति), सिमेंटिक सेगमेंटेशन>इमेज (निचला बायाँ) और मनुष्यों और जानवरों की पोज़-गाइडेड इमेज जनरेशन (निचला बायाँ) की अनुमति देते हैं।*
*ControlNet के विभिन्न तरीके डेप्थ>इमेज (शीर्ष पंक्ति), सिमेंटिक सेगमेंटेशन>इमेज (निचला बायाँ) और मनुष्यों और जानवरों की पोज़-गाइडेड इमेज जनरेशन (निचला बायाँ) की अनुमति देते हैं।*
ControlNet केवल टेक्स्ट प्रॉम्प्ट्स पर निर्भर नहीं करता; यह अलग-अलग न्यूरल नेटवर्क ब्रांचेज़, या एडाप्टर्स, का उपयोग करता है, जो इन कंडीशनिंग सिग्नल्स को प्रोसेस करते हैं, जबकि बेस मॉडल की जेनरेटिव क्षमताओं को बनाए रखते हैं। इससे अत्यधिक अनुकूलित आउटपुट्स प्राप्त होते हैं जो उपयोगकर्ता विनिर्देशों के साथ निकटता से संरेखित होते हैं, जिससे यह कम्पोजिशन, संरचना, या गति पर सटीक नियंत्रण की आवश्यकता वाले अनुप्रयोगों के लिए अमूल्य हो जाता है।
 *गाइडिंग पोज़ के साथ, ControlNet के माध्यम से विभिन्न सटीक आउटपुट प्रकार प्राप्त किए जा सकते हैं।* स्रोत: https://arxiv.org/pdf/2302.05543
*गाइडिंग पोज़ के साथ, ControlNet के माध्यम से विभिन्न सटीक आउटपुट प्रकार प्राप्त किए जा सकते हैं।* स्रोत: https://arxiv.org/pdf/2302.05543
हालांकि, ये एडाप्टर-आधारित सिस्टम्स, जो आंतरिक रूप से केंद्रित न्यूरल प्रक्रियाओं के सेट पर बाहरी रूप से काम करते हैं, कई कमियों के साथ आते हैं। एडाप्टर्स को स्वतंत्र रूप से प्रशिक्षित किया जाता है, जिसके कारण कई एडाप्टर्स के संयोजन पर ब्रांच टकराव हो सकता है, जिसके परिणामस्वरूप अक्सर कम गुणवत्ता वाले जनरेशन होते हैं। वे पैरामीटर रिडंडेंसी भी लाते हैं, प्रत्येक एडाप्टर के लिए अतिरिक्त कम्प्यूटेशनल संसाधनों और मेमोरी की आवश्यकता होती है, जिससे स्केलिंग अक्षम हो जाती है। इसके अलावा, उनकी लचीलापन के बावजूद, एडाप्टर्स अक्सर मल्टी-कंडीशन जनरेशन के लिए पूरी तरह से फाइन-ट्यून किए गए मॉडल्स की तुलना में उप-इष्टतम परिणाम देते हैं। ये मुद्दे एडाप्टर-आधारित विधियों को उन कार्यों के लिए कम प्रभावी बना सकते हैं जिनमें कई नियंत्रण सिग्नल्स का सहज एकीकरण आवश्यक होता है।
आदर्श रूप से, ControlNet की क्षमताओं को मॉडल में मॉड्यूलर तरीके से मूल रूप से एकीकृत किया जाना चाहिए, जिससे भविष्य में एक साथ वीडियो/ऑडियो जनरेशन या मूल लिप-सिंक क्षमताओं जैसे नवाचार संभव हो सकें। वर्तमान में, प्रत्येक अतिरिक्त सुविधा या तो पोस्ट-प्रोडक्शन कार्य बन जाती है या एक गैर-मूल प्रक्रिया जो फाउंडेशन मॉडल के संवेदनशील वेट्स को नेविगेट करनी पड़ती है।
FullDiT
FullDiT, चीन से एक नया दृष्टिकोण, जो ControlNet-शैली की सुविधाओं को प्रशिक्षण के दौरान एक जेनरेटिव वीडियो मॉडल में सीधे एकीकृत करता है, न कि उन्हें बाद में विचार के रूप में मानने के।
 *नए पेपर से: FullDiT दृष्टिकोण पहचान थोपना, डेप्थ और कैमरा मूवमेंट को मूल जनरेशन में शामिल कर सकता है, और इनमें से किसी भी संयोजन को एक साथ बुला सकता है।* स्रोत: https://arxiv.org/pdf/2503.19907
*नए पेपर से: FullDiT दृष्टिकोण पहचान थोपना, डेप्थ और कैमरा मूवमेंट को मूल जनरेशन में शामिल कर सकता है, और इनमें से किसी भी संयोजन को एक साथ बुला सकता है।* स्रोत: https://arxiv.org/pdf/2503.19907
FullDiT, जैसा कि **FullDiT: मल्टी-टास्क वीडियो जेनरेटिव फाउंडेशन मॉडल विथ फुल अटेंशन** नामक पेपर में उल्लिखित है, पहचान हस्तांतरण, डेप्थ-मैपिंग, और कैमरा मूवमेंट जैसे मल्टी-टास्क शर्तों को एक प्रशिक्षित जेनरेटिव वीडियो मॉडल के मूल में एकीकृत करता है। लेखकों ने एक प्रोटोटाइप मॉडल और प्रोजेक्ट साइट पर उपलब्ध संबंधित वीडियो क्लिप्स विकसित किए हैं।
**प्ले करने के लिए क्लिक करें। केवल मूल प्रशिक्षित फाउंडेशन मॉडल के साथ ControlNet-शैली उपयोगकर्ता थोपन के उदाहरण।** स्रोत: https://fulldit.github.io/
लेखक FullDiT को टेक्स्ट-टू-वीडियो (T2V) और इमेज-टू-वीडियो (I2V) मॉडल्स के लिए एक प्रूफ-ऑफ-कॉन्सेप्ट के रूप में प्रस्तुत करते हैं जो उपयोगकर्ताओं को केवल एक इमेज या टेक्स्ट प्रॉम्प्ट से अधिक नियंत्रण प्रदान करते हैं। चूंकि कोई समान मॉडल्स मौजूद नहीं हैं, शोधकर्ताओं ने मल्टी-टास्क वीडियोज़ का मूल्यांकन करने के लिए **FullBench** नामक एक नया बेंचमार्क बनाया, जिसमें उनके द्वारा डिज़ाइन किए गए टेस्ट्स में अत्याधुनिक प्रदर्शन का दावा किया गया है। हालांकि, लेखकों द्वारा डिज़ाइन किए गए FullBench की वस्तुनिष्ठता का परीक्षण नहीं किया गया है, और इसके 1,400 मामलों का डेटासेट व्यापक निष्कर्षों के लिए बहुत सीमित हो सकता है।
FullDiT की वास्तुकला का सबसे रोमांचक पहलू इसकी नई प्रकार की नियंत्रण को शामिल करने की संभावना है। लेखक नोट करते हैं:
**‘इस कार्य में, हमने केवल कैमरा, पहचान और डेप्थ जानकारी की नियंत्रण शर्तों की खोज की है। हमने ऑडियो, स्पीच, पॉइंट क्लाउड, ऑब्जेक्ट बाउंडिंग बॉक्स, ऑप्टिकल फ्लो आदि जैसे अन्य शर्तों और मोडालिटीज की आगे जांच नहीं की। हालांकि FullDiT का डिज़ाइन अन्य मोडालिटीज को न्यूनतम वास्तुकला संशोधन के साथ सहजता से एकीकृत कर सकता है, मौजूदा मॉडल्स को नई शर्तों और मोडालिटीज में जल्दी और लागत-प्रभावी ढंग से अनुकूलित करने का तरीका अभी भी एक महत्वपूर्ण प्रश्न है जो आगे की खोज की आवश्यकता है।'**
जबकि FullDiT मल्टी-टास्क वीडियो जनरेशन में एक कदम आगे का प्रतिनिधित्व करता है, यह मौजूदा वास्तुकलाओं पर आधारित है न कि एक नया प्रतिमान पेश करता है। फिर भी, यह ControlNet-शैली की सुविधाओं के साथ मूल रूप से एकीकृत एकमात्र वीडियो फाउंडेशन मॉडल के रूप में खड़ा है, और इसकी वास्तुकला भविष्य के नवाचारों को समायोजित करने के लिए डिज़ाइन की गई है।
**प्ले करने के लिए क्लिक करें। प्रोजेक्ट साइट से उपयोगकर्ता-नियंत्रित कैमरा मूव्स के उदाहरण।**
पेपर, नौ शोधकर्ताओं द्वारा लिखित, क्वाइशो टेक्नोलॉजी और द चाइनीज़ यूनिवर्सिटी ऑफ हॉन्गकॉन्ग से, **FullDiT: मल्टी-टास्क वीडियो जेनरेटिव फाउंडेशन मॉडल विथ फुल अटेंशन** शीर्षक है। प्रोजेक्ट पेज और नया बेंचमार्क डेटा हगिंग फेस पर उपलब्ध हैं।
विधि
FullDiT का एकीकृत ध्यान तंत्र क्रॉस-मोडल प्रतिनिधित्व सीखने को बढ़ाने के लिए डिज़ाइन किया गया है, जो शर्तों के बीच स्थानिक और अस्थायी संबंधों को कैप्चर करता है।
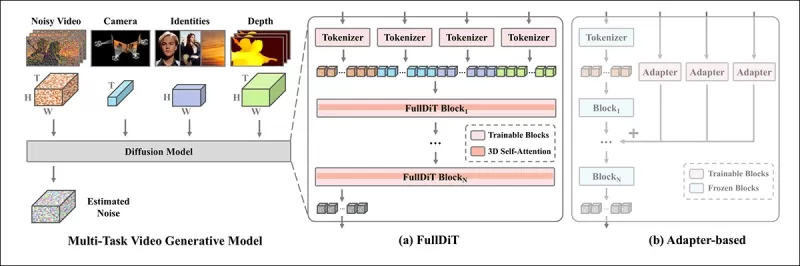 *नए पेपर के अनुसार, FullDiT कई इनपुट शर्तों को पूर्ण स्व-ध्यान के माध्यम से एकीकृत करता है, उन्हें एक एकीकृत अनुक्रम में परिवर्तित करता है। इसके विपरीत, एडाप्टर-आधारित मॉडल्स (सबसे बाएँ) प्रत्येक इनपुट के लिए अलग-अलग मॉड्यूल्स का उपयोग करते हैं, जिसके परिणामस्वरूप रिडंडेंसी, टकराव, और कमज़ोर प्रदर्शन होता है।*
*नए पेपर के अनुसार, FullDiT कई इनपुट शर्तों को पूर्ण स्व-ध्यान के माध्यम से एकीकृत करता है, उन्हें एक एकीकृत अनुक्रम में परिवर्तित करता है। इसके विपरीत, एडाप्टर-आधारित मॉडल्स (सबसे बाएँ) प्रत्येक इनपुट के लिए अलग-अलग मॉड्यूल्स का उपयोग करते हैं, जिसके परिणामस्वरूप रिडंडेंसी, टकराव, और कमज़ोर प्रदर्शन होता है।*
एडाप्टर-आधारित सेटअप्स के विपरीत, जो प्रत्येक इनपुट स्ट्रीम को अलग-अलग प्रोसेस करते हैं, FullDiT की साझा ध्यान संरचना ब्रांच टकरावों से बचती है और पैरामीटर ओवरहेड को कम करती है। लेखक दावा करते हैं कि वास्तुकला नए इनपुट प्रकारों के लिए बिना बड़े रीडिज़ाइन के स्केल कर सकती है और मॉडल स्कीमा प्रशिक्षण के दौरान न देखी गई शर्त संयोजनों, जैसे कि कैमरा गति को चरित्र पहचान के साथ जोड़ने, के लिए सामान्यीकरण के संकेत दिखाता है।
**प्ले करने के लिए क्लिक करें। प्रोजेक्ट साइट से पहचान जनरेशन के उदाहरण।**
FullDiT की वास्तुकला में, सभी कंडीशनिंग इनपुट्स—जैसे कि टेक्स्ट, कैमरा गति, पहचान, और डेप्थ—को पहले एक एकीकृत टोकन प्रारूप में परिवर्तित किया जाता है। ये टोकन फिर एक एकल लंबे अनुक्रम में संनादित किए जाते हैं, जिसे पूर्ण स्व-ध्यान का उपयोग करके ट्रांसफॉर्मर लेयर्स के स्टैक के माध्यम से प्रोसेस किया जाता है। यह दृष्टिकोण ओपन-सोरा प्लान और मूवी जेन जैसे पूर्व कार्यों का अनुसरण करता है।
यह डिज़ाइन मॉडल को सभी शर्तों के बीच अस्थायी और स्थानिक संबंधों को संयुक्त रूप से सीखने की अनुमति देता है। प्रत्येक ट्रांसफॉर्मर ब्लॉक पूरे अनुक्रम पर काम करता है, जिससे प्रत्येक इनपुट के लिए अलग-अलग मॉड्यूल्स पर निर्भर किए बिना मोडालिटीज के बीच गतिशील इंटरैक्शन सक्षम होते हैं। वास्तुकला को विस्तार योग्य बनाया गया है, जिससे भविष्य में अतिरिक्त नियंत्रण सिग्नल्स को शामिल करना बिना बड़े संरचनात्मक परिवर्तनों के आसान हो जाता है।
तीन की शक्ति
FullDiT प्रत्येक नियंत्रण सिग्नल को एक मानकीकृत टोकन प्रारूप में परिवर्तित करता है ताकि सभी शर्तों को एक एकीकृत ध्यान ढांचे में एक साथ प्रोसेस किया जा सके। कैमरा गति के लिए, मॉडल प्रत्येक फ्रेम के लिए बाह्य पैरामीटर्स—जैसे कि स्थिति और अभिविन्यास—के अनुक्रम को एन्कोड करता है। ये पैरामीटर्स टाइमस्टैम्प किए जाते हैं और एम्बेडिंग वेक्टर्स में प्रोजेक्ट किए जाते हैं जो सिग्नल की अस्थायी प्रकृति को दर्शाते हैं।
पहचान जानकारी को अलग तरह से व्यवहार किया जाता है, क्योंकि यह स्वाभाविक रूप से स्थानिक है न कि अस्थायी। मॉडल पहचान मैप्स का उपयोग करता है जो यह दर्शाते हैं कि प्रत्येक फ्रेम के किन हिस्सों में कौन से चरित्र मौजूद हैं। इन मैप्स को पैच में विभाजित किया जाता है, प्रत्येक पैच को एक एम्बेडिंग में प्रोजेक्ट किया जाता है जो स्थानिक पहचान संकेतों को कैप्चर करता है, जिससे मॉडल को फ्रेम के विशिष्ट क्षेत्रों को विशिष्ट इकाइयों के साथ जोड़ने की अनुमति मिलती है।
डेप्थ एक स्थान-समय सिग्नल है, और मॉडल इसे डेप्थ वीडियोज़ को 3D पैच में विभाजित करके संभालता है जो स्थान और समय दोनों को फैलाते हैं। इन पैच को फिर इस तरह से एम्बेड किया जाता है जो फ्रेम्स में उनकी संरचना को संरक्षित करता है।
एक बार एम्बेड होने के बाद, सभी कंडीशन टोकन (कैमरा, पहचान, और डेप्थ) को एक एकल लंबे अनुक्रम में संनादित किया जाता है, जिससे FullDiT उन्हें पूर्ण स्व-ध्यान का उपयोग करके एक साथ प्रोसेस कर सकता है। यह साझा प्रतिनिधित्व मॉडल को मोडालिटीज और समय के बीच इंटरैक्शन को सीखने में सक्षम बनाता है बिना अलग-अलग प्रोसेसिंग स्ट्रीम्स पर निर्भर किए।
डेटा और टेस्ट
FullDiT के प्रशिक्षण दृष्टिकोण ने प्रत्येक कंडीशनिंग प्रकार के लिए चयनित रूप से एनोटेटेड डेटासेट्स पर निर्भर किया, न कि सभी शर्तों को एक साथ मौजूद होने की आवश्यकता थी।
टेक्स्टुअल शर्तों के लिए, पहल मिराडेटा प्रोजेक्ट में उल्लिखित संरचित कैप्शनिंग दृष्टिकोण का अनुसरण करती है।
 *मिराडेटा प्रोजेक्ट से वीडियो संग्रह और एनोटेशन पाइपलाइन।* स्रोत: https://arxiv.org/pdf/2407.06358
*मिराडेटा प्रोजेक्ट से वीडियो संग्रह और एनोटेशन पाइपलाइन।* स्रोत: https://arxiv.org/pdf/2407.06358
कैमरा गति के लिए, रियलएस्टेट10K डेटासेट मुख्य डेटा स्रोत था, क्योंकि इसमें कैमरा पैरामीटर्स के उच्च-गुणवत्ता वाले ग्राउंड-ट्रुथ एनोटेशन्स थे। हालांकि, लेखकों ने देखा कि केवल स्थिर-दृश्य कैमरा डेटासेट्स जैसे रियलएस्टेट10K पर प्रशिक्षण से जनरेटेड वीडियोज़ में गतिशील वस्तु और मानव गतिविधियों में कमी आती थी। इसे संतुलित करने के लिए, उन्होंने अधिक गतिशील कैमरा गतियों वाले आंतरिक डेटासेट्स का उपयोग करके अतिरिक्त फाइन-ट्यूनिंग की।
पहचान एनोटेशन्स को कॉन्सेप्टमास्टर प्रोजेक्ट के लिए विकसित पाइपलाइन का उपयोग करके जनरेट किया गया, जिसने ठीक-ठाक पहचान जानकारी के कुशल फ़िल्टरिंग और निष्कर्षण की अनुमति दी।
 *कॉन्सेप्टमास्टर ढांचा पहचान डिकपलिंग मुद्दों को संबोधित करने के लिए डिज़ाइन किया गया है, जबकि अनुकूलित वीडियोज़ में कॉन्सेप्ट निष्ठा को संरक्षित करता है।* स्रोत: https://arxiv.org/pdf/2501.04698
*कॉन्सेप्टमास्टर ढांचा पहचान डिकपलिंग मुद्दों को संबोधित करने के लिए डिज़ाइन किया गया है, जबकि अनुकूलित वीडियोज़ में कॉन्सेप्ट निष्ठा को संरक्षित करता है।* स्रोत: https://arxiv.org/pdf/2501.04698
डेप्थ एनोटेशन्स पांडा-70M डेटासेट से डेप्थ एनीथिंग का उपयोग करके प्राप्त किए गए।
डेटा-ऑर्डरिंग के माध्यम से अनुकूलन
लेखकों ने एक प्रगतिशील प्रशिक्षण अनुसूची भी लागू की, जिसमें अधिक चुनौतीपूर्ण शर्तों को प्रशिक्षण में पहले पेश किया गया ताकि मॉडल सरल कार्यों को जोड़ने से पहले मजबूत प्रतिनिधित्व प्राप्त कर सके। प्रशिक्षण क्रम टेक्स्ट से कैमरा शर्तों, फिर पहचान, और अंत में डेप्थ तक आगे बढ़ा, जिसमें आसान कार्य आम तौर पर बाद में और कम उदाहरणों के साथ पेश किए गए।
लेखक इस तरह से कार्यभार को क्रमबद्ध करने के मूल्य पर जोर देते हैं:
**‘पूर्व-प्रशिक्षण चरण के दौरान, हमने नोट किया कि अधिक चुनौतीपूर्ण कार्यों को विस्तारित प्रशिक्षण समय की मांग होती है और उन्हें सीखने की प्रक्रिया में पहले पेश किया जाना चाहिए। ये चुनौतीपूर्ण कार्य जटिल डेटा वितरणों को शामिल करते हैं जो आउटपुट वीडियो से काफी भिन्न होते हैं, जिसके लिए मॉडल को उन्हें सटीक रूप से कैप्चर और प्रतिनिधित्व करने की पर्याप्त क्षमता की आवश्यकता होती है।**
**‘इसके विपरीत, आसान कार्यों को बहुत जल्दी पेश करने से मॉडल उन्हें पहले सीखने को प्राथमिकता दे सकता है, क्योंकि वे अधिक तत्काल अनुकूलन प्रतिक्रिया प्रदान करते हैं, जो अधिक चुनौतीपूर्ण कार्यों के अभिसरण को बाधित कर सकता है।'**
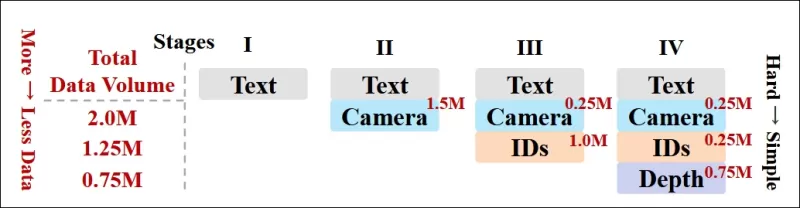 *शोधकर्ताओं द्वारा अपनाए गए डेटा प्रशिक्षण क्रम का एक चित्रण, जिसमें लाल रंग अधिक डेटा मात्रा को दर्शाता है।*
*शोधकर्ताओं द्वारा अपनाए गए डेटा प्रशिक्षण क्रम का एक चित्रण, जिसमें लाल रंग अधिक डेटा मात्रा को दर्शाता है।*
प्रारंभिक पूर्व-प्रशिक्षण के बाद, एक अंतिम फाइन-ट्यूनिंग चरण ने मॉडल को दृश्य गुणवत्ता और गति गतिशीलता को बेहतर बनाने के लिए और परिष्कृत किया। इसके बाद, प्रशिक्षण एक मानक डिफ्यूजन ढांचे का अनुसरण करता है: वीडियो लेटेंट्स में शोर जोड़ा गया, और मॉडल ने एम्बेडेड कंडीशन टोकन का उपयोग करके शोर को भविष्यवाणी करने और हटाने का सीखा।
FullDiT का प्रभावी ढंग से मूल्यांकन करने और मौजूदा विधियों के साथ निष्पक्ष तुलना प्रदान करने के लिए, और किसी अन्य उपयुक्त बेंचमार्क की अनुपस्थिति में, लेखकों ने **FullBench** पेश किया, जिसमें 1,400 अलग-अलग टेस्ट केस शामिल हैं।
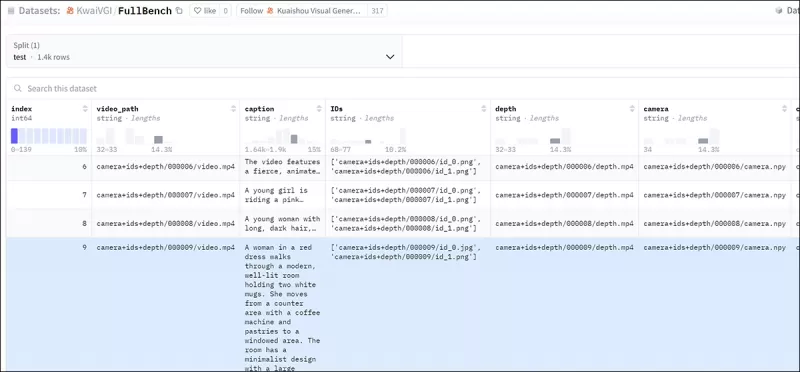 *नए FullBench बेंचमार्क के लिए एक डेटा एक्सप्लोरर उदाहरण।* स्रोत: https://huggingface.co/datasets/KwaiVGI/FullBench
*नए FullBench बेंचमार्क के लिए एक डेटा एक्सप्लोरर उदाहरण।* स्रोत: https://huggingface.co/datasets/KwaiVGI/FullBench
प्रत्येक डेटा पॉइंट ने विभिन्न कंडीशनिंग सिग्नल्स के लिए ग्राउंड ट्रुथ एनोटेशन्स प्रदान किए, जिसमें कैमरा गति, पहचान, और डेप्थ शामिल थे।
मेट्रिक्स
लेखकों ने FullDiT का मूल्यांकन दस मेट्रिक्स का उपयोग करके किया, जो प्रदर्शन के पांच मुख्य पहलुओं को कवर करते हैं: टेक्स्ट संरेखण, कैमरा नियंत्रण, पहचान समानता, डेप्थ सटीकता, और सामान्य वीडियो गुणवत्ता।
टेक्स्ट संरेखण को CLIP समानता का उपयोग करके मापा गया, जबकि कैमरा नियंत्रण को रोटेशन त्रुटि (RotErr), ट्रांसलेशन त्रुटि (TransErr), और कैमरा गति स्थिरता (CamMC) के माध्यम से मूल्यांकन किया गया, जो कैमराCtrl प्रोजेक्ट में CamI2V के दृष्टिकोण का अनुसरण करता है।
पहचान समानता को DINO-I और CLIP-I का उपयोग करके मूल्यांकन किया गया, और डेप्थ नियंत्रण सटीकता को मीन एब्सोल्यूट एरर (MAE) का उपयोग करके मात्रात्मक किया गया।
वीडियो गुणवत्ता को मिराडेटा से तीन मेट्रिक्स के साथ आंका गया: चिकनाई के लिए फ्रेम-स्तर CLIP समानता; गतिशीलता के लिए ऑप्टिकल फ्लो-आधारित गति दूरी; और दृश्य आकर्षण के लिए LAION-एस्थेटिक स्कोर।
प्रशिक्षण
लेखकों ने FullDiT को एक आंतरिक (अप्रकाशित) टेक्स्ट-टू-वीडियो डिफ्यूजन मॉडल का उपयोग करके प्रशिक्षित किया, जिसमें लगभग एक बिलियन पैरामीटर्स थे। उन्होंने पूर्व विधियों के साथ तुलना में निष्पक्षता बनाए रखने और पुनरुत्पादन सुनिश्चित करने के लिए जानबूझकर एक मध्यम पैरामीटर आकार चुना।
चूंकि प्रशिक्षण वीडियोज़ की लंबाई और रिज़ॉल्यूशन में भिन्नता थी, लेखकों ने प्रत्येक बैच को एक सामान्य रिज़ॉल्यूशन में रीसाइज़ और पैड करके मानकीकृत किया, प्रति अनुक्रम 77 फ्रेम्स का नमूना लिया, और प्रशिक्षण प्रभावशीलता को अनुकूलित करने के लिए लागू ध्यान और हानि मास्क का उपयोग किया।
एडम ऑप्टिमाइज़र को 64 NVIDIA H800 GPUs के क्लस्टर पर 1×10−5 की लर्निंग रेट पर उपयोग किया गया, जिसमें कुल 5,120GB VRAM थी (ध्यान दें कि उत्साही संश्लेषण समुदायों में, RTX 3090 पर 24GB अभी भी एक शानदार मानक माना जाता है)।
मॉडल को लगभग 32,000 चरणों के लिए प्रशिक्षित किया गया, जिसमें प्रति वीडियो तीन पहचानों तक, साथ ही 20 फ्रेम्स की कैमरा शर्तों और 21 फ्रेम्स की डेप्थ शर्तों को शामिल किया गया, दोनों को कुल 77 फ्रेम्स से समान रूप से नमूना लिया गया।
अनुमान के लिए, मॉडल ने 384×672 पिक्सल के रिज़ॉल्यूशन पर वीडियोज़ जनरेट किए (लगभग 15 फ्रेम्स प्रति सेकंड पर पांच सेकंड) 50 डिफ्यूजन अनुमान चरणों और पांच के क्लासिफायर-मुक्त मार्गदर्शन स्केल के साथ।
पूर्व विधियाँ
कैमरा-टू-वीडियो मूल्यांकन के लिए, लेखकों ने FullDiT की तुलना MotionCtrl, CameraCtrl, और CamI2V के साथ की, जिसमें सभी मॉडल्स को रियलएस्टेट10k डेटासेट का उपयोग करके प्रशिक्षित किया गया ताकि स्थिरता और निष्पक्षता सुनिश्चित हो।
पहचान-कंडीशन्ड जनरेशन में, चूंकि कोई तुलनीय ओपन-सोर्स मल्टी-आइडेंटिटी मॉडल्स उपलब्ध नहीं थे, मॉडल की तुलना 1B-पैरामीटर कॉन्सेप्टमास्टर मॉडल के साथ की गई, जिसमें समान प्रशिक्षण डेटा और वास्तुकला का उपयोग किया गया।
डेप्थ-टू-वीडियो कार्यों के लिए, Ctrl-Adapter और ControlVideo के साथ तुलना की गई।
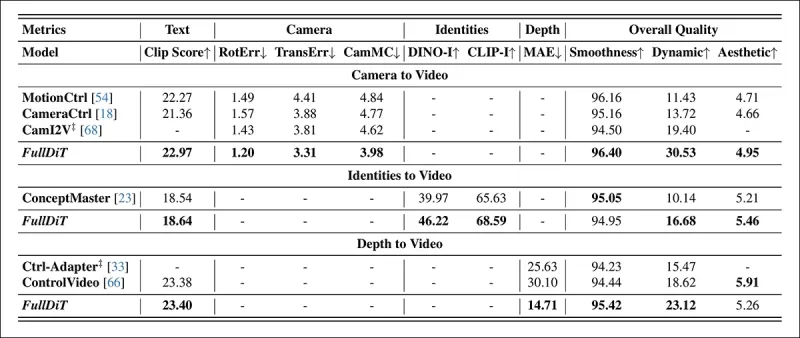 *एकल-कार्य वीडियो जनरेशन के लिए मात्रात्मक परिणाम। FullDiT की तुलना कैमरा-टू-वीडियो जनरेशन के लिए MotionCtrl, CameraCtrl, और CamI2V के साथ; पहचान-टू-वीडियो के लिए कॉन्सेप्टमास्टर (1B पैरामीटर संस्करण); और डेप्थ-टू-वीडियो के लिए Ctrl-Adapter और ControlVideo के साथ की गई। सभी मॉडल्स का मूल्यांकन उनके डिफॉल्ट सेटिंग्स का उपयोग करके किया गया। स्थिरता के लिए, प्रत्येक विधि से 16 फ्रेम्स को समान रूप से नमूना लिया गया, जो पूर्व मॉडल्स के आउटपुट लंबाई से मेल खाता है।*
*एकल-कार्य वीडियो जनरेशन के लिए मात्रात्मक परिणाम। FullDiT की तुलना कैमरा-टू-वीडियो जनरेशन के लिए MotionCtrl, CameraCtrl, और CamI2V के साथ; पहचान-टू-वीडियो के लिए कॉन्सेप्टमास्टर (1B पैरामीटर संस्करण); और डेप्थ-टू-वीडियो के लिए Ctrl-Adapter और ControlVideo के साथ की गई। सभी मॉडल्स का मूल्यांकन उनके डिफॉल्ट सेटिंग्स का उपयोग करके किया गया। स्थिरता के लिए, प्रत्येक विधि से 16 फ्रेम्स को समान रूप से नमूना लिया गया, जो पूर्व मॉडल्स के आउटपुट लंबाई से मेल खाता है।*
परिणामों से संकेत मिलता है कि FullDiT, कई कंडीशनिंग सिग्नल्स को एक साथ संभालने के बावजूद, टेक्स्ट, कैमरा गति, पहचान, और डेप्थ नियंत्रणों से संबंधित मेट्रिक्स में अत्याधुनिक प्रदर्शन प्राप्त करता है।
समग्र गुणवत्ता मेट्रिक्स में, सिस्टम ने आम तौर पर अन्य विधियों से बेहतर प्रदर्शन किया, हालांकि इसकी चिकनाई कॉन्सेप्टमास्टर से थोड़ी कम थी। यहाँ लेखक टिप्पणी करते हैं:
**‘FullDiT की चिकनाई कॉन्सेप्टमास्टर से थोड़ी कम है क्योंकि चिकनाई की गणना आसन्न फ्रेम्स के बीच CLIP समानता पर आधारित है। चूंकि FullDiT कॉन्सेप्टमास्टर की तुलना में काफी अधिक गतिशीलता प्रदर्शित करता है, चिकनाई मेट्रिक आसन्न फ्रेम्स के बीच बड़े बदलावों से प्रभावित होता है।**
**‘एस्थेटिक स्कोर के लिए, चूंकि रेटिंग मॉडल पेंटिंग शैली में छवियों को प्राथमिकता देता है और ControlVideo आम तौर पर इस शैली में वीडियोज़ जनरेट करता है, यह सौंदर्यशास्त्र में उच्च स्कोर प्राप्त करता है।'**
गुणात्मक तुलना के संबंध में, FullDiT प्रोजेक्ट साइट पर नमूना वीडियोज़ का उल्लेख करना बेहतर हो सकता है, क्योंकि PDF उदाहरण स्वाभाविक रूप से स्थिर हैं (और यहाँ पूरी तरह से पुनरुत्पादन के लिए बहुत बड़े भी हैं)।
 *PDF में पुनरुत्पादित गुणात्मक परिणामों का पहला खंड। अतिरिक्त उदाहरणों के लिए, जो यहाँ पुनरुत्पादन के लिए बहुत व्यापक हैं, कृपया स्रोत पेपर देखें।*
*PDF में पुनरुत्पादित गुणात्मक परिणामों का पहला खंड। अतिरिक्त उदाहरणों के लिए, जो यहाँ पुनरुत्पादन के लिए बहुत व्यापक हैं, कृपया स्रोत पेपर देखें।*
लेखक टिप्पणी करते हैं:
**‘FullDiT बेहतर पहचान संरक्षण प्रदर्शित करता है और [कॉन्सेप्टमास्टर] की तुलना में बेहतर गतिशीलता और दृश्य गुणवत्ता के साथ वीडियोज़ जनरेट करता है। चूंकि कॉन्सेप्टमास्टर और FullDiT एक ही बैकबोन पर प्रशिक्षित हैं, यह पूर्ण ध्यान के साथ शर्त इंजेक्शन की प्रभावशीलता को उजागर करता है।**
**‘…[अन्य] परिणाम मौजूदा डेप्थ-टू-वीडियो और कैमरा-टू-वीडियो विधियों की तुलना में FullDiT की बेहतर नियंत्रणीयता और जनरेशन गुणवत्ता को प्रदर्शित करते हैं।'**
 *PDF के उदाहरणों का एक खंड जिसमें FullDiT के कई सिग्नल्स के साथ आउटपुट दिखाए गए हैं। अतिरिक्त उदाहरणों के लिए कृपया स्रोत पेपर और प्रोजेक्ट साइट देखें।*
*PDF के उदाहरणों का एक खंड जिसमें FullDiT के कई सिग्नल्स के साथ आउटपुट दिखाए गए हैं। अतिरिक्त उदाहरणों के लिए कृपया स्रोत पेपर और प्रोजेक्ट साइट देखें।*
निष्कर्ष
FullDiT एक अधिक व्यापक वीडियो फाउंडेशन मॉडल की दिशा में एक रोमांचक कदम का प्रतिनिधित्व करता है, लेकिन सवाल यह है कि क्या ControlNet-शैली की सुविधाओं की मांग उनके बड़े पैमाने पर कार्यान्वयन को उचित ठहराती है, विशेष रूप से ओपन-सोर्स प्रोजेक्ट्स के लिए। इन प्रोजेक्ट्स को व्यावसायिक समर्थन के बिना आवश्यक विशाल GPU प्रोसेसिंग शक्ति प्राप्त करने में कठिनाई होगी।
प्राथमिक चुनौती यह है कि डेप्थ और पोज़ जैसे सिस्टम्स का उपयोग आम तौर पर कॉम्फीUI जैसे जटिल उपयोगकर्ता इंटरफेस के साथ गैर-तुच्छ परिचय की आवश्यकता होती है। इसलिए, इस तरह के एक कार्यात्मक ओपन-सोर्स मॉडल की सबसे अधिक संभावना छोटी VFX कंपनियों द्वारा विकसित की जाएगी, जिनके पास ऐसे मॉडल को निजी तौर पर क्यूरेट करने और प्रशिक्षित करने के लिए संसाधन या प्रेरणा की कमी हो।
दूसरी ओर, API-चालित 'रेंट-ए-AI' सिस्टम्स सीधे प्रशिक्षित सहायक नियंत्रण सिस्टम्स के साथ मॉडल्स के लिए सरल और अधिक उपयोगकर्ता-अनुकूल व्याख्यात्मक विधियों को विकसित करने के लिए अच्छी तरह से प्रेरित हो सकते हैं।
**प्ले करने के लिए क्लिक करें। FullDiT का उपयोग करके वीडियो जनरेशन पर डेप्थ+टेक्स्ट नियंत्रण लागू किए गए।**
*लेखक किसी भी ज्ञात बेस मॉडल (जैसे, SDXL, आदि) को निर्दिष्ट नहीं करते हैं।*
**पहली बार गुरुवार, 27 मार्च, 2025 को प्रकाशित**
संबंधित लेख
 प्रामाणिक वीडियो सामग्री में सूक्ष्म अभी तक प्रभावशाली एआई संशोधनों का अनावरण
2019 में, नैन्सी पेलोसी का एक भ्रामक वीडियो, फिर यूएस हाउस ऑफ रिप्रेजेंटेटिव्स के अध्यक्ष, व्यापक रूप से प्रसारित किया गया। वीडियो, जिसे उसे नशे में दिखाने के लिए संपादित किया गया था, एक स्पष्ट याद दिलाता था कि मीडिया कितनी आसानी से हेरफेर कर सकता था। अपनी सादगी के बावजूद, इस घटना ने टी पर प्रकाश डाला
Openai ने सोरा के वीडियो जनरेटर को चैट करने के लिए लाने की योजना बनाई है
Openai ने अपने AI वीडियो जनरेशन टूल, सोरा को अपने लोकप्रिय उपभोक्ता चैटबॉट, CHATGPT में एकीकृत करने की योजना बनाई है। यह कंपनी के नेताओं द्वारा डिस्कॉर्ड पर हाल ही में कार्यालय समय के सत्र के दौरान प्रकट किया गया था। वर्तमान में, सोरा केवल दिसंबर में Openai द्वारा लॉन्च किए गए एक समर्पित वेब ऐप के माध्यम से सुलभ है, जिससे उपयोगकर्ता की अनुमति मिलती है
Bytedance DeepFake AI वीडियो मार्केट में शामिल होता है
Bytedance, Tiktok के पीछे के लोगों ने अपनी नवीनतम AI निर्माण, Omnihuman-1 को दिखाया है, और यह बहुत अच्छा है। यह नई प्रणाली सुपर यथार्थवादी वीडियो को कोड़ा दे सकती है, और इसकी सभी आवश्यकताएं सिर्फ एक ही संदर्भ छवि और कुछ ऑडियो है। क्या अच्छा है आप वीडियो के पहलू अनुपात को बदल सकते हैं और
सूचना (1)
0/200
प्रामाणिक वीडियो सामग्री में सूक्ष्म अभी तक प्रभावशाली एआई संशोधनों का अनावरण
2019 में, नैन्सी पेलोसी का एक भ्रामक वीडियो, फिर यूएस हाउस ऑफ रिप्रेजेंटेटिव्स के अध्यक्ष, व्यापक रूप से प्रसारित किया गया। वीडियो, जिसे उसे नशे में दिखाने के लिए संपादित किया गया था, एक स्पष्ट याद दिलाता था कि मीडिया कितनी आसानी से हेरफेर कर सकता था। अपनी सादगी के बावजूद, इस घटना ने टी पर प्रकाश डाला
Openai ने सोरा के वीडियो जनरेटर को चैट करने के लिए लाने की योजना बनाई है
Openai ने अपने AI वीडियो जनरेशन टूल, सोरा को अपने लोकप्रिय उपभोक्ता चैटबॉट, CHATGPT में एकीकृत करने की योजना बनाई है। यह कंपनी के नेताओं द्वारा डिस्कॉर्ड पर हाल ही में कार्यालय समय के सत्र के दौरान प्रकट किया गया था। वर्तमान में, सोरा केवल दिसंबर में Openai द्वारा लॉन्च किए गए एक समर्पित वेब ऐप के माध्यम से सुलभ है, जिससे उपयोगकर्ता की अनुमति मिलती है
Bytedance DeepFake AI वीडियो मार्केट में शामिल होता है
Bytedance, Tiktok के पीछे के लोगों ने अपनी नवीनतम AI निर्माण, Omnihuman-1 को दिखाया है, और यह बहुत अच्छा है। यह नई प्रणाली सुपर यथार्थवादी वीडियो को कोड़ा दे सकती है, और इसकी सभी आवश्यकताएं सिर्फ एक ही संदर्भ छवि और कुछ ऑडियो है। क्या अच्छा है आप वीडियो के पहलू अनुपात को बदल सकते हैं और
सूचना (1)
0/200
![DonaldLee]() DonaldLee
DonaldLee
 28 जुलाई 2025 6:50:02 पूर्वाह्न IST
28 जुलाई 2025 6:50:02 पूर्वाह्न IST
The idea of AI taking over VFX in films is wild! I mean, total control over video generation? That’s some sci-fi stuff coming to life. But I wonder if these models like Hunyuan can really nail the tiny details directors obsess over. Exciting times! 🎥


 0
0
हुनयुआन और वान 2.1 जैसे वीडियो फाउंडेशन मॉडल्स ने महत्वपूर्ण प्रगति की है, लेकिन फिल्म और टीवी प्रोडक्शन में आवश्यक विस्तृत नियंत्रण, विशेष रूप से विजुअल इफेक्ट्स (VFX) के क्षेत्र में, वे अक्सर कमी महसूस करते हैं। पेशेवर VFX स्टूडियोज में, इन मॉडल्स को, स्टेबल डिफ्यूजन, कंडिंस्की और फ्लक्स जैसे पहले के इमेज-आधारित मॉडल्स के साथ, विशिष्ट रचनात्मक मांगों को पूरा करने के लिए उनके आउटपुट को परिष्कृत करने के लिए डिज़ाइन किए गए टूल्स के सुइट के साथ उपयोग किया जाता है। जब कोई डायरेक्टर बदलाव की मांग करता है, जैसे कि, "यह बहुत अच्छा लग रहा है, लेकिन क्या हम इसे थोड़ा और [n] कर सकते हैं?", तो यह कहना पर्याप्त नहीं है कि मॉडल में ऐसे समायोजन करने की सटीकता की कमी है।
इसके बजाय, एक AI VFX टीम पारंपरिक CGI और कम्पोजिशनल तकनीकों के संयोजन का उपयोग करेगी, साथ ही कस्टम-विकसित वर्कफ्लोज़ के साथ, वीडियो संश्लेषण की सीमाओं को और आगे बढ़ाने के लिए। यह दृष्टिकोण क्रोम जैसे डिफॉल्ट वेब ब्राउज़र का उपयोग करने के समान है; यह बॉक्स से बाहर कार्यात्मक है, लेकिन इसे अपनी आवश्यकताओं के अनुरूप बनाने के लिए, आपको कुछ प्लगइन्स इंस्टॉल करने होंगे।
नियंत्रण प्रेमी
डिफ्यूजन-आधारित इमेज संश्लेषण के क्षेत्र में, सबसे महत्वपूर्ण तृतीय-पक्ष सिस्टम्स में से एक है ControlNet। यह तकनीक जेनरेटिव मॉडल्स में संरचित नियंत्रण लाती है, जिससे उपयोगकर्ता एज मैप्स, डेप्थ मैप्स, या पोज़ जानकारी जैसे अतिरिक्त इनपुट्स का उपयोग करके इमेज या वीडियो जनरेशन को गाइड कर सकते हैं।
*ControlNet के विभिन्न तरीके डेप्थ>इमेज (शीर्ष पंक्ति), सिमेंटिक सेगमेंटेशन>इमेज (निचला बायाँ) और मनुष्यों और जानवरों की पोज़-गाइडेड इमेज जनरेशन (निचला बायाँ) की अनुमति देते हैं।*
ControlNet केवल टेक्स्ट प्रॉम्प्ट्स पर निर्भर नहीं करता; यह अलग-अलग न्यूरल नेटवर्क ब्रांचेज़, या एडाप्टर्स, का उपयोग करता है, जो इन कंडीशनिंग सिग्नल्स को प्रोसेस करते हैं, जबकि बेस मॉडल की जेनरेटिव क्षमताओं को बनाए रखते हैं। इससे अत्यधिक अनुकूलित आउटपुट्स प्राप्त होते हैं जो उपयोगकर्ता विनिर्देशों के साथ निकटता से संरेखित होते हैं, जिससे यह कम्पोजिशन, संरचना, या गति पर सटीक नियंत्रण की आवश्यकता वाले अनुप्रयोगों के लिए अमूल्य हो जाता है।
*गाइडिंग पोज़ के साथ, ControlNet के माध्यम से विभिन्न सटीक आउटपुट प्रकार प्राप्त किए जा सकते हैं।* स्रोत: https://arxiv.org/pdf/2302.05543
हालांकि, ये एडाप्टर-आधारित सिस्टम्स, जो आंतरिक रूप से केंद्रित न्यूरल प्रक्रियाओं के सेट पर बाहरी रूप से काम करते हैं, कई कमियों के साथ आते हैं। एडाप्टर्स को स्वतंत्र रूप से प्रशिक्षित किया जाता है, जिसके कारण कई एडाप्टर्स के संयोजन पर ब्रांच टकराव हो सकता है, जिसके परिणामस्वरूप अक्सर कम गुणवत्ता वाले जनरेशन होते हैं। वे पैरामीटर रिडंडेंसी भी लाते हैं, प्रत्येक एडाप्टर के लिए अतिरिक्त कम्प्यूटेशनल संसाधनों और मेमोरी की आवश्यकता होती है, जिससे स्केलिंग अक्षम हो जाती है। इसके अलावा, उनकी लचीलापन के बावजूद, एडाप्टर्स अक्सर मल्टी-कंडीशन जनरेशन के लिए पूरी तरह से फाइन-ट्यून किए गए मॉडल्स की तुलना में उप-इष्टतम परिणाम देते हैं। ये मुद्दे एडाप्टर-आधारित विधियों को उन कार्यों के लिए कम प्रभावी बना सकते हैं जिनमें कई नियंत्रण सिग्नल्स का सहज एकीकरण आवश्यक होता है।
आदर्श रूप से, ControlNet की क्षमताओं को मॉडल में मॉड्यूलर तरीके से मूल रूप से एकीकृत किया जाना चाहिए, जिससे भविष्य में एक साथ वीडियो/ऑडियो जनरेशन या मूल लिप-सिंक क्षमताओं जैसे नवाचार संभव हो सकें। वर्तमान में, प्रत्येक अतिरिक्त सुविधा या तो पोस्ट-प्रोडक्शन कार्य बन जाती है या एक गैर-मूल प्रक्रिया जो फाउंडेशन मॉडल के संवेदनशील वेट्स को नेविगेट करनी पड़ती है।
FullDiT
FullDiT, चीन से एक नया दृष्टिकोण, जो ControlNet-शैली की सुविधाओं को प्रशिक्षण के दौरान एक जेनरेटिव वीडियो मॉडल में सीधे एकीकृत करता है, न कि उन्हें बाद में विचार के रूप में मानने के।
*नए पेपर से: FullDiT दृष्टिकोण पहचान थोपना, डेप्थ और कैमरा मूवमेंट को मूल जनरेशन में शामिल कर सकता है, और इनमें से किसी भी संयोजन को एक साथ बुला सकता है।* स्रोत: https://arxiv.org/pdf/2503.19907
FullDiT, जैसा कि **FullDiT: मल्टी-टास्क वीडियो जेनरेटिव फाउंडेशन मॉडल विथ फुल अटेंशन** नामक पेपर में उल्लिखित है, पहचान हस्तांतरण, डेप्थ-मैपिंग, और कैमरा मूवमेंट जैसे मल्टी-टास्क शर्तों को एक प्रशिक्षित जेनरेटिव वीडियो मॉडल के मूल में एकीकृत करता है। लेखकों ने एक प्रोटोटाइप मॉडल और प्रोजेक्ट साइट पर उपलब्ध संबंधित वीडियो क्लिप्स विकसित किए हैं।
**प्ले करने के लिए क्लिक करें। केवल मूल प्रशिक्षित फाउंडेशन मॉडल के साथ ControlNet-शैली उपयोगकर्ता थोपन के उदाहरण।** स्रोत: https://fulldit.github.io/
लेखक FullDiT को टेक्स्ट-टू-वीडियो (T2V) और इमेज-टू-वीडियो (I2V) मॉडल्स के लिए एक प्रूफ-ऑफ-कॉन्सेप्ट के रूप में प्रस्तुत करते हैं जो उपयोगकर्ताओं को केवल एक इमेज या टेक्स्ट प्रॉम्प्ट से अधिक नियंत्रण प्रदान करते हैं। चूंकि कोई समान मॉडल्स मौजूद नहीं हैं, शोधकर्ताओं ने मल्टी-टास्क वीडियोज़ का मूल्यांकन करने के लिए **FullBench** नामक एक नया बेंचमार्क बनाया, जिसमें उनके द्वारा डिज़ाइन किए गए टेस्ट्स में अत्याधुनिक प्रदर्शन का दावा किया गया है। हालांकि, लेखकों द्वारा डिज़ाइन किए गए FullBench की वस्तुनिष्ठता का परीक्षण नहीं किया गया है, और इसके 1,400 मामलों का डेटासेट व्यापक निष्कर्षों के लिए बहुत सीमित हो सकता है।
FullDiT की वास्तुकला का सबसे रोमांचक पहलू इसकी नई प्रकार की नियंत्रण को शामिल करने की संभावना है। लेखक नोट करते हैं:
**‘इस कार्य में, हमने केवल कैमरा, पहचान और डेप्थ जानकारी की नियंत्रण शर्तों की खोज की है। हमने ऑडियो, स्पीच, पॉइंट क्लाउड, ऑब्जेक्ट बाउंडिंग बॉक्स, ऑप्टिकल फ्लो आदि जैसे अन्य शर्तों और मोडालिटीज की आगे जांच नहीं की। हालांकि FullDiT का डिज़ाइन अन्य मोडालिटीज को न्यूनतम वास्तुकला संशोधन के साथ सहजता से एकीकृत कर सकता है, मौजूदा मॉडल्स को नई शर्तों और मोडालिटीज में जल्दी और लागत-प्रभावी ढंग से अनुकूलित करने का तरीका अभी भी एक महत्वपूर्ण प्रश्न है जो आगे की खोज की आवश्यकता है।'**
जबकि FullDiT मल्टी-टास्क वीडियो जनरेशन में एक कदम आगे का प्रतिनिधित्व करता है, यह मौजूदा वास्तुकलाओं पर आधारित है न कि एक नया प्रतिमान पेश करता है। फिर भी, यह ControlNet-शैली की सुविधाओं के साथ मूल रूप से एकीकृत एकमात्र वीडियो फाउंडेशन मॉडल के रूप में खड़ा है, और इसकी वास्तुकला भविष्य के नवाचारों को समायोजित करने के लिए डिज़ाइन की गई है।
**प्ले करने के लिए क्लिक करें। प्रोजेक्ट साइट से उपयोगकर्ता-नियंत्रित कैमरा मूव्स के उदाहरण।**
पेपर, नौ शोधकर्ताओं द्वारा लिखित, क्वाइशो टेक्नोलॉजी और द चाइनीज़ यूनिवर्सिटी ऑफ हॉन्गकॉन्ग से, **FullDiT: मल्टी-टास्क वीडियो जेनरेटिव फाउंडेशन मॉडल विथ फुल अटेंशन** शीर्षक है। प्रोजेक्ट पेज और नया बेंचमार्क डेटा हगिंग फेस पर उपलब्ध हैं।
विधि
FullDiT का एकीकृत ध्यान तंत्र क्रॉस-मोडल प्रतिनिधित्व सीखने को बढ़ाने के लिए डिज़ाइन किया गया है, जो शर्तों के बीच स्थानिक और अस्थायी संबंधों को कैप्चर करता है।
*नए पेपर के अनुसार, FullDiT कई इनपुट शर्तों को पूर्ण स्व-ध्यान के माध्यम से एकीकृत करता है, उन्हें एक एकीकृत अनुक्रम में परिवर्तित करता है। इसके विपरीत, एडाप्टर-आधारित मॉडल्स (सबसे बाएँ) प्रत्येक इनपुट के लिए अलग-अलग मॉड्यूल्स का उपयोग करते हैं, जिसके परिणामस्वरूप रिडंडेंसी, टकराव, और कमज़ोर प्रदर्शन होता है।*
एडाप्टर-आधारित सेटअप्स के विपरीत, जो प्रत्येक इनपुट स्ट्रीम को अलग-अलग प्रोसेस करते हैं, FullDiT की साझा ध्यान संरचना ब्रांच टकरावों से बचती है और पैरामीटर ओवरहेड को कम करती है। लेखक दावा करते हैं कि वास्तुकला नए इनपुट प्रकारों के लिए बिना बड़े रीडिज़ाइन के स्केल कर सकती है और मॉडल स्कीमा प्रशिक्षण के दौरान न देखी गई शर्त संयोजनों, जैसे कि कैमरा गति को चरित्र पहचान के साथ जोड़ने, के लिए सामान्यीकरण के संकेत दिखाता है।
**प्ले करने के लिए क्लिक करें। प्रोजेक्ट साइट से पहचान जनरेशन के उदाहरण।**
FullDiT की वास्तुकला में, सभी कंडीशनिंग इनपुट्स—जैसे कि टेक्स्ट, कैमरा गति, पहचान, और डेप्थ—को पहले एक एकीकृत टोकन प्रारूप में परिवर्तित किया जाता है। ये टोकन फिर एक एकल लंबे अनुक्रम में संनादित किए जाते हैं, जिसे पूर्ण स्व-ध्यान का उपयोग करके ट्रांसफॉर्मर लेयर्स के स्टैक के माध्यम से प्रोसेस किया जाता है। यह दृष्टिकोण ओपन-सोरा प्लान और मूवी जेन जैसे पूर्व कार्यों का अनुसरण करता है।
यह डिज़ाइन मॉडल को सभी शर्तों के बीच अस्थायी और स्थानिक संबंधों को संयुक्त रूप से सीखने की अनुमति देता है। प्रत्येक ट्रांसफॉर्मर ब्लॉक पूरे अनुक्रम पर काम करता है, जिससे प्रत्येक इनपुट के लिए अलग-अलग मॉड्यूल्स पर निर्भर किए बिना मोडालिटीज के बीच गतिशील इंटरैक्शन सक्षम होते हैं। वास्तुकला को विस्तार योग्य बनाया गया है, जिससे भविष्य में अतिरिक्त नियंत्रण सिग्नल्स को शामिल करना बिना बड़े संरचनात्मक परिवर्तनों के आसान हो जाता है।
तीन की शक्ति
FullDiT प्रत्येक नियंत्रण सिग्नल को एक मानकीकृत टोकन प्रारूप में परिवर्तित करता है ताकि सभी शर्तों को एक एकीकृत ध्यान ढांचे में एक साथ प्रोसेस किया जा सके। कैमरा गति के लिए, मॉडल प्रत्येक फ्रेम के लिए बाह्य पैरामीटर्स—जैसे कि स्थिति और अभिविन्यास—के अनुक्रम को एन्कोड करता है। ये पैरामीटर्स टाइमस्टैम्प किए जाते हैं और एम्बेडिंग वेक्टर्स में प्रोजेक्ट किए जाते हैं जो सिग्नल की अस्थायी प्रकृति को दर्शाते हैं।
पहचान जानकारी को अलग तरह से व्यवहार किया जाता है, क्योंकि यह स्वाभाविक रूप से स्थानिक है न कि अस्थायी। मॉडल पहचान मैप्स का उपयोग करता है जो यह दर्शाते हैं कि प्रत्येक फ्रेम के किन हिस्सों में कौन से चरित्र मौजूद हैं। इन मैप्स को पैच में विभाजित किया जाता है, प्रत्येक पैच को एक एम्बेडिंग में प्रोजेक्ट किया जाता है जो स्थानिक पहचान संकेतों को कैप्चर करता है, जिससे मॉडल को फ्रेम के विशिष्ट क्षेत्रों को विशिष्ट इकाइयों के साथ जोड़ने की अनुमति मिलती है।
डेप्थ एक स्थान-समय सिग्नल है, और मॉडल इसे डेप्थ वीडियोज़ को 3D पैच में विभाजित करके संभालता है जो स्थान और समय दोनों को फैलाते हैं। इन पैच को फिर इस तरह से एम्बेड किया जाता है जो फ्रेम्स में उनकी संरचना को संरक्षित करता है।
एक बार एम्बेड होने के बाद, सभी कंडीशन टोकन (कैमरा, पहचान, और डेप्थ) को एक एकल लंबे अनुक्रम में संनादित किया जाता है, जिससे FullDiT उन्हें पूर्ण स्व-ध्यान का उपयोग करके एक साथ प्रोसेस कर सकता है। यह साझा प्रतिनिधित्व मॉडल को मोडालिटीज और समय के बीच इंटरैक्शन को सीखने में सक्षम बनाता है बिना अलग-अलग प्रोसेसिंग स्ट्रीम्स पर निर्भर किए।
डेटा और टेस्ट
FullDiT के प्रशिक्षण दृष्टिकोण ने प्रत्येक कंडीशनिंग प्रकार के लिए चयनित रूप से एनोटेटेड डेटासेट्स पर निर्भर किया, न कि सभी शर्तों को एक साथ मौजूद होने की आवश्यकता थी।
टेक्स्टुअल शर्तों के लिए, पहल मिराडेटा प्रोजेक्ट में उल्लिखित संरचित कैप्शनिंग दृष्टिकोण का अनुसरण करती है।
*मिराडेटा प्रोजेक्ट से वीडियो संग्रह और एनोटेशन पाइपलाइन।* स्रोत: https://arxiv.org/pdf/2407.06358
कैमरा गति के लिए, रियलएस्टेट10K डेटासेट मुख्य डेटा स्रोत था, क्योंकि इसमें कैमरा पैरामीटर्स के उच्च-गुणवत्ता वाले ग्राउंड-ट्रुथ एनोटेशन्स थे। हालांकि, लेखकों ने देखा कि केवल स्थिर-दृश्य कैमरा डेटासेट्स जैसे रियलएस्टेट10K पर प्रशिक्षण से जनरेटेड वीडियोज़ में गतिशील वस्तु और मानव गतिविधियों में कमी आती थी। इसे संतुलित करने के लिए, उन्होंने अधिक गतिशील कैमरा गतियों वाले आंतरिक डेटासेट्स का उपयोग करके अतिरिक्त फाइन-ट्यूनिंग की।
पहचान एनोटेशन्स को कॉन्सेप्टमास्टर प्रोजेक्ट के लिए विकसित पाइपलाइन का उपयोग करके जनरेट किया गया, जिसने ठीक-ठाक पहचान जानकारी के कुशल फ़िल्टरिंग और निष्कर्षण की अनुमति दी।
*कॉन्सेप्टमास्टर ढांचा पहचान डिकपलिंग मुद्दों को संबोधित करने के लिए डिज़ाइन किया गया है, जबकि अनुकूलित वीडियोज़ में कॉन्सेप्ट निष्ठा को संरक्षित करता है।* स्रोत: https://arxiv.org/pdf/2501.04698
डेप्थ एनोटेशन्स पांडा-70M डेटासेट से डेप्थ एनीथिंग का उपयोग करके प्राप्त किए गए।
डेटा-ऑर्डरिंग के माध्यम से अनुकूलन
लेखकों ने एक प्रगतिशील प्रशिक्षण अनुसूची भी लागू की, जिसमें अधिक चुनौतीपूर्ण शर्तों को प्रशिक्षण में पहले पेश किया गया ताकि मॉडल सरल कार्यों को जोड़ने से पहले मजबूत प्रतिनिधित्व प्राप्त कर सके। प्रशिक्षण क्रम टेक्स्ट से कैमरा शर्तों, फिर पहचान, और अंत में डेप्थ तक आगे बढ़ा, जिसमें आसान कार्य आम तौर पर बाद में और कम उदाहरणों के साथ पेश किए गए।
लेखक इस तरह से कार्यभार को क्रमबद्ध करने के मूल्य पर जोर देते हैं:
**‘पूर्व-प्रशिक्षण चरण के दौरान, हमने नोट किया कि अधिक चुनौतीपूर्ण कार्यों को विस्तारित प्रशिक्षण समय की मांग होती है और उन्हें सीखने की प्रक्रिया में पहले पेश किया जाना चाहिए। ये चुनौतीपूर्ण कार्य जटिल डेटा वितरणों को शामिल करते हैं जो आउटपुट वीडियो से काफी भिन्न होते हैं, जिसके लिए मॉडल को उन्हें सटीक रूप से कैप्चर और प्रतिनिधित्व करने की पर्याप्त क्षमता की आवश्यकता होती है।**
**‘इसके विपरीत, आसान कार्यों को बहुत जल्दी पेश करने से मॉडल उन्हें पहले सीखने को प्राथमिकता दे सकता है, क्योंकि वे अधिक तत्काल अनुकूलन प्रतिक्रिया प्रदान करते हैं, जो अधिक चुनौतीपूर्ण कार्यों के अभिसरण को बाधित कर सकता है।'**
*शोधकर्ताओं द्वारा अपनाए गए डेटा प्रशिक्षण क्रम का एक चित्रण, जिसमें लाल रंग अधिक डेटा मात्रा को दर्शाता है।*
प्रारंभिक पूर्व-प्रशिक्षण के बाद, एक अंतिम फाइन-ट्यूनिंग चरण ने मॉडल को दृश्य गुणवत्ता और गति गतिशीलता को बेहतर बनाने के लिए और परिष्कृत किया। इसके बाद, प्रशिक्षण एक मानक डिफ्यूजन ढांचे का अनुसरण करता है: वीडियो लेटेंट्स में शोर जोड़ा गया, और मॉडल ने एम्बेडेड कंडीशन टोकन का उपयोग करके शोर को भविष्यवाणी करने और हटाने का सीखा।
FullDiT का प्रभावी ढंग से मूल्यांकन करने और मौजूदा विधियों के साथ निष्पक्ष तुलना प्रदान करने के लिए, और किसी अन्य उपयुक्त बेंचमार्क की अनुपस्थिति में, लेखकों ने **FullBench** पेश किया, जिसमें 1,400 अलग-अलग टेस्ट केस शामिल हैं।
*नए FullBench बेंचमार्क के लिए एक डेटा एक्सप्लोरर उदाहरण।* स्रोत: https://huggingface.co/datasets/KwaiVGI/FullBench
प्रत्येक डेटा पॉइंट ने विभिन्न कंडीशनिंग सिग्नल्स के लिए ग्राउंड ट्रुथ एनोटेशन्स प्रदान किए, जिसमें कैमरा गति, पहचान, और डेप्थ शामिल थे।
मेट्रिक्स
लेखकों ने FullDiT का मूल्यांकन दस मेट्रिक्स का उपयोग करके किया, जो प्रदर्शन के पांच मुख्य पहलुओं को कवर करते हैं: टेक्स्ट संरेखण, कैमरा नियंत्रण, पहचान समानता, डेप्थ सटीकता, और सामान्य वीडियो गुणवत्ता।
टेक्स्ट संरेखण को CLIP समानता का उपयोग करके मापा गया, जबकि कैमरा नियंत्रण को रोटेशन त्रुटि (RotErr), ट्रांसलेशन त्रुटि (TransErr), और कैमरा गति स्थिरता (CamMC) के माध्यम से मूल्यांकन किया गया, जो कैमराCtrl प्रोजेक्ट में CamI2V के दृष्टिकोण का अनुसरण करता है।
पहचान समानता को DINO-I और CLIP-I का उपयोग करके मूल्यांकन किया गया, और डेप्थ नियंत्रण सटीकता को मीन एब्सोल्यूट एरर (MAE) का उपयोग करके मात्रात्मक किया गया।
वीडियो गुणवत्ता को मिराडेटा से तीन मेट्रिक्स के साथ आंका गया: चिकनाई के लिए फ्रेम-स्तर CLIP समानता; गतिशीलता के लिए ऑप्टिकल फ्लो-आधारित गति दूरी; और दृश्य आकर्षण के लिए LAION-एस्थेटिक स्कोर।
प्रशिक्षण
लेखकों ने FullDiT को एक आंतरिक (अप्रकाशित) टेक्स्ट-टू-वीडियो डिफ्यूजन मॉडल का उपयोग करके प्रशिक्षित किया, जिसमें लगभग एक बिलियन पैरामीटर्स थे। उन्होंने पूर्व विधियों के साथ तुलना में निष्पक्षता बनाए रखने और पुनरुत्पादन सुनिश्चित करने के लिए जानबूझकर एक मध्यम पैरामीटर आकार चुना।
चूंकि प्रशिक्षण वीडियोज़ की लंबाई और रिज़ॉल्यूशन में भिन्नता थी, लेखकों ने प्रत्येक बैच को एक सामान्य रिज़ॉल्यूशन में रीसाइज़ और पैड करके मानकीकृत किया, प्रति अनुक्रम 77 फ्रेम्स का नमूना लिया, और प्रशिक्षण प्रभावशीलता को अनुकूलित करने के लिए लागू ध्यान और हानि मास्क का उपयोग किया।
एडम ऑप्टिमाइज़र को 64 NVIDIA H800 GPUs के क्लस्टर पर 1×10−5 की लर्निंग रेट पर उपयोग किया गया, जिसमें कुल 5,120GB VRAM थी (ध्यान दें कि उत्साही संश्लेषण समुदायों में, RTX 3090 पर 24GB अभी भी एक शानदार मानक माना जाता है)।
मॉडल को लगभग 32,000 चरणों के लिए प्रशिक्षित किया गया, जिसमें प्रति वीडियो तीन पहचानों तक, साथ ही 20 फ्रेम्स की कैमरा शर्तों और 21 फ्रेम्स की डेप्थ शर्तों को शामिल किया गया, दोनों को कुल 77 फ्रेम्स से समान रूप से नमूना लिया गया।
अनुमान के लिए, मॉडल ने 384×672 पिक्सल के रिज़ॉल्यूशन पर वीडियोज़ जनरेट किए (लगभग 15 फ्रेम्स प्रति सेकंड पर पांच सेकंड) 50 डिफ्यूजन अनुमान चरणों और पांच के क्लासिफायर-मुक्त मार्गदर्शन स्केल के साथ।
पूर्व विधियाँ
कैमरा-टू-वीडियो मूल्यांकन के लिए, लेखकों ने FullDiT की तुलना MotionCtrl, CameraCtrl, और CamI2V के साथ की, जिसमें सभी मॉडल्स को रियलएस्टेट10k डेटासेट का उपयोग करके प्रशिक्षित किया गया ताकि स्थिरता और निष्पक्षता सुनिश्चित हो।
पहचान-कंडीशन्ड जनरेशन में, चूंकि कोई तुलनीय ओपन-सोर्स मल्टी-आइडेंटिटी मॉडल्स उपलब्ध नहीं थे, मॉडल की तुलना 1B-पैरामीटर कॉन्सेप्टमास्टर मॉडल के साथ की गई, जिसमें समान प्रशिक्षण डेटा और वास्तुकला का उपयोग किया गया।
डेप्थ-टू-वीडियो कार्यों के लिए, Ctrl-Adapter और ControlVideo के साथ तुलना की गई।
*एकल-कार्य वीडियो जनरेशन के लिए मात्रात्मक परिणाम। FullDiT की तुलना कैमरा-टू-वीडियो जनरेशन के लिए MotionCtrl, CameraCtrl, और CamI2V के साथ; पहचान-टू-वीडियो के लिए कॉन्सेप्टमास्टर (1B पैरामीटर संस्करण); और डेप्थ-टू-वीडियो के लिए Ctrl-Adapter और ControlVideo के साथ की गई। सभी मॉडल्स का मूल्यांकन उनके डिफॉल्ट सेटिंग्स का उपयोग करके किया गया। स्थिरता के लिए, प्रत्येक विधि से 16 फ्रेम्स को समान रूप से नमूना लिया गया, जो पूर्व मॉडल्स के आउटपुट लंबाई से मेल खाता है।*
परिणामों से संकेत मिलता है कि FullDiT, कई कंडीशनिंग सिग्नल्स को एक साथ संभालने के बावजूद, टेक्स्ट, कैमरा गति, पहचान, और डेप्थ नियंत्रणों से संबंधित मेट्रिक्स में अत्याधुनिक प्रदर्शन प्राप्त करता है।
समग्र गुणवत्ता मेट्रिक्स में, सिस्टम ने आम तौर पर अन्य विधियों से बेहतर प्रदर्शन किया, हालांकि इसकी चिकनाई कॉन्सेप्टमास्टर से थोड़ी कम थी। यहाँ लेखक टिप्पणी करते हैं:
**‘FullDiT की चिकनाई कॉन्सेप्टमास्टर से थोड़ी कम है क्योंकि चिकनाई की गणना आसन्न फ्रेम्स के बीच CLIP समानता पर आधारित है। चूंकि FullDiT कॉन्सेप्टमास्टर की तुलना में काफी अधिक गतिशीलता प्रदर्शित करता है, चिकनाई मेट्रिक आसन्न फ्रेम्स के बीच बड़े बदलावों से प्रभावित होता है।**
**‘एस्थेटिक स्कोर के लिए, चूंकि रेटिंग मॉडल पेंटिंग शैली में छवियों को प्राथमिकता देता है और ControlVideo आम तौर पर इस शैली में वीडियोज़ जनरेट करता है, यह सौंदर्यशास्त्र में उच्च स्कोर प्राप्त करता है।'**
गुणात्मक तुलना के संबंध में, FullDiT प्रोजेक्ट साइट पर नमूना वीडियोज़ का उल्लेख करना बेहतर हो सकता है, क्योंकि PDF उदाहरण स्वाभाविक रूप से स्थिर हैं (और यहाँ पूरी तरह से पुनरुत्पादन के लिए बहुत बड़े भी हैं)।
*PDF में पुनरुत्पादित गुणात्मक परिणामों का पहला खंड। अतिरिक्त उदाहरणों के लिए, जो यहाँ पुनरुत्पादन के लिए बहुत व्यापक हैं, कृपया स्रोत पेपर देखें।*
लेखक टिप्पणी करते हैं:
**‘FullDiT बेहतर पहचान संरक्षण प्रदर्शित करता है और [कॉन्सेप्टमास्टर] की तुलना में बेहतर गतिशीलता और दृश्य गुणवत्ता के साथ वीडियोज़ जनरेट करता है। चूंकि कॉन्सेप्टमास्टर और FullDiT एक ही बैकबोन पर प्रशिक्षित हैं, यह पूर्ण ध्यान के साथ शर्त इंजेक्शन की प्रभावशीलता को उजागर करता है।**
**‘…[अन्य] परिणाम मौजूदा डेप्थ-टू-वीडियो और कैमरा-टू-वीडियो विधियों की तुलना में FullDiT की बेहतर नियंत्रणीयता और जनरेशन गुणवत्ता को प्रदर्शित करते हैं।'**
*PDF के उदाहरणों का एक खंड जिसमें FullDiT के कई सिग्नल्स के साथ आउटपुट दिखाए गए हैं। अतिरिक्त उदाहरणों के लिए कृपया स्रोत पेपर और प्रोजेक्ट साइट देखें।*
निष्कर्ष
FullDiT एक अधिक व्यापक वीडियो फाउंडेशन मॉडल की दिशा में एक रोमांचक कदम का प्रतिनिधित्व करता है, लेकिन सवाल यह है कि क्या ControlNet-शैली की सुविधाओं की मांग उनके बड़े पैमाने पर कार्यान्वयन को उचित ठहराती है, विशेष रूप से ओपन-सोर्स प्रोजेक्ट्स के लिए। इन प्रोजेक्ट्स को व्यावसायिक समर्थन के बिना आवश्यक विशाल GPU प्रोसेसिंग शक्ति प्राप्त करने में कठिनाई होगी।
प्राथमिक चुनौती यह है कि डेप्थ और पोज़ जैसे सिस्टम्स का उपयोग आम तौर पर कॉम्फीUI जैसे जटिल उपयोगकर्ता इंटरफेस के साथ गैर-तुच्छ परिचय की आवश्यकता होती है। इसलिए, इस तरह के एक कार्यात्मक ओपन-सोर्स मॉडल की सबसे अधिक संभावना छोटी VFX कंपनियों द्वारा विकसित की जाएगी, जिनके पास ऐसे मॉडल को निजी तौर पर क्यूरेट करने और प्रशिक्षित करने के लिए संसाधन या प्रेरणा की कमी हो।
दूसरी ओर, API-चालित 'रेंट-ए-AI' सिस्टम्स सीधे प्रशिक्षित सहायक नियंत्रण सिस्टम्स के साथ मॉडल्स के लिए सरल और अधिक उपयोगकर्ता-अनुकूल व्याख्यात्मक विधियों को विकसित करने के लिए अच्छी तरह से प्रेरित हो सकते हैं।
**प्ले करने के लिए क्लिक करें। FullDiT का उपयोग करके वीडियो जनरेशन पर डेप्थ+टेक्स्ट नियंत्रण लागू किए गए।**
*लेखक किसी भी ज्ञात बेस मॉडल (जैसे, SDXL, आदि) को निर्दिष्ट नहीं करते हैं।*
**पहली बार गुरुवार, 27 मार्च, 2025 को प्रकाशित**










 प्रामाणिक वीडियो सामग्री में सूक्ष्म अभी तक प्रभावशाली एआई संशोधनों का अनावरण
2019 में, नैन्सी पेलोसी का एक भ्रामक वीडियो, फिर यूएस हाउस ऑफ रिप्रेजेंटेटिव्स के अध्यक्ष, व्यापक रूप से प्रसारित किया गया। वीडियो, जिसे उसे नशे में दिखाने के लिए संपादित किया गया था, एक स्पष्ट याद दिलाता था कि मीडिया कितनी आसानी से हेरफेर कर सकता था। अपनी सादगी के बावजूद, इस घटना ने टी पर प्रकाश डाला
प्रामाणिक वीडियो सामग्री में सूक्ष्म अभी तक प्रभावशाली एआई संशोधनों का अनावरण
2019 में, नैन्सी पेलोसी का एक भ्रामक वीडियो, फिर यूएस हाउस ऑफ रिप्रेजेंटेटिव्स के अध्यक्ष, व्यापक रूप से प्रसारित किया गया। वीडियो, जिसे उसे नशे में दिखाने के लिए संपादित किया गया था, एक स्पष्ट याद दिलाता था कि मीडिया कितनी आसानी से हेरफेर कर सकता था। अपनी सादगी के बावजूद, इस घटना ने टी पर प्रकाश डाला
 Openai ने सोरा के वीडियो जनरेटर को चैट करने के लिए लाने की योजना बनाई है
Openai ने अपने AI वीडियो जनरेशन टूल, सोरा को अपने लोकप्रिय उपभोक्ता चैटबॉट, CHATGPT में एकीकृत करने की योजना बनाई है। यह कंपनी के नेताओं द्वारा डिस्कॉर्ड पर हाल ही में कार्यालय समय के सत्र के दौरान प्रकट किया गया था। वर्तमान में, सोरा केवल दिसंबर में Openai द्वारा लॉन्च किए गए एक समर्पित वेब ऐप के माध्यम से सुलभ है, जिससे उपयोगकर्ता की अनुमति मिलती है
Openai ने सोरा के वीडियो जनरेटर को चैट करने के लिए लाने की योजना बनाई है
Openai ने अपने AI वीडियो जनरेशन टूल, सोरा को अपने लोकप्रिय उपभोक्ता चैटबॉट, CHATGPT में एकीकृत करने की योजना बनाई है। यह कंपनी के नेताओं द्वारा डिस्कॉर्ड पर हाल ही में कार्यालय समय के सत्र के दौरान प्रकट किया गया था। वर्तमान में, सोरा केवल दिसंबर में Openai द्वारा लॉन्च किए गए एक समर्पित वेब ऐप के माध्यम से सुलभ है, जिससे उपयोगकर्ता की अनुमति मिलती है
 Bytedance DeepFake AI वीडियो मार्केट में शामिल होता है
Bytedance, Tiktok के पीछे के लोगों ने अपनी नवीनतम AI निर्माण, Omnihuman-1 को दिखाया है, और यह बहुत अच्छा है। यह नई प्रणाली सुपर यथार्थवादी वीडियो को कोड़ा दे सकती है, और इसकी सभी आवश्यकताएं सिर्फ एक ही संदर्भ छवि और कुछ ऑडियो है। क्या अच्छा है आप वीडियो के पहलू अनुपात को बदल सकते हैं और
28 जुलाई 2025 6:50:02 पूर्वाह्न IST
Bytedance DeepFake AI वीडियो मार्केट में शामिल होता है
Bytedance, Tiktok के पीछे के लोगों ने अपनी नवीनतम AI निर्माण, Omnihuman-1 को दिखाया है, और यह बहुत अच्छा है। यह नई प्रणाली सुपर यथार्थवादी वीडियो को कोड़ा दे सकती है, और इसकी सभी आवश्यकताएं सिर्फ एक ही संदर्भ छवि और कुछ ऑडियो है। क्या अच्छा है आप वीडियो के पहलू अनुपात को बदल सकते हैं और
28 जुलाई 2025 6:50:02 पूर्वाह्न IST
The idea of AI taking over VFX in films is wild! I mean, total control over video generation? That’s some sci-fi stuff coming to life. But I wonder if these models like Hunyuan can really nail the tiny details directors obsess over. Exciting times! 🎥
0













